HunyuanDiT
HunyuanDiT 是腾讯开源的一款强大文生图模型,基于多分辨率扩散 Transformer 架构打造。它核心解决了传统 AI 绘画工具在理解复杂中文提示词时不够精准、生成高分辨率图像细节模糊的痛点,能够实现对中文语义的细粒度理解,从而生成更符合用户意图的高质量图像。
这款工具特别适合研究人员探索扩散模型前沿技术,开发者进行二次开发或集成应用,以及设计师和创作者用于实际工作流中快速产出视觉素材。得益于其对中文语境的自然掌握,国内用户无需刻意转换思维即可轻松上手。
HunyuanDiT 的技术亮点在于其独特的多分辨率训练策略,既保证了生成效率又提升了画面细节表现力。此外,它生态完善,不仅原生支持 LoRA 微调和 ControlNet 精确控制,还兼容 ComfyUI、Diffusers 等主流框架,甚至提供了针对低显存显卡的优化方案,让不同配置的用户都能流畅体验先进的 AI 创作能力。
使用场景
某电商公司的设计团队需要为“双十一”大促快速生成大量包含特定中文成语、古诗词或复杂文化元素的商品宣传海报,以迎合国内消费者的审美偏好。
没有 HunyuanDiT 时
- 中文语义理解偏差:使用国外主流模型时,输入“龙腾虎跃”或“水墨山水”等具有深厚文化底蕴的提示词,生成的图像往往只体现字面意思(如真的画一条龙和老虎在跳),缺乏意境和神韵。
- 文字渲染乱码:试图让模型直接在图中生成中文标语时,输出结果多为无法识别的伪汉字或乱码,设计师必须后期手动 PS 添加文字,效率极低。
- 多分辨率适配困难:为了适配手机竖屏、PC 横屏及户外大屏等不同渠道,需要针对不同分辨率反复调整参数或裁剪图片,导致主体构图经常崩坏或细节丢失。
- 细粒度控制缺失:难以精准控制画面中多个中文元素的相对位置和交互关系,修改一次需求往往需要重新生成数十张图才能碰巧得到一张可用的。
使用 HunyuanDiT 后
- 深度中文语境还原:HunyuanDiT 凭借细粒度的中文理解能力,能准确捕捉“留白”、“气韵生动”等抽象概念,生成的画面完美契合中国传统美学风格。
- 原生中文文本支持:直接输入中文标语即可在图中生成清晰、正确的汉字,大幅减少了后期排版和修图的工作量,实现了从提示词到成图的一站式产出。
- 灵活的多分辨率生成:利用其强大的多分辨率 Diffusion Transformer 架构,同一套提示词可直接生成任意比例的高质量图像,且主体结构和细节始终保持一致。
- 精准的细节操控:通过自然语言即可精确描述物体间的空间关系(如“灯笼挂在屋檐左下角”),显著提升了首图可用率,将单张海报的平均制作时间从 30 分钟缩短至 5 分钟。
HunyuanDiT 通过突破性的中文语义理解与多分辨率生成技术,彻底解决了本土化创意内容生产中“懂中文难、出图慢、控图弱”的核心痛点。
运行环境要求
- Linux
- 需要 NVIDIA GPU
- 标准推理未明确最低显存,但提供 6GB 显存优化脚本
- 训练及高性能推理建议更高显存
- 支持 CUDA 11 和 CUDA 12(官方提供对应 Docker 环境)
- V100 显卡需使用 scaled attention 替代 flash attention
未说明

快速开始

Hunyuan-DiT:一款具备细粒度中文理解能力的强大多分辨率扩散Transformer







本仓库包含我们探索Hunyuan-DiT的论文所用的PyTorch模型定义、预训练权重以及推理/采样代码。您可以在我们的项目页面上找到更多可视化内容。
🔥🔥🔥 最新消息!!
- 2024年12月17日::tada: 使用“精炼梯度检查点”和“低比特优化器”优化LoRA训练。只需使用
--lowbit-opt即可开始。 - 2024年9月13日:🎉 IPAdapter已正式被HunYuanDiT支持。相关文档请参见./ipadapter。同时,在V100 GPU上,已采用缩放注意力机制替代Flash Attention。
- 2024年8月26日,🎉 HunYuanDIT Controlnet和LoRA已正式被ComfyUI支持。相关文档请参见./comfyui。
- 2024年7月15日:🚀 HunYuanDiT与Shakker.Ai联合推出了基于HunYuanDiT 1.2模型的微调活动。通过发布基于HunYuanDiT的LoRA或微调模型,您最高可获得来自Shakker.Ai的230美元奖励。详情请参见Shakker.Ai。
- 2024年7月15日::tada: 更新ComfyUI以支持标准化工作流,并兼容t2i模块权重及1.1/1.2版本的LoRA训练权重,还包括由Kohya或官方脚本训练的权重。
- 2024年7月15日::zap: 我们提供适用于CUDA 11/12的Docker环境,让您无需复杂安装,一键即可体验!详情请参见dockers。
- 2024年7月8日::tada: HYDiT-v1.2版本发布。请查看HunyuanDiT-v1.2和Distillation-v1.2以获取更多详细信息。
- 2024年7月3日::tada: Kohya-hydit版本现已适用于v1.1和v1.2模型,并提供GUI进行推理。官方Kohya版本正在审核中。详情请参见kohya。
- 2024年6月27日::art: Hunyuan-Captioner发布,为训练数据提供细粒度描述。详情请参见mllm。
- 2024年6月27日::tada: 在diffusers中支持LoRa和ControlNet。详情请参见diffusers。
- 2024年6月27日::tada: 发布了适用于6GB显存GPU的推理脚本。详情请参见lite。
- 2024年6月19日::tada: ControlNet发布,支持Canny、姿态和深度控制。详情请参见训练/推理代码。
- 2024年6月13日::zap: HYDiT-v1.1版本发布,该版本缓解了图像过度饱和的问题,并减轻了水印问题。请查看HunyuanDiT-v1.1和Distillation-v1.1以获取更多信息。
- 2024年6月13日::truck: 训练代码发布,提供全参数训练和LoRA训练。
- 2024年6月6日::tada: Hunyuan-DiT现已可在ComfyUI中使用。详情请参见ComfyUI。
- 2024年6月6日:🚀 我们推出了Hunyuan-DiT加速版——Distillation,可在NVIDIA GPU上实现**50%**的加速效果。详情请参见Distillation。
- 2024年6月5日:🤗 Hunyuan-DiT现已在🤗 Diffusers中可用!请参见下方的示例。
- 2024年6月4日::globe_with_meridians: 支持通过腾讯云链接下载预训练模型!详情请参见下方的链接。
- 2024年5月22日:🚀 我们推出了Hunyuan-DiT的TensorRT版本,可在NVIDIA GPU上实现**47%**的加速效果。请参见TensorRT-libs获取使用说明。
- 2024年5月22日:💬 现在支持演示多轮文本生成图像的功能。请参见下方的脚本。
🤖 在网页上试用
欢迎来到我们的基于网页的腾讯Hunyuan机器人,在这里您可以探索我们的创新产品!只需输入以下建议提示,或任何其他包含绘画相关关键词的创意提示,即可激活Hunyuan文生图功能。尽情发挥您的创造力,绘制任何您想要的画面,全部免费!
