MiMo-V2-Flash
MiMo-V2-Flash 是小米开源的一款高效混合专家(MoE)大语言模型,专为高速推理、代码生成及智能体任务打造。它拥有 3090 亿总参数,但每次推理仅激活 150 亿参数,在保持顶尖性能的同时大幅降低了计算成本。
针对传统大模型在处理长上下文时显存占用高、生成速度慢的痛点,MiMo-V2-Flash 引入了创新的混合注意力架构,通过滑动窗口与全局注意力的巧妙结合,将键值缓存存储需求降低近 6 倍,并支持长达 256k 的上下文窗口。此外,其独有的多令牌预测(MTP)技术能让输出速度提升三倍,显著加速推理过程及强化学习训练。在智能体能力方面,经过大规模代理强化学习优化,它在 SWE-Bench 等复杂编程与推理基准测试中表现卓越。
这款模型非常适合需要部署高性能 AI 应用的开发者、追求极致效率的研究人员,以及希望构建自主智能体系统的工程师。无论是处理超长文档分析、复杂代码编写,还是开发自动化工作流,MiMo-V2-Flash 都能提供强劲且经济的技术支持。
使用场景
某大型电商平台的后端团队正面临“双 11"大促前的紧急任务,需要在 48 小时内重构并修复遗留系统中数百个复杂的订单处理微服务代码。
没有 MiMo-V2-Flash 时
- 推理成本高昂:面对数百万行代码库的长上下文分析需求,传统大模型显存占用极大,导致团队不得不缩减并发实例数量,严重拖慢整体进度。
- 响应速度迟缓:在生成复杂逻辑代码或进行多步推理时,模型逐字输出的延迟过高,开发人员大量时间浪费在等待补全上,打断心流。
- 长文档理解割裂:由于上下文窗口限制或注意力机制效率低,模型难以同时兼顾全局架构文档与局部代码细节,常出现“顾头不顾尾”的逻辑错误。
- 智能体执行乏力:在自动修复 Bug(SWE-Bench 类任务)时,旧模型缺乏足够的代理规划能力,往往需要人工反复介入修正中间步骤。
使用 MiMo-V2-Flash 后
- 极致降本增效:凭借 309B 总参数仅激活 15B 的 MoE 架构及混合注意力机制,KV 缓存减少近 6 倍,团队得以低成本部署高并发实例,全量扫描代码库。
- 三倍输出加速:利用多令牌预测(MTP)技术,代码生成速度提升三倍,开发者几乎能实时获得完整的函数实现,大幅缩短编码循环。
- 超长上下文无损:原生支持 256k 上下文窗口,MiMo-V2-Flash 能一次性读完整个微服务模块的设计文档与所有依赖文件,确保重构逻辑的全局一致性。
- 自主闭环修复:得益于强大的代理能力与强化学习训练,它能独立规划并执行复杂的代码修复任务,显著减少人工干预,按时交付高质量代码。
MiMo-V2-Flash 通过平衡超长上下文理解与极致推理效率,将原本需要数周的高强度代码重构工作压缩至几天内高质量完成。
运行环境要求
未说明(模型总参数量 309B,激活参数 15B,采用 FP8 混合精度训练,推测推理需要高性能多卡集群或专用推理框架支持)
未说明
快速开始

MiMo-V2-Flash
MiMo-V2-Flash 是一种专家混合模型(MoE),总参数量达 3090亿,活跃参数量为 150亿。该模型专为高速推理和智能体工作流而设计,采用新颖的混合注意力架构和多标记预测(MTP)技术,在显著降低推理成本的同时,实现了业界领先的性能。
1. 简介
MiMo-V2-Flash 在长上下文建模能力和推理效率之间取得了全新的平衡。其主要特性包括:
