awesome-datascience
awesome-datascience 是一个专为数据科学爱好者打造的开源学习资源库,旨在帮助初学者和从业者系统性地掌握数据科学知识并解决现实世界的问题。面对“什么是数据科学”以及“该从何学起”的常见困惑,它提供了一条清晰的学习路径,涵盖从基础概念到高级算法的全方位内容。
该资源库解决了学习资源分散、入门门槛高的问题,将教程、免费课程、大学项目、机器学习算法(如监督学习、深度学习)、主流工具包(PyTorch、TensorFlow 等)、模型评估方案以及可视化利器整合在一处。此外,它还收录了丰富的行业文献、播客、技术博客、数据集甚至趣味漫画,帮助用户在理论学习之外,也能通过社区交流和实战竞赛提升技能。
无论是刚入门的学生、希望转型的开发者,还是寻求灵感的研究人员,都能在这里找到适合自己的成长阶梯。其独特的亮点在于不仅关注技术硬实力,还精心整理了社交媒体账号、通讯期刊和行业活动信息,构建了一个完整的数据科学生态圈。跟随 awesome-datascience 的步骤,你可以轻松开启数据科学之旅,将理论知识转化为解决实际问题的强大能力。
使用场景
某初创公司的数据分析师李明刚转岗负责构建用户流失预测模型,面对海量且分散的技术资源感到无从下手。
没有 awesome-datascience 时
- 学习路径迷茫:在知乎、谷歌和各类博客间反复跳转,花费数天仍无法理清“数据科学到底该学什么”的核心知识体系。
- 工具选型困难:面对 PyTorch、TensorFlow 等众多深度学习框架及评估工具,缺乏权威的对比指南,担心选错技术栈导致后期重构。
- 资源质量参差不齐:找到的免费课程和教程大多过时或缺乏实战案例,难以直接应用于解决公司真实的业务问题。
- 社区融入缓慢:不知道有哪些活跃的 Slack 群组或 GitHub 组织,遇到报错只能独自摸索,严重拖慢项目进度。
使用 awesome-datascience 后
- 路线清晰明确:直接参照"Where do I Start"和分类详细的目录,快速建立起从基础算法到高级架构的系统化学习地图。
- 高效决策工具:利用"The Data Science Toolbox"中整理好的生态列表(如 Evidently AI 用于模型监控),迅速锁定最适合当前场景的开源库。
- 实战资源直达:通过精选的 MOOCs、书籍和真实数据集链接,直接获取经过验证的高质量内容,将理论快速转化为代码实现。
- 融入专业圈子:一键访问推荐的社交媒体账号和竞赛平台,迅速连接行业专家,在遇到瓶颈时能及时获得社区支持。
awesome-datascience 将原本需要数周的信息搜集与筛选工作压缩至几小时,让数据科学家能专注于解决真正的业务难题而非寻找入门钥匙。
运行环境要求
未说明
未说明

快速开始

令人惊叹的数据科学
![]()
欢迎贡献内容,请参阅 CONTRIBUTING.md。
一个开源的数据科学资源库,用于学习并应用相关概念以解决现实世界的问题。
这是开始学习 数据科学 的捷径。只需按照步骤回答以下问题:“什么是数据科学?我应该学习哪些内容才能掌握数据科学?”
赞助商
| 赞助商 | 简介 |
|---|---|
| --- | 成为首位赞助商吧!github@academic.io |
目录
什么是数据科学?
数据科学如今是计算机和互联网领域最热门的话题之一。人们从各种应用和系统中积累了海量数据,而现在正是对这些数据进行分析的时机。接下来的步骤是从数据中提炼出有价值的见解,并对未来做出预测。在这里你可以找到关于“数据科学”这一主题的最大问题,以及来自专家的数百条回答。
| 链接 | 预览 |
|---|---|
| 面向初学者的数据科学 | 微软很高兴推出一门为期10周、包含20节课的数据科学课程。 |
| O’Reilly:什么是数据科学 | 数据科学家将创业精神与耐心相结合,愿意逐步构建数据产品,具备探索能力,并能不断迭代解决方案。他们本质上是跨学科的。他们能够处理问题的各个方面,从最初的数据收集和数据清洗,到得出结论。他们善于跳出固有思维模式,提出看待问题的新方法,或者应对范围极为宽泛的问题:“这里有很多数据,你能从中创造出什么?” |
| Quora:什么是数据科学 | 数据科学是技术、算法开发和数据推理等多个领域的结合,旨在研究和分析数据,从而为复杂问题找到创新性解决方案。简而言之,数据科学的核心在于通过分析数据,寻找创造性的方法来推动业务增长。 |
| 21世纪最性感的职业 | 如今的数据科学家类似于20世纪八九十年代华尔街的“量化分析师”。那时,拥有物理和数学背景的人纷纷涌入投资银行和对冲基金,在那里他们可以设计全新的算法和数据策略。随后,多所大学开设了金融工程硕士项目,培养出第二代人才,这些人才更容易被主流企业所接纳。这一模式在20世纪90年代再次上演,当时搜索引擎工程师凭借其稀缺的专业技能,很快便成为计算机科学专业教学的重点内容。 |
| 维基百科 | 数据科学是一门跨学科领域,它运用科学方法、流程、算法和系统,从结构化与非结构化数据中提取知识和洞见。数据科学与数据挖掘、机器学习和大数据密切相关。 |
| 如何成为一名数据科学家 | 数据科学家是大数据的驾驭者,负责收集和分析大量结构化与非结构化数据。数据科学家的工作融合了计算机科学、统计学和数学。他们对数据进行分析、处理和建模,然后解读结果,为企业和其他组织制定可执行的行动计划。 |
| 数据科学的简短历史 | 数据科学家之所以变得炙手可热,很大程度上是因为成熟的统计学与年轻的计算机科学相结合。术语“数据科学”直到近期才出现,专门用来指代一种新兴职业——即能够从海量大数据中提炼出价值的职业。然而,对数据的理解由来已久,科学家、统计学家、图书馆员、计算机科学家等各界人士多年来一直在探讨这一话题。以下时间线梳理了“数据科学”这一术语的演变及其使用情况、对其定义的各种尝试,以及相关概念。 |
| 数据科学家的软件开发资源 | 数据科学家专注于通过探索性分析、统计学和模型来理解数据。而软件开发者则运用一套不同的知识体系和工具。尽管两者的工作重点看似不同,但数据科学团队仍可受益于采纳软件开发的最佳实践。版本控制、自动化测试等开发技能有助于创建可复现且适合生产的代码和工具。 |
| 数据科学家职业发展路线图 | 在当今这个数据驱动的世界里,每天约产生3.2877亿TB的数据,数据科学无疑是一个极佳的职业选择。而且这一数字还在与日俱增,随之而来的是对能够利用这些数据推动业务增长的熟练数据科学家的需求也在迅速上升。 |
| 规划你的数据科学家之路 | 数据科学是当前需求量最大的职业之一。随着企业越来越依赖数据来做决策,对专业数据科学家的需求也急剧增加。无论是科技公司、医疗机构,还是政府机构,数据科学家都在将原始数据转化为有价值洞察方面发挥着关键作用。那么,对于刚刚起步的人来说,究竟该如何成为一名数据科学家呢? |
我从哪里开始?
虽然不是绝对必要,但掌握一门编程语言对于成为一名高效的数据科学家至关重要。目前最受欢迎的语言是 Python,紧随其后的是 R。Python 是一种通用脚本语言,在众多领域都有广泛应用。而 R 则是一种专门用于统计分析的领域特定语言,内置了大量常用的统计工具。
Python 无疑是科学界最流行的语言,这在很大程度上归功于其易用性以及由社区驱动的丰富软件包生态系统。安装软件包主要有两种方式:Pip(通过 pip install 调用),它是 Python 自带的包管理器;以及 Anaconda(通过 conda install 调用),它是一个功能强大的包管理工具,不仅可以为 Python 和 R 安装软件包,还能下载 Git 等可执行文件。
与 R 不同,Python 并非从一开始就专为数据科学设计,但有许多第三方库可以弥补这一不足。本文档后面会提供更为详尽的软件包列表,不过以下四个库是开启数据科学之旅的良好起点:Scikit-Learn 是一个通用的数据科学库,实现了最流行的算法,并配有丰富的文档、教程和示例。即使你倾向于自己编写实现代码,Scikit-Learn 仍然是了解许多常见算法底层原理的重要参考。借助 Pandas,你可以将数据整理并分析成方便的表格格式。Numpy 提供了高效的数学运算工具,尤其擅长处理向量和矩阵操作。而基于 Matplotlib 的 Seaborn 则能快速生成美观的数据可视化图表,自带许多实用的默认设置,并提供图库展示如何制作常见的数据可视化效果。
在踏上数据科学家之路时,选择哪种语言并不特别重要,Python 和 R 各有优劣。挑选一门你喜欢的语言,并查看我们下面列出的其中一门 免费课程 吧!