您可以使用类似自然语言的简单提示:
画一只穿着西装的猪
draw a pig in a suit
生成一幅画,赛博朋克风,跑车
generate a painting, cyberpunk style, sports car
或者通过多轮语言交互来创作图片:
画一个木制的鸟
draw a wooden bird
变成玻璃的
turn into glass
🤗 社区贡献排行榜
由 @TTPlanetPig 贡献
- HunyuanDIT_v1.2 ControlNet 模型
- HunyuanDIT_v1.2 ComfyUI 节点
- Comfyui_TTP_CN_Preprocessor:https://github.com/TTPlanetPig/Comfyui_TTP_CN_Preprocessor
- Comfyui_TTP_Toolset:https://github.com/TTPlanetPig/Comfyui_TTP_Toolset
-
- Kohya_ss-hydit 训练工具:https://github.com/zml-ai/HunyuanDIT-PRE/tree/main/kohya_ss-hydit
由 @CrazyBoyM(B站UP主 飞鸟白菜)贡献
- HunyuanDIT_v1.2 ControlNet 的 ComfyUI 支持:https://github.com/comfyanonymous/ComfyUI/pull/4245
由 @L_A_X 贡献
- 面向动漫的 HunyuanDIT_v1.2 基础模型
📑 开源计划
- Hunyuan-DiT(文本到图像模型)
- 推理
- 检查点
- 蒸馏版
- TensorRT 版
- 训练
- LoRA
- Controlnet(姿态、Canny、深度)
- 6GB 显存 GPU 推理
- IP-adapter
- Hunyuan-DiT-S 检查点(0.7B 模型)
- MLLM
- Hunyuan-Captioner(对原始图像-文本对进行重新标注)
- 推理
- Hunyuan-DialogGen(提示增强模型)
- 推理
- Hunyuan-Captioner(对原始图像-文本对进行重新标注)
- Web Demo(Gradio)
- 多轮 T2I Demo(Gradio)
- CLI Demo
- ComfyUI
- Diffusers
- Kohya
- WebUI
目录
- Hunyuan-DiT:一款具有细粒度中文理解能力的强大多分辨率扩散Transformer
摘要
我们提出了 Hunyuan-DiT,这是一种能够对英语和中文进行细粒度理解的文本到图像扩散Transformer。为了构建 Hunyuan-DiT,我们精心设计了 Transformer 结构、文本编码器和位置编码。此外,我们从零开始搭建了一整套数据流水线,用于更新和评估数据,以实现模型的迭代优化。为了实现细粒度的语言理解,我们训练了一个多模态大语言模型来优化图像的标题描述。最终,Hunyuan-DiT 能够与用户进行多轮多模态对话,根据上下文生成并不断优化图像。 通过我们精心设计的、由超过 50 名专业人类评估员参与的整体评估协议,Hunyuan-DiT 在中文到图像生成方面相较于其他开源模型树立了新的最先进水平。
🎉 Hunyuan-DiT 主要特性
中英双语 DiT 架构
Hunyuan-DiT 是一种在潜在空间中的扩散模型,如图所示。遵循潜在扩散模型的思路,我们使用一个预训练的变分自编码器(VAE)将图像压缩到低维潜在空间,并训练一个扩散模型来学习数据分布。我们的扩散模型采用 Transformer 参数化。为了编码文本提示,我们结合使用了预训练的中英双语 CLIP 和多语言 T5 编码器。
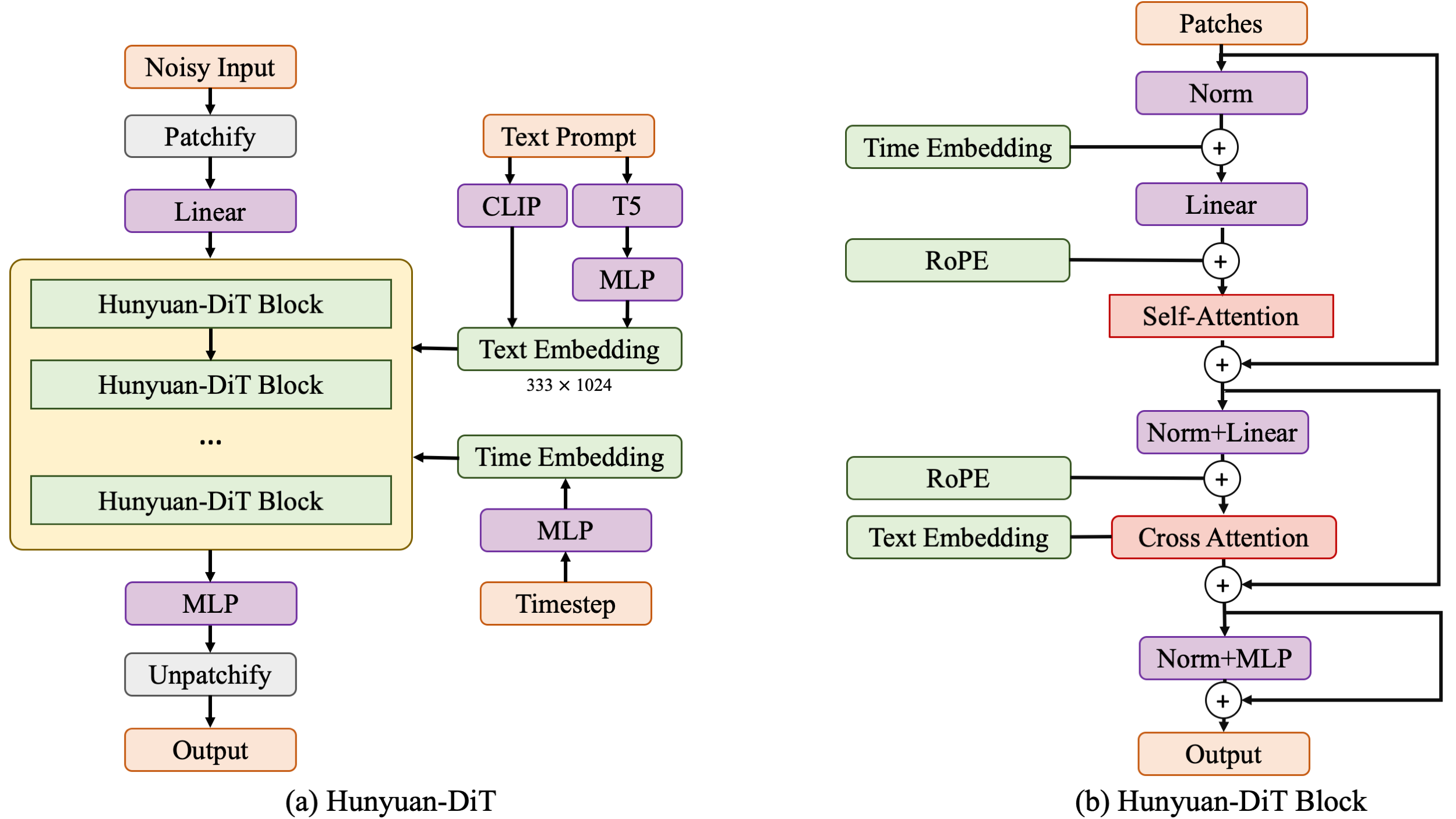
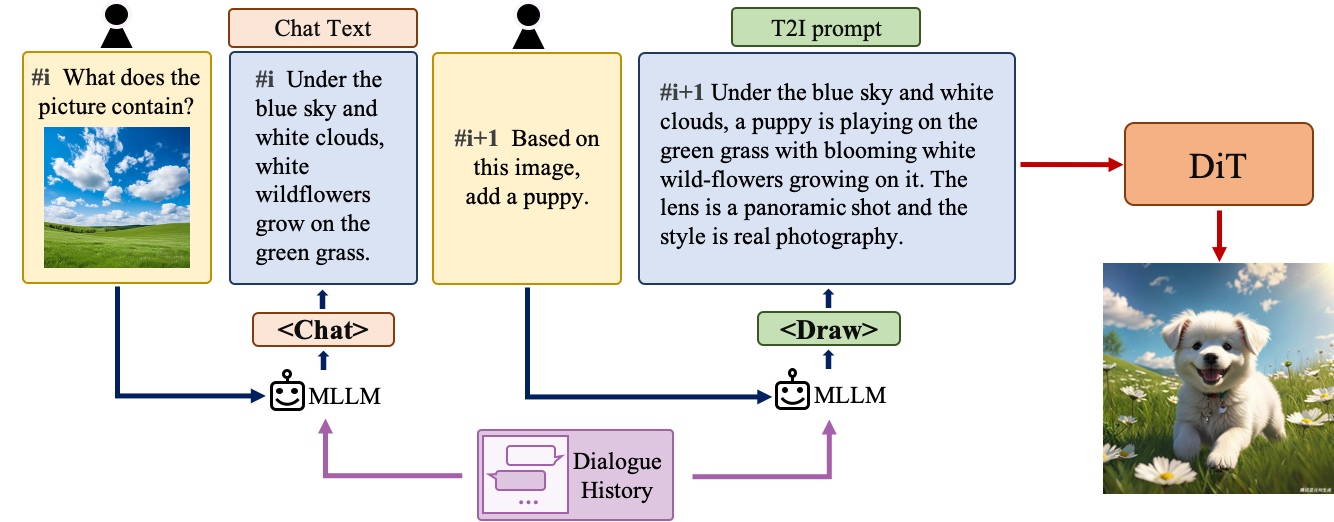
多轮文本到图像生成
理解自然语言指令并进行多轮交互对于文本到图像系统至关重要。这有助于构建一个动态且迭代的创作过程,逐步将用户的想法变为现实。在这一部分,我们将详细介绍我们如何赋予 Hunyuan-DiT 多轮对话和图像生成的能力。我们训练 MLLM 来理解用户的多轮对话,并输出用于图像生成的新文本提示。
📈 比较
为了全面比较 HunyuanDiT 与其他模型的生成能力,我们构建了一个包含文本与图像一致性、是否排除 AI 伪影、主体清晰度和美学四个维度的测试集。共有50多位专业评估者参与了此次评估。
| 模型 | 开源 | 文本与图像一致性 (%) | 是否排除 AI 伪影 (%) | 主体清晰度 (%) | 美学 (%) | 综合 (%) |
|---|---|---|---|---|---|---|
| SDXL | ✔ | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 |
| PixArt-α | ✔ | 68.3 | 60.9 | 93.2 | 77.5 | 45.5 |
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 |
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 |
| MidJourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 |
| DALL-E 3 | ✘ | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 |
| Hunyuan-DiT | ✔ | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 |
🎥 可视化
- 中国元素

- 长文本输入

- 多轮 Text2Image 生成
https://github.com/Tencent/tencent.github.io/assets/27557933/94b4dcc3-104d-44e1-8bb2-dc55108763d1
📜 系统要求
本仓库包含 DialogGen(提示增强模型)和 Hunyuan-DiT(文本到图像模型)。
下表展示了运行这些模型所需的硬件配置(批量大小 = 1):
| 模型 | --load-4bit (DialogGen) | GPU 峰值内存 | GPU |
|---|---|---|---|
| DialogGen + Hunyuan-DiT | ✘ | 32G | A100 |
| DialogGen + Hunyuan-DiT | ✔ | 22G | A100 |
