xLAM
xLAM 是 Salesforce 推出的一系列“大型动作模型”(Large Action Models),旨在为 AI 智能体系统注入强大的执行力。与传统大语言模型侧重文本生成不同,xLAM 专注于精准理解和调用外部工具与 API,让 AI 不仅能“思考”,更能高效地“行动”,从而解决复杂任务中规划与执行脱节的难题。
该项目特别适合 AI 开发者、研究人员以及希望构建自动化工作流的企业技术团队使用。无论是开发需要频繁调用数据库、搜索接口或专业软件的行业智能体,还是研究多轮函数调用的学术场景,xLAM 都能提供坚实的底层支持。其核心技术亮点在于卓越的函数调用能力,最新版本 xLAM-2-fc-r 已在权威的伯克利函数调用排行榜(BFCL)上斩获第一。此外,项目还开源了配套的 ActionStudio 框架及专用的 APIGen-MT 数据集,大幅降低了从模型训练到实际部署的门槛,帮助用户轻松打造具备高度自主性的 AI 代理系统。
使用场景
某电商平台的智能客服团队正试图升级系统,使其能自动处理用户复杂的“查询订单并申请退款”等多步操作请求。
没有 xLAM 时
- 意图识别割裂:传统模型只能回答静态问题,无法理解“先查单再退款”这种需要按顺序执行多个动作的复杂指令。
- 开发成本高昂:工程师需为每个新业务场景(如改地址、换货)硬编码大量的规则脚本和 API 调用逻辑,维护困难。
- 错误率高企:面对用户模糊的自然语言描述,系统常因参数提取不准而调用错误的接口,导致操作失败或数据混乱。
- 多轮交互笨拙:系统缺乏记忆与规划能力,一旦用户中途补充信息,往往需要重新开始整个流程,体验极差。
使用 xLAM 后
- 原生动作规划:xLAM 作为大型动作模型,能直接将自然语言转化为精确的多步函数调用序列,自动完成“查询 - 判断 - 执行”闭环。
- 零代码扩展:只需提供新的 API 文档,xLAM 即可通过微调快速学会新技能,无需重写底层业务逻辑代码。
- 参数精准映射:凭借在 BFCL 榜单领先的函数调用能力,xLAM 能从口语化表达中精准提取结构化参数,大幅降低接口调用错误。
- 流畅多轮协同:支持复杂的多轮对话状态追踪,即使用户中途修改需求,xLAM 也能动态调整执行计划,无缝继续任务。
xLAM 将原本需要繁琐硬编码的自动化流程,转变为模型原生的智能决策能力,让 AI Agent 真正具备了像人类一样操作软件系统的执行力。
运行环境要求
- 未说明
运行大模型推理必需 NVIDIA GPU(基于代码示例中的 device_map="auto"和 torch_dtype),具体显存需求取决于所选模型参数量(1B 至 141B 不等),需支持 bfloat16 数据类型
未说明

快速开始

![]()
![]()

论文 | 模型说明 | 框架 | 安装 | 训练 | 基准测试 | 致谢
🎉🎉🎉 新闻
- [08-20.2025] 🎉🎉🎉 ActionStudio 和 LATTE(与视觉专家共同思考的学习)均已被 EMNLP 2025 主会场接收!
- [08-05.2025] 💫 ActionStudio 已更新新功能,改进了训练配置跟踪,并进行了整体代码优化!
- [05-12.2025] 我们的 NAACL 2025 口头报告 的 xLAM 演示文稿现已发布! 📂 我们还开源了 APIGen-MT-5k,这是一个紧凑而强大的数据集,用于探索多轮函数调用。
- [04-15.2025] 🏆🏆🏆 xLAM-2-fc-r 在最新的 BFCL 排行榜上获得第一名!
- [04-15.2025]:🚀🚀🚀 ActionStudio 现已开源! 请查看我们的 论文 和 代码以获取完整详情。
- [04-15.2025]:📢📢📢 APIGen-MT 现已开源! 更多信息请参阅我们的 论文 和 项目网站!
- [11.2024]:添加了与 xLAM 模型交互的 最新示例和分词器信息。
- [09.2024]:如果您有任何反馈,请加入我们的 Discord 社区!
- [09.2024]:请查阅我们的 xLAM 技术报告论文。
- [08.2024]:我们很高兴地宣布推出完整的 xLAM 家族,这是一套大型行动模型!从“小型巨人”到工业级强大力量。这些模型取得了令人瞩目的成绩,在 伯克利函数调用排行榜 上分别位列第 1 和第 6 名。 请查看我们的 Hugging Face 收藏。
- [07.2024]:我们很高兴地宣布推出两款函数调用模型:xLAM-1b-fc-r 和 xLAM-7b-fc-r。这些模型在 伯克利函数调用排行榜 上分别位列第 3 和第 25 名,表现优于许多规模大得多的模型。敬请期待更多强大模型的发布。
- [06.2024] 查看我们最新的工作 APIGen,这是用于函数调用的最佳开源模型。我们的数据集 xlam-function-calling-60k 目前是 HuggingFace 上排名前三的趋势数据集,在截至 2024 年 7 月 4 日的 173,670 个数据集中脱颖而出。另请参阅 Salesforce CEO 的推特、VentureBeat 和 新智元。
- [03.2024] xLAM 模型已发布!您可以将其与 AgentLite 基准测试或其他基准测试一起使用,其性能可与 GPT-4 相媲美!
- [02.2024] AgentOhana 和 xLAM 的首次发布 论文!
