In-Context-LoRA
In-Context LoRA 是一个专为扩散变换器(Diffusion Transformers)设计的灵活生成式 AI 框架。它核心解决了传统模型在面对新任务时往往需要大量数据重新训练或微调的痛点,通过“上下文学习”机制,让用户仅需提供少量参考图像(如几张设计草图或角色照片),模型即可零样本(Zero-shot)理解并执行复杂的视觉生成任务。
该技术特别适用于设计师、创意工作者以及 AI 研究人员。设计师可以利用它快速完成虚拟试衣、产品外观设计、视觉身份迁移或电影分镜生成等工作,大幅降低多任务适配的成本;研究人员则能借助其开源的训练配置和预训练模型,探索生成模型在泛化能力上的边界。目前社区已基于该技术开发了多种 ComfyUI 工作流,涵盖从服装换款到角色扮演等丰富场景。
In-Context LoRA 的独特亮点在于其高效的适应性:无需针对每个新任务单独训练庞大的模型参数,而是通过动态调整注意力机制中的上下文令牌,实现“即插即用”的任务切换。这种设计不仅保留了高质量生成的特性,还显著提升了模型处理多样化现实世界设计任务的灵活性,是连接通用大模型与垂直应用场景的有力桥梁。
使用场景
一家电商设计团队急需为新款羽绒服生成多套营销海报,要求模特穿着该服装在雪地、城市街头等不同场景中保持服装细节完全一致。
没有 In-Context-LoRA 时
- 重训成本高昂:每更换一款新服装或一种新风格,都需要收集大量数据并重新训练专属 LoRA 模型,耗时数小时甚至数天。
- 特征一致性差:传统图生图或 ControlNet 方法难以在复杂背景变换中完美保留服装的纹理、Logo 和剪裁细节,常出现“变形”或“穿帮”。
- 工作流割裂:设计师需在多个插件间反复切换尝试,无法通过简单的参考图直接驱动生成,迭代效率极低。
- 零样本能力弱:面对从未见过的服装设计任务,通用模型往往无法理解指令,导致生成结果与实物严重不符。
使用 In-Context-LoRA 后
- 免训即时生效:只需提供一张服装参考图作为上下文输入,In-Context-LoRA 即可在不进行任何额外训练的情况下,立即适配新任务。
- 精准特征迁移:利用扩散 Transformer 的注意力机制,将参考图中的服装细节完美“迁移”至不同姿态和背景中,确保像素级的一致性。
- 流程极简统一:在 ComfyUI 中通过单一节点加载预训练模型,设计师可像搭积木一样快速构建虚拟试衣、故事板生成等工作流。
- 强大泛化能力:凭借优秀的零样本泛化性,无论是卡通转写实还是跨风格产品设计,都能高质量完成,大幅拓展创意边界。
In-Context-LoRA 通过将“训练”转化为“推理时的上下文学习”,彻底打破了定制化生成的效率瓶颈,让高质量视觉创作变得像对话一样简单。
运行环境要求
- 未说明
需要单张 GPU,显存至少 24GB(可通过调整配置中的 resolution 参数适配不同显存限制),具体显卡型号和 CUDA 版本未说明
未说明

快速开始
在上下文LoRA (IC-LoRA)
🔥 最新消息!
- [2024-12-17] 🚀 我们很高兴地发布了**IDEA-Bench,这是一个全面的基准测试,旨在评估生成模型的零样本任务泛化能力。该基准包含275个独特案例中的100个真实世界设计任务。尽管其定位为通用型,表现最佳的模型EMU2在该基准上的得分也仅为100分中的6.81分**,这凸显了当前该领域的挑战。快来探索这个基准,挑战模型性能的极限吧!
- [2024-11-16] 🌟 社区持续以IC-LoRA进行创新!令人兴奋的项目包括用于虚拟试穿、产品设计、物体迁移、角色扮演等任务的模型、ComfyUI节点和工作流。请在**使用IC-LoRA的社区创作**中探索他们的作品。衷心感谢所有贡献者的卓越努力!
- [2024-11-07] 🚀 我们发布了**10个预训练模型,适用于在上下文LoRA,涵盖电影分镜生成、视觉形象设计和视觉特效等多种任务。详情请参见模型库**。我们还提供了针对ComfyUI的示例工作流。
- [2024-11-01] 📂 **在上下文LoRA**的数据和训练配置现已开放下载!
