AngelSlim
AngelSlim 是一款专为大模型压缩打造的高效工具包,旨在让庞大的 AI 模型变得更轻量、更易部署。它解决了大模型在资源受限设备上运行困难、推理速度慢以及存储成本高等痛点,通过统一的框架集成了多种主流压缩算法,让用户能轻松实现模型“瘦身”而不损失核心能力。
无论是希望将大语言模型部署到手机或边缘设备的开发者,还是致力于探索新型压缩算法的研究人员,AngelSlim 都能提供强大的支持。其独特亮点在于不仅支持常见的 INT4、FP8 等量化技术,还原创了 Sherry(1.25 bit 超低位宽量化)、DAQ(保持知识的小参数更新量化)以及 SpecExit(推理早退机制)等前沿算法。此外,它还全面支持 Eagle3 投机解码训练框架,覆盖从文本、多模态到音频的各类模型,并兼容 Qwen3、DeepSeek、Hunyuan 等主流开源模型系列。凭借完善的文档和活跃的社区支持,AngelSlim 正成为连接高效算法与实际应用的重要桥梁。
使用场景
某初创团队试图将 72B 参数的多模态大模型部署到资源受限的边缘服务器上,以提供实时的工业质检服务。
没有 AngelSlim 时
- 显存爆满无法运行:原始模型体积巨大,远超边缘设备显存上限,导致服务根本无法启动。
- 算法适配成本极高:团队需手动为不同层编写量化代码,面对 FP8、INT4 等多种算法,调试周期长达数周。
- 推理延迟不可接受:即使勉强通过裁剪运行,单次推理耗时超过 2 秒,完全无法满足生产线实时检测需求。
- 精度损失难以控制:缺乏专业的后训练量化(PTQ)策略,模型压缩后识别准确率大幅下降,误报率飙升。
使用 AngelSlim 后
- 端侧顺利部署:利用 AngelSlim 的 Sherry 1.25 bit 或 INT4 量化算法,模型体积压缩至原来的 1/4,成功载入边缘设备。
- 一站式高效压缩:借助其高度集成的框架,一键调用针对 Qwen2.5-VL 等模型的预设配置,半天内即可完成压缩流程。
- 推理速度显著提升:结合 Eagle3 投机解码技术,推理吞吐量提升数倍,单张图片检测延迟降低至 200 毫秒以内。
- 知识保留完好:通过 DAQ 等先进算法,在参数量剧烈缩减的同时,有效保留了模型核心知识,准确率几乎无损。
AngelSlim 让超大模型在低算力设备上实现了“跑得动、跑得快、跑得准”的落地闭环。
运行环境要求
- 未说明
需要 NVIDIA GPU(文中提及单卡可运行 Qwen3-235B 等大模型量化,暗示对显存及算力有较高要求,具体型号及 CUDA 版本未明确列出)
未说明

快速开始
中文 | English
![]()
一款更易用、更全面、更高效的大型模型压缩工具集。
✒️ 技术报告 | 📖 文档 | 🤗 Hugging Face | 🤖 ModelScope
{kind=link}
📣最新动态
- [26/03/25] 我们发布了DAQ,这是一种在训练后微调过程中保持知识的同时,参数更新量相对较小的量化算法。[论文] | [文档]
- [26/02/09] 我们发布了HY-1.8B-2Bit,这是一款2比特的端侧大语言模型,[Hugging Face]。
- [26/01/13] 我们发布了v0.3版本。我们支持Eagle3用于全规模LLM/VLM/音频模型的训练与部署,详情请参见指导文档。同时,我们还发布了Sherry,一种硬件友好的1.25比特量化算法[论文] | [代码]🔥🔥🔥
- [25/11/05] 我们发布了v0.2版本。新增对
GLM-4.6、Qwen3-VL和Qwen3-Omni等模型的量化支持,开源了Eagle3推测解码训练框架,并更新了扩散模型量化工具。 - [25/09/30] 我们发布了SpecExit,一种推理早停算法:[论文] | [文档] | [vLLM代码]
- [25/09/26] 我们发布了TEQUILA,一种三值量化算法[论文] | [代码]
- [25/09/24] 我们现在支持对Qwen3系列模型进行NVFP4的PTQ量化。同时,我们也开源了Qwen3-32B-NVFP4和Qwen3-235B-A22B-NVFP4权重。
往期新闻
- [25/09/01] 我们现在支持对Hunyuan-MT-7B翻译模型进行FP8量化。并启用了Eagle3的Torch推理和基准测试评估功能。此外,我们还实现了对FLUX的量化与缓存支持,以及对Seed-OSS的量化支持。
- [25/08/06] 我们现在支持对
Hunyuan 0.5B/1.8B/4B/7B以及多模态模型Qwen2.5VL 3B/7B/32B/72B进行量化,包括FP8/INT4等算法;同时也支持对DeepSeek-R1/V3和Kimi-K2进行量化,涵盖FP8-Static和W4A8-FP8等算法。我们还开源了Hunyuan 1.8B/4B/7B系列Eagle3模型权重。 - [25/07/04] 我们现在支持对
Hunyuan/Qwen2.5/Qwen3/DeepSeek-R1-Distill-Qwen等模型进行量化,包括INT8/FP8/INT4等算法。我们还开源了Qwen3系列Eagle3模型权重。
🌟核心特性
- 高度集成:该工具集将主流压缩算法整合进统一框架,为开发者提供一键式访问,使用极为便捷。
- 持续创新:除了集成业界广泛使用的算法外,我们还在不断研究更优的压缩算法,未来将逐步开源。
- 性能驱动:我们在模型压缩工作流及算法部署中持续优化端到端性能,例如实现单GPU上对Qwen3-235B和DeepSeek-R1等模型的量化。
