LLM-RL-Papers
LLM-RL-Papers 是一个专注于追踪大语言模型(LLM)与强化学习(RL)交叉研究前沿的开源知识库。它主要解决该领域论文更新快、方向分散,导致研究人员难以高效获取“控制类”应用(如游戏智能体、机器人导航等)最新进展的痛点。
该项目不仅持续监控 arXiv 上的最新论文,还创新性地按技术方法对文献进行了系统化梳理。其核心亮点在于将论文分为“直接行动”与“间接引导”等类别,清晰展示了 LLM 如何作为策略教师、反馈机制或规划核心来增强 RL 代理的决策能力。此外,项目收录了多篇高质量的综述文章,帮助读者快速构建从概念分类到具体方法的完整知识体系。
LLM-RL-Papers 特别适合人工智能领域的研究人员、算法工程师以及对具身智能感兴趣的学生使用。无论是希望寻找灵感的开发者,还是试图把握学科融合趋势的学者,都能在这里找到极具价值的参考资源。作为一个社区驱动的项目,它也欢迎用户提交优质的新论文,共同维护这一活跃的知识共享生态。
使用场景
某机器人实验室团队正致力于开发能理解自然语言指令并在动态环境中自主导航的服务机器人,急需融合大语言模型(LLM)的语义理解与强化学习(RL)的决策控制能力。
没有 LLM-RL-Papers 时
- 信息检索低效:研究人员需在 arXiv 上手动筛选海量论文,难以快速定位同时涉及"LLM"与"RL"且专注于“控制”领域的最新成果。
- 技术路线迷茫:面对分散的研究,团队难以厘清如“直接动作生成”或“间接策略指导”等具体技术路径的优劣,导致实验方向反复试错。
- 前沿案例缺失:缺乏类似
SRLM(人机交互导航)或RE-MOVE(动态环境自适应)等具体落地案例参考,算法设计往往脱离实际场景需求。 - 协作壁垒高:团队成员各自阅读文献,缺乏统一的知识库共享机制,导致重复劳动且难以形成合力突破技术瓶颈。
使用 LLM-RL-Papers 后
- 精准追踪前沿:团队直接利用该工具监控 arXiv 交叉研究,瞬间获取按方法分类的最新论文列表,将文献调研时间从数天缩短至几小时。
- 清晰技术图谱:通过工具整理的综述(如 Taxonomy Tree)和分类(Direct/Indirect Action),团队迅速锁定了适合动态导航的“基于语言反馈的策略改进”路线。
- 复用成熟方案:参考列表中
Octopus和Inner Monologue等具体论文的实验设置,团队快速复现了基线模型,显著提升了机器人对复杂指令的响应准确率。 - 高效知识协同:团队成员将验证有效的论文通过 PR 贡献回仓库,构建了实验室专属的动态知识库,加速了从理论到实机部署的迭代周期。
LLM-RL-Papers 通过结构化聚合跨领域前沿成果,将原本分散的探索转化为可控的技术演进,极大加速了具身智能系统的研发落地。
运行环境要求
未说明
未说明

