300Days__MachineLearningDeepLearning
300Days__MachineLearningDeepLearning 是一位开发者记录的"300 天数据科学之旅”开源项目,旨在系统性地分享机器学习与深度学习的学习路径与实践成果。该项目解决了初学者在面对海量学习资源时容易迷失方向、缺乏系统性实战演练的痛点,通过整合经典教材、前沿论文与代码实现,提供了一条清晰的进阶路线。
内容涵盖从基础的《机器学习实战》到深度的 PyTorch、Fastai 框架应用,并包含了大量动手项目,如房价预测、手写数字识别、风格迁移、情感分析及生成对抗网络(GAN)等。其独特亮点在于“学练结合”的模式:不仅列出了完成状态的书单和资源,还配套了完整的 Notebook 代码复现,让读者能直接运行并理解算法从理论到落地的全过程。
这套资源非常适合希望系统入门或巩固基础的 AI 开发者、计算机专业学生及自学者使用。对于想要摆脱碎片化知识积累,希望通过结构化项目和经典案例深入理解模型原理的研究人员,300Days__MachineLearningDeepLearning 也是一份极具参考价值的实战指南。
使用场景
一名刚转行数据科学的工程师,正试图在三个月内从零掌握机器学习与深度学习核心技能,以应对公司新启动的图像识别项目。
没有 300Days__MachineLearningDeepLearning 时
- 学习路径混乱:面对海量的经典教材(如《动手学深度学习》、《Speech and Language Processing》)和论文,不知从何入手,容易在理论海洋中迷失方向。
- 理论与实践脱节:读懂了逻辑回归或 LeNet 架构的数学公式,却缺乏从零手写代码的实现参考,导致无法真正理解算法底层逻辑。
- 项目落地困难:在处理具体任务(如情感分析、犬种分类)时,找不到涵盖数据预处理、模型构建到调优的完整 Notebook 范例,反复踩坑。
- 技术栈覆盖不全:难以系统性地同时掌握 PyTorch、Fastai、Keras 等多个主流框架的最佳实践,知识体系支离破碎。
使用 300Days__MachineLearningDeepLearning 后
- 路线清晰高效:直接跟随作者验证过的"300 天”书单与完成状态,按部就班地攻克从基础机器学习到 BERT、GAN 等前沿模型的学习关卡。
- 代码级深度理解:参考“从零实现逻辑回归”和"LeNet 架构复现”等源码,将抽象理论转化为可运行的代码,彻底吃透算法原理。
- 场景化快速复用:利用现成的 CIFAR10 物体识别、RNN/CNN 情感分析及自然语言推断项目笔记,快速迁移解决公司业务中的类似痛点。
- 全框架实战能力:通过 Fastai 系列教程(如熊检测器、数字分类器),迅速掌握多框架下的模型生产与部署流程,提升工程化水平。
300Days__MachineLearningDeepLearning 不仅是一份资源清单,更是一条经过实战验证的、从理论入门到项目落地的系统化成长捷径。
运行环境要求
未说明
未说明

快速开始
300天数据之旅:机器学习与深度学习

| 书籍与资源 | 完成状态 |
|---|---|
| 1. 从零开始的机器学习 | :white_check_mark: |
| 2. 机器学习全面指南 | :white_check_mark: |
| 3. 使用Scikit-Learn、Keras和TensorFlow的动手机器学习 | :white_check_mark: |
| 4. 语音与语言处理 | |
| 5. 机器学习速成课程 | :white_check_mark: |
| 6. 用PyTorch进行深度学习:第一部分 | :white_check_mark: |
| 7. 深入深度学习 | :white_check_mark: |
| 8. 逻辑回归文档 | :white_check_mark: |
| 9. 使用Fastai和PyTorch的编码者深度学习 | :white_check_mark: |
| 10. 解决几乎任何机器学习问题的方法 | |
| 11. PyImageSearch |
| 研究论文 |
|---|
| 1. 基于梯度的深度架构训练实用建议 |
| 项目与笔记本 |
|---|
| 1. 加州房价预测 |
| 2. 从零开始实现逻辑回归 |
| 3. LeNet网络架构的实现 |
| 4. 神经网络风格迁移 |
| 5. 基于CIFAR10数据集的图像目标识别 |
| 6. 基于ImageNet数据集的犬种分类 |
| 7. 情感分析数据集笔记本 |
| 8. 使用RNN进行情感分析 |
| 9. 使用CNN进行情感分析 |
| 10. 自然语言推理数据集 |
| 11. 自然语言推理:注意力机制 |
| 12. 自然语言推理:BERT模型 |
| 13. 深度卷积生成对抗网络 |
| 14. Fastai:入门笔记本 |
| 15. Fastai:图像检测 |
| 16. Fastai:训练分类器 |
| 17. Fastai:图像分类 |
| 18. Fastai:多标签分类与回归 |
| 19. Fastai:图像回归 |
| 20. Fastai:高级分类任务 |
| 21. Fastai:协同过滤 |
| 22. Fastai:表格数据建模 |
| 23. Fastai:自然语言处理 |
| 24. Fastai:数据清洗 |
| 25. Fastai:从零开始构建语言模型 |
| 26. Fastai:卷积神经网络 |
| 27. Fastai:残差网络 |
| 28. Fastai:架构细节 |
| 29. Fastai:训练过程 |
| 30. Fastai:神经网络基础 |
| 31. Fastai:利用CAM解释CNN |
| 32. Fastai:从零开始构建Fastai Learner |
| 33. Fastai:胸部X光片分类 |
| 34. 监督学习与无监督学习 |
| 35. 评估指标 |
| 36. OpenCV笔记本 |
| 37. OpenCV项目I |
| 38. OpenCV项目II |
| 39. 卷积操作 |
| 40. 卷积层 |
| 41. Fastai:Transformer模型 |
300天数据之旅第一天!
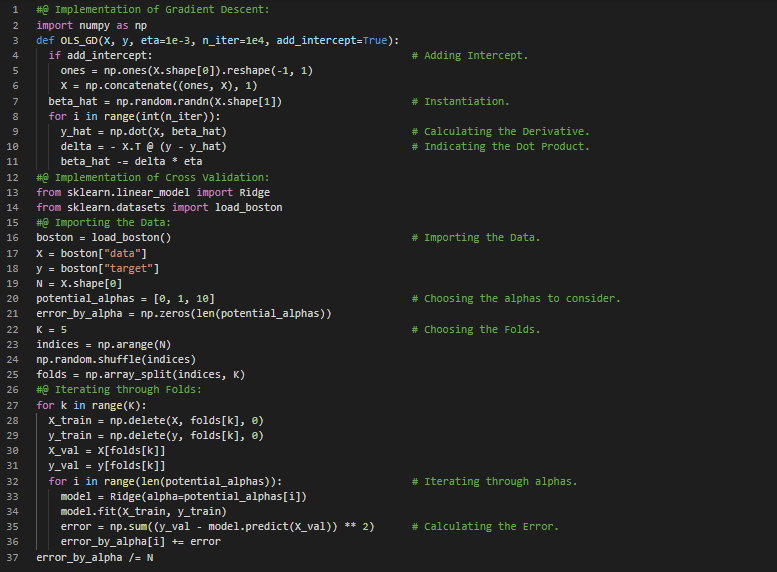
- 梯度下降与交叉验证:梯度下降是一种迭代方法,用于近似使可微损失函数最小化的参数。交叉验证则是一种重采样技术,用于在有限的数据样本上评估机器学习模型,其核心思想是将数据划分为若干组。在我的机器学习和深度学习之旅中,今天我简要了解了微积分、矩阵、矩阵微积分、随机变量、密度函数、分布、独立性、最大似然估计以及条件概率等基础概念。我还阅读并实现了梯度下降和交叉验证的相关内容。我从零开始这段旅程,并以《从零开始的机器学习》一书为指导。这里展示了梯度下降和交叉验证的具体实现截图。希望你也花些时间阅读上述书籍中的相关内容。我对接下来的日子充满期待!!
- 书籍:
300天数据之旅第2天!
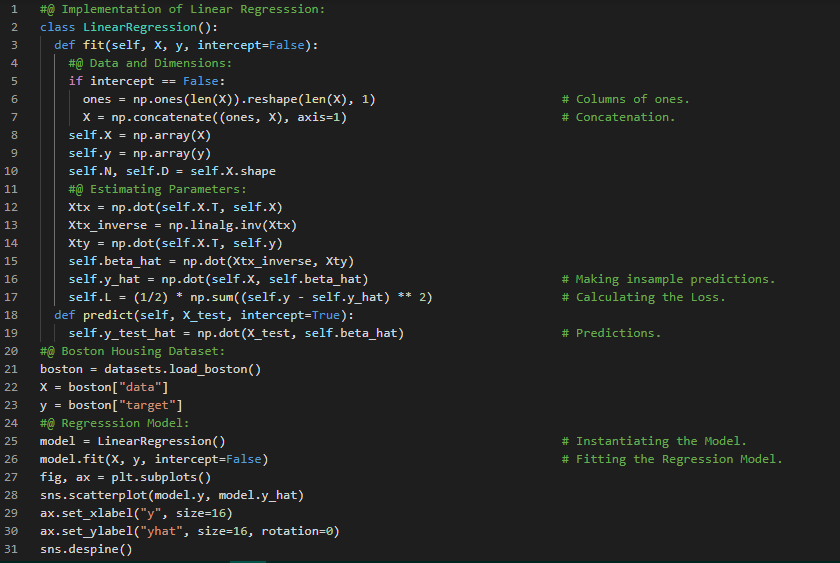
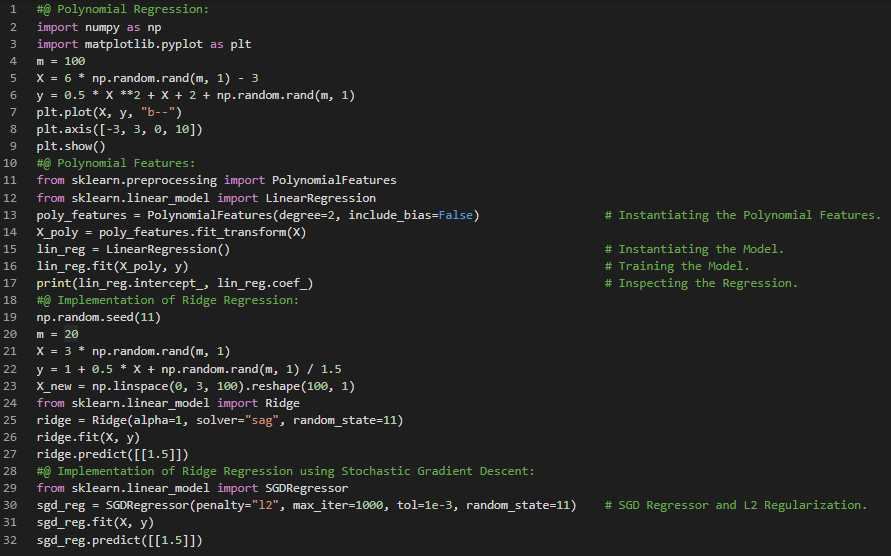
- 普通线性回归:线性回归是一种用于建模标量响应变量(因变量)与一个或多个解释变量(自变量)之间关系的线性方法。在我的机器学习和深度学习之旅中,今天我阅读并实现了关于普通线性回归、参数估计、最小化损失和最大化似然等内容,并根据《从零开始的机器学习》一书构建和实现了线性回归模型。此外,我还开始阅读《机器学习全面指南》,这本书侧重于相关主题背后的数学和理论。通过这本书,我学习了回归、普通最小二乘法、向量微积分、正交投影、岭回归、特征工程、拟合椭圆、多项式特征、超参数与验证、误差及交叉验证等内容。我在截图中展示了使用Python实现的线性回归及其可视化效果。希望你也花些时间阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 从零开始的机器学习
- 机器学习全面指南
300天数据之旅第3天!
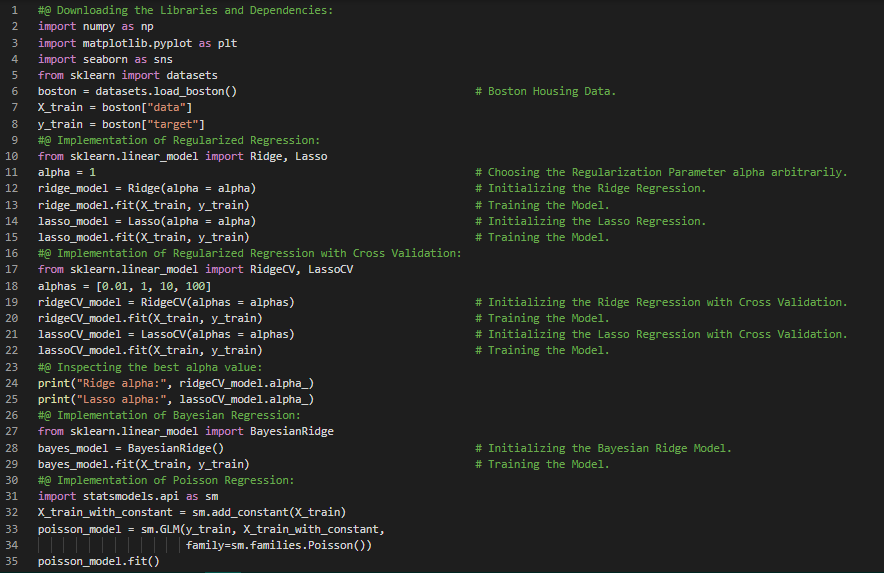
- 在我的机器学习和深度学习之旅中,今天我阅读并实现了关于正则化回归(如岭回归和Lasso回归)、贝叶斯回归、广义线性模型以及泊松回归等内容,并根据《从零开始的机器学习》一书进行了相应的构建和实现。同时,我也继续阅读《机器学习全面指南》,该书专注于相关主题背后的数学和理论。通过这本书,我学习了回归中的最大似然估计(MLE)和最大后验估计(MAE)、概率模型、偏差-方差权衡、评估指标、偏差-方差分解、替代分解、多元高斯分布、从数据中估计高斯分布、加权最小二乘法、岭回归和广义最小二乘法等内容。我在截图中展示了使用Python实现的岭回归、Lasso回归、交叉验证、贝叶斯回归和泊松回归。希望你也花些时间阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 从零开始的机器学习
- 机器学习全面指南
300天数据之旅第4天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实现了关于判别分类器的内容,包括二分类和多分类逻辑回归、感知机算法、参数估计、费舍尔线性判别分析及费舍尔准则等,并根据《从零开始的机器学习》一书进行了相应的构建和实现。此外,我还继续阅读《机器学习全面指南》,该书着重讲解相关主题背后的数学和理论。通过这本书,我学习了核函数与岭回归、线性代数推导、计算分析、稀疏最小二乘法、正交匹配追踪、总体最小二乘法、低秩表示、降维、主成分分析、投影、坐标变换、最小化重构误差以及概率主成分分析等内容。我在截图中展示了使用Python实现的二分类和多分类逻辑回归、感知机算法以及费舍尔线性判别分析。希望你也花些时间阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 从零开始的机器学习
- 机器学习全面指南
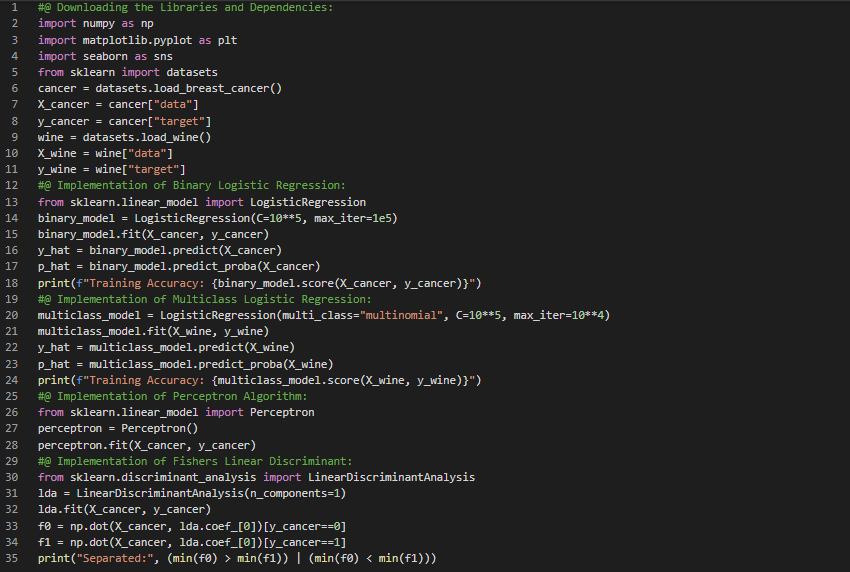
300天数据之旅第5天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实现了关于生成式分类器的内容,包括线性判别分析(LDA)、二次判别分析(QDA)、朴素贝叶斯、参数估计及数据似然度等,并根据《从零开始的机器学习》一书进行了相应的构建和实现。同时,我也继续阅读《机器学习全面指南》,该书专注于相关主题背后的数学和理论。通过这本书,我学习了生成式与判别式分类、贝叶斯决策规则、最小二乘支持向量机、特征扩展、神经网络扩展、二分类和多分类逻辑回归、损失函数、训练过程、多分类扩展、高斯判别分析、QDA和LDA分类以及支持向量机等内容。我在截图中展示了使用Python实现的LDA、QDA和朴素贝叶斯,并附带了可视化效果。希望你也花些时间阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 从零开始的机器学习
- 机器学习全面指南
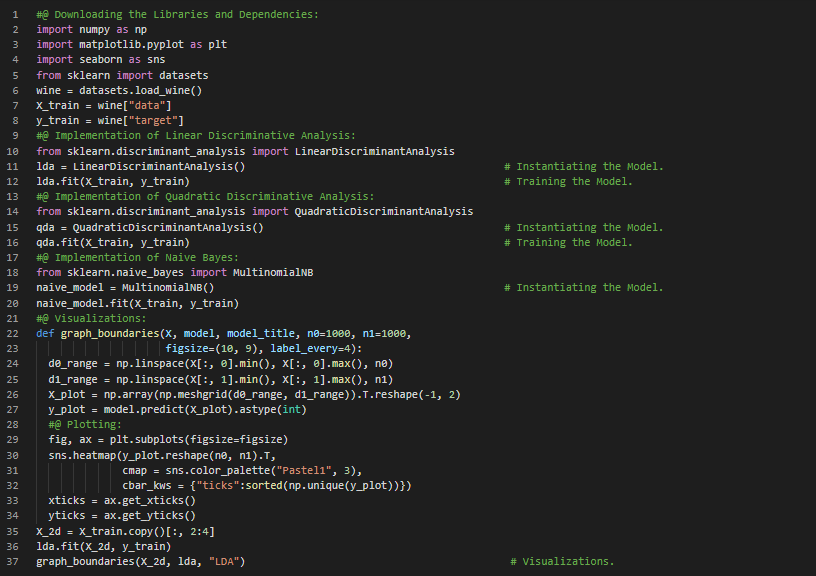
300天数据之旅第6天!
- 决策树:决策树是一种可解释的机器学习方法,适用于回归和分类任务。它是一种类似流程图的结构,其中每个内部节点代表对某个属性的测试,而每个分支则表示测试的结果。在我的机器学习和深度学习之旅中,今天我阅读了关于决策树的内容,包括回归树和分类树、树的构建、分裂与预测、超参数、剪枝与正则化等,并参考《从零开始的机器学习》一书进行了相关理论的学习和实现。此外,我还阅读了《机器学习全面指南》,该书侧重于相关主题背后的数学和理论知识。书中涵盖了决策树学习、熵与信息量、基尼不纯度、停止条件、随机森林、提升算法及AdaBoost、梯度提升以及K均值聚类等内容。我在截图中展示了使用Python实现的回归树和分类树。希望你也花些时间阅读上述主题和书籍。对未来几天充满期待!!
- 书籍:
- 从零开始的机器学习
- 机器学习全面指南
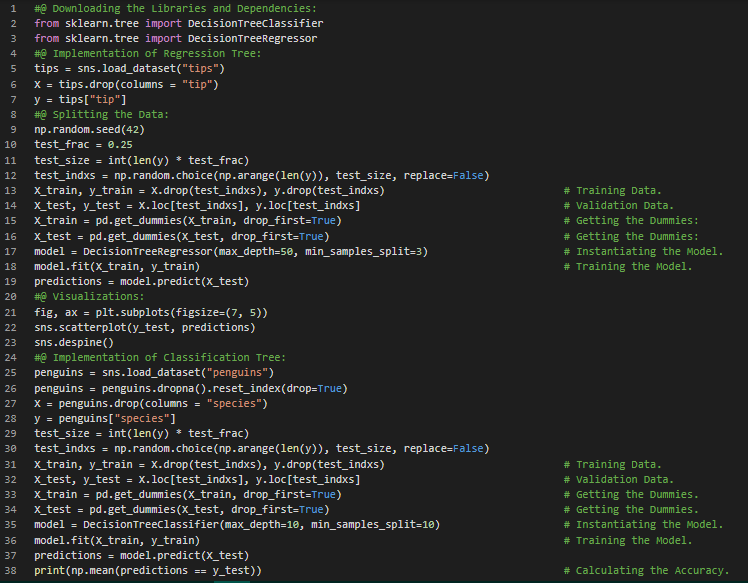
300天数据之旅第7天!
- 树集成方法:集成方法通过结合多个简单模型(通常称为“学习器”)的输出,来构建一个方差较低的优秀模型。由于决策树本身具有较高的方差,往往难以达到与其他预测算法相当的精度,而集成方法则可以有效降低这种方差。在我的机器学习和深度学习之旅中,今天我阅读并实现了关于树集成方法的内容,例如用于决策树的Bagging、自助法、随机森林及其操作流程、提升算法、用于二分类的AdaBoost、加权分类树、离散型AdaBoost算法以及用于回归的AdaBoost等,并参考《从零开始的机器学习》一书进行了相关理论的学习和实现。我在截图中展示了使用Python实现的Bagging、随机森林和AdaBoost,并采用了不同的基础估计器。希望你也花些时间阅读上述主题和书籍。对未来几天充满期待!!
- 书籍:
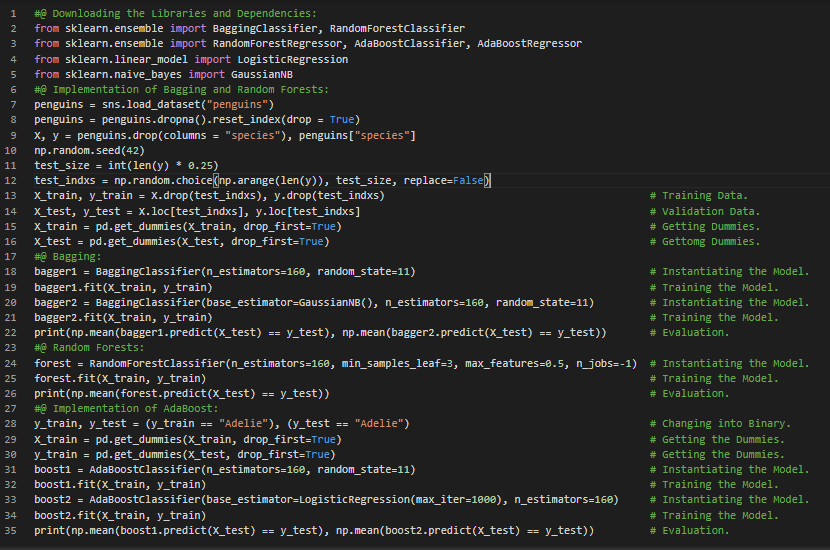
300天数据之旅第8天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实现了关于神经网络的内容,内容来自《从零开始的机器学习》一书。书中介绍了模型结构、各层之间的通信、激活函数(如ReLU、Sigmoid、线性激活函数)、优化方法、反向传播、梯度计算、链式法则及注意事项、损失函数等,并详细讲解了如何使用循环方式和矩阵方式进行模型构建及其实现。此外,我还阅读了《机器学习全面指南》,该书专注于相关主题背后的数学和理论。书中涉及卷积神经网络及其各层、池化层、CNN的反向传播、ResNet以及对CNN的直观理解等内容。除此之外,我还观看了几段关于神经网络和深度学习的视频。我在截图中展示了使用TensorFlow的Functional API和Sequential API实现的简单神经网络。希望你也花些时间阅读上述主题和书籍。对未来几天充满期待!!
- 书籍:
- 从零开始的机器学习
- 机器学习全面指南
300天数据之旅第9天!
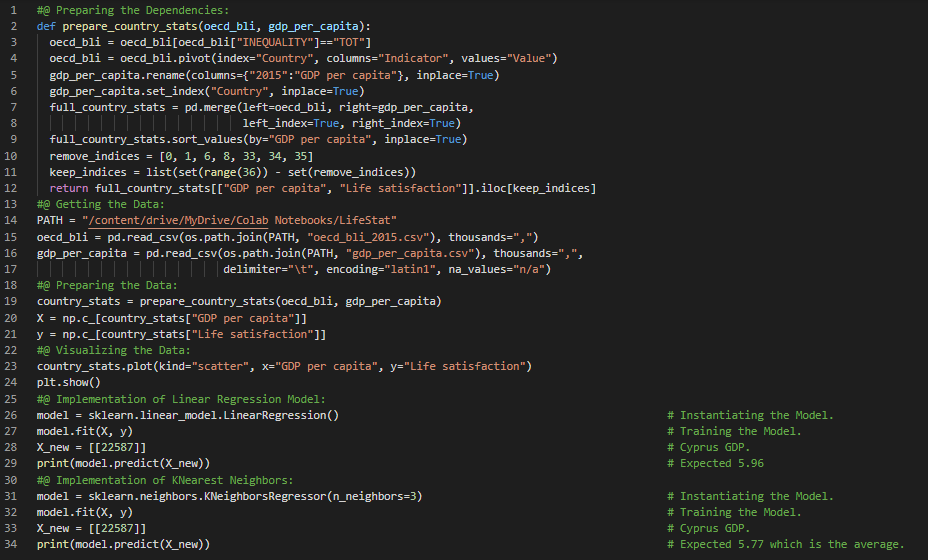
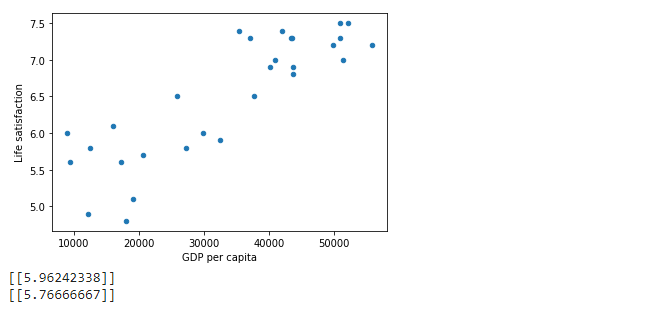
- 强化学习:在强化学习中,被称为“智能体”的学习系统可以在特定环境中观察环境状态,选择并执行动作,从而获得奖励或因负面行为而受到惩罚。它必须通过自我学习,找到一种能够随着时间推移获得最大累积奖励的最佳策略。在我的机器学习和深度学习之旅中,今天我开始阅读并实践《动手学机器学习:基于Scikit-Learn、Keras和TensorFlow》一书的内容。书中简要介绍了机器学习的全景,包括监督学习、无监督学习、半监督学习、强化学习、批处理学习与在线学习、基于实例的学习与基于模型的学习等不同类型的学习系统。我在截图中展示了使用Python实现的简单线性回归和K近邻算法,并附带了一个简单的图表。希望你也花些时间阅读上述主题和书籍。对未来几天充满期待!!
- 书籍:
- 动手学机器学习:基于Scikit-Learn、Keras和TensorFlow
300天数据之旅第10天!
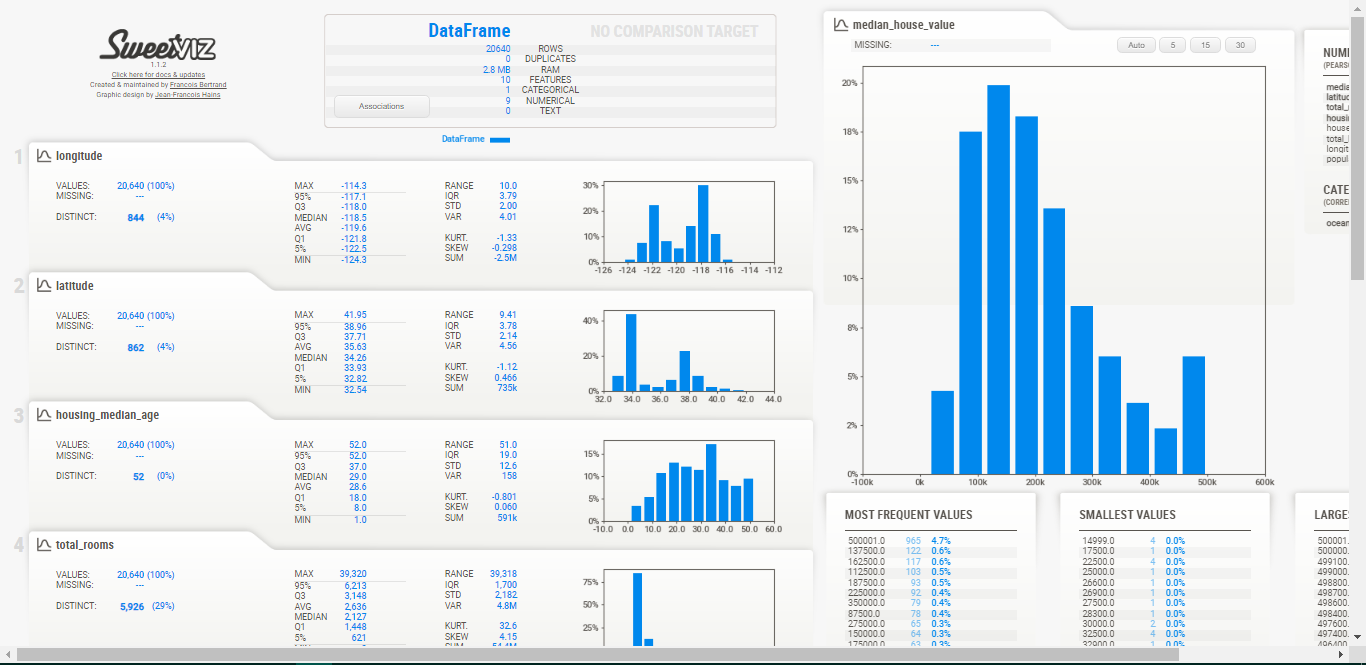
- 在我的机器学习和深度学习之旅中,今天我阅读了关于机器学习主要挑战的内容,包括训练数据不足、训练数据缺乏代表性、数据质量差、特征无关、过拟合与欠拟合、数据集划分中的问题、超参数调优与模型选择以及数据不匹配等问题,内容来自《动手学机器学习:基于Scikit-Learn、Keras和TensorFlow》一书。随后,我开始着手处理该书中包含的“加州房价”数据集,在这个项目中我将构建一个加州房价预测模型。我在截图中展示了使用Python进行数据处理的简单实现以及一些探索性数据分析技术。此外,我还演示了使用Sweetviz库进行数据分析的方法。非常感谢Chanin Nantasenamat在其视频中分享了关于该库的信息。希望你也花些时间阅读上述主题和书籍。对未来几天充满期待!!
- 书籍:
- 动手学机器学习:基于Scikit-Learn、Keras和TensorFlow
- Chanin Nantasenamat关于Sweetviz的视频
- 加州房价数据集
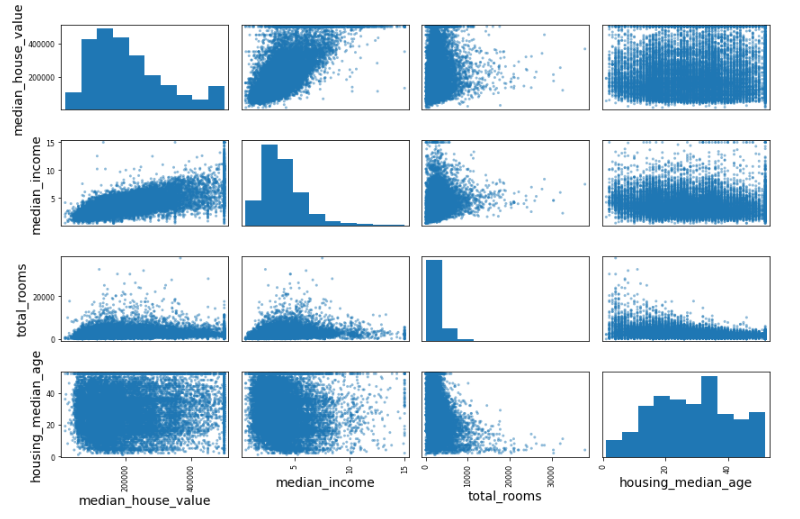
300天数据之旅第11天!
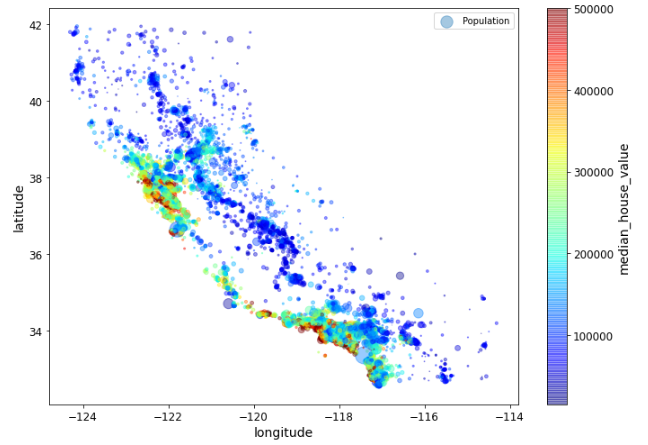
- 在我的机器学习和深度学习之旅中,今天我学习并实践了从属性创建类别、分层抽样、通过可视化数据获取洞察、散点图、相关性、散点矩阵以及属性组合等内容,这些内容均来自《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书。我继续使用该书中包含的“加州房价”数据集进行练习。该数据集基于1990年加州人口普查的数据。在这个项目中,我将构建一个加州房价预测模型。目前我仍在继续推进这个项目。在这里的截图中,我展示了使用Python实现的分层抽样、利用散点矩阵计算相关性以及属性组合的方法。此外,我还展示了使用散点图计算相关性的截图。希望大家也能花些时间来研究这些内容,并阅读上述书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
- 加州房价
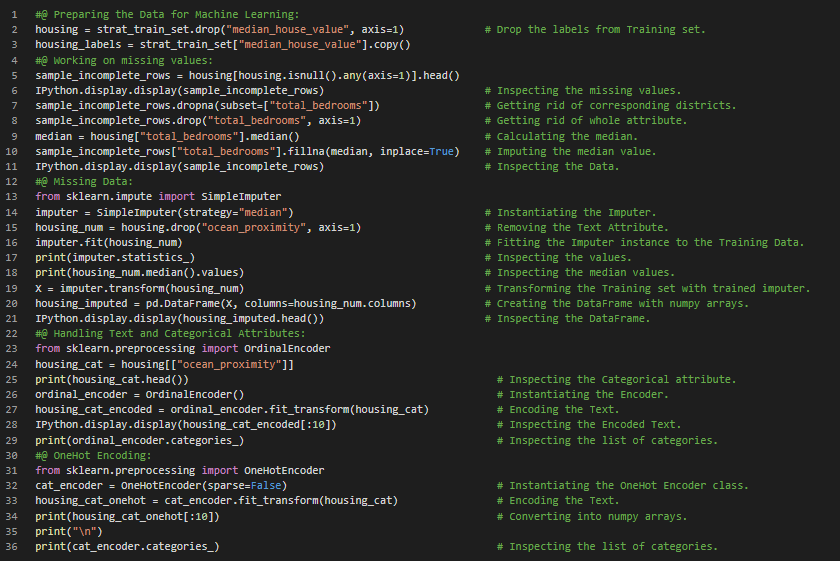
300天数据之旅第12天!
- 在我的机器学习和深度学习之旅中,今天我学习并实践了为机器学习算法准备数据、数据清洗、简单插补器、序数编码器、独热编码器、特征缩放、转换管道、标准化缩放器、列变换器、线性回归、决策树回归器以及交叉验证等内容,这些内容均来自《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书。我继续使用该书中包含的“加州房价”数据集进行练习。该数据集基于1990年加州人口普查的数据。在这个项目中,我将构建一个加州房价预测模型。笔记本中几乎涵盖了上述所有主题。在这里的截图中,我展示了使用Python实现的数据准备、缺失值处理、独热编码器、列变换器、线性回归、决策树回归器以及交叉验证的过程。希望大家也能花些时间来研究这些内容,并阅读上述书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
- 加州房价
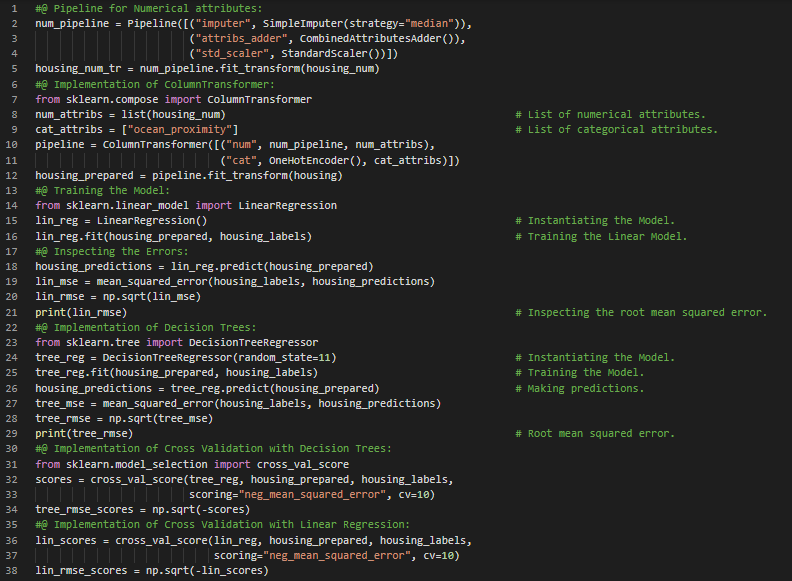
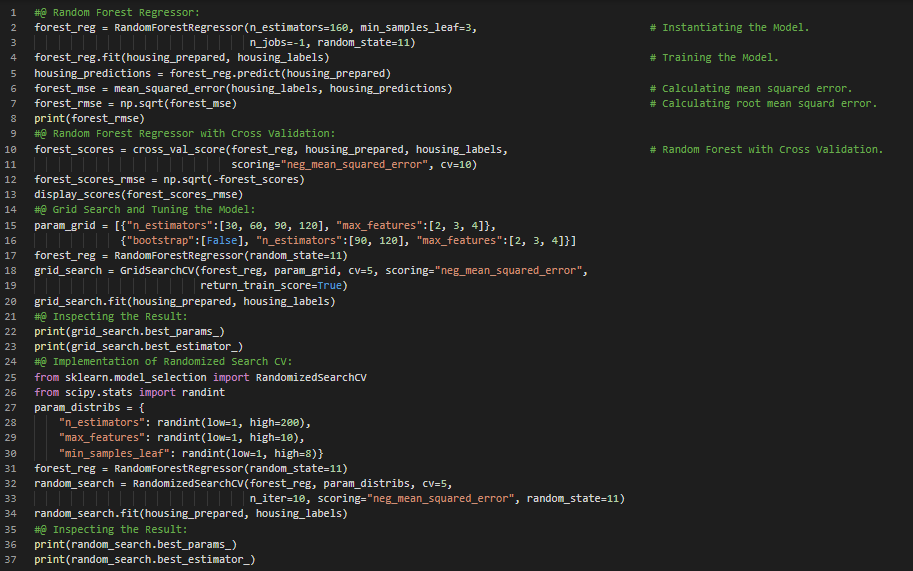
300天数据之旅第13天!
- 在我的机器学习和深度学习之旅中,今天我学习并实践了随机森林回归器、集成学习、模型调优、网格搜索、随机搜索、分析最佳模型及误差、模型评估、交叉验证等与之相关的主题,这些内容均来自《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书。我已经完成了对该书中包含的“加州房价”数据集的处理。该数据集基于1990年加州人口普查的数据。我使用随机森林回归器构建了一个加州房价预测模型,用于预测加州房屋的价格。在这里的截图中,我展示了使用Python实现的随机森林回归器、通过网格搜索和随机搜索进行模型调优以及交叉验证的过程。希望大家也能花些时间来研究这些内容,并阅读上述书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
- 加州房价
300天数据之旅第14天!
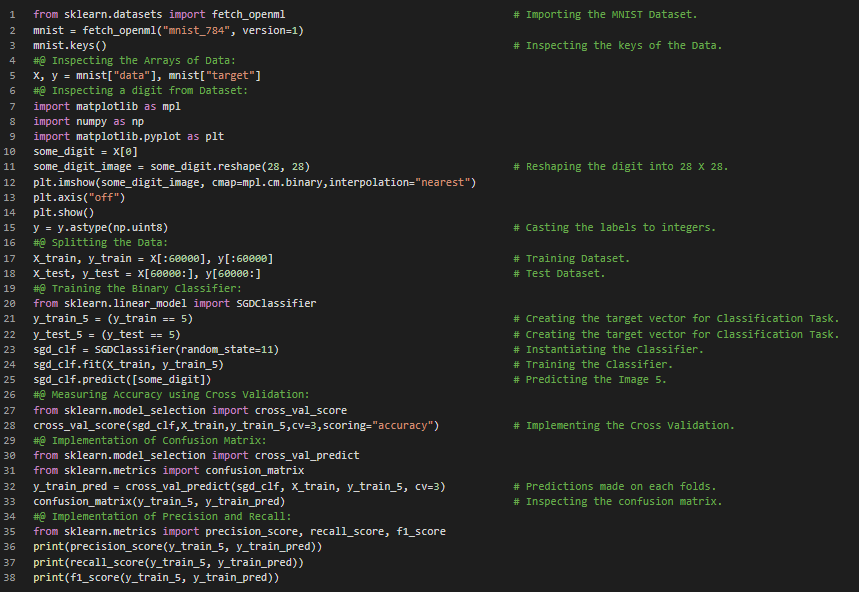
- 混淆矩阵:混淆矩阵是评估分类器性能的一种更有效的方法。其基本思想是统计属于类别A的样本被错误地分类为类别B的次数。这种方法需要有一组预测结果,以便将其与实际标签进行比较。在我的机器学习和深度学习之旅中,今天我阅读并实践了分类、使用随机梯度下降训练二分类器、通过交叉验证衡量准确率、交叉验证的实现、混淆矩阵、精确率和召回率及其曲线等相关内容,这些内容均来自《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书。在这里的截图中,我展示了在MNIST数据集中使用SGD分类器进行分类,并计算精确率和召回率的过程。同时,我还展示了精确率和召回率的曲线。希望大家也能花些时间来研究这些内容,并阅读上述书籍。我对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
300天数据之旅第15天!
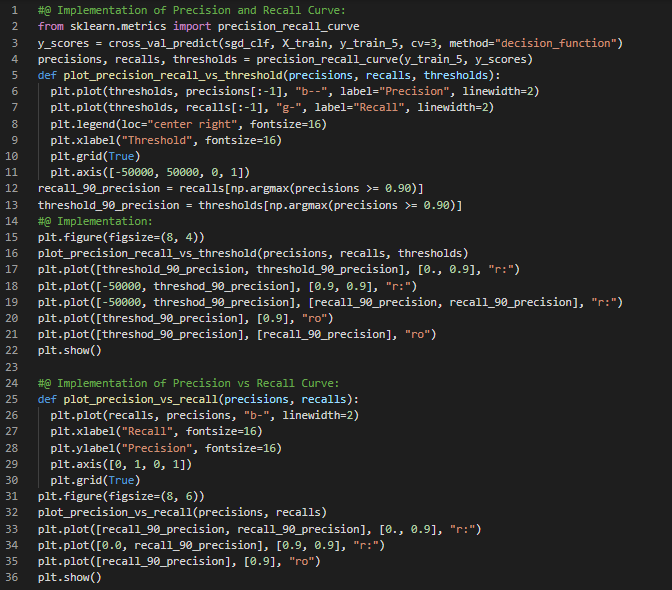
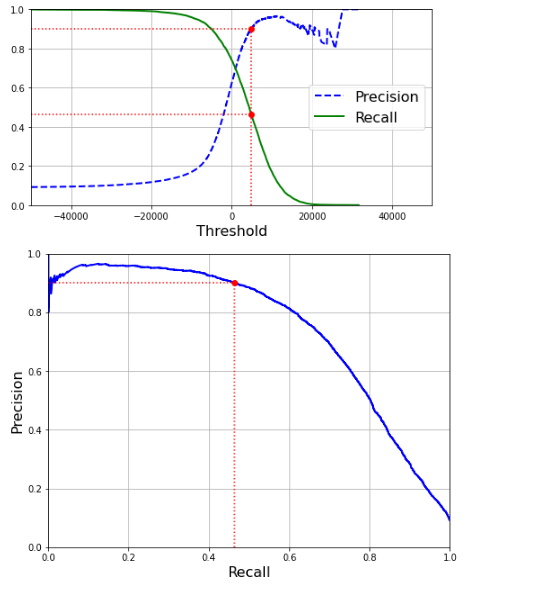
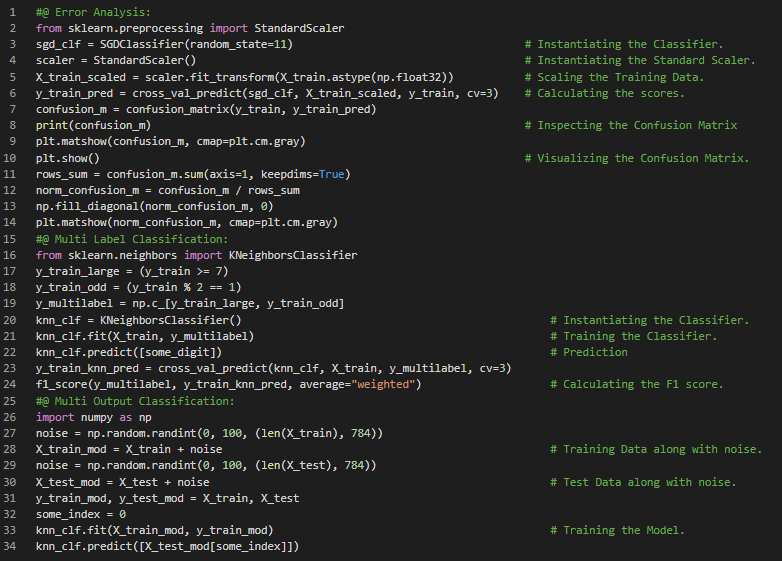
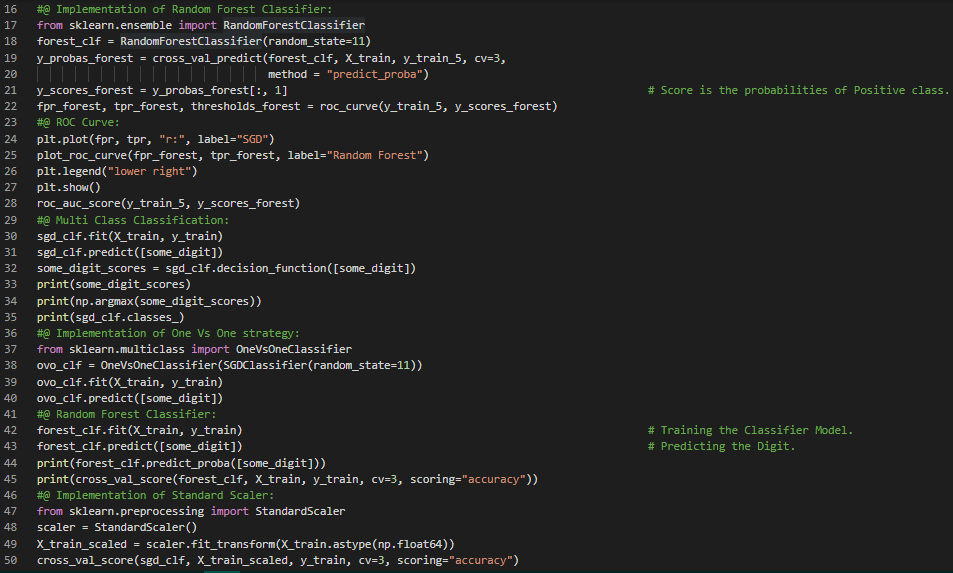
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了ROC曲线、随机森林分类器、SGD分类器、多分类问题、一对一和一对多策略、交叉验证、使用混淆矩阵进行误差分析、K近邻分类器、多输出分类、噪声、精确率与召回率的权衡等主题,内容均来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我已经完成了这本书中的“分类”章节。我在截图中展示了ROC曲线、随机森林分类器在多分类中的应用、一对一策略、标准化缩放、误差分析、多标签分类以及使用Scikit-Learn实现的多输出分类的代码实现。希望你也能够尝试这些内容,并花些时间阅读上述主题和书籍。我对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
300天数据之旅第16天!
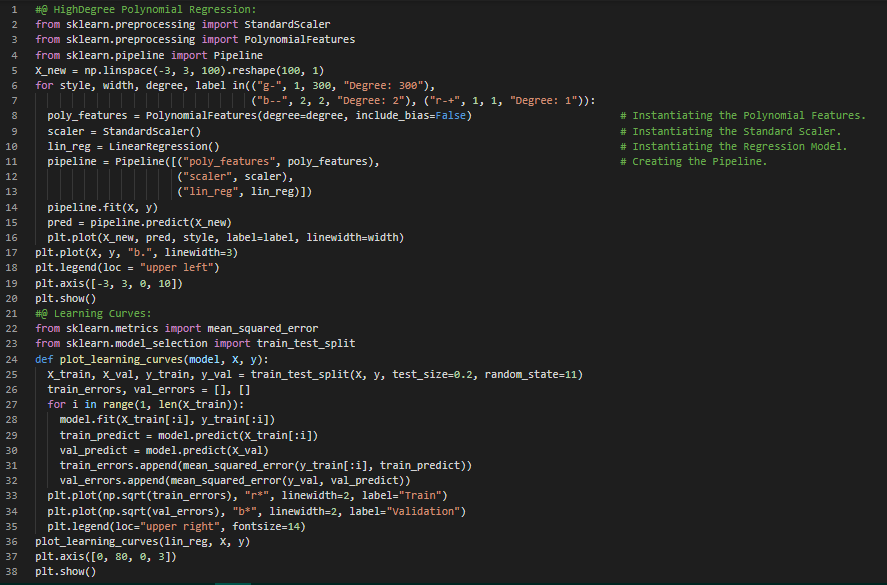
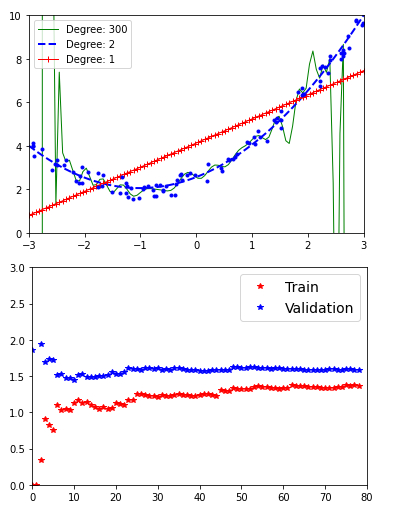
- 岭回归:岭回归是一种正则化的线性回归方法,即在损失函数中加入一个正则化项,迫使学习算法不仅拟合数据,还要尽可能地使模型权重保持较小。在我的机器学习和深度学习之旅中,今天我阅读并实践了模型训练、线性回归、正规方程及其计算复杂度、损失函数与梯度下降(包括批量梯度下降、收敛速度、随机梯度下降、小批量梯度下降)、多项式回归及多项式特征、学习曲线、偏差与方差的权衡、正则化线性模型(如岭回归)等内容,这些内容同样来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了多项式回归、学习曲线和岭回归的实现,并用Python进行了可视化。希望你能花些时间去实践这些内容,并阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
300天数据之旅第17天!
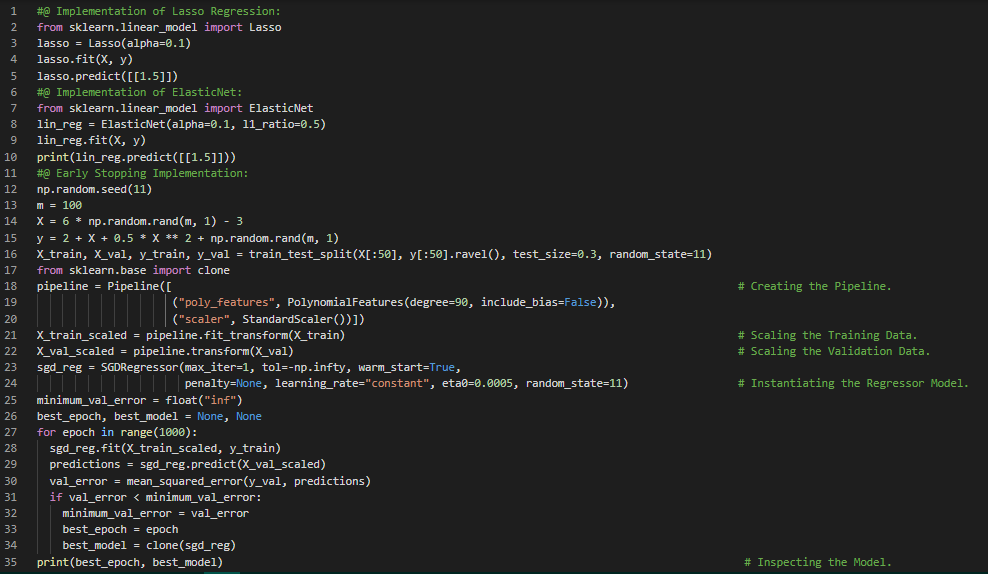
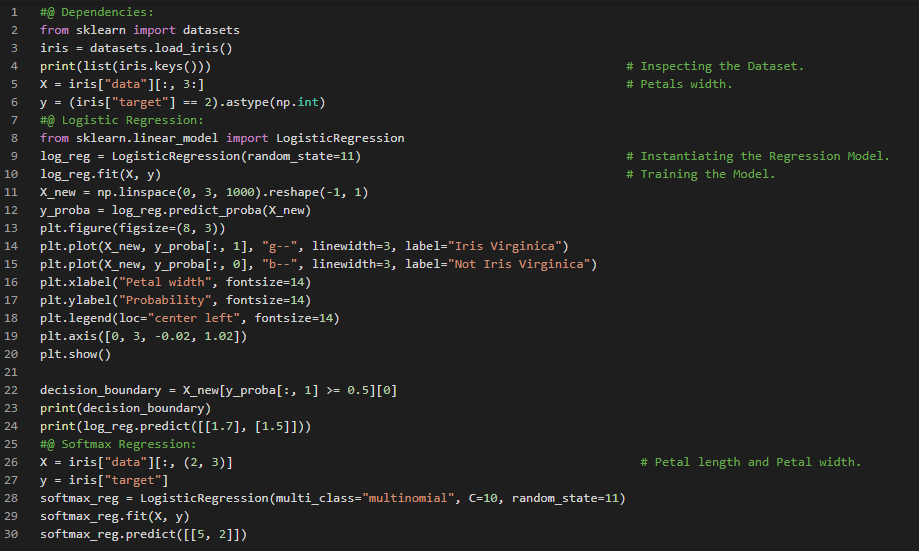
- 弹性网络:弹性网络介于岭回归和Lasso回归之间。其正则化项r是岭回归和Lasso回归正则化项的简单混合。当r等于0时,它等同于岭回归;当r等于1时,它等同于Lasso回归。在我的机器学习和深度学习之旅中,今天我阅读并实践了Lasso回归、弹性网络、早停法、SGD回归器、逻辑回归、概率估计、训练与损失函数、Sigmoid函数、决策边界、Softmax回归或多项式逻辑回归、交叉熵等相关主题,内容均来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我刚刚开始阅读支持向量机这一主题。我在截图中展示了使用Scikit-Learn实现的Lasso回归、弹性网络、早停法、逻辑回归和Softmax回归的简单代码。希望你能花些时间去实践这些内容,并阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
300天数据之旅第18天!
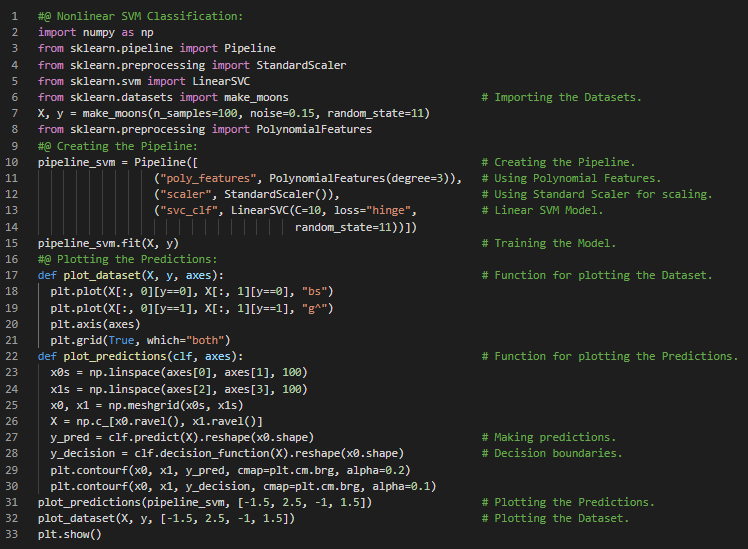
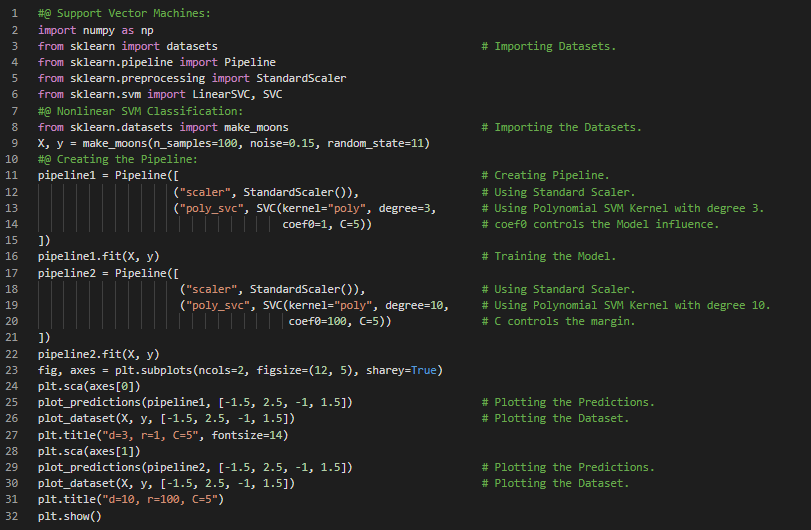
- 支持向量机:支持向量机(SVM)是一种功能强大且用途广泛的机器学习模型,能够执行线性和非线性分类、回归,甚至异常值检测。SVM特别适合处理复杂但规模中等的数据集的分类任务。在我的机器学习和深度学习之旅中,今天我阅读并实践了支持向量机、线性SVM分类、软间隔分类、非线性SVM分类、多项式回归、多项式核、添加相似性特征、高斯RBF核、计算复杂度、SVM回归(包括线性和非线性)等相关内容,这些内容同样来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了使用SVC和Linear SVC实现的非线性SVM分类,并用Python进行了可视化。希望你能花些时间去实践这些内容,并阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
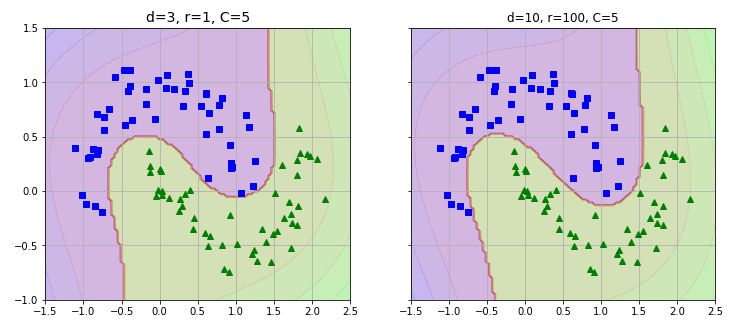
300天数据之旅第19天!
- 投票分类器:投票分类器是指将多个不同分类器的预测结果进行集成,最终以得票最多的类别作为预测结果的分类器。其中,多数投票的分类器称为硬投票分类器。在我的机器学习和深度学习之旅中,今天我阅读并实践了集成学习与随机森林、投票分类器(包括硬投票和软投票分类器)等相关内容。实际上,我也已经和一支优秀的团队一起开始了研究项目。我在截图中展示了使用Scikit-Learn实现的硬投票和软投票分类器的代码。希望你能花些时间去实践这些内容,并阅读上述主题。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
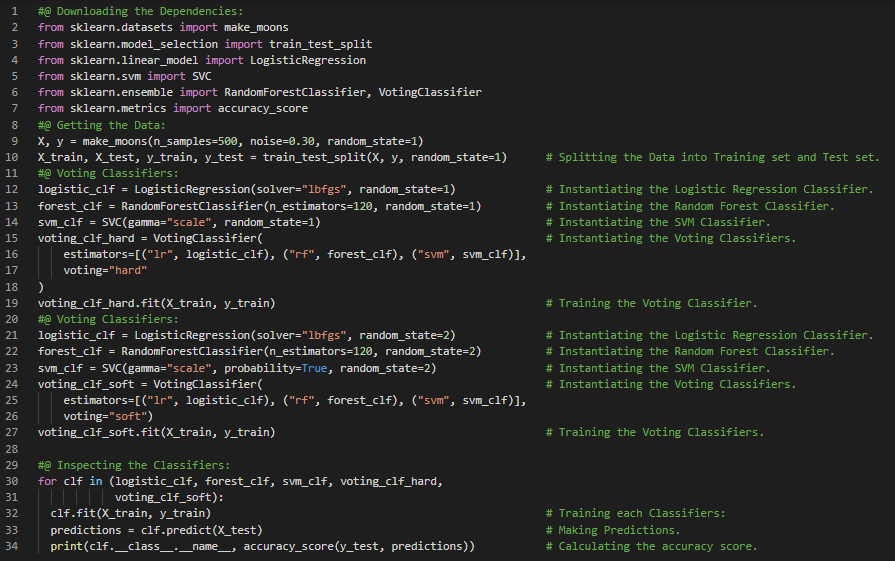
300天数据之旅第20天!
- CART训练算法:这是Scikit Learn中用于实现分类与回归树(CART)训练算法的实现,用来训练决策树,也称为生长树。其工作原理是利用某个特征和阈值将训练集划分为两个子集。在我的机器学习和深度学习之旅中,今天我阅读并实践了关于决策函数与预测、决策树、决策树分类器、做出预测、基尼不纯度、白盒模型与黑盒模型、类别概率估计、CART训练算法、计算复杂度、熵、正则化超参数、决策树回归器、损失函数以及不稳定性等内容,这些内容均来自书籍《使用Scikit Learn、Keras和TensorFlow动手学机器学习》。我在这里通过Python实现了决策树分类器和决策树回归器的简单应用,并进行了可视化展示。希望大家也能花些时间动手实践,并阅读上述主题及书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手学机器学习》
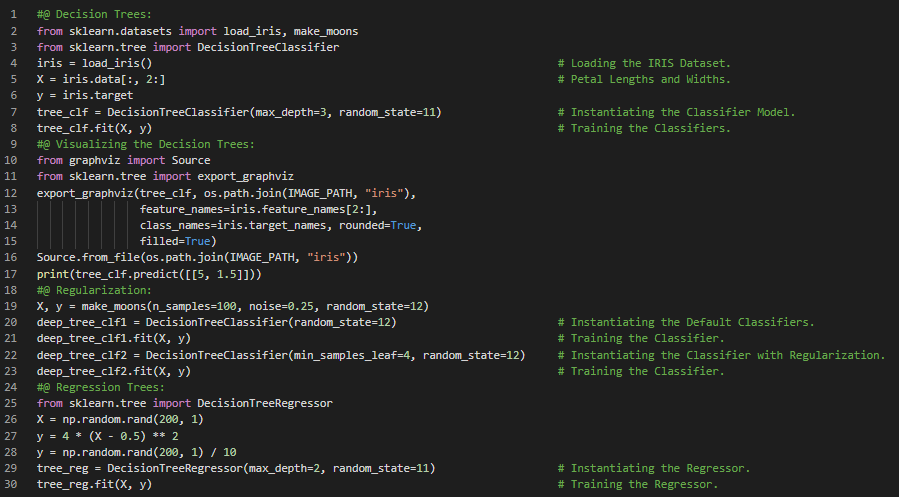
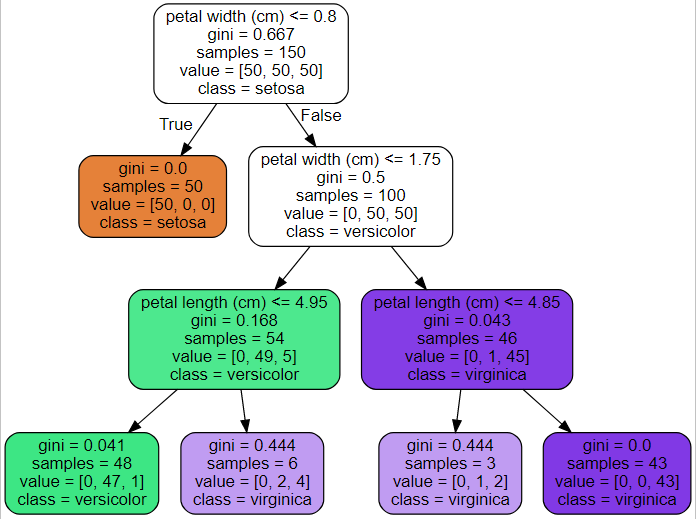
300天数据之旅第21天!
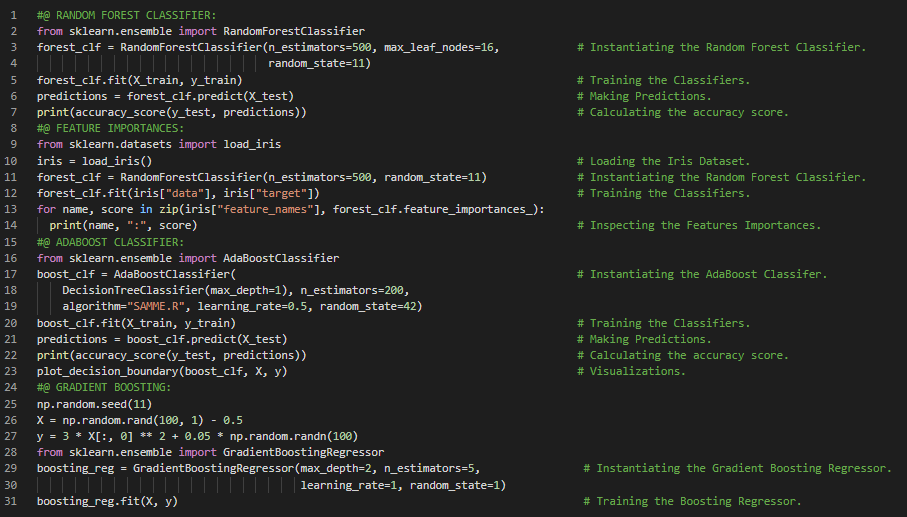
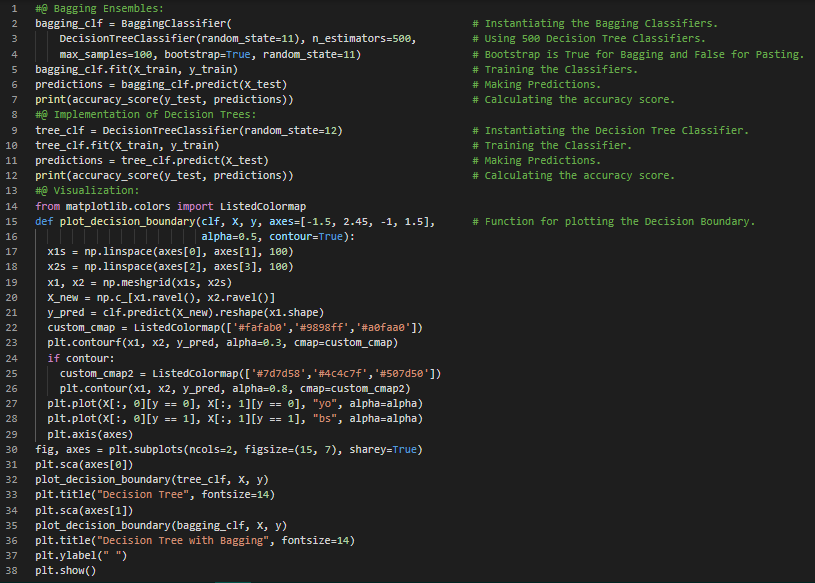
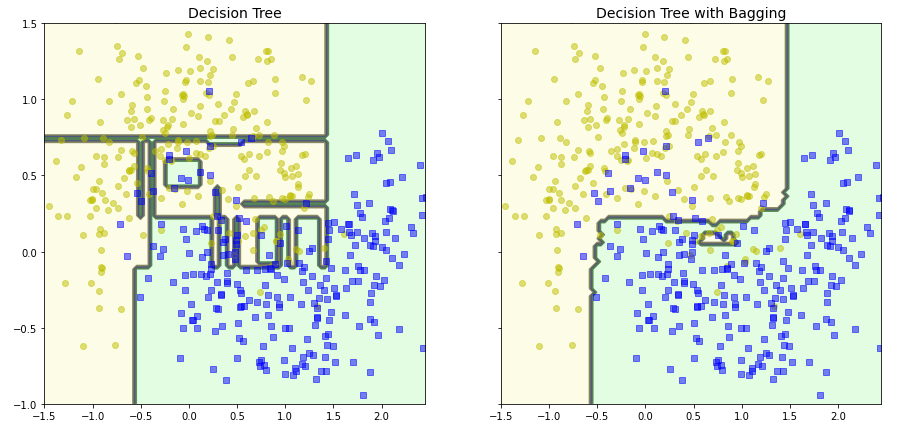
- Bagging与Pasting:这是一种方法,它对每个预测器使用相同的训练算法,但在训练时会从训练集中抽取不同的随机子集。如果抽样是有放回的,则称为Bagging;如果是无放回的,则称为Pasting。在我的机器学习和深度学习之旅中,今天我阅读并实践了关于集成学习与随机森林、投票分类器、Scikit Learn中的Bagging与Pasting、袋外评估、随机补丁与随机子空间、随机森林、极端随机树集成、特征重要性、提升方法、AdaBoost、梯度提升等主题,这些内容同样来自书籍《使用Scikit Learn、Keras和TensorFlow动手学机器学习》。我在这里通过Python实现了Bagging集成、决策树、随机森林分类器、特征重要性、AdaBoost分类器以及梯度提升,并附上了截图。希望大家也能花些时间动手实践,并阅读上述主题及书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手学机器学习》
300天数据之旅第22天!
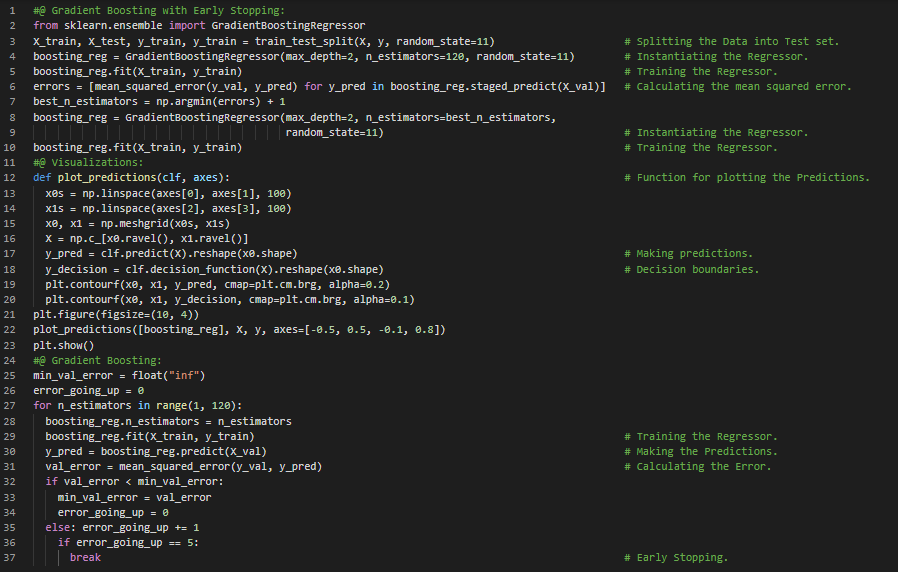
- 流形学习:流形学习是指一类降维算法,它们通过建模训练样本所处的流形来工作,这依赖于流形假设——即大多数现实世界中的高维数据集实际上位于一个低得多的维数流形上。在我的机器学习和深度学习之旅中,今天我阅读并实践了关于梯度提升、早停法、随机梯度提升、极端梯度提升(XGBoost)、堆叠与融合、降维、维度灾难、降维方法、投影与流形学习等内容,这些内容同样来自书籍《使用Scikit Learn、Keras和TensorFlow动手学机器学习》。我在这里通过Scikit Learn实现了带有早停法的梯度提升,并进行了可视化展示。希望大家也能花些时间动手实践,并阅读上述主题及书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手学机器学习》
300天数据之旅第23天!
- 增量主成分分析:增量PCA或IPCA算法允许我们将训练集拆分成多个小批量,然后每次只输入一个小批量给IPCA算法处理。这种方法对于大型训练集非常有用,同时也适用于在线应用PCA。在我的机器学习和深度学习之旅中,今天我阅读并实践了关于主成分分析(PCA)、保持方差、主成分、降维投影、解释方差比例、选择合适的维度数量、PCA在压缩与解压缩中的应用、重构误差、随机PCA、奇异值分解(SVD)、增量PCA等内容,这些内容均来自书籍《使用Scikit Learn、Keras和TensorFlow动手学机器学习》。我在这里通过Scikit Learn实现了PCA、随机PCA和增量PCA,并附上了相应的可视化图示。希望大家也能花些时间动手实践这些内容,同时阅读上述主题及书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手学机器学习》
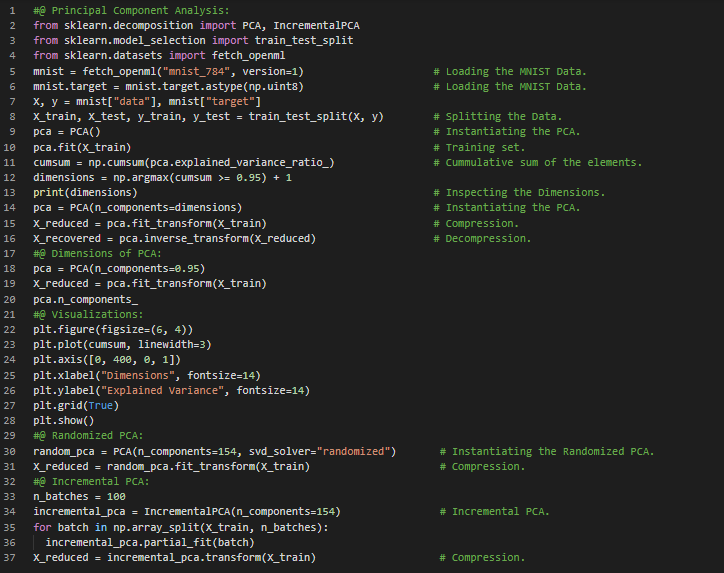
300天数据之旅第24天!
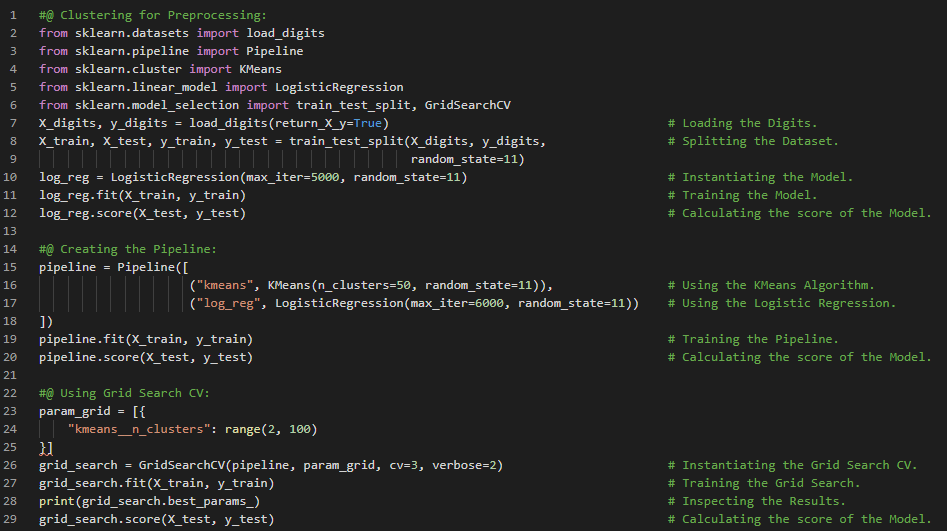
- 聚类:聚类算法的目标是将相似的实例分组到同一个簇中。它是数据分析、客户细分、推荐系统、搜索引擎、图像分割、降维等领域的强大工具。在我的机器学习和深度学习之旅中,今天我阅读并实现了核主成分分析、核函数的选择与超参数调优、管道与网格搜索、局部线性嵌入、多维尺度分析、Isomap和线性判别分析等降维技术,以及无监督学习中的聚类和K均值聚类算法等内容,这些内容均来自《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》一书。我在截图中展示了核PCA、网格搜索交叉验证以及K均值聚类算法的实现,并用Python进行了可视化。希望大家也能花些时间实践这些内容,并阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》
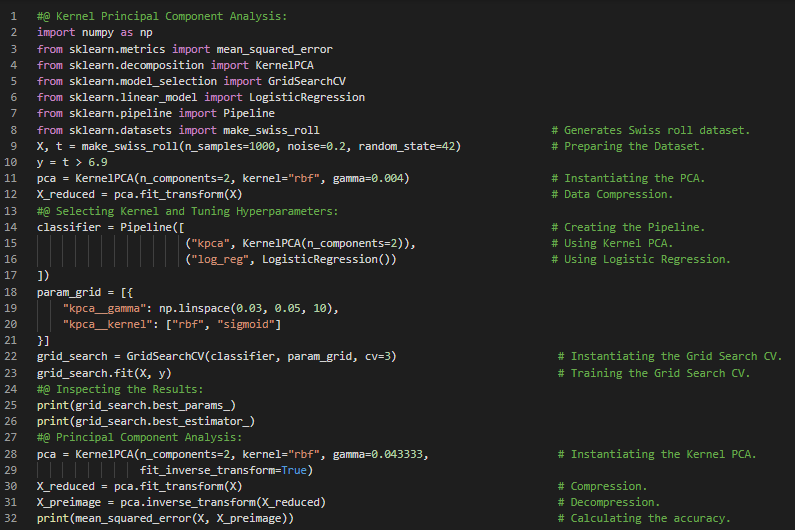
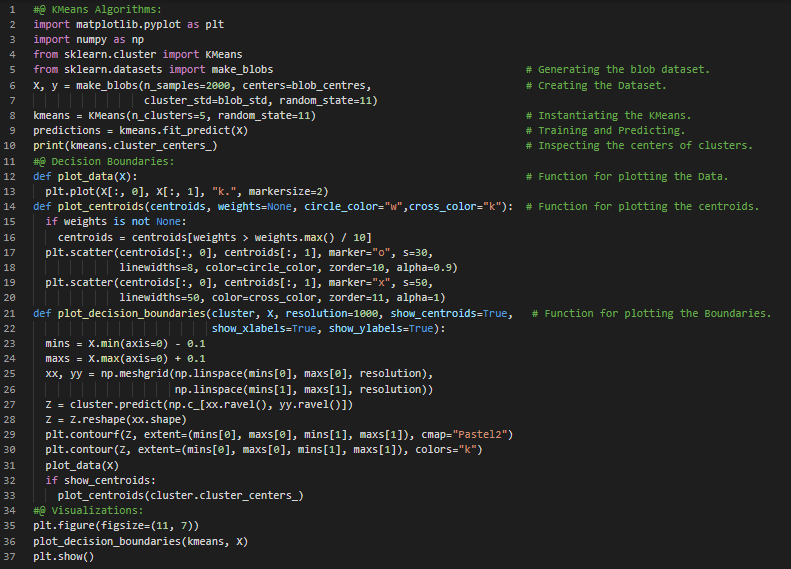
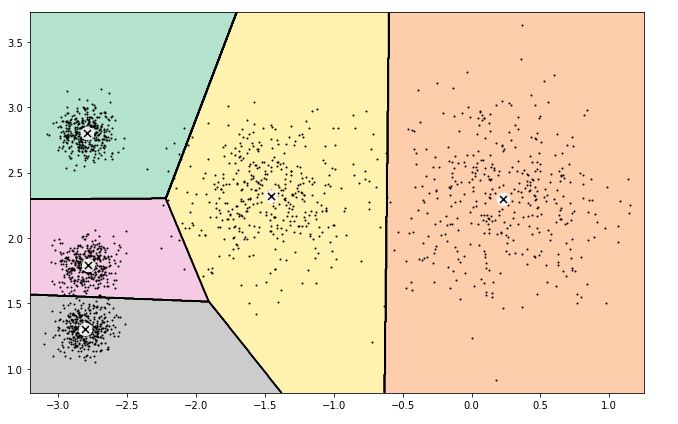
300天数据之旅第25天!
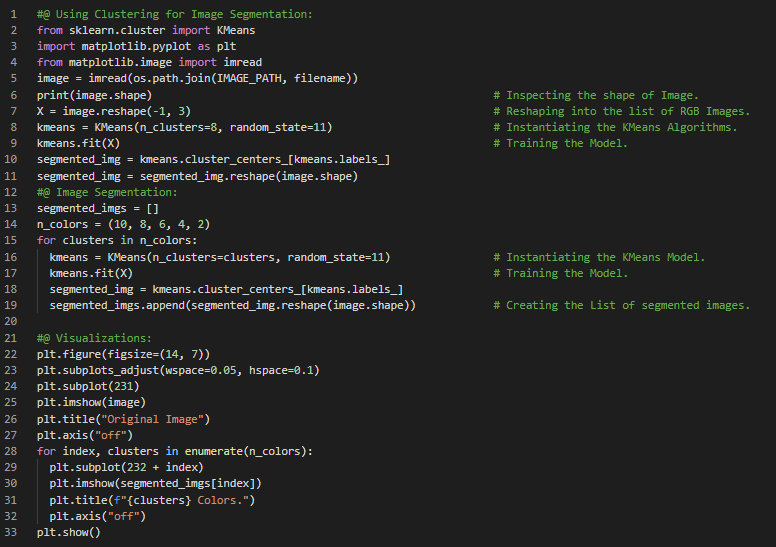
- 图像分割:图像分割是将图像划分为多个区域的任务。在语义分割中,属于同一类对象的所有像素会被分配到同一个区域;而在实例分割中,属于单个对象的所有像素则会被分配到同一个区域。在我的机器学习和深度学习之旅中,今天我阅读并实现了K均值算法、质心初始化、加速版K均值和小批量K均值、寻找最佳簇数(肘部法则与轮廓系数)、K均值的局限性、利用聚类进行图像分割及预处理(如降维)等内容,这些内容同样来自《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》一书。我在截图中展示了用于图像分割和预处理的聚类算法实现,并用Python进行了可视化。希望大家也能花些时间实践这些内容,并阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》

300天数据之旅第26天!
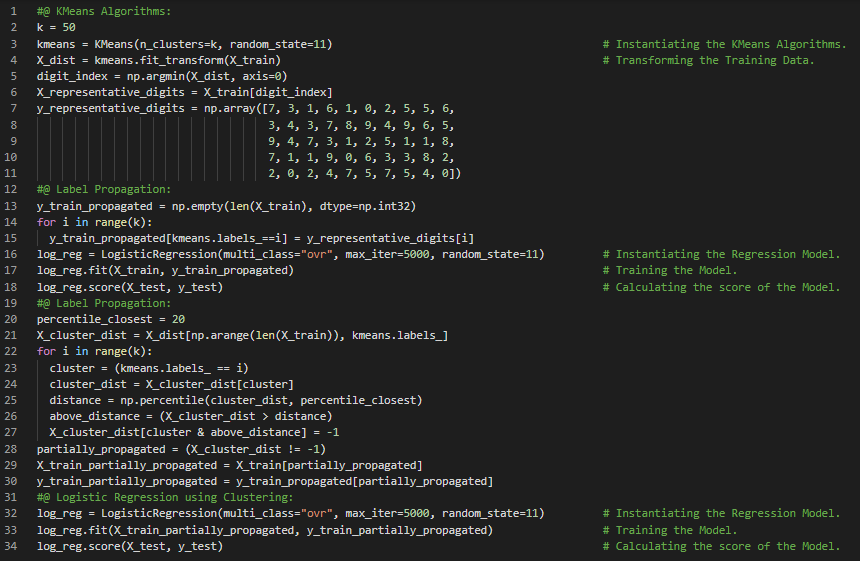
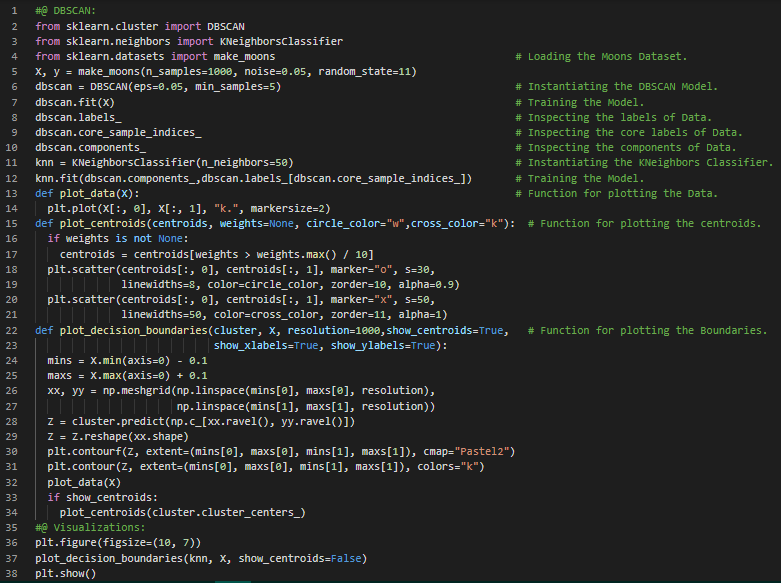
- 高斯混合模型:高斯混合模型是一种概率模型,它假设数据是由多个未知参数的高斯分布混合生成的。每个由单一高斯分布生成的数据点会形成一个通常呈椭球形的簇。在我的机器学习和深度学习之旅中,今天我阅读并实现了利用聚类算法进行半监督学习、主动学习与不确定性采样、DBSCAN、凝聚聚类、BIRCH算法、均值漂移与亲和力传播算法、谱聚类、高斯混合模型、期望最大化算法等内容,这些内容均来自《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》一书。我在截图中展示了用于半监督学习和DBSCAN的聚类算法实现,并用Python进行了可视化。希望大家也能花些时间实践这些内容,并阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》
300天数据之旅第27天!
- 异常检测:异常检测又称离群点检测,是指识别那些严重偏离正常模式的实例。这些偏离正常模式的实例被称为异常或离群点,而正常的实例则称为内点。异常检测在欺诈检测等领域非常有用。在我的机器学习和深度学习之旅中,今天我阅读并实现了高斯混合模型、基于高斯混合模型的异常检测、新奇性检测、簇数的选择、贝叶斯信息准则、赤池信息准则、似然函数、贝叶斯高斯混合模型、快速MCD、孤立森林、局部离群因子、一类支持向量机等内容,这些内容同样来自《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》一书。我刚刚开始从这本书中学习神经网络和深度学习。我在截图中展示了高斯混合模型的实现,并用Python进行了可视化。希望大家也能花些时间实践这些内容,并阅读上述主题和书籍。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit Learn、Keras和TensorFlow动手实践机器学习》
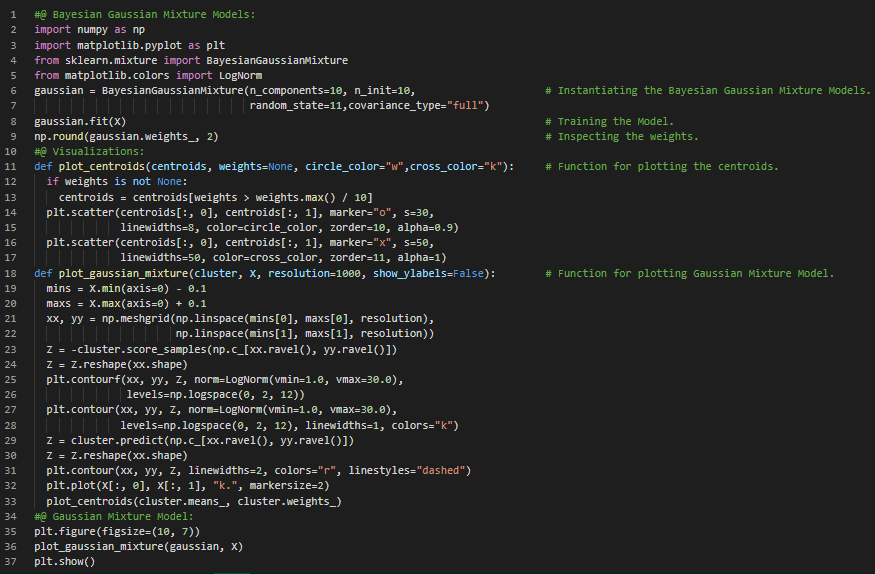
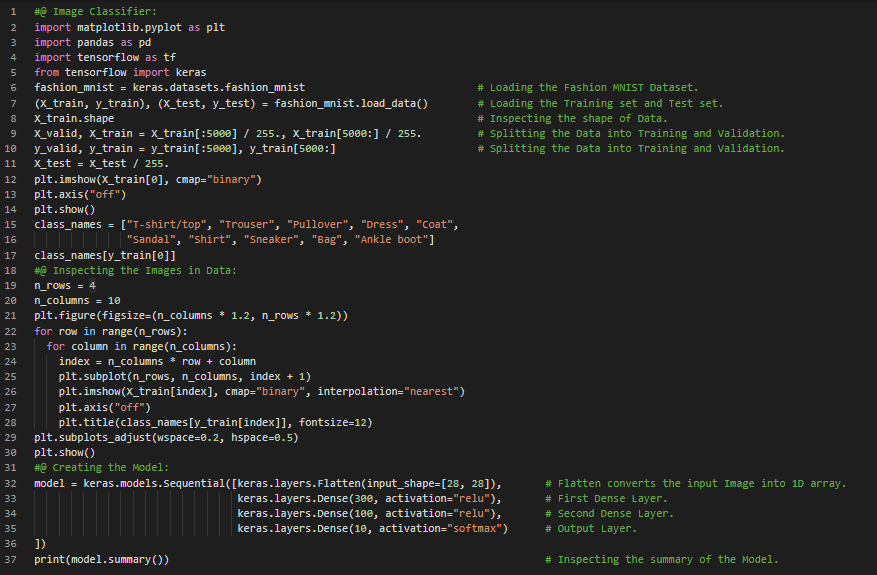
300天数据之旅第28天!
