MCP-Universe
MCP-Universe 是一个专为构建、优化和评估基于模型上下文协议(MCP)的 AI 智能体而设计的综合框架。它致力于解决当前大模型在真实场景中应用工具时的痛点,填补了现有基准测试过于简单、缺乏实际交互环境的空白。通过连接真实的 MCP 服务器,MCP-Universe 能够在包含长程推理、复杂陌生工具空间以及动态实时数据的真实环境中,对智能体进行严谨的性能评测。
该平台特别适合 AI 研究人员、开发者以及需要验证智能体落地能力的团队使用。它不仅提供了一套行业领先的基准测试套件(如最新的 MCPMark),帮助量化智能体在处理多步骤任务时的表现,还内置了多个生产级开发工具。其中独特的技术亮点包括"MCP+"模块,它能通过精准的上下文管理将大模型的 Token 成本降低高达 75%,同时不牺牲输出质量;此外,其支持的“深度研究智能体”可通过并行调用工具显著提升执行效率。无论是希望复现前沿研究成果,还是旨在打造能高效操作真实世界工具的 AI 应用,MCP-Universe 都提供了一个从实验到部署的完整生态系统。
使用场景
某金融科技团队正在开发一个能自动连接内部数据库、实时新闻源和交易 API 的复杂投资分析 Agent,以辅助分析师进行多步骤的市场调研与决策。
没有 MCP-Universe 时
- 评估脱离实际:团队只能使用简化的静态数据集测试 Agent,无法验证其在连接真实 MCP 服务器处理动态金融数据时的长程推理能力。
- 上下文成本高昂:Agent 调用工具返回的冗长原始数据直接填入上下文,导致 LLM Token 消耗巨大,单次深度调研成本难以承受。
- 研发效率低下:缺乏统一的框架来编排并行工具调用,开发“广度优先”的深度研究功能需从零构建,耗时且容易出错。
- 基准缺失:没有行业标准基准(如 MCPMark)对标,难以量化 Agent 在陌生工具空间中的真实性能差距。
使用 MCP-Universe 后
- 真实场景验证:利用内置的 MCPMark 基准和真实服务器交互环境,团队直接在动态金融场景中评估 Agent,精准捕捉长任务链中的推理断点。
- 成本大幅降低:集成 MCP+ 模块进行精确上下文管理,自动过滤冗余输出,在不牺牲分析质量的前提下将 Token 成本降低了 75%。
- 高效并行扩展:借助原生的深度研究 Agent(Deep Research Agent)架构,轻松实现多工具并行调用,显著提升了市场情报收集的宽度与效率。
- 可视化迭代:通过框架提供的运行日志可视化和标准化报告,团队能快速定位故障并量化性能提升,加速产品迭代周期。
MCP-Universe 通过提供真实的基准测试、极致的成本控制及高效的编排能力,让复杂工具型 AI Agent 从实验室原型快速走向生产级应用。
运行环境要求
- Linux
- macOS
未说明
未说明

快速开始
 MCP-Universe
MCP-Universe
🎉 最新动态
📊 MCPMark 评估 - MCP-Universe 现在支持对 MCPMark 任务进行评估
🚀 MCP+ - 基于 MCP 客户端的代理式封装,可将 token 成本降低多达 75%
🔬 深度研究代理 - 通过并行工具调用扩展深度研究代理的宽度,从而提升性能和效率
什么是 MCP-Universe?