初学者路线图
如果你刚刚起步,这里有一条简单的推荐路径:
- 学习 Python – 从基础开始:变量、循环、函数
- 学习核心库 – Pandas、NumPy、Matplotlib、Scikit-Learn
- 通过初级项目练习 – 尝试在 Kaggle 上完成泰坦尼克号生存预测或房价预测项目
- 学习数学基础 – 统计学、线性代数、概率论
- 进入机器学习领域 – 监督学习 → 非监督学习 → 深度学习
代理
本节包含对数据科学工作流有用的代理框架和工具。
框架
- ADK-Rust - 基于 Rust 的生产级 AI 代理开发工具包,采用模型无关的设计(支持 Gemini、OpenAI、Anthropic 等),支持多种代理类型(LLM、图谱、工作流),并具备 MCP 支持和内置遥测功能。
工具
- Frostbyte MCP - 一款 MCP 服务器,为 AI 代理提供 13 种数据工具:实时加密货币价格、IP 地理定位、DNS 查询、网页抓取转 Markdown、代码执行和截图等。只需一个 API 密钥即可使用 40 多项服务。
- Arch Tools - 61 款适用于数据科学工作流的生产级 AI API 工具:代码分析、网页抓取、自然语言处理、图像生成、加密货币数据和搜索等。支持 REST API 和 MCP 协议。GitHub
研究与知识检索
- BGPT MCP - 一个 MCP 服务器,为 AI 代理提供基于原始实验数据构建的科学论文数据库,这些数据是从全文研究中提取的。每篇论文返回 25 余个结构化字段,包括方法、结果、样本量和质量评分。GitHub
工作流
- sim - Sim Studio 的界面轻量且直观,能够快速构建和部署与您常用工具连接的 LLM。
学习资源
怎样学习数据科学呢?当然是通过实践数据科学!好吧,好吧——但这对你刚开始学习时可能帮助不大。在这一部分,我们按投入程度由低到高的顺序列出了几种学习资源:教程、大规模开放在线课程 (MOOCs)、强化课程 和 高校。
教程
- 1000个数据科学项目,你可以在浏览器中使用IPython运行。
- #tidytuesday - 一个面向R生态系统的每周数据项目。
- 以你的方式进行数据科学
- DataCamp速查表 数据科学速查表。
- PySpark速查表
- 使用Python的机器学习、数据科学和深度学习
- 潜狄利克雷分配指南
- 克林顿·谢泼德所著《Python遗传算法》一书中的源代码教程
- 用于机器学习信号处理的入门教程
- 实时部署 Python时间序列模型部署教程。
- 数据科学中的Python:初学者指南
- 机器学习面试的最小可行学习计划
- 通过构建扎实的项目来理解并掌握机器学习工程
- 12个免费的数据科学项目,用于练习Python和Pandas
- 数据科学新手的最佳简历
- 用Java理解数据科学课程
- 数据分析面试题(从初级到高级)
- 顶级100+数据科学面试题及答案
- DataDriven - SQL、Python和数据建模面试题
免费课程
- 使用R的数据科学家
- 使用Python的数据科学家
- 遗传算法OCW课程
- AI专家路线图 - 成为人工智能专家的路线图
- 凸优化 - 凸优化(凸分析基础;最小二乘法、线性和二次规划、半定规划、极小极大问题、极值体积等问题;最优性条件、对偶理论等)
- 从数据中学习 - 介绍机器学习,涵盖基本理论、算法和应用
- Kaggle - 学习数据科学、机器学习、Python等
- ML可观测性基础 - 学习如何监控并定位生产环境中机器学习问题的根本原因。
- Weights & Biases高效MLOps:模型开发 - 使用W&B构建端到端机器学习系统的免费课程和认证
- Scaler提供的数据科学Python课程 - 本课程旨在帮助初学者掌握在当今数据驱动世界中脱颖而出所需的关键技能。全面的课程将为你提供统计学、编程、数据可视化和机器学习的坚实基础。
- MLSys-NYU-2022 - 纽约大学坦登学院2022年金融机器学习课程的幻灯片、脚本和资料。
- 动手训练和部署机器学习 - 一门动手实践课程,用于训练和部署一个预测加密货币价格的无服务器API。
- LLMOps:使用大型语言模型构建真实世界的应用程序 - 学习如何使用该领域最新的工具和技术,利用LLM构建现代软件。
- 视觉模型提示工程 - 在这门来自DeepLearning.AI的免费课程中,学习如何使用自然语言、坐标点、边界框、分割掩码,甚至其他图像来提示最先进的计算机视觉模型。
- IBM数据科学课程 - 免费资源,了解什么是数据科学以及它在不同行业中的应用。
MOOC课程
- Coursera 数据科学导论
- 数据科学——9步课程,Coursera上的专项课程
- 数据挖掘——5步课程,Coursera上的专项课程
- 机器学习——5步课程,Coursera上的专项课程
- CS 109 数据科学
- OpenIntro
- CS 171 可视化
- 流程挖掘:数据科学实战
- 牛津深度学习
- 牛津深度学习——视频
- 牛津机器学习
- UBC 机器学习——视频
- 数据科学专项课程
- Coursera 大数据专项课程
- Edx 的“面向数据科学与分析的统计思维”
- IBM 认知课堂人工智能
- Udacity——深度学习
- Keras实战
- 微软数据科学专业项目
- COMP3222/COMP6246——机器学习技术
- CS 231——用于视觉识别的卷积神经网络
- Coursera TensorFlow实战
- Coursera 深度学习专项课程
- 365 数据科学课程
- Coursera 自然语言处理专项课程
- Coursera GAN专项课程
- Codecademy 数据科学
- 线性代数——吉尔伯特·斯特兰格的线性代数课程
- 2020年线性代数展望(G. 斯特兰格)
- 数据科学Python基础课程
- 数据科学:统计学与机器学习
- 面向生产的机器学习工程(MLOps)
- 明尼苏达大学推荐系统专项课程,这是一项专注于推荐系统的中级/高级专项课程。
- 斯坦福人工智能专业项目
- 使用Python的数据科学家
- Julia编程
- Scaler 数据科学与机器学习项目
- 数据科学技能树
- 面向初学者的数据科学——与AI导师一起学习
- 面向初学者的机器学习——与AI导师一起学习
- 数据科学导论
- 数据科学Python入门
- 谷歌高级数据分析证书——涵盖数据分析、统计学和机器学习基础的专业课程。
- 机器语言使用分析——语料库语言学基础——由北莱茵-威斯特法伦州资助的德语文本挖掘/语料库语言学课程材料
- 为德语研究者准备的编程——由北莱茵-威斯特法伦州资助的面向数字人文领域的Python编程课程材料
集中培训项目
大学
- 提供数据科学学位的高校列表。
- 伯克利大学数据科学学位项目
- 弗吉尼亚大学数据科学学位项目
- 威斯康星大学数据科学学位项目
- 数据科学与应用理学学士学位
- 波士顿大学计算机信息系统硕士项目
- 亚利桑那州立大学在线商业分析硕士项目
- 雪城大学应用数据科学硕士项目
- 洛芬纳大学管理与数据科学硕士学位
- 墨尔本大学数据科学硕士学位
- 爱丁堡大学数据科学理学硕士项目
- 女王大学管理分析硕士学位
- 伊利诺伊理工学院应用数据科学硕士学位
- 密歇根大学应用数据科学硕士学位
- 埃因霍温理工大学数据科学与人工智能硕士学位
- 格拉纳达大学数据科学与计算机工程硕士学位
数据科学工具箱
本节收集了数据科学领域中常用的软件包、工具、算法及其他实用资源。
算法
以下是一些机器学习和数据挖掘算法及模型,可帮助您理解数据并从中提取有意义的信息。
三种类型的机器学习系统
- 基于人类监督的训练
- 基于增量式在线学习
- 基于数据点比较与模式识别
比较
- datacompy - DataComPy 是一个用于比较两个 Pandas DataFrame 的工具包。
监督学习
无监督学习
半监督学习
强化学习
数据挖掘算法
现代数据挖掘算法
- XGBoost (极端梯度提升)
- LightGBM (轻量级梯度提升机)
- CatBoost
- HDBSCAN (基于密度的层次化空间聚类,适用于噪声数据)
- FP-Growth (频繁模式增长算法)
- 孤立森林
- 深度嵌入聚类 (DEC)
- TPU (Top-k 周期性和高实用价值模式)
- 上下文感知规则挖掘 (基于 Transformer 的框架)
深度学习架构
通用机器学习工具包
- scikit-learn
- scikit-multilearn
- sklearn-expertsys
- scikit-feature
- scikit-rebate
- seqlearn
- sklearn-bayes
- sklearn-crfsuite
- sklearn-deap
- sigopt_sklearn
- sklearn-evaluation
- scikit-image
- scikit-opt
- scikit-posthocs
- feature-engine
- pystruct
- Shogun
- xLearn
- cuML
- causalml
- mlpack
- MLxtend
- modAL
- Sparkit-learn
- hyperlearn
- dlib
- imodels
- jSciPy - SciPy信号处理模块的Java移植版,提供滤波器、变换及其他科学计算工具。
- RuleFit
- pyGAM
- Deepchecks
- scikit-survival
- interpretable
- XGBoost
- LightGBM
- CatBoost
- PerpetualBooster
- JAX
深度学习工具包
PyTorch 生态系统
- PyTorch
- torchvision
- torchtext
- torchaudio
- ignite
- PyTorchNet
- PyToune
- skorch
- PyVarInf
- pytorch_geometric
- GPyTorch
- pyro
- Catalyst
- pytorch_tabular
- Yolov3
- Yolov5
- Yolov8
TensorFlow 生态系统
- TensorFlow
- TensorLayer
- TFLearn
- Sonnet
- tensorpack
- TRFL
- Polyaxon
- NeuPy
- tfdeploy
- tensorflow-upstream
- TensorFlow Fold
- tensorlm
- TensorLight
- Mesh TensorFlow
- Ludwig
- TF-Agents
- TensorForce
Keras 生态系统
可视化工具
- altair
- amcharts
- anychart
- bokeh
- Comet
- slemma
- cartodb
- Cube
- d3plus
- Data-Driven Documents(D3js)
- dygraphs
- exhibit
- gephi
- ggplot2
- Glue
- Google Chart Gallery
- Highcharts
- import.io
- Matplotlib
- nvd3
- Netron
- Openrefine
- plot.ly
- raw
- Resseract Lite
- Seaborn
- techanjs
- Timeline
- variancecharts
- vida
- vizzu
- Wrangler
- r2d3
- NetworkX
- Redash
- Metabase
- C3
- TensorWatch
- geomap
- Dash
- MetaReview - 免费在线元分析平台,配备11种交互式D3.js统计图表(森林图、漏斗图、Galbraith图、L'Abbé图、Baujat图等),5种效应量指标,AI文献筛选功能以及可直接发表的报告导出功能。github.com
其他工具
| 链接 | 描述 |
|---|---|
| 数据科学生命周期流程 | 数据科学生命周期流程是一种帮助数据科学团队从想法到价值持续、可重复实现的流程。该流程在此仓库中被详细记录。 |
| 数据科学生命周期模板仓库 | 数据科学生命周期项目的模板仓库。 |
| TabGAN | 使用GAN、扩散模型和LLM生成合成表格数据,并结合对抗性过滤和隐私度量。 |
| RexMex | 用于公平评估的通用推荐指标库。 |
| ChemicalX | 基于PyTorch的深度学习库,用于药物对评分。 |
