MarkLLM
MarkLLM 是一款专为大型语言模型(LLM)文本水印技术打造的开源工具包,旨在帮助开发者轻松实现生成内容的溯源与版权保护。随着 AI 生成文本的泛滥,如何区分人类创作与机器生成内容成为行业难题,MarkLLM 通过集成多种先进的水印算法,让模型在输出文本时嵌入难以察觉的标记,从而有效解决内容归属验证和防止滥用等问题。
该工具特别适合人工智能研究人员、大模型开发者以及关注内容安全的企业技术团队使用。无论是想要复现前沿论文算法的学者,还是需要在产品中落地水印功能的工程师,都能通过 MarkLLM 快速上手。其核心亮点在于高度的模块化设计,不仅支持多种主流水印方案的即插即用,还提供了从水印嵌入到检测验证的完整流程演示。此外,项目背后团队在 ICLR、ACL 等顶会上发表了多篇关于语义鲁棒性水印和防伪造水印的研究成果,这些前沿技术也在工具中得到了体现或参考。MarkLLM 致力于降低技术门槛,推动文本水印技术在社区中的普及与应用,让 AI 生成内容更加透明可信。
使用场景
某金融科技公司正在部署自研的合规报告生成大模型,亟需解决内容版权归属及防止模型被非法蒸馏的问题。
没有 MarkLLM 时
- 版权难以举证:当发现竞争对手发布的研报与自家模型输出高度相似时,因缺乏隐蔽的技术标识,无法从法律层面证明对方窃取了生成内容。
- 防御手段缺失:面对黑产通过大量查询进行“知识蒸馏”以复制模型能力的行为,团队没有任何技术机制来追踪或阻断这种未经授权的知识迁移。
- 算法复现困难:研究人员想验证最新的学术水印方案(如语义不变性水印),却需要从零阅读论文并复现复杂的数学逻辑,耗时数周且容易出错。
- 评估标准混乱:缺乏统一的测试框架,难以量化水印在保持文本流畅度的同时,抵抗改写、翻译等攻击的鲁棒性。
使用 MarkLLM 后
- 隐形确权溯源:集成 MarkLLM 的水印算法后,模型生成的每份报告都嵌入了人眼不可见但可机器检测的数字指纹,为版权纠纷提供了确凿的技术证据。
- 主动防御蒸馏:利用工具内置的防蒸馏水印策略,一旦检测到异常的批量查询试图提取模型知识,系统能迅速识别并标记来源,有效遏制模型被盗用。
- 一键集成前沿算法:开发人员直接调用 MarkLLM 封装好的接口,几分钟内即可部署 ICLR 2024 等顶会提出的最新水印方案,无需重复造轮子。
- 标准化鲁棒评测:通过工具自带的评估模块,团队能快速测试水印在经历删改、润色后的存活率,确保在不妨碍用户阅读体验的前提下实现强防护。
MarkLLM 将复杂的水印学术研究转化为工业界开箱即用的防御武器,让大模型内容拥有了可验证的“数字身份证”。
运行环境要求
- 未说明
未说明(通常运行 LLM 水印算法及加载模型需要 NVIDIA GPU,具体显存取决于所选模型大小)
未说明
快速开始

面向大语言模型水印的开源工具包
![]()
🎉 我们欢迎PR! 如果你已经实现了一个大语言模型水印算法,或者有兴趣贡献一个,我们非常乐意将其加入MarkLLM。加入我们的社区,帮助让文本水印技术对每个人来说更加易用吧!