- 修正线性单元函数或ReLU:它是一个连续函数,但在0点处不可导,因为斜率在此处发生突变,导致梯度下降法在该点附近来回震荡。尽管如此,ReLU表现非常好,并且计算速度快。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书中关于人工神经网络简介、生物神经元、神经元的逻辑运算、感知机、赫布学习、多层感知机与反向传播、梯度下降、双曲正切函数和修正线性单元函数、回归型MLP、分类型MLP、Softmax激活函数等内容。我在快照中展示了使用Sequential API构建图像分类器的实现,并结合Keras进行了可视化。希望大家也能花些时间动手实践这些内容,并阅读上述书籍及相关主题。我对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
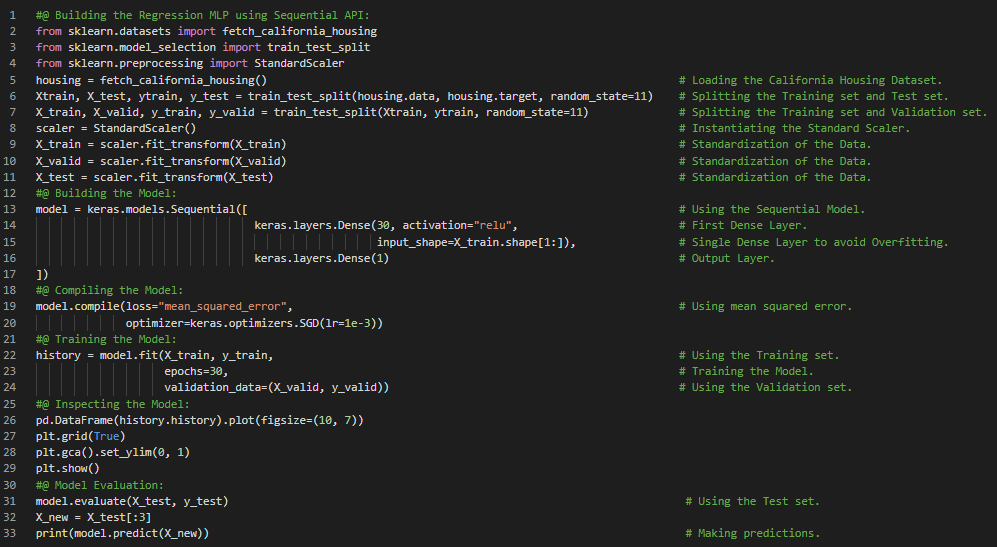
300天数据之旅第29天!
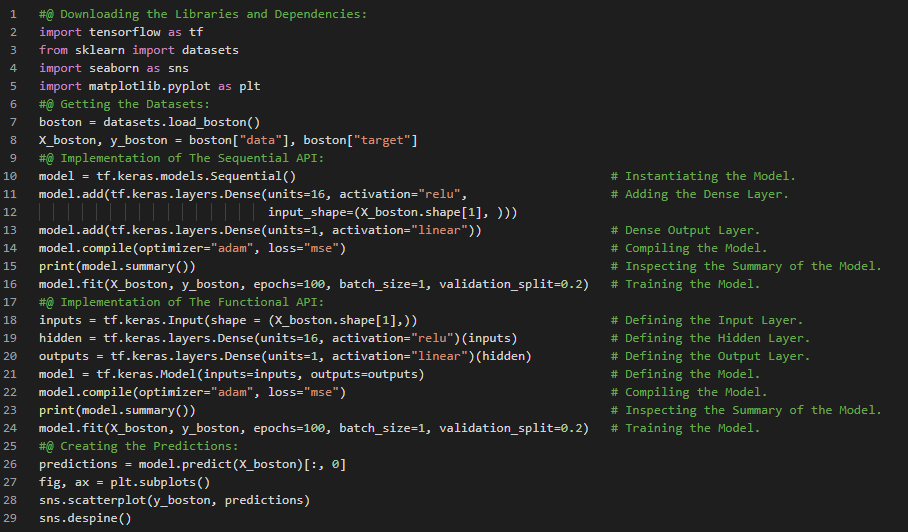
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书中关于使用Sequential API创建模型、编译模型、损失函数与激活函数、训练与评估模型、学习曲线、利用模型进行预测、使用Sequential API构建回归型MLP、使用Functional API构建复杂模型、深度神经网络等内容。我在快照中展示了使用Sequential API和Functional API构建回归型MLP的实现。希望大家能从中获得一些启发,并花时间动手实践。同时,也建议大家抽出时间阅读并实践上述书籍中的相关内容。我对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
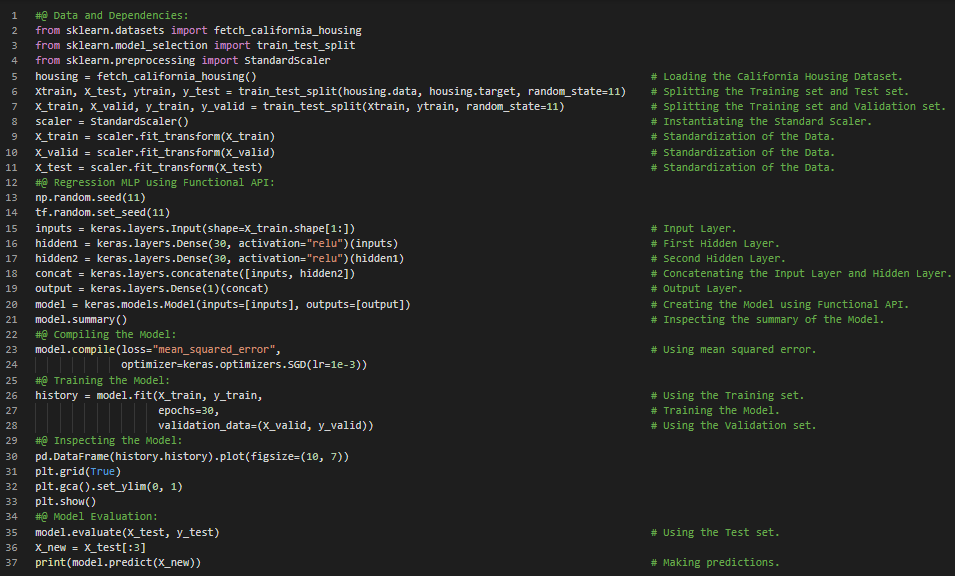
300天数据之旅第30天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书中关于使用Functional API构建复杂模型、深度神经网络架构、ReLU激活函数、处理模型中的多个输入、均方误差损失函数和随机梯度下降优化器、处理多个输出或用于正则化的辅助输出等内容。我在快照中展示了使用Keras Functional API处理多个输入,以及使用相同方法处理多个输出或用于正则化的辅助输出的实现。希望大家能从中获得一些见解,并加以实践。同时也建议大家花些时间阅读上述及下方提到的书籍中的相关内容。我对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
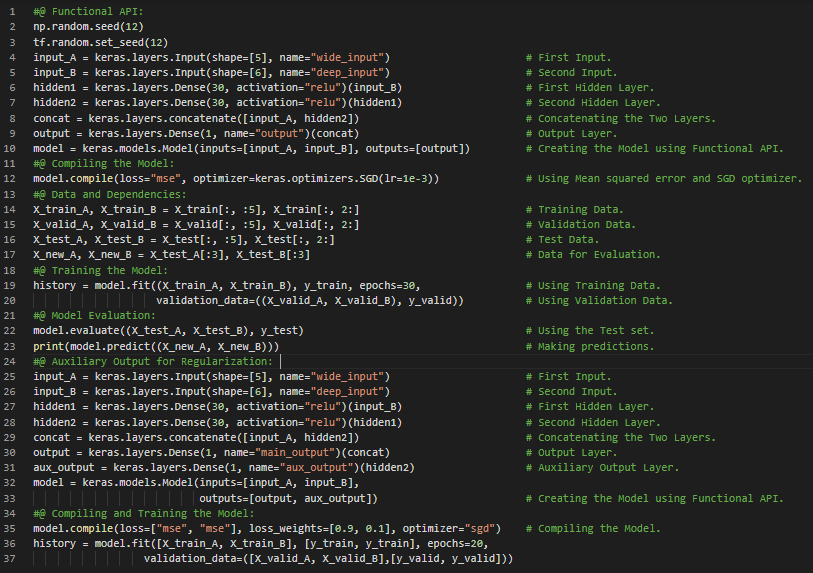
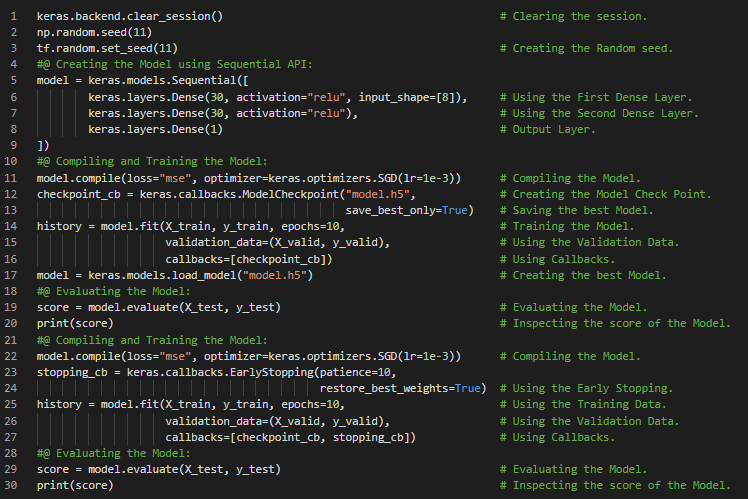
300天数据之旅第31天!
- 回调与早停:早停是一种方法,允许你指定任意数量的训练轮次,一旦模型在验证集上的表现不再提升,便会自动停止训练。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书中关于使用子类化API、Sequential API和Functional API构建动态模型、保存与恢复模型、使用回调、模型检查点、早停、Weights & Biases等内容。我在快照中展示了使用子类化API构建动态模型,以及使用回调和早停的实现。希望大家能从中获得一些启发,并加以实践。同时也建议大家花些时间阅读上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
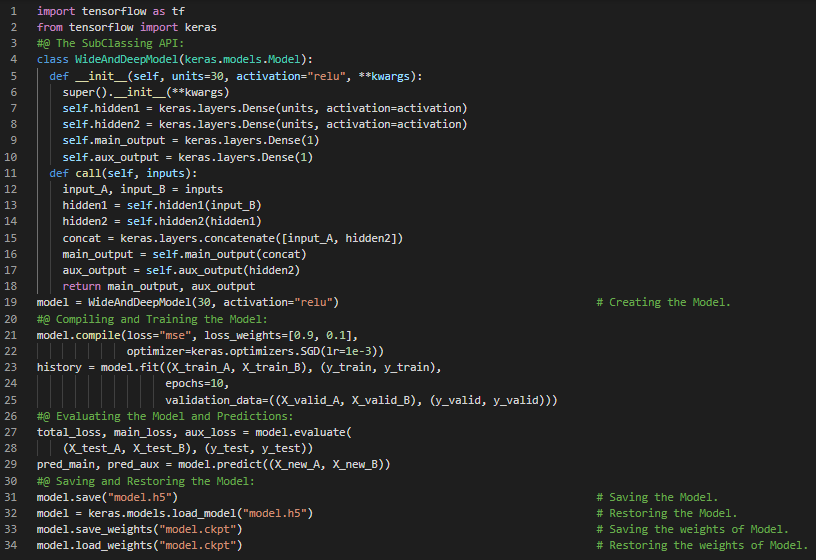
300天数据之旅第32天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》一书中关于使用TensorBoard进行可视化、学习曲线、微调神经网络超参数、随机搜索交叉验证、回归器、用于优化超参数的库如Hyperopt、Talos等、隐藏层数量、每层隐藏神经元数量、学习率、批量大小及其他超参数等内容。此外,我还花了一段时间阅读了一篇名为《基于梯度的深度架构训练实用建议》的论文。在这篇文章中,我了解了深度学习与贪心式逐层预训练、在线学习以及泛化误差的优化等相关内容。我在快照中展示了超参数调优、Keras回归器和随机搜索交叉验证的实现。希望大家能从中获得一些启发,并加以实践。同时也建议大家花些时间阅读上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Scikit-Learn、Keras和TensorFlow动手学机器学习》
- 论文:
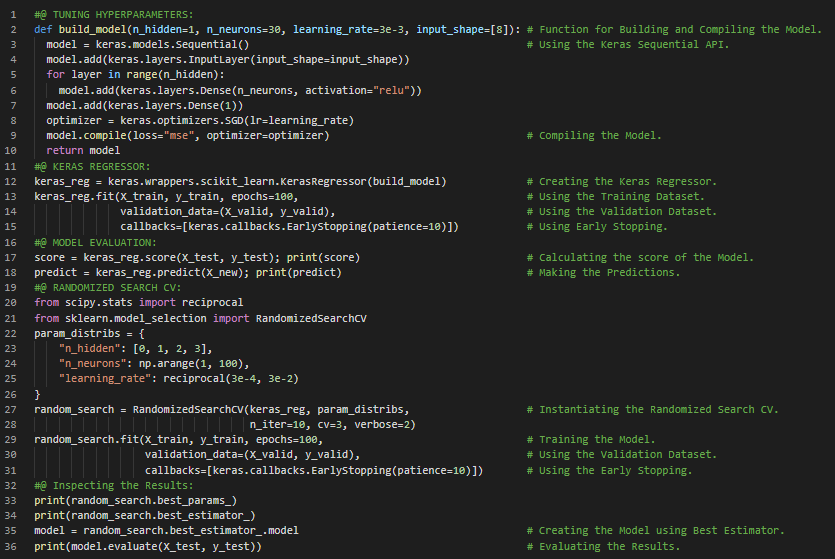
300天数据之旅第33天!
- 梯度消失问题:在反向传播和计算梯度的过程中,随着算法不断向深层传递,梯度往往会越来越小,从而阻碍训练收敛到较好的解。这便导致了梯度消失问题。在我的机器学习与深度学习学习旅程中,今天我阅读并实践了深度神经网络的训练、梯度消失与爆炸问题、Glorot和He初始化、非饱和激活函数、批量归一化及其实现、逻辑斯谛与Sigmoid激活函数、SELU激活函数、ReLU激活函数及其变体、Leaky ReLU和参数化Leaky ReLU等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了Leaky ReLU和批量归一化的实现。希望你能从中获得一些启发,并进一步实践。也建议你花些时间阅读上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
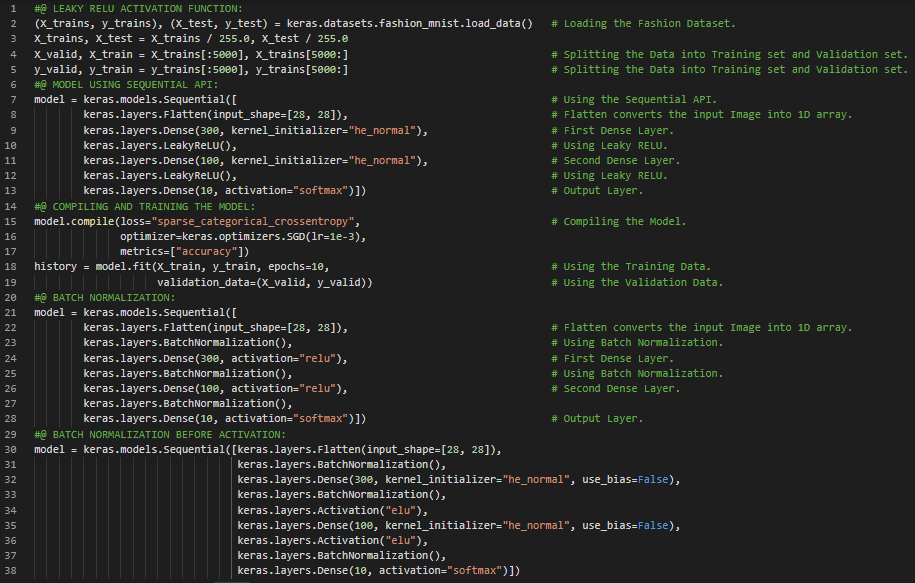
300天数据之旅第34天!
- 梯度裁剪:梯度裁剪是一种缓解梯度爆炸问题的技术,它通过在反向传播过程中对梯度进行裁剪,使其不超过某个阈值,通常用于循环神经网络中。在我的机器学习与深度学习学习旅程中,今天我阅读并实践了梯度裁剪、批量归一化、复用预训练层、深度神经网络与迁移学习、无监督预训练、受限玻尔兹曼机、辅助任务上的预训练、自监督学习、更快的优化器、梯度下降优化器、动量优化、Nesterov加速梯度等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了使用Keras和Sequential API进行迁移学习的简单实现。希望你能从中获得一些启发,并进一步实践。也建议你花些时间阅读上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
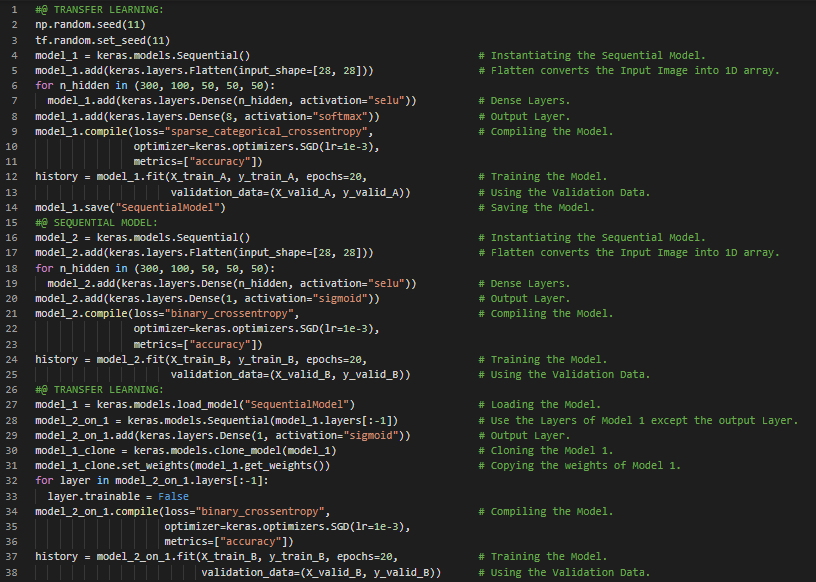
300天数据之旅第35天!
- Adam优化器:Adam即自适应矩估计,结合了动量优化和RMSProp的思想——动量优化会跟踪过去梯度的指数衰减平均值,而RMSProp则跟踪过去平方梯度的指数衰减平均值。在我的机器学习与深度学习学习旅程中,今天我阅读并实践了AdaGrad算法、梯度下降法、RMSProp算法、自适应矩估计(即Adam优化器)、Adamax、Nadam优化、稀疏模型的训练、双重平均法、学习率调度、幂次调度、指数调度、分段常数调度、性能调度等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了指数调度和分段常数调度的实现。希望你能从中获得一些启发,并进一步实践。也建议你花些时间阅读上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
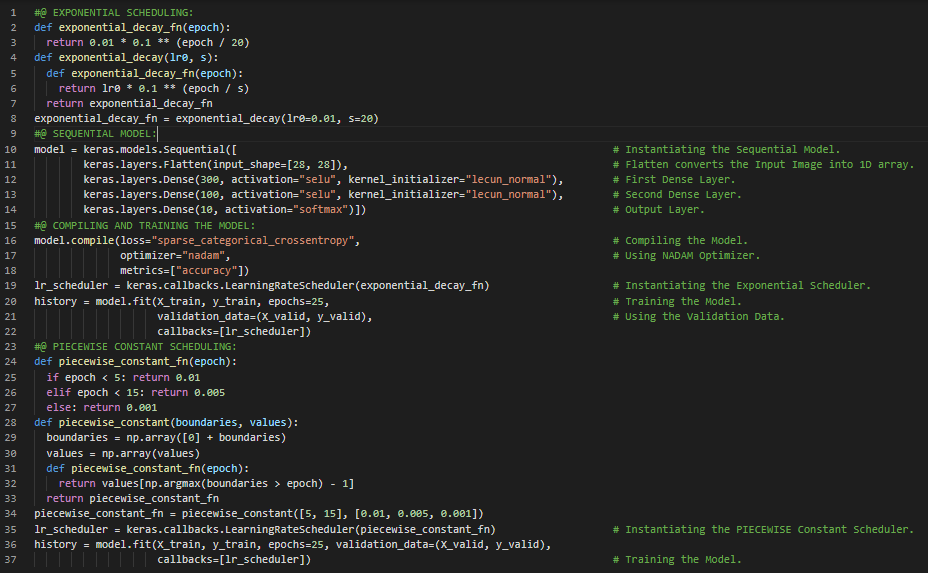
300天数据之旅第36天!
- 深度神经网络:在大多数情况下无需过多超参数调优即可良好工作的最佳深度神经网络配置如下:卷积核初始化采用LeCun初始化,激活函数选用SELU,不进行归一化处理,使用早停法作为正则化手段,优化器选择Nadam,学习率调度采用性能调度。在我的机器学习与深度学习学习旅程中,今天我阅读并实践了通过正则化避免过拟合、L1和L2正则化、Dropout正则化、自归一化、批量归一化、蒙特卡洛Dropout、最大范数正则化、SELU和Leaky ReLU等激活函数、Nadam优化等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了使用Keras实现L2正则化和Dropout正则化的代码。希望你能从中获得一些启发,并进一步实践。也建议你花些时间阅读上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
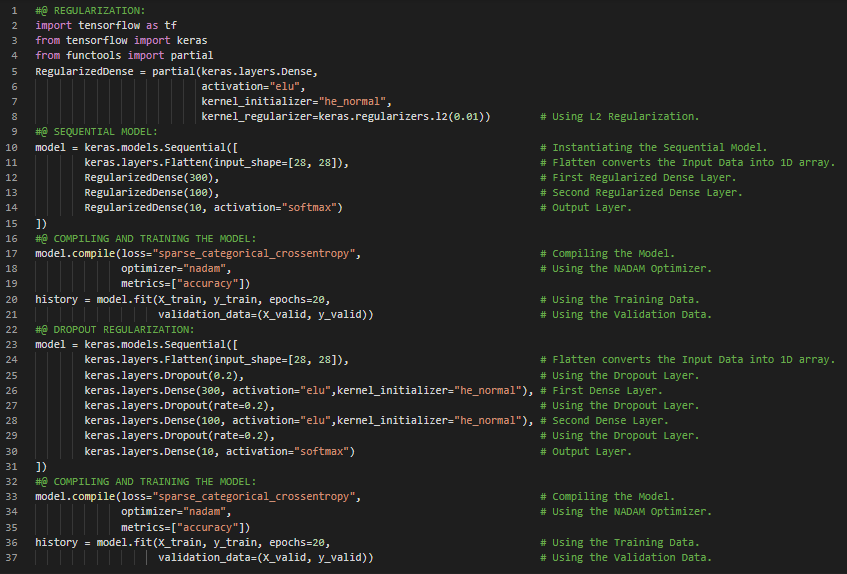
300天数据之旅第37天!
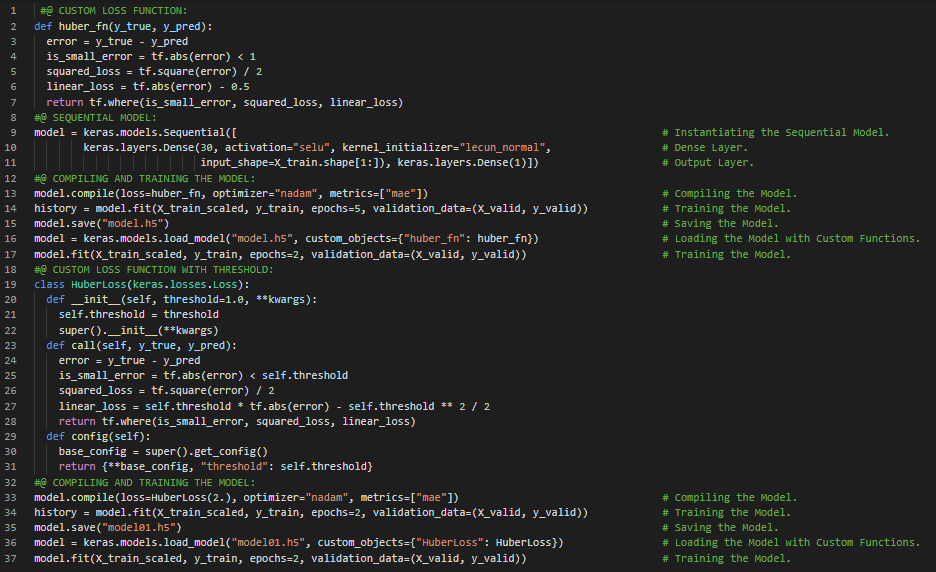
- 在我的机器学习与深度学习学习旅程中,今天我阅读并实践了使用TensorFlow自定义模型及训练、高级深度学习API、输入输出与预处理、低级深度学习API、部署与优化、TensorFlow架构、张量与运算、Keras低级API、张量与NumPy、稀疏张量、数组、字符串张量、自定义损失函数、保存与加载包含自定义组件的模型等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。此外,我还开始阅读《语音与语言处理》一书。书中涉及正则表达式、文本标准化、分词、词形还原、词干提取、句子分割、编辑距离等内容。我在截图中展示了自定义损失函数的简单实现。希望你也花些时间阅读上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
- 《语音与语言处理》链接
300天数据之旅第38天!
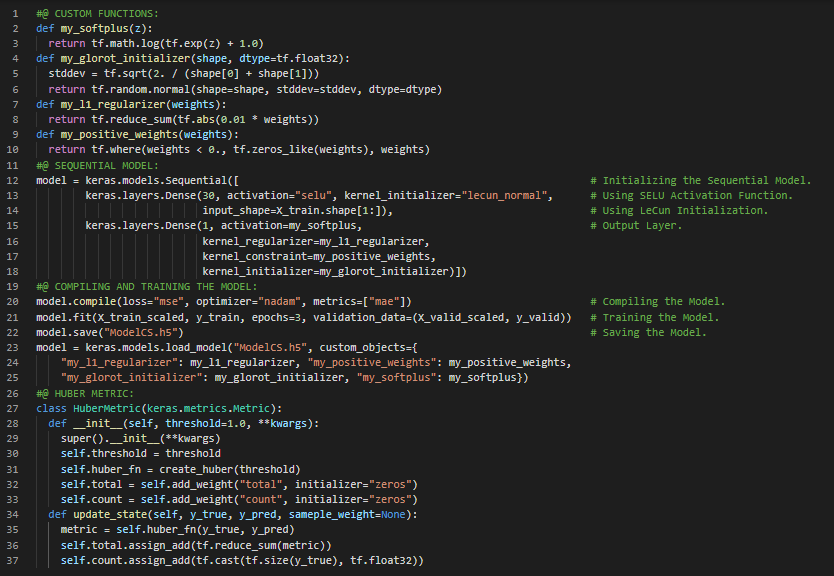
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了自定义激活函数、初始化器、正则化器与约束条件、自定义指标、MAE和MSE、流式指标、自定义层、自定义模型、基于模型内部机制的损失函数与指标,以及《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书中与此相关的其他主题。此外,我还开始阅读《语音与语言处理》这本书。在这一部分,我学习了正则表达式、基本正则表达式模式、或运算、范围、克莱尼星号、通配符表达式、分组与优先级、运算符层级、贪婪匹配与非贪婪匹配、序列与锚点、计数器等主题。我在截图中展示了自定义激活函数、初始化器、正则化器、约束条件和自定义指标的实现。希望你也花些时间阅读上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
- 《语音与语言处理》(链接)
300天数据之旅第39天!
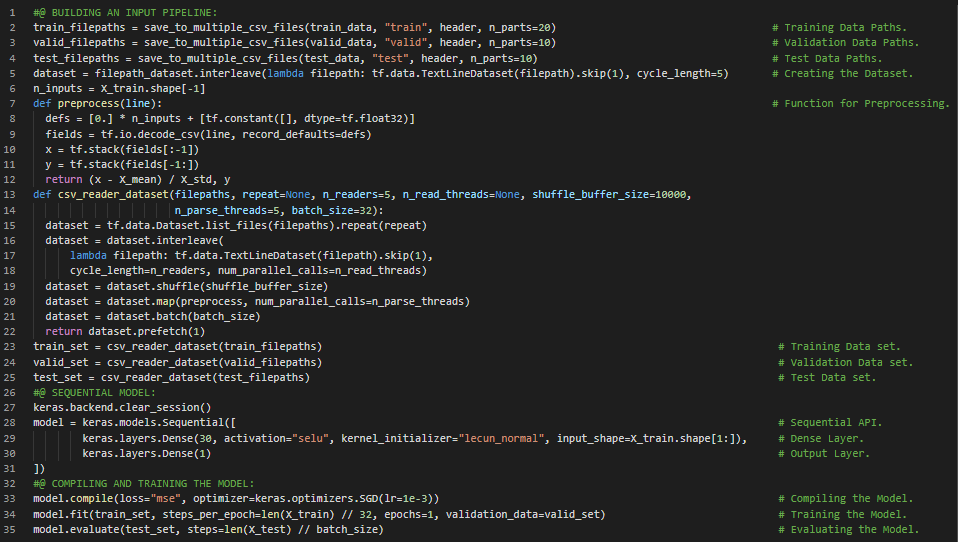
- 预取与数据API:预取是指在资源被需要之前就将其加载,以减少等待该资源的时间。换句话说,当训练算法正在处理一个批次时,数据集会同时并行准备下一个批次,从而显著提升性能。在我的机器学习和深度学习之旅中,今天我阅读并实践了使用TensorFlow加载和预处理数据、数据API、转换链式操作、数据集打乱、梯度下降、多文件行间交错、并行处理、数据集预处理、解码、预取、多线程等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了使用TensorFlow实现数据API的简单示例。希望你能从中获得一些启发,并进一步实践。也希望大家能抽出时间阅读上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
300天数据之旅第40天!
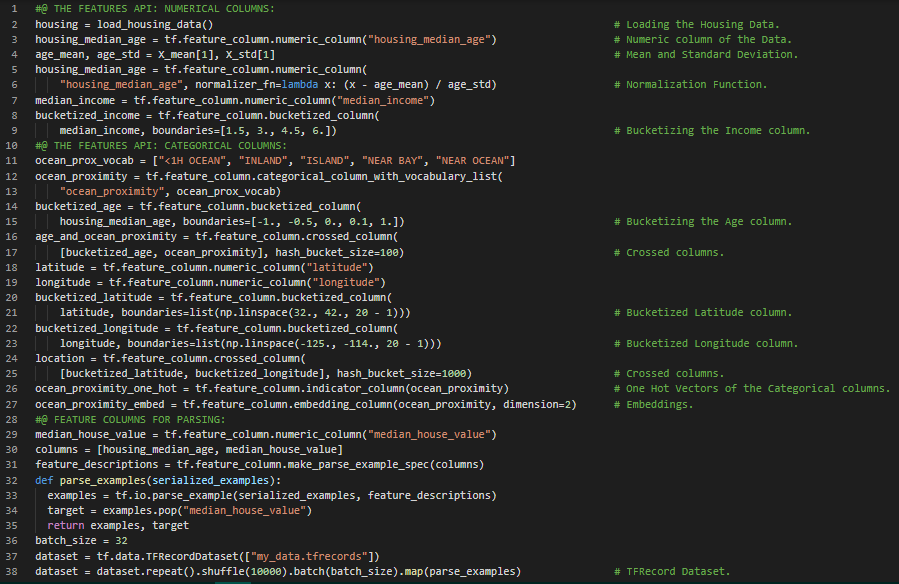
- 嵌入与表示学习:嵌入是一个可训练的稠密向量,用于表示某个类别。类别的表示越准确,神经网络就越容易做出精确的预测,因此嵌入必须能够有效地表示各类别。这被称为表示学习。在我的机器学习和深度学习之旅中,今天我阅读并实践了特征API、列变换器、数值与类别特征、交叉类别特征、使用独热编码和嵌入进行类别特征编码、表示学习、词嵌入、使用特征列进行解析、在模型中使用特征列等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了在数值和类别列中使用特征API进行解析的简单实现。希望你也花些时间阅读上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
300天数据之旅第41天!
- 卷积层:卷积神经网络中最关键的构建模块就是卷积层。第一层卷积神经网络中的神经元并非与输入图像的每个像素相连,而只与其感受野内的像素相连。同样地,第二层卷积神经网络中的每个神经元也只与第一层内一个小矩形区域内的神经元相连。在我的机器学习和深度学习之旅中,今天我阅读并实践了使用卷积神经网络进行深度计算机视觉、视觉皮层的结构、卷积层、零填充、滤波器、多特征图堆叠、填充、内存需求、池化层、不变性、卷积神经网络架构等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了卷积神经网络架构的简单实现。希望你能从中获得一些启发,并继续深入研究。也希望你能抽出时间阅读上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
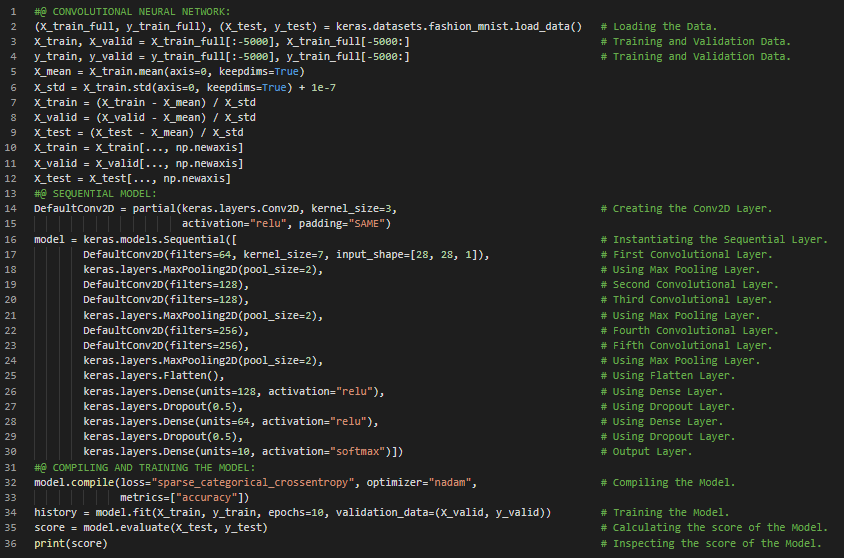
300天数据之旅第42天!
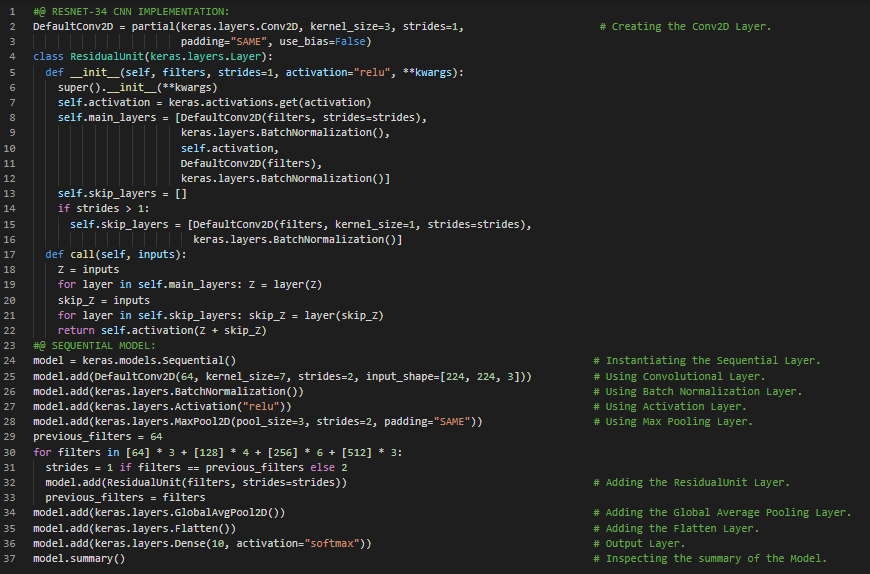
- ResNet模型:残差网络(ResNet)由何凯明开发,凭借一个由152层组成的超深卷积神经网络赢得了2015年ILSVRC挑战赛冠军。该网络使用跳跃连接,也称为捷径连接:输入到某一层的信号也会被加到稍靠上方的一层输出上。在我的机器学习和深度学习之旅中,今天我阅读并实践了LeNet-5架构、AlexNet卷积神经网络架构、数据增强、局部响应归一化、GoogLeNet架构、Inception模块、VGGNet、残差网络(ResNet)、残差学习、Xception或极端Inception、挤压与激励网络(SENet)等内容,这些都来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了使用Keras实现ResNet 34卷积神经网络的过程。希望你能从中获得一些启发,并继续深入研究。也希望你能抽出时间阅读上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
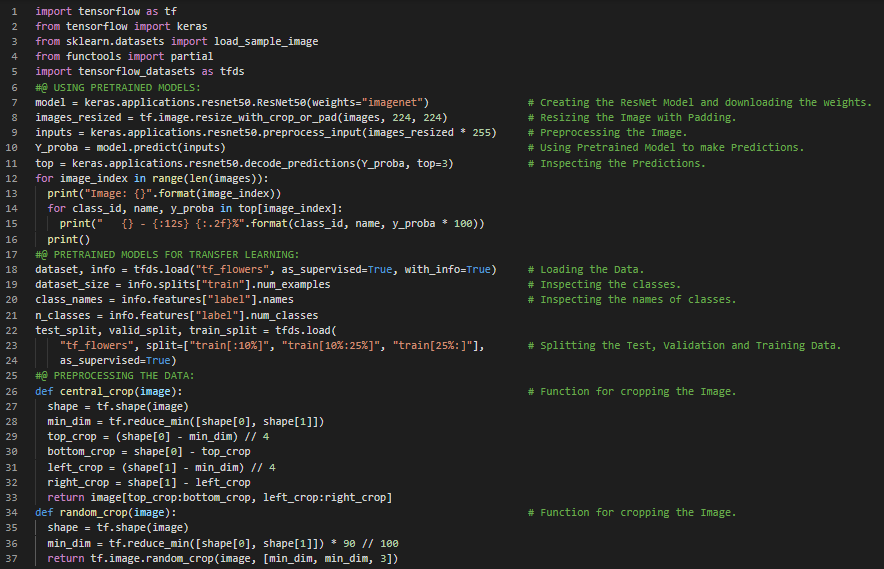
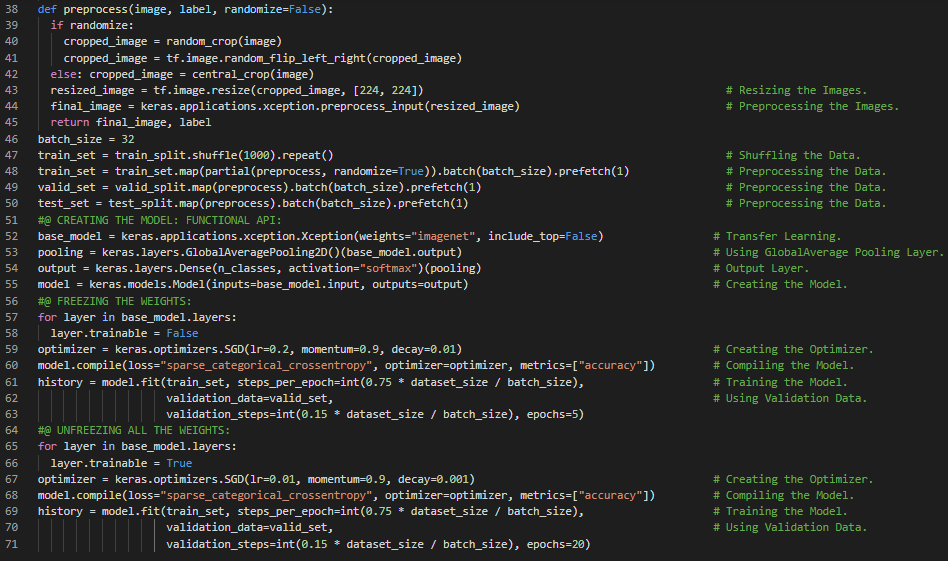
第43天,300天数据之旅!
- Xception模型:Xception是Extreme Inception的缩写,是GoogLeNet架构的一种变体,由François Chollet于2016年提出。它融合了GoogLeNet和ResNet架构的思想,但用一种称为深度可分离卷积的特殊层替换了Inception模块。在我的机器学习和深度学习之旅中,今天我阅读并实践了关于使用Keras中的预训练模型、GoogLeNet和残差网络(ResNet)、ImageNet、用于迁移学习的预训练模型、Xception模型、卷积神经网络、批处理、预取、全局平均池化等内容,这些内容均来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我在截图中展示了ResNet和Xception等预训练模型在迁移学习中的实现。希望你能从中获得一些启发,并进一步深入研究。也希望大家能花些时间阅读上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
第44天,300天数据之旅!
- 语义分割:在语义分割中,每个像素都会根据其所属物体的类别进行分类,但同一类别的不同物体不会被区分开来。在我的机器学习和深度学习之旅中,今天我阅读并实践了关于分类与定位、计算机视觉中的众包、交并比指标、目标检测、全卷积网络(FCN)、VALID填充、YOLO架构、平均精度均值(MAP)、卷积神经网络、语义分割等内容,这些内容均来自《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》一书。我刚刚完成了这本书的学习。我在截图中展示了分类与定位的实现以及相应的可视化效果。希望你能从中获得一些见解,并继续深入研究。也希望大家能花些时间阅读上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学机器学习:使用Scikit-Learn、Keras和TensorFlow》
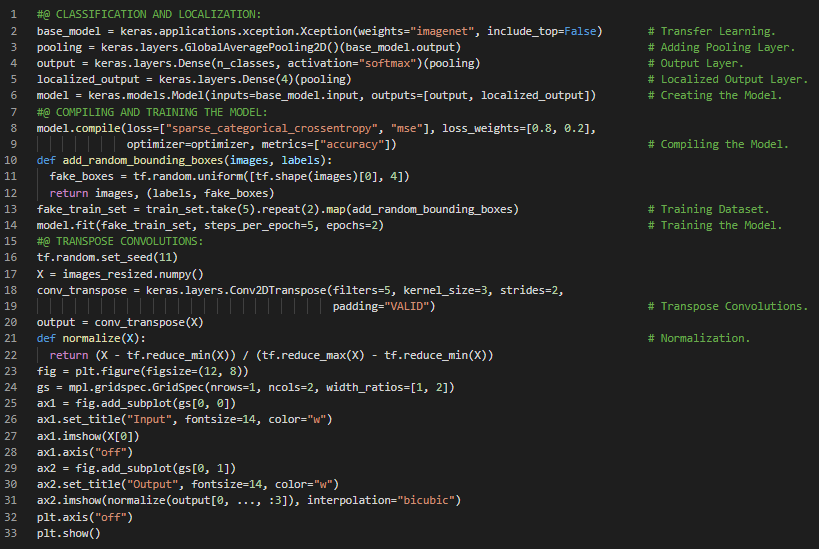

第45天,300天数据之旅!
- 经验风险最小化:训练模型意味着从有标签的样本中学习所有权重和偏置的良好值。在监督学习中,机器学习算法通过检查大量样本,尝试找到一个能够最小化损失的模型,这一过程被称为经验风险最小化。在我的机器学习和深度学习之旅中,今天我开始学习Google的《机器学习速成课程》。在这里,我学习了机器学习哲学、机器学习基础及其应用、标签与特征、有标签与无标签样本、模型与推理、回归与分类、线性回归、权重与偏置、训练与损失、经验风险最小化、均方误差(MSE)、降低损失、梯度下降等内容。我在截图中展示了简单的基本循环神经网络的实现。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习上述及下方提到的课程内容。对接下来的日子充满期待!!
- 课程:
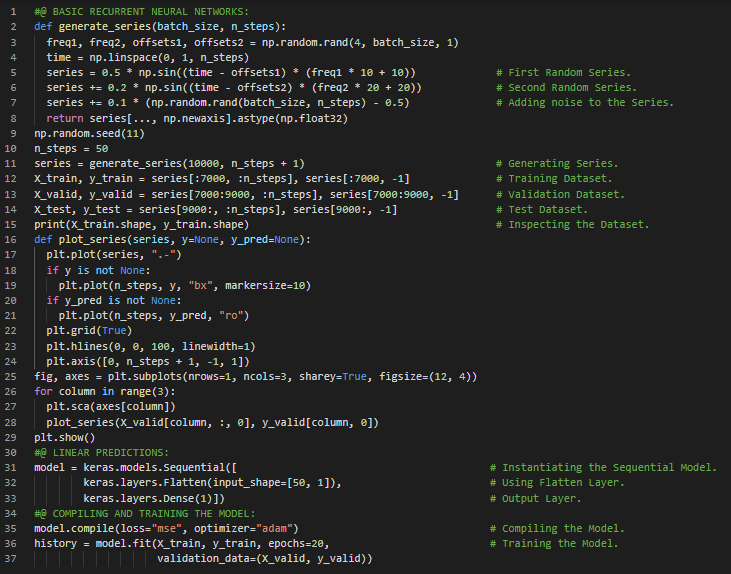
第46天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我继续学习Google的《机器学习速成课程》。在这里,我学习并实践了关于学习率或步长、机器学习算法中的超参数、回归、梯度下降、优化学习率、随机梯度下降(SGD)、批次与批量大小、小批量随机梯度下降、收敛、TensorFlow工具包层次结构等内容。此外,我还花了一些时间阅读《语音与语言处理》一书。书中介绍了正则表达式与模式、精确率与召回率、克莱尼星号、常用字符的别名、用于计数的RE运算符等内容。我在截图中展示了使用Keras实现的简单循环神经网络和深度RNN。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习上述及下方提到的课程和书籍内容。对接下来的日子充满期待!!
- 课程:
- 书籍:
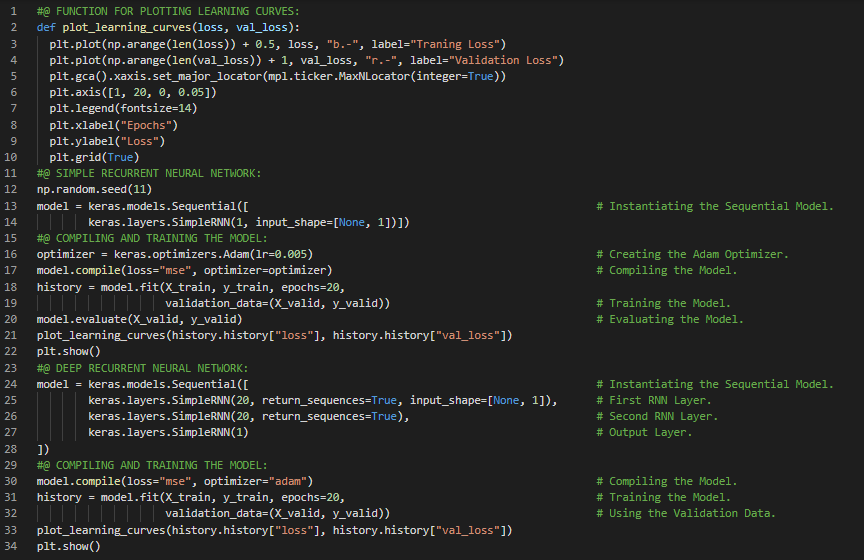
第47天,300天数据之旅!
- 特征向量与特征工程:特征工程是指将原始数据转换为特征向量,即构成数据集样本的一组浮点数值。在我的机器学习和深度学习之旅中,今天我继续学习Google的《机器学习速成课程》。在这里,我学习并实践了关于模型泛化、过拟合、梯度下降与损失、统计学习理论与计算学习理论、数据平稳性、数据拆分与验证集、表示与特征工程、特征向量、分类特征与词汇表、独热编码与稀疏表示、良好特征的特性等内容。我在截图中展示了RNN及其GRU单元的简单实现。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习上述及下方提到的课程和书籍内容。对接下来的日子充满期待!!
- 课程:
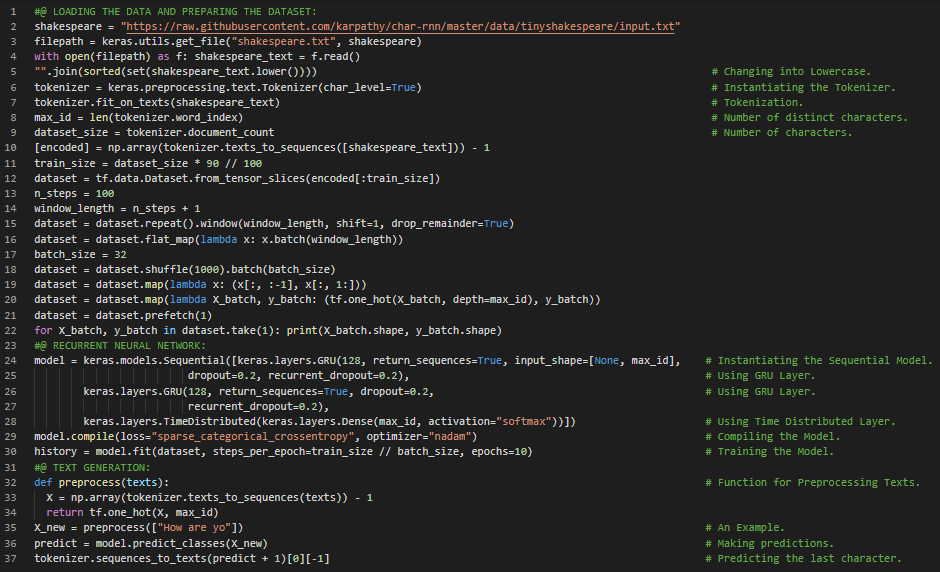
300天数据之旅第48天!
- 特征缩放:特征缩放是指将浮点型特征值从其自然范围转换到标准范围,例如0到1。如果特征集包含多个特征,那么特征缩放可以帮助梯度下降更快地收敛。在我的机器学习和深度学习之旅中,今天我学习了谷歌的《机器学习速成课程》。在这里,我学习并实现了特征值的缩放、极端异常值的处理、分箱、数据清洗、标准差、特征交叉与合成特征、非线性编码、随机梯度下降、交叉乘积、独热向量的交叉、用于简化的正则化、泛化曲线、L2正则化、早停法、Lambda参数与学习率等主题。我在截图中展示了使用Sequential API实现的简单线性回归模型。希望你能从中获得一些启发,并加以实践。我也希望你能花些时间学习上述及下方提到的课程内容。对接下来的日子充满期待!!
- 课程:
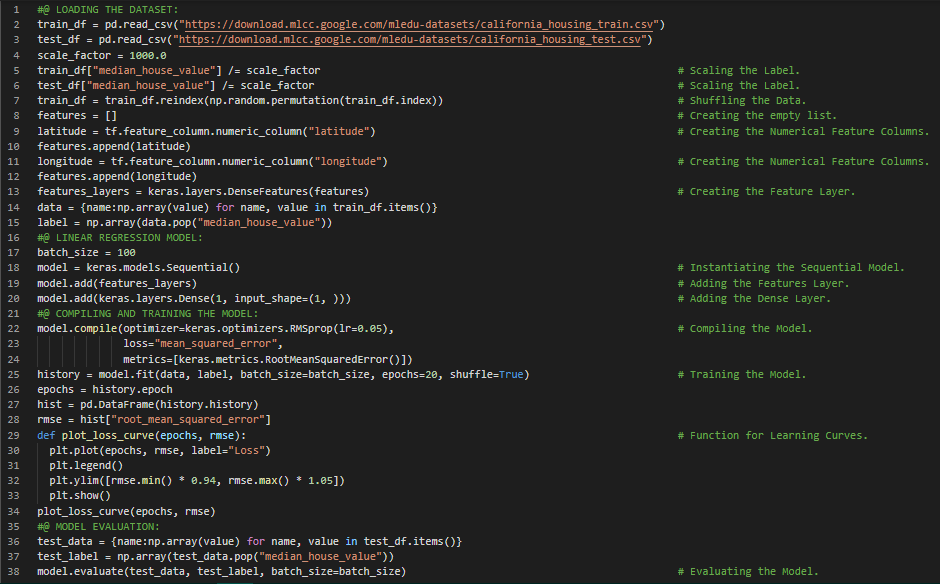
300天数据之旅第49天!
- 预测偏差:预测偏差是用来衡量预测值的平均值与数据集中标签平均值之间差距的一个指标。预测偏差与偏置是完全不同的概念。在我的机器学习和深度学习之旅中,今天我同样学习了谷歌的《机器学习速成课程》。在这里,我学习并实现了逻辑回归与概率计算、Sigmoid函数、二分类、对数损失与正则化、早停法、L1和L2正则化、分类与阈值设定、混淆矩阵、类别不平衡与准确率、精确率与召回率、ROC曲线、曲线下面积(AUC)、预测偏差、校准层、分桶、稀疏性、特征交叉与独热编码等主题。我在截图中展示了使用Keras实现的归一化与二分类的简单案例。希望你能从中获得一些见解,并进一步实践。我也希望你能花些时间学习上述及下方提到的课程内容。对接下来的日子充满期待!!
- 课程:
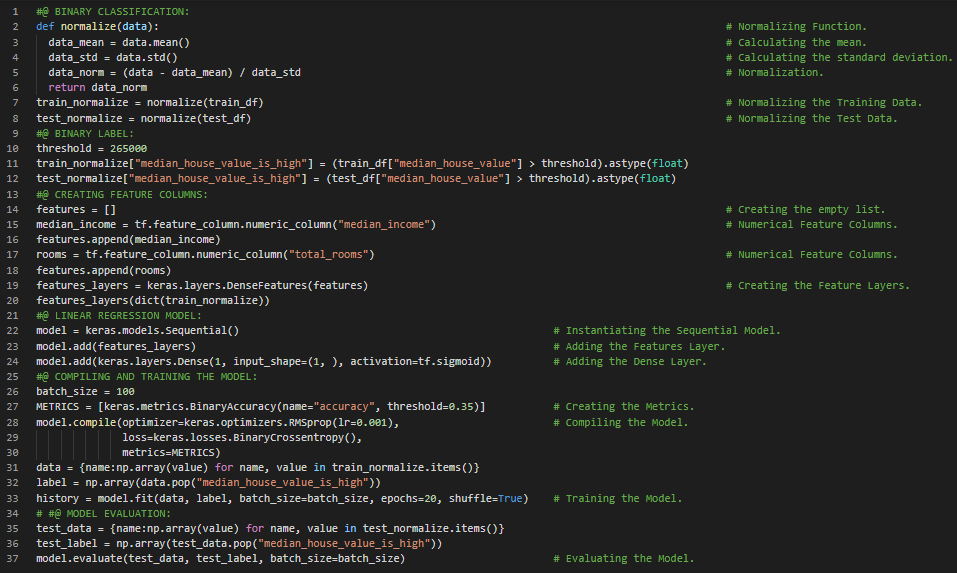
300天数据之旅第50天!
- 分类数据与稀疏张量:分类数据指的是输入特征,这些特征代表来自有限选择集合中的一个或多个离散项。而稀疏张量则是指只有少量非零元素的张量。在我的机器学习和深度学习之旅中,今天我继续学习了谷歌的《机器学习速成课程》。在这里,我学习并实现了神经网络、隐藏层与激活函数、非线性分类与特征交叉、Sigmoid函数、修正线性单元(ReLU)、反向传播、梯度消失与爆炸问题、Dropout正则化、多分类神经网络、Softmax、逻辑回归、嵌入、协同过滤、稀疏特征、主成分分析、Word2Vec等主题。我在截图中展示了多分类任务中深度神经网络的简单实现。希望你能从中获得一些启发,并加以实践。我也希望你能花些时间学习上述及下方提到的课程内容。对接下来的日子充满期待!!
- 课程:
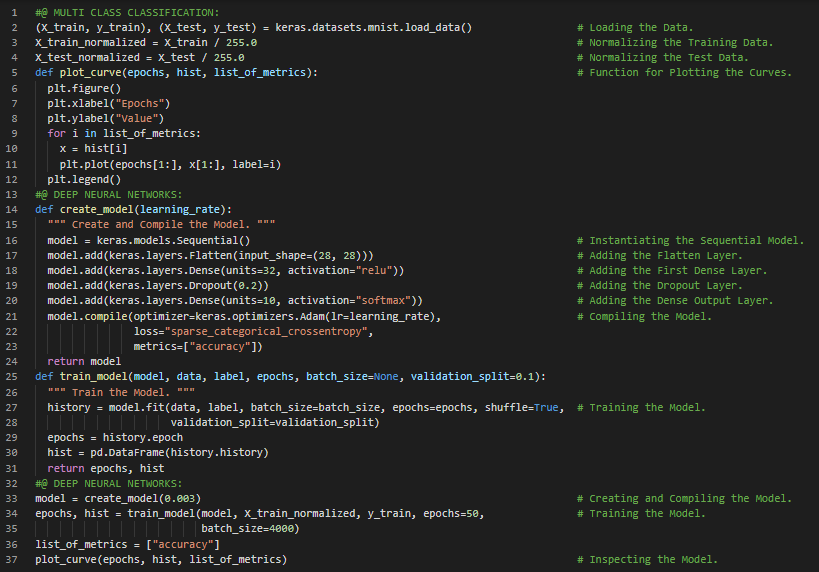
300天数据之旅第51天!
- 深度学习:深度学习是一类属于人工智能的算法,它通过提供指导性示例来训练称为深度神经网络的数学实体。深度学习利用大量数据来近似复杂的函数。在我的机器学习和深度学习之旅中,今天我开始阅读并实践《用PyTorch进行深度学习》这本书。在这里,我了解了PyTorch核心、深度学习简介与革命、张量与数组、深度学习的竞争格局、实用库、能够识别图像主体的预训练神经网络、ImageNet、图像识别、AlexNet与ResNet、Torch Vision模块等主题。我在截图中展示了使用PyTorch获取用于图像识别的预训练神经网络的实现。希望你能从中获得一些启发,并加以实践。我也希望你能花些时间学习上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
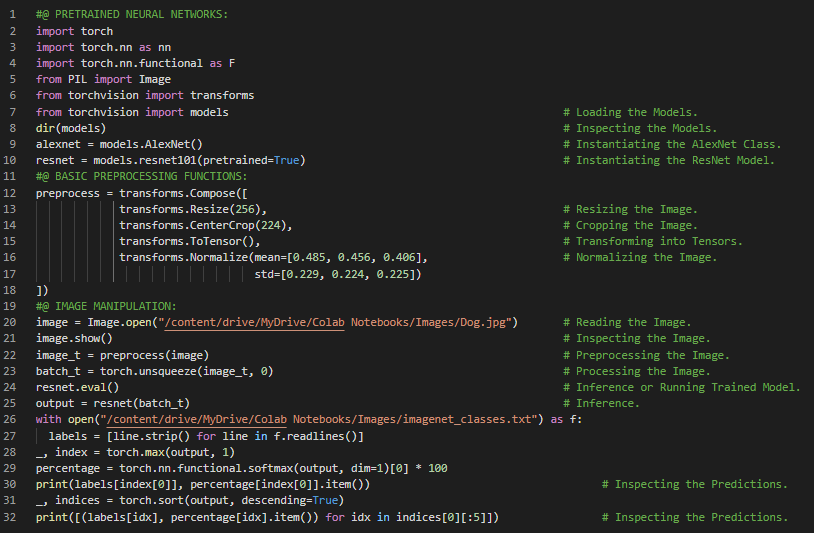
300天数据之旅第52天!
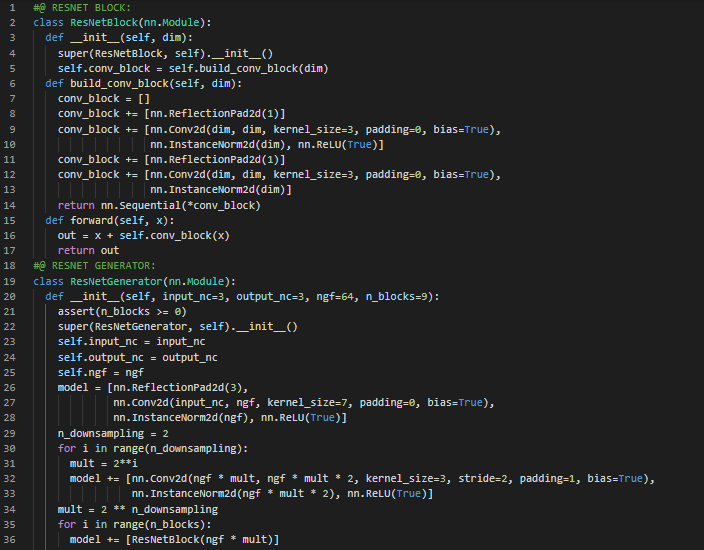
- GAN游戏:GAN代表生成对抗网络,“生成”意味着创造,“对抗”表示两个神经网络在竞争以智胜对方,“网络”则指神经网络。循环GAN可以在无需显式提供训练集中匹配对的情况下,将一个领域的图像转换为另一个领域的图像。在我的机器学习和深度学习之旅中,今天我继续阅读并实践《用PyTorch进行深度学习》这本书。在这里,我学习了预训练模型、生成对抗网络(GAN)、ResNet生成器与判别器模型、循环GAN架构、Torch Vision模块、深度伪造技术、以及能将马变成斑马的神经网络等主题。我在截图中展示了使用PyTorch实现的将马变成斑马的循环GAN。希望你能从中获得一些启发,并加以实践。我也希望你能花些时间学习上述及下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
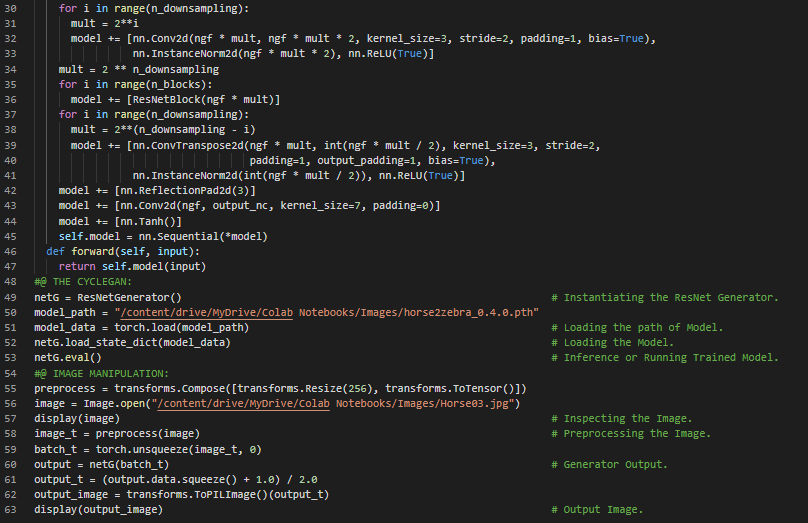

300天数据之旅第53天!
- 张量与多维数组:张量是PyTorch中的基本数据结构。张量是一种数组,它是一种存储数字集合的数据结构,这些数字可以通过索引单独访问,并且可以使用多个索引来进行索引。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用PyTorch进行深度学习》这本书的内容。在这里,我学习了描述场景的预训练神经网络——NeuralTalk2模型、循环神经网络、Torch Hub、基础构建块:张量、将世界视为浮点数、多维数组与张量、列表与张量索引、命名张量、爱因斯坦求和约定、广播等主题。我在这里通过截图展示了使用PyTorch对张量索引和命名张量的简单实现。希望你能从中获得一些启发,并进一步深入研究。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
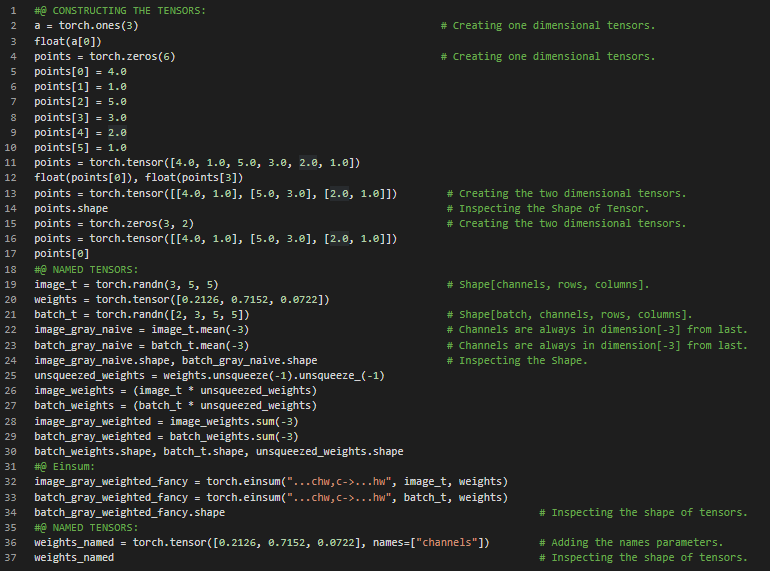
300天数据之旅第54天!
- 张量与多维数组:张量是PyTorch中的基本数据结构。张量是一种数组,它是一种存储数字集合的数据结构,这些数字可以通过索引单独访问,并且可以使用多个索引来进行索引。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用PyTorch进行深度学习》这本书的内容。在这里,我学习了命名张量、更改命名张量的名称、张量广播、无名维度、张量元素类型、指定数值数据类型、张量API、创建操作、索引、随机采样、序列化、并行计算、张量存储、引用存储、对存储进行索引等主题。我在这里通过截图展示了使用PyTorch对命名张量、张量数据类型属性以及张量API的简单实现。希望你能从中获得一些启发,并进一步深入研究。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
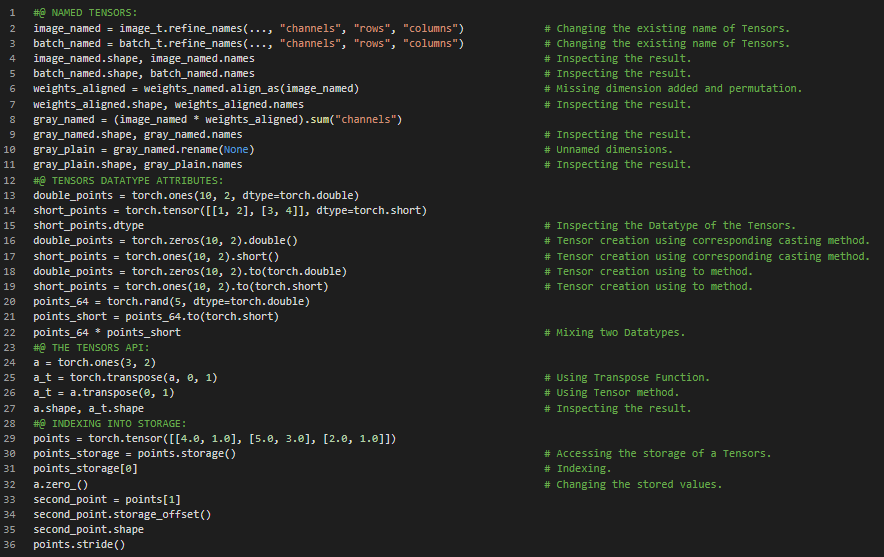
300天数据之旅第55天!
- 颜色通道编码:将颜色编码为数字最常见的方式是RGB模式,其中一种颜色由三个数字表示,分别代表红色、绿色和蓝色的强度。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用PyTorch进行深度学习》这本书的内容。在这里,我学习了张量元数据,如大小、偏移量和步幅、不复制地转置张量、高维空间中的转置、连续张量、管理张量设备属性(如在GPU和CPU之间切换)、NumPy互操作性、广义张量、张量序列化、用张量表示数据、处理图像、添加颜色通道、改变布局等主题。我在这里通过截图展示了使用PyTorch处理图像的实现,包括改变布局和使用Permute方法以及连续张量的操作。希望你能从中获得一些启发,并进一步深入研究。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
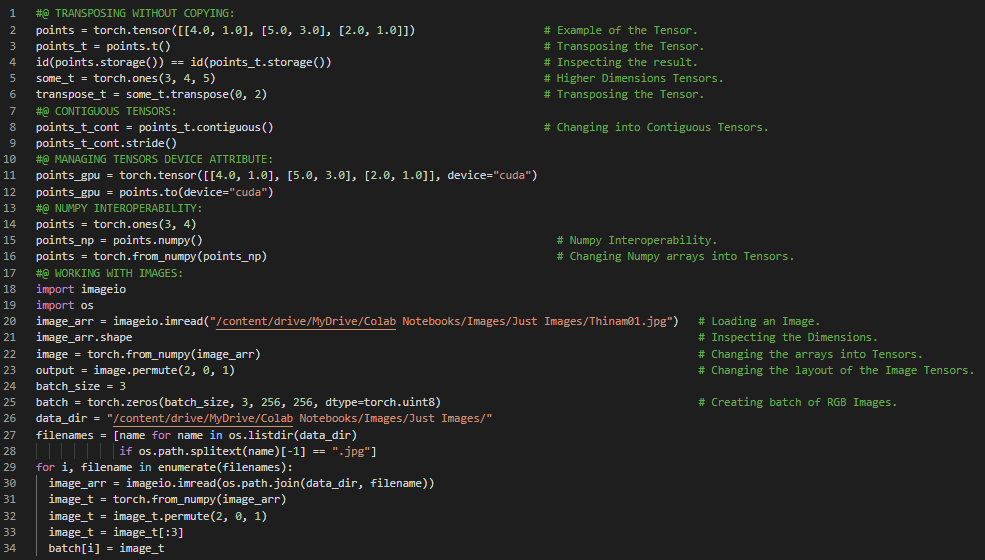
300天数据之旅第56天!
- 连续值、有序值和分类值:连续值是可以用单位进行计数和测量的数值。有序值是连续值的一种,但其值之间没有固定的相互关系。分类值则是可能性的枚举。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用PyTorch进行深度学习》这本书的内容。在这里,我学习了图像数据的归一化、处理3D图像或体积图像数据、表示表格数据、使用NumPy加载数据张量、连续值、有序值、分类值、比率尺度和区间尺度、名义尺度、独热编码与嵌入、单例维度等主题。我在这里通过截图展示了使用PyTorch对图像数据归一化、体积数据、表格数据以及独热编码的实现。希望你能从中获得一些启发,并进一步深入研究。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
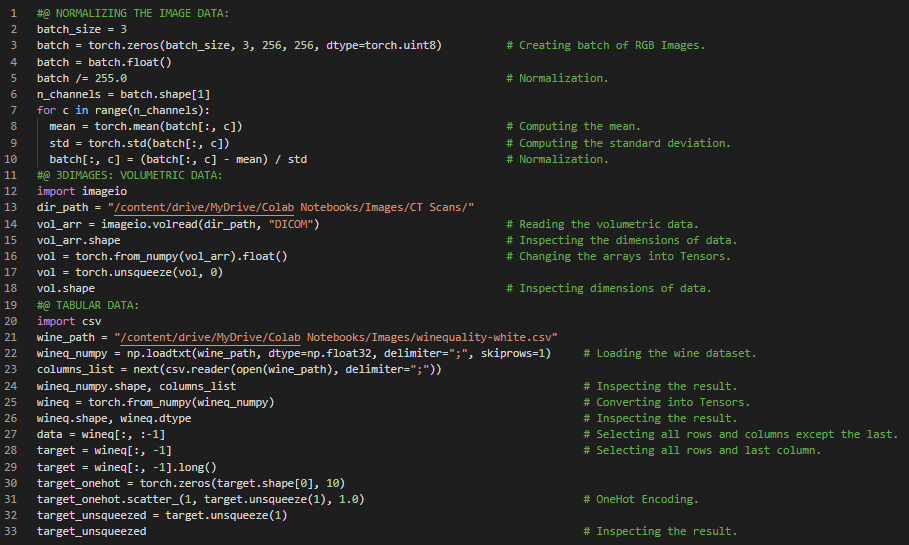
300天数据之旅第57天!
- 连续值、有序值和分类值:连续值是可以用单位进行计数和测量的数值。有序值是连续值的一种,但其值之间没有固定的相互关系。分类值则是可能性的枚举。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用PyTorch进行深度学习》这本书的内容。在这里,我学习了连续数据与分类数据、PyTorch张量API、在表格数据中寻找阈值、高级索引、处理时间序列数据、在数据中添加时间维度、按时间段塑造数据、张量与数组等主题。我在这里通过截图展示了使用PyTorch处理分类数据、时间序列数据以及寻找阈值的实现。希望你能从中获得一些启发,并进一步深入研究。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
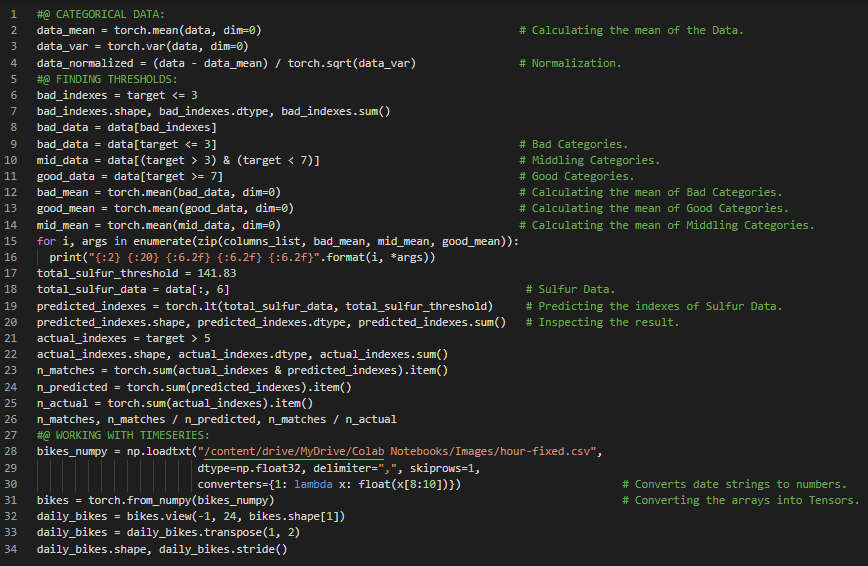
300天数据之旅第58天!
- 编码与ASCII:每个书面字符都由一个代码表示,该代码对应一段适当长度的二进制序列,以便唯一地标识每个字符,这种表示方法称为编码。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了时间序列数据处理、有序变量、独热编码与拼接、unsqueeze与单例维度、均值、标准差及变量重缩放、文本表示、自然语言处理与循环神经网络、将文本转换为数字、Project Gutenberg语料库、字符的独热编码、编码与ASCII、嵌入以及文本处理等相关主题。我在截图中展示了使用PyTorch实现的时间序列数据和文本表示。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
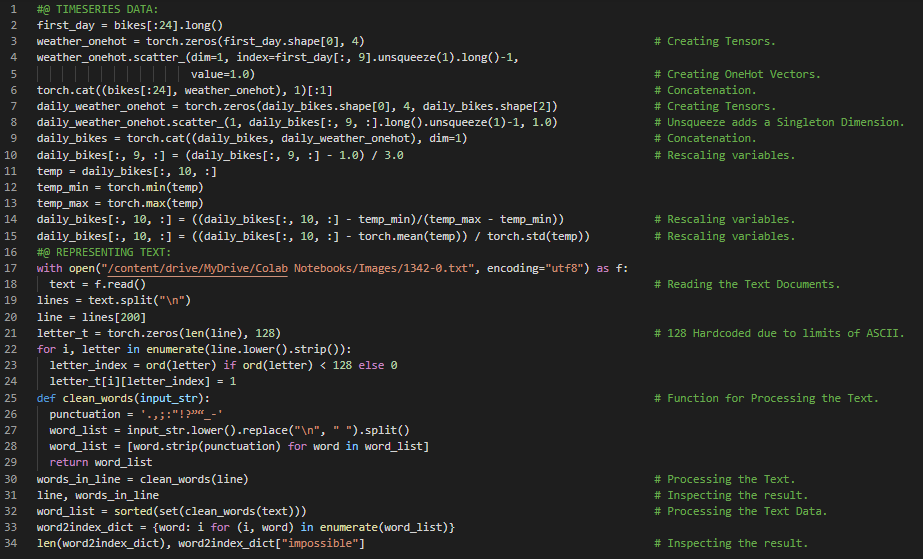
300天数据之旅第59天!
- 损失函数:损失函数是一种计算单一数值的函数,学习过程会尝试最小化这个数值。损失的计算通常涉及比较某些训练样本的期望输出与实际输出之间的差异。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了独热编码与向量、使用张量表示数据、文本嵌入、自然语言处理、学习机制、开普勒的建模启示、离心率、参数估计、权重、偏置与梯度、简单线性模型、损失函数或代价函数、均方损失、广播等主题。我在截图中展示了使用PyTorch实现的文本表示、学习机制和简单线性模型的简单示例。希望你能从中获得一些见解,并进一步探索。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
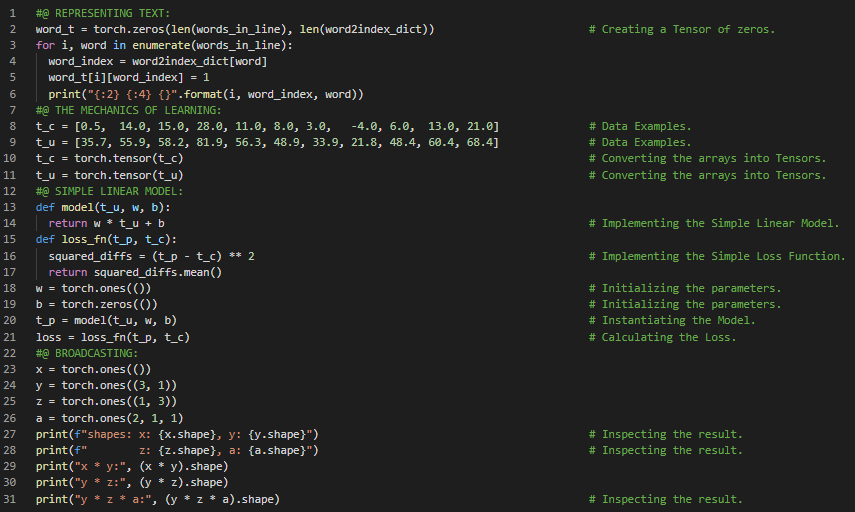
300天数据之旅第60天!
- 梯度下降法:梯度下降法是一种一阶迭代优化算法,用于寻找可微函数的局部最小值。简单来说,梯度就是函数关于各个参数的导数。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了代价函数或损失函数、利用梯度下降法优化参数、降低损失函数、参数估计、学习机制、缩放因子与学习率、模型评估、计算损失函数和线性函数的导数、定义梯度函数、偏导数以及迭代模型、训练循环等相关主题。我在截图中展示了损失函数、导数计算、梯度函数和训练循环的实现。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
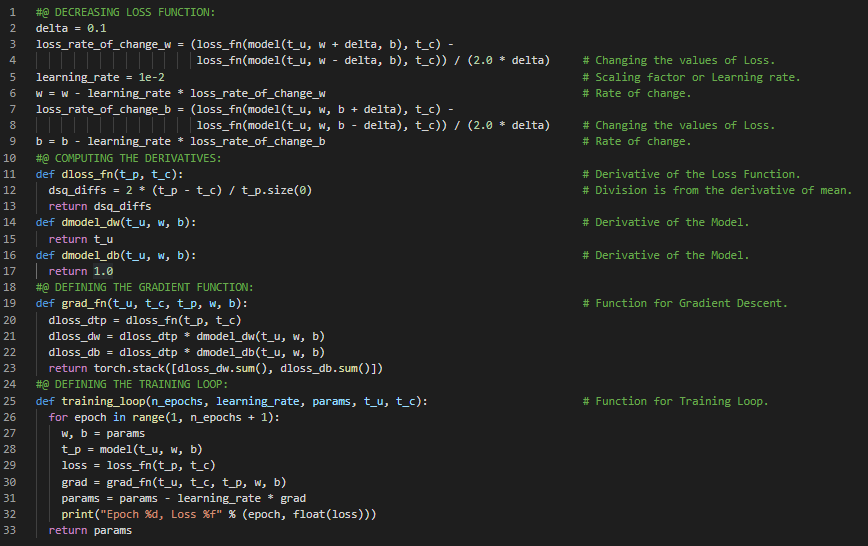
300天数据之旅第61天!
- 超参数调优:超参数调优是指在训练过程中调整模型的参数和控制训练方式的超参数。超参数通常是手动设置的。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了梯度下降法、优化训练循环、过拟合、收敛与发散、学习率、超参数调优、输入归一化、数据可视化或绘图、参数解包、PyTorch的自动求导与反向传播、链式法则、线性模型等相关主题。我在截图中展示了使用PyTorch实现的训练循环、梯度下降法以及数据可视化等简单示例。希望你能从中获得一些启发,并继续探索。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
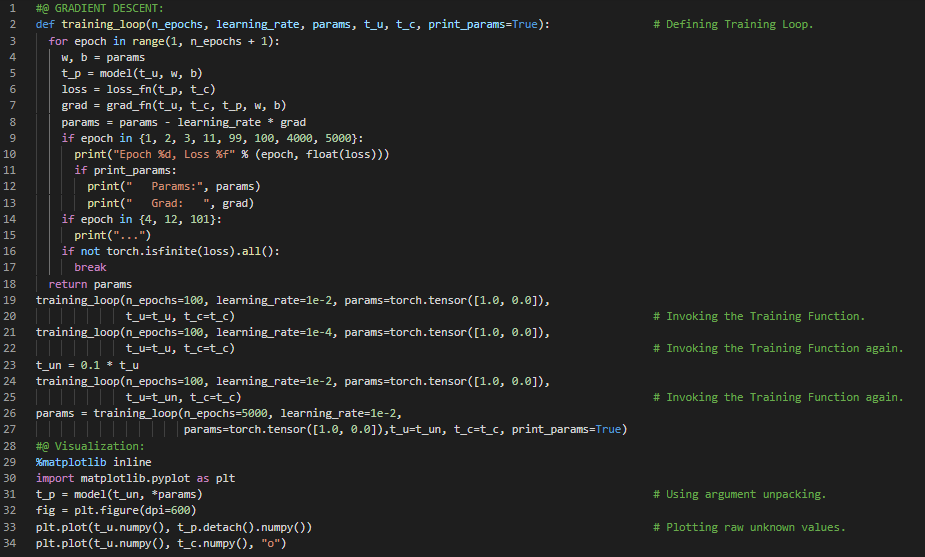
300天数据之旅第62天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了梯度下降法、PyTorch的自动求导与反向传播、链式法则与张量、grad属性与参数、简单线性函数与简单损失函数、累积梯度、清零梯度、启用自动求导的训练循环、优化器以及Torch的Optim子模块等相关主题。我在截图中展示了使用PyTorch实现的简单线性模型与损失函数、启用自动求导的训练循环。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
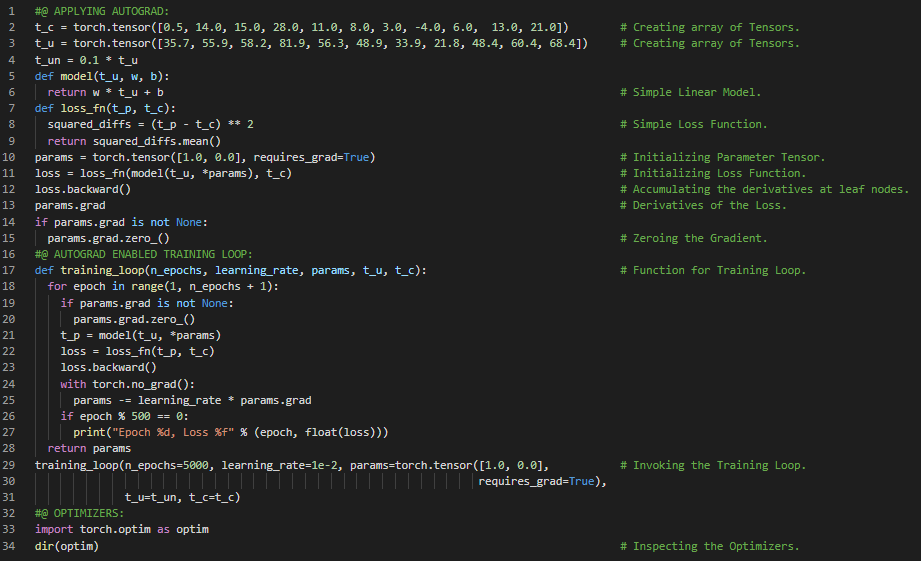
300天数据之旅第63天!
- 随机梯度下降:随机梯度下降(SGD)之所以得名,是因为梯度通常是通过对所有输入样本的随机子集取平均来计算的。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了优化器、原始梯度下降优化、随机梯度下降、动量参数、小批量、学习率与参数、Optim模块、神经网络模型、Adam优化器、反向传播、权重优化、训练、验证与过拟合、评估训练损失、泛化到验证集、过拟合与正则化项等主题。我在截图中展示了SGD和Adam优化器的实现以及训练循环。这是前一张截图的延续。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
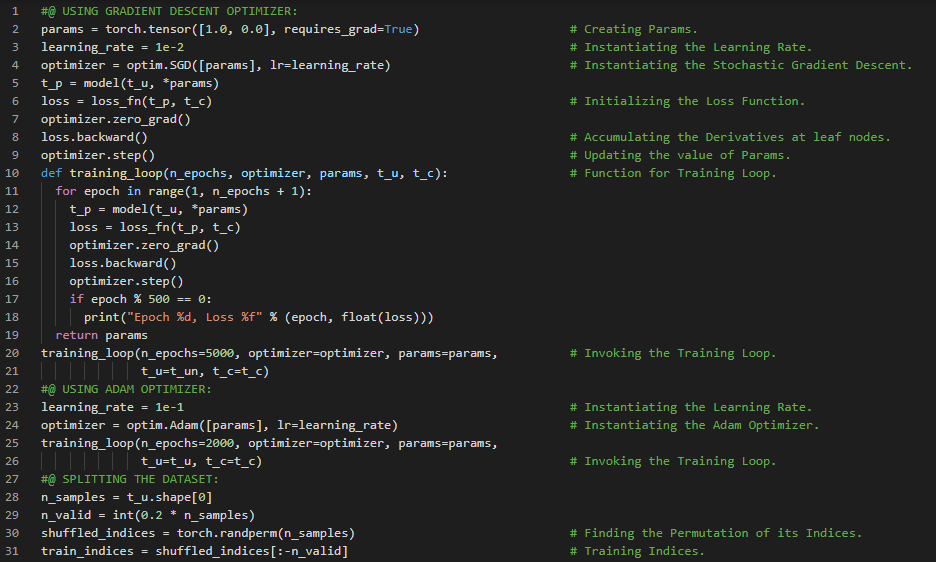
300天数据之旅第64天!
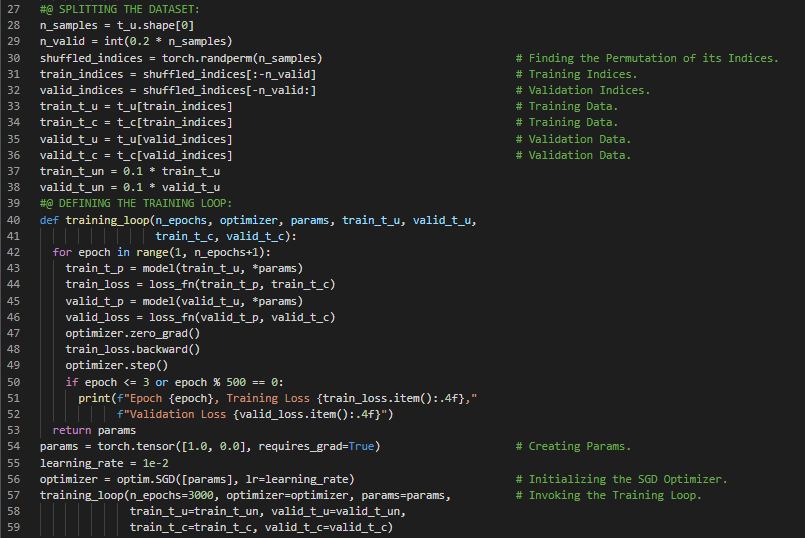
- 激活函数:激活函数是非线性的,这使得整个网络能够近似更复杂的函数。它们是可微的,因此可以通过它们计算梯度。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我正在学习如何使用神经网络来拟合数据、人工神经元、学习过程与损失函数、非线性激活函数、权重与偏置、构建多层网络、理解误差函数、限制和压缩输出范围、Tanh和ReLU激活函数、选择激活函数、PyTorch的NN模块等主题。我在截图中展示了使用PyTorch实现的简单线性模型和训练循环。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
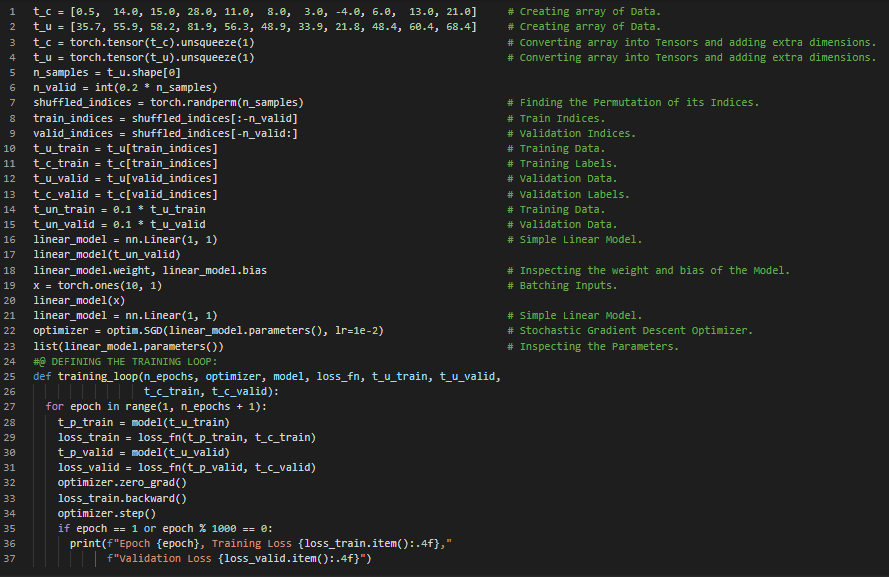
300天数据之旅第65天!