注:本仓库仅用于 研究目的。
与 xLAM 相关的所有数据均因 内部规定 而 部分公开,旨在支持代理研究社区的发展。
由大型语言模型(LLMs)驱动的自主代理近年来备受研究关注。然而,要充分挖掘 LLM 在基于代理的任务中的潜力,仍面临诸多挑战,尤其是由于来自不同来源的异构数据通常具有多轮对话轨迹。
本仓库推出的 xLAM 能够整合来自不同环境的代理轨迹,覆盖广泛场景。它将这些轨迹统一为一致的格式,从而简化通用数据加载器的构建,该加载器专为代理训练而优化。借助数据统一化,我们的训练流程能够在不同数据源之间保持平衡,并在数据划分和模型训练过程中确保各设备间的独立随机性。
模型说明
| 模型 | 总参数量 | 上下文长度 | 发布日期 | 类别 | 下载模型 | 下载 GGUF 文件 |
|---|---|---|---|---|---|---|
| Llama-xLAM-2-70b-fc-r | 700亿 | 128k | 2025年3月26日 | 多轮对话、函数调用 | 🤗 链接 | 无 |
| Llama-xLAM-2-8b-fc-r | 80亿 | 128k | 2025年3月26日 | 多轮对话、函数调用 | 🤗 链接 | 🤗 链接 |
| xLAM-2-32b-fc-r | 320亿 | 32k(最大128k)* | 2025年3月26日 | 多轮对话、函数调用 | 🤗 链接 | 无 |
| xLAM-2-3b-fc-r | 30亿 | 32k(最大128k)* | 2025年3月26日 | 多轮对话、函数调用 | 🤗 链接 | 🤗 链接 |
| xLAM-2-1b-fc-r | 10亿 | 32k(最大128k)* | 2025年3月26日 | 多轮对话、函数调用 | 🤗 链接 | 🤗 链接 |
| xLAM-7b-r | 72.4亿 | 32k | 2024年9月5日 | 通用、函数调用 | 🤗 链接 | -- |
| xLAM-8x7b-r | 467亿 | 32k | 2024年9月5日 | 通用、函数调用 | 🤗 链接 | -- |
| xLAM-8x22b-r | 1410亿 | 64k | 2024年9月5日 | 通用、函数调用 | 🤗 链接 | -- |
| xLAM-1b-fc-r | 13.5亿 | 16k | 2024年7月17日 | 函数调用 | 🤗 链接 | 🤗 链接 |
| xLAM-7b-fc-r | 69.1亿 | 4k | 2024年7月17日 | 函数调用 | 🤗 链接 | 🤗 链接 |
| xLAM-v0.1-r | 467亿 | 32k | 2024年3月18日 | 通用、函数调用 | 🤗 链接 | -- |
xLAM 系列在多项任务上表现优异,包括通用任务和函数调用。 在参数量相同的情况下,这些模型经过了广泛的智能体任务和场景的微调,同时保留了原始模型的能力。
📦 模型命名规范
xLAM-7b-r:大型行动模型 v1.0 或 v2.0 的通用版本,针对广泛的智能体能力进行了微调。-r后缀表示这是一个 研究 版本。xLAM-7b-fc-r:专门用于 函数调用 任务的变体,同样标记为 研究 使用。- ✅ 所有模型均与 VLLM、FastChat 和基于 Transformers 的推理框架完全兼容。
部署与交互 xLAM 模型
🤗 使用 Transformers 进行推理
以下是使用最新模型的一个示例:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r")