MCP-Universe 是一个全面的生态系统,用于构建、优化和评估与模型上下文协议(MCP)交互的 AI 代理。除了我们行业领先的现实世界 MCP 服务器交互基准测试之外,MCP-Universe 还提供了生产就绪的代理开发工具,包括专门的研究代理(Deep Research Agent)、智能上下文管理(MCP+)以及复杂的编排工作流。
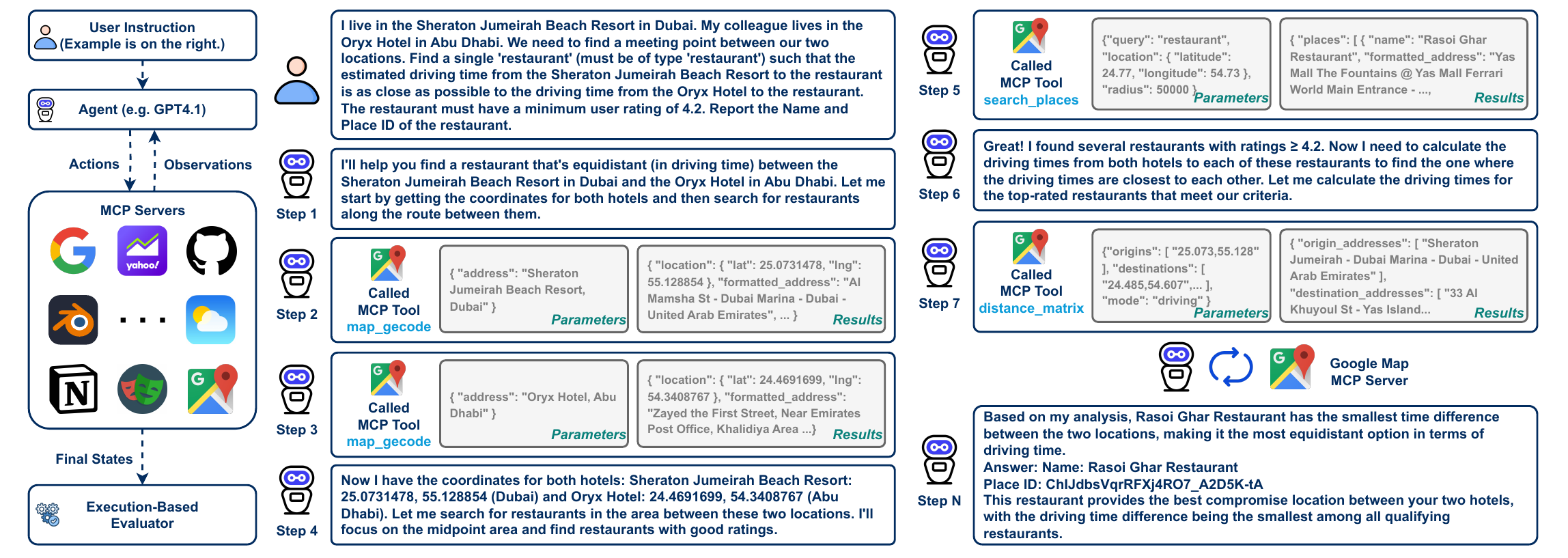
基准测试: 与依赖过于简单任务的现有基准不同,MCP-Universe 通过与实际的 MCP 服务器交互,在真实场景中评估大语言模型,填补了关键空白,捕捉到真实的应用挑战,例如:
- 🎯 多步骤任务中的长时序推理
- 🔧 包含多种 MCP 服务器的大型、陌生工具空间
- 🌍 真实世界的数据源和实时环境
- ⚡ 具有时间敏感性真值的动态评估
目录
最新动态
MCPMark 基准测试
📊 使用 MCPMark 评估 MCP 代理
MCP-Universe 现在支持评估 MCPMark 基准,能够对 MCP 代理进行全面的测试和基准评估。您可以在 MCP-Universe 框架内直接运行 MCPMark 评估,以衡量代理在 MCP 任务上的表现。
📚 资源:
MCP+: 针对 MCP 代理的精准上下文管理
🚀 在不牺牲质量的前提下,将 LLM 的 token 成本降低多达 75%
MCP 工具通常会返回大量冗长的输出,这不仅浪费了 LLM 的上下文窗口,还会增加成本。MCP+ 通过智能后处理包装您的 MCP 客户端,在数据到达 LLM 之前仅提取相关信息。
✨ 主要特性
- 💰 巨大的成本节约:工具输出的 token 节省可达 50-75%
- ⚡ 无需代码更改:可直接替换标准 MCP 客户端
深度研究代理:宽深(W&D)研究
🔬 通过并行工具调用扩展研究宽度
2026年2月11日 — 我们推出了宽深(W&D)研究代理,它通过每轮更多的并行工具调用来扩展“宽度”。这种方法在 BrowseComp、HLE 和 GAIA 基准上提高了准确性,同时减少了轮次、API 费用和实际耗时。我们的 W&D 代理配合 GPT-5-medium 在 BrowseComp 上达到了 62.2%,优于 GPT-5-high 深度研究(54.9%)。
📚 资源:
架构概述
MCPUniverse 架构由以下关键组件组成:
- 智能体(
mcpuniverse/agent/):不同智能体类型的基类实现 - 工作流(
mcpuniverse/workflows/):编排与协调层 - MCP 服务器(
mcpuniverse/mcp/):协议管理和外部服务集成 - 大模型集成(
mcpuniverse/llm/):多提供商语言模型支持 - 基准测试(
mcpuniverse/benchmark/):评估与测试框架 - 仪表盘(
mcpuniverse/dashboard/):可视化与监控界面
下图展示了高层视图:
┌─────────────────────────────────────────────────────────────────┐
│ 应用层 │
├─────────────────────────────────────────────────────────────────┤
│ 仪表盘 │ Web API │ Python 库 │ 基准测试 │
│ (Gradio) │ (FastAPI) │ │ │
└─────────────┬─────────────────┬────────────────┬────────────────┘
│ │ │
┌─────────────▼─────────────────▼────────────────▼────────────────┐
│ 编排层 │
├─────────────────────────────────────────────────────────────────┤
│ 工作流 │ 基准测试运行器 │
│ (链、路由器等) │ (评估引擎) │
└─────────────┬─────────────────┬────────────────┬────────────────┘
│ │ │
┌─────────────▼─────────────────▼────────────────▼────────────────┐
│ 智能体层 │
├─────────────────────────────────────────────────────────────────┤
│ BasicAgent │ ReActAgent │ FunctionCall │ 其他 │
│ │ │ 智能体 │ 智能体 │
└─────────────┬─────────────────┬────────────────┬────────────────┘