- 激活函数:激活函数是非线性的,这使得整个网络能够近似更复杂的函数。它们是可微的,因此可以通过它们计算梯度。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了PyTorch的NN模块、简单线性模型、输入数据的批处理、批次优化、均方误差损失函数、训练循环、神经网络、序列模型、Tanh激活函数、检查参数、权重与偏置、OrderedDict模块、与线性模型的对比、过拟合等主题。我在截图中展示了使用PyTorch实现的简单序列模型和OrderedDict子模块。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
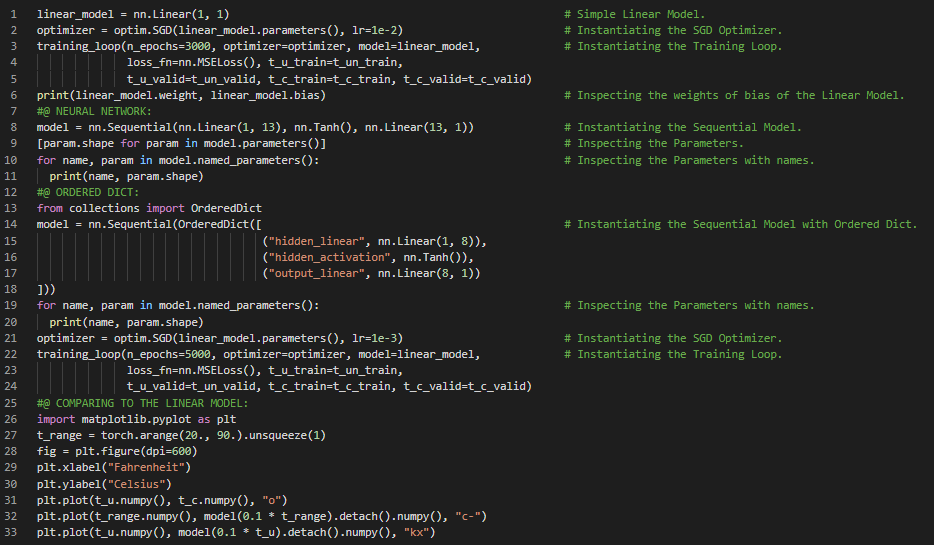
300天数据之旅第66天!
- 计算机视觉:计算机视觉是一门跨学科的科学领域,研究计算机如何从数字图像或视频中获取高层次的理解。它旨在理解和自动化人类视觉系统所能完成的任务。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我开始了“从图像中学习”这一新主题。我学习了简单的图像识别、CIFAR10小型图像数据集、Torch Vision模块、数据集类、可迭代数据集、Python图像处理库(PIL包)、数据集变换、数组与张量、Permute函数等主题。我在截图中展示了使用PyTorch实现的Torch Vision模块及CIFAR10数据集的简单应用。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
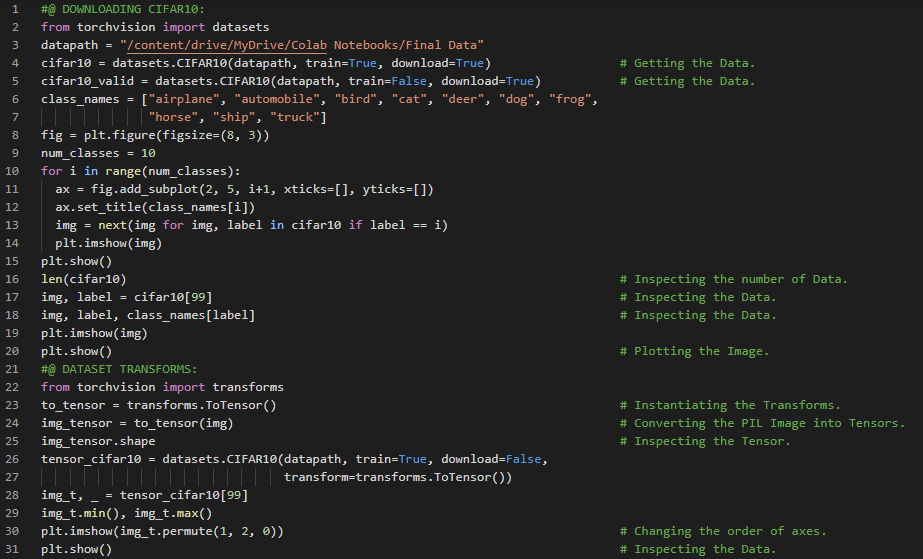
300天数据之旅第67天!
- 计算机视觉:计算机视觉是一门跨学科的科学领域,研究计算机如何从数字图像或视频中获取高层次的理解。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了排列函数、数据归一化、堆叠、均值与标准差、Torch Vision模块及其子模块、CIFAR10数据集、PIL包、图像识别、数据集的构建、全连接神经网络模型的构建、序列模型、简单线性模型、分类与回归问题、独热编码与Softmax等主题。我在截图中展示了使用Torch Vision模块进行数据归一化、数据集构建以及神经网络模型实现的过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
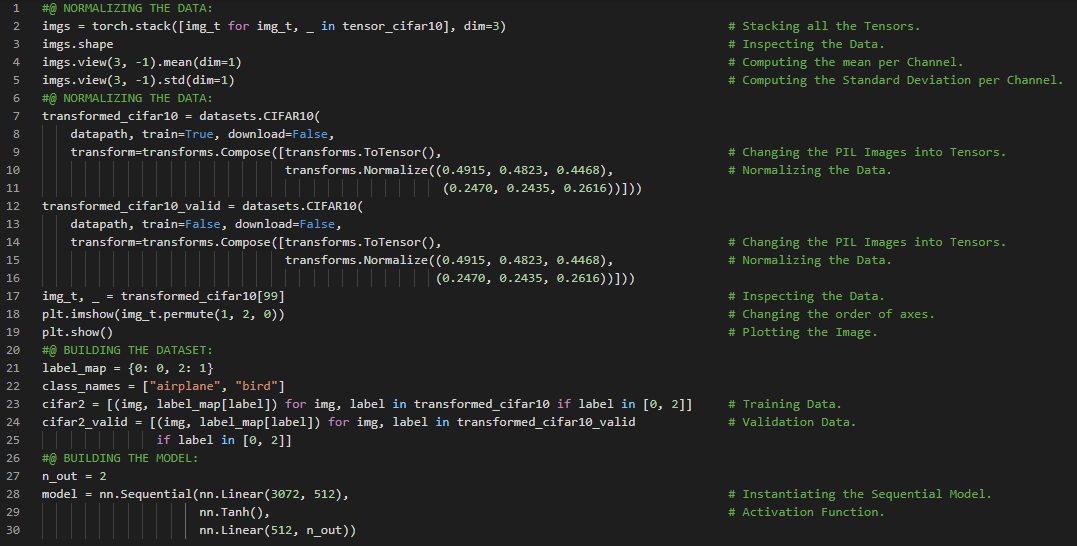
300天数据之旅第68天!
- Softmax函数:Softmax函数是一种将一个数值向量映射为另一个相同维度的向量的函数,其中输出值满足概率约束。Softmax是一个单调递增函数,输入中的较小值会对应输出中的较小值。在机器学习和深度学习的学习旅程中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在此过程中,我学习了如何将输出表示为概率、Softmax函数、PyTorch的NN模块、反向传播、分类损失函数、均方误差损失、负对数似然损失或NLL损失、Log Softmax函数、分类器的训练、随机梯度下降、超参数、小批量处理等主题。我在截图中展示了使用PyTorch实现的Softmax函数、构建神经网络模型以及训练循环。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
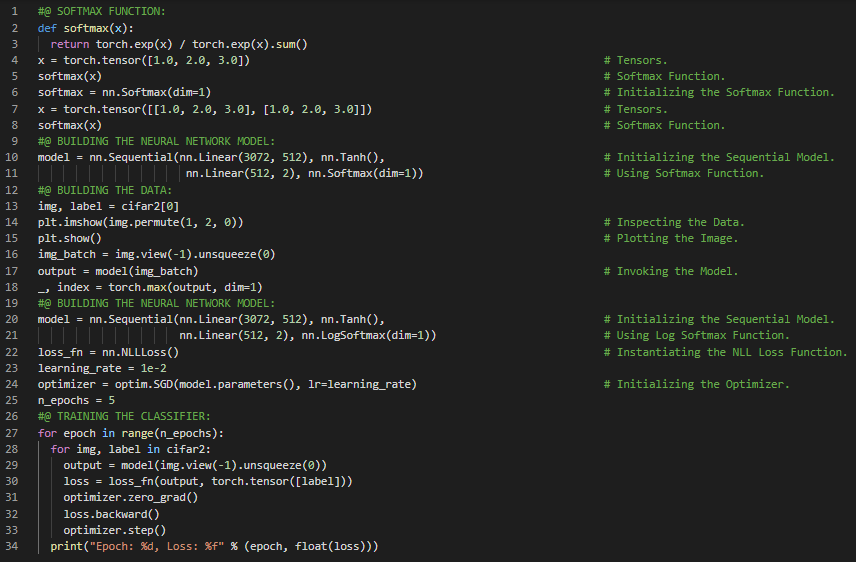
300天数据之旅第69天!
- 交叉熵损失:交叉熵损失是目标分布下预测分布的负对数似然值。Log Softmax函数与NLL损失函数的组合等价于直接使用交叉熵损失。在机器学习和深度学习的学习旅程中,今天我同样阅读并实践了《使用PyTorch进行深度学习》一书的内容。在此,我学习了梯度下降、小批量与数据加载器、随机梯度下降、神经网络模型、Log Softmax函数、NLL损失函数、交叉熵损失函数、可训练参数、权重与偏置、平移不变性、数据增强、Torch Vision及NN模块等相关内容。我在截图中展示了使用PyTorch构建深度神经网络、训练循环以及模型评估的实现过程。希望你能从中获得一些见解,并进一步实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
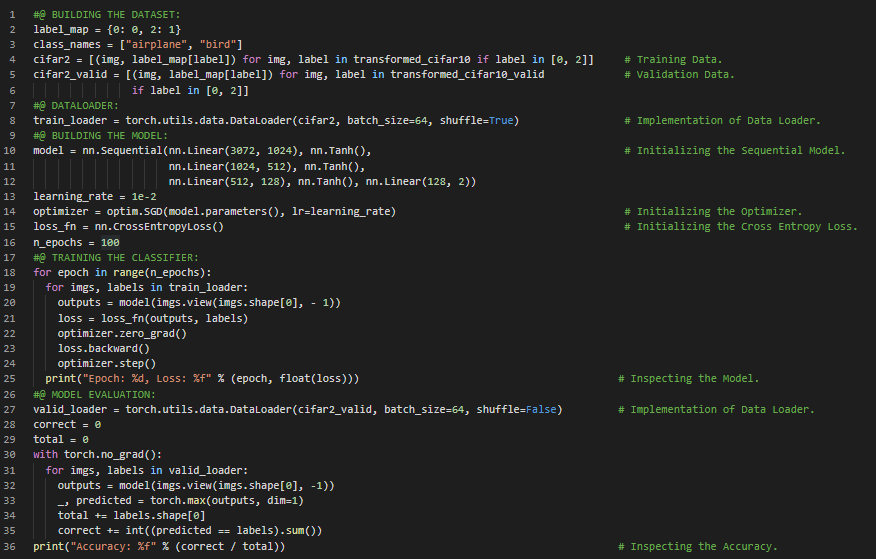
300天数据之旅第70天!
- 平移不变性:平移不变性使卷积神经网络对平移具有不变性,也就是说,即使输入图像发生平移,CNN仍然能够正确识别其所属类别。在机器学习和深度学习的学习旅程中,今天我继续阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我开始学习“利用卷积进行泛化”这一主题。我了解了卷积神经网络、平移不变性、权重与偏置、离散互相关、局部性或对邻域数据的局部操作、模型参数、多通道图像、边界填充、卷积核大小、用卷积检测特征等内容。我在截图中展示了使用PyTorch实现的简单CNN以及数据构建过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
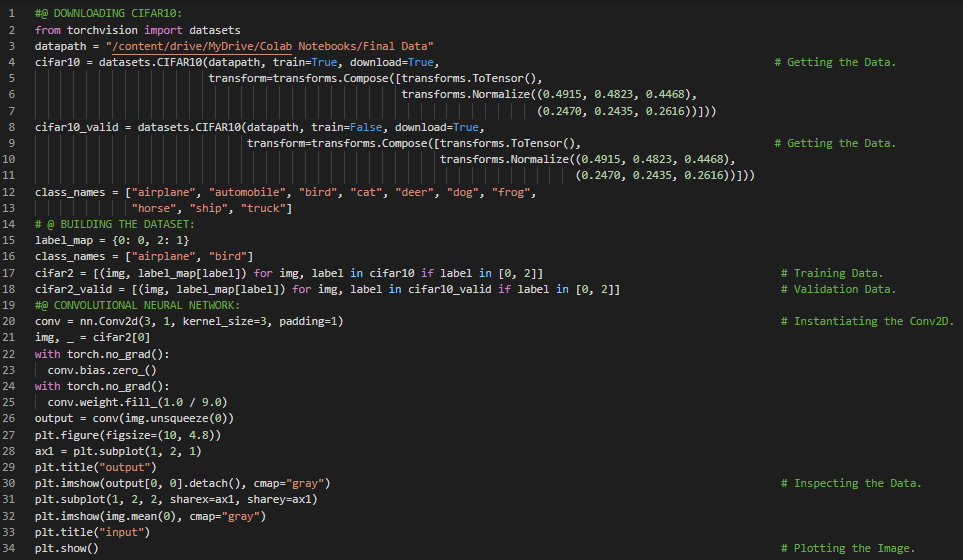
300天数据之旅第71天!
- 下采样:下采样是指将图像尺寸缩小一半的操作,相当于以四个相邻像素作为输入,生成一个输出像素。下采样的原理可以通过多种方式实现。在机器学习和深度学习的学习旅程中,今天我继续阅读并实践了《使用PyTorch进行深度学习》一书的内容。在此,我学习了卷积核大小、图像填充、边缘检测卷积核、局部性和平移不变性、学习率与权重更新、最大池化层与下采样、步幅、卷积神经网络、感受野、Tanh激活函数、简单线性模型、序列模型、模型参数等相关内容。我在截图中展示了使用PyTorch实现的卷积神经网络、图像绘制以及模型参数的检查过程。希望你能从中获得一些见解,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
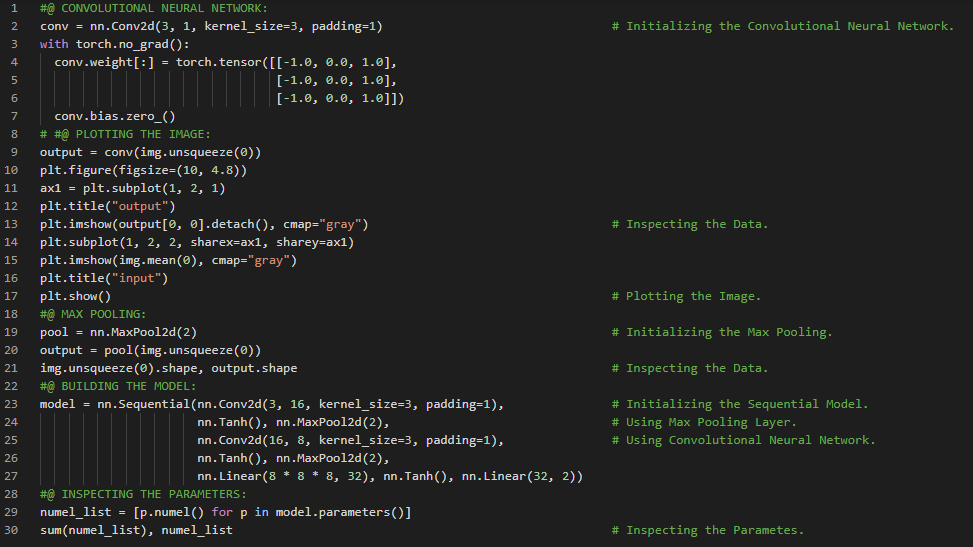
300天数据之旅第72天!
- 下采样:下采样是指将图像尺寸缩小一半的操作,相当于以四个相邻像素作为输入,生成一个输出像素。下采样的原理可以通过多种方式实现。在机器学习和深度学习的学习旅程中,今天我继续阅读并实践了《使用PyTorch进行深度学习》一书的内容。在此,我学习了NN模块的子类化、顺序式API与模块化API、前向传播函数、线性模型、最大池化层、数据填充、卷积神经网络架构、ResNet、卷积核大小及其属性、Tanh激活函数、模型参数、函数式API、无状态模块等相关内容。我在截图中展示了使用顺序式API和函数式API对NN模块进行子类化的实现过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
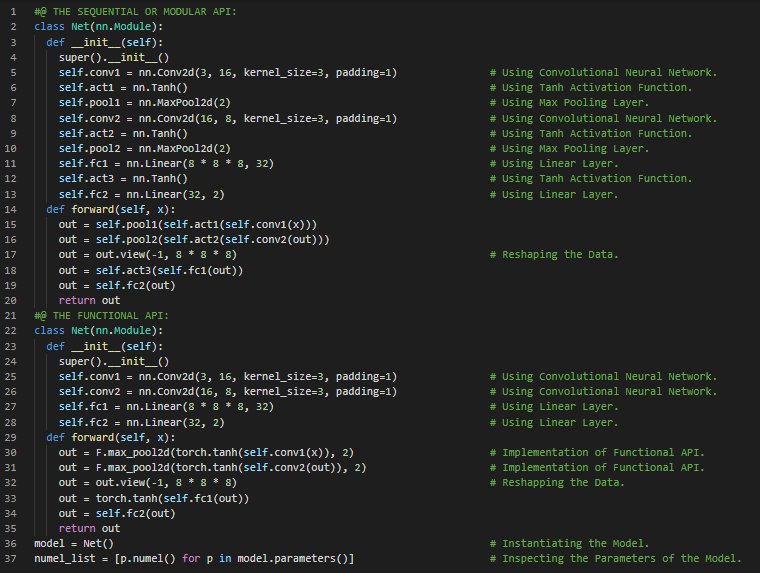
300天数据之旅第73天!
- 下采样:下采样是将图像尺寸缩小一半的过程,相当于以四个相邻像素作为输入,生成一个输出像素。下采样的原理可以通过多种方式实现。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了Torch NN模块、函数式API、卷积神经网络及其训练过程、数据加载器模块、网络的前向传播与反向传播、随机梯度下降优化器、梯度清零、交叉熵损失函数、模型评估以及梯度下降等相关内容。我在截图中展示了使用PyTorch实现的训练循环和模型评估过程。实际上,这延续了昨天的截图内容。希望你能从中获得一些启发,并进一步实践。也期待你花时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
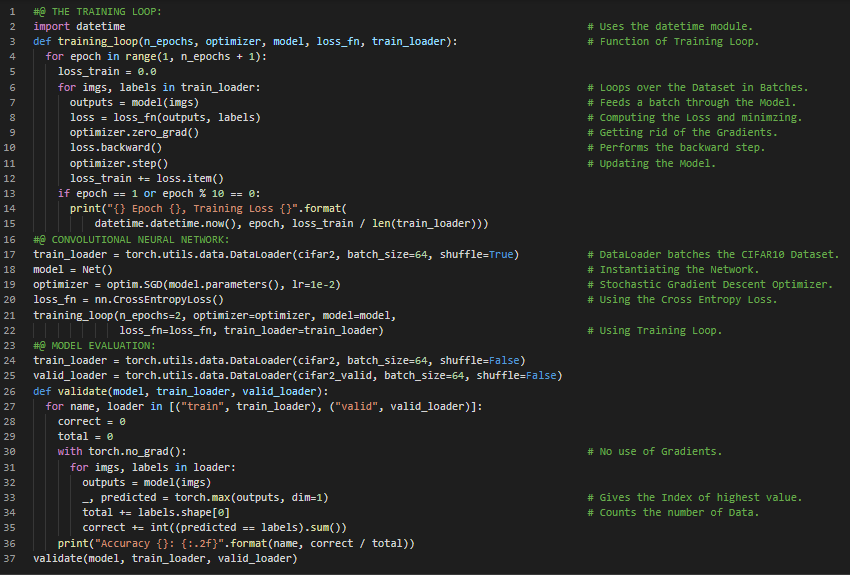
300天数据之旅第74天!
- 下采样:下采样是将图像尺寸缩小一半的过程,相当于以四个相邻像素作为输入,生成一个输出像素。下采样的原理可以通过多种方式实现,例如最大池化。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了模型、权重和参数的保存与加载、在GPU上训练模型、Torch NN模块及其子模块、映射位置关键字、模型设计、长短期记忆网络(LSTM)、为网络增加记忆容量或宽度、前馈网络、过拟合等问题。我在截图中展示了使用PyTorch为网络增加记忆容量或宽度的实现方法。希望你能从中获得一些启发,并继续深入研究。也期待你花时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
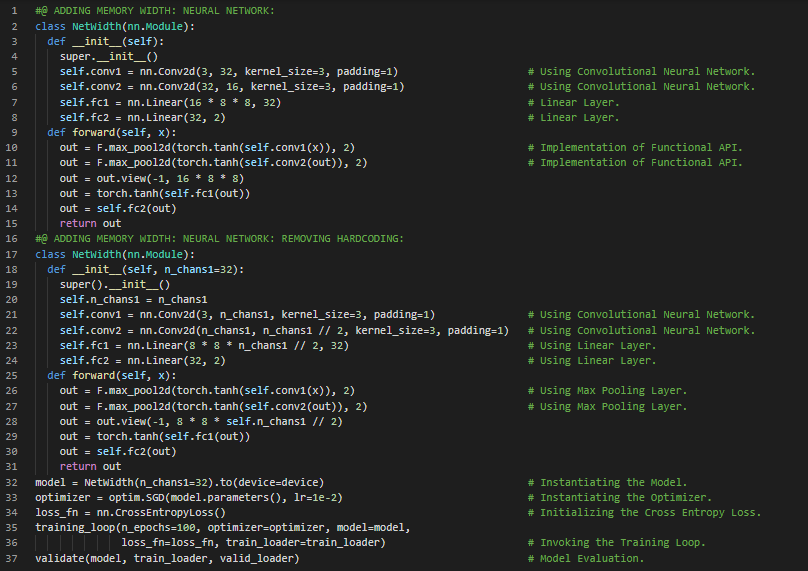
300天数据之旅第75天!
- L2正则化:L2正则化是模型中所有权重平方的总和,而L1正则化则是所有权重绝对值的总和。L2正则化也被称为权重衰减。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了卷积神经网络、L2正则化和L1正则化、优化与泛化、权重衰减、PyTorch NN模块及其子模块、随机梯度下降优化器、过拟合与丢弃层、深度神经网络、随机化等相关内容。我在截图中展示了使用PyTorch实现L2正则化和丢弃层的方法。希望你能从中获得一些启发,并继续探索。也期待你花时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
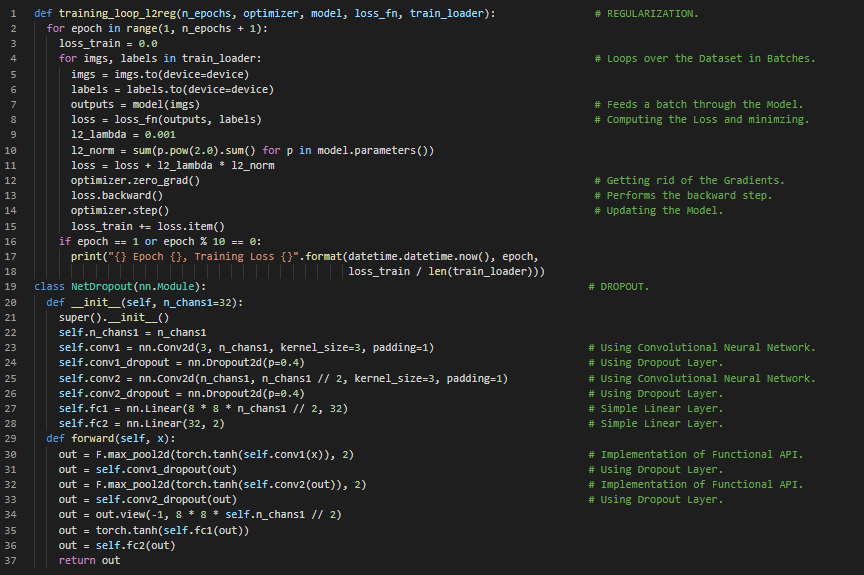
300天数据之旅第76天!
- L2正则化:L2正则化是模型中所有权重平方的总和,而L1正则化则是所有权重绝对值的总和。L2正则化也被称为权重衰减。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了丢弃层模块、批量归一化和非线性激活函数、正则化与原则性增强、卷积神经网络、小批量和标准差、深度神经网络及深度模块、跳跃连接机制、ReLU激活函数、函数式API的实现等相关内容。我在截图中展示了使用PyTorch实现批量归一化、深度神经网络及深度模块的方法。希望你能从中获得一些启发,并继续深入研究。也期待你花时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
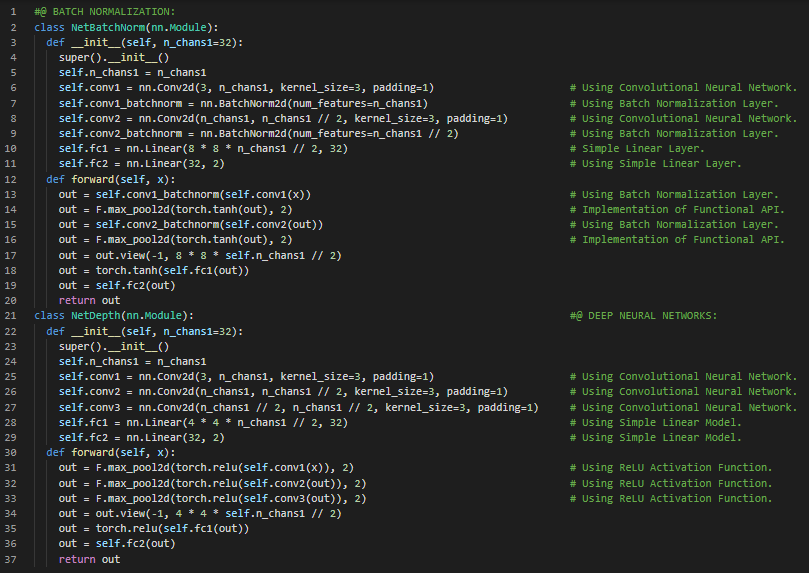
300天数据之旅第77天!
- 恒等映射:当第一层激活的输出除了通过标准的前馈路径外,还被用作最后一层的输入时,就称为恒等映射。恒等映射可以缓解梯度消失的问题。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》一书的内容。在这里,我学习了卷积神经网络、跳跃连接、ResNet架构、简单线性层、最大池化层、恒等映射、高速公路网络、UNet模型、密集网络和超深度神经网络、序列式和函数式API、前向传播与反向传播、Torch Vision模块及其子模块、批量归一化层、自定义初始化等相关内容。我在截图中展示了使用PyTorch实现ResNet架构和超深度神经网络的方法。希望你能从中获得一些启发,并继续探索。也期待你花时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
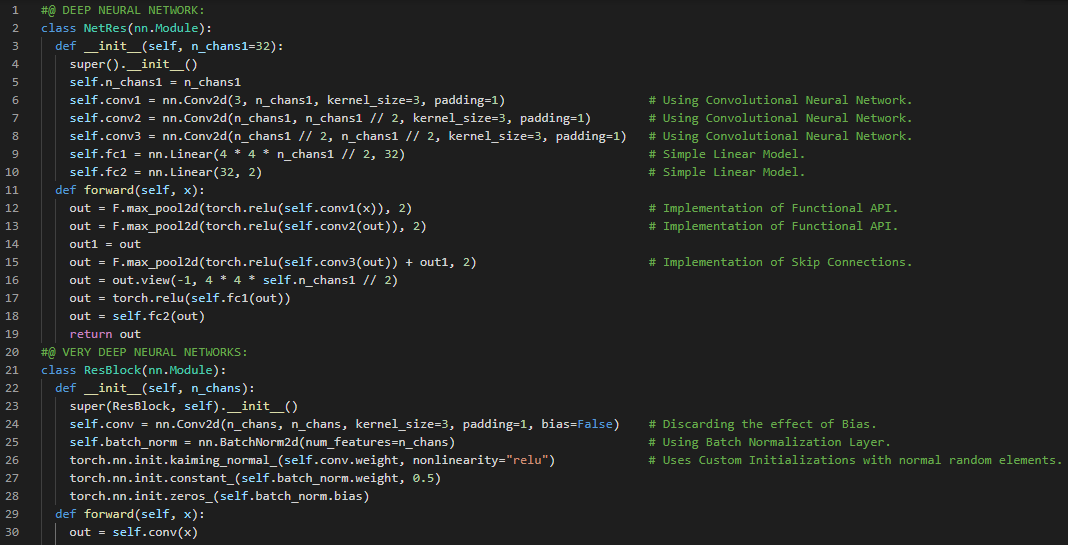
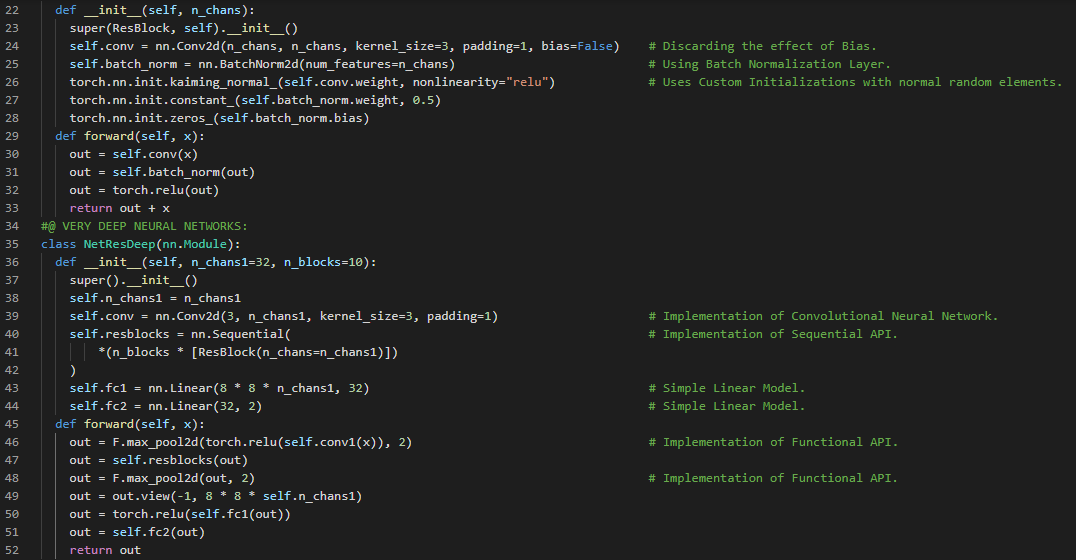
300天数据之旅第78天!
- 体素:体素是大家熟悉的2D像素在3D空间中的对应物。它不是表示一个面积,而是表示一个体积。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》这本书的内容。在这里,我学习了CT扫描数据集、体素、分割、分组与分类、结节、3D卷积、神经网络、LUNA数据集的下载、数据加载、数据解析、训练集与验证集等主题。我还开始处理LUNA数据集,即2016年肺结节分析数据集。LUNA大型挑战赛结合了一个开放的数据集和高质量的患者CT扫描标签——其中许多包含肺结节,并且对基于该数据的分类器进行了公开排名。我在截图中展示了使用PyTorch准备数据的实现过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
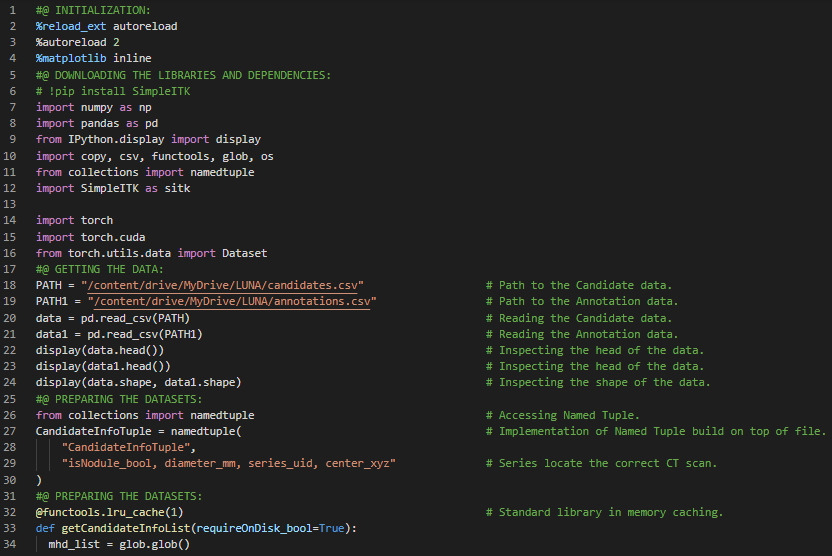
300天数据之旅第79天!
- 在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《使用PyTorch进行深度学习》这本书的内容。在这里,我学习了数据加载与解析、CT扫描数据集、数据流水线等相关主题。此外,我还了解了自动编码器、循环神经网络以及长短期记忆网络(LSTM)、数据处理、独热编码、训练集与验证集的随机划分等内容。我继续研究LUNA数据集,即2016年肺结节分析数据集。LUNA大型挑战赛结合了一个开放的数据集和高质量的患者CT扫描标签——其中许多包含肺结节,并且对基于该数据的分类器进行了公开排名。我在截图中展示了使用PyTorch进行简单数据准备的实现过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
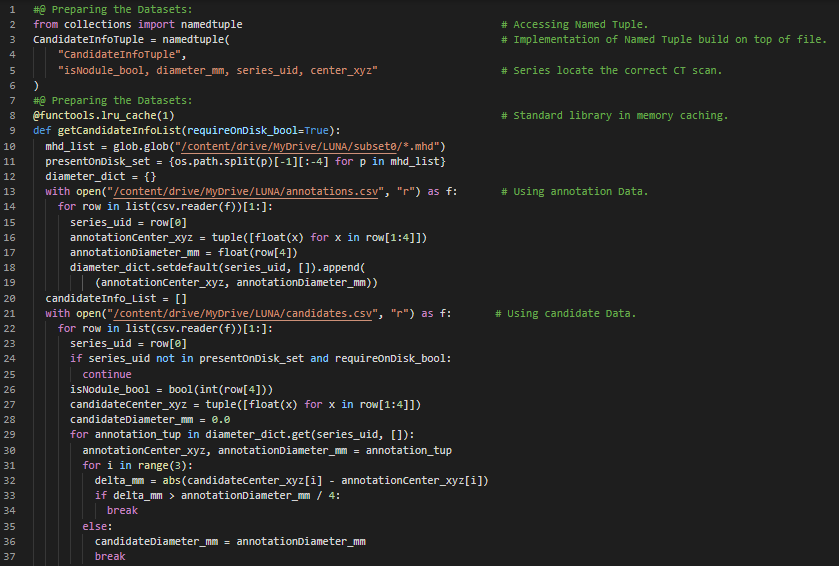
300天数据之旅第80天!
- 在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《使用PyTorch进行深度学习》这本书的内容。在这里,我学习了单个CT扫描数据集的加载、3D结节密度数据、SimpleITK库、亨氏单位、体素、批归一化、使用患者坐标系加载结节、毫米与体素地址之间的转换、数组坐标、矩阵乘法等相关主题。此外,我还学习了使用LSTM的自动编码器、有状态解码器模型以及数据可视化技术。我继续研究LUNA数据集,即2016年肺结节分析数据集。我在截图中展示了使用PyTorch在CT扫描数据集中实现患者坐标与数组坐标之间转换的代码。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
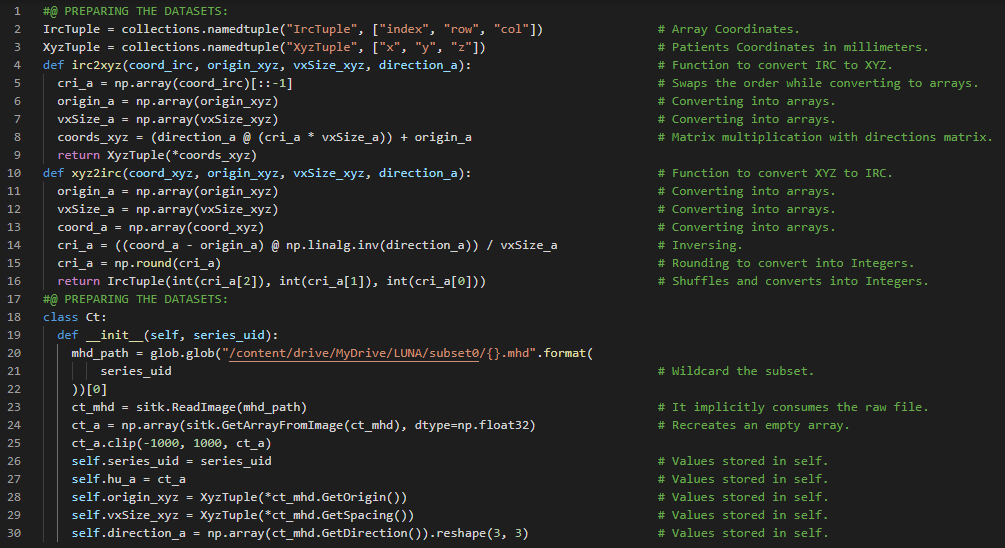
300天数据之旅第81天!
- 体素与结节:体素是大家熟悉的2D像素在3D空间中的对应物。它不是表示一个面积,而是表示一个体积。由增生细胞组成的肺部组织团块称为肿瘤。而宽度只有几毫米的小型肿瘤则被称为结节。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用PyTorch进行深度学习》这本书的内容。在这里,我学习了PyTorch数据集实例的实现、LUNA数据集类、交叉熵损失、正负结节、数组与张量、候选数组缓存、训练集与验证集、数据可视化等相关主题。此外,我还学习了数据归一化、方差阈值、RDKIT库等内容。我在截图中展示了使用PyTorch准备LUNA数据集的实现过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
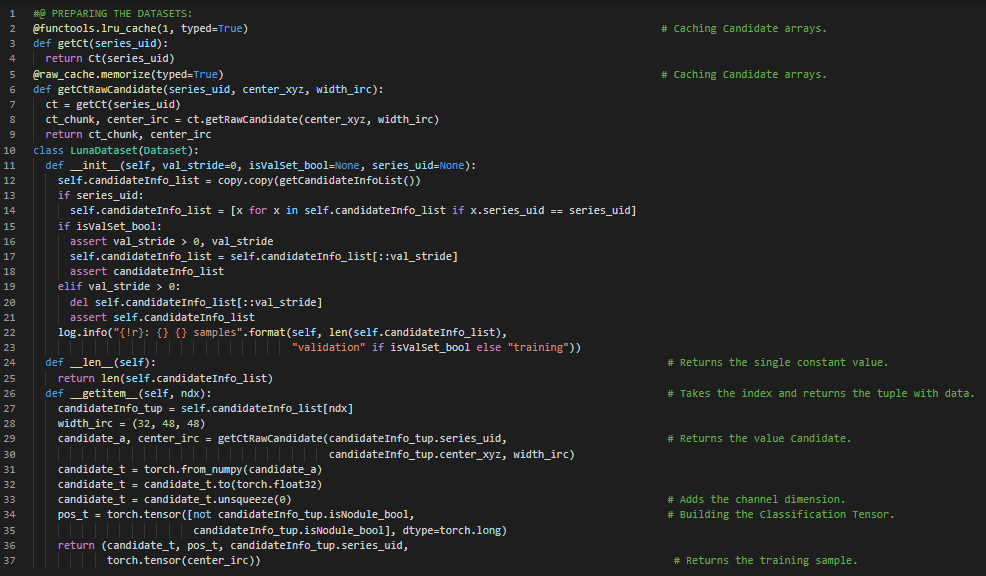
300天数据之旅第82天!
- 标签算法:学习预测非互斥类别的问题称为多标签分类。自动标签问题通常被描述为多标签分类问题。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入理解深度学习》这本书的内容。在这里,我学习了机器学习的激励性示例、学习算法、训练过程、数据、特征、模型、目标函数、优化算法、监督学习、回归、二分类、多分类和层次分类、交叉熵与均方误差损失函数、梯度下降、标签算法等相关主题。我在截图中展示了使用PyTorch进行数据准备、归一化、去除低方差特征以及构建数据加载器的实现过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
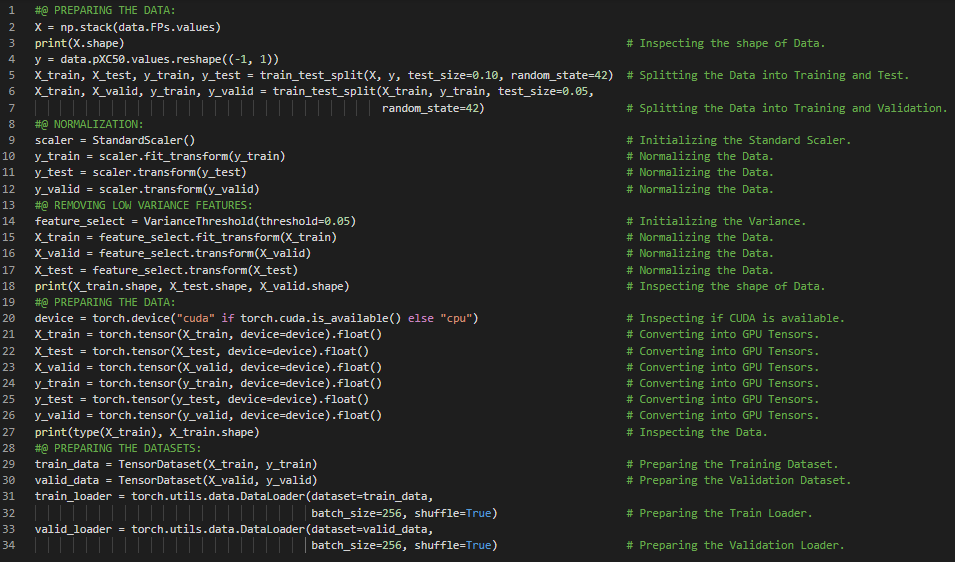
第83天,300天数据之旅!
- 强化学习:强化学习描述了一类非常通用的问题,其中智能体在一系列时间步中与环境交互,接收观测并选择行动。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在此过程中,我学习了搜索算法、推荐系统、序列学习、标注与解析、机器翻译、无监督学习、与环境交互及强化学习、数据处理、数学运算、广播机制、索引与切片、张量内存优化、数据类型转换等主题。我在截图中展示了使用PyTorch实现的数学运算、张量拼接、广播机制和数据类型转换。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
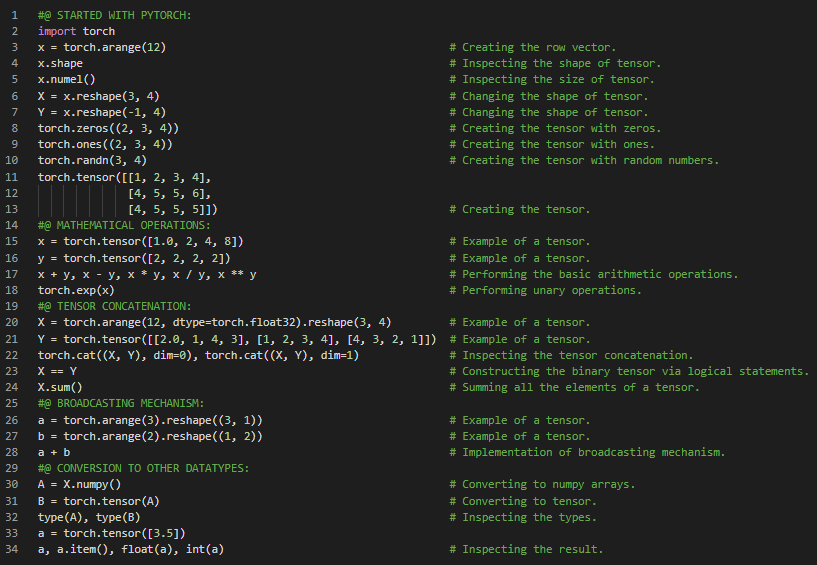
第84天,300天数据之旅!
- 张量:张量是指用任意维度的数组来描述的代数对象,可以有多个轴。向量是一阶张量,矩阵是二阶张量。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在此过程中,我学习了数据处理、读取数据集、处理缺失值、处理分类数据、转换为张量格式、线性代数(如标量、向量、长度、维度与形状)、矩阵、对称矩阵、张量、张量算术的基本性质、降维与非降维求和、点积、矩阵-向量乘法等主题。我在截图中展示了使用PyTorch实现的数据处理、缺失值处理、标量、向量、矩阵和点积的操作。希望你能从中获得一些见解,并进一步实践。也建议你花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
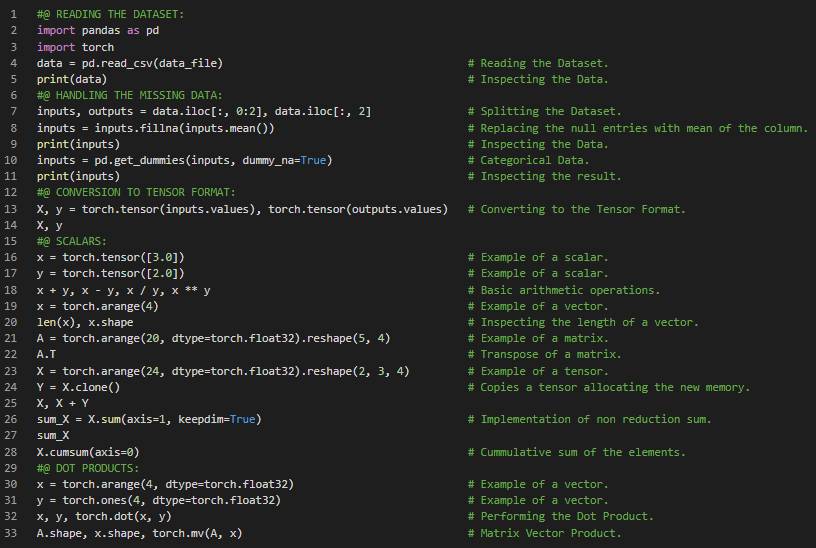
第85天,300天数据之旅!
- 穷竭法:古代通过在圆形等曲面图形内嵌入多边形,使这些多边形更接近圆的形状,从而计算曲面面积的方法称为穷竭法。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在此过程中,我学习了矩阵乘法、L1和L2范数归一化、Frobenius范数归一化、微积分、穷竭法、导数与微分、偏导数、梯度下降、链式法则、自动微分、非标量变量的反向传播、分离计算图、反向传播、利用控制流计算梯度等主题。我在截图中展示了使用PyTorch实现的矩阵乘法、L1、L2和Frobenius范数归一化、导数与微分、自动微分以及梯度计算。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
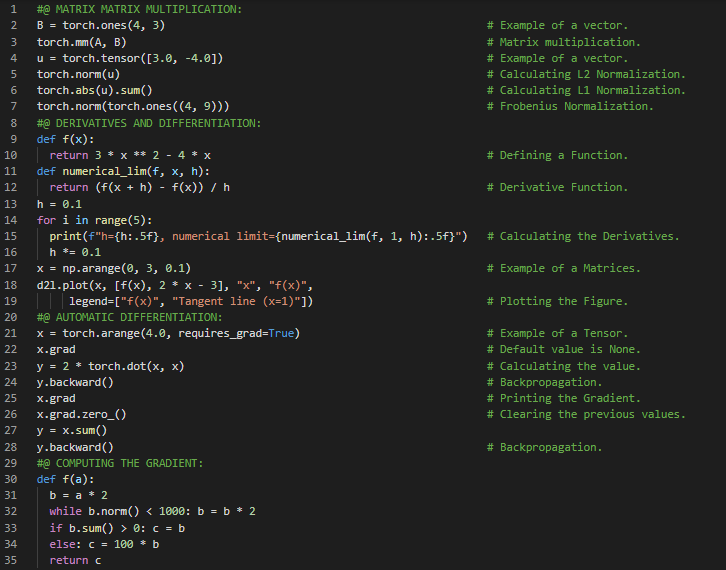
第86天,300天数据之旅!
- 穷竭法:古代通过在圆形等曲面图形内嵌入多边形,使这些多边形更接近圆的形状,从而计算曲面面积的方法称为穷竭法。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在此过程中,我学习了概率、基础概率论、采样、多项分布、概率论公理、随机变量、处理多个随机变量、联合概率、条件概率、贝叶斯定理、边缘化、独立性与依赖性、期望与方差、模块中的类与函数等主题。我在截图中展示了使用PyTorch实现的多项分布、概率可视化以及导数与微分操作。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
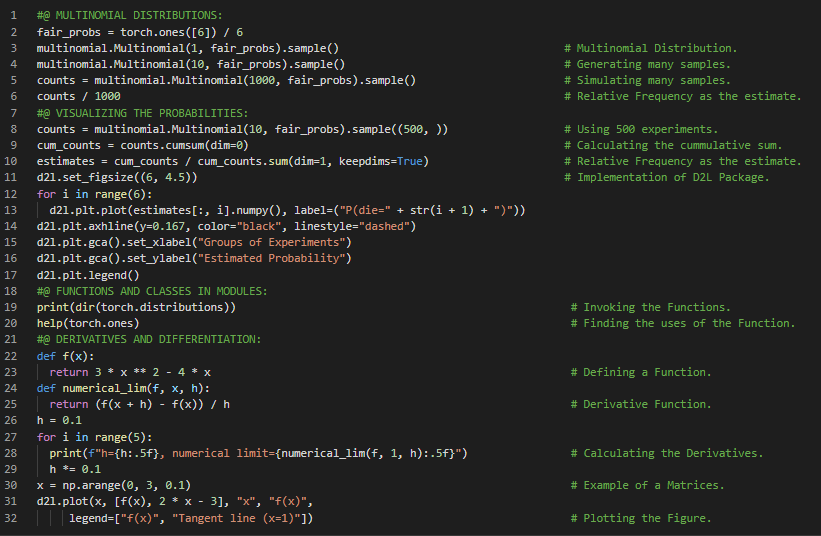
第87天,300天数据之旅!
- 超参数:那些可以在训练过程中调整但不会在训练循环中更新的参数被称为超参数。超参数调优是指选择和调整超参数的过程,通常需要根据训练结果进行反复试验。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在此过程中,我学习了线性回归、线性回归的基本要素、线性模型与变换、损失函数、解析解、小批量随机梯度下降、利用已学模型进行预测、速度向量化、正态分布与平方损失、从线性回归到深度神经网络、生物学解释、超参数调优等主题。我在截图中展示了使用Python实现的速度向量化和正态分布操作。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
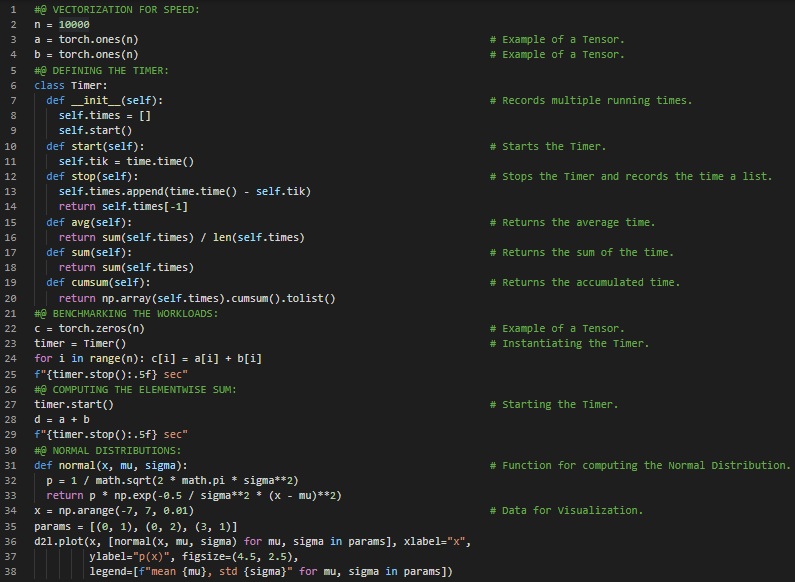
300天数据之旅第88天!
- 超参数:在训练过程中可调但不更新的参数称为超参数。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了从零开始实现线性回归、数据流水线、深度学习框架、生成人工数据集、散点图与相关性、读取数据集、小批量处理、特征与标签、并行计算、初始化模型参数、小批量随机梯度下降、定义简单线性回归模型、广播机制、向量与标量等主题。我在截图中展示了使用PyTorch生成合成数据集、绘制散点图、读取数据集、初始化模型参数以及定义线性回归模型的实现过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
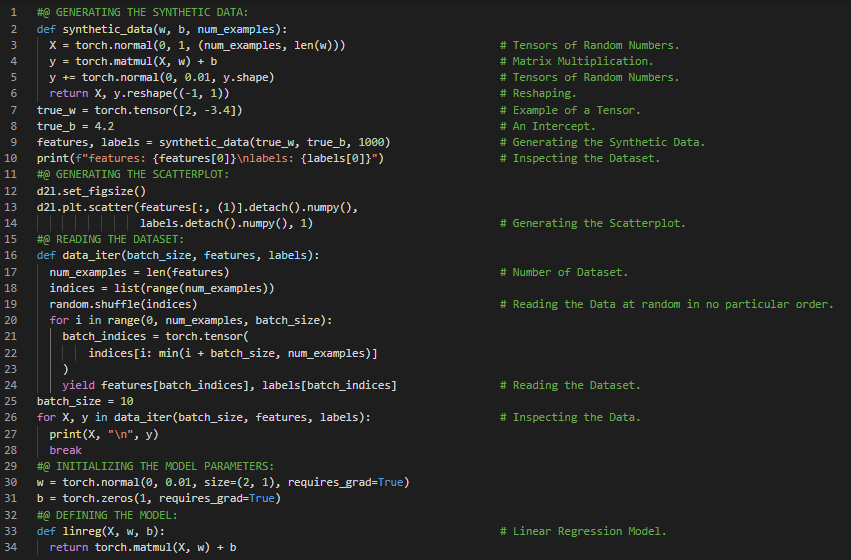
300天数据之旅第89天!
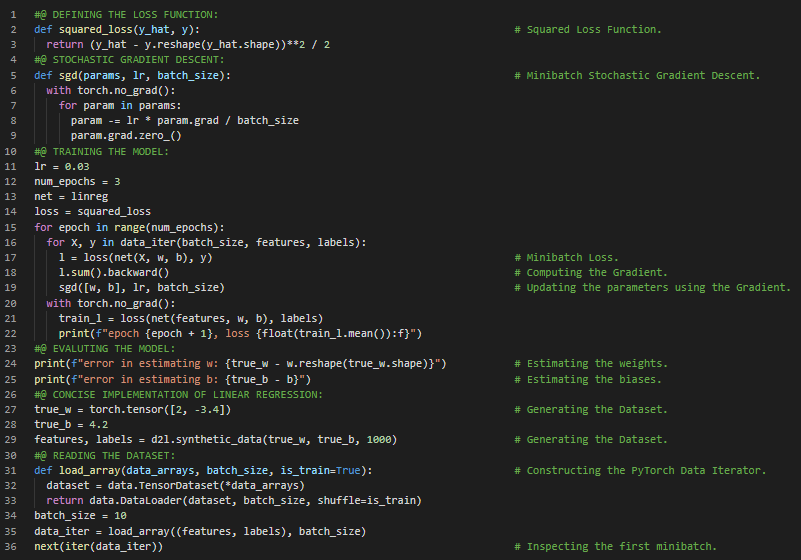
- 线性回归:线性回归是一种线性方法,用于建模标量响应与一个或多个解释变量(即因变量和自变量)之间的关系。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了线性回归、损失函数的定义、优化算法的定义、小批量随机梯度下降、模型训练、张量与微分、线性回归的简洁实现、生成合成数据集、模型评估等相关内容。我在截图中展示了使用PyTorch定义损失函数、执行小批量随机梯度下降、训练与评估模型、线性回归的简洁实现以及读取数据集的实现过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
300天数据之旅第90天!
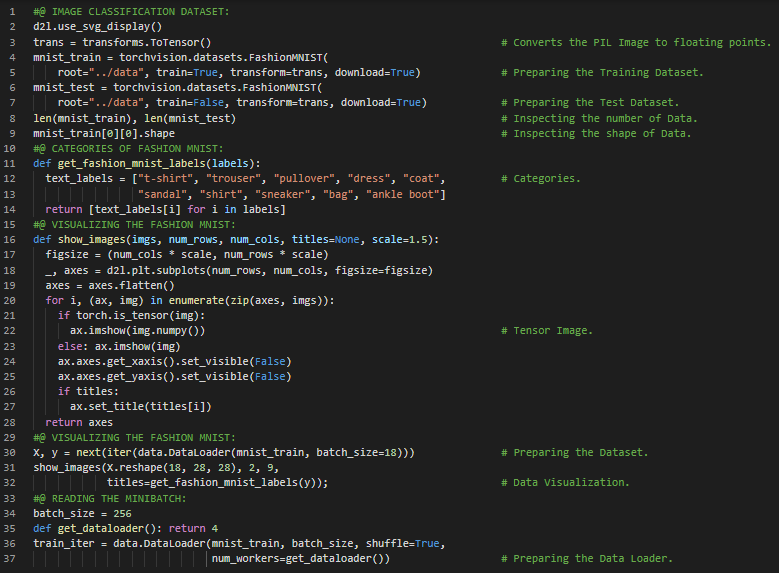
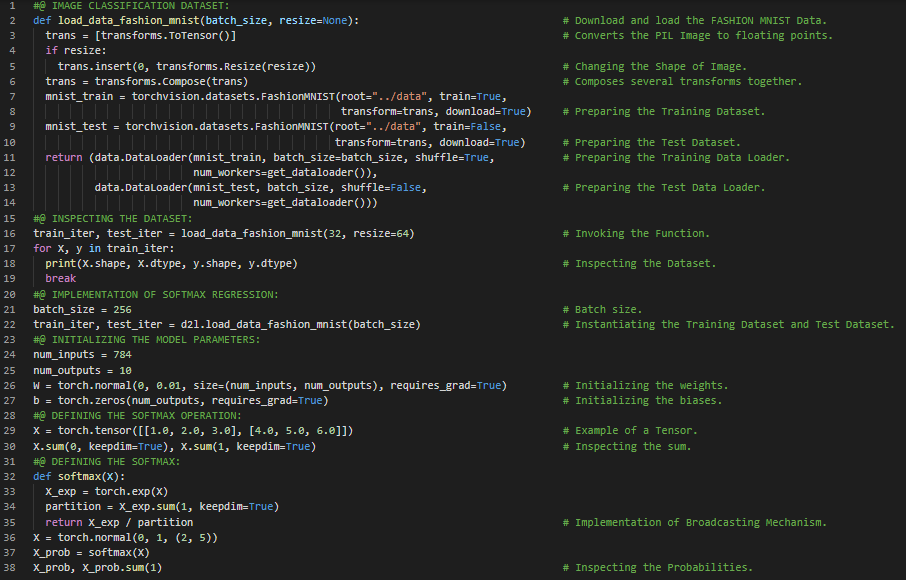
- 线性回归:线性回归是一种线性方法,用于建模标量响应与一个或多个解释变量(即因变量和自变量)之间的关系。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了Softmax回归、分类问题、网络架构、全连接层的参数化代价、Softmax运算、小批量的向量化、损失函数、对数似然、Softmax及其导数、交叉熵损失、信息论基础、熵与惊讶度、模型预测与评估、图像分类数据集等相关内容。我在截图中展示了使用PyTorch实现图像分类数据集、可视化、Softmax回归及运算,并附带模型参数的实现过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
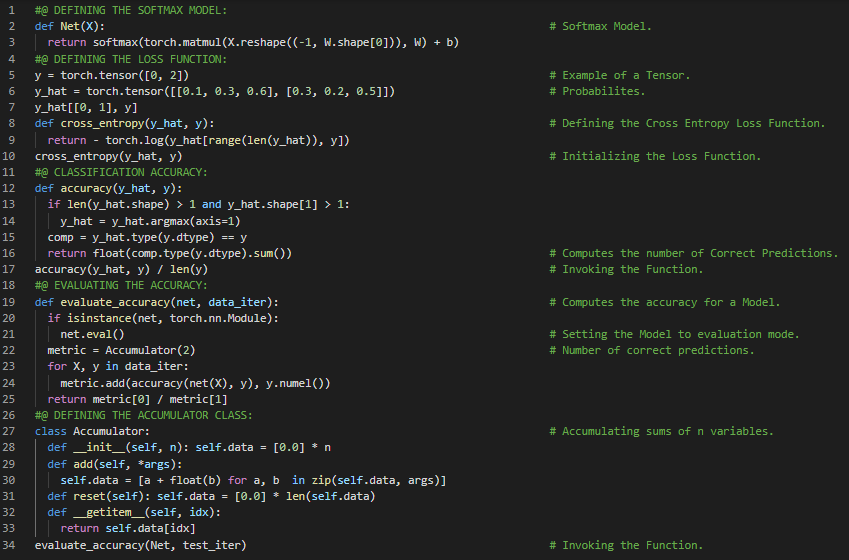
300天数据之旅第91天!
- 激活函数:激活函数通过计算加权总和并加上偏置来决定神经元是否被激活。它们是可微分的运算符。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了交叉熵损失函数、分类准确率与训练、Softmax回归、模型参数、优化算法、多层感知机、隐藏层、线性模型的问题、从线性到非线性模型、通用逼近定理、激活函数如ReLU函数、Sigmoid函数、Tanh函数、导数与梯度等相关内容。我在截图中展示了使用PyTorch实现Softmax回归模型、分类准确率、ReLU函数、Sigmoid函数、Tanh函数,并配有可视化效果。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
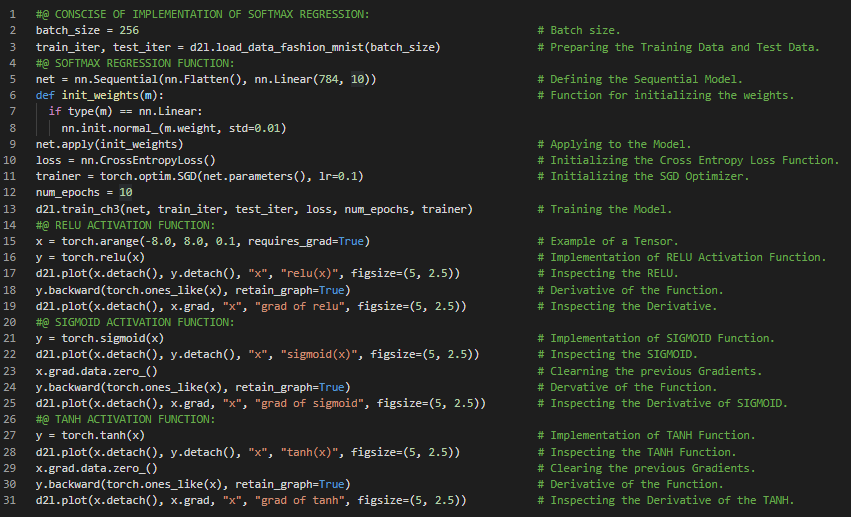
300天数据之旅第92天!
- 激活函数:激活函数通过计算加权总和并加上偏置来决定神经元是否被激活。它们是可微分的运算符。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了多层感知机的实现、模型参数的初始化、ReLU激活函数、交叉熵损失函数、模型训练、全连接层、简单线性层、Softmax回归及函数、随机梯度下降、Sequential API、高级API、学习率、权重与偏置、张量、超参数等相关内容。我在截图中展示了使用PyTorch实现多层感知机、ReLU激活函数、模型训练及模型评估的过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
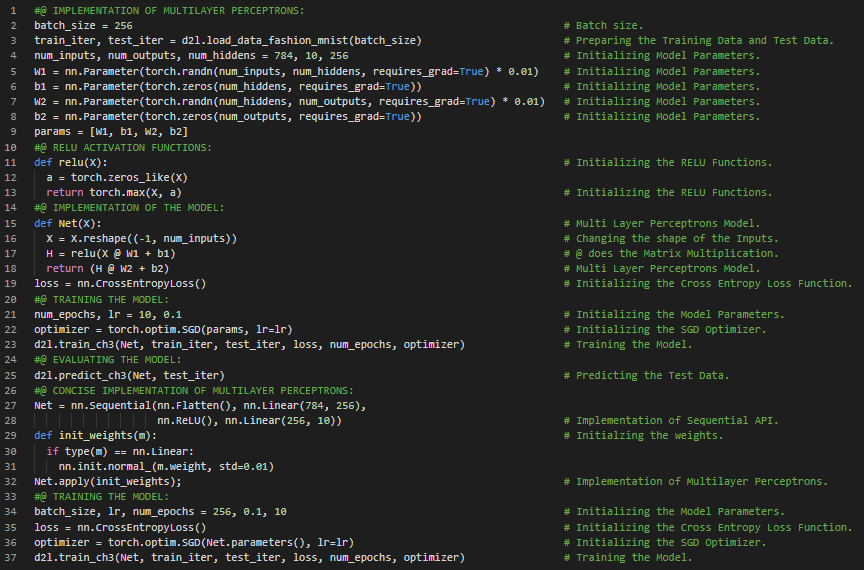
300天数据之旅第93天!
- 多层感知机:最简单的深度神经网络称为多层感知机。它们由多层神经元组成。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了模型选择、欠拟合、过拟合、训练误差与泛化误差、统计学习理论、模型复杂度、早停法、训练集、测试集和验证集、K折交叉验证、数据集大小、多项式回归、数据集的生成、模型的训练与测试、三阶多项式函数拟合、线性函数拟合、高阶多项式函数拟合、权重衰减、归一化等主题。我在截图中展示了使用PyTorch生成数据集、定义训练函数以及进行多项式函数拟合的实现过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
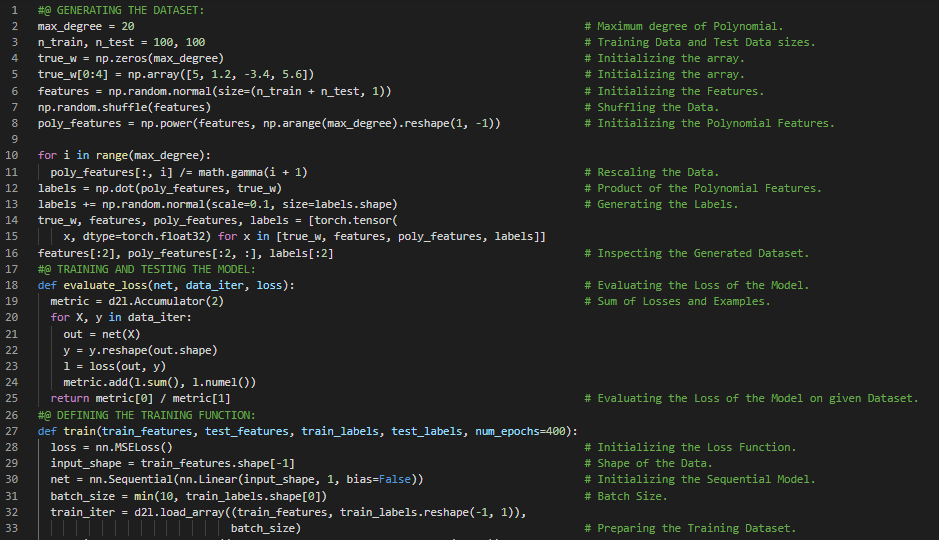
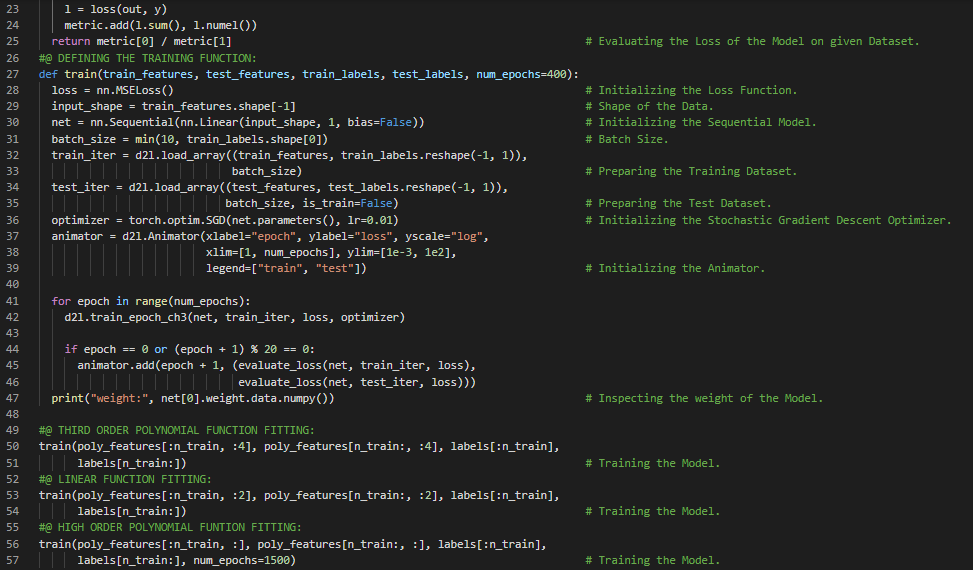
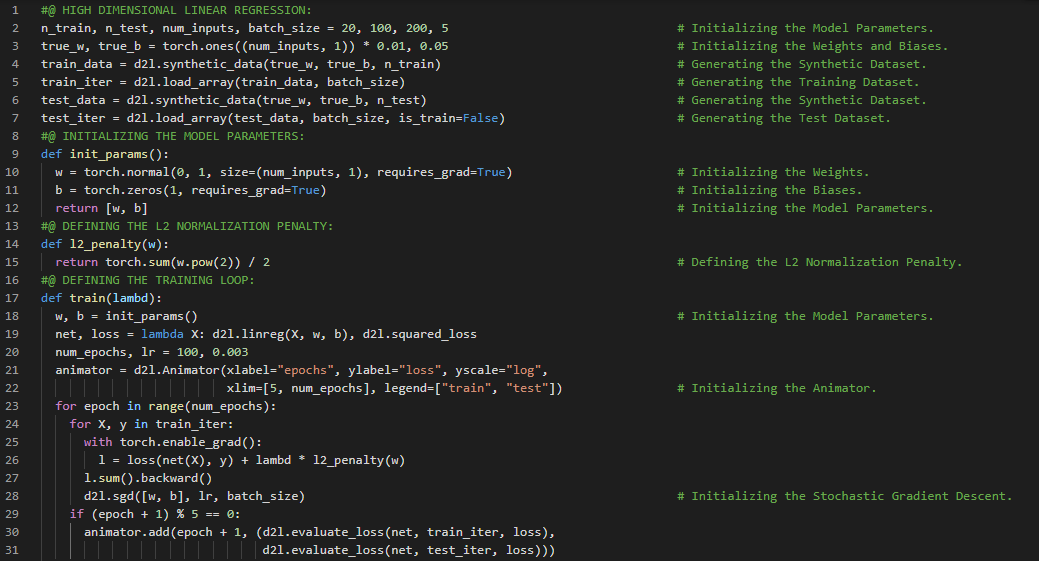
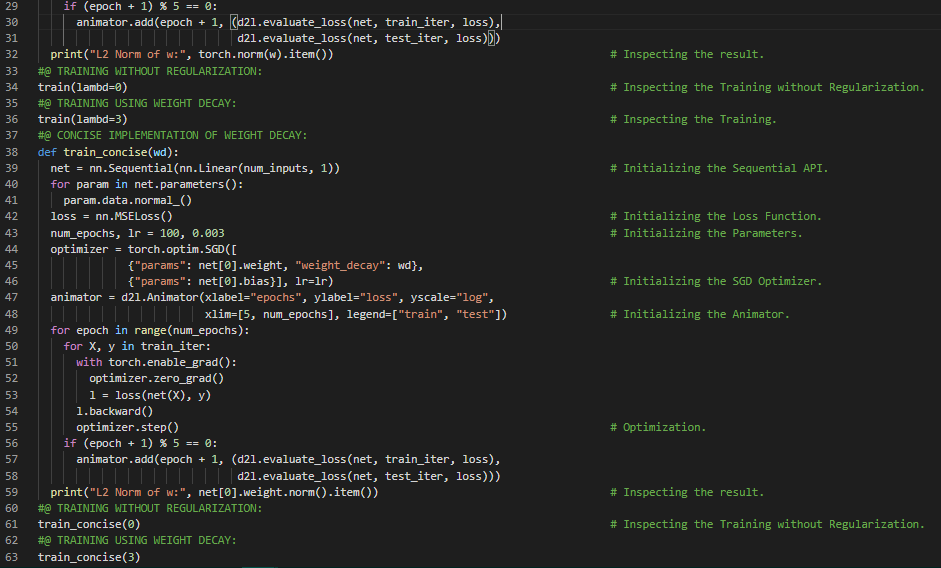
300天数据之旅第94天!
- 多层感知机:最简单的深度神经网络称为多层感知机。它们由多层神经元组成,每一层都与下一层完全连接,接收来自下层的输入,并影响上层。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了高维线性回归、模型参数、L2正则化惩罚项的定义、训练循环的定义、正则化与权重衰减、Dropout与过拟合、偏差与方差权衡、高斯分布、随机梯度下降、训练误差与测试误差等相关内容。我在截图中展示了使用PyTorch实现高维线性回归、模型参数、L2正则化惩罚项以及正则化和权重衰减的过程。希望你能从中获得一些见解,并加以实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
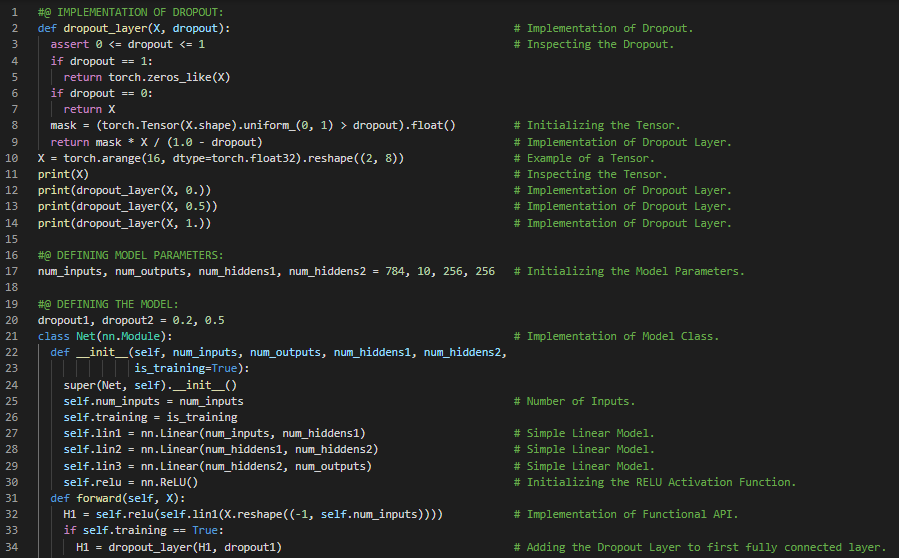
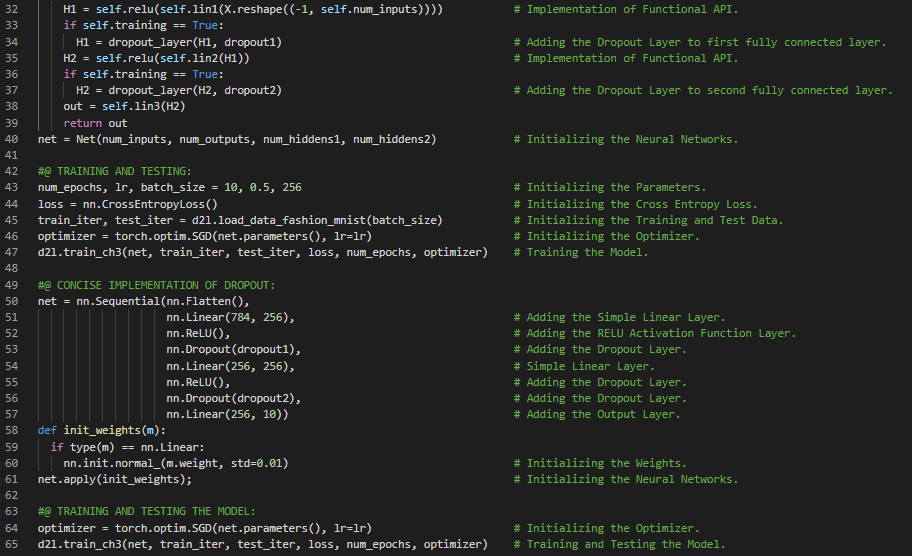
300天数据之旅第95天!
- Dropout与协同适应:Dropout是在前向传播过程中,在计算每一层时注入噪声的过程。协同适应则是神经网络中的一种现象,表现为每一层都依赖于前一层激活的具体模式。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了Dropout、过拟合、泛化误差、偏差与方差权衡、通过扰动提高鲁棒性、L2正则化与权重衰减、协同适应、Dropout概率、Dropout层、Fashion MNIST数据集、激活函数、随机梯度下降、Sequential API与Functional API等相关内容。我在截图中展示了使用PyTorch实现Dropout层以及训练和测试模型的过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
300天数据之旅第96天!
- Dropout与协同适应:Dropout是在前向传播过程中,在计算每一层时注入噪声的过程。协同适应则是神经网络中的一种现象,表现为每一层都依赖于前一层激活的具体模式。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了前向传播、反向传播与计算图、数值稳定性、梯度消失与爆炸、打破对称性、参数初始化、环境与分布偏移、协变量偏移、标签偏移、概念偏移、非平稳分布、经验风险与真实风险、批量学习、在线学习、强化学习等相关内容。我在截图中展示了使用PyTorch进行数据预处理和数据准备的实现过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 预测房价
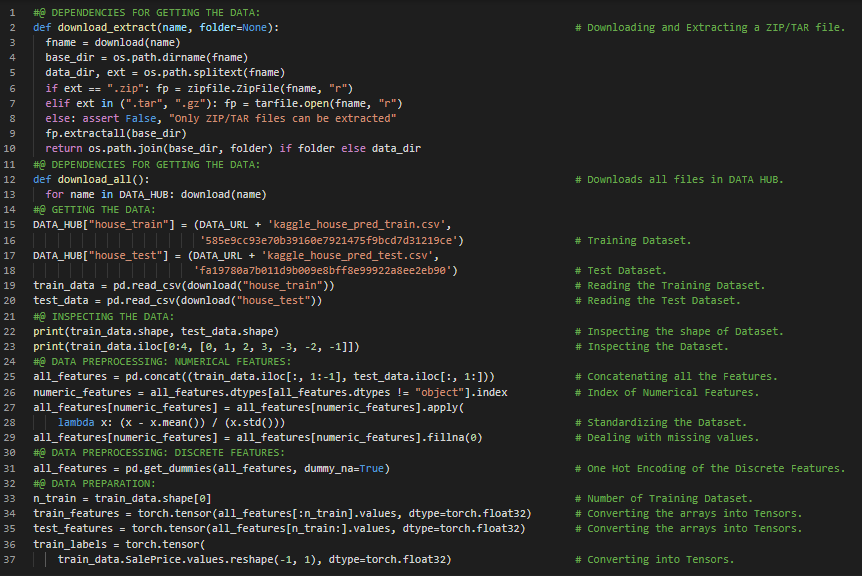
300天数据之旅第97天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了深度网络的训练与构建、数据集的下载与缓存、数据预处理、回归问题、数据集的访问与读取、数值型特征与离散类别型特征、优化与方差、数组与张量、简单线性模型、Sequential API、均方根误差、Adam优化器、超参数调优、K折交叉验证、训练误差与验证误差、模型选择、过拟合与正则化等主题。我在这里通过截图展示了使用PyTorch实现的简单线性模型、均方根误差、训练函数以及K折交叉验证。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
- 预测房价
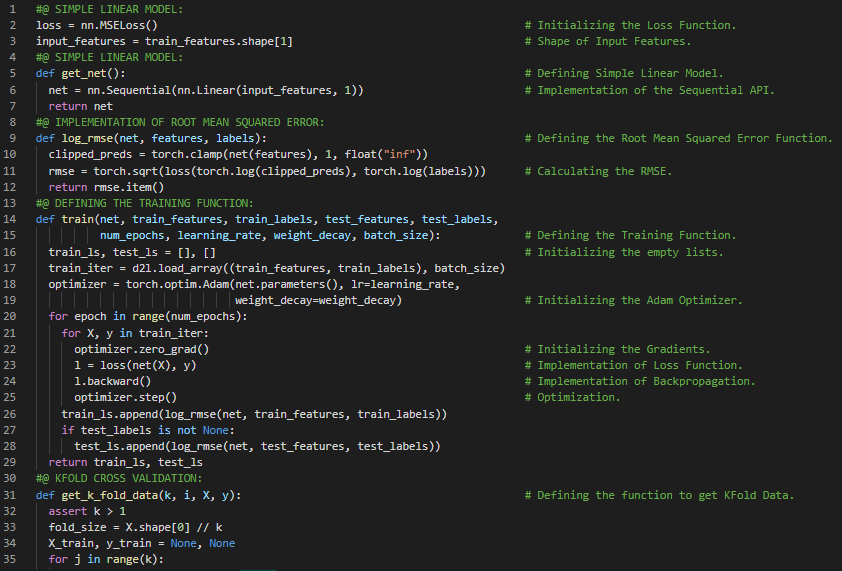
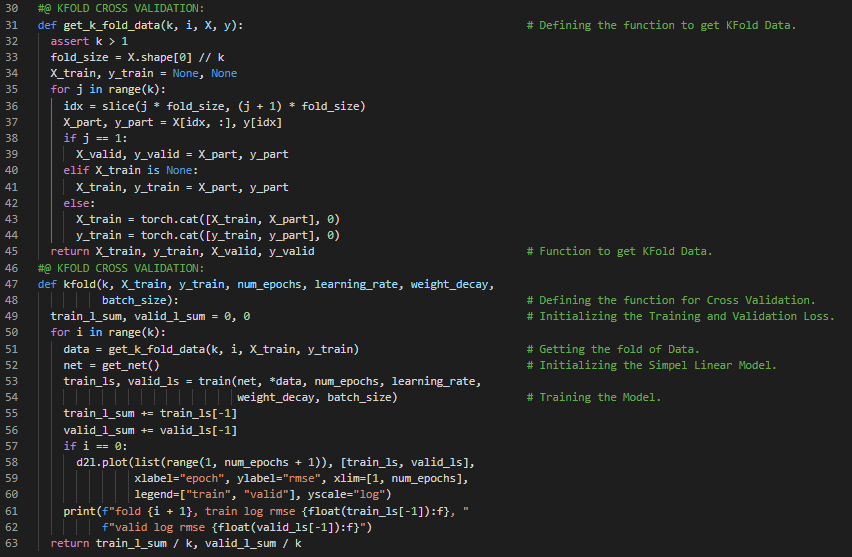
300天数据之旅第98天!
- 常量参数:常量参数是指既不是前一层计算结果,也不是神经网络中可更新参数的项。在我的机器学习和深度学习之旅中,今天我同样阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了K折交叉验证、训练与预测、超参数优化、深度学习计算、层与块、Softmax回归、多层感知机、ResNet架构、前向传播与反向传播函数、ReLU激活函数、Sequential块的实现、MLP的实现、常量参数等主题。我在这里通过截图展示了使用PyTorch实现的MLP、Sequential API类以及前向传播函数。希望你能从中获得一些见解,并进一步探索。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
- 预测房价
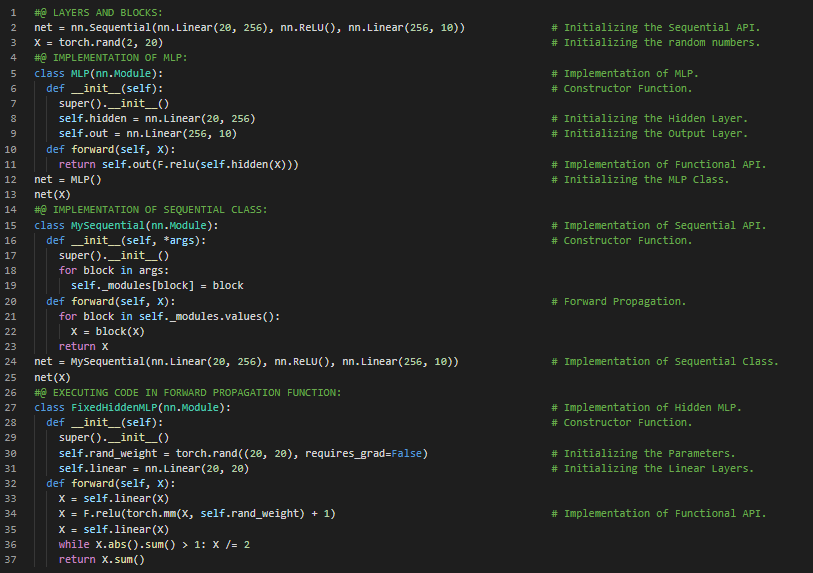
300天数据之旅第99天!
- 常量参数:常量参数是指既不是前一层计算结果,也不是神经网络中可更新参数的项。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了参数管理、参数访问、目标参数、从嵌套块中收集参数、参数初始化、自定义初始化、共享参数、延迟初始化、多层感知机、输入维度、自定义层的定义、无参数层、前向传播函数、常量参数、Xavier初始化、权重与偏置等主题。我在这里通过截图展示了使用PyTorch实现的参数访问、参数初始化、共享参数以及无参数层。希望你能从中获得一些启发,并进一步研究。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
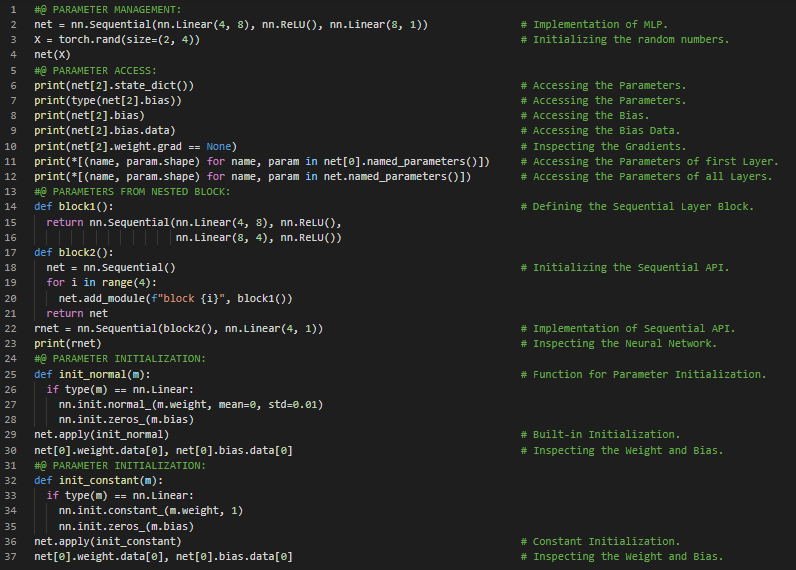
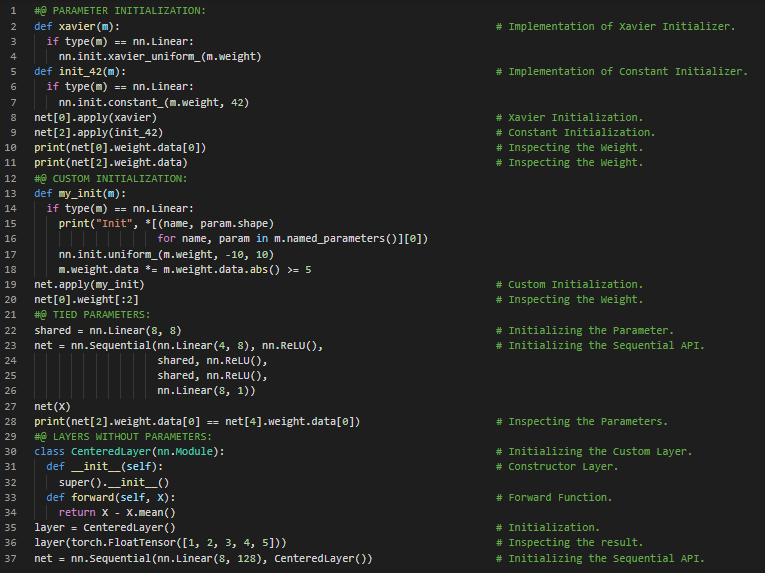
300天数据之旅第100天!
- 不变性和局部性原则:平移不变性原则指出,无论同一图像区域出现在何处,网络对其的响应都应相同。局部性原则则强调,网络应专注于局部区域,而不受远处区域内容的影响。在我的机器学习和深度学习之旅中,今天我依然阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了全连接层到卷积层的转换、平移不变性、局部性原则、对MLP的约束、卷积神经网络、互相关运算、图像与通道、文件IO、张量及模型参数的加载与保存、自定义层、有参数层等主题。我在这里通过截图展示了使用PyTorch实现的有参数层、张量及模型参数的加载与保存。希望你能从中获得一些启发,并进一步探索。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
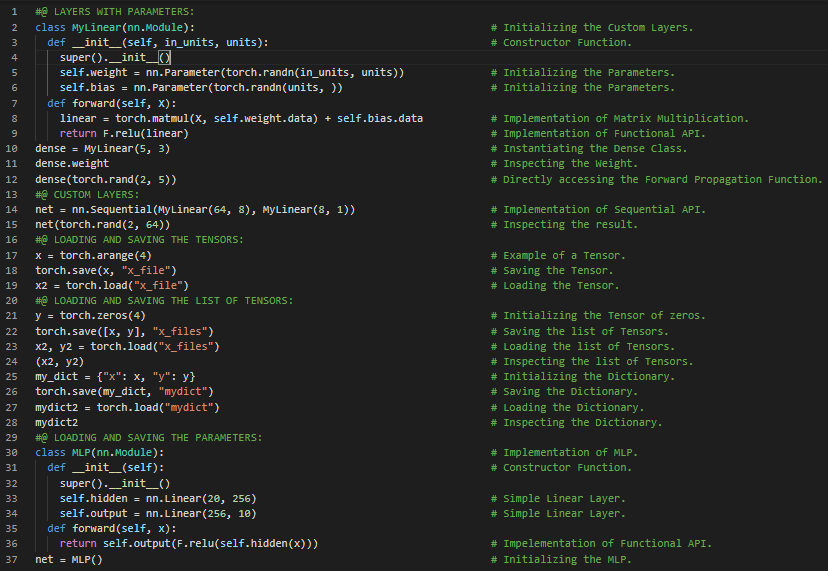
300天数据之旅第101天!
- 不变性和局部性原则:平移不变性原则指出,无论同一图像区域出现在何处,网络对其的响应都应相同。局部性原则则强调,网络应专注于局部区域,而不受远处区域内容的影响。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了卷积神经网络、用于图像的卷积、互相关运算、卷积层、构造函数与前向传播函数、权重与偏置、图像中的物体边缘检测、卷积核的学习、反向传播、特征图与感受野、卷积核参数等主题。我在这里通过截图展示了使用PyTorch实现的互相关运算、卷积层以及卷积核的学习。希望你能从中获得一些启发,并进一步研究。也希望大家能花些时间学习上述书籍及其他相关资料中的内容。对接下来的日子充满期待!!