model = AutoModelForCausalLM.from_pretrained("Salesforce/Llama-xLAM-2-3b-fc-r", torch_dtype=torch.bfloat16, device_map="auto")
# 示例对话与工具调用
messages = [
{"role": "user", "content": "你好,最近怎么样?"},
{"role": "assistant", "content": "谢谢!我很好。有什么可以帮您的吗?"},
{"role": "user", "content": "伦敦现在的天气如何?"},
]
tools = [
{
"name": "get_weather",
"description": "获取某个地点的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "城市和州,例如旧金山,加州"},
"unit": {"type": "string", "enum": ["摄氏度", "华氏度"], "description": "返回的温度单位"}
},
"required": ["location"]
}
}
]
print("====== 应用聊天模板后的提示 ======")
print(tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, tokenize=False))
inputs = tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
input_ids_len = inputs["input_ids"].shape[-1] # 获取输入 token 的长度
inputs = {k: v.to(model.device) for k, v in inputs.items()}
print("====== 模型响应 ======")
outputs = model.generate(**inputs, max_new_tokens=256)
generated_tokens = outputs[:, input_ids_len:] # 取出新生成的 tokens
print(tokenizer.decode(generated_tokens[0], skip_special_tokens=True))
注意: 不同的应用可能需要调整 Temperature 参数。通常,较低的 Temperature 有助于实现确定性的结果。 此外,对于需要严格遵循特定格式或函数调用的任务,明确包含格式化指令是非常重要且必要的。
⚡📈 使用 vLLM 进行推理
xLAM 模型也可以使用 vLLM 高效地进行高吞吐量推理服务。请使用 vllm>=0.6.5,因为较早版本会导致基于 Qwen 的模型性能下降。
设置与服务
- 安装所需版本的 vLLM:
pip install "vllm>=0.6.5"
- 将工具解析器插件下载到本地路径:
wget https://huggingface.co/Salesforce/xLAM-2-1b-fc-r/raw/main/xlam_tool_call_parser.py
- 启动兼容 OpenAI API 的端点:
MODEL_NAME_OR_PATH="Salesforce/xLAM-2-1b-fc-r"
ASSIGNED_MODEL_NAME="xlam-2-1b-fc-r" # vLLM 使用分配的模型名称作为引用
NUM_ASSIGNED_GPUS=1 # 对于 70B 参数的模型需要 4 张 GPU,每张 80GB 显存
