mlbookcamp-code
mlbookcamp-code 是畅销书《Machine Learning Bookcamp》的官方配套代码库,旨在通过实战项目帮助学习者从零掌握机器学习全流程。它解决了初学者在理论学习与工程落地之间难以跨越的鸿沟,提供了从数据探索、模型构建、评估调优到云端部署的完整可运行示例。
这套资源特别适合希望系统提升技能的开发者、数据科学入门者以及相关专业学生。不同于仅包含理论公式的教材,mlbookcamp-code 强调“做中学”,涵盖了线性回归预测车价、逻辑回归分析用户流失、决策树集成学习以及基于 TensorFlow 的深度学习等核心场景。其独特的技术亮点在于完整的工程化视野:不仅讲解算法原理,还深入展示了如何使用 Flask 搭建服务、利用 Docker 容器化环境、借助 AWS Elastic Beanstalk 上云,甚至涉及 Serverless 架构与 Kubernetes 编排等前沿部署方案。
无论你是想夯实基础,还是希望了解如何将模型真正转化为生产级服务,mlbookcamp-code 都提供了一条清晰、免费且循序渐进的学习路径。配合其在线课程 Machine Learning Zoomcamp,用户可以随时加入社区交流,在实际编码中构建扎实的机器学习能力体系。
使用场景
某初创金融科技公司的数据团队正急需构建一个用户信贷违约预测模型,并计划将其快速部署到云端以支持实时审批业务。
没有 mlbookcamp-code 时
- 团队成员需从零摸索 CRISP-DM 项目管理流程,导致需求分析与模型训练阶段脱节,项目进度严重滞后。
- 在特征工程和模型选择上缺乏标准参考,成员各自为战,花费大量时间重复编写基础的线性回归和决策树代码。
- 模型评估指标理解不一,有人仅关注准确率而忽略召回率,导致高风险违约用户被错误放行。
- 模型部署环节成为瓶颈,团队不熟悉 Docker 容器化及 AWS 服务配置,多次尝试均因环境依赖问题失败。
- 缺乏系统的学习路径,新入职分析师面对复杂的神经网络和集成学习概念感到无从下手,培训成本高昂。
使用 mlbookcamp-code 后
- 直接复用书中第 1 章的 CRISP-DM 框架和第 6 章的违约预测代码,团队迅速统一了项目节奏,将开发周期缩短了 50%。
- 基于第 2 章和第 3 章提供的完整 Notebook 示例,成员快速掌握了从数据清洗到逻辑回归、随机森林的标准实现流程。
- 利用第 4 章详细的评估指标教程,团队建立了包含混淆矩阵、ROC 曲线在内的标准化评估体系,显著提升了风控精度。
- 参照第 5 章和第 8 章的部署方案,顺利使用 Flask、Docker 及 AWS Lambda 将模型封装为微服务,实现了无缝上线。
- 依托 Machine Learning Zoomcamp 的免费课程结构,新员工通过实战代码快速上手,团队整体技术栈迅速对齐。
mlbookcamp-code 通过提供端到端的实战代码与系统化学习路径,将原本分散且高门槛的机器学习工程落地过程转变为高效、可复制的标准作业流。
运行环境要求
- Linux
- macOS
- Windows
- 第 7-9 章涉及深度学习,建议使用 NVIDIA GPU(具体型号和显存未说明)
- 附录 D 提及可在 AWS SageMaker 租用带 GPU 的实例
未说明

快速开始
机器学习读书营
《机器学习读书营》一书中的代码
实用链接:
- https://mlbookcamp.com:补充材料
- https://datatalks.club:讨论数据的地方(以及本书:加入
#ml-bookcamp频道,提问关于本书的问题并报告任何问题)
机器学习 Zoom 营

机器学习 Zoom 营是一门基于该书的课程。
- 它是在线且免费的。
- 您可以随时加入。
- 更多信息请参见课程仓库。
阅读计划
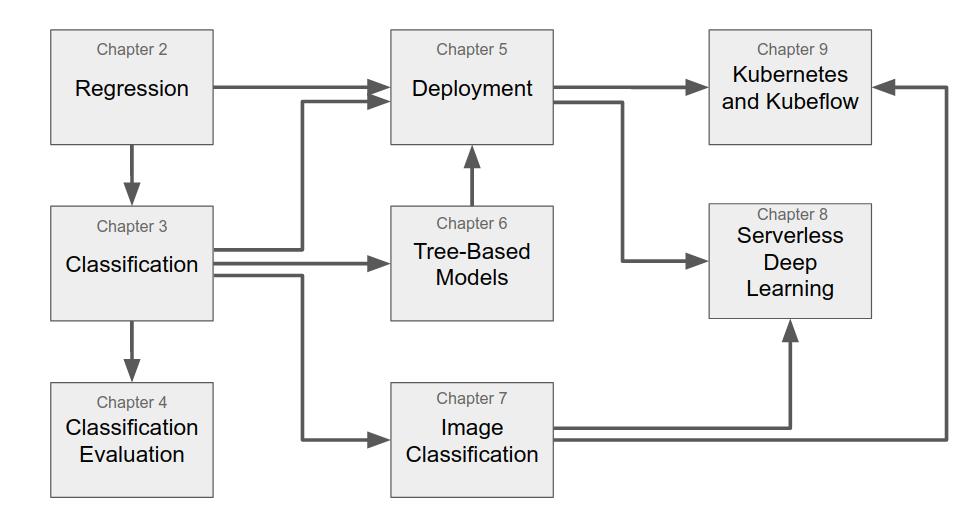
章节
第1章:机器学习简介
- 理解机器学习及其能够解决的问题
- CRISP-DM:组织成功的机器学习项目
- 训练和选择机器学习模型
- 进行模型验证
无代码
第2章:用于回归的机器学习
- 使用线性回归模型创建汽车价格预测项目
- 使用 Jupyter 笔记本进行初步探索性数据分析
- 设置验证框架
- 从头实现线性回归模型
- 对模型进行简单的特征工程
- 通过正则化控制模型