- 书籍:
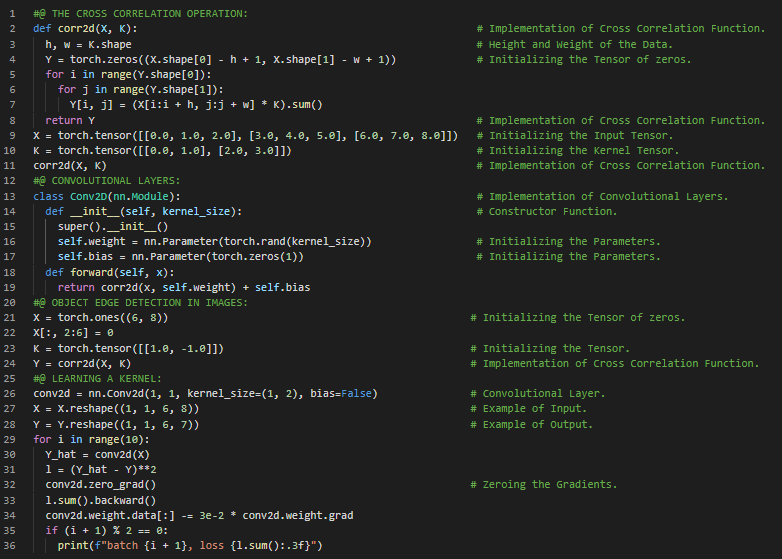
第102天,300天数据之旅!
- 最大池化:池化操作由一个固定形状的窗口组成,该窗口按照步幅在输入的所有区域上滑动,为每个位置计算出一个输出值,这个输出值可以是池化窗口内元素的最大值或平均值。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了填充与步幅、步幅卷积、互相关、多输入多输出通道、卷积层、最大池化层和平均池化层、池化窗口与操作、卷积神经网络、LeNet架构、监督学习、卷积编码器、Sigmoid激活函数以及与此相关的其他主题。我在这里通过快照展示了使用PyTorch实现的卷积神经网络、填充、步幅和池化层,以及多通道的实现。希望你能从中获得一些启发,并进一步深入研究。我也希望你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
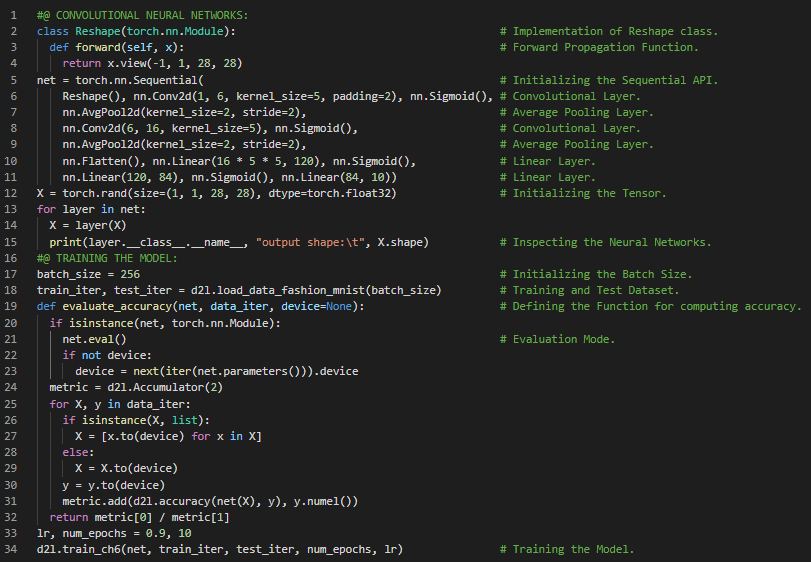
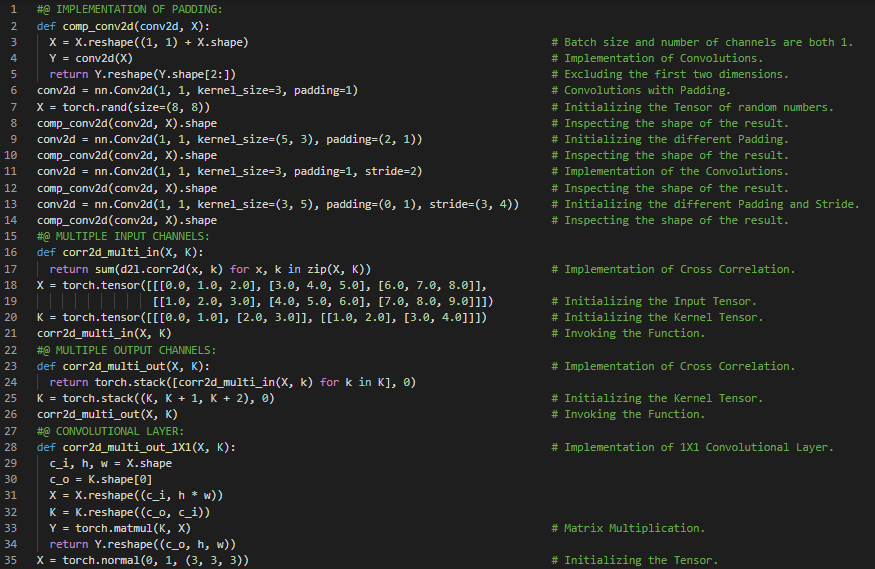
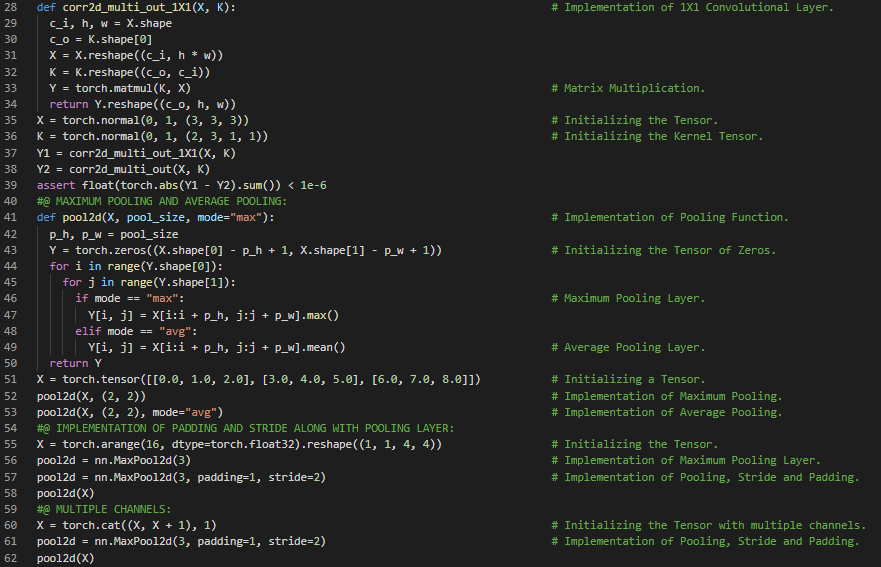
第103天,300天数据之旅!
- VGG网络:VGG网络通过可重用的卷积块构建网络。VGG模型由每个卷积块中的卷积层数量和输出通道数来定义。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了卷积神经网络、监督学习、深度CNN和AlexNet、支持向量机与特征、表示学习、数据与硬件加速器问题、LeNet和AlexNet的架构、ReLU等激活函数、使用CNN块的网络、VGG神经网络架构、填充与池化、卷积层、Dropout、全连接层和线性层,以及与此相关的其他主题。我在这里通过快照展示了使用PyTorch实现的AlexNet架构和VGG网络架构,以及CNN块的应用。希望你能从中获得一些启发,并进一步深入研究。我也希望你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
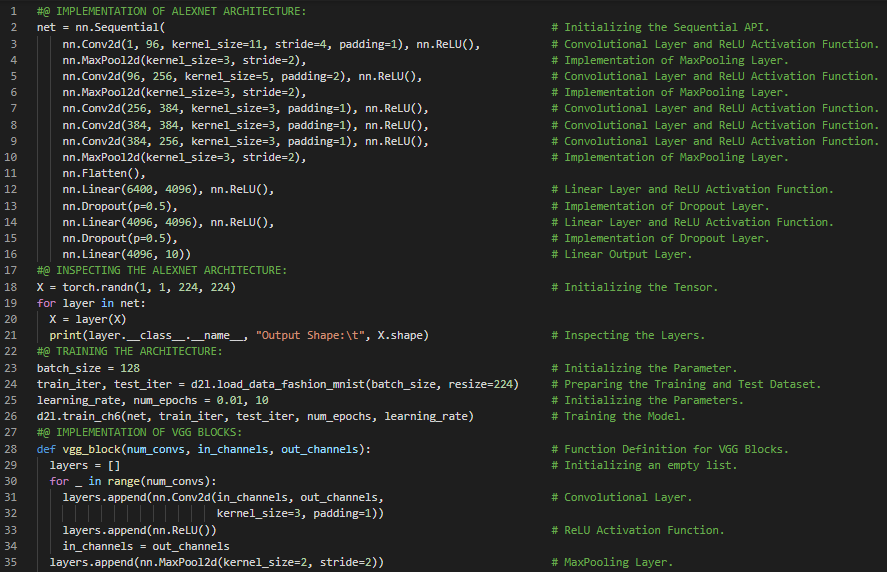
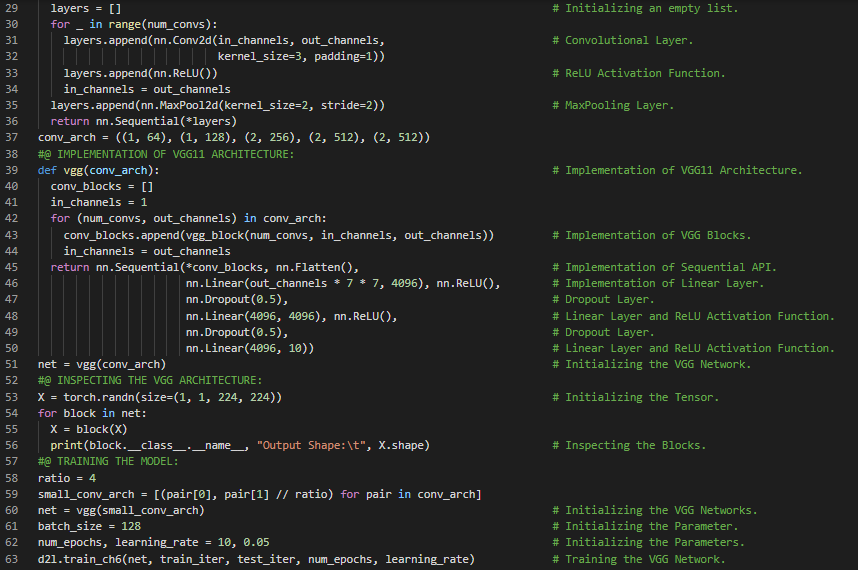
第104天,300天数据之旅!
- VGG网络:VGG网络通过可重用的卷积块构建网络。VGG模型由每个卷积块中的卷积层数量和输出通道数来定义。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了网络中的网络(NIN)架构、NIN块与模型、卷积层、ReLU激活函数、顺序API与函数式API、全局平均池化层、具有并行拼接的网络(GoogLeNet)、Inception块、GoogLeNet模型与架构、最大池化层、模型训练,以及与此相关的其他主题。我在这里通过快照展示了使用PyTorch实现的NIN块与模型、Inception块以及GoogLeNet模型。希望你能从中获得一些启发,并进一步深入研究。我也希望你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
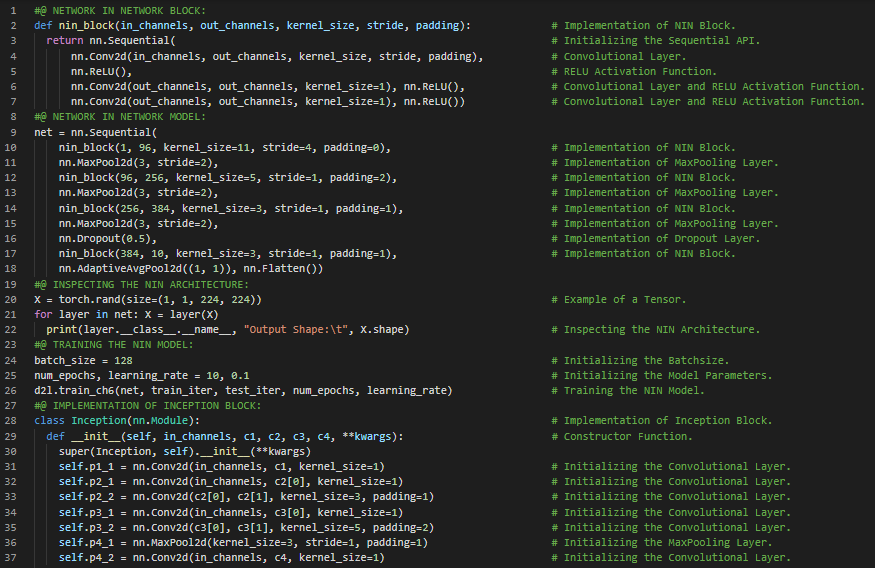
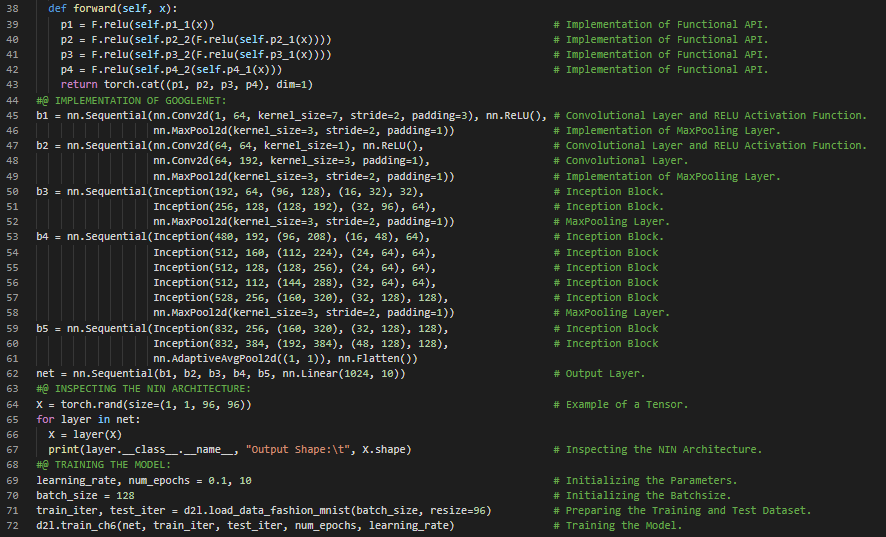
第105天,300天数据之旅!
- 批量归一化:批量归一化通过利用小批量的均值和标准差,持续调整神经网络的中间输出,从而使中间输出的值更加稳定。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了批量归一化、深度神经网络的训练、尺度参数与偏移参数、批量归一化层、全连接层、卷积层、预测时的批量归一化、张量、均值与方差、在LeNet中应用BN、使用高级API进行BN的简洁实现、内部协变量偏移、Dropout层、残差网络(ResNet)、函数类、残差块等与此相关的其他主题。我在这里通过快照展示了使用PyTorch实现的批量归一化架构。希望你能从中获得一些启发,并进一步深入研究。我也希望你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
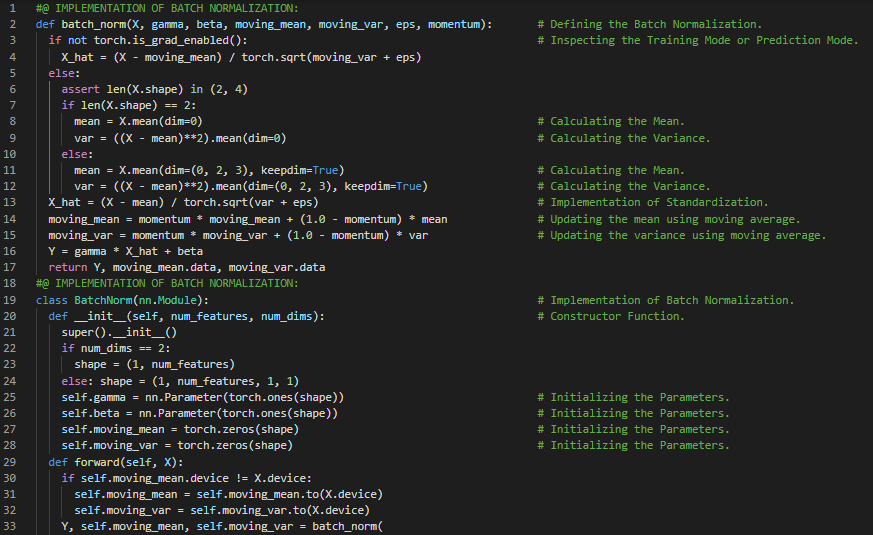
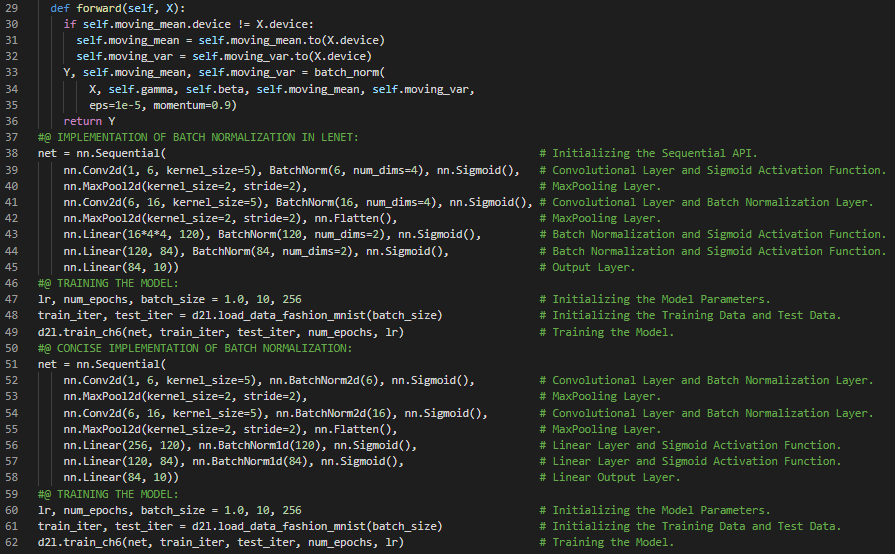
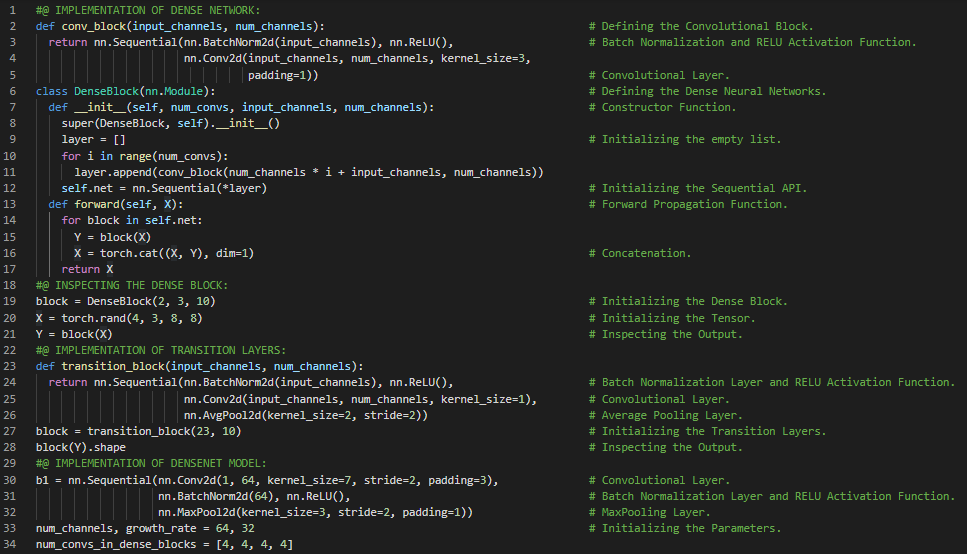
第106天,300天数据之旅!
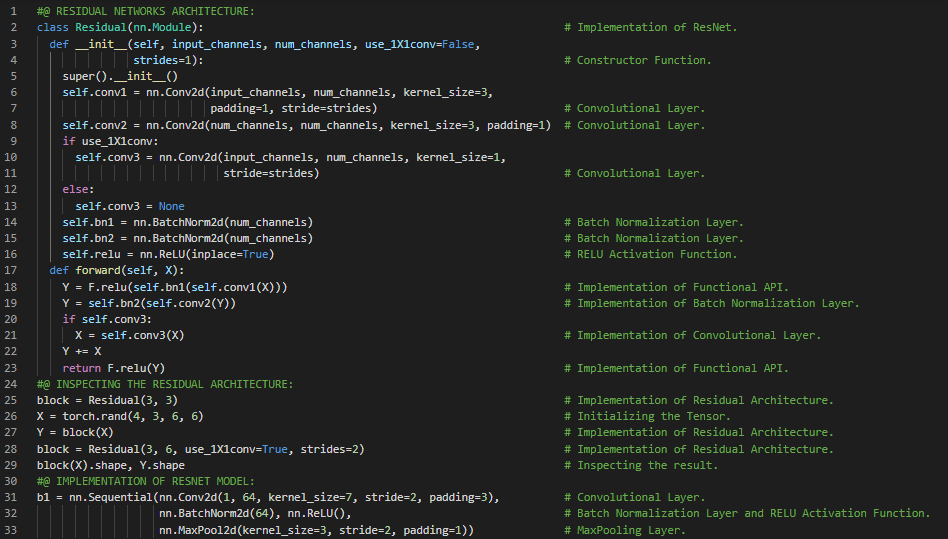
- 批量归一化:批量归一化通过利用小批量的均值和标准差,持续调整神经网络的中间输出,从而使中间输出的值更加稳定。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了密集连接神经网络(DenseNet)、密集块、批量归一化、激活函数与卷积层、过渡层、残差网络(ResNet)、函数类、残差块、残差映射、残差连接、ResNet模型、最大和平均池化层、模型训练,以及与此相关的其他主题。我在这里通过快照展示了使用PyTorch实现的ResNet架构和ResNet模型。希望你能从中获得一些启发,并进一步深入研究。我也希望你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
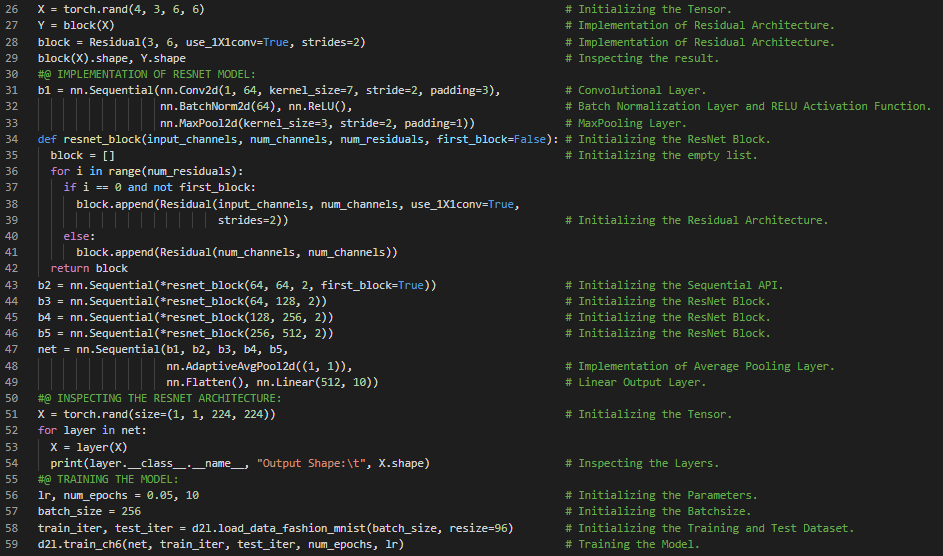
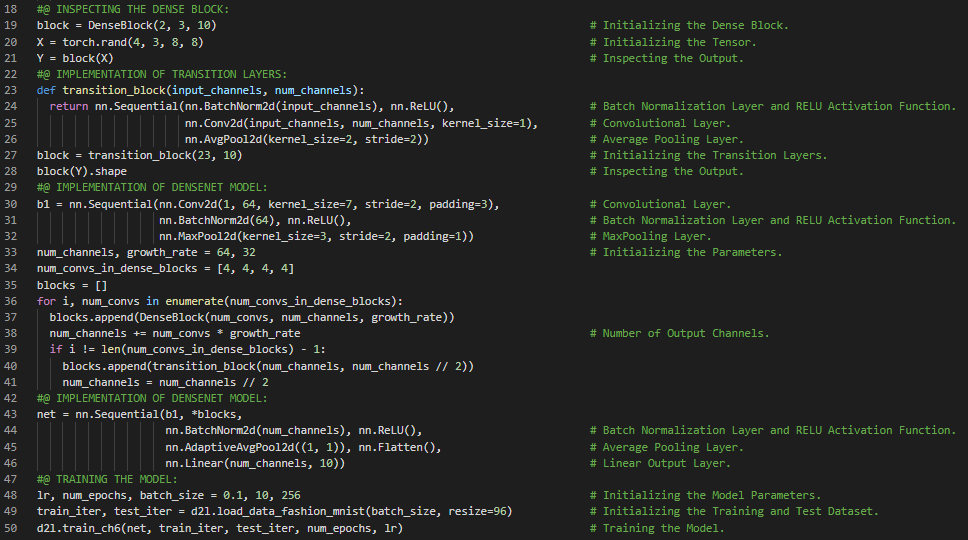
300天数据之旅第107天!
- 序列模型:在已知观测值之外进行的预测称为外推。而在现有观测值之间进行的估计则称为插值。序列模型需要专门的统计工具来进行估计,比如自回归模型。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了DenseNet模型、卷积层、循环神经网络、序列模型、插值与外推、统计工具、自回归模型、潜在自回归模型、马尔可夫模型、强化学习算法、因果关系、条件概率分布、训练多层感知机、单步预测等与此相关的主题。我在截图中展示了使用PyTorch实现的DenseNet架构以及简单的RNN实现。希望你能从中获得一些启发,并进一步深入研究。也期待你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
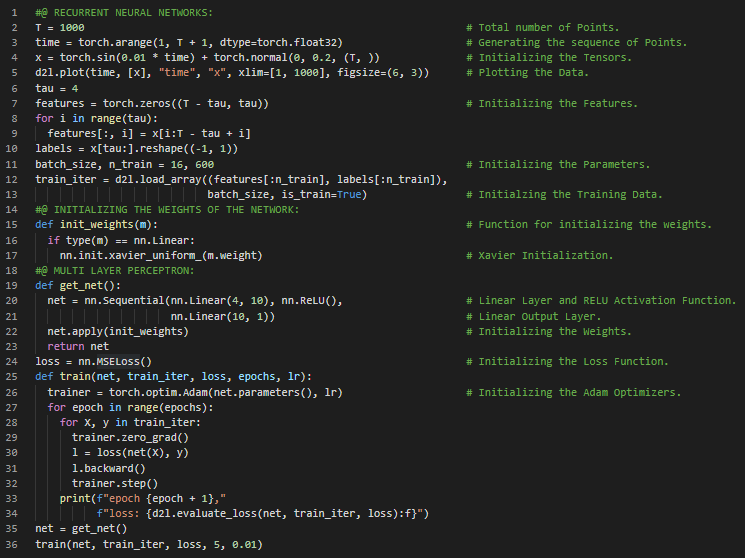
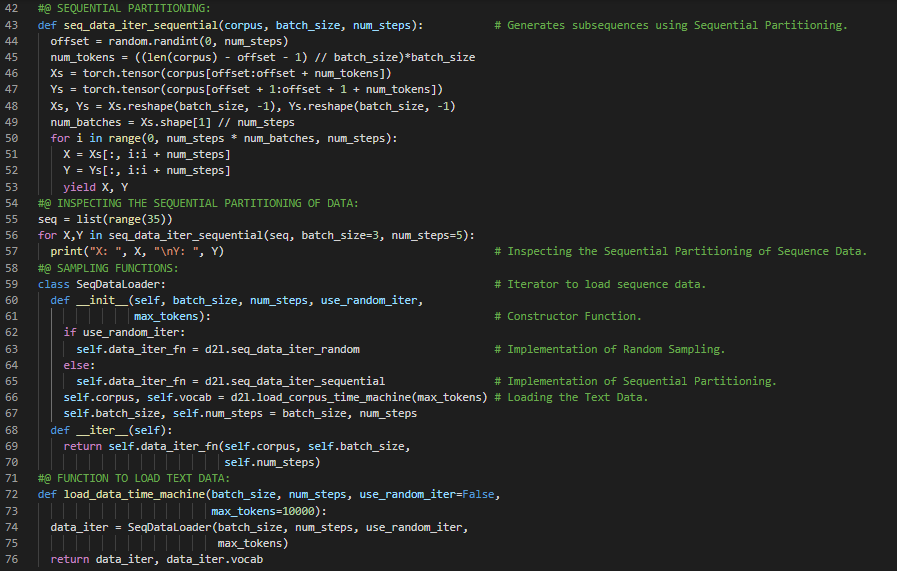
300天数据之旅第108天!
- 分词与词汇表:分词是将字符串或文本拆分为一系列标记的过程。词汇表则是将字符串标记映射为数字索引的字典。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了文本预处理、文本语料库、分词函数、序列模型与数据集、词汇表、字典、多层感知机、单步预测、多步预测、张量、循环神经网络等与此相关的主题。我在截图中展示了使用PyTorch读取数据集、进行分词和构建词汇表的实现过程。希望你能从中获得一些见解,并继续深入探索。也期待你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
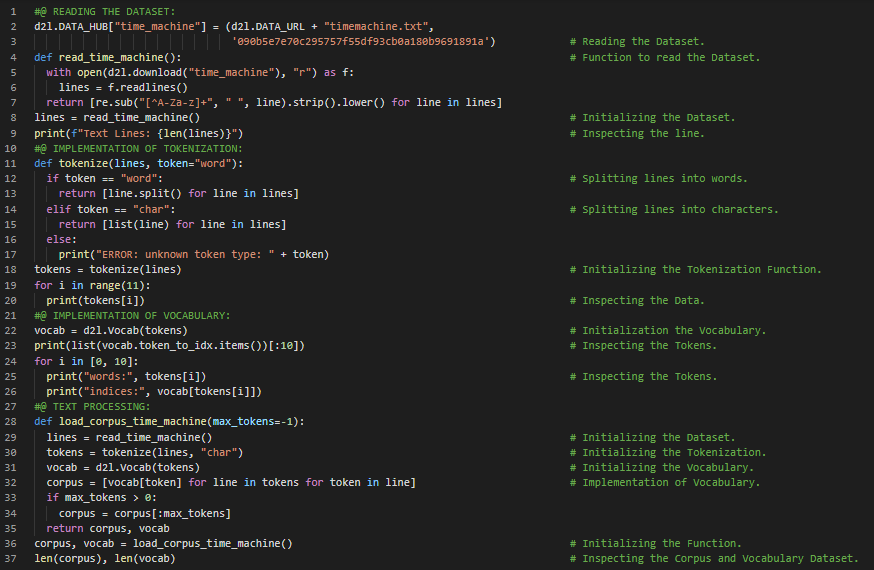
300天数据之旅第109天!
- 顺序划分:顺序划分是一种在遍历小批量时保持分割子序列顺序的策略。它确保在迭代过程中,两个相邻小批量中的子序列在原始序列中也是相邻的。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了语言模型与序列数据集、条件概率、拉普拉斯平滑、马尔可夫模型与N元模型、一元模型、二元模型和三元模型、自然语言统计、停用词、词频、齐普夫定律、长序列数据的读取、小批量、随机采样、顺序划分等与此相关的主题。我在截图中展示了使用PyTorch实现的一元、二元和三元模型词频、随机采样以及顺序划分的过程。希望你能从中获得一些启发,并继续深入研究。也期待你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
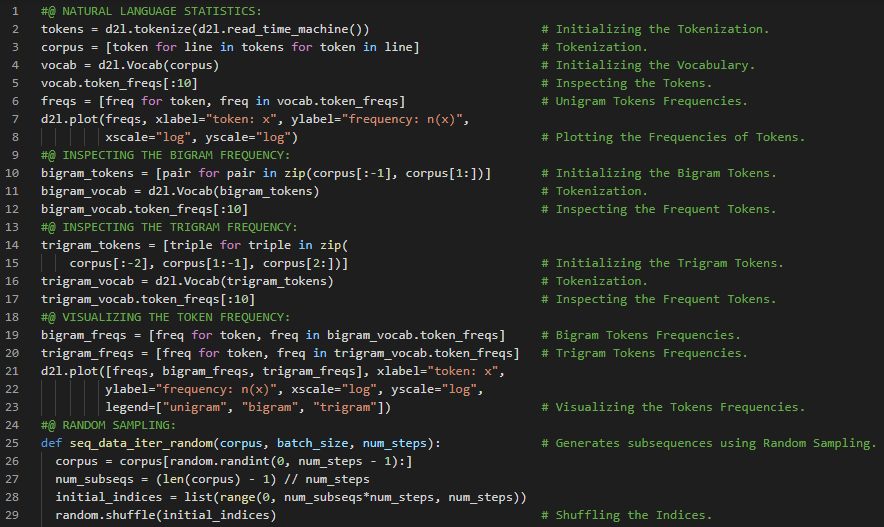
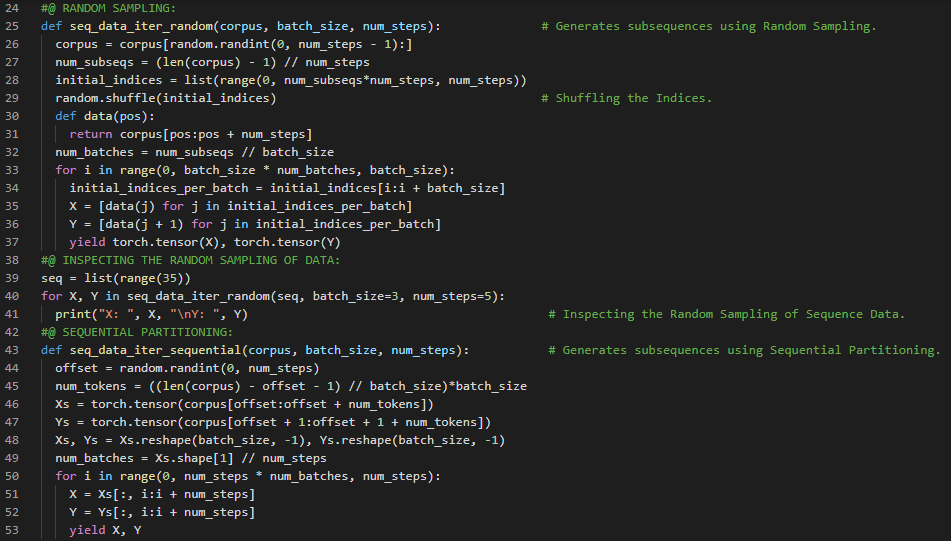
300天数据之旅第110天!
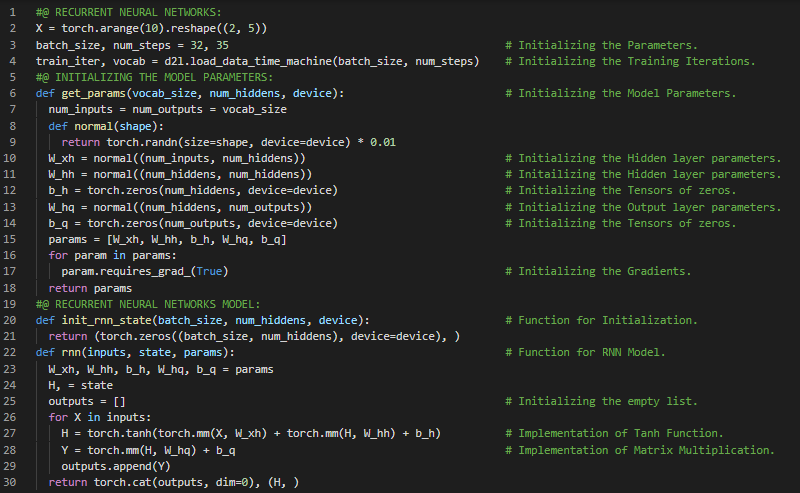
- 循环神经网络:循环神经网络是一种利用递归计算来更新隐藏状态的网络结构。RNN的隐藏状态可以捕捉到当前时间步之前整个序列的历史信息。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了循环神经网络(RNN)、隐藏状态、无隐藏状态的神经网络、有隐藏状态的神经网络、RNN层、基于RNN的字符级语言模型、困惑度、从零开始实现RNN、独热编码、词汇表、模型参数初始化、RNN模型、小批量和双曲正切激活函数、预测与预热期、梯度裁剪、反向传播等与此相关的主题。我在截图中展示了使用PyTorch实现的RNN模型、梯度裁剪以及模型训练的过程。希望你能从中获得一些启发,并继续深入研究。也期待你能花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
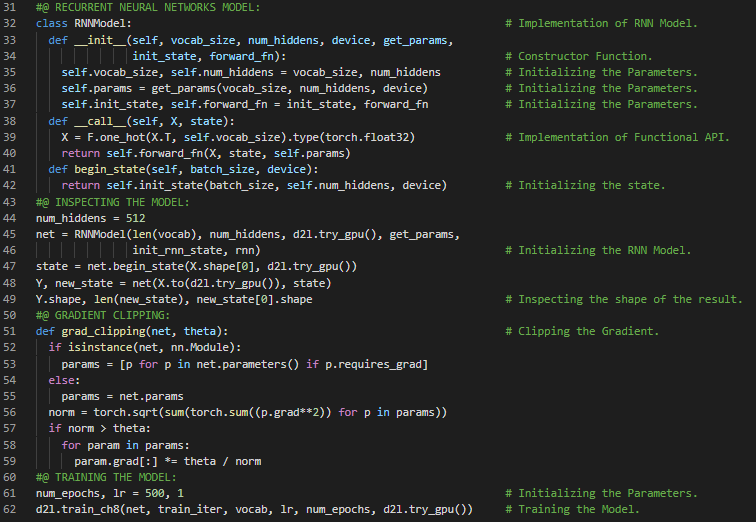
300天数据之旅第111天!
- 循环神经网络:循环神经网络是一种通过递归计算隐藏状态的网络。RNN的隐藏状态可以捕捉序列到当前时间步的历史信息。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了循环神经网络的实现、RNN模型的定义、训练与预测、随时间反向传播、梯度爆炸、梯度消失、RNN中梯度的分析、完整计算、截断时间步、随机截断、RNN中的梯度计算策略、激活函数、常规截断等主题。我在截图中展示了使用PyTorch实现的循环神经网络、训练与预测过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
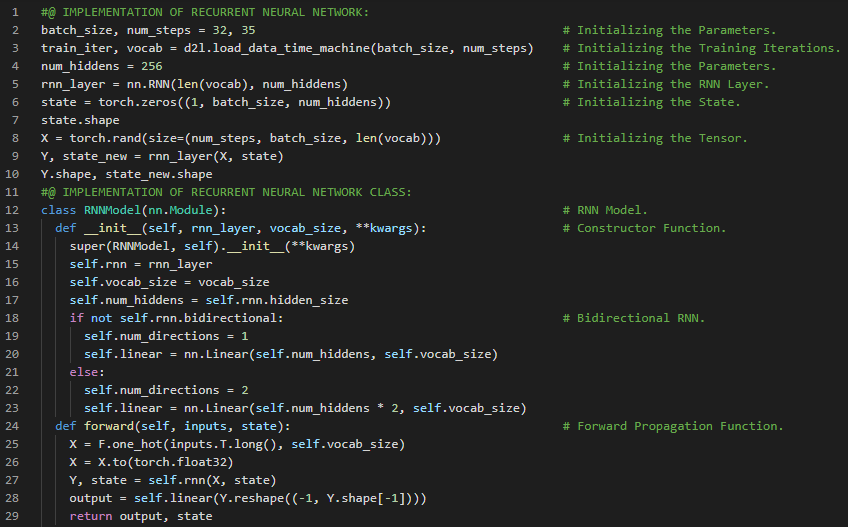
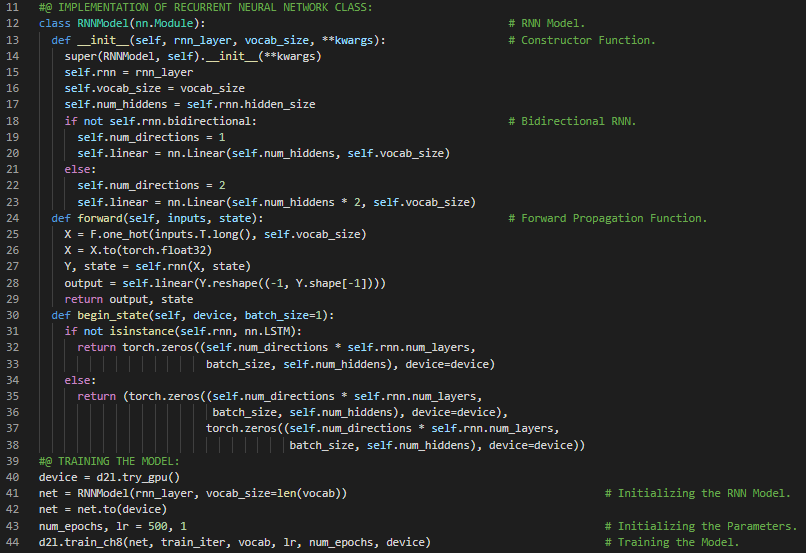
300天数据之旅第112天!
- 门控循环单元:门控循环单元(GRU)是循环神经网络中的一种门控机制,用于决定何时更新隐藏状态以及何时重置隐藏状态。它旨在解决标准RNN中存在的梯度消失问题。在我的机器学习和深度学习之旅中,今天我同样阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了现代循环神经网络、梯度裁剪、门控循环单元(GRU)、记忆细胞、门控隐藏状态、重置门与更新门、广播操作、候选隐藏状态、哈达玛积运算符、隐藏状态、模型参数初始化、GRU模型的定义、训练与预测等相关主题。我在截图中展示了使用PyTorch实现的门控循环单元、GRU模型、训练与预测的过程。希望你能从中获得一些见解,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
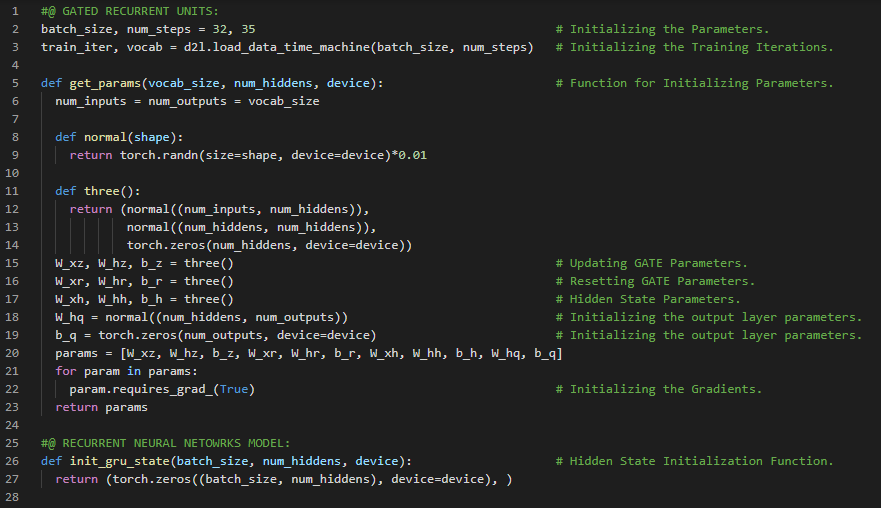
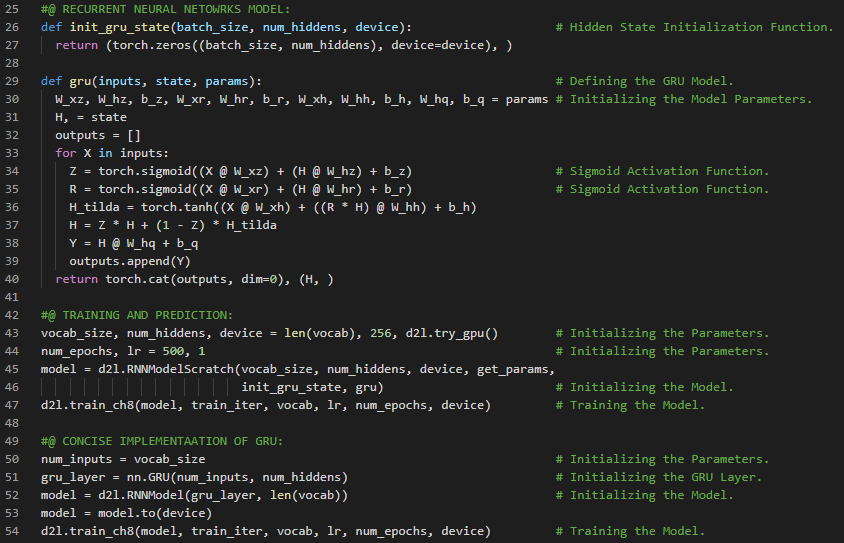
300天数据之旅第113天!
- 长短期记忆网络:长短期记忆网络(LSTM)是循环神经网络的一种,能够学习序列预测问题中的顺序依赖关系。LSTM具有输入门、遗忘门和输出门,用于控制信息的流动。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了长短期记忆网络(LSTM)、门控记忆细胞、输入门、遗忘门和输出门、候选记忆细胞、双曲正切激活函数、sigmoid激活函数、记忆细胞、隐藏状态、模型参数初始化、LSTM模型的定义、训练与预测、门控循环单元(GRU)、高斯分布等相关主题。我在截图中展示了使用PyTorch实现的长短期记忆网络模型、训练与预测过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
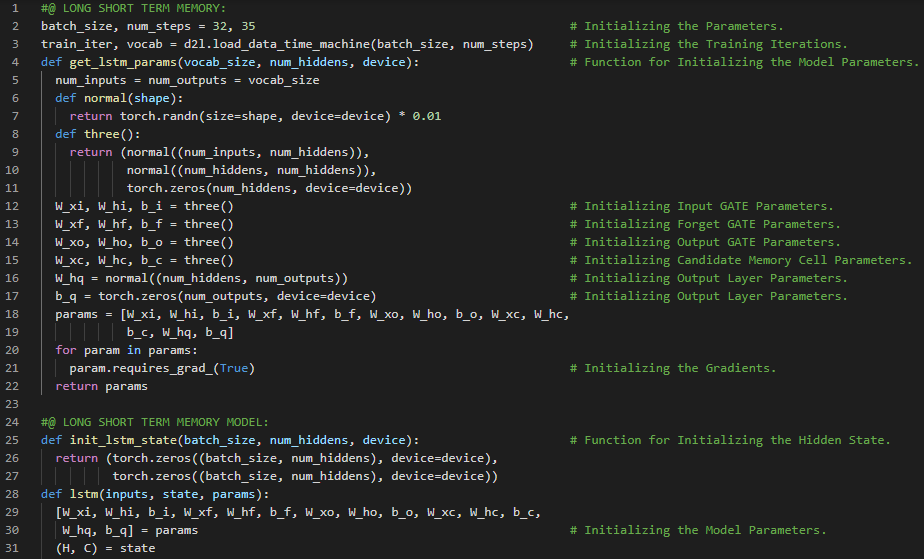
300天数据之旅第114天!
- 长短期记忆网络:长短期记忆网络(LSTM)是循环神经网络的一种,能够学习序列预测问题中的顺序依赖关系。LSTM具有输入门、遗忘门和输出门,用于控制信息的流动。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了深层循环神经网络、函数依赖关系、双向循环神经网络、隐马尔可夫模型中的动态规划、双向模型、计算成本与应用、机器翻译与数据集、数据集预处理、分词、词汇表、文本序列填充等相关主题。我在截图中展示了使用PyTorch实现的数据集下载、预处理、分词及构建词汇表的过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
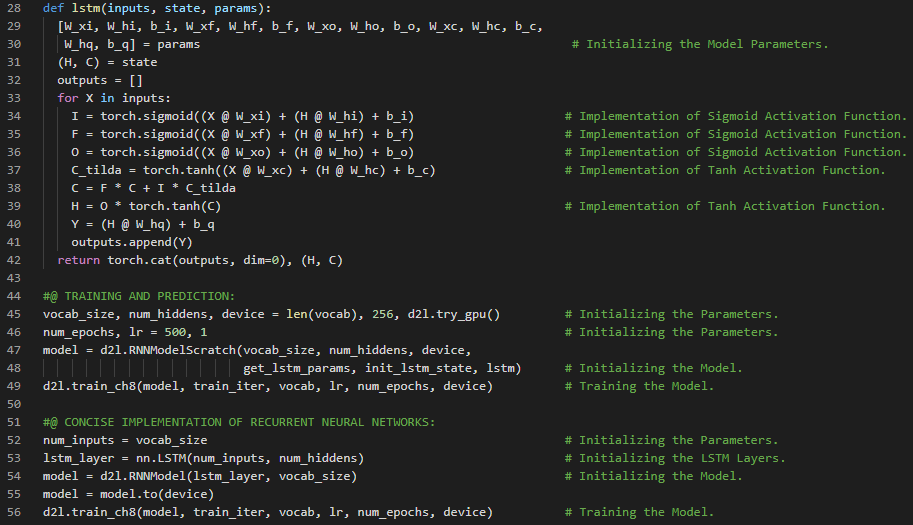
- 书籍:
300天数据之旅第115天!
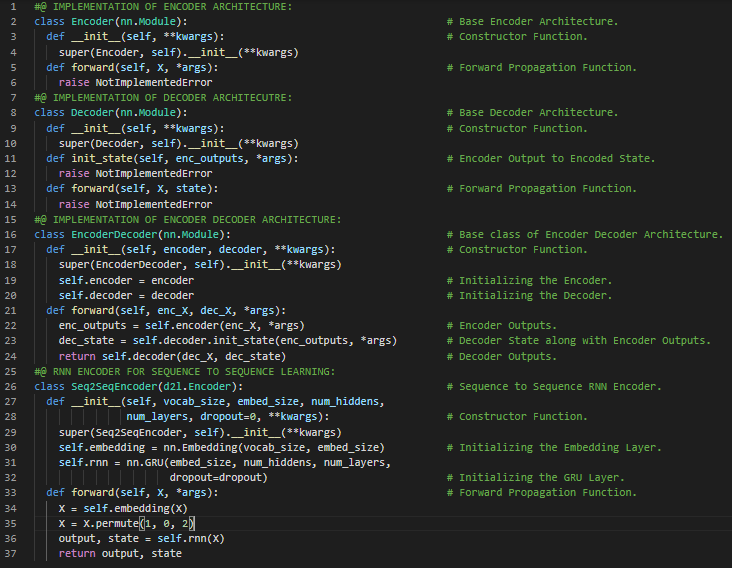
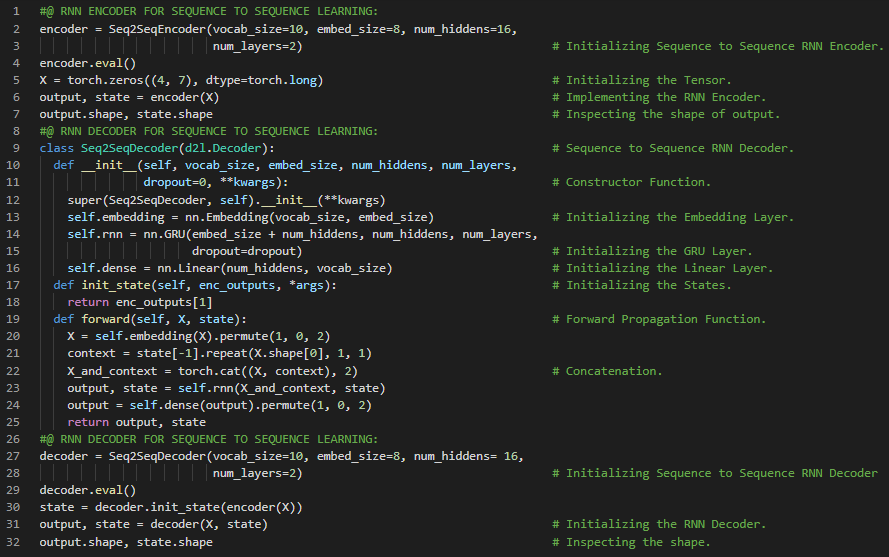
- 编码器-解码器架构:编码器接收变长序列作为输入,并将其转换为固定形状的状态。解码器则将这种固定形状的编码状态映射回变长序列。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了编码器与解码器架构、机器翻译模型、序列转导模型、前向传播函数、序列到序列学习、循环神经网络、嵌入层、门控循环单元(GRU)层、隐藏状态与单元、RNN编码器-解码器架构、词汇表等相关主题。我在截图中展示了使用PyTorch实现的编码器、解码器架构以及用于序列到序列学习的RNN编码器-解码器模型。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
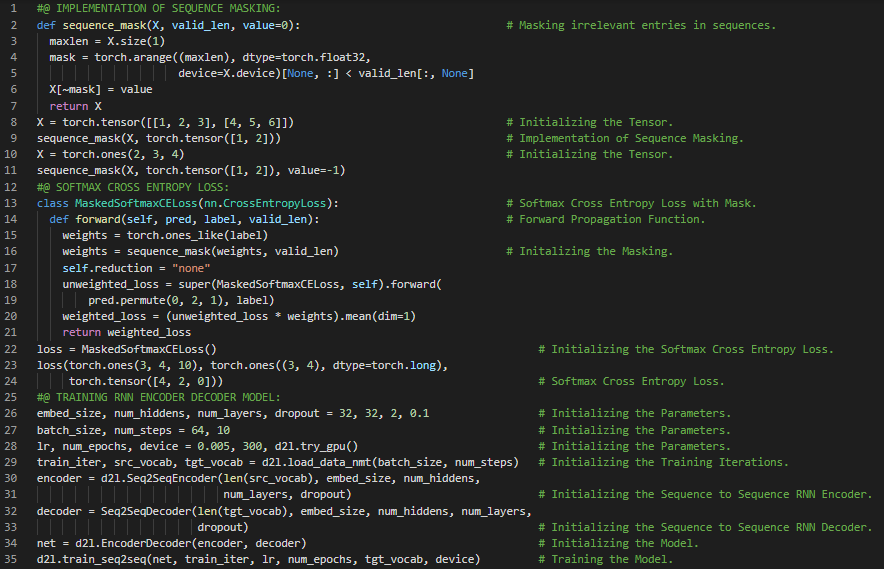
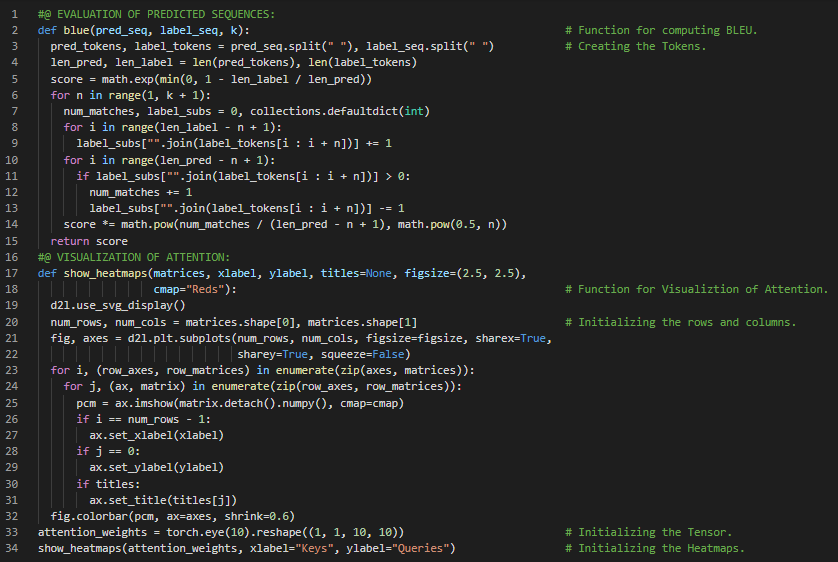
300天数据之旅第116天!
- 序列搜索:贪婪搜索是基于输入序列生成输出序列的条件概率。束搜索是贪婪搜索的一种改进版本,引入了一个名为“束宽”的超参数。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了Softmax交叉熵损失函数、序列掩码、教师强制、训练与预测、预测序列的评估、BLEU(双语评估替代)指标、RNN编码器-解码器模型、束搜索、贪婪搜索、穷举搜索、注意力机制、注意力线索、非自主性线索与自主性线索、查询、键与值、注意力池化等主题。我在截图中展示了使用PyTorch实现的序列掩码、Softmax交叉熵损失、RNN编码器-解码器模型的训练以及BLEU的计算过程。希望你能从中获得一些启发,并进一步深入研究。也期待你能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
300天数据之旅第117天!
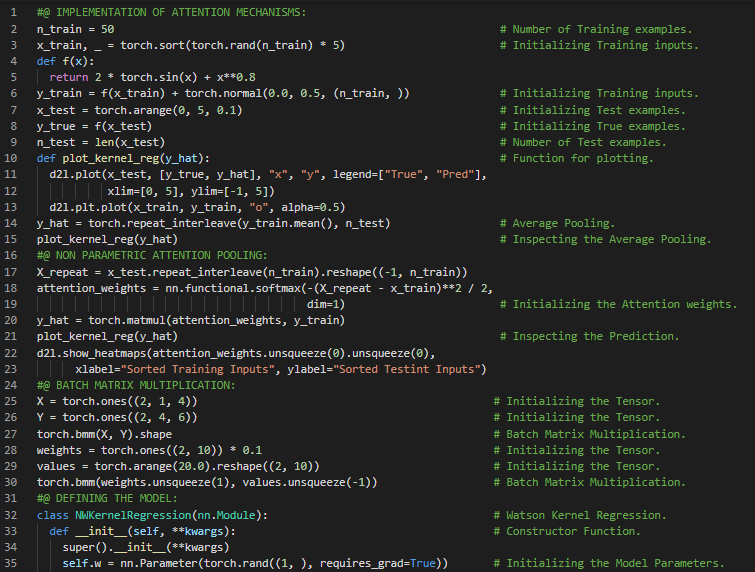
- 注意力池化:注意力池化会根据权重选择性地聚合数值或感官输入,从而生成输出。它体现了查询与键之间的交互作用。在我的机器学习和深度学习之旅中,今天我同样阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了注意力池化,即纳达拉亚-沃森核回归、查询(自主性线索)与键(非自主性线索)、数据集的生成、平均池化、非参数化注意力池化、注意力权重、高斯核、参数化注意力池化、批量矩阵乘法、模型定义、模型训练、随机梯度下降、MSE损失函数等主题。我在截图中展示了使用PyTorch实现的注意力机制、非参数化注意力池化、批量矩阵乘法、NW核回归模型、训练与预测等内容。希望你能从中获得一些见解,并继续探索相关领域。也希望你能抽出时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
300天数据之旅第118天!
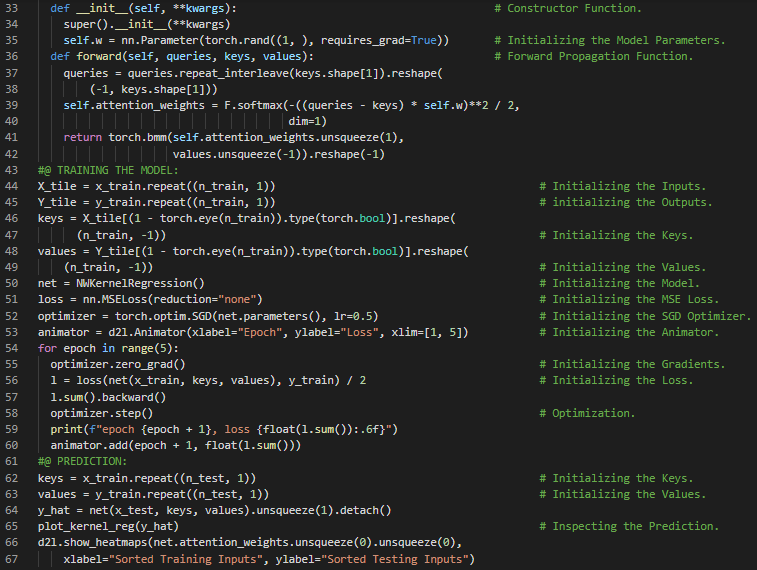
- 注意力池化:注意力池化会根据权重选择性地聚合数值或感官输入,从而生成输出。它体现了查询(自主性线索)与键(非自主性线索)之间的交互作用。注意力池化实际上是训练输出的加权平均。它可以是参数化的,也可以是非参数化的。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了注意力评分函数、高斯核、注意力权重、Softmax激活函数、掩码Softmax操作、文本序列、概率分布、加性注意力、查询、键与值、Tanh激活函数、Dropout与线性层、注意力池化等主题。我在截图中展示了使用PyTorch实现的掩码Softmax操作和加性注意力。希望你能从中获得一些启发,并进一步研究这些内容。也期待你能花些时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
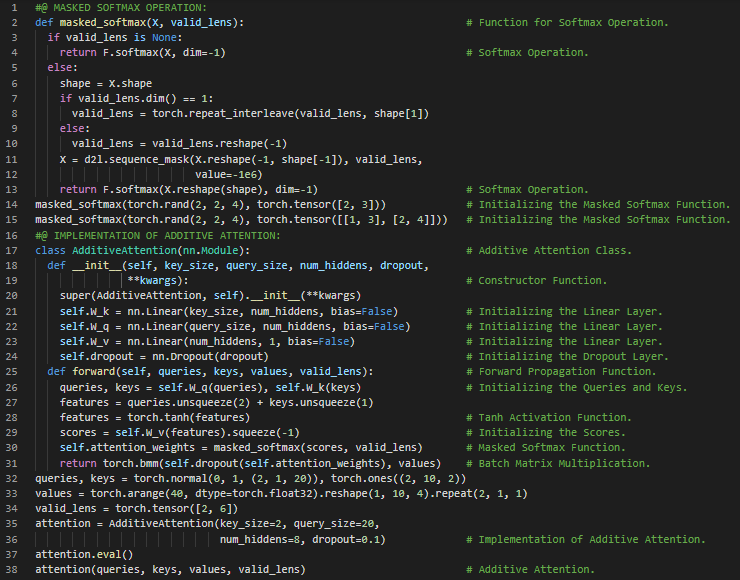
300天数据之旅第119天!
- 注意力池化:注意力池化会根据权重选择性地聚合数值或感官输入,从而生成输出。它体现了查询(自主性线索)与键(非自主性线索)之间的交互作用。注意力池化是训练输出的加权平均,可以是参数化的,也可以是非参数化的。在我的机器学习和深度学习之旅中,今天我依然阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了缩放点积注意力、查询、键与值、加性注意力、注意力池化、Bahdanau注意力、RNN编码器-解码器架构、隐藏状态、嵌入、带注意力的解码器定义、序列到序列注意力解码器等主题。我在截图中展示了使用PyTorch实现的缩放点积注意力和序列到序列注意力解码器模型。希望你能从中获得一些启发,并继续深入研究。也期待你能花些时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
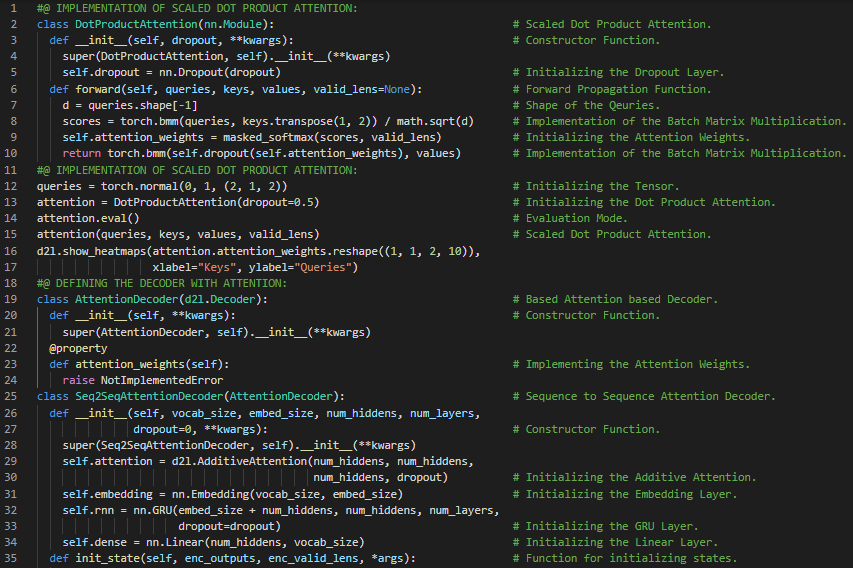
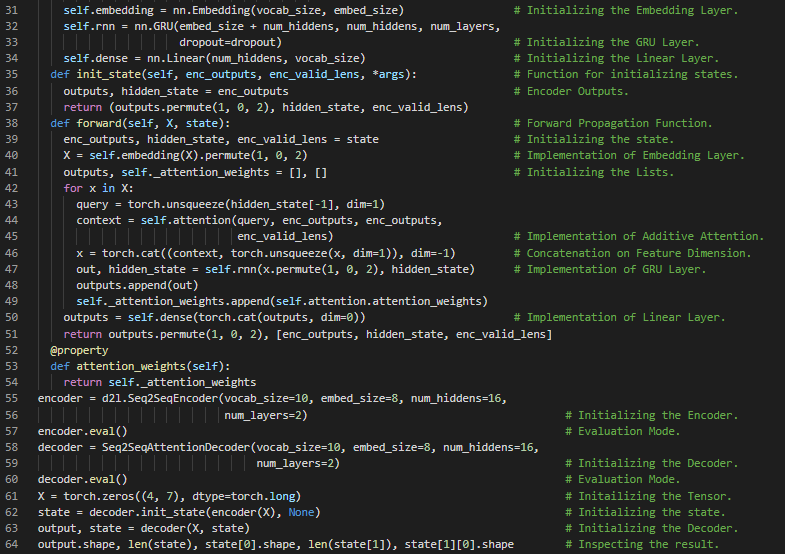
300天数据之旅第120天!
- 多头注意力机制:多头注意力机制是一种注意力机制的设计,它通过并行运行多次注意力机制来实现。与只进行一次注意力池化不同,查询、键和值可以被转换为学习到的线性投影,然后并行输入到注意力池化中。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了Bahdanau注意力机制、循环神经网络编码器-解码器架构、序列到序列模型的训练、嵌入层、注意力权重、GRU、热力图、多头注意力机制、查询、键和值、注意力池化、加性注意力和缩放点积注意力、转置函数等主题。我在截图中展示了使用PyTorch实现的多头注意力机制。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
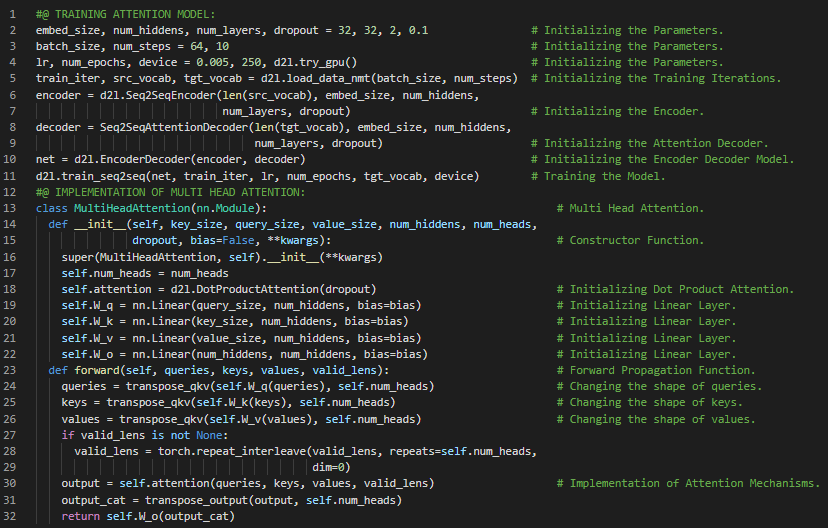
300天数据之旅第121天!
- 多头注意力机制:多头注意力机制是一种注意力机制的设计,它通过并行运行多次注意力机制来实现。与只进行一次注意力池化不同,查询、键和值可以被转换为学习到的线性投影,然后并行输入到注意力池化中。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了多头注意力机制、查询、键和值、注意力池化、缩放点积注意力、自注意力和位置编码、循环神经网络、内部注意力机制、CNN、RNN和自注意力的比较、填充标记、绝对位置信息、相对位置信息等主题。我在截图中展示了使用PyTorch实现的位置编码。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
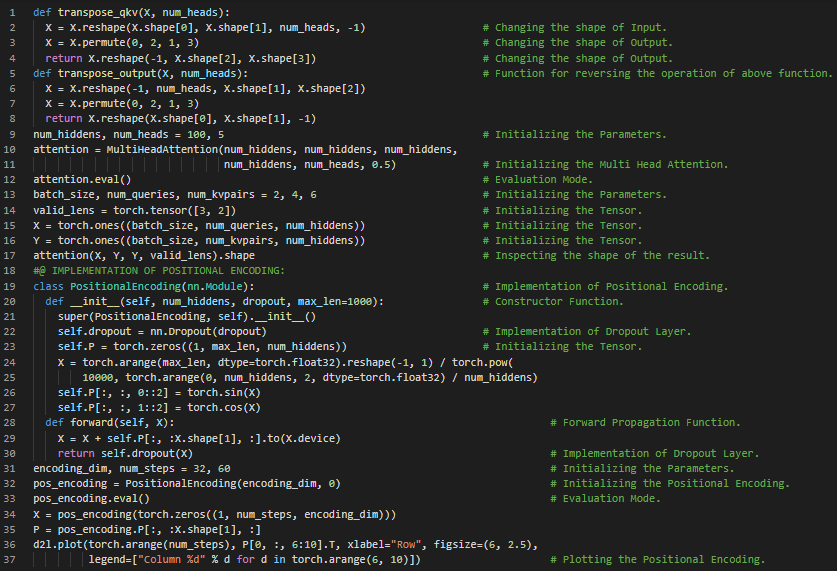
300天数据之旅第122天!
- Transformer架构:Transformer是一种利用编码器和解码器两部分将一个序列转换为另一个序列的架构,它使用了自注意力机制。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了Transformer、自注意力、编码器和解码器架构、序列嵌入、位置编码、逐位置前馈网络、残差连接和层归一化、编码器模块和多头自注意力、Transformer解码器、查询、键和值、缩放点积注意力等主题。我在截图中展示了使用PyTorch实现的逐位置前馈网络、残差连接和层归一化、编码器、解码器模块以及Transformer解码器。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
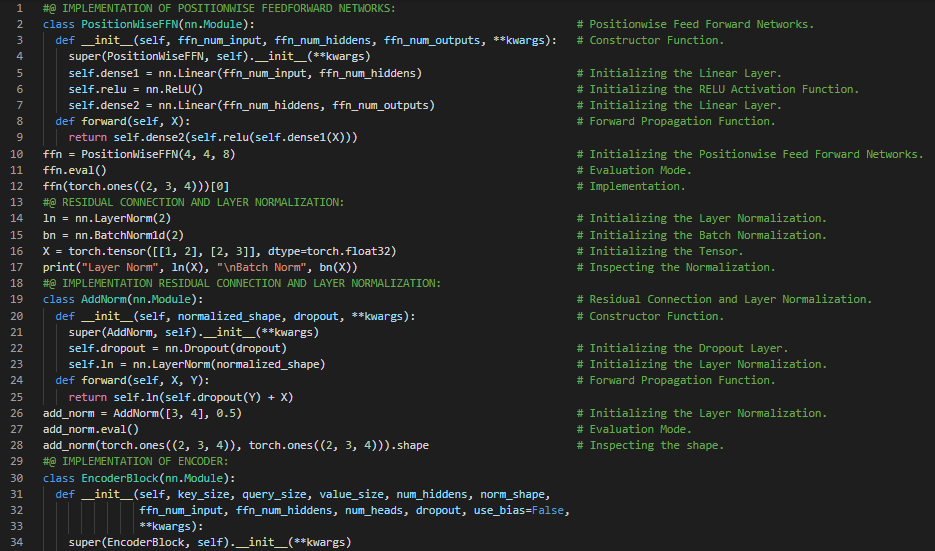
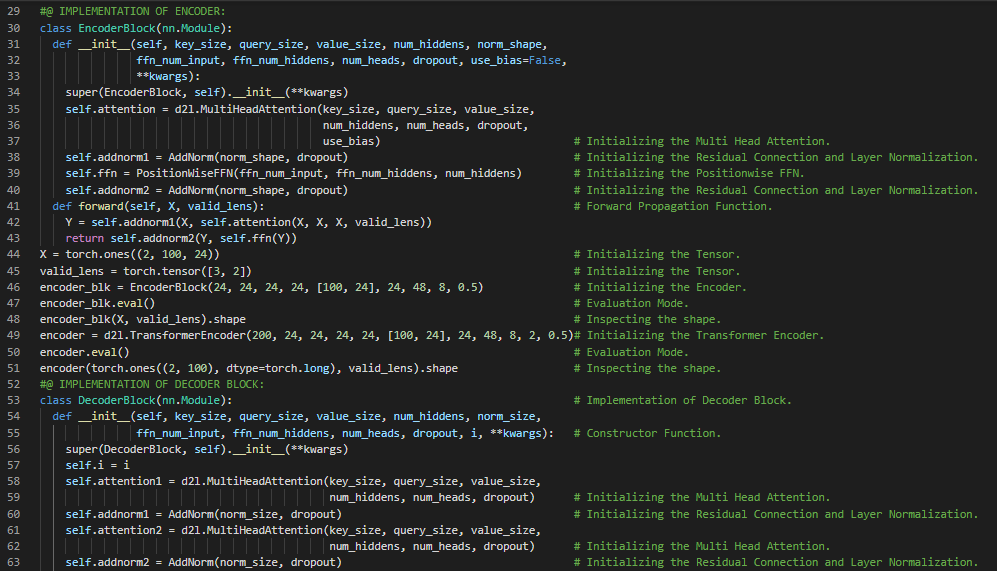
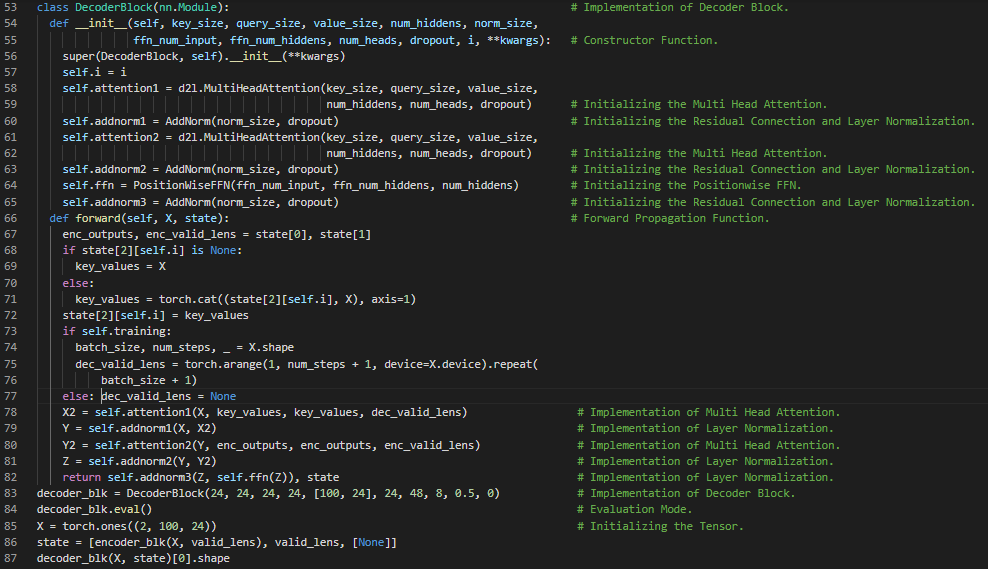
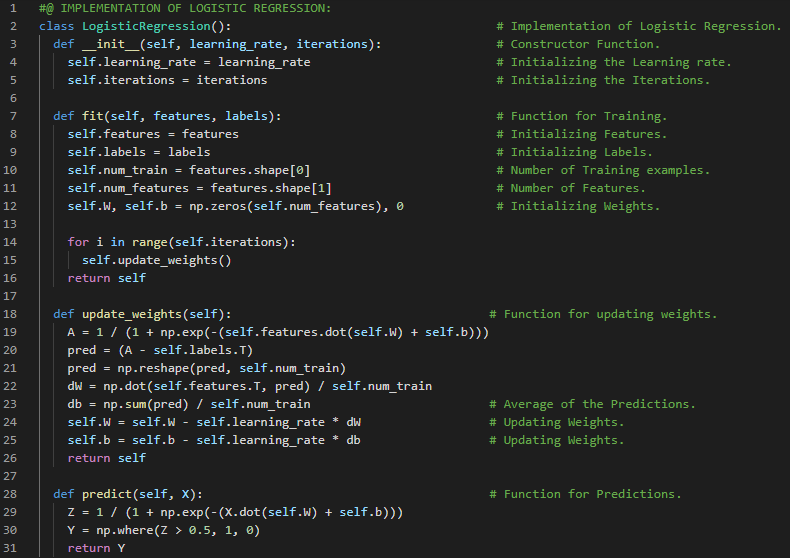
300天数据之旅第123天!
- Transformer架构:Transformer是一种利用编码器和解码器两部分将一个序列转换为另一个序列的架构,它使用了自注意力机制。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了解码器架构、自注意力、编码器-解码器注意力、逐位置前馈网络、残差连接、Transformer解码器、嵌入层、序列块、Transformer架构的训练等主题。我还学习了逻辑回归、Sigmoid激活函数、权重初始化、梯度下降、损失函数等内容。我在截图中展示了使用NumPy从零开始实现的逻辑回归、使用PyTorch实现的Transformer解码器以及训练过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
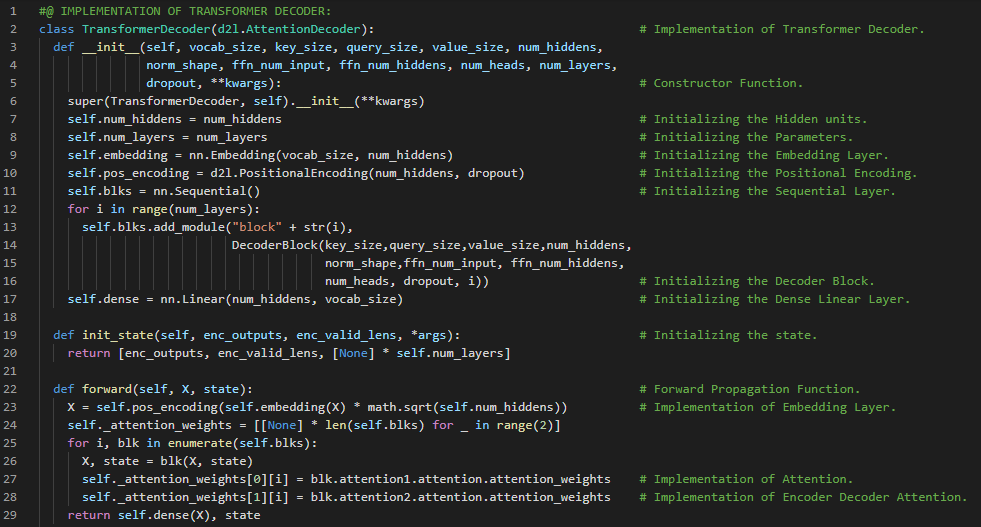
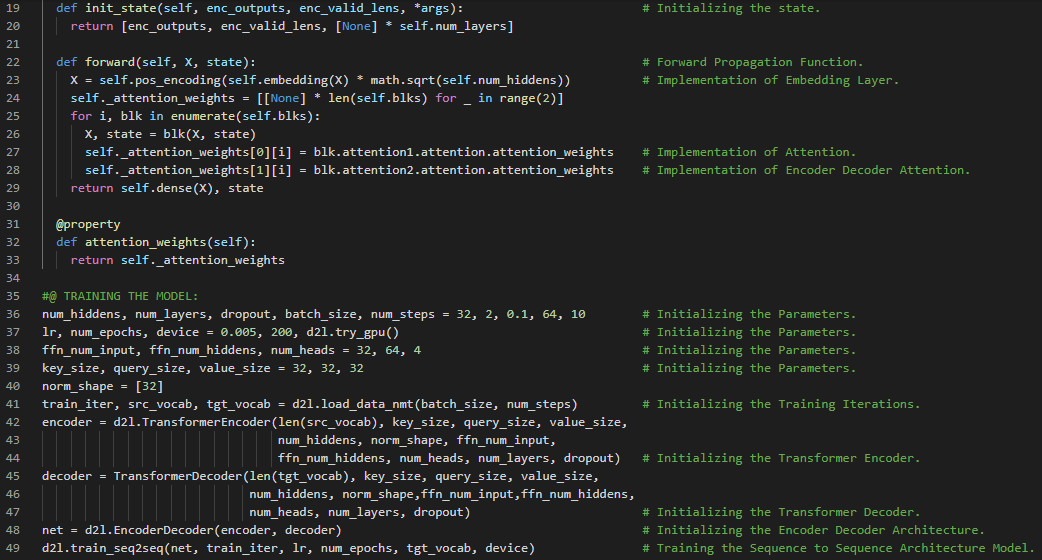
300天数据之旅第124天!
- Transformer架构:Transformer是一种通过编码器和解码器两部分将一个序列转换为另一个序列的架构,它利用了自注意力机制。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了优化算法与深度学习、目标函数与最小化、优化的目标、泛化误差、训练误差、风险函数与经验风险函数、优化挑战、局部极小值与全局极小值、鞍点、海森矩阵与特征值、梯度消失、凸性、凸集与凸函数、Jensen不等式以及与此相关的其他主题。我在这里用PyTorch实现了局部极小值、鞍点、梯度消失和凸函数的相关内容,并附上了截图。希望你能从中获得一些启发,并进一步深入研究。同时,也建议你花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
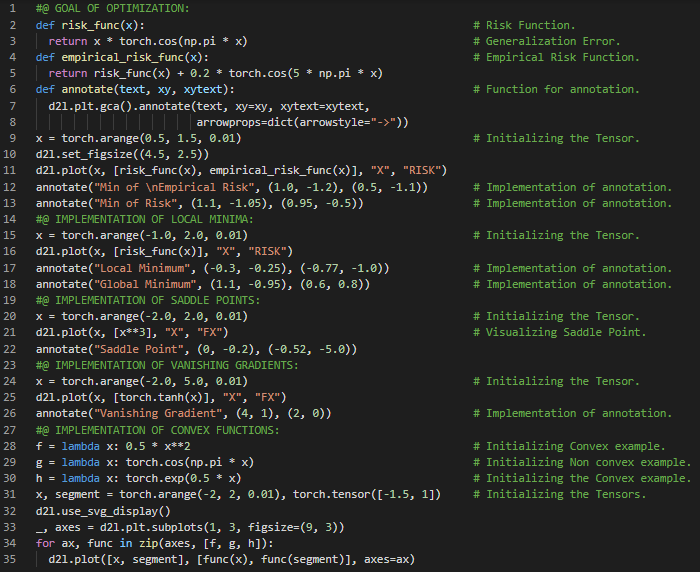
300天数据之旅第125天!
- 梯度下降法:梯度下降法是一种优化算法,通过沿着负梯度方向迭代更新参数来最小化可微函数。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了凸性和二阶导数、约束优化、拉格朗日函数与乘子、惩罚项、投影、梯度裁剪、随机梯度下降法、一维梯度下降法、目标函数、学习率、局部极小值与全局极小值、多元梯度下降法以及其他相关主题。我在这里用PyTorch实现了一维梯度下降法、局部极小值和多元梯度下降法,并附上了截图。希望你能从中获得一些见解,并加以实践。同时,也建议你花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
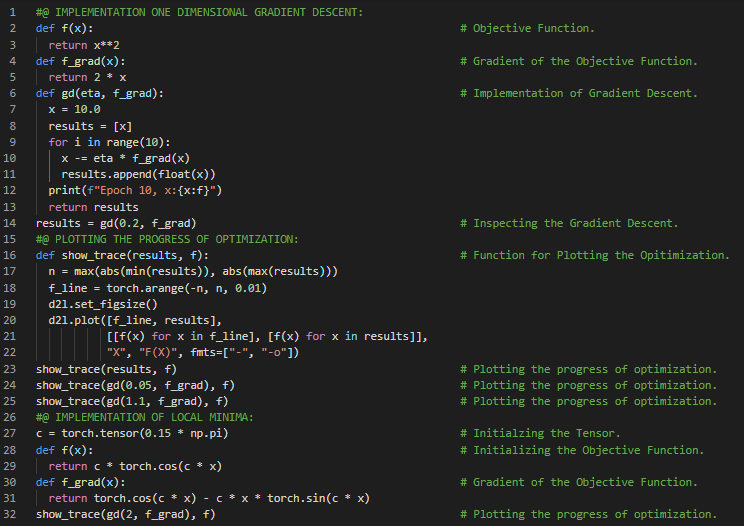
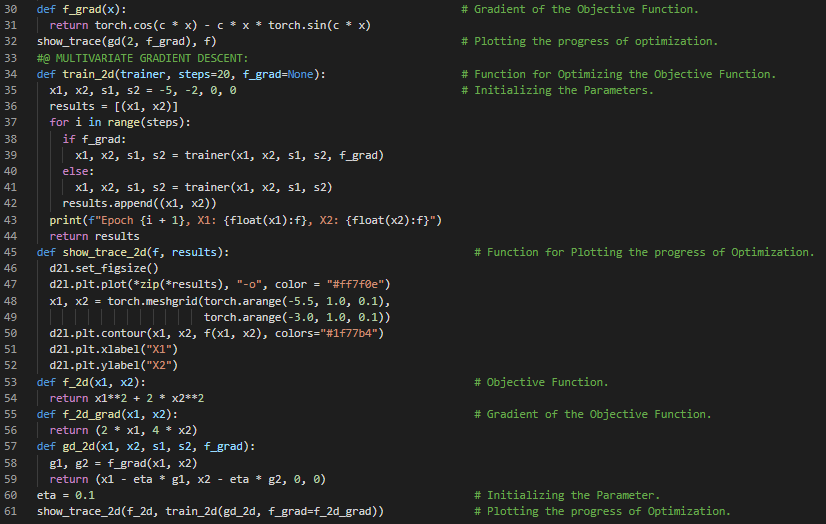
300天数据之旅第126天!
- 梯度下降法:梯度下降法是一种优化算法,通过沿着负梯度方向迭代更新参数来最小化可微函数。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了多元梯度下降法、自适应方法、学习率、牛顿法、泰勒展开、海森矩阵、梯度与反向传播、非凸函数、收敛性分析、线性收敛、预处理、带线搜索的梯度下降法、随机梯度下降法、损失函数以及其他相关主题。我在这里用PyTorch实现了牛顿法、非凸函数和随机梯度下降法,并附上了截图。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
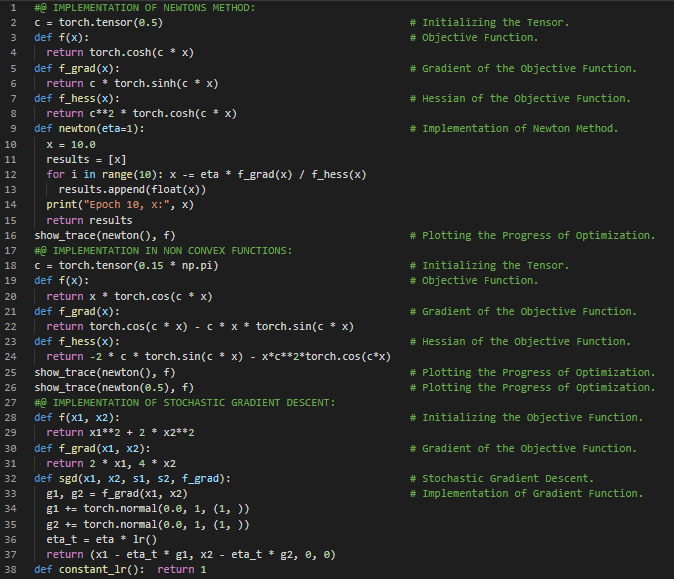
300天数据之旅第127天!
- 随机梯度下降法:随机梯度下降法是一种用于优化具有适当可微性质的目标函数的迭代方法,它是梯度下降法的一种变体,通过计算误差并更新模型来进行优化。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了随机梯度下降法、动态学习率、指数衰减与多项式衰减、凸目标的收敛性分析、随机梯度与有限样本、小批量随机梯度下降法、向量化与缓存、矩阵乘法、小批量、方差、梯度实现等相关主题。我在这里用PyTorch实现了随机梯度下降法和小批量随机梯度下降法,并附上了截图。希望你能从中获得一些见解,并加以实践。同时,也建议你花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
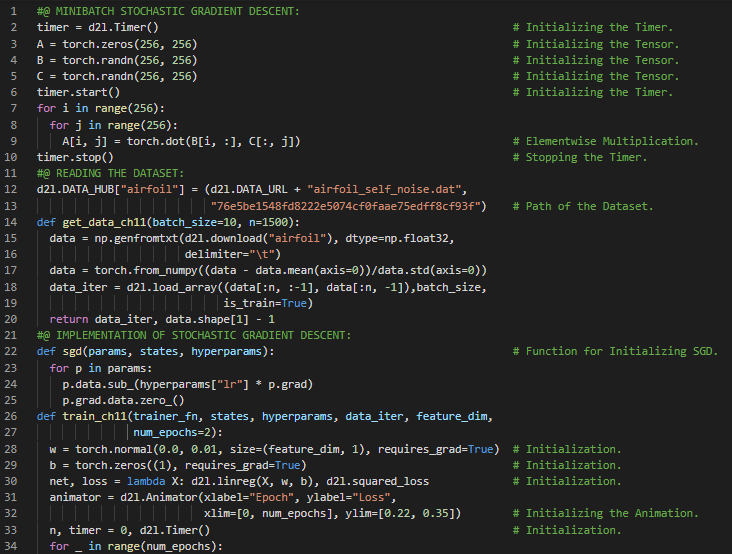
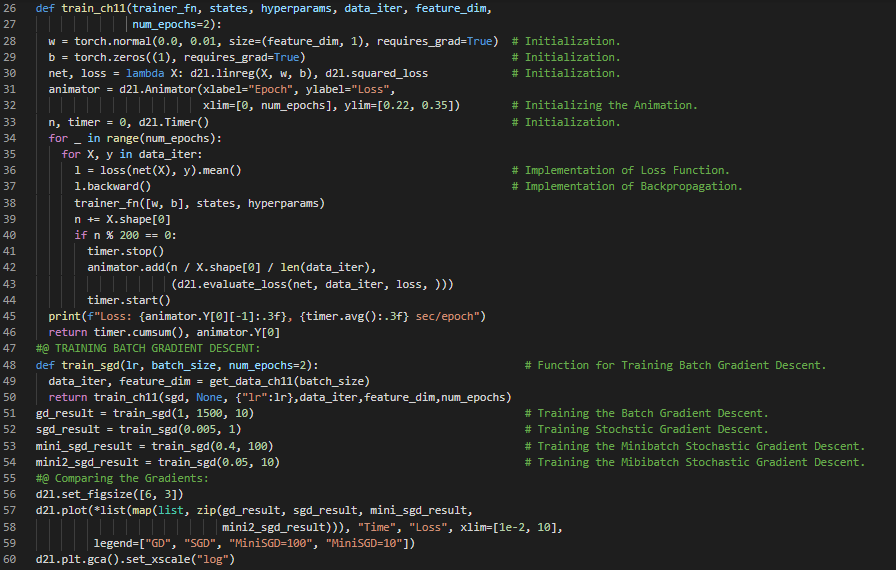
300天数据之旅第128天!
