AgentLab
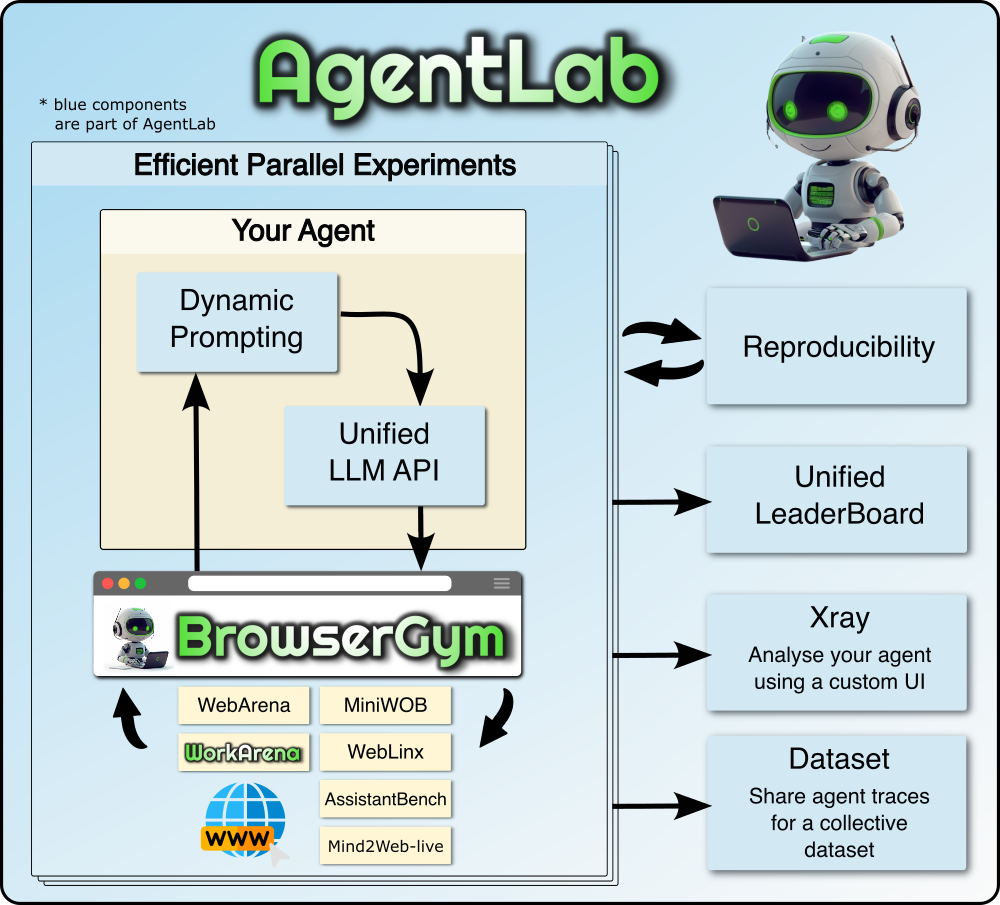
AgentLab 是一个专为网页智能体(Web Agents)研发打造的开源框架,旨在简化智能体的开发、测试与基准评估流程。在人工智能自动操作网页的任务中,研究人员常面临实验难以复现、大规模并行测试复杂以及不同基准标准不统一等挑战。AgentLab 通过提供一套可扩展的架构,有效解决了这些痛点,确保实验结果既高效又可重复验证。
这款工具特别适合 AI 研究人员和开发者使用,尤其是那些致力于提升智能体在 WebArena、WorkArena 等多样化任务中表现的专业团队。虽然它功能强大,但需注意其定位是科研加速工具,而非面向普通消费者的成品软件。
AgentLab 的技术亮点在于其强大的工程化能力:支持利用 Ray 进行大规模并行实验,显著缩短测试周期;提供统一的 LLM API,无缝对接 OpenAI、Azure、OpenRouter 及本地部署模型;此外,它还深度集成了 BrowserGym 生态系统,内置多种主流评测基准,并提供可视化的助手界面与排行榜功能,帮助团队快速分析结果并迭代优化智能体策略。
使用场景
某 AI 实验室的研究团队正致力于优化基于大模型的网页自动化代理(Web Agent),需要在 WebArena 和 WorkArena 等多个基准测试上验证新算法的泛化能力与稳定性。
没有 AgentLab 时
- 环境搭建繁琐:每次切换 benchmark(如从 WebArena 切到 WorkArena)都需要手动配置独立的 Docker 环境和数据集,耗时且容易出错。
- 实验难以并行:缺乏统一的调度框架,无法利用 Ray 进行大规模并行测试,跑完 800+ 个任务往往需要数天时间。
- 结果不可复现:由于随机种子管理混乱和日志记录不规范,不同成员跑出的数据对不上,论文实验结果难以被团队内部复现。
- 模型适配成本高:每更换一个后端 LLM(如从 OpenAI 切换到自部署的 TGI 模型),都需要重写大量的 API 对接代码。
使用 AgentLab 后
- 一键基准切换:通过内置的 BrowserGym 支持,仅需修改配置文件即可在 WebArena、WorkArena 等主流榜单间无缝切换,环境自动就绪。
- 高效并行执行:原生集成 Ray 框架,将数百个任务的测试时间从数天压缩至数小时,大幅加速迭代周期。
- 确保科研复现性:内置严格的种子控制和自动化日志系统,确保每一次实验轨迹可追溯、结果可精确复现,满足顶会发表要求。
- 统一模型接口:提供标准化的 LLM API 层,支持 OpenRouter、Azure 及本地模型即插即用,让研究者专注于算法逻辑而非工程适配。
AgentLab 将研究人员从繁琐的工程基建中解放出来,使其能专注于核心算法创新,并以工业级的标准快速产出可复现的高水平科研成果。
运行环境要求
- 未说明 (支持 Playwright 的平台通常包括 Linux
- macOS
- Windows)
未说明 (框架主要依赖 LLM API,本地推理需求取决于所选模型后端)
未说明 (并行运行 10-50 个任务时建议具备充足内存)

快速开始



[!WARNING] AgentLab旨在提供一个开放、易用且可扩展的框架,以加速网络智能体研究领域的发展。 它并非面向消费者的成品,请谨慎使用!
AgentLab是一个用于在各种由BrowserGym支持的 基准测试上开发和评估智能体的框架。更多详细信息请参阅我们的 BrowserGym生态系统论文。
AgentLab的特点:
- 使用ray轻松进行大规模并行智能体实验
- 为基于BrowserGym构建智能体提供的基础组件
- 统一的LLM API,适用于OpenRouter、OpenAI、Azure或使用TGI自托管的模型
- 运行WebArena等基准测试的首选方式
- 多种可重复性功能
- 统一的排行榜
🎯 支持的基准测试
| 基准测试 | 设置 链接 |
# 任务 模板 |
种子 多样性 |
最大 步数 |
多标签页 | 托管方式 | BrowserGym 排行榜 |
