autokernel
AutoKernel 是一款专为 GPU 内核优化设计的自动化研究工具。它能接收任意 PyTorch 模型,自动识别计算瓶颈,并生成经过高度优化的 Triton 或 CUDA C++ 内核代码,让用户在休息醒来后即可获得性能显著提升的模型。
该工具主要解决了深度学习开发中手动编写和优化底层 GPU 内核门槛高、耗时长的痛点。传统方式需要专家耗费大量时间进行微调和基准测试,而 AutoKernel 通过自主智能体模拟“研究团队”的工作流:先对模型进行性能剖析定位瓶颈,再提取关键算子,随后由智能体循环执行“修改代码 - 运行基准测试 - 验证正确性 - 保留或回滚”的过程,直至找到最优解。整个过程基于阿姆达尔定律智能调度优化顺序,确保整体加速效果最大化。
AutoKernel 特别适合 AI 基础设施工程师、高性能计算研究人员以及希望深入优化模型推理速度的开发者使用。其独特亮点在于内置了严谨的五阶段正确性验证机制(涵盖数值稳定性、确定性等),并配有详尽的优化策略文档,使智能体能连续运行十小时以上而不迷失方向。只需简单的命令行操作,即可将原本复杂的内核调优工作转化为全自动化的流程,大幅提升研发效率。
使用场景
某 AI 初创团队正在将自研的 7B 参数大语言模型部署到 H100 集群,却因推理延迟过高而面临上线瓶颈。
没有 autokernel 时
- 定位困难:工程师需手动运行复杂的性能分析工具,在数百个算子中艰难排查耗时最长的“元凶”,往往耗费数天才能锁定瓶颈。
- 优化门槛高:针对识别出的瓶颈算子,资深工程师需手工编写并反复调试底层的 Triton 或 CUDA C++ 代码,对硬件架构知识要求极高且极易出错。
- 验证繁琐:每次修改内核后,必须人工设计多轮测试用例来验证数值正确性和边界情况,稍有不慎就会导致模型输出异常,迭代周期漫长。
- 全局视野缺失:难以直观判断单个算子的优化对整体模型速度的实际贡献,常出现“局部最优但整体提升微弱”的资源浪费情况。
使用 autokernel 后
- 自动诊断:autokernel 一键扫描 PyTorch 模型,自动按 GPU 耗时排序并精准提取出前 5 个关键瓶颈算子,瞬间完成定位。
- 无人值守优化:autokernel 驱动 AI 代理自主编写、编译并基准测试优化的 Triton 内核,团队只需睡一觉,醒来即可获得经过数百次迭代的最优代码。
- 严谨自测:autokernel 内置五阶段自动化验证流程(含数值稳定性与确定性检查),确保每个新生成的内核在提速的同时严格保证数学等价性。
- 智能调度:基于阿姆达尔定律,autokernel 自动计算并优先优化对端到端延迟影响最大的算子,确保每一分算力投入都转化为实际的推理加速。
autokernel 将原本需要资深专家数周完成的底层内核优化工作,转变为 overnight 的自动化流程,让团队能专注于模型算法本身而非硬件适配。
运行环境要求
- Linux
必需 NVIDIA GPU (测试于 H100/A100/RTX 4090),v1.3.0 更新支持 AMD ROCm GPU (MI300X/MI325X 等)
未说明
快速开始
AutoKernel
针对 GPU 内核的自动研究工具。 只需提供任意 PyTorch 模型,然后安心入睡,醒来时即可获得优化后的 Triton 或 CUDA C++ 内核。
灵感来源于 @karpathy/autoresearch —— 该工具展示了用于大语言模型训练研究的自主 AI 代理。AutoKernel 将同样的理念应用于 GPU 内核优化:代理会修改单个文件,运行固定的评估流程,决定保留或回滚更改,并无限循环重复这一过程。
