top-cvpr-2025-papers
top-cvpr-2025-papers 是一个精心整理的 CVPR 2025 会议论文合集,旨在帮助开发者与研究人员快速锁定计算机视觉领域最具影响力与创新性的研究成果。面对今年高达一万三千多篇的投稿量,从中筛选出真正有价值的“皇冠明珠”绝非易事,而该资源库恰好解决了这一信息过载难题,让用户无需在海量文献中盲目摸索。
无论是高校科研人员、算法工程师,还是对前沿视觉技术充满好奇的学习者,都能在这里高效获取所需资讯。其独特亮点在于不仅提供了论文原文链接,还深度整合了开源代码仓库、演示视频及在线交互 Demo(如 Hugging Face 空间),实现了从理论到实践的无缝衔接。目前收录的内容涵盖 3D 视觉等热门方向,包括 VGGT、MASt3R-SLAM 等备受瞩目的重点项目。通过这种“论文 + 代码 + 演示”的一站式呈现方式,top-cvpr-2025-papers 极大地降低了复现顶级算法的门槛,是跟进年度技术风向的理想起点。
使用场景
某自动驾驶初创公司的算法团队正急需为新一代机器人引入实时高精度的 3D 重建与定位(SLAM)能力,以应对复杂的动态城市道路环境。
没有 top-cvpr-2025-papers 时
- 信息过载难筛选:面对 CVPR 2025 接收的 2878 篇论文,研究人员需耗费数天在海量列表中人工翻阅,难以快速锁定真正具有落地价值的“皇冠明珠”。
- 复现门槛高:找到潜在论文后,往往发现官方代码未开源、链接失效或缺乏演示 Demo,导致技术验证周期被无限拉长。
- 错失前沿突破:由于缺乏 curated(精选)视角,团队可能忽略像
MASt3R-SLAM这样结合了 3D 重建先验的实时密集 SLAM 突破性成果,仍在使用过时的技术方案。 - 协作效率低下:团队成员各自搜索,信息不同步,导致重复劳动且难以形成统一的技术选型共识。
使用 top-cvpr-2025-papers 后
- 精准直达核心:团队直接通过该仓库的"3D Vision"分类,秒级定位到带有🔥标记的
MASt3R-SLAM和VGGT等顶尖论文,将调研时间从数天压缩至几小时。 - 一站式复现资源:每个条目均附带经过验证的 Paper、Code、Video 及 Hugging Face Demo 链接,工程师可立即运行 Demo 验证效果并基于官方代码进行二次开发。
- 技术选型前瞻:借助精选列表,团队迅速采纳了融合 3D 重建先验的最新架构,显著提升了机器人在弱纹理区域的定位鲁棒性,保持技术领先性。