| FileShot.io | 安全的零知识加密文件共享(浏览器端AES-256-GCM)。无需注册,MIT许可,可自行部署,支持可选链接过期功能。 |
| CorpusExplorer | 面向语料库语言学家和文本/数据挖掘爱好者的软件。可构建超过60种语言的语料库,并使用50多种工具和可视化方法。 |
| PyTorch Geometric Temporal | 动态图上的表示学习。 |
| Little Ball of Fur | 一个具有Scikit-Learn风格API的NetworkX图采样库。 |
| Karate Club | 一个具有Scikit-Learn风格API的NetworkX无监督机器学习扩展库。 |
| ML Workspace | 一体化的基于Web的机器学习和数据科学IDE。该工作区以Docker容器形式部署,预装了多种流行的数据科学库(如TensorFlow、PyTorch)和开发工具(如Jupyter、VS Code)。 |
| xonsh shell | 一款由Python驱动的Shell,能够集成、管理和编排主要用Python编写的数据科学库,从而构建流水线、代码和基于命令的工作流。它也可以用作Jupyter Notebook的内核。 |
| Neptune.ai | 一个社区友好的平台,支持数据科学家创建和分享机器学习模型。Neptune促进团队协作、基础设施管理、模型比较和可重复性。 |
| steppy | 轻量级的Python库,用于快速且可重复的机器学习实验。提供简洁的接口,便于设计清晰的机器学习流水线。 |
| steppy-toolkit | 精选的神经网络、变换器和模型集合,使您的机器学习工作更高效、更有效。 |
| Google Datalab | 使用熟悉的语言(如Python和SQL)交互式地轻松探索、可视化、分析和转换数据。 |
| Hortonworks Sandbox | 一个个人化的便携式Hadoop环境,附带十几个交互式Hadoop教程。 |
| R | 一个用于统计计算和图形绘制的免费软件环境。 |
| Tidyverse | 一组专为数据科学设计的R包集合。所有包共享共同的设计理念、语法和数据结构。 |
| RStudio | R的强大用户界面——IDE。它是免费开源的,可在Windows、Mac和Linux上运行。 |
| Python - Pandas - Anaconda | 完全免费的企业级Python发行版,适用于大规模数据处理、预测分析和科学计算。 |
| Pandas GUI | Pandas的GUI界面。 |
| Polars | 一个面向Rust和Python的快速DataFrame库,旨在作为Pandas的更快替代品。 |
| CiteMe | 基于AI的学术引用生成器。搜索11+个学术数据库(OpenAlex、PubMed、Semantic Scholar、CrossRef、SciELO),并按40+种引用格式生成参考文献。提供Web应用、浏览器扩展、Google Docs插件和公共API。 |
| Scikit-Learn | Python中的机器学习。 |
| NumPy | NumPy是Python科学计算的基础。它支持大型多维数组和矩阵,并包含一系列高级数学函数来操作这些数组。 |
| Vaex | Vaex是一个Python库,允许您以高速可视化大型数据集并计算统计数据。 |
| SciPy | SciPy与NumPy数组协同工作,提供高效的数值积分和优化算法。 |
| 数据科学工具箱 | Coursera课程。 |
| 数据科学工具箱 | 博客。 |
| Wolfram数据科学平台 | 将数值、文本、图像、GIS或其他数据交由Wolfram处理,进行全面的数据科学分析和可视化,并自动生成丰富的交互式报告——这一切都由革命性的基于知识的Wolfram语言驱动。 |
| Datadog | 高规模数据科学的解决方案、代码和DevOps工具。 |
| Variance | 无需编写JavaScript即可构建强大的Web数据可视化。 |
| Kite开发工具包 | Kite软件开发工具包(Apache许可证,版本2.0),简称Kite,是一套专注于简化在Hadoop生态系统之上构建系统的库、工具、示例和文档。 |
| Domino Data Labs | 运行、扩展、共享和部署您的模型——无需任何基础设施或设置。 |
| Apache Flink | 一个高效、分布式、通用的数据处理平台。 |
| Apache Hama | Apache Hama是Apache顶级开源项目,允许您进行超越MapReduce的高级分析。 |
| Weka | Weka是一组用于数据挖掘任务的机器学习算法。 |
| Octave | GNU Octave是一种高级解释型语言,主要用于数值计算。(免费Matlab) |
| Apache Spark | 极速集群计算。 |
| Hydrosphere Mist | 一个服务,用于将Apache Spark分析作业和机器学习模型暴露为实时、批处理或响应式Web服务。 |
| Data Mechanics | 一个数据科学和工程平台,使Apache Spark对开发者更加友好且更具成本效益。 |
| Caffe | 深度学习框架。 |
| Torch | 一个用于LuaJIT的科学计算框架。 |
| Nervana基于Python的深度学习框架 | 英特尔® Nervana™参考深度学习框架,致力于在所有硬件上实现最佳性能。 |
| Skale | 在NodeJS中进行高性能分布式数据处理。 |
| Aerosolve | 一个为人类设计的机器学习软件包。 |
| 英特尔框架 | 英特尔®深度学习框架。 |
| Datawrapper | 一个开源数据可视化平台,帮助每个人创建简单、正确且可嵌入的图表。也在github.com上。 |
| Tensor Flow | TensorFlow是一个用于机器智能的开源软件库。 |
| 自然语言工具包 | 一个入门级但功能强大的自然语言处理和分类工具包。 |
| Annotation Lab | 免费的端到端无代码文本标注和DL模型训练/调优平台。开箱即用支持命名实体识别、分类、关系抽取和断言状态等Spark NLP模型。对用户、团队、项目和文档提供无限支持。 |
| nlp-toolkit for node.js | 本模块涵盖一些基本的NLP原理和实现。重点在于性能。在处理NLP样本或训练数据时,我们很快就会耗尽内存。因此,本模块中的每个实现都以流式方式编写,只在当前步骤处理的数据保留在内存中。 |
| Julia | 一种用于技术计算的高级、高性能动态编程语言。 |
| IJulia | 一个结合了Jupyter交互式环境的Julia语言后端。 |
| Apache Zeppelin | 一个基于Web的笔记本,支持数据驱动的交互式数据分析和协作文档,使用SQL、Scala等语言。 |
| Featuretools | 一个用Python编写的开源自动特征工程框架。 |
| Optimus | 清洗、预处理、特征工程、探索性数据分析以及易于使用的ML,后端基于PySpark。 |
| Albumentations | 一个快速且与框架无关的图像增强库,实现了多样化的增强技术。开箱即用支持分类、分割和检测。曾用于赢得Kaggle、Topcoder以及CVPR研讨会相关的一系列深度学习竞赛。 |
| DVC | 一个开源的数据科学版本控制系统。它有助于跟踪、组织和使数据科学项目可重复。在最基本的情况下,它可以帮助版本控制和共享大型数据及模型文件。 |
| Lambdo | 一个工作流引擎,通过将特征工程和机器学习、模型训练和预测、表格填充和列评估结合在一个分析管道中,显著简化了数据分析过程。 |
| Feast | 一个用于管理、发现和访问机器学习特征的特征存储库。Feast为模型训练和模型服务提供一致的特征视图。 |
| Polyaxon | 一个用于可重复和可扩展的机器学习和深度学习的平台。 |
| UBIAI | 一个易于使用的文本标注工具,适用于团队,具有最全面的自动标注功能。支持NER、关系和文档分类,以及发票标签的OCR标注。 |
| Trains | 自动化实验管理器、版本控制和AI的DevOps工具。 |
| Hopsworks | 一个开源的密集型数据机器学习平台,带有特征存储库。可以摄取并管理用于在线(MySQL Cluster)和离线(Apache Hive)访问的特征,在大规模上训练和部署模型。 |
| MindsDB | MindsDB是一个面向开发者的可解释AutoML框架。使用MindsDB,您可以在一行代码中构建、训练和使用最先进的ML模型。 |
| Lightwood | 一个基于PyTorch的框架,将机器学习问题分解为更小的模块,这些模块可以无缝拼接在一起,目标是用一行代码构建预测模型。 |
| AWS Data Wrangler | 一个开源的Python包,将Pandas库的功能扩展到AWS,连接DataFrames和AWS相关的数据服务(Amazon Redshift、AWS Glue、Amazon Athena、Amazon EMR等)。 |
| Amazon Rekognition | AWS Rekognition是一项服务,允许使用亚马逊云服务的开发人员将其应用程序添加图像分析功能。对资产进行编目、自动化工作流,并从您的媒体和应用程序中提取意义。 |
| Amazon Textract | 自动从任何文档中提取印刷文本、手写内容和数据。 |
| Amazon Lookout for Vision | 使用计算机视觉检测产品缺陷,以自动化质量检验。识别缺失的产品组件、车辆和结构损坏,以及不规则之处,从而实现全面的质量控制。 |
| Amazon CodeGuru | 使用ML驱动的建议自动审查代码并优化应用程序性能。 |
| CML | 一个开源工具包,用于在数据科学项目中使用持续集成。通过GitHub Actions和GitLab CI,在类似生产环境的环境中自动训练和测试模型,并在拉取/合并请求上自动生成可视化报告。 |
| Dask | 一个开源的Python库,帮助您轻松地将分析代码迁移到分布式计算系统(大数据)。 |
| DuckDB | 一个进程内SQL OLAP数据库管理系统。 |
| Statsmodels | 一个基于Python的推论统计、假设检验和回归框架。 |
| Gensim | 一个用于自然语言文本主题建模的开源库。 |
| spaCy | 一个高性能的自然语言处理工具包。 |
| Grid Studio | Grid Studio是一个基于Web的电子表格应用程序,完全集成了Python编程语言。 |
| Python数据科学手册 | Python数据科学手册:完整文本以Jupyter Notebooks形式呈现 |
| Shapley | 一个数据驱动的框架,用于量化机器学习集成中分类器的价值。 |
| DAGsHub | 一个基于开源工具构建的数据、模型和管道管理平台。 |
| Deepnote | 一种新型的数据科学笔记本。兼容Jupyter,支持实时协作,并在云端运行。 |
| Valohai | 一个MLOps平台,负责机器编排、自动可重复性和部署。 |
| PyMC3 | 一个用于概率编程的Python库(贝叶斯推断和机器学习)。 |
| PyStan | Python接口,用于Stan(贝叶斯推断和建模)。 |
| hmmlearn | 无监督学习和隐马尔可夫模型的推断。 |
| Chaos Genius | 基于ML的分析引擎,用于异常检测和根本原因分析。 |
| Nimblebox | 一个全栈MLOps平台,旨在帮助全球的数据科学家和机器学习从业者通过他们的网页浏览器发现、创建和发布多云应用。 |
| Towhee | 一个Python库,帮助您将非结构化数据编码为嵌入。 |
| LineaPy | 曾经因为清理冗长、混乱的Jupyter笔记本而感到沮丧吗?借助LineaPy,一个开源的Python库,只需两行代码就能将混乱的开发代码转化为生产流水线。 |
| envd | 🏕️ 为数据科学和AI/ML工程团队提供的机器学习开发环境。 |
| 探索数据科学库 | 一个搜索引擎🔍工具,用于发现和查找精选的热门和新兴库、顶尖作者、热门项目工具包、讨论、教程和学习资源。 |
| MLEM | 🐶 按照GitOps原则版本化和部署您的ML模型。 |
| MLflow | 一个MLOps框架,用于管理ML模型的整个生命周期。 |
| cleanlab | 一个Python库,专注于以数据为中心的AI,并自动检测ML数据集中的各种问题。 |
