我们欢迎各位就尚未提及的相关工作提出议题,我们将在下一次更新中予以回应!
🎉 新闻
- [2025-11-05] 🔥 很高兴发布关于智能体记忆的论文列表,涵盖上下文管理和经验学习方面的突破性进展,这些进展为自我改进的人工智能智能体提供了强大支持。请查看:GitHub
- [2025-10] 🎉 荣幸受邀在BAAI、Qingke Talk以及腾讯Wiztalk上发表演讲!以下是演讲幻灯片:Slides。
- [2025-09-18] 🎉 我们已更新了综述中按类别结构整理的完整论文列表!
- [2025-09-12] 🎉 我们的综述在🤗 Hugging Face Daily Papers上被评为今日最佳论文#1!
- [2025-09-11] 🔥 很高兴发布我们的大型推理模型强化学习综述!我们很快将用新的分类结构更新完整的论文列表。请查看:论文。
- [2025-08-15] 🔥 推出SSRL:一种无需依赖外部搜索引擎的智能体搜索强化学习研究。请查看:GitHub和论文。
- [2025-05-27] 🔥 推出MARTI:一个基于大语言模型的多智能体强化训练与推理框架。请查看:GitHub。
- [2025-04-23] 🔥 推出TTRL:一种开源解决方案,用于在没有真实标签的数据(尤其是测试数据)上进行在线强化学习。请查看:GitHub和论文。
- [2025-03-20] 🔥 我们很高兴推出关于推理模型强化学习的论文和项目合集!
🎈 引用
如果您觉得本综述有所帮助,请引用我们的工作:
@article{zhang2025survey,
title={A survey of reinforcement learning for large reasoning models},
author={Zhang, Kaiyan and Zuo, Yuxin and He, Bingxiang and Sun, Youbang and Liu, Runze and Jiang, Che and Fan, Yuchen and Tian, Kai and Jia, Guoli and Li, Pengfei and others},
journal={arXiv preprint arXiv:2509.08827},
year={2025}
}
📖 目录
🗺️ 概述
本综述全面探讨了大型推理模型的强化学习。
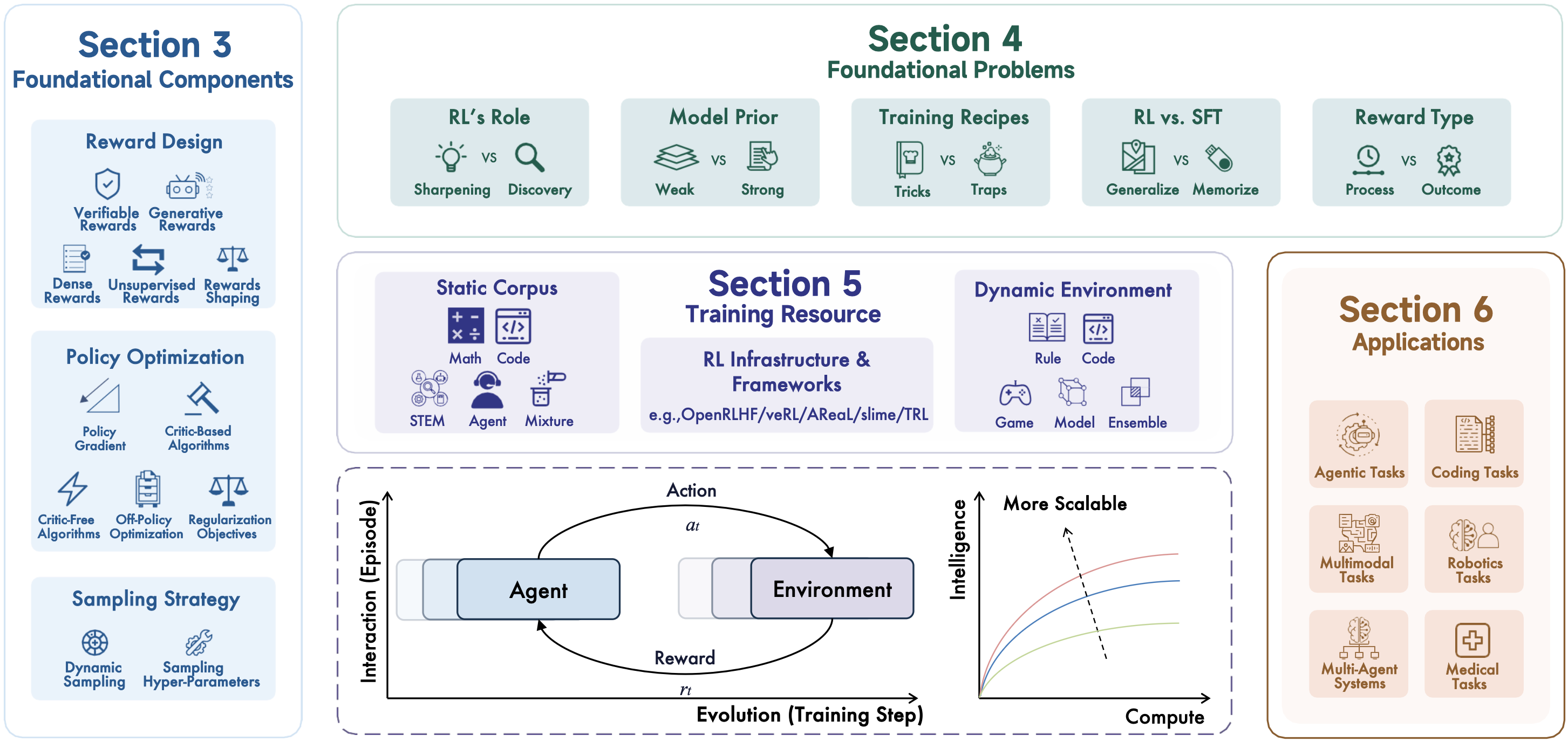
我们将综述分为五个主要部分:
- 基础组件: 奖励设计、策略优化和采样策略
- 基础问题: 大型推理模型强化学习中的关键争论与挑战
- 训练资源: 静态语料库、动态环境和基础设施
- 应用: 不同领域的实际应用
- 未来方向: 新兴的研究机遇与挑战
📄 论文列表
前沿模型
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
Intern-S1 |
Intern-S1:科学多模态基础模型 |
 |
 |
| 2025-08 |
GLM-4.5 |
GLM-4.5:智能体、推理与编码(ARC)基础模型 |
|
 |
| 2025-08 |
gpt-oss |
gpt-oss-120b & gpt-oss-20b 模型卡片 |
|
 |
| 2025-08 |
InternVL3.5 |
InternVL3.5:在通用性、推理能力和效率方面推进开源多模态模型 |
|
 |
| 2025-07 |
Kimi K2 |
Kimi K2:开放的智能体式人工智能 |
|
 |
| 2025-07 |
Step 3 |
Step-3:规模大但价格亲民——面向低成本解码的模型与系统协同设计 |
|
 |
| 2025-07 |
GLM-4.1V-Thinking |
GLM-4.5V 和 GLM-4.1V-Thinking:迈向基于可扩展强化学习的多功能多模态推理 |
|
 |
| 2025-07 |
Skywork-R1V3 |
Skywork-R1V3 技术报告 |
|
 |
| 2025-07 |
GLM-4.5V |
GLM-4.5V 和 GLM-4.1V-Thinking:迈向基于可扩展强化学习的多功能多模态推理 |
|
|
| 2025-06 |
Magistral |
Magistral |
|
- |
| 2025-06 |
Minimax-M1 |
MiniMax-M1:利用闪电注意力高效扩展推理时计算资源 |
|
 |
| 2025-05 |
MiMo |
MiMo:释放语言模型的推理潜力——从预训练到后训练 |
|
 |
| 2025-05 |
Qwen3 |
Qwen3 技术报告 |
|
 |
| 2025-05 |
Llama-Nemotron-Ultra |
Llama-Nemotron:高效推理模型 |
|
 |
| 2025-05 |
INTELLECT-2 |
INTELLECT-2:通过全球去中心化强化学习训练的推理模型 |
|
- |
| 2025-05 |
Hunyuan-TurboS |
Hunyuan-TurboS:通过 Mamba-Transformer 协同与自适应思维链推进大型语言模型 |
|
 |
| 2025-05 |
Skywork OR-1 |
Skywork 开放推理器 1 技术报告 |
|
 |
| 2025-04 |
Phi-4 Reasoning |
Phi-4-reasoning 技术报告 |
|
- |
| 2025-04 |
Skywork-R1V2 |
Skywork R1V2:用于推理的多模态混合强化学习 |
|
|
| 2025-04 |
InternVL3 |
InternVL3:探索开源多模态模型的高级训练与推理时策略 |
|
|
| 2025-03 |
ORZ |
Open-Reasoner-Zero:在基础模型上扩展强化学习的开源方法 |
|
 |
| 2025-01 |
DeepSeek-R1 |
DeepSeek-R1:通过强化学习激励大型语言模型的推理能力 |
|
 |
| - |
QwQ |
QwQ-32B:拥抱强化学习的力量 |
 |
 |
| - |
Seed-OSS |
Seed-OSS 开源模型 |
 |
 |
| - |
ERNIE-4.5-Thinking |
ERNIE 4.5 技术报告 |
|
- |
奖励设计
生成式奖励
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
CAPO |
CAPO:通过可验证的生成式信用分配提升大模型推理能力 |
|
 |
| 2025-08 |
CompassVerifier |
CompassVerifier:用于大模型评估与结果奖励的统一且鲁棒的验证器 |
|
 |
| 2025-08 |
Cooper |
Cooper:在大语言模型强化学习中协同优化策略与奖励模型 |
|
 |
| 2025-08 |
ReviewRL |
ReviewRL:迈向基于强化学习的自动化科学评审 |
|
 |
| 2025-08 |
Rubicon |
基于评分标准锚点的强化学习 |
|
- |
| 2025-08 |
RuscaRL |
打破探索瓶颈:面向通用大模型推理的评分标准辅助强化学习 |
|
- |
| 2025-07 |
OMNI-THINKER |
OMNI-THINKER:通过混合奖励的多任务强化学习提升大模型跨领域泛化能力 |
|
- |
| 2025-07 |
URPO |
URPO:面向大语言模型的统一奖励与策略优化框架 |
|
- |
| 2025-07 |
RaR |
评分标准即奖励:超越可验证领域的强化学习 |
|
- |
| 2025-07 |
RLCF |
对齐语言模型时,检查清单比奖励模型更有效 |
|
- |
| 2025-07 |
PCL |
针对语言模型的完成后学习 |
|
- |
| 2025-07 |
K2 |
KIMI K2:开放的代理智能 |
|
- |
| 2025-07 |
LIBRA |
LIBRA:通过学会思考来评估和改进奖励模型 |
|
- |
| 2025-07 |
TP-GRPO |
善于学习者会反思自己的思维:生成式PRM使大型推理模型成为更高效的数学学习者 |
|
 |
| 2025-06 |
RewardAnything |
RewardAnything:可泛化的遵循原则的奖励模型 |
|
|
| 2025-06 |
Writing-Zero |
Writing-Zero:弥合不可验证任务与可验证奖励之间的鸿沟 |
|
- |
| 2025-06 |
Critique-GRPO |
Critique-GRPO:利用自然语言和数值反馈推进大模型推理 |
|
 |
| 2025-06 |
PAG |
PAG:以策略作为生成式验证器的多轮强化大模型自我修正 |
|
- |
| 2025-06 |
GRAM |
GRAM:用于奖励泛化的生成式基础奖励模型 |
|
 |
| 2025-06 |
ProxyReward |
从通用到定向奖励:在开放式长上下文生成任务中超越GPT-4 |
|
- |
| 2025-06 |
QA-LIGN |
QA-LIGN:通过宪法式分解问答对大模型进行对齐 |
|
- |
| 2025-05 |
RM-R1 |
RM-R1:将奖励建模视为推理 |
|
 |
| 2025-05 |
J1 |
J1:通过强化学习激励“法官型”大模型思考 |
|
- |
| 2025-05 |
TinyV |
TinyV:减少验证中的假阴性有助于提升大模型推理的强化学习效果 |
|
 |
| 2025-05 |
General-Reasoner |
General-reasoner:推动大模型在所有领域的推理能力 |
|
- |
| 2025-05 |
RRM |
奖励推理模型 |
|
- |
| 2025-05 |
RL Tango |
RL Tango:为语言推理同时强化生成器与验证器 |
|
 |
| 2025-05 |
Think-RM |
Think-RM:在生成式奖励模型中实现长 horizon 推理 |
|
 |
| 2025-04 |
JudgeLRM |
JudgeLRM:将大型推理模型用作评判者 |
|
 |
| 2025-04 |
GenPRM |
GenPRM:通过生成式推理扩展过程奖励模型的测试时计算规模 |
|
 |
| 2025-04 |
DeepSeek-GRM |
通用奖励建模的推理时扩展 |
|
- |
| 2025-04 |
AIR |
AIR:偏好数据集中标注、指令与响应对的系统性分析 |
|
- |
| 2025-04 |
Pairwise-RL |
用于RLHF的统一成对框架:连接生成式奖励建模与策略优化 |
|
