RCLI
RCLI 是一款专为 macOS 设计的本地化语音 AI 助手,让你无需联网即可通过自然对话操控电脑、查询文档。它彻底解决了用户对云端隐私泄露的担忧以及网络延迟问题,所有语音识别、大模型推理、语音合成及视觉分析均在设备本地完成,端到端响应速度低于 200 毫秒。
无论是希望提升效率的普通用户,还是关注数据隐私的开发者和研究人员,都能从中受益。你可以直接用语音控制 Spotify 播放、调节音量或打开应用(支持 40 余种系统操作),也能让它“阅读”你的本地文档并回答相关问题,甚至分析屏幕内容或摄像头画面。
RCLI 的核心亮点在于其强大的本地运行能力。它基于 Apple Silicon 芯片优化,内置完整的 STT+LLM+TTS+VLM 流水线。特别是其搭载的 MetalRT 引擎(需 M3 及以上芯片),能充分发挥苹果显卡性能;而在 M1/M2 设备上也能自动兼容运行。整个工具无需配置 API 密钥,安装后即可通过简单的命令行启动,既保护了数据安全,又带来了流畅的离线智能体验。
使用场景
资深开发者李明正在 MacBook Pro 上赶工,他需要一边查阅本地存储的数百页技术文档,一边快速切换应用并分析屏幕上的报错信息,同时严格确保代码和文档数据不上传云端。
没有 RCLI 时
- 操作割裂低效:必须频繁在终端、浏览器和文档阅读器之间手动切换,打断心流,无法通过语音直接控制 Spotify 播放背景乐或调整音量。
- 本地检索困难:查找本地 PDF 或 Markdown 笔记中的特定参数时,只能依赖关键词搜索,难以理解上下文语义,往往需要打开多个文件人工比对。
- 隐私安全顾虑:不敢将敏感的私有代码库或内部文档投喂给云端 AI 助手,担心数据泄露或被用于模型训练。
- 视觉分析缺失:遇到屏幕上的复杂图表或即时报错弹窗,无法直接让 AI“看”懂并解释,只能截图后手动上传到外部工具分析。
使用 RCLI 后
- 全语音流畅操控:李明只需口述指令,RCLI 即可在毫秒级延迟内完成打开 Safari、切换歌曲或调节系统音量等 40 多种 macOS 原生操作,全程无需动手。
- 智能本地问答:直接对着麦克风提问“上次那个异步处理的方案在哪”,RCLI 利用本地 RAG 技术在约 4 毫秒内从海量文档中精准定位并口头回答,无需打开文件。
- 数据绝对私有:所有语音识别、大模型推理及文档分析均在 Apple Silicon 芯片本地完成,无需联网,彻底杜绝了敏感数据外泄风险。
- 实时视觉洞察:遇到报错时,直接让 RCLI 分析当前屏幕或摄像头画面,它能立即识别问题根源并给出修复建议,实现真正的“所见即所问”。
RCLI 将 Mac 变成了真正懂你、保护隐私且能眼观六路的本地智能副驾驶,让开发者在零云依赖下实现效率与安全的双重飞跃。
运行环境要求