- 随机梯度下降法:随机梯度下降法是一种用于优化具有适当可微性质的目标函数的迭代方法,它是梯度下降法的一种变体,通过计算误差并更新模型来进行优化。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了动量法、随机梯度下降法、滑动平均、方差、加速梯度、病态问题与收敛性、有效样本权重、实际实验、动量法与SGD的结合实现、理论分析、二次凸函数、标量函数以及其他相关主题。我在这里用PyTorch实现了动量法、有效样本权重和标量函数的相关内容,并附上了截图。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习上述书籍及其他相关资料。对接下来的日子充满期待!!
- 书籍:
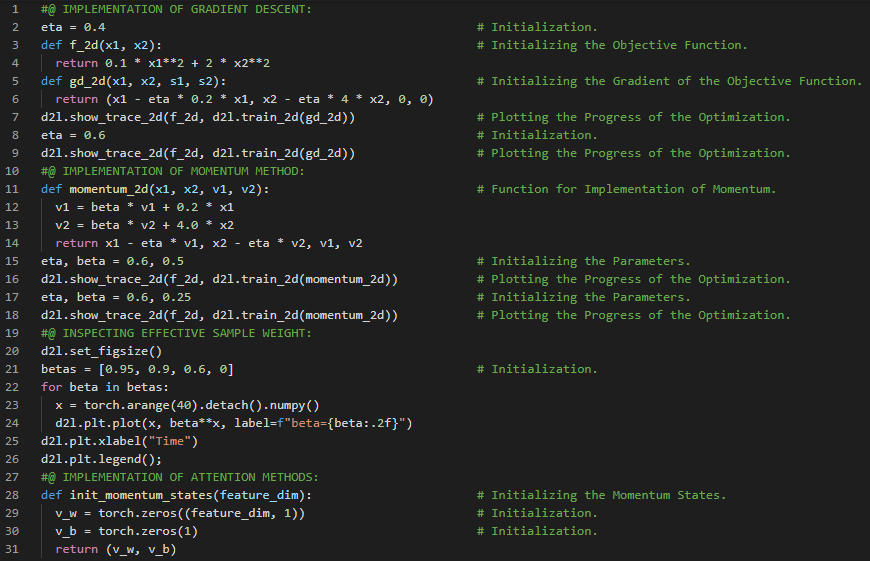
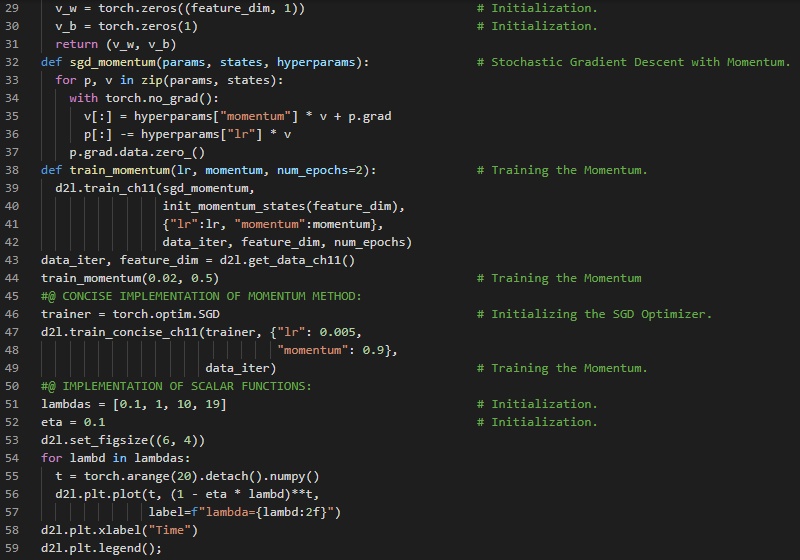
300天数据之旅第129天!
- 随机梯度下降:随机梯度下降是一种用于优化具有适当可微性质的目标函数的迭代方法。它是梯度下降算法的一种变体,通过计算误差并更新模型来实现优化。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了Adagrad优化算法、稀疏特征与学习率、预处理、随机梯度下降算法、相关算法、从零开始实现Adagrad、深度学习与计算约束、学习率等主题。我在截图中展示了使用PyTorch从零开始实现Adagrad优化算法的过程。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
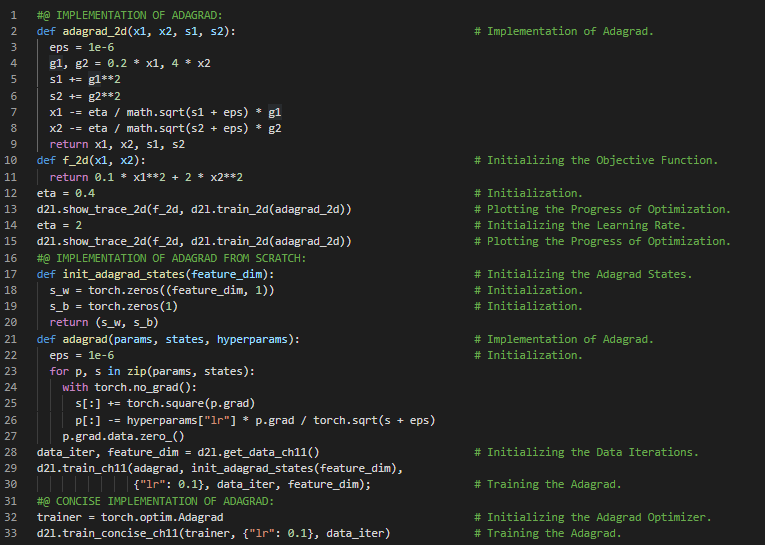
300天数据之旅第130天!
- RMSProp优化算法:RMSProp是一种基于梯度的优化算法,它利用近期梯度的大小来对梯度进行归一化处理。该算法解决了Adagrad学习率急剧衰减的问题,通过将学习率除以梯度平方的指数加权移动平均值来进行调整。在我的机器学习和深度学习之旅中,今天我同样阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了RMSProp优化算法、学习率、漏斗式平均与动量法、从零开始实现RMSProp、梯度下降算法、预处理等相关主题。我在截图中展示了使用PyTorch从零开始实现RMSProp优化算法的过程。希望你能从中获得一些见解,并进一步探索。也希望大家能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
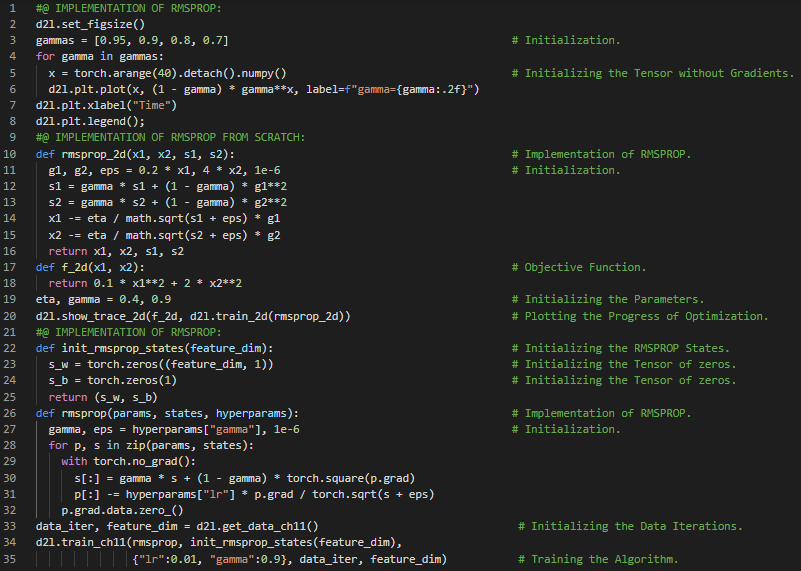
300天数据之旅第131天!
- RMSProp优化算法:RMSProp是一种基于梯度的优化算法,它利用近期梯度的大小来对梯度进行归一化处理。该算法解决了Adagrad学习率急剧衰减的问题,通过将学习率除以梯度平方的指数加权移动平均值来进行调整。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了Adadelta优化算法、学习率、漏斗式平均、动量、梯度下降、Adadelta的简洁实现、Adam优化算法、向量化与小批量随机梯度下降、权重参数、归一化、Adam算法的简洁实现等相关主题。我在截图中展示了使用PyTorch从零开始实现Adadelta优化算法和Adam优化算法的过程。希望你也能够花些时间学习上述书籍中提到的内容。对接下来的日子充满期待!!
- 书籍:
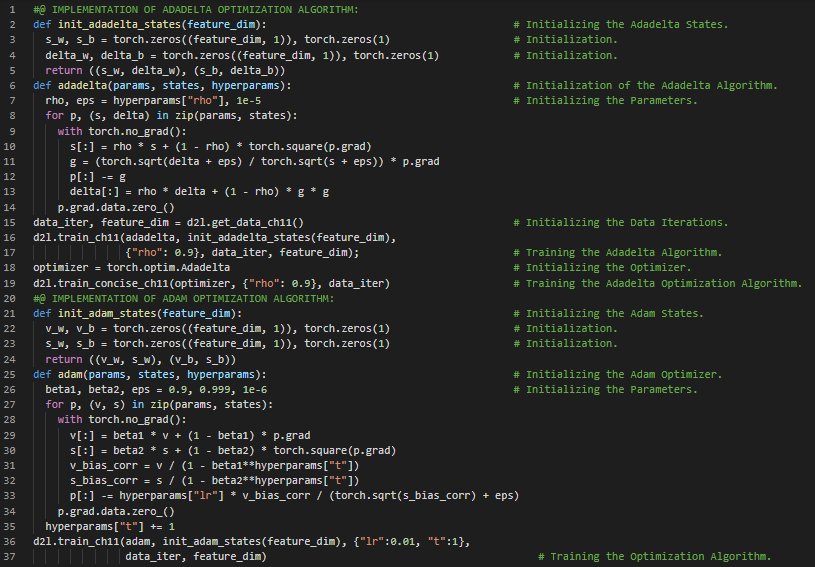
300天数据之旅第132天!
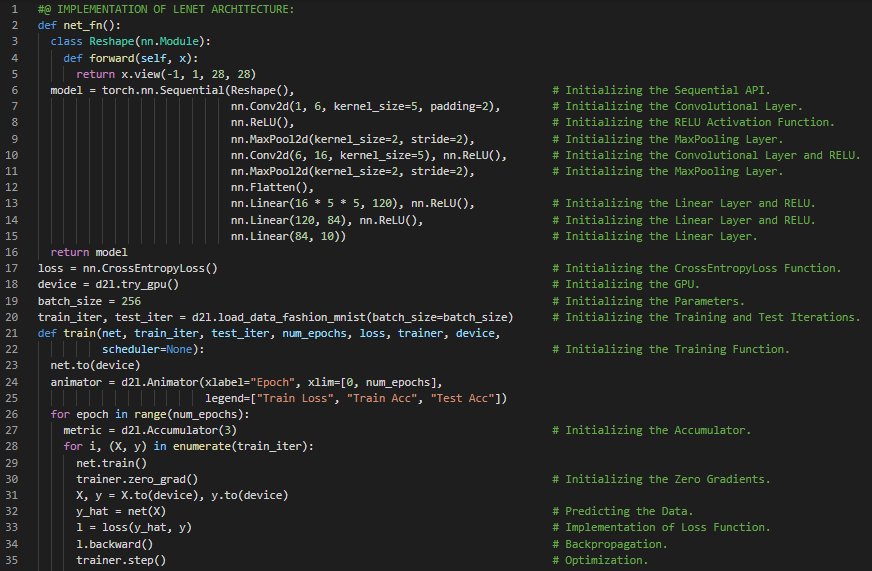
- Adam优化器:Adam使用指数加权移动平均(也称为漏斗式平均)来同时估计动量和梯度的二阶矩。它结合了多种优化算法的优点,在小批量随机梯度下降的基础上应用EWMA。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了Adam和Yogi优化算法、方差、小批量随机梯度下降、学习率调度、权重向量、卷积层、全连接层、最大池化层、Sequential API、ReLU、交叉熵损失、调度器、过拟合等相关主题。我在截图中展示了使用PyTorch实现LeNet架构和Yogi优化算法的过程。希望你能从中获得一些启发,并进一步研究。也希望大家能花些时间学习上述书籍中提到的内容。对接下来的日子充满期待!!
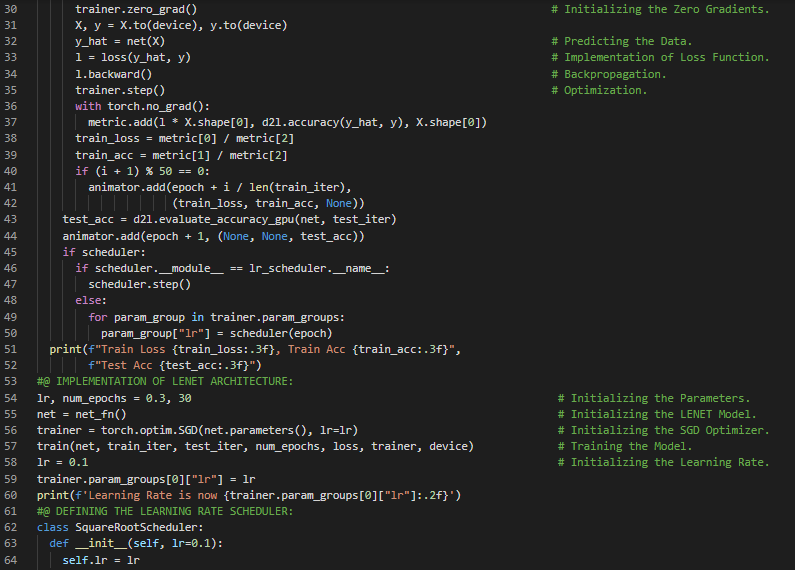
- 书籍:
300天数据之旅第133天!
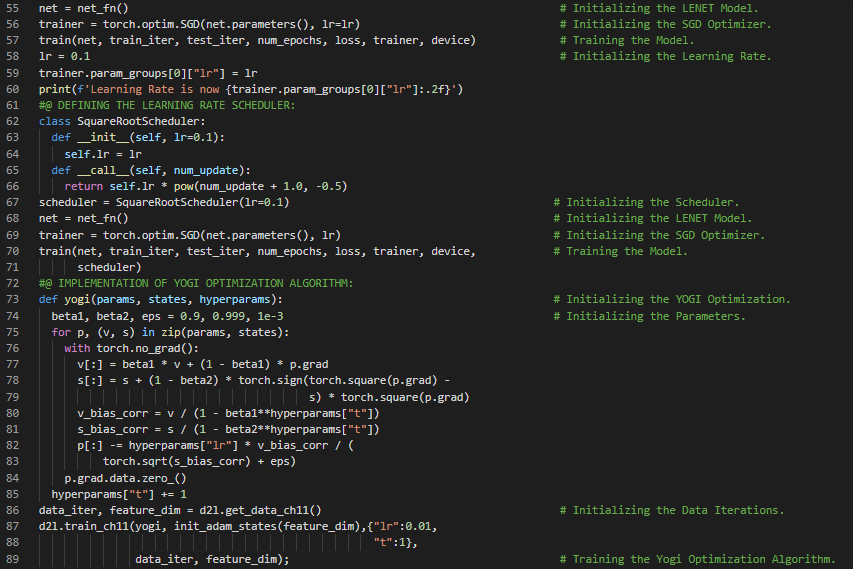
- Adam优化器:Adam使用指数加权移动平均(也称为漏斗式平均)来同时估计动量和梯度的二阶矩。它结合了多种优化算法的优点,在小批量随机梯度下降的基础上应用EWMA。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了学习率调度、平方根调度、因子调度、学习率与多项式衰减、多因子调度、分段常数调度、优化与局部最小值、余弦调度等相关主题。我在截图中展示了使用PyTorch实现多因子调度和余弦调度的过程。希望你能从中获得一些见解,并进一步探索。也希望大家能花些时间学习上述书籍中提到的内容。对接下来的日子充满期待!!
- 书籍:
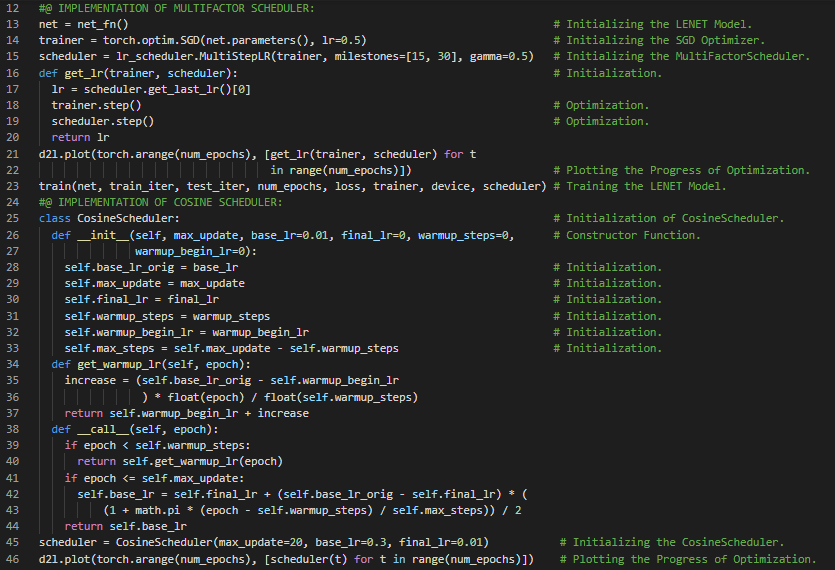
第134天,300天数据之旅!
- Adam优化器:Adam使用指数加权移动平均(也称为漏桶平均)来估计梯度的动量和二阶矩。它结合了多种优化算法的优点,在小批量随机梯度下降的基础上应用EWMA。在我的机器学习和深度学习旅程中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了模型计算性能、编译器与解释器、符号式编程与命令式编程、混合编程、动态计算图、混合顺序执行、通过混合加速、多层感知机、异步计算等主题。我在这里的截图中展示了使用PyTorch实现的混合顺序执行、通过混合加速以及异步计算。希望你能从中获得一些启发,并进一步实践。我也希望你能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
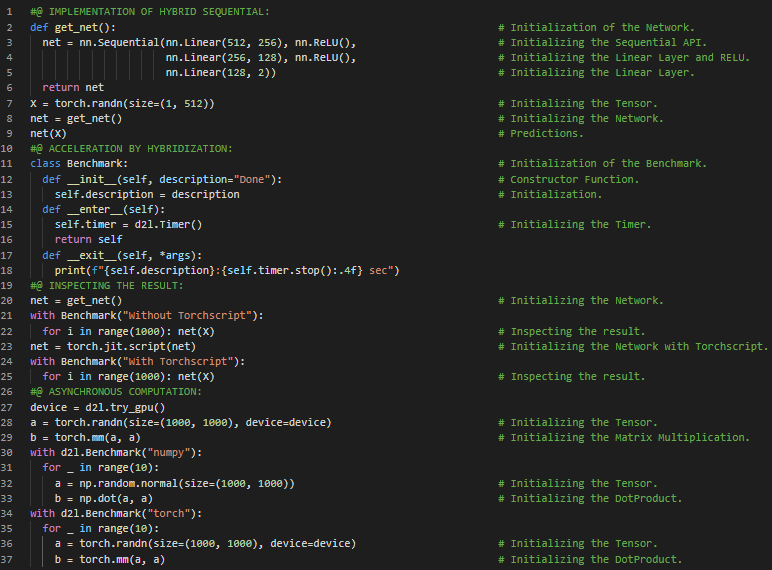
第135天,300天数据之旅!
- Adam优化器:Adam使用指数加权移动平均(也称为漏桶平均)来估计梯度的动量和二阶矩。它结合了多种优化算法的特点,在小批量随机梯度下降的基础上应用EWMA。在我的机器学习和深度学习旅程中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了异步计算、屏障与阻塞机制、优化计算与内存占用、自动并行化、并行计算与通信、多GPU训练、问题分解、数据并行、网络划分、逐层划分、数据并行划分等主题。我在这里的截图中展示了使用PyTorch初始化模型参数和定义LeNet模型的实现。目前我仍在继续完成LeNet模型的实现。希望你能从中获得一些见解,并加以实践。我也希望你能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
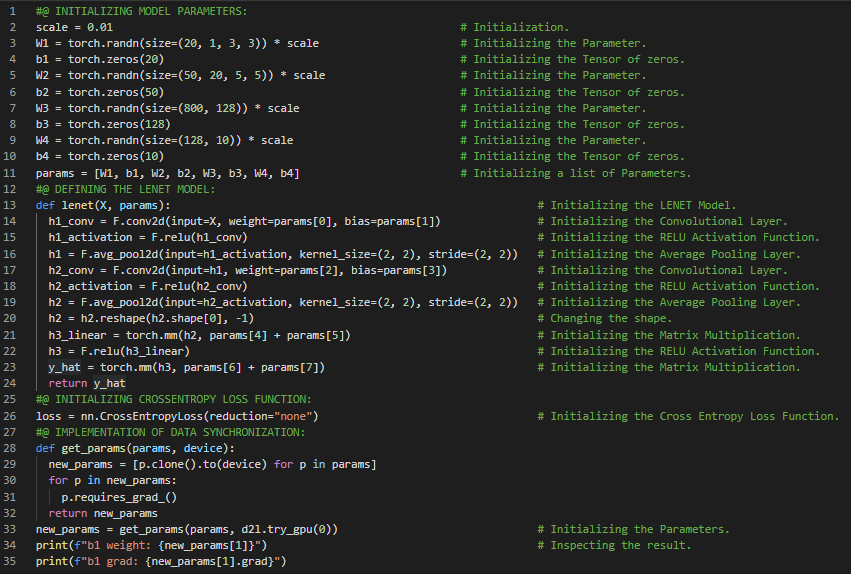
第136天,300天数据之旅!
- Adam优化器:Adam使用指数加权移动平均(也称为漏桶平均)来估计梯度的动量和二阶矩。它结合了多种优化算法的特点,在小批量随机梯度下降的基础上应用EWMA。在我的机器学习和深度学习旅程中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了多GPU训练、LeNet架构、数据同步、模型并行、数据广播、数据分发、优化算法、反向传播实现、模型动画、交叉熵损失函数、卷积层、ReLU激活函数、矩阵乘法、平均池化层等主题。我在这里的截图中展示了使用PyTorch实现的数据分发、数据同步以及训练函数。希望你能从中获得一些启发,并加以实践。我也希望你能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
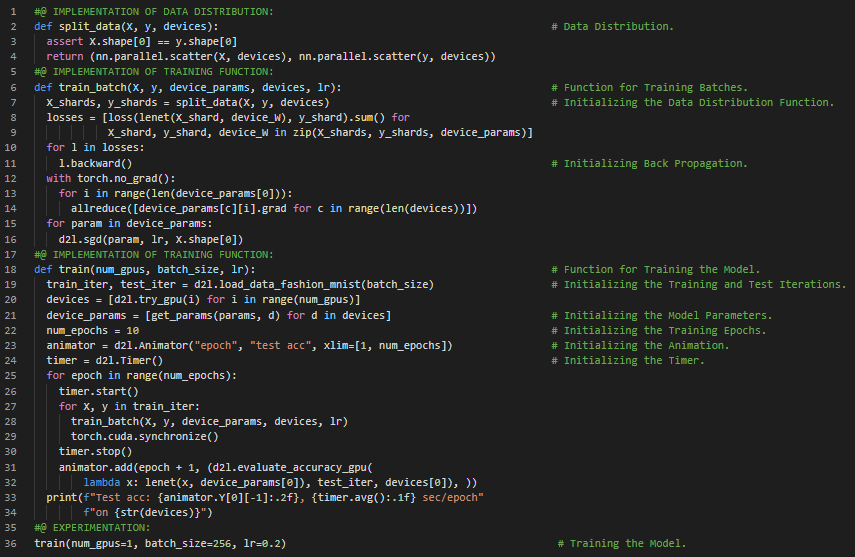
第137天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了优化与同步、ResNet神经网络架构、卷积层、批归一化层、步幅与填充、Sequential API、参数初始化与逻辑、小批量梯度下降、ResNet模型训练、随机梯度下降优化器、交叉熵损失函数、反向传播、并行化等主题。我在这里的截图中展示了使用PyTorch实现的ResNet架构、模型初始化及训练过程。希望你能从中获得一些启发,并加以实践。我也希望你能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
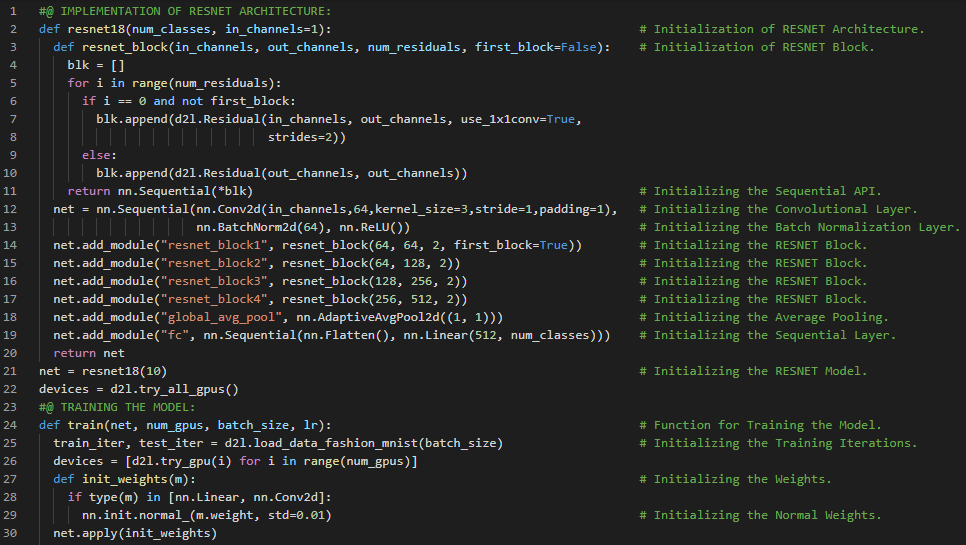
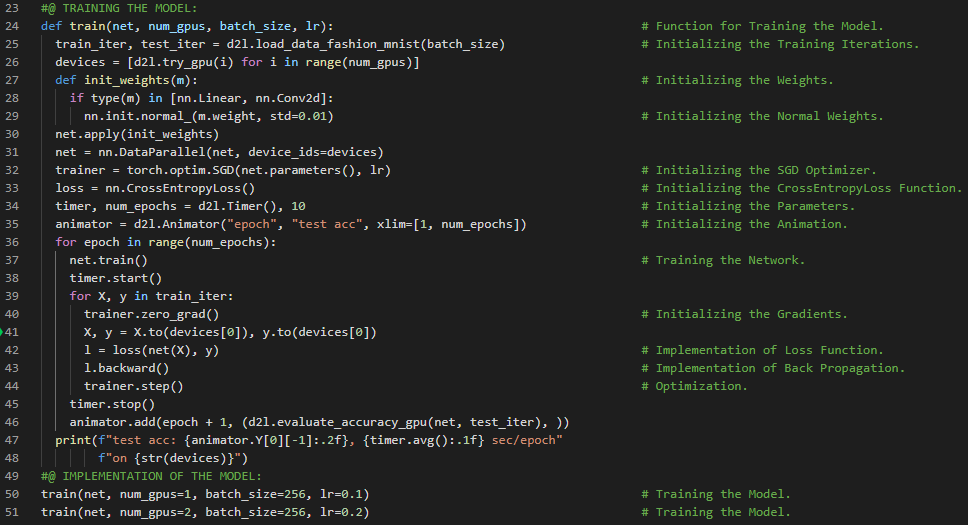
第138天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《动手学深度学习》一书的内容。在这里,我学习了计算机视觉应用、图像增强、深度神经网络、常见的图像增强方法如翻转和裁剪、水平翻转与垂直翻转、改变图像颜色、叠加多种图像增强方法、CIFAR10数据集、Torch Vision模块以及随机色彩抖动实例等主题。我在这里的截图中展示了使用PyTorch实现的图像翻转、裁剪以及改变图像颜色的操作。希望你能从中获得一些启发,并加以实践。我也希望你能花些时间学习上述书籍中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
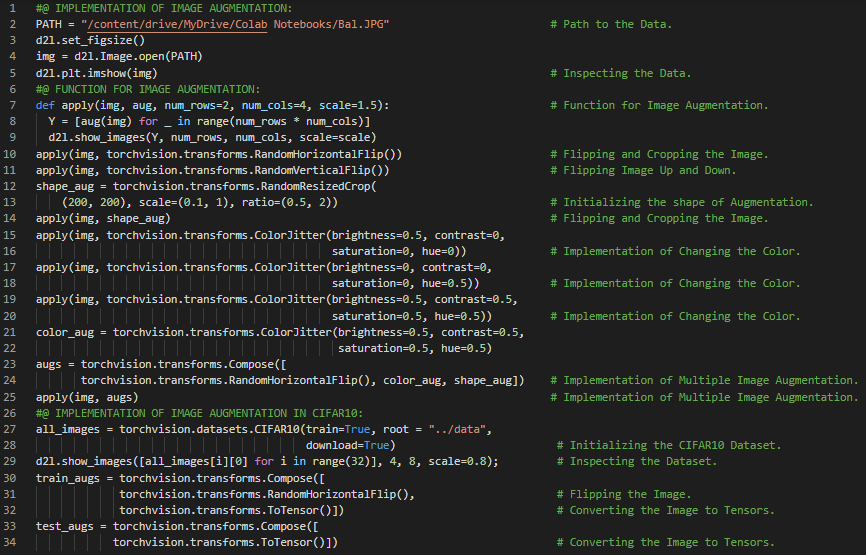
300天数据之旅第139天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了图像增强、CIFAR10数据集、多GPU训练模型、模型微调、过拟合、预训练神经网络、目标初始化、ResNet模型、ImageNet数据集、RGB图像的归一化、均值与标准差、Torch Vision模块、图像翻转与裁剪、Adam优化算法、交叉熵损失函数等主题。我在截图中展示了使用PyTorch进行图像增强和图像归一化训练模型的实现。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
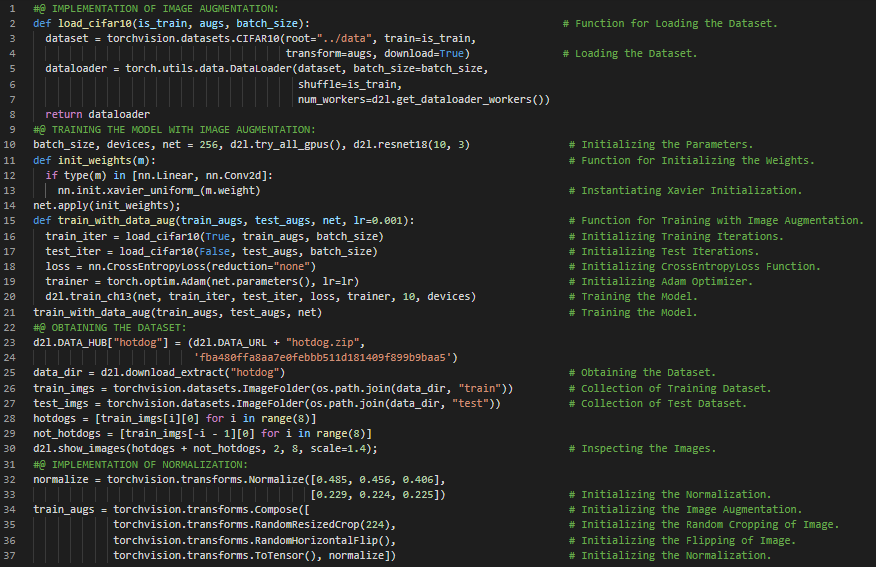
300天数据之旅第140天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了模型微调、预训练神经网络、图像归一化、均值与标准差、模型的定义与初始化、交叉熵损失函数、DataLoader类、学习率与随机梯度下降、模型参数、迁移学习、源模型与目标模型、权重与偏置等主题。我在截图中展示了使用PyTorch进行图像归一化、图像翻转与裁剪以及训练预训练模型的实现。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
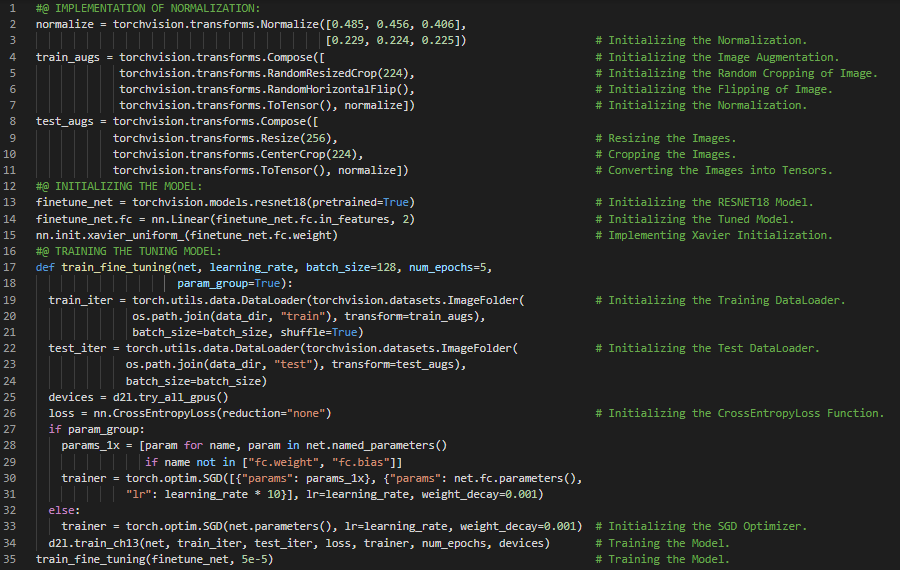
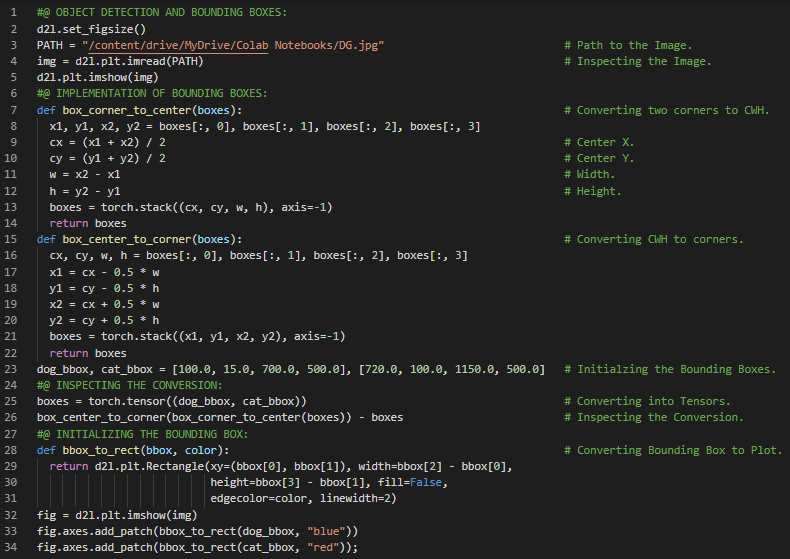
300天数据之旅第141天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了目标检测与目标识别、图像分类与计算机视觉、图像与边界框、目标位置与坐标轴等主题。此外,我还花了一些时间阅读《语音与语言处理》一书。在这里,我学习了正则表达式、或运算、分组与优先级、精确率与召回率、替换与捕获组、前瞻断言、词汇、语料库等内容。我在截图中展示了使用PyTorch进行目标检测与边界框的简单实现。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
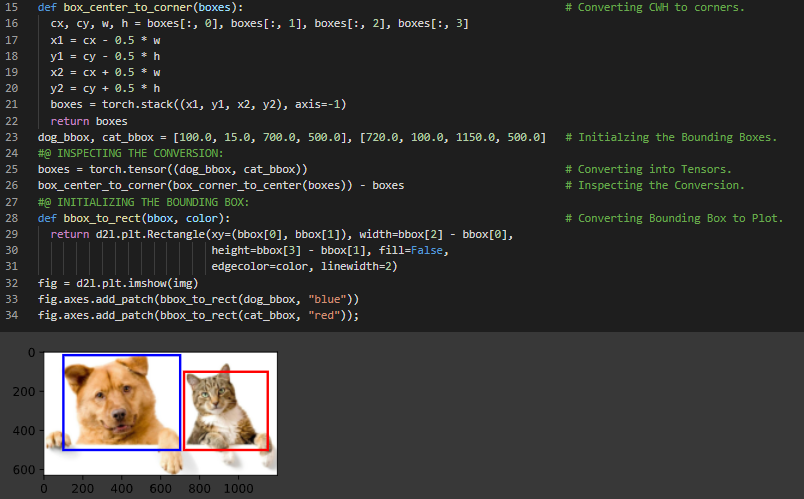
300天数据之旅第142天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了计算机视觉、锚框、目标检测算法、边界框、生成多个锚框、计算复杂度、尺寸与比例等主题。此外,我还花了一些时间阅读《语音与语言处理》一书。在这里,我学习了文本归一化、用于粗粒度分词与归一化的Unix工具、单词分词、命名实体识别、Penn Treebank分词等内容。我在截图中展示了使用PyTorch生成锚框、目标检测与边界框的实现。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
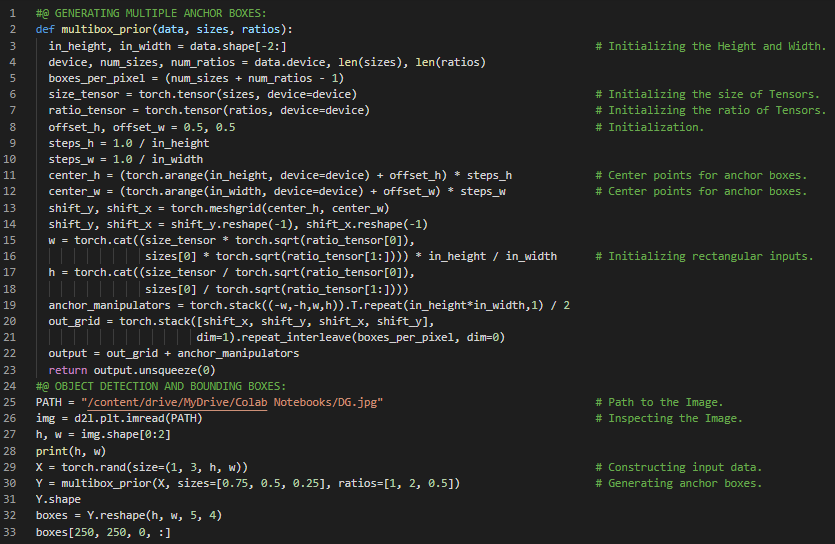
300天数据之旅第143天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了计算机视觉、生成多个锚框、批量大小、坐标值、交并比算法、Jaccard指数、计算复杂度、尺寸与比例等主题。此外,我还花了一些时间阅读《语音与语言处理》一书。在这里,我学习了用于分词的字节对编码算法、子词标记、WordPiece与贪婪分词算法、最大匹配算法、单词归一化、词形还原与词干提取、Porter词干提取器等内容。我在截图中展示了使用PyTorch生成锚框和交并比算法的实现。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习上述书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
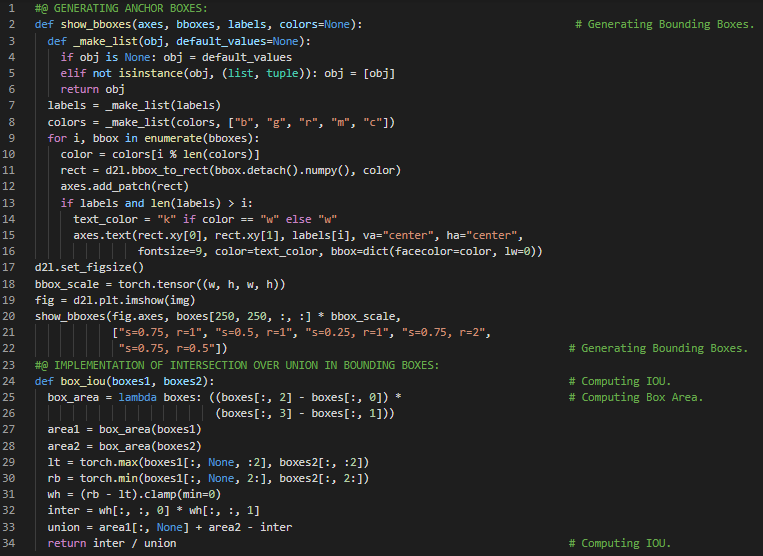
第144天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了计算机视觉、训练集锚框的标注、目标检测与图像识别、真实框索引、锚框与偏移框、交并比及Jaccard算法等相关内容。此外,我还花了一些时间阅读《语音与语言处理》一书。在这本书中,我学习了句子分割、最小编辑距离算法、维特比算法、N元语言模型、概率、拼写纠正与语法错误纠正等内容。我在截图中展示了使用PyTorch实现训练集锚框标注和初始化偏移框的过程。希望你能从中获得一些启发,并进一步实践。也希望大家能抽出时间学习上述两本书中的相关主题。对接下来的日子充满期待!!
- 书籍:
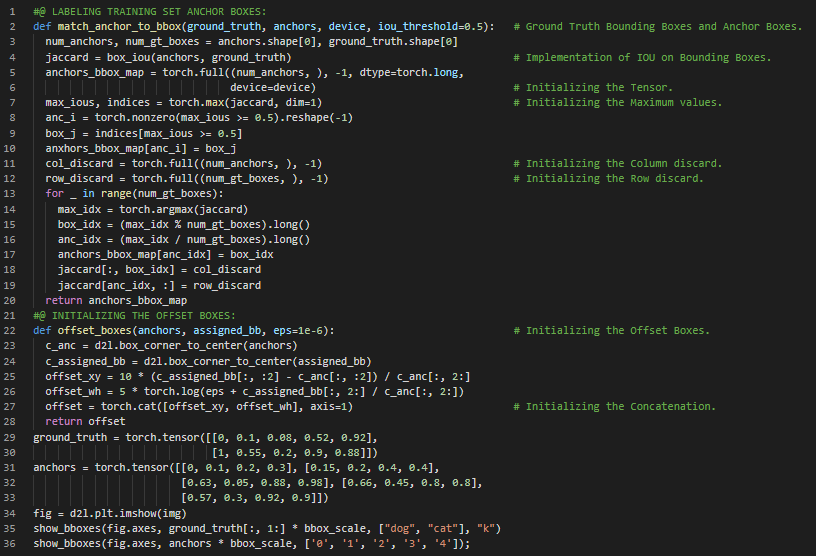
第145天,300天数据之旅!
- 图像分割:图像分割是将数字图像划分为多个区域或像素集合的过程。其目标是将图像简化为更易分析且有意义的形式。在我的机器学习和深度学习旅程中,今天我同样阅读并实践了《深入浅出深度学习》一书。在这里,我学习了非极大值抑制算法、预测边界框、真实边界框、置信度、批量大小、交并比算法或Jaccard指数、宽高比、预测用边界框、多盒目标函数、锚框等相关内容。我在截图中展示了使用PyTorch初始化多盒锚框和预测边界框的实现过程。希望你能从中获得一些见解,并加以实践。也希望大家能抽出时间学习上述两本书中的相关主题。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(链接)
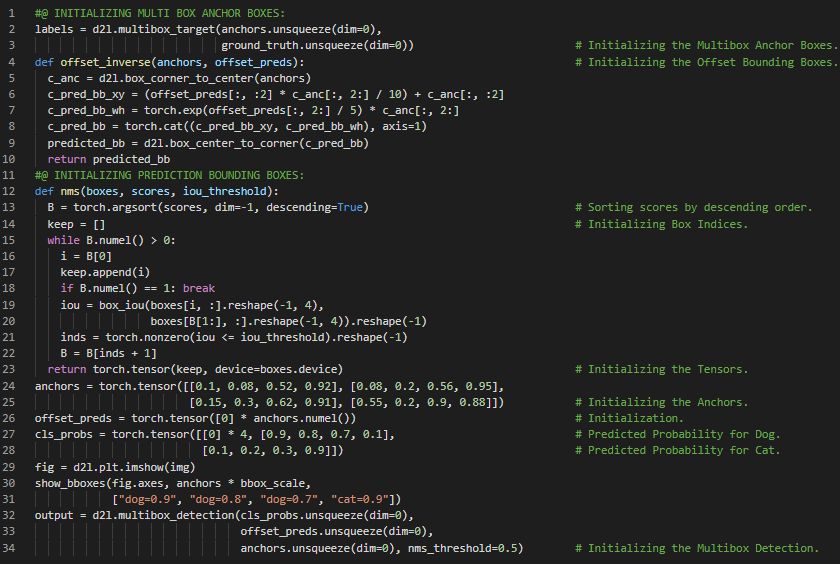
第146天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了多尺度目标检测、生成多个锚框、目标检测、单次多框检测算法、类别预测层、边界框预测层、多尺度预测结果的拼接、高宽下采样模块、卷积神经网络层、ReLU与最大池化层等相关内容。此外,我还花了一段时间阅读《语音与语言处理》一书。在这里,我了解了词性标注、信息抽取、命名实体识别、正则表达式等内容。我在截图中展示了使用PyTorch初始化类别预测层和高宽下采样模块的实现过程。希望你能从中获得一些启发,并继续深入研究。也希望大家能抽出时间学习上述两本书中的相关主题。对接下来的日子充满期待!!
- 书籍:
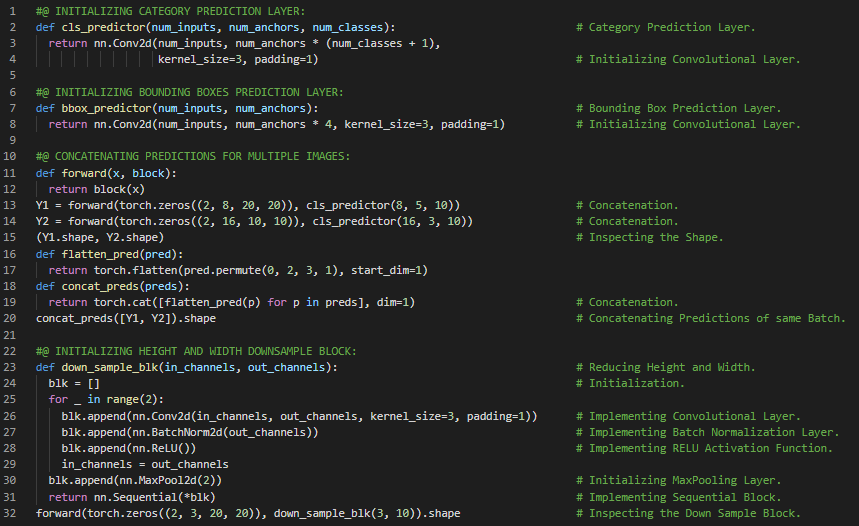
第147天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了单次多框检测算法、基础神经网络、高宽下采样模块、类别预测层、边界框预测层、多尺度特征块、Sequential API等内容。此外,我还花了一些时间阅读《语音与语言处理》一书。在这里,我学习了N元语言模型、概率链式法则、马尔可夫模型、最大似然估计、相对频率、语言模型评估、对数概率、困惑度、泛化与零值、稀疏性等内容。我在截图中展示了使用PyTorch实现基础SSD网络和完整SSD模型的过程。希望你能从中获得一些启发,并继续探索。也希望大家能抽出时间学习上述两本书中的相关主题。对接下来的日子充满期待!!
- 书籍:
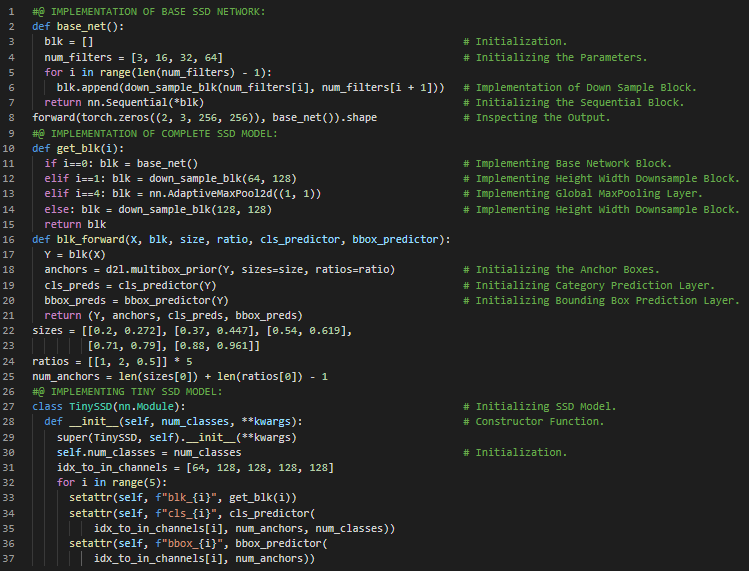
第148天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了单次多框检测模型、Tiny SSD模型的实现、前向传播函数、数据读取与初始化、目标检测、多尺度特征块、全局最大池化层等内容。此外,我还花了一些时间阅读《语音与语言处理》一书。在这里,我了解了未知词或词汇表外单词、OOV率、平滑处理、拉普拉斯平滑、文本分类、加一平滑、最大似然估计、加K平滑等内容。我在截图中展示了使用PyTorch实现单次多框检测模型和数据集初始化的过程。希望你能从中获得一些启发,并继续深入研究。也希望大家能抽出时间学习上述两本书中的相关主题。对接下来的日子充满期待!!
- 书籍:
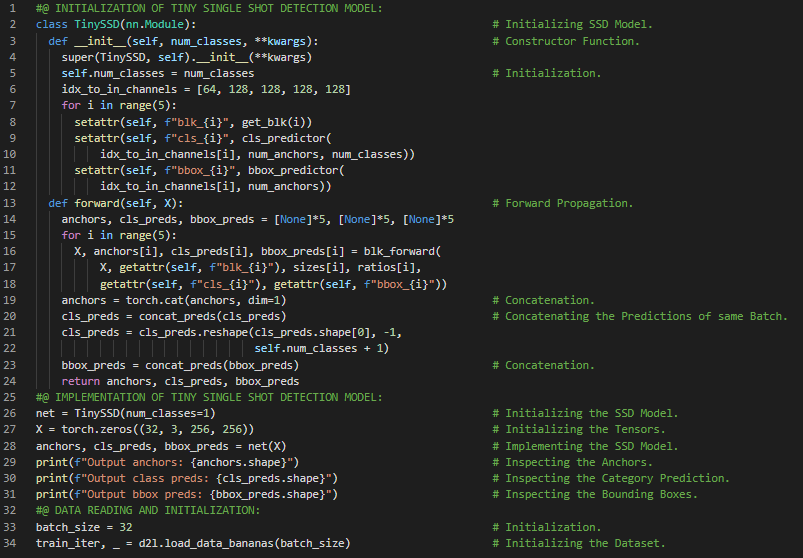
第149天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了Softmax激活函数、卷积层、单次多框检测模型的训练、多尺度锚框、交叉熵损失函数、L1正则化损失函数、平均绝对误差、准确率、类别损失与偏移损失等主题。此外,我还花了一些时间阅读《语音与语言处理》一书,在这里我了解了回退与插值、Katz回退、Kneser Ney平滑、绝对折扣法、网络与愚蠢回退、困惑度与熵的关系等内容。我在快照中展示了使用PyTorch实现的单次多框检测模型训练、损失函数及评估函数。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习上述两本书中的相关主题。对接下来的日子充满期待!!
- 书籍:
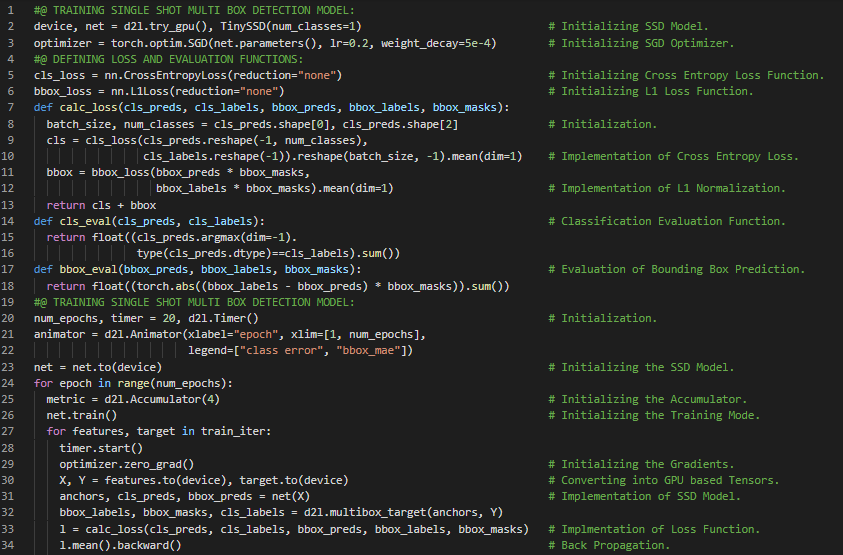
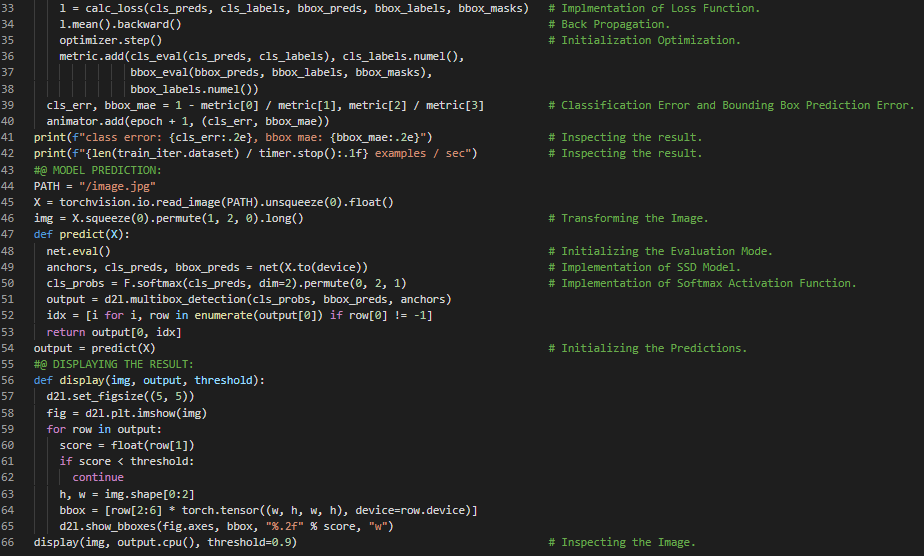
第150天,300天数据之旅!
- 图像分割:图像分割是将数字图像划分为多个区域或像素集合的过程。其目标是将图像简化为更易于分析且具有实际意义的形式。在我的机器学习和深度学习之旅中,今天我同样阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了基于区域的卷积神经网络、Fast R-CNN、Faster R-CNN、Mask R-CNN、类别预测层、边界框预测层、支持向量机、RoI池化层与RoI对齐层、像素级语义、图像分割与实例分割、Pascal VOC2012语义分割、RGB通道、数据预处理等相关内容。我在快照中展示了使用PyTorch实现的语义分割及数据预处理过程。希望你能从中获得一些见解,并进一步实践。同时也建议你花些时间学习上述两本书中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》链接
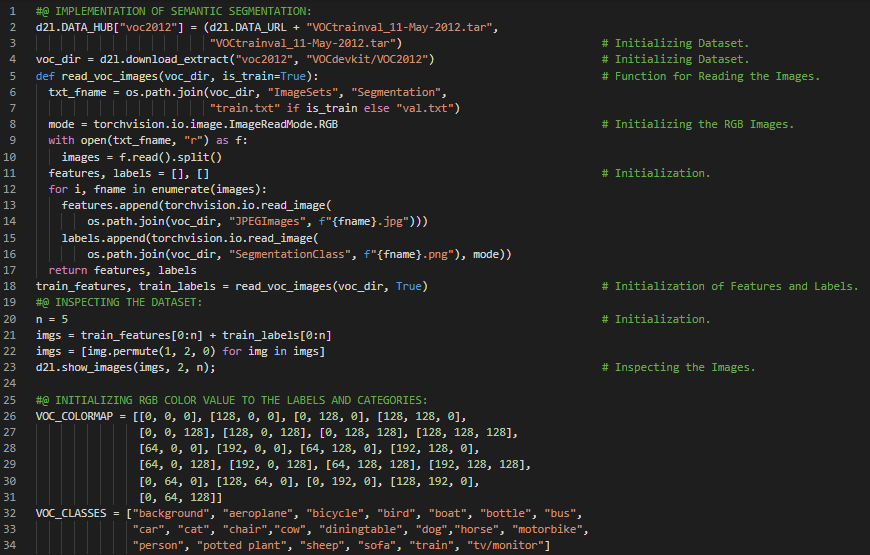
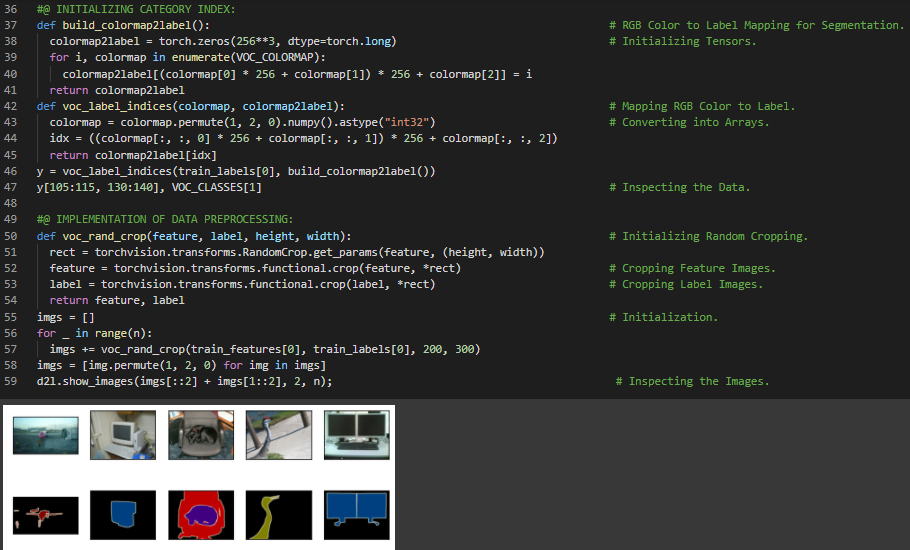
第151天,300天数据之旅!
- 序列到序列模型:序列到序列神经网络可以采用模块化且可重用的编码器-解码器架构构建。编码器模型会生成一个“思想向量”,即对输入数据进行密集且固定维度表示的向量。而解码器模型则利用这些思想向量来生成输出序列。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了用于自定义语义分割的数据集类、RGB通道、图像归一化、随机裁剪操作、序列到序列循环神经网络、标签编码器、独热编码器、编码与向量化、长短期记忆网络(LSTM)等相关内容。我在快照中展示了使用PyTorch实现的自定义语义分割数据集类。希望你能从中获得一些启发,并加以实践。同时也建议你花些时间学习上述两本书中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》链接
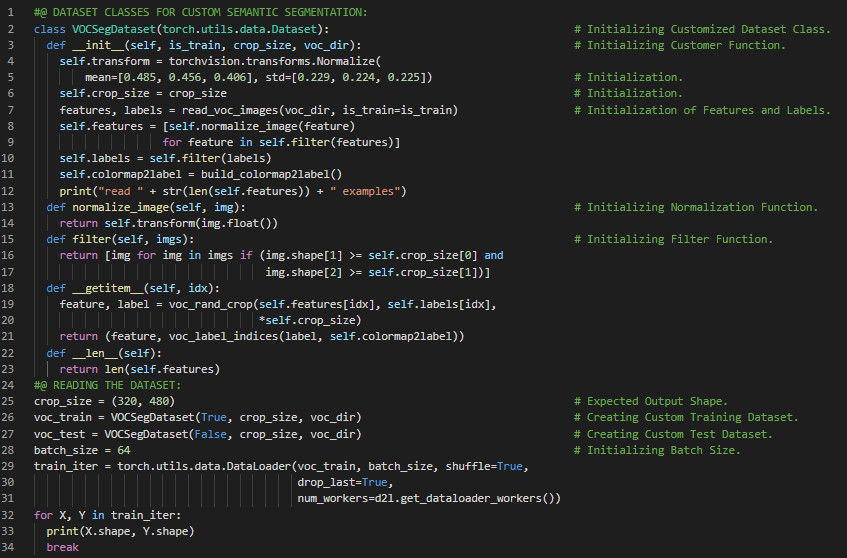
第152天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了转置卷积层、卷积神经网络、基本的二维转置卷积、矩阵广播、卷积核大小、填充、步幅与通道数、与矩阵转置的类比关系、矩阵乘法与矩阵向量乘法等相关内容。此外,我还花了一些时间阅读《语音与语言处理》一书,在这里我了解了朴素贝叶斯与情感分类、文本分类、垃圾邮件检测、概率分类器、多项式朴素贝叶斯分类器、词袋模型、多层感知器、未知词与停用词等内容。我在快照中展示了使用PyTorch实现的转置卷积、填充、步幅以及矩阵乘法等内容。希望你能从中获得一些启发,并加以实践。同时也建议你花些时间学习上述两本书中的相关内容。对接下来的日子充满期待!!
- 书籍:
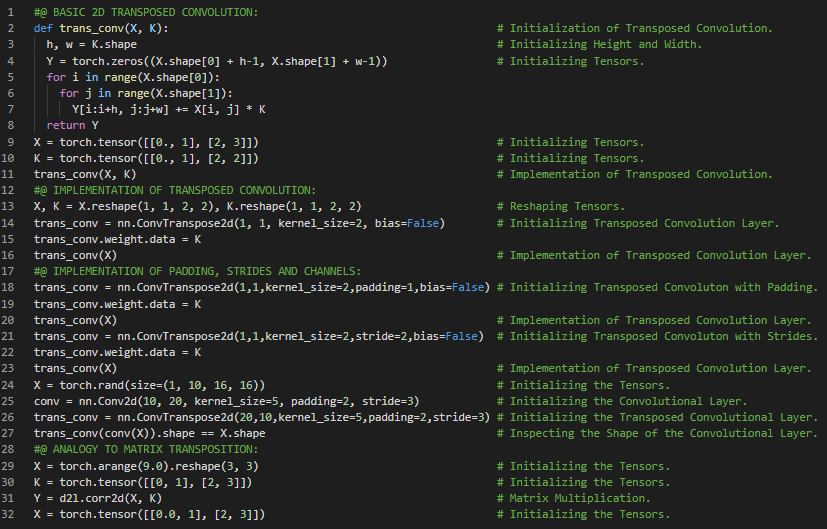
第153天,300天数据之旅!
- 转置卷积:转置卷积的特点在于,其步幅和填充并不像标准卷积那样对应于在输入图像周围添加的零的数量以及卷积核滑动时的位移量。在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了全卷积神经网络、语义分割原理、转置卷积层、如何构建预训练神经网络模型、全局平均池化层、展平层、图像处理与上采样、双线性插值核函数等相关内容。我在快照中展示了使用PyTorch实现的全卷积层、预训练神经网络、双线性插值核函数以及转置卷积层的过程。希望你能从中获得一些见解,并进一步实践。同时也建议你花些时间学习上述两本书中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》链接
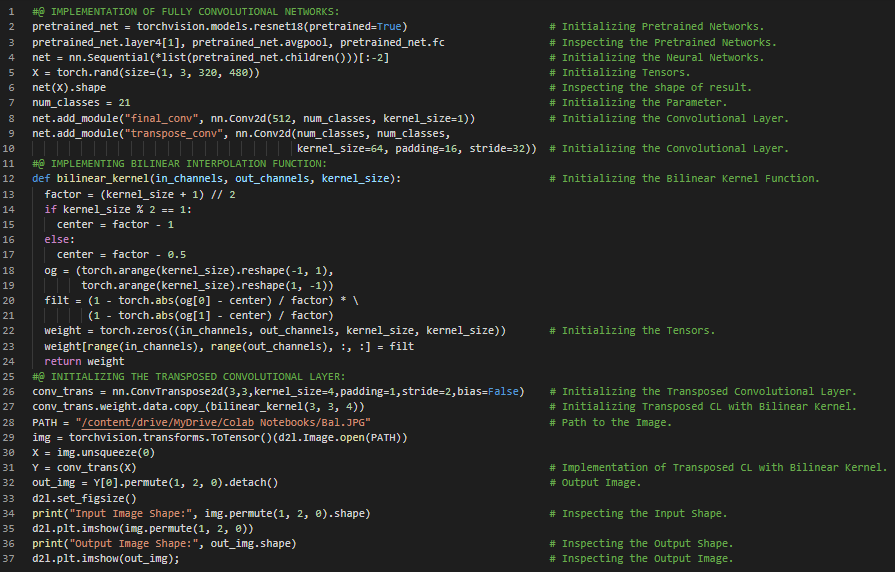
300天数据之旅第154天!
- 神经风格迁移算法:其任务是将一个领域的图像风格转换为另一个领域的图像风格。它通过操纵图像或视频,使其呈现出另一幅图像的外观。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在此过程中,我学习了 Softmax 交叉熵损失函数、随机梯度下降法、卷积神经网络、神经网络风格迁移、合成图像、RGB 通道、归一化等与之相关的多个主题。此外,我还花了一些时间阅读《语音与语言处理》一书。书中介绍了如何优化朴素贝叶斯用于情感分析、情感词典、朴素贝叶斯作为语言模型、精确率、召回率和 F1 分数、多标签及多项式分类等内容。目前,我已开始使用神经网络进行风格迁移的工作,相关笔记本如下所示,但我仍在继续完善。
- 书籍:
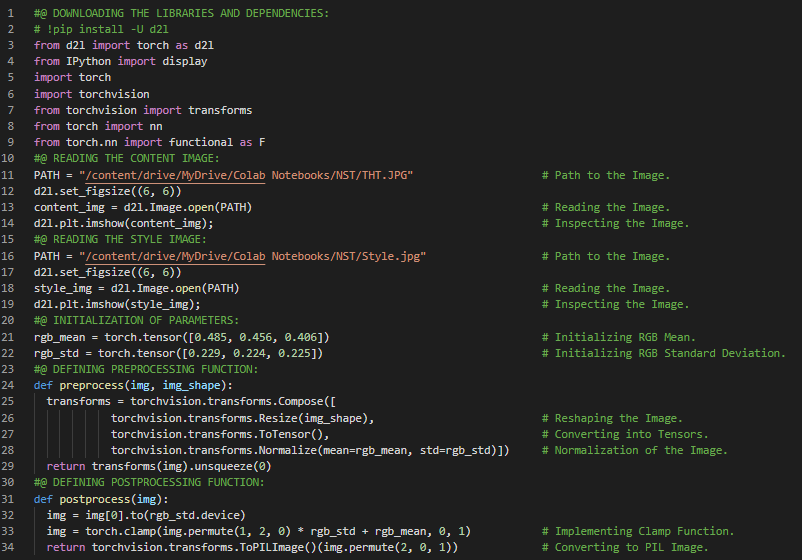
300天数据之旅第155天!
- 神经风格迁移算法:其任务是将一个领域的图像风格转换为另一个领域的图像风格。它通过操纵图像或视频,使其呈现出另一幅图像的外观。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在此过程中,我学习了神经网络风格迁移、卷积神经网络、内容图像与风格图像的读取、图像的预处理与后处理、图像特征提取、合成图像、VGG 神经网络、均方误差损失函数、总变差损失函数、图像 RGB 通道的归一化等与之相关的多个主题。目前,我仍在利用神经网络进行风格迁移的工作,相关笔记本如下所示,但我仍在继续推进。我在截图中展示了使用 PyTorch 实现的特征提取函数和均方误差损失函数的代码,希望你能从中获得一些启发,并尝试实践。同时,也期待你能够花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
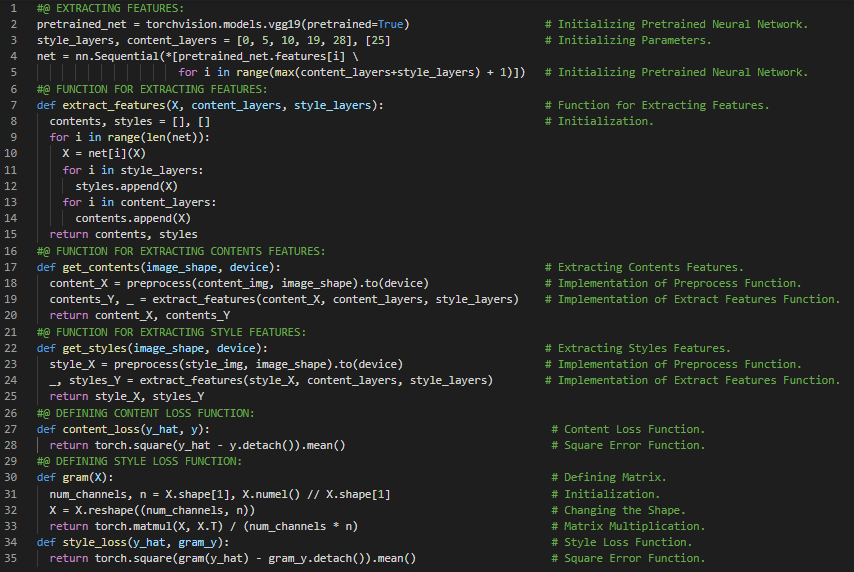
300天数据之旅第156天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在此过程中,我学习了合成图像的创建与初始化、同步函数、Adam 优化器、Gram 矩阵、卷积神经网络、神经网络风格迁移、损失函数等与之相关的多个主题。此外,我还花了一些时间阅读《语音与语言处理》一书。书中介绍了测试集与交叉验证、统计显著性检验、朴素贝叶斯分类器、自助法、逻辑回归、生成式与判别式分类器、特征表示、Sigmoid 分类、权重与偏置项等与之相关的多个主题。目前,我已经完成了使用神经网络进行风格迁移的工作。相关笔记本如下所示,但我仍在持续更新。
- 书籍:
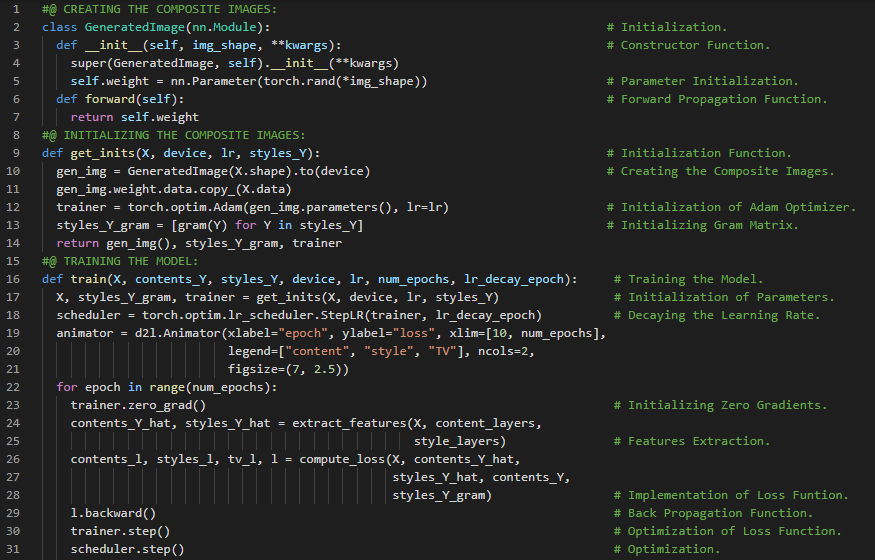
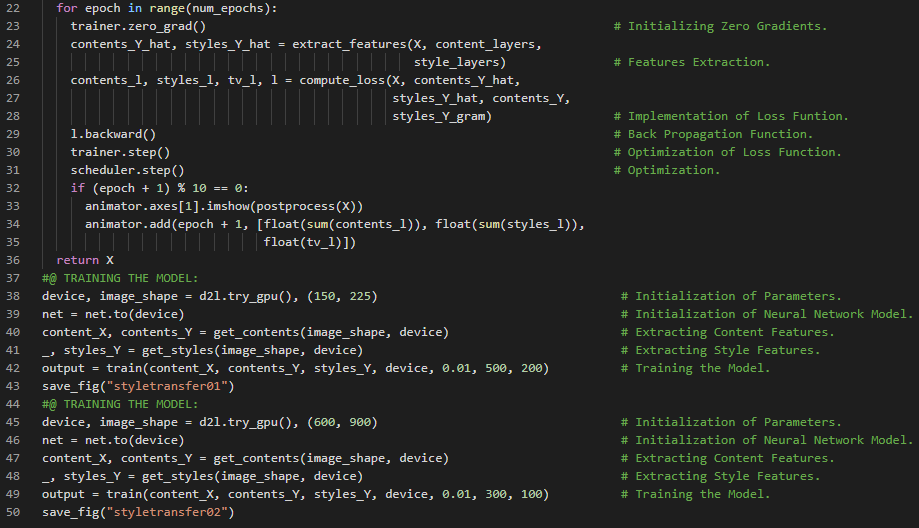
300天数据之旅第157天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在此过程中,我学习了计算机视觉、图像分类、CIFAR10 数据集、数据的获取与整理以及数据增强等与之相关的多个主题。除此之外,我还了解了数据抓取与 Scrapy 框架、命名实体识别与 SpaCy 库、使用 SpaCy 训练的 Transformer 模型、地理编码等与之相关的多个主题。目前,我已经完成了神经网络风格迁移笔记本的工作,并开始着手制作关于图像目标识别——CIFAR10 数据集的笔记本。所有相关笔记本如下所示。我在截图中展示了 CIFAR10 数据集的获取与整理过程的实现代码,希望你能从中有所收获,并进一步探索实践。同时,也期待你能够花些时间学习上述及下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
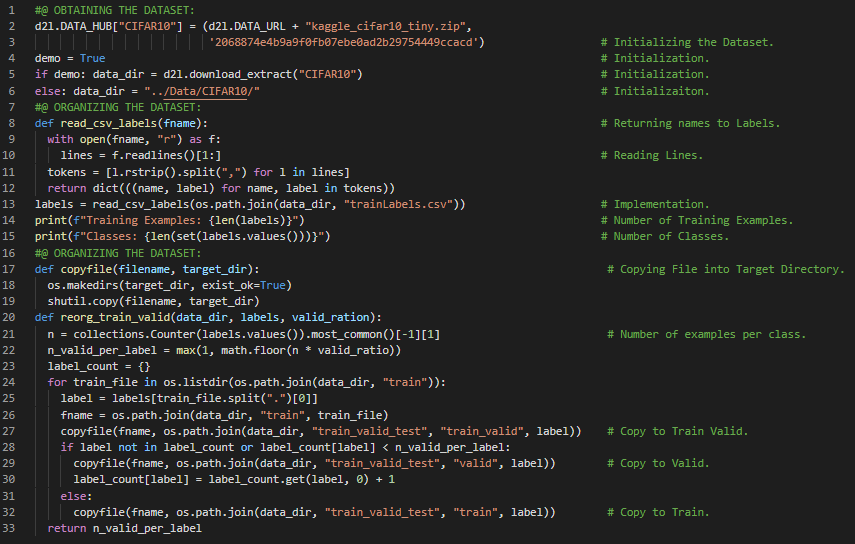
第158天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了计算机视觉、图像分类、图像增强与过拟合、RGB通道归一化、数据加载器和验证集等主题。此外,我还了解了斯坦福的NER算法、NLTK、命名实体识别等相关内容。我已经完成了使用神经网络进行风格迁移的笔记本项目,并开始着手处理图像中的物体识别:CIFAR10笔记本。所有笔记本都列在下方。我在截图中展示了使用PyTorch实现数据集获取与整理、图像增强及归一化的过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 神经网络风格迁移(Neural Networks Style Transfer)
- 图像中的物体识别:CIFAR10(CIFAR10__Recognition)
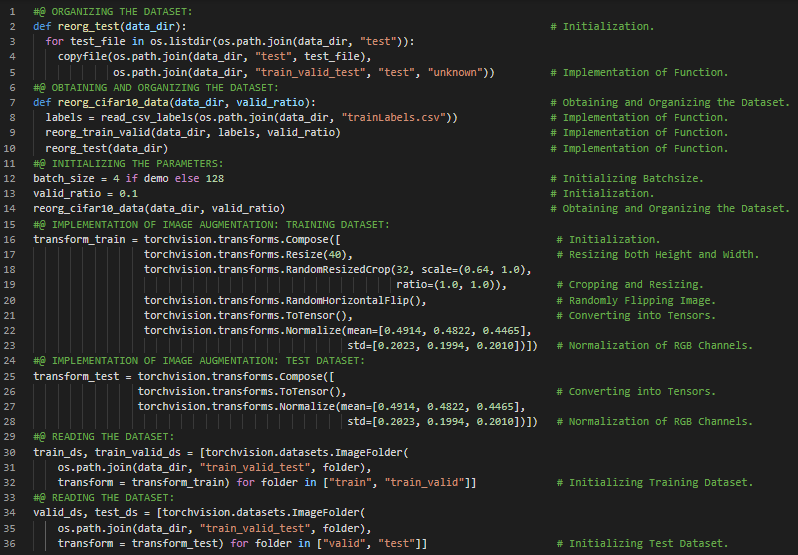
第159天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书。在这里,我学习了计算机视觉、ResNet模型与残差块、Xavier随机初始化、交叉熵损失函数、训练函数的定义、随机梯度下降、学习率调度器、评估指标等内容。此外,我还花了一些时间阅读《语音与语言处理》一书,在这里我了解了情感分类、逻辑回归中的学习、条件最大似然估计、损失函数等相关内容。目前我正在完成图像中的物体识别:CIFAR10笔记本项目。该笔记本如下所示。我在截图中展示了使用PyTorch定义训练函数的实现过程。希望你能从中获得一些见解,并加以实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 图像中的物体识别:CIFAR10(CIFAR10__Recognition)
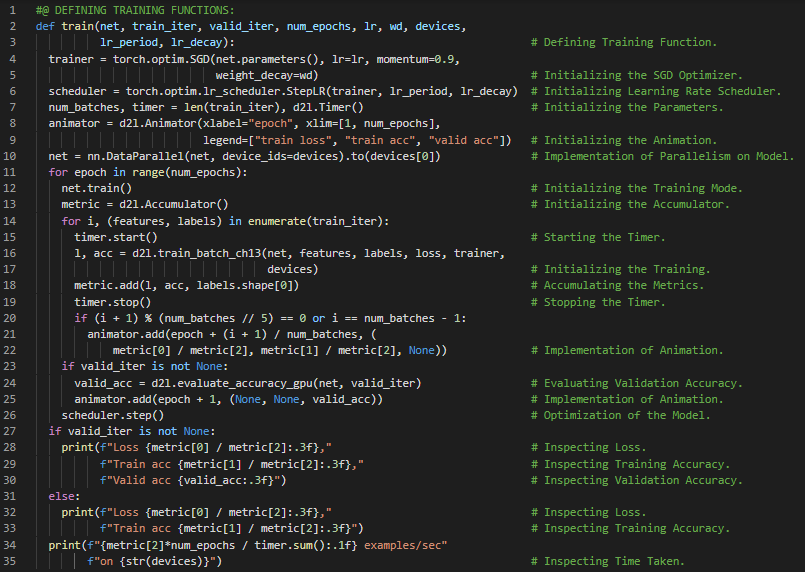
第160天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书。在这里,我学习了ImageNet数据集、数据集的获取与整理、图像增强技术如翻转与缩放、调整亮度与对比度、迁移学习与特征提取、图像归一化等内容。我已经完成了图像中的物体识别:CIFAR10笔记本项目,并开始着手处理犬种识别:ImageNet笔记本。所有笔记本都列在下方。我在截图中展示了使用PyTorch实现图像增强与归一化、定义神经网络模型及损失函数的过程。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 图像中的物体识别:CIFAR10(CIFAR10__Recognition)
- 犬种识别:ImageNet(DogBreedClassification)
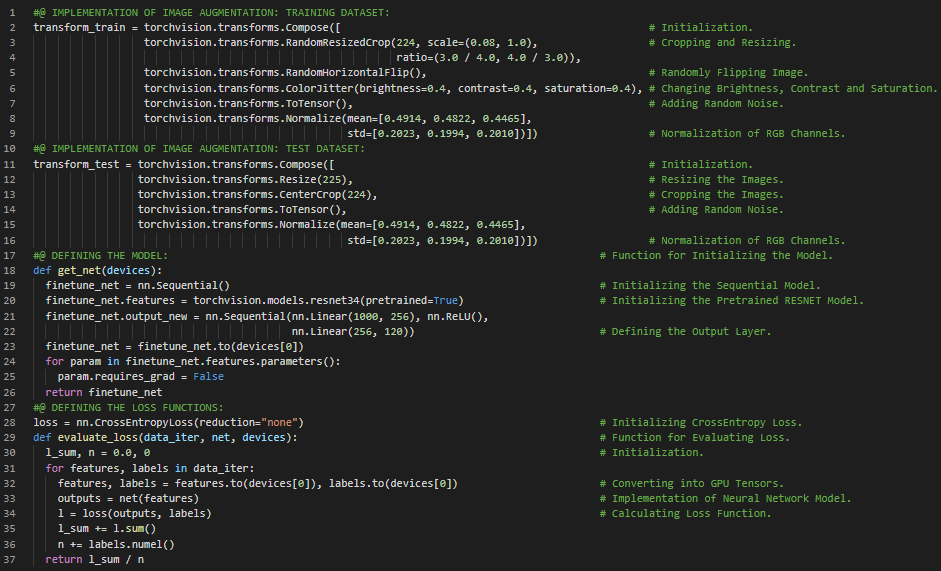
第161天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了训练函数的定义、计算机视觉、超参数、随机梯度下降优化函数、学习率调度与优化、训练损失与验证损失等内容。此外,我还花了一些时间阅读《语音与语言处理》一书,在这里我了解了逻辑回归的梯度、SGD算法、小批量训练等相关内容。目前我正在处理犬种识别:ImageNet笔记本项目。该笔记本如下所示。我在截图中展示了使用PyTorch定义训练函数的实现过程。希望你能从中获得一些启发,并继续努力。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 《语音与语言处理》(Speech and Language Processing)
- 图像中的物体识别:CIFAR10(CIFAR10__Recognition)
- 犬种识别:ImageNet(DogBreedClassification)
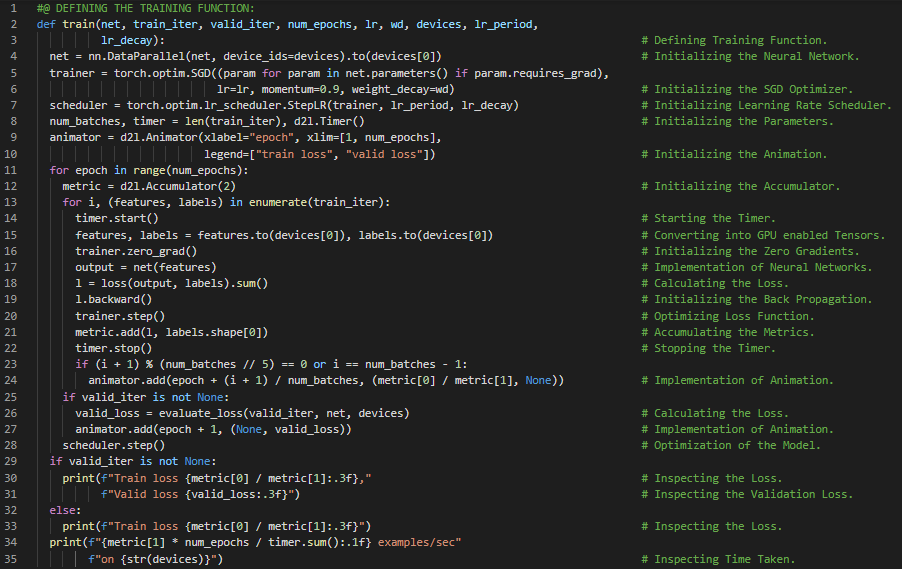
第162天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我继续阅读并实践了《深入浅出深度学习》一书。在这里,我学习了预训练文本表示、词嵌入与Word2Vec、独热编码、Skip-Gram模型及其训练、连续词袋模型及其训练、近似训练、负采样、层次化Softmax、数据集的读取与处理、子采样、词汇表等内容。除此之外,我还阅读了关于如何利用异构编码器改善化学自编码器潜在空间及分子多样性的相关内容。目前我正在处理犬种识别:ImageNet笔记本项目。该笔记本如下所示。我在截图中展示了使用PyTorch实现数据集读取与预处理、子采样以及比较的过程。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 图像中的物体识别:CIFAR10(CIFAR10__Recognition)
- 犬种识别:ImageNet(DogBreedClassification)
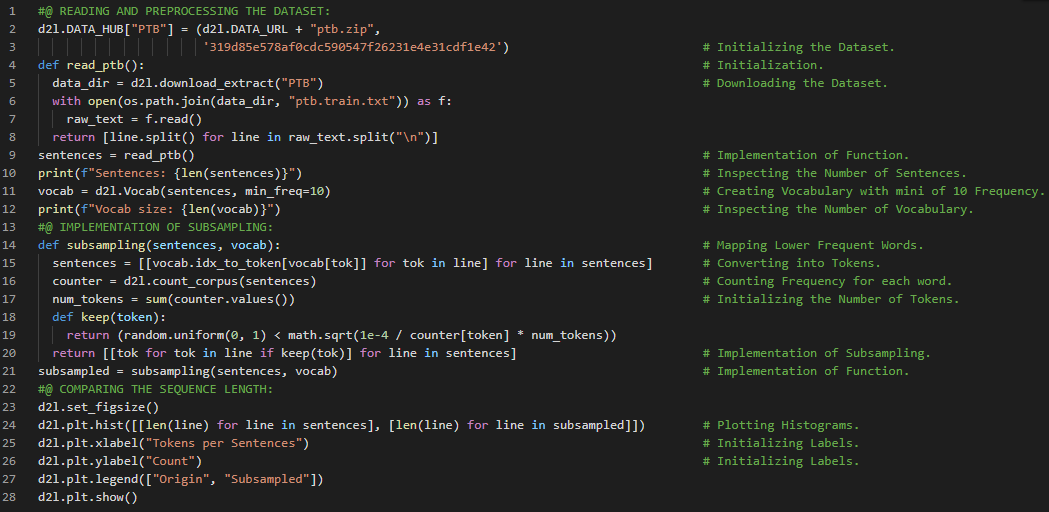
300天数据之旅第163天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了子采样、提取中心目标词与上下文词、最大上下文窗口大小、Penn Tree Bank 数据集以及预训练词嵌入等内容。此外,我还花了一些时间阅读《语音与语言处理》一书,在这里我了解了正则化与过拟合、曼哈顿距离、Lasso 和 Ridge 回归、多项逻辑回归、MLR 中的特征、MLR 的学习过程、模型解释、梯度方程推导等内容。我还完成了“犬种识别:ImageNet”笔记本的工作。在截图中,我展示了使用 PyTorch 提取中心目标词和上下文词的实现。希望你能从中获得一些启发。也希望大家能花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
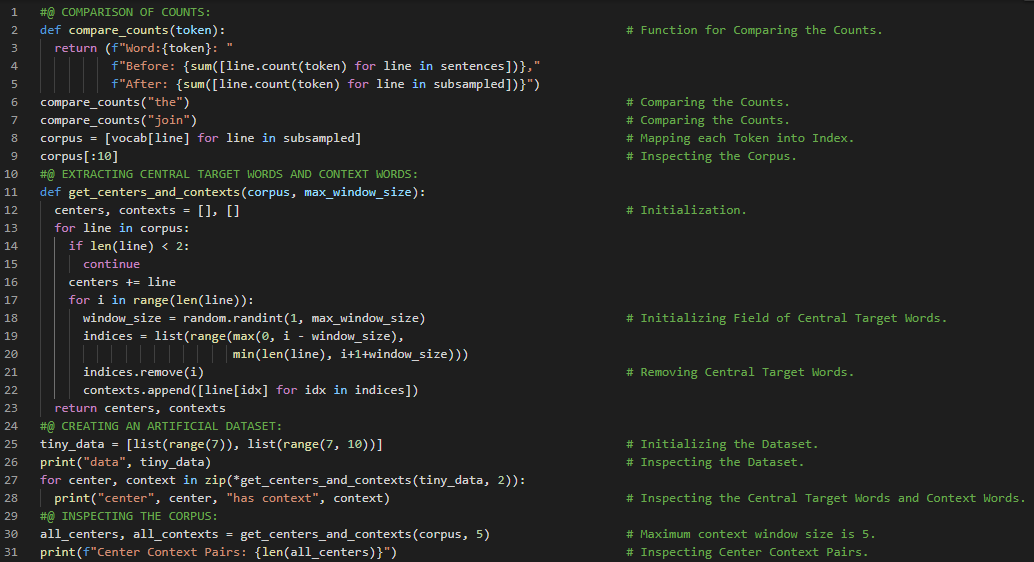
300天数据之旅第164天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了子采样与负采样、词嵌入与 Word2Vec、概率、分批读取、拼接与填充、随机小批量等内容。此外,我还花了一些时间阅读《语音与语言处理》一书,在这里我了解了向量语义与嵌入、词汇语义、词元与词义、词义消歧、词语相似度、对比原则、表示学习、同义性等内容。在截图中,我展示了使用 PyTorch 进行负采样的实现。希望你能从中获得一些启发。也希望大家能花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
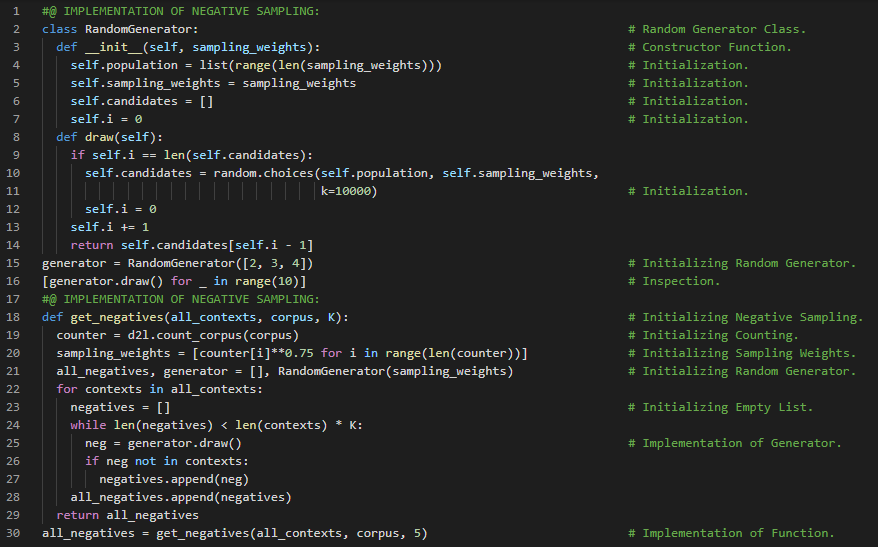
300天数据之旅第165天!