| Hunyuan-DiT | - | 11G | A100 |
| Hunyuan-DiT | - | 14G | RTX3090/RTX4090 |
- 需要支持 CUDA 的 NVIDIA 显卡。
- 我们已测试过 V100 和 A100 显卡。
- 最低要求:显存至少需要 11GB。
- 推荐:为获得更好的生成效果,建议使用 32GB 显存的显卡。
- 测试过的操作系统:Linux
🛠️ 依赖与安装
首先克隆仓库:
git clone https://github.com/tencent/HunyuanDiT
cd HunyuanDiT
Linux 安装指南
我们提供了一个 environment.yml 文件来设置 Conda 环境。
Conda 的安装说明请参见 这里。
推荐使用 CUDA 11.7 和 12.0 及以上版本。
# 1. 准备 Conda 环境
conda env create -f environment.yml
# 2. 激活环境
conda activate HunyuanDiT
# 3. 安装 pip 依赖
python -m pip install -r requirements.txt
# 4. 安装 flash attention v2 以加速(需 CUDA 11.6 或以上)
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.1.2.post3
此外,您也可以使用 Docker 来设置环境。
# 1. 使用以下链接下载 Docker 镜像 tar 文件。
# 对于 CUDA 12
wget https://dit.hunyuan.tencent.com/download/HunyuanDiT/hunyuan_dit_cu12.tar
# 对于 CUDA 11
wget https://dit.hunyuan.tencent.com/download/HunyuanDiT/hunyuan_dit_cu11.tar
# 2. 导入 Docker tar 文件并查看镜像元信息
# 对于 CUDA 12
docker load -i hunyuan_dit_cu12.tar
# 对于 CUDA 11
docker load -i hunyuan_dit_cu11.tar
docker image ls
# 3. 根据镜像运行容器
docker run -dit --gpus all --init --net=host --uts=host --ipc=host --name hunyuandit --security-opt=seccomp=unconfined --ulimit=stack=67108864 --ulimit=memlock=-1 --privileged docker_image_tag
🧱 下载预训练模型
要下载模型,首先需要安装 huggingface-cli。(详细说明请参见 这里。)
python -m pip install "huggingface_hub[cli]"
然后使用以下命令下载模型:
# 创建一个名为 'ckpts' 的目录,用于保存模型,这是运行演示的前提条件。
mkdir ckpts
# 使用 huggingface-cli 工具下载模型。
# 下载时间可能因网络状况而异,从10分钟到1小时不等。
huggingface-cli download Tencent-Hunyuan/HunyuanDiT-v1.2 --local-dir ./ckpts
💡使用 huggingface-cli 的提示(网络问题)
1. 使用 HF 镜像
如果在中国境内遇到下载速度较慢的情况,可以尝试使用镜像来加快下载速度。例如:
HF_ENDPOINT=https://hf-mirror.com huggingface-cli download Tencent-Hunyuan/HunyuanDiT-v1.2 --local-dir ./ckpts
2. 断点续传
huggingface-cli 支持断点续传功能。如果下载过程中断,只需重新运行下载命令即可继续完成下载。
注意:如果在下载过程中出现类似 No such file or directory: 'ckpts/.huggingface/.gitignore.lock' 的错误,可以忽略该错误并重新运行下载命令。
所有模型都会自动下载。有关该模型的更多信息,请访问 Hugging Face 仓库 这里。
| 模型 | 参数量 | Hugging Face 下载地址 | 腾讯云 下载地址 |
|---|---|---|---|
| mT5 | 1.6B | mT5 | mT5 |
| CLIP | 350M | CLIP | CLIP |
| Tokenizer | - | Tokenizer | Tokenizer |
| DialogGen | 7.0B | DialogGen | DialogGen |
| sdxl-vae-fp16-fix | 83M | sdxl-vae-fp16-fix | sdxl-vae-fp16-fix |
| Hunyuan-DiT-v1.0 | 1.5B | Hunyuan-DiT | Hunyuan-DiT-v1.0 |
| Hunyuan-DiT-v1.1 | 1.5B | Hunyuan-DiT-v1.1 | Hunyuan-DiT-v1.1 |
| Hunyuan-DiT-v1.2 | 1.5B | Hunyuan-DiT-v1.2 | Hunyuan-DiT-v1.2 |
| Data demo | - | - | Data demo |
:truck: 训练
数据准备
请参考以下命令准备训练数据。
- 安装依赖
我们提供了一个高效的数据管理库 IndexKits,支持在训练过程中管理数亿条数据,更多信息请参见 文档。
# 1 安装依赖
cd HunyuanDiT
pip install -e ./IndexKits
- 数据下载
您可以自由下载 数据示例。
# 2 数据下载
wget -O ./dataset/data_demo.zip https://dit.hunyuan.tencent.com/download/HunyuanDiT/data_demo.zip
unzip ./dataset/data_demo.zip -d ./dataset
mkdir ./dataset/porcelain/arrows ./dataset/porcelain/jsons
- 数据转换
为训练数据创建一个 CSV 文件,字段如下表所示。
| 字段 | 必需 | 描述 | 示例 |
|---|---|---|---|
image_path |