快速开始
LLM RL 论文
- 关注 LLM 与强化学习的最新交叉研究;
- 重点在于结合两者的功能实现 控制(如游戏角色、机器人);
- 如果你读到了优秀的论文,欢迎随时提交 PR 分享。
目录
→Text2Reward:面向强化学习的自动化密集奖励函数生成
→[自精炼大型语言模型作为机器人深度强化学习的自动化奖励函数设计者](#self-refined-large-language-model-as-automated-reward-function-designer-for-deep-reinforcement-learning-in-robotics)
→[面向机器人技能合成的语言到奖励](#language-to-rewards-for-robotic-skill-synthesis)
→[基于语言模型的奖励设计](#reward-design-with-language-models)
→[阅读并收获奖励:借助说明书学习玩Atari游戏](#read-and-reap-the-rewards-learning-to-play-atari-with-the-help-of-instruction-manuals)
技能规划
状态表示
任务建议
→语言与草图:一种由 LLM 驱动的交互式多模态多任务机器人导航框架
→LgTS:利用 LLM 生成的子目标为强化学习智能体进行动态任务采样
Transformer 框架
研究综述
基于大语言模型的多智能体强化学习:现状与未来方向
- 论文链接:arXiv 2405.11106
- 概述:
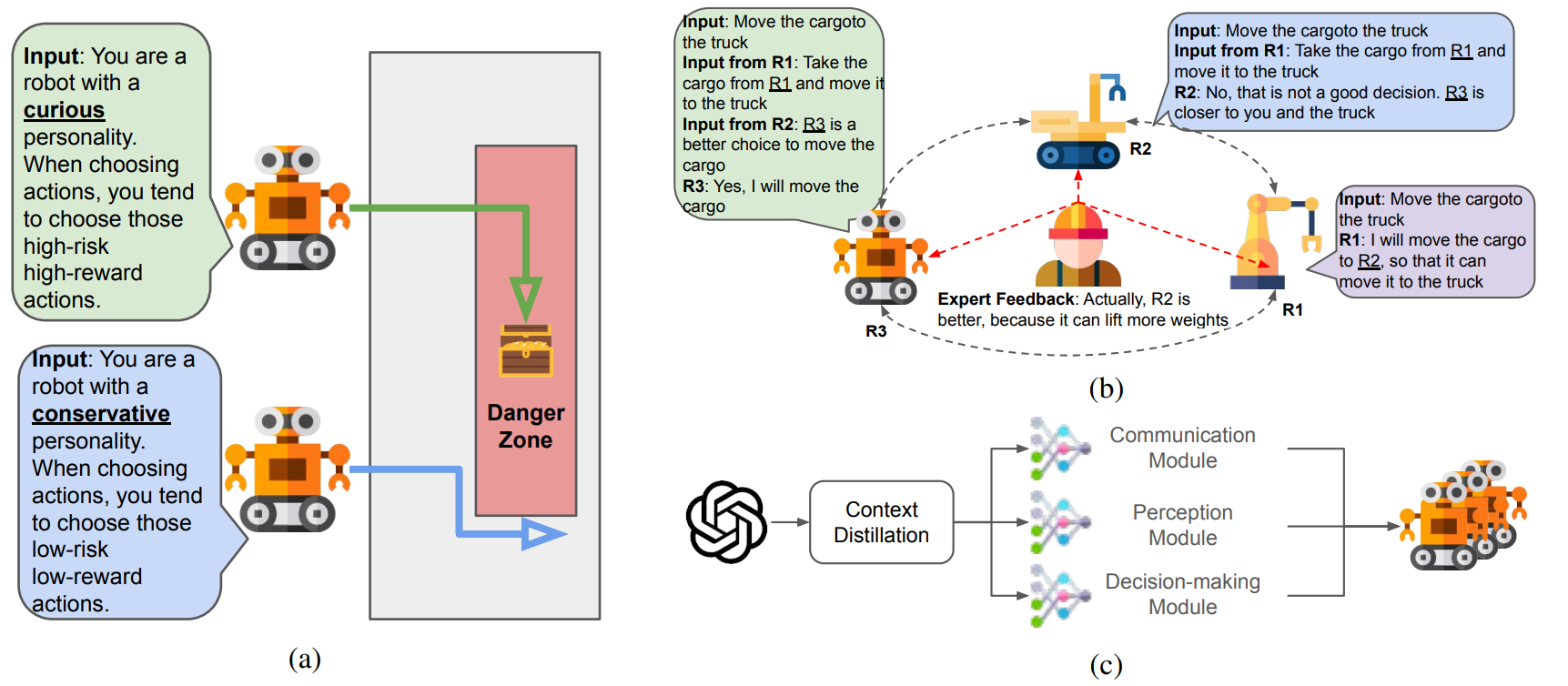
语言条件下的多智能体强化学习(MARL)的潜在研究方向。
(a) 具有人格特征的合作,其中不同机器人由指令定义的不同人格进行协作。
(b) 支持人类参与的框架,即人类监督机器人并提供反馈。
(c) 传统的MARL与LLM协同设计,将关于LLM各方面的知识提炼到可在设备端运行的小型模型中。
基于大型语言模型的游戏智能体综述
- 论文链接:arXiv 2404.02039,主页
- 概述:
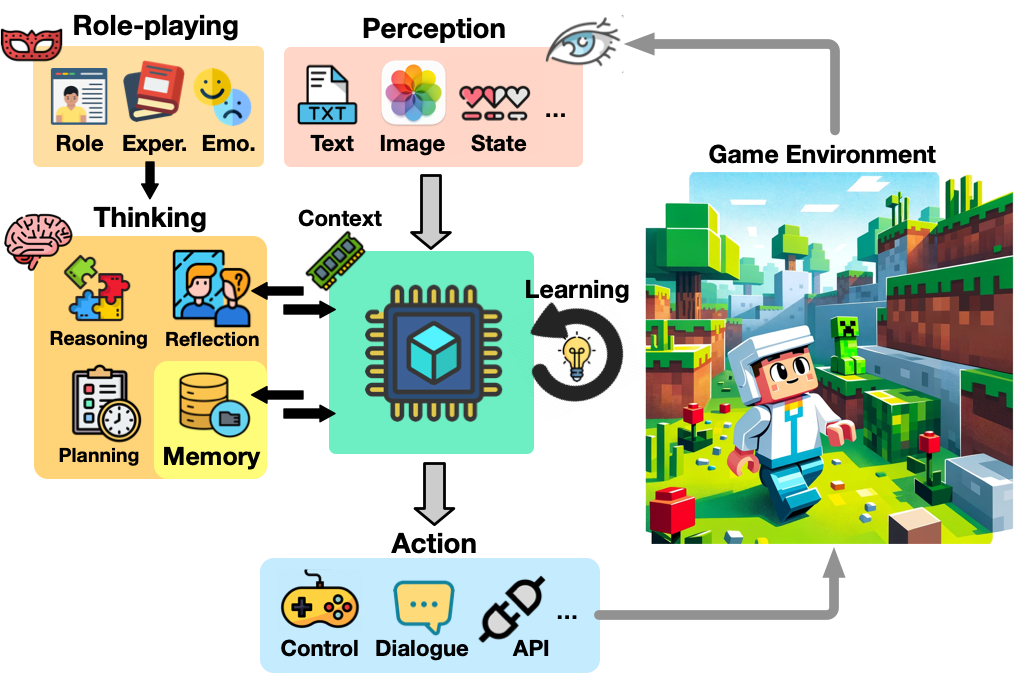
LLMGAs的概念架构。在每个游戏步骤中,感知模块从游戏环境中获取多模态信息,包括文本、图像、符号状态等。智能体从记忆模块中检索关键记忆,并将其与感知到的信息一起作为输入用于思考(推理、规划和反思),从而制定策略并做出明智决策。角色扮演模块影响决策过程,以确保智能体的行为与其设定的角色一致。随后,行动模块将生成的行动描述转化为可执行且合法的动作,以改变下一游戏步骤中的游戏状态。最后,学习模块通过积累的游戏经验不断提升智能体的认知能力和游戏水平。
大型语言模型增强的强化学习综述:概念、分类与方法
- 论文链接:arXiv 2403.00282
- 概述:
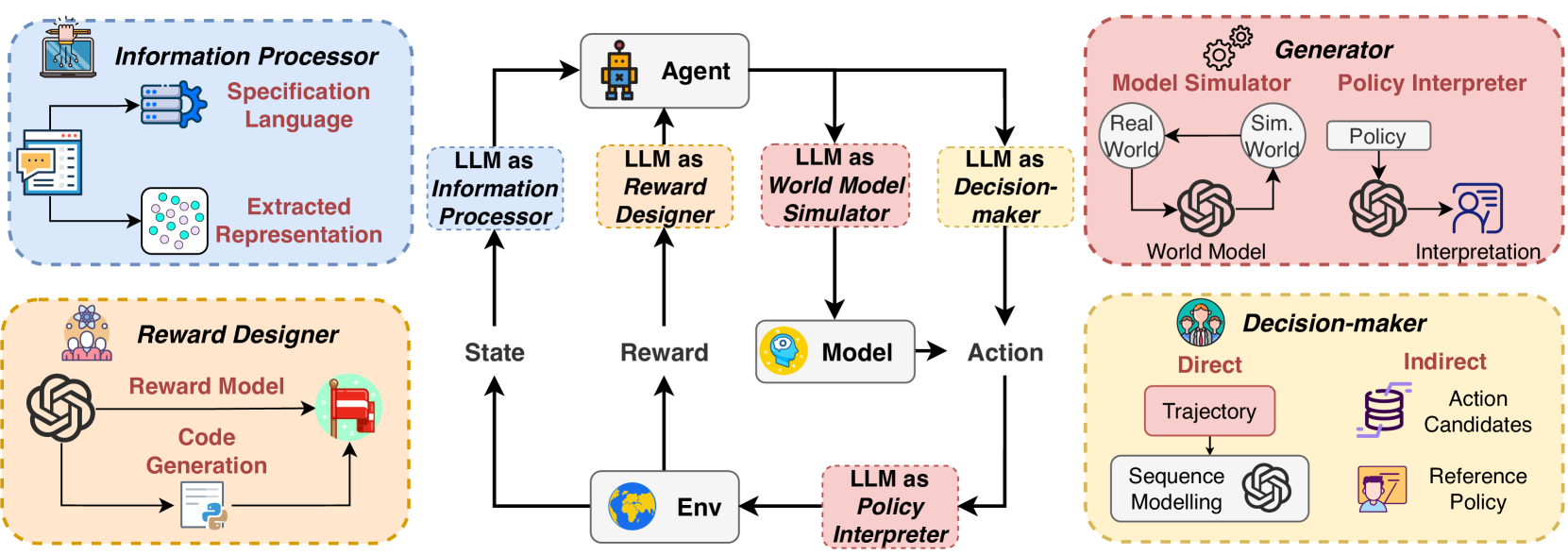
经典智能体-环境交互中LLM增强的RL框架,其中LLM在增强RL方面发挥着不同的作用。
强化学习与大型语言模型的协同关系分类树
论文链接:arXiv 2402.01874
概述:
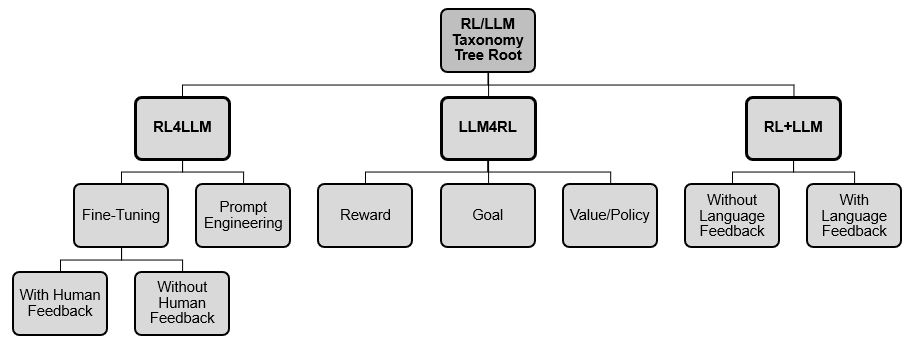
本研究提出了一种基于RL和LLM相互作用方式的新型分类体系,分为三大类:
- RL4LLM:利用RL提升LLM在自然语言处理相关任务中的性能。
- LLM4RL:使用LLM辅助训练一个不直接涉及自然语言的任务的RL模型。
- RL+LLM:将LLM和RL智能体嵌入到一个共同的规划框架中,而两者互不参与对方的训练或微调。
LLM RL论文
语言条件下的多机器人导航离线强化学习
- 论文链接:arXiv2407.20164,主页
- 概述:
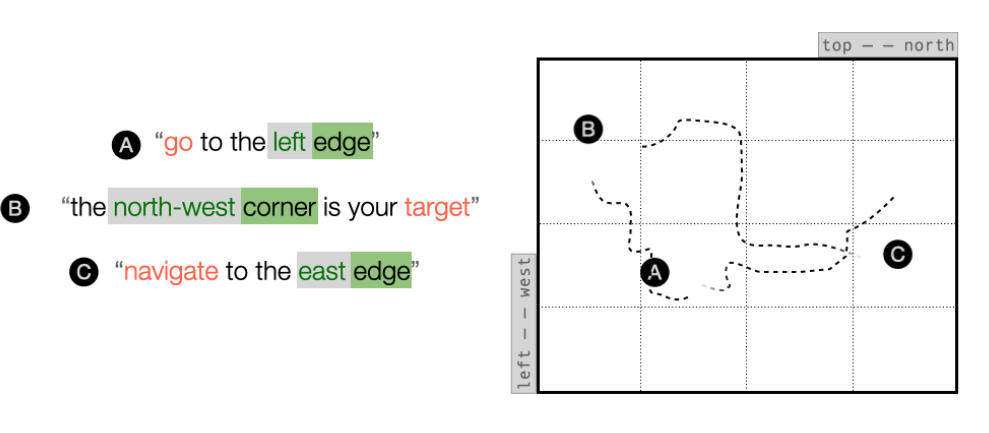
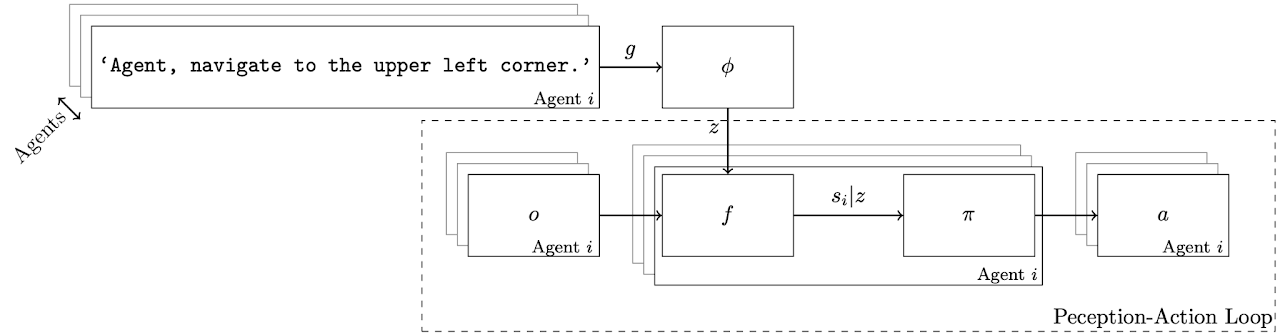
所提出的多机器人模型架构。每个智能体接收不同的自然语言任务和局部观测。他们使用LLM将每个自然语言任务gi总结为潜在表示zi。函数f是一个图神经网络,它将局部观测o1, o2, ...以及任务嵌入z1, z2, ...编码为每个智能体i的任务依赖状态表示si|z。他们学习一种基于状态-任务表示的局部策略π。函数π和f完全通过离线强化学习从固定数据集中学习得到。由于他们只对每个任务计算一次zi,因此LLM并不参与感知-行动循环,从而使策略能够快速执行。
LLM赋能的强化学习状态表示
- 论文链接:arXiv2407.15019,主页
- 概述:
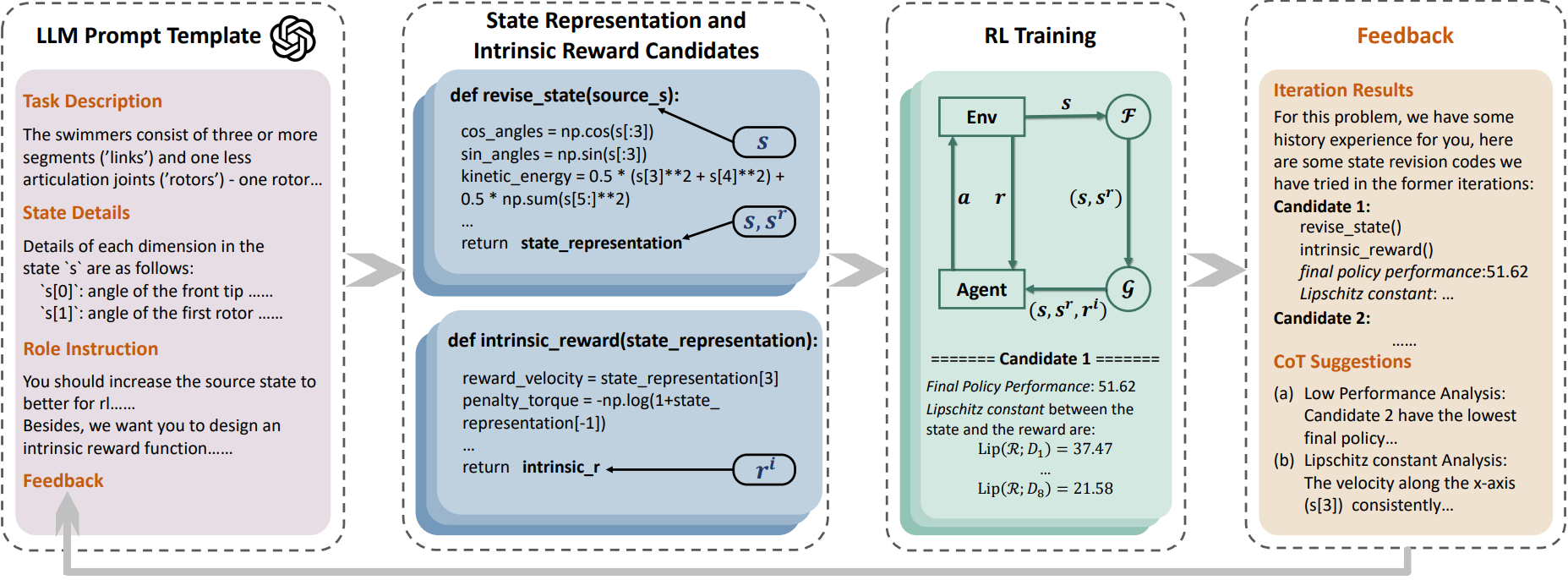
强化学习中传统的状态表示往往忽略关键的任务相关信息,这给价值网络建立准确的状态到任务奖励映射带来了巨大挑战。传统方法通常依赖大量样本学习来丰富状态表示中的任务特定信息,但这会导致样本效率低下和时间成本高昂。最近,功能强大的大型语言模型(LLMs)为无需过多人工干预的任务相关注入提供了有前景的替代方案。受此启发,我们提出了LLM赋能的状态表示(LESR),这是一种新颖的方法,利用LLM自主生成与任务相关的状态表示代码,从而帮助增强网络映射的连续性,并促进高效训练。实验结果表明,LESR具有较高的样本效率,在Mujoco任务中累积奖励平均比现有基准高出29%,在Gym-Robotics任务中成功率则高出30%。
iLLM-TSC:融合强化学习与大型语言模型以改进交通信号控制策略
- 论文链接:arXiv2407.06025,主页
- 概述:
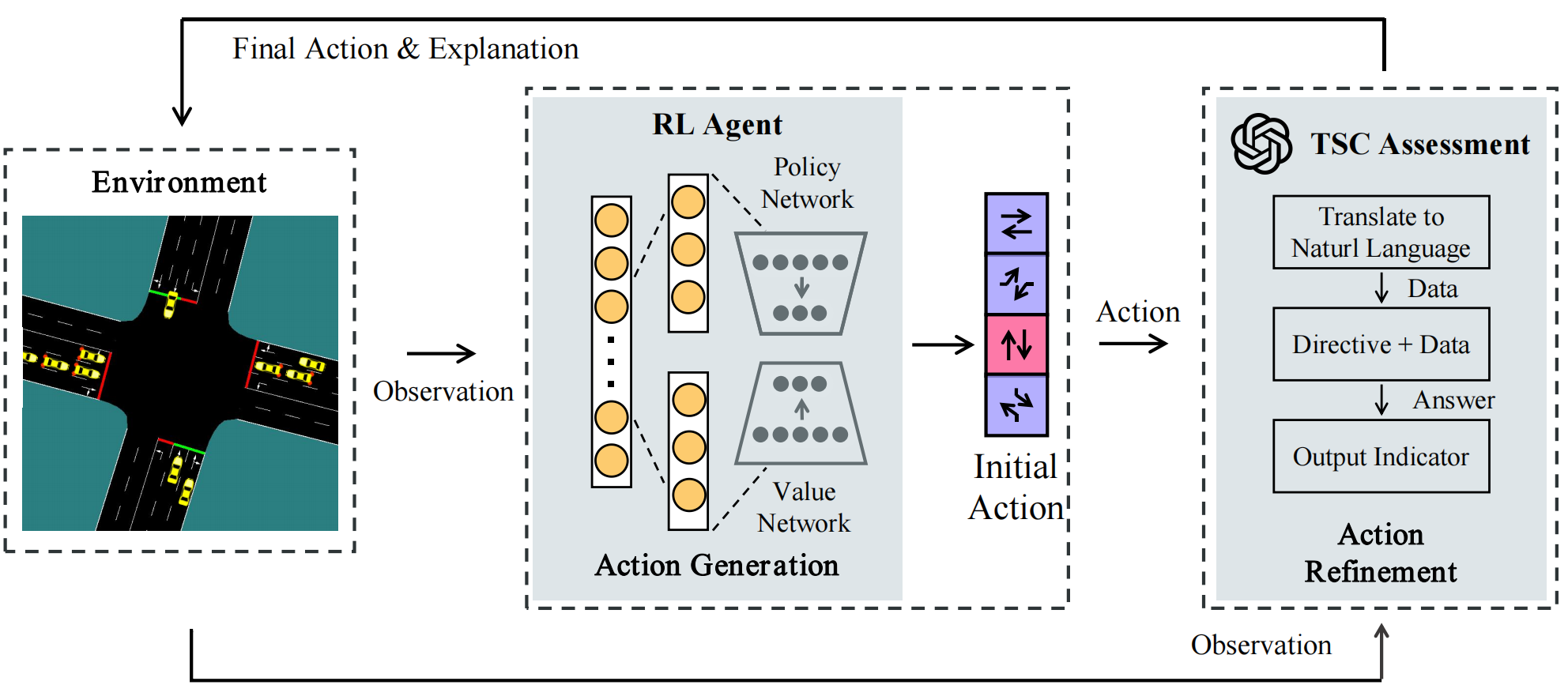
作者介绍了一种名为iLLM-TSC的框架,将LLM与RL智能体结合用于交通信号控制。该框架首先由RL智能体根据环境观测和从环境中学习到的策略做出初步决策。随后,LLM智能体会结合实际情况,并利用其对复杂环境的理解进一步优化这些决策。这种方法增强了TSC系统对现实条件的适应能力,同时提高了整个框架的稳定性。有关RL智能体和LLM智能体组件的详细信息将在后续章节中介绍。
大型语言模型引导的六自由度飞行控制强化学习
- 论文链接:IEEE 2406 2024.3411015
- 概述:
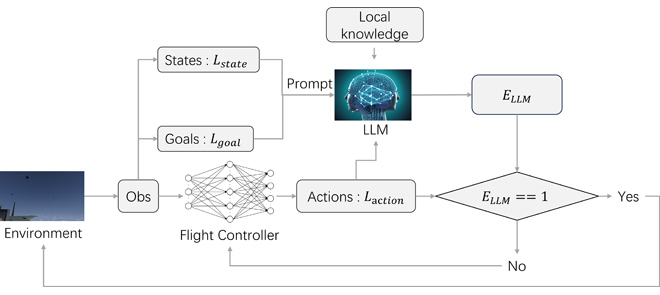
LLM引导的强化学习框架。 本文提出了一种用于IFC的LLM引导深度强化学习框架,利用LLM引导的深度强化学习在计算资源有限的情况下实现智能飞行控制。LLM基于局部知识在训练过程中提供直接指导,从而提升DRL中智能体与环境交互生成数据的质量,加速训练进程,并为智能体提供及时反馈,部分缓解稀疏奖励问题。此外,他们还提出了一种有效的奖励函数,以全面平衡飞机的耦合控制,确保稳定、灵活的控制效果。最后,仿真和实验表明,所提出的技术在各类飞行任务中均表现出良好的性能、鲁棒性和适应性,为未来智能空战决策领域的研究奠定了基础。
代理式技能发现
- 论文链接:arXiv 2405.15019,主页
- 概述:
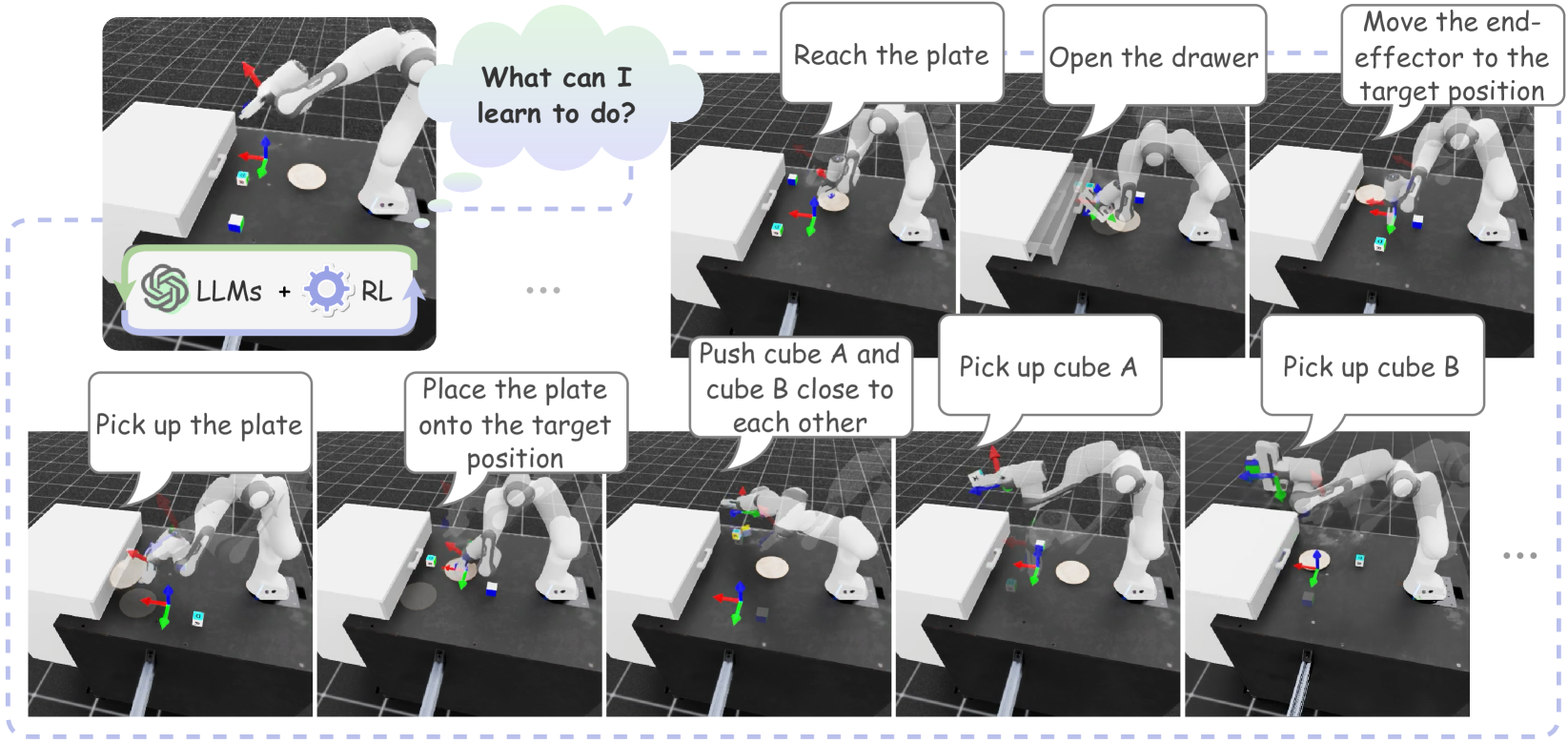
代理式技能发现逐步获取用于桌面操作的上下文技能。
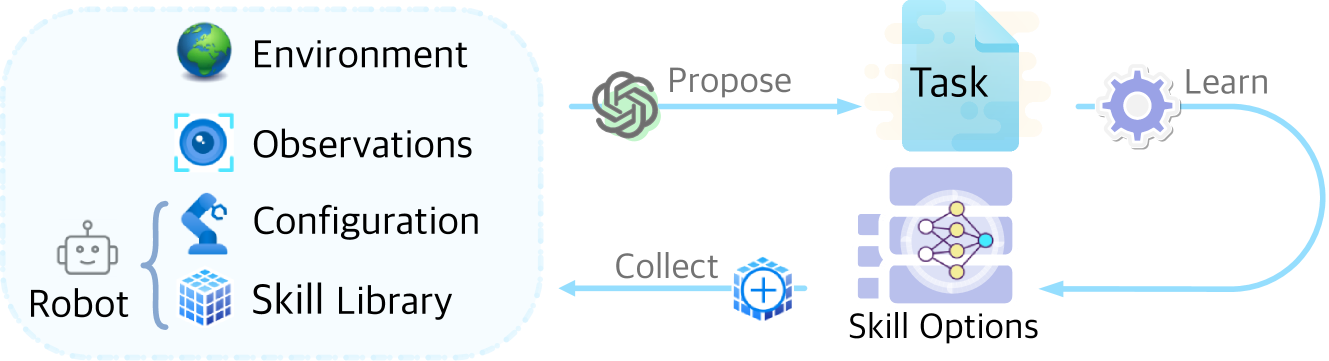
ASD的上下文技能获取循环。给定环境设置和机器人当前的能力,LLM会持续提议机器人需要完成的任务,成功完成后这些任务将被收集为已习得的技能,每项技能都有多个神经网络变体(选项)。
HighwayLLM:基于RL启发的语言模型在高速公路驾驶中的决策与导航
- 论文链接:arXiv 2405.13547
- 概述:
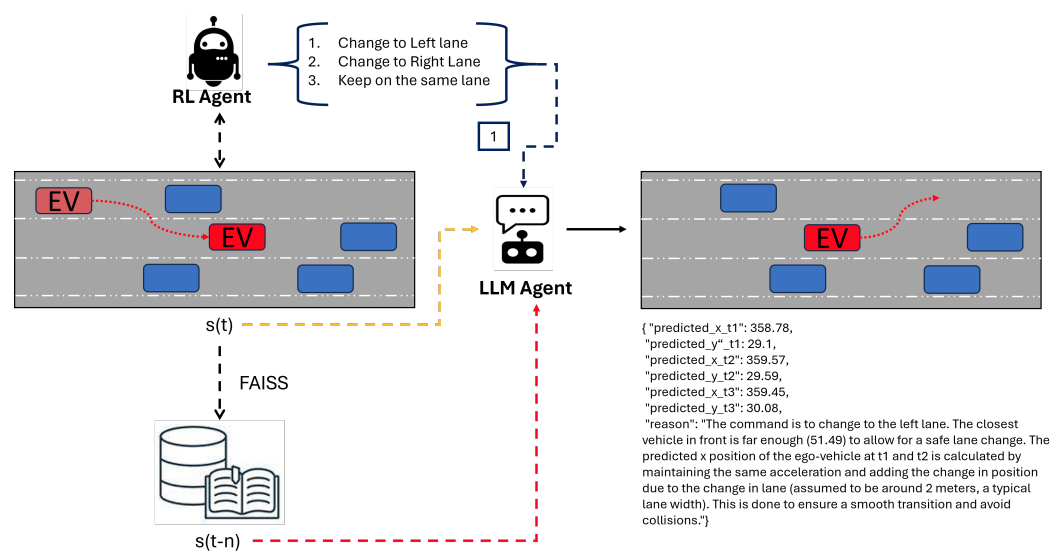
基于LLM的车辆轨迹规划结构:RL智能体观察交通状况(周围车辆),并给出一个换道的高层动作。随后,LLM智能体通过FAISS检索highD数据集,并提供接下来的三个轨迹点。
LEAGUE++:通过大型语言模型引导的技能获取赋能持续机器人学习
- 论文链接:https://openreview.net/forum?id=xXo4JL8FvV,[主页](https://sites.google.com/view/continuallearning)
- 概述:
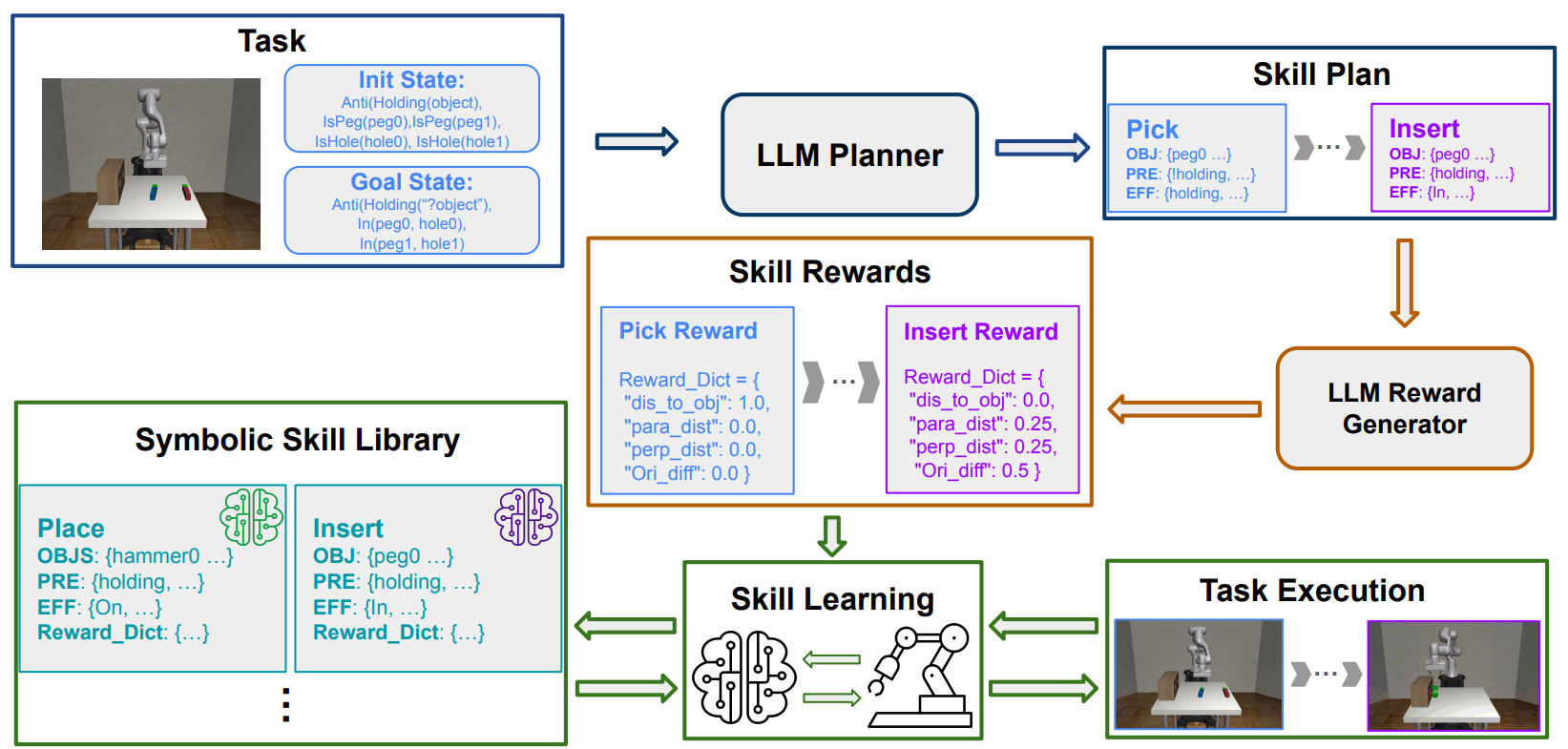
作者提出了一套利用LLM引导持续学习的框架。他们将LLM集成用于TAMP的任务分解和操作符创建,并为RL技能学习生成密集奖励,从而实现针对长时程任务的在线自主学习。同时,他们还使用语义技能库来提高新技能的学习效率。
基于大型语言模型回放的离线强化学习所构建的知识型智能体
- 论文链接:arXiv 2404.09248,
- 概述:
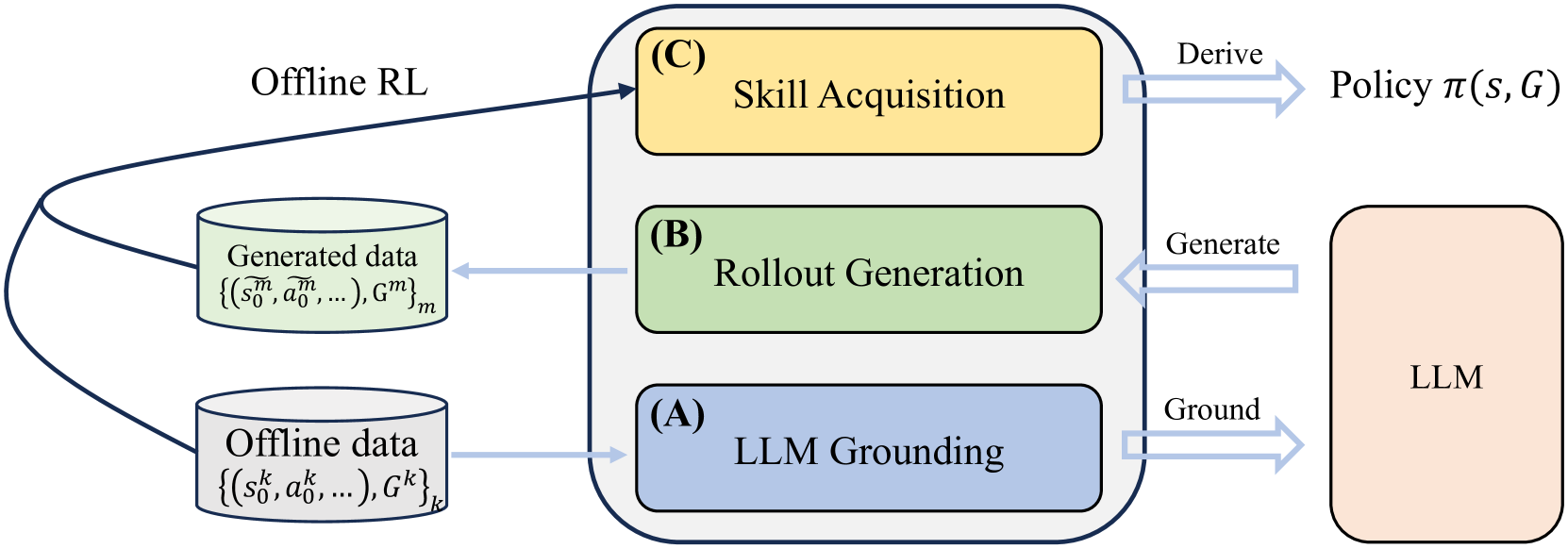
KALM的整体流程,包含三个关键模块: (A) LLM接地模块,负责将LLM置于环境中,并使其与环境数据输入对齐; (B) 回放生成模块,提示LLM生成关于新技能的数据; (C) 技能获取模块,利用离线强化学习训练策略。最终,KALM得到一个既基于离线数据又基于想象数据训练的策略。
通过语言模型集成与关键场景生成提升自动驾驶汽车训练
- 论文链接:arXiv 2404.08570,
- 概述:
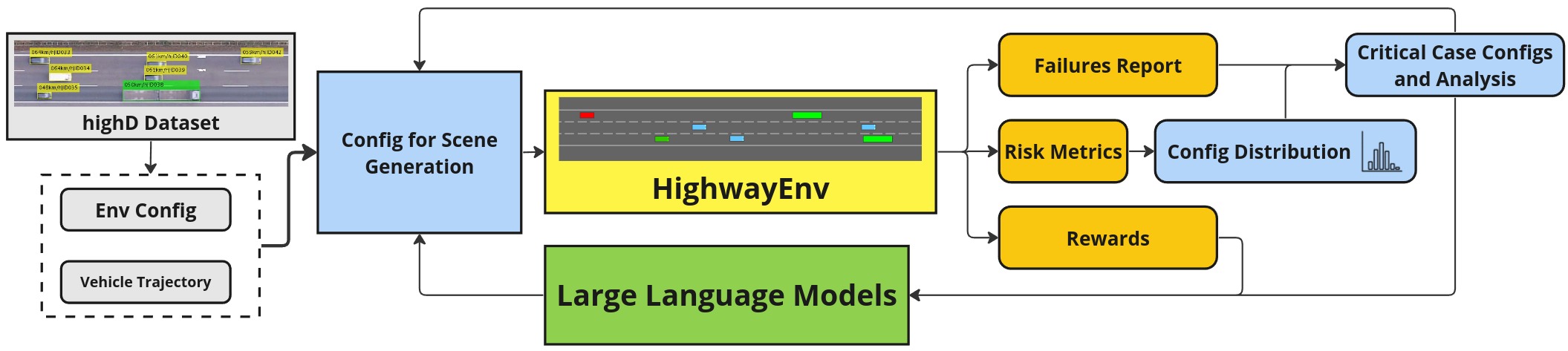
CRITICAL框架的组件架构图。该框架首先根据highD数据集中的典型真实交通情况设置环境配置。这些配置随后被用来生成高速公路环境场景。每完成一轮模拟后,作者会收集包括失败报告、风险指标和奖励在内的数据,重复这一过程多次,以积累一系列带有相应场景风险评估的配置文件。为了增强RL训练,作者会基于风险指标分析配置分布,识别出那些有利于生成关键场景的配置。然后,他们要么直接使用这些配置生成新场景,要么让LLM生成关键场景。
基于大型语言模型的四足机器人长时程运动与操作
- 论文链接:arXiv 2404.05291
- 概述:

长时程运动-操作任务的分层系统概述。该系统由用于任务分解的推理层(黄色)和用于技能执行的控制层(紫色)组成。根据长时程任务的语言描述(顶部),一系列LLM智能体进行高层任务规划,并生成参数化的机器人技能函数调用。控制层则通过RL实例化中层运动规划和底层控制技能。
对你的机器人吼一吼:通过语言纠正即时改进
论文链接:arXiv 2403.12910,主页
框架概述:
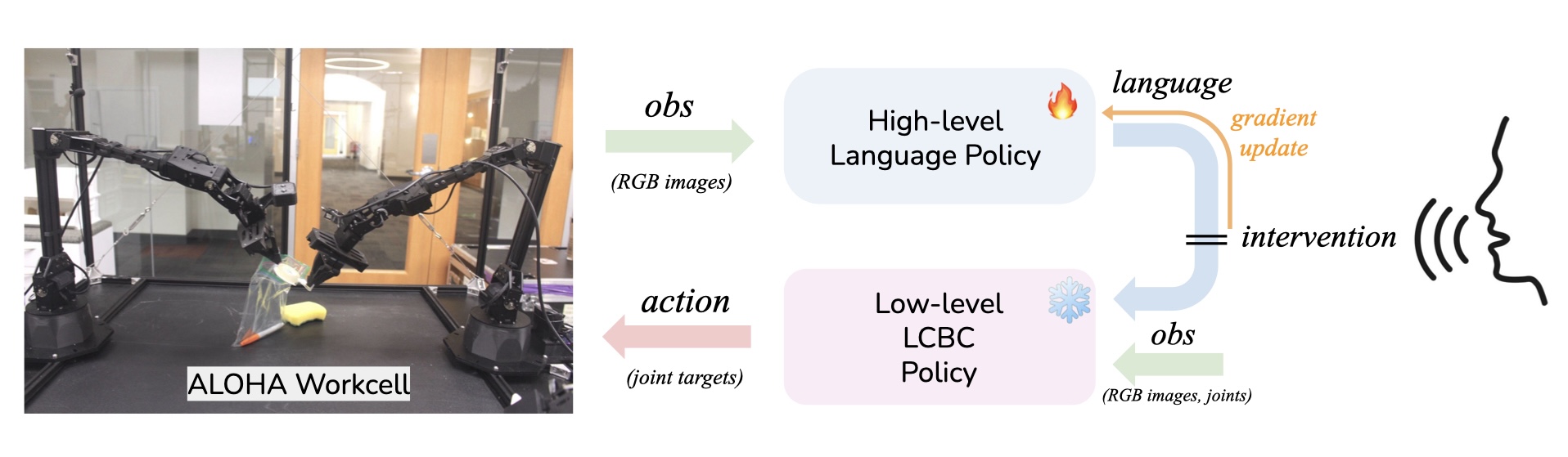
作者采用分层架构,高层策略生成语言指令,供低层策略执行相应的技能。部署过程中,人类可以通过纠正性语言命令进行干预,临时覆盖高层策略,直接影响低层策略以实现实时调整。这些干预随后会被用来微调高层策略,从而提升其未来的性能。
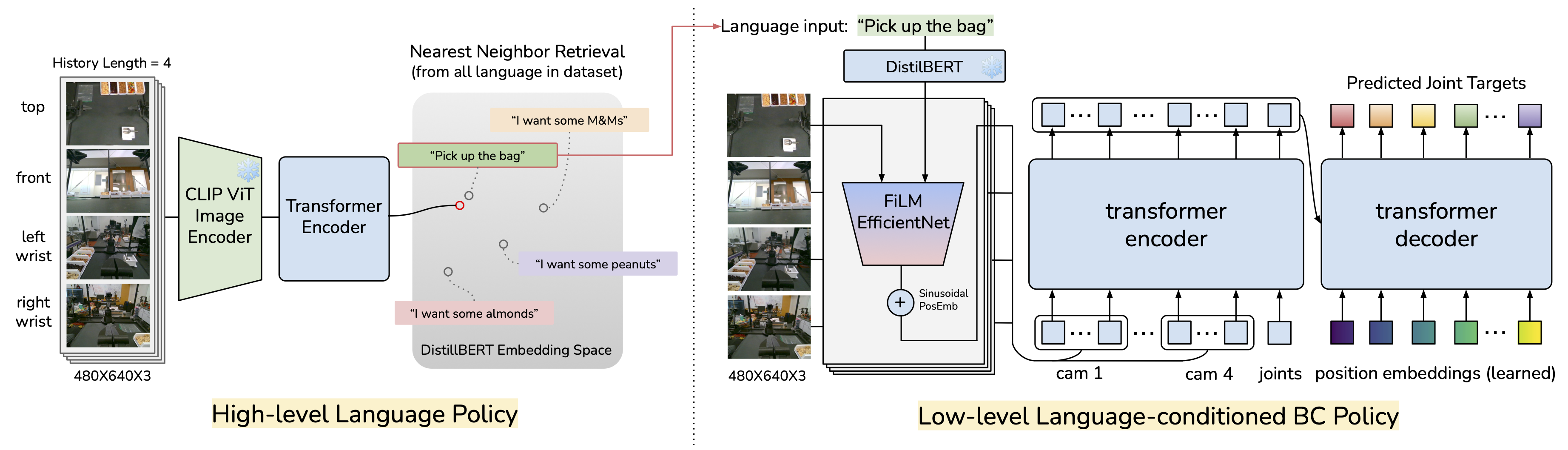
系统以RGB图像和机器人当前的关节位置作为输入,输出用于电机动作的目标关节位置。高层策略使用视觉Transformer对视觉输入进行编码,并预测语言嵌入。低层策略则使用ACT——一种基于Transformer的模型——在语言指令的指导下生成精确的机器人动作。这种架构使机器人能够理解“拿起包”之类的指令,并将其转化为目标关节的动作。
SRLM:结合大型语言模型与深度强化学习的人机交互社交机器人导航
- 论文链接:arXiv 2403.15648
- 概述:
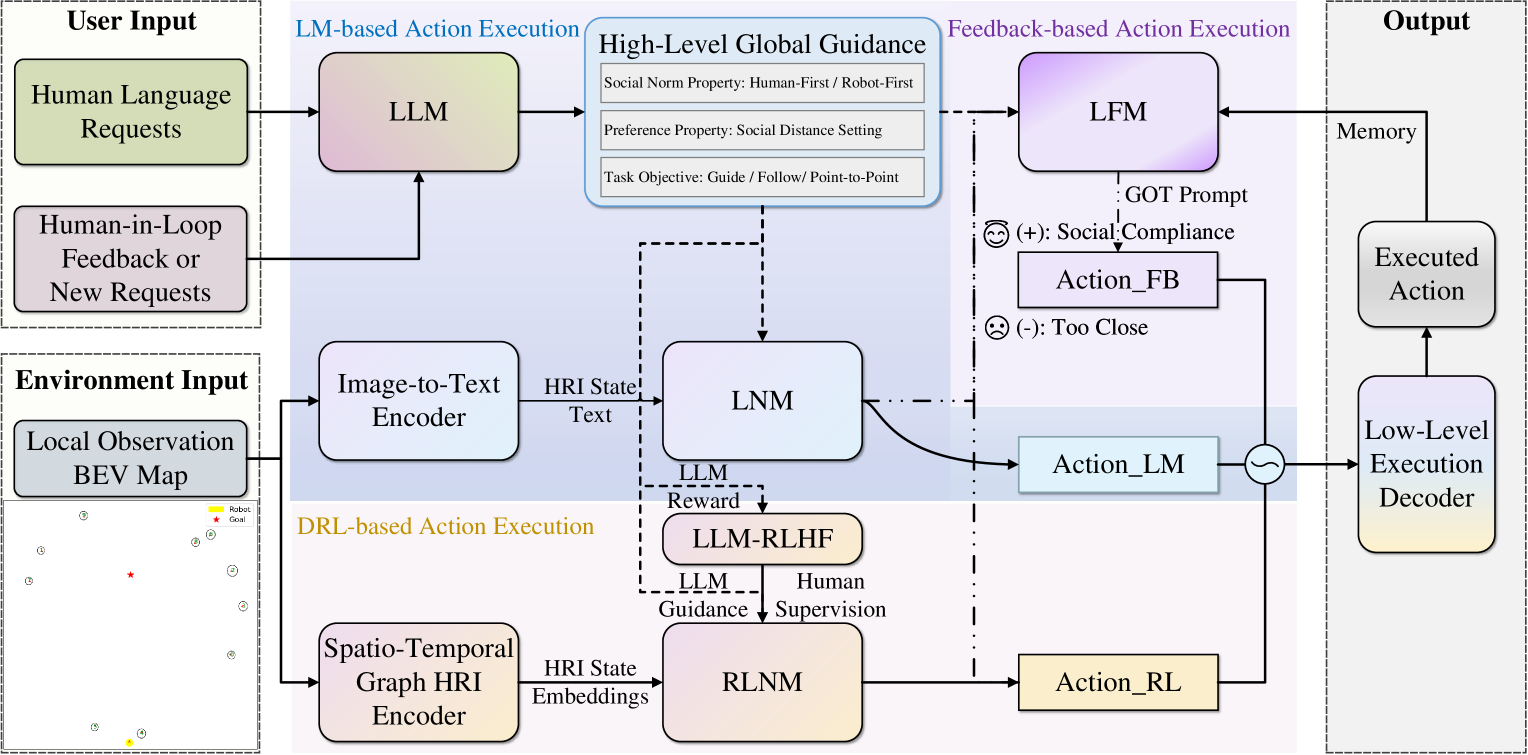
SRLM架构:SRLM被实现为一种人机协作的交互式社交机器人导航框架,它结合了基于语言模型的规划器、基于反馈的规划器以及基于深度强化学习的规划器来执行人类指令。首先,用户请求或实时反馈会通过大型语言模型处理并重新规划为高层次的任务指导,传递给三个动作执行器。接着,图像转文本编码器和时空图人机交互编码器将机器人的局部观测信息转换为特征,作为LNM和RLNM的输入,从而生成基于强化学习的动作、基于语言模型的动作以及基于反馈的动作。最后,这三个动作由一个低层执行解码器自适应地融合,作为SRLM的机器人行为输出。
EnvGen:利用大型语言模型生成与适配环境,用于具身智能体的训练
论文链接:arXiv 2403.12014 ,主页
框架概述:
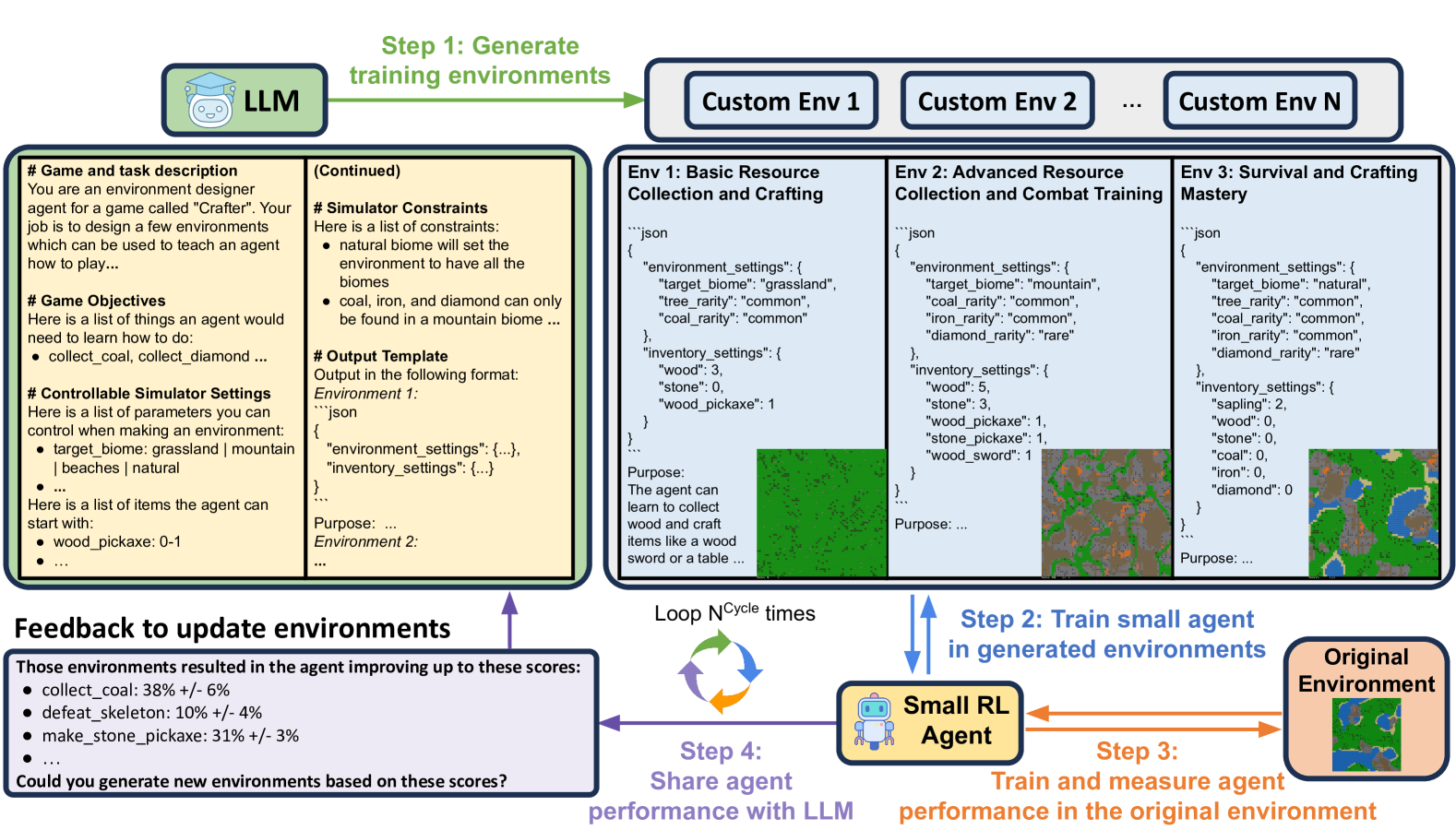
在EnvGen框架中,作者使用大型语言模型生成多种环境,使智能体能够有效学习不同技能。整个训练过程分为N个循环,每个循环包含以下四个步骤。
第1步: 向大型语言模型提供一个由四个部分组成的提示(即任务描述、环境细节、输出模板以及上一循环的反馈),并要求模型填充模板,输出可用于训练智能体不同技能的各种环境配置。
第2步: 在大型语言模型生成的环境中训练一个小规模的强化学习智能体。
第3步: 将智能体迁移到原始环境中进行训练,以提升其泛化能力,并通过让智能体探索原始环境来评估其训练进展。
第4步: 将智能体在原始环境中的表现(由第3步测量得到)作为反馈提供给大型语言模型,以便在下一循环中调整环境设置,重点关注智能体表现较弱的技能。
评论: 本文的亮点在于利用大型语言模型设计初始训练环境条件,这有助于强化学习智能体更快地掌握长时程任务的策略。该方法通过将长时程任务分解为更小的任务并反复训练,从而加速了强化学习的效率。此外,文中还引入了一种反馈机制,允许大型语言模型根据强化学习的训练效果不断调整环境条件。仅需与大型语言模型进行四次交互,便能显著提升强化学习的训练效率,并降低对大型语言模型的使用成本。
LEAGUE++:通过大型语言模型引导的技能获取,赋能持续性机器人学习
- 论文链接:https://openreview.net/forum?id=xXo4JL8FvV,[主页](https://sites.google.com/view/continuallearning)
- 概述:
本文提出了一种利用大型语言模型引导持续学习的框架。该框架整合了大型语言模型,用于处理TAMP中的任务分解和操作符生成,并为强化学习技能学习生成密集奖励信号,从而实现针对长时程任务的在线自主学习。同时,该框架还使用语义技能库来提升新技能的学习效率。
RLingua:利用大型语言模型提升机器人操控中的强化学习样本效率
论文链接:arXiv 2403.06420,主页
框架概述:
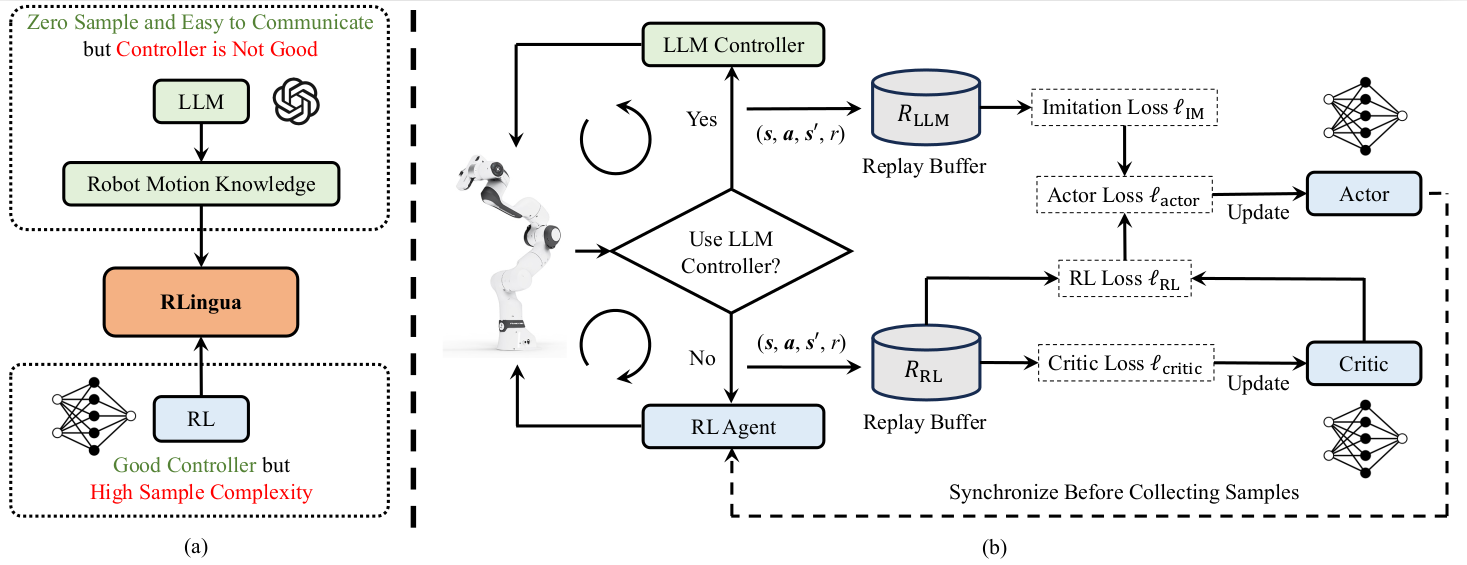
(a) 动机:大型语言模型无需环境样本,且非专业人士也能轻松与其沟通。然而,直接由大型语言模型生成的机器人控制器性能可能较差。相比之下,强化学习可以训练出高性能的机器人控制器,但其缺点是样本复杂度高。(b) 框架:RLingua将大型语言模型关于机器人运动的内部知识提取出来,形成一段不完善的代码化控制器,然后通过与环境交互收集数据。机器人控制策略则同时利用收集到的大型语言模型示范数据以及在线训练策略收集的交互数据进行训练。
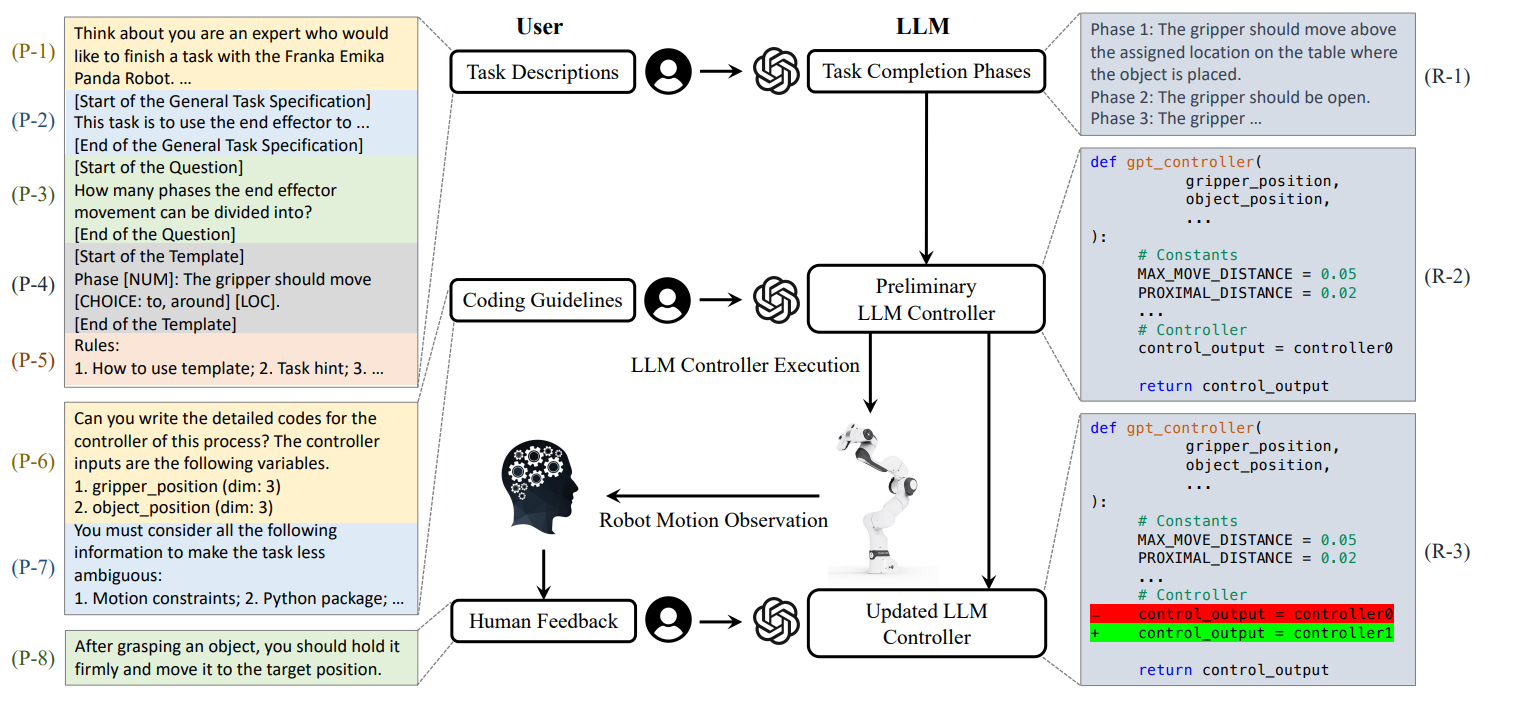
带有人类反馈的提示设计框架。任务描述和编码指南按顺序被提示,人类反馈则是在观察初步的大型语言模型控制器在机器人上的执行过程后提供的。
评论:
本文的亮点在于同时应用大型语言模型和强化学习来为在线训练策略生成训练数据。由大型语言模型生成的控制代码也被视为一种策略,实现了数学意义上的统一。该策略的主要作用是运行在机器人上并收集数据。文章的重点在于大型语言模型的提示设计,即两种类型的提示流程——带人类反馈的和带代码模板的——以及如何设计这些提示。提示的设计非常细致,值得借鉴。
RL-GPT:将强化学习与“代码即策略”相结合
论文链接:arXiv 2402.19299 ,主页
框架概述:

整体框架由一个慢速智能体(橙色)和一个快速智能体(绿色)组成。慢速智能体负责分解任务并确定“需要学习哪些动作”。快速智能体则负责编写代码及强化学习配置,以供底层执行使用。
评论:
该框架整合了“代码即策略”、“强化学习训练”和“大型语言模型规划”。首先,大型语言模型将任务分解为若干动作,再根据复杂程度进一步细分。简单的动作可以直接编码实现,而复杂的动作则采用代码与强化学习相结合的方式。此外,框架还引入了一个Critic模块,用于持续优化代码和规划方案。本文的亮点在于将大型语言模型生成的代码融入强化学习的动作空间进行训练,这种互动式的做法值得借鉴。
大型语言模型如何引导强化学习?一种基于价值的方法
论文链接:arXiv 2402.16181 ,主页
框架概述:
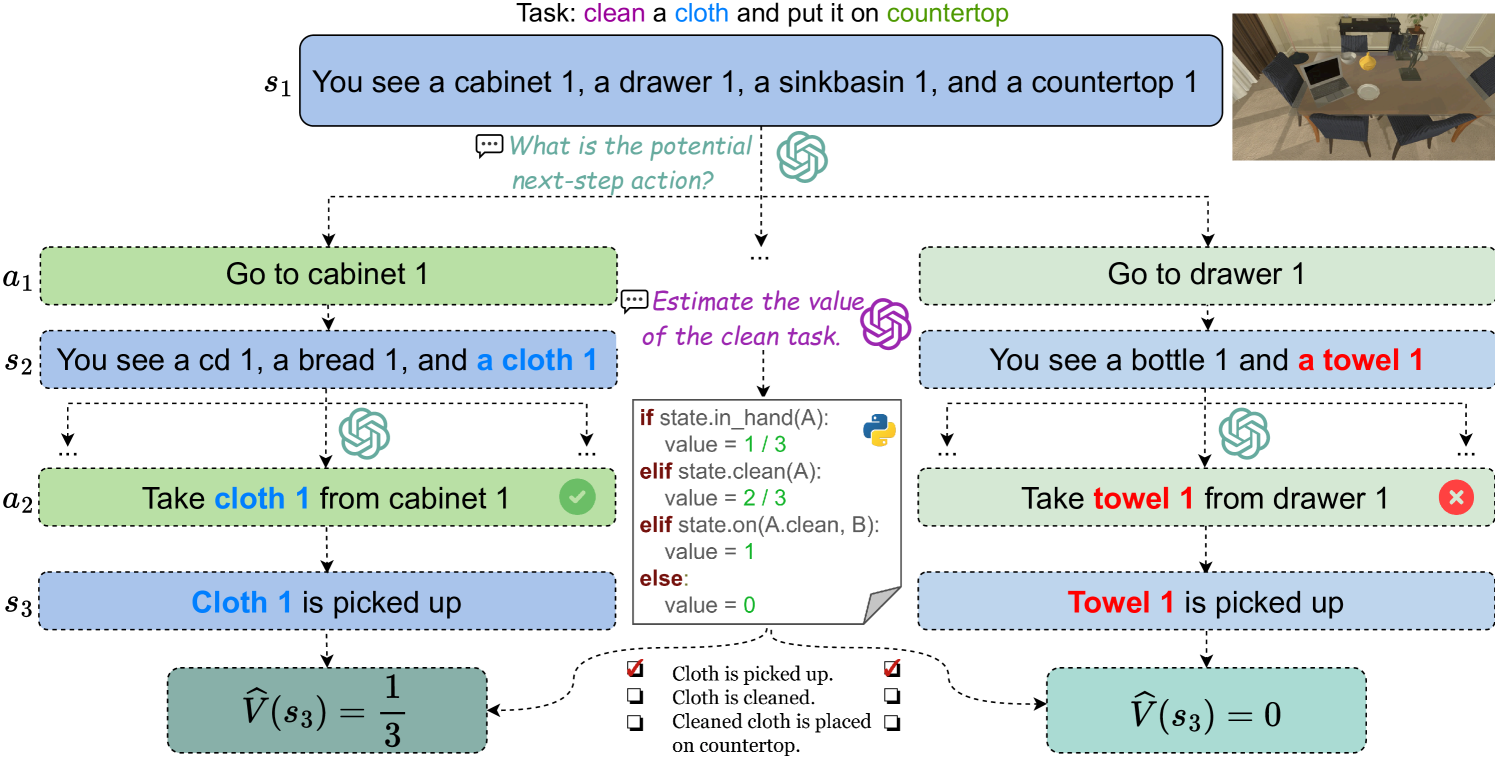
在ALFWorld环境中,当N=2且BFS树的宽度设置为k=3时,SLINVIT算法的演示。任务是“清洗一块布并将它放在台面上”。大型语言模型可能出现的幻觉问题,即本应取毛巾而非布,可通过我们强化学习框架中固有的探索机制加以解决。
评论
本文的核心思想是将任务分配给大语言模型,在广度优先搜索(BFS)框架下进行充分探索,生成多种策略,并提出两种估值方法。一种方法基于代码,适用于目标实现需要满足多个前提条件的场景;另一种方法则依赖蒙特卡洛方法。随后,选择价值最高的最优策略,并将其与强化学习策略相结合,以增强数据采样和策略改进。
PREDILECT:在强化学习中利用零样本语言推理定义偏好
- 论文链接:arXiv 2402.15420,主页
- 概述:
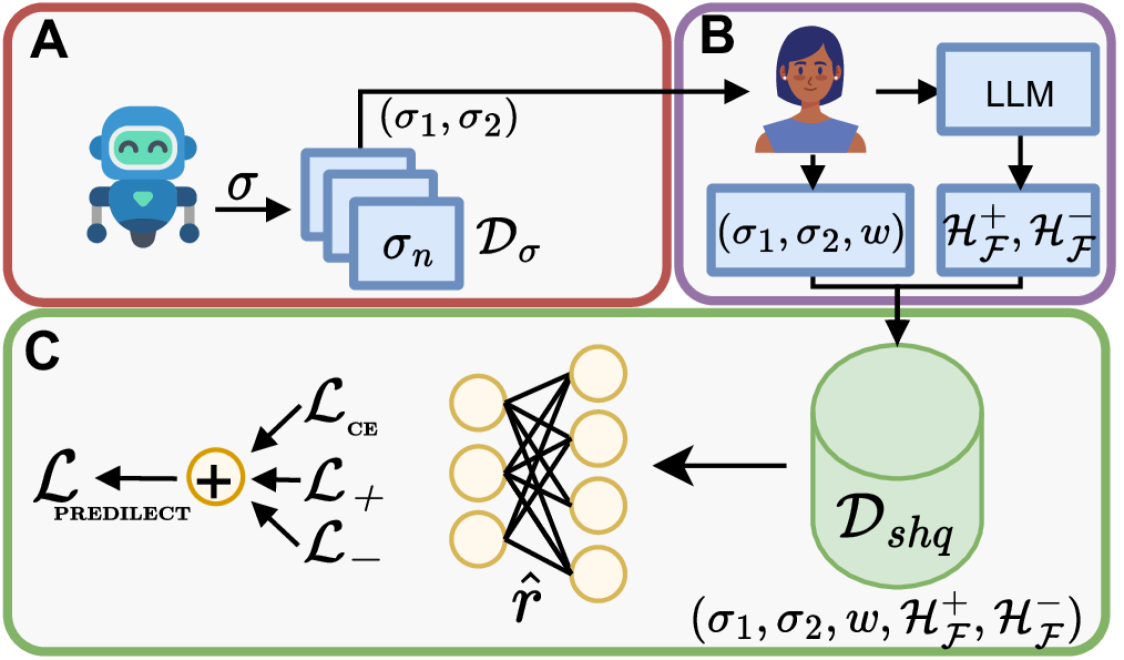
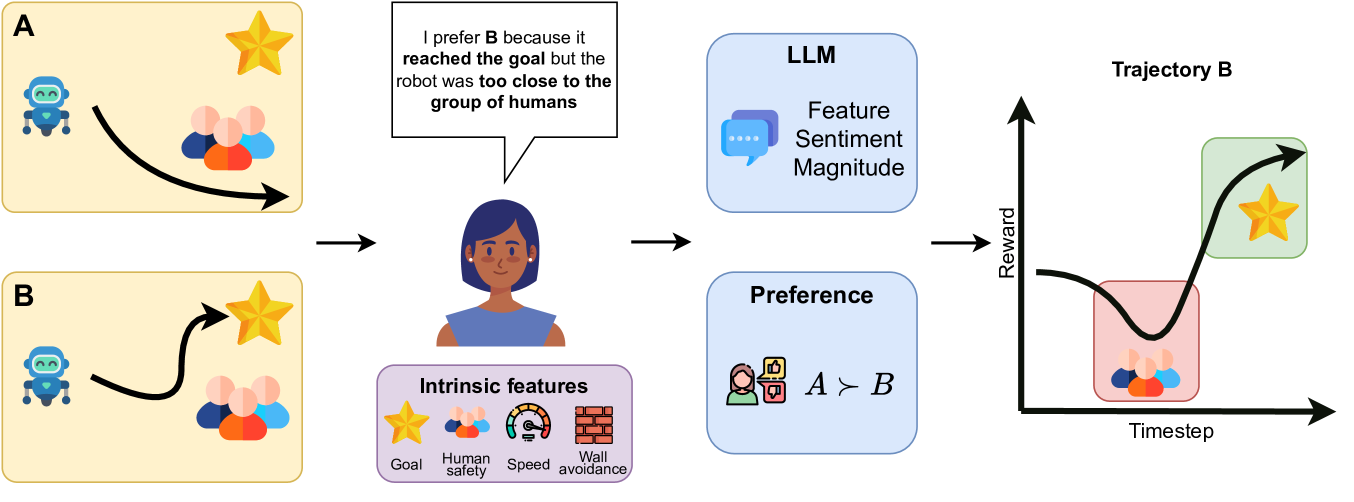
PREDILECT在社交导航场景中的概览:首先,向人类展示两条轨迹A和B。他们表明对其中一条轨迹的偏好,并提供一段额外的文本提示以阐述其见解。随后,可以使用大语言模型提取特征情感,揭示其文本提示中蕴含的因果推理,并将其处理后映射为一组内在价值。最后,利用这些偏好和强调的见解更准确地定义奖励函数。
基于语言反馈模型的策略改进
论文链接:arXiv 2402.07876
框架概述:

自然语言强化学习
论文链接:arXiv 2402.07157
框架概述:
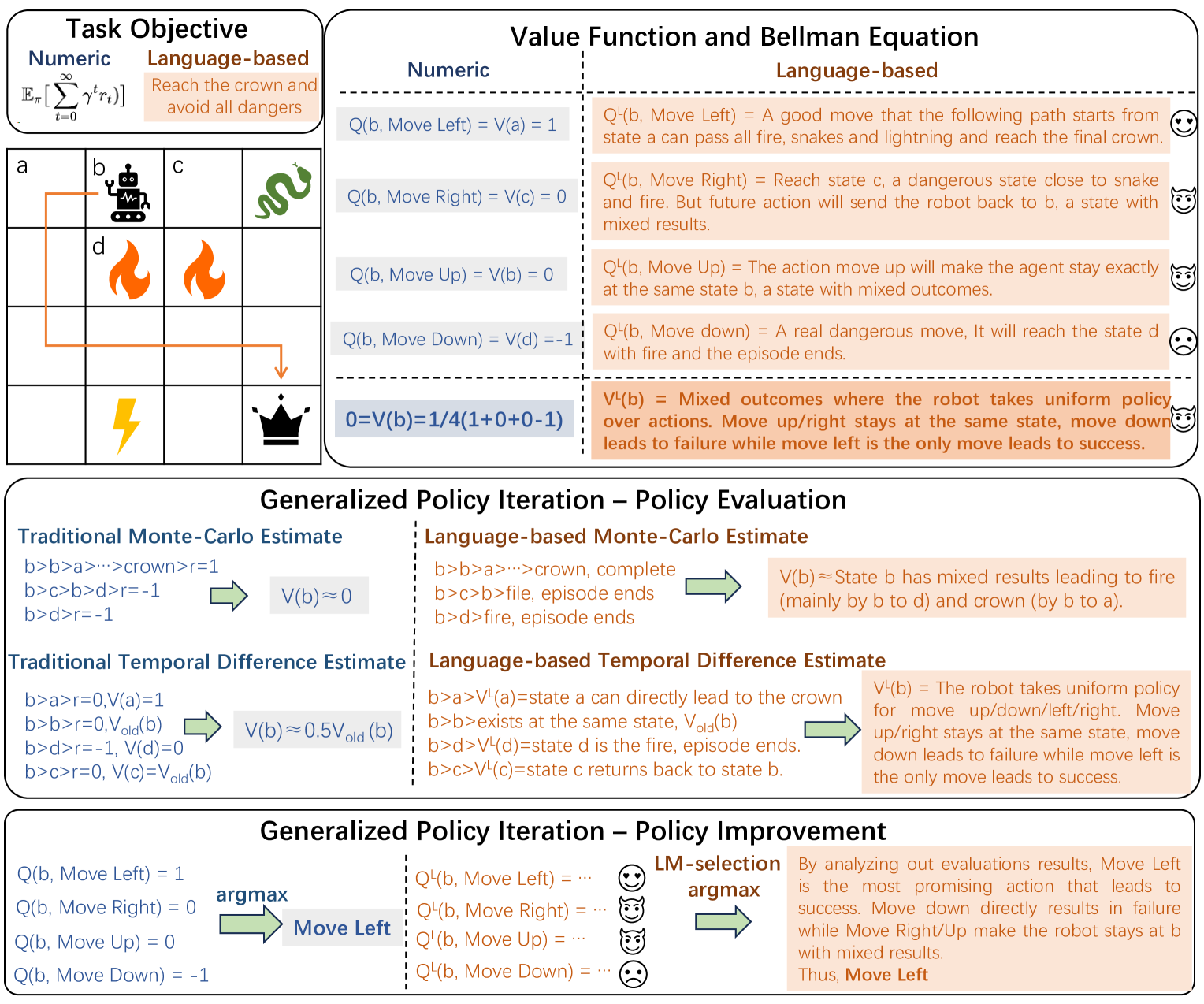
作者通过一个网格世界MDP示例,展示了NLRL与传统RL在任务目标、价值函数、贝尔曼方程以及广义策略迭代方面的差异。在这个网格世界中,机器人需要到达皇冠位置并避开所有危险。他们假设机器人在每个非终止状态都采取最优行动,但在状态b处则采用均匀随机策略。
评论:
本文将强化学习作为大语言模型的一个流程,这是一种引人入胜的研究方法。框架内的最优策略与任务描述高度一致。每个状态及状态-动作值的质量取决于它们与任务描述的契合程度。状态-动作描述既包含奖励,也描述了下一个状态。而状态描述则是对所有可能状态-动作描述的总结。
在策略估计阶段,状态描述模仿了强化学习中常用的蒙特卡洛(MC)或时序差分(TD)方法。MC侧重于多步移动,根据最终状态进行评估;而TD则强调单步移动,返回下一个状态的描述。最后,大语言模型综合所有结果,得出当前状态的描述。在策略改进阶段,大语言模型会选择最佳的状态-动作对来决定行动。
基于大语言模型的层次化持续强化学习
论文链接:arXiv 2401.15098
框架概述:
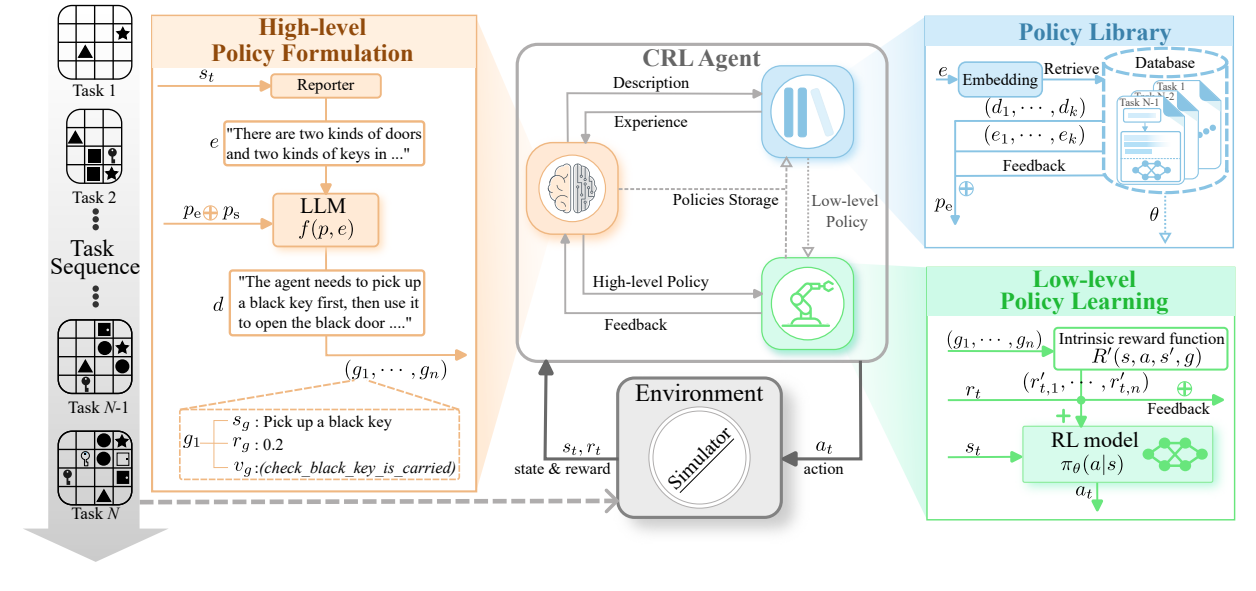
所提出的框架示意图。中间部分展示了Hi-Core内部交互(浅灰色线)和外部交互(深灰色线)。在内部,CRL智能体分为两层:高层策略制定(橙色)和低层策略学习(绿色)。此外,还构建了一个策略库(蓝色),用于存储和检索策略。周围的三个方框展示了当智能体遇到新任务时的内部工作流程。
方法概述:
高层使用大语言模型生成一系列目标g_i。低层则是一个以目标为导向的强化学习系统,需根据这些目标生成策略。策略库用于存储成功的策略。当遇到新任务时,策略库可以调用相关经验,帮助高低层策略智能体完成任务。
真知源于实践:通过强化学习使大语言模型与具身环境对齐
论文链接:arXiv 2401.14151,主页
框架概述:

TWOSOME如何利用动作的联合概率生成策略的概述。标记块中的颜色区域表示相应标记在动作中的概率。
方法概述:
作者提出了在线框架True knoWledge cOmeS frOM practicE(TWOSOME)。该框架部署具身化的大语言模型智能体,通过强化学习高效地与环境互动并对齐,从而解决无需预先准备数据集或了解环境先验知识的决策任务。他们利用大语言模型提供的每个标记的日志似然分数计算各动作的联合概率,进而形成有效的行为策略。
AutoRT:用于大规模机器人编排的具身基础模型
论文链接:arXiv 2401.12963,主页
框架概述:
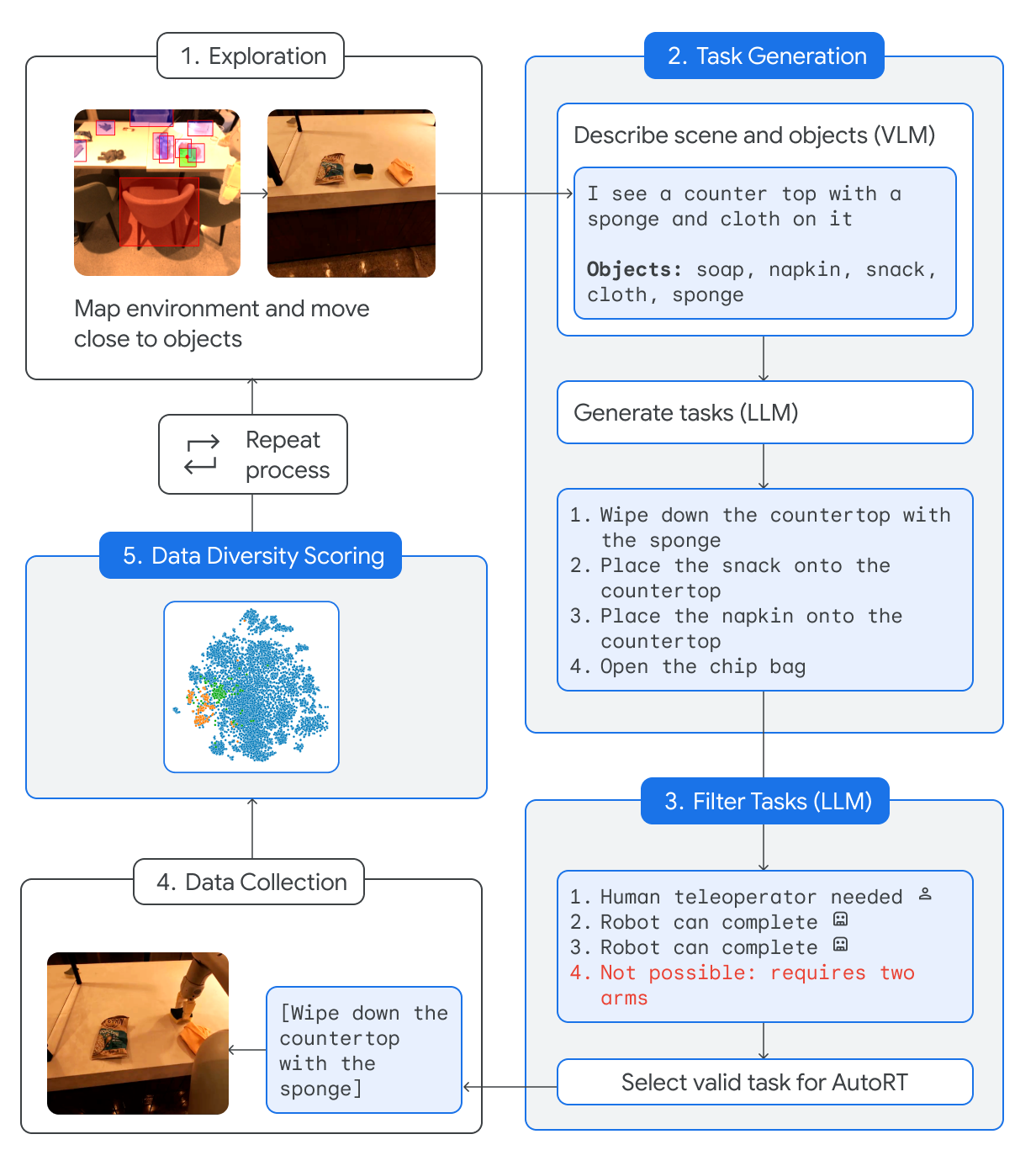
AutoRT旨在探索将机器人扩展到非结构化的“野外”环境中。作者使用视觉语言模型对机器人所见内容进行开放词汇描述,再将这些描述传递给大语言模型,由后者生成自然语言指令。随后,另一家大语言模型会依据所谓的“机器人宪章”对这些建议进行评审,以优化指令,使其更加安全且易于执行。这样一来,他们便可以在更多样化的环境中运行机器人,即使事先并不知道机器人会遇到哪些物体,也能收集关于自动生成任务的数据。
评论:
本文的主要贡献在于设计了一种框架,该框架利用语言学习模型(LLM)根据当前场景和技能为机器人分配任务。在任务执行阶段,可以采用多种机器人学习方法,例如强化学习(RL)。执行过程中获得的数据会被添加到数据库中。
通过这一迭代过程,并随着越来越多的机器人加入,数据收集过程可以实现自动化和加速。这些高质量的数据可用于未来训练更多的机器人。这项工作为基于大量真实物理数据的机器人学习奠定了基础。
基于大语言模型反馈的强化学习以对抗目标误泛化
- 论文链接:arXiv 2401.07181,
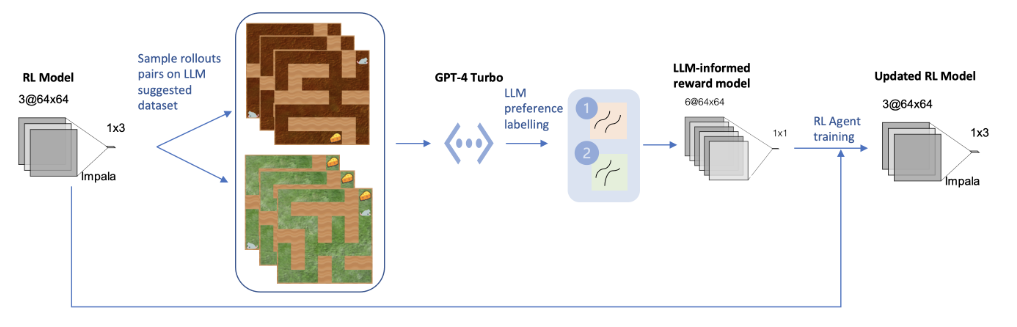
LLM偏好建模与奖励模型。RL智能体部署在LLM生成的数据集上,并存储其轨迹数据。LLM会比较成对的轨迹并给出偏好,这些偏好用于训练一个新的奖励模型。随后,该奖励模型会被整合到智能体剩余的训练步中。
Auto MC-Reward:利用大语言模型为我的世界游戏设计自动化密集奖励机制
- 论文链接:arXiv 2312.09238,主页
- 概述:
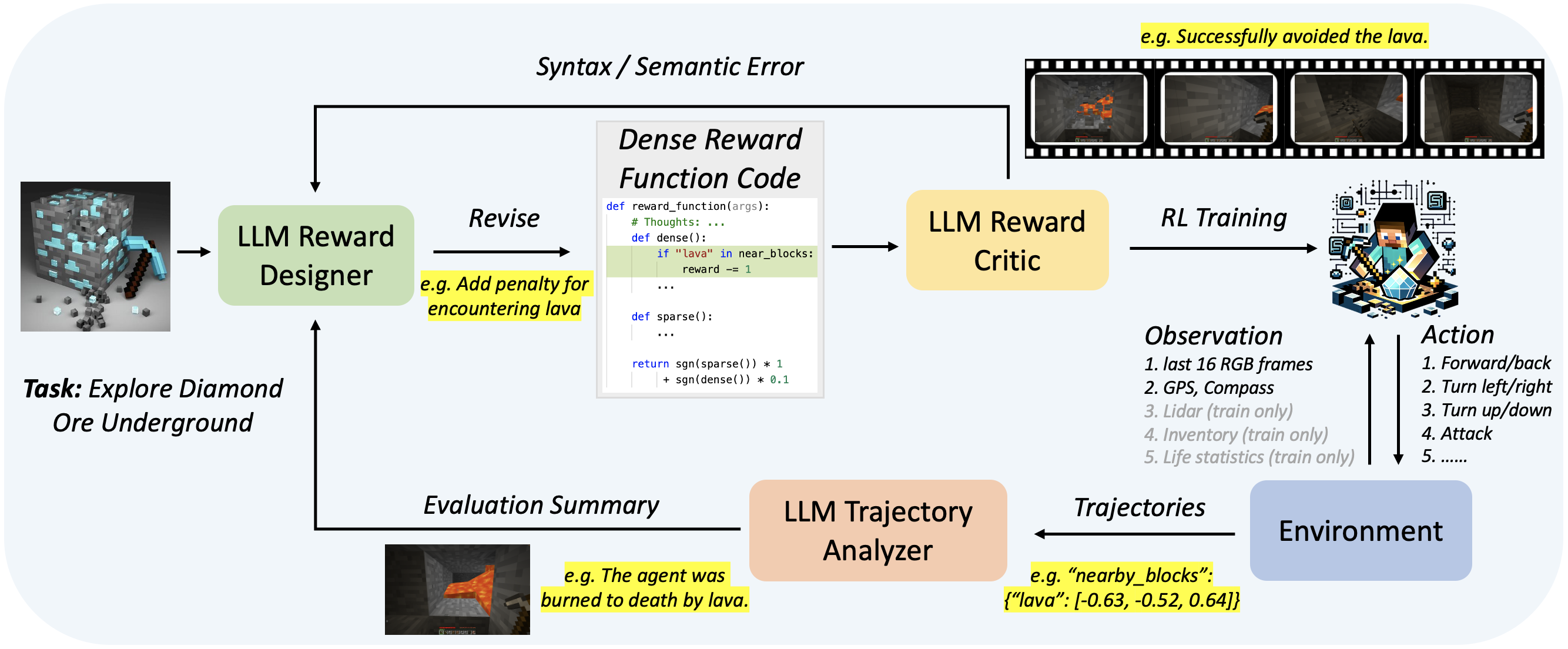
Auto MC-Reward框架概览。Auto MC-Reward由三个基于LLM的关键组件构成:奖励设计师、奖励评论家和轨迹分析器。通过智能体与环境之间的持续交互,不断迭代出合适的密集奖励函数,用于特定任务的强化学习训练,从而使模型能够更好地完成任务。图中展示了一个探索钻石矿石的例子:i) 轨迹分析器发现失败轨迹中的智能体会因熔岩而死亡,于是建议在遇到熔岩时给予惩罚;ii) 奖励设计师采纳该建议并更新奖励函数;iii) 修改后的奖励函数经过奖励评论家的审核后,最终智能体通过左转避开了熔岩。
大语言模型作为策略教师用于训练强化学习智能体
论文链接:arXiv 2311.13373,主页
框架概述:
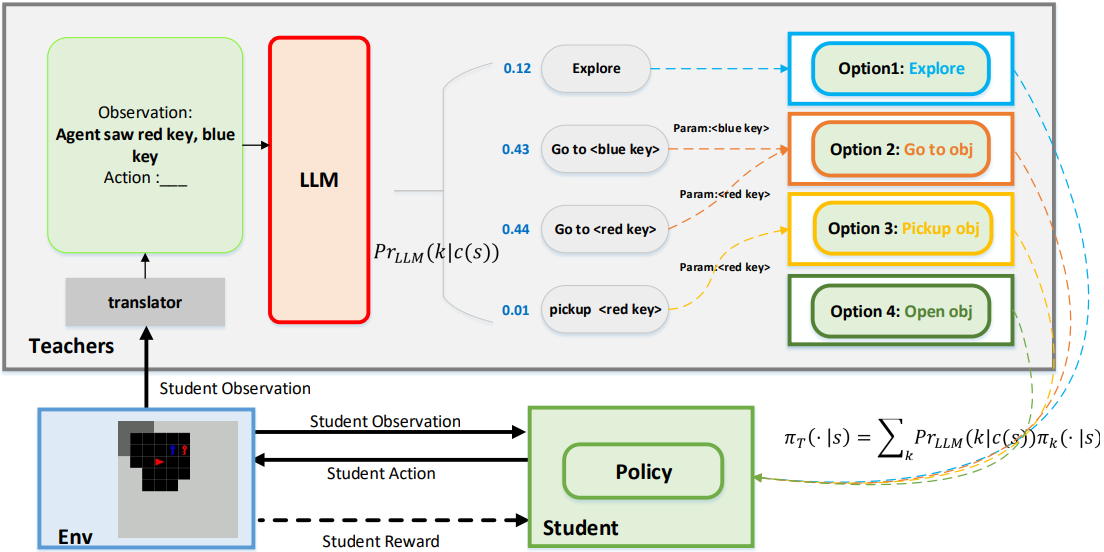
以MiniGrid环境为例的LLM4Teach框架示意图。基于LLM的教师智能体根据环境提供的状态观测结果,给出软性指导。这些指导表现为一组建议动作的概率分布。学生智能体被训练同时优化两个目标。第一个目标是最大化预期回报,这与传统RL算法相同。另一个目标则是鼓励学生智能体遵循教师提供的指导。随着训练过程中学生智能体专业技能的提升,第二个目标的权重会随时间逐渐降低,从而减少其对教师的依赖。
语言与草图:一个由LLM驱动的交互式多模态多任务机器人导航框架
论文链接:arXiv 2311.08244
框架概述:
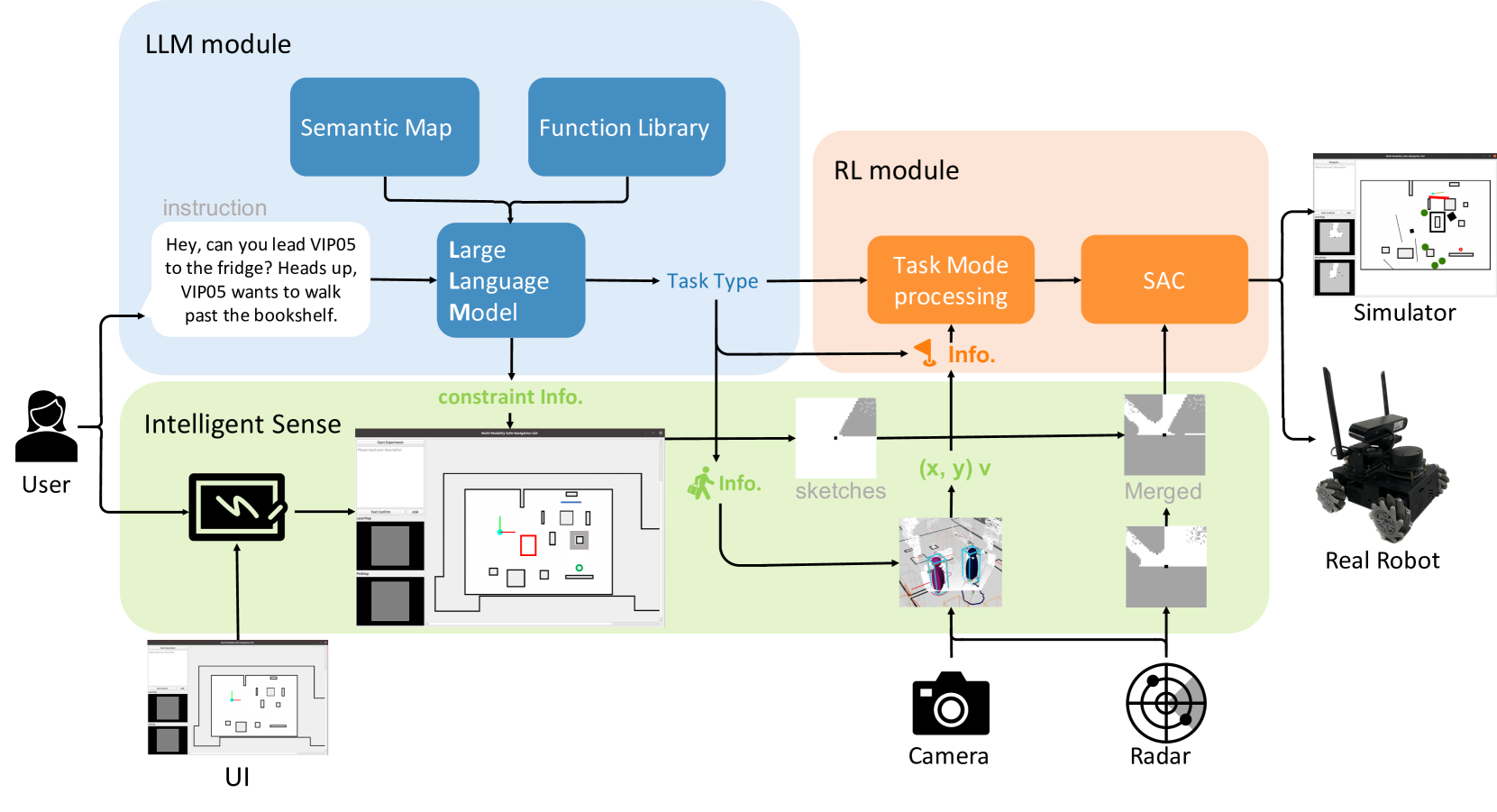
该框架包含一个LLM模块、一个智能感知模块和一个强化学习模块。
LLM增强的层次化智能体
论文链接:arXiv 2311.05596
框架概述:
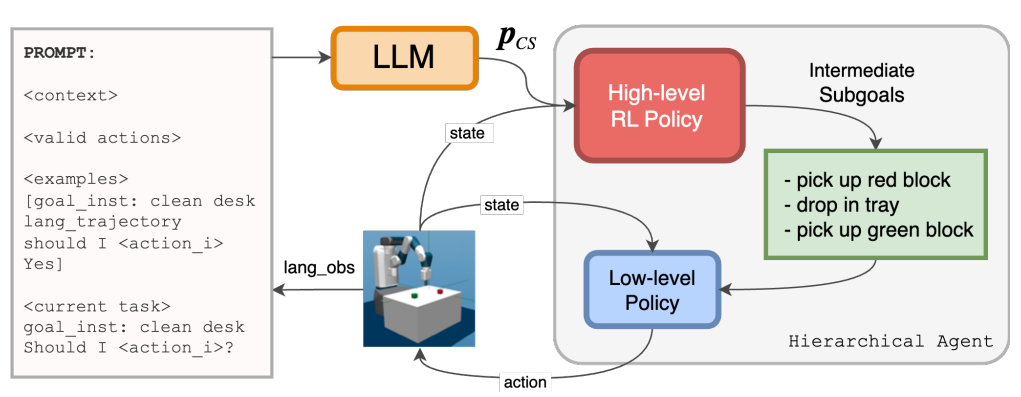
LLM用于指导高层策略并加速学习。它会根据上下文、一些示例以及当前的任务和观测结果进行提示。LLM的输出会影响高层动作的选择。
通过大语言模型的反馈加速机器人操作的强化学习
- 论文链接:arXiv 2311.02379
- 概述:
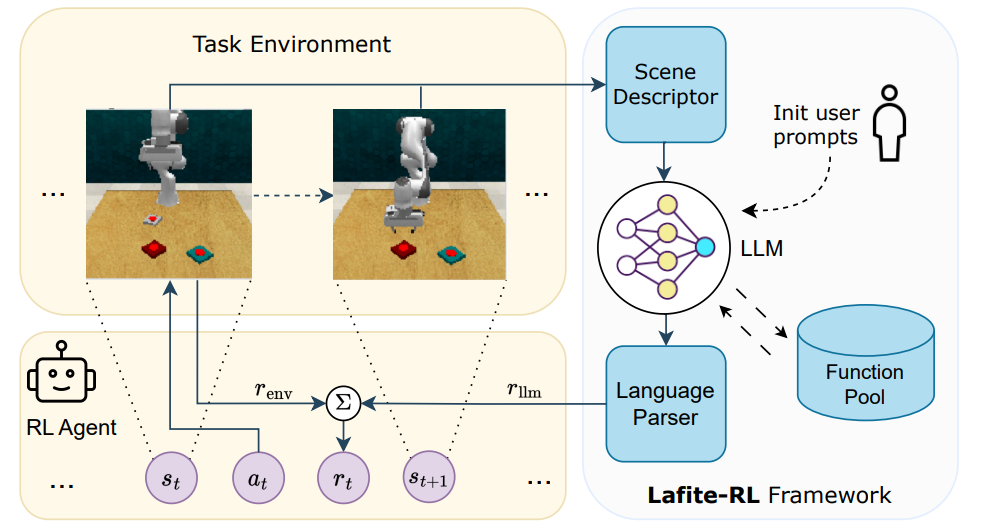
所提出的Lafite-RL框架示意图。在开始学习一项任务之前,用户会提供设计好的提示,包括当前任务背景和期望的机器人行为描述,以及针对LLM任务的具体规则说明。随后,Lafite-RL使LLM能够“观察”并理解场景信息,其中包括机器人的过往动作,并根据当前任务要求评估这些动作。语言解析器将LLM的响应转化为评估反馈,用于构建交互式奖励。
解放预训练语言模型的力量用于离线强化学习
- 论文链接:arXiv 2310.20587,主页
- 概述:
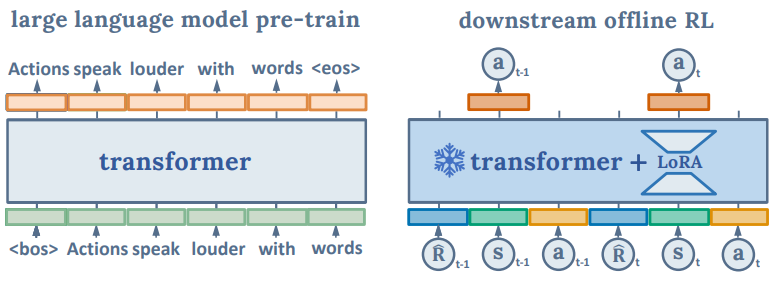
LaMo框架概览。LaMo主要分为两个阶段:(1) 在语言任务上预训练LM;(2) 冻结预训练的注意力层,用MLP替换线性投影,并使用LoRA适配RL任务。作者还在离线RL阶段将语言损失作为正则化项应用。
大语言模型作为具泛化能力的具身任务策略
- 论文链接:arXiv 2310.17722,主页
- 概述:

通过结合强化学习与预训练的LLM,并仅最大化稀疏奖励,该方法可以学习到一种能够泛化到新型语言重排任务的策略。该方法对未见过的物体和场景、以描述或活动解释方式指代物体的新方法,甚至包括变量数量的重排、空间描述和条件语句等新型任务描述,均表现出强大的泛化能力。
Eureka:通过编码型大语言模型实现人类水平的奖励设计
论文链接:arXiv 2310.12931,主页
框架概述:
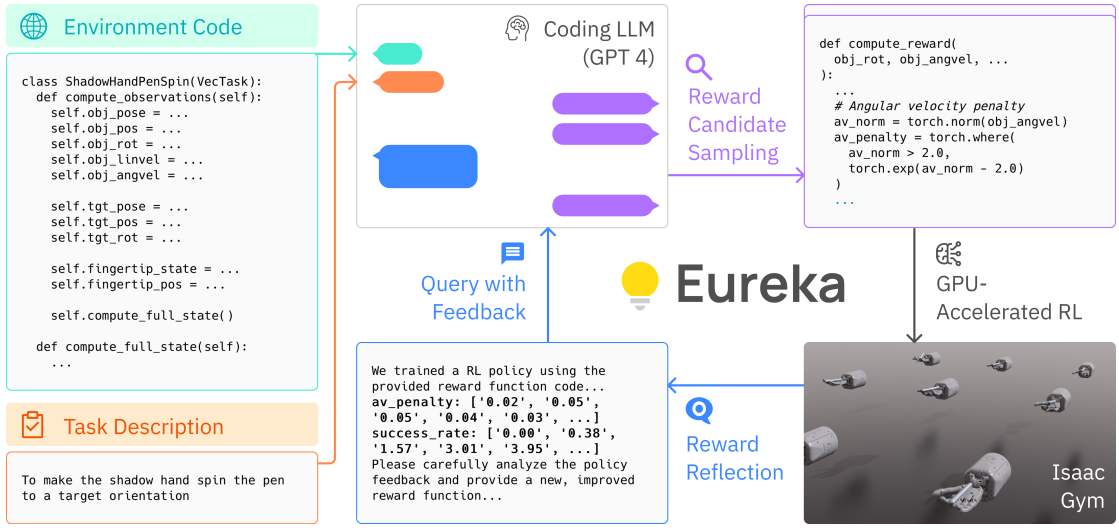
EUREKA以未经修改的环境源代码和语言任务描述为上下文,零次调用直接从编码型LLM生成可执行的奖励函数。随后,它在奖励采样、GPU加速的奖励评估和奖励反思之间反复迭代,逐步改进其奖励输出。
评论
本文中的LLM被用于设计RL的奖励函数。主要关注点是如何创建一个精心设计的奖励函数。有两种方法:
- 进化搜索:最初生成大量奖励函数,并使用硬编码的方法对其进行评估。
- 奖励反思:在训练过程中,保存中间奖励变量并反馈给LLM,从而可以在原有奖励函数的基础上进行改进。
第一种方法更偏向于静态分析,而第二种方法则强调动态分析。通过结合这两种方法,可以选择并优化最佳的奖励函数。
AMAGO:面向自适应智能体的可扩展上下文强化学习
- 论文链接:arXiv 2310.09971,主页
- 概述:
上下文强化学习技术通过使用序列模型,从测试时的经验中推断未知环境的身份,从而解决记忆和元学习问题。AMAGO则针对核心技术挑战,旨在统一端到端离策略强化学习与长序列Transformer的性能,以将记忆能力和对新环境的适应能力推向新的极限。
LgTS:利用LLM生成的子目标进行动态任务采样的强化学习智能体
- 论文链接:arXiv 2310.09454
- 概述:

(a) 网格世界领域及描述符。智能体(红色三角形)需要收集其中一把钥匙并打开门才能到达目标; (b) 发送给LLM的提示,其中包含关于LLM应生成路径数量的信息,以及诸如实体、谓词、环境的高层初始状态和目标状态等符号信息(对于某些谓词的真值是否已知不做假设)。LLM返回的是一组以有序列表形式表示的路径。这些路径随后被转换为有向无环图(DAG)。图b中,LgTS选择的路径在DAG中以红色突出显示。
Octopus:基于环境反馈的具身视觉—语言编程器
- 论文链接:arXiv 2310.08588,主页
- 概述:
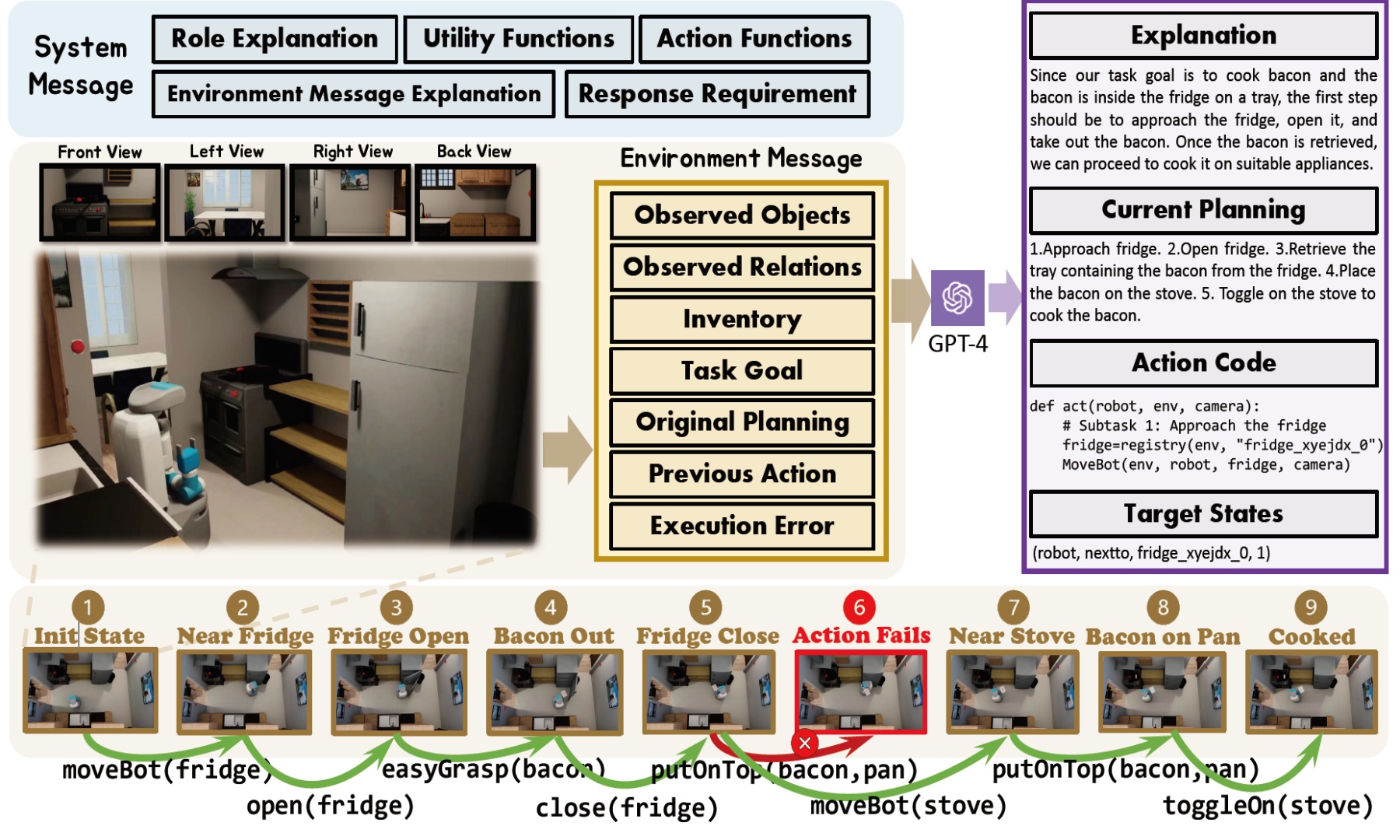
GPT-4通过环境消息感知环境,并根据详细的系统消息生成预期的计划和代码。这些代码随后在模拟器中执行,引导智能体进入下一个状态。对于每个状态,作者都会收集环境消息,其中观察到的物体和关系会被自我的视角图像所替代,作为训练输入。而GPT-4的响应则作为训练输出。环境反馈,特别是对每个目标状态是否达成的判断,会被记录下来用于RLEF训练。
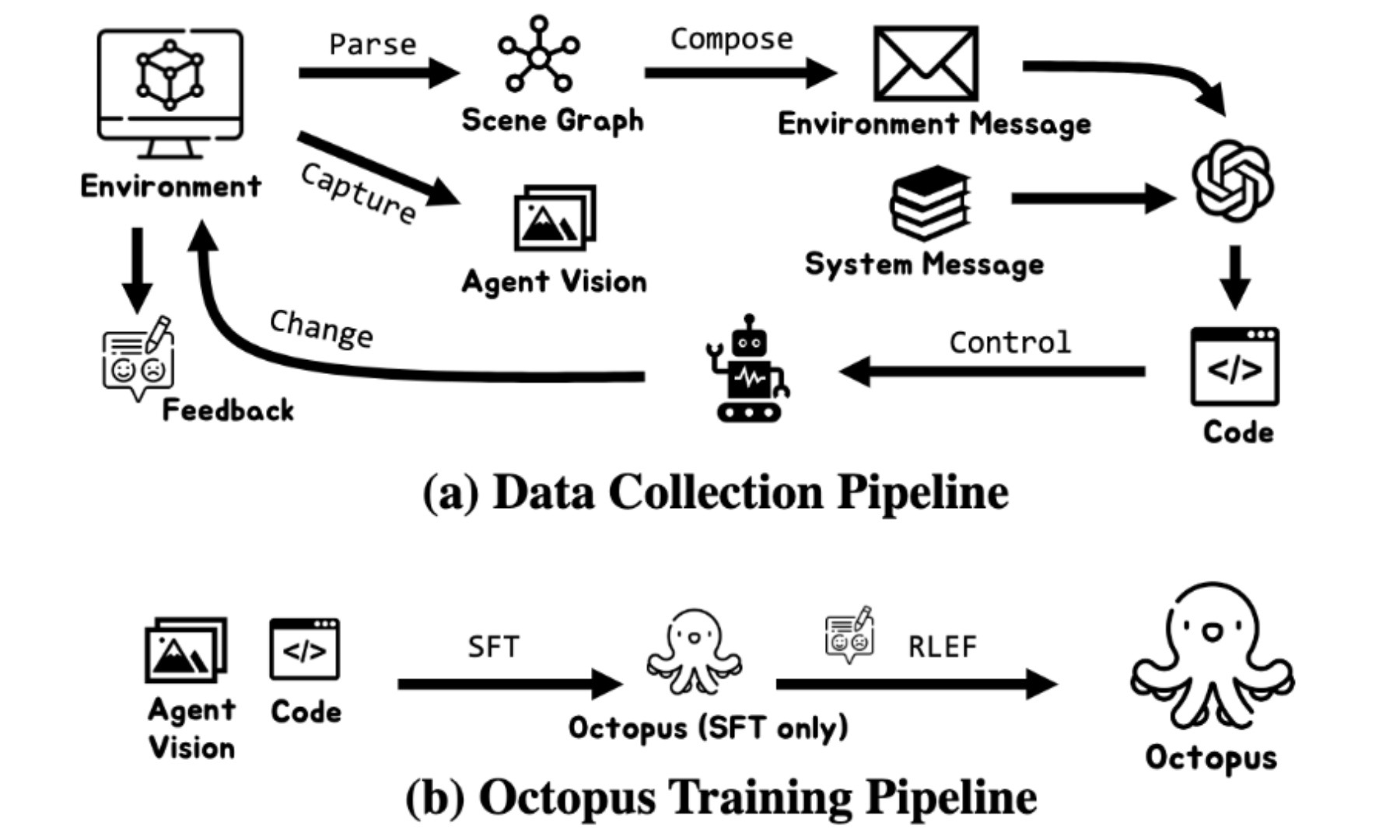
提供的图片展示了一个全面的数据收集和训练流程。在数据收集管道中,环境信息被捕捉并解析为场景图,然后组合生成环境消息和系统消息。这些消息随后驱动智能体的控制,最终生成可执行的代码。对于Octopus训练管道,智能体的视觉和代码会被输入到Octopus模型中,采用SFT和RLEF两种技术进行训练。附带的文字强调了结构良好的系统消息对于GPT-4有效生成代码的重要性,并指出了因错误而面临的挑战,同时突出了该模型在处理各种任务时的适应性。总之,该管道提供了一种从环境理解到行动执行的全方位智能体训练方法。
Motif:来自人工智能反馈的内在动机
- 论文链接:arXiv 2310.00166,主页
- 概述:
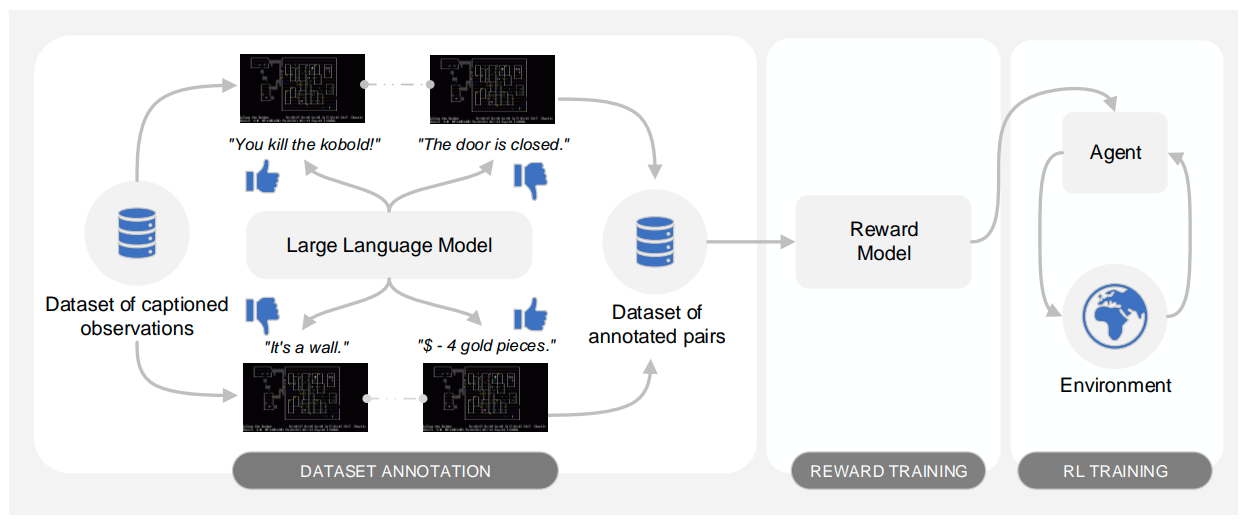
Motif三个阶段的示意图。在第一阶段,即数据集标注阶段,作者从LLM中提取出对成对说明文字的偏好,并将相应的观测对及其标注保存到数据集中。第二阶段是奖励训练阶段,作者将这些偏好提炼成基于观测的标量奖励函数。第三阶段则是强化学习训练阶段,作者使用从偏好中提取的奖励函数,可能结合来自环境的奖励信号,与智能体进行交互式强化学习训练。
Text2Reward:强化学习中的自动化密集奖励函数生成
论文链接:arXiv 2309.11489
框架概述:
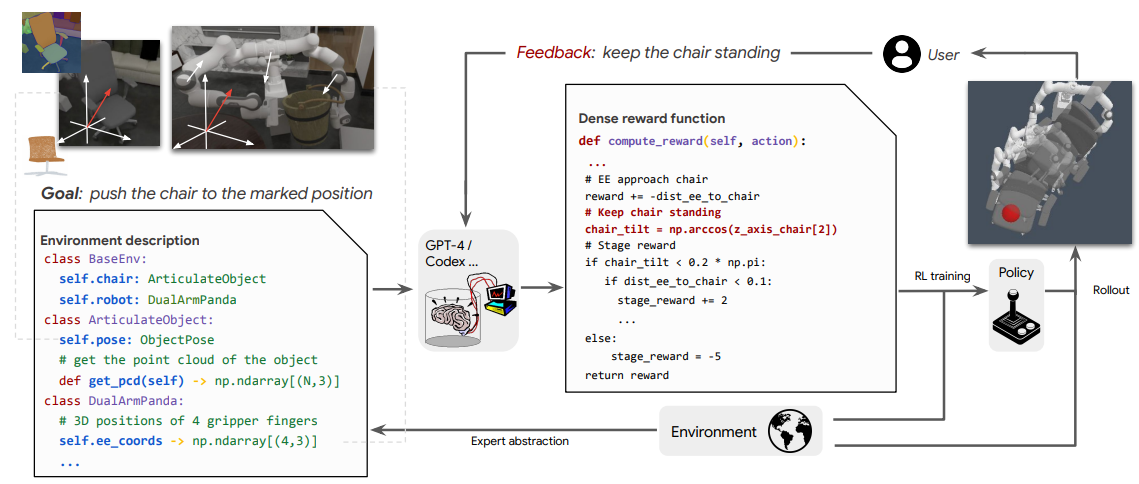
专家抽象层将环境抽象为一个Python类的层次结构。用户指令用自然语言描述要实现的目标。用户反馈允许用户总结失败模式或偏好,这些信息可用于改进奖励代码。
State2Explanation:基于概念的解释,助力智能体学习和用户理解
- 论文链接:arXiv 2309.12482
- 概述:
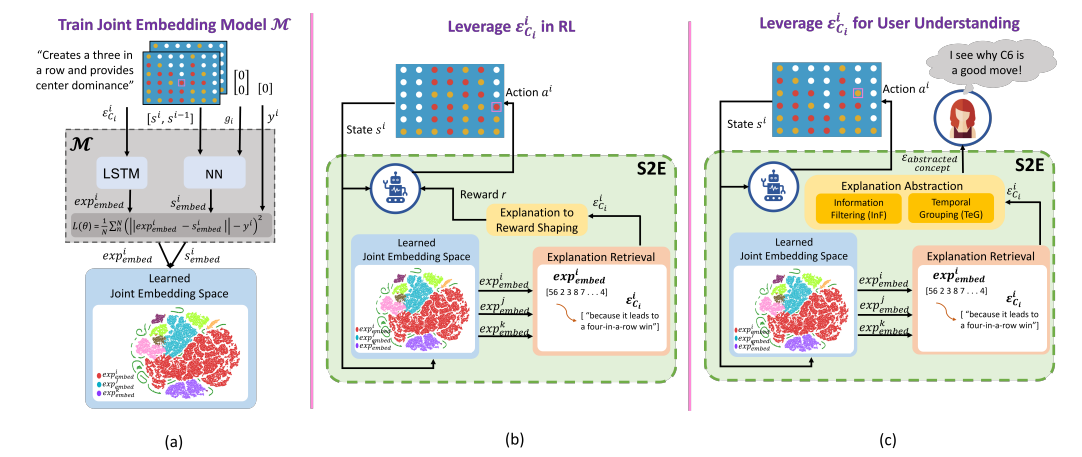
S2E框架包括(a)学习一个联合嵌入模型M,从中提取epsilon并加以利用;(b)在智能体训练过程中用于指导奖励塑造,促进智能体学习;(c)在部署阶段为终端用户提供关于智能体行为的epsilon解释。
自我精炼的大规模语言模型:用于机器人深度强化学习的自动化奖励函数设计者
论文链接:arXiv 2309.06687
框架概述:
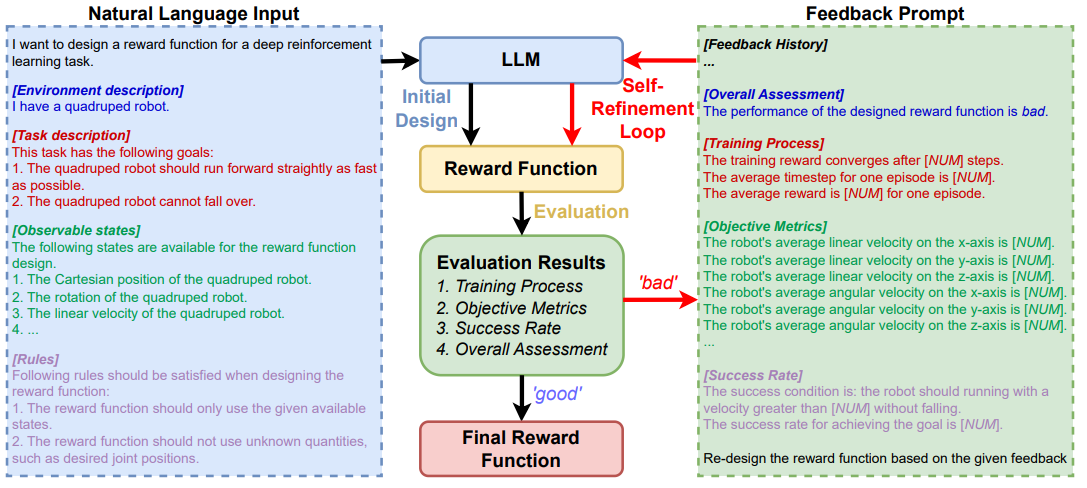
提出的用于奖励函数设计的自我精炼LLM框架。它包括三个步骤:初始设计、评估和自我精炼循环。这里以四足机器人前向奔跑任务为例。
RLAdapter:连接大型语言模型与开放世界中的强化学习
论文链接:arXiv 2309.17176
框架概述:
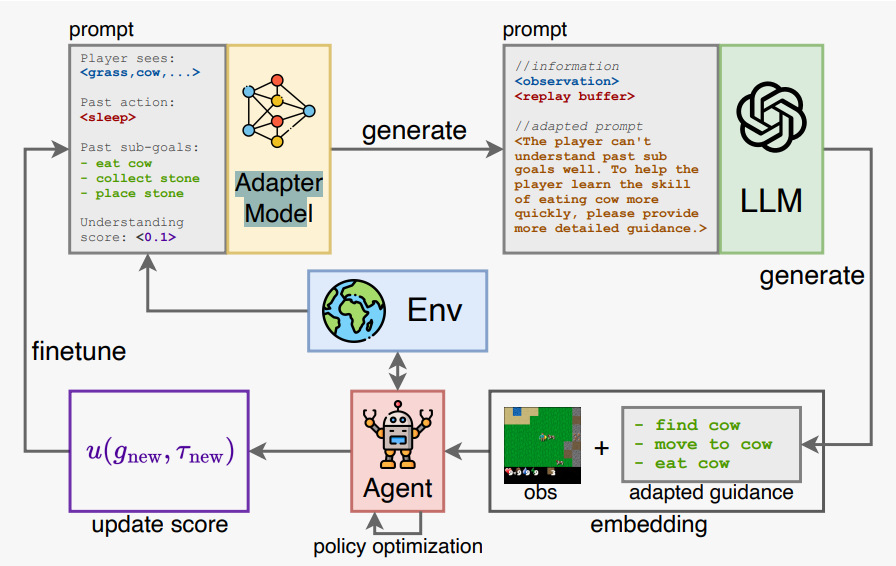
RLAdapter的整体框架。除了接收来自环境和历史信息的输入外,适配器模型的提示还包含一个理解分数。该分数计算智能体最近的动作与LLM建议的子目标之间的语义相似度,从而判断智能体当前是否准确理解了LLM的指导。通过智能体的反馈以及对适配器模型的持续微调,可以使LLM始终与任务的实际状况保持一致。这反过来又确保了所提供的指导最符合智能体优先的学习需求。
评论:
这篇论文开发了RLAdapter框架,除了强化学习和大型语言模型之外,还额外引入了一个适配器模型。
ExpeL:LLM智能体是经验型学习者
- 论文链接:arXiv 2308.10144,主页
- 概述:
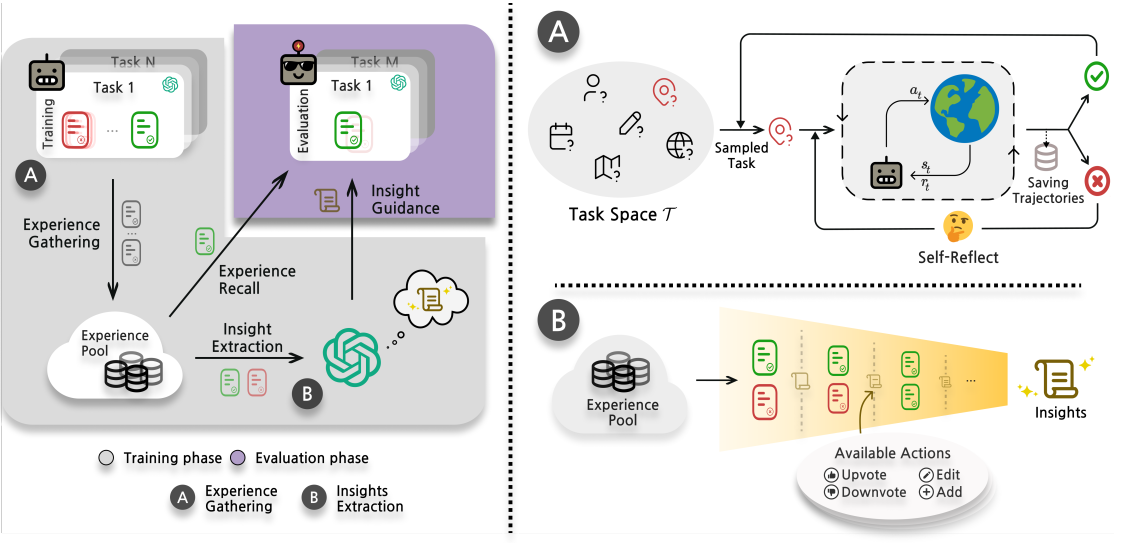
左图:ExpeL 分为三个阶段:(1) 将成功和失败的经验收集到池中。 (2) 从这些经验中提取/抽象出跨任务的知识。 (3) 在评估任务中应用所获得的洞见,并回忆过去的成功经验。 右图:(A) 展示了通过反思进行经验收集的过程,使智能体在对失败进行自我反思后能够重新尝试任务。(B) 展示了洞见提取步骤。当面对成功/失败配对或 L 个成功案例列表时,智能体可以使用 ADD、UPVOTE、DOWNVOTE 和 EDIT 等操作动态修改现有的洞见列表。这一过程的重点在于提取常见的失败模式或最佳实践。
面向机器人技能合成的语言到奖励系统
- 论文链接:arXiv 2306.08647,主页
- 概述:

奖励转换器的详细数据流。运动描述语言模型接收用户输入,用自然语言描述用户指定的运动;而奖励编码器则将该运动转化为奖励参数。
利用语言学习世界模型
- 论文链接:arXiv2308.01399,主页
- 概述:
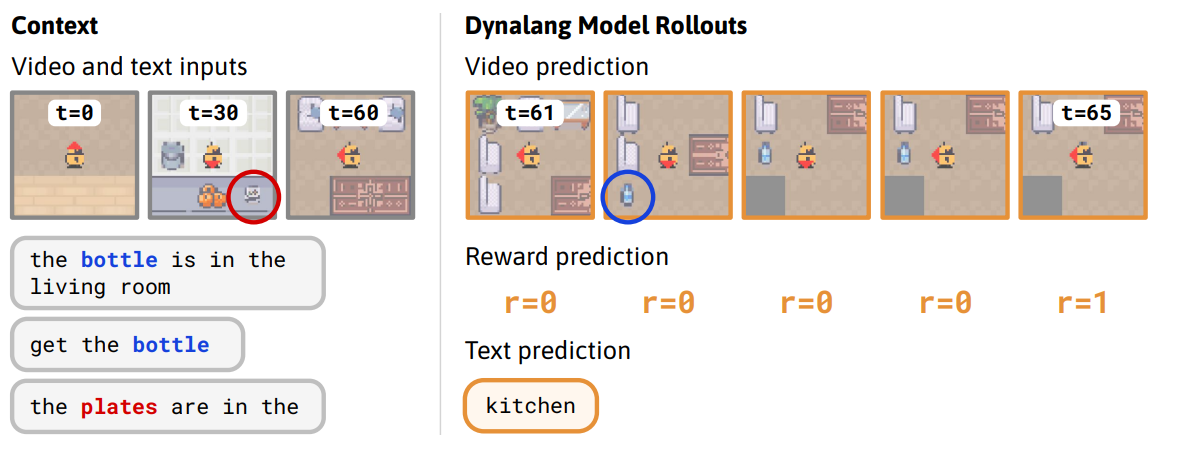
Dynalang 学习使用语言对未来(文本+图像)观测值和奖励进行预测,从而帮助其完成任务。在此,作者展示了在 HomeGrid 环境中的真实模型预测结果。智能体探索了多个房间,并从环境中获取视频和语言观测信息。根据过去的文本“瓶子在客厅里”,智能体在第 61 至 65 个时间步预测它将在客厅的最后一个角落看到瓶子。根据描述任务的文本“拿瓶子”,智能体预测自己会因拿起瓶子而获得奖励。此外,智能体还能预测未来的文本观测:给定前缀“盘子在”以及在第 30 个时间步观察到的台面上的盘子,模型预测最有可能出现的下一个词是“厨房”。
基于强化学习实现智能体与大语言模型之间的智能交互
- 论文链接:arXiv 2306.03604,主页
- 概述:
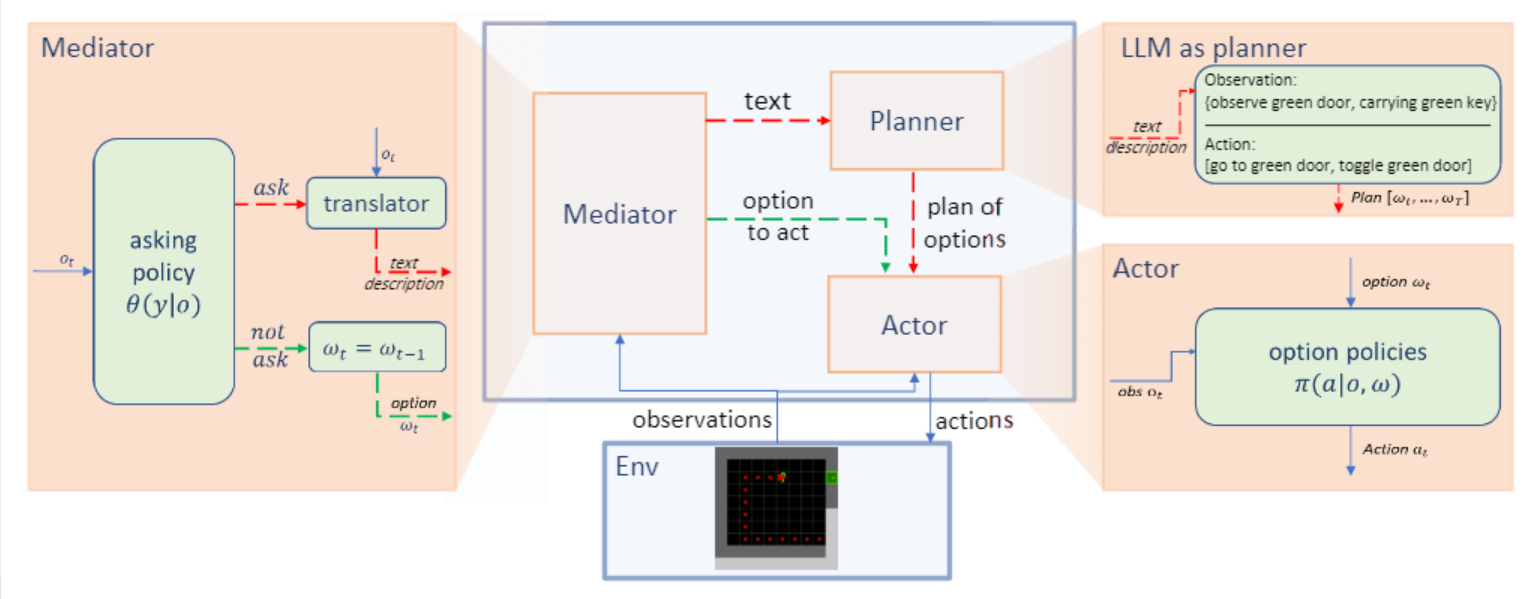
规划者-执行者-中介范式概览及交互示例。在每个时间步,中介接收观测 o_t 作为输入,并决定是否向 LLM 规划者请求新指令。当请求策略决定发起请求时,如红色虚线所示,翻译器会将 o_t 转换为文本描述,规划者据此输出新的计划供执行者遵循。另一方面,当中介决定不请求时,如绿色虚线所示,中介直接返回给执行者,指示其继续执行当前计划。
基于语言模型的奖励设计
论文链接:arXiv 2303.00001
框架概述:
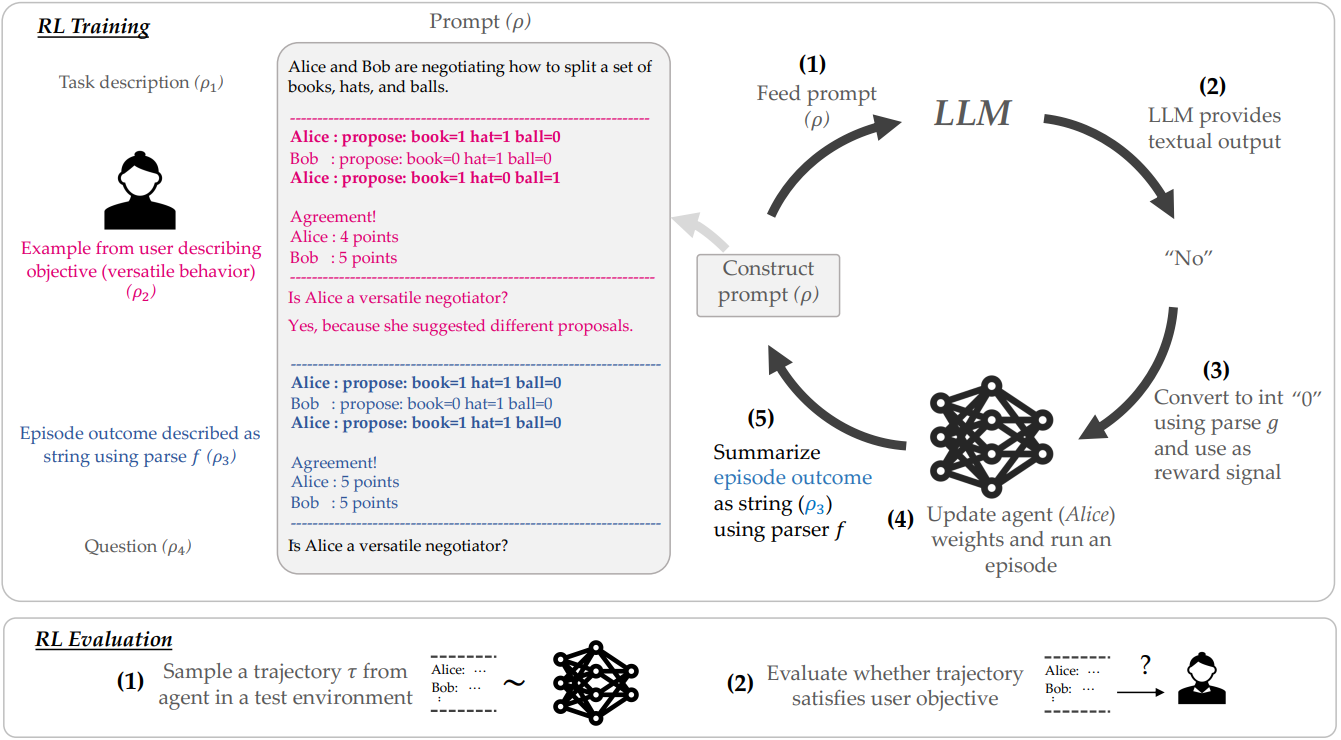
框架在 DEAL OR NO DEAL 谈判任务上的示意图。用户在训练前提供期望谈判行为的示例及其解释(例如灵活性)。在训练过程中,(1) 用户向 LLM 提供任务描述、用户对其目标的描述、将一轮结果转换为字符串,以及询问该轮结果是否满足用户目标的问题。(2-3) 随后,他们将 LLM 的回复解析回字符串,并将其用作 RL 智能体 Alice 的奖励信号。(4) Alice 更新其权重并展开新一轮实验。(5) 他们再次将实验结果解析为字符串,继续训练。在评估阶段,他们从 Alice 的轨迹中采样,并评估其是否符合用户的目标。
面向开放世界长时限任务的技能强化学习与规划
论文链接:arXiv 2303.16563,主页
框架概述:
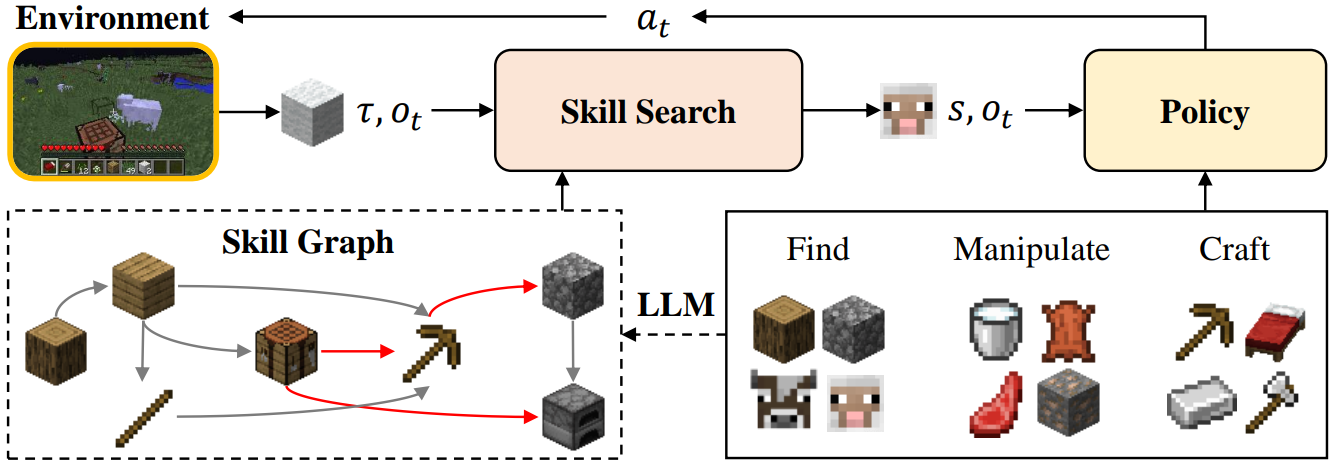
作者将 Minecraft 中的基本技能分为三类:发现技能、操作技能和制作技能。他们利用强化学习训练策略来掌握这些技能。借助 LLM,作者提前提取技能之间的关系并构建技能图,如虚线框所示。在线规划时,技能搜索算法会在预生成的图上遍历,将任务分解为可执行的技能序列,并交互式地选择相应的策略来解决复杂任务。
评论
本文的亮点在于使用 LLM 生成技能图,从而明确各技能之间的先后顺序。当输入一项任务时,框架会使用深度优先搜索在技能图上查找,以确定每一步应选择的技能。强化学习负责执行具体技能并更新状态,通过迭代这一过程,将复杂任务分解为易于管理的部分。
该框架有待改进的地方包括:
- 目前需要人工预先提供可用技能。未来,框架应具备自主学习新技能的能力。
- 框架中 LLM 的作用主要是建立技能之间的关系。或许这一功能也可以通过硬编码实现,例如查询 Minecraft 库来生成技能图。
RE-MOVE:基于语言反馈的自适应策略设计,用于动态环境中的机器人导航任务
- 论文链接:arXiv 2303.07622,主页
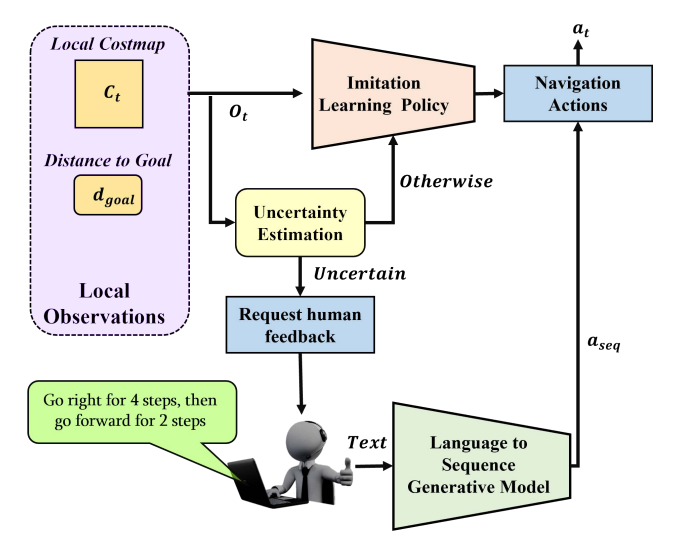
- 概述:
基于内部向外的任务语言开发与翻译的自然语言条件强化学习
- 论文链接:arXiv 2302.09368
- 概述:
自然语言条件强化学习(NLC-RL)使智能体能够遵循人类指令。以往的方法通常通过提供自然语言指令并训练一个遵循策略来实现自然语言条件强化学习。在这种“外向式”方法中,策略需要同时理解自然语言并完成任务。然而,不受限制的自然语言示例往往会给具体的强化学习任务带来额外的复杂性,从而分散策略学习完成任务的注意力。为了减轻策略的学习负担,作者提出了一种“内向式”自然语言条件强化学习方案,开发了一种与任务相关且独特的任务语言(TL)。该任务语言用于强化学习中,以实现高效且有效的策略训练。此外,还训练了一个翻译器将自然语言翻译成任务语言。他们将这一方案实现为TALAR(带有谓词表示的任务语言),该模型学习多个谓词来建模对象关系作为任务语言。实验表明,TALAR不仅更好地理解了自然语言指令,还生成了更好的指令遵循策略,成功率达到13.4%,并且能够适应未见过的自然语言表达方式。此外,任务语言还可以作为一种有效的任务抽象,天然地与层次化强化学习兼容。
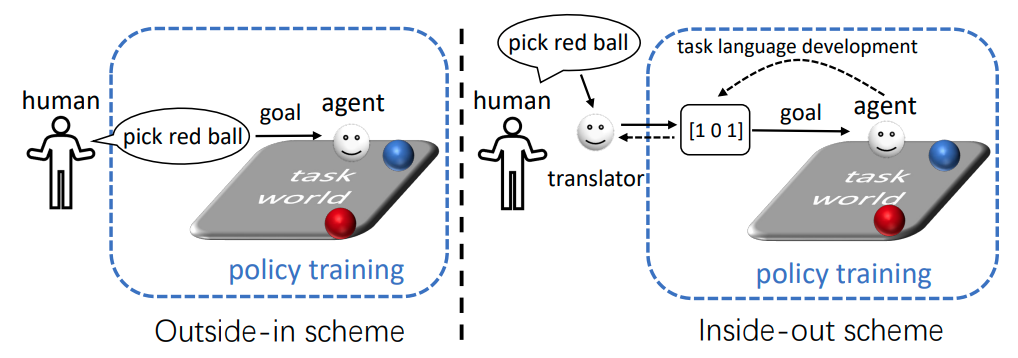
NLC-RL中OIL和IOL方案的示意图。 左图:OIL直接将自然语言指令暴露给策略。 右图:IOL开发了一种任务语言,它是与任务相关的、对自然语言指令的独特表示。 实线表示指令执行过程,虚线表示任务语言的开发和翻译。
大型语言模型在强化学习中的引导式预训练
论文链接:arXiv 2302.06692 ,主页
框架概述:
ELLM利用预训练的大规模语言模型(LLM),以一种与任务无关的方式建议可能有用的目标。基于LLM的上下文敏感性和常识能力,ELLM训练强化学习智能体去追求那些很可能有意义的目标,而无需直接的人工干预。