PORT=8000
vllm serve $MODEL_NAME_OR_PATH \
--tensor-parallel-size $NUM_ASSIGNED_GPUS \
--served-model-name $ASSIGNED_MODEL_NAME \
--port $PORT \
--gpu-memory-utilization 0.9 \
--enable-auto-tool-choice \
--tool-parser-plugin ./xlam_tool_call_parser.py \
--tool-call-parser xlam
注意:请确保已下载工具解析器插件文件,并且在 --tool-parser-plugin 中指定的路径正确指向您本地的文件副本。xLAM 系列模型都使用 相同 的工具调用解析器,因此您只需为所有模型下载一次即可。
使用 OpenAI API 测试
以下是一个最小示例,用于测试已部署端点上的工具使用情况:
import openai
import json
# 配置客户端以使用本地 vLLM 端点
client = openai.OpenAI(
base_url="http://localhost:8000/v1", # 默认 vLLM 服务器端口
api_key="empty" # 可以为任意字符串
)
# 定义一个工具/函数
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取某个地点的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和州,例如旧金山, CA"
},
"unit": {
"type": "string",
"enum": ["摄氏度", "华氏度"],
"description": "返回温度的单位"
}
},
"required": ["location"]
}
}
}
]
messages = [
{"role": "system", "content": "你是一个可以使用工具的帮助助手。"},
{"role": "user", "content": "旧金山的天气怎么样?"}
]
# 创建聊天完成请求
if tools is None or tools==[]: # 日常对话
response = client.chat.completions.create(
model="xlam-2-1b-fc-r", # 分配的模型名称
messages=messages
)
else: # 函数调用
response = client.chat.completions.create(
model="xlam-2-1b-fc-r", # 分配的模型名称
messages=messages,
tools=tools,
tool_choice="auto"
)
# 打印响应
print("助手的回答:")
print(json.dumps(response.model_dump(), indent=2))
如需了解更多高级配置和部署选项,请参阅 vLLM 文档。
🧠 APIGen-MT: 基于模拟人机交互的多轮数据生成代理式流水线
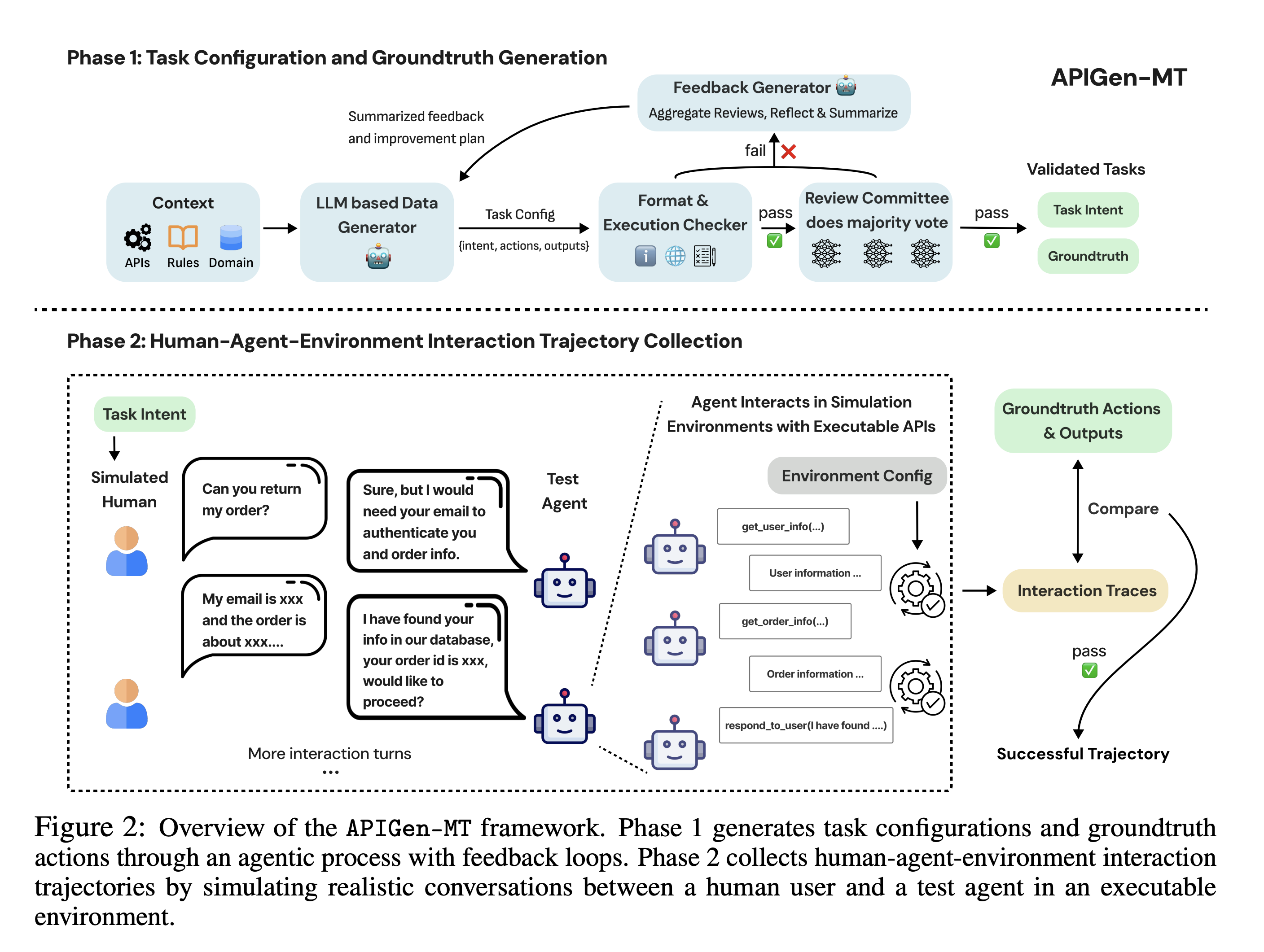
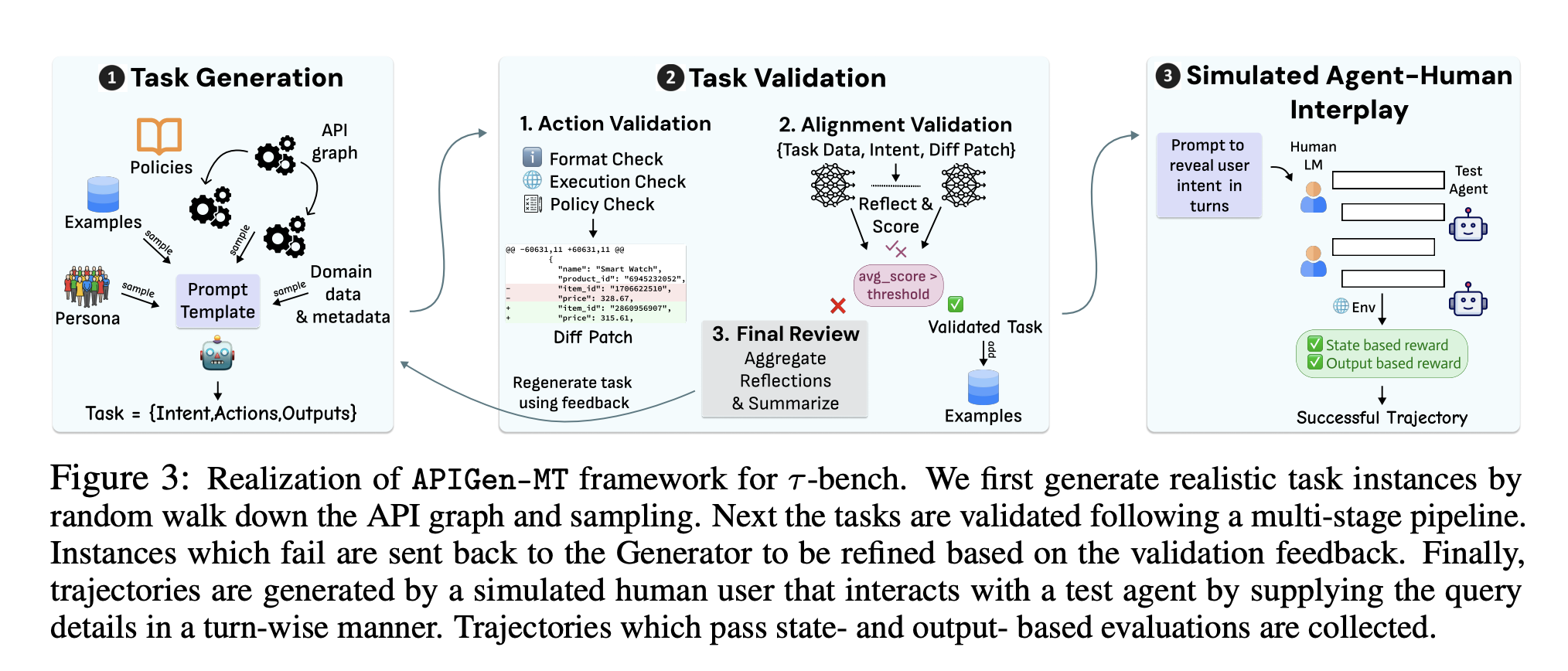
🧠 ActionStudio: 用于大型动作模型的数据生成与训练的轻量级框架