🔥 如果你对扩散模型(图像/视频)的水印感兴趣,请参考我们团队的MarkDiffusion工具包。
💡 我们团队的其他一些可能让你感兴趣的水印论文 ✨
-
刘艾伟、潘雷伊、胡旭明、孟啸、文立杰
-
刘艾伟、潘雷伊、胡旭明、李书昂、文立杰、Irwin King、Philip S. Yu
(ACM Computing Surveys) 大语言模型时代文本水印综述
刘艾伟*、潘雷伊*、陆一健、李晶晶、胡旭明、张曦、文立杰、Irwin King、熊辉、Philip S. Yu
**(ICLR 2025 Spotlight) 用户能否通过精心设计的提示识别出已加水印的大语言模型?
刘艾伟、关晟、刘一鸣、潘雷伊、张艺飞、方连成、文立杰、Philip S. Yu、胡旭明
**(ACL 2025 Main) 大语言模型水印能否稳健地防止未经授权的知识蒸馏?
潘雷伊、刘艾伟、黄世宇、陆一健、胡旭明、文立杰、Irwin King、Philip S. Yu
**(NAACL 2025 Findings) WaterSeeker:开创性地高效检测大型文档中的加水印片段
潘雷伊、刘艾伟、陆一健、高子天、狄一辰、文立杰、Irwin King、Philip S. Yu
**(ACL 2024 Main) 基于熵的文本水印检测方法
陆一健、刘艾伟、于典志、李晶晶、Irwin King
**(ACL 2024 Main) 水印能否在翻译中存活?关于大语言模型文本水印的跨语言一致性
何志伟、周炳林、郝洪坤、刘艾伟、王兴、涂兆鹏、张卓生、王睿







目录
❗❗❗ 注意事项
随着 MarkLLM 仓库内容日益丰富、体积不断增大,我们已在 Hugging Face 上创建了一个名为 Generative-Watermark-Toolkits 的模型存储库,以方便用户使用。该仓库包含了多种涉及自训练模型的水印算法的默认模型。我们已从主仓库中相应水印算法的 model/ 文件夹中移除了模型权重。在使用代码时,请先根据配置路径从 Hugging Face 仓库下载对应的模型,并将其保存到 model/ 目录下,再运行代码。
更新日志
- 🎉 (2025.09.22) 新增 SemStamp 水印方法。感谢 Huan Wang 的 PR!
- 🎉 (2025.09.17) 新增 IE 水印方法。感谢 Tianle Gu 的 PR!
- 🎉 (2025.09.14) 新增 Watermark Stealing 攻击方法。感谢 Shuhao Zhang 的 PR!
- 🎉 (2025.07.17) 新增 k-SemStamp 水印方法。感谢 Huan Wang 的 PR!
- 🎉 (2025.07.17) 新增 Adaptive Watermark 水印方法。感谢 Yepeng Liu 的 PR!
- 🎉 (2025.05.24) 新增 MorphMark 水印方法。感谢 Zongqi Wang 的 PR!
- 🎉 (2025.03.12) 新增 Permute-and-Flip (PF) 水印方法。感谢 Zian Wang 的 PR!
- 🎉 (2025.02.27) 为 Unbiased 水印方法新增 δ-reweight 和 LLR 分数检测功能。
- 🎉 (2025.01.08) 为水印方法添加 AutoConfiguration 功能。
- 🎉 (2024.12.21) 在
MarkvLLM_demo.py中提供将 VLLM 与 MarkLLM 集成的示例代码。感谢 @zhangjf-nlp 的 PR! - 🎉 (2024.11.21) 支持 SynthID-Text 方法(Nature)的失真版本。
- 🎉 (2024.11.03) 新增 SynthID-Text 方法(Nature),并支持均值、加权均值和贝叶斯等检测方法。
- 🎉 (2024.11.01) 新增 TS-Watermark 方法(ICML 2024)。感谢 Kyle Zheng 和 Minjia Huo 的 PR!
- 🎉 (2024.10.07) 提供 EXP 水印算法的一种等价替代实现(EXPGumbel),采用 Gumbel 噪声。通过此实现,用户可以通过调整配置文件中的采样温度来改变水印强度。
- 🎉 (2024.10.07) 新增 Unbiased 水印方法。
- 🎉 (2024.10.06) 我们很高兴地宣布,我们的论文“MarkLLM: 一个用于 LLM 水印的开源工具包”已被 EMNLP 2024 Demo 接受!
- 🎉 (2024.08.08) 新增 DiPmark 水印方法。感谢 Sheng Guan 的 PR!
- 🎉 (2024.08.01) 作为 python 包 发布!尝试运行
pip install markllm。我们在本文末尾提供了用户示例。 - 🎉 (2024.07.13) 新增 ITSEdit 水印方法。感谢 Yiming Liu 的 PR!
- 🎉 (2024.07.09) 为 KGW 添加更多哈希方案(跳过、最小值、加法、自哈希)。感谢 Yichen Di 的 PR!
- 🎉 (2024.07.08) 为 Christ 系列水印方法添加 top-k 过滤器。感谢 Kai Shi 的 PR!
- 🎉 (2024.07.03) 更新了反向翻译攻击。感谢 Zihan Tang 的 PR!
- 🎉 (2024.06.19) 根据强水印不可行性结果的相关论文(ICML,2024年;博客),更新了随机游走攻击。感谢 Hanlin Zhang 的 PR!
- 🎉 (2024.05.23) 我们非常高兴地宣布,我们的网站演示已正式上线!