必需 | 图像路径 | ./dataset/porcelain/images/0.png |
text_zh |
必需 | 文本 | 青花瓷风格,一只蓝色的鸟儿站在蓝色的花瓶上,周围点缀着白色花朵,背景是白色 |
md5 |
可选 | 图像 MD5(消息摘要算法 5) | d41d8cd98f00b204e9800998ecf8427e |
width |
可选 | 图像宽度 | 1024 |
height |
可选 | 图像高度 | 1024 |
⚠️ 可选字段如 MD5、宽度和高度可以省略。如果省略,下面的脚本会自动计算它们。但在处理大规模训练数据时,这一过程可能会比较耗时。
我们使用 Arrow 作为训练数据格式,它提供了一种标准且高效的内存中数据表示方式。我们提供了一个转换脚本,用于将 CSV 文件转换为 Arrow 格式。
# 3 数据转换
python ./hydit/data_loader/csv2arrow.py ./dataset/porcelain/csvfile/image_text.csv ./dataset/porcelain/arrows 1
- 数据选择与配置文件创建
我们通过 YAML 文件来配置训练数据。在这些文件中,您可以设置标准的数据处理策略,例如过滤、复制、去重等操作。更多详情请参见 ./IndexKits。
有关示例文件,请参阅 文件。完整的参数配置文件请参见 文件。
- 使用 YAML 文件创建训练数据索引文件。
# 单分辨率数据准备
idk base -c dataset/yamls/porcelain.yaml -t dataset/porcelain/jsons/porcelain.json
# 多分辨率数据准备
idk multireso -c dataset/yamls/porcelain_mt.yaml -t dataset/porcelain/jsons/porcelain_mt.json
porcelain 数据集的目录结构如下:
cd ./dataset
porcelain
├──images/ (图像文件)
│ ├──0.png
│ ├──1.png
│ ├──......
├──csvfile/ (包含文本-图像对的 CSV 文件)
│ ├──image_text.csv
├──arrows/ (包含所有必要训练数据的 Arrow 文件)
│ ├──00000.arrow
│ ├──00001.arrow
│ ├──......
├──jsons/ (最终的训练数据索引文件,在训练时从 Arrow 文件中读取数据)
│ ├──porcelain.json
│ ├──porcelain_mt.json
全参数训练
要求:
- 最低要求是一张至少有 20GB 显存的 GPU,但我们建议使用约 30GB 显存的 GPU,以避免主机内存换出。
- 此外,我们鼓励用户利用多节点上的多张 GPU 来加速大规模数据集的训练。
注意:
- 个人用户也可以使用轻量级的 Kohya 模型,在约 16GB 显存的情况下对模型进行微调。目前,我们正努力进一步降低面向个人用户的工业级框架的显存占用。
- 如果您的 GPU 显存充足,请尝试移除
--cpu-offloading或--gradient-checkpointing,以减少时间开销。
对于分布式训练,您可以通过调整 --hostfile 和 --master_addr 等参数灵活控制 单节点 或 多节点 训练。更多详情请参见 链接。
# 单分辨率训练
PYTHONPATH=./ sh hydit/train.sh --index-file dataset/porcelain/jsons/porcelain.json
# 多分辨率训练
PYTHONPATH=./ sh hydit/train.sh --index-file dataset/porcelain/jsons/porcelain_mt.json --multireso --reso-step 64
# 使用旧版本 HunyuanDiT(<= v1.1)进行训练
PYTHONPATH=./ sh hydit/train_v1.1.sh --index-file dataset/porcelain/jsons/porcelain.json
保存检查点后,您可以使用以下命令评估模型。
# 推理
# 请将 'log_EXP/xxx/checkpoints/final.pt' 替换为您实际的路径。
python sample_t2i.py --infer-mode fa --prompt "青花瓷风格,一只可爱的哈士奇" --no-enhance --dit-weight log_EXP/xxx/checkpoints/final.pt --load-key module
# 旧版本 HunyuanDiT(<= v1.1)
# 请将 'log_EXP/xxx/checkpoints/final.pt' 替换为您实际的路径。
python sample_t2i.py --infer-mode fa --prompt "青花瓷风格,一只可爱的哈士奇" --model-root ./HunyuanDiT-v1.1 --use-style-cond --size-cond 1024 1024 --beta-end 0.03 --no-enhance --dit-weight log_EXP/xxx/checkpoints/final.pt --load-key module
LoRA
我们提供了LoRA的训练和推理脚本,详细说明请参阅./lora。
# 训练瓷器风格的LoRA。
PYTHONPATH=./ sh lora/train_lora_with_fa.sh --index-file dataset/porcelain/jsons/porcelain.json
# 使用训练好的LoRA权重进行推理。
python sample_t2i.py --infer-mode fa --prompt "青花瓷风格,一只小狗" --no-enhance --lora-ckpt log_EXP/001-lora_porcelain_ema_rank64/checkpoints/0001000.pt
如果无法安装flash_attn,可以使用以下代码:
# 训练瓷器风格的LoRA。
PYTHONPATH=./ sh lora/train_lora.sh --index-file dataset/porcelain/jsons/porcelain.json
# 使用训练好的LoRA权重进行推理。
python sample_t2i.py --infer-mode torch --prompt "青花瓷风格,一只小狗" --no-enhance --lora-ckpt log_EXP/001-lora_porcelain_ema_rank64/checkpoints/0001000.pt