- macOS
- 必需 Apple Silicon 芯片 (M1/M2/M3/M4)
- 若要使用高性能 MetalRT 引擎,必须为 M3 或更新版本 (支持 Metal 3.1+)
- M1/M2 会自动回退到 llama.cpp 引擎
- 无需 NVIDIA GPU 或 CUDA
未说明 (默认模型包约 1GB,建议具备运行本地 LLM 的常规内存)

快速开始

用语音与你的 Mac 交流,查询你的文档,无需云端。
RCLI 是一款适用于 macOS 的设备端语音 AI。它是一个完整的 STT + LLM + TTS + VLM 流程,原生运行在 Apple Silicon 上——通过语音实现 40 种 macOS 操作,在你的文档上进行本地 RAG 查询,支持设备端视觉功能(摄像头和屏幕分析),端到端延迟低于 200 毫秒。无需云端,无需 API 密钥。
由 RunAnywhere, Inc. 专为 Apple Silicon 打造的专有 GPU 推理引擎 MetalRT 提供动力。
演示
实时屏幕录制,基于 Apple Silicon——无云端、无剪辑、无花招。
|
语音对话 自然交谈——RCLI 在设备端聆听、理解并响应。 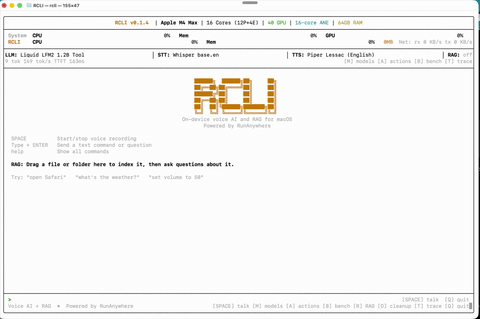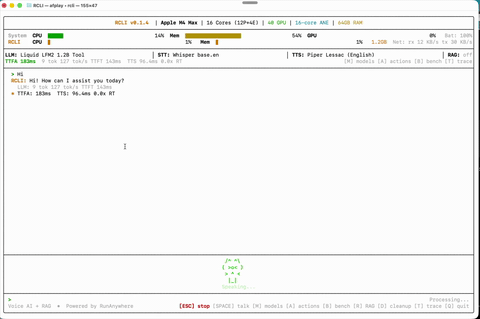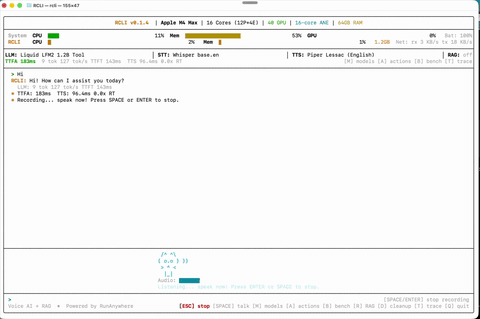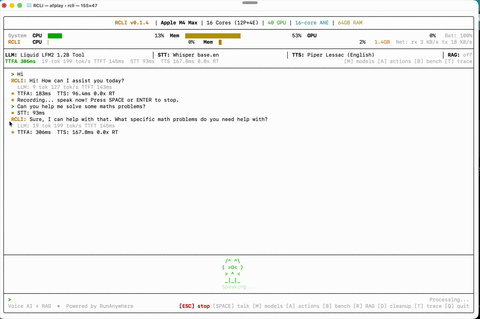
点击观看完整音频视频 |
应用控制 控制 Spotify、调节音量——通过语音实现 38 种 macOS 操作。 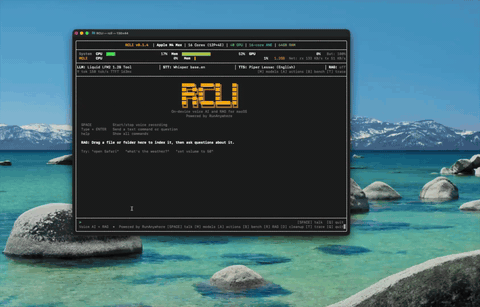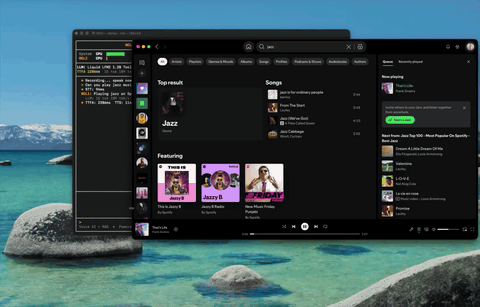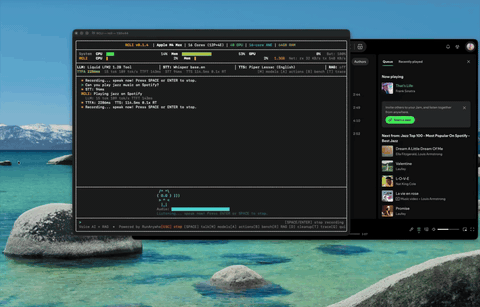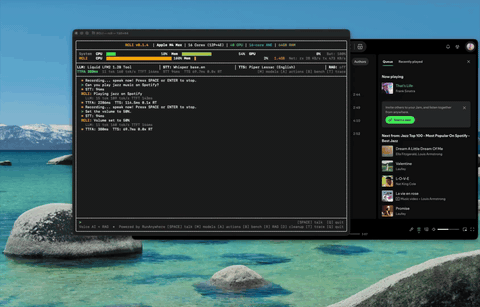
点击观看完整音频视频 |
|
模型 浏览模型、热插拔 LLM——全部通过 TUI 完成。 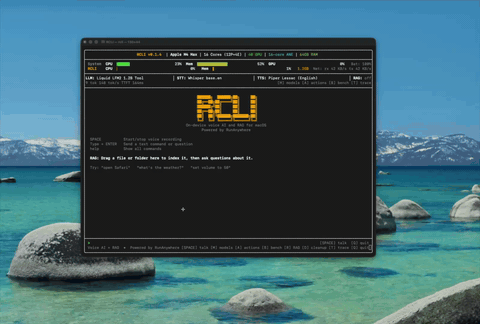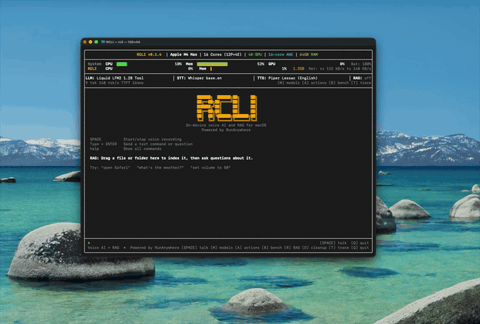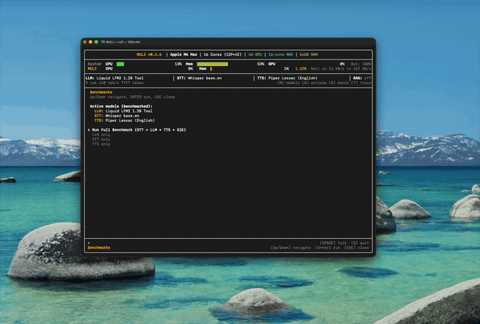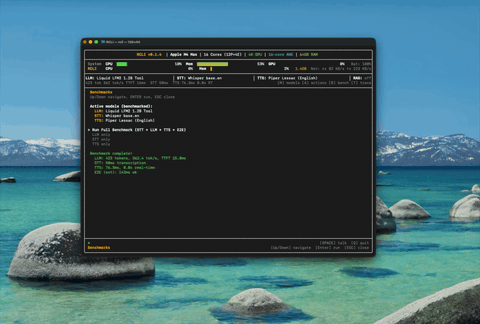
点击观看完整音频视频 |