MarkLLM 简介
概述
MarkLLM 是一个开源工具包,旨在促进大型语言模型(LLMs)中水印技术的研究与应用。随着大型语言模型的广泛应用,确保机器生成文本的真实性和来源变得至关重要。MarkLLM 简化了对水印技术的访问、理解和评估,使其既适用于研究人员,也便于更广泛的社区使用。

MarkLLM 的主要特性
实现框架:MarkLLM 提供了一个统一且可扩展的平台,用于实现各种 LLM 水印算法。目前支持来自两个重要家族的九种具体算法,从而促进了水印技术的集成与扩展。
框架设计:
当前支持的算法:
可视化解决方案:该工具包包含自定义可视化工具,能够在不同场景下清晰、深入地展示各类水印算法的工作原理。这些可视化工具有助于揭示算法机制,使用户更容易理解。

评估模块:MarkLLM 拥有 12 种评估工具,涵盖可检测性、鲁棒性以及对文本质量的影响,以其全面的评估方法在水印技术评估领域脱颖而出。此外,它还提供可定制的自动化评估流程,以满足不同需求和场景,进一步提升了工具包的实用性。
工具:
- 水印检测成功率计算器:FundamentalSuccessRateCalculator、DynamicThresholdSuccessRateCalculator
- 文本编辑器:WordDeletion、SynonymSubstitution、ContextAwareSynonymSubstitution、GPTParaphraser、DipperParaphraser、RandomWalkAttack
- 文本质量分析器:PPLCalculator、LogDiversityAnalyzer、BLEUCalculator、PassOrNotJudger、GPTDiscriminator
管道:
- 水印检测管道:WatermarkedTextDetectionPipeline、UnwatermarkedTextDetectionPipeline
- 文本质量管道:DirectTextQualityAnalysisPipeline、ReferencedTextQualityAnalysisPipeline、ExternalDiscriminatorTextQualityAnalysisPipeline
如何在您自己的代码中使用该工具包
环境设置
- Python 3.10
- PyTorch
- 运行
pip install -r requirements.txt
提示: 如果您希望使用 EXPEdit 或 ITSEdit 算法,您需要导入 .pyx 文件。以 EXPEdit 为例:
- 运行
python watermark/exp_edit/cython_files/setup.py build_ext --inplace - 将生成的
.so文件移动到watermark/exp_edit/cython_files/目录下。
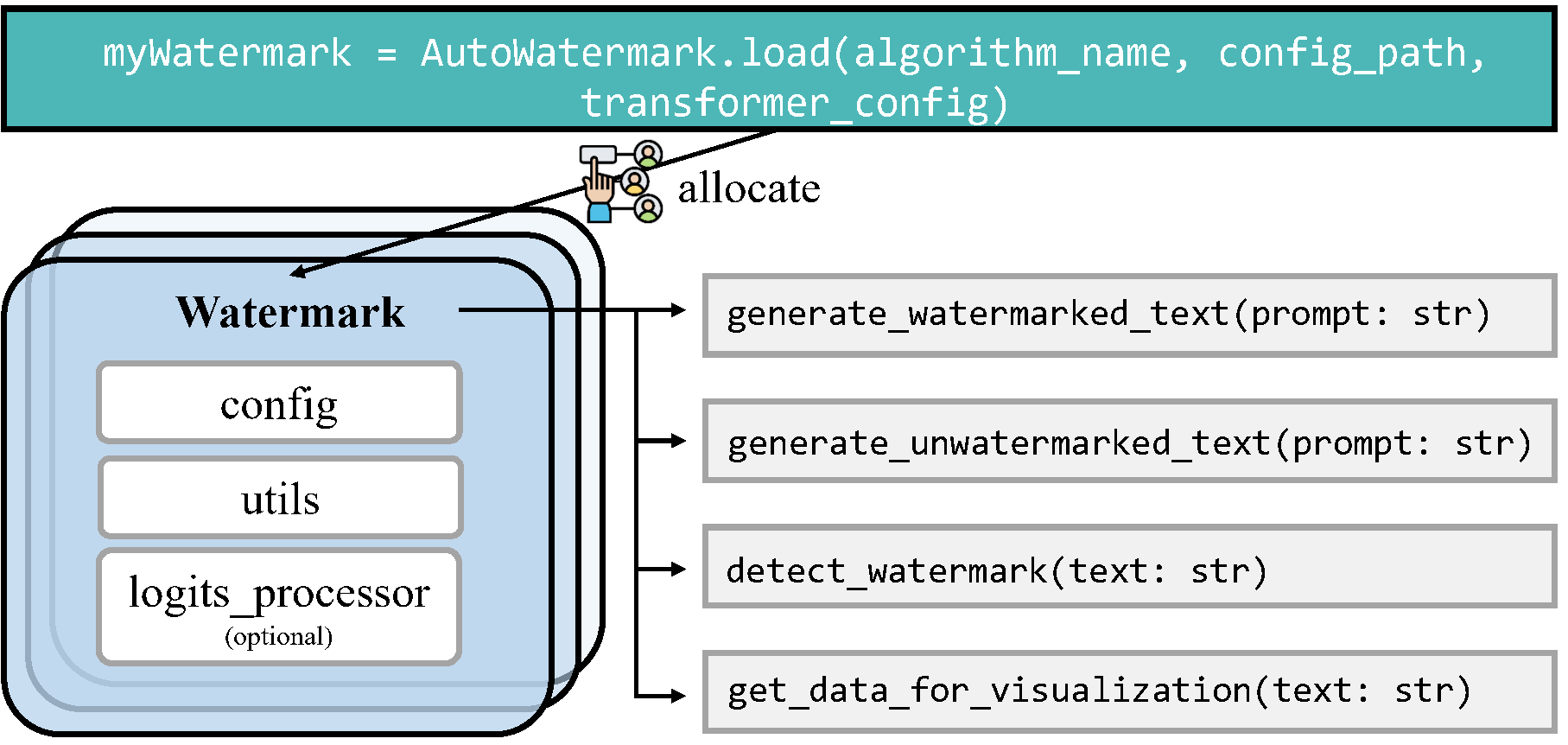
调用水印算法
import torch
from watermark.auto_watermark import AutoWatermark
from utils.transformers_config import TransformersConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# 设备
device = "cuda" if torch.cuda.is_available() else "cpu"
# Transformers 配置
transformers_config = TransformersConfig(model=AutoModelForCausalLM.from_pretrained('facebook/opt-1.3b').to(device),
tokenizer=AutoTokenizer.from_pretrained('facebook/opt-1.3b'),
vocab_size=50272,
device=device,