| AutoGluon | AutoML,轻松为图像、文本、表格、时间序列和多模态数据生成准确的预测。 |
| Arize AI | Arize AI社区级别的可观ility工具,用于监控生产中的机器学习模型,并找出数据质量和性能漂移等问题的根本原因。 |
| Aureo.io | Aureo.io是一个低代码平台,专注于构建人工智能。它为用户提供创建流水线、自动化并与人工智能模型集成的能力——所有这些都基于他们自己的基础数据。 |
| ERD Lab | 免费的云端实体关系图(ERD)工具,专为开发者设计。 |
| Arize-Phoenix | MLOps在一个笔记本中——揭示洞察、发现问题、监控并微调您的模型。 |
| Comet | 一个MLOps平台,具备实验跟踪、模型生产管理、模型注册表和完整的数据 lineage,支持您的ML工作流程从训练直接到生产。 |
| Opik | 评估、测试和交付LLM应用程序,贯穿您的开发和生产周期。 |
| Synthical | 基于AI的协作研究环境。在同一平台上查找相关论文、创建书目管理集合并总结内容。 |
| teeplot | 一个工作流工具,用于自动整理数据可视化输出。 |
| Streamlit | 一个用于机器学习和数据科学项目的应用框架。 |
| Gradio | 围绕机器学习模型创建可定制的UI组件。 |
| Weights & Biases | 实验跟踪、数据集版本化和模型管理。 |
| DVC | 一个开源的机器学习项目版本控制系统。 |
| Optuna | 自动超参数优化软件框架。 |
| Ray Tune | 可扩展的超参数调优库。 |
| Apache Airflow | 一个用于以编程方式编写、调度和监控工作流的平台。 |
| Prefect | 一个用于现代数据堆栈的工作流管理系统。 |
| Kedro | 一个开源的Python框架,用于创建可重复、可维护的数据科学代码。 |
| Hamilton | 一个轻量级的库,用于编写和管理可靠的数据转换。 |
| SHAP | 一种博弈论方法,用于解释任何机器学习模型的输出。 |
| InterpretML | InterpretML实现了可解释提升机(EBM),这是一种基于广义加性模型(GAMs)的现代、完全可解释的机器学习模型。这个开源包还提供了EBM、其他玻璃盒模型以及黑盒解释的可视化工具。 |
| LIME | 解释任何机器学习分类器的预测结果。 |
| flyte | 一个用于机器学习的工作流自动化平台。 |
| dbt | 一个用于数据构建的工具。 |
| zasper | 一个为数据科学量身定制的超级IDE。 |
| skrub | 一个Python库,用于简化表格型机器学习的预处理和特征工程。 |
| Codeflash | 每次都能快速交付Python代码。 |
| Hugging Face | 一个流行的开源平台,用于分享ML模型、数据集以及合作开展NLP和生成式AI项目。 |
| Chinese-Elite | 一个开源项目,利用LLM解析公开数据,自动绘制关系网络,并以交互式图的形式展示。 |
| Desbordante | 一个开源的数据剖析工具,专门用于发现和验证复杂模式,例如数值关联规则、差异依赖、否定约束等。 |
| dna-claude-analysis | 一个个人基因组分析工具包,使用Python脚本对原始DNA数据进行17类分析(健康风险、祖先、药效基因组学、营养、心理学等),并生成终端风格的单页HTML可视化。 |
| RunMat | 快速MATLAB语法运行时,具备自动CPU/GPU执行和融合数组内核。 |
| Turbostream | 一个终端UI,用于试验自定义规则引擎和对实时数据流进行选择性LLM分析,无需担心流媒体基础设施或背压问题。 |
| WFGY ProblemMap | 开源的“失败地图”,列出了LLM和RAG流水线中常见的16种问题,附有可观察的症状和针对数据科学团队的建议修复方案。 |
| Deploybase | 实时追踪所有云和推理提供商的GPU和LLM价格。 |
| DeepAnalyze | 一个自主型LLM,用于自主数据科学,能够在无需人工干预的情况下完成广泛的数据科学任务。 |
文学与媒体
本节包含一些额外的阅读材料、值得关注的频道以及值得收听的演讲。
书籍
- 《从零开始的数据科学:Python基础原理》(https://www.amazon.com/Data-Science-Scratch-Principles-Python-dp-1492041130/dp/1492041130/ref=dp_ob_title_bk)
- 《Python人工智能——Tutorialspoint教程》(https://www.tutorialspoint.com/artificial_intelligence_with_python/artificial_intelligence_with_python_tutorial.pdf)
- 《从零开始的机器学习》(https://dafriedman97.github.io/mlbook/content/introduction.html)
- 《概率机器学习导论》(https://probml.github.io/pml-book/book1.html)
- 《如何在数据科学领域领导》(https://www.manning.com/books/how-to-lead-in-data-science)——抢先体验版
- 《用数据对抗用户流失》(https://www.manning.com/books/fighting-churn-with-data)
- 《使用Python和Dask的大规模数据科学》(https://www.manning.com/books/data-science-with-python-and-dask)
- 《Python数据科学手册》(https://jakevdp.github.io/PythonDataScienceHandbook/)
- 《数据科学家手册:25位杰出数据科学家的建议与洞见》(https://www.thedatasciencehandbook.com/)
- 《像数据科学家一样思考》(https://www.manning.com/books/think-like-a-data-scientist)
- 《数据科学入门》(https://www.manning.com/books/introducing-data-science)
- 《R语言实战数据科学》(https://www.manning.com/books/practical-data-science-with-r)
- 《日常数据科学》(https://www.amazon.com/dp/B08TZ1MT3W/ref=cm_sw_r_cp_apa_fabc_a0ceGbWECF9A8)及[更便宜的PDF版本](https://gum.co/everydaydata)
- 《探索数据科学》(https://www.manning.com/books/exploring-data-science)——免费电子书试读版
- 《探索数据丛林》(https://www.manning.com/books/exploring-the-data-jungle)——免费电子书试读版
- 《Python经典计算机科学问题》(https://www.manning.com/books/classic-computer-science-problems-in-python)
- 《程序员数学》(https://www.manning.com/books/math-for-programmers)——抢先体验版
- 《R语言实战(第三版)》(https://www.manning.com/books/r-in-action-third-edition)——抢先体验版
- 《数据科学读书营》(https://www.manning.com/books/data-science-bookcamp)——抢先体验版
- 《数据科学思维:下一场科学、技术和经济革命》(https://www.springer.com/gp/book/9783319950914)
- 《应用数据科学:数据驱动型企业的经验教训》(https://www.springer.com/gp/book/9783030118204)
- 《数据科学家手册》(https://www.amazon.com/Data-Science-Handbook-Field-Cady/dp/1119092949)
- 《自然语言处理 essentials》(https://www.manning.com/books/getting-started-with-natural-language-processing)——抢先体验版
- 《挖掘海量数据集》(http://www.mmds.org/)——由在线课程配套的免费电子书
- 《Pandas实战》(https://www.manning.com/books/pandas-in-action)——抢先体验版
- 《遗传算法与遗传编程》(https://www.taylorfrancis.com/books/9780429141973)
- 《进化算法进展》(https://www.intechopen.com/books/advances_in_evolutionary_algorithms)——免费下载
- 《遗传编程:新方法与成功应用》(https://www.intechopen.com/books/genetic-programming-new-approaches-and-successful-applications)——免费下载
- 《进化算法》(https://www.intechopen.com/books/evolutionary-algorithms)——免费下载
- 《遗传编程进展,第3卷》(http://www0.cs.ucl.ac.uk/staff/W.Langdon/aigp3/)——免费下载
- 《遗传算法与进化计算》(https://www.talkorigins.org/faqs/genalg/genalg.html)——免费下载
- 《凸优化》(https://web.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf)——斯蒂芬·博伊德的《凸优化》一书——免费下载
- 《使用Python和PySpark进行数据分析》(https://www.manning.com/books/data-analysis-with-python-and-pyspark)——抢先体验版
- 《R语言与数据科学》(https://r4ds.had.co.nz/)
- 《打造数据科学职业生涯》(https://www.manning.com/books/build-a-career-in-data-science)
- 《机器学习读书营》(https://mlbookcamp.com/)——抢先体验版
- 《动手学机器学习:Scikit-Learn、Keras和TensorFlow 第2版》(https://www.oreilly.com/library/view/hands-on-machine-learning/9781492032632/)
- 《高效的数据科学基础设施》(https://www.manning.com/books/effective-data-science-infrastructure)
- 《实用MLOps:如何为生产级模型做好准备》(https://valohai.com/mlops-ebook/)
- 《使用Python和PySpark进行数据分析》(https://www.manning.com/books/data-analysis-with-python-and-pyspark)
- 《回归分析:友好指南》(https://www.manning.com/books/regression-a-friendly-guide)——抢先体验版
- 《流式系统:大规模数据处理的何、何地、何时和如何》(https://www.oreilly.com/library/view/streaming-systems/9781491983867/)
- 《命令行上的数据科学:用久经考验的工具迎接未来》(https://www.oreilly.com/library/view/data-science-at/9781491947845/)