文档智能(RAG) 导入文档、用语音提问——约 4 毫秒的混合检索。 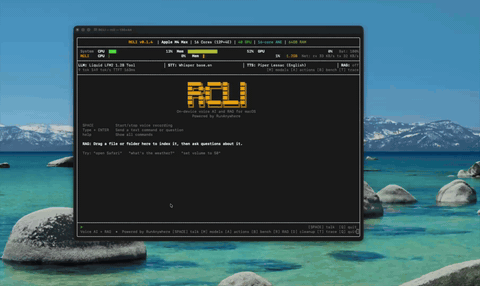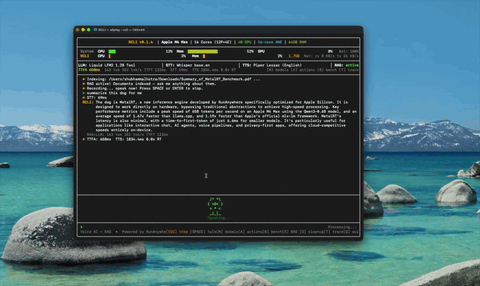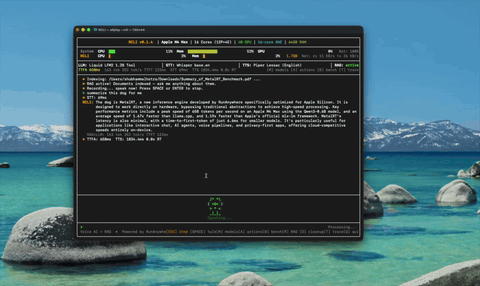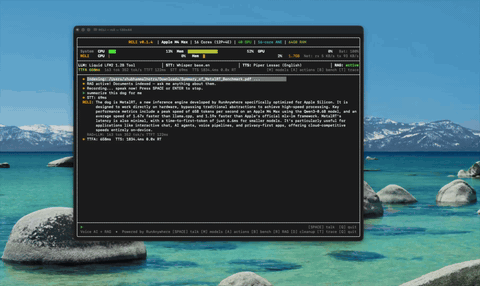
点击观看完整音频视频 |
安装
[重要提示] 需要 macOS 13+ 和 Apple Silicon。MetalRT 引擎要求 M3 或更高版本。 M1/M2 Mac 将自动回退到 llama.cpp。
一条命令:
curl -fsSL https://raw.githubusercontent.com/RunanywhereAI/RCLI/main/install.sh | bash
或通过 Homebrew:
brew tap RunanywhereAI/rcli https://github.com/RunanywhereAI/RCLI.git
brew install rcli
rcli setup # 必需步骤——下载 AI 模型(约 1GB,一次性)
升级到最新版本:
brew update
brew upgrade rcli
故障排除:SHA256 不匹配或版本过时
如果 brew install 或 brew upgrade 因校验和错误而失败:
# 强制刷新 tap 以获取最新 formula
cd $(brew --repo RunanywhereAI/rcli) && git fetch origin && git reset --hard origin/main
brew reinstall rcli
如果仍然无效,请清理 tap 并清除下载缓存:
brew untap RunanywhereAI/rcli
rm -rf "$(brew --cache)/downloads/"*rcli*
brew tap RunanywhereAI/rcli https://github.com/RunanywhereAI/RCLI.git
brew install rcli
rcli setup
快速入门
rcli # 交互式 TUI(按住说话 + 文本输入)
rcli listen # 连续语音模式
rcli ask "open Safari" # 一次性的命令
rcli ask "play some jazz on Spotify"
rcli vlm photo.jpg "what's in this image?" # 视觉分析
rcli camera # 实时摄像头 VLM
rcli screen # 屏幕截图 VLM
rcli metalrt # MetalRT GPU 引擎管理
rcli llamacpp # llama.cpp 引擎管理
基准测试
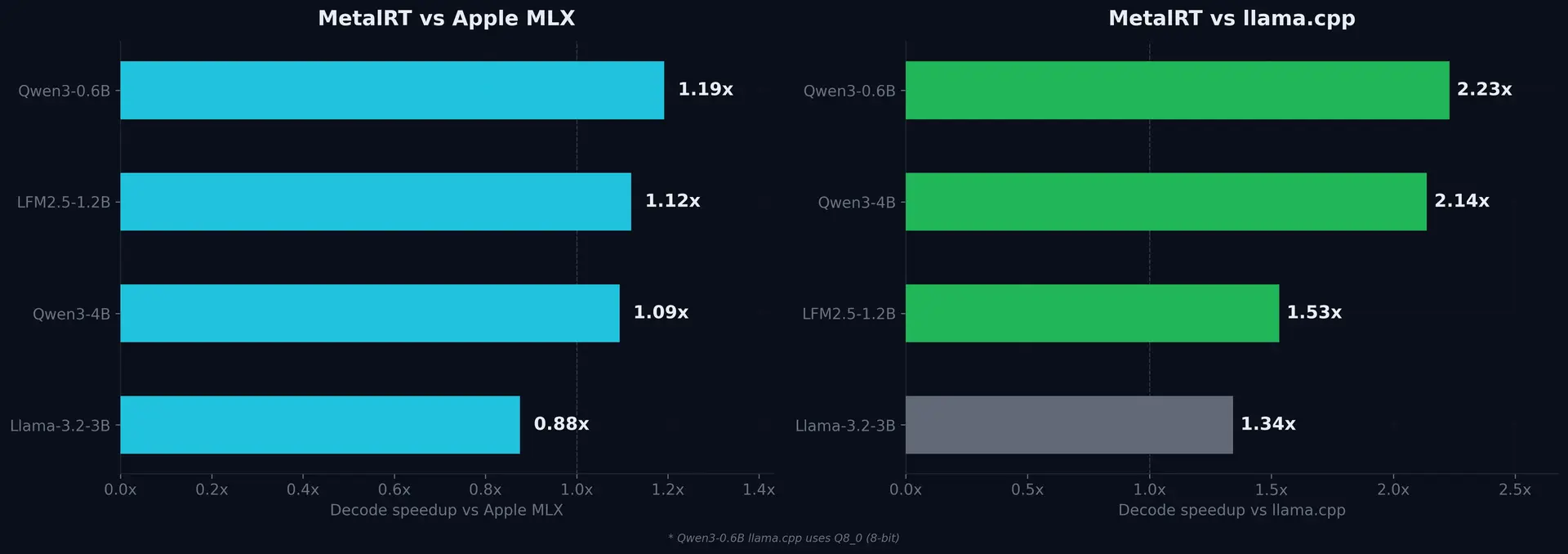