max_new_tokens=200,
min_length=230,
do_sample=True,
no_repeat_ngram_size=4)
# 加载水印算法
myWatermark = AutoWatermark.load('KGW',
algorithm_config='config/KGW.json',
transformers_config=transformers_config)
# 提示词
prompt = 'Good Morning.'
# 生成并检测
watermarked_text = myWatermark.generate_watermarked_text(prompt)
detect_result = myWatermark.detect_watermark(watermarked_text)
unwatermarked_text = myWatermark.generate_unwatermarked_text(prompt)
detect_result = myWatermark.detect_watermark(unwatermarked_text)
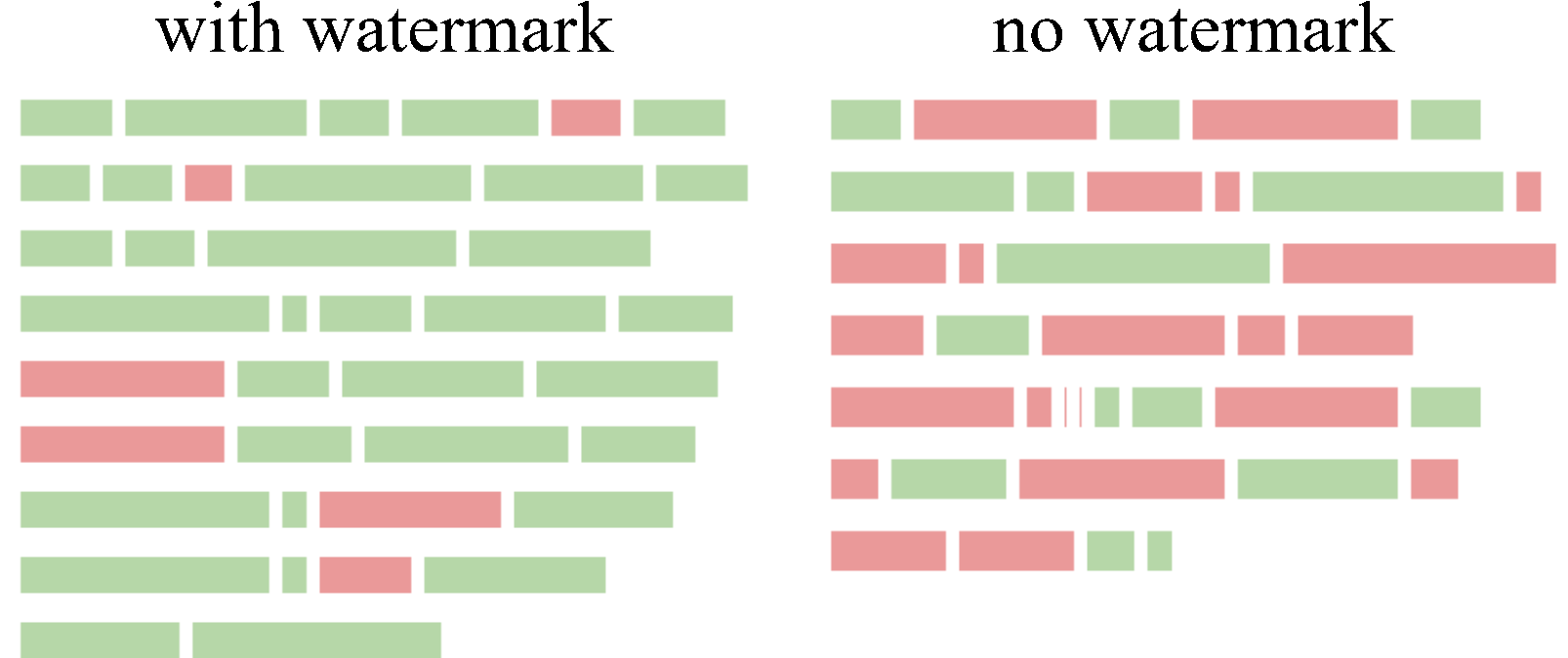
可视化机制
假设您已经有一对 watermarked_text 和 unwatermarked_text,并且希望通过水印算法可视化它们之间的差异,并在加水印的文本中特别突出水印部分,您可以使用 visualize/ 目录下的可视化工具。
KGW 家族
import torch
from visualize.font_settings import FontSettings
from watermark.auto_watermark import AutoWatermark
from utils.transformers_config import TransformersConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
from visualize.visualizer import DiscreteVisualizer
from visualize.legend_settings import DiscreteLegendSettings
from visualize.page_layout_settings import PageLayoutSettings
from visualize.color_scheme import ColorSchemeForDiscreteVisualization
# 加载水印算法
device = "cuda" if torch.cuda.is_available() else "cpu"
transformers_config = TransformersConfig(
model=AutoModelForCausalLM.from_pretrained('facebook/opt-1.3b').to(device),
tokenizer=AutoTokenizer.from_pretrained('facebook/opt-1.3b'),
vocab_size=50272,
device=device,
max_new_tokens=200,
min_length=230,
do_sample=True,
no_repeat_ngram_size=4)
myWatermark = AutoWatermark.load('KGW',
algorithm_config='config/KGW.json',
transformers_config=transformers_config)
# 获取用于可视化的数据
watermarked_data = myWatermark.get_data_for_visualization(watermarked_text)
unwatermarked_data = myWatermark.get_data_for_visualization(unwatermarked_text)