💼技术概览
| 场景 | 模型 | 压缩策略 | ||
|---|---|---|---|---|
| 量化 | 推测解码 | 其他技术 | ||
| 大型语言模型(LLMs) |
|
|||
| 视觉语言模型(VLMs) |
|
|||
| 扩散模型 | - |
|
||
| 语音模型(TTS/ASR) |
|
|||
🛎️使用方法
1. 安装 AngelSlim
我们建议使用 pip 安装最新稳定版的 AngelSlim:
pip install angelslim
或者,您也可以克隆仓库,并以可编辑模式从源码安装:
cd AngelSlim && python setup.py install
更多详细的安装说明及平台特定指导,请参阅安装文档。
2. 快速入门
2.1 推测解码
安装 AngelSlim 后,您可以使用以下脚本快速开始 Eagle3 训练:
# 启动 vLLM 服务器
bash scripts/speculative/run_vllm_server.sh
# 生成训练数据
bash scripts/speculative/generate_data_for_target_model.sh
# 对 Eagle3 模型进行在线训练
bash scripts/speculative/train_eagle3_online.sh
Eagle3 的训练与部署指南:LLM | VLM | 音频(ASR) | 音频(TTS)。
2.2 LLM/VLM/音频模型量化
安装 AngelSlim 后,您可以通过以下一条命令脚本对 Qwen3-1.7B 模型进行静态 FP8 量化:
python3 tools/run.py -c configs/qwen3/fp8_static/qwen3-1_7b_fp8_static.yaml
此示例通过在从 HuggingFace 加载的模型上执行 PTQ 校准,生成量化的模型权重。
代码方式启动
要对 Qwen3-1.7B 进行动态 FP8 量化:
from angelslim.engine import Engine
slim_engine = Engine()
# 准备模型
slim_engine.prepare_model(model_name="Qwen", model_path="Qwen/Qwen3-1.7B",)
# 初始化压缩器
slim_engine.prepare_compressor("PTQ", default_method="fp8_dynamic")
# 压缩模型
slim_engine.run()
# 保存压缩后的模型
slim_engine.save("./output")
更多详情请参阅快速入门文档。
2.3 扩散模型量化
使用 scripts/diffusion/run_diffusion.py 进行量化和推理:
# 在线量化与推理
python scripts/diffusion/run_diffusion.py \
--model-name-or-path black-forest-labs/FLUX.1-schnell \
--quant-type fp8-per-tensor \
--prompt "一只猫拿着写着‘hello world’的牌子" \
--height 1024 --width 1024 --steps 4 --guidance 0.0 --seed 0
更多量化推理方法,请参阅扩散模型量化文档。
2.4 Token 压缩(VLM)
AngelSlim 提供了一个通用的元数据驱动框架,用于视觉 token 的剪枝和合并。您可以通过烟雾测试快速验证一种压缩策略(例如 VisionZip):
python tools/test_universal_pruning.py \
--model_path "Qwen/Qwen2.5-VL-3B-Instruct" \
--config "configs/qwen2_5_vl/pruning/visionzip_r0.9.yaml"
有关实施新策略的更多详细信息,请参阅Token Compressor 文档。
3. 部署与测试
3.1 离线推理
要使用通过 transformers 加载的量化模型进行离线推理测试。
运行脚本详情
python scripts/deploy/offline.py $MODEL_PATH "你好,我叫"
其中 $MODEL_PATH 是量化模型输出的路径。
3.2 API 服务部署
指定量化模型路径 MODEL_PATH 后,您可以使用 vLLM 和 SGLang 推理框架部署一个兼容 OpenAI 的 API 服务。
运行脚本详情
vLLM
使用以下脚本启动一个 vLLM 服务器,推荐版本为
vllm>=0.8.5.post1。对于 MOE INT8 量化模型,需要 vllm>=0.9.0。bash scripts/deploy/run_vllm.sh --model-path $MODEL_PATH --port 8080 -d 0,1,2,3 -t 4 -p 1 -g 0.8 --max-model-len 4096其中
-d表示可见设备,-t表示张量并行规模,-p表示流水线并行规模,-g表示 GPU 内存利用率。SGLang
使用以下脚本启动一个 SGLang 服务器,推荐版本为