- [2024-10-31] 📜 我们的最新论文**在上下文LoRA**提出了一种灵活的框架,可适应多种任务。
- [2024-10-19] 🎨 我们发布了论文**Group Diffusion Transformers**,这是在上下文LoRA的前身,能够支持30种视觉生成任务的零样本应用。
- [2024-4-18] 💻 我们发布了**代码和模型,用于FlashFace**——Group Diffusion Transformers的早期版本——验证了注意力机制中token拼接技术在定制化生成场景中的应用。
欢迎来到扩散Transformer中的在上下文LoRA官方仓库(论文和项目页面)。
使用IC-LoRA的社区创作
我们非常高兴地展示社区利用在上下文LoRA(IC-LoRA)所开发的创新项目。如果您有其他推荐或项目想要分享,请随时提交拉取请求!
| 项目名称 | 类型 | 支持的任务 | 示例结果 |
|---|---|---|---|
| 1. Comfyui_Object_Migration | ComfyUI节点 & 工作流 & LoRA模型 | 衣物迁移、卡通服装转写实风格等 |  |
| 2. Flux Simple Try On - In Context Lora | LoRA模型 & ComfyUI工作流 | 虚拟试穿 |   |
| 3. Flux In Context - visual identity Lora in Comfy | ComfyUI工作流 | 视觉形象迁移 |  |
| 4. Workflows Flux In Context Lora For Product Design | ComfyUI工作流 | 产品设计、角色扮演等 |  |
| 5. Flux Product Design - In Context Lora | LoRA模型 & ComfyUI工作流 | 产品设计 |  |
| 6. In Context lora + Character story generator + flux+ shichen | ComfyUI工作流 | 角色电影故事生成 | 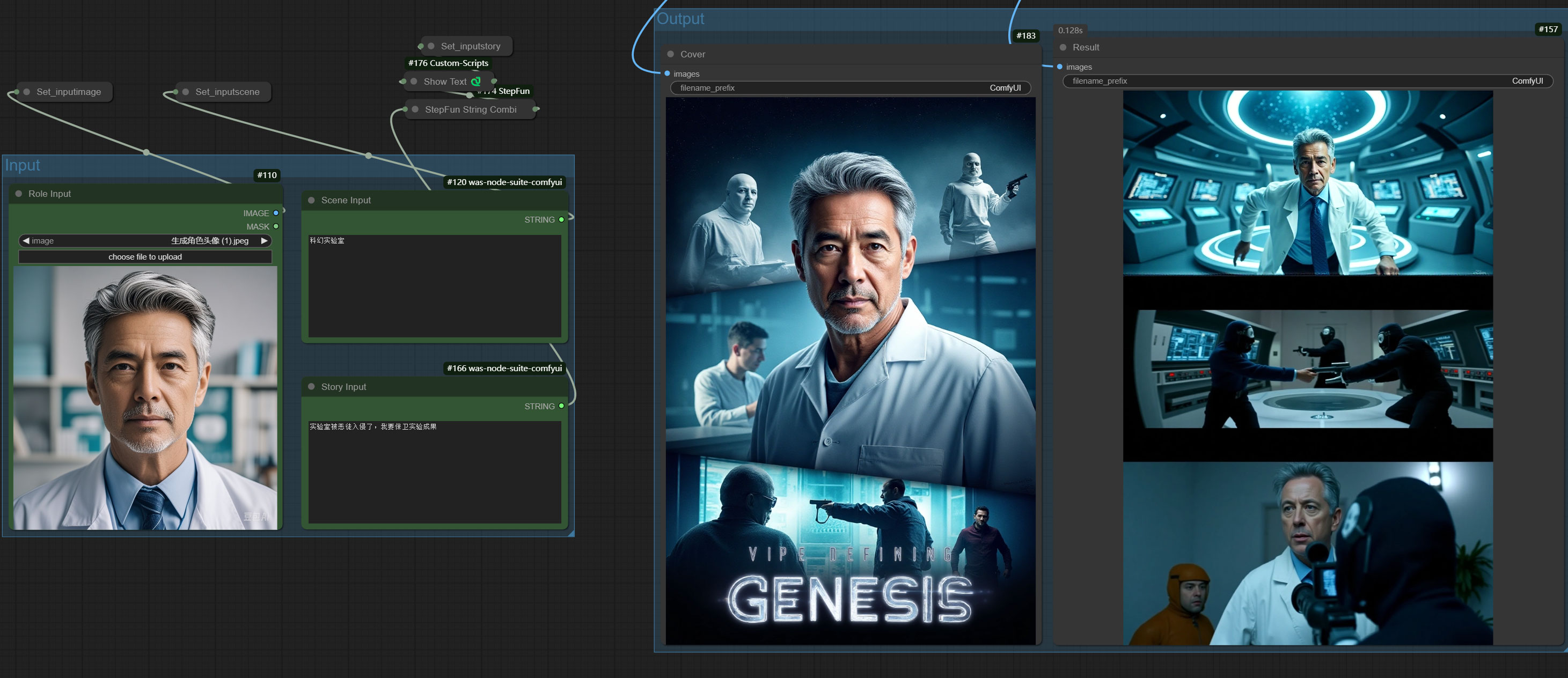 |
| 7. In- Context-Lora|Cute 4koma 可爱四格漫画 | LoRA模型 & ComfyUI工作流 | 漫画条生成 |  |
| 8. Creative Effects & Design LoRA Pack (In-Context LORA) | LoRA模型 & ComfyUI工作流 | 电影镜头生成等 |  |
我们向所有为推动IC-LoRA生态系统发展做出杰出贡献的伙伴致以最诚挚的谢意。
核心理念
IC-LoRA的核心思想是将条件图像和目标图像拼接成一张复合图像,并使用自然语言来定义任务。这种方法使得IC-LoRA能够无缝适配于各种应用场景。
特性
- 任务无关框架:IC-LoRA是一个通用框架,但针对不同应用仍需进行特定任务的微调。
- 可定制图像集生成:您可以对文本到图像模型进行微调,以生成具有自定义内在关系的图像集。
- 基于图像集的条件控制:您还可以让一组图像的生成依赖于另一组图像,从而实现广泛的可控生成应用。
如需更详细的信息和示例,请阅读我们的论文或访问我们的项目页面。
快速入门
您可以直接使用开源的AI工具包来训练IC-LoRA模型。我们在本仓库中提供了示例训练数据及配置文件:
- 配置文件:
config/movie-shots.yml(放置于AI工具包的config/目录下) - 示例训练数据:
data/movie-shots.zip(解压至AI工具包的data/movie-shots目录)
安装好必要的依赖并设置好AI工具包后,您可以通过以下命令开始训练:
python run.py config/movie-shots.yml
训练可在单块至少拥有24GB显存的GPU上运行(可根据不同GPU显存限制调整config/movie-shots.yml中的resolution参数)。整个训练过程通常只需数小时即可完成。