# 初始化可视化工具
visualizer = DiscreteVisualizer(color_scheme=ColorSchemeForDiscreteVisualization(),
font_settings=FontSettings(),
page_layout_settings=PageLayoutSettings(),
legend_settings=DiscreteLegendSettings())
# 可视化
watermarked_img = visualizer.visualize(data=watermarked_data,
show_text=True,
visualize_weight=True,
display_legend=True)
unwatermarked_img = visualizer.visualize(data=unwatermarked_data,
show_text=True,
visualize_weight=True,
display_legend=True)
# 保存
watermarked_img.save("KGW_watermarked.png")
unwatermarked_img.save("KGW_unwatermarked.png")
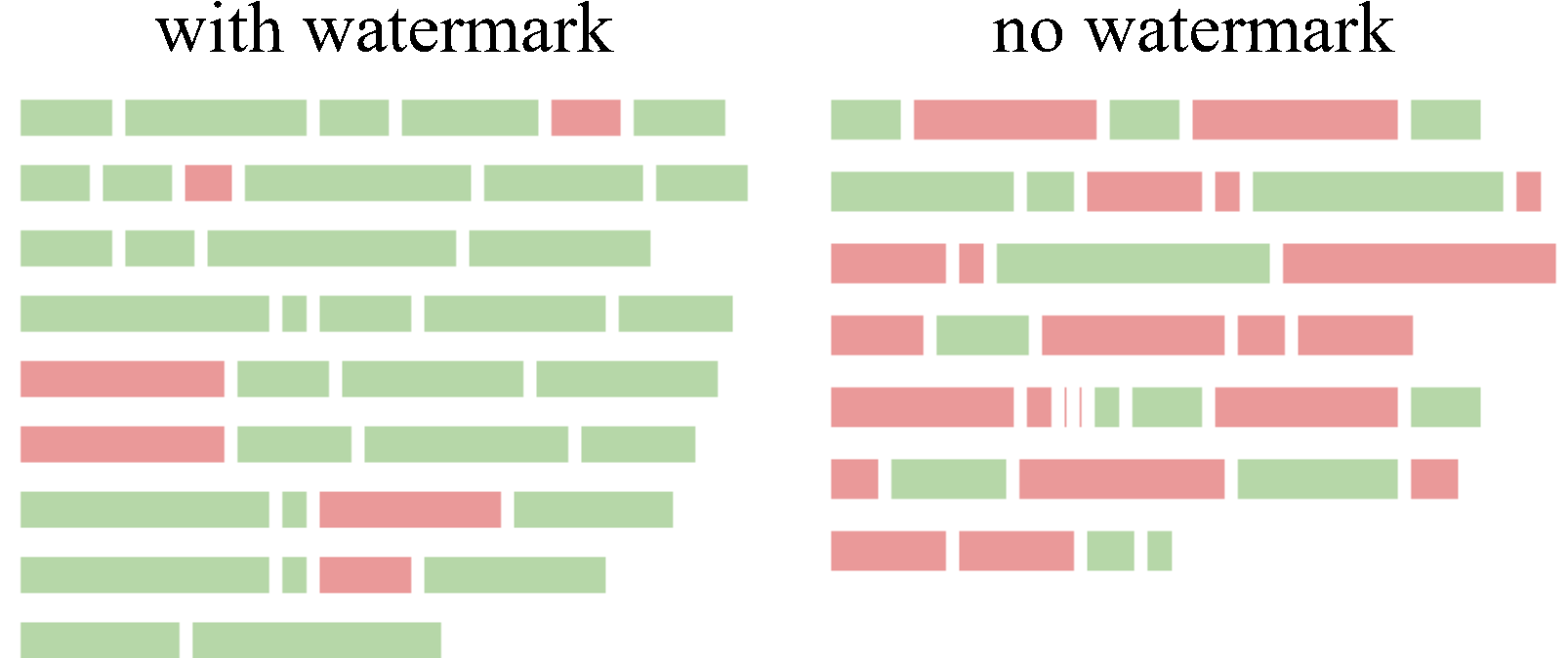
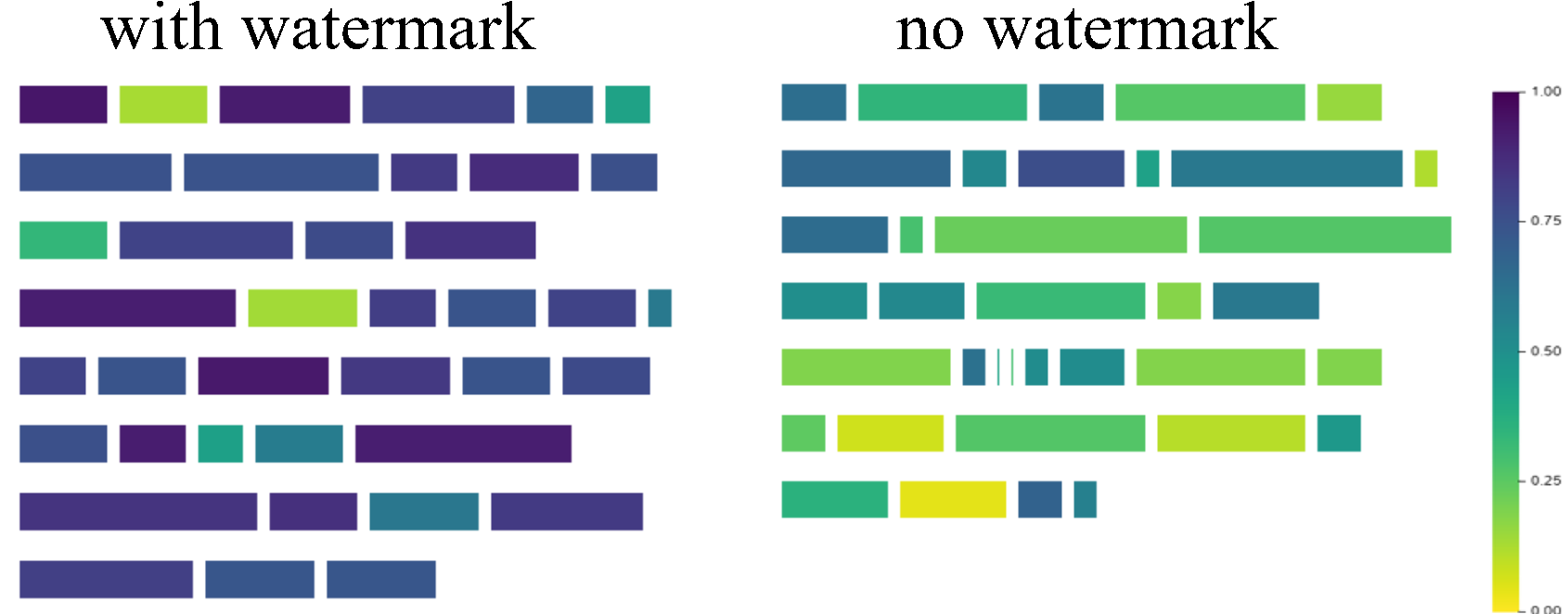
Christ 家族
import torch
from visualize.font_settings import FontSettings
from watermark.auto_watermark import AutoWatermark
from utils.transformers_config import TransformersConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
from visualize.visualizer import ContinuousVisualizer
from visualize.legend_settings import ContinuousLegendSettings
from visualize.page_layout_settings import PageLayoutSettings
from visualize.color_scheme import ColorSchemeForContinuousVisualization
# 加载水印算法
device = "cuda" if torch.cuda.is_available() else "cpu"
transformers_config = TransformersConfig(
model=AutoModelForCausalLM.from_pretrained('facebook/opt-1.3b').to(device),
tokenizer=AutoTokenizer.from_pretrained('facebook/opt-1.3b'),
vocab_size=50272,
device=device,
max_new_tokens=200,
min_length=230,
do_sample=True,
no_repeat_ngram_size=4)
myWatermark = AutoWatermark.load('EXP',
algorithm_config='config/EXP.json',
transformers_config=transformers_config)
# 获取用于可视化的数据
watermarked_data = myWatermark.get_data_for_visualization(watermarked_text)
unwatermarked_data = myWatermark.get_data_for_visualization(unwatermarked_text)