│ │ │
┌─────────────▼─────────────────▼────────────────▼────────────────┐
│ 基础设施层 │
├─────────────────────────────────────────────────────────────────┤
│ MCP 管理器 │ LLM 管理器 │ 内存系统 │ 追踪器 │
│ (服务器与 │ (多模型 │ (RAM, Redis) │ (日志记录) │
│ 客户端) │ 支持) │ │ │
└─────────────────┴─────────────────┴─────────────────┴───────────┘
更多信息请参见 这里。
快速入门
为了简化流程,我们在该仓库中遵循 特性分支工作流。为确保代码质量,我们已将 PyLint 集成到 CI 中,以强制执行 Python 编码规范。
先决条件
- Python:需版本 3.10 或更高。
- Docker:用于运行 Docker 化的 MCP 服务器。
- PostgreSQL(可选):用于数据库存储和持久化。
- Redis(可选):用于缓存和内存管理。
安装步骤
克隆仓库
git clone https://github.com/SalesforceAIResearch/MCP-Universe.git cd MCP-Universe创建并激活虚拟环境
python3 -m venv venv source venv/bin/activate安装依赖
pip install -r requirements.txt pip install -r dev-requirements.txt平台特定要求
Linux:
sudo apt-get install libpq-devmacOS:
brew install postgresql配置 pre-commit 钩子
pre-commit install环境配置
cp .env.example .env # 根据您的 API 密钥和配置编辑 .env 文件
快速测试
要运行基准测试,您需要先设置环境变量:
- 将
.env.example文件复制为名为.env的新文件。 - 在
.env文件中,设置智能体使用的各种服务所需的 API 密钥,例如OPENAI_API_KEY和GOOGLE_MAPS_API_KEY。
以编程方式执行基准测试的示例代码如下:
from mcpuniverse.tracer.collectors import MemoryCollector # 您也可以使用 SQLiteCollector
from mcpuniverse.benchmark.runner import BenchmarkRunner
async def test():
trace_collector = MemoryCollector()
# 选择 "mcpuniverse/benchmark/configs" 文件夹下的基准配置文件
benchmark = BenchmarkRunner("dummy/benchmark_1.yaml")
# 运行指定的基准测试
results = await benchmark.run(trace_collector=trace_collector)
# 获取追踪记录
trace_id = results[0].task_trace_ids["dummy/tasks/weather_1.json"]
trace_records = trace_collector.get(trace_id)
评估大模型与智能体
本节提供了使用 MCP-Universe 基准套件评估大模型和 AI 智能体的完整说明。该框架支持跨多个领域的评估,包括网络搜索、位置导航、浏览器自动化、财务分析、代码库管理以及 3D 设计等。
先决条件
在运行基准测试之前,请确保已完成 快速入门 部分,并具备以下条件:
- Python:版本 3.10 或更高
- Docker:已安装且可在环境中使用
- 已通过
pip install -r requirements.txt安装所有必要依赖 - 激活的虚拟环境
- 对您计划评估的服务拥有适当的 API 访问权限
环境配置
1. 初始设置
复制环境模板并配置您的 API 凭证:
cp .env.example .env
2. API 密钥与配置
在您的 .env 文件中配置以下环境变量。所需的密钥取决于您计划评估的基准测试领域:
核心大模型提供商
| 环境变量 | 提供商 | 描述 | 必需项 |
|---|---|---|---|
OPENAI_API_KEY |
OpenAI | GPT 模型(gpt-5 等)的 API 密钥 | 所有领域 |
ANTHROPIC_API_KEY |