MetalRT 解码吞吐量 vs llama.cpp 和 Apple MLX 在 Apple M3 Max 上的对比
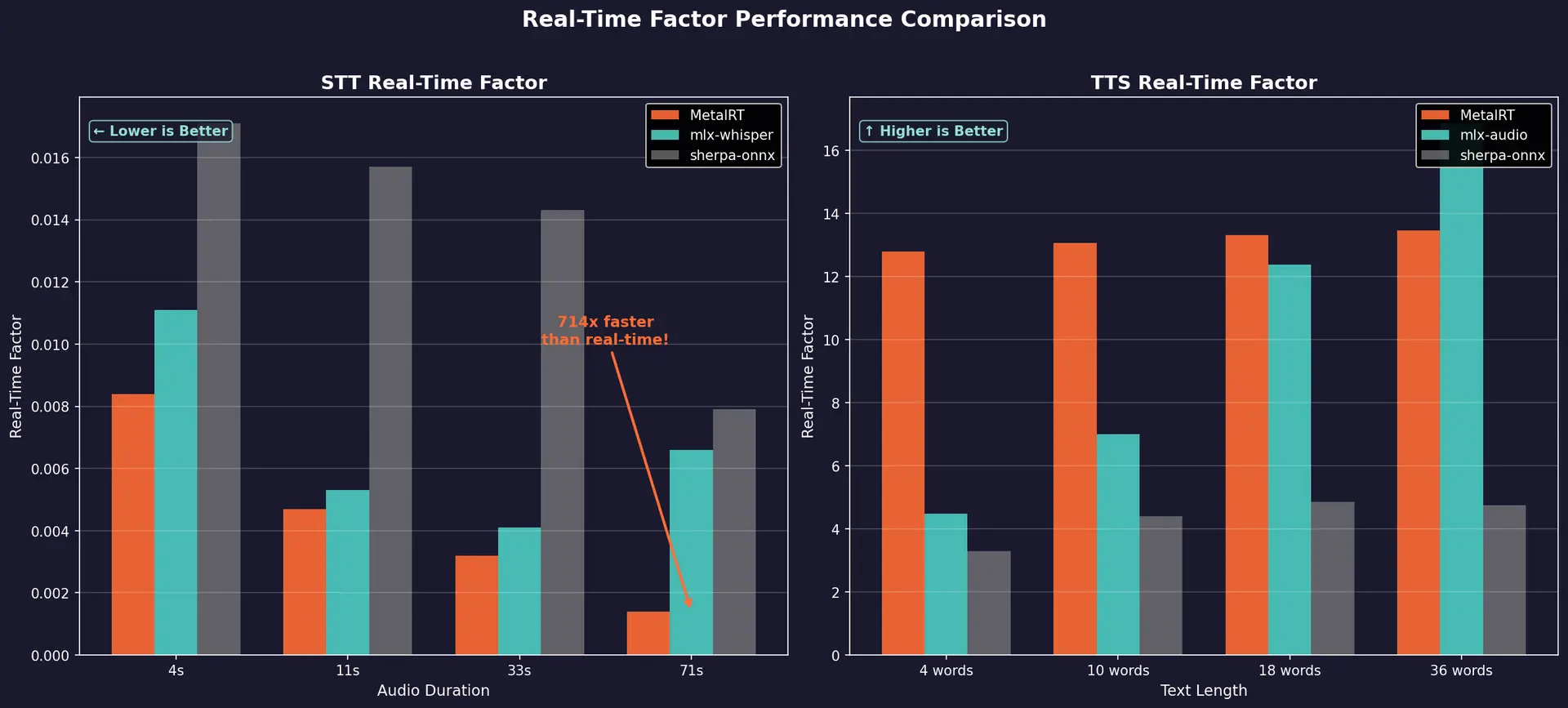
STT 和 TTS 实时因子——数值越低越好。MetalRT 的 STT 速度比实时快 714 倍。
更多信息:
- https://www.runanywhere.ai/blog/metalrt-fastest-llm-decode-engine-apple-silicon
- https://www.runanywhere.ai/blog/metalrt-speech-fastest-stt-tts-apple-silicon
- https://www.runanywhere.ai/blog/fastvoice-on-device-voice-ai-pipeline-apple-silicon
功能
语音流水线
一个完整的 STT + LLM + TTS 流水线,运行在 Metal GPU 上,采用三个并发线程:
- VAD — Silero 语音活动检测
- STT — Zipformer 流式传输 + Whisper / Parakeet 离线模型
- LLM — Qwen3 / LFM2 / Qwen3.5,支持 KV 缓存延续和 Flash Attention
- TTS — 双缓冲句级合成(当前句子播放时,下一句已准备就绪)
- 工具调用 — LLM 原生工具调用格式(Qwen3、LFM2 等)
- 多轮记忆 — 滑动窗口对话历史,按 token 预算修剪
视觉(VLM)
使用设备端视觉语言模型分析图像、摄像头捕捉内容以及屏幕区域。VLM 通过 Metal GPU 在 llama.cpp 引擎上运行——无需云端。
- 图像分析 —
rcli vlm photo.jpg "describe this"用于单张图像查询 - 摄像头 — 在 TUI 中按下 V 键,或运行
rcli camera进行实时摄像头分析 - 屏幕截图 — 在 TUI 中按下 S 键,或运行
rcli screen分析屏幕区域 - 模型 — Qwen3 VL 2B、Liquid LFM2 VL 1.6B、SmolVLM 500M——可通过
rcli models vlm按需下载
注意: 目前 VLM 仅在 llama.cpp 引擎上可用。MetalRT 对 VLM 的支持即将推出。
40 个 macOS 操作
通过语音或文本控制您的 Mac。LLM 会将意图路由到通过 AppleScript 和 shell 命令在本地执行的操作。
| 类别 | 示例 |
|---|---|
| 生产力 | create_note、create_reminder、run_shortcut |