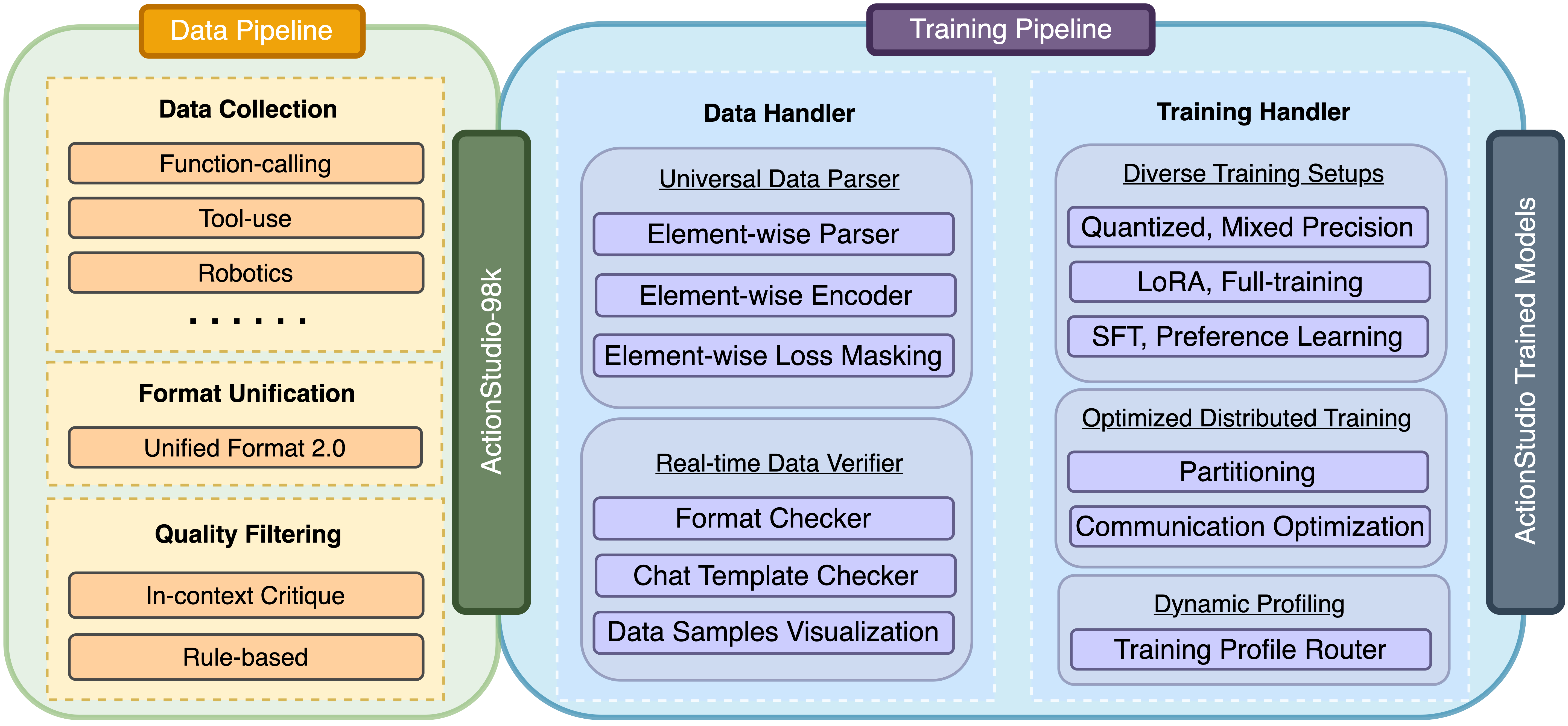
❤️ 更多详情请参阅 ActionStudio.md。
📦 安装
🔧 依赖项
从根 xLAM 目录(即 setup.py 所在的位置)安装依赖项:
conda create --name actionstudio python=3.10
bash requirements.sh
🚀 安装 ActionStudio
开发版本(最新):
要使用处于积极开发中的最新代码,请从根 xLAM 目录(即 setup.py 所在的位置)以 可编辑模式 安装 ActionStudio:
pip install -e .
🗂️ 结构
actionstudio/
├── datasets/ # 开源的“统一轨迹数据集”
├── examples/ # 使用示例和配置
│ ├── data_configs/ # 数据混合的 YAML 配置文件
│ ├── deepspeed_configs/ # DeepSpeed 训练配置文件
│ └── trainings/ # 各种训练方法的 Bash 脚本(“README.md”)
├── src/ # 源代码
│ ├── data_conversion/ # 将轨迹转换为训练数据(“README.md”)
│ └── criticLAM/ # 批评者大型动作模型的实现(“README.md”)
└── foundation_modeling/ # 核心建模组件
├── data_handlers/
├── train/
├── trainers/
└── utils/
🔍 大多数顶级文件夹都包含带有详细说明和解释的 README.md 文件。
⚡ 效率
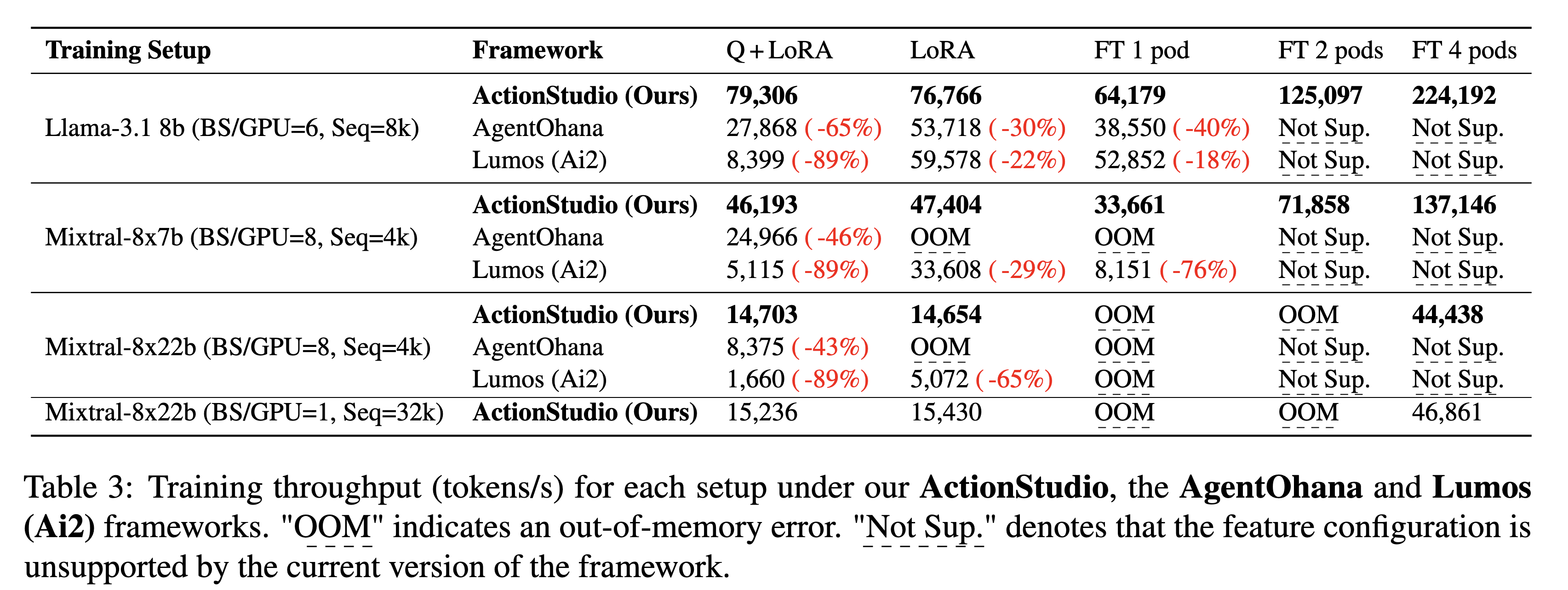
📜 许可证
代码采用 Apache 2.0 许可证,数据集则采用 CC-BY-NC-4.0 许可证。所提供的数据仅用于研究目的。
🛠️ 代码更新历史
💫 2025年8月5日
统一配置跟踪 现在每次运行都会将其完整的训练配置写入一个单独的 JSON 文件中——以唯一的模型 ID 为键——保存在 model_config_files 中,以便于参考和复现。
HF ⇄ DeepSpeed 一致性 解决了 Hugging Face 和 DeepSpeed 之间超参数设置的不一致问题,以确保两者完全同步。
学习率调度器调整 优化了默认调度器参数,使预热过程更加平滑,收敛更加稳定。
代码整体清理 简化了模块结构,移除了无效路径,并添加了内联文档,以方便维护。
2025年5月9日
- 修复了 data_verifier 中的参数错误。参考 #24。
2025年4月14日
- 更新了依赖项版本,以支持最新的模型和技术
- 添加了自动计算和分配训练步数的功能
- 启用了训练结束时的自动检查点合并功能。
- 📄 请参阅 actionstudio/examples/trainings/README.md 以获取训练示例和使用说明
- 改进了文档和代码注释
部署和交互 xLAM 模型
⚠️ 注意: 如需使用 xLAM v1.0 模型,请参阅 示例笔记本及分词器信息。
xLAM v2.0 模型在 v1.0 的基础上进行了优化,结构更加完善,并采用了标准的对话格式,因此可以直接与 vLLM、Transformers 等主流推理框架兼容——无需任何特殊设置。
🔍 不过,我们仍然建议您查看上述笔记本,以便更好地理解对话格式逻辑和分词器的行为。
💬 将 xLAM 作为 OpenAI 兼容的聊天 API 提供服务