- 高效协同决策:仓库结构清晰,成为团队内部的技术雷达,成员基于同一份高质量清单讨论,快速达成技术路线共识。
top-cvpr-2025-papers 通过将海量学术成果转化为可立即执行工程资源,极大地缩短了从前沿理论到实际产品落地的距离。
运行环境要求
未说明
未说明

快速开始


👋 你好
计算机视觉与模式识别大会规模宏大。仅在 2025 年, 就有 13,008 篇论文提交,其中 2,878 篇被接收。我创建了这个仓库, 旨在帮助您查找 CVPR 会议中最为顶尖的论文。如果您寻找的论文未列入我的精选名单, 请查看完整的接收论文列表。
🗞️ 论文与海报
🔥 - 重点推荐论文
3D 视觉
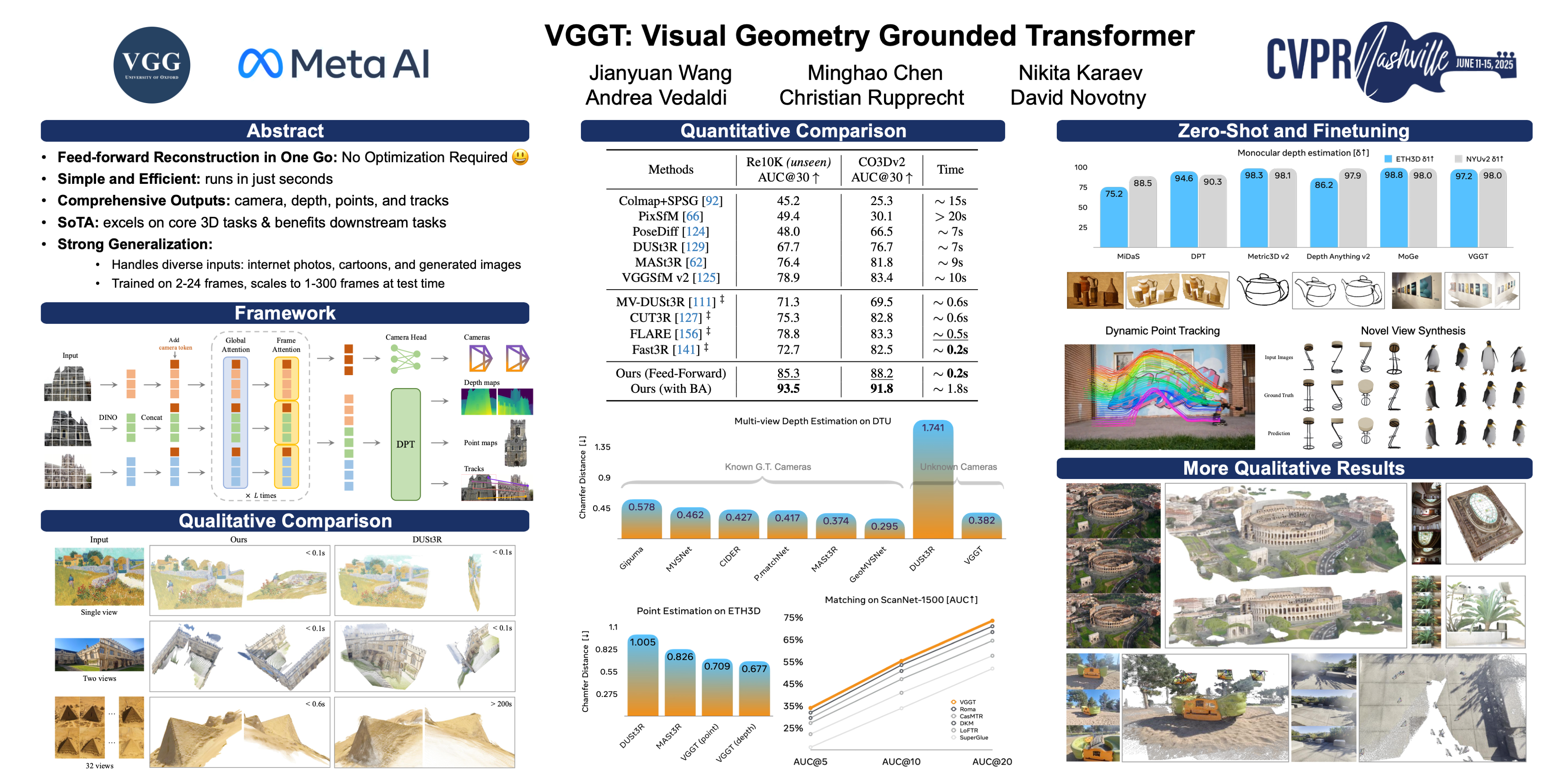 🔥 VGGT: 视觉几何基础Transformer
🔥 VGGT: 视觉几何基础Transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, David Novotny
[论文] [代码] [视频] [演示]
主题:3D 视觉
会话:周五 6月13日 太平洋夏令时下午2点—4点 海报展示2 #86
 🔥 MASt3R-SLAM: 基于3D重建先验知识的实时稠密SLAM
🔥 MASt3R-SLAM: 基于3D重建先验知识的实时稠密SLAM
Riku Murai, Eric Dexheimer, Andrew J. Davison
[论文] [代码] [视频]
主题:3D 视觉
会话:周六 6月14日 太平洋夏令时下午3点—5点 海报展示4 #83
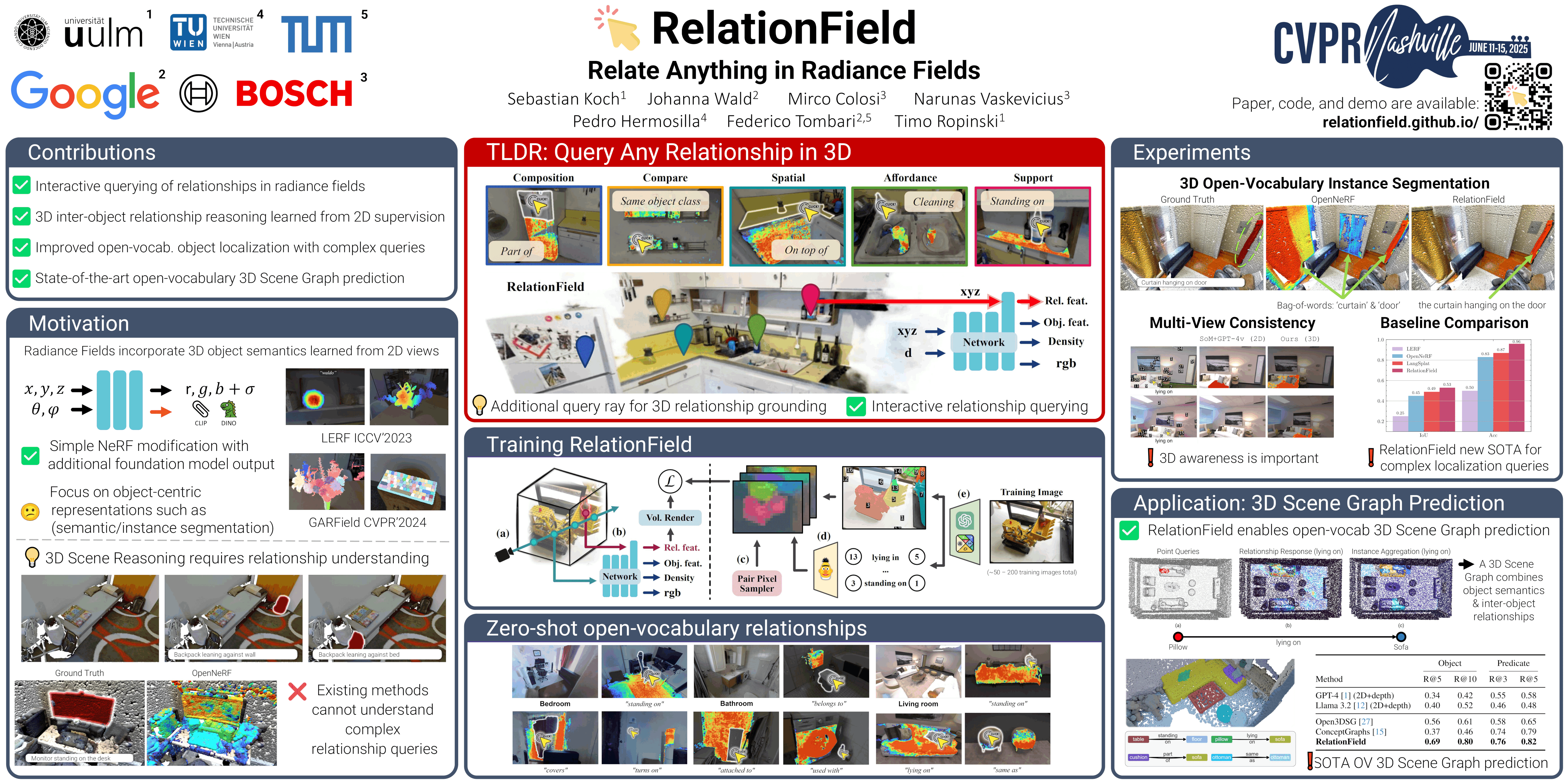 RelationField: 在辐射场中关联任何内容
RelationField: 在辐射场中关联任何内容
Sebastian Koch, Johanna Wald, Mirco Colosi, Narunas Vaskevicius, Pedro Hermosilla, Federico Tombari, Timo Ropinski
[论文] [代码] [视频]
主题:3D 视觉
会话:周日 6月15日 太平洋夏令时上午8:30—10:30 海报展示5 #190
深度估计
 UniK3D: 通用相机单目3D估计
UniK3D: 通用相机单目3D估计