sglang>=0.4.6.post1。bash scripts/deploy/run_sglang.sh --model-path $MODEL_PATH --port 8080 -d 0,1,2,3 -t 4 -g 0.8
3.3 服务调用
通过 OpenAI 的 API 格式发起请求。
运行脚本详情
bash scripts/deploy/openai.sh -m $MODEL_PATH -p "你好,我叫" --port 8080 --max-tokens 4096 --temperature 0.7 --top-p 0.8 --top-k 20 --repetition-penalty 1.05 --system-prompt "你是一个乐于助人的助手。"
其中 -p 是输入提示。
3.4 性能评估
使用 lm-evaluation-harness,推荐版本为 lm-eval>=0.4.8,评估量化模型性能。
运行脚本详情
bash scripts/deploy/lm_eval.sh -d 0,1 -t 2 -g 0.8 -r $RESULT_PATH -b "auto" --tasks ceval-valid,mmlu,gsm8k,humaneval -n 0 $MODEL_PATH
其中 RESULT_PATH 是保存测试结果的目录,-b 表示批量大小,--tasks 指定评估任务,-n 表示少样本示例的数量。
更多详细信息,请参阅部署文档。
📈 基准测试
1. 推测解码
我们使用 vLLM 对 AngelSlim 训练的 Eagle3 模型进行了评估,涵盖代码生成、数学推理、指令遵循、文本生成以及多模态理解等任务。在 num_speculative_tokens = 2 或 4 的设置下,我们训练的模型在推理加速和上下文长度方面的表现如下,接受长度为 1.8–3.5,最大加速比为 1.4–1.9×。
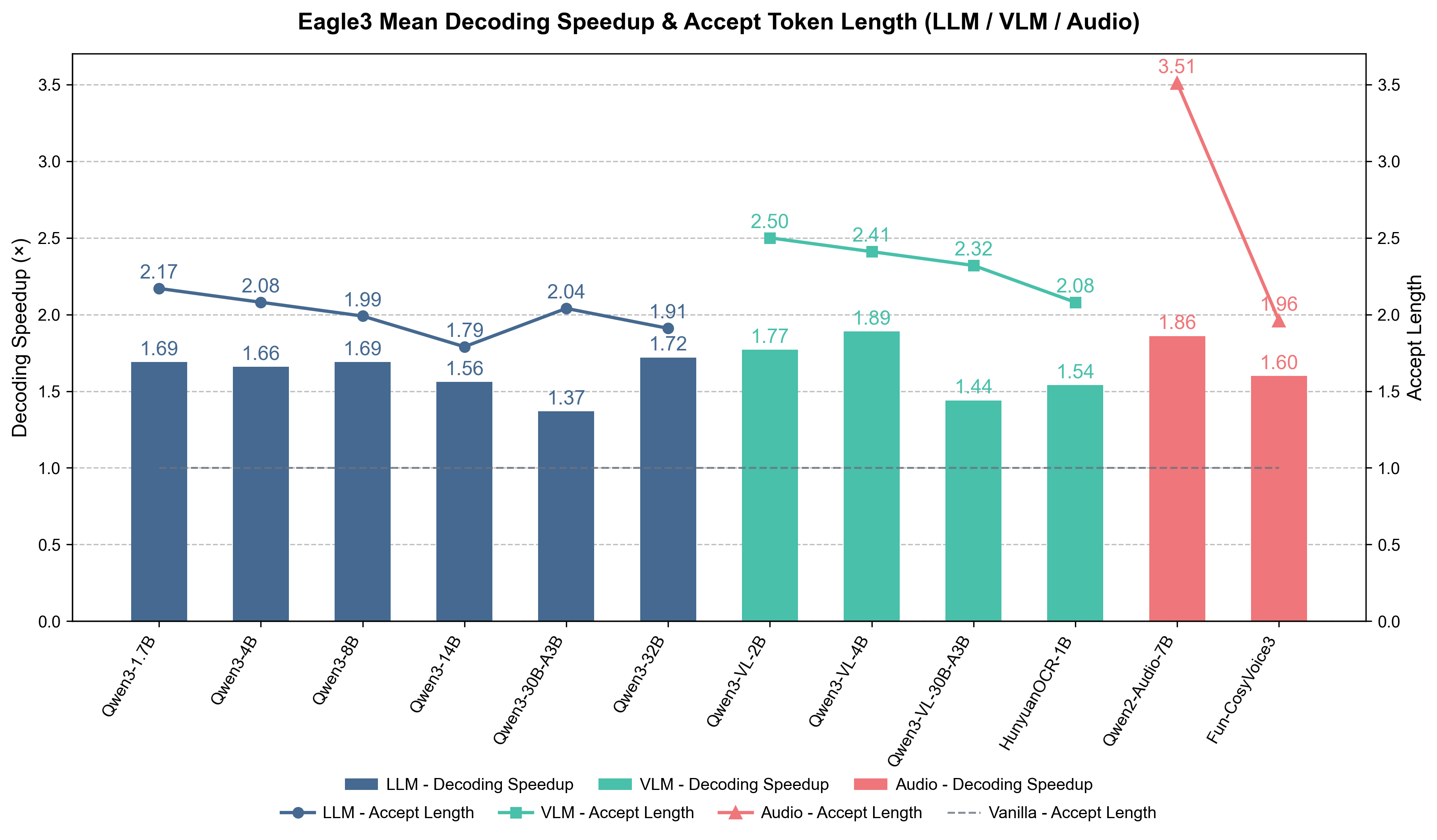
1.1 Qwen3 系列模型
在 vLLM(v0.11.2)上,使用 Eagle3 推理解码技术对 Qwen3 系列模型在 MT-bench、HumanEval、GSM8K 和 Alpaca 上的基准测试结果,采用单 GPU 配置(tp=1, ep=1, num_speculative_tokens=2, batch_size=1, output_len=1024)。
| 模型 | 方法 | GSM8K | Alpaca | HumanEval | MT-bench | 平均 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | ||
| Qwen3-1.7B | Vanilla | 376.42 | 1 | 378.86 | 1 | 378.38 | 1 | 390.53 | 1 | 381.05 | 1 |
| Eagle3 | 616.9 | 2.13 | 653.29 | 2.19 | 680.1 | 2.2 | 621.44 | 2.17 | 642.93 | 2.17 | |
| Qwen3-4B | Vanilla | 229.05 | 1 | 235.29 | 1 | 234.66 | 1 | 234.04 | 1 | 233.26 | 1 |
| Eagle3 | 389.35 | 2.07 | 395.97 | 2.1 | 377.84 | 2.08 | 384.6 | 2.07 | 386.94 | 2.08 | |
| Qwen3-8B | Vanilla | 149.63 | 1 | 149.93 | 1 | 153.85 | 1 | 153.81 | 1 | 151.81 | 1 |
| Eagle3 | 257.32 | 2 | 266.69 | 2.02 | 244.89 | 1.97 | 258.2 | 1.97 | 257.52 | 1.99 | |
| Qwen3-14B | Vanilla | 92.97 | 1 | 92.66 | 1 | 92.94 | 1 | 94.46 | 1 | 93.26 | 1 |
| Eagle3 | 153.72 | 1.87 | 140.46 | 1.78 | 144.68 | 1.76 | 142.45 | 1.74 | 145.33 | 1.79 | |
| Qwen3-32B | Vanilla | 43.49 | 1 | 43.38 | 1 | 43.19 | 1 | 43.3 | 1 | 43.32 | 1 |
| Eagle3 | 80.43 | 2.01 | 72.49 | 1.9 | 71.57 | 1.86 | 74.1 | 1.86 | 74.1 | 1.91 | |
| Qwen3-30B-A3B | Vanilla | 311.84 | 1 | 320.43 | 1 | 325.77 | 1 | 325.42 | 1 | 320.87 | 1 |
| Eagle3 | 453.97 | 2.1 | 432.45 | 2.04 | 428.81 | 2.02 | 437.06 | 2.01 | 438.07 | 2.04 | |
1.2 视觉语言模型
1.2.1 Qwen3-VL 系列模型
在 vLLM(v0.12.0)上,使用 Eagle3 推理解码技术对 Qwen3-VL 系列模型在语言和多模态任务上的基准测试结果,采用单 GPU 配置(tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024)。