- 《Python机器学习——Tutorialspoint教程》(https://www.tutorialspoint.com/machine_learning_with_python/machine_learning_with_python_tutorial.pdf)
- 《深度学习》(https://www.deeplearningbook.org/)
- 《设计云数据平台》(https://www.manning.com/books/designing-cloud-data-platforms)——抢先体验版
- 《统计学习导论及其在R中的应用》(https://www.statlearning.com/)
- 《统计学习要素:数据挖掘、推断与预测》(https://hastie.su.domains/ElemStatLearn/)
- 《使用PyTorch的深度学习》(https://www.simonandschuster.com/books/Deep-Learning-with-PyTorch/Eli-Stevens/9781617295263)
- 《神经网络与深度学习》(http://neuralnetworksanddeeplearning.com)
- 《深度学习烹饪书》(https://www.oreilly.com/library/view/deep-learning-cookbook/9781491995839/)
- 《Python机器学习入门》(https://www.oreilly.com/library/view/introduction-to-machine/9781449369880/)
- 《人工智能:计算智能体基础(第二版)》(https://artint.info/index.html)——免费HTML版本
- 《人工智能探秘:思想与成就的历史》(https://ai.stanford.edu/~nilsson/QAI/qai.pdf)——免费下载
- 《数据科学中的图算法》(https://www.manning.com/books/graph-algorithms-for-data-science)——抢先体验版
- 《数据网格实战》(https://www.manning.com/books/data-mesh-in-action)——抢先体验版
- 《Julia用于数据分析》(https://www.manning.com/books/julia-for-data-analysis)——抢先体验版
- 《数据科学中的因果推断》(https://www.manning.com/books/julia-for-data-analysis)——抢先体验版
- 《正则表达式谜题与AI编码助手》(https://www.manning.com/books/regular-expression-puzzles-and-ai-coding-assistants)——作者:大卫·梅茨
- 《深入深度学习》(https://d2l.ai/)
- 《数据为所有人》(https://www.manning.com/books/data-for-all)
- 《可解释的机器学习:让黑盒模型变得可解释的指南》(https://christophm.github.io/interpretable-ml-book/)——免费GitHub版本
- 《数据科学基础》(https://www.cs.cornell.edu/jeh/book.pdf)——免费下载
- 《Comet for DataScience:提升您管理和优化数据科学项目生命周期的能力》(https://www.amazon.com/Comet-Data-Science-Enhance-optimize/dp/1801814430)
- 《面向数据科学家的软件工程》(https://www.manning.com/books/software-engineering-for-data-scientists)——抢先体验版
- 《Julia用于数据科学》(https://www.manning.com/books/julia-for-data-science)——抢先体验版
- 《统计学习入门》(https://www.statlearning.com/)——下载页面
- 《机器学习完全入门》(https://www.amazon.in/Machine-Learning-Absolute-Beginners-Introduction-ebook/dp/B07335JNW1)
- 《统一业务、数据与代码:使用JSON Schema设计数据产品》(https://learning.oreilly.com/library/view/unifying-business-data/9781098144999/)
- 《掌握贝叶斯》(https://www.manning.com/books/grokking-bayes)
- 《机器学习Q与AI》(https://sebastianraschka.com/books/ml-q-and-ai)
- 《JavaScript用于数据科学》(https://third-bit.com/js4ds/)——免费HTML页面
- 《应用数据科学》(https://angewandtedatascience.de/)——一本关于应用数据科学的德语书籍
- 《人工智能背后的数学》(https://www.freecodecamp.org/news/the-math-behind-artificial-intelligence-book):这是一本由FreeCodeCamp免费发布的书籍,以通俗易懂的语言从工程学角度讲解了人工智能背后的数学知识。
图书优惠(联盟营销)
期刊、出版物和杂志
- ICML - 国际机器学习大会
- GECCO - 遗传与进化计算会议(GECCO)
- epjdatascience
- 数据科学期刊 - 一本致力于广泛应用统计方法的国际期刊
- 大数据研究
- 大数据期刊
- 大数据与社会
- 数据科学期刊
- datatau.com/news - 类似于Hacker News,但专注于数据领域
- 数据科学Trello看板
- Medium数据科学专题 - Medium上关于数据科学的相关文章
- Towards Data Science遗传算法专题 - Towards Data Science上关于遗传算法的相关文章
- Maxim AI。用于AI智能体模拟、评估及可观测性的工具。
新闻通讯
- AI Weekly - 由行业领袖精选的人工智能情报简报,涵盖模型、融资、政策及应用等内容。自2017年起每周三刊,订阅用户超过4万人。
- DataTalks.Club。一份关于数据相关话题的每周通讯。存档。
- The Analytics Engineering Roundup。一份关于数据科学的通讯。存档。
- Techpresso。一份免费的每日通讯,覆盖人工智能、机器学习及科技领域中最具影响力的发展动态。存档。
邮件列表
- 工作组 - 数字人文领域的研究软件工程。这是数字人文领域研究软件工程(DH-RSE)工作组的邮件列表。
博主
- Wes McKinney - Wes McKinney 档案。
- Matthew Russell - 开采社交网络。
- Greg Reda - Greg Reda 个人博客
- Julia Evans - Recurse Center 校友
- Hakan Kardas - 个人主页
- Sean J. Taylor - 个人主页
- Drew Conway - 个人主页
- Hilary Mason - 个人主页
- Noah Iliinsky - 个人博客
- Matt Harrison - 个人博客
- Vamshi Ambati - AllThings Data Sciene
- Prash Chan - 关于主数据管理和相关热点的技术博客
- Clare Corthell - 开源数据科学硕士项目
- Datawrangling 由 Peter Skomoroch 运营。机器学习、数据挖掘等。
- Quora 数据科学 - 来自专家的数据科学问答
- Siah 是伯克利大学的一名博士生
- Louis Dorard 是一位对网络和大小数据情有独钟的技术爱好者
- Machine Learning Mastery 致力于帮助专业程序员自信地应用机器学习算法来解决复杂问题。
- Daniel Forsyth - 个人博客
- Data Science Weekly - 每周新闻博客
- Revolution Analytics - 数据科学博客
- R Bloggers - R 语言博主
- The Practical Quant 大数据
- Yet Another Data Blog 又一个数据博客
- KD Nuggets 数据挖掘、分析、大数据、数据、科学——这不是博客,而是一个门户网站
- Meta Brown - 个人博客
- Data Scientist 正在构建数据科学家文化。
- WhatSTheBigData 涉及上述内容的一部分、全部,甚至更多,本博客探讨其对信息技术、商业世界、政府机构以及我们生活的影响。
- Tevfik Kosar - Magnus Notitia
- New Data Scientist 社会科学家如何进入大数据领域
- Harvard Data Science - 关于统计计算与可视化的思考
- Data Science 101 - 学习成为一名数据科学家
- Kaggle 历年解决方案
- DataScientistJourney
- 纽约出租车可视化博客
- Data-Mania
- Data-Magnum
- datascopeanalytics
- 数字化转型
- datascientistjourney
- Data Mania 博客 - 文件抽屉 - Chris Said 的科学博客
- Emilio Ferrara 的个人主页
- DataNews
- Reddit 文本挖掘
- Periscopic
- Hilary Parker
- Data Stories
- 数据科学实验室
- 意义之所在
- 数据之地的冒险
- Dataclysm
- FlowingData - 可视化与统计
- Calculated Risk
- O'Reilly 学习博客
- Dominodatalab
- i am trask - 机器学习工艺博客
- 实用数据科学手册 - 面向现实问题的数据驱动解决方案指南与配方
- Dataconomy - 关注新兴数据经济的博客
- Springboard - 为数据科学学习者提供资源的博客
- Analytics Vidhya - 一个关于数据科学和分析学习资料的综合性网站。
- 奥卡姆剃刀 - 专注于网络分析。
- Data School - 针对初学者的数据科学教程!
- Colah 的博客 - 理解神经网络的博客!
- Sebastian 的博客 - 自然语言处理与迁移学习的博客!
- Distill - 专门用于清晰解释机器学习的平台!
- Chris Albon 的网站 - 数据科学与人工智能笔记
- Andrew Carr - 使用冷门编程语言进行数据科学
- floydhub - 进化算法博客
- Jingles - 复习并提炼学术论文中的关键概念
- nbshare - 数据科学笔记本
- Loic Tetrel - 数据科学博客
- Chip Huyen 的博客 - 机器学习工程、MLOps 以及初创企业中机器学习的应用
- Maria Khalusova - 数据科学博客
- Aditi Rastogi - ML、DL、数据科学博客
- Santiago Basulto - 使用 Python 进行数据科学
- Akhil Soni - ML、DL 和数据科学
- Akhil Soni - ML、DL 和数据科学
- Applied AI Blogs - 深入探讨人工智能、机器学习和数据科学概念,并结合实际应用的文章。
- Scaler Blogs - 软件开发、人工智能以及科技行业职业发展的教育内容。
- Mlu github - Mlu 是亚马逊开发的工具,旨在帮助机器学习从业者。你可以在这里通过实时图表学习从基础到高级的所有知识。
- Jan Oliver Rüdiger - ML、DL 和数据科学——专注于文本/数据挖掘
演示文稿
- 如何成为一名数据科学家
- 数据科学导论
- 面向企业大数据的数据科学入门
- 如何面试数据科学家
- 如何与统计学家共享数据
- 数据科学领域卓越职业生涯的科学
- 数据科学家是做什么的?