Luigi Piccinelli, Christos Sakaridis, Mattia Segu, Yung-Hsu Yang, Siyuan Li, Wim Abbeloos, Luc Van Gool
[论文] [代码] [演示]
主题: 深度估计
会话: 周五 6月13日 太平洋夏令时上午8:30 — 上午10:30 海报展示1 #80
 🔥 DepthCrafter: 为开放世界视频生成一致的长深度序列
🔥 DepthCrafter: 为开放世界视频生成一致的长深度序列
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, Ying Shan
[论文] [代码] [演示]
主题: 深度估计
会话: 周五 6月13日 太平洋夏令时上午8:30 — 上午10:30 海报展示1 #171
 Video Depth Anything: 超长视频的一致深度估计
Video Depth Anything: 超长视频的一致深度估计
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, Bingyi Kang
[论文] [代码] [演示]
主题: 深度估计
会话: 周日 6月15日 太平洋夏令时上午8:30 — 上午10:30 海报展示5 #169
可解释性与可理解性
 🔥 通过视觉精确搜索解释对象级基础模型
🔥 通过视觉精确搜索解释对象级基础模型
Ruoyu Chen, Siyuan Liang, Jingzhi Li, Shiming Liu, Maosen Li, Zhen Huang, Hua Zhang, Xiaochun Cao
[论文] [代码] [Colab]
主题: 可解释性与可理解性
会话: 周日 6月15日 太平洋夏令时下午2点 — 下午4点 海报展示6 #372
凝视目标估计
 🔥 Gaze-LLE: 基于大规模学习编码器的凝视目标估计
🔥 Gaze-LLE: 基于大规模学习编码器的凝视目标估计
Fiona Ryan, Ajay Bati, Sangmin Lee, Daniel Bolya, Judy Hoffman, James M. Rehg
[论文] [代码] [演示] [Colab]
主题: 凝视目标估计
会话: 周日 6月15日 太平洋夏令时下午2点 — 下午4点 海报展示6 #98
生成模型
 MMAudio: 操控多模态联合训练以实现高质量的视频转音频合成
MMAudio: 操控多模态联合训练以实现高质量的视频转音频合成