工作原理
向 AutoKernel 提供任意 PyTorch 模型,它将执行以下步骤:
- 性能剖析:识别哪些 GPU 内核是性能瓶颈。
- 提取瓶颈内核:将每个瓶颈内核单独提取为独立的 Triton 或 CUDA C++ 内核。
- 自主优化:对每个内核进行持续优化(编辑、基准测试、保留或回滚——直至满意)。
- 端到端验证:确保整体正确性,并报告总加速效果。
代理会读取 program.md 文件——即“研究组织代码”——其中包含详细的自主操作指南。它会逐个内核编辑 kernel.py 文件,运行 bench.py 脚本(包含五阶段正确性检查和 Roofline 分析的固定基准测试),并根据结果决定是否保留或回滚更改。调度器会利用阿姆达尔定律来判断何时切换到下一个内核。
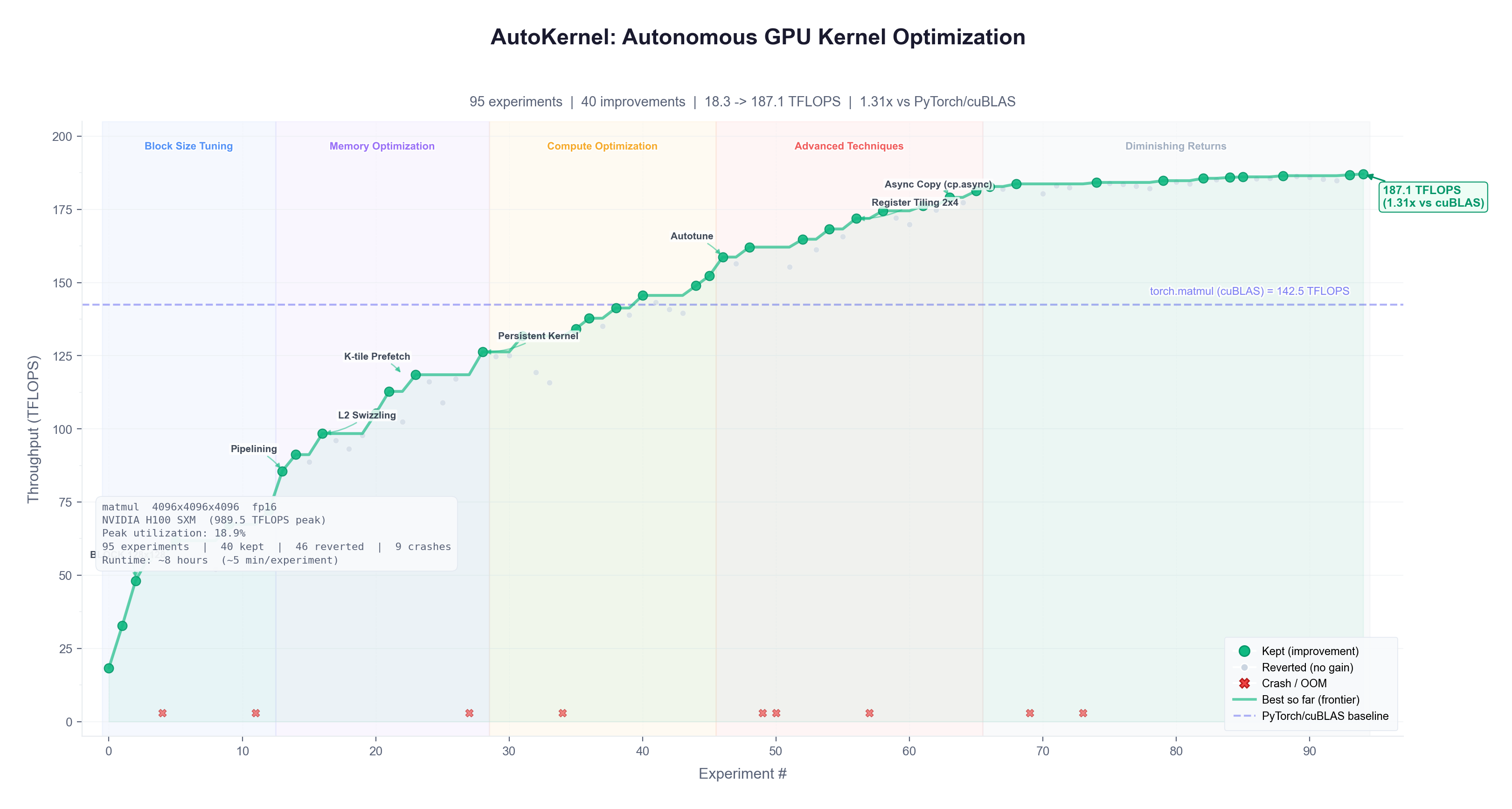
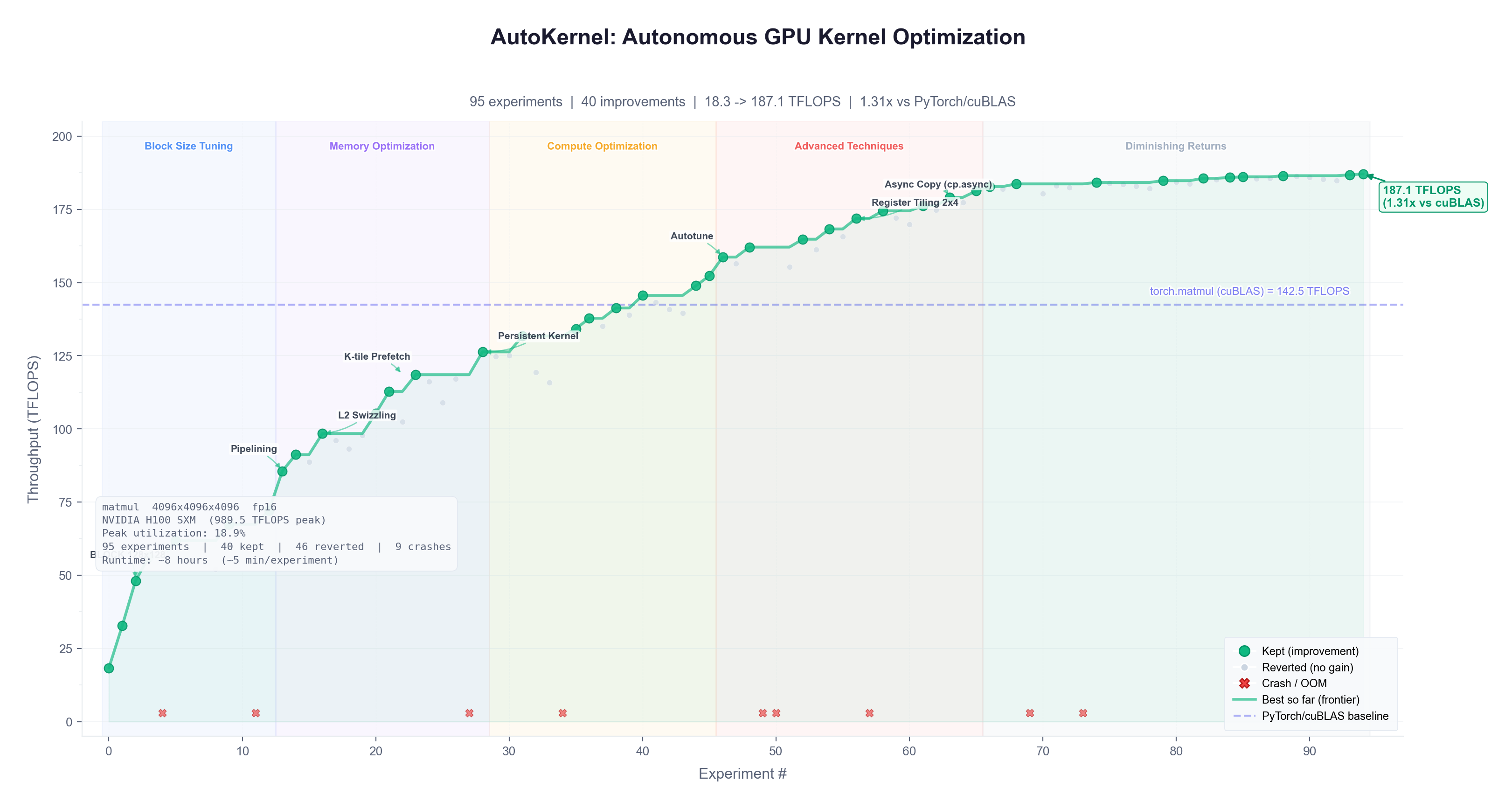
每次实验大约耗时 90 秒,因此每小时可完成约 40 次实验,整夜下来则能完成约 320 次,覆盖所有内核。
快速入门
要求:NVIDIA GPU(已测试 H100/A100/RTX 4090)、Python 3.10+、uv。
# 安装 uv(如果尚未安装)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 克隆并设置环境
git clone https://github.com/RightNow-AI/autokernel.git
cd autokernel
uv sync
# 一次性设置:测试数据与基线
uv run prepare.py
# 对模型进行性能剖析(内置 GPT-2、LLaMA、BERT 模型,无需 transformers 库)
uv run profile.py --model models/llama_7b.py --class-name LlamaModel \
--input-shape 1,512 --dtype float16
# 提取前 5 个瓶颈内核
uv run extract.py --top 5
# 验证基准测试是否正常运行
uv run bench.py
启动代理
在此目录下启动 Claude、Codex 或任何编码代理:
请阅读 program.md,我们开始新的实验吧。先从设置开始。
代理将执行以下操作:
- 对您的模型进行性能剖析,并给出优化计划。
- 创建一个分支(例如
autokernel/mar10-llama7b)。 - 按优先级顺序优化每个瓶颈内核。
- 验证端到端正确性,并报告总加速效果。
program.md 文件内容详尽,旨在让代理能够连续运行 10 小时以上而不会卡住。它包含了六层优化策略、决策框架、异常处理机制以及基于阿姆达尔定律的推理逻辑。
流程概述
profile.py extract.py bench.py (循环) verify.py
任意 PyTorch ──> 按 GPU 时间排序内核 ──> 生成基线 ──> 优化每个 ──> 端到端
模型 内核 Triton/CUDA 内核 内核(代理) 验证
| 工具 | 功能 |
|---|---|
profile.py |
使用 torch.profiler 对任意 PyTorch 模型进行性能剖析,按 GPU 时间对内核排序,并分类为计算密集型或内存密集型。 |
extract.py |