多场景图像字幕生成提示
作为参考,我们提供一个用于生成多场景图像字幕的示例提示:
为这张包含三个电影镜头的图像创作一段简短描述,整段字幕以[MOVIE-SHOTS]作为前缀,随后给出图像的整体概述。每个场景的细节应连贯地融入同一句话中,并使用特定标记[SCENE-1]、[SCENE-2]、[SCENE-3]标明各场景描述的起始位置。如有需要,可为角色随机命名,姓名用“<”和“>”括起来。确保整段描述语义连贯、一气呵成,且字数不超过512字。
模型动物园
以下是10个上下文LoRA模型及其推荐设置。我们为ComfyUI提供了一个示例工作流。
| 任务 | 模型 | 推荐设置 | 示例提示 |
|---|---|---|---|
| 1. 情侣形象设计 | couple-profile.safetensors |
width: 2048, height: 1024 |
这张由两部分组成的图像描绘了一对穿着侦探装的卡通猫;[左]一只身穿风衣、头戴费多拉帽的黑猫手持放大镜向右凝视,而[右]一只系着蝴蝶结领结、戴着同色帽子的白猫则好奇地挑了挑眉毛,在昏暗的背景衬托下营造出一种趣味十足的黑色电影风格场景。 |
| 2. 电影分镜头脚本 | film-storyboard.safetensors |
width: 1024, height: 1536 |
[电影镜头] 在一场热闹的节日里,[场景1] 我们看到害羞的男孩<Leo>站在熙熙攘攘的嘉年华边缘,眼睛因五彩缤纷的游乐设施和欢声笑语而睁得大大的;[场景2] 镜头切换到他勉强尝试一项惊险刺激的游戏,朋友们在一旁为他加油助威;[场景3] 最后是胜利的时刻——他赢得了一只巨大的毛绒熊,脸上洋溢着自豪的笑容,高高举起让所有人都能看到。 |
| 3. 字体设计 | font-design.safetensors |
width: 1792, height: 1216 |
这组四联图展示了一种充满活力的波普艺术风格的趣味气泡字体。[左上] 是用亮粉色书写的“Pop Candy”,背景点缀着波点图案;[右上] 是紫色的“Sweet Treat”,周围环绕着糖果插画;[左下] 是用多种鲜艳色彩拼接而成的“Yum!”;[右下] 则是在条纹背景上的“Delicious”,非常适合用于有趣、适合儿童的产品。 |
| 4. 家居装饰 | home-decoration.safetensors |
width: 1344, height: 1728 |
这组四联图展示了一个充满温暖木色调与舒适装饰元素的乡村风格客厅;[左上] 是一个巨大的石制壁炉,木架上摆满了书籍和蜡烛;[右上] 是一张铺着格子毯的复古皮质沙发,搭配各种质感丰富的靠垫;[左下] 是一个角落,摆放着一把木制扶手椅,旁边的小桌上放着一杯冒着热气的饮品和一本经典书籍;[右下] 则是一个舒适的阅读角,设有窗边座椅、柔软的毛皮披肩以及整齐堆放的装饰木柴。 |
| 5. 肖像插画 | portrait-illustration.safetensors |
width: 1152, height: 1088 |
这张双联图呈现了一幅从写实肖像到趣味插画的转变过程,既保留了细节又富有艺术气息;[左] 是一张照片,拍摄的是一个女子站在热闹的集市中,头戴宽檐帽,身着飘逸的波西米亚长裙,斜挎着皮质挎包;[右] 则是一幅插画,夸张地表现了她的配饰和面部特征,波西米亚长裙被绘制成充满活力的图案和大胆的色彩,而背景则简化为抽象的市场摊位,使画面显得生动活泼。 |
| 6. 人物摄影 | portrait-photography.safetensors |
width: 1344, height: 1728 |
这组[四联]图片描绘了一位年轻艺术家在明亮而富有灵感的工作室中的创作过程;[左上] 她站在一幅巨大的画布前,手持画笔为尚未完成的作品添上鲜艳的色彩;[右上] 她坐在一张杂乱的木桌上,一边在笔记本上勾勒创意,身边散落着各种美术用品;[左下] 她停下脚步,退后几步仔细端详自己的作品,若有所思地调整着眼镜;[右下] 则是在调色板上直接混合颜料,尝试不同的肌理效果,她专注的表情充分展现了对艺术的执着。 |