我们提供了两种训练好的LoRA权重,分别适用于“瓷器”和“玉石”风格,详情请见Hugging Face链接。
cd HunyuanDiT
# 使用huggingface-cli工具下载模型。
huggingface-cli download Tencent-Hunyuan/HYDiT-LoRA --local-dir ./ckpts/t2i/lora
# 快速入门
python sample_t2i.py --infer-mode fa --prompt "青花瓷风格,一只猫在追蝴蝶" --no-enhance --load-key ema --lora-ckpt ./ckpts/t2i/lora/porcelain
| 训练数据示例 | |||
 |
 |
 |
 |
| 青花瓷风格,一只蓝色的鸟儿站在蓝色的花瓶上,周围点缀着白色花朵,背景是白色 (Porcelain style, a blue bird stands on a blue vase, surrounded by white flowers, with a white background. ) | 青花瓷风格,这是一幅蓝白相间的陶瓷盘子,上面描绘着一只狐狸和它的幼崽在森林中漫步,背景是白色 (Porcelain style, this is a blue and white ceramic plate depicting a fox and its cubs strolling in the forest, with a white background.) | 青花瓷风格,在黑色背景上,一只蓝色的狼站在蓝白相间的盘子上,周围是树木和月亮 (Porcelain style, on a black background, a blue wolf stands on a blue and white plate, surrounded by trees and the moon.) | 青花瓷风格,在蓝色背景上,一只蓝色蝴蝶和白色花朵被放置在中央 (Porcelain style, on a blue background, a blue butterfly and white flowers are placed in the center.) |
| 推理结果示例 | |||
 |
 |
 |
 |
| 青花瓷风格,苏州园林 (Porcelain style, Suzhou Gardens.) | 青花瓷风格,一朵荷花 (Porcelain style, a lotus flower.) | 青花瓷风格,一只羊(Porcelain style, a sheep.) | 青花瓷风格,一个女孩在雨中跳舞(Porcelain style, a girl dancing in the rain.) |
🔑 推理
6GB显存下的推理
基于huggingface/diffusers,现在可以在6GB以下显存的GPU上运行HunyuanDiT。我们在此提供快速入门的说明和演示。
6GB版本支持Nvidia Ampere架构系列显卡,如RTX 3070/3080/4080/4090、A100等。
您只需安装以下库即可:
pip install -U bitsandbytes
pip install git+https://github.com/huggingface/diffusers
pip install "torch>=2.7.1"
随后,您就可以直接在6GB以下显存的GPU上享受HunyuanDiT文生图之旅了!
以下是一个演示:
cd HunyuanDiT
# 快速入门
model_id=Tencent-Hunyuan/HunyuanDiT-v1.2-Diffusers-Distilled
prompt=一个宇航员在骑马
infer_steps=50
guidance_scale=6
python3 lite/inference.py ${model_id} ${prompt} ${infer_steps} ${guidance_scale}
更多细节请参阅./lite。
使用Gradio
在运行以下命令前,请确保已激活conda环境。
# 默认启动中文界面,并使用Flash Attention加速。
python app/hydit_app.py --infer-mode fa
# 使用特定端口和主机
python app/hydit_app.py --infer-mode fa --server_name 0.0.0.0 --server_port 443 --load-key distill
# 如果显存不足,可以关闭增强模型。
# 增强功能将在您不带`--no-enhance`标志重启应用后恢复可用。
python app/hydit_app.py --no-enhance --infer-mode fa
# 启动英文界面
python app/hydit_app.py --lang en --infer-mode fa
# 启动多轮文生图界面。
# 如果您的显存低于32GB,请使用`--load-4bit`启用4位量化,这至少需要22GB显存。
python app/multiTurnT2I_app.py --infer-mode fa
随后,您可以通过http://0.0.0.0:443访问演示页面。需要注意的是,这里的0.0.0.0应替换为您的服务器IP地址X.X.X.X。
使用🤗 Diffusers
请提前安装PyTorch 2.0或更高版本,以满足diffusers库指定版本的要求。
安装🤗 diffusers,确保版本不低于0.28.1:
pip install git+https://github.com/huggingface/diffusers.git
或者
pip install diffusers
您可以使用以下Python脚本生成中英文提示下的图像:
import torch
from diffusers import HunyuanDiTPipeline
pipe = HunyuanDiTPipeline.from_pretrained("Tencent-Hunyuan/HunyuanDiT-v1.2-Diffusers", torch_dtype=torch.float16)
pipe.to("cuda")
# 您也可以使用英文提示,因为HunyuanDiT同时支持中英文
# prompt = "An astronaut riding a horse"
prompt = "一个宇航员在骑马"
image = pipe(prompt).images[0]