- 混合注意力架构:以 5:1 的比例交替使用滑动窗口注意力(SWA)和全局注意力(GA),并采用激进的 128 个标记窗口。这一设计将 KV 缓存存储需求降低了近 6 倍,同时通过可学习的 注意力汇点偏置 维持了长上下文性能。
- 多标记预测(MTP):配备轻量级 MTP 模块(每层 0.33B 参数),采用密集前馈网络实现。这使得推理时的输出速度提升至三倍,并有望加速强化学习训练中的部署过程。
- 高效的预训练:使用 FP8 混合精度和原生 32k 序列长度,在 27T 标记数据上进行训练。上下文窗口最长可达 256k 标记。
- 智能体能力:在后训练阶段采用多教师在线策略蒸馏(MOPD)和大规模智能体强化学习,从而在 SWE-Bench 和复杂推理任务中表现出色。
2. 模型下载
| 模型 | 总参数 | 活跃参数 | 上下文长度 | 下载 |
|---|---|---|---|---|
| MiMo-V2-Flash-Base | 309B | 15B | 256k | 🤗 HuggingFace |
| MiMo-V2-Flash | 309B | 15B | 256k | 🤗 HuggingFace |
[!重要提示] 我们还开源了 3 层 MTP 权重,以促进社区研究。
3. 评估结果
基础模型评估
MiMo-V2-Flash-Base 在标准基准测试中表现出色,超越了参数量远超其自身的模型。
| 类别 | 基准测试 | 设置/长度 | MiMo-V2-Flash Base | Kimi-K2 Base | DeepSeek-V3.1 Base | DeepSeek-V3.2 Exp Base |
|---|---|---|---|---|---|---|
| 参数量 | 激活参数 / 总参数 | - | 150亿 / 3090亿 | 320亿 / 10430亿 | 370亿 / 6710亿 | 370亿 / 6710亿 |
| 通用任务 | BBH | 3-shot | 88.5 | 88.7 | 88.2 | 88.7 |
| MMLU | 5-shot | 86.7 | 87.8 | 87.4 | 87.8 | |
| MMLU-Redux | 5-shot | 90.6 | 90.2 | 90.0 | 90.4 | |
| MMLU-Pro | 5-shot | 73.2 | 69.2 | 58.8 | 62.1 | |
| DROP | 3-shot | 84.7 | 83.6 | 86.3 | 86.6 | |
| ARC-Challenge | 25-shot | 95.9 | 96.2 | 95.6 | 95.5 | |
| HellaSwag | 10-shot | 88.5 | 94.6 | 89.2 | 89.4 | |
| WinoGrande | 5-shot | 83.8 | 85.3 | 85.9 | 85.6 | |
| TriviaQA | 5-shot | 80.3 | 85.1 | 83.5 | 83.9 | |
| GPQA-Diamond | 5-shot | 55.1 | 48.1 | 51.0 | 52.0 | |
| SuperGPQA | 5-shot | 41.1 | 44.7 | 42.3 | 43.6 | |
| SimpleQA | 5-shot | 20.6 | 35.3 | 26.3 | 27.0 | |
| 数学 | GSM8K | 8-shot | 92.3 | 92.1 | 91.4 | 91.1 |