- |
| 2025-04 |
xVerify |
xVerify:高效推理模型评估用答案验证器 |
|
 |
| 2025-04 |
Seed-Thinking-v1.5 |
Seed1.5-Thinking:借助强化学习推进卓越推理模型的发展 |
|
- |
| 2025-04 |
ThinkPRM |
会思考的进程奖励模型 |
|
 |
| 2025-03 |
- |
跨越奖励之桥:通过可验证奖励在不同领域扩展强化学习 |
|
- |
| 2025-02 |
- |
数学推理的自奖励修正 |
|
 |
| 2024-10 |
GenRM |
生成式奖励模型 |
|
- |
| 2024-08 |
CLoud |
大声批评型奖励模型 |
|
 |
| 2024-08 |
Generative Verifier |
生成式验证器:将奖励建模视为下一个词预测 |
|
- |
| 2024-01 |
Self-Rewarding LM |
自奖励语言模型 |
|
- |
| 2023-10 |
Auto-J |
用于评估对齐情况的生成式评判者 |
|
 |
| 2023-06 |
Judge LLM-as-a-Judge |
使用mt-bench和chatbot arena评判“法官型”大模型 |
|
 |
密集奖励
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
Tree-GRPO |
面向LLM智能体强化学习的树搜索 |
|
 |
| 2025-09 |
AttnRL |
注意力作为指南针:推理模型中基于过程监督的强化学习的高效探索 |
|
 |
| 2025-09 |
TARL |
面向交互式多模态工具使用智能体的过程监督强化学习 |
|
- |
| 2025-09 |
PROF |
不止于正确性:通过强化学习训练协调过程与结果奖励 |
|
 |
| 2025-09 |
HICRA |
通过强化学习在LLM中涌现层次化推理 |
|
- |
| 2025-08 |
KlearReasoner |
Klear-Reasoner:通过梯度保持剪裁策略优化提升推理能力 |
|
 |
| 2025-08 |
CAPO |
CAPO:通过可验证的生成式信用分配增强LLM推理能力 |
|
|
| 2025-08 |
GTPO & GRPO-S |
GTPO和GRPO-S:结合策略熵的标记级和序列级奖励塑造 |
|
- |
| 2025-08 |
VSRM |
通过可验证的逐步奖励促进高效推理 |
|
- |
| 2025-08 |
G-RA |
基于门控奖励稳定长期多轮强化学习 |
|
- |
| 2025-08 |
SSPO |
SSPO:用于过程监督和推理压缩的自追踪逐步偏好优化 |
|
- |
| 2025-08 |
AIRL-S |
你的RL奖励函数就是最好的PRM用于搜索:统一RL与基于搜索的TTS |
|
- |
| 2025-08 |
TreePO |
TreePO:利用启发式树状建模弥合策略优化、有效性与推理效率之间的差距 |
|
 |
| 2025-08 |
MUA-RL |
MUA-RL:面向代理式工具使用的多轮用户交互智能体强化学习 |
|
- |
| 2025-07 |
SPRO |
通过重新定义逐步优势进行自我引导的过程奖励优化,以加强过程强化 |
|
- |
| 2025-07 |
FR3E |
首次返回,激发熵的探索 |
|
- |
| 2025-07 |
ARPO |
代理式强化策略优化 |
|
 |
| 2025-07 |
TP-GRPO |
好的学习者会思考自己的思维:生成式PRM使大型推理模型成为更高效的数学学习者 |
|
|
| 2025-06 |
TreeRPO |
TreeRPO:树相对策略优化 |
|
 |
| 2025-06 |
TreeRL |
TreeRL:基于在线策略树搜索的LLM强化学习 |
|
 |
| 2025-06 |
Entropy Advantage |
带有探索的推理:LLM强化学习的熵视角 |
|
- |
| 2025-06 |
ReasonFlux-PRM |
ReasonFlux-PRM:面向LLM长链式思维推理的轨迹感知PRM |
|
 |
| 2025-05 |
S-GRPO |
S-GRPO:通过强化学习实现推理模型的早期退出 |
|
- |
| 2025-05 |
GiGPO |
面向LLM智能体训练的组内组策略优化 |
|
 |
| 2025-05 |
- |
通过轮次级信用分配强化LLM智能体的多轮推理 |
|
- |
| 2025-05 |
Tango |
RL探戈:联合强化生成器与验证器进行语言推理 |
|
|
| 2025-05 |
StepSearch |
StepSearch:通过逐步近端策略优化激发LLM的搜索能力 |
|
 |
| 2025-05 |
- |
通过大型语言模型奖励分解,使对话智能体与全局反馈对齐 |
|
- |
| 2025-05 |
Tool-Star |
Tool-Star:通过强化学习赋能LLM驱动的多工具推理者 |
|
 |
| 2025-05 |
SPA-RL |
SPA-RL:通过逐步进展归因强化LLM智能体 |
|
 |
| 2025-05 |
SPO |
段落策略优化:大型语言模型RL中的有效段级信用分配 |
|
 |
| 2025-04 |
GenPRM |
GenPRM:通过生成式推理扩展过程奖励模型的测试时计算 |
|
|
| 2025-04 |
PURE |
停止求和:最小形式的信用分配就是过程奖励模型进行推理所需要的全部 |
|
 |
| 2025-03 |
MRT |
通过元强化微调优化测试时计算 |
|
 |
| 2025-03 |
SWEET-RL |
SWEET-RL:在协作推理任务上训练多轮LLM智能体 |
|
 |
| 2025-02 |
PRIME |
通过隐式奖励进行过程强化 |
|
 |
| 2024-12 |
Implicit PRM |
无需过程标签即可获得免费的过程奖励 |
|
 |
| 2024-10 |
VinePPO |
VinePPO:改进LLM RL训练中的信用分配 |
|
 |
| 2024-10 |
PAV |
奖励进展:扩展用于LLM推理的自动化过程验证器 |
|
- |
| 2024-04 |
- |
从$r$到$Q^*$:你的语言模型其实是一个Q函数 |
|
- |
| 2024-03 |
GELI |
通过将一次全局显式标注分解为局部隐式多模态反馈来改进对话智能体 |
|
- |
| 2023-12 |
Math-Shepherd |
Math-Shepherd:无需人工标注即可逐步验证并强化LLM |
|
- |
| 2023-05 |
PRM800K |
让我们一步步验证吧 |
|
 |
| 2022-11 |
- |
利用过程与结果反馈解决数学应用题 |
|
- |
无监督奖励
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
Vision-Zero |
Vision-Zero:通过策略性游戏化自我博弈实现可扩展的多模态语言模型自我改进 |
|
 |
| 2025-08 |
Co-Reward |
Co-Reward:基于对比一致性的自监督强化学习用于大语言模型推理 |
|
 |
| 2025-08 |
SQLM |
自提问语言模型 |
|
 |
| 2025-08 |
R-zero |
R-Zero:从零数据开始自我演化的推理型大语言模型 |
|
 |
| 2025-08 |
ETTRL |
ETTRL:通过熵机制在大语言模型测试时强化学习中平衡探索与利用 |
|
- |
| 2025-07 |
RLSF |
基于自我反馈的强化学习对大语言模型进行后训练 |
|
- |
| 2025-06 |
RLSC |
只需置信度:语言模型的小样本强化学习微调 |
|
- |
| 2025-06 |
RPT |
强化预训练 |
|
- |
| 2025-06 |
CoVo |
一致性路径通向真理:用于大语言模型推理的自奖励强化学习 |
|
 |
| 2025-06 |
SEAL |
自适应语言模型 |
|
- |
| 2025-06 |
Spurious Rewards |
虚假奖励:重新思考 RLVR 中的训练信号 |
|
 |
| 2025-06 |
No Free Lunch |
没有免费的午餐:重新思考大语言模型推理的内部反馈 |
|
- |
| 2025-05 |
Absolute Zero |
Absolute Zero:零数据下的强化自我博弈推理 |
|
 |
| 2025-05 |
EM-RL |
熵最小化在大语言模型推理中的不合理有效性 |
|
 |
| 2025-05 |
SSR-Zero |
SSR-Zero:用于机器翻译的简单自奖励强化学习 |
|
 |
| 2025-05 |
- |
来自格式和长度的代理信号:无需真实答案的强化学习解决数学问题 |
|
 |
| 2025-05 |
RLIF |
学习在没有外部奖励的情况下进行推理 |
|
 |
| 2025-05 |
SeRL |
SeRL:针对有限数据的大语言模型自我博弈强化学习 |
|
 |
| 2025-05 |
SRT |
大型推理模型能否自我训练? |
|
 |
| 2025-05 |
RENT-RL |
单纯最大化置信度即可提升推理能力 |
|
 |
| 2025-04 |
EMPO |
正确的问题本身就是答案的一半:完全无监督的大语言模型推理激励机制 |
|
 |
| 2025-04 |
TRANS-ZERO |
TRANS-ZERO:自我博弈激励大语言模型进行无平行语料的多语言翻译 |
|
 |
| 2025-04 |
TTRL |
TTRL:测试时强化学习 |
|
 |
| 2025-04 |
One-Shot-RLVR |
使用单个训练样例对大语言模型进行推理强化学习 |
|
 |
| 2025-02 |
CAGSR |
一种使用交叉注意力信号对大语言模型进行微调的自监督强化学习方法 |
|
- |
| 2024-07 |
MINIMO |
从内在动机出发学习形式数学 |
|
 |
奖励塑造
| 日期 |
名称 |
标题 |
论文 |
GitHub |
| 2025-09 |
CDE |
CDE:用于大型语言模型高效强化学习的 curiosity-driven 探索 |
|
- |
| 2025-09 |
DARLING |
联合强化语言模型生成中的多样性和质量 |
|
 |
| 2025-09 |
DRER |
通过 RL 增强的思维链重新思考大型语言模型中的推理质量 |
|
- |
| 2025-09 |
OBE |