|---|---|---|---|---|---|---|---|
| WebArena | 设置 | 812 | 无 | 30 | 是 | 自托管(docker) | 即将推出 |
| WebArena-Verified | 设置 | 812 | 无 | 30 | 是 | 自托管 | 即将推出 |
| WorkArena L1 | 设置 | 33 | 高 | 30 | 否 | 演示实例 | 即将推出 |
| WorkArena L2 | 设置 | 341 | 高 | 50 | 否 | 演示实例 | 即将推出 |
| WorkArena L3 | 设置 | 341 | 高 | 50 | 否 | 演示实例 | 即将推出 |
| WebLinx | - | 31586 | 无 | 1 | 否 | 自托管(数据集) | 即将推出 |
| VisualWebArena | 设置 | 910 | 无 | 30 | 是 | 自托管(docker) | 即将推出 |
| AssistantBench | 设置 | 214 | 无 | 30 | 是 | 实时网页 | 即将推出 |
| GAIA(即将推出) | - | - | 无 | - | - | 实时网页 | 即将推出 |
| Mind2Web-live(即将推出) | - | - | 无 | - | - | 实时网页 | 即将推出 |
| MiniWoB | 设置 | 125 | 中等 | 10 | 否 | 自托管(静态文件) | 即将推出 |
| OSWorld | 设置 | 369 | 无 | - | - | 自托管 | 即将推出 |
| TimeWarp | 设置 | 1386 | 无 | 30 | 是 | 自托管 | 即将推出 |
🛠️ 设置AgentLab
AgentLab需要Python 3.11或3.12。
pip install agentlab
如果尚未完成,请安装Playwright:
playwright install
请务必按照设置列中提供的说明准备所需的基准测试。
export AGENTLAB_EXP_ROOT=<实验结果根目录> # 默认为$HOME/agentlab_results
export OPENAI_API_KEY=<你的OpenAI API密钥> # 如果使用OpenAI模型
设置OpenRouter API
export OPENROUTER_API_KEY=<你的OpenRouter API密钥> # 如果使用OpenRouter模型
设置Azure API
export AZURE_OPENAI_API_KEY=<你的Azure API密钥> # 如果使用Azure模型
export AZURE_OPENAI_ENDPOINT=<你的端点> # 如果使用Azure模型
🤖 UI-助手
使用助手为你工作(需自行承担费用和风险)。
agentlab-assistant --start_url https://www.google.com
尝试你自己的智能体:
agentlab-assistant --agent_config="module.path.to.your.AgentArgs"
🚀 启动实验
# 导入你的智能体配置,该配置扩展了bgym.AgentArgs类
# 确保从 PYTHONPATH 中可访问的模块导入此对象,以便正确反序列化
from agentlab.agents.generic_agent import AGENT_4o_MINI
from agentlab.experiments.study import make_study
study = make_study(
benchmark="miniwob", # 或 "webarena", "workarena_l1" ...
agent_args=[AGENT_4o_MINI],
comment="我的第一个研究",
)
study.run(n_jobs=5)
重新启动未完成或出错的任务
from agentlab.experiments.study import Study