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, Yuki Mitsufuji
[论文] [代码] [视频] [演示] [Colab]
主题: 生成模型
分会场: 周日 6月15日 太平洋夏令时下午2点 — 下午4点 海报展示6 #260
 SemanticDraw: 基于图像扩散模型实现实时交互式内容创作
SemanticDraw: 基于图像扩散模型实现实时交互式内容创作
Jaerin Lee, Daniel Sungho Jung, Kanggeon Lee, Kyoung Mu Lee
[论文] [代码] [视频] [演示] [Colab]
主题: 生成模型
分会场: 周六 6月14日 太平洋夏令时上午8:30 — 上午10:30 海报展示3 #226
图像匹配
 MINIMA: 模态不变图像匹配
MINIMA: 模态不变图像匹配
Jiangwei Ren, Xingyu Jiang, Zizhuo Li, Dingkang Liang, Xin Zhou, Xiang Bai
[论文] [代码] [演示]
主题: 图像匹配
分会场: 周日 6月15日 太平洋夏令时上午8:30 — 上午10:30 海报展示5 #190
图像矢量化
 基于语义简化的分层图像矢量化
基于语义简化的分层图像矢量化
Zhenyu Wang, Jianxi Huang, Zhida Sun, Yuanhao Gong, Daniel Cohen-Or, Min Lu
[论文] [代码] [视频]
主题: 图像矢量化
分会场: 周五 6月13日 太平洋夏令时下午2点 — 下午4点 海报展示2 #226
目标跟踪
 🔥 MITracker: 多视角融合的视觉目标跟踪
🔥 MITracker: 多视角融合的视觉目标跟踪
徐孟杰、朱一涛、姜浩天、李佳明、沈振荣、王晟、黄浩林、王欣宇、杨庆、张翰、王倩
[论文] [代码]
主题:目标跟踪
分会场:6月15日(周日)下午2点—4点 太平洋夏令时 海报展示6 #98
 将多目标跟踪视为ID预测
将多目标跟踪视为ID预测
高若鹏、齐骥、王利民
[论文] [代码]
主题:目标跟踪
分会场:6月15日(周日)下午2点—4点 太平洋夏令时 海报展示6 #163
EdgeTAM:端侧万物跟踪模型
周冲、朱晨晨、熊云阳、萨克沙姆·苏里、肖凡艺、吴乐萌、拉古拉曼·克里希纳穆尔蒂、戴博、罗伊·陈昌、维卡斯·钱德拉、比尔盖·索兰
[论文] [代码] [演示]
主题:目标跟踪