面向 LLM 推理的基于结果的探索 |
|
- |
| 2025-08 |
Pass@kTraining |
用于自适应平衡大型推理模型探索与利用的 Pass@k 训练 |
|
 |
| 2025-05 |
PKPO |
Pass@K 策略优化:解决更难的强化学习问题 |
|
- |
| 2025-05 |
rl-without-gt |
来自格式和长度的替代信号:无需真实答案的数学问题求解强化学习 |
|
|
| 2025-03 |
CrossDomain-RLVR |
跨越奖励之桥:通过可验证奖励拓展跨不同领域的强化学习 |
|
- |
| 2025-01 |
DeepSeek-R1 |
DeepSeek-R1:通过强化学习激励 LLM 的推理能力 |
|
|
| 2024-09 |
Qwen2.5-Math |
Qwen2.5-math 技术报告:通过自我改进迈向数学专家模型 |
|
 |
策略优化
策略梯度目标
| 日期 |
名称 |
标题 |
论文 |
GitHub |
| 2017-07 |
PPO |
近端策略优化算法 |
|
- |
| - |
PG |
带函数近似的强化学习策略梯度方法。 |
|
- |
| - |
REINFORCE |
用于联结主义强化学习的简单统计梯度跟踪算法 |
|
- |
| - |
TRPO |
信任区域策略优化 |
|
- |
基于评价器的算法
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
VL-DAC |
在合成世界中利用强化学习提升视觉-语言模型训练,以实现现实世界的成功 |
|
 |
| 2025-08 |
VRPO |
VRPO:在噪声监督下重新思考价值建模以进行稳健的强化学习训练 |
|
- |
| 2025-05 |
VerIPO |
VerIPO:具有迭代策略优化的长推理视频-R1模型 |
|
 |
| 2025-04 |
VAPO |
Vapo:用于高级推理任务的高效且可靠的强化学习 |
|
- |
| 2025-03 |
VCPPO |
PPO在长CoT中崩溃的背后是什么?价值优化才是关键 |
|
- |
| 2025-03 |
Open reasoner-zero |
open reasoner-zero:一种在基础模型上扩展强化学习的开源方法 |
|
|
| 2025-02 |
PRIME |
通过隐式奖励进行过程强化 |
|
|
| 2024-12 |
Implicit PRM |
无需过程标签即可获得免费的过程奖励 |
|
 |
| 2023-12 |
Math-shepherd |
Math-shepherd:无需人工标注即可逐步验证并强化LLM |
|
- |
| 2015-06 |
GAE |
使用广义优势估计进行高维连续控制 |
|
- |
| - |
Autopsv |
Autopsv:自动化过程监督验证器。 |
|
 |
无评论家算法
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
UPGE |
面向大型语言模型后训练的统一视角 |
|
 |
| 2025-09 |
SPO |
单流策略优化 |
|
- |
| 2025-08 |
LitePPO |
第一部分:技巧还是陷阱?深入探讨用于LLM推理的强化学习 |
|
- |
| 2025-07 |
R1-RE |
R1-RE:基于RLVR的跨领域关系抽取 |
|
- |
| 2025-07 |
GSPO |
群组序列策略优化 |
|
- |
| 2025-06 |
CISPO |
MiniMax-M1:通过闪电注意力高效扩展推理时计算 |
|
|
| 2025-05 |
KRPO |
基于卡尔曼滤波增强的群组相对策略优化,用于语言模型推理 |
|
 |
| 2025-05 |
CPGD |
CPGD:迈向稳定的语言模型规则基强化学习 |
|
 |
| 2025-05 |
NFT |
在数学推理中弥合监督学习与强化学习 |
|
- |
| 2025-05 |
Clip-Cov/KL-Cov |
强化学习在推理型语言模型中的熵机制 |
|
 |
| 2025-03 |
OpenVLThinker |
OpenVLThinker:通过迭代SFT-RL循环实现复杂的视觉-语言推理 |
|
 |
| 2025-03 |
DAPO |
DAPO:大规模开源LLM强化学习系统 |
|
 |
| 2025-03 |
Dr. GRPO |
理解类似R1-Zero的训练:一个关键视角 |
|
 |
| 2025-01 |
Kimi k1.5 |
Kimi k1.5:利用LLM扩展强化学习 |
|
- |
| 2024-02 |
RLOO |
回归基础:重新审视针对LLM人类反馈学习的强化风格优化 |
|
- |
| 2024-02 |
GRPO |
DeepSeekMath:突破开放语言模型的数学推理极限 |
|
 |
| 2023-10 |
ReMax |
ReMax:一种简单、有效且高效的大型语言模型对齐方法 |
|
 |
| - |
REINFORCE |
用于联结主义强化学习的简单统计梯度跟随算法 |
|
- |
| - |
REINFORCE++ |
REINFORCE++:一种对提示和奖励模型均具有鲁棒性的高效RLHF算法 |
|
 |
| - |
VinePPO |
VINEPPO:通过精细化信用分配释放LLM推理的RL潜力 |
|
|
| - |
FlashRL |
基于量化回放的快速RL训练 |
|
 |
离策略优化
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
BRIDGE |
超越两阶段训练:LLM 推理中的协作式 SFT 和 RL |
|
 |
| 2025-09 |
HPT |
通往大语言模型后训练统一视角之路 |
|
|
| 2025-08 |
DFT |
关于 SFT 的泛化:基于奖励校正的强化学习视角 |
|
 |
| 2025-08 |
RED |
回忆-扩展动力学:通过可控探索与精细化离线整合提升小型语言模型性能 |
|
 |
| 2025-07 |
Prefix‑RFT |
使用前缀采样融合监督与强化微调 |
|
- |
| 2025-07 |
ReMix |
挤干湿海绵:面向大语言模型的高效离策略强化微调 |
|
 |
| 2025-06 |
ReLIFT |
学习强化学习无法做到的事:针对最难问题的交错式在线微调 |
|
 |
| 2025-06 |
BREAD |
BREAD:基于专家锚点的分支式 rollout,连接 SFT 和 RL 以实现推理 |
|
- |
| 2025-06 |
SRFT |
SRFT:一种结合监督与强化微调的单阶段推理方法 |
|
- |
| 2025-05 |
AMPO |
通过模式策略优化实现社交语言代理的自适应思维 |
|
 |
| 2025-05 |
UFT |
UFT:统一监督与强化微调 |
|
 |
| 2025-04 |
LUFFY |
在离策略指导下学习推理 |
|
 |
| 2025-03 |
SPO |
软策略优化:面向序列模型的在线离策略 RL |
|
|
| 2025-03 |
TOPR |
TAPERED OFF-POLICY REINFORCE:稳定高效的 LLM 强化学习 |
|
- |
| 2024-05 |
IFT |
直观微调:迈向将对齐简化为单一过程 |
|
 |
| 2023-05 |
DPO |
直接偏好优化:你的语言模型其实是一个奖励模型 |
|
- |
| 2015-11 |
- |
深度卷积网络的定点量化 |
|
- |
| - |
- |
你的高效 RL 框架其实暗中为你带来了离策略 RL 训练 |
|
 |
离策略优化(经验回放)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
SAPO |
分享即关怀:通过集体强化学习经验共享实现高效的语言模型后训练 |
|
- |
| 2025-09 |
SEELE |
停留在最佳状态:基于能力自适应提示支架的响应式推理进化 |
|
 |
| 2025-08 |
Memory-R1 |
Memory-R1:通过强化学习增强大型语言模型智能体的记忆管理与利用能力 |
|
- |
| 2025-07 |
RLEP |
RLEP:面向LLM推理的带经验回放的强化学习 |
|
 |
| 2025-06 |
EFRame |
EFRame:基于探索-过滤-重放强化学习框架的深度推理 |
|
 |
| 2025-05 |
ARPO |
ARPO:带有经验回放的GUI智能体端到端策略优化 |
|
 |
| 2025-04 |
- |
通过回顾性回放提升LLM推理的强化学习探索 |
|
- |
正则化目标
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-10 |
ASPO |
ASPO:非对称重要性采样策略优化 |
|
 |
| 2025-09 |
CE-GPPO |
CE-GPPO:强化学习中基于梯度保留剪裁的协调熵策略优化 |
|
 |
| 2025-09 |
CDE |
CDE:用于大语言模型高效强化学习的 curiosity-driven 探索 |
|
- |
| 2025-09 |
DPH RL |
散度的选择:可验证奖励下缓解强化学习多样性崩溃被忽视的关键 |
|
 |
| 2025-09 |
empgseed-seed |
利用不确定性:面向长时序 LLM 代理的熵调节策略梯度 |
|
- |
| 2025-07 |
Archer |
稳定知识,促进推理:RLVR 的双令牌约束 |
|
 |
| 2025-06 |
Bingo |
Bingo:通过动态且基于重要性的强化学习提升 LLM 的高效推理能力 |
|
 |
| 2025-06 |
HighEntropy RL |
超越 80/20 法则:高熵少数令牌驱动 LLM 推理的有效强化学习 |
|
- |
| 2025-06 |
Entropy RL |
带探索的推理:LLM 强化学习的熵视角 |
|
- |
| 2025-06 |
ALP RL |
恰到好处的思考:自适应长度惩罚强化学习实现高效推理 |
|
- |
| 2025-05 |
DisCO |
DisCO:利用判别式约束优化强化大型推理模型 |
|
 |
| 2025-05 |
Skywork OR1 |
Skywork Open Reasoner 1 技术报告 |
|
|
| 2025-05 |
Entropy Mechanism |
推理语言模型强化学习的熵机制 |
|
|
| 2025-05 |
ProRL |
ProRL:延长强化学习时间扩大大语言模型的推理边界 |