| 7. PPT模板 | ppt-templates.safetensors |
width: 1984, height: 1152 |
这组四联图展示了一个以乡村为主题的烹饪工作坊PPT模板;[左上] 以温暖的大地色调介绍了“从农场到餐桌的烹饪”;[右上] 按照“食材”、“准备”和“上菜”等环节组织内容;[左下] 列出了时令农产品的清单;[右下] 包含了厨师简介短文。 |
| 8. 沙尘暴视觉特效 | sandstorm-visual-effect.safetensors |
width: 1408, height: 1600 |
[沙尘暴警示] 这张双联图通过沙尘暴视觉特效展示了骑自行车者经历的变化;[上] 上半部分描绘了一位身穿鲜艳骑行服的骑手在晴朗开阔的公路上稳步前行,背景是宁静的天空,凸显了他的专注与决心;[下] 下半部分则将场景转变为狂暴的沙尘暴,沙粒在自行车和骑手周围剧烈翻滚,背景变得阴沉而混乱,强调了无序与力量。 |
| 9. 魔术烟花视觉特效 | sparklers-visual-effect.safetensors |
width: 960, height: 1088 |
[真实魔术烟花叠加] 这张双联图生动地展现了林间求婚仪式在魔术烟花叠加下的变化;[上] 第一幅画面描绘了一位男士在黄昏时分跪在森林空地上向伴侣求婚,背景光线温暖自然;[下] 第二幅画面则加入了闪耀的魔术烟花,围绕这对情侣组成了心形图案,进一步烘托出浪漫与喜悦的氛围。 |
| 10. 视觉识别设计 | visual-identity-design.safetensors |
width: 1472, height: 1024 |
这组双联图展示了某生鲜品牌欢快的品牌形象,左侧画面是一个微笑的菠萝图形,品牌名“Fresh Tropic”以轻松随意的字体印在浅水蓝色背景上;[左] 而右侧画面则将这一设计应用到了一款可重复使用的购物袋上,黑色的菠萝标志由一位身处市场的消费者手持,突显了该品牌亲民且环保的理念。 |
许可证
本仓库以 FLUX 作为基础模型。用户在使用本代码时,必须遵守 FLUX 的许可证条款。更多详情请参阅 FLUX 的许可证。
免责声明:请注意,本仓库提供的训练数据可能包含受版权保护的内容。这些开源数据仅用于参考和教育目的。如果您计划将这些数据用于商业用途,您有责任获得必要的许可,并确保遵守所有适用的版权法律法规。
引用
如果您在研究中认为本工作有所帮助,请考虑引用以下文献:
@article{lhhuang2024iclora,
title={扩散 Transformer 的上下文 LoRA},
author={Huang, Lianghua 和 Wang, Wei 和 Wu, Zhi-Fan 和 Shi, Yupeng 和 Dou, Huanzhang 和 Liang, Chen 和 Feng, Yutong 和 Liu, Yu 和 Zhou, Jingren},
journal={arXiv 预印本 arxiv:2410.23775},
year={2024}
}
@article{lhhuang2024groupdiffusion,
title={群体扩散 Transformer 是无监督多任务学习者},
author={Huang, Lianghua 和 Wang, Wei 和 Wu, Zhi-Fan 和 Dou, Huanzhang 和 Shi, Yupeng 和 Feng, Yutong 和 Liang, Chen 和 Liu, Yu 和 Zhou, Jingren},
journal={arXiv 预印本 arxiv:2410.15027},
year={2024}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器