您可以使用以下两种方法之一将 xLAM 模型部署为 OpenAI 兼容的聊天完成 API。
📌 以下示例使用
Salesforce/xLAM-8x7b-r,在 4×A100 (40GB) 的配置上运行。
方法 1:使用 vLLM(推荐)
vLLM 提供高效的推理服务,延迟更低。要使用 vLLM 提供模型服务:
vllm serve Salesforce/xLAM-8x7b-r --host 0.0.0.0 --port 8000 --tensor-parallel-size 4
方法 2:使用 FastChat
FastChat 提供功能更丰富的推理服务。要使用 FastChat 提供服务:
- 启动控制器:
python3 -m fastchat.serve.controller --host 0.0.0.0
- 启动 OpenAI 兼容的 API 服务器:
python3 -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8000
- 启动模型工作进程:
python3 -m fastchat.serve.vllm_worker \
--model-names "Salesforce/xLAM-8x7b-r" \
--model-path Salesforce/xLAM-8x7b-r \
--host 0.0.0.0 \
--port 31005 \
--worker-address http://localhost:31001 \
--num-gpus 4 \
--limit-worker-concurrency 64
使用聊天完成 API 处理 xLAM 1.0 系列模型
模型提供服务后,您可以使用以下 xLAM 客户端与其交互,以实现函数调用或其他应用:
from xLAM.client import xLAMChatCompletion, xLAMConfig
# 配置客户端
config = xLAMConfig(base_url="http://localhost:8000/v1/", model="Salesforce/xLAM-8x7b-r")
llm = xLAMChatCompletion.from_config(config)
# 示例对话
messages = [
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "纽约现在的天气怎么样?"},
{"role": "assistant", "content": "要获取纽约的天气信息,我需要调用 get_weather 函数。", "tool_calls": {"name": "get_weather", "arguments": '{"location": "纽约", "unit": "华氏度"}'}},
{"role": "tool", "name": "get_weather", "content": '{"temperature": 72, "description": "多云"}'},
{"role": "user", "content": "现在请查询旧金山的天气。"}
]
# 示例函数定义(可选)
tools = [
{
"name": "get_weather",
"description": "获取某个地点的当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "描述": "城市和州,例如旧金山、纽约"},
"unit": {"type": "string", "枚举值为 '摄氏度' 和 '华氏度'", "描述": "返回温度的单位"}