|
- |
| 2025-05 |
Short RL |
通过长度感知优化实现推理模型的高效强化学习训练 |
|
 |
| 2025-03 |
DAPO |
DAPO:大规模开源 LLM 强化学习系统 |
|
- |
| 2025-03 |
L1 |
L1:利用强化学习控制推理模型的思考时长 |
|
 |
采样策略
动态与结构化采样
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-10 |
EEPO |
EEPO:通过先采样后遗忘增强探索的策略优化 |
|
 |
| 2025-09 |
AttnRL |
注意力作为指南:推理模型中基于过程监督的强化学习高效探索 |
|
- |
| 2025-09 |
DACE |
知道何时探索:难度感知置信度作为大语言模型强化学习的指导 |
|
- |
| 2025-09 |
Parallel-R1 |
Parallel-R1:通过强化学习实现并行思维 |
|
 |
| 2025-08 |
G^2RPO-A |
G^2RPO-A:自适应引导下的引导式群体相对策略优化 |
|
 |
| 2025-08 |
RuscaRL |
打破探索瓶颈:用于通用大语言模型推理的评分标准支撑强化学习 |
|
- |
| 2025-08 |
TreePO |
TreePO:利用启发式树状建模弥合策略优化与推理效率之间的差距 |
|
|
| 2025-07 |
ARPO |
主体式强化策略优化 |
|
|
| 2025-06 |
TreeRPO |
TreeRPO:树状相对策略优化 |
|
|
| 2025-06 |
E2H |
由易到难的任务课程式强化学习提升大语言模型推理能力 |
|
- |
| 2025-06 |
TreeRL |
TreeRL:基于策略树搜索的大语言模型强化学习 |
|
|
| 2025-05 |
ToTRL |
ToTRL:通过解谜解锁大语言模型思维树推理潜力 |
|
- |
| 2025-03 |
DARS |
DARS:通过动态动作重采样和自适应树遍历提升编码智能体性能 |
|
 |
| 2025-03 |
DAPO |
DAPO:大规模开源大语言模型强化学习系统 |
|
|
| 2025-02 |
PRIME |
通过隐式奖励进行过程强化 |
|
|
| - |
POLARIS |
POLARIS:一种针对先进推理模型的强化学习规模化后训练方案 |
|
 |
采样超参数
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
GFPO |
多采样少思考:用于简洁推理的分组过滤策略优化 |
|
- |
| 2025-06 |
AceReason-Nemotron 1.1 |
AceReason-Nemotron 1.1:通过SFT与RL协同推进数学与代码推理 |
|
- |
| 2025-06 |
T-PPO |
截断近端策略优化 |
|
- |
| 2025-06 |
Confucius3-Math |
Confucius3-Math:面向中国中小学数学学习的轻量级高性能推理LLM |
|
 |
| 2025-05 |
E3-RL4LLMs |
提升LLM强化学习中的效率与探索能力 |
|
 |
| 2025-05 |
AceReason-Nemotron |
AceReason-Nemotron:通过强化学习推进数学和代码推理 |
|
- |
| 2025-05 |
Pro-RL |
ProRL:延长型强化学习拓展大语言模型的推理边界 |
|
- |
| 2025-03 |
- |
输出长度对DeepSeek-R1强制思维安全性的影响 |
|
- |
| 2025-03 |
DAPO |
DAPO:大规模开源LLM强化学习系统 |
|
|
| 2025-02 |
PRIME |
通过隐式奖励进行过程强化 |
|
|
| 2025-02 |
- |
训练语言模型以高效推理 |
|
- |
| - |
DeepScaleR |
DeepScaleR:通过强化学习扩展,以1.5B模型超越O1预览 |
|
 |
| - |
POLARIS |
POLARIS:针对高级推理模型的训练后强化学习扩展方案 |
|
|
训练资源
静态语料库(代码)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-05 |
rStar-Coder |
rStar-Coder:利用大规模验证数据集扩展竞赛编程推理能力 |
|
 |
| 2025-04 |
Z1 |
Z1:基于代码的高效测试时扩展 |
|
 |
| 2025-04 |
OpenCodeReasoning |
OpenCodeReasoning:推进竞赛编程的数据蒸馏技术 |
|
- |
| 2025-04 |
LeetCodeDataset |
LeetCodeDataset:用于代码大模型稳健评估与高效训练的时间序列数据集 |
|
 |
| 2025-03 |
KodCode |
KodCode:多样化、高挑战性且可验证的合成编程数据集 |
|
- |
| 2025-01 |
SWE-Fixer |
SWE-Fixer:训练开源大模型以高效解决 GitHub 问题 |
|
 |
| 2024-12 |
SWE-Gym |
使用 SWE-Gym 训练软件工程智能体和验证器 |
|
 |
| - |
Code-R1 |
Code-R1:通过可靠奖励重现代码领域的 R1 |
|
 |
| - |
codeforces-cots |
CodeForces CoTs |
|
- |
| - |
DeepCoder |
DeepCoder:O3-mini 级别的全开源 14B 编码器 |
|
 |
静态语料库(STEM)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
SSMR-Bench |
为评估与强化学习合成乐谱问题 |
|
 |
| 2025-09 |
Loong |
Loong:通过验证器大规模合成长链式思维 |
|
 |
| 2025-07 |
MegaScience |
MegaScience:推动科学推理后训练数据集的前沿 |
|
- |
| 2025-06 |
ReasonMed |
ReasonMed:一个由多智能体生成的 37 万条数据集,用于推进医学推理 |
|
 |
| 2025-05 |
ChemCoTDataset |
超越化学问答:用模块化化学操作评估大模型的化学推理能力 |
|
- |
| 2025-02 |
NaturalReasoning |
NaturalReasoning:在真实场景中使用 280 万个高挑战性问题进行推理 |
|
- |
| 2025-01 |
SCP-116K |
SCP-116K:高质量的问题-解答数据集,以及高等教育科学领域自动化提取的通用流程 |
|
- |
静态语料库(数学)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-07 |
MiroMind-M1-RL-62K |
MiroMind-M1:基于上下文感知多阶段策略优化的开源数学推理进展 |
|
 |
| 2025-04 |
DeepMath |
DeepMath-103K:用于推进推理的大规模、具有挑战性、去污染且可验证的数学数据集 |
|
 |
| 2025-04 |
OpenMathReasoning |
AIMO-2 冠军方案:使用 OpenMathReasoning 数据集构建最先进的数学推理模型 |
|
 |
| 2025-03 |
STILL-3-RL |
关于激发和改进 R1 类推理模型的实证研究 |
|
 |
| 2025-03 |
Light-R1 |
Light-R1:从零开始及更进一步的长 COT 课程化 SFT、DPO 和 RL |
|
- |
| 2025-03 |
DAPO |
DAPO:大规模开源 LLM 强化学习系统 |
|
|
| 2025-03 |
OpenReasoningZero |
Open-Reasoner-Zero:在基础模型上扩展强化学习的开源方法 |
|
|
| 2025-02 |
PRIME |
通过隐式奖励进行过程强化 |
|
|
| 2025-02 |
LIMO |
Limo:少即是多,用于推理 |
|
 |
| 2025-02 |
LIMR |
Limr:少即是多,用于 RL 扩展 |
|
 |
| 2025-02 |
Big-MATH |
Big-Math:用于语言模型中强化学习的大规模高质量数学数据集 |
|
- |
| - |
NuminaMath 1.5 |
Numinamath:ai4maths 领域内最大的公开数据集,包含 86 万对竞赛数学题目与解答 |
|
 |
| - |
OpenR1-Math |
Open R1:DeepSeek-R1 的完全开源复现 |
|
 |
| - |
DeepScaleR |
DeepScaleR:通过 RL 扩展超越 O1 预览版的 15 亿参数模型 |
|
- |
静态语料库(代理)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
ASearcher |
超越十步:利用大规模异步强化学习解锁长 horizon 的智能体搜索 |
|
- |
| 2025-07 |
WebShaper |
WebShaper:通过信息搜索形式化实现智能体式数据合成 |
|
- |
| 2025-05 |
ZeroSearch |
ZeroSearch:无需实际搜索即可激励大模型的搜索能力 |
|
 |
| 2025-04 |
ToolRL |
ToolRL:奖励是工具学习所需的一切 |
|
 |
| 2025-03 |
Search-R1 |
Search-R1:利用强化学习训练大模型进行推理并调用搜索引擎 |
|
 |
| 2025-03 |
ToRL |
ToRL:扩展工具集成的强化学习 |
|
 |
| - |
MicroThinker |
MiroVerse V0.1:一个可复现、全轨迹、不断增长的深度研究数据集 |
|
- |
| 2025-03 |
DeepRetrieval |
DeepRetrieval:利用强化学习通过大语言模型“黑掉”真实搜索引擎和检索器 |
|
 |
静态语料库(混合)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
Graph-R1 |
Graph-R1:用 NP-Hard 图问题释放大模型的推理能力 |
|
- |
| 2025-06 |
RewardAnything |