- 子采样:子采样是一种通过选择原始数据的子集来减少数据规模的方法。子集由一个参数决定。子采样旨在尽量减少高频词对词嵌入模型训练的影响。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了词嵌入、批次、损失函数与填充、中心词与上下文词、负采样、数据加载器实例、词汇表、子采样、数据迭代、掩码变量等内容。在截图中,我展示了使用 PyTorch 读取批次以及加载 PTB 数据集的函数的实现。希望你能从中获得一些启发。也希望大家能花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
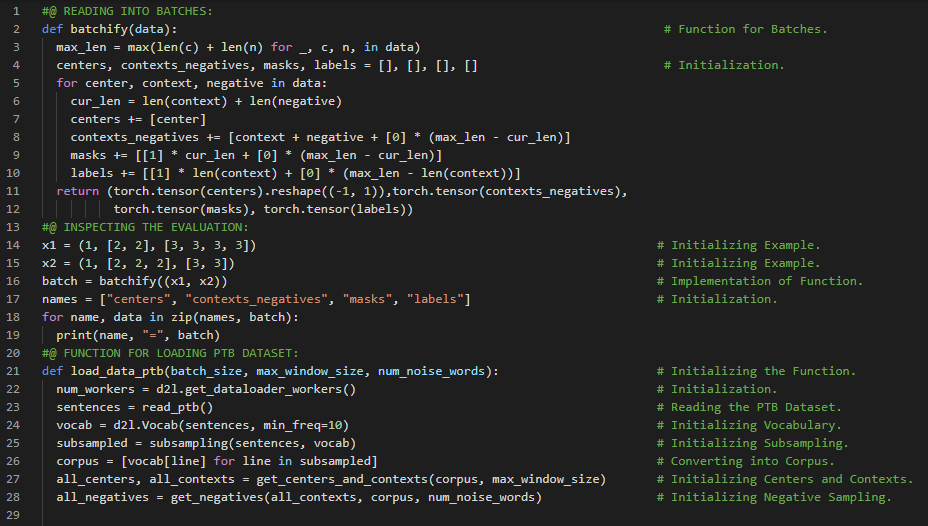
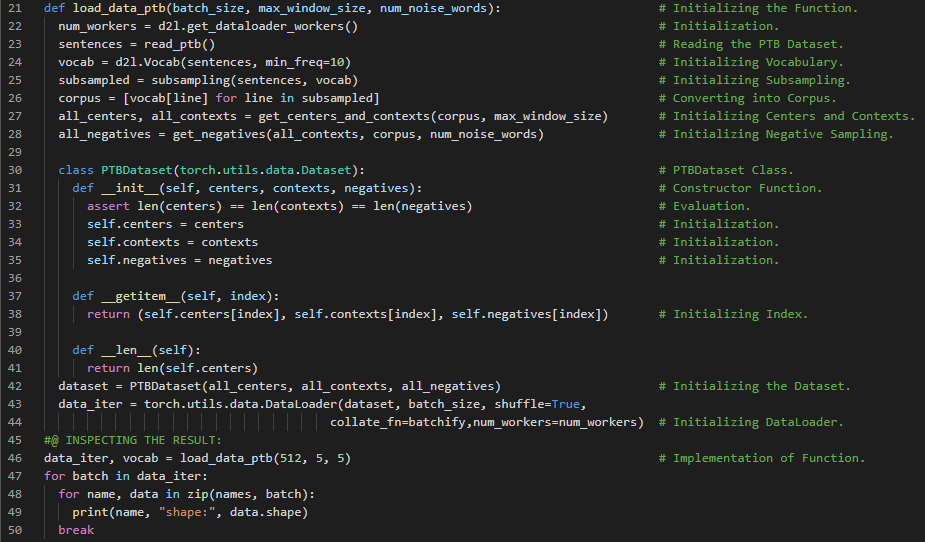
300天数据之旅第166天!
- 词嵌入:词嵌入是指用实值向量来表示单词的一种方法,通常用于文本分析。这种向量编码了单词的意义,使得在向量空间中距离较近的单词往往具有相似的含义。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了词嵌入、Word2Vec、Skip Gram 模型、嵌入层、词向量、Skip Gram 模型前向计算、批量矩阵乘法、二元交叉熵损失函数、负采样、掩码变量与填充、模型参数初始化等内容。在截图中,我展示了使用 PyTorch 实现的嵌入层、Skip Gram 模型前向计算以及二元交叉熵损失函数。希望你能从中获得一些启发。也希望大家能花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
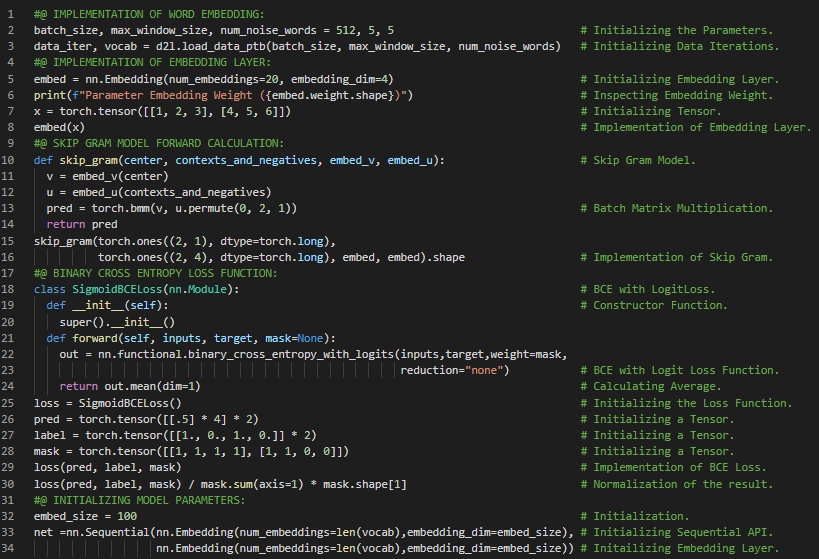
300天数据之旅第167天!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了训练 Skip Gram 模型、损失函数、应用词嵌入模型、负采样、使用 Global Vectors 或 Glove 进行词嵌入、条件概率、Glove 模型、交叉熵损失函数等内容。此外,我还花了一些时间阅读《语音与语言处理》一书,在这里我了解了词语相关性、语义场、语义框架与角色、内涵与情感、向量语义、嵌入等内容。在截图中,我展示了使用 PyTorch 训练词嵌入模型的实现。希望你能从中获得一些启发。也希望大家能花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
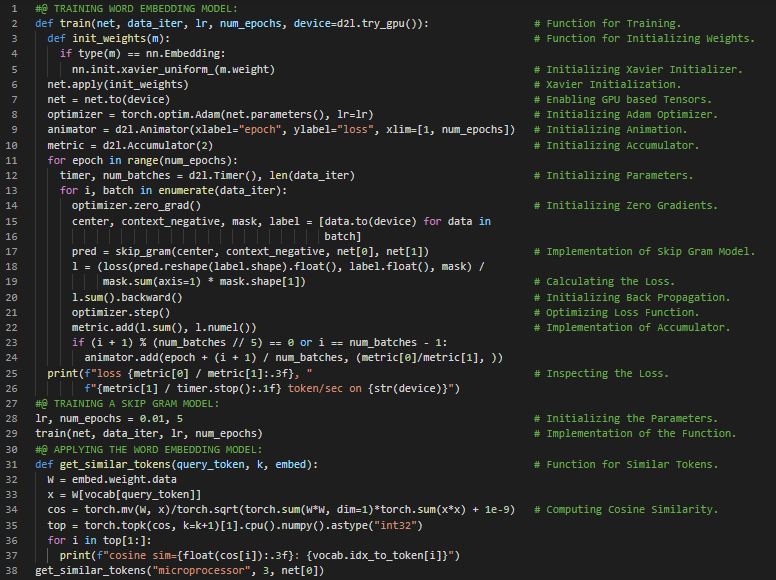
第168天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了子词嵌入、FastText 和字节对编码、寻找同义词和类比关系、预训练词向量、标记嵌入、中心词与上下文词等主题。此外,我还花了一些时间阅读《语音与语言处理》一书。在这本书中,我学习了词与向量、向量与文档、词项-文档矩阵、信息检索、行向量与上下文矩阵等相关内容。我在截图中展示了使用 PyTorch 实现定义标记嵌入类的代码。希望你能从中获得一些启发。也希望大家能抽出时间学习下面提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 《语音与语言处理》(Speech and Language Processing)
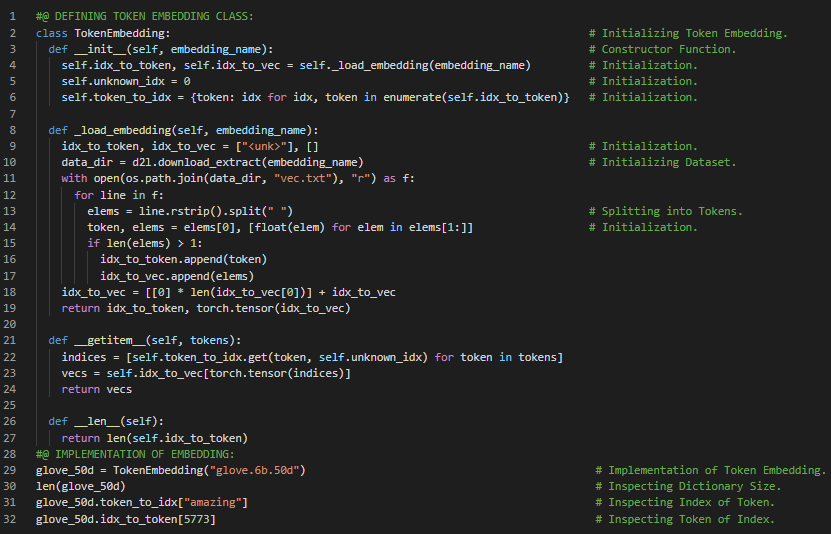
第169天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了寻找同义词和类比关系、词嵌入模型与 Word2Vec、应用预训练词向量、余弦相似度等主题。同时,我也花了一些时间阅读《语音与语言处理》一书。在这本书中,我了解了用余弦值衡量相似性、点积与内积、向量中词语的权重、词频-逆文档频率(TFIDF)、集合频率、TFIDF 向量模型的应用等内容。我在截图中展示了使用 PyTorch 实现余弦相似度以及寻找同义词和类比关系的代码。希望你能从中获得一些见解。也希望大家能抽出时间学习下面提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 《语音与语言处理》(Speech and Language Processing)
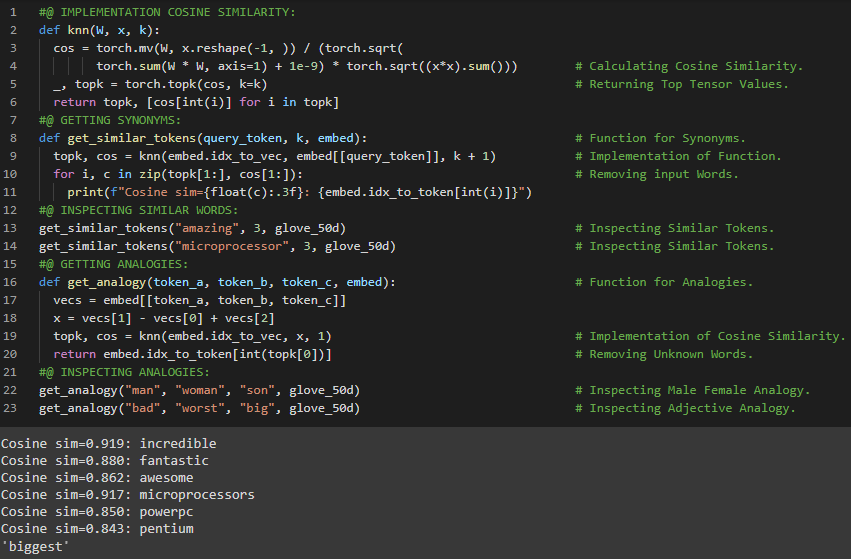
第170天,300天数据之旅!
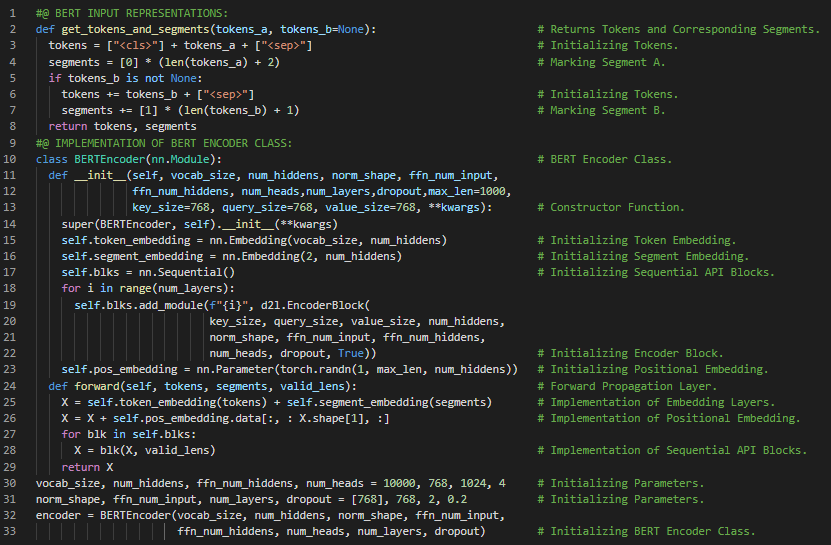
- 来自 Transformer 的双向编码器表示:ELMO 双向编码上下文,但采用特定任务的架构;GPT 则是任务无关的,仅从左到右编码上下文。而 BERT 不仅双向编码上下文,而且只需对架构进行少量改动即可适用于广泛的自然语言处理任务。在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了 BERT 架构、从上下文无关到上下文敏感、词嵌入模型与 Word2Vec、从任务特定到任务无关、来自语言模型的嵌入或 ELMO 架构、输入表示、标记、片段和位置嵌入以及可学习的位置嵌入等相关内容。我在截图中展示了使用 PyTorch 实现 BERT 输入表示和 BERT 编码器类的代码。希望你能从中获得一些启发。也希望大家能抽出时间学习下面提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
第171天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了 BERT 编码器类、预训练任务、掩码语言建模、多层感知机、前向推理、BERT 输入序列、双向上下文编码等内容。此外,我还花了一些时间阅读《语音与语言处理》一书。在这本书中,我学习了点互信息(PMI)、拉普拉斯平滑、Word2Vec、带有负采样的跳字模型(SGNS)、分类器、逻辑斯蒂函数与 S 形函数、余弦相似度与点积等相关内容。我在截图中展示了使用 PyTorch 实现掩码语言建模和 BERT 编码器的代码。希望你能从中获得一些启发,并进一步深入研究。也希望大家能抽出时间学习下面提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 《语音与语言处理》(Speech and Language Processing)
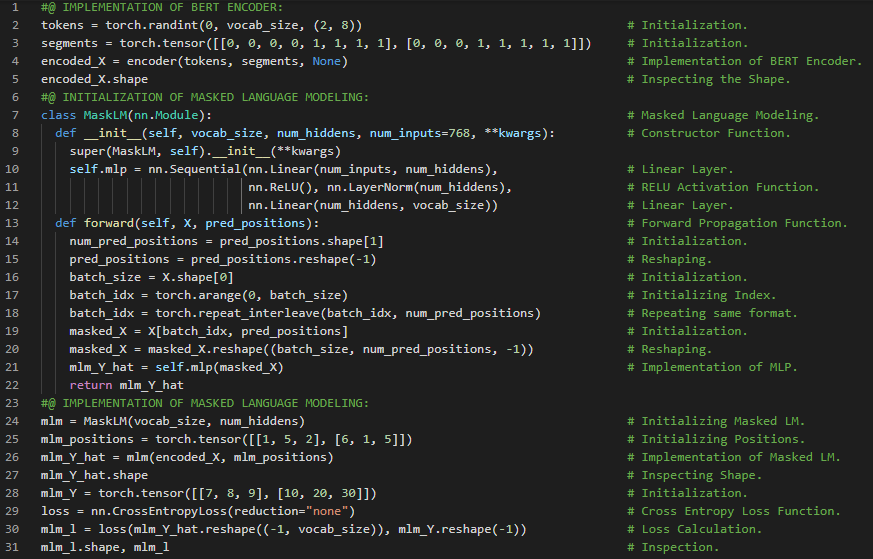
第172天,300天数据之旅!
- 来自 Transformer 的双向编码器表示:ELMO 双向编码上下文,但采用特定任务的架构;GPT 是任务无关的,仅从左到右编码上下文。而 BERT 则双向编码上下文,且只需对架构进行少量改动即可适应多种 NLP 任务。BERT 的嵌入是标记、片段和位置嵌入三者的总和。在我的机器学习和深度学习旅程中,今天我阅读并实践了《深入浅出深度学习》一书。在这里,我学习了来自 Transformer 的双向编码器表示(即 BERT 架构)、下一句预测模型、交叉熵损失函数、多层感知机、BERT 模型、掩码语言建模、BERT 编码器、BERT 模型的预训练等内容。我在截图中展示了使用 PyTorch 实现下一句预测和 BERT 模型的代码。希望你能从中获得一些启发,并继续深入研究。也希望大家能抽出时间学习下面提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
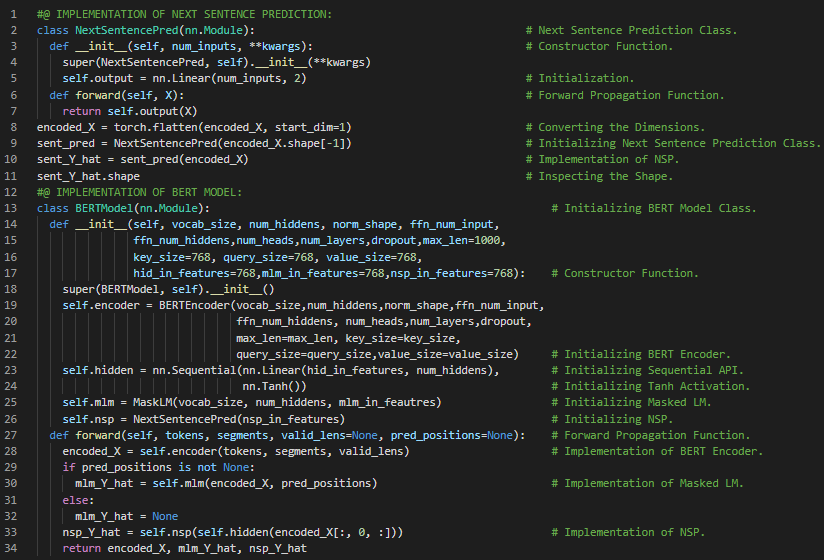
第173天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了BERT模型的预训练及其数据集、定义预训练任务的帮助函数、生成下一句预测任务、生成掩码语言建模任务、序列标记等与之相关的主题。此外,我还花了一些时间阅读《语音与语言处理》一书。书中我了解了跳字嵌入的学习、二分类器、目标与上下文嵌入、嵌入的可视化、嵌入的语义属性等主题。我在截图中展示了使用PyTorch实现的下一句预测任务和掩码语言建模任务的代码。希望你能从中获得一些启发,并加以实践。也希望大家能抽出时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 《语音与语言处理》(Speech and Language Processing)
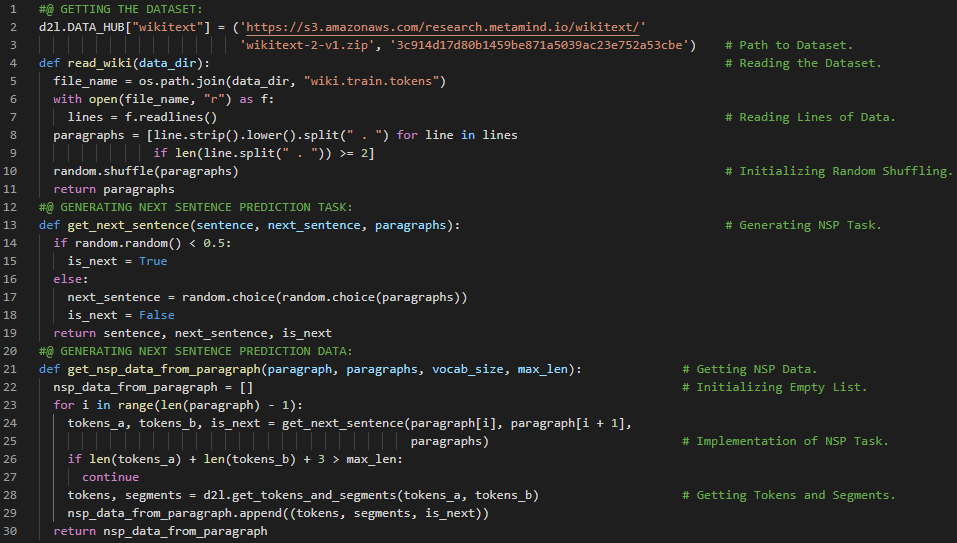
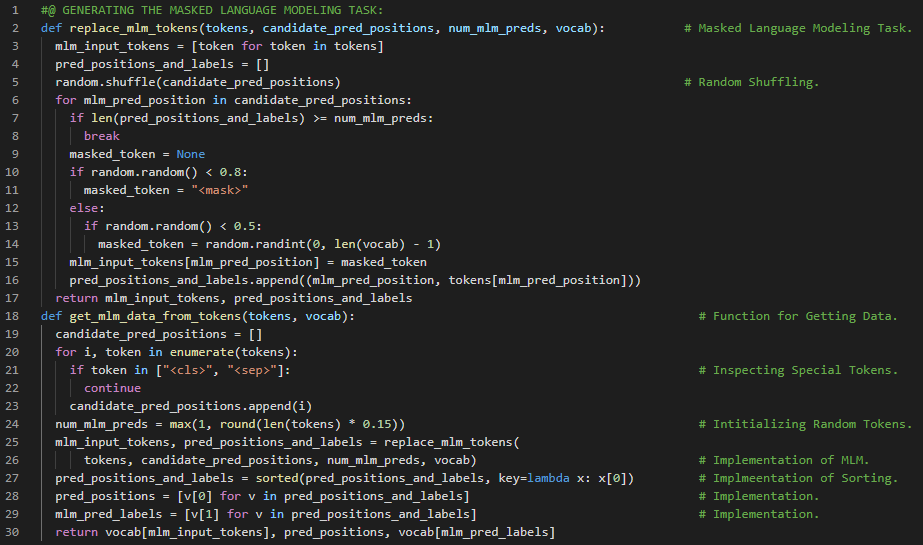
第174天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了BERT模型的预训练、下一句预测任务和掩码语言建模任务、将文本转换为预训练数据集等与之相关的主题。此外,我还了解了Scorer以及SpaCy模型的示例实例、长短期记忆神经网络、Smiles向量化器、前馈神经网络等相关内容。我在截图中展示了使用PyTorch将文本转换为预训练数据集的实现过程。希望你能从中获得一些见解,并进一步实践。也希望大家能抽出时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
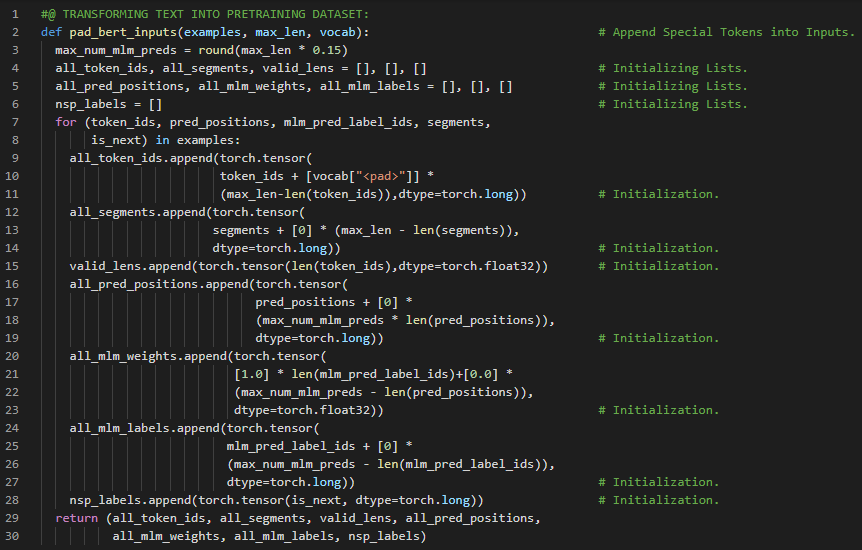
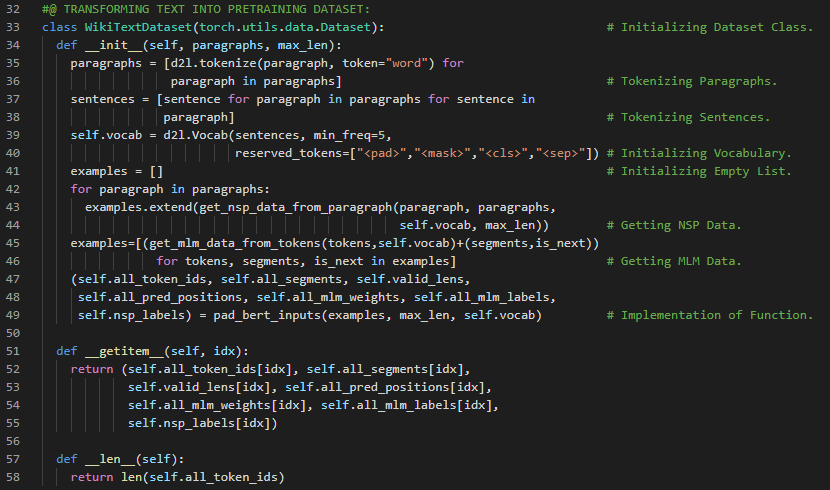
第175天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了BERT模型的预训练、交叉熵损失函数、Adam优化函数、梯度清零、反向传播与优化、掩码语言建模损失和下一句预测损失等与之相关的主题。我在截图中展示了使用PyTorch实现的BERT模型预训练、从BERT模型获取损失以及训练神经网络模型的过程。希望你能从中获得一些启发,并加以实践。也希望大家能抽出时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
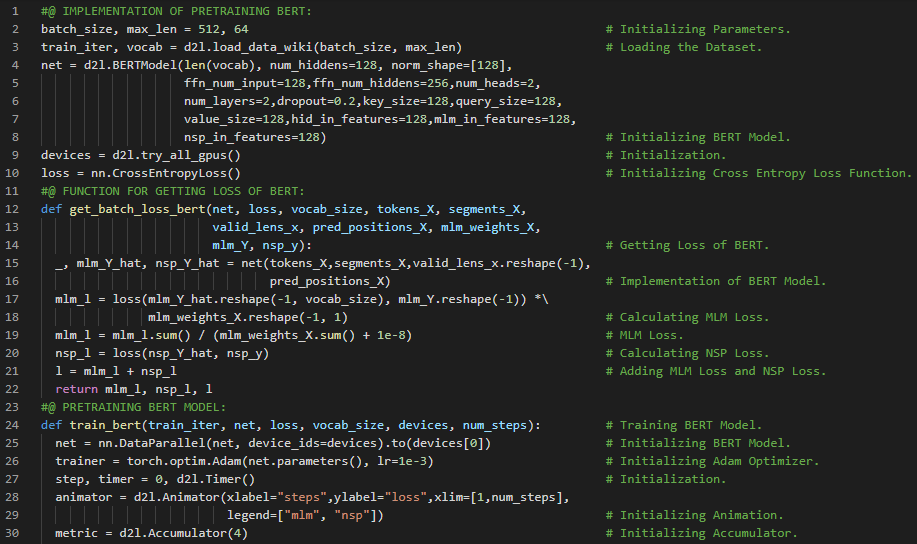
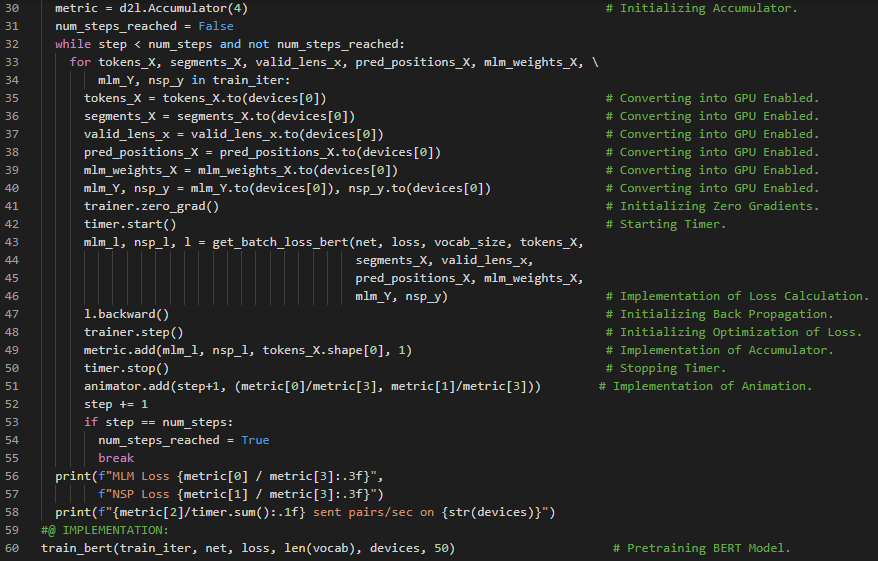
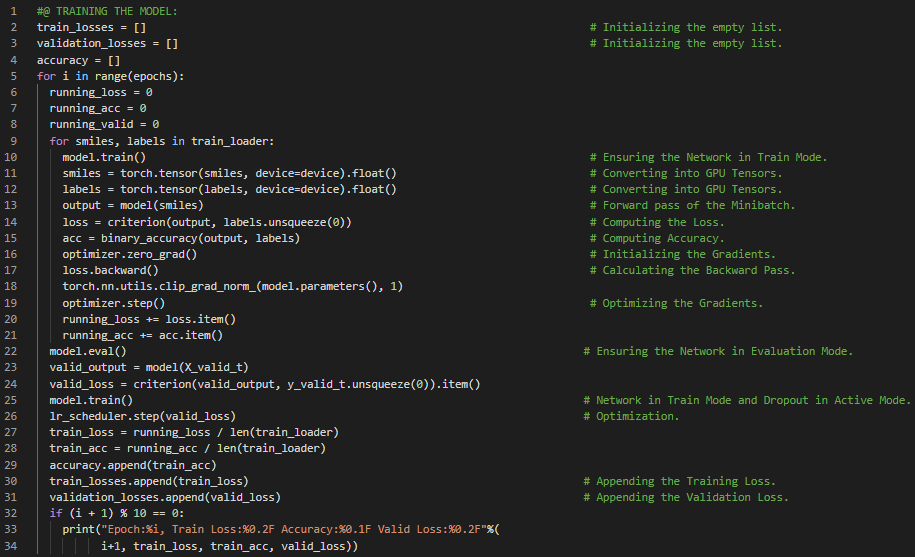
第176天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了自然语言处理的应用、NLP架构与预训练、情感分析及其数据集、文本分类、分词与词汇表、填充至相同长度等与之相关的主题。除此之外,我还了解了命名实体识别、频率分布、NLTK、列表扩展等相关内容。我在截图中展示了使用PyTorch读取数据集、进行分词与构建词汇表、并将文本填充至固定长度的实现过程。希望你能从中获得一些启发,并加以实践。也希望大家能抽出时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 《情感分析数据集笔记本》(Sentiment Analysis Dataset Notebook)
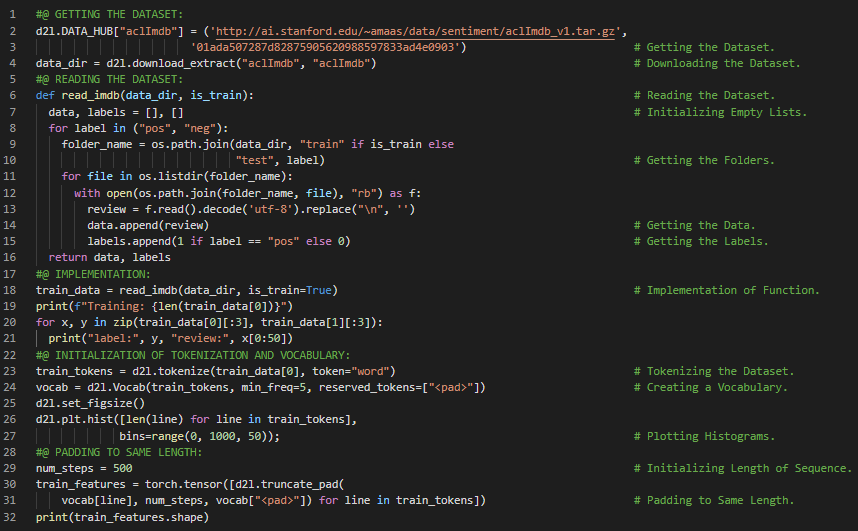
第177天,300天数据之旅!
- 情感分析:情感分析是利用自然语言处理、文本分析、计算语言学和生物特征技术,系统地识别、提取、量化和研究情感状态及主观信息的一种方法。它广泛应用于客户声音材料,如评论和调查回复、在线和社交媒体内容,以及医疗保健领域的资料,其应用范围涵盖市场营销、客户服务到临床医学等多个领域。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了创建数据迭代、分词与词汇表、截断与填充、循环神经网络模型与情感分析、预训练词向量与GloVe、双向LSTM与嵌入层、线性层与解码、编码与序列数据、Xavier初始化等与之相关的主题。我在截图中展示了使用PyTorch实现的双向循环神经网络模型。希望你能从中获得一些启发,并加以实践。也希望大家能抽出时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《深入浅出深度学习》(Dive into Deep Learning)
- 《情感分析数据集笔记本》(Sentiment Analysis Dataset Notebook)
- 《基于RNN的情感分析》(Sentiment Analysis with RNN)
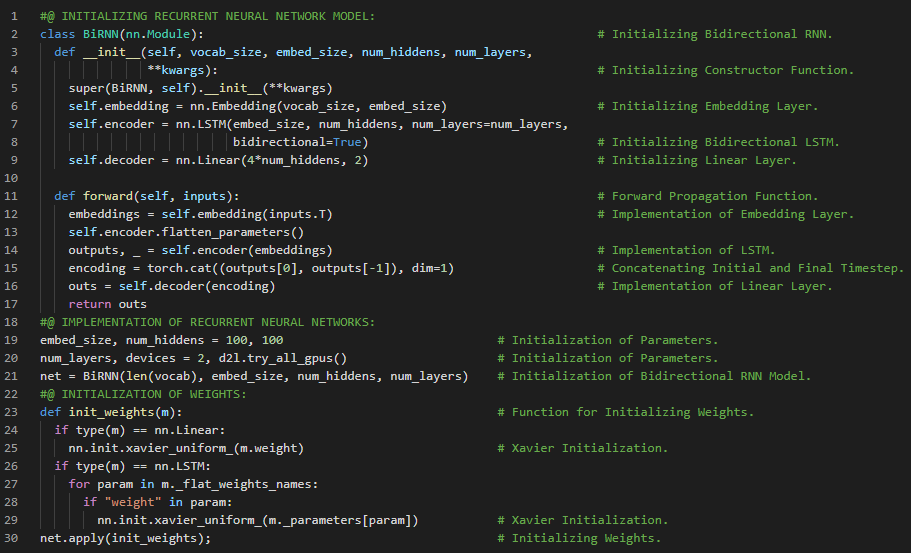
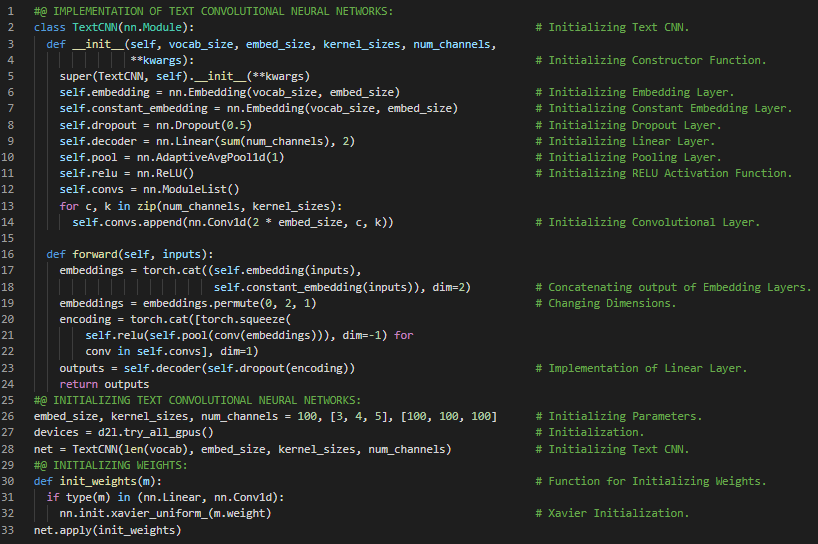
300天数据之旅第178天!
- 情感分析:情感分析是利用自然语言处理、文本分析、计算语言学和生物特征识别技术,系统地识别、提取、量化并研究情感状态和主观信息。它广泛应用于客户反馈材料(如评论和调查回复)、在线和社交媒体内容以及医疗保健相关资料中,适用于市场营销、客户服务和临床医学等多种场景。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了词向量与词汇表、双向RNN模型的训练与评估、情感分析、一维卷积神经网络、一维互相关运算、时序最大池化层、Text CNN模型、ReLU激活函数和Dropout层等主题。我在截图中展示了使用PyTorch实现文本卷积神经网络的过程。希望你能从中获得一些启发,并进一步实践。同时,也建议你花时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
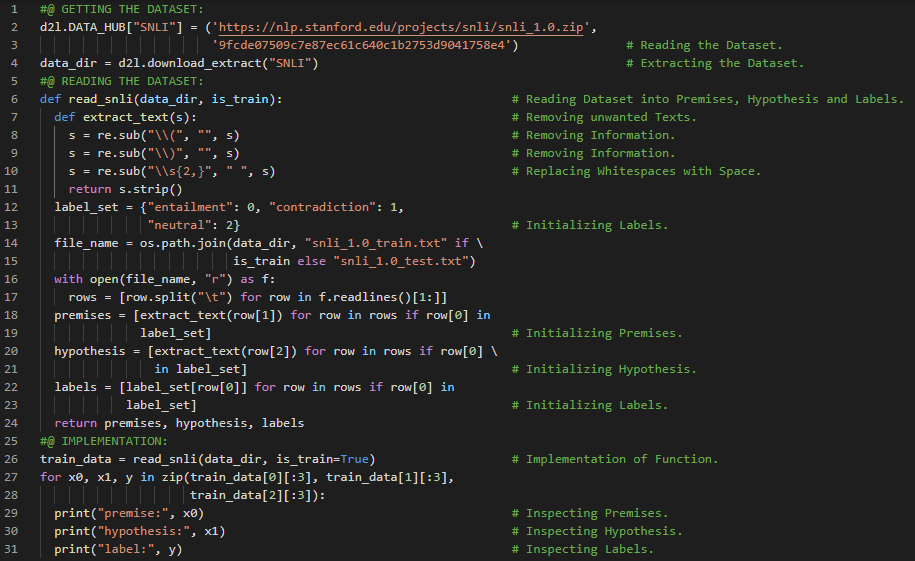
300天数据之旅第179天!
- 自然语言推理:自然语言推理是指从一个前提推断出假设的过程,其中前提和假设都是文本序列。它用于确定两段文本之间的逻辑关系。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了自然语言推理及其数据集、前提、假设、蕴含、矛盾和中性等概念,还了解了斯坦福自然语言推理数据集、SNLI数据集的读取等内容。我在截图中展示了使用PyTorch读取SNLI数据集的实现过程。希望你能从中获得一些见解,并继续深入探索。同时,也建议你花时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
300天数据之旅第180天!
- 自然语言推理:自然语言推理是指从一个前提推断出假设的过程,其中前提和假设都是文本序列。它用于确定两段文本之间的逻辑关系。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了自然语言推理及SNLI数据集、前提、假设和标签、词汇表、序列的填充与截断、数据集与DataLoader模块等相关知识。此外,我还了解了混淆矩阵与分类报告、文本数据的频率分布和词云等内容。我在截图中展示了使用PyTorch加载SNLI数据集的实现过程。希望你能从中获得一些启发,并继续深入研究。同时,也建议你花时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
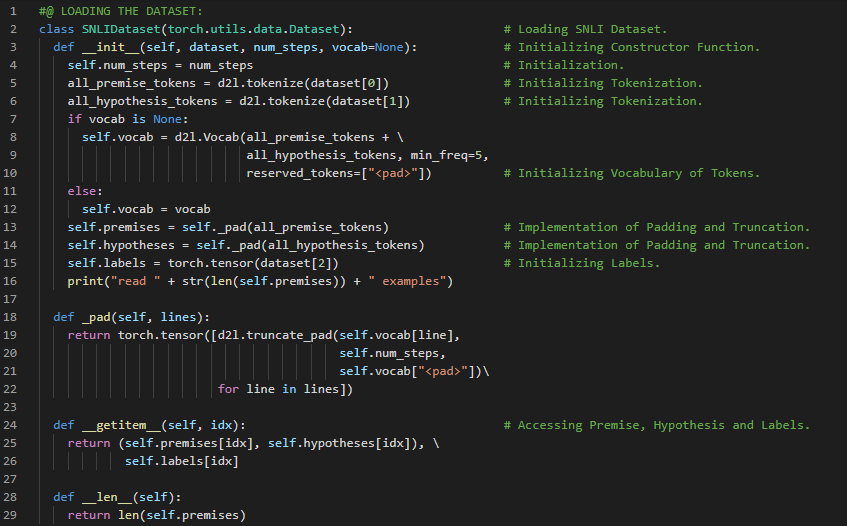
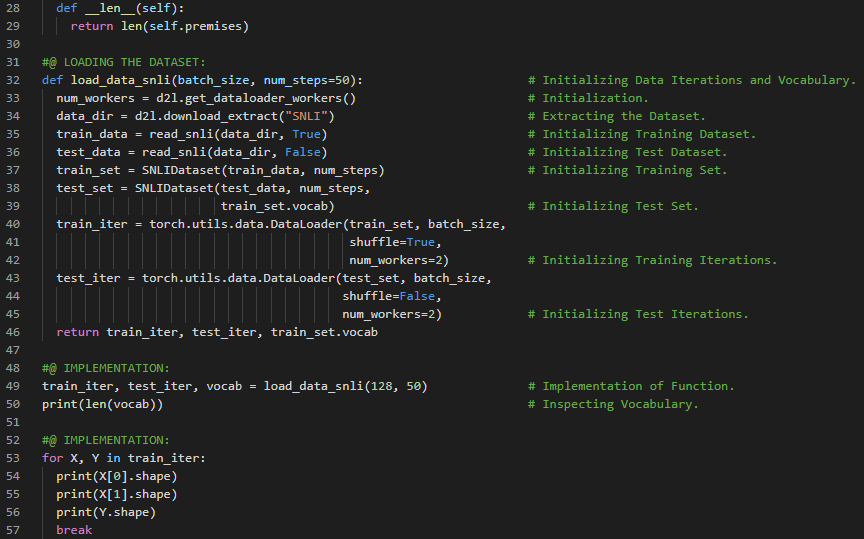
300天数据之旅第181天!
- 自然语言推理:自然语言推理是指从一个前提推断出假设的过程,其中前提和假设都是文本序列。它用于确定两段文本之间的逻辑关系。在我的机器学习和深度学习之旅中,今天我阅读并实践了《深入浅出深度学习》一书的内容。在这里,我学习了基于注意力机制的自然语言推理、带有注意力机制的多层感知机(MLP)、前提与假设的对齐、词嵌入与注意力权重等相关知识。我在截图中展示了使用PyTorch实现MLP与注意力机制的过程。希望你能从中获得一些启发,并继续深入研究。同时,也建议你花时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
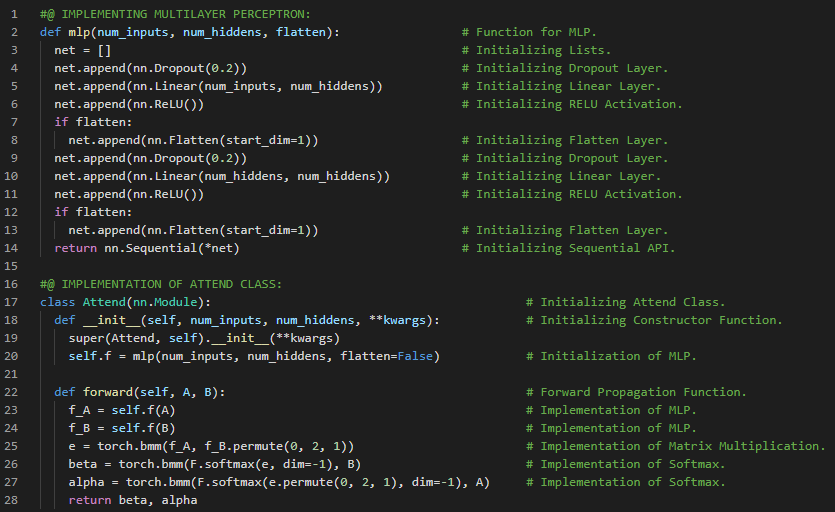
第182天,300天数据之旅!
- 比较与聚合类:比较类将一个序列中的某个词与其软对齐的另一个序列中的对应词进行比较。聚合类则将两组比较向量进行聚合,以推断逻辑关系。它会将两种摘要结果的拼接输入到多层感知机(MLP)中,从而得到逻辑关系的分类结果。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了比较词序列、软对齐、多层感知机(MLP)分类器、聚合比较向量、线性层与拼接、可分解注意力模型、嵌入层等主题。我在截图中展示了使用PyTorch实现的比较类、聚合类以及可分解注意力模型。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对未来充满期待!!
- 书籍:
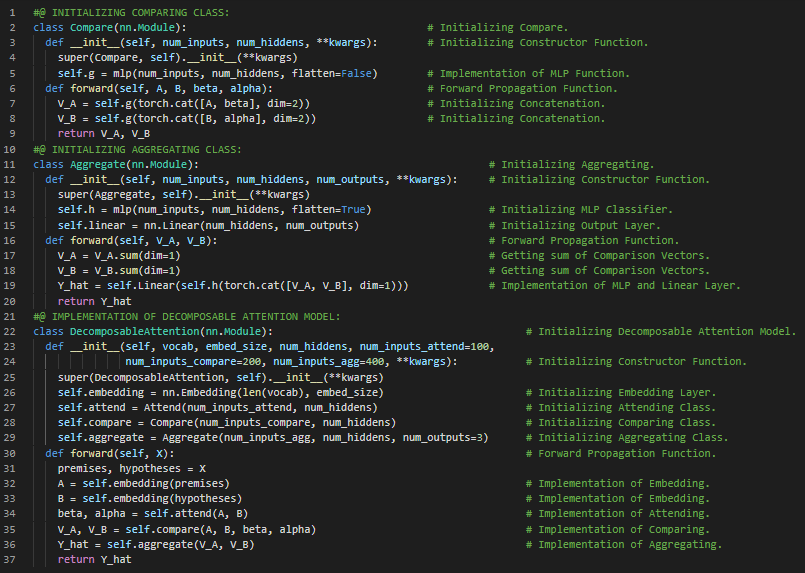
第183天,300天数据之旅!
- 比较与聚合类:比较类将一个序列中的某个词与其软对齐的另一个序列中的对应词进行比较。聚合类则将两组比较向量进行聚合,以推断逻辑关系。它会将两种摘要结果的拼接输入到多层感知机(MLP)中,从而得到逻辑关系的分类结果。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了可分解注意力模型、嵌入层和线性层、注意力模型的训练与评估、自然语言推理、蕴含、矛盾与中性、预训练的GloVe词嵌入、SNLI数据集、Adam优化器和交叉熵损失函数、前提与假设等主题。我在截图中展示了使用PyTorch实现的注意力模型训练与评估过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对未来充满期待!!
- 书籍:
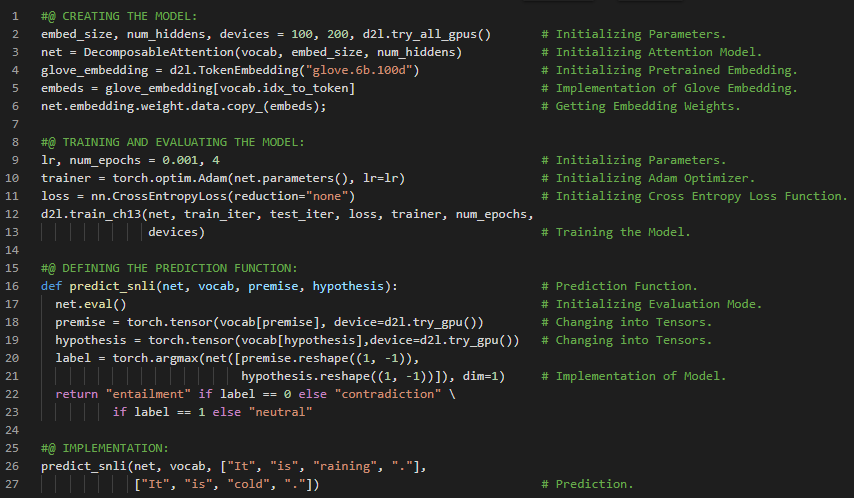
第184天,300天数据之旅!
- BERT模型笔记:对于序列级和标记级的自然语言处理任务,如单文本分类、文本对分类或回归以及文本标注,BERT只需进行极少的架构改动即可适用。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了BERT在序列级和标记级任务上的微调、单文本分类、文本对分类或回归、文本标注、问答、自然语言推理以及预训练的BERT模型、加载预训练的BERT模型及其参数、语义文本相似度、词性标注等主题。我在截图中展示了使用PyTorch加载预训练BERT模型及参数的实现。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对未来充满期待!!
- 书籍:
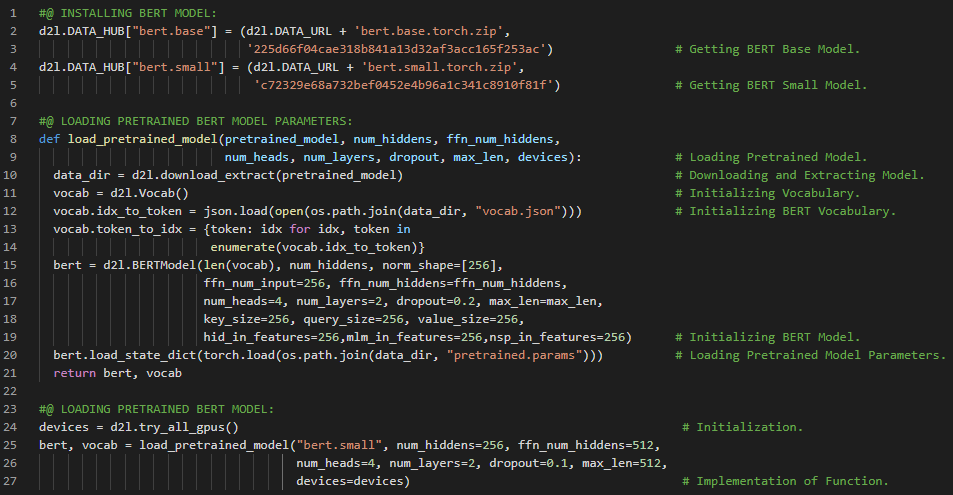
第185天,300天数据之旅!
- BERT模型笔记:对于序列级和标记级的自然语言处理任务,如单文本分类、文本对分类或回归以及文本标注,BERT只需进行极少的架构改动即可适用。在我的机器学习和深度学习之旅中,今天我阅读并实现了《动手学深度学习》一书中的内容。在这里,我学习了加载预训练的BERT模型及其参数、用于微调BERT模型的数据集、前提、假设和输入序列、分词与词汇表、截断与填充标记、自然语言推理等主题。我在截图中展示了使用PyTorch构建用于微调BERT模型的数据集,并生成训练和测试样本的过程。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对未来充满期待!!
- 书籍:
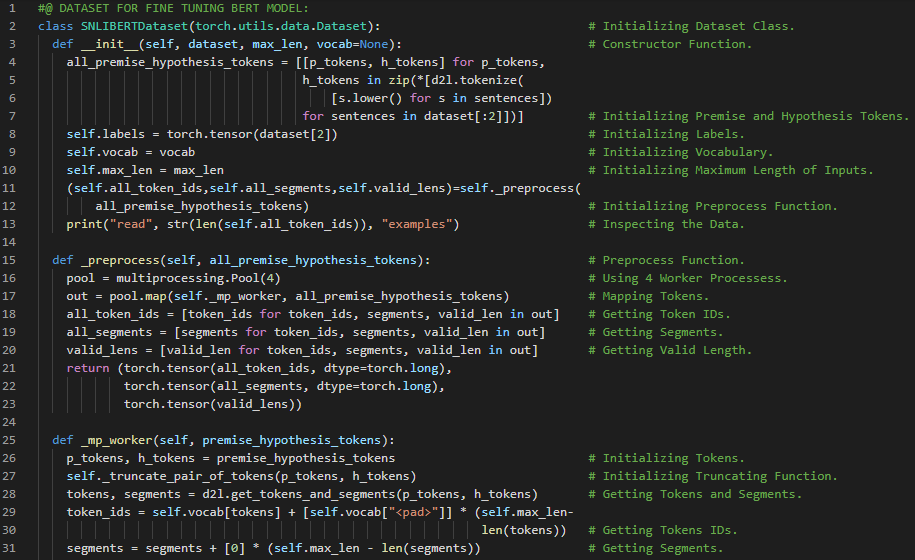
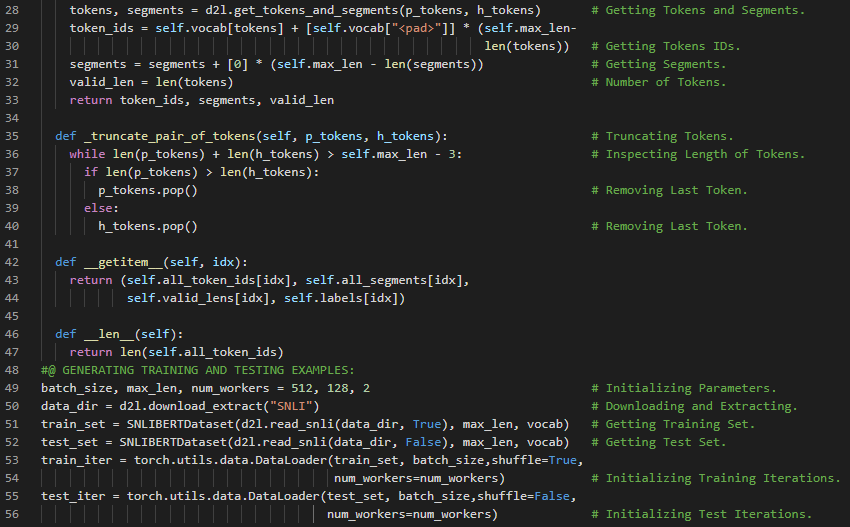
第186天,300天数据之旅!
- 生成对抗网络:生成对抗网络由两个深度网络组成——生成器和判别器。生成器通过最大化交叉熵损失来生成尽可能接近真实图像的图像,以欺骗判别器;而判别器则通过最小化交叉熵损失来区分生成的图像和真实图像。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了生成对抗网络、生成器和判别器网络、判别器的更新等主题。此外,我还阅读了推荐系统、协同过滤、显式与隐式反馈、推荐任务等相关内容。我在截图中展示了使用PyTorch实现的生成器和判别器网络以及优化过程的简单示例。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学深度学习》(Dive into Deep Learning)
- 《自然语言推理:注意力机制》(Natural Language Inference: Attention)
- 《自然语言推理:BERT模型》(Natural Language Inference: BERT)
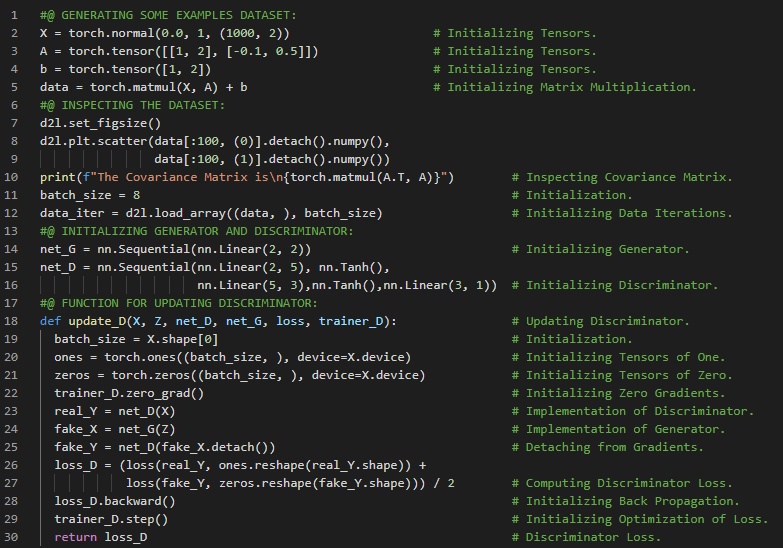
第187天,300天数据之旅!
- 生成对抗网络:生成对抗网络由两个深度网络组成——生成器和判别器。生成器通过最大化交叉熵损失来生成尽可能接近真实图像的图像,以欺骗判别器;而判别器则通过最小化交叉熵损失来区分生成的图像和真实图像。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了生成器和判别器网络、二元交叉熵损失函数、Adam优化器、归一化张量、高斯分布、真实数据与生成数据等相关知识。我在截图中展示了使用PyTorch实现的生成器更新和训练函数的简单示例。希望你能从中获得一些见解,并加以实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学深度学习》(Dive into Deep Learning)
- 《自然语言推理:注意力机制》(Natural Language Inference: Attention)
- 《自然语言推理:BERT模型》(Natural Language Inference: BERT)
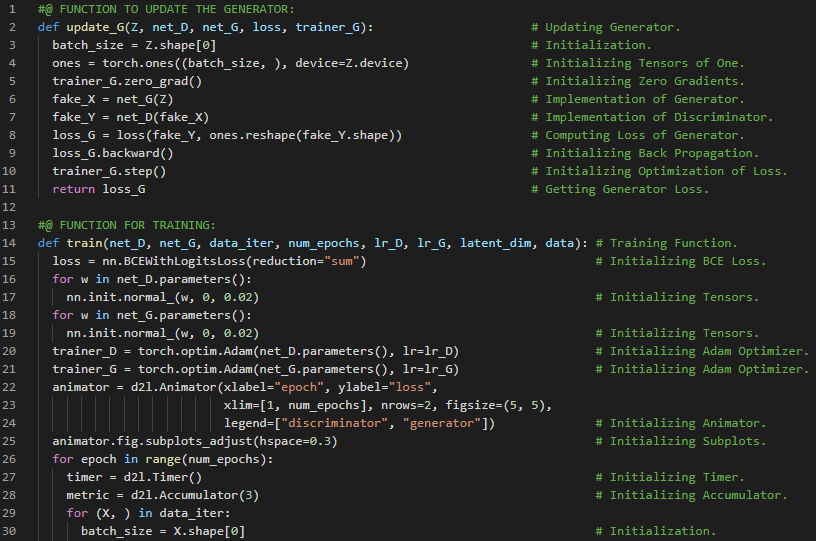
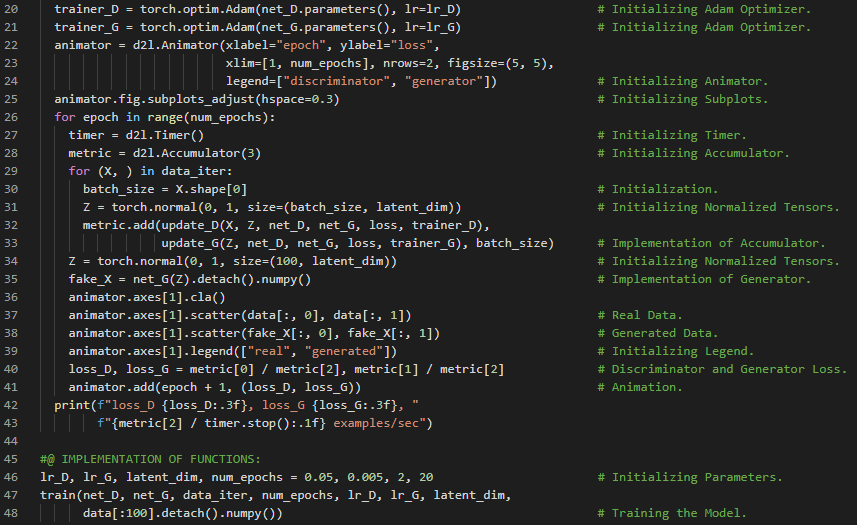
第188天,300天数据之旅!
- 生成对抗网络:生成对抗网络由两个深度网络组成——生成器和判别器。生成器通过最大化交叉熵损失来生成尽可能接近真实图像的图像,以欺骗判别器;而判别器则通过最小化交叉熵损失来区分生成的图像和真实图像。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了深度卷积生成对抗网络、宝可梦数据集、图像的缩放与归一化、数据加载器、生成器模块、转置卷积层、批量归一化层、ReLU激活函数等相关知识。此外,我还了解了四分位距、平均绝对偏差、箱线图、密度图、频数表等内容。我在截图中展示了使用PyTorch实现的生成器模块和宝可梦数据集的代码。希望你能从中获得一些启发,并继续深入研究。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学深度学习》(Dive into Deep Learning)
- 《深度卷积GAN》(Deep Convolutional GAN)
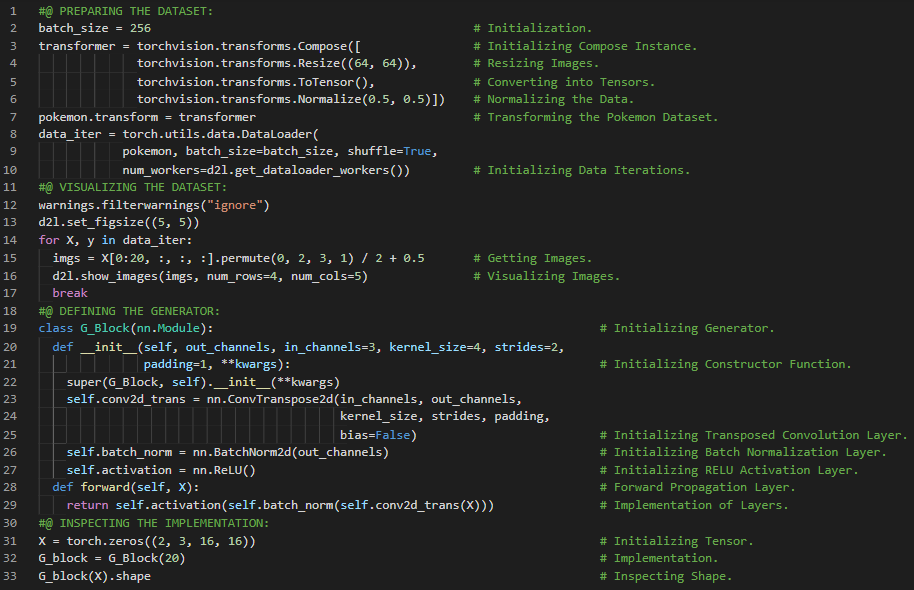
第189天,300天数据之旅!
- 生成对抗网络:生成对抗网络由两个深度网络组成——生成器和判别器。生成器通过最大化交叉熵损失来生成尽可能接近真实图像的图像,以欺骗判别器;而判别器则通过最小化交叉熵损失来区分生成的图像和真实图像。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了深度卷积生成对抗网络、生成器和判别器网络、Leaky ReLU激活函数及“ReLU死亡”问题、批量归一化、卷积层、步幅与填充等相关知识。我在截图中展示了使用PyTorch实现的判别器模块和生成器模块的代码。希望你能从中获得一些见解,并继续探索。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《动手学深度学习》(Dive into Deep Learning)
- 《深度卷积GAN》(Deep Convolutional GAN)
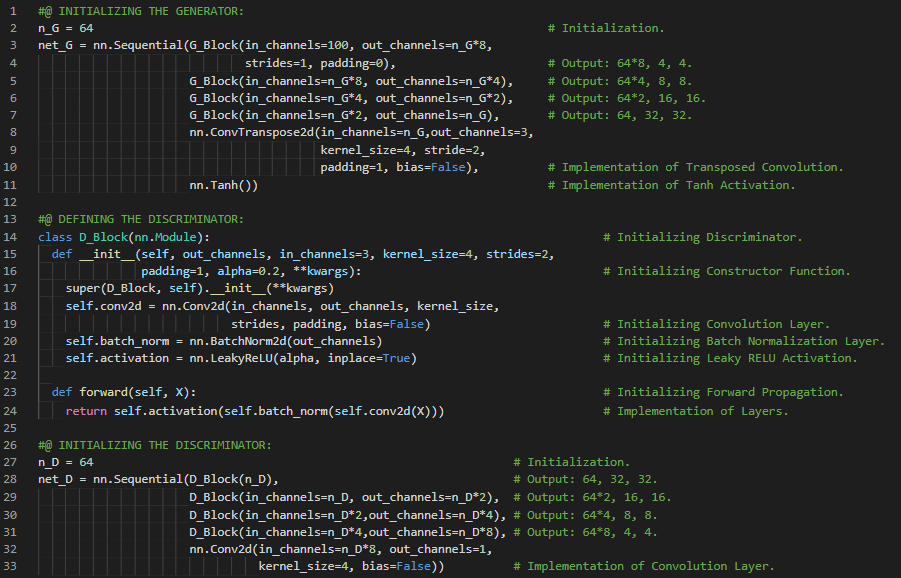
第190天,300天数据之旅!
- 生成对抗网络:生成对抗网络由两个深度神经网络组成——生成器和判别器。生成器通过最大化交叉熵损失来生成尽可能接近真实图像的图像,以欺骗判别器;而判别器则通过最小化交叉熵损失来区分生成的图像和真实图像。在我的机器学习和深度学习之旅中,今天我阅读并实践了《动手学深度学习》一书中的内容。在这里,我学习了深度卷积生成对抗网络、生成器和判别器模块、交叉熵损失函数、Adam优化器以及与此相关的其他主题。我在截图中展示了使用PyTorch训练生成器和判别器网络的实现过程。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
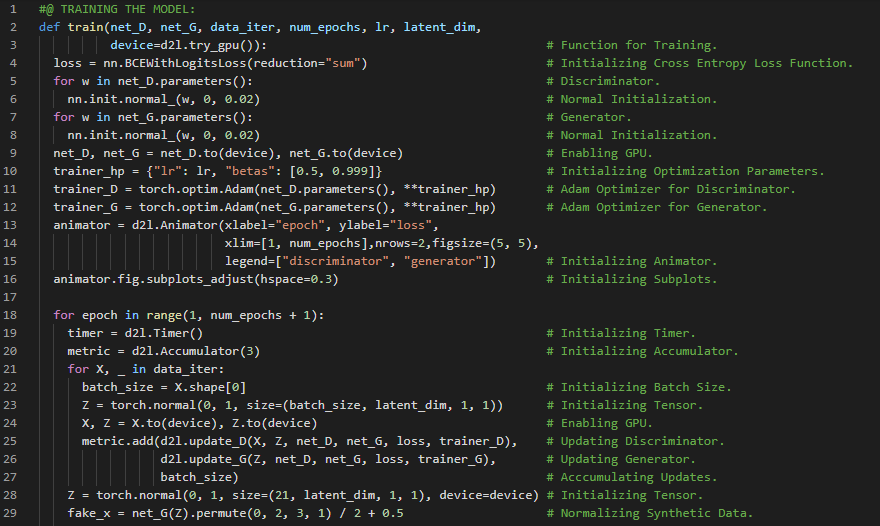
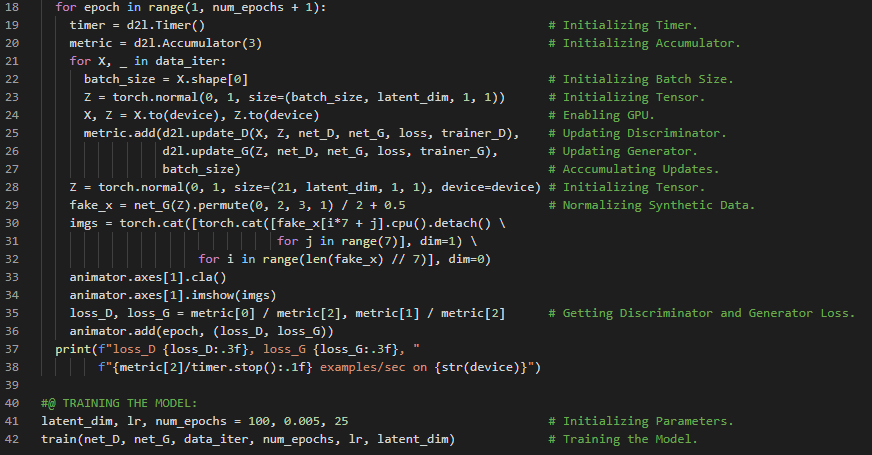
第191天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,今天我开始阅读并实践《用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了深度学习的实际应用、深度学习的各个领域、神经网络简史、Fastai与Jupyter Notebook、猫狗分类、图像加载器、预训练模型、ResNet和CNN、错误率等主题。我在截图中展示了使用Fastai进行猫狗分类的实现过程。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《用Fastai和PyTorch进行编码的深度学习》
- Fastai入门笔记本(链接)
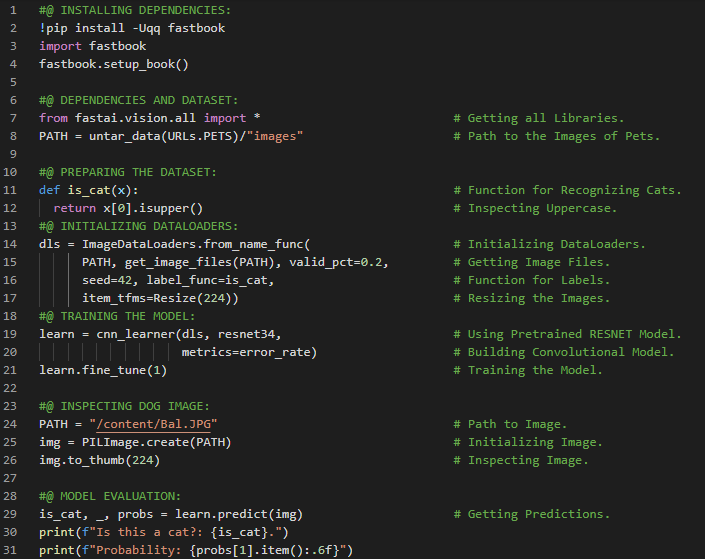
第192天,300天数据之旅!
- 迁移学习:迁移学习是指将预训练模型用于与其原始训练任务不同的新任务的过程。微调是迁移学习的一种技术,它通过使用与预训练时不同的任务再训练若干轮,从而更新预训练模型的参数。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了机器学习与权重分配、神经网络与随机梯度下降、机器学习固有的局限性、图像识别、分类与回归、过拟合与验证集、迁移学习、语义分割、情感分类、数据加载器等主题。我在截图中展示了使用Fastai进行语义分割和情感分类的实现过程。希望你能从中获得一些启发,并继续深入研究。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《用Fastai和PyTorch进行编码的深度学习》
- Fastai入门笔记本(链接)
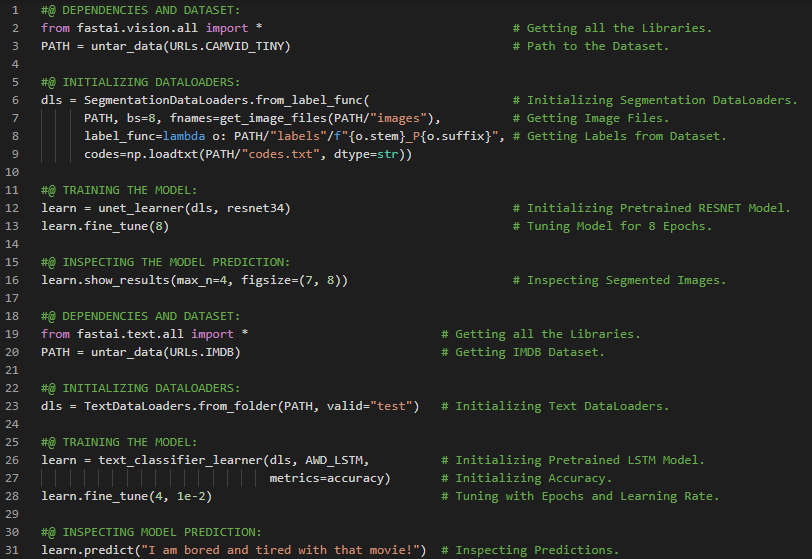
第193天,300天数据之旅!
- 迁移学习:迁移学习是指将预训练模型用于与其原始训练任务不同的新任务的过程。微调是迁移学习的一种技术,它通过使用与预训练时不同的任务再训练若干轮,从而更新预训练模型的参数。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了表格数据与分类、表格数据加载器、类别型与连续型数据、推荐系统与协同过滤、模型用的数据集、验证集与测试集、测试集中的评判标准等主题。我在截图中展示了使用Fastai进行表格数据分类和构建推荐系统模型的实现过程。希望你能从中获得一些启发,并继续探索。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《用Fastai和PyTorch进行编码的深度学习》
- Fastai入门笔记本(链接)
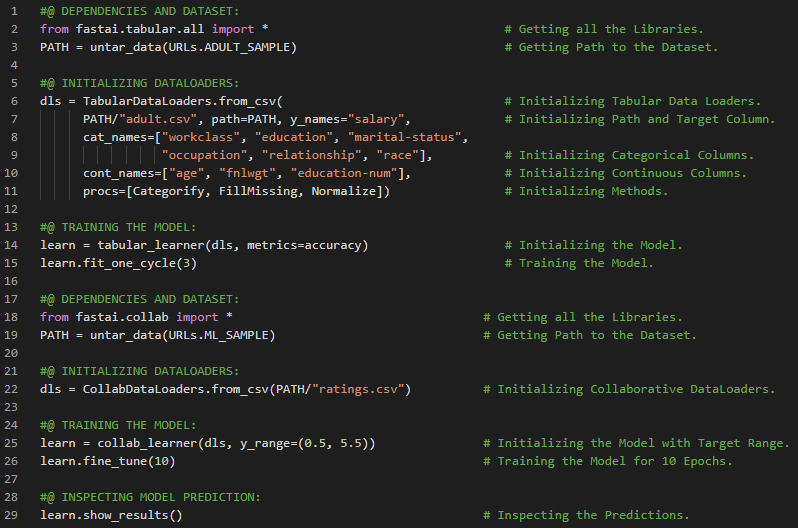
第194天,300天数据之旅!
- 驱动链方法:可以概括为:首先明确目标,然后思考为达成该目标可以采取哪些行动,以及现有或可获取的数据如何提供帮助,最后构建一个模型,用以确定最佳行动方案,从而在实现目标方面取得最佳效果。在我的机器学习和深度学习之旅中,今天我阅读并实践了《用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了深度学习的实践、深度学习现状、计算机视觉、文本与自然语言处理、文本与图像结合、表格数据与推荐系统、驱动链方法、数据收集与DuckDuckGo搜索引擎、问卷调查等主题。我在截图中展示了使用DuckDuckGo和Fastai进行目标检测数据收集的实现过程。希望你能从中获得一些启发,并继续深入研究。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《用Fastai和PyTorch进行编码的深度学习》
- Fastai图像检测示例(链接)
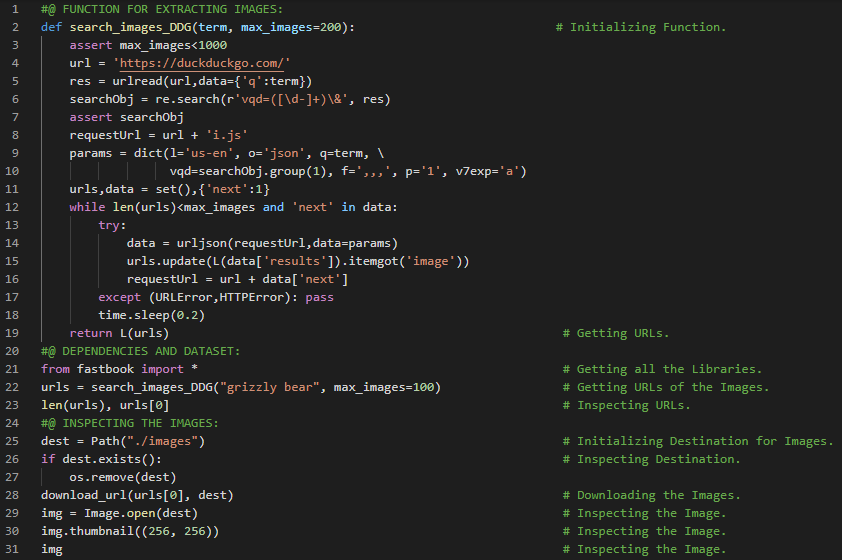
第195天,300天数据之旅!
- 传动系统方法:可以这样概括:首先明确你的目标,然后思考为了达成这个目标你可以采取哪些行动,以及你已经拥有或能够获取哪些有助于实现目标的数据,最后构建一个模型,用以确定最佳行动方案,从而在你的目标范围内取得最佳结果。在我的机器学习和深度学习之旅中,今天我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此过程中,我学习了Fastai的依赖项与函数、有偏数据集、从数据到数据加载器、Data Block API、因变量与自变量、随机划分、图像变换等主题。这里我还展示了如何利用Duck Duck Go和Fastai收集数据并初始化数据加载器的实现。希望你能从中获得一些启发,并进一步深入研究。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:图像检测
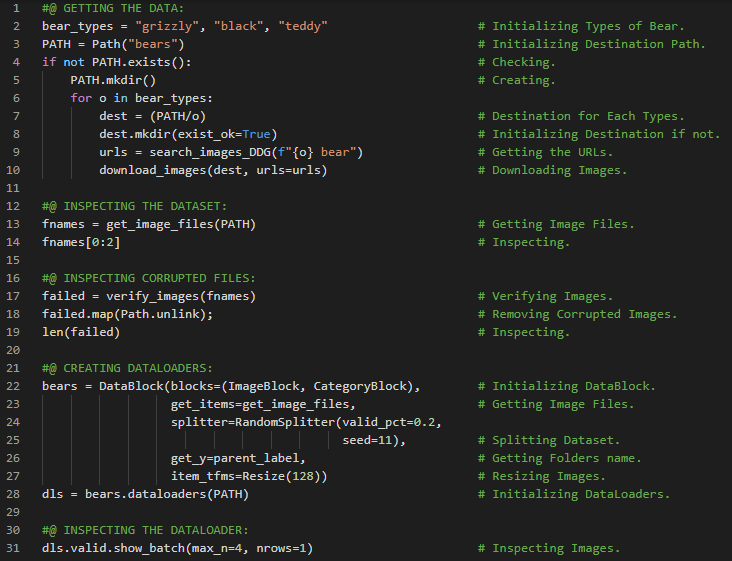
第196天,300天数据之旅!
- 数据增强:数据增强是指通过对输入数据进行随机变换,使其看起来不同,但不改变数据的本质含义。RandomResizedCrop就是数据增强的一个具体例子。在我的机器学习和深度学习之旅中,我继续阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了数据加载器、图像块、图像的缩放、挤压与拉伸、图像填充、数据增强、图像变换、模型训练与误差率、随机缩放与裁剪等相关知识。这里我还展示了使用Fastai实现数据加载器、数据增强以及模型训练的过程。希望你能从中获得一些见解,并加以实践。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:图像检测
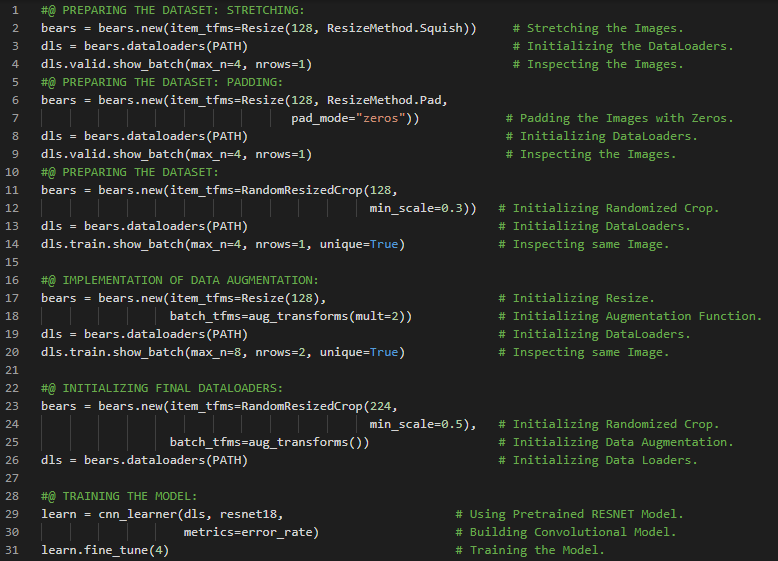
第197天,300天数据之旅!
- 数据增强:数据增强是指通过对输入数据进行随机变换,使其看起来不同,但不改变数据的本质含义。RandomResizedCrop就是数据增强的一个具体例子。在我的机器学习和深度学习之旅中,我继续阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了预训练模型的微调、数据增强与变换、分类结果解释与混淆矩阵、数据集清洗、推理模型与参数、Notebook与Widgets等相关知识。这里我还展示了使用Fastai实现分类结果解释、数据集清洗、推理模型与参数的简单应用。希望你能从中获得一些启发,并进一步探索。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:图像检测
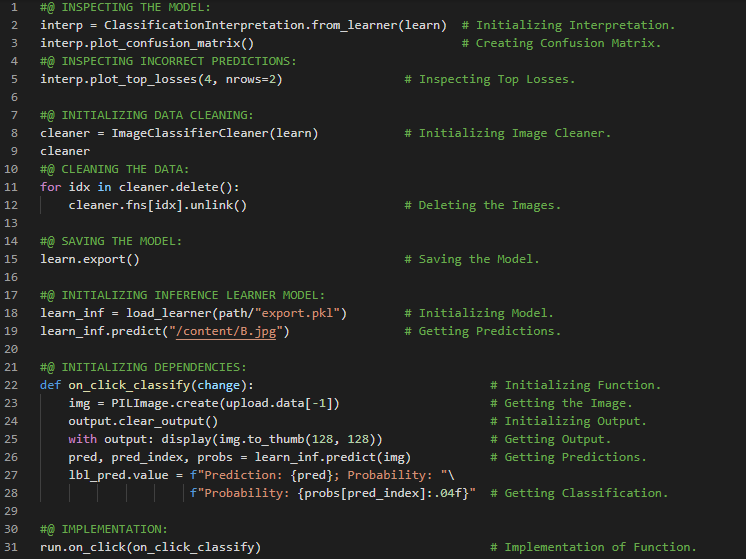
第198天,300天数据之旅!
- 数据伦理:伦理是指关于善恶的合理标准,它规定了人类应当如何行事。它是对个人伦理标准的研究与发展。申诉机制、反馈循环、偏见等都是数据伦理的重要体现。在我的机器学习和深度学习之旅中,我继续阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了数据伦理、错误与申诉、反馈循环、偏见、将机器学习融入产品设计、数字分类器的训练、像素与计算机视觉、坚韧精神与深度学习、像素相似性、列表推导式等相关知识。这里我还展示了使用Fastai实现像素与计算机视觉的简单应用。希望你能从中获得一些启发,并加以实践。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
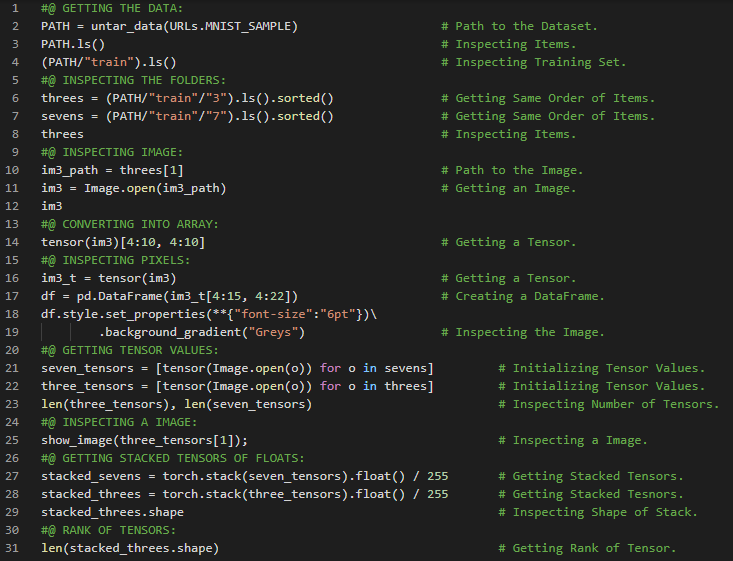
第199天,300天数据之旅!
- L1范数与L2范数:取差值绝对值的平均值称为平均绝对差,即L1范数;而取差值平方的平均值后再开方,则称为均方根误差,即L2范数。在我的机器学习和深度学习之旅中,我继续阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了张量的秩、平均绝对差(L1范数)与均方根误差(L2范数)、Numpy数组与PyTorch张量、利用广播机制计算指标等相关知识。这里我还展示了使用Fastai实现数组与张量、L1与L2范数的简单应用。希望你能从中获得一些启发,并进一步探索。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
300天数据之旅第200天!
- L1范数和L2范数:将差值的绝对值取平均,称为平均绝对误差或L1范数。将差值的平方取平均后再开方,称为均方根误差或L2范数。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了如何利用广播机制计算指标、平均绝对误差、随机梯度下降、参数初始化、损失函数、梯度计算、反向传播与导数、学习率优化等主题。我在截图中展示了使用Fastai实现的简单随机梯度下降算法。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
300天数据之旅第201天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了梯度下降过程、参数初始化、预测计算与检查、损失及均方误差的计算、梯度计算与反向传播、权重更新与参数调整、重复迭代与停止条件等相关内容。我在截图中展示了使用Fastai和PyTorch实现的梯度下降过程。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
300天数据之旅第202天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了MNIST损失函数、矩阵与向量、自变量、权重与偏置、参数、矩阵乘法与数据集类、梯度下降过程与学习率、激活函数等相关内容。我在截图中展示了使用Fastai和PyTorch实现的数据集类和矩阵乘法。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
300天数据之旅第203天!
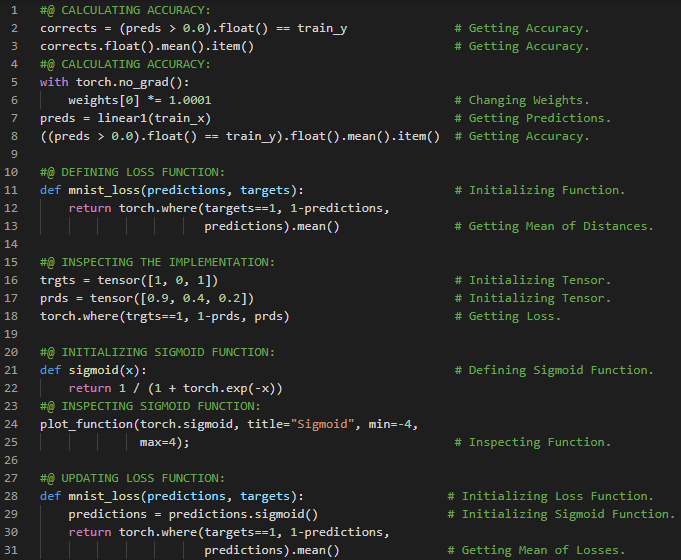
- 准确率与损失函数:准确率等指标与损失函数的关键区别在于,损失函数用于驱动自动化学习,而指标则用于帮助人类理解模型的表现。损失函数必须是一个具有有意义导数的函数,而指标则侧重于模型的性能评估。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了矩阵乘法、激活函数、损失函数、梯度与斜率、Sigmoid函数、准确率指标及其理解等相关内容。我在截图中展示了使用Fastai和PyTorch实现的损失函数与Sigmoid函数。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
300天数据之旅第204天!
- SGD与小批量:根据梯度来调整或更新权重,以考虑下一轮学习过程中涉及的一些细节的过程,称为优化步骤。每次对少量数据计算平均损失的操作称为一个小批量。小批量中包含的数据数量称为批次大小。较大的批次大小能够提供更准确、更稳定的基于损失函数的梯度估计,而单个样本的批次则会导致不精确且不稳定的梯度。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了随机梯度下降与小批量、优化步骤、批次大小、数据加载器与数据集、参数初始化、权重与偏置、反向传播与梯度、损失函数等相关内容。我在截图中展示了使用Fastai和PyTorch实现的数据加载器与梯度计算。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
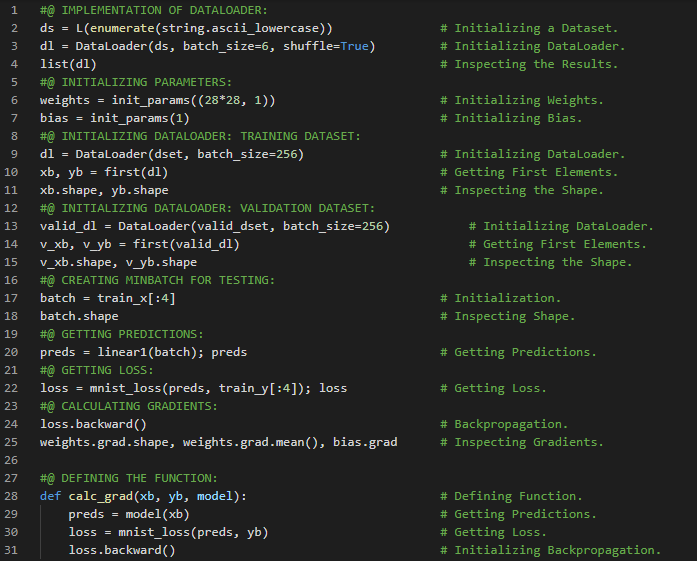
第205天,300天数据之旅!