},
"required": ["location"]
}
},
{
"name": "search",
"description": "在互联网上搜索信息",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "描述": "搜索关键词,例如 '最新的 AI 新闻'"}
},
"required": ["query"]
}
},
{
"name": "respond",
"description": "当您准备好回复时,请使用此函数。该函数允许助手根据输入消息和对话上下文生成适当的回复。对于简单问题,生成简洁的回答;对于复杂问题,生成更详细的回答。",
"parameters": {
"type": "object",
"properties": {
"message": {"type": "string", "描述": "要回复的消息内容"}
},
"required": ["message"]
}
}
]
response = llm.completion(messages, tools=tools)
print(response)
-->
:trophy: 基准测试(xLAM-2-fc 系列)
伯克利函数调用排行榜(BFCL v3)
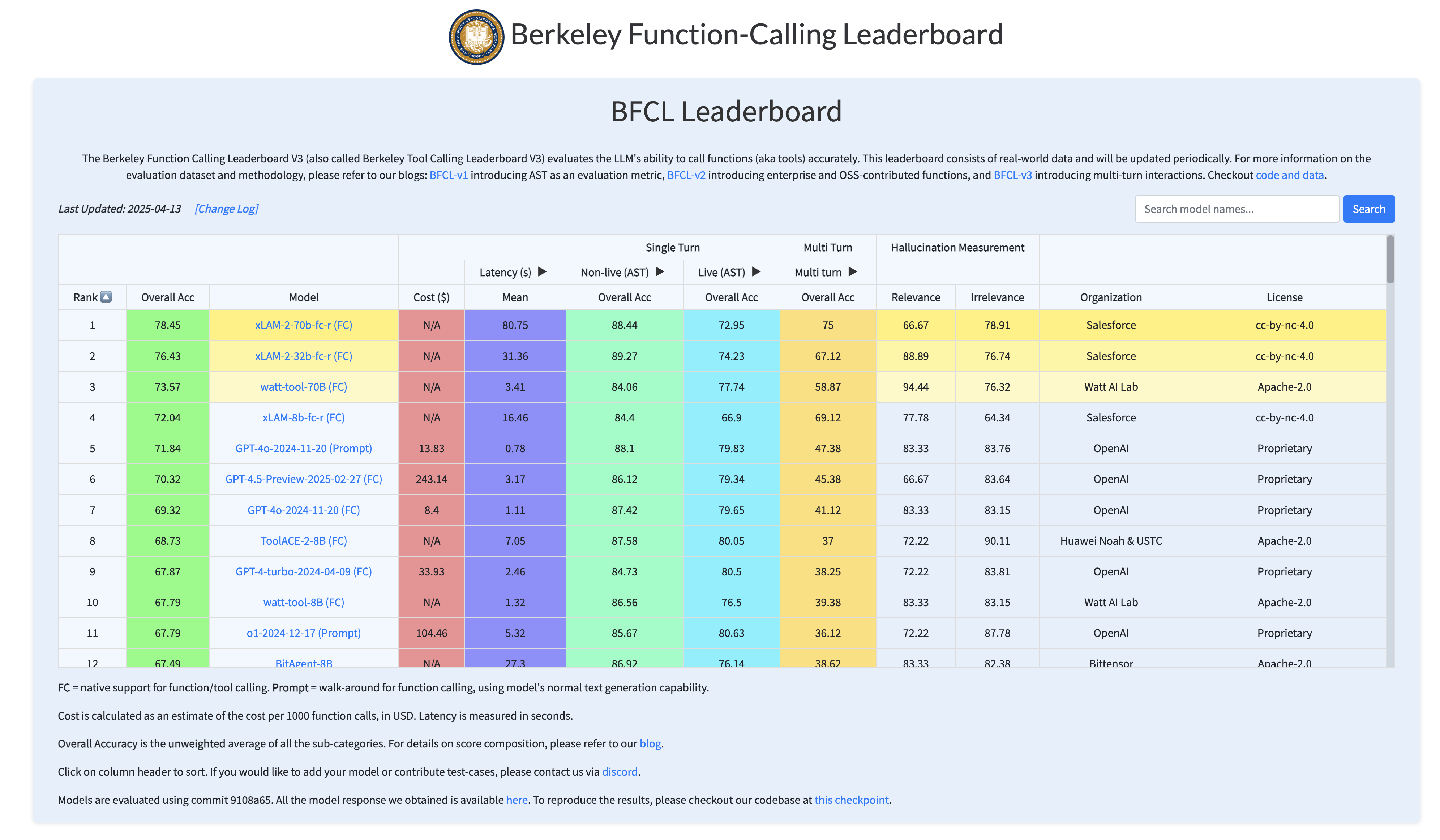
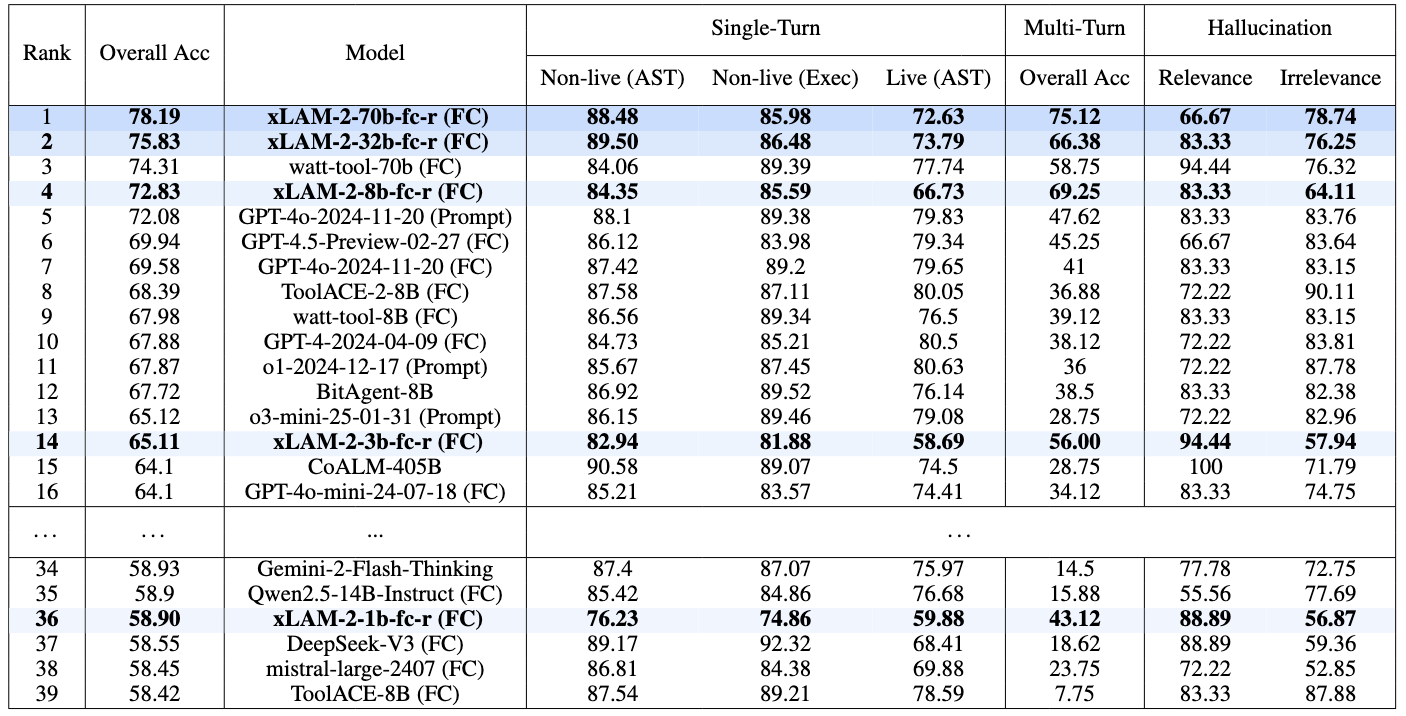
不同模型在 BFCL 排行榜上的性能对比。排名基于综合准确率,即各评估类别的加权平均值。“FC”代表函数调用模式,与通过自定义“提示”提取函数调用的方式相对。
τ-bench 基准测试
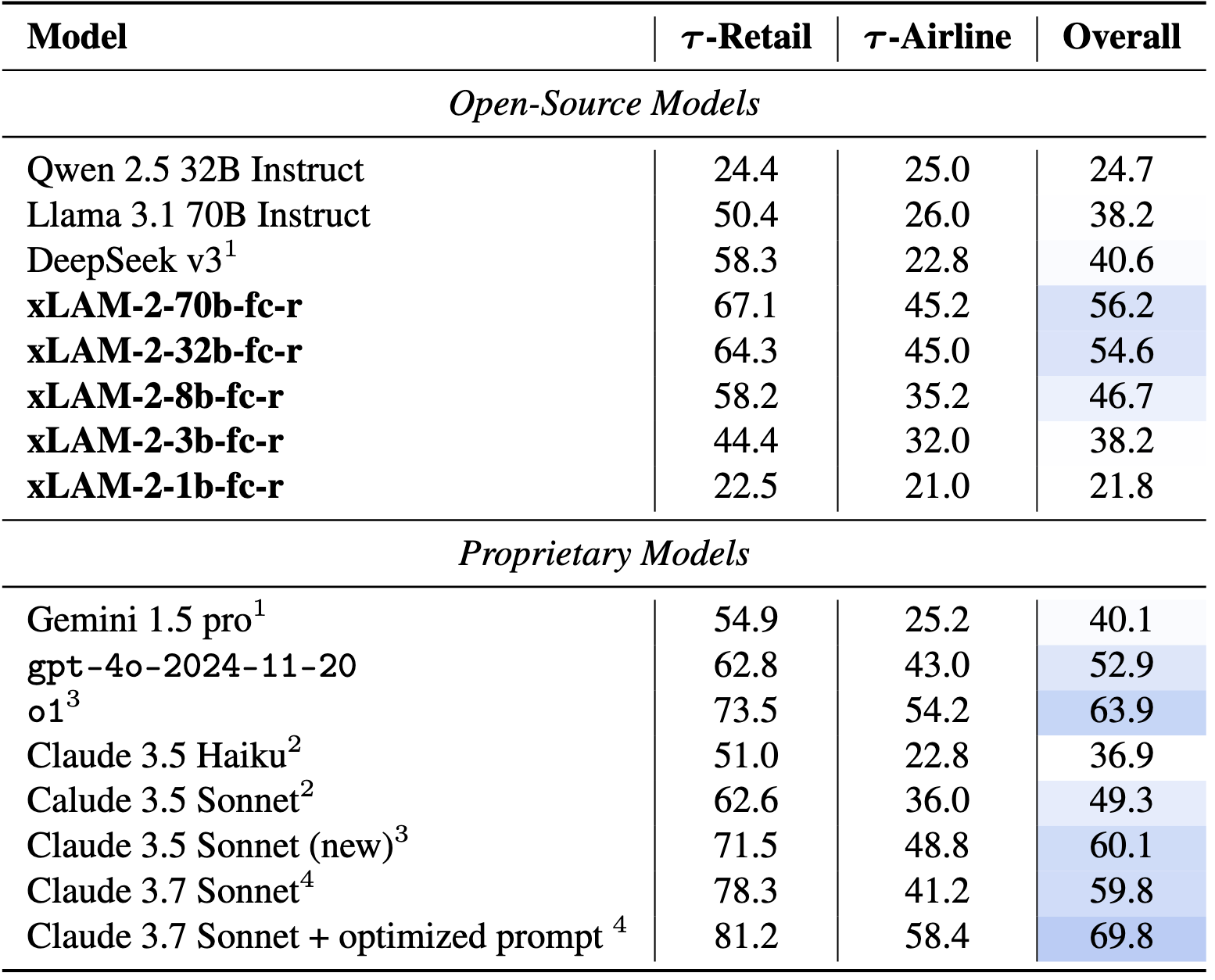
τ-bench 基准测试中至少进行 5 次试验后的成功率(pass@1)。我们的 xLAM-2-70b-fc-r 模型在 τ-bench 上的整体成功率达到 56.2%,显著优于基础 Llama 3.1 70B Instruct 模型(38.2%)以及其他开源模型,如 DeepSeek v3(40.6%)。值得注意的是,我们的最佳模型甚至超越了专有模型,例如 GPT-4o(52.9%),并接近最新模型 Claude 3.5 Sonnet(新)(60.1%)的表现。
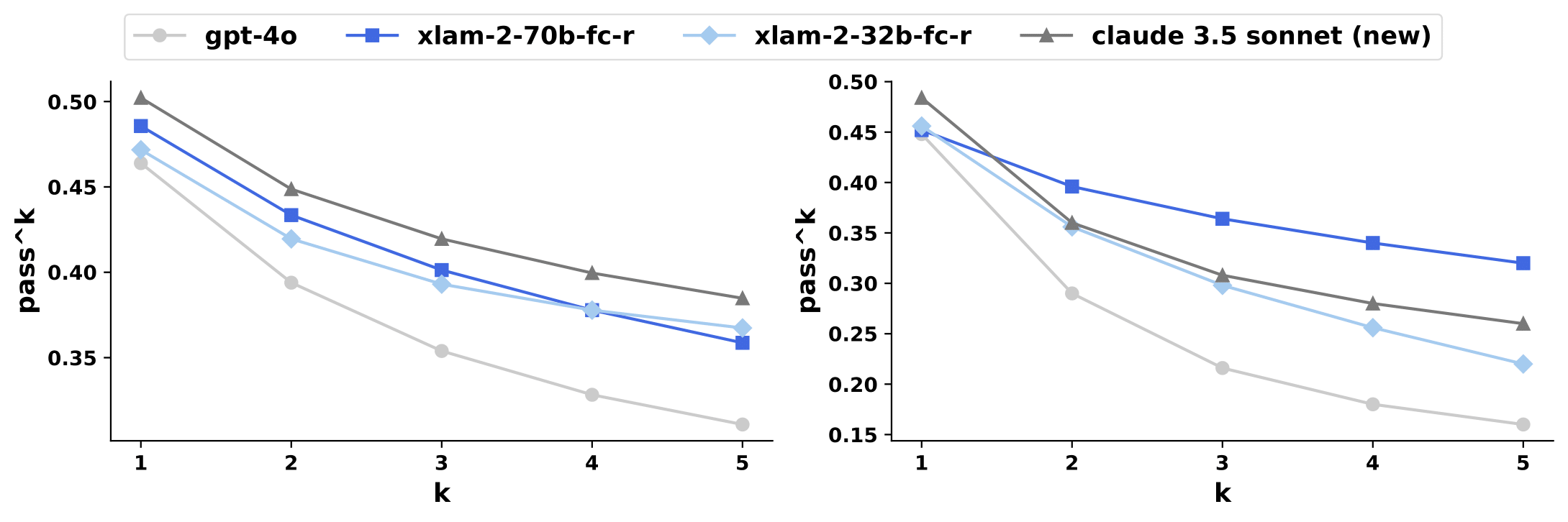
Pass^k 曲线用于衡量给定任务的所有 5 次独立试验均成功的概率,取 τ-retail(左)和 τ-airline(右)领域的所有任务的平均值。数值越高,表明模型的一致性越好。
:trophy: 基准测试(xLAM 1.0 系列)
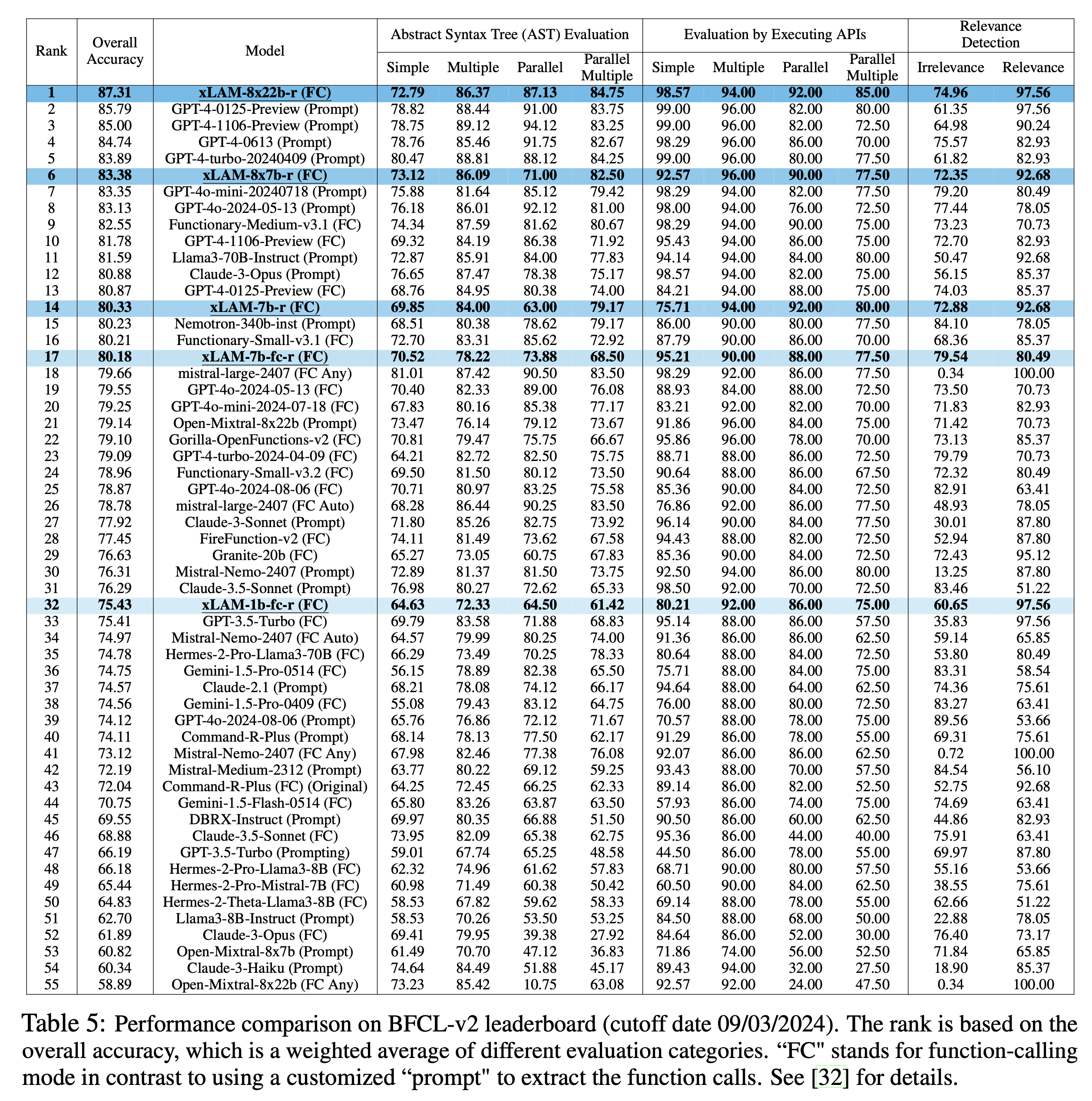
伯克利函数调用排行榜(BFCL)
BOLAA
网上商店
| LLM 名称 | ZS | ZST | ReaAct | PlanAct | PlanReAct | BOLAA |
|---|---|---|---|---|---|---|
| Llama-2-70B-chat | 0.0089 | 0.0102 | 0.4273 | 0.2809 | 0.3966 | 0.4986 |
| Vicuna-33B | 0.1527 | 0.2122 | 0.1971 | 0.3766 | 0.4032 | 0.5618 |