| MATH | 4-shot | 71.0 | 70.2 | 62.6 | 62.5 | |
| AIME 24&25 | 2-shot | 35.3 | 31.6 | 21.6 | 24.8 | |
| 代码 | HumanEval+ | 1-shot | 70.7 | 84.8 | 64.6 | 67.7 |
| MBPP+ | 3-shot | 71.4 | 73.8 | 72.2 | 69.8 | |
| CRUXEval-I | 1-shot | 67.5 | 74.0 | 62.1 | 63.9 | |
| CRUXEval-O | 1-shot | 79.1 | 83.5 | 76.4 | 74.9 | |
| MultiPL-E HumanEval | 0-shot | 59.5 | 60.5 | 45.9 | 45.7 | |
| MultiPL-E MBPP | 0-shot | 56.7 | 58.8 | 52.5 | 50.6 | |
| BigCodeBench | 0-shot | 70.1 | 61.7 | 63.0 | 62.9 | |
| LiveCodeBench v6 | 1-shot | 30.8 | 26.3 | 24.8 | 24.9 | |
| SWE-Bench (AgentLess) | 3-shot | 30.8 | 28.2 | 24.8 | 9.4* | |
| 中文 | C-Eval | 5-shot | 87.9 | 92.5 | 90.0 | 91.0 |
| CMMLU | 5-shot | 87.4 | 90.9 | 88.8 | 88.9 | |
| C-SimpleQA | 5-shot | 61.5 | 77.6 | 70.9 | 68.0 | |
| 多语言 | GlobalMMLU | 5-shot | 76.6 | 80.7 | 81.9 | 82.0 |
| INCLUDE | 5-shot | 71.4 | 75.3 | 77.2 | 77.2 | |
| 长上下文 | NIAH-Multi | 32K | 99.3 | 99.8 | 99.7 | 85.6* |
| 64K | 99.9 | 100.0 | 98.6 | 85.9* | ||
| 128K | 98.6 | 99.5 | 97.2 | 94.3* | ||
| 256K | 96.7 | - | - | - | ||
| GSM-Infinite Hard | 16K | 37.7 | 34.6 | 41.5 | 50.4 | |
| 32K | 33.7 | 26.1 | 38.8 | 45.2 | ||
| 64K | 31.5 | 16.0 | 34.7 | 32.6 | ||
| 128K | 29.0 | 8.8 | 28.7 | 25.7 |
* 表示该模型可能未能遵循提示或格式要求。
训练后模型评估
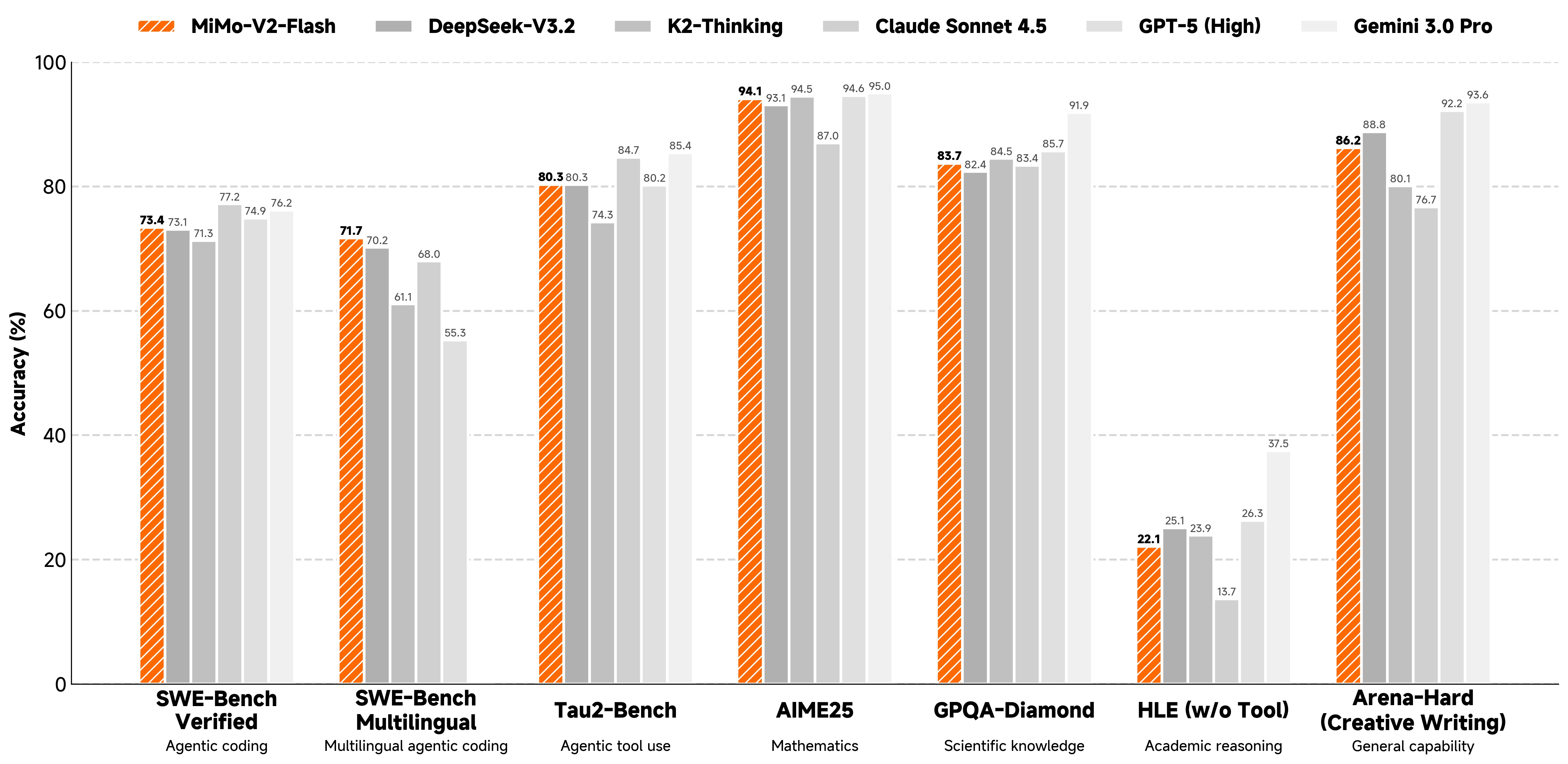
遵循我们的基于MOPD和智能体强化学习的训练后范式,该模型在推理能力和智能体性能方面均达到了当前最优水平。
| 基准测试 | MiMo-V2 Flash | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | Gemini-3.0 Pro | Claude Sonnet 4.5 | GPT-5 High |
|---|---|---|---|---|---|---|