# 初始化可视化工具
visualizer = ContinuousVisualizer(color_scheme=ColorSchemeForContinuousVisualization(),
font_settings=FontSettings(),
page_layout_settings=PageLayoutSettings(),
legend_settings=ContinuousLegendSettings())
# 可视化
watermarked_img = visualizer.visualize(data=watermarked_data,
show_text=True,
visualize_weight=True,
display_legend=True)
unwatermarked_img = visualizer.visualize(data=unwatermarked_data,
show_text=True,
visualize_weight=True,
display_legend=True)
# 保存
watermarked_img.save("EXP_watermarked.png")
unwatermarked_img.save("EXP_unwatermarked.png")
有关如何使用可视化工具的更多示例,请参阅项目目录中的 test/test_visualize.py 脚本。
应用评估流水线
使用水印检测流水线
import torch
from evaluation.dataset import C4Dataset
from watermark.auto_watermark import AutoWatermark
from utils.transformers_config import TransformersConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
from evaluation.tools.text_editor import TruncatePromptTextEditor, WordDeletion
from evaluation.tools.success_rate_calculator import DynamicThresholdSuccessRateCalculator
from evaluation.pipelines.detection import WatermarkedTextDetectionPipeline, UnWatermarkedTextDetectionPipeline, DetectionPipelineReturnType
# 加载数据集
my_dataset = C4Dataset('dataset/c4/processed_c4.json')
# 设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Transformers 配置
transformers_config = TransformersConfig(
model=AutoModelForCausalLM.from_pretrained('facebook/opt-1.3b').to(device),
tokenizer=AutoTokenizer.from_pretrained('facebook/opt-1.3b'),
vocab_size=50272,
device=device,
max_new_tokens=200,
do_sample=True,
min_length=230,
no_repeat_ngram_size=4)
# 加载水印算法
my_watermark = AutoWatermark.load('KGW',
algorithm_config='config/KGW.json',
transformers_config=transformers_config)