- SGD与小批量:根据梯度来调整或更新权重的过程,以便在学习过程的下一阶段考虑一些细节,这一过程被称为优化步骤。每次对少量数据计算平均损失称为一个小批量。小批量中包含的数据项数量称为批次大小。较大的批次大小意味着可以从损失函数更准确、更稳定地估计数据集的梯度;而单个样本的批次则会导致梯度不精确且不稳定。在我的机器学习和深度学习旅程中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了梯度计算与反向传播、权重、偏置与参数、梯度清零、训练循环与学习率、准确率与评估、创建优化器等主题。我在截图中展示了使用Fastai和PyTorch进行梯度计算、准确率评估和训练的实现。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
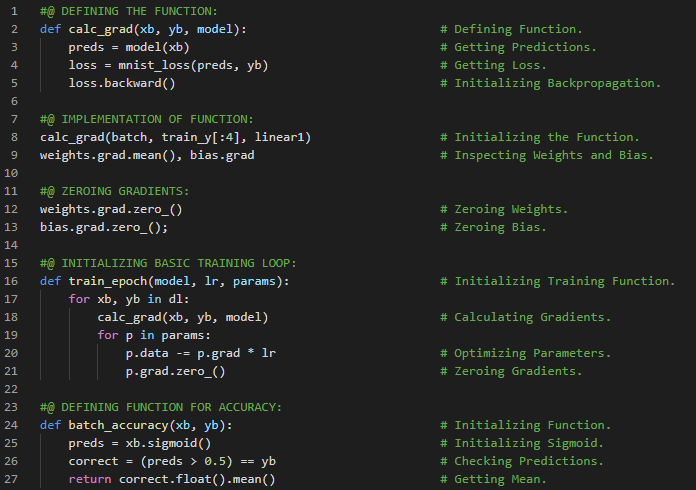
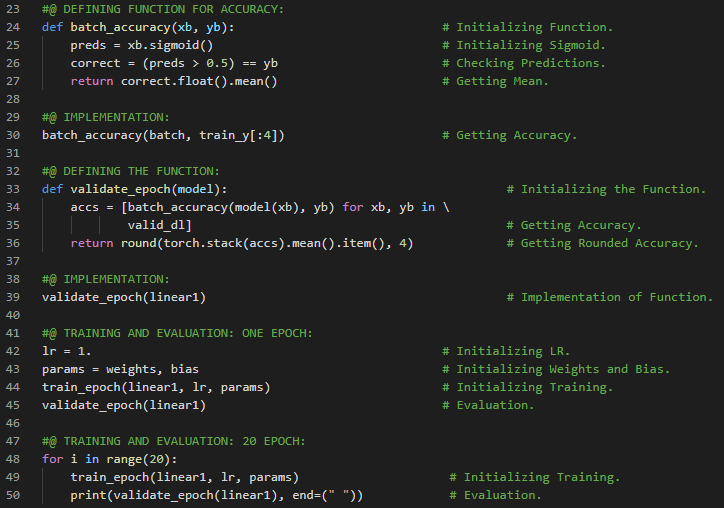
第206天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了创建优化器、线性模块、权重与偏置、模型参数、优化与梯度清零、SGD类、数据加载器以及Fastai的学习者类等相关内容。我在截图中展示了使用Fastai和PyTorch创建优化器和学习者类的实现。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
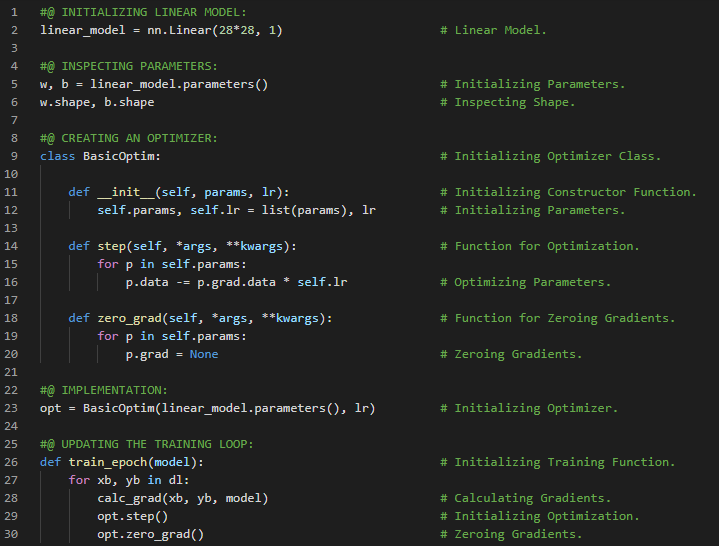
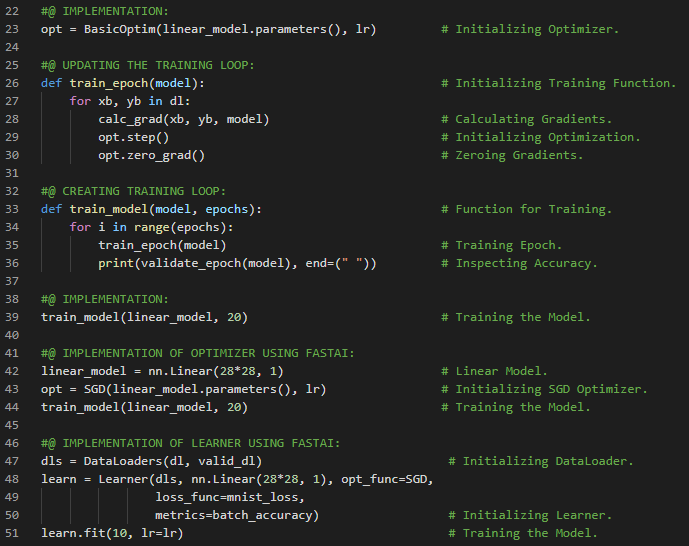
第207天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了添加非线性、简单线性分类器、基础神经网络、权重与偏置张量、修正线性单元(ReLU)激活函数、通用逼近定理、序列模块等相关内容。我在截图中展示了使用Fastai和PyTorch创建简单神经网络的实现。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:训练分类器
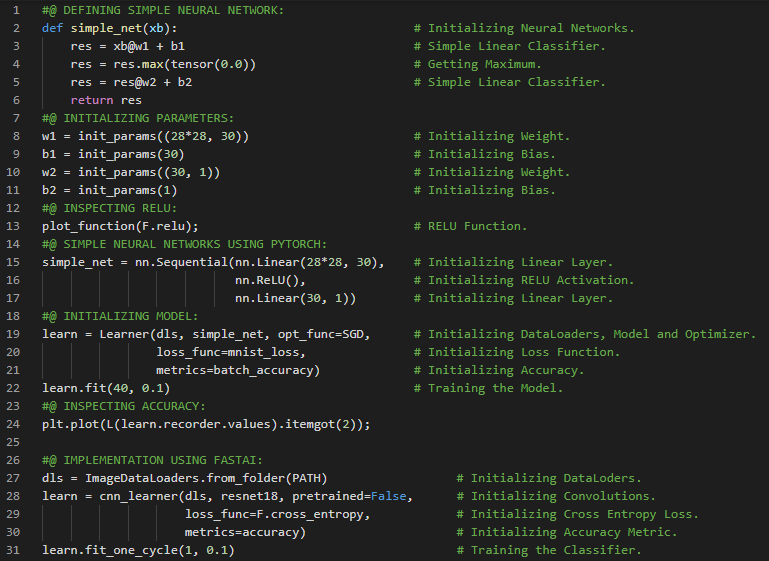
第208天,300天数据之旅!
- 在我的机器学习和深度学习旅程中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了图像分类、定位、正则表达式、数据块与数据加载器、正则表达式标签器、数据增强、预缩放、检查与调试数据块、项目与批次变换等相关内容。我在截图中展示了使用Fastai和PyTorch创建并调试数据块及数据加载器的实现。我将Resize用作大尺寸的项目变换,而将RandomResizedCrop用作小尺寸的批次变换。如果aug transforms函数中传入了min scale参数,如下面的DataBlock调用所示,则会添加RandomResizedCrop。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:图像分类
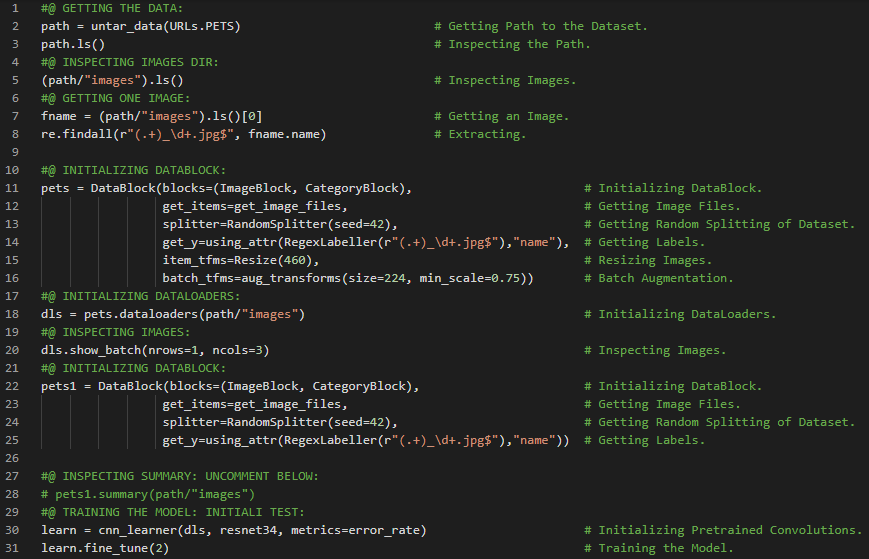
第209天,300天数据之旅!
- 指数函数:指数函数被定义为e**x,其中e是一个特殊的数字,约等于2.718。它是自然对数函数的逆函数。指数函数始终为正,并且增长非常迅速。在我的机器学习和深度学习旅程中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了交叉熵损失函数、查看激活值与标签、Softmax激活函数、Sigmoid函数、指数函数、负对数似然、二分类等相关内容。我在截图中展示了使用Fastai和PyTorch实现Softmax函数和负对数似然的代码。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:图像分类
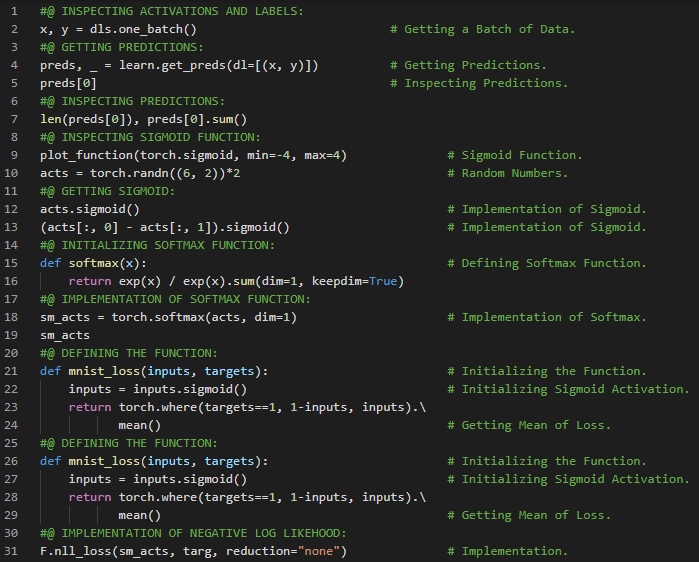
300天数据之旅第210天!
- 指数函数:指数函数定义为 e**x,其中 e 是一个特殊的数,约等于 2.718。它是自然对数函数的反函数。指数函数始终为正,并且增长非常迅速。在我的机器学习和深度学习之旅中,我阅读并实践了《使用 Fastai 和 PyTorch 的编码者深度学习》一书的内容。在这里,我学习了对数函数、负对数似然、交叉熵损失函数、Softmax 函数、模型解释、混淆矩阵、模型改进、学习率查找器、对数尺度等主题。我在截图中展示了使用 Fastai 和 PyTorch 实现的交叉熵损失、混淆矩阵和学习率查找器。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用 Fastai 和 PyTorch 的编码者深度学习》
- Fastai:图像分类
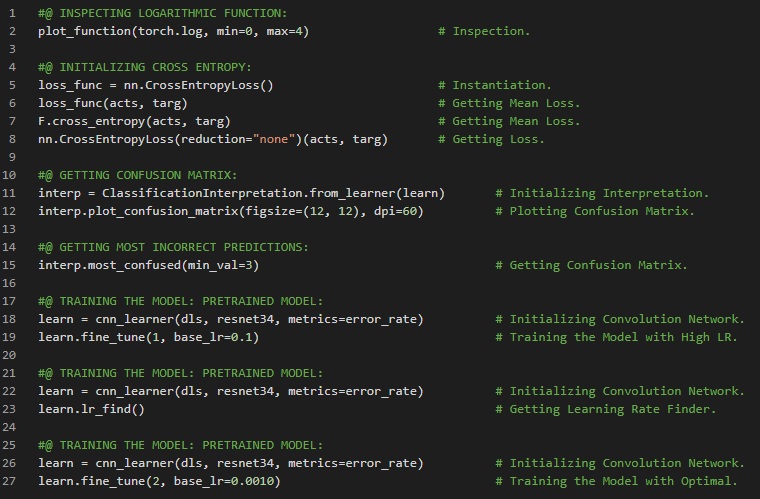
300天数据之旅第211天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用 Fastai 和 PyTorch 的编码者深度学习》一书的内容。在这里,我学习了解冻与迁移学习、冻结预训练层、区分性学习率、选择 epoch 数量、更深的网络架构等相关内容。我在截图中展示了使用 Fastai 和 PyTorch 实现的解冻与迁移学习以及区分性学习率。希望你能从中获得一些见解,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用 Fastai 和 PyTorch 的编码者深度学习》
- Fastai:图像分类
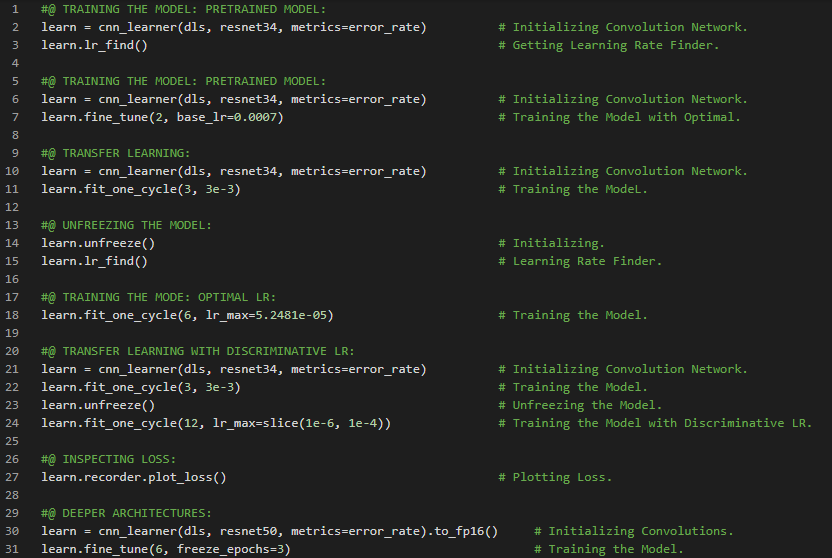
300天数据之旅第212天!
- 多标签分类:多标签分类是指识别图像中可能包含多种类别对象的问题。在我的机器学习和深度学习之旅中,我阅读并实践了《使用 Fastai 和 PyTorch 的编码者深度学习》一书的内容。在这里,我学习了图像分类问卷、多标签分类与回归、Pascal 数据集、Pandas 和 DataFrame、构建 DataBlock、数据集和数据加载器、Lambda 函数等相关内容。我在截图中展示了使用 Fastai 和 PyTorch 实现的创建 DataBlock 和数据加载器的过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用 Fastai 和 PyTorch 的编码者深度学习》
- Fastai:多标签分类与回归
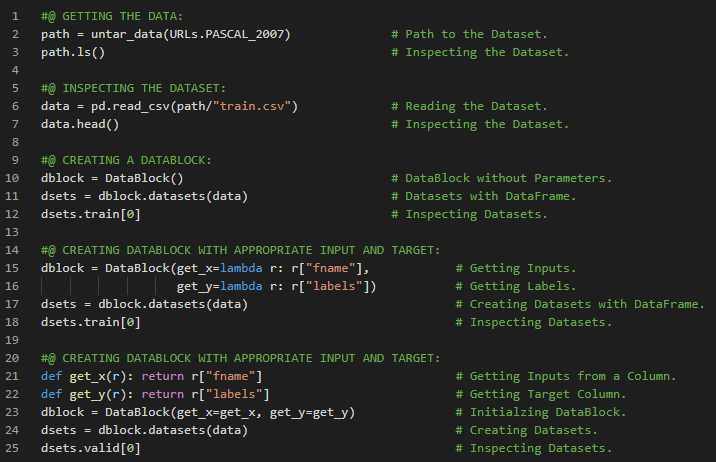
300天数据之旅第213天!
- 多标签分类:多标签分类是指识别图像中可能包含多种类别对象的问题。在我的机器学习和深度学习之旅中,我阅读并实践了《使用 Fastai 和 PyTorch 的编码者深度学习》一书的内容。在这里,我学习了 Lambda 函数、图像块和多类别块等转换块、独热编码、数据划分、数据加载器、数据集和 DataBlock、调整大小和裁剪等相关内容。我在截图中展示了使用 Fastai 和 PyTorch 实现的创建 DataBlock 和数据加载器的过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用 Fastai 和 PyTorch 的编码者深度学习》
- Fastai:多标签分类与回归
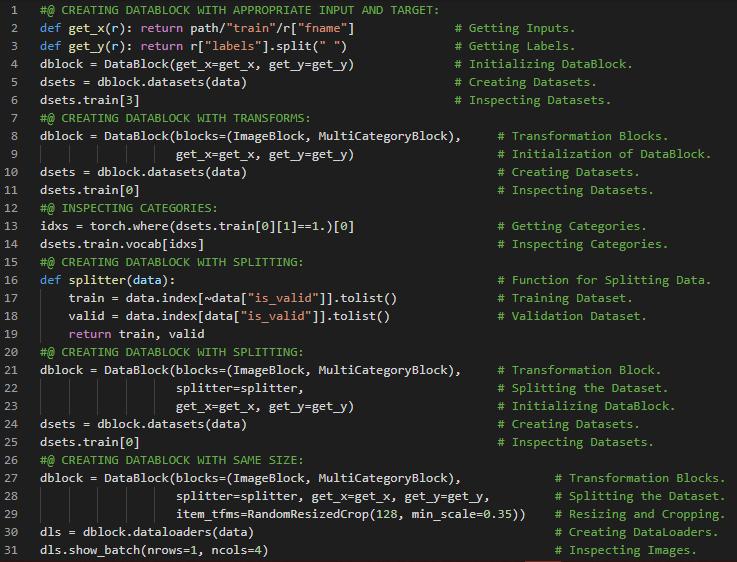
300天数据之旅第214天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用 Fastai 和 PyTorch 的编码者深度学习》一书的内容。在这里,我学习了二元交叉熵损失函数、数据加载器和学习器、获取模型激活值、Sigmoid 和 Softmax 函数、独热编码、计算准确率、部分函数等相关内容。F.binary_cross_entropy 及其模块等效形式 nn.BCELoss 会在独热编码的目标上计算交叉熵,但不包含初始的 Sigmoid 操作。通常,F.binary_cross_entropy_with_logits 或 nn.BCEWithLogitsLoss 会将 Sigmoid 和二元交叉熵合并到一个函数中进行计算。类似地,对于单标签数据集,F.nll_loss 或 nn.NLLoss 用于不包含初始 Softmax 的版本,而 F.cross_entropy 或 nn.CrossEntropyLoss 则用于包含初始 Softmax 的版本。我在截图中展示了使用 Fastai 和 PyTorch 实现的交叉熵损失函数和准确率计算。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用 Fastai 和 PyTorch 的编码者深度学习》
- Fastai:多标签分类与回归
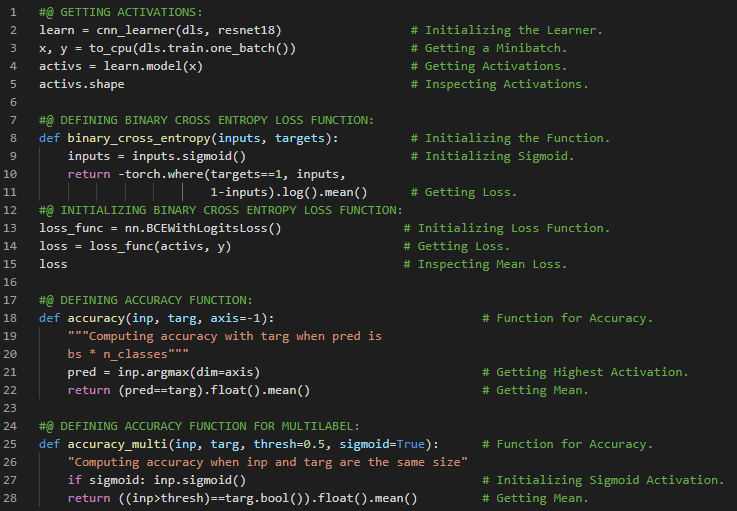
300天数据之旅第215天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了多标签分类与阈值、Sigmoid激活函数、过拟合、图像回归、验证损失与指标、部分函数等主题。其中,F.binary_cross_entropy及其模块等价形式nn.BCELoss会在one-hot编码的目标上计算交叉熵,但不包含初始的Sigmoid操作。通常,F.binary_cross_entropy_with_logits或nn.BCEWithLogitsLoss则在一个函数中同时完成Sigmoid和二元交叉熵的计算。类似地,对于单标签数据集,可以使用F.nll_loss或nn.NLLoss(不含初始Softmax版本)以及F.cross_entropy或nn.CrossEntropyLoss(含初始Softmax版本)。我在截图中展示了使用Fastai和PyTorch训练卷积网络,并结合准确率与阈值的实现。希望你能从中获得一些启发,并进一步实践。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:多标签分类与回归
- Fastai:图像回归
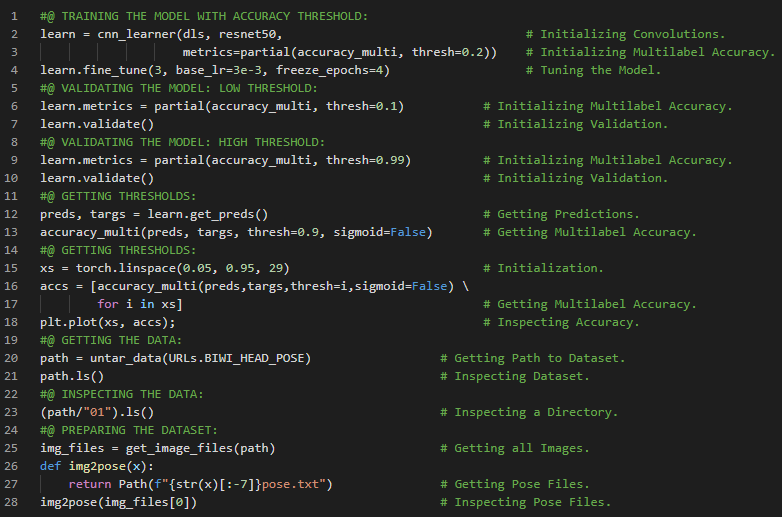
300天数据之旅第216天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了图像回归与定位、数据集的组装、DataBlock和DataLoaders的初始化、点标注与数据增强、模型训练、Sigmoid范围、MSE损失函数、迁移学习等主题。我在截图中展示了使用Fastai和PyTorch进行DataBlock和DataLoaders初始化,以及图像回归训练的实现。希望你能从中获得一些见解,并加以实践。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- Fastai:多标签分类与回归
- Fastai:图像回归
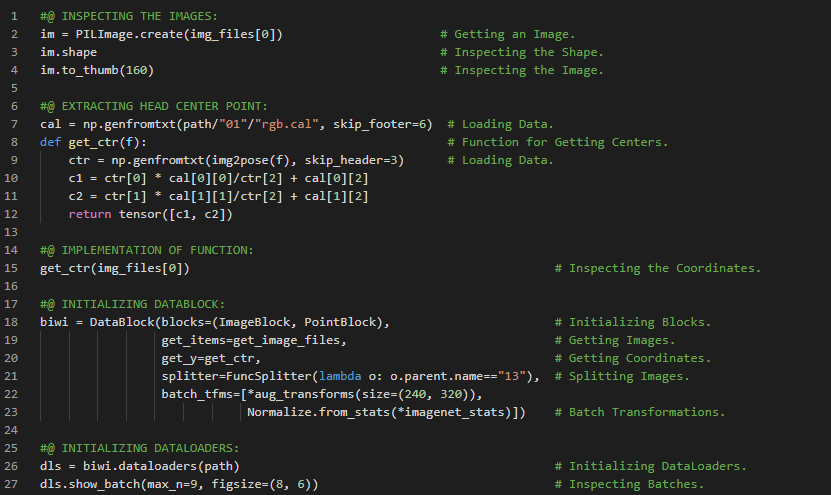
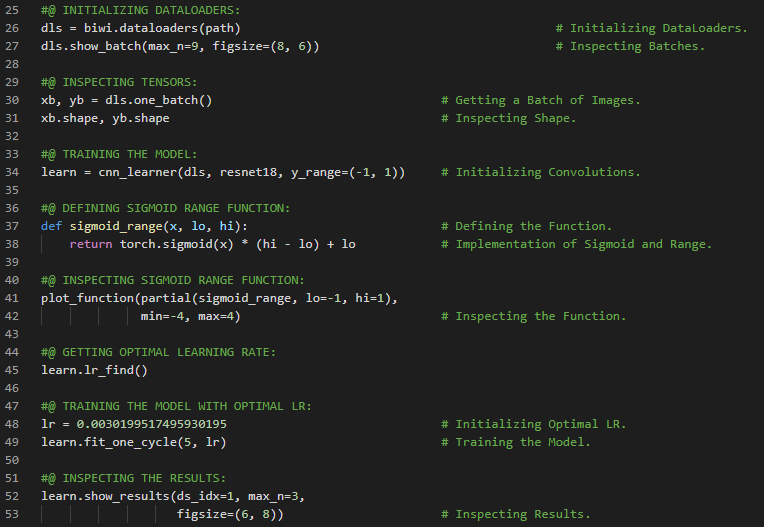
300天数据之旅第217天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了Imagenette分类、DataBlock和DataLoaders、数据归一化与归一化函数、渐进式调整大小与数据增强、迁移学习、均值与标准差等主题。渐进式调整大小是指随着训练的进行,逐步使用更大尺寸的图像。我在截图中展示了使用Fastai和PyTorch进行DataBlock和DataLoaders初始化、数据归一化以及渐进式调整大小的实现。希望你能从中获得一些启发,并加以实践。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 高级分类
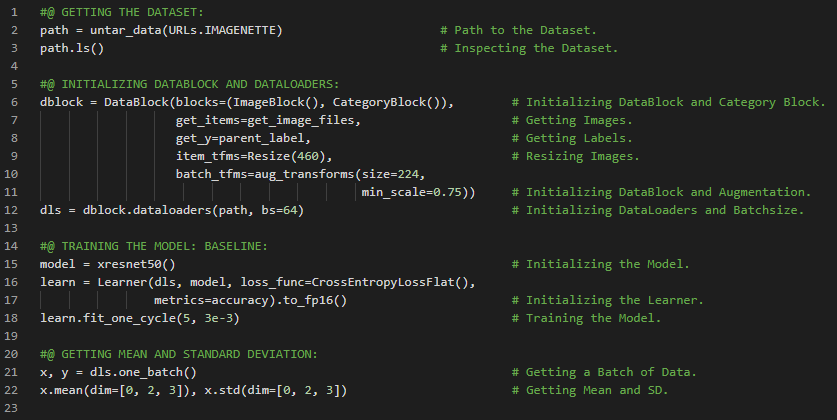
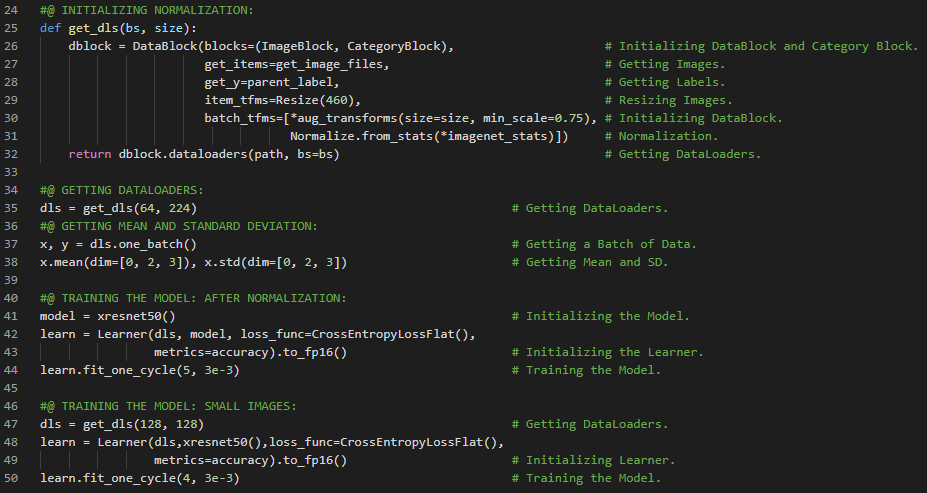
300天数据之旅第218天!
- 标签平滑:标签平滑是一种在训练过程中将所有的标签1替换为略小于1的数值,将0替换为略大于0的数值的方法。这种方法可以使训练更加稳健,即使存在标签错误的数据,也能得到一个在推理时泛化能力更强的模型。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了渐进式调整大小、测试时数据增强、Mixup数据增强、线性组合、回调函数、标签平滑与交叉熵损失函数等主题。在推理或验证阶段,通过数据增强为每张图像生成多个版本,然后对每个增强版本的预测结果取平均值或最大值,这一过程被称为测试时数据增强。我在截图中展示了使用Fastai和PyTorch进行渐进式调整大小、测试时数据增强、Mixup数据增强以及标签平滑的实现。希望你能从中获得一些启发,并加以实践。也建议花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 高级分类
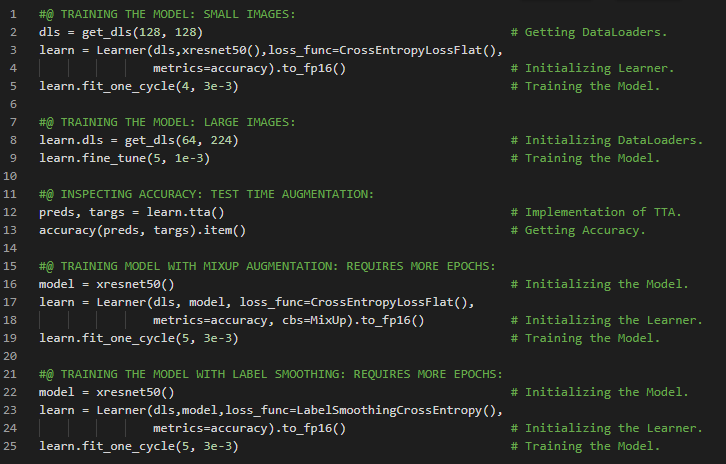
300天数据之旅第219天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了协同过滤、隐因子的学习、损失函数与随机梯度下降、创建DataLoader、批次处理、点积与矩阵乘法等主题。将两个向量的对应元素相乘后再求和的数学运算称为点积。我在截图中展示了如何使用Fastai和PyTorch初始化数据集并创建DataLoader的实现。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 协同过滤
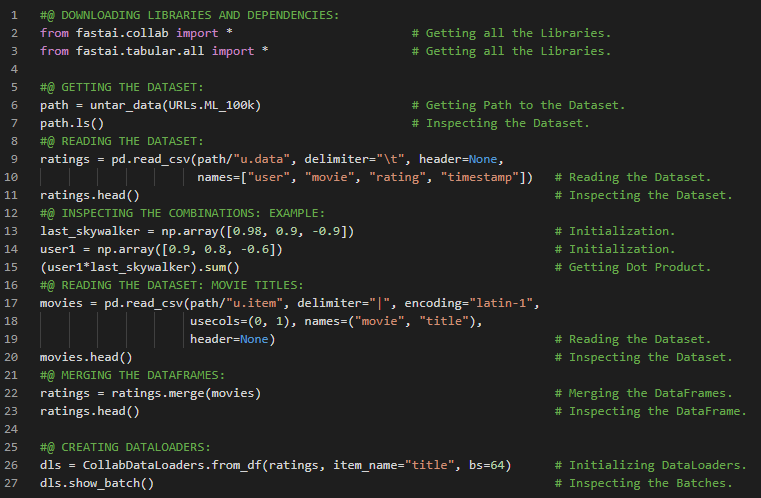
300天数据之旅第220天!
- 嵌入层:这种特殊的层通过整数索引到一个向量中,但其导数的计算方式却与用独热编码向量进行矩阵乘法时完全相同,这样的层就被称为嵌入层。利用一种计算捷径,可以直接通过索引来完成与独热编码矩阵的乘法运算。而负责执行这种乘法运算的矩阵则被称为嵌入矩阵。在我的机器学习和深度学习之旅中,我继续阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了创建DataLoader、嵌入矩阵、协同过滤、Python面向对象编程、继承、模块与前向传播函数、批次与Learner、Sigmoid范围等相关内容。我在截图中展示了使用Fastai和PyTorch实现的嵌入层、点积类以及Sigmoid范围的代码。希望你能从中获得一些见解,并进一步实践。也希望大家能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 协同过滤
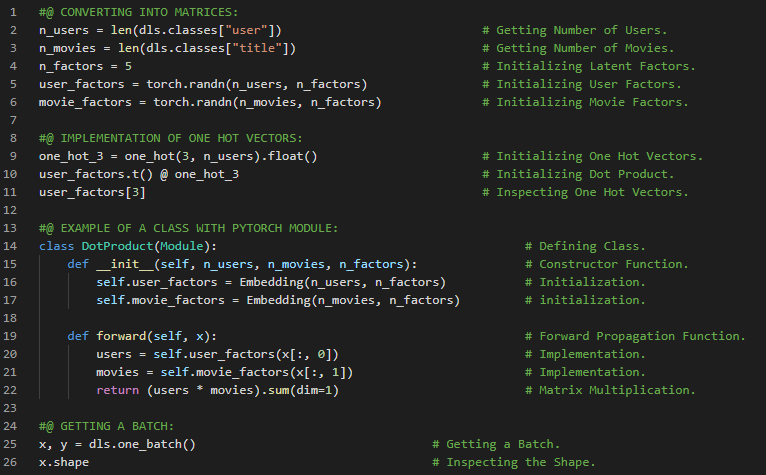
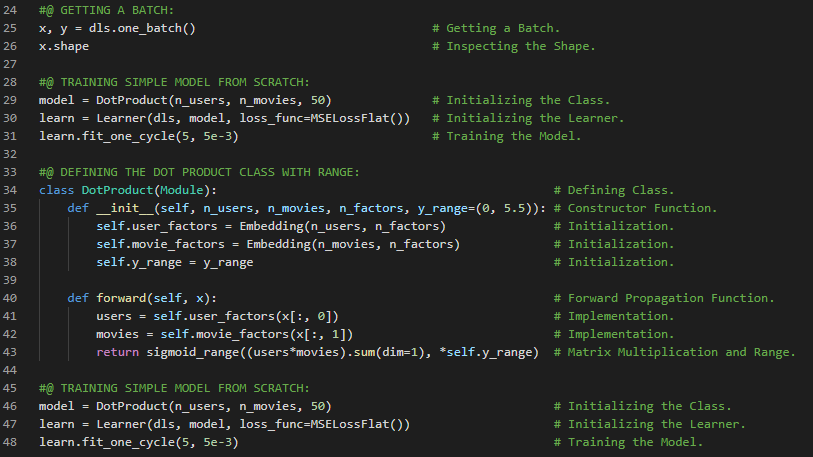
300天数据之旅第221天!
- 嵌入层:这种特殊的层通过整数索引到一个向量中,但其导数的计算方式却与用独热编码向量进行矩阵乘法时完全相同,这样的层就被称为嵌入层。利用一种计算捷径,可以直接通过索引来完成与独热编码矩阵的乘法运算。而负责执行这种乘法运算的矩阵则被称为嵌入矩阵。在我的机器学习和深度学习之旅中,我继续阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了协同过滤、权重衰减或L2正则化、过拟合、创建嵌入层与权重矩阵、参数模块等相关内容。权重衰减是指在损失函数中加入权重平方和的项。其原理是:系数越大,损失函数中的“峡谷”就越陡峭。我在截图中展示了使用Fastai和PyTorch实现的偏置、权重衰减及权重矩阵的代码。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 协同过滤
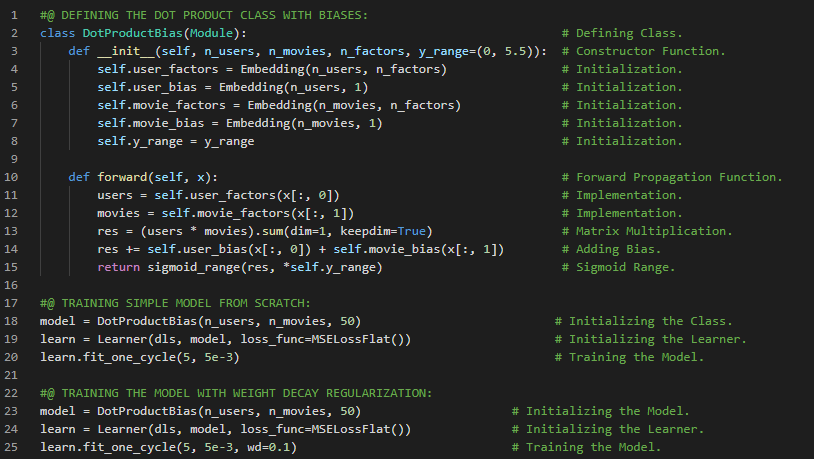
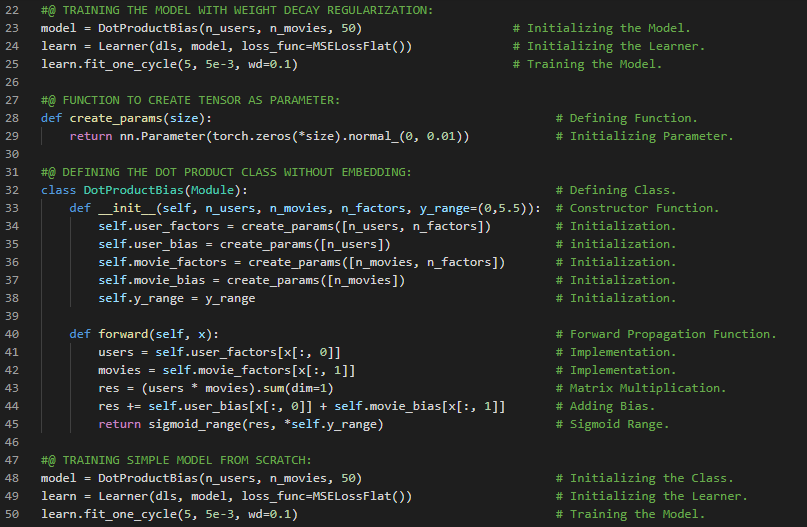
300天数据之旅第222天!
- 嵌入层:这种特殊的层通过整数索引到一个向量中,但其导数的计算方式却与用独热编码向量进行矩阵乘法时完全相同,这样的层就被称为嵌入层。利用一种计算捷径,可以直接通过索引来完成与独热编码矩阵的乘法运算。而负责执行这种乘法运算的矩阵则被称为嵌入矩阵。在我的机器学习和深度学习之旅中,我继续阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了嵌入层与偏置的解读、主成分分析(PCA)、协作学习模型、嵌入距离与余弦相似度、协同过滤模型的自举法、概率矩阵分解或点积模型等相关内容。我在截图中展示了使用Fastai和PyTorch实现的偏置解读、协作学习模型以及嵌入距离的代码。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 协同过滤
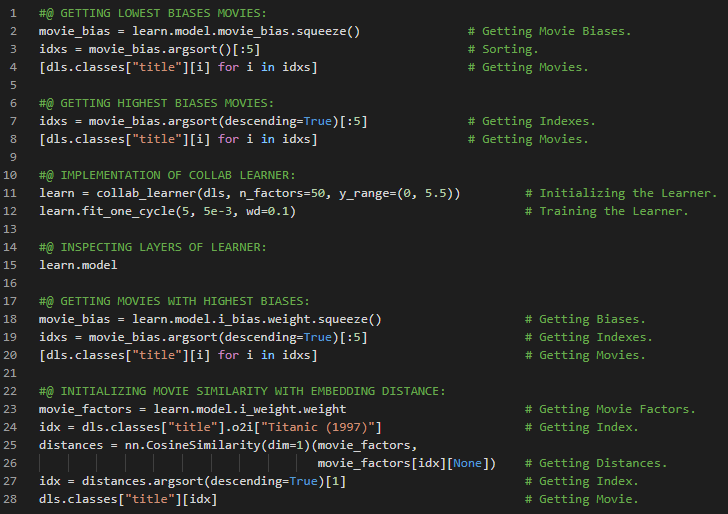
300天数据之旅第223天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了深度学习与协同过滤、嵌入矩阵、线性函数、ReLU及非线性函数、Sigmoid范围、前向传播函数、表格模型和嵌入神经网络等相关主题。在Python中,参数列表中的
kwargs表示“将任何额外的关键字参数放入名为kwargs的字典中”。而调用时的kwargs则表示“将kwargs字典中的所有键值对作为命名参数插入此处”。我在截图中展示了使用Fastai和PyTorch实现的协同过滤和神经网络的深度学习应用。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!! - 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 协同过滤
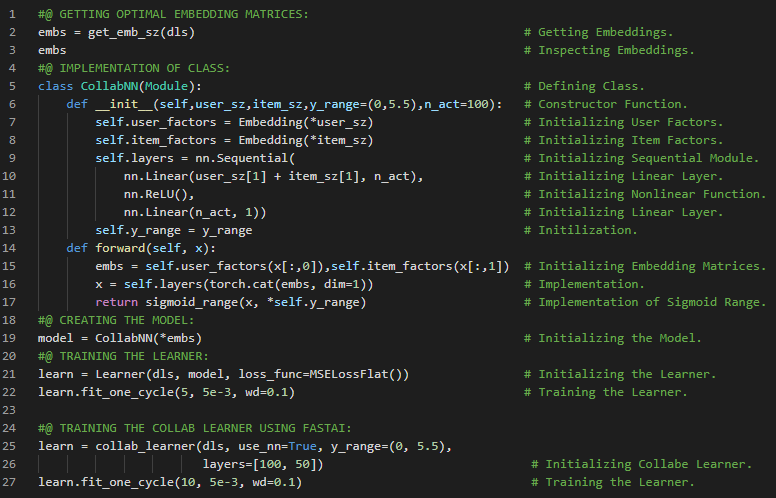
300天数据之旅第224天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了表格建模、分类嵌入、连续与分类变量、推荐系统、表格数据集、序数列、决策树、日期处理、表格Pandas以及表格Proc对象等相关主题。我在截图中展示了使用Fastai和PyTorch实现的日期处理、表格Pandas和表格Proc的应用。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
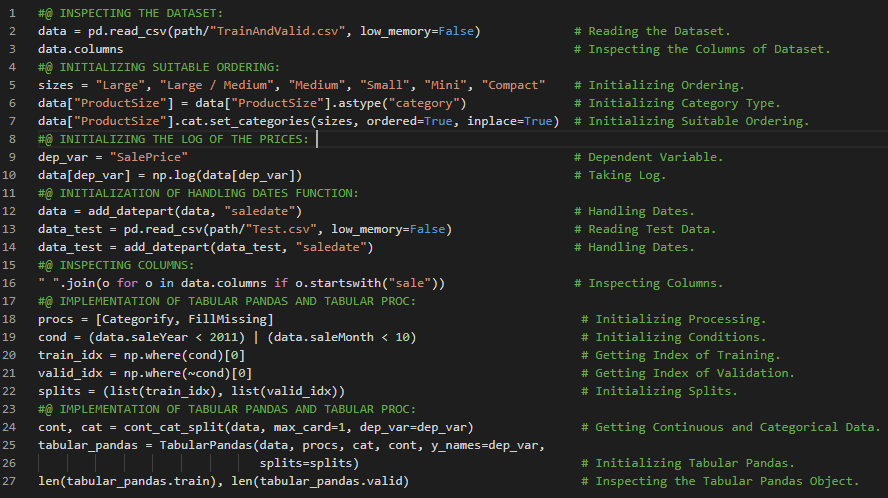
300天数据之旅第225天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了表格建模、创建决策树、叶节点、均方根误差、DTreeviz库、停止准则、过拟合等相关主题。我在截图中展示了使用Fastai和PyTorch实现的创建决策树和叶节点的过程。希望你能从中获得一些 insights,并继续深入实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
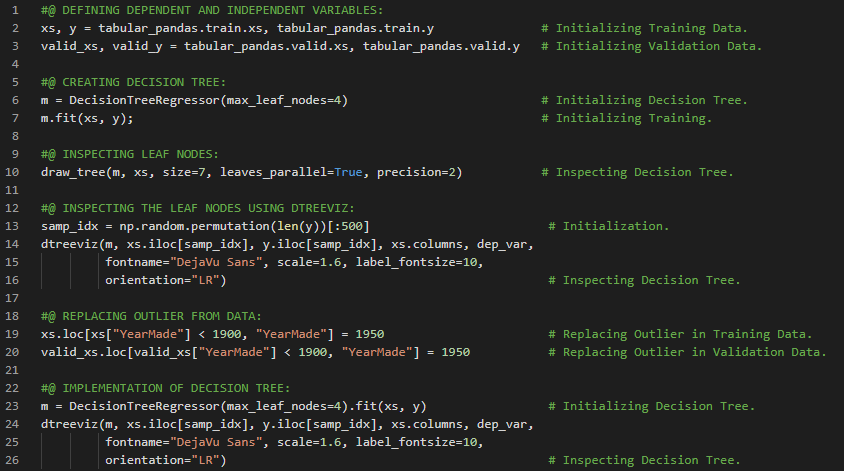
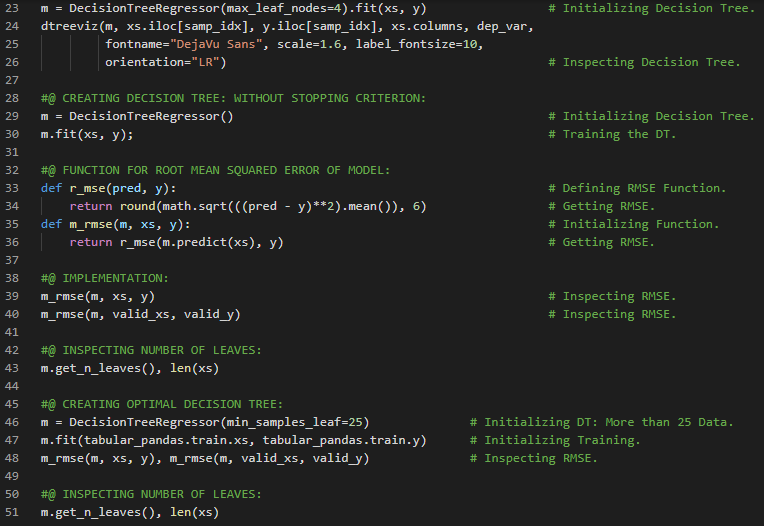
300天数据之旅第226天!
- 随机森林:随机森林是一种通过平均大量决策树预测结果的模型,这些决策树是通过随机调整各种参数生成的,这些参数决定了用于训练树的数据以及其他树的配置。Bagging是一种特殊的集成方法,用于将多个模型的结果结合起来。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了分类变量、随机森林与Bagging预测器、集成、最优参数、袋外误差、用于预测置信度的树方差与标准差、模型解释等相关主题。“袋外误差”(OOB误差)是一种在训练数据集中衡量预测误差的方法,它只将那些未被包含在训练中的样本对应的树的误差计入计算。我在截图中展示了使用Fastai和PyTorch实现的随机森林构建及模型解释过程。希望你能从中获得一些启示,并继续实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
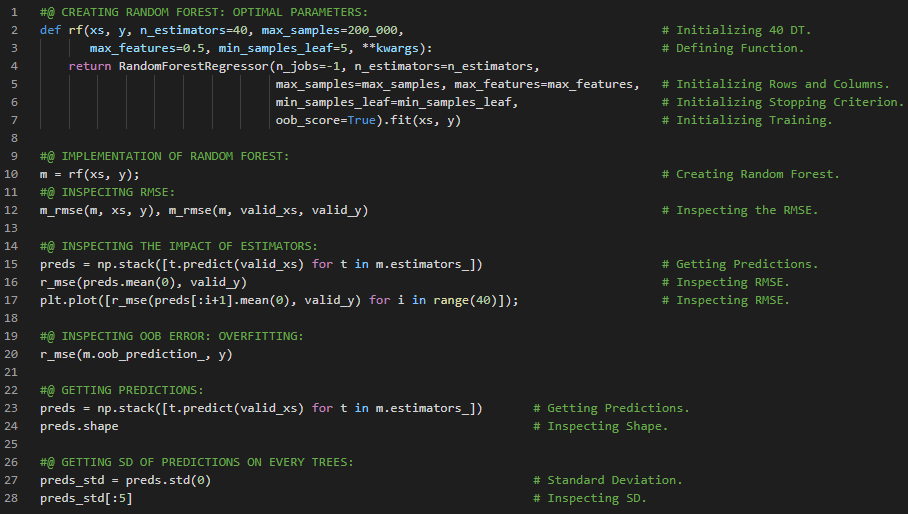
300天数据之旅第227天!
- 随机森林:随机森林是一种通过平均大量决策树预测结果的模型,这些决策树是通过随机调整各种参数生成的,这些参数决定了用于训练树的数据以及其他树的配置。Bagging是一种特殊的集成方法,用于将多个模型的结果结合起来。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了随机森林、特征重要性、移除低重要性变量、移除冗余特征、确定特征相似性、秩相关性、OOB评分等相关主题。我在截图中展示了使用Fastai和PyTorch实现的随机森林及特征重要性的应用。希望你能从中获得一些 insights,并继续深入实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
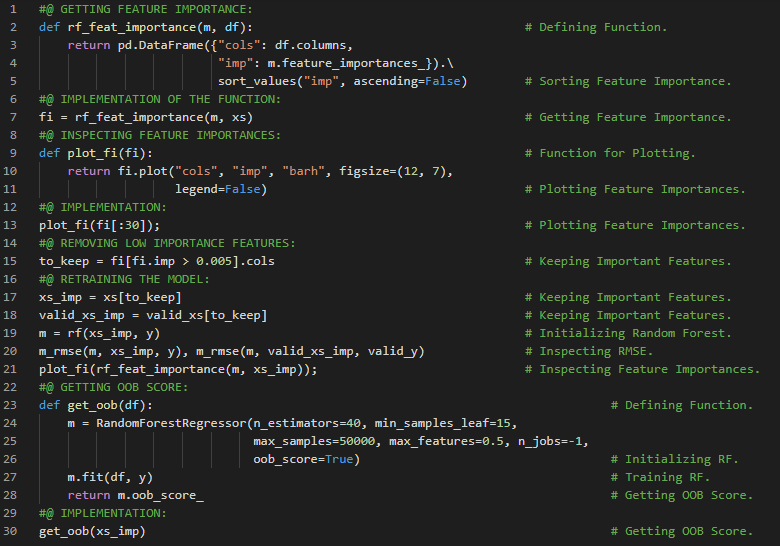
300天数据之旅第228天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书。在这里,我学习了去除冗余特征、确定相似性、OOB得分、部分依赖图、数据泄露、均方根误差等内容。通过计算各棵树预测结果的标准差,可以衡量预测的相对置信度;标准差越小,模型的一致性越高。我在截图中展示了使用Fastai和PyTorch实现去除冗余特征及部分依赖图的过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
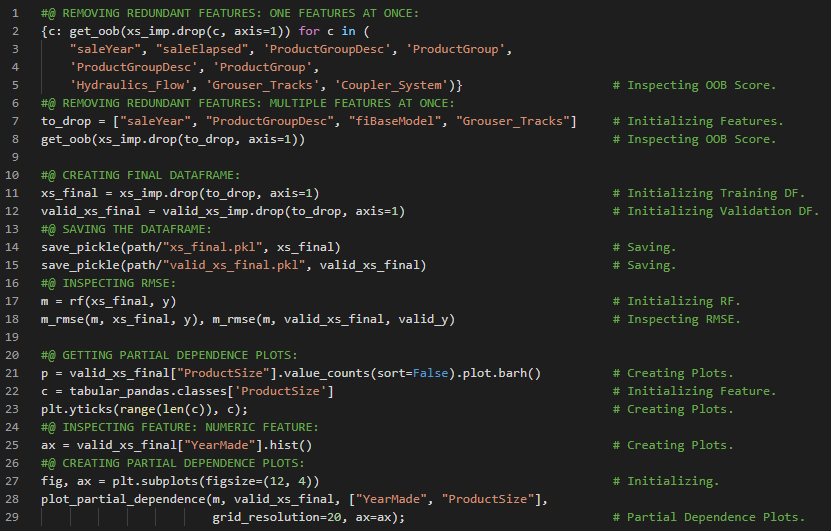
300天数据之旅第229天!
- 随机森林模型只是简单地对多棵树的预测结果取平均,因此它永远无法预测训练数据范围之外的值。随机森林无法对外部数据类型进行外推,即无法处理域外数据。这里的“预测”就是随机森林直接做出的预测结果;而“偏差”则是基于因变量均值得出的预测。同样,“贡献”则表示每个自变量对最终预测结果的总影响。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书。在此,我学习了树解释器、冗余特征、瀑布图、随机森林、预测、偏差与贡献、外推问题、unsqueeze方法、域外数据等内容。我在截图中展示了使用Fastai和PyTorch实现树解释器、瀑布图以及外推问题的过程。希望你能从中获得一些洞见,并进一步探索。也建议你花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
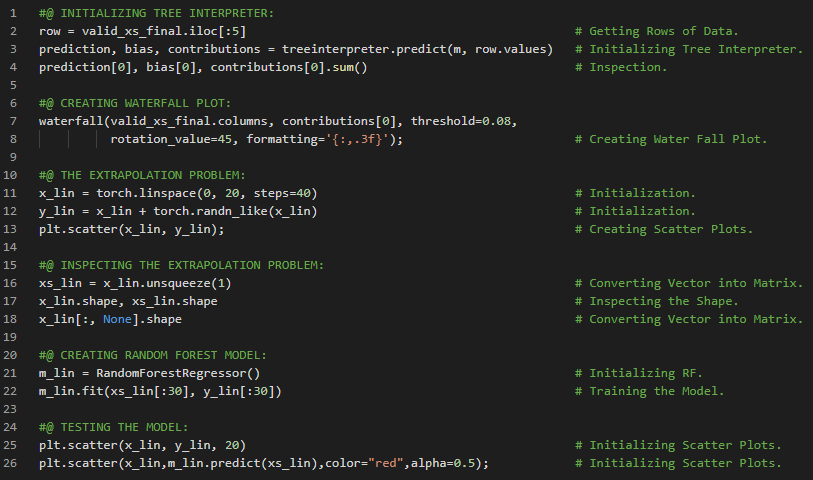
300天数据之旅第230天!
- 随机森林模型只是简单地对多棵树的预测结果取平均,因此它永远无法预测训练数据范围之外的值。随机森林无法对外部数据类型进行外推,即无法处理域外数据。这里的“预测”就是随机森林直接做出的预测结果;而“偏差”则是基于因变量均值得出的预测。同样,“贡献”则表示每个自变量对最终预测结果的总影响。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书。在此,我学习了外推问题与随机森林、识别域外数据、均方根误差与特征重要性、直方图等内容。我在截图中展示了使用Fastai和PyTorch实现识别域外数据及RMSE的过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
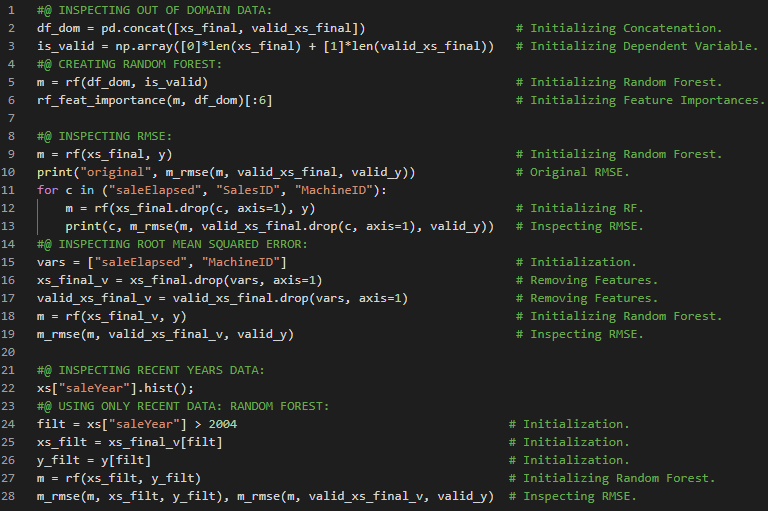
300天数据之旅第231天!
- 随机森林:随机森林模型只是简单地对多棵树的预测结果取平均,因此它永远无法预测训练数据范围之外的值。随机森林无法对外部数据类型进行外推,即无法处理域外数据。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书。在此,我学习了表格建模与神经网络、连续型与类别型特征、嵌入矩阵、均方误差与回归、表格学习器与学习率、集成学习、Bagging与Boosting、嵌入组合等内容。集成学习是一种泛化技术,通过结合多个模型的预测结果来提高整体性能。我在截图中展示了使用Fastai和PyTorch实现表格建模与神经网络以及集成学习的过程。希望你能从中获得一些启发,并继续深入研究。也建议你花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 表格建模
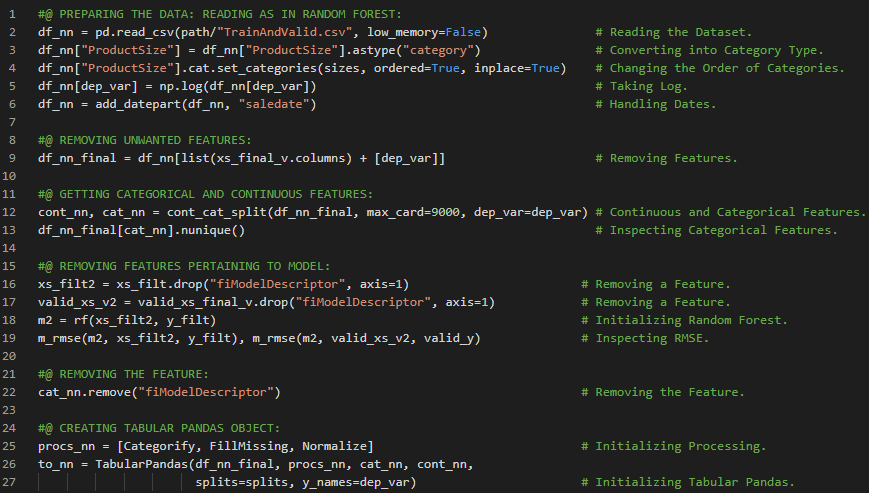
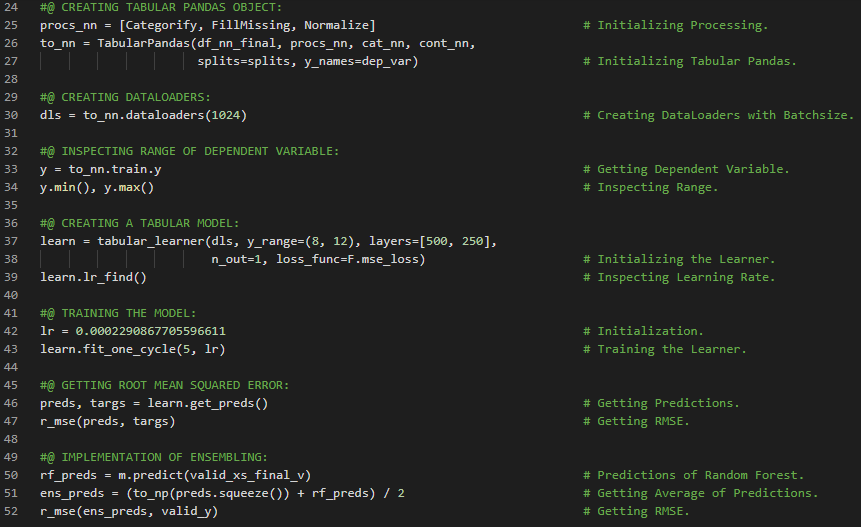
300天数据之旅第232天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书。在此,我学习了自然语言处理与语言模型、自监督学习、文本预处理、分词、数值化与嵌入矩阵、子词与字符、标记等内容。其中,“标记”是分词过程生成的列表中的一个元素,它可以是一个完整的词、词的一部分、子词或单个字符。我在截图中展示了使用Fastai和PyTorch加载数据及进行单词分词的实现过程。希望你能从中获得一些启发,并继续深入学习。也建议你花些时间学习下方提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 自然语言处理
300天数据之旅第233天!
- 分词:子词分词根据最常出现的子字符串将单词拆分成更小的部分。单词分词则不仅按空格分割句子,还会应用特定语言的规则,在没有空格的情况下尝试分离语义单元。子词分词提供了一种在字符级分词(使用较小的子词汇表)和单词级分词(使用较大的子词汇表)之间灵活切换的方式,并且无需为每种语言单独开发算法即可处理所有人类语言。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此书中,我学习了关于单词分词、子词分词、设置方法、词汇表、使用Fastai进行数值化、嵌入矩阵等内容。我在截图中展示了使用Fastai和PyTorch实现子词分词与数值化的过程。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 自然语言处理
300天数据之旅第234天!
- 分词:子词分词根据最常出现的子字符串将单词拆分成更小的部分。单词分词则不仅按空格分割句子,还会应用特定语言的规则,在没有空格的情况下尝试分离语义单元。子词分词提供了一种在字符级分词(使用较小的子词汇表)和单词级分词(使用较大的子词汇表)之间灵活切换的方式,并且无需为每种语言单独开发算法即可处理所有人类语言。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此书中,我学习了关于使用Fastai进行数值化、嵌入矩阵、为语言模型创建批次、分词、训练文本分类器、利用DataBlock构建语言模型、数据加载器、微调语言模型及迁移学习等内容。我在截图中展示了使用Fastai和PyTorch为语言模型创建数据加载器和Data Block的实现过程。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 自然语言处理
300天数据之旅第235天!
- 编码器:编码器是指不包含任务特定输出层的模型。在视觉CNN中,“编码器”一词与“主体”含义相近,但在NLP和生成模型中,“编码器”这一术语更为常用。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此书中,我学习了关于编码器模型、文本生成与分类、创建分类器数据加载器、嵌入、数据增强、分类器的微调、区分性学习率与逐步解冻、虚假信息与语言模型等内容。我在截图中展示了使用Fastai和PyTorch,通过区分性学习率与逐步解冻来训练文本分类器模型的过程。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 自然语言处理
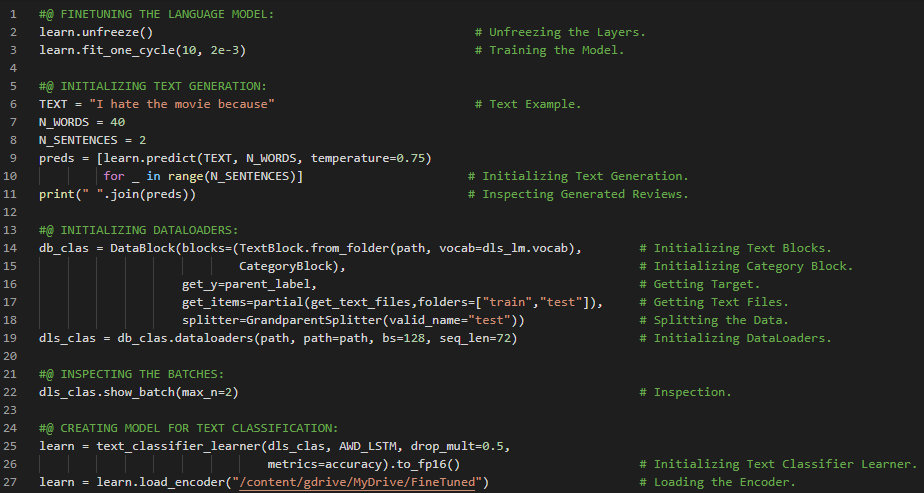
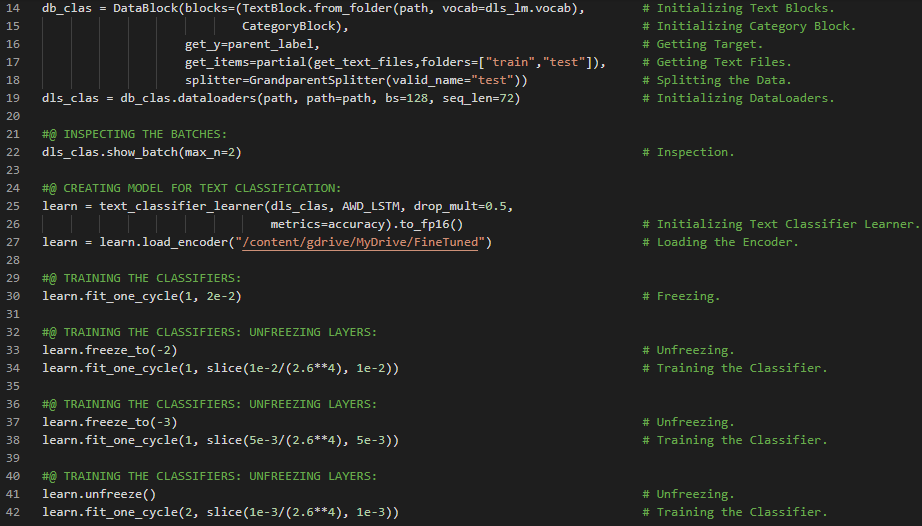
300天数据之旅第236天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此书中,我学习了关于使用Fastai进行数据清洗、分词与数值化、创建数据加载器和Data Block、中级API、变换、解码方法、数据增强、裁剪与填充等内容。我在截图中展示了使用Fastai和PyTorch进行数据加载器创建、分词与数值化的实现过程。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 数据清洗
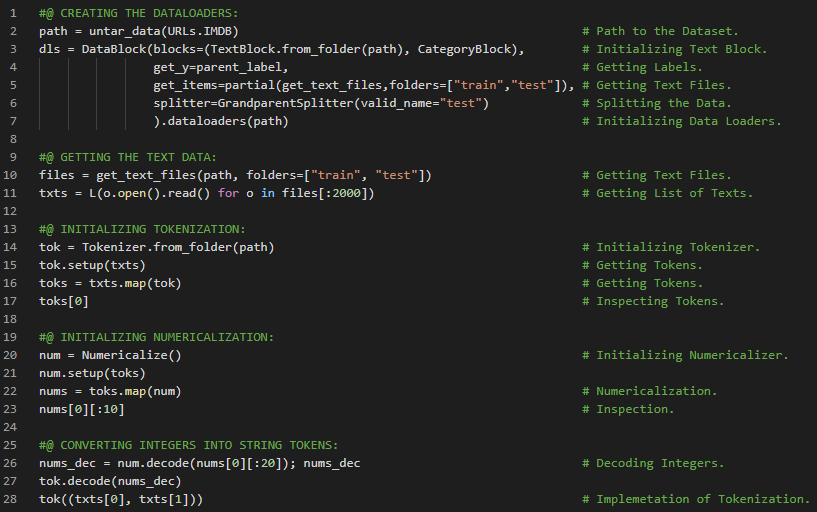
300天数据之旅第237天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此书中,我学习了关于数据清洗、装饰器、流水线方法、转换后的集合、训练集与验证集、数据加载器对象、分类方法、变换等内容。我在截图中展示了使用Fastai和PyTorch实现流水线类和转换后的集合的过程。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 数据清洗
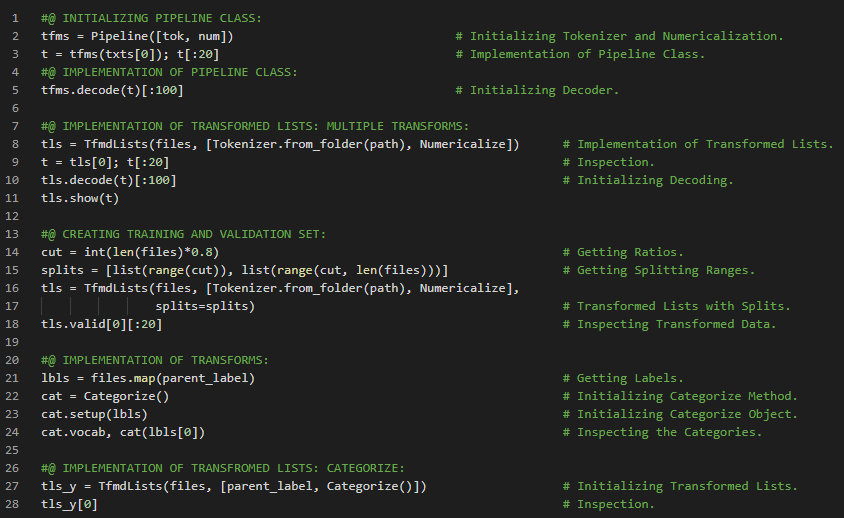
300天数据之旅第238天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了数据集类、转换集合、管道、分类方法、数据加载器和数据块、文本块、部分函数、类别块等主题。这里我展示了使用Fastai和PyTorch实现的数据集类、转换集合和数据加载器的代码示例。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 数据清洗
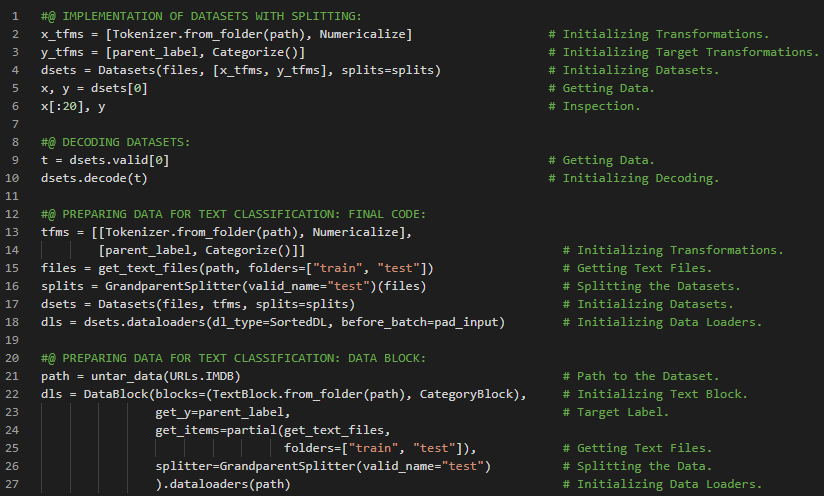
300天数据之旅第239天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了如何将中级数据API应用于暹罗对和计算机视觉、数据加载器、变换与图像调整大小、数据增强、子类、转换集合等主题。数据集类可以同时对同一原始对象应用两个或多个管道,并将结果组合成一个元组。它会自动完成设置并将数据索引到数据集中。这里我展示了使用Fastai和PyTorch实现的暹罗图像对象及数据增强的代码示例。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 数据清洗
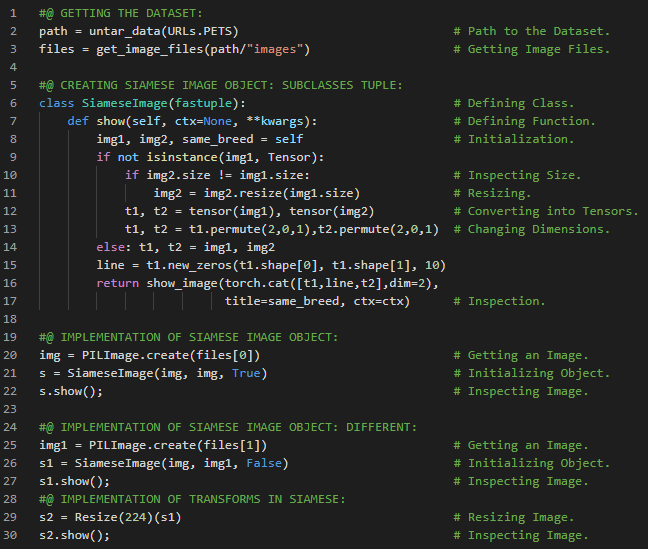
300天数据之旅第240天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了暹罗变换对象、随机拆分、转换集合与数据集类、数据加载器、ToTensor方法和IntToFloatTensor方法、数据归一化与批量归一化等主题。ToTensor方法用于将图像转换为张量。IntToFloatTensor方法则将包含0至255整数的图像张量转换为浮点张量,并除以255使值范围在0到1之间。这里我展示了使用Fastai和PyTorch实现的暹罗变换对象及数据增强的代码示例。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 数据清洗
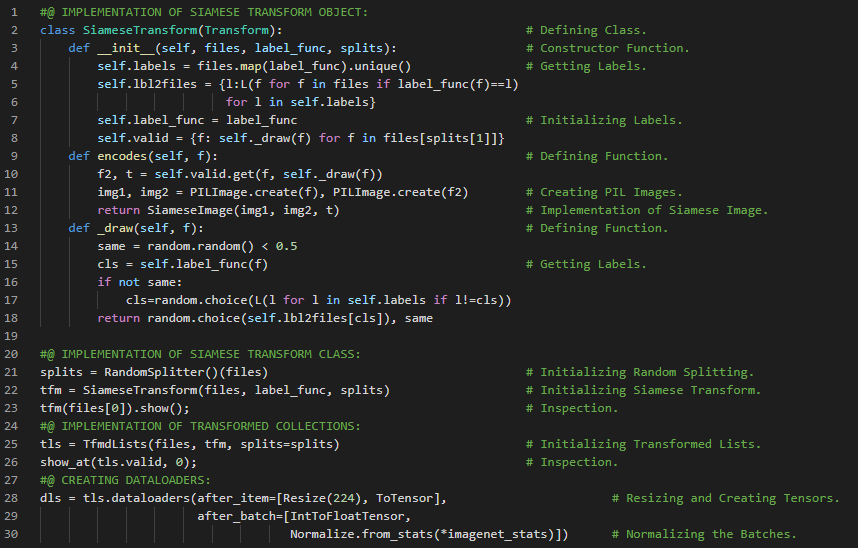
300天数据之旅第241天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了从零开始构建语言模型、数据拼接与分词、词汇表与数值化、神经网络、自变量与因变量、张量序列等主题。这里我展示了使用Fastai和PyTorch准备语言模型张量序列的代码示例。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
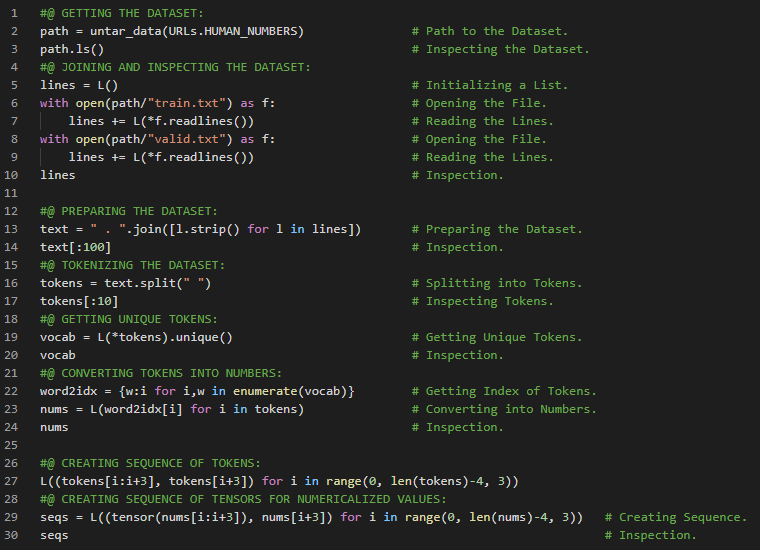
300天数据之旅第242天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了使用PyTorch从零开始构建语言模型、张量序列、创建数据加载器与设置批次大小、神经网络架构与线性层、词嵌入与激活函数、权重矩阵、创建学习者与训练等主题。我将构建一个神经网络架构,该架构以三个词作为输入,输出每个可能的下一个词的概率预测。我将使用三个标准的线性层。第一层仅使用第一个词的词嵌入作为激活;第二层使用第二个词的词嵌入加上第一层的输出激活;第三层则使用第三个词的词嵌入加上第二层的输出激活。其关键在于,每个词都会根据其前面的词所处的信息上下文来被解释。这三个层将共享同一权重矩阵。这里我展示了使用Fastai和PyTorch实现的数据加载器创建、从零开始构建语言模型以及训练的代码示例。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
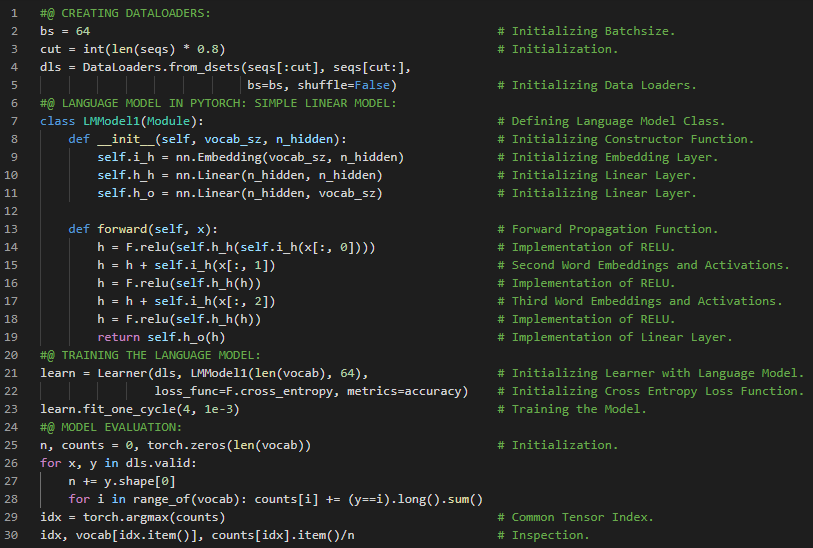
第243天,300天数据之旅!
- 时间反向传播:时间反向传播是一种将每个时间步都视为一层的神经网络当作一个大型模型来处理,并以常规方式计算其梯度的方法。为了避免内存和时间耗尽,BPTT技术会每隔几个时间步断开隐藏状态中计算步骤的历史记录。隐藏状态被定义为循环神经网络每一步更新的激活值。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了循环神经网络、NN的隐藏状态、RNN的改进、RNN状态的维护、展开表示、反向传播与导数、detach方法、有状态RNN、时间反向传播等主题。我在截图中展示了使用Fastai和PyTorch实现的循环神经网络和语言模型。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
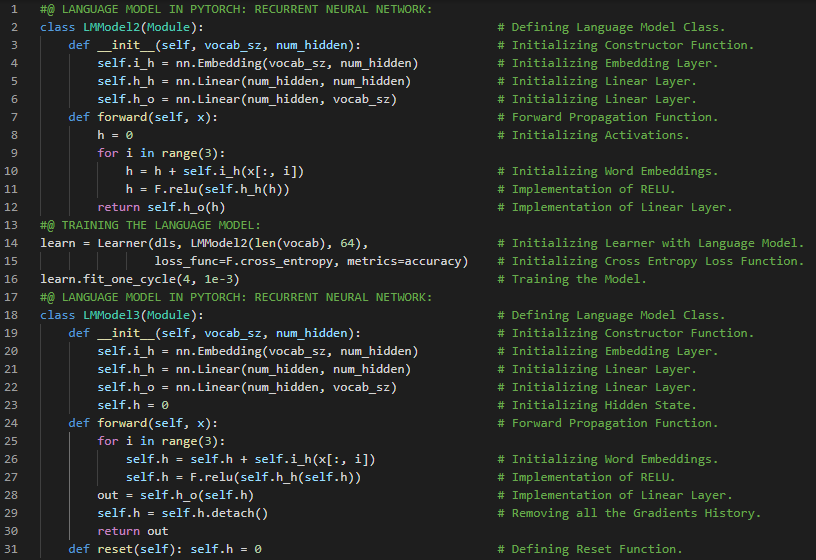
第244天,300天数据之旅!
- 时间反向传播:时间反向传播是一种将每个时间步都视为一层的神经网络当作一个大型模型来处理,并以常规方式计算其梯度的方法。为了避免内存和时间耗尽,BPTT技术会每隔几个时间步断开隐藏状态中计算步骤的历史记录。隐藏状态被定义为循环神经网络每一步更新的激活值。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了时间反向传播、LMDataLoader对象及数据集整理、数据加载器的创建、回调函数与重置方法、增加信号等内容。我在截图中展示了使用Fastai和PyTorch实现的数据集整理、数据加载器创建、回调函数与重置方法等内容。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
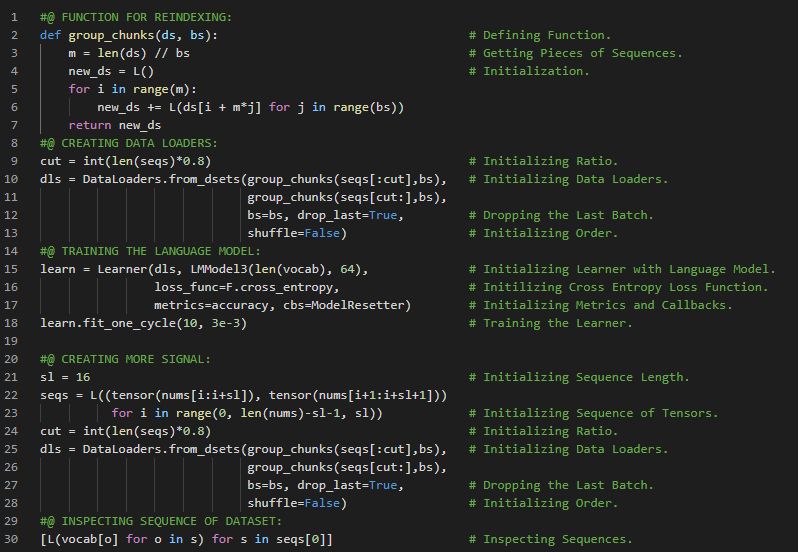
第245天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了创建更多信号或序列、交叉熵损失函数与flatten方法、多层循环神经网络与激活函数、展开表示、Stack等内容。单层循环神经网络的表现优于多层循环神经网络,因为更深的模型容易导致激活值爆炸或消失。我在截图中展示了使用Fastai和PyTorch实现的创建更多信号和多层循环神经网络的内容。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
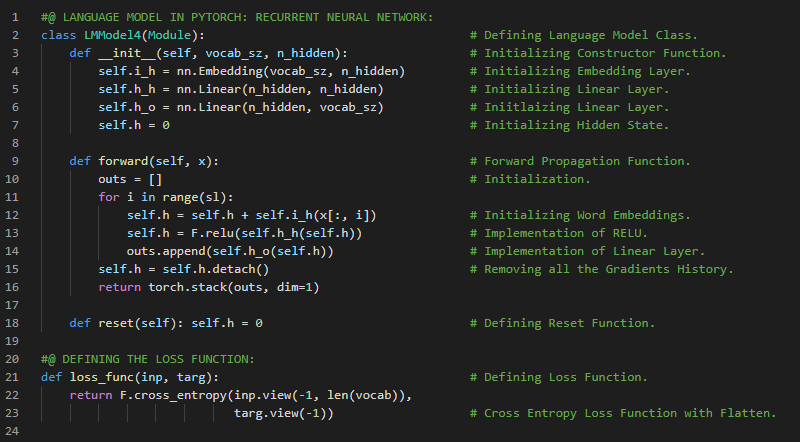
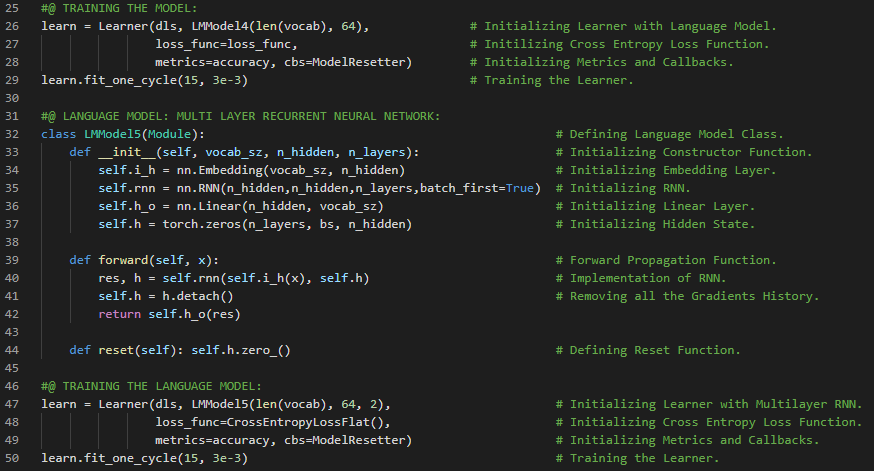
第246天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了激活值爆炸与消失、矩阵乘法、长短期记忆网络与RNN的架构、Sigmoid和Tanh函数、隐藏状态与细胞状态、遗忘门、输入门、细胞门和输出门、Chunk方法等内容。我在截图中展示了使用Fastai和PyTorch实现的长短期记忆网络。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
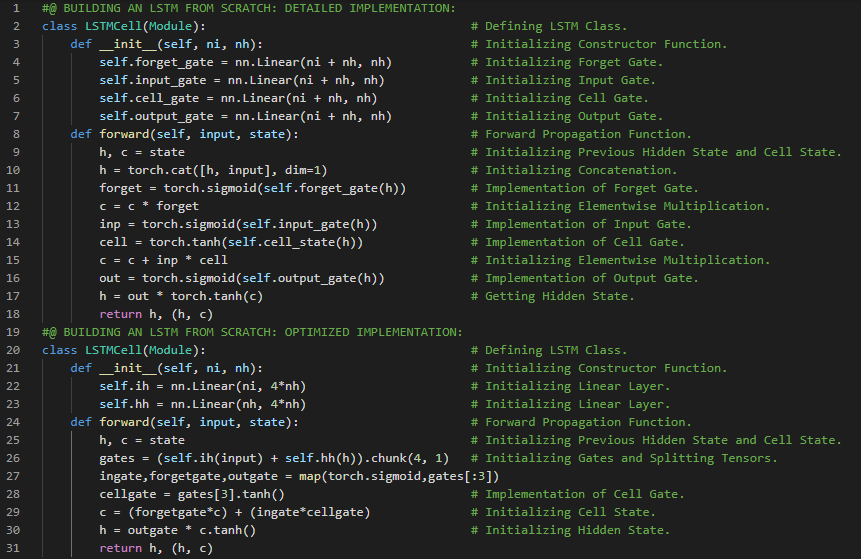
第247天,300天数据之旅!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了使用LSTM训练语言模型、嵌入层、线性层、LSTM的过拟合与正则化、Dropout正则化、训练与推理、伯努利方法等内容。Dropout是一种正则化技术,在训练时会随机将部分激活值设为零。我在截图中展示了使用Fastai和PyTorch实现的基于长短期记忆网络和Dropout的语言模型。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
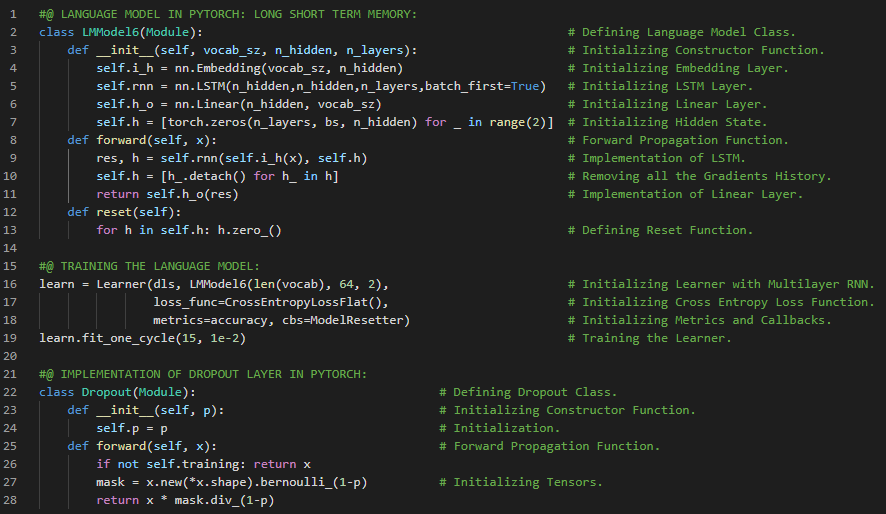
300天数据之旅第248天!
- 激活正则化:激活正则化是在LSTM产生的最终激活值上添加一个小的惩罚项,以使其尽可能小。这是一种与权重衰减非常相似的正则化方法。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书中的内容。在这里,我了解了激活正则化和时间激活正则化、基于长短期记忆网络的语言模型、权重衰减、训练权重共享的正则化LSTM、权重共享与输入嵌入、文本学习器、交叉熵损失函数以及与此相关的其他主题。我在截图中展示了使用Fastai和PyTorch实现的正则化长短期记忆语言模型,以及正则化的Dropout和激活正则化。希望你能从中获得一些启发,并进一步实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始构建语言模型
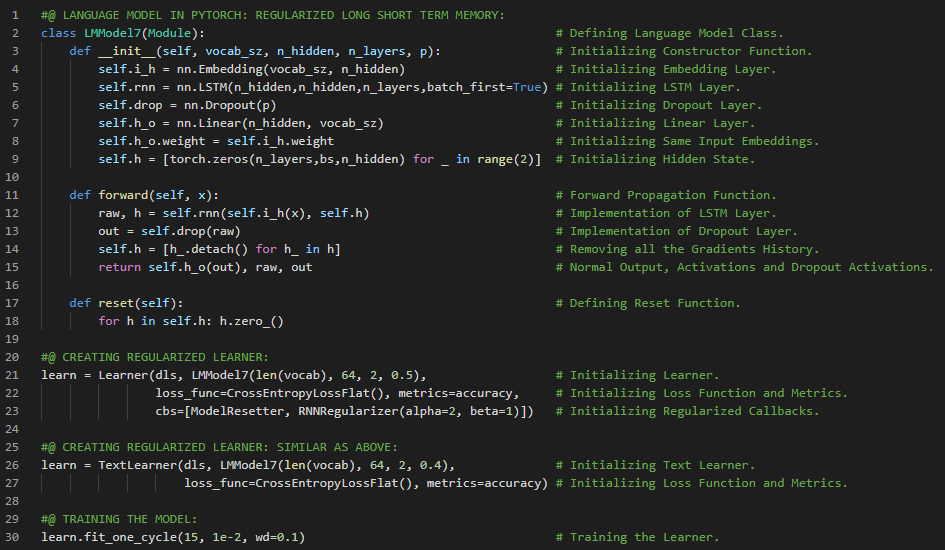
300天数据之旅第249天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书中的内容。在这里,我学习了卷积神经网络、卷积的魔力、特征工程、卷积核与矩阵、卷积核映射、嵌套列表推导式、矩阵乘法等主题。特征工程是指通过对输入数据进行新的变换,使其更易于建模的过程。我在截图中展示了使用Fastai和PyTorch实现的特征工程和卷积核映射。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 卷积神经网络
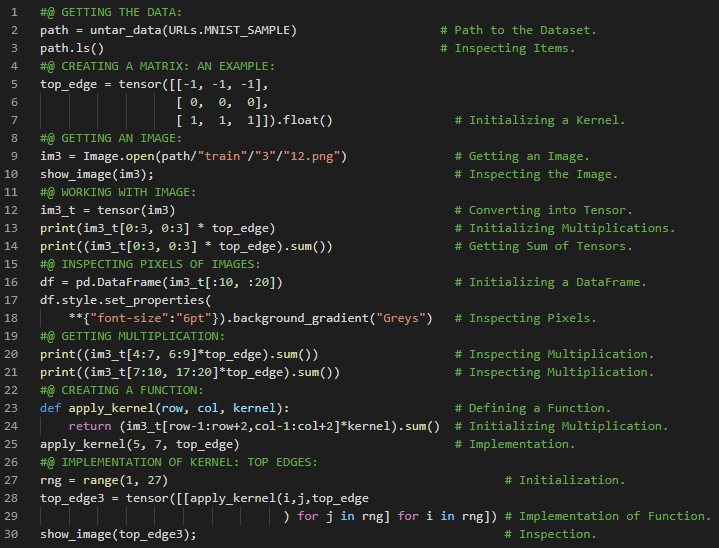
300天数据之旅第250天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书中的内容。在这里,我学习了使用PyTorch进行卷积、张量的秩、创建数据块和数据加载器、图像的通道、unsqueeze方法与单位轴、步幅与填充、理解卷积方程、矩阵乘法、权重共享等主题。通道是图像中的单一基本颜色。对于普通的全彩色图像,有三个通道:红色、绿色和蓝色。传递给卷积的卷积核必须是4阶张量。我在截图中展示了使用Fastai和PyTorch实现的卷积和数据加载器。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 卷积神经网络
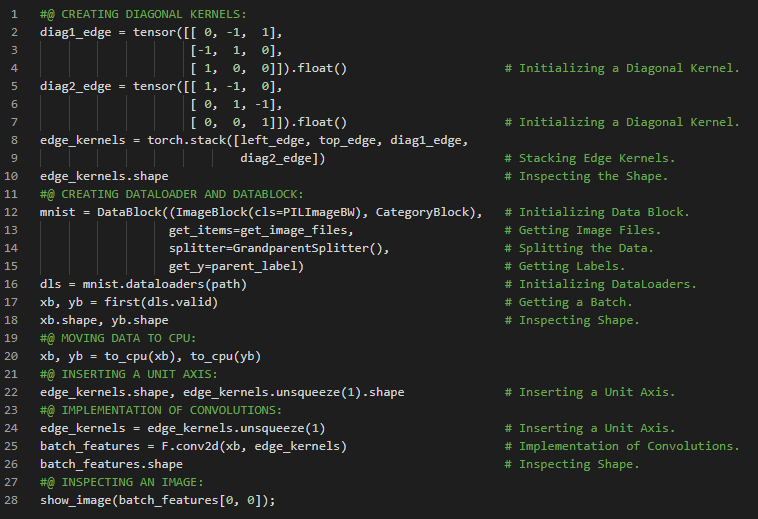
300天数据之旅第251天!