- 构建数据初创公司:快速、大规模且专注
- 如何用深度学习赢得数据科学竞赛
- 全栈数据科学家
播客
- AI在家
- AI今日
- 对抗性学习
- 下午茶时间数据科学
- 思维链
- 数据工程播客
- 在家学数据科学
- 数据科学混合
- 数据怀疑论者
- 数据故事
- 数据广播
- 数据框架
- DataTalks.Club
- 梯度下降
- 机器学习101
- 让我们谈数据(巴西)
- 线性离题
- 非标准偏差
- O'Reilly数据秀播客
- 偏导数
- 超级数据科学
- 数据工程秀
- 激进AI播客
- 重点是什么
- 分析工程播客
YouTube 视频与频道
- 什么是机器学习?
- 吴恩达:深度学习、自学学习和无监督特征学习
- Data36 - 托米·梅斯特为初学者讲解的数据科学
- 深度学习:来自大数据的智能
- 采访谷歌人工智能与深度学习“教父”杰弗里·辛顿
- 使用Python入门深度学习
- 什么是机器学习,它是如何工作的?
- CampusX
- 数据学校 - 数据科学教育
- 梅拉妮·沃里克为新手讲解的神经网络(2015年5月)
- 于戈·拉罗谢尔的神经网络视频系列
- Google DeepMind联合创始人谢恩·莱格 - 机器超智能
- 数据科学入门
- 利用遗传算法的数据科学
- 面向初学者的数据科学
- DataTalks.Club
- Mildlyoverfitted - 中级机器学习/深度学习主题教程
- mlops.community - 对行业专家关于生产级机器学习的访谈
- ML Street Talk - 不加掩饰的技术性和非商业性,因此你不会听到任何烦人的推销。
- 3Blue1Brown的神经网络
- Sentdex从零开始讲解的神经网络
- Manning Publications YouTube频道
- 请教钟博士:如何在数据科学领域领导 - 第1部分
- 请教钟博士:如何在数据科学领域领导 - 第2部分
- 请教钟博士:如何在数据科学领域领导 - 第3部分
- 请教钟博士:如何在数据科学领域领导 - 第4部分
- 请教钟博士:如何在数据科学领域领导 - 第5部分
- 请教钟博士:如何在数据科学领域领导 - 第6部分
- 回归模型:应用简单的泊松回归
- 深度学习架构
- 时间序列建模与分析
- 塞拉诺学院
- 端到端数据科学播放列表
- 数据科学导论 - LinkedIn
社交
以下是一些社交媒体链接。与更多数据科学家交流吧!
Facebook 账号
- Data
- Big Data Scientist
- Data Science Day
- Data Science Academy
- Facebook 数据科学页面
- Data Science London
- Data Science Technology and Corporation
- 数据科学 - 封闭群组
- 数据科学中心
- 大数据 Hadoop NoSQL Hive HBase
- 分析、数据挖掘、预测建模、人工智能
- 使用 R 语言进行大数据分析
- R 与 Hadoop 结合的大数据分析
- 大数据学习
- 大数据、数据科学、数据挖掘与统计学
- 大数据/Hadoop 专家
- 数据挖掘/机器学习/人工智能
- 数据挖掘/大数据 - 社交网络分析
- 实用数据科学指南
- 伊斯坦布尔数据科学
- 数据科学博客
Twitter 账号
| 描述 | |
|---|---|
| Big Data Combine | 面向希望将其模型转化为交易策略的数据科学家的快速、实时选拔活动 |
| Big Data Mania | 数据可视化达人、数据记者、增长黑客、《数据科学傻瓜书》(2015年)作者 |
| Big Data Science | 大数据、数据科学、预测建模、商业分析、Hadoop、决策与运筹学。 |
| Charlie Greenbacker | @ExploreAltamira 的数据科学总监 |
| Chris Said | Twitter 的数据科学家 |
| Clare Corthell | 开发、设计、数据科学 @mattermark #hackerei |
| DADI Charles-Abner | #数据科学家 @Ekimetrics. , #机器学习 #数据可视化 #动态图表 #Hadoop #R #Python #NLP #比特币 #数据爱好者 |
| Data Science Central | Data Science Central 是面向大数据从业者的行业唯一资源。 |
| Data Science London | 数据科学。大数据。数据黑客。数据成瘾者。数据初创企业。开放数据 |
| Data Science Renee | 记录我从 SQL 数据分析师到攻读工程硕士学位并最终成为数据科学家的成长历程 |
| Data Science Report | 我们的使命是帮助指导和推动数据科学与分析领域的职业发展 |
| Data Science Tips | 全球数据科学家的技巧与窍门!#数据科学 #大数据 |
| Data Vizzard | 数据可视化、安全、军事 |
| DataScienceX | |
| deeplearning4j | |
| DJ Patil | 白宫数据主管,RelateIQ 副总裁。 |
| Domino Data Lab | |
| Drew Conway | 数据极客、黑客、冲突研究者。 |
| Emilio Ferrara | #网络、#机器学习 和 #数据科学。我在 #社交媒体 领域工作。印第安纳大学博士后研究员 |
| Erin Bartolo | 与 #大数据 同行——对它的炒作既爱又恨。@iSchoolSU #数据科学 项目负责人。 |
| Greg Reda | 在 GrubHub 工作,专注于数据和 pandas |
| Gregory Piatetsky | KDnuggets 总裁,分析/大数据/数据挖掘/数据科学专家,KDD 和 SIGKDD 联合创始人,曾担任两家初创公司的首席科学家,兼职哲学家。 |
| Hadley Wickham | RStudio 的首席科学家,同时兼任奥克兰大学、斯坦福大学和莱斯大学的统计学兼职教授。 |
| Hakan Kardas | 数据科学家 |
| Hilary Mason | @accel 的驻院数据科学家。 |
| Jeff Hammerbacher | 转发关于数据科学的内容 |
| John Myles White | Facebook 的科学家兼 Julia 开发者。著有《黑客机器学习》和《用于网站优化的赌徒算法》。推文仅代表个人观点。 |
| Juan Miguel Lavista | 微软数据科学团队的首席数据科学家 |
| Julia Evans | 黑客——Pandas——数据分析 |
| Kenneth Cukier | 《经济学人》的数据编辑,以及《大数据》一书的共同作者(http://www.big-data-book.com/)。 |