| 通信 | send_message、facetime_call |
| 媒体 | play_on_spotify、play_apple_music、play_pause、next_track、set_music_volume |
| 系统 | open_app、quit_app、set_volume、toggle_dark_mode、screenshot、lock_screen |
| 网络 | search_web、search_youtube、open_url、open_maps |
运行 rcli actions 查看全部 40 个,或在 TUI 操作面板中启用/禁用它们。
提示: 如果工具调用感觉不可靠,请在 TUI 中按 X 清除对话并重置上下文。对于小型 LLM,累积的上下文可能会降低工具调用的准确性——重新开始一个全新的上下文通常可以解决这个问题。
RAG(本地文档问答)
索引本地文档,并通过语音进行查询。混合向量 + BM25 检索,在 5000 多个分块上延迟约为 4 毫秒。支持 PDF、DOCX 和纯文本。
rcli rag ingest ~/Documents/notes
rcli ask --rag ~/Library/RCLI/index "summarize the project plan"
交互式 TUI
一个终端仪表盘,具有按住说话功能、实时硬件监控、模型管理和操作浏览器。
| 键 | 动作 |
|---|---|
| SPACE | 按住说话 |
| V | 相机 — 使用 VLM 捕获并分析 |
| S | 屏幕 — 使用 VLM 捕获并分析屏幕区域 |
| M | 模型 — 浏览、下载、热插拔 LLM/STT/TTS/VLM |
| A | 操作 — 浏览、启用/禁用 macOS 操作 |
| R | RAG — 索引文档 |
| X | 清除对话并重置上下文 |
| T | 切换工具调用跟踪 |
| ESC | 停止/关闭/退出 |
MetalRT GPU 引擎
MetalRT 是由 RunAnywhere, Inc. 专门为 Apple Silicon 打造的高性能 GPU 推理引擎。它为 LLM、STT 和 TTS 提供最快的设备端推理——LLM 吞吐量高达 550 tok/s,端到端语音延迟低于 200 毫秒。
需要 Apple M3 或更高版本。 MetalRT 使用 M3、M3 Pro、M3 Max、M4 及更高芯片上可用的 Metal 3.1 GPU 特性。M1/M2 的支持即将推出。在 M1/M2 上,RCLI 会自动回退到开源 llama.cpp 引擎。
MetalRT 会在 rcli setup 时自动安装(选择“MetalRT”或“两者”)。也可以单独安装:
rcli metalrt install
rcli metalrt status
支持的模型: Qwen3 0.6B、Qwen3 4B、Llama 3.2 3B、LFM2.5 1.2B(LLM)· Whisper Tiny/Small/Medium(STT)· Kokoro 82M,带 28 种声音(TTS)
MetalRT 采用 专有许可 分发。如需许可咨询,请联系 founder@runanywhere.ai。
支持的模型
RCLI 支持 LLM、STT、TTS、VLM、VAD 和嵌入等领域的 20 多种模型。所有模型都在 Apple Silicon 上本地运行。使用 rcli models 浏览、下载或切换模型。
LLM: LFM2 1.2B(默认)、LFM2 350M、LFM2.5 1.2B、LFM2 2.6B、Qwen3 0.6B、Qwen3.5 0.8B/2B/4B、Qwen3 4B
STT: Zipformer(流式)、Whisper base.en(离线,默认)、Parakeet TDT 0.6B(约 1.9% WER)
TTS: Piper Lessac/Amy、KittenTTS Nano、Matcha LJSpeech、Kokoro 英语/多语言
VLM: Qwen3 VL 2B、Liquid LFM2 VL 1.6B、SmolVLM 500M——可通过 rcli models vlm 按需下载(仅限 llama.cpp 引擎)
默认安装(rcli setup):约 1GB——LFM2 1.2B + Whisper + Piper + Silero VAD + Snowflake 嵌入。VLM 模型按需下载。
rcli models # 交互式模型管理
rcli models vlm # 下载/管理 VLM 模型
rcli upgrade-llm # 引导式 LLM 升级
rcli voices # 浏览和切换 TTS 音色
rcli cleanup # 删除未使用的模型
从源代码构建
仅 CPU 构建,使用 llama.cpp + sherpa-onnx(无 MetalRT):
git clone https://github.com/RunanywhereAI/RCLI.git && cd RCLI
bash scripts/setup.sh
bash scripts/download_models.sh
mkdir -p build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release
cmake --build . -j$(sysctl -n hw.ncpu)
./rcli
所有依赖项均已打包或通过 CMake 获取。需要 CMake 3.15+ 和 Apple Clang(C++17)。