RewardAnything:可泛化的遵循原则的奖励模型 |
|
|
| 2025-06 |
guru-RL-92k |
从跨领域视角重新审视用于大模型推理的强化学习 |
|
- |
| 2025-05 |
Llama-Nemotron-PT |
Llama-Nemotron:高效推理模型 |
|
- |
| 2025-05 |
SkyWork OR1 |
Skywork 开放推理器 1 技术报告 |
|
|
| 2025-03 |
OpenVLThinker |
OpenVLThinker:通过迭代 SFT-RL 循环实现复杂的视觉-语言推理 |
|
|
| - |
AM-DS-R1-0528-Distilled |
AM-DeepSeek-R1-0528-蒸馏版 |
|
 |
| - |
dolphin-r1 |
海豚 R1 数据集 |
|
- |
| - |
SYNTHETIC-1/2 |
SYNTHETIC-1 发布:来自 Deepseek-R1 的两百万条协作生成的推理轨迹 |
|
- |
动态环境(基于规则)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-06 |
ProtoReasoning |
ProtoReasoning:以原型为基础实现大模型的可泛化推理 |
|
- |
| 2025-05 |
SynLogic |
SynLogic:大规模合成可验证推理数据,用于学习逻辑推理及其他任务 |
|
 |
| 2025-05 |
Reasoning Gym |
REASONING GYM:具有可验证奖励的强化学习推理环境 |
|
 |
| 2025-05 |
Enigmata |
Enigmata:利用合成可验证谜题扩展大语言模型的逻辑推理能力 |
|
 |
| 2025-02 |
AutoLogi |
AutoLogi:自动构建逻辑谜题,用于评估大语言模型的推理能力 |
|
 |
| 2025-02 |
Logic-RL |
Logic-RL:基于规则的强化学习释放大模型的推理潜能 |
|
 |
动态环境(代码类)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-06 |
AgentCPM-GUI |
AgentCPM-GUI:通过强化微调构建移动端可用的智能体 |
|
 |
| 2025-06 |
MedAgentGym |
MedAgentGym:大规模训练基于代码的医学推理大模型智能体 |
|
 |
| 2025-05 |
MLE-Dojo |
MLE-Dojo:赋能机器学习工程领域大模型智能体的交互式环境 |
|
 |
| 2025-05 |
SWE-rebench |
SWE-rebench:软件工程智能体的任务收集与去污评估自动化流水线 |
|
- |
| 2025-05 |
ZeroGUI |
ZeroGUI:零人力成本的在线 GUI 自动化学习 |
|
 |
| 2025-04 |
R2E-Gym |
R2E-Gym:程序化环境生成与混合验证器,助力开放权重软件工程智能体规模化 |
|
 |
| 2025-03 |
ReSearch |
ReSearch:通过强化学习让大模型学会搜索式推理 |
|
 |
| 2025-02 |
MLGym |
MLGym:推进 AI 研究智能体的新框架与基准 |
|
 |
| 2024-07 |
AppWorld |
AppWorld:用于评测交互式编程智能体的可控应用与人物世界 |
|
 |
动态环境(游戏类)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
PuzzleJAX |
PuzzleJAX:推理与学习的基准测试 |
|
 |
| 2025-06 |
Play to Generalize |
Play to Generalize:通过游戏玩乐学习推理 |
|
 |
| 2025-06 |
Optimus-3 |
Optimus-3:迈向具有可扩展任务专家的通用多模态 Minecraft 智能体 |
|
 |
| 2025-05 |
lmgame-Bench |
lmgame-Bench:大语言模型在玩游戏方面表现如何? |
|
 |
| 2025-05 |
G1 |
G1:通过强化学习自举视觉-语言模型的感知与推理能力 |
|
 |
| 2025-05 |
Code2Logic |
Code2Logic:基于游戏代码的数据合成以增强 VLM 的通用推理能力 |
|
 |
| 2025-05 |
KORGym |
KORGym:用于 LLM 推理评估的动态游戏平台 |
|
 |
| 2025-04 |
Cross-env-coop |
跨环境合作实现零样本多智能体协作 |
|
 |
| 2022-03 |
ScienceWorld |
ScienceWorld:你的智能体比五年级学生更聪明吗? |
|
 |
| 2020-10 |
ALFWorld |
ALFWorld:对齐文本与具身环境以实现交互式学习 |
|
 |
动态环境(基于模型)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-06 |
SwS |
SwS:强化学习中基于自我意识的弱点驱动问题合成,用于 LLM 推理 |
|
 |
| 2025-06 |
SPIRAL |
SPIRAL:零和博弈中的自我博弈通过多智能体多回合强化学习激励推理 |
|
 |
| 2025-05 |
Absolute Zero |
Absolute Zero:无数据条件下的强化自我博弈推理 |
|
|
| 2025-04 |
TextArena |
TextArena |
|
 |
| 2025-03 |
SWEET-RL |
SWEET-RL:训练多回合 LLM 智能体进行协作式推理任务 |
|
|
| - |
Genie 3 |
Genie 3:世界模型的新前沿 |
|
- |
动态环境(基于集成)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
InternBootcamp |
InternBootcamp 技术报告:通过可验证的任务扩展提升大模型推理能力 |
|
 |
| - |
SYNTHETIC-2 |
SYNTHETIC-2 发布:四百万条协作生成的推理轨迹 |
|
- |
强化学习基础设施(主要)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-06 |
ROLL |
大规模学习的强化学习优化:高效且易用的扩展库 |
|
 |
| 2025-05 |
AReaL |
AReaL:面向语言推理的大规模异步强化学习系统 |
|
 |
| 2024-09 |
veRL |
HybridFlow:灵活高效的 RLHF 框架 |
|
 |
| 2024-05 |
OpenRLHF |
OpenRLHF:易用、可扩展且高性能的 RLHF 框架 |
|
|
| - |
TRL |
Transformer 强化学习 |
- |
 |
| - |
NeMo-RL |
Nemo RL:可扩展且高效的后训练库 |
- |
 |
| - |
slime |
slime:基于 SGLang 的原生后训练框架,用于强化学习扩展 |
- |
 |
| - |
RLinf |
RLinf:面向智能体 AI 的强化学习基础设施 |
- |
 |
强化学习基础设施(次要)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
RL-Factory |
RLFactory:用于大语言模型多轮工具使用的即插即用强化学习后训练框架 |
|
 |
| 2025-09 |
verl-tool |
VerlTool:迈向具有工具使用的整体智能体强化学习 |
|
 |
| 2025-09 |
dLLM-RL |
革新扩散型大语言模型的强化学习框架 |
|
 |
| 2025-08 |
agent-lightning |
Agent Lightning:使用强化学习训练任何AI智能体 |
|
 |
| 2025-05 |
verl-agent |
用于大语言模型智能体训练的组内策略优化 |
|
|
| 2025-04 |
VLM-R1 |
VLM-R1:稳定且可推广的R1风格大型视觉-语言模型 |
|
 |
| - |
rllm |
rLLM:用于语言智能体后训练的框架 |
- |
|
| - |
EasyR1 |
EasyR1:高效、可扩展的多模态强化学习训练框架 |
- |
 |
| - |
verifiers |
Verifiers:在可验证环境中使用大语言模型进行强化学习 |
- |
 |
| - |
prime-rl |
PRIME-RL:大规模去中心化强化学习训练 |
- |
 |
| - |
MARTI |
基于大语言模型的多智能体强化训练与推理框架 |
- |
|
应用
编码智能体
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
- |
面向机器学习工程代理的强化学习 |
|
- |
| 2025-09 |
- |
利用强化学习提升SLM工具使用能力 |
|
- |
| 2025-09 |
SimpleTIR |
SimpleTIR:面向多轮工具集成推理的端到端强化学习 |
|
 |
| 2025-09 |
- |
收益递减的错觉:LLM中的长程执行测量 |
|
 |
| 2025-08 |
GLM-4.5 |
GLM-4.5:具身、推理与编码(ARC)基础模型 |
|
|
| 2025-08 |
FormaRL |
FormaRL:无需标注数据的自动形式化增强 |
|
 |
| 2025-08 |
RLTR |
不需良好答案即可鼓励良好过程:面向LLM代理规划的强化学习 |
|
- |
| 2025-07 |
ARPO |
具身强化策略优化 |
|
 |
| 2025-07 |
Kimi K2 |
Kimi K2:开放具身智能 |
|
- |
| 2025-07 |
AutoTIR |
AutoTIR:通过强化学习实现自主工具集成推理 |
|
 |
| 2025-06 |
CoRT |
CoRT:思维中的代码集成推理 |
|
 |
| 2025-05 |
EvoScale |
Satori-SWE:面向样本高效软件工程的进化式测试时缩放 |
|
 |
| 2025-03 |
ToRL |
ToRL:工具集成强化学习的规模化 |
|
|
| 2025-02 |
SWE-RL |
SWE-RL:基于开源软件进化的强化学习推进LLM推理 |
|
 |
| - |