| Kevin Davenport | https://www.meetup.com/San-Diego-Data-Science-R-Users-Group/ 的组织者 |
| Kevin Markham | 数据科学讲师,Data School 的创始人 |
| Kim Rees | 交互式数据可视化及工具。数据漫游者。 |
| Kirk Borne | 数据科学家,天体物理学博士,顶级 #大数据 影响者。 |
| Linda Regber | 数据故事讲述者,擅长数据可视化。 |
| Luis Rei | 博士生。编程、移动、Web。人工智能、智能机器人、机器学习、数据挖掘、自然语言处理、数据科学。 |
| Mark Stevenson | Salt (@SaltJobs) 的数据分析招聘专家 分析 - 洞察 - 大数据 - 数据科学 |
| Matt Harrison | 全栈 Python 爱好者的观点,作家、讲师,目前从事数据科学家工作。偶尔也会兼顾父亲、丈夫的角色,以及有机园艺。 |
| Matthew Russell | 挖掘社交网络。 |
| Mert Nuhoğlu | BizQualify 的数据科学家,开发者 |
| Monica Rogati | Jawbone 的数据工作者。曾在 LinkedIn 将数据转化为故事和产品。文本挖掘、应用机器学习、推荐系统。前游戏玩家、前机器编码员;也是一名取名者。 |
| Noah Iliinsky | 可视化与交互设计师。务实的骑行者。著有可视化相关书籍:https://www.oreilly.com/pub/au/4419 |
| Paul Miller | 云计算/大数据/开放数据分析师及顾问。作家、演讲者和主持人。Gigaom 研究分析师。 |
| Peter Skomoroch | 创建智能系统以自动化任务并改善决策。企业家,曾任 LinkedIn 首席数据科学家。机器学习、产品设计、网络 |
| Prash Chan | IBM 的解决方案架构师,主攻主数据管理、数据质量和数据治理,同时也是博客作者。关注数据科学、Hadoop、大数据和云技术。 |
| Quora Data Science | Quora 的数据科学话题 |
| R-Bloggers | 转发来自 R 社区博客、数据科学会议,以及(!)面向数据科学家的招聘信息。 |
| Rand Hindi | |
| Randy Olson | 研究人工智能的计算机科学家。数据极客。@DataIsBeautiful 社区领袖。#开放科学 的倡导者。 |
| Recep Erol | UALR 的数据科学极客 |
| Ryan Orban | 数据科学家,遗传折纸爱好者,硬件发烧友 |
| Sean J. Taylor | 社会科学家。黑客。Facebook 数据科学团队成员。关键词:实验、因果推断、统计学、机器学习、经济学。 |
| Silvia K. Spiva | 思科的 #数据科学 工作 |
| Harsh B. Gupta | BBVA Compass 的数据科学家 |
| Spencer Nelson | 数据极客 |
| Talha Oz | 喜欢 ABM、SNA、DM、ML、NLP、HI、Python、Java。顶尖的 Kaggle 用户/数据科学家 |
| Tasos Skarlatidis | 复杂事件处理、大数据、人工智能和机器学习。热衷于编程和开源。 |
| Terry Timko | 信息政府;大数据;数据即服务;数据科学;开放、社交和商业数据的融合 |
| Tony Baer | Ovum 的 IT 分析师,主要关注大数据和数据管理,并涉及部分系统工程领域。 |
| Tony Ojeda | 数据科学家、作家、企业家。@DataCommunityDC 的联合创始人,@DistrictDataLab 的创始人。#数据科学 #大数据 #DataDC |
| Vamshi Ambati | PayPal 的数据科学工作。#NLP、#机器学习;卡内基梅隆大学校友(博客:https://allthingsds.wordpress.com ) |
| Wes McKinney | Pandas(Python 数据分析库)。 |
| WileyEd | 高级经理——@Seagate 大数据分析——麦肯锡校友 #大数据 + #分析 推广者 #Hadoop、#云、#数字 和 #R 的狂热爱好者 |
| WNYC 数据新闻团队 | @WNYC 的数据新闻团队。践行数据驱动型新闻报道,将其可视化,并公开我们的工作过程。 |
| Alexey Grigorev | 数据科学作家 |
| İlker Arslan | 数据科学作家。主要分享关于 Julia 编程的内容 |
| INEVITABLE | 怀揣 AI 和数据科学梦想的初创公司,位于英国英格兰 |
| Jan Oliver Rüdiger | ML、DL 和 数据科学——尤其侧重于文本/数据挖掘 |
Telegram 频道
- Open Data Science – 首个 Telegram 数据科学频道。涵盖与数据科学相关的所有技术和热门内容:人工智能、大数据、机器学习、统计学、基础数学及其应用。
- Loss function porn — 以视频或图形可视化形式呈现的精美数据科学/机器学习主题帖子。
- Machinelearning – 每日机器学习新闻。
Slack 社区
GitHub 群组
数据科学竞赛
一些数据挖掘竞赛平台
有趣的内容
信息图
| 预览 | 描述 |
|---|---|
 |
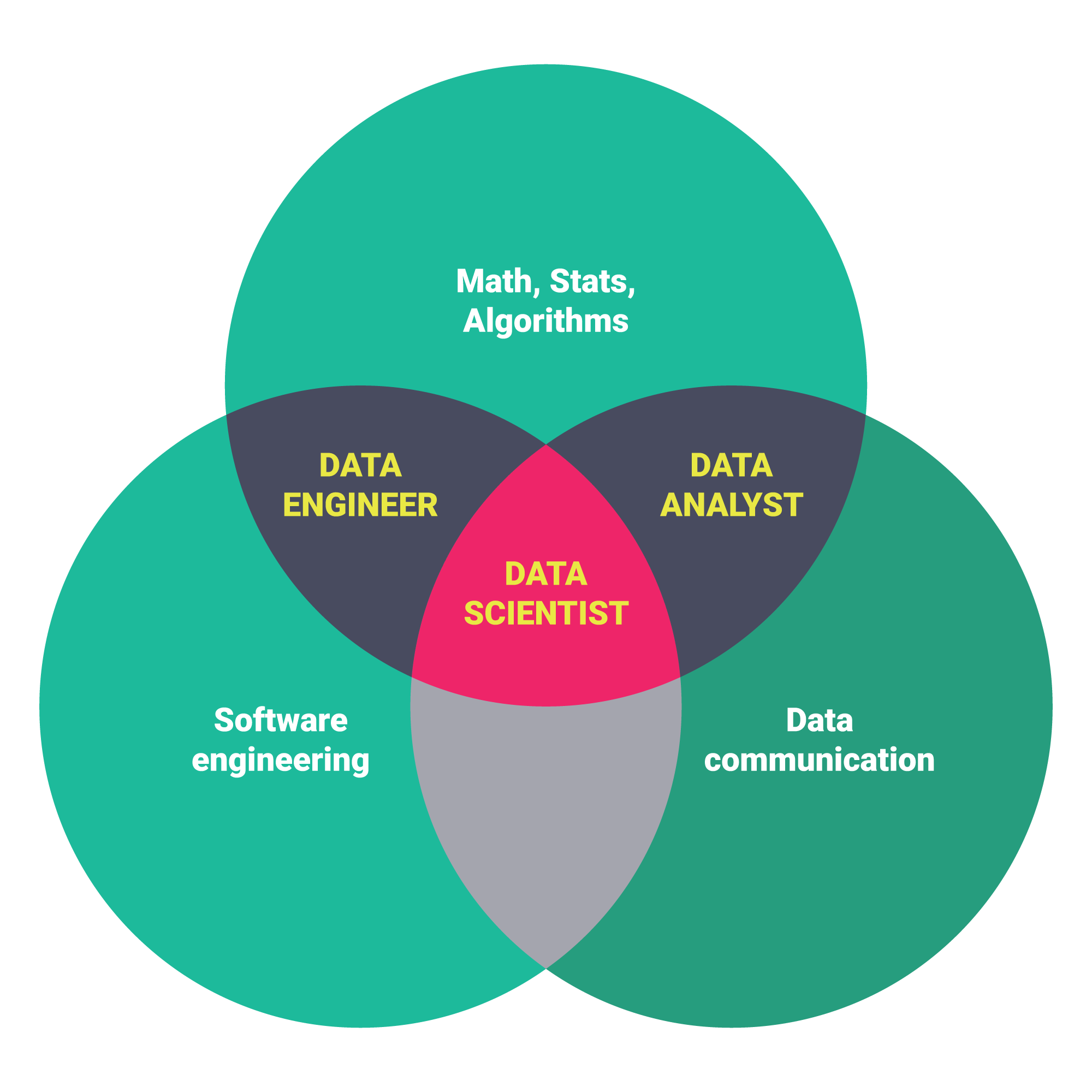
数据科学家与数据工程师的关键区别 |
 |
由DataCamp 提供的“成为数据科学家的八步”可视化指南 (img) |
 |
关于所需技能的思维导图 (img) |
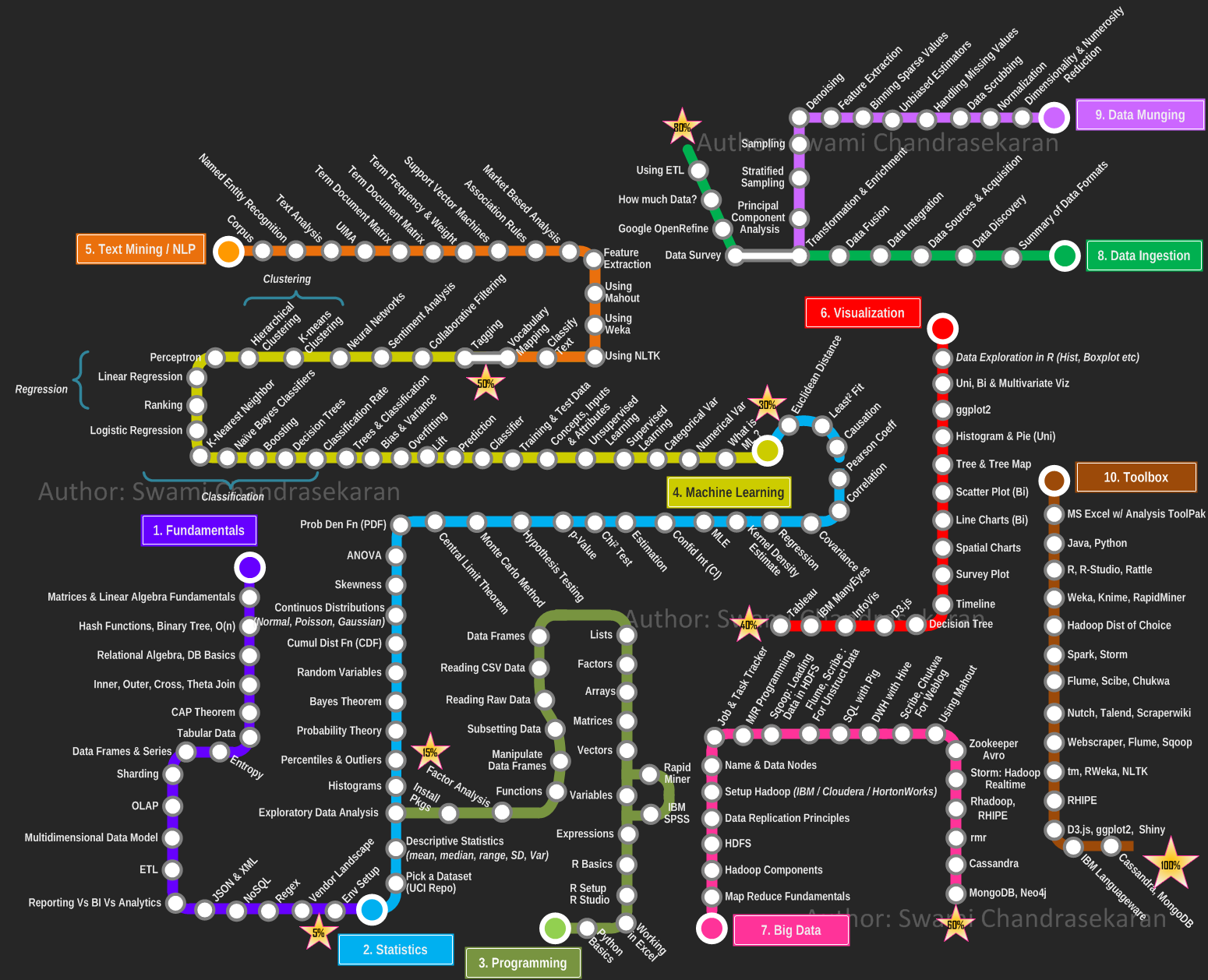 |
Swami Chandrasekaran 制作了一份基于地铁线路图的课程体系(链接)。 |
 |
由@kzawadz 通过twitter 发布 |
 |
由Data Science Central 制作 |
 |
数据科学之争:R 语言 vs Python |
 |
如何选择统计学或机器学习方法 |
 |
如何选择合适的估计器 |
 |
数据科学行业:各角色及其职责 |
 |
数据科学 |
 |
来自Springboard 的不同数据科学技能与岗位角色 |
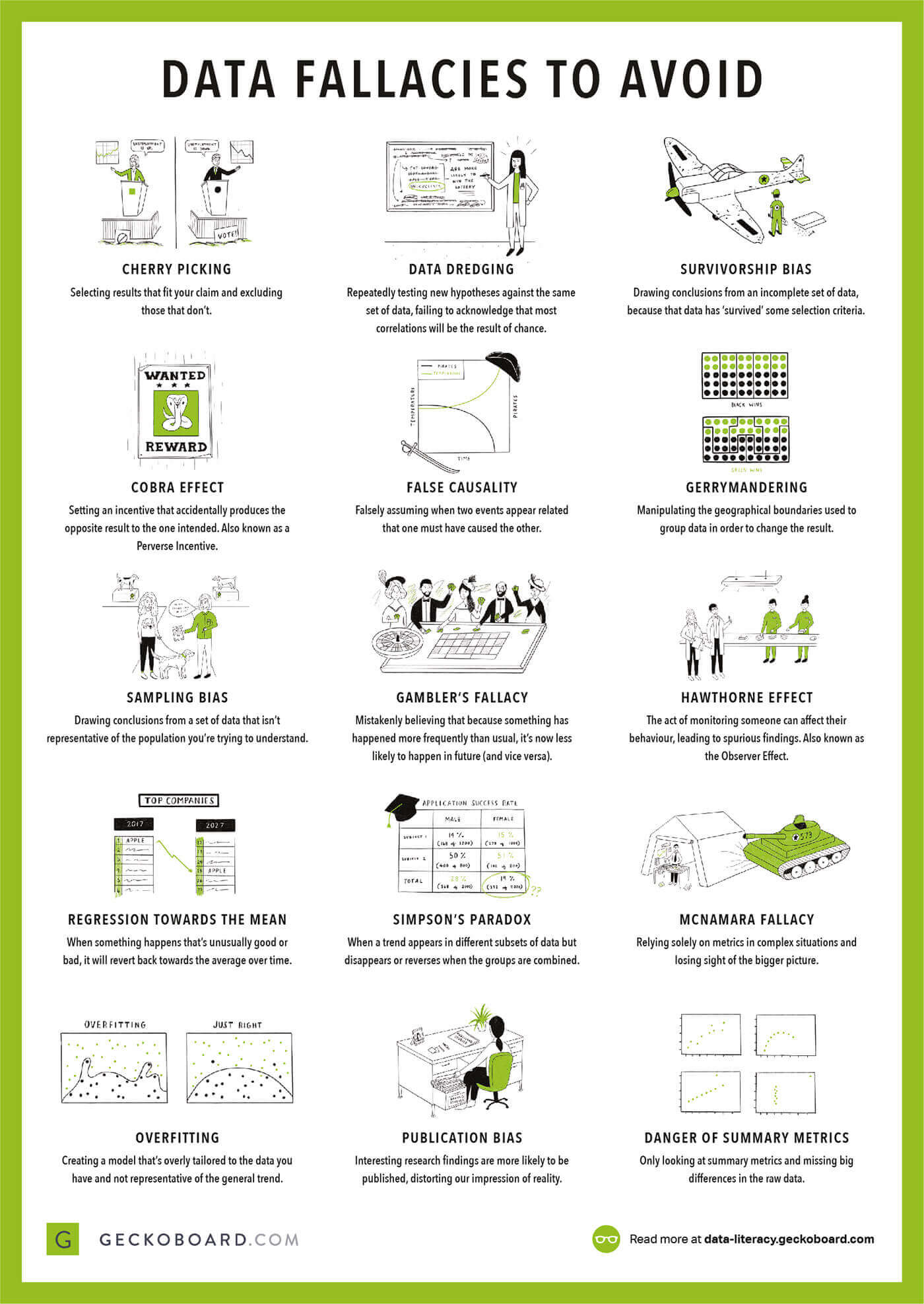 |
一种简单友好的方式,用于教导非数据科学家或非统计学家的同事如何避免数据中的错误。出自 Geckoboard 的数据素养课程。 |
数据集
- Academic Torrents
- ADS-B Exchange - 针对飞机及自动相关监视广播(ADS-B)数据源的特定数据集。