您还可以使用我们的蒸馏模型更快地生成图像:
import torch
from diffusers import HunyuanDiTPipeline
pipe = HunyuanDiTPipeline.from_pretrained("Tencent-Hunyuan/HunyuanDiT-v1.2-Diffusers-Distilled", torch_dtype=torch.float16)
pipe.to("cuda")
# 您也可以使用英文提示,因为HunyuanDiT同时支持中英文
# prompt = "一个宇航员在骑马"
prompt = "一个宇航员在骑马"
image = pipe(prompt, num_inference_steps=25).images[0]
更多详情请参见 HunyuanDiT-v1.2-Diffusers-Distilled
更多功能: 关于 LoRA 和 ControlNet 等其他功能,请查看 ./diffusers 的 README 文件。
命令行使用
我们提供了几个快速入门的命令:
# 仅文本到图像。Flash Attention 模式
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚" --no-enhance
# 生成其他尺寸的图像。
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚" --image-size 1280 768
# 提示增强 + 文本到图像。DialogGen 使用 4 位量化加载,但可能会损失性能。
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚" --load-4bit
更多示例提示可在 example_prompts.txt 中找到。
更多配置
我们列出了一些更实用的配置,方便使用:
| 参数 | 默认值 | 说明 |
|---|---|---|
--prompt |
无 | 图像生成的文本提示 |
--image-size |
1024 1024 | 生成图像的尺寸 |
--seed |
42 | 图像生成的随机种子 |
--infer-steps |
100 | 采样步骤数 |
--negative |
- | 图像生成的负面提示 |
--infer-mode |
torch | 推理模式(torch、fa 或 trt) |
--sampler |
ddpm | 扩散采样器(ddpm、ddim 或 dpmms) |
--no-enhance |
False | 禁用提示增强模型 |
--model-root |
ckpts | 模型检查点的根目录 |
--load-key |
ema | 加载学生模型或 EMA 模型(ema 或 module) |
--load-4bit |
Fasle | 使用 4 位量化加载 DialogGen 模型 |
使用 ComfyUI
- 支持两种工作流:标准 ComfyUI 和 Diffusers 包装器,推荐使用前者。
- 支持 HunyuanDiT-v1.1 和 v1.2。
- 支持由 Kohya 训练的 module、lora 和 clip lora 模型。
- 支持由 HunyunDiT 官方训练脚本训练的 module、lora 模型。
- 支持 ControlNet。
更多详情请参见 ./comfyui
使用 Kohya
我们支持 kohya_ss GUI 的自定义代码,以及用于 HunyuanDiT 的 sd-scripts 训练代码。
 更多详情请参见 ./kohya_ss-hydit
更多详情请参见 ./kohya_ss-hydit
使用旧版本
- Hunyuan-DiT <= v1.1
# ============================== v1.1 ==============================
# 下载模型
huggingface-cli download Tencent-Hunyuan/HunyuanDiT-v1.1 --local-dir ./HunyuanDiT-v1.1
# 使用模型进行推理
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚" --model-root ./HunyuanDiT-v1.1 --use-style-cond --size-cond 1024 1024 --beta-end 0.03
# ============================== v1.0 ==============================
# 下载模型
huggingface-cli download Tencent-Hunyuan/HunyuanDiT --local-dir ./HunyuanDiT-v1.0
# 使用模型进行推理
python sample_t2i.py --infer-mode fa --prompt "渔舟唱晚" --model-root ./HunyuanDiT-v1.0 --use-style-cond --size-cond 1024 1024 --beta-end 0.03
:building_construction: 适配器
ControlNet
我们提供了 ControlNet 的训练脚本,详细信息请参阅 ./controlnet。
# 训练 Canny ControlNet。
PYTHONPATH=./ sh hydit/train_controlnet.sh
我们提供了三种类型的已训练 ControlNet 权重,分别对应 canny、depth 和 pose 模式,详情请见 链接:
cd HunyuanDiT
# 使用 huggingface-cli 工具下载模型。
# 我们建议在 ControlNet 推理时使用蒸馏权重作为基础模型,因为我们提供的预训练权重正是基于这些权重训练的。
huggingface-cli download Tencent-Hunyuan/HYDiT-ControlNet-v1.2 --local-dir ./ckpts/t2i/controlnet
huggingface-cli download Tencent-Hunyuan/Distillation-v1.2 ./pytorch_model_distill.pt --local-dir ./ckpts/t2i/model