- 通道与特征:通道与特征这两个术语经常可以互换使用,它们指的是权重矩阵第二轴的大小,也就是卷积后每个网格单元的激活数量。通道通常指输入数据,即网络内部的颜色或激活值。使用步幅为2的卷积往往会增加特征的数量,因为激活图中的激活数量会减少到原来的四分之一。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书中的内容。在这里,我学习了卷积神经网络、重构、通道与特征、理解卷积运算、偏置、感受野、对RGB图像的卷积、随机梯度下降等主题。我在截图中展示了使用Fastai和PyTorch实现的卷积神经网络及学员训练过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 卷积神经网络
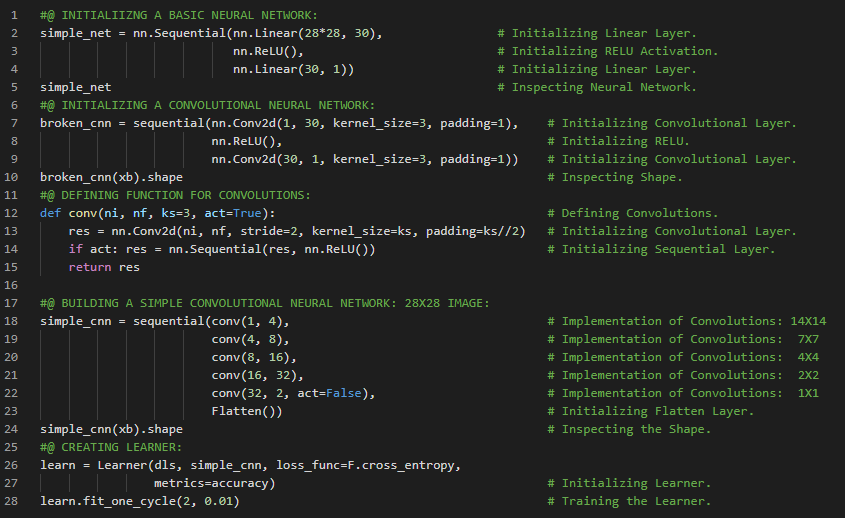
300天数据之旅第252天!
- 通道与特征:通道与特征这两个术语经常可以互换使用,它们指的是权重矩阵第二轴的大小,也就是卷积后每个网格单元的激活数量。通道通常指输入数据,即网络内部的颜色或激活值。使用步幅为2的卷积往往会增加特征的数量,因为激活图中的激活数量会减少到原来的四分之一。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书中的内容。在这里,我学习了提高卷积神经网络训练稳定性、批量大小与数据集划分、简单基准网络、激活与卷积核尺寸、激活统计回调、学习率、创建学员及训练等主题。我在截图中展示了使用Fastai和PyTorch实现的卷积神经网络及学员训练过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 卷积神经网络
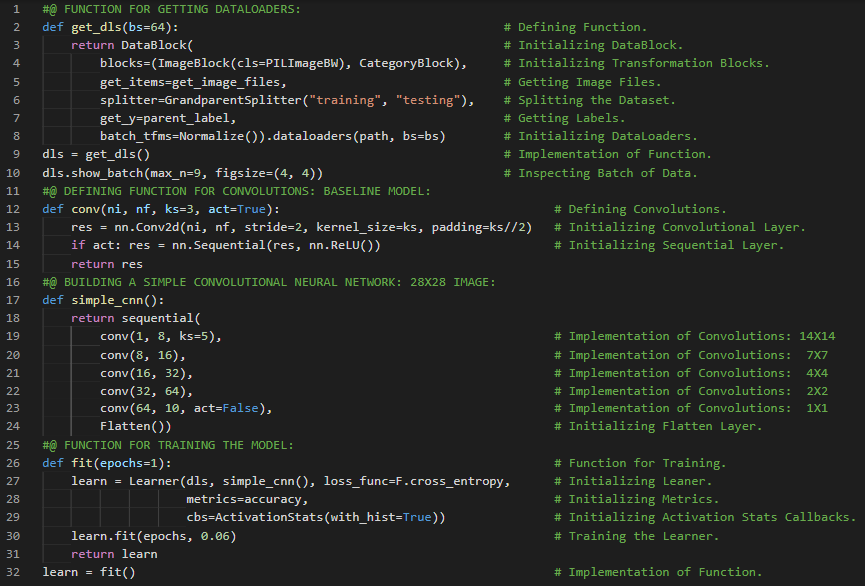
300天数据之旅第253天!
- 单周期训练:单周期训练是预热和退火的结合。预热阶段,学习率从最小值逐渐增加到最大值;退火阶段,则从最大值逐步降低回最小值。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书中的内容。在此过程中,我学习了激活统计回调、增大批次大小、激活函数、单周期训练、预热与退火、超级收敛、学习率与动量、彩色维度及直方图等主题。这里我通过截图展示了利用Fastai和PyTorch实现的增大批次大小、单周期训练以及检查动量和激活的过程。希望你能从中获得一些启发,并进一步实践。也建议你花些时间深入学习书中提到的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 【卷积神经网络】(https://github.com/ThinamXx/Fastai/blob/main/12.%20Convolutional%20Neural%20Networks/CNN.ipynb)
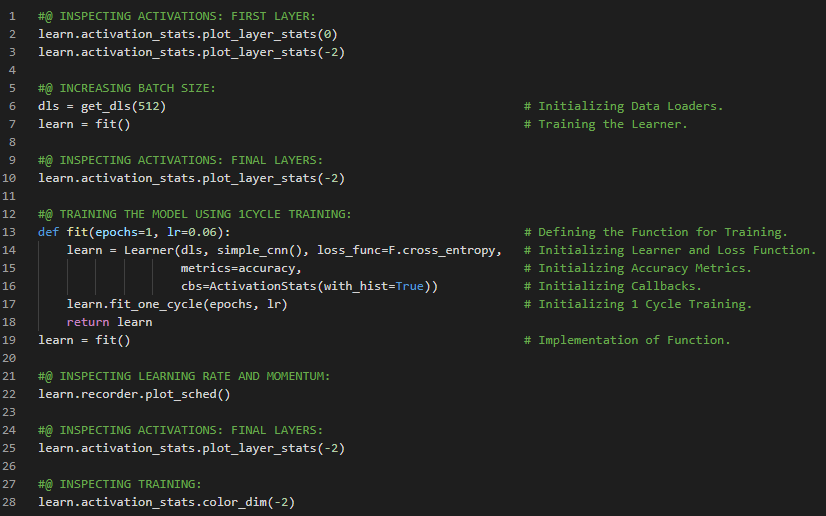
300天数据之旅第254天!
- 全卷积网络:全卷积网络的核心思想是在卷积网格上对激活值取平均。这种网络通常包含多层卷积,其中最后几层会采用步幅为2的卷积,随后接一个自适应平均池化层、一个用于去除单位轴的展平层,最后是线性层。较大的批次由于基于更多数据计算梯度,因此梯度更为准确。然而,更大的批次意味着每个 epoch 中的批次数量减少,从而减少了模型更新权重的机会。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书中的内容。在此期间,我学习了残差网络(ResNet)、卷积神经网络、步幅与填充、全卷积网络、自适应平均池化层、展平层、激活函数和矩阵乘法等相关主题。这里我通过截图展示了利用Fastai和PyTorch实现的数据准备和全卷积网络的过程。希望你能从中获得一些见解,并加以实践。同时,也建议你花些时间学习下文提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 【残差网络】(https://github.com/ThinamXx/Fastai/blob/main/13.%20ResNets/ResNets.ipynb)
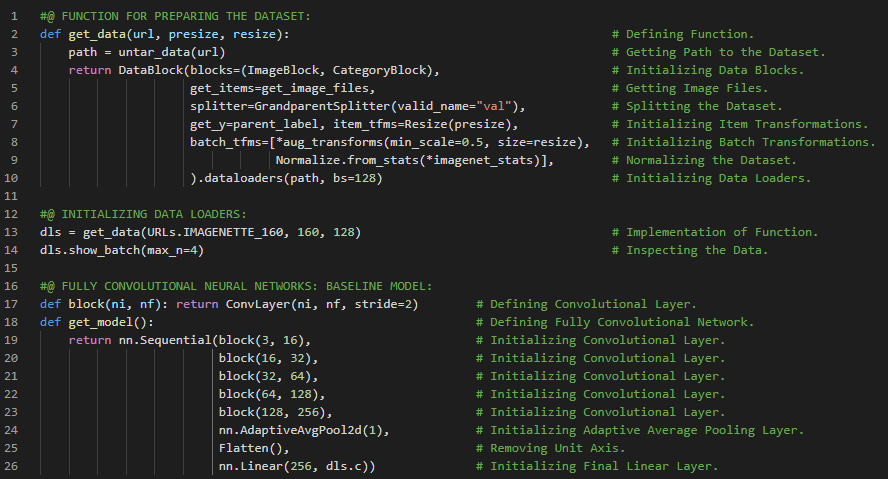
300天数据之旅第255天!
- 全卷积网络:全卷积网络的理念是在卷积网格上对激活值取平均。这种网络通常包含多层卷积,其中最后几层会采用步幅为2的卷积,随后接一个自适应平均池化层、一个用于去除单位轴的展平层,最后是线性层。较大的批次由于基于更多数据计算梯度,因此梯度更为准确。然而,更大的批次意味着每个 epoch 中的批次数量减少,从而减少了模型更新权重的机会。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书中的内容。在此过程中,我学习了全卷积神经网络、ResNet搭建、跳跃连接、恒等映射、SGD优化器、批量归一化层、可训练参数、真实身份路径、卷积神经网络、平均池化层等相关主题。这里我通过截图展示了利用Fastai和PyTorch实现的ResNet架构及跳跃连接的过程。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习下文提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 【残差网络】(https://github.com/ThinamXx/Fastai/blob/main/13.%20ResNets/ResNets.ipynb)
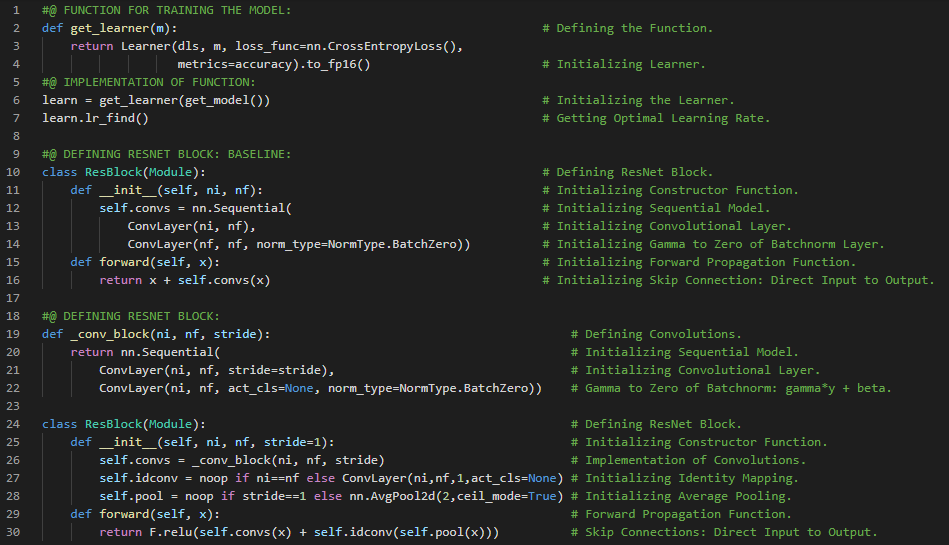
300天数据之旅第256天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书中的内容。在此过程中,我学习了残差网络、ReLU激活函数、跳跃连接、训练更深的模型、神经网络损失景观、网络茎部、卷积层、最大池化层等相关主题。所谓“茎部”,指的是卷积神经网络的前几层,其结构与网络主体部分不同。这里我通过截图展示了利用Fastai和PyTorch实现的训练更深的模型和网络茎部的过程。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习下文提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 【残差网络】(https://github.com/ThinamXx/Fastai/blob/main/13.%20ResNets/ResNets.ipynb)
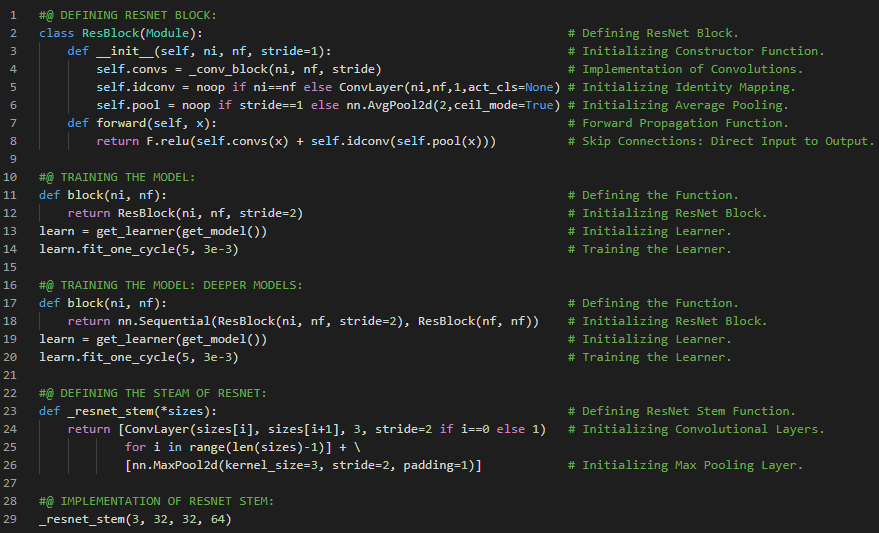
300天数据之旅第257天!
- 瓶颈层:瓶颈层采用三层卷积:开头和结尾各一个1×1卷积,中间一个3×3卷积。1×1卷积速度更快,便于在输入和输出端使用更多滤波器。这两个1×1卷积先减少通道数,再恢复通道数,形成所谓的“瓶颈”。整体效果是能够在相同时间内使用更多的滤波器。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书中的内容。在此过程中,我学习了网络茎部、残差网络架构、瓶颈层、卷积神经网络、渐进式调整尺寸等相关主题。这里我通过截图展示了利用Fastai和PyTorch实现的训练更深的网络和瓶颈层的过程。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习下文提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 【残差网络】(https://github.com/ThinamXx/Fastai/blob/main/13.%20ResNets/ResNets.ipynb)
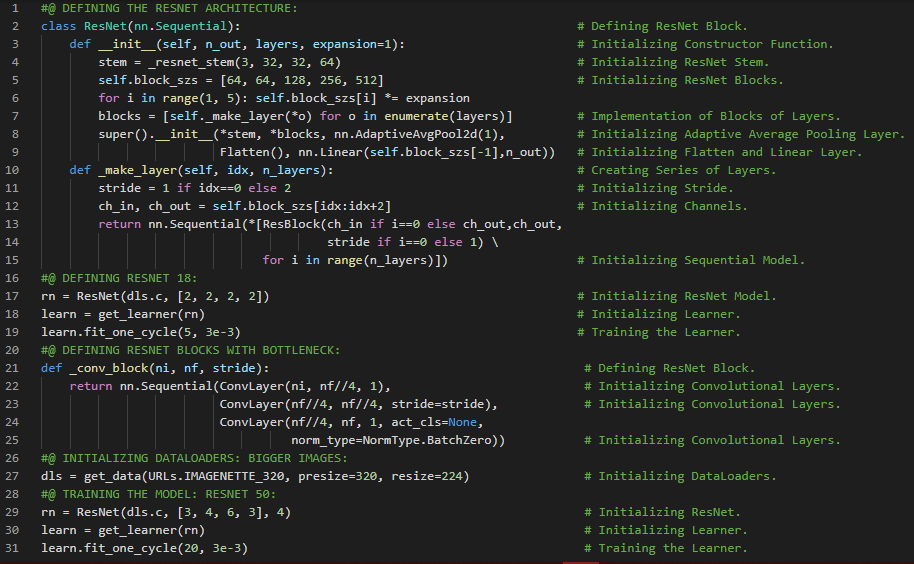
300天数据之旅第258天!
- 分割函数:分割函数是告诉fastai库如何将模型拆分为参数组的函数,这些参数组在迁移学习过程中仅用于训练模型的头部部分。
params函数则简单地返回给定模块的所有参数。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我了解了网络的主体与头部、批归一化层、U-Net学习器及其架构、生成式视觉模型、最近邻插值、转置卷积、暹罗网络、损失函数以及分割函数等相关内容。我在截图中展示了使用Fastai和PyTorch实现的暹罗网络模型、损失函数和分割函数。希望你能从中获得一些启发,并进一步深入研究。也建议花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!! - 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 架构细节
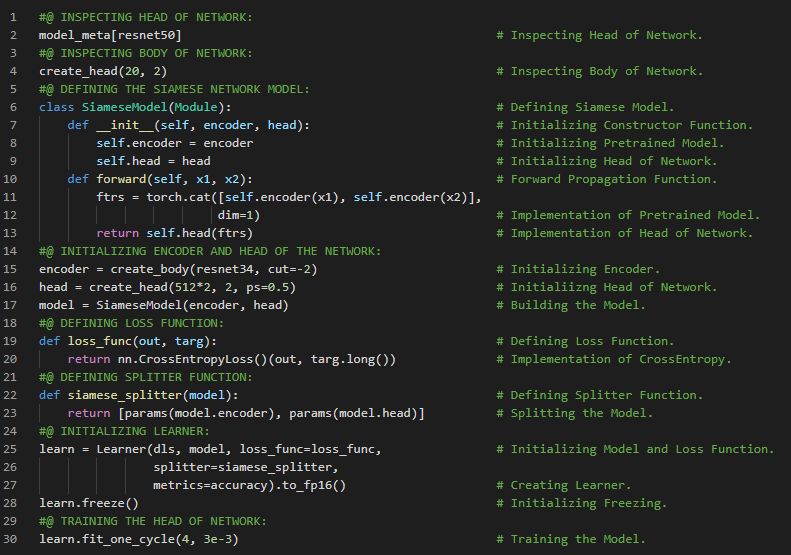
300天数据之旅第259天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了随机梯度下降、损失函数、权重更新、优化函数、创建数据块和数据加载器、ResNet模型及学习器、训练过程等相关内容。我在截图中展示了使用Fastai和PyTorch准备数据集和构建基线模型的实现。希望你能从中获得一些见解,并继续深入探索。也建议花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 训练过程
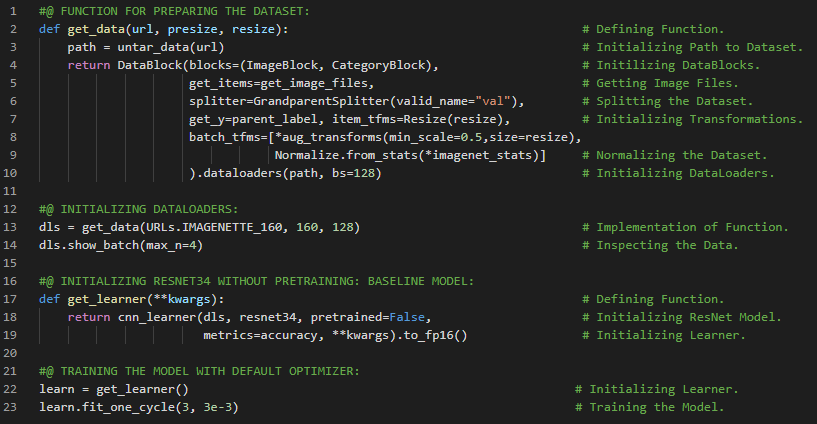
300天数据之旅第260天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了训练过程、随机梯度下降、优化函数、学习率查找器、动量、优化器回调、梯度清零、偏函数等相关内容。我在截图中展示了用于优化器和SGD的函数实现。希望你能从中获得一些启发,并继续深入研究。也建议花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 训练过程
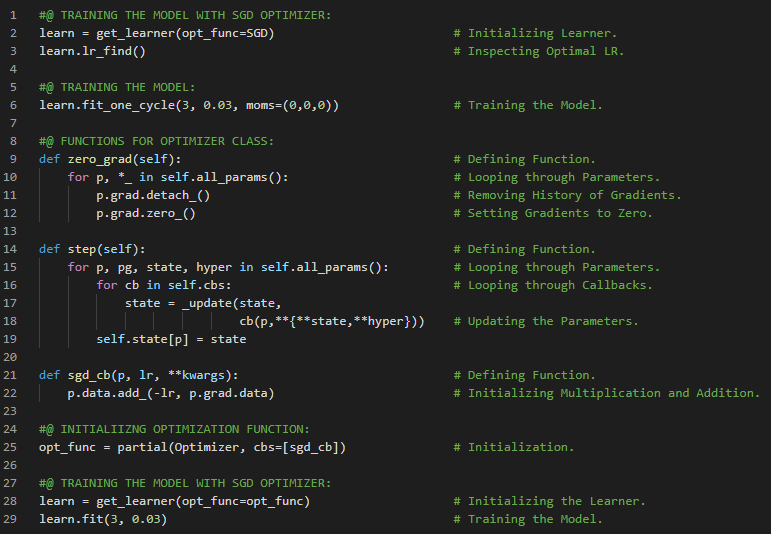
300天数据之旅第261天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了随机梯度下降和优化函数、动量、指数加权移动平均、梯度平均、回调、RMSProp、自适应学习率、发散与ε等相关内容。我在截图中展示了使用Fastai和PyTorch实现的动量和RMSProp。希望你能从中获得一些见解,并继续深入研究。也建议花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 训练过程
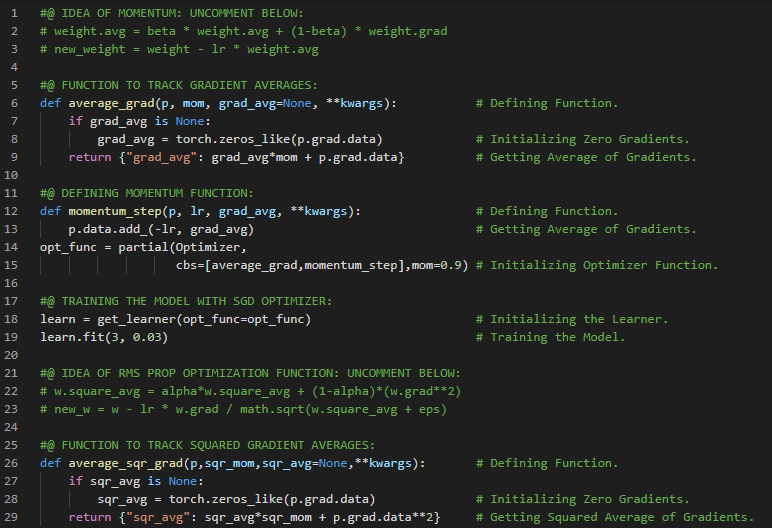
300天数据之旅第262天!
- Adam优化器:Adam结合了带有动量的SGD和RMSProp的思想,它利用梯度的移动平均作为方向,并除以梯度平方的移动平均的平方根,从而为每个参数提供自适应的学习率。它采用无偏移的移动平均。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了RMSProp优化器、SGD、Adam优化器、梯度的无偏移移动平均、动量参数、解耦权重衰减、L1和L2正则化、回调等相关内容。我在截图中展示了使用Fastai和PyTorch实现的RMSProp和Adam优化器。希望你能从中获得一些启发,并继续深入研究。也建议花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 训练过程
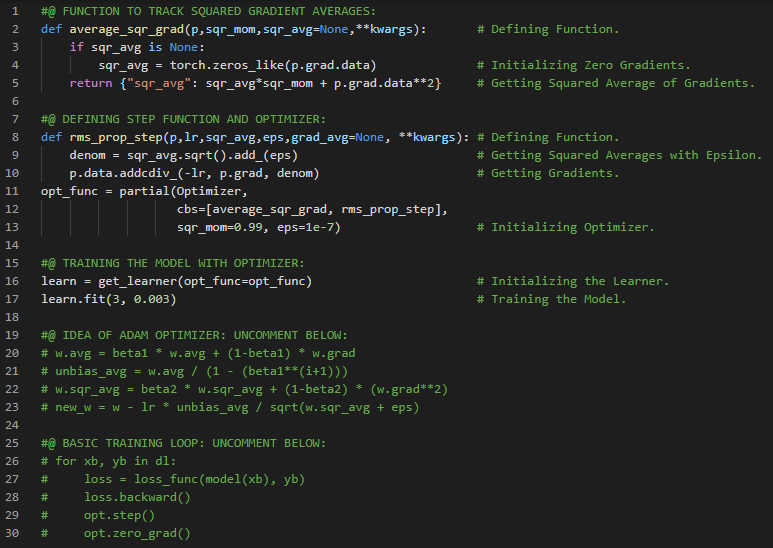
300天数据之旅第263天!
- Adam优化器:Adam结合了带有动量的SGD和RMSProp的思想,它利用梯度的移动平均作为方向,并除以梯度平方的移动平均的平方根,从而为每个参数提供自适应的学习率。它采用无偏移的移动平均。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了创建回调、损失函数、模型重置回调、RNN正则化、回调顺序与异常处理、随机梯度下降等相关内容。我在截图中展示了使用Fastai和PyTorch实现的模型重置回调和RNN正则化回调。希望你能从中获得一些见解,并继续深入研究。也建议花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch进行编码的深度学习》
- 训练过程
300天数据之旅第264天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书的内容。在这里,我学习了神经网络、从头构建神经网络、模拟一个神经元、非线性激活函数、隐藏层大小、全连接层和密集层、线性层、从零开始实现矩阵乘法、逐元素运算等主题。我在截图中展示了使用Fastai和PyTorch实现的从零开始的矩阵乘法和逐元素运算。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下面提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 神经网络基础
300天数据之旅第265天!
- 前向传播与反向传播:计算给定损失对其参数的所有梯度被称为反向传播。同样,根据矩阵乘积计算模型在给定输入上的输出则称为前向传播。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书的内容。在这里,我学习了标量广播、向量与矩阵的广播、unsqueeze方法、爱因斯坦求和约定、矩阵乘法、前向与反向传播、定义和初始化层、激活函数、线性层、权重与偏置等主题。我在截图中展示了使用Fastai和PyTorch实现的爱因斯坦求和约定以及线性层的定义和初始化。希望你能从中获得一些见解,并加以实践。也希望大家能花些时间学习下面提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 神经网络基础
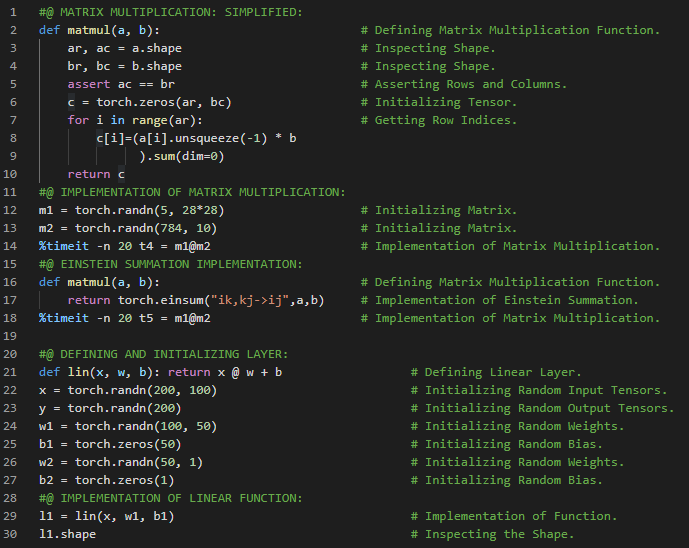
300天数据之旅第266天!
- 前向传播与反向传播:计算给定损失对其参数的所有梯度被称为反向传播。同样,根据矩阵乘积计算模型在给定输入上的输出则称为前向传播。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书的内容。在这里,我学习了均值与标准差、矩阵乘法、Xavier初始化、ReLU激活函数、Kaiming初始化、权重与激活等主题。我在截图中展示了使用Fastai和PyTorch实现的Xavier初始化、ReLU激活函数和矩阵乘法。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习下面提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 神经网络基础
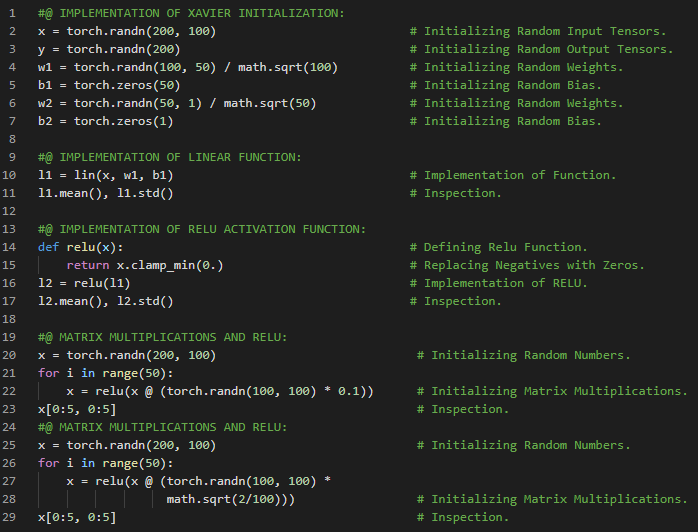
300天数据之旅第267天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书的内容。在这里,我学习了Kaiming初始化、前向传播、均方误差损失函数、梯度与反向传播、线性层与ReLU激活函数、链式法则、反向传播等主题。我在截图中展示了使用Fastai和PyTorch实现的Kaiming初始化、MSE损失函数和梯度。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习下面提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 神经网络基础
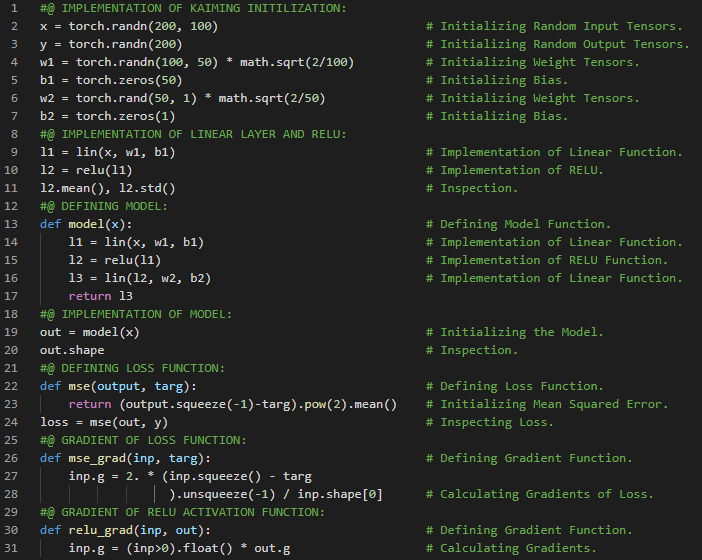
300天数据之旅第268天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书的内容。在这里,我学习了矩阵乘法的梯度、符号计算、前向与反向传播函数、模型参数、权重与偏置、模型重构、可调用模块等主题。我在截图中展示了使用Fastai和PyTorch实现的ReLU模块、线性模块和均方误差模块。希望你能从中获得一些启发,并加以实践。也希望大家能花些时间学习下面提到的书籍中的内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 神经网络基础
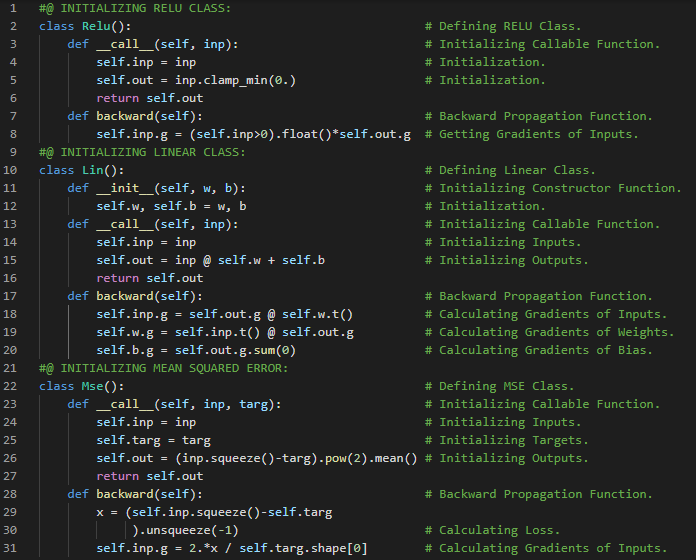
300天数据之旅第269天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了模型架构的初始化、可调用函数、前向与反向传播函数、线性函数、均方误差损失函数、ReLU激活函数、反向传播函数与梯度、Squeeze函数等主题。此外,我还了解了扰动与神经网络、梯度消失问题以及卷积神经网络。我在截图中展示了使用Fastai和PyTorch实现定义模型架构、层函数和ReLU的过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 神经网络基础
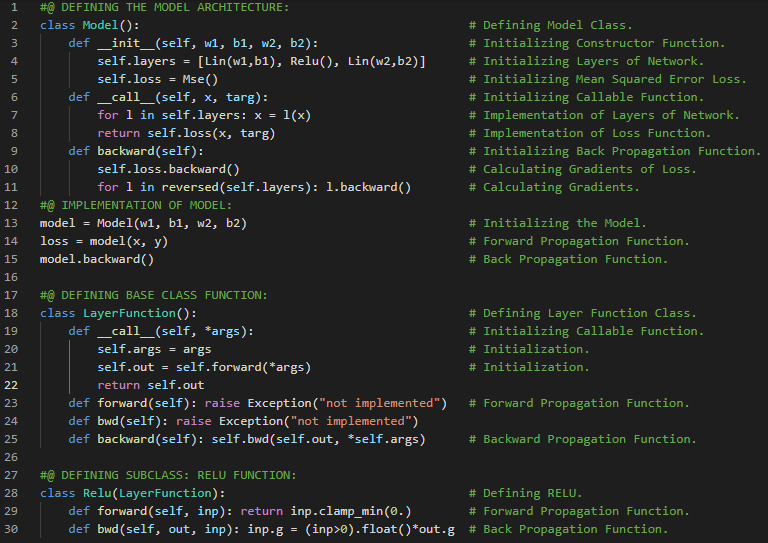
300天数据之旅第270天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了定义基类和子类、线性层、ReLU激活函数及非线性变换、均方误差函数、超类初始化器、Kaiming初始化、逐元素算术运算与广播等主题。我在截图中展示了使用Fastai和PyTorch实现定义线性层和线性模型的过程。希望你能从中获得一些见解,并进一步实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 神经网络基础
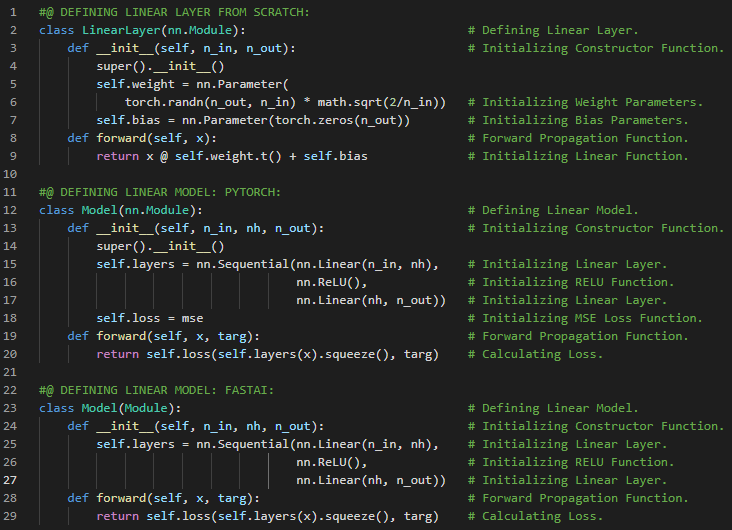
300天数据之旅第271天!
- 类别激活图:类别激活图利用平均池化层之前的最后一层卷积层的输出与预测结果,生成模型决策的热力图可视化。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了CNN解释、类别激活图、钩子、热力图可视化、激活值与卷积层、点积、特征图、数据加载器等相关主题。我在截图中展示了使用Fastai和PyTorch实现定义钩子函数和解码图像的过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 带有CAM的CNN解释
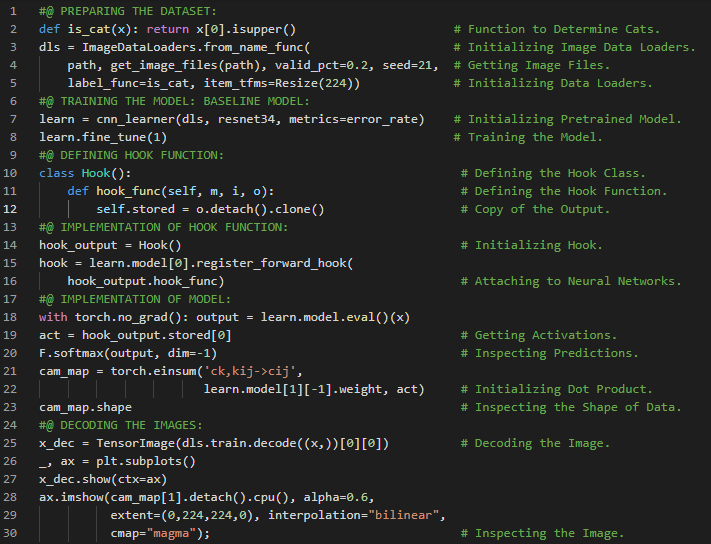
300天数据之旅第272天!
- 类别激活图:类别激活图利用平均池化层之前的最后一层卷积层的输出与预测结果,生成模型决策的热力图可视化。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了钩子类与上下文管理器、梯度类别激活图、热力图可视化、激活值与权重、梯度与反向传播、模型解释等相关主题。我在截图中展示了使用Fastai和PyTorch实现定义钩子函数、激活值、梯度及热力图可视化的过程。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 带有CAM的CNN解释
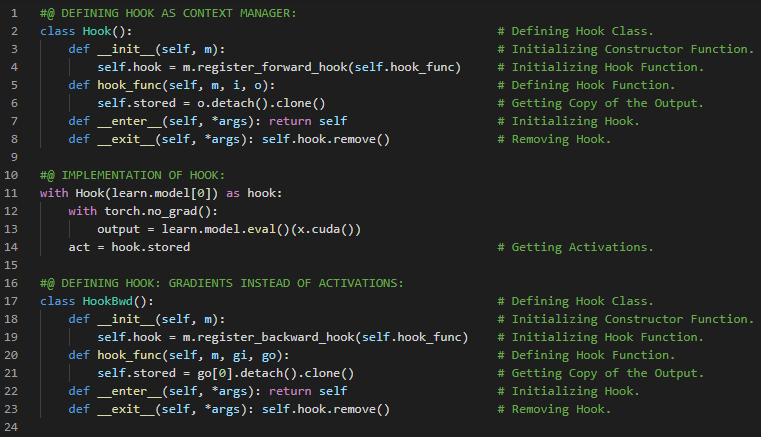
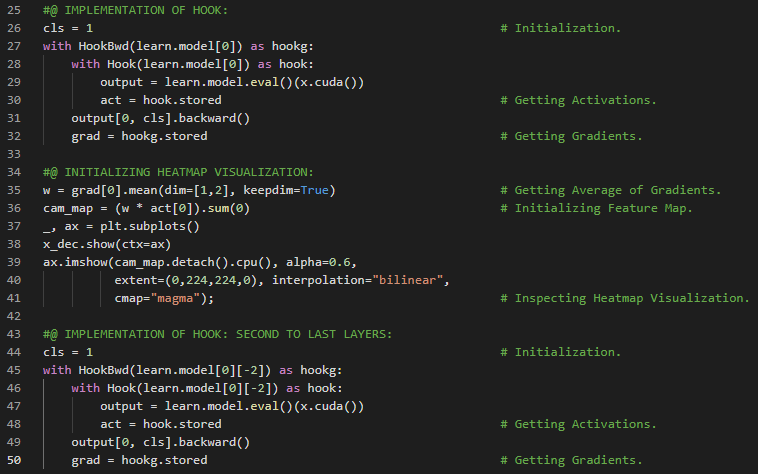
300天数据之旅第273天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了从零开始构建Fastai Learner、因变量与自变量、词汇表、数据集与索引等相关主题。我还了解了卷积神经网络、扰动和损失函数。我在截图中展示了使用Fastai和PyTorch准备训练集和验证集的过程。希望你能从中获得一些启发,并加以实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始的Fastai Learner
300天数据之旅第274天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在此期间,我学习了创建批处理函数、并行预处理、解码图像、数据加载器类、归一化与图像统计信息、调整轴顺序、精度等相关主题。我在截图中展示了使用Fastai和PyTorch实现数据加载器初始化与归一化的过程。希望你能从中获得一些见解,并加以实践。也建议你花些时间学习下方提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始的Fastai Learner
300天数据之旅第275天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书。在这里,我学习了模块与参数、前向传播函数、卷积层、训练属性、Kaiming归一化和Xavier归一化初始化器、变换函数、权重与偏置、线性模型、张量等主题。我在截图中展示了如何使用Fastai和PyTorch定义模块:卷积层和线性模型的实现。希望你能从中获得一些启发,并进一步实践。也希望大家能花些时间学习下面提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始的Fastai学习者
300天数据之旅第276天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书。在这里,我学习了卷积神经网络、线性模型、测试模块、序列模块、参数、自适应池化层及均值、步幅、钩子函数、流水线等主题。我在截图中展示了如何使用Fastai和PyTorch实现测试模块、序列模块和卷积神经网络。希望你能从中获得一些 insights,并加以实践。也希望大家能花些时间学习下面提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始的Fastai学习者
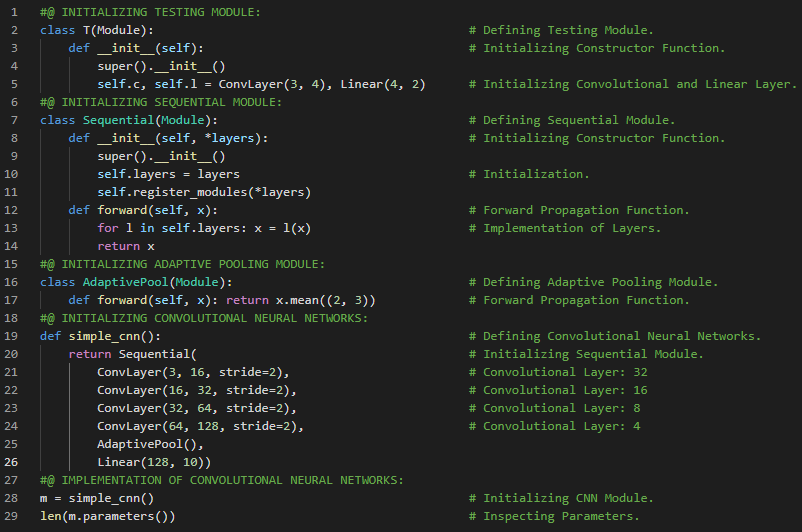
300天数据之旅第277天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书。在这里,我学习了损失函数、负对数似然函数、Log Softmax函数、指数之和的对数、随机梯度下降优化器函数、数据加载器、训练集和验证集等主题。我在截图中展示了如何使用Fastai和PyTorch实现负对数似然函数、交叉熵损失函数、SGD优化器和数据加载器。希望你能从中获得一些 insights,并加以实践。也希望大家能花些时间学习下面提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始的Fastai学习者
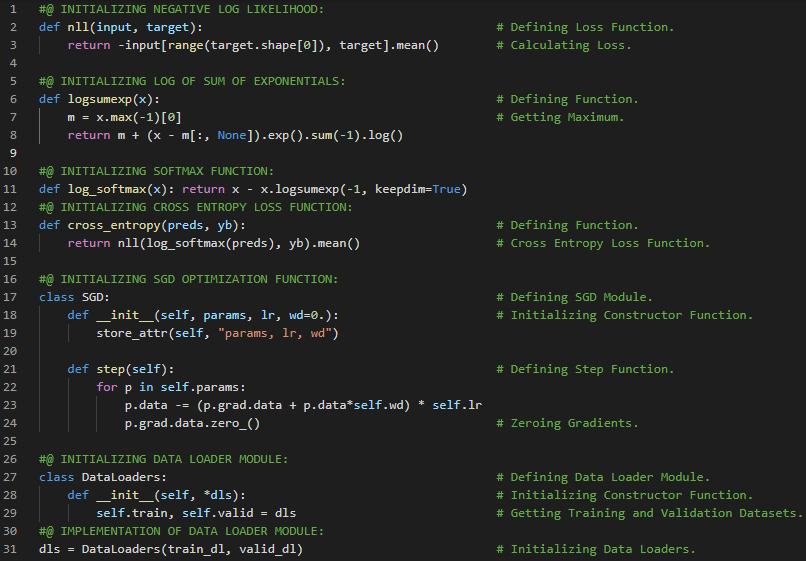
300天数据之旅第278天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书。在这里,我学习了数据、卷积神经网络模型、损失函数、随机梯度下降与优化函数、学习者、回调函数、参数、训练与轮次等主题。我在截图中展示了如何使用Fastai和PyTorch实现学习者和回调函数。希望你能从中获得一些 insights,并加以实践。也希望大家能花些时间学习下面提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 从零开始的Fastai学习者
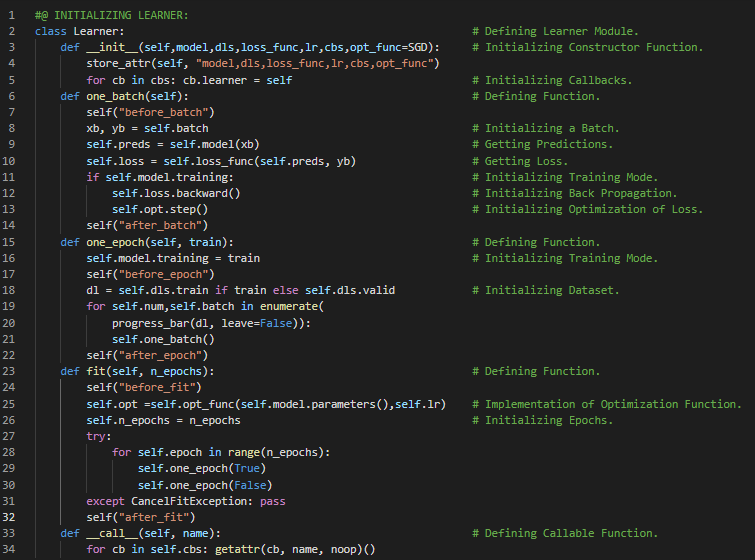
300天数据之旅第279天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书。在这里,我学习了二分类、胸部X光片、DICOM(医学数字成像与通信标准)、绘制DICOM数据、随机分割函数、医学影像、像素数据等主题。我在截图中展示了如何使用Fastai和PyTorch获取DICOM文件并进行检查。希望你能从中获得一些 insights,并加以实践。也希望大家能花些时间学习下面提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 胸部X光片分类
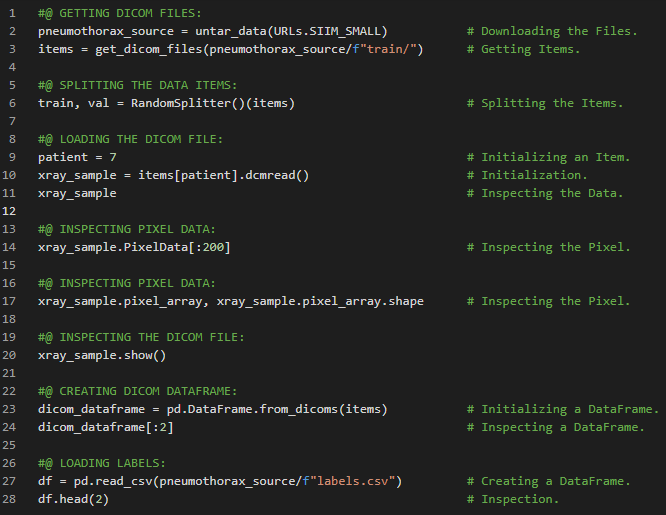
300天数据之旅第280天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》这本书。在这里,我学习了二分类、数据块和数据加载器的初始化、图像块与类别块、批量变换、预训练模型的训练、学习率查找器、张量与概率、模型解释等主题。我在截图中展示了如何使用Fastai和PyTorch实现数据块和数据加载器的初始化、预训练模型的训练以及模型解释。希望你能从中获得一些 insights,并加以实践。也希望大家能花些时间学习下面提到的书籍内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 胸部X光片分类
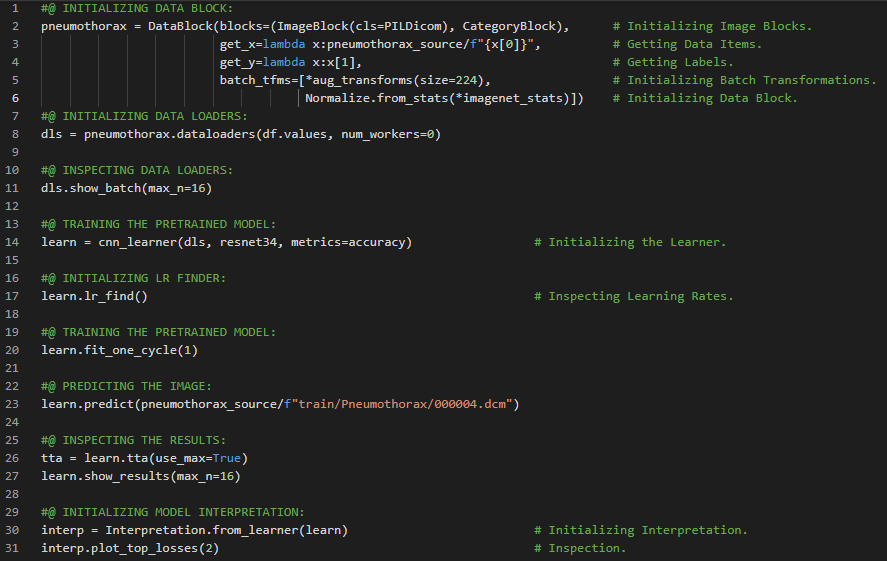
300天数据之旅第281天!
- 灵敏度与特异性:灵敏度 = 真阳性 /(真阳性 + 假阴性)。它也被称为第二类错误。特异性 = 真阴性 /(假阳性 + 真阴性)。它也被称为第一类错误。在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch的编码者深度学习》一书的内容。在这里,我学习了灵敏度与特异性、阳性预测值与阴性预测值、混淆矩阵与模型解释、第一类与第二类错误、准确率与患病率等主题。我在截图中展示了使用Fastai和PyTorch实现的混淆矩阵、灵敏度与特异性以及准确率。希望你能从中获得一些启发,并进一步深入研究。我也希望你能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 【胸部X光片分类】(https://github.com/ThinamXx/Fastai/blob/main/19.%20Chest%20XRays%20Classification/XRays%20Classification.ipynb)
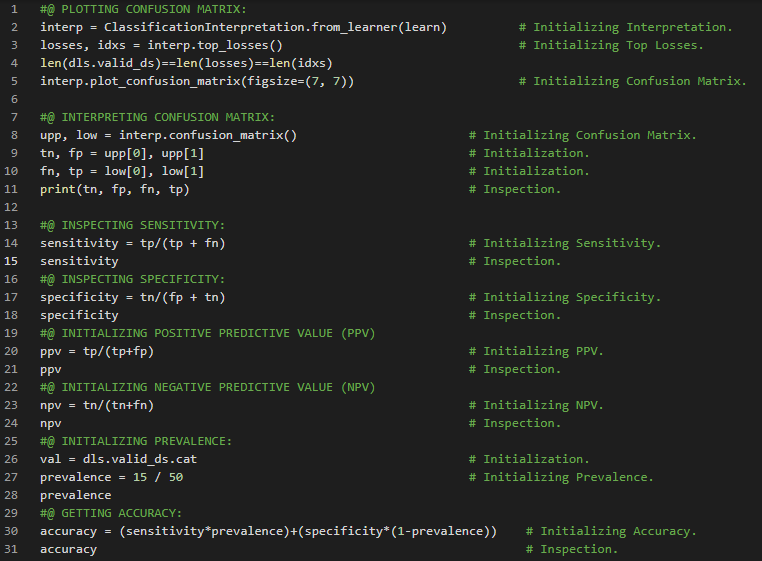
300天数据之旅第282天!
- 交叉验证:交叉验证是构建机器学习模型过程中的一个步骤,它帮助我们确保模型能够准确地拟合数据,同时避免过拟合。在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》一书的内容。在这里,我学习了监督学习与无监督学习、特征、样本与目标、分类与回归、聚类、t分布随机邻域嵌入、二维数组、交叉验证、过拟合等主题。我在截图中展示了TSNE降维和数据集准备的实现。希望你能从中获得一些见解,并加以实践。我也希望你能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 【监督学习与无监督学习】(https://github.com/ThinamXx/ApproachingAnyMachineLearning/blob/main/01.%20Supervised%20Unsupervised%20Learning/Supervised%20Unsupervised.ipynb)
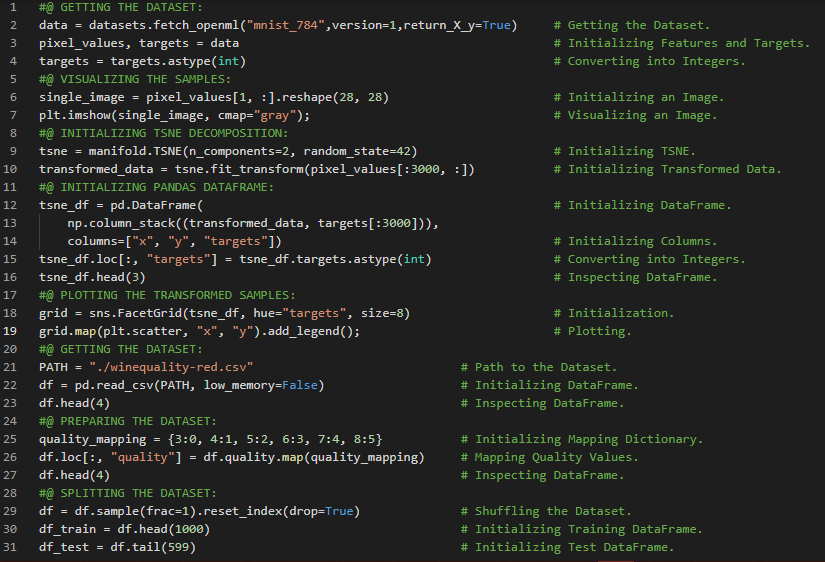
300天数据之旅第283天!
- 交叉验证:交叉验证是构建机器学习模型过程中的一个步骤,它帮助我们确保模型能够准确地拟合数据,同时避免过拟合。在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》一书的内容。在这里,我学习了决策树与分类、特征与参数、准确率与模型预测、过拟合与模型泛化、训练损失与验证损失、交叉验证等主题。我在截图中展示了决策树分类器和模型评估的实现。希望你能从中获得一些见解,并加以实践。我也希望你能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 【监督学习与无监督学习】(https://github.com/ThinamXx/ApproachingAnyMachineLearning/blob/main/01.%20Supervised%20Unsupervised%20Learning/Supervised%20Unsupervised.ipynb)
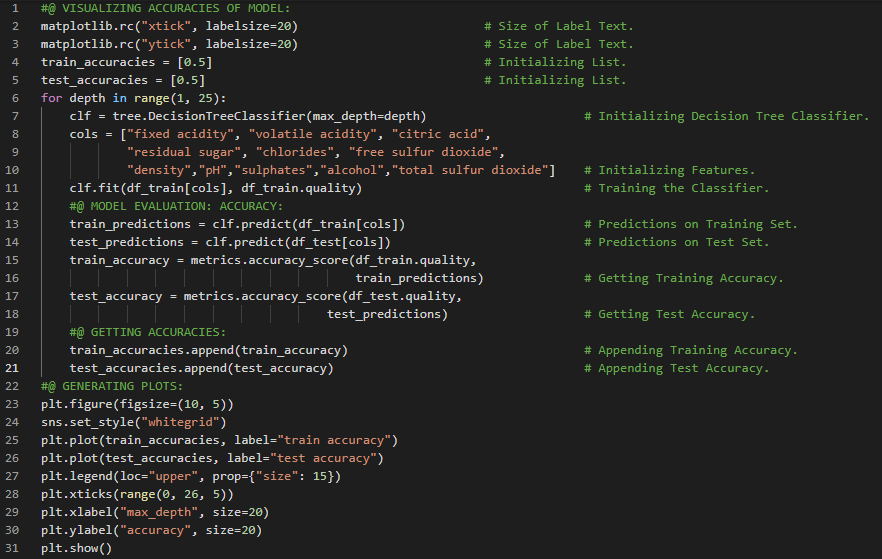
300天数据之旅第284天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》一书的内容。在这里,我学习了分层K折交叉验证、偏斜数据集与分类、数据分布、留出法交叉验证、时间序列数据、回归与斯特格斯法则、概率、评估指标与准确率等主题。我在截图中展示了标签分布与分层K折交叉验证的实现。希望你能从中获得一些见解,并加以实践。我也希望你能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 【监督学习与无监督学习】(https://github.com/ThinamXx/ApproachingAnyMachineLearning/blob/main/01.%20Supervised%20Unsupervised%20Learning/Supervised%20Unsupervised.ipynb)
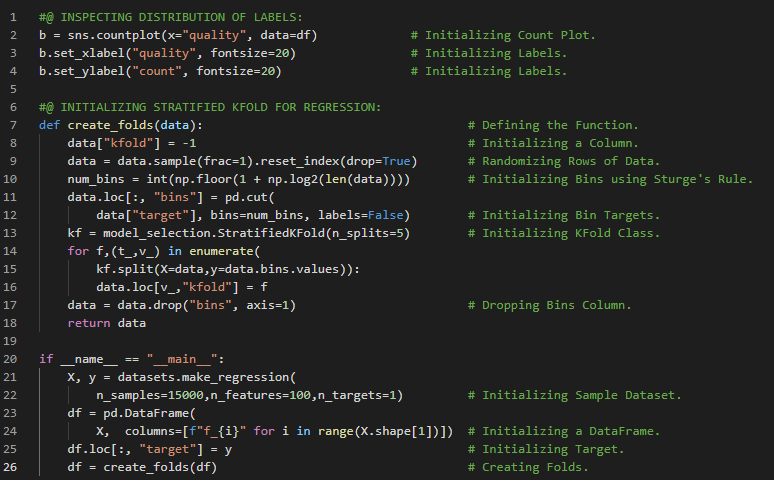
300天数据之旅第285天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》一书的内容。在这里,我学习了评估指标与准确率分数、训练集与验证集、精确率与召回率、真正例与真负例、假正例与假负例、二分类等主题。我在截图中展示了真负例、假负例、假正例以及准确率分数的实现。希望你能从中获得一些见解,并加以实践。我也希望你能花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 【评估指标】(https://github.com/ThinamXx/ApproachingAnyMachineLearning/blob/main/02.%20Evaluation%20Metrics/Evaluation%20Metrics.ipynb)
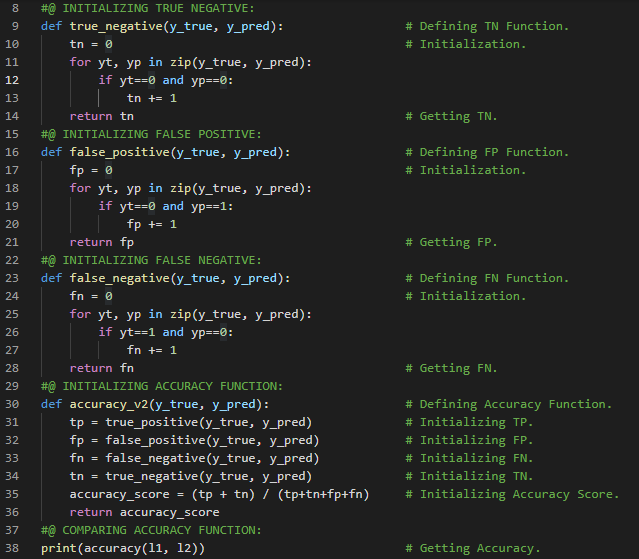
300天数据之旅第286天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》这本书的内容。在这里,我学习了真正例率、召回率与灵敏度、假正例率与特异性、ROC曲线下面积、预测、概率与阈值、对数损失函数、多分类以及宏平均精确率等主题。我在截图中展示了真负例率、假正例率、对数损失函数和宏平均精确率的实现。希望你能从中获得一些见解,并进一步深入研究。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 评估指标
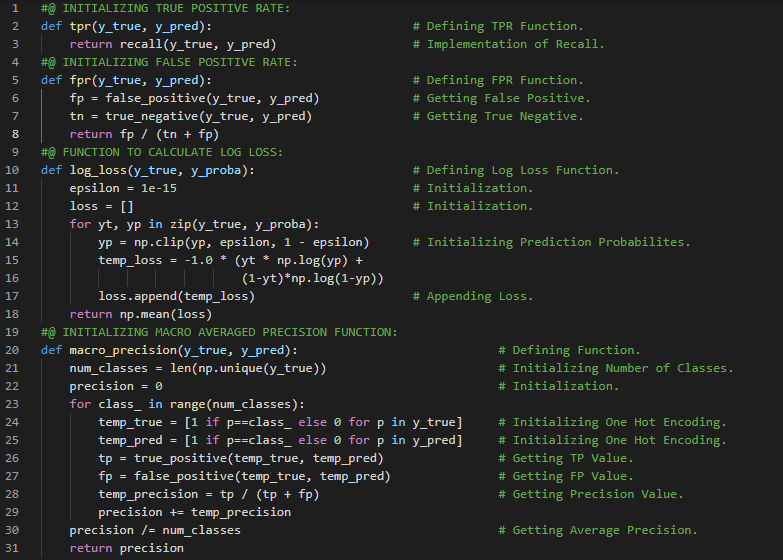
300天数据之旅第287天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》这本书的内容。在这里,我学习了多分类、宏平均精确率、微平均精确率、加权精确率、召回指标、随机森林回归器、均方误差、均方根误差等主题。我在截图中展示了微平均精确率和加权精确率的实现。希望你能从中获得一些见解,并继续探索。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 评估指标
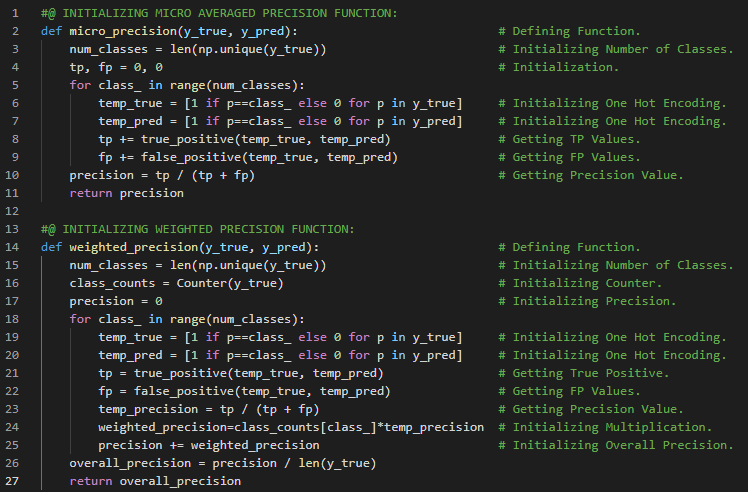
300天数据之旅第288天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》这本书的内容。在这里,我学习了多分类的召回指标、加权F1分数、混淆矩阵、第一类错误和第二类错误、AUC曲线、多标签分类以及平均精确度等主题。我在截图中展示了加权F1分数和平均精确率的实现。希望你能从中获得一些见解,并继续深入研究。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 评估指标
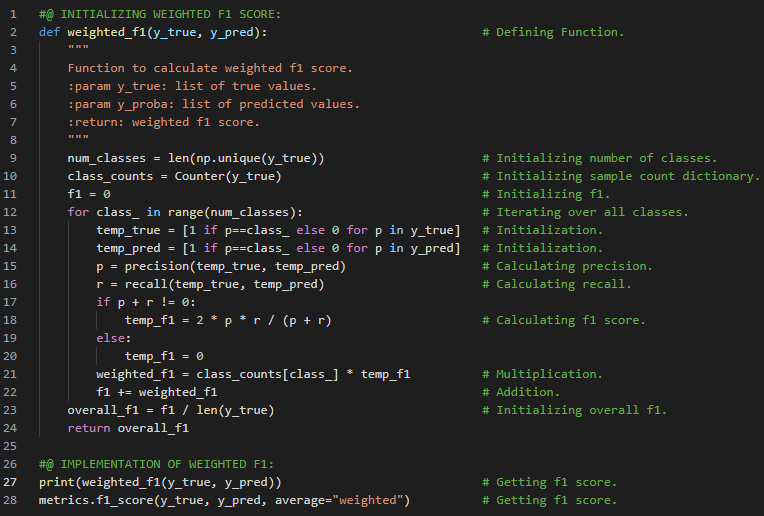
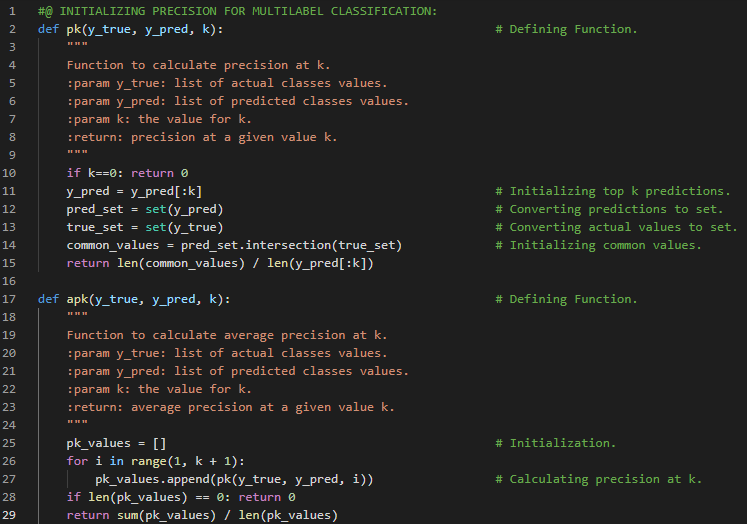
300天数据之旅第289天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《接近几乎任何机器学习问题》这本书的内容。在这里,我学习了回归评估指标,如平均绝对误差和平均误差、均方根误差、对数平方误差、平均绝对百分比误差、R²和决定系数、Cohen's Kappa评分、MCC评分等主题。我在截图中展示了平均绝对误差和平均误差、对数平方误差、平均绝对百分比误差、R²和MCC评分的实现。希望你能从中获得一些见解,并继续深入研究。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 书籍:
- 《使用Fastai和PyTorch的编码者深度学习》
- 评估指标
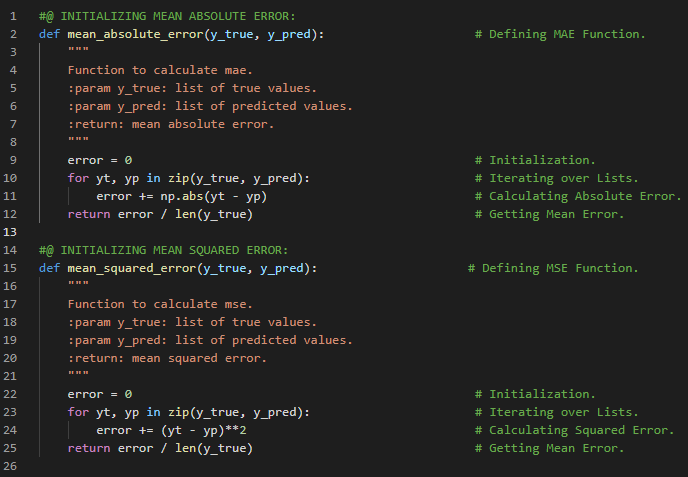
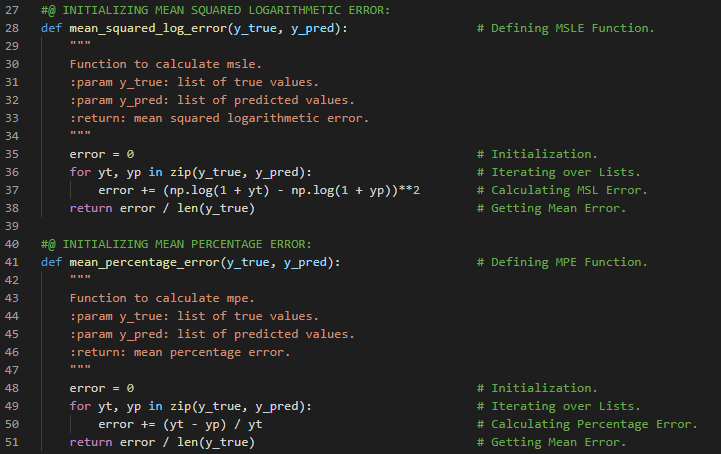
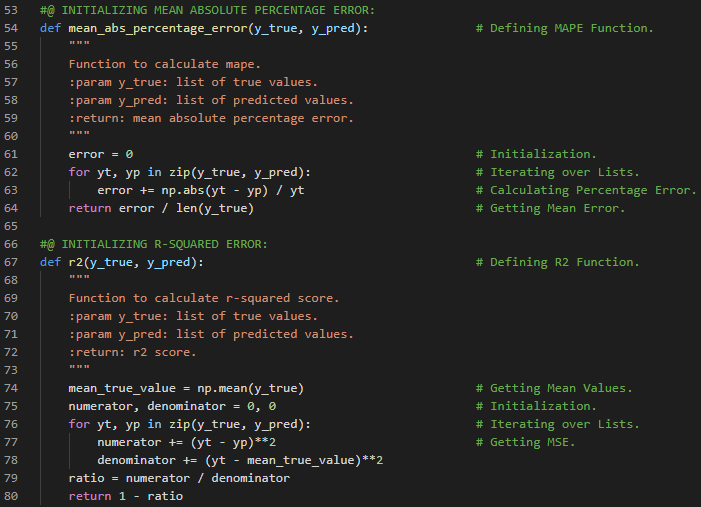
300天数据之旅第290天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了目标检测与微调、图像分割、张量与宽高比、数组、数据集和数据加载器等内容。我还开始学习Coursera上的“面向生产的机器学习工程”专项课程。在这里,我学习了机器学习项目的步骤与案例研究、机器学习项目生命周期等主题。我在截图中展示了数据集类的实现。希望你能从中获得一些见解,并继续深入研究。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 资源:
- 《面向生产的机器学习工程》
300天数据之旅第291天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客的内容。在这里,我学习了OpenCV、图像的加载与显示、像素访问、数组切片与裁剪、图像缩放与旋转、图像平滑、图像绘制等主题。此外,我还学习了Coursera“面向生产的机器学习工程”专项课程中的机器学习项目生命周期、部署模式和管道监控等内容。我在截图中展示了使用OpenCV进行图像缩放与旋转、图像平滑以及图像绘制的实现。希望你能从中获得一些见解,并继续深入研究。也建议你花些时间学习下方提到的书籍中的相关内容。对未来几天充满期待!!
- 资源:
- 《面向生产的机器学习工程》
- PyImageSearch
- OpenCV笔记本
300天数据之旅第292天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客中的内容。在这里,我学习了OpenCV、物体计数、图像灰度化、边缘检测、阈值分割、轮廓检测与绘制、腐蚀与膨胀、掩码与位运算等主题。此外,我还阅读了Coursera“面向生产的机器学习工程”专项课程中的建模概述、关键挑战以及低平均误差等内容。在截图中,我展示了使用OpenCV实现的图像灰度化、边缘检测、阈值分割、轮廓检测与绘制、腐蚀与膨胀等操作。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 资源:
- 面向生产的机器学习工程
- PyImageSearch
- OpenCV笔记本
300天数据之旅第293天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客中的内容。在这里,我学习了OpenCV、图像旋转、图像预处理、旋转矩阵与中心坐标、图像解析、边缘检测与轮廓检测、图像掩码与模糊处理等主题。此外,我还阅读了Coursera“面向生产的机器学习工程”专项课程中的基准模型、模型选择与训练、误差分析与优先级排序等内容。在截图中,我展示了使用OpenCV实现的图像旋转以及获取图像感兴趣区域的操作。希望你能从中获得一些 insights,并进一步实践。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 资源:
- 面向生产的机器学习工程
- PyImageSearch
- OpenCV项目I
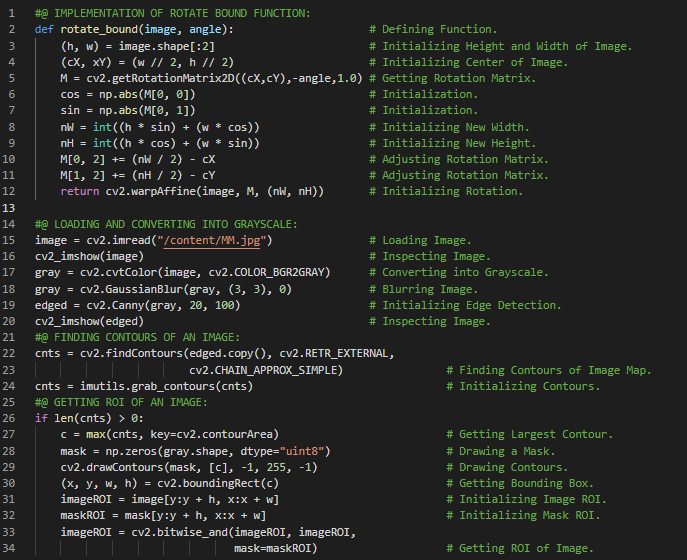
300天数据之旅第294天!
- 直方图匹配:直方图匹配可以作为一种归一化技术,用于图像处理流水线中进行颜色校正和颜色匹配,从而在光照条件变化时仍能获得一致且归一化的图像表示。在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客中的内容。在这里,我学习了OpenCV、颜色检测、RGB色彩空间、直方图匹配、像素分布、累积分布、图像缩放等主题。此外,我还阅读了Coursera“面向生产的机器学习工程”专项课程中的偏斜数据集、性能审计、以数据为中心的人工智能开发以及数据增强等内容。在截图中,我展示了使用OpenCV实现的直方图匹配操作。希望你能从中获得一些 insights,并加以实践。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 资源:
- 面向生产的机器学习工程
- PyImageSearch
- OpenCV项目II
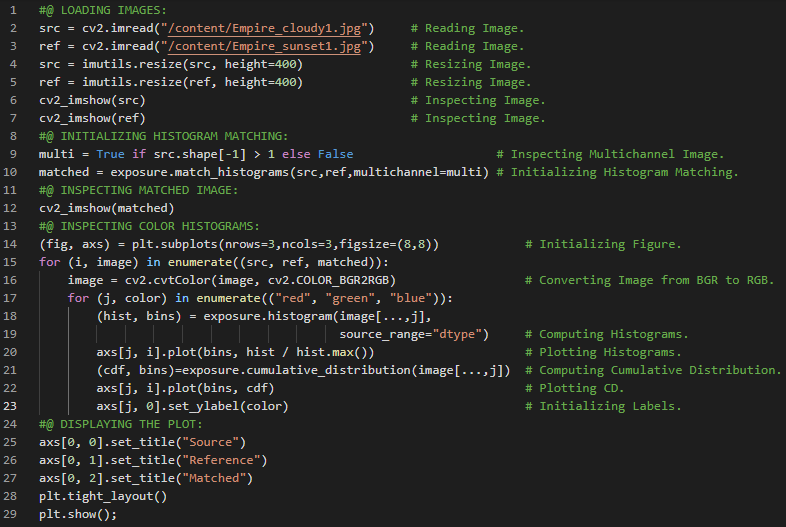
300天数据之旅第295天!
- 直方图匹配:直方图匹配可以作为一种归一化技术,用于图像处理流水线中进行颜色校正和颜色匹配,从而在光照条件变化时仍能获得一致且归一化的图像表示。在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客中的内容。在这里,我学习了卷积神经网络、卷积矩阵、卷积核、空间维度、填充、图像感兴趣区域、逐元素乘法与加法、强度重缩放、拉普拉斯核、模糊检测与平滑处理等主题。在截图中,我展示了卷积方法的实现以及卷积核的构建过程。希望你能从中获得一些 insights,并继续深入研究。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 资源:
- 面向生产的机器学习工程
- PyImageSearch
- 卷积
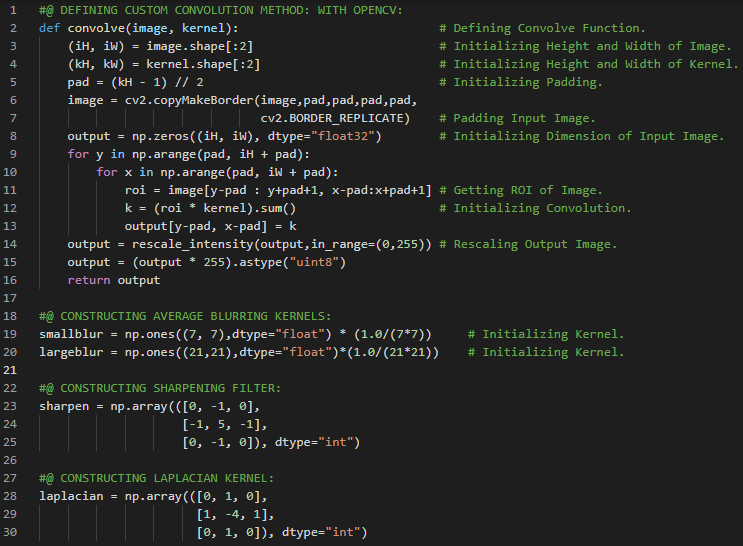
300天数据之旅第296天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客中的内容。在这里,我学习了卷积层、滤波器与卷积核大小、步幅、填充、输入数据格式、扩张率、激活函数、权重与偏置、卷积核与偏置的初始化与正则化、泛化与过拟合、卷积核与偏置的约束、加州理工学院数据集、带步幅的网络等主题。在截图中,我展示了带步幅的网络的实现。希望你能从中获得一些 insights,并继续探索。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 资源:
- 面向生产的机器学习工程
- PyImageSearch
- 卷积层
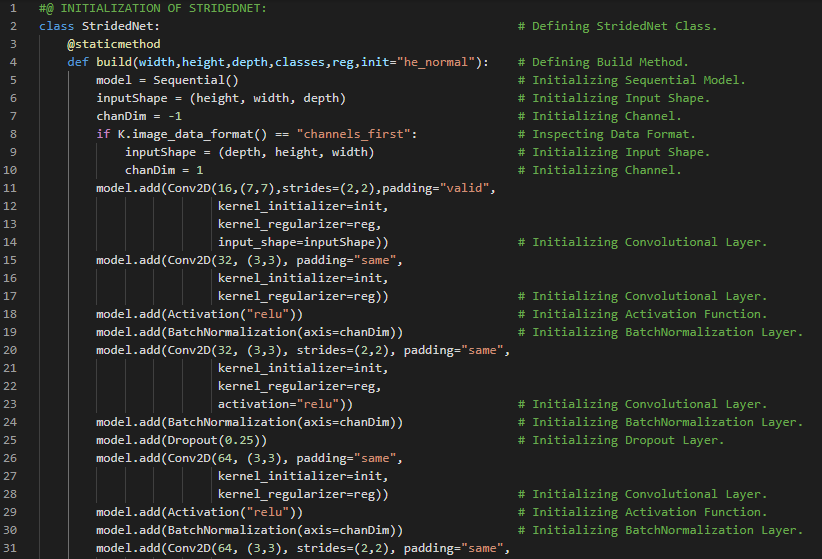
300天数据之旅第297天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客中的内容。在这里,我学习了卷积神经网络架构、步幅网络、标签二值化与独热编码、图像数据生成器与数据增强、图像加载与调整大小等主题。我在截图中展示了标签二值化和数据集准备的实现过程。希望你能从中获得一些启发,并加以实践。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 资源:
- 生产环境中的机器学习工程
- PyImageSearch
- 卷积层
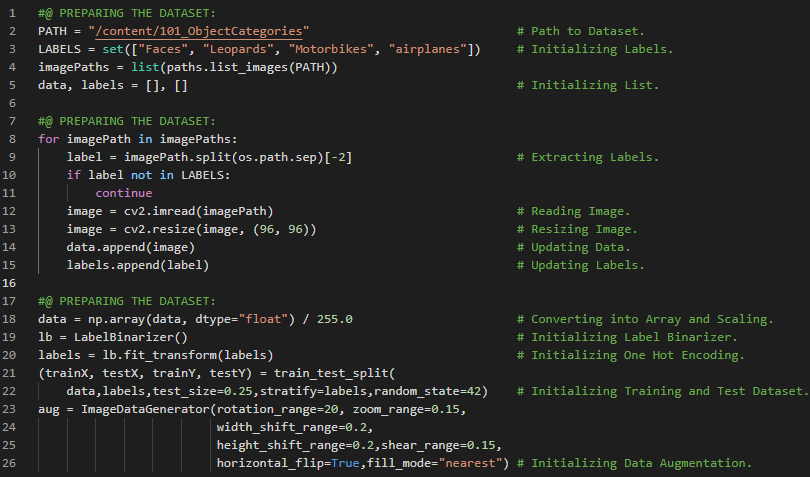
300天数据之旅第298天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了PyImageSearch博客中的内容。在这里,我学习了卷积神经网络、Adam优化函数、编译与训练步幅网络模型、数据增强与图像数据生成器、分类报告、绘制训练损失与准确率曲线、过拟合与泛化等主题。我在截图中展示了模型编译与训练、分类报告以及训练损失和准确率的实现过程。希望你能从中获得一些见解,并进一步实践。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 资源:
- 生产环境中的机器学习工程
- PyImageSearch
- 卷积层
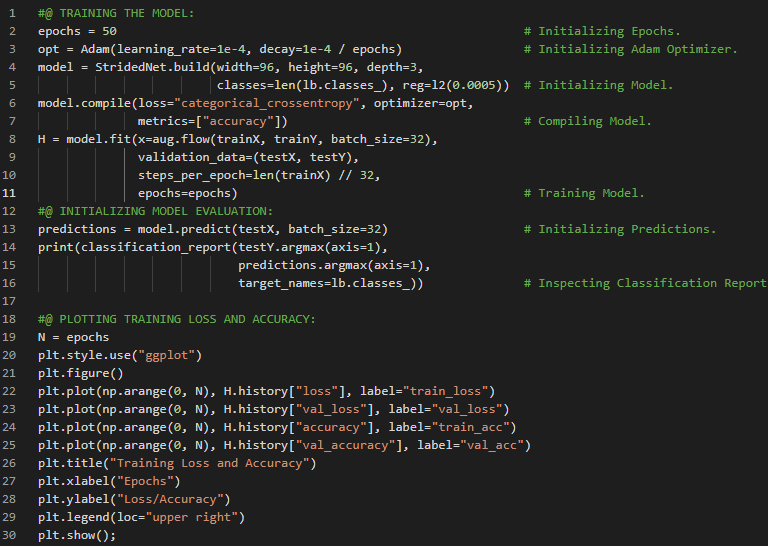
300天数据之旅第299天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了Transformer模型、GPT-2预训练模型与分词器、编码与解码方法、数据集准备、Transform方法、数据加载器等主题。我在截图中展示了使用Fastai和PyTorch实现的预训练GPT-2模型与分词器,以及转换后的数据加载器。希望你能从中获得一些启发,并继续深入学习。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 使用Fastai和PyTorch进行编码的深度学习
- Transformer
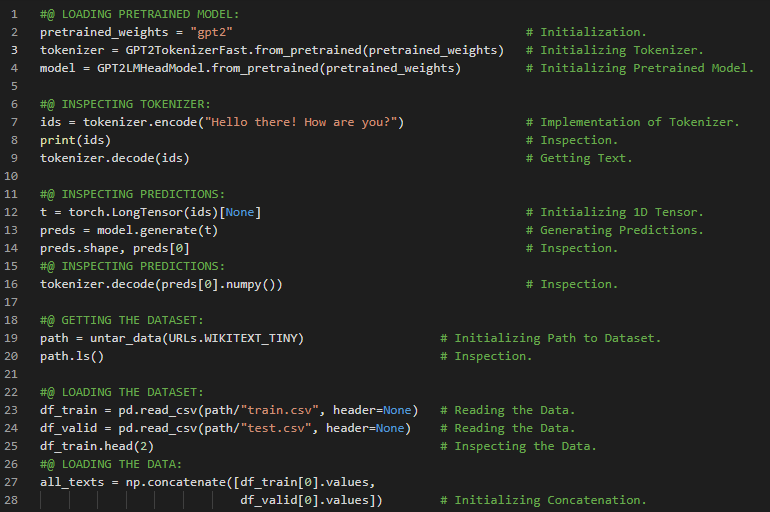
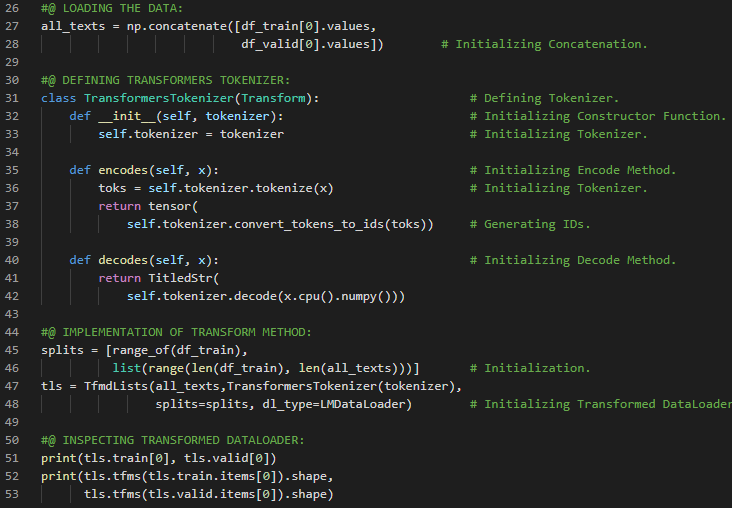
300天数据之旅第300天!
- 在我的机器学习和深度学习之旅中,我阅读并实践了《使用Fastai和PyTorch进行编码的深度学习》一书的内容。在这里,我学习了Transformer模型、数据加载器、批次大小与序列长度、语言模型、GPT-2模型的微调、回调函数、学习者对象、困惑度与交叉熵损失函数、学习率查找器、训练与生成预测等内容。我在截图中展示了使用Fastai和PyTorch初始化数据加载器、微调GPT-2模型以及使用学习率查找器的过程。希望你能从中获得一些见解,并继续深入学习。同时,也建议你花些时间学习下方提到的书籍中的相关内容。对接下来的日子充满期待!!
- 书籍:
- 使用Fastai和PyTorch进行编码的深度学习
- Transformer
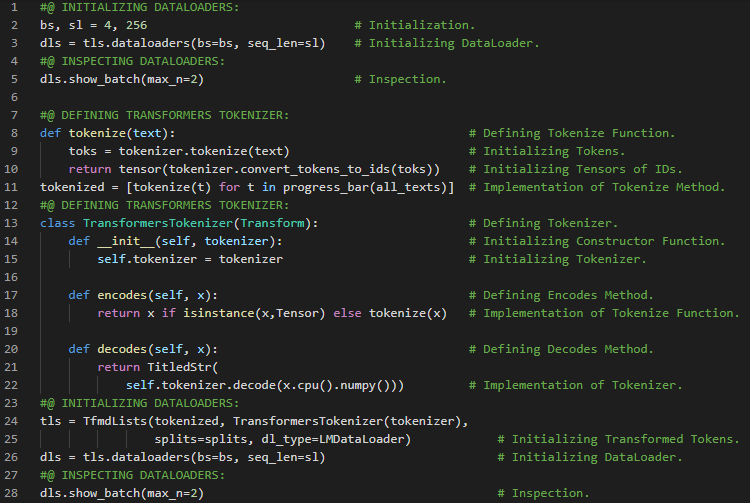
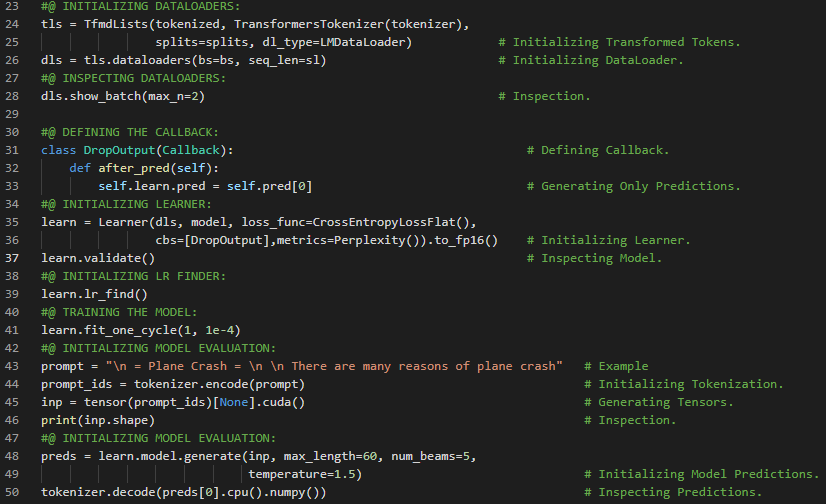
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备