study = Study.load("/path/to/your/study/dir")
study.find_incomplete(include_errors=True)
study.run()
请参阅 main.py 以使用各种选项启动实验。这就像一个懒惰的命令行界面,实际上更加方便。只需根据需要注释或取消注释所需行,或随意修改(但不要推送到仓库)。
作业超时
野生网络、Playwright 和 asyncio 的复杂性有时会导致作业挂起。这会使工作进程失效,直到研究被终止并重新启动。如果您按顺序运行作业或使用少量工作进程,这可能会使整个研究停滞,直到您手动终止并重新启动它。在 Ray 并行后端中,我们实现了一个系统,可以自动终止超过指定超时时间的作业。当任务挂起限制您的实验时,此功能尤为有用。
调试
为了调试,请以 n_jobs=1 运行实验,并使用 VSCode 的调试模式。这样可以在断点处暂停执行。
关于并行作业
一个代理处理一个任务对应于一个作业。进行消融研究或在数百个任务上进行多种子随机搜索,可能会生成超过 10,000 个作业。因此,高效的并行执行至关重要。代理通常会等待 LLM 服务器的响应或 Web 服务器的更新。因此,在一台计算机上,您可以并行运行 10–50 个作业,具体数量取决于可用的 RAM。
⚠️ (Visual)WebArena 注意事项:这些基准测试具有任务依赖关系,旨在尽量减少任务之间对实例的“污染”。例如,处理第 323 个任务的代理可能会改变实例状态,从而使第 201 个任务无法完成。为了解决这个问题,Ray 后端会考虑任务依赖关系,从而实现一定程度的并行性。在 WebArena 上,您可以禁用依赖关系以提高并行度,但这可能会降低 1–2% 的性能。
⚠️ (Visual)WebArena 实例重置:在评估代理之前,实例会自动重置,这一过程大约需要 5 分钟。当评估多个代理时,make_study 函数会返回一个 SequentialStudies 对象,以确保每个代理都能按顺序正确评估。AgentLab 目前不支持跨多个实例的评估,但您可以编写一个快速脚本来处理这种情况,或者向 AgentLab 提交拉取请求。为了获得更流畅的并行体验,建议使用 WorkArena 等基准测试。
🔍 分析结果
加载结果
类 ExpResult 提供了特定实验所有信息的惰性加载器。您可以使用 yield_all_exp_results 递归地查找目录中的所有结果。最后,load_result_df 会将所有汇总信息收集到一个数据框中。有关示例用法,请参阅 inspect_results.ipynb。
from agentlab.analyze import inspect_results
# 将研究中所有实验的汇总信息加载到数据框中
result_df = inspect_results.load_result_df("path/to/your/study")
# 加载第一个实验的详细结果
exp_result = bgym.ExpResult(result_df["exp_dir"][0])
第 0 步的截图 = exp_result.screenshots[0]
第 0 步的动作 = exp_result.steps_info[0].action
AgentXray
https://github.com/user-attachments/assets/06c4dac0-b78f-45b7-9405-003da4af6b37
在终端中执行:
agentlab-xray
您可以加载 AGENTLAB_EXP_ROOT 目录中以前或正在进行的实验,并在 Gradio 界面中可视化结果。
按照以下顺序选择:
- 您想要可视化的实验
- 如果有多个代理,请选择代理
- 任务
- 种子
选择完成后,您可以看到代理在给定任务上的操作轨迹。单击剖析图像以选择某个步骤,并观察代理采取的动作。
⚠️ 注意:Gradio 仍在开发中,经常会出现意外行为。目前看来,版本 5.5 运行正常。如果您不确定显示的信息是否正确,请刷新页面并再次选择您的实验。