- 使用模型预测汽车价格
代码:chapter-02-car-price/02-carprice.ipynb
第3章:用于分类的机器学习
- 使用逻辑回归预测将流失的客户
- 进行探索性数据分析以识别重要特征
- 对分类变量进行编码以便在机器学习模型中使用
- 使用逻辑回归进行分类
代码:chapter-03-churn-prediction/03-churn.ipynb
第4章:分类的评估指标
- 准确率作为评估二元分类模型的一种方式及其局限性
- 使用混淆矩阵确定模型出错的位置
- 从混淆矩阵推导出精确率、召回率等其他指标
- 使用 ROC 曲线和 AUC 进一步了解二元分类模型的性能
- 通过交叉验证确保模型表现最佳
- 调整模型参数以获得最佳预测性能
代码:chapter-03-churn-prediction/04-metrics.ipynb
第5章:部署机器学习模型
- 使用 Pickle 保存模型
- 使用 Flask 提供模型服务
- 使用 Pipenv 管理依赖项
- 使用 Docker 使服务自包含
- 使用 AWS Elastic Beanstalk 将其部署到云端
第6章:决策树与集成学习
- 使用基于树的模型预测违约风险
- 决策树及决策树学习算法
- 随机森林:将多棵树组合成一个模型
- 梯度提升作为另一种组合决策树的方式
代码:chapter-06-trees/06-trees.ipynb
第7章:神经网络与深度学习
- 用于图像分类的卷积神经网络
- TensorFlow 和 Keras——构建神经网络的框架
- 使用预训练的神经网络
- 卷积神经网络的内部机制
- 使用迁移学习训练模型
- 数据增强——生成更多训练数据的过程
代码:chapter-07-neural-nets/07-neural-nets-train.ipynb
第8章:无服务器深度学习
- 使用 TensorFlow-Lite 提供模型服务——一种轻量级的 TensorFlow 模型应用环境
- 使用 AWS Lambda 部署深度学习模型
- 通过 API Gateway 将 Lambda 函数公开为 Web 服务
第9章:Kubernetes 和 Kubeflow
Kubernetes:
- 理解在云中部署和提供模型的不同方法
- 使用 TensorFlow-Serving 提供 Keras 和 TensorFlow 模型服务
- 将 TensorFlow-Serving 部署到 Kubernetes 上
Kubeflow:
- 使用 Kubeflow 和 KFServing 简化部署流程
来自 mlbookcamp.com 的文章:
附录
附录 A:设置环境
- 安装 Anaconda,这是一个包含我们所需大多数科学库的 Python 发行版
- 从远程机器运行 Jupyter Notebook 服务
- 安装并配置 Kaggle 命令行界面工具,以便访问 Kaggle 上的数据集
- 使用 Web 界面和命令行界面在 AWS 上创建 EC2 实例
代码:无代码
来自 mlbookcamp.com 的文章:
附录 B:Python 入门
- 基础 Python 语法:变量和控制流结构
- 集合:列表、元组、集合和字典
- 列表解析:操作集合的一种简洁方式
- 可重用性:函数、类和导入代码
- 包管理:使用 pip 安装库
- 运行 Python 脚本
来自 mlbookcamp.com 的文章:
附录 C:NumPy 和线性代数入门
- 一维和二维 NumPy 数组
- 随机生成 NumPy 数组
- NumPy 数组上的操作:逐元素运算、汇总运算、排序和过滤
- 线性代数中的乘法:向量-向量、矩阵-向量和矩阵-矩阵乘法
- 求矩阵的逆以及求解正规方程
来自 mlbookcamp.com 的文章:
附录 D:Pandas 入门
- Pandas 中的主要数据结构:DataFrame 和 Series
- 访问 DataFrame 的行和列
- 逐元素和汇总运算
- 处理缺失值
- 排序和分组
附录 E:AWS SageMaker
- 提高 GPU 配额限制
- 在 AWS SageMaker 中租用带有 GPU 的 Jupyter Notebook
版本历史
chapter7-model2025/08/11相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备