分会场:6月14日(周六)上午8:30—10:30 太平洋夏令时 海报展示3 #304
 基于SAM2的干扰物感知记忆用于视觉目标跟踪
基于SAM2的干扰物感知记忆用于视觉目标跟踪
约瓦娜·维德诺维奇、艾伦·卢克齐奇、马泰伊·克里斯坦
[论文] [代码]
主题:目标跟踪
分会场:6月15日(周日)上午8:30—10:30 太平洋夏令时 海报展示5 #309
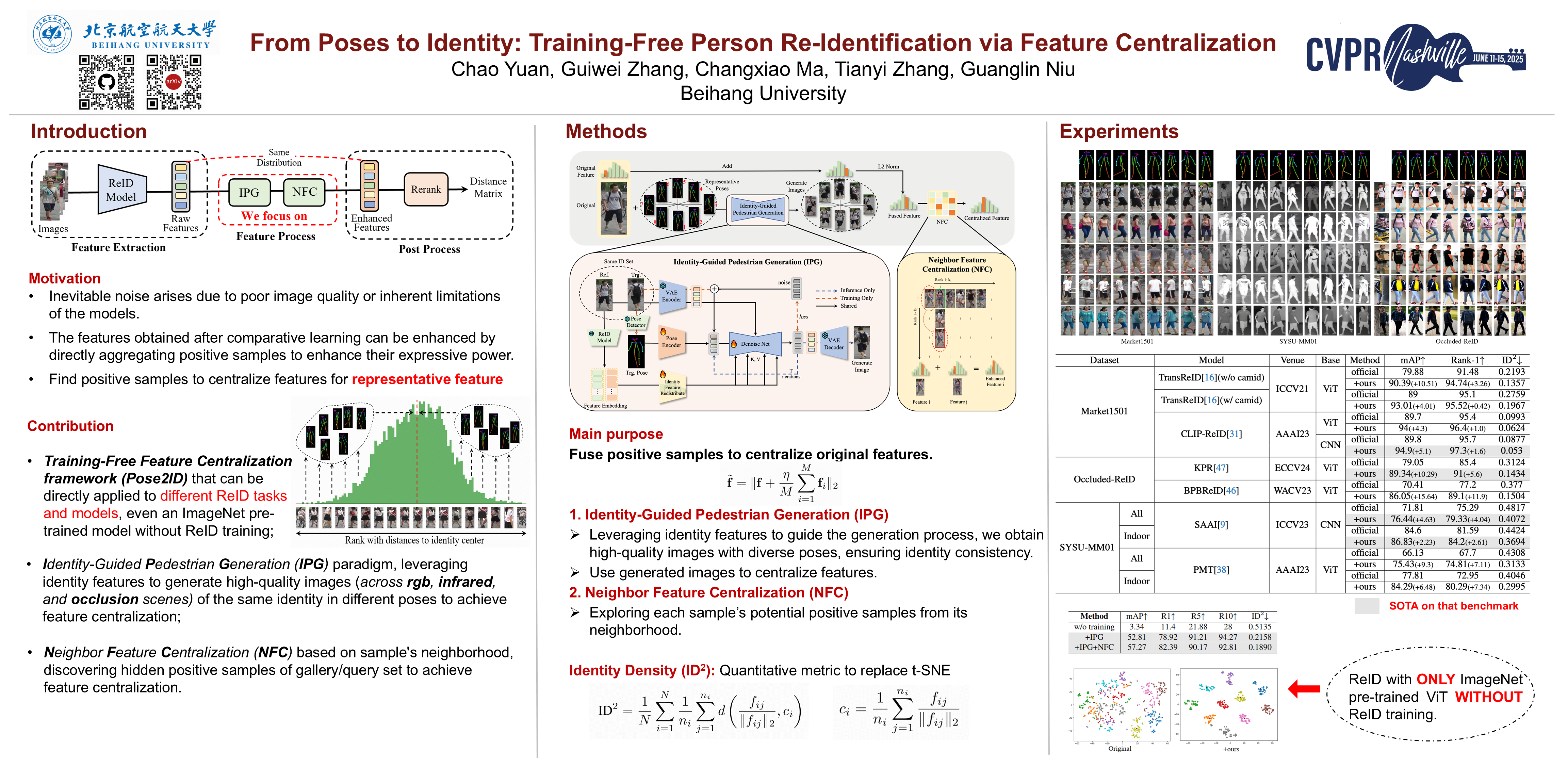 从姿态到身份:基于特征中心化的免训练人体重识别
从姿态到身份:基于特征中心化的免训练人体重识别
袁超、张贵伟、马长啸、张天义、牛广林
[论文] [代码]
主题:目标跟踪
分会场:6月15日(周日)上午8:30—10:30 太平洋夏令时 海报展示5 #190
开放世界检测
 🔥 基于多模态大语言模型的零样本异常检测与推理
🔥 基于多模态大语言模型的零样本异常检测与推理
Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, Vishal M. Patel, Isht Dwivedi
[论文] [代码] [视频]
主题:开放世界检测
分会场:6月14日(周六)下午3点—5点 太平洋夏令时 海报展示4 #435
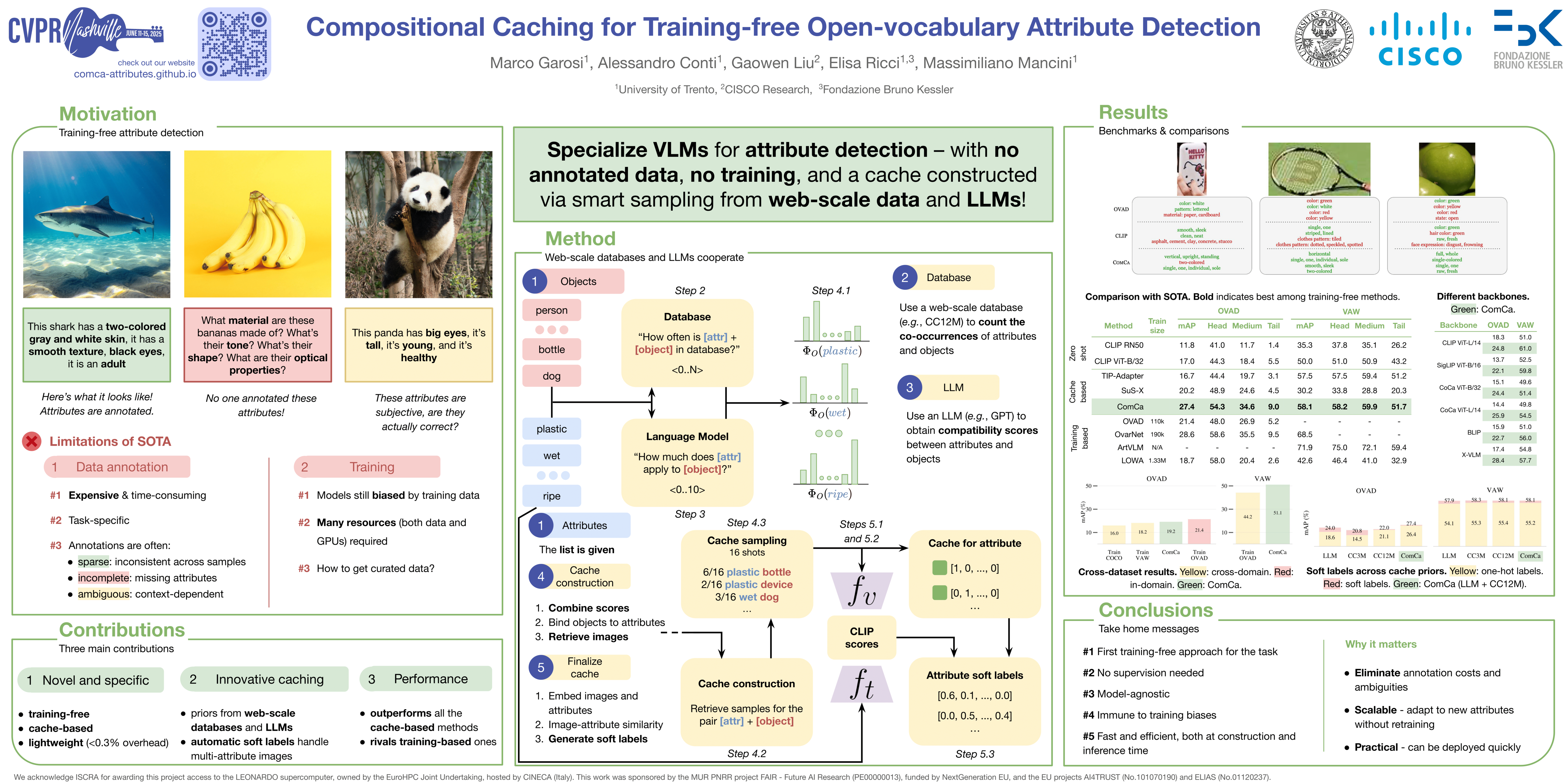 🔥 用于免训练开放词汇属性检测的组合式缓存
🔥 用于免训练开放词汇属性检测的组合式缓存
Marco Garosi, Alessandro Conti, Gaowen Liu, Elisa Ricci, Massimiliano Mancini
[论文] [代码] [视频]
主题:开放世界检测
分会场:6月14日(周六)上午8:30—10:30 太平洋夏令时 海报展示3 #426
姿态估计
 🔥 使用生物力学精确骨架重建人体
🔥 使用生物力学精确骨架重建人体
Yan Xia, Xiaowei Zhou, Etienne Vouga, Qixing Huang, Georgios Pavlakos
[论文] [代码] [演示] [Colab]
主题:姿态估计
分会场:6月13日(周五)下午2点—4点 太平洋夏令时 海报展示2 #91
分割
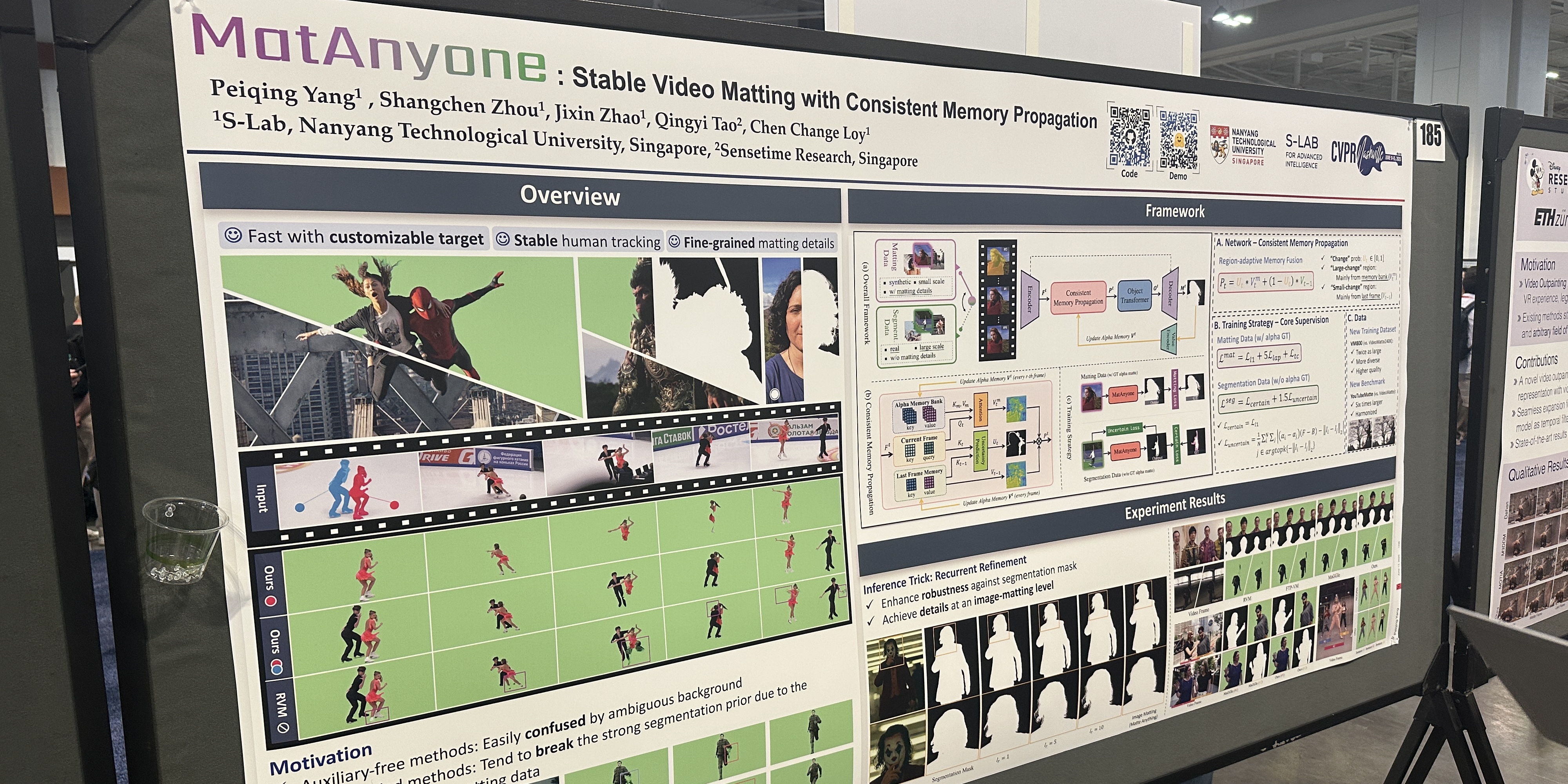 MatAnyone:具有持续记忆传播的稳定视频抠图
MatAnyone:具有持续记忆传播的稳定视频抠图