| Mixtral-8x7B-Instruct-v0.1 | 0.4634 | 0.4592 | 0.5638 | 0.4738 | 0.3339 | 0.5342 |
| GPT-3.5-Turbo | 0.4851 | 0.5058 | 0.5047 | 0.4930 | 0.5436 | 0.6354 |
| GPT-3.5-Turbo-Instruct | 0.3785 | 0.4195 | 0.4377 | 0.3604 | 0.4851 | 0.5811 |
| GPT-4-0613 | 0.5002 | 0.4783 | 0.4616 | 0.7950 | 0.4635 | 0.6129 |
| xLAM-v0.1-r | 0.5201 | 0.5268 | 0.6486 | 0.6573 | 0.6611 | 0.6556 |
HotpotQA
| LLM 名称 | ZS | ZST | ReaAct | PlanAct | PlanReAct |
|---|---|---|---|---|---|
| Mixtral-8x7B-Instruct-v0.1 | 0.3912 | 0.3971 | 0.3714 | 0.3195 | 0.3039 |
| GPT-3.5-Turbo | 0.4196 | 0.3937 | 0.3868 | 0.4182 | 0.3960 |
| GPT-4-0613 | 0.5801 | 0.5709 | 0.6129 | 0.5778 | 0.5716 |
| xLAM-v0.1-r | 0.5492 | 0.4776 | 0.5020 | 0.5583 | 0.5030 |
AgentLite
请注意: AgentLite 提供的所有提示都被视为 xLAM-v0.1-r 的“未见提示”,这意味着该模型并未使用与这些提示相关的数据进行训练。
网上商店
| LLM 名称 | Act | ReAct | BOLAA |
|---|---|---|---|
| GPT-3.5-Turbo-16k | 0.6158 | 0.6005 | 0.6652 |
| GPT-4-0613 | 0.6989 | 0.6732 | 0.7154 |
| xLAM-v0.1-r | 0.6563 | 0.6640 | 0.6854 |
HotpotQA
| 简单 | 中等 | 困难 | ||||
|---|---|---|---|---|---|---|
| LLM 名称 | F1 分数 | 准确率 | F1 分数 | 准确率 | F1 分数 | 准确率 |
| GPT-3.5-Turbo-16k-0613 | 0.410 | 0.350 | 0.330 | 0.25 | 0.283 | 0.20 |
| GPT-4-0613 | 0.611 | 0.47 | 0.610 | 0.480 | 0.527 | 0.38 |
| xLAM-v0.1-r | 0.532 | 0.45 | 0.547 | 0.46 | 0.455 | 0.36 |
ToolBench
| LLM 名称 | 未见指令与相同集合 | 未见工具与已见类别 | 未见工具与未见类别 |
|---|---|---|---|
| TooLlama V2 | 0.4385 | 0.4300 | 0.4350 |
| GPT-3.5-Turbo-0125 | 0.5000 | 0.5150 | 0.4900 |
| GPT-4-0125-preview | 0.5462 | 0.5450 | 0.5050 |
| xLAM-v0.1-r | 0.5077 | 0.5650 | 0.5200 |