Anthropic | Claude 模型的 API 密钥 | 所有领域 |
GEMINI_API_KEY |
Gemini 模型的 API 密钥 | 所有领域 |
注意:您只需为打算在评估中使用的 LLM 提供商配置相应的 API 密钥。
领域特定服务
| 环境变量 | 服务 | 描述 | 设置说明 |
|---|---|---|---|
SERP_API_KEY |
SerpAPI | 用于搜索基准测试的网络搜索 API | 获取 API 密钥 |
GOOGLE_MAPS_API_KEY |
Google 地图 | 地理定位和地图服务 | 设置指南 |
GITHUB_PERSONAL_ACCESS_TOKEN |
GitHub | 用于仓库操作的个人访问令牌 | 令牌设置 |
GITHUB_PERSONAL_ACCOUNT_NAME |
GitHub | 您的 GitHub 用户名 | 不适用 |
NOTION_API_KEY |
Notion | 用于访问 Notion 工作区的集成令牌 | 集成设置 |
NOTION_ROOT_PAGE |
Notion | 您的 Notion 工作区的根页面 ID | 参见下方的配置示例 |
系统路径
| 环境变量 | 描述 | 示例 |
|---|---|---|
BLENDER_APP_PATH |
Blender 可执行文件的完整路径(我们使用 v4.4.0) | /Applications/Blender.app/Contents/MacOS/Blender |
MCPUniverse_DIR |
您的 MCP-Universe 仓库的绝对路径 | /Users/username/MCP-Universe |
配置示例
Notion 根页面 ID: 如果您的 Notion 页面 URL 是:
https://www.notion.so/your_workspace/MCP-Evaluation-1dd6d96e12345678901234567eaf9eff
则设置 NOTION_ROOT_PAGE=MCP-Evaluation-1dd6d96e12345678901234567eaf9eff
Blender 安装:
- 从 blender.org 下载 Blender v4.4.0。
- 按照 安装指南 安装我们修改后的 Blender MCP 服务器。
- 设置 Blender 可执行文件的路径。
⚠️ 安全建议
🔒 重要安全提示
请在运行基准测试前仔细阅读并遵循以下安全指南:
🚨 GitHub 集成:至关重要 - 我们强烈建议您使用一个专门的测试 GitHub 账户来进行基准测试。AI 代理将在 GitHub 仓库中执行实际操作,这可能会修改或损坏您的个人仓库。
🔐 API 密钥管理:
- 将 API 密钥安全存储,切勿将其提交到版本控制系统中。
- 使用环境变量或安全的密钥管理系统。
- 定期轮换您的 API 密钥以增强安全性。
🛡️ 访问权限:
- 为每个服务集成授予最小必要的权限。
- 审查并限制 API 密钥的作用范围,仅允许执行必要操作。
- 监控 API 使用情况,并设置适当的速率限制。
⚡ Blender 操作:3D 设计基准测试将执行可能修改或创建您系统上文件的 Blender 命令。请确保已做好充分备份,必要时在隔离环境中运行。
基准测试配置
领域特定配置文件
每个基准测试领域都有一个专用的 YAML 配置文件,位于 mcpuniverse/benchmark/configs/test/ 中。要评估您的 LLM/代理,请修改相应的配置文件:
| 领域 | 配置文件 | 描述 |
|---|---|---|
| 网络搜索 | web_search.yaml |
搜索引擎和信息检索任务 |
| 位置导航 | location_navigation.yaml |
地理和地图相关查询 |
| 浏览器自动化 | browser_automation.yaml |
网页交互和自动化场景 |
| 财务分析 | financial_analysis.yaml |
市场数据分析和财务计算 |
| 仓库管理 | repository_management.yaml |
Git 操作和代码仓库任务 |
| 3D 设计 | 3d_design.yaml |
基于 Blender 的 3D 建模和设计任务 |
LLM 模型配置
在每个配置文件中,更新 LLM 规格以匹配您的目标模型:
kind: llm
spec:
name: llm-1
type: openai # 或 anthropic、google 等
config:
model_name: gpt-4o # 替换为您目标模型
执行
运行单个基准测试
使用以下命令执行特定领域的基准测试:
# 设置 Python 路径并运行单个基准测试
export PYTHONPATH=.