| 模型 | 方法 | GSM8K | Alpaca | HumanEval | MT-bench | MATH-500 | MMMU | MMStar | 平均 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | 吞吐量(tokens/s) | 接受长度 | |||
| Qwen3-VL-2B-Instruct | Vanilla | 348.55 | 1 | 350.9 | 1 | 346.07 | 1 | 346.31 | 1 | 82.96 | 1 | 83.27 | 1 | 81.63 | 1 | 234.24 | 1 | |
| Eagle3 | 511.52 | 2.11 | 560.55 | 2.26 | 826.01 | 3.39 | 555.22 | 2.29 | 163.09 | 2.57 | 154.18 | 2.55 | 139.73 | 2.31 | 415.76 | 2.5 | ||
| Qwen3-VL-4B-Instruct | Vanilla | 212.87 | 1 | 213.24 | 1 | 211.69 | 1 | 212.1 | 1 | 67.96 | 1 | 65.88 | 1 | 67.75 | 1 | 150.21 | 1 | |
| Eagle3 | 415.29 | 2.57 | 372.89 | 2.26 | 459.37 | 2.82 | 382.33 | 2.34 | 141.87 | 2.72 | 104.44 | 2.05 | 107.07 | 2.1 | 107.07 | 2.1 | 283.32 | 2.41 |
| Qwen3-VL-30B-A3B-Instruct | Vanilla | 179.94 | 1 | 184.6 | 1 | 168.68 | 1 | 180.57 | 1 | 31.08 | 1 | 31.51 | 1 | 30.93 | 1 | 115.33 | 1 | |
| Eagle3 | 281.93 | 2.82 | 241.42 | 2.13 | 223.05 | 2.57 | 240.47 | 2.19 | 75.31 | 2.79 | 48.47 | 1.78 | 52.57 | 1.94 | 166.17 | 2.32 | ||
1.2.2 HunyuanOCR 模型
在 vLLM(v0.13.0)上使用 Eagle3 推测解码对 HunyuanOCR 进行基准测试的结果,数据集为 OmniDocBench,采用单 GPU(tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024)。
| 模型 | 方法 | OmniDocBench | |
|---|---|---|---|
| 吞吐量(tokens/s) | 接受长度 | ||
| Hunyuan-OCR | Vanilla | 70.12 | 1 |
| Eagle3 | 108.1 | 2.08 | |
1.3 音频模型
1.3.1 Qwen2-Audio 模型
在 vLLM(v0.12.0)上使用 Eagle3 推测解码对 Qwen2-Audio 进行基准测试的结果,数据集为 LibriSpeech,采用单 GPU(tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024)。
| 模型 | 方法 | LibriSpeech | |
|---|---|---|---|
| 吞吐量(tokens/s) | 接受长度 | ||
| Qwen2-Audio | Vanilla | 78.76 | 1 |
| Eagle3 | 146.66 | 3.51 | |
1.3.2 Fun-CosyVoice3 模型
在单 GPU(tp=1, ep=1, num_speculative_tokens=4, batch_size=1, output_len=1024)条件下,使用 Eagle3 推测解码对 Fun-CosyVoice3 进行基准测试的结果,数据集为 LibriTTS。
| 模型 | 方法 | LibriTTS | |
|---|---|---|---|
| 吞吐量(tokens/s) | 接受长度 | ||
| Fun-CosyVoice3 | Vanilla | - | 1 |
| Eagle3 | - | 1.96 | |
适配于 Transformers 后端推理,仅显示接受长度。vLLM 加速约 1.6 倍,基于基础 LLM 加速估算得出。
2. 量化
以下展示了部分选定模型的性能测试结果。如需完整基准测试,请参阅 Benchmark 文档
2.1 Hunyuan 系列模型
Hunyuan-Instruct 模型分别采用 FP8、INT4-AWQ 和 INT4-GPTQ 量化算法,在包括 OlympiadBench、AIME 2024 和 DROP 在内的数据集上的基准测试结果:
| 模型 | 量化方式 | OlympiadBench | AIME 2024 | DROP | GPQA-Diamond |
|---|---|---|---|---|---|
| Hunyuan-A13B-Instruct | BF16 | 82.7 | 87.30 | 91.1 | 71.2 |
| FP8-Static | 83.0 | 86.7 | 91.1 | - | |