# 快速入门
python3 sample_controlnet.py --infer-mode fa --no-enhance --load-key distill --infer-steps 50 --control-type canny --prompt "在夜晚的酒店门前,一座古老的中国风格的狮子雕像矗立着,它的眼睛闪烁着光芒,仿佛在守护着这座建筑。背景是夜晚的酒店前,构图方式是特写,平视,居中构图。这张照片呈现了真实摄影风格,蕴含了中国雕塑文化,同时展现了神秘氛围" --condition-image-path https://oss.gittoolsai.com/images/Tencent-Hunyuan_HunyuanDiT_readme_ebbf8f65c4e8.jpg --control-weight 1.0
| 条件输入 | ||
| Canny ControlNet | Depth ControlNet | Pose ControlNet |
| 在夜晚的酒店门前,一座古老的中国风格的狮子雕像矗立着,它的眼睛闪烁着光芒,仿佛在守护着这座建筑。背景是夜晚的酒店前,构图方式是特写,平视,居中构图。这张照片呈现了真实摄影风格,蕴含了中国雕塑文化,同时展现了神秘氛围 (At night, an ancient Chinese-style lion statue stands in front of the hotel, its eyes gleaming as if guarding the building. The background is the hotel entrance at night, with a close-up, eye-level, and centered composition. This photo presents a realistic photographic style, embodies Chinese sculpture culture, and reveals a mysterious atmosphere.) |
在茂密的森林中,一只黑白相间的熊猫静静地坐在绿树红花中,周围是山川和海洋。背景是白天的森林,光线充足。照片采用特写、平视和居中构图的方式,呈现出写实的效果 (In the dense forest, a black and white panda sits quietly among the green trees and red flowers, surrounded by mountains and oceans. The background is a daytime forest with ample light. The photo uses a close-up, eye-level, and centered composition to create a realistic effect.) |
在白天的森林中,一位穿着绿色上衣的亚洲女性站在大象旁边。照片采用了中景、平视和居中构图的方式,呈现出写实的效果。这张照片蕴含了人物摄影文化,并展现了宁静的氛围 (In the daytime forest, an Asian woman wearing a green shirt stands beside an elephant. The photo uses a medium shot, eye-level, and centered composition to create a realistic effect. This picture embodies the character photography culture and conveys a serene atmosphere.) |
 |
 |
 |
| ControlNet 输出 | ||
 |
 |
 |
IP-Adapter
我们提供了 IP-Adapter 的训练脚本,详细信息请参阅 ./ipadapter。
# 训练 IP-Adapter。
PYTHONPATH=./ sh hydit/train_ipadapter.sh
我们提供了训练好的 IP-Adapter 权重,详情请见 链接:
cd HunyuanDiT
# 使用 huggingface-cli 工具下载模型。
# 我们建议在 IP-Adapter 推理时使用模块权重作为基础模型,因为我们提供的预训练权重正是基于这些权重训练的。
huggingface-cli download Tencent-Hunyuan/IP-Adapter ipa.pt --local-dir ./ckpts/t2i/model
huggingface-cli download Tencent-Hunyuan/IP-Adapter clip_img_encoder.pt --local-dir ./ckpts/t2i/model/clip_img_encoder
# 快速入门
python3 sample_ipadapter.py --infer-mode fa --ref-image-path https://oss.gittoolsai.com/images/Tencent-Hunyuan_HunyuanDiT_readme_8af468f74f94.png --i-scale 1.0 --prompt 一只老虎在海洋中游泳,背景是海洋。构图方式是居中构图,呈现了动漫风格和文化,营造了平静的氛围。 --infer-steps 100 --is-ipa True --load-key distill
参考输入及 IP-Adapter 结果示例如下:
| 参考输入 | |||||
 |
 |
 |
|||
| IP-Adapter 输出 | |||||
| 一只老虎在奔跑。 (A tiger running.) |
一个卡通美女,抱着一只小猪。 (A cartoon beauty holding a little pig.) |
一片紫色薰衣草地。 (A purple lavender field.) |
|||
 |
 |
 |
|||
| 一只老虎在看书。 (A tiger is reading a book.) |
一个卡通美女,穿着绿色衣服。 (A cartoon beauty wearing green clothes.) |
一片紫色薰衣草地,有一只可爱的小狗。 (A purple lavender field with a cute puppy.) |
|||
 |
 |
 |
一只老虎在咆哮。 (A tiger is roaring.) |
一个卡通美女,戴着墨镜。 (A cartoon beauty wearing sunglasses.) |
水墨风格,一片紫色薰衣草地。 (Ink style. A purple lavender field.) |
 |
 |  |

| 模式 | 提示模板 | 描述 |