# 位置导航
python tests/benchmark/mcpuniverse/test_benchmark_location_navigation.py
# 浏览器自动化
python tests/benchmark/mcpuniverse/test_benchmark_browser_automation.py
# 财务分析
python tests/benchmark/mcpuniverse/test_benchmark_financial_analysis.py
# 仓库管理
python tests/benchmark/mcpuniverse/test_benchmark_repository_management.py
# 网络搜索
python tests/benchmark/mcpuniverse/test_benchmark_web_search.py
# 3D 设计
python tests/benchmark/mcpuniverse/test_benchmark_3d_design.py
批量执行
要对所有领域进行全面评估:
#!/bin/bash
export PYTHONPATH=.
domains=("location_navigation" "browser_automation" "financial_analysis"
"repository_management" "web_search" "3d_design")
for domain in "${domains[@]}"; do
echo "正在运行基准测试:$domain"
python "tests/benchmark/mcpuniverse/test_benchmark_${domain}.py"
echo "已完成:$domain"
done
保存运行日志
如果您想保存运行日志,可以将 trace_collector 传递给基准测试运行函数:
from mcpuniverse.tracer.collectors import FileCollector
trace_collector = FileCollector(log_file="log/location_navigation.log")
benchmark_results = await benchmark.run(trace_collector=trace_collector)
将基准测试结果保存为报告
如果您想保存基准测试结果报告,可以使用 BenchmarkReport 来导出报告:
from mcpuniverse.benchmark.report import BenchmarkReport
report = BenchmarkReport(benchmark, trace_collector=trace_collector)
report.dump()
可视化代理运行信息
要运行基准测试并查看中间结果和实时进度,可以将 callbacks=get_vprint_callbacks() 传递给运行函数:
from mcpuniverse.callbacks.handlers.vprint import get_vprint_callbacks
benchmark_results = await benchmark.run(
trace_collector=trace_collector,
callbacks=get_vprint_callbacks()
)
这将在基准测试运行时打印出中间结果。
有关更多详细信息,请参阅代码中的文档或仓库中现有的配置示例。
创建自定义基准测试
一个基准测试由三个主要的配置元素定义:任务定义、代理/工作流定义以及基准测试本身的配置。下面是一个使用简单“天气预报”任务的示例。
任务定义
任务定义以 JSON 格式提供,例如:
{
"category": "general",
"question": "旧金山现在的天气如何?",
"mcp_servers": [
{
"name": "weather"
}
],
"output_format": {
"city": "<城市>",
"weather": "<天气预报结果>"
},
"evaluators": [
{
"func": "json -> get(city)",
"op": "=",
"value": "San Francisco"
}
]
}
字段说明:
- category:任务类别,例如“general”、“google-maps”等。您可以为该属性设置任何值。
- question:您希望在此任务中提出的主要问题。这被视为用户消息。
- mcp_servers:此框架支持的 MCP 服务器列表。
- output_format:代理响应的期望输出格式。
- evaluators:用于评估的测试列表。对于每个测试/评估器,它有三个属性:“func”表示如何从代理响应中提取值,“op”是比较运算符,“value”是真实值。 它将评估 op(func(...), value, op_args...)。“op”可以是“=”,“<”,“>”或其他自定义运算符。
在“evaluators”中,您需要编写一条规则(“func”属性),说明如何提取用于测试的值。在上面的示例中,“json -> get(city)”会先进行 JSON 解码,然后提取键“city”的值。此仓库中预定义了几种函数:
- json:执行 JSON 解码。
- get:获取某个键的值。
- len:获取列表的长度。
- foreach:执行 FOR-EACH 循环。
例如,假设我们定义了如下数据:
data = {"x": [{"y": [1]}, {"y": [1, 1]}, {"y": [1, 2, 3, 4]}]}
那么 get(x) -> foreach -> get(y) -> len 将执行以下操作:
- 获取“x”的值:
[{"y": [1]}, {"y": [1, 1]}, {"y": [1, 2, 3, 4]}]。 - 执行 foreach 循环,获取“y”的值:
[[1], [1, 1], [1, 2, 3, 4]]。 - 获取每个列表的长度:
[1, 2, 4]。
如果这些预定义的函数不够用,您可以实现自定义函数。有关更多详细信息,请参阅 此 文档。
基准测试定义
在 YAML 文件中定义代理和基准测试。以下是一个简单的天气预报基准测试:
kind: llm
spec:
name: llm-1
type: openai
config:
model_name: gpt-4o
---
kind: agent
spec:
name: ReAct-agent
type: react
config:
llm: llm-1
instruction: 您是一名天气预报代理。
servers:
- name: weather
---
kind: benchmark
spec:
description: 测试天气预报代理
agent: ReAct-agent
tasks:
- dummy/tasks/weather.json
基准测试定义主要包括两部分:代理定义和基准测试配置。基准测试配置很简单——您只需指定要使用的代理(通过已定义的代理名称)以及要评估的任务列表。每个任务条目都是任务配置文件的路径。它可以是完整文件路径,也可以是相对路径。如果是相对路径(如“dummy/tasks/weather.json”),则应将其放置在本仓库的 mcpuniverse/benchmark/configs 文件夹中。
该框架提供了一种灵活的方式来定义简单代理(如 ReAct)以及更复杂的多步骤代理工作流。
- 指定 LLM:首先声明您希望代理使用的大型语言模型(LLM)。每个 LLM 组件必须被分配一个唯一的名称(例如“llm-1”)。这些名称作为标识符,框架使用它们来连接不同的组件。
- 定义代理:接下来,通过提供代理的名称并选择代理类来定义代理。代理类可在
mcpuniverse.agent 包中找到。
常用类包括“basic”、“function-call”和“react”。在代理规范(
spec.config)中,您还必须通过设置“llm”字段来指示代理应使用哪个 LLM 实例。 - 创建复杂的工作流:除了简单代理外,该框架还支持定义复杂的编排型工作流,其中多个代理相互协作以解决更复杂的任务。
例如:
kind: llm
spec:
name: llm-1
type: openai
config:
model_name: gpt-4o
---
kind: agent
spec:
name: basic-agent
type: basic
config:
llm: llm-1
instruction: 返回某个地点的纬度和经度。
---
kind: agent
spec:
name: function-call-agent
type: function-call
config:
llm: llm-1
instruction: 您是一名天气预报代理。请根据给定的纬度和经度返回今天的天气情况。
servers:
- name: weather
---
kind: workflow
spec:
name: orchestrator-workflow
type: orchestrator
config:
llm: llm-1
agents:
- basic-agent
- function-call-agent
---
kind: benchmark
spec:
description: 测试天气预报代理
agent: orchestrator-workflow
tasks:
- dummy/tasks/weather.json
引用
如果您在研究中使用 MCP-Universe,请引用我们的论文:
@misc{mcpuniverse,
title={MCP-Universe: 使用现实世界模型上下文协议服务器对大型语言模型进行基准测试},
author={Ziyang Luo 和 Zhiqi Shen 和 Wenzhuo Yang 和 Zirui Zhao 和 Prathyusha Jwalapuram 和 Amrita Saha 和 Doyen Sahoo 和 Silvio Savarese 和 Caiming Xiong 和 Junnan Li},
year={2025},
eprint={2508.14704},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2508.14704},
}
版本历史
v1.1.32026/03/25v1.1.22026/03/10v1.1.12026/03/03v1.1.02026/02/26v1.0.42025/10/16v1.0.32025/10/07v1.0.22025/09/18v1.0.12025/09/05v1.0.02025/09/04常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
opencode
OpenCode 是一款开源的 AI 编程助手(Coding Agent),旨在像一位智能搭档一样融入您的开发流程。它不仅仅是一个代码补全插件,而是一个能够理解项目上下文、自主规划任务并执行复杂编码操作的智能体。无论是生成全新功能、重构现有代码,还是排查难以定位的 Bug,OpenCode 都能通过自然语言交互高效完成,显著减少开发者在重复性劳动和上下文切换上的时间消耗。 这款工具专为软件开发者、工程师及技术研究人员设计,特别适合希望利用大模型能力来提升编码效率、加速原型开发或处理遗留代码维护的专业人群。其核心亮点在于完全开源的架构,这意味着用户可以审查代码逻辑、自定义行为策略,甚至私有化部署以保障数据安全,彻底打破了传统闭源 AI 助手的“黑盒”限制。 在技术体验上,OpenCode 提供了灵活的终端界面(Terminal UI)和正在测试中的桌面应用程序,支持 macOS、Windows 及 Linux 全平台。它兼容多种包管理工具,安装便捷,并能无缝集成到现有的开发环境中。无论您是追求极致控制权的资深极客,还是渴望提升产出的独立开发者,OpenCode 都提供了一个透明、可信
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。