| Int4-GPTQ | 82.7 | 86.7 | 91.1 | - | |
| Int4-AWQ | 82.6 | 85.6 | 91.0 | - | |
| Hunyuan-7B-Instruct | BF16 | 76.5 | 81.1 | 85.9 | 60.1 |
| FP8-Static | 76.6 | 80.9 | 86.0 | 60.1 | |
| Int4-GPTQ | 76.2 | 81.0 | 85.7 | 60.0 | |
| Int4-AWQ | 76.4 | 80.9 | 85.9 | 60.1 | |
| Hunyuan-4B-Instruct | BF16 | 73.1 | 78.3 | 78.2 | 61.1 |
| FP8-Static | 73.1 | 76.6 | 78.3 | 60.2 | |
| Int4-GPTQ | 72.9 | - | 78.1 | 58.1 | |
| Int4-AWQ | 72.8 | - | 78.2 | - | |
| Hunyuan-1.8B-Instruct | BF16 | 63.4 | 56.7 | 76.7 | 47.2 |
| FP8-Static | 62.5 | 55.2 | 75.1 | 47.7 | |
| Int4-GPTQ | 60.9 | - | 73.0 | 44.4 | |
| Int4-AWQ | 61.7 | - | 71.7 | 43.6 | |
| Hunyuan-0.5B-Instruct | BF16 | 29.6 | 17.2 | 52.8 | 23.3 |
| FP8-Static | 29.6 | 17.2 | 51.6 | 22.5 | |
| Int4-GPTQ | 26.8 | - | 50.9 | 23.3 | |
| Int4-AWQ | 26.3 | - | 48.9 | 23.3 |
2.2 通义千问3系列模型
通义千问3系列模型在CEVAL、MMLU、GSM8K和HUMANEVAL等数据集上,采用FP8-Static、FP8-Dynamic、INT4-GPTQ和INT4-AWQ量化算法的评测结果如下:
| 模型 | 量化方式 | CEVAL | MMLU | GSM8K | HUMANEVAL |
|---|---|---|---|---|---|
| Qwen3-0.6B | BF16 | 45.84 | 47.21 | 42.99 | 19.51 |
| FP8-Static | 45.99 | 46.87 | 38.06 | 18.90 | |
| FP8-Dynamic | 45.99 | 46.93 | 38.29 | 20.73 | |
| INT8-Dynamic | 45.17 | 46.95 | 41.17 | 21.34 | |
| Qwen3-8B | BF16 | 79.27 | 74.78 | 87.79 | 63.41 |
| FP8-Static | 78.23 | 74.79 | 86.96 | 62.20 | |
| FP8-Dynamic | 78.45 | 74.75 | 87.64 | 62.80 | |
| INT8-Dynamic | 78.01 | 74.84 | 86.96 | 67.07 | |
| INT4-GPTQ | 77.19 | 73.26 | 86.43 | 62.20 | |
| INT4-AWQ | 76.15 | 73.59 | 86.96 | 63.41 | |
| Qwen3-14B | BF16 | 83.06 | 78.90 | 88.40 | 55.49 |
| FP8-Static | 82.62 | 78.57 | 89.46 | 57.32 | |
| FP8-Dynamic | 82.24 | 78.92 | 88.32 | 52.44 | |
| INT8-Dynamic | 81.87 | 78.13 | 86.28 | 56.10 | |
| INT4-GPTQ | 81.05 | 78.02 | 87.34 | 57.93 | |
| INT4-AWQ | 82.02 | 77.68 | 84.23 | 61.59 | |
| Qwen3-32B | BF16 | 86.55 | 82.00 | 74.53 | 37.80 |
| FP8-Static | 86.92 | 81.78 | 70.20 | 39.63 | |
| FP8-Dynamic | 86.55 | 81.89 | 70.43 | 38.41 | |
| INT4-GPTQ | 86.18 | 81.01 | - | 43.29 | |
| INT4-AWQ | 86.18 | 81.54 | - | 36.59 | |
| Qwen3-30B-A3B | BF16 | 83.66 | 79.36 | 89.99 | 31.71 |
| FP8-Static | 83.95 | 79.47 | 89.01 | 31.10 | |
| FP8-Dynamic | 84.10 | 79.40 | 89.16 | 32.93 | |
| INT8-Dynamic | 83.36 | 79.48 | 89.16 | 34.15 | |
| Qwen3-235B-A22B | BF16 | 89.60 | 86.28 | 85.29 | 27.44 |
| FP8-Static | 89.67 | 86.19 | 86.96 | 27.44 | |