# 初始化流水线
pipeline1 = WatermarkedTextDetectionPipeline(
dataset=my_dataset,
text_editor_list=[TruncatePromptTextEditor(), WordDeletion(ratio=0.3)],
show_progress=True,
return_type=DetectionPipelineReturnType.SCORES)
pipeline2 = UnWatermarkedTextDetectionPipeline(dataset=my_dataset,
text_editor_list=[],
show_progress=True,
return_type=DetectionPipelineReturnType.SCORES)
# 评估
calculator = DynamicThresholdSuccessRateCalculator(labels=['TPR', 'F1'], rule='best')
print(calculator.calculate(pipeline1.evaluate(my_watermark), pipeline2.evaluate(my_watermark)))
使用文本质量分析流水线
import torch
from evaluation.dataset import C4Dataset
from watermark.auto_watermark import AutoWatermark
from utils.transformers_config import TransformersConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
from evaluation.tools.text_editor import TruncatePromptTextEditor
from evaluation.tools.text_quality_analyzer import PPLCalculator
from evaluation.pipelines.quality_analysis import DirectTextQualityAnalysisPipeline, QualityPipelineReturnType
# 加载数据集
my_dataset = C4Dataset('dataset/c4/processed_c4.json')
# 设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Transformer 配置
transformers_config = TransformersConfig(
model=AutoModelForCausalLM.from_pretrained('facebook/opt-1.3b').to(device), tokenizer=AutoTokenizer.from_pretrained('facebook/opt-1.3b'),
vocab_size=50272,
device=device,
max_new_tokens=200,
min_length=230,
do_sample=True,
no_repeat_ngram_size=4)
# 加载水印算法
my_watermark = AutoWatermark.load('KGW',
algorithm_config='config/KGW.json',
transformers_config=transformers_config)
# 初始化流水线
quality_pipeline = DirectTextQualityAnalysisPipeline(
dataset=my_dataset,
watermarked_text_editor_list=[TruncatePromptTextEditor()],
unwatermarked_text_editor_list=[],