Qwen3-Coder |
Qwen3-Coder:世界中的具身编程。 |
- |
 |
搜索代理
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
SSRL |
SSRL:自搜索强化学习 |
|
 |
| 2025-07 |
WebSailor |
WebSailor:面向网络智能体的超人类推理导航 |
|
 |
| 2025-07 |
WebShaper |
WebShaper:通过信息搜索形式化实现智能体式数据合成 |
|
|
| 2025-05 |
ZeroSearch |
ZeroSearch:无需搜索即可激励大语言模型的搜索能力 |
|
|
| 2025-05 |
SEM |
SEM:用于搜索高效大型语言模型的强化学习 |
|
- |
| 2025-05 |
S3 |
s3:通过强化学习训练搜索智能体并不需要那么多数据 |
|
 |
| 2025-05 |
StepSearch |
StepSearch:通过分步近端策略优化激发大语言模型的搜索能力 |
|
|
| 2025-05 |
R1-Searcher++ |
R1-Searcher++:通过强化学习激励大语言模型的动态知识获取能力 |
|
 |
| 2025-04 |
ReZero |
ReZero:通过再试一次来提升大语言模型的搜索能力 |
|
- |
| 2025-03 |
DeepRetrieval |
DeepRetrieval:利用强化学习,通过大语言模型攻破真实的搜索引擎和检索系统 |
|
|
| 2025-03 |
Search-R1 |
Search-R1:通过强化学习训练大语言模型进行推理并利用搜索引擎 |
|
|
| 2025-03 |
R1-Searcher |
R1-Searcher:通过强化学习激励大语言模型的搜索能力 |
|
 |
浏览器使用型智能体
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-05 |
WebAgent-R1 |
WebAgent-R1:通过端到端多轮强化学习训练网络智能体 |
|
 |
| 2025-05 |
WebDancer |
WebDancer:迈向自主信息搜索智能体 |
|
|
| 2025-04 |
DeepResearcher |
DeepResearcher:在真实环境中通过强化学习扩展深度研究 |
|
 |
| 2024-11 |
Web-RL |
WebRL:通过自我进化在线课程强化学习训练大语言模型网络智能体 |
|
 |
| 2021-12 |
WebGPT |
WebGPT:借助浏览器与人类反馈的问答系统 |
|
- |
深度研究型智能体
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
SFR-DeepResearch |
SFR-DeepResearch:面向自主推理单智能体的有效强化学习 |
|
- |
| 2025-09 |
DeepDive |
DeepDive:利用知识图谱与多轮强化学习推进深度搜索智能体 |
|
 |
| 2025-08 |
Webwatcher |
Webwatcher:突破视觉-语言深度研究智能体的新边界 |
|
|
| 2025-08 |
ASearcher |
超越十轮:通过大规模异步强化学习解锁长 horizon 智能体式搜索 |
|
 |
| 2025-08 |
Atom-searcher |
Atom-searcher:通过细粒度原子思维奖励提升智能体式深度研究能力 |
|
 |
| 2025-08 |
MedResearcher-R1 |
Medreseacher-r1:基于知识驱动轨迹合成框架的专家级医学深度研究者 |
|
 |
| 2025-06 |
Jan-nano |
Jan-nano 技术报告 |
|
- |
| 2025-04 |
WebThinker |
WebThinker:以深度研究能力赋能大型推理模型 |
|
 |
| - |
Kimi-Researcher |
Kimi-Researcher——用于新兴智能体能力的端到端强化学习训练 |
|
- |
| - |
Mirothinker |
Mirothinker:一个开源的智能体模型系列,专为深度研究及复杂长 horizon 问题解决而训练 |
|
 |
GUI&计算机代理
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
UI-TARS 2 |
UI-TARS-2 技术报告:通过多轮强化学习推进 GUI 智能体 |
|
 |
| 2025-08 |
GUI-RC |
基于区域一致性的 GUI 对齐测试时强化学习 |
|
 |
| 2025-08 |
Os-r1 |
OS-R1:利用强化学习进行智能体式操作系统内核调优 |
|
 |
| 2025-08 |
ComputerRL |
ComputerRL:面向计算机使用智能体的端到端在线强化学习规模化 |
|
- |
| 2025-08 |
Mobile-Agent-v3 |
Mobile-Agent-v3:用于 GUI 自动化的基础智能体 |
|
 |
| 2025-08 |
SWIRL |
SWIRL:移动 GUI 控制中交错强化学习的分阶段工作流 |
|
 |
| 2025-08 |
InquireMobile |
InquireMobile:通过强化微调教导基于 VLM 的移动智能体请求人类协助 |
|
- |
| 2025-07 |
MobileGUI-RL |
MobileGUI-RL:在在线环境中通过强化学习推进移动 GUI 智能体 |
|
- |
| 2025-06 |
GUI-Critic-R1 |
三思而后行:用于 GUI 自动化事前错误诊断的 GUI-Critic-R1 模型 |
|
|
| 2025-06 |
GUI-Reflection |
GUI-Reflection:以自我反思行为赋能多模态 GUI 模型 |
|
- |
| 2025-06 |
Mobile-R1 |
Mobile-R1:通过任务级奖励实现基于 VLM 的移动智能体的交互式强化学习 |
|
- |
| 2025-05 |
UIShift |
UIShift:通过自监督强化学习提升基于 VLM 的 GUI 智能体 |
|
 |
| 2025-05 |
GUI-G1 |
GUI-G1:理解 GUI 智能体中类似 R1-Zero 的视觉对齐训练 |
|
 |
| 2025-05 |
ARPO |
ARPO:具有经验回放功能的 GUI 智能体端到端策略优化 |
|
|
| 2025-05 |
ZeroGUI |
ZeroGUI:以零人力成本实现在线 GUI 学习自动化 |
|
|
| 2025-04 |
GUI-R1 |
GUI-R1:一种适用于 GUI 智能体的通用 R1 式视觉-语言行动模型 |
|
 |
| 2025-03 |
UI-R1 |
UI-R1:通过强化学习提升 GUI 智能体的高效动作预测 |
|
 |
| 2025-01 |
UI-TARS |
UI-TARS:以原生智能体开创 GUI 自动化交互 |
|
 |
推荐智能体
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-07 |
Shop-R1 |
Shop-R1:通过强化学习奖励大模型模拟在线购物中的人类行为 |
|
- |
| 2025-03 |
Rec-R1 |
Rec-R1:通过强化学习连接大模型与推荐系统 |
|
 |
智能体(其他)
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-07 |
OpenTable-R1 |
OpenTable-R1:用于开放域表格问答的强化学习增强工具智能体 |
|
 |
| 2025-07 |
LaViPlan |
LaViPlan:基于 RLVR 的语言引导视觉路径规划 |
|
- |
| 2025-06 |
Drive-R1 |
Drive-R1:通过强化学习在 VLM 中连接推理与规划以实现自动驾驶 |
|
- |
| - |
EPO |
EPO:面向大模型智能体强化学习的熵正则化策略优化 |
|
 |
代码生成
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
Proof2Silicon |
Proof2Silicon:基于强化学习的提示修复用于验证代码与硬件生成 |
|
- |
| 2025-09 |
AR$^2$ |
AR$^2$:面向大型语言模型抽象推理的对抗性强化学习 |
|
 |
| 2025-09 |
Dream-Coder |
Dream-Coder 7B:开源的代码扩散语言模型 |
|
 |
| 2025-08 |
MSRL |
打破SFT平台期:用于图表到代码生成的多模态结构化强化学习 |
|
- |
| 2025-07 |
CogniSQL-R1-Zero |
CogniSQL-R1-Zero:用于高效SQL生成的轻量级强化推理 |
|
- |
| 2025-07 |
Leanabell-Prover-V2 |
Leanabell-Prover-V2:通过强化学习实现的验证器集成推理,用于形式化定理证明 |
|
 |
| 2025-07 |
StepFun-Prover |
StepFun-Prover预览版:让我们一步步思考并验证 |
|
 |
| 2025-06 |
MedAgentGym |
MedAgentGym:大规模训练基于代码的医学推理LLM智能体 |
|
|
| 2025-05 |
Fortune |
Fortune:公式驱动的强化学习,用于语言模型中的符号表推理 |
|
 |
| 2025-05 |
VeriReason |
VeriReason:利用测试平台反馈的强化学习,用于增强推理能力的Verilog生成 |
|
 |
| 2025-05 |
ReEX-SQL |
ReEx-SQL:通过执行感知的强化学习实现文本到SQL的推理 |
|
- |
| 2025-05 |
AceReason-Nemotron |
AceReason-Nemotron:通过强化学习推进数学与代码推理 |
|
- |
| 2025-05 |
SkyWork OR1 |
Skywork开放推理器1技术报告 |
|
|
| 2025-05 |
CodeV-R1 |
CodeV-R1:增强推理能力的Verilog生成 |
|
 |
| 2025-05 |
AReaL |
AREAL:面向语言推理的大规模异步强化学习系统 |
|
|
| 2025-04 |
SQL-R1 |