将前 N 个瓶颈内核提取为独立的 Triton 或 CUDA C++ 内核文件(通过 --backend triton|cuda 指定后端)。 |
orchestrate.py |
多内核调度器:使用阿姆达尔定律决定下一个优化的内核,并跟踪整体进度。 |
bench.py |
固定基准测试:包括五阶段正确性检查(烟雾测试、形状扫描、数值稳定性、确定性、边界情况)以及性能和 Roofline 分析。 |
verify.py |
将优化后的内核重新集成到模型中,检查端到端正确性,并报告总加速效果。 |
支持的内核类型
涵盖现代深度学习核心操作的 9 种内核类型:
| 内核 | 描述 | 关键指标 |
|---|---|---|
| matmul | 密集矩阵乘法 (M x K) @ (K x N) | TFLOPS |
| softmax | 行并行数值稳定的 softmax | GB/s |
| layernorm | 带仿射变换的层归一化 | GB/s |
| rmsnorm | RMS 归一化(LLaMA 风格) | GB/s |
| flash_attention | 缩放点积注意力,带因果掩码 | TFLOPS |
| fused_mlp | SwiGLU 风格的融合 MLP(门控 + 上升 + 下降) | TFLOPS |
| cross_entropy | 融合交叉熵损失 | GB/s |
| rotary_embedding | 旋转位置嵌入(RoPE) | GB/s |
| reduce | 并行规约(求和) | GB/s |
每种内核在 reference.py 中都有 PyTorch 参考实现,在 kernels/ 目录中有 Triton 初始内核,在 kernels/cuda/ 目录中有 CUDA C++ 初始内核。
示例模型
AutoKernel 自带了自包含的模型定义(无需 transformers 库):
| 模型 | 文件 | 参数量 | 使用方法 |
|---|---|---|---|
| GPT-2 Small | models/gpt2.py |
1.24 亿 | --class-name GPT2 --input-shape 1,1024 |
| LLaMA(精简版) | models/llama_7b.py |
1.6 亿 | --class-name LlamaModel --input-shape 1,512 |
| LLaMA 7B | models/llama_7b.py |
70 亿 | --class-name LlamaModel7B --input-shape 1,2048 |
| BERT-base | models/bert_base.py |
1.1 亿 | --class-name BertModel --input-shape 8,512 |
| 自定义 | models/custom.py |
-- | 您可以在此基础上构建自己的模型模板。 |
对于 HuggingFace 模型(需运行 uv sync --extra models):
uv run profile.py --module transformers --class-name AutoModelForCausalLM \
--pretrained meta-llama/Llama-2-7b-hf --input-shape 1,2048 --dtype float16
KernelBench 集成