| 推理 | ||||||
| MMLU-Pro | 84.9 | 84.6 | 85.0 | 90.1 | 88.2 | 87.5 |
| GPQA-Diamond | 83.7 | 84.5 | 82.4 | 91.9 | 83.4 | 85.7 |
| HLE (无工具) | 22.1 | 23.9 | 25.1 | 37.5 | 13.7 | 26.3 |
| AIME 2025 | 94.1 | 94.5 | 93.1 | 95.0 | 87.0 | 94.6 |
| HMMT Feb. 2025 | 84.4 | 89.4 | 92.5 | 97.5 | 79.2 | 88.3 |
| LiveCodeBench-v6 | 80.6 | 83.1 | 83.3 | 90.7 | 64.0 | 84.5 |
| 通用写作 | ||||||
| Arena-Hard (困难提示) | 54.1 | 71.9 | 53.4 | 72.6 | 63.3 | 71.9 |
| Arena-Hard (创意写作) | 86.2 | 80.1 | 88.8 | 93.6 | 76.7 | 92.2 |
| 长上下文 | ||||||
| LongBench V2 | 60.6 | 45.1 | 58.4 | 65.6 | 61.8 | - |
| MRCR | 45.7 | 44.2 | 55.5 | 89.7 | 55.4 | - |
| 代码智能体 | ||||||
| SWE-Bench 验证版 | 73.4 | 71.3 | 73.1 | 76.2 | 77.2 | 74.9 |
| SWE-Bench 多语言版 | 71.7 | 61.1 | 70.2 | - | 68.0 | 55.3 |
| Terminal-Bench 困难版 | 30.5 | 30.6 | 35.4 | 39.0 | 33.3 | 30.5 |
| Terminal-Bench 2.0 | 38.5 | 35.7 | 46.4 | 54.2 | 42.8 | 35.2 |
| 通用智能体 | ||||||
| BrowseComp | 45.4 | - | 51.4 | - | 24.1 | 54.9 |
| BrowseComp (带上下文管理) | 58.3 | 60.2 | 67.6 | 59.2 | - | - |
| $\tau^2$-Bench | 80.3 | 74.3 | 80.3 | 85.4 | 84.7 | 80.2 |
4. 模型架构
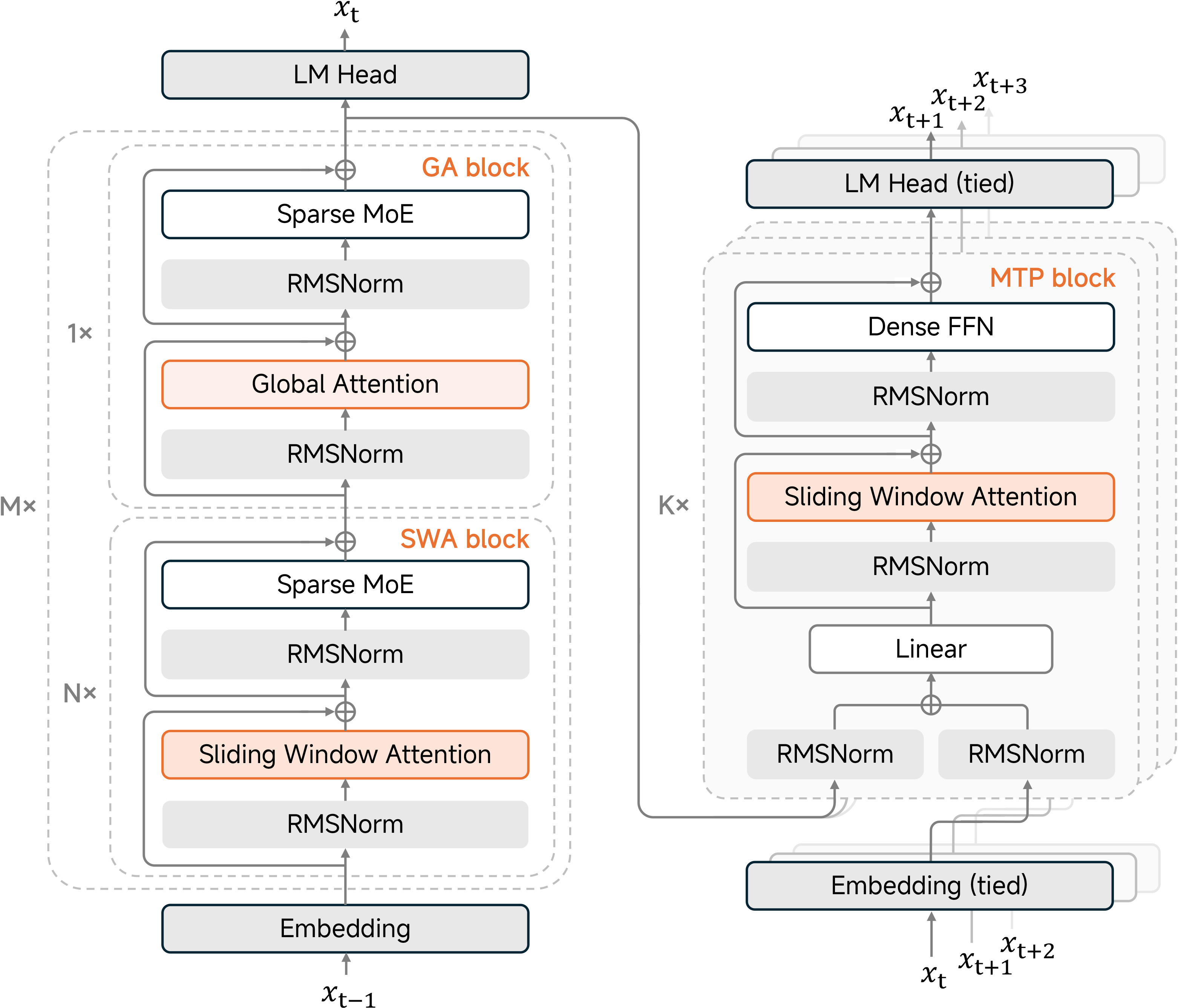
混合滑动窗口注意力
MiMo-V2-Flash通过交错使用局部滑动窗口注意力(SWA)和全局注意力(GA),解决了长上下文带来的二次复杂度问题。
- 配置: 由$M=8$个混合块堆叠而成。每个块包含$N=5$层SWA,随后是一层GA。
- 效率: SWA层采用128个标记的窗口大小,显著减少了KV缓存。
- Sink偏置: 应用了可学习的注意力sink偏置,以在激进的窗口大小下仍保持性能。
轻量级多标记预测(MTP)
与传统的推测解码不同,我们的MTP模块在训练和推理中都是原生集成的。
- 结构: 使用密集FFN(而非MoE)和SWA(而非GA),以保持较低的参数量(每个块0.33B)。
- 性能: 促进了自推测解码,使生成速度提高三倍,并缓解了小批量强化学习训练中的GPU空闲问题。
5. 训练后技术亮点