| FP8-Dynamic | 89.67 | 86.18 | 85.22 | 28.05 | |
| INT8-Dynamic | 88.93 | 86.20 | 86.20 | 23.78 |
2.3 深势系列模型
深势R1-0528系列模型在GPQA Diamond、AIME 2024、SimpleQA和LiveCodeBench等数据集上,采用FP8-Block-Wise和W4A8-FP8量化算法的评测结果如下:
| 模型 | 量化方式 | GPQA Diamond | AIME 2024 | SimpleQA | LiveCodeBench |
|---|---|---|---|---|---|
| DeepSeek-R1-0528 | FP8-Block-Wise | 78.28 | 88.67 | 27.8 | 77.1 |
| W4A8-FP8 | 77.37 | 88.67 | 26.83 | 78.86 |
注
- 上述结果基于使用TRT-LLM部署的5次测试运行的平均值
- 评估过程中使用的超参数如下:
{ "top_k": 20, "top_p": 0.6, "temperature": 0.7, "output_seq_len": 32768, "max_input_seq_len": 16384 }
2.4 通义千问-VL系列模型
Qwen3-VL评测
通义千问3VL系列模型在MMMU_VAL、DocVQA_VAL和ChartQA_TEST等数据集上,采用BF16、FP8-Static和FP8-Dynamic量化算法的评测结果如下:
| 模型 | 量化 | MMMU_VAL | DocVQA_VAL | ChartQA_TEST |
|---|---|---|---|---|
| Qwen3-VL-32B-Instruct | BF16 | 60.11 | 96.08 | 94.64 |
| FP8-Static | 61.22 | 96.00 | 94.64 | |
| FP8-Dynamic | 60.78 | 96.19 | 94.72 | |
| Qwen3-VL-30B-A3B-Instruct | BF16 | 50.44 | 95.28 | 95.36 |
| FP8-Dynamic | 50.67 | 95.25 | 95.20 |
Qwen2.5VL 基准测试
Qwen2.5VL 系列模型在 BF16、FP8-Static、FP8-Dynamic、INT4-GPTQ、INT4-AWQ 量化算法下,于 MMMU_VAL、DocVQA_VAL 和 ChartQA_TEST 数据集上的基准测试结果如下:
| 模型 | 量化 | MMMU_VAL | MMLDocVQA_VALU | ChartQA_TEST |
|---|---|---|---|---|
| Qwen2.5VL-3B | BF16 | 47.11 | 78.57 | 80.32 |
| FP8-Static | 47.33 | 79.34 | 79.68 | |
| FP8-Dynamic | 45.99 | 46.93 | 38.29 | |
| INT4-GPTQ | 46.56 | 77.20 | 78.96 | |
| INT4-AWQ | 45.78 | - | 79.60 | |
| Qwen2.5VL-7B | BF16 | 45.44 | 89.71 | 84.64 |
| FP8-Static | 47.00 | 89.83 | 85.92 | |
| FP8-Dynamic | 47.22 | 89.80 | 88.64 | |
| INT4-GPTQ | 46.67 | 90.45 | - | |
| INT4-AWQ | 45.67 | 89.28 | - | |
| Qwen2.5VL-32B | BF16 | 57.00 | 90.03 | - |
| FP8-Static | 57.00 | 89.88 | - | |
| FP8-Dynamic | 56.44 | 89.88 | - | |
| INT4-GPTQ | 55.22 | 89.80 | - | |
| INT4-AWQ | 55.22 | 90.30 | - | |
| Qwen2.5VL-72B | BF16 | 58.78 | 94.39 | 85.60 |
| FP8-Static | 57.89 | 94.41 | 85.84 | |
| FP8-Dynamic | 58.67 | 94.38 | 85.60 | |
| INT4-GPTQ | 57.56 | 94.46 | 86.48 | |
| INT4-AWQ | 58.78 | 94.19 | 87.28 |
2.5 Qwen-Omni 系列模型
Qwen3-Omni 文本到文本基准测试
Qwen3-Omni 系列模型在 BF16、FP8-Static 和 FP8-Dynamic 下,于 aime25、gpqa_diamond 和 mmlu_redux 上的基准测试结果如下:
| 模型 | 量化 | aime25 | gpqa_diamond | mmlu_redux |
|---|---|---|---|---|
| Qwen3-Omni-30B-A3B-Instruct | BF16 | 73.32 | 56.77 | 88.09 |
| FP8-Static | 71.33 | 56.57 | 87.91 | |