🏆 排行榜
所有基准测试的官方统一 排行榜。
正在开展更多使用 GenericAgent 的参考实验。我们也在开发代码,以便自动将研究推送到排行榜。
🤖 实现新代理
可以从 agentlab/agents/most_basic_agent/most_basic_agent.py 中的 MostBasicAgent 获取灵感。为了更好地与工具集成,务必在 AgentArgs API 和扩展的 bgym.AbstractAgentArgs 中实现大多数功能。
如果您认为您的代理应直接纳入 AgenLab,请告知我们,我们可以将其添加到 agentlab/agents/ 目录中,并以您的代理名称命名。
↻ 可重复性
在动态基准测试中评估代理时,有几个因素会影响结果的可重复性。
影响可重复性的因素
- 软件版本:Playwright 或软件栈中任何包的不同版本都可能影响基准测试或代理的行为。
- 基于 API 的 LLM 默默变化:即使版本固定,LLM 也可能被更新,例如为了融入最新的网络知识。
- 实时网站:
- WorkArena:演示实例大多固定在特定版本,但 ServiceNow 有时会推送一些小的修改。
- AssistantBench 和 GAIA:这些基准测试依赖于代理在开放网络中导航。体验可能会因国家或地区而异,某些网站默认语言可能不同。
- 随机性代理:将 LLM 的温度设置为 0 可以减少大部分随机性。
- 非确定性任务:对于固定的种子,变化应该很小
可复现性功能
Study包含一个关于可复现性的信息字典,包括基准测试版本、软件包版本和提交哈希值。Study类允许自动将您的结果上传到reproducibility_journal.csv。这使得填充大量参考点变得更加容易。要使用此功能,您需要先git clone该仓库,并通过pip install -e .进行安装。- 排行榜中的已复现结果。对于可复现的智能体,我们鼓励用户尝试复现其结果,并将其上传到排行榜。排行榜中有一个特殊列,用于记录某个智能体在特定基准测试上的所有已复现结果。
- ReproducibilityAgent:您可以运行此智能体 来处理现有的研究,它会尝试在相同的任务种子上重新执行相同的操作。两次提示的可视化差异将在 AgentXray 的 AgentInfo HTML 选项卡中显示。您可以在某些任务上检查两次执行之间的具体变化。注意:此功能目前处于测试阶段,可能需要根据您自己的智能体进行一些调整。
变量
以下是 AgentLab 使用的相关环境变量列表:
OPENAI_API_KEY:默认用于 OpenAI 的大语言模型。AZURE_OPENAI_API_KEY:默认用于 AzureOpenAI 的大语言模型。AZURE_OPENAI_ENDPOINT:用于指定您的 Azure 终端地址。OPENAI_API_VERSION:用于 Azure API 的版本号。OPENROUTER_API_KEY:用于 Openrouter API。AGENTLAB_EXP_ROOT:您希望存储实验结果的路径,默认为~/agentlab-results。AGENTXRAY_SHARE_GRADIO:启用后,AgentXRay 启动时会打开一个公共隧道。RAY_PUBLIC_DASHBOARD(true / false):用于指定 Ray 仪表板是否应对外公开(0.0.0.0)或仅限本地访问(127.0.0.1)。RAY_DASHBOARD_PORT(整数):用于指定 Ray 仪表板的访问端口。
其他
如果您希望更快地下载 Hugging Face 模型:
pip install hf-transfer
pip install torch
export HF_HUB_ENABLE_HF_TRANSFER=1
📝 引用本工作
如果您希望引用 AgentLab,请使用以下两个 BibTeX 条目:
@article{
chezelles2025browsergym,
title={The BrowserGym Ecosystem for Web Agent Research},