Peiqing Yang, Shangchen Zhou, Jixin Zhao, Qingyi Tao, Chen Change Loy
[论文] [代码] [视频] [演示]
主题:分割
分会场:6月13日(周五)下午2点—4点 太平洋夏令时 海报展示2 #185
立体匹配
 🔥 FoundationStereo:零样本立体匹配
🔥 FoundationStereo:零样本立体匹配
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, Stan Birchfield
[论文] [代码] [视频]
主题:立体匹配
分会场:6月13日(周五)下午2点—4点 太平洋夏令时 海报展示2 #81
视频理解
 迈向通用足球视频理解
迈向通用足球视频理解
Jiayuan Rao, Haoning Wu, Hao Jiang, Ya Zhang, Yanfeng Wang, Weidi Xie
[论文] [代码]
主题:视频理解
分会场:6月13日(周五)下午2点—4点 太平洋夏令时 海报展示2 #185
视觉-语言模型
 FastVLM:视觉语言模型的高效视觉编码
FastVLM:视觉语言模型的高效视觉编码
Pavan Kumar Anasosalu Vasu、Fartash Faghri、Chun-Liang Li、Cem Koc、Nate True、Albert Antony、Gokul Santhanam、James Gabriel、Peter Grasch、Oncel Tuzel、Hadi Pouransari
[论文] [代码]
主题: 视觉-语言模型
会场: 周六 6月14日 太平洋夏令时下午3点—5点 海报展示4 #378
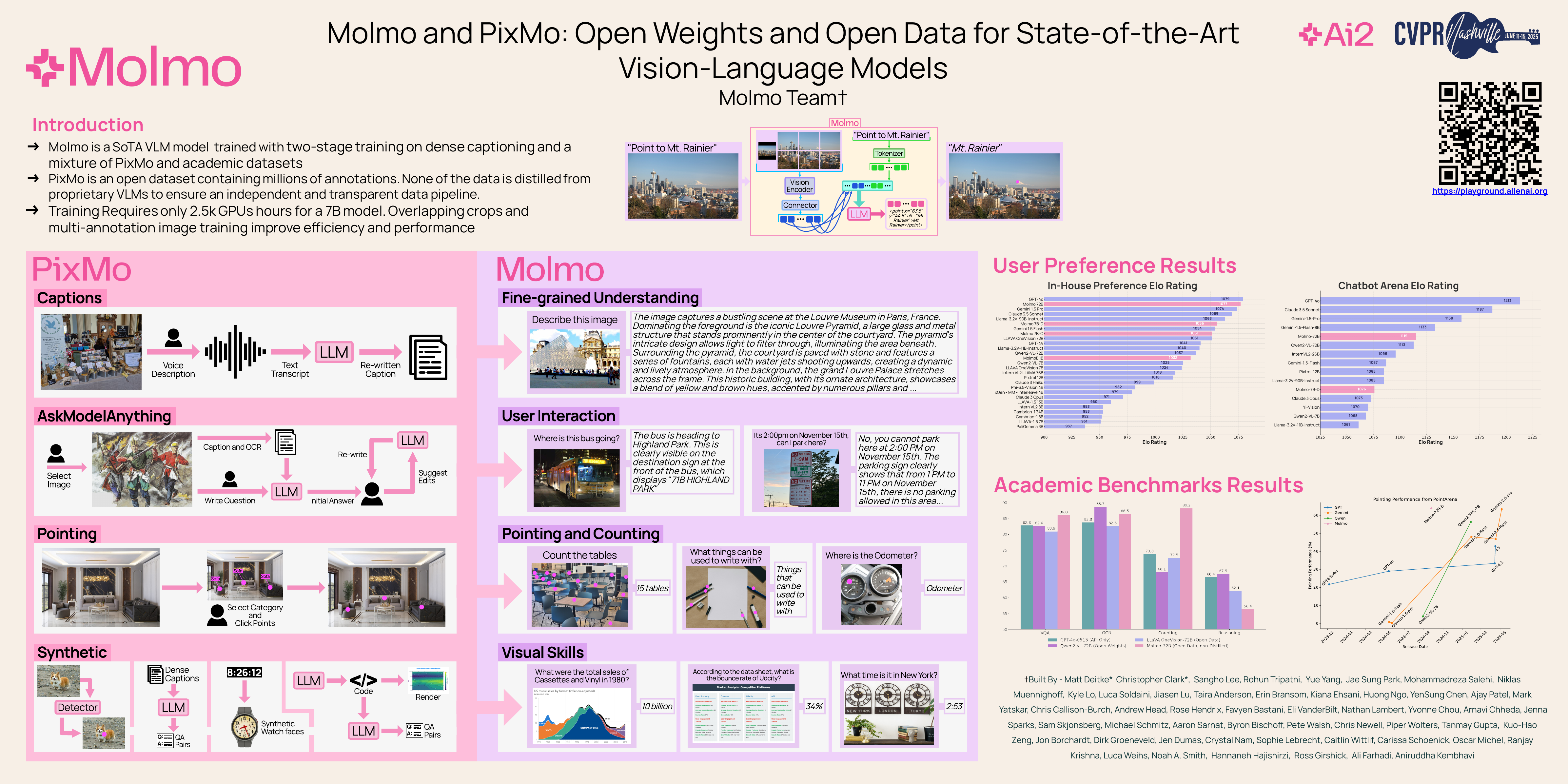 🔥 Molmo和PixMo:用于最先进视觉-语言模型的开放权重与开放数据
🔥 Molmo和PixMo:用于最先进视觉-语言模型的开放权重与开放数据
Matt Deitke、Christopher Clark、Sangho Lee、Rohun Tripathi、Yue Yang、Jae Sung Park、Mohammadreza Salehi、Niklas Muennighoff、Kyle Lo、Luca Soldaini、Jiasen Lu、Taira Anderson、Erin Bransom、Kiana Ehsani、Huong Ngo、YenSung