| FP8-Dynamic | 73.33 | 55.15 | 88.07 |
注
- 上述评估结果是通过 vLLM 框架部署并取 5 次运行的平均值获得的(vLLM 仅支持思考器组件)。
- 评估过程中使用的超参数如下:
{ "top_p": 0.95, "temperature": 0.6, "do_sample": true, "max-model-len 65536": 65536 }
2.6 其他模型
其他模型如 GLM-4.6、Qwen2.5 和 Seed-OSS 已经使用 FP8-Static、FP8-Dynamic、INT4-GPTQ 和 INT4-AWQ 等量化策略,在 CEVAL、MMLU 和 GSM8K 等基准测试上进行了评估。
基准测试实验详情
| 模型 | 量化 | CEVAL | MMLU | GSM8K |
|---|---|---|---|---|
| Qwen2.5-1.5B-Instruct | BF16 | 67.01 | 60.05 | 54.28 |
| FP8-Static | 66.27 | 60.23 | - | |
| FP8-Dynamic | 66.79 | 60.08 | 51.71 | |
| Qwen2.5-7B-Instruct | BF16 | 81.20 | 74.55 | 79.98 |
| FP8-Static | 81.13 | 74.03 | 79.30 | |
| FP8-Dynamic | 80.31 | 74.07 | 79.00 | |
| INT4-GPTQ | 79.05 | 73.05 | 74.75 | |
| INT4-AWQ | 79.35 | 73.22 | 79.38 | |
| Qwen2.5-32B-Instruct | BF16 | 87.30 | 83.21 | 81.73 |
| FP8-Static | 87.59 | 83.08 | 81.58 | |
| FP8-Dynamic | 87.30 | 83.04 | 81.58 | |
| INT4-GPTQ | 86.70 | 82.45 | 82.03 | |
| INT4-AWQ | 87.00 | 82.64 | - | |
| DeepSeek-R1-Distill-Qwen-7B | BF16 | 53.49 | 53.80 | 75.74 |
| FP8-Static | 53.57 | 54.17 | 76.19 | |
| FP8-Dynamic | 52.97 | 54.13 | 74.15 | |
| INT4-GPTQ | 51.86 | 52.44 | 75.89 | |
| INT4-AWQ | 53.49 | 53.70 | - | |
| DeepSeek-R1-Distill-Qwen-14B | BF16 | 77.71 | 74.28 | 85.67 |
| FP8-Static | 77.56 | 74.66 | 86.73 | |
| FP8-Dynamic | 76.82 | 74.63 | 87.11 | |
| INT4-GPTQ | 74.29 | 72.37 | 84.61 | |
| INT4-AWQ | 74.81 | 73.00 | 86.05 | |
| DeepSeek-R1-Distill-Qwen-32B | BF16 | 84.18 | 80.89 | 87.41 |
| FP8-Static | 83.43 | 80.90 | 87.57 | |
| FP8-Dynamic | 83.73 | 81.10 | 86.43 | |
| INT4-GPTQ | 84.10 | 79.80 | 86.73 | |
| INT4-AWQ | 82.84 | 80.15 | 87.19 |
3. Token压缩(VLM)
我们在多个多模态基准测试上,针对Qwen2.5-VL-3B-Instruct模型评估了多种视觉Token压缩策略。您可以通过以下命令复现这些结果:
python tools/run_pruning_eval.py \
--model_path "Qwen/Qwen2.5-VL-3B-Instruct" \
--configs "configs/qwen2_5_vl/pruning/visionzip_r0.9.yaml" \
--tasks "textvqa" \
--output_dir "./results/visionzip_test"
详细基准测试结果(Qwen2.5-VL-3B-Instruct)
| 方法 | AI2D | ChartQA | DocVQA | MMBCN | MMB | MME | MMStar | OCRBench | POPE | SQA | VQAText | 平均 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 基线 | 79.11 | 83.56 | 92.48 | 73.28 | 77.32 | 1517 | 56.05 | 80.10 | 87.41 | 80.81 | 78.79 | 100.0% |
| 保留25%的Token(75%压缩率) | ||||||||||||
| FastV | 72.70 | 70.04 | 75.98 | 63.40 | 66.92 | 1437 | 47.39 | 36.60 | 86.42 | 79.33 | 68.12 | 86.02% |