AutoKernel 与 KernelBench 集成,后者是评估 AI 生成 GPU 内核的标准基准测试平台(涵盖 4 个难度级别的 250 多个问题)。虽然大多数 KernelBench 评估采用一次性的 LLM 生成方式,但 AutoKernel 每个问题会进行 50–300+ 次迭代优化实验——系统性地探索优化空间,而非随机猜测。
# 安装 KernelBench 的依赖
uv sync --extra kernelbench
# 从 HuggingFace 获取 Level 1 问题
uv run kernelbench/bridge.py fetch --source hf --level 1
# 设置特定问题以进行优化
uv run kernelbench/bridge.py setup --level 1 --problem 1 --source hf
# 评估(正确性及相对于 PyTorch 参考的加速效果)
uv run kernelbench/bench_kb.py
# 批量评分整个级别(计算 fast_p 指标)
uv run kernelbench/scorer.py --level 1
代理会读取 kernelbench/program_kb.md 文件,以获取 KernelBench 特定的优化指导:
如何编写 ModelNew 类、何时使用 CUDA C++ 或 Triton、针对不同问题级别的融合策略,
以及为 KernelBench 的 fast_p 指标量身定制的编辑-保留/回滚循环。
| 工具 | 功能 |
|---|---|
kernelbench/bridge.py |
从 HuggingFace 或本地仓库加载问题,缓存并生成初始 kernel.py 文件 |
kernelbench/bench_kb.py |
对比评估 ModelNew 和 Model:进行 5 次正确性测试 + CUDA 事件计时 + 稳定性 + 确定性 |
kernelbench/scorer.py |
在一个级别内批量评估,并在不同阈值下(1.0x、1.5x、2.0x、3.0x、5.0x)计算 fast_p |
kernelbench/program_kb.md |
针对 KernelBench 模式的代理操作指南 |
HuggingFace 内核导出
将优化后的内核导出到 HuggingFace Hub,便于分发。用户只需一行代码即可加载您的内核:
from kernels import get_kernel
module = get_kernel("your-username/kernel-name")
# 导出一个优化后的 CUDA 内核
uv run export_hf.py --name my_matmul
# 上传至 Hub(需先安装 `pip install kernels` 并登录 HuggingFace)
cd workspace/hf_export/my_matmul
kernels upload . --repo_id your-username/my_matmul
项目结构
autokernel/
kernel.py 代理每次修改的文件(一次只改一个内核)
program.md 代理的操作说明——“研究组织代码”
bench.py 固定的基准测试 + 5 阶段正确性测试框架
reference.py PyTorch 参考实现(真实结果)
prepare.py 一次性设置:测试数据、基线
profile.py 分析任意 PyTorch 模型,按 GPU 时间对内核排序
extract.py 将瓶颈内核提取到 workspace/ 目录