MiMo-V2-Flash利用一套训练后流水线,通过创新的知识蒸馏和强化学习策略,最大限度地提升推理和智能体能力。
5.1 多教师在线策略知识蒸馏(MOPD)
我们引入了多教师在线策略知识蒸馏(MOPD),这是一种将知识蒸馏表述为强化学习过程的新范式。
- 密集的标记级指导: 与依赖稀疏序列级反馈的方法不同,MOPD利用领域专家模型(教师)在每个标记位置提供监督。
- 在线策略优化: 学生模型从自身生成的响应中学习,而不是从固定的数据集中学习。这消除了暴露偏差,并确保更小、更稳定的梯度更新。
- 固有的奖励鲁棒性: 奖励来源于学生和教师之间的分布差异,使整个过程自然抵抗奖励欺骗。
5.2 扩展智能体强化学习
我们大幅扩展了智能体训练环境,以提升智能和泛化能力。
- 大规模代码智能体环境: 我们利用真实的GitHub问题创建了超过10万个可验证的任务。我们的自动化流水线维护着一个Kubernetes集群,能够运行超过1万个并发Pod,环境搭建成功率达到70%。
- 面向Web开发的多模态验证器: 对于Web开发任务,我们采用基于视觉的验证器,通过录制视频而非静态截图来评估代码执行情况。这减少了视觉幻觉,确保功能正确性。
- 跨领域泛化: 我们的实验表明,大规模的代码智能体强化学习训练能够有效泛化到其他领域,从而提升数学和通用智能体任务的表现。
5.3 高级强化学习基础设施
为了支持大规模MoE模型的高吞吐量强化学习训练,我们在SGLang和Megatron-LM的基础上实现了多项基础设施优化。
- Rollout路由重放(R3):解决推理与训练过程中MoE路由在数值精度上的不一致问题。R3在训练阶段复用推理阶段精确路由选择出的专家,从而确保一致性,且开销极低。
- 请求级前缀缓存:在多轮对话式智能体训练中,该缓存会存储前几轮的KV状态及路由选择的专家。它避免了重复计算,并保证各轮之间的采样一致性。
- 细粒度数据调度器:我们将推理引擎扩展为按细粒度序列而非微批次进行调度。结合部分推理机制,这显著减少了因长尾延迟任务导致的GPU空闲时间。
- 工具箱与工具管理器:采用两层设计,利用Ray Actor池来处理资源竞争问题。它消除了工具执行的冷启动延迟,并将任务逻辑与系统策略隔离开来。
6. 推理与部署
MiMo-V2-Flash支持FP8混合精度推理。我们推荐使用SGLang以获得最佳性能。
使用SGLang快速入门
请参照https://lmsys.org/blog/2025-12-16-mimo-v2-flash/,按照以下方式安装兼容版本的SGLang。
pip install sglang==0.5.6.post2.dev8005+pr.15207.g39d5bd57a \
--index-url https://sgl-project.github.io/whl/pr/ \
--extra-index-url https://pypi.org/simple
#启动服务端
SGLANG_ENABLE_SPEC_V2=1 python3 -m sglang.launch_server \
--model-path XiaomiMiMo/MiMo-V2-Flash \
--served-model-name mimo-v2-flash \
--pp-size 1 \
--dp-size 2 \
--enable-dp-attention \
--tp-size 8 \
--moe-a2a-backend deepep \
--page-size 1 \