| VisionZip | 74.19 | 71.32 | 70.11 | 67.35 | 71.22 | 1452 | 49.37 | 42.50 | 85.51 | 81.36 | 68.12 | 87.34% |
| HiPrune | 73.83 | 72.76 | 72.10 | 67.27 | 72.34 | 1449 | 48.93 | 41.30 | 85.86 | 80.91 | 69.27 | 87.67% |
| VisionSelector | 75.19 | 73.72 | 90.24 | 68.81 | 72.59 | 1521 | 49.97 | 61.80 | 85.36 | 80.37 | 76.86 | 93.62% |
| DivPrune | 73.06 | 62.96 | 78.46 | 67.10 | 71.82 | 1459 | 48.38 | 51.40 | 86.81 | 80.22 | 68.91 | 88.15% |
| DART | 71.08 | 65.20 | 79.72 | 65.38 | 71.05 | 1428 | 48.78 | 41.80 | 80.97 | 80.91 | 68.25 | 86.17% |
| VisPruner | 74.29 | 68.20 | 72.52 | 67.35 | 70.88 | 1458 | 49.74 | 44.80 | 86.59 | 81.46 | 69.62 | 87.87% |
| SCOPE | 75.84 | 74.00 | 82.40 | 68.81 | 72.94 | 1471 | 50.35 | 56.00 | 86.62 | 80.96 | 74.04 | 91.98% |
| IDPruner | 75.94 | 75.84 | 90.00 | 69.42 | 73.80 | 1505 | 49.49 | 64.90 | 86.26 | 80.42 | 53.31 | 73.00% |
| 保留10%的Token(90%压缩率) | ||||||||||||
| FastV | 65.87 | 29.72 | 36.89 | 48.37 | 51.98 | 1257 | 37.28 | 13.90 | 79.50 | 77.05 | 57.75 | 65.30% |
| VisionZip | 67.65 | 51.60 | 37.88 | 59.62 | 63.06 | 1338 | 42.82 | 21.40 | 81.14 | 80.47 | 51.56 | 72.75% |
| HiPrune | 67.75 | 53.20 | 41.15 | 59.45 | 63.14 | 1326 | 41.08 | 20.30 | 80.90 | 80.96 | 53.31 | 73.00% |
| VisionSelector | 70.50 | 65.92 | 79.94 | 59.97 | 64.69 | 1374 | 42.86 | 45.20 | 82.66 | 80.61 | 71.57 | 84.42% |
| DivPrune | 67.71 | 43.12 | 58.03 | 61.25 | 65.12 | 1389 | 40.43 | 27.90 | 82.24 | 79.18 | 56.87 | 75.50% |
| DART | 67.49 | 47.56 | 60.23 | 57.99 | 63.83 | 1299 | 42.18 | 23.40 | 74.20 | 78.63 | 58.02 | 74.09% |
| VisPruner | 67.75 | 47.92 | 48.65 | 59.28 | 63.32 | 1305 | 41.51 | 22.50 | 78.74 | 79.77 | 54.95 | 73.19% |
| SCOPE | 69.75 | 56.24 | 55.01 | 64.26 | 67.18 | 1390 | 44.35 | 30.80 | 83.34 | 80.47 | 62.58 | 79.37% |
| IDPruner | 71.79 | 63.32 | 79.38 | 63.57 | 68.21 | 1438 | 44.05 | 45.50 | 84.51 | 80.57 | 70.02 | 85.71% |
📝 许可证
本项目的代码以AngelSlim许可证开源。
🔗 引用
@article{angelslim2026,
title={AngelSlim: 一个更易用、全面且高效的大型模型压缩工具包},
author={Hunyuan AI Infra团队},
journal={arXiv预印本 arXiv:2602.21233},
year={2026}
}
💬 技术讨论
AngelSlim由腾讯Hunyuan AI Infra团队开发,新功能会不断迭代更新。如果您有任何问题或建议,请在Github Issues中提交,或加入我们的微信讨论群。
⭐ 请给本仓库标星,以便关注我们的最新进展。如果您有兴趣加入我们实习或全职工作,请将简历发送至:lucayu@tencent.com。
版本历史
v0.3.02026/01/13v0.2.02025/11/05v0.1.02025/08/06常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。