SQL-R1:通过强化学习训练自然语言到SQL的推理模型 |
|
 |
| 2025-04 |
Kimina-Prover |
Kimina-Prover预览版:迈向使用强化学习的大型形式化推理模型 |
|
- |
| 2025-04 |
DeepSeek-Prover-V2 |
DeepSeek-Prover-V2:通过强化学习进行子目标分解,推进形式数学推理 |
|
 |
| 2025-03 |
Reasoning-SQL |
Reasoning-SQL:采用SQL定制的部分奖励的强化学习,用于增强文本到SQL的推理能力 |
|
- |
| - |
code-r1 |
Code-R1:以可靠奖励重现R1用于代码 |
- |
|
| - |
Open-R1 |
Open-R1:DeepSeek-R1的完全开源复现 |
|
|
| - |
DeepCoder |
Deepcoder:一个完全开源的o3-mini级别的14b编码器 |
|
|
软件工程
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-08 |
UTRL |
通过对抗性强化学习学习生成单元测试 |
|
- |
| 2025-07 |
RePaCA |
RePaCA:利用推理型大语言模型进行静态自动化补丁正确性评估 |
|
- |
| 2025-07 |
Repair-R1 |
Repair-R1:修复前先测试 |
|
 |
| 2025-06 |
CURE |
通过强化学习协同进化LLM编码器和单元测试器 |
|
 |
| 2025-05 |
REAL |
利用程序分析反馈训练语言模型生成高质量代码 |
|
- |
| 2025-05 |
Afterburner |
Afterburner:强化学习助力自我改进的代码效率优化 |
|
 |
| 2024-09 |
RepoGenReflex |
RepoGenReflex:通过言语强化与检索增强生成提升仓库级代码补全能力 |
|
- |
| 2024-07 |
RLCoder |
RLCoder:用于仓库级代码补全的强化学习 |
|
 |
多模态理解
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
Vision-Zero |
Vision-Zero:通过策略性游戏化自对弈实现可扩展的多模态大模型自我改进 |
|
|
| 2025-09 |
ReAd-R |
AdsQA:迈向广告视频理解 |
|
 |
| 2025-09 |
Keye |
Kwai Keye-VL 1.5 技术报告 |
|
 |
| 2025-08 |
Sifthinker |
Sifthinker:面向视觉推理的空间感知图像焦点 |
|
 |
| 2025-07 |
Long-RL |
将强化学习扩展到长视频 |
|
 |
| 2025-06 |
RefSpatial |
RoboRefer:面向机器人技术的视觉-语言模型中结合推理的空间指代 |
|
 |
| 2025-06 |
Ego-R1 |
Ego-R1:用于超长第一人称视频推理的工具链式思维 |
|
 |
| 2025-05 |
VerIPO |
VerIPO:具有迭代策略优化的长推理视频-R1 模型 |
|
|
| 2025-05 |
Openthinkimg |
Openthinkimg:通过视觉工具强化学习学会用图像思考 |
|
 |
| 2025-05 |
Visual Planning |
Visual Planning:让我们只用图像思考 |
|
 |
| 2025-05 |
VideoRFT |
Videorft:通过强化微调激励多模态大模型的视频推理能力 |
|
 |
| 2025-05 |
Deepeyes |
Deepeyes:通过强化学习激励“用图像思考” |
|
 |
| 2025-05 |
Visionary-R1 |
Visionary-R1:利用强化学习缓解视觉推理中的捷径问题 |
|
 |
| 2025-05 |
CoF |
链式聚焦:基于强化学习的自适应多模态推理视觉搜索与缩放 |
|
 |
| 2025-05 |
GRIT |
GRIT:教导多模态大模型用图像思考 |
|
 |
| 2025-05 |
Pixel Reasoner |
像素推理者:以好奇心驱动的强化学习激励像素空间推理 |
|
 |
| 2025-05 |
- |
不要只看一次:迈向带有选择性视觉重访的多模态交互式推理 |
|
 |
| 2025-05 |
Ground-R1 |
Ground-R1:通过强化学习激励 grounded 视觉推理 |
|
 |
| 2025-05 |
TACO |
TACO:在多模态大模型中通过强化学习实现思考与回答的一致性,以优化长链条推理和高效数据学习 |
|
- |
| 2025-05 |
Qwen-LA |
Qwen 再次关注:引导视觉-语言推理模型重新关注视觉信息 |
|
 |
| 2025-05 |
TW-GRPO |
通过专注式思考强化视频推理 |
|
 |
| 2025-05 |
Spatial-MLLM |
Spatial-MLLM:提升多模态大模型在基于视觉的空间智能方面的能力 |
|
 |
| 2025-04 |
R1-Zero-VSI |
通过类似 R1-Zero 的训练改进视觉-空间推理 |
|
 |
| 2025-04 |
Spacer |
Spacer:强化多模态大模型的视频空间推理能力 |
|
 |
| 2025-04 |
Videochat-R1 |
Videochat-R1:通过强化微调提升时空感知能力 |
|
 |
| 2025-04 |
VLM-R1 |
VLM-R1:一种稳定且可泛化的 R1 式大型视觉-语言模型 |
|
|
| 2025-03 |
OpenVLThinker |
OpenVLThinker:通过迭代 SFT-RL 循环实现复杂的视觉-语言推理 |
|
|
| 2025-03 |
Visual-RFT |
Visual-RFT:视觉强化微调 |
|
 |
| 2025-03 |
Vision-R1 |
Vision-R1:激励多模态大语言模型的推理能力 |
|
 |
| 2025-03 |
VisRL |
VisRL:基于强化推理的意图驱动视觉感知 |
|
 |
| 2025-03 |
Metaspatial |
Metaspatial:为元宇宙中的视觉-语言模型强化 3D 空间推理能力 |
|
 |
| 2025-03 |
Video-R1 |
Video-R1:强化多模态大模型的视频推理能力 |
|
 |
多模态生成
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
IGPO |
基于修复引导的扩散大语言模型策略优化 |
|
- |
| 2025-08 |
Qwen-Image |
Qwen-Image 技术报告 |
|
 |
| 2025-08 |
TempFlow-GRPO |
TempFlow-GRPO:流模型中时间对 GRPO 的重要性 |
|
 |
| 2025-07 |
MixGRPO |
MixGRPO:通过混合 ODE-SDE 解锁基于流的 GRPO 效率 |
|
 |
| 2025-06 |
FocusDiff |
Focusdiff:通过强化学习推进自回归视觉生成中的细粒度文本-图像对齐 |
|
 |
| 2025-06 |
SUDER |
通过双重自我奖励强化多模态理解和生成 |
|
- |
| 2025-05 |
T2I-R1 |
T2I-R1:通过语义级和标记级协同思维链强化图像生成 |
|
 |
| 2025-05 |
Flow-GRPO |
Flow-GRPO:通过在线强化学习训练流匹配模型 |
|
 |
| 2025-05 |
DanceGRPO |
DanceGRPO:释放 GRPO 在视觉生成中的潜力 |
|
 |
| 2025-05 |
GoT-R1 |
GoT-R1:利用强化学习释放多模态大语言模型在视觉生成中的推理能力 |
|
 |
| 2025-05 |
ULM-R1 |
面向统一多模态理解和生成的协同强化学习 |
|
 |
| 2025-05 |
RePrompt |
Reprompt:通过强化学习实现推理增强型重提示技术用于文本到图像生成 |
|
 |
| 2025-05 |
InfLVG |
InfLVG:通过 GRPO 强化推理时一致性的长视频生成 |
|
 |
| 2025-05 |
Reasongen-R1 |
Reasongen-R1:通过 SFT 和 RL 为自回归图像生成模型提供思维链 |
|
 |
| 2025-04 |
PhysAR |
利用扩散时间步标记通过强化学习进行物理合理视频生成 |
|
- |
机器人任务
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
SimpleVLA-RL |
SimpleVLA-RL:通过强化学习扩展VLA训练 |
|
 |
| 2025-06 |
TGRPO |
TGRPO:基于轨迹级分组相对策略优化的视觉-语言-动作模型微调 |
|
- |
| 2025-05 |
ReinboT |
ReinboT:利用强化学习增强机器人视觉-语言操控能力 |
|
 |
| 2025-05 |
RIPT-VLA |
视觉-语言-动作模型的交互式后训练 |
|
 |
| 2025-05 |
VLA-RL |
VLA-RL:通过可扩展的强化学习实现精通且通用的机器人操控 |
|
 |
| 2025-05 |
RFTF |
RFTF:面向具身智能体的时序反馈强化微调 |
|
- |
| 2025-05 |
VLA泛化 |
强化学习能为VLA泛化带来什么?一项实证研究 |
|
 |
| 2025-02 |
ConRFT |
ConRFT:基于一致性策略的VLA模型强化微调方法 |
|
 |
| 2024-11 |
GRAPE |
GRAPE:通过偏好对齐泛化机器人策略 |
|
|
| - |
RLinf |
RLinf:面向代理型AI的强化学习基础设施 |
|
- |
| - |
EPO |
EPO:面向LLM代理强化学习的熵正则化策略优化 |
|
|
多智能体系统
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-10 |
AgentFlow |
流式智能体系统优化:用于高效规划与工具使用的框架 |
|
 |
| 2025-09 |
SoftRankPO, |
学会深思熟虑:基于多智能体强化学习的元策略协作,赋能智能体LLM |
|
- |
| 2025-09 |
BFS-Prover-V2 |