|---|---|---|
| caption_zh | 描述这张图片 | 中文描述 |
| insert_content | 根据提示词“{}”,描述这张图片 | 带有插入知识的描述 |
| caption_en | Please describe the content of this image | 英文描述 |
a. 单张图片中文推理
python mllm/caption_demo.py --mode "caption_zh" --image_file "mllm/images/demo1.png" --model_path "./ckpts/captioner"
b. 在描述中插入特定知识
python mllm/caption_demo.py --mode "insert_content" --content "宫保鸡丁" --image_file "mllm/images/demo2.png" --model_path "./ckpts/captioner"
c. 单张图片英文推理
python mllm/caption_demo.py --mode "caption_en" --image_file "mllm/images/demo3.png" --model_path "./ckpts/captioner"
d. 多张图片中文推理
### 将多张图片转换为 csv 文件。
python mllm/make_csv.py --img_dir "mllm/images" --input_file "mllm/images/demo.csv"
### 多张图片推理
python mllm/caption_demo.py --mode "caption_zh" --input_file "mllm/images/demo.csv" --output_file "mllm/images/demo_res.csv" --model_path "./ckpts/captioner"
(可选)若需将输出的 csv 文件转换为 Arrow 格式,请参阅 数据准备 #3 获取详细说明。
Gradio
要在本地启动 Gradio 演示,请依次运行以下命令。更多详细说明请参考 LLaVA。
cd mllm
python -m llava.serve.controller --host 0.0.0.0 --port 10000
python -m llava.serve.gradio_web_server --controller http://0.0.0.0:10000 --model-list-mode reload --port 443
python -m llava.serve.model_worker --host 0.0.0.0 --controller http://0.0.0.0:10000 --port 40000 --worker http://0.0.0.0:40000 --model-path "../ckpts/captioner" --model-name LlavaMistral
随后可以通过 http://0.0.0.0:443 访问演示。需要注意的是,这里的 0.0.0.0 需要替换为您的服务器 IP 地址 X.X.X.X。
🚀 加速(适用于 Linux)
我们提供了 HunyuanDiT 的 TensorRT 版本,用于加速推理(比 flash attention 更快)。 详情请参见 Tencent-Hunyuan/TensorRT-libs。
我们提供了 HunyuanDiT 的蒸馏版本,用于加速推理。 详情请参见 Tencent-Hunyuan/Distillation。
🔗 BibTeX
如果您在研究和应用中发现 Hunyuan-DiT 或 DialogGen 有所帮助,请使用以下 BibTeX 引用:
@misc{li2024hunyuandit,
title={Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding},
author={Zhimin Li and Jianwei Zhang and Qin Lin and Jiangfeng Xiong and Yanxin Long and Xinchi Deng and Yingfang Zhang and Xingchao Liu and Minbin Huang and Zedong Xiao and Dayou Chen and Jiajun He and Jiahao Li and Wenyue Li and Chen Zhang and Rongwei Quan and Jianxiang Lu and Jiabin Huang and Xiaoyan Yuan and Xiaoxiao Zheng and Yixuan Li and Jihong Zhang and Chao Zhang and Meng Chen and Jie Liu and Zheng Fang and Weiyan Wang and Jinbao Xue and Yangyu Tao and Jianchen Zhu and Kai Liu and Sihuan Lin and Yifu Sun and Yun Li and Dongdong Wang and Mingtao Chen and Zhichao Hu and Xiao Xiao and Yan Chen and Yuhong Liu and Wei Liu and Di Wang and Yong Yang and Jie Jiang and Qinglin Lu},
year={2024},
eprint={2405.08748},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{huang2024dialoggen,
title={DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation},
author={Huang, Minbin and Long, Yanxin and Deng, Xinchi and Chu, Ruihang and Xiong, Jiangfeng and Liang, Xiaodan and Cheng, Hong and Lu, Qinglin and Liu, Wei},
journal={arXiv preprint arXiv:2403.08857},
year={2024}
}
星级历史

常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。