ELLM使用GPT-3来建议合适的探索目标,并利用SentenceBERT嵌入计算建议目标与示范行为之间的相似度,以此作为内在动机奖励。
评论:
这篇论文是最早将LLM用于强化学习目标规划的研究之一。ELLM框架会将当前环境信息和可用动作传递给LLM,使其能够根据常识设计出多个合理的目标,然后由强化学习执行其中一个目标。奖励函数则根据目标和状态嵌入的相似度来确定。由于嵌入也是由SentenceBERT模型生成的,因此可以说奖励实际上是由LLM生成的。
在交互式环境中通过在线强化学习实现大型语言模型的具身化
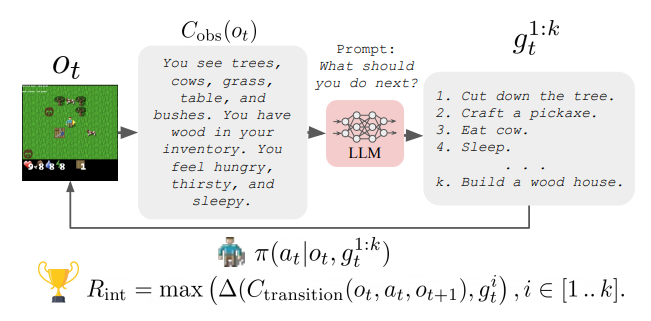
论文链接:arXiv 2302.02662 ,主页
框架概述:
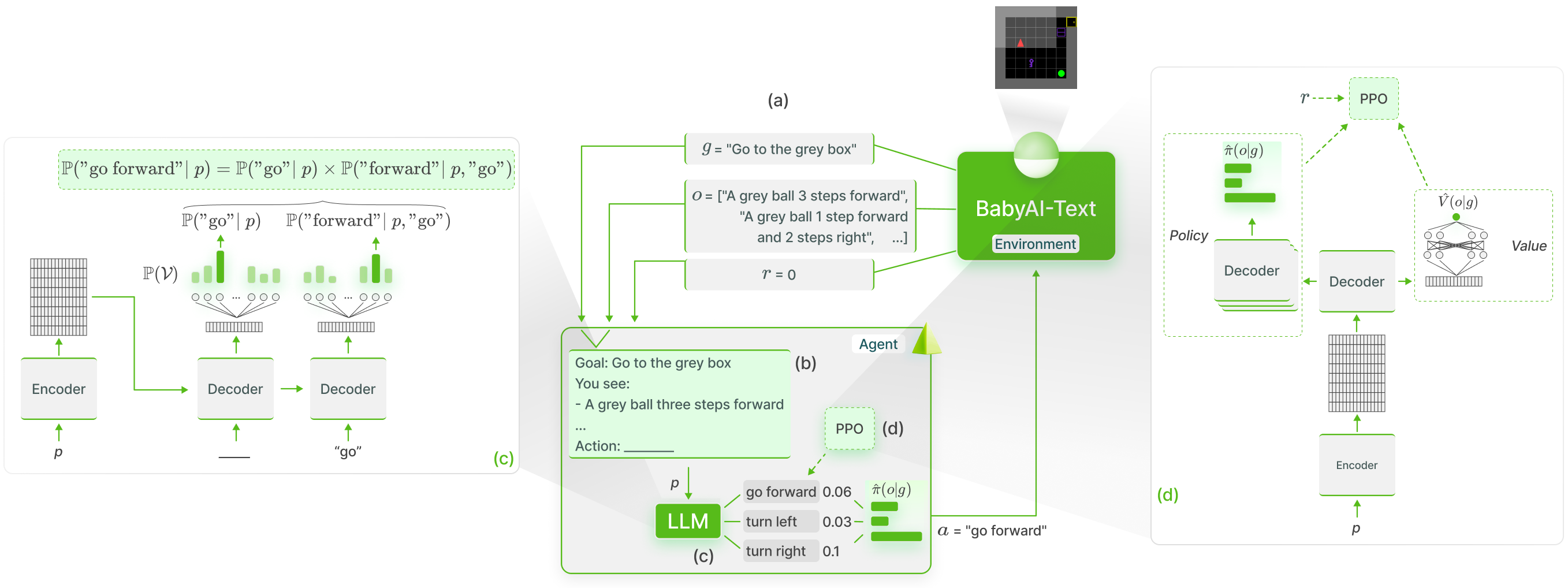
GLAM方法:作者在文本交互式强化学习环境(BabyAI-Text)中使用LLM作为智能体策略,在该环境中LLM通过在线强化学习(PPO)被训练以实现语言目标,从而实现功能性的具身化。(a)BabyAI-Text为当前回合提供目标描述、智能体观测描述以及当前步骤的标量奖励。(b)每一步,他们将目标描述和观测整合成一个提示词发送给我们的LLM。(c)对于每个可能的动作,他们使用编码器生成提示词的表示,并计算在给定提示词条件下构成该动作的标记的条件概率。一旦估算出每个动作的概率,他们就会对这些概率进行softmax归一化,并根据该分布采样一个动作。也就是说,LLM就是我们的智能体策略。(d)他们利用环境返回的奖励,通过PPO微调LLM。为此,他们在LLM的基础上添加了一个价值头来估计当前观测的价值。最后,他们通过LLM(及其价值头)反向传播梯度。
评论:
本文使用BabyAI-Text将Gridworld中的目标和观测转化为文本描述,这些描述可以进一步转换为输入LLM的提示词。LLM输出动作的概率,随后LLM输出的动作概率、MLC获得的值估计以及奖励会被输入到PPO中进行训练。最终,智能体会输出一个合适的动作。在实验中,作者使用了GFlan-T5模型,经过25万步的训练后,成功率达到80%,相比其他方法有了显著提升。
阅读并收获奖励:借助说明书学习玩Atari游戏
- 论文链接:arXiv 2302.04449
- 概述:
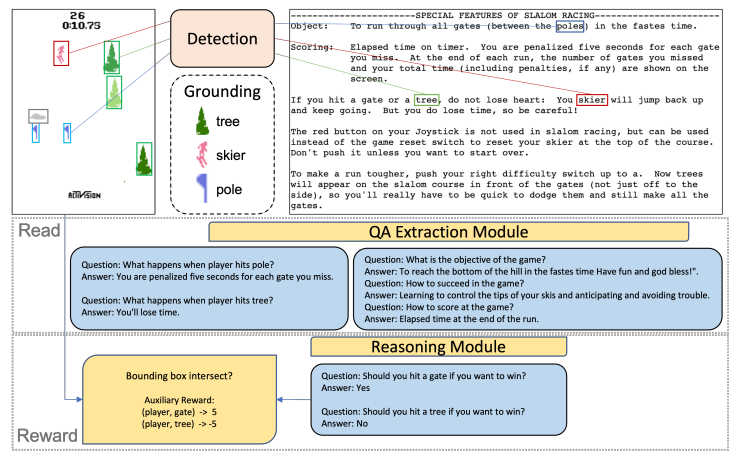
“阅读与奖励”框架概览。系统接收环境中的当前帧和说明书作为输入。经过目标检测和具身化处理后,QA提取模块会从说明书中提取并总结相关信息,推理模块则根据QA提取模块的输出,为游戏中检测到的事件分配辅助奖励。“是/否”答案随后被映射为+5/−5的辅助奖励。
与语言模型协作进行具身推理
论文链接:arXiv 2302.00763
框架概述:
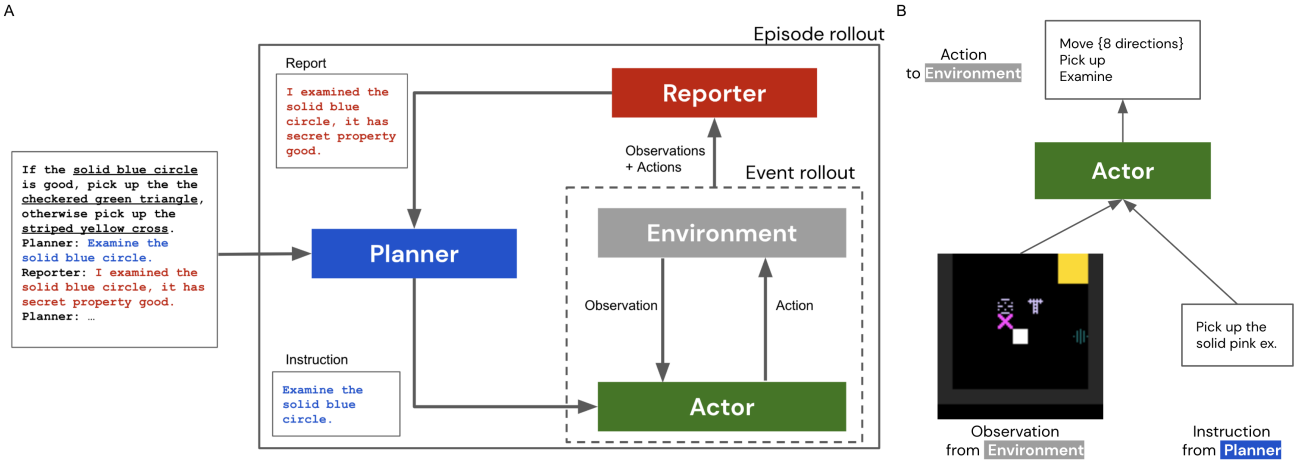
A. 规划者-执行者-报告者范式的示意图及三者之间交互的示例。B. PycoLab环境的观测空间和动作空间。
评论:
本文提出的框架简单明了,是早期将LLM用于强化学习策略的研究之一。在这个框架中,规划者是LLM,而报告者和执行者则是强化学习组件。任务要求先检查物品的属性,再选择具有“良好”属性的物品。框架从规划者开始,向其提供任务描述和历史执行记录。规划者随后为执行者选择一个行动。执行者执行动作后会得到结果。报告者观察环境并向规划者反馈,这一过程不断重复。
变压器是样本高效的世界模型
- 论文链接:arXiv 2209.00588,主页
内心独白:通过语言模型规划实现具身推理
- 论文链接:arXiv 2207.05608,主页
- 概述:
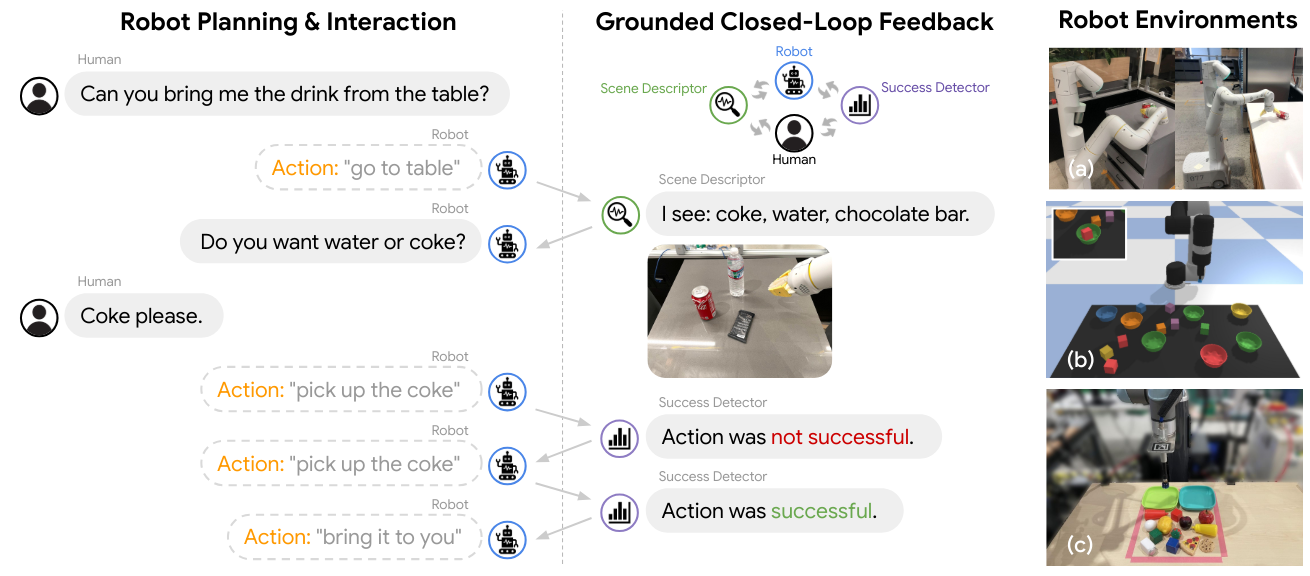
内心独白通过结合一系列感知模型(如场景描述符和成功检测器)与预训练的语言条件机器人技能,为基于大型语言模型的机器人规划提供 grounded 的闭环反馈。实验表明,该系统能够在模拟和真实环境中,针对 (a) 移动操作和 (b,c) 桌面操作等复杂长 horizon 任务进行推理和重规划,从而完成目标。
做我能做的,而不是我说的:将语言 grounding 到机器人 affordance 中
论文链接:arXiv 2204.01691,主页
框架概述:
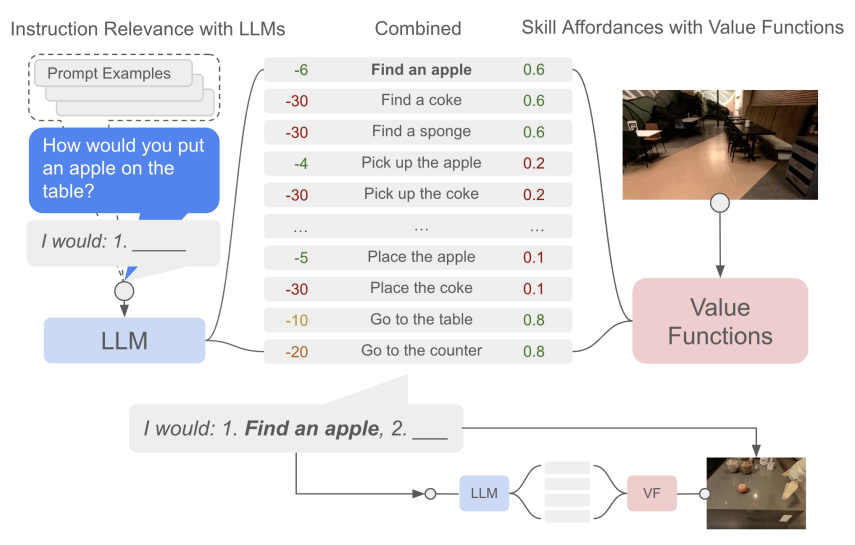
给定一个高层指令,SayCan 将来自 LLM 的概率(即某项技能对指令有用的概率)与来自价值函数的概率(即成功执行该技能的概率)相结合,以选择要执行的技能。这样生成的技能既可行又有效。随后,将该技能附加到响应中,并再次查询模型,这一过程不断重复,直到输出步骤为终止。
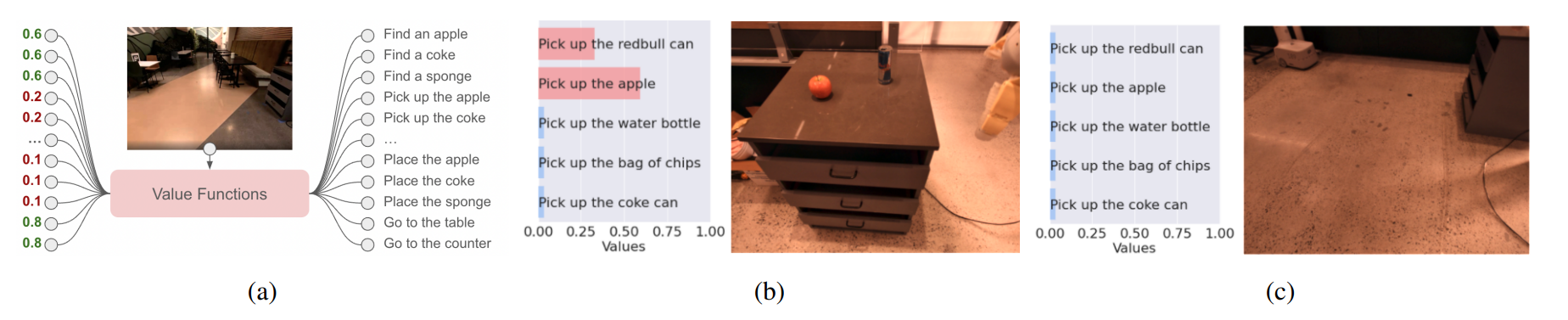
会查询一个价值函数模块 (a),根据当前观测结果构建动作基元的价值函数空间。以“pick”价值函数为例,在 (b) 场景中,“拿起红色的公牛罐头”和“拿起苹果”的值较高,因为这两个物体都在场景中;而在 (c) 场景中,机器人正在空旷的空间中导航,因此没有任何拿起动作能获得高值。
保持冷静并探索:用于文本类游戏中动作生成的语言模型
- 论文链接:arXiv 2010.02903,主页
- 概述:
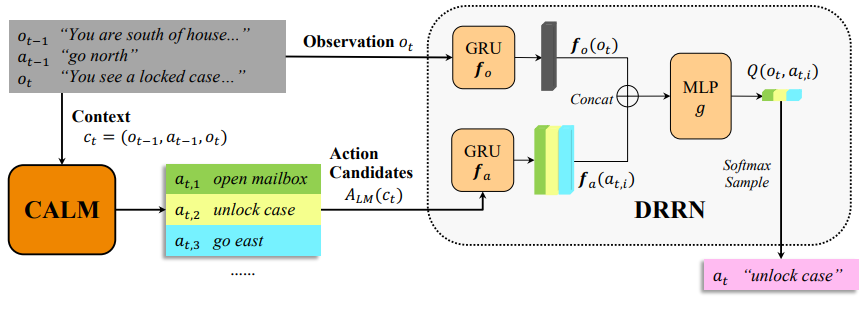
CALM 与一个强化学习智能体——DDRN——结合用于游戏玩法。CALM 基于人类游戏的转录本进行训练,以生成动作。在每个状态下,CALM 会根据游戏上下文生成候选动作,而 DRRN 则计算这些动作的 Q 值,从而选择最终的动作。一旦训练完成,单个 CALM 实例即可用于为任何文本类游戏生成动作。
强化学习的基础方法
理解强化学习中的基础方法,如课程学习、RLHF 和人机协作强化学习(HITL),对我们的研究至关重要。这些方法构成了现代强化学习技术的基石。通过研究这些早期方法,我们可以更深入地理解强化学习背后的原理和机制。这些知识能够为当前语言模型学习(LLM)与强化学习交叉领域的研究提供指导和启发,帮助我们开发出更有效、更具创新性的解决方案。
在强化学习中使用自然语言进行奖励塑造
论文链接:arXiv 1903.02020
框架概述:
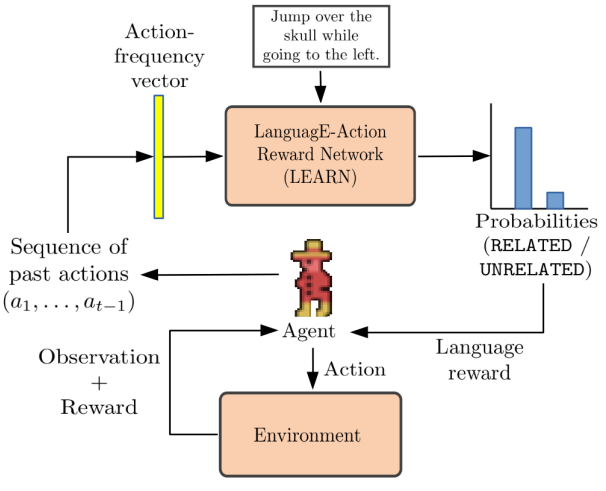
该框架由标准的强化学习模块组成,包含智能体与环境的交互循环,并在此基础上增加了一个语言动作奖励网络(LEARN)模块。
评论:
本文提出了一种利用自然语言提供奖励的方法。当时还没有大型语言模型,因此作者使用了大量的现有游戏视频及其对应的语言描述作为数据集。他们训练了一个前馈神经网络(FNN),该网络可以输出当前轨迹与语言指令之间的关系,并将这一输出作为中间奖励。通过将其与原始稀疏的环境奖励相结合,强化学习智能体能够基于目标和语言指令更快地学习到最优策略。
DQN-TAMER:具有难以处理反馈的人机协作强化学习
- 论文链接:arXiv 1810.11748
- 概述:
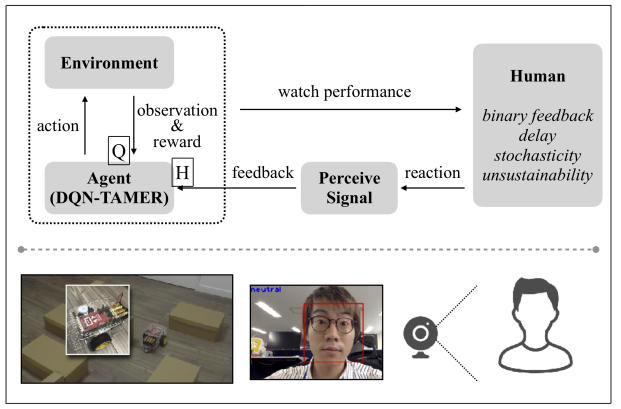
人机协作强化学习及模型(DQNTAMER)的概览。智能体在给定环境中与人类观察者异步交互。DQN-TAMER 根据两个模型来决定行动:一个模型(Q)用于估计来自环境的奖励,另一个模型(H)则用于获取来自人类的反馈。
利用示范克服强化学习中的探索问题
- 论文链接:arXiv 1709.10089,主页
- 概述:
在奖励稀疏的环境中进行探索一直是强化学习(RL)中一个持续存在的难题。许多任务天然适合采用稀疏奖励的形式,而手动设计奖励函数往往会导致次优性能。然而,随着任务时间跨度或动作空间维度的增加,找到非零奖励的难度会呈指数级增长。这使得许多现实世界中的任务超出了强化学习方法的实际应用范围。在本工作中,我们利用示范来克服探索问题,成功地学习执行具有长时程、多步骤的连续控制型机器人任务,例如用机械臂堆叠积木。我们的方法基于深度确定性策略梯度和事后经验回放技术,在模拟机器人任务上比纯强化学习快了一个数量级。该方法实现简单,仅需额外收集一小批示范数据。此外,我们的方法还能解决仅靠强化学习或行为克隆都无法完成的任务,并且通常表现优于示范策略。
强化学习智能体的自动目标生成
- 论文链接:arXiv 1705.06366,主页
- 概述:
强化学习(RL)是一种强大的技术,可用于训练智能体完成特定任务;然而,通过强化学习训练得到的智能体只能实现其奖励函数所指定的单一任务。这种方法在需要智能体执行多样化任务的场景中扩展性较差,例如导航到房间内的不同位置或将物体移动到不同的地点。为此,作者提出了一种方法,使智能体能够自动发现其在环境中所能完成的任务范围。作者使用一个生成网络为智能体提出待完成的任务,每个任务被定义为到达状态空间中的某个参数化子集。生成网络通过对抗训练进行优化,以生成始终符合智能体能力水平的任务,从而自动形成一套课程体系。作者证明,借助这一框架,智能体可以在没有任何环境先验知识的情况下,高效且自动地学习执行一系列广泛的任务,即使只有稀疏奖励可用。
开源强化学习环境
优秀的强化学习环境:https://github.com/clvrai/awesome-rl-envs
该仓库包含一个全面的、分类整理的强化学习环境列表。
Mine Dojo:https://github.com/MineDojo/MineDojo
MineDojo基于Minecraft构建了一个庞大的模拟环境套件,包含数千种多样化的任务,并提供了对73万条YouTube视频、7000页维基百科和34万篇Reddit帖子组成的互联网规模知识库的开放访问权限。

MineRL:https://github.com/minerllabs/minerl ,https://minerl.readthedocs.io/en/latest/
MineRL是一个功能丰富的Python 3库,它提供了一个与OpenAI Gym兼容的接口,用于与电子游戏Minecraft进行交互,并附带人类玩家的游戏数据集。





ALFworld:https://github.com/alfworld/alfworld?tab=readme-ov-file ,https://alfworld.github.io/
ALFWorld 包含交互式的TextWorld环境(Côté等),这些环境与ALFRED数据集中体现的身体化世界相对应(Shridhar等)。这些对齐的环境允许智能体在抽象空间中进行推理并学习高层策略,然后再通过低层执行来解决具体的任务。

Skillhack:https://github.com/ucl-dark/skillhack
Minigrid:https://github.com/Farama-Foundation/MiniGrid?tab=readme-ov-file

Crafter:https://github.com/danijar/crafter?tab=readme-ov-file
OpenAI procgen:https://github.com/openai/procgen

Petting ZOO MPE:https://pettingzoo.farama.org/environments/mpe/

OpenAI 多智能体粒子环境:https://github.com/openai/multiagent-particle-envs
多智能体强化学习环境:https://github.com/Bigpig4396/Multi-Agent-Reinforcement-Learning-Environment
MAgent2:https://github.com/Farama-Foundation/MAgent2?tab=readme-ov-file
 |
 |
 |
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器