author={Thibault Le Sellier de Chezelles and Maxime Gasse and Alexandre Lacoste and Massimo Caccia and Alexandre Drouin and L{\'e}o Boisvert and Megh Thakkar and Tom Marty and Rim Assouel and Sahar Omidi Shayegan and Lawrence Keunho Jang and Xing Han L{\`u} and Ori Yoran and Dehan Kong and Frank F. Xu and Siva Reddy and Graham Neubig and Quentin Cappart and Russ Salakhutdinov and Nicolas Chapados},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2025},
url={https://openreview.net/forum?id=5298fKGmv3},
note={Expert Certification}
}
@inproceedings{workarena2024,
title = {{W}ork{A}rena: How Capable are Web Agents at Solving Common Knowledge Work Tasks?},
author = {Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Vazquez, David and Chapados, Nicolas and Lacoste, Alexandre},
booktitle = {Proceedings of the 41st International Conference on Machine Learning},
pages = {11642--11662},
year = {2024},
editor = {Salakhutdinov, Ruslan and Kolter, Zico and Heller, Katherine and Weller, Adrian and Oliver, Nuria and Scarlett, Jonathan and Berkenkamp, Felix},
volume = {235},
series = {Proceedings of Machine Learning Research},
month = {21--27 Jul},
publisher = {PMLR},
url = {https://proceedings.mlr.press/v235/drouin24a.html},
}
以下是它们的使用示例:
我们使用 AgentLab 框架来运行和管理我们的实验 \cite{workarena2024,chezelles2025browsergym}。
跟踪记录
《Web 代理研究的 BrowserGym 生态系统》论文中的跟踪记录可在 Huggingface 上获取。
版本历史
v0.4.22026/01/20v0.4.12025/12/05v0.4.02025/02/11v0.3.22024/12/09v0.3.2.dev112024/12/09v0.3.2.dev102024/12/09v0.3.2.dev92024/12/09v0.3.2.dev72024/12/05v0.3.2.dev62024/12/05v0.3.2.dev52024/12/05v0.3.2.dev42024/12/05v0.3.2.dev32024/12/050.3.2.dev22024/12/050.3.2.dev12024/12/05v0.3.12024/11/26v0.3.02024/11/14常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器