CLI 参考
rcli 交互式 TUI(按住说话 + 文本 + 跟踪)
rcli listen 连续语音模式
rcli ask <text> 一次性文本命令
rcli vlm <image> [prompt] 使用 VLM 分析图像
rcli camera [prompt] 实时摄像头捕捉 + VLM 分析
rcli screen [prompt] 屏幕截图 + VLM 分析
rcli actions [name] 列出操作或显示详细信息
rcli rag ingest <dir> 为 RAG 索引文档
rcli rag query <text> 查询已索引的文档
rcli models [llm|stt|tts|vlm] 管理 AI 模型
rcli voices 管理 TTS 音色
rcli metalrt MetalRT GPU 引擎管理
rcli llamacpp llama.cpp 引擎管理
rcli setup 下载默认模型
rcli info 显示引擎和模型信息
选项:
--models <dir> 模型目录(默认:~/Library/RCLI/models)
--rag <index> 加载 RAG 索引以获取基于文档的答案
--gpu-layers <n> LLM 的 GPU 层数(默认:99 = 全部)
--ctx-size <n> LLM 的上下文大小(默认:4096)
--no-speak 仅输出文本(不使用 TTS)
--verbose, -v 调试日志
贡献
欢迎贡献。请参阅 CONTRIBUTING.md 了解构建说明以及如何添加新的操作、模型或音色。
许可证
RCLI 采用 MIT 许可证 开源。
MetalRT 是 RunAnywhere, Inc. 的专有软件,采用单独的 许可证 分发。
由 RunAnywhere, Inc. 构建
版本历史
v0.3.72026/03/15v0.3.62026/03/12v0.3.52026/03/12v0.3.42026/03/11v0.3.32026/03/10v0.3.22026/03/10v0.3.12026/03/10v0.3.02026/03/10v0.2.92026/03/10v0.2.82026/03/10v0.2.72026/03/10v0.2.62026/03/10v0.2.52026/03/10v0.2.42026/03/10v0.2.32026/03/10v0.2.22026/03/10v0.2.12026/03/10v0.1.52026/03/05v0.1.42026/03/05v0.1.32026/03/04常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器