- AI Displacement Tracker - 结构化数据集,追踪92起与人工智能相关的裁员事件,涉及12个国家、11个行业的453,748名员工。提供JSON和CSV格式,采用CC-BY-4.0许可。
- hadoopilluminated.com
- data.gov - 美国政府开放数据的官方平台
- 美国人口普查局
- enigma.com - 探索公共数据的世界——快速搜索并分析由政府、公司和组织发布的数十亿条公开记录。
- datahub.io
- aws.amazon.com/datasets
- datacite.org
- 欧洲数据官方门户
- NASDAQ:DATA - Nasdaq Data Link,一流的金融、经济及另类数据源。
- 国会股票大脑 - 免费的AI驱动工具,根据重要性对美国国会议员的《STOCK法案》交易披露进行评分。基于537位议员的公开交易申报生成机器评分信号。
- figshare.com
- GeoLite Legacy 可下载数据库
- Hugging Face 数据集
- Quora关于大型数据集的回答
- 公共大数据集
- Kaggle 数据集
- 人类遗传变异深度目录
- 社区维护的知名人物、地点和事物数据库
- 谷歌公共数据
- 世界银行数据
- 纽约出租车数据
- Open Data Philly 为费城市民连接数据资源
- grouplens.org 提供电影(含评分)、书籍和维基数据集示例
- 加州大学欧文分校机器学习存储库 - 包含适合机器学习的数据集
- 研究级数据集 由Hilary Mason整理
- 国家环境信息中心
- ClimateData.us(相关:美国气候韧性工具箱)
- r/datasets
- MapLight - 为公众免费提供多种数据集。点击下方数据集了解更多详情。
- GHDx - 健康指标与评估研究所——全球健康与人口统计数据目录,包含IHME的研究成果
- 圣路易斯联邦储备经济数据 - FRED
- 新西兰经济研究所 – Data1850
- 开放数据源
- 联合国儿童基金会数据
- undata
- NASA社会经济数据与应用中心 - SEDAC
- GDELT项目
- 瑞典统计局
- StackExchange 数据探索器 - 开源工具,用于对Stack Exchange网络中的公开数据运行任意查询。
- 旧金山政府开放数据
- IBM资产数据集
- 开放数据指数
- 公共Git档案
- GHTorrent
- 微软研究院开放数据
- 印度开放政府数据平台
- 谷歌数据集搜索(测试版)
- NAYN.CO土耳其新闻分类数据
- 新冠疫情数据
- 谷歌新冠疫情开放数据
- 安然邮件数据集
- 5000张服装图片
- IBB开放门户
- 人道主义数据交换平台
- 25万+份职位招聘信息 - 一份不断扩充的历史职位数据集,涵盖2020年至今的卢森堡地区招聘信息。AWS数据交换平台上托管了超过25万份职位信息,可免费获取。
- FinancialData.Net - 金融数据集(股市数据、财务报表、可持续发展数据等)。
- 谷歌数据集搜索 – 在全网查找各类数据集。
- notesjor语料库集合 - 免费语料库(超过60亿词素),以德语为主,涵盖历史与现代德语。
- CLARIN存储库 - CLARIN是欧洲的科学数据存储库。
- GBIF - 全球生物多样性信息设施:24亿+物种出现记录。免费开放API,适用于生态建模和机器学习研究。
- FAOSTAT - 联合国粮农组织关于食品生产、贸易、土地利用和排放的统计数据,覆盖245多个国家。提供免费API和批量下载功能。
- FirstData - 全球最全面的权威数据源知识库。收录来自各国政府、国际组织和研究机构的210余种精选来源。支持MCP集成,适用于AI智能体。采用MIT许可证。
- latamdata-py - 一个Python软件包,可一键访问来自拉丁美洲的38个开放研究数据集(健康、神经科学、心理健康、经济学等)。使用pip install latamdata-py即可安装。
- ZipCheckup - 面向美国42,000多个邮政编码区的免费ZIP级别环境安全数据:水质、空气质量、PFAS污染、氡气、铅含量、洪水风险等11个领域。提供公共REST API、npm/PyPI软件包,并采用CC BY 4.0许可。
漫画
其他超赞列表
- 更多令人惊叹的列表可以在 awesome-awesomeness 中找到。
- 超赞机器学习
- 列表
- 超赞数据可视化
- 超赞 Python
- 数据科学 IPython 笔记本。
- 超赞 R
- 超赞数据集
- 超赞机器学习与深度学习教程
- 超赞数据科学创意
- 面向软件工程师的机器学习
- 社区精选的数据科学资源
- 源代码上的超赞机器学习
- 超赞社区发现
- 超赞图分类
- 超赞决策树论文
- 超赞欺诈检测论文
- 超赞梯度提升论文
- 超赞计算机视觉模型
- 超赞蒙特卡洛树搜索
- 常见统计与机器学习术语表
- 100 篇自然语言处理论文
- 超赞游戏数据集
- 数据科学面试题
- 超赞可解释图推理
- 顶级数据科学面试题
- 超赞药物协同、相互作用及多药联用预测
- 深度学习面试题
- 2023 年数据科学未来趋势
- 生成式 AI 如何改变创意工作
- 什么是生成式 AI?
- 100 多道机器学习面试题(从入门到高级)
- 数据科学项目
- 数据科学是好职业吗?
- 数据科学的未来:预测与趋势
- 数据科学与机器学习:有什么区别?
- 数据科学中的 AI:用途、角色和工具
- 顶级 13 种数据科学编程语言
- 40 多个数据分析项目创意
- 最佳带证书的数据科学课程
- 生成式 AI 模型
- 超赞数据分析 - 一个精心挑选的数据分析工具、库和资源列表。
- 超赞证据综合 - 一个精选的开源工具列表,用于系统综述、荟萃分析和证据综合。
爱好
版本历史
v2026.04.01.12026/04/01v2026.02.03.12026/02/03v2026.01.24.12026/01/23v2025.12.31.12025/12/31v2025.11.03.12025/11/03v2025.10.21.12025/10/21v2025.09.13.12025/09/12v2025.08.18.12025/08/18v2025.01.02.12025/01/02v2024.08.29.12024/08/29v2024.07.01.12024/07/01v2024.06.02.12024/06/02v2023.10.312023/10/31v2023.09.292023/09/29v2023.04.32023/04/03v2023.03.132023/03/13v2023.02.212023/02/21v2022.12.012022/12/012022.10.142022/10/15常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备