扩展多回合离线强化学习与多智能体树搜索技术,应用于LLM步骤证明器 |
|
- |
| 2025-08 |
MAGRPO |
LLM与多智能体强化学习的协作 |
|
- |
| 2025-06 |
AlphaEvolve |
AlphaEvolve:面向科学与算法发现的编程智能体 |
|
- |
| 2025-06 |
JoyAgents-R1 |
JoyAgents-R1:结合强化学习的多功能多LLM智能体联合进化动力学 |
|
- |
| 2025-03 |
ReMA |
ReMA:利用多智能体强化学习让LLM学会元思考 |
|
 |
| 2025-02 |
CTRL |
通过强化学习教导语言模型进行批判性评估 |
|
 |
| 2025-02 |
Maporl |
MAPoRL2:基于强化学习的大型语言模型协同后训练 |
|
 |
| 2023-11 |
LLaMAC |
基于大型语言模型的智能体在大规模决策中的控制:演员-评论家方法 |
|
- |
科学任务
| 日期 |
名称 |
标题 |
论文 |
Github |
| 2025-09 |
Baichuan-M2 |
百川-M2:基于大型验证器系统的医疗能力扩展 |
|
- |
| 2025-08 |
CX-Mind |
CX-Mind:通过课程引导的强化学习实现胸片交错推理的开创性多模态大语言模型 |
|
 |
| 2025-08 |
MORE-CLEAR |
MORE-CLEAR:利用增强状态表示的临床笔记多模态离线强化学习 |
|
- |
| 2025-08 |
ARMed |
突破奖励崩溃:具有增强语义区分能力的开放式医疗推理自适应强化学习 |
|
- |
| 2025-08 |
ProMed |
ProMed:基于夏普利信息增益指导的主动式医疗LLM强化学习 |
|
 |
| 2025-08 |
OwkinZero |
OwkinZero:用AI加速生物发现 |
|
- |
| 2025-08 |
MolReasoner |
MolReasoner:迈向分子LLM的有效且可解释的推理 |
|
 |
| 2025-08 |
MedGR$^2$ |
MedGR$^2$:通过生成式奖励学习突破医疗推理的数据壁垒 |
|
- |
| 2025-07 |
MedGround-R1 |
MedGround-R1:通过空间-语义奖励的群体相对策略优化推进医学图像定位 |
|
 |
| 2025-07 |
MedGemma |
MedGemma技术报告 |
|
- |
| 2025-06 |
MMedAgent-RL |
MMedAgent-RL:优化多智能体协作以实现多模态医疗推理 |
|
- |
| 2025-06 |
Cell-o1 |
Cell-o1:通过强化学习训练LLM解决单细胞推理难题 |
|
 |
| 2025-06 |
MedAgentGym |
MedAgentGym:大规模训练基于代码的LLM代理进行医疗推理 |
|
|
| 2025-06 |
Med-U1 |
Med-U1:通过大规模强化学习激励LLM中的统一医疗推理 |
|
 |
| 2025-06 |
MedVIE |
通过强化学习实现高效的医疗视觉-推理框架 |
|
- |
| 2025-06 |
LA-CDM |
基于强化学习的语言代理用于假设驱动的临床决策制定 |
|
- |
| 2025-06 |
ether0 |
训练用于化学科学推理的模型 |
|
 |
| 2025-06 |
Gazal-R1 |
Gazal-R1:通过参数高效的两阶段训练实现最先进的医疗推理 |
|
- |
| 2025-05 |
DRG-Sapphire |
LLM中分布外推理的强化学习:诊断相关分组编码的实证研究 |
|
 |
| 2025-05 |
BioReason |
BioReason:在DNA-LLM模型中激励多模态生物推理 |
|
 |
| 2025-05 |
EHRMIND |
通过强化学习训练LLM完成基于电子健康记录的推理任务 |
|
- |
| 2025-04 |
Open-Medical-R1 |
Open-Medical-R1:如何在医学领域选择RLVR训练数据 |
|
 |
| 2025-04 |
ChestX-Reasoner |
ChestX-Reasoner:通过逐步验证推进放射学基础模型 |
|
- |
| 2025-04 |
BoxMed-RL |
像放射科医生一样思考:链式思维与强化学习用于可验证报告生成 |
|
- |
| 2025-03 |
PPME |
通过临床经验学习提升大型语言模型代理的交互式诊断能力 |
|
- |
| 2025-03 |
DOLA |
使用DOLA进行自主放疗计划:一种保护隐私的基于LLM的优化代理 |
|
- |
| 2025-02 |
Baichuan-M1 |
百川-M1:推动大语言模型的医疗能力 |
|
- |
| 2025-02 |
MedVLM-R1 |
MedVLM-R1:通过强化学习激励视觉-语言模型(VLMs)的医疗推理能力 |
|
- |
| 2025-02 |
Med-RLVR |
Med-RLVR:通过强化学习从3B基础模型中涌现医疗推理 |
|
- |
| 2025-01 |
MedXpertQA |
MedXpertQA:专家级医疗推理与理解的基准测试 |
|
 |
| 2024-12 |
HuatuoGPT-o1 |
华佗GPT-o1:迈向基于LLM的复杂医疗推理 |
|
 |
| - |
Pro-1 |
Pro-1 |
|
 |
| - |
rbio |
rbio1:以生物世界模型作为软验证器训练科学推理LLM |
|
 |
| - |
EPO |
EPO:用于LLM代理强化学习的熵正则化策略优化 |
|
|
🌟 致谢
本调查是在原始的 Awesome RL Reasoning Recipes 仓库基础上扩展和完善的。我们衷心感谢所有贡献者的辛勤付出,并对他们对 Awesome RL Reasoning Recipes 的持续关注表示诚挚的感谢。此前仓库的内容可在此处查看:这里。
✨ 星标历史

Awesome-RL-for-LRMs 快速上手指南
Awesome-RL-for-LRMs 并非一个可直接安装运行的软件库或框架,而是一个由清华大学 C3I 团队维护的开源论文与项目综述列表。它旨在系统性地梳理“大型推理模型(Large Reasoning Models, LRMs)中的强化学习(RL)”领域的最新进展、前沿模型、奖励设计、策略优化算法及应用场景。
本指南将帮助开发者快速利用该资源追踪技术动态、查找相关代码实现及阅读核心论文。
环境准备
由于本项目本质为资料索引,无需特定的系统环境或复杂的依赖安装。您只需具备以下基础条件即可开始使用:
- 操作系统:Windows / macOS / Linux 均可。
- 网络环境:
- 能够访问 GitHub 以浏览项目列表和源代码。
- 能够访问 arXiv 或 Hugging Face Papers 以阅读论文。
- 国内用户建议:若访问 GitHub 或 arXiv 较慢,可配置本地 hosts 或使用学术加速镜像(如 arXiv 国内镜像站)。
- 工具要求:现代浏览器(推荐 Chrome 或 Edge)。
获取与浏览步骤
您无需通过包管理器安装该项目,直接通过以下方式获取内容:
1. 访问在线仓库(推荐)
直接在浏览器中打开项目主页,查看分类整理的论文列表和最新动态:
# 在浏览器地址栏输入以下网址
https://github.com/TsinghuaC3I/Awesome-RL-Reasoning-Recipes
(注:原 README 中提供的链接指向 TsinghuaC3I/Awesome-RL-Reasoning-Recipes,请以此为准)
2. 克隆本地浏览(可选)
如果您希望离线查看或贡献内容,可以将仓库克隆到本地:
git clone https://github.com/TsinghuaC3I/Awesome-RL-Reasoning-Recipes.git
cd Awesome-RL-Reasoning-Recipes
克隆后,您可以直接使用 Markdown 阅读器(如 VS Code、Typora)打开 README.md 文件进行浏览。
3. 订阅动态
关注项目的 News 板块或 Watch 该仓库,以获取关于新发布模型(如 GLM-4.5, Qwen3, Kimi K2 等)和新论文的分类更新通知。
基本使用
本项目的核心用法是按图索骥:根据您的需求查找对应的论文、技术报告或开源代码实现。
场景一:查找特定领域的前沿模型
如果您想了解最新的具身智能或推理大模型,请查阅 Frontier Models 章节。
- 操作:在页面中找到对应模型名称(例如
Qwen3 或 GLM-4.5)。
- 行动:点击表格中的
Paper 按钮阅读技术报告,点击 Github 按钮跳转至官方代码仓库进行复现或微调。
场景二:研究特定 RL 算法实现
如果您正在开发基于 RL 的推理模型,需要参考具体的奖励设计或策略优化算法:
- 操作:利用目录跳转到 Paper List 下的子分类,例如:
Reward Design -> Dense Rewards (密集奖励设计)Policy Optimization -> Critic-Free Algorithms (无评论家算法)Sampling Strategy (采样策略)
- 行动:列表中提供了该细分领域的相关论文链接及对应的开源项目地址(如有),可直接前往学习具体实现细节。
场景三:寻找训练资源与环境
如果您需要构建自己的 RL 训练环境或寻找数据集:
- 操作:查阅 Training Resource 章节。
- 内容:这里汇总了静态语料库(代码、数学、STEM 等)和动态环境(基于规则、代码、游戏等)的相关资源链接,以及 RL 基础设施(Infrastructure)的推荐方案。
引用本项目
如果在您的研究或工作中使用了该综述列表,请在您的论文中添加以下引用:
@article{zhang2025survey,
title={A survey of reinforcement learning for large reasoning models},
author={Zhang, Kaiyan and Zuo, Yuxin and He, Bingxiang and Sun, Youbang and Liu, Runze and Jiang, Che and Fan, Yuchen and Tian, Kai and Jia, Guoli and Li, Pengfei and others},
journal={arXiv preprint arXiv:2509.08827},
year={2025}
}