analyzer=PPLCalculator(
model=AutoModelForCausalLM.from_pretrained('..model/llama-7b/', device_map='auto'), tokenizer=LlamaTokenizer.from_pretrained('..model/llama-7b/'),
device=device),
unwatermarked_text_source='natural',
show_progress=True,
return_type=QualityPipelineReturnType.MEAN_SCORES)
# 评估
print(quality_pipeline.evaluate(my_watermark))
有关如何使用这些流水线的更多示例,请参阅项目目录中的 test/test_pipeline.py 脚本。
利用示例脚本来进行评估
在我们仓库的 evaluation/examples/ 目录中,您会找到一组专门用于系统化和自动化评估各种算法的 Python 脚本。通过使用这些示例,您可以快速有效地评估我们工具包中每种算法的可检测性、鲁棒性以及对文本质量的影响。
注意:要执行 evaluation/examples/ 中的脚本,首先需要运行以下命令来设置环境变量。
export PYTHONPATH="path_to_the_MarkLLM_project:$PYTHONPATH"
更多用户示例
额外的用户示例可在 test/ 目录中找到。要执行其中包含的脚本,首先需要运行以下命令来设置环境变量。
export PYTHONPATH="path_to_the_MarkLLM_project:$PYTHONPATH"
演示 Jupyter 笔记本
除了我们提供的 Colab Jupyter 笔记本之外(由于存储限制,部分模型无法下载),您还可以轻松地在本地机器上使用 MarkLLM_demo.ipynb 进行部署。
引用
@inproceedings{pan-etal-2024-markllm,
title = "{M}ark{LLM}: 用于大语言模型水印的开源工具包",
author = "潘雷毅 和 刘艾伟 和 何志伟 和 高子腾 和 赵轩东 和 陆义健 和 周炳林 和 刘书亮 和 胡旭明 和 文立杰 和 金尔文 和 余Philip S.",
editor = "埃尔南德斯·法里亚斯,黛丽娅·伊拉苏 和 霍普,汤姆 和 李曼玲",
booktitle = "2024年自然语言处理经验方法会议:系统演示论文集",
month = nov,
year = "2024",
address = "美国佛罗里达州迈阿密",
publisher = "计算语言学协会",
url = "https://aclanthology.org/2024.emnlp-demo.7",
pages = "61--71",
abstract = "针对大语言模型(LLMs)的水印技术,通过在模型输出中嵌入不易察觉但可被算法检测的信号来识别由LLM生成的文本,在缓解LLM潜在滥用方面变得至关重要。然而,现有的LLM水印算法种类繁多、机制复杂,且评估流程和视角多样,这给研究人员及学术界理解、实现和评估最新进展带来了挑战。为解决这些问题,我们提出了MarkLLM——一个用于LLM水印的开源工具包。MarkLLM提供了一个统一且可扩展的框架,用于实现各类LLM水印算法,并配备用户友好的界面以降低使用门槛。此外,它还通过自动可视化这些算法的底层机制,进一步提升理解度。在评估方面,MarkLLM提供了涵盖三个视角的12种工具以及两类自动化评估流水线。借助MarkLLM,我们旨在支持研究人员的工作,同时提高公众对LLM水印技术的理解与参与度,促进共识形成,并推动该领域的研究与应用进一步发展。我们的代码可在https://github.com/THU-BPM/MarkLLM获取。",
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器