Chen、Ajay Patel、Mark Yatskar、Chris Callison-Burch、Andrew Head、Rose Hendrix、Favyen Bastani、Eli VanderBilt、Nathan Lambert、Yvonne Chou、Arnavi Chheda、Jenna Sparks、Sam Skjonsberg、Michael Schmitz、Aaron Sarnat、Byron Bischoff、Pete Walsh、Chris Newell、Piper Wolters、Tanmay Gupta、Kuo-Hao Zeng、Jon Borchardt、Dirk Groeneveld、Crystal Nam、Sophie Lebrecht、Caitlin Wittlif、Carissa Schoenick、Oscar Michel、Ranjay Krishna、Luca Weihs、Noah A. Smith、Hannaneh Hajishirzi、Ross Girshick、Ali Farhadi、Aniruddha Kembhavi
[论文] [演示]
主题: 视觉-语言模型
会场: 周五 6月13日 太平洋夏令时上午8:30—10:30 海报展示1 #80
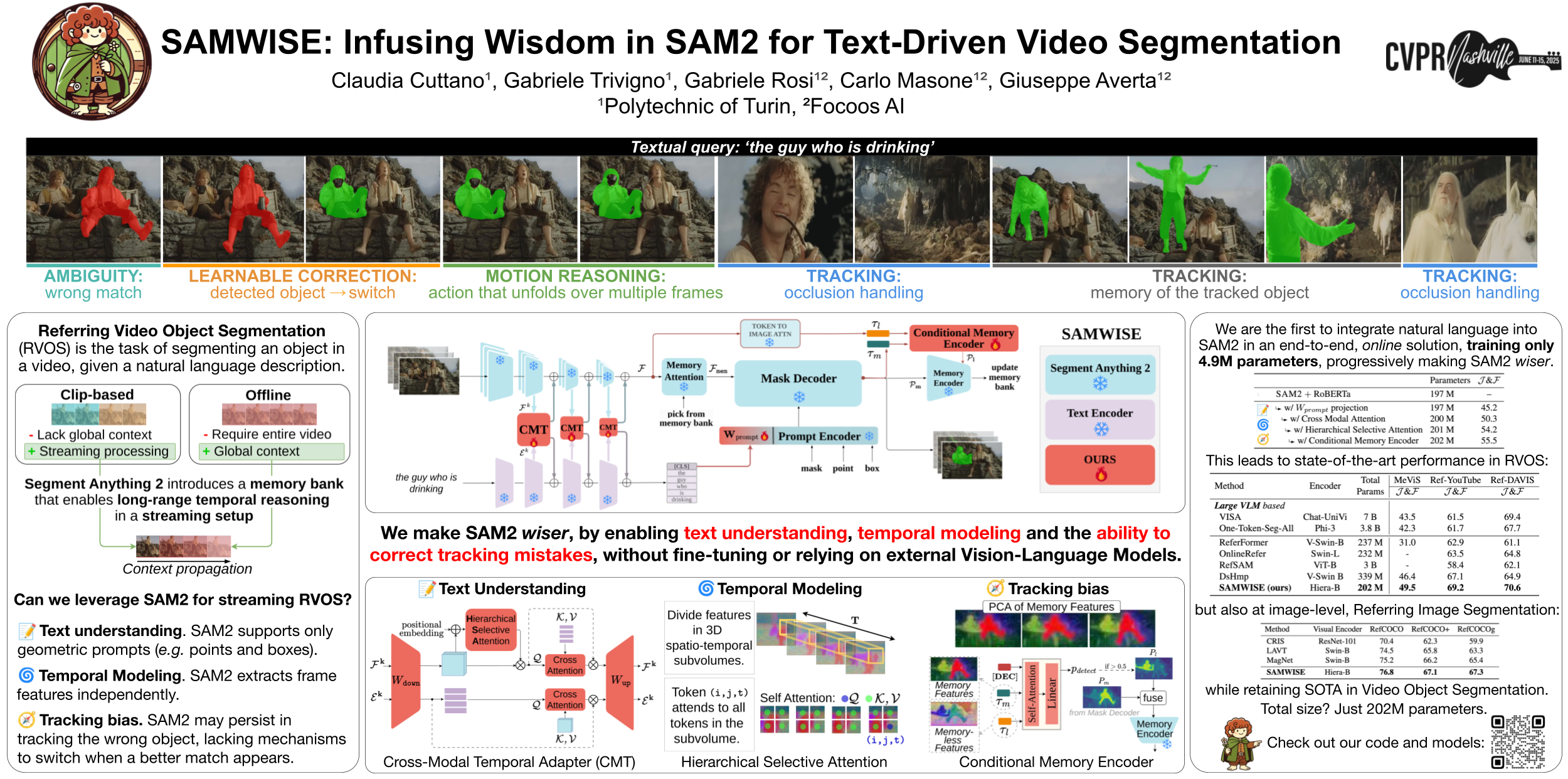 🔥 SAMWISE:将智慧注入SAM2以实现文本驱动的视频分割
🔥 SAMWISE:将智慧注入SAM2以实现文本驱动的视频分割
Claudia Cuttano、Gabriele Trivigno、Gabriele Rosi、Carlo Masone、Giuseppe Averta
[论文] [代码] [视频]
主题: 视觉-语言模型
会场: 周五 6月13日 太平洋夏令时上午8:30—10:30 海报展示1 #308
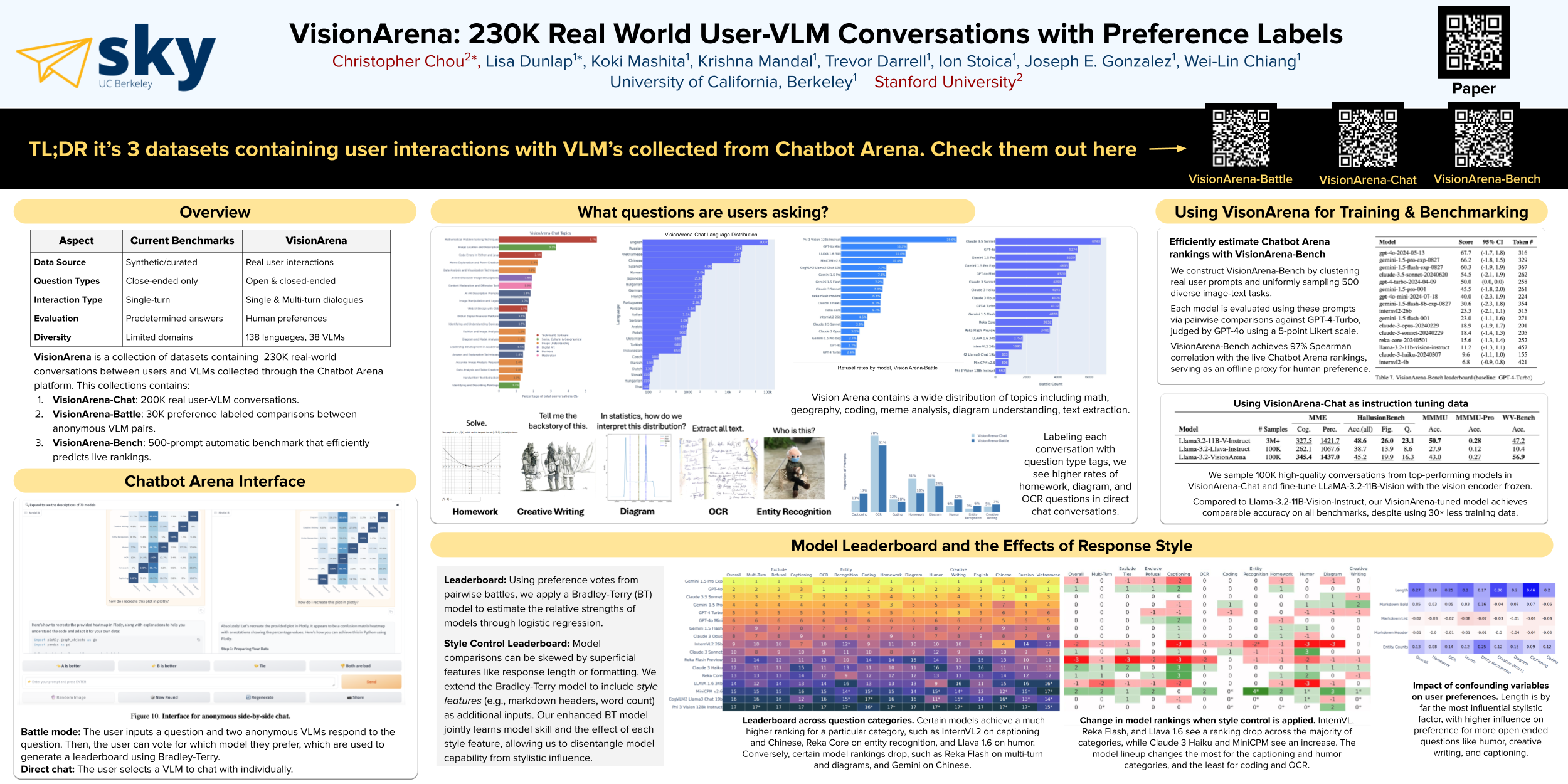 VisionArena:带有偏好标签的23万份真实世界用户-VLM对话
VisionArena:带有偏好标签的23万份真实世界用户-VLM对话
Christopher Chou、Lisa Dunlap、Koki Mashita、Krishna Mandal、Trevor Darrell、Ion Stoica、Joseph E. Gonzalez、Wei-Lin Chiang
[论文] [演示]
主题: 视觉-语言模型