--host 0.0.0.0 \
--port 9001 \
--trust-remote-code \
--mem-fraction-static 0.75 \
--max-running-requests 128 \
--chunked-prefill-size 16384 \
--reasoning-parser qwen3 \
--tool-call-parser mimo \
--context-length 262144 \
--attention-backend fa3 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--enable-mtp
#发送请求
curl -i http://localhost:9001/v1/chat/completions \
-H 'Content-Type:application/json' \
-d '{
"messages" : [{
"role": "user",
"content": "Nice to meet you MiMo"
}],
"model": "mimo-v2-flash",
"max_tokens": 4096,
"temperature": 0.8,
"top_p": 0.95,
"stream": true,
"chat_template_kwargs": {
"enable_thinking": true
}
}'
通知事项
1. 系统提示词
[!IMPORTANT] 强烈建议使用以下系统提示词,请从英文版或中文版中选择。
英文:
You are MiMo, an AI assistant developed by Xiaomi.
Today's date: {date} {week}. Your knowledge cutoff date is December 2024.
中文:
你是MiMo(中文名称也是MiMo),是小米公司研发的AI智能助手。
今天的日期:{date} {week},你的知识截止日期是2024年12月。
2. 采样参数
[!IMPORTANT] 推荐的采样参数如下:
top_p=0.95数学、写作、Web开发等任务可设置为
temperature=0.8;对于代理类任务(如氛围编码、工具调用等),建议设置为
temperature=0.3。
3. 工具使用注意事项
[!IMPORTANT] 在多轮工具调用的思考模式下,模型会在返回
tool_calls的同时附带reasoning_content字段。若要继续对话,用户必须将所有历史reasoning_content保留在后续每次请求的messages数组中。
7. 引用
如果您觉得我们的工作有所帮助,请引用我们的技术报告:
@misc{xiao2026mimov2flashtechnicalreport,
title={MiMo-V2-Flash 技术报告},
author={LLM-Core Xiaomi},
year={2026},
eprint={2601.02780},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.02780},
}
8. 联系方式
如有任何问题,请通过mimo@xiaomi.com联系我们,加入下方的微信群组,或直接提交问题。




常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备