会场: 周五 6月13日 太平洋夏令时上午8:30—10:30 海报展示1 #353
 DINOv2与文本相遇:图像级与像素级视觉-语言对齐的统一框架
DINOv2与文本相遇:图像级与像素级视觉-语言对齐的统一框架
Cijo Jose、Théo Moutakanni、Dahyun Kang、Federico Baldassarre、Timothée Darcet、Hu Xu、Daniel Li、Marc Szafraniec、Michaël Ramamonjisoa、Maxime Oquab、Oriane Siméoni、Huy V. Vo、Patrick Labatut、Piotr Bojanowski
[论文] [代码] [视频] [Colab]
主题: 视觉-语言模型
会场: 周日 6月15日 太平洋夏令时上午8:30—10:30 海报展示5 #169
视觉智能体
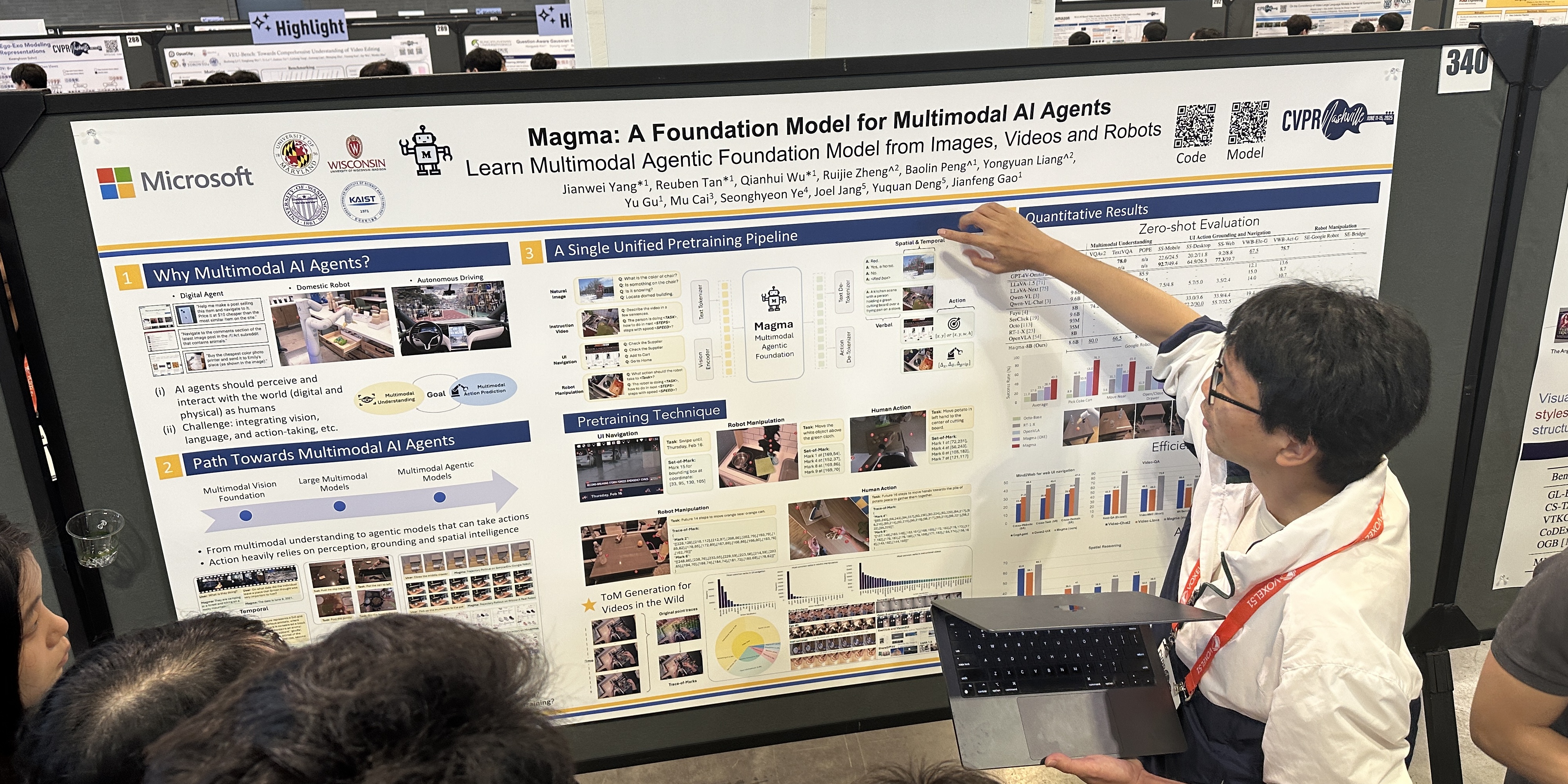 Magma:多模态AI智能体的基础模型
Magma:多模态AI智能体的基础模型
杨建伟、鲁本·谭、吴千慧、郑睿杰、彭宝林、梁永源、顾宇、蔡牧、叶成贤、张乔尔、邓宇泉、拉尔斯·利登、高建峰
[论文] [代码] [视频] [演示]
主题:视觉智能体
分会场:6月14日(周六)太平洋夏令时上午8:30—10:30 海报展示3 #340
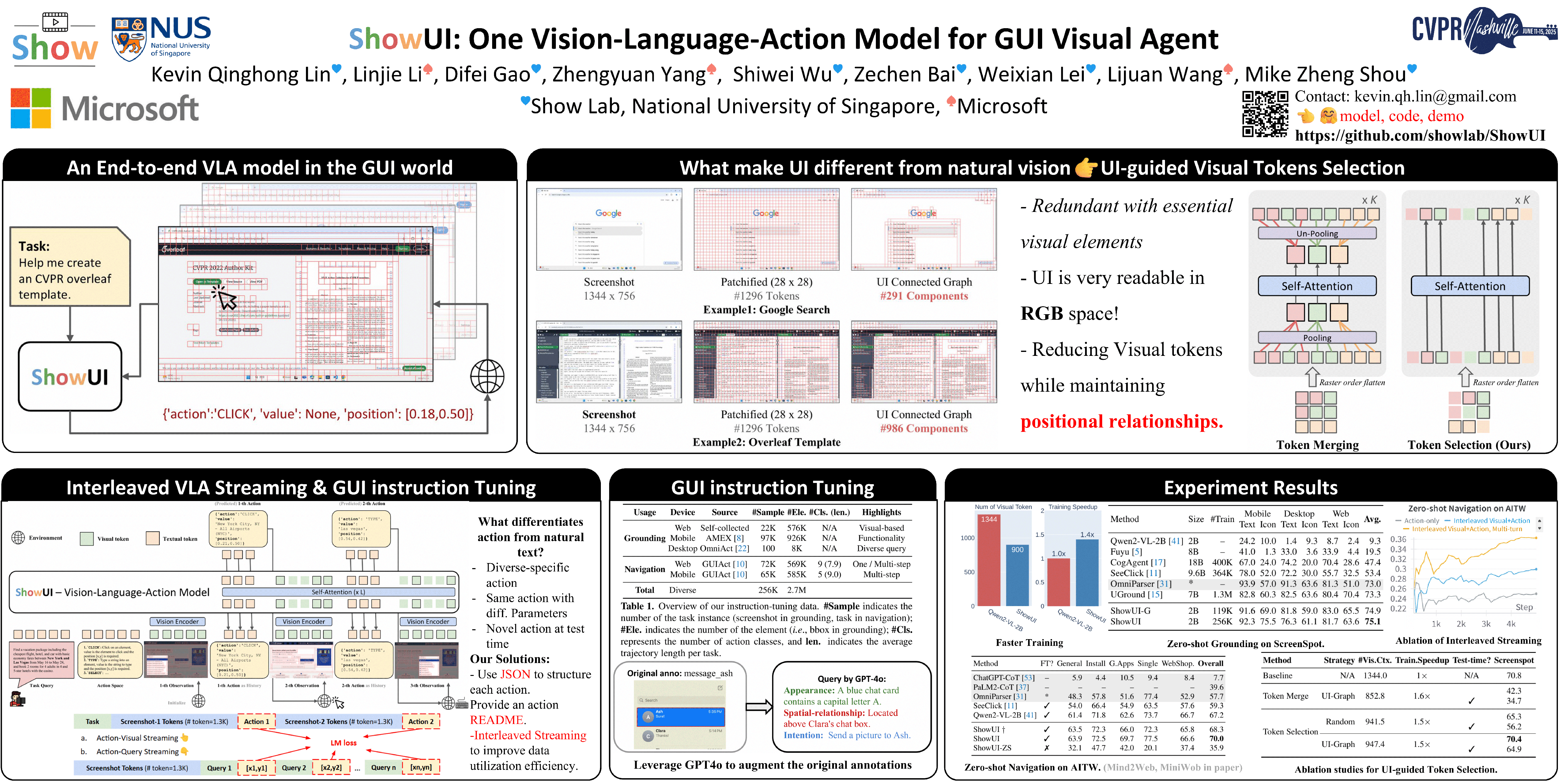 ShowUI:用于GUI视觉智能体的单一视觉-语言-动作模型
ShowUI:用于GUI视觉智能体的单一视觉-语言-动作模型
林庆鸿、李林杰、高迪飞、杨正元、吴世伟、白泽辰、雷伟贤、王丽娟、赵Mike
[论文] [代码] [演示]
主题:视觉智能体
分会场:6月14日(周六)太平洋夏令时下午3:00—5:00 海报展示4 #352
 基于动态API的空间推理视觉智能体AI
基于动态API的空间推理视觉智能体AI
达米亚诺·马尔西利、罗洪·阿格拉瓦尔、易松·岳、乔治娅·吉奥克萨里
[论文] [代码] [视频]
主题:视觉智能体
分会场:6月14日(周六)太平洋夏令时下午3:00—5:00 海报展示4 #352
🦸 贡献
我们非常希望得到您的帮助,让这个仓库变得更加完善!如果您知道这里尚未列出的优秀论文,或者有任何改进建议,欢迎随时提交 issue 或 pull request。
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备