orchestrate.py 多内核调度器(阿姆达尔定律)
verify.py 端到端模型验证 + 加速效果报告
export_hf.py 将优化后的内核导出为 HuggingFace Kernels 格式
analysis.py 实验可视化(生成 https://oss.gittoolsai.com/images/RightNow-AI_autokernel_readme_18212f72a48c.png)
kernels/ 初始 Triton 内核(9 种类型)
kernels/cuda/ 初始 CUDA C++ 内核(9 种类型,支持 Tensor Core 加速)
kernelbench/ KernelBench 集成(桥接、评估框架、评分器)
models/ 自包含的模型定义(GPT-2、LLaMA、BERT)
workspace/ 运行时生成的中间文件(已忽略在 Git 中)
设计选择
双后端:Triton + CUDA C++。 Triton 适合快速迭代(类似 Python 的语法,编译只需几秒)。CUDA C++ 则用于追求极致性能(通过 wmma、PTX 内建指令和共享内存无冲突布局直接访问 Tensor Core)。Triton 的性能通常能达到 cuBLAS 的 80%-95%;而 CUDA C++ 则可以持平甚至超越 cuBLAS。两种后端共享相同的 kernel_fn() 接口——bench.py 在两者上都能以相同方式运行。
正确性第一。 基准测试会在测量性能之前先对比内核输出与 PyTorch 结果。如果内核速度很快但结果错误,则会立即回滚。这样可以防止代理通过生成无效结果来“优化”。
阿姆达尔定律调度。 调度器会根据影响优先级排序。例如,在占总耗时 60% 的内核上实现 1.5 倍加速(整体加速 1.25 倍),远胜于在仅占 5% 的内核上实现 3 倍加速(整体加速仅 1.03 倍)。当收益递减时,调度器会停止进一步优化。
单一可修改文件。 代理仅需修改 kernel.py 文件。这样范围可控,差异易于审查,回滚也更干净。
TSV 日志记录。 结果会保存到纯文本的 results.tsv 文件中。格式简单易读、适合 Git 管理且易于解析,无需额外基础设施。
结果格式
每次实验都会记录到 results.tsv 文件中(制表符分隔):
| 列名 | 描述 |
|---|---|
experiment |
实验序号(0 表示基线) |
tag |
简短标识符 |
kernel_type |
内核类型(如 matmul) |
throughput_tflops |
测得的吞吐量(越高越好) |
latency_us |
执行时间,单位为微秒 |
pct_peak |
占 GPU 理论峰值的比例 |
speedup_vs_pytorch |
相对于 PyTorch/cuBLAS 的加速倍数 |
correctness |
PASS、FAIL、TIMEOUT 或 CRASH |
peak_vram_mb |
GPU 内存峰值用量 |
description |
尝试的内容 |
致谢
本项目是 面向 GPU 内核的自动研究 —— 直接受到 Andrej Karpathy 的 autoresearch 启发,该实验最初旨在探索由 AI 代理自主进行 LLM 训练的研究。Karpathy 证明了 AI 代理可以在一夜之间完成数百次实验,系统地探索搜索空间并记录每一步结果。AutoKernel 将这一流程应用到 GPU 内核优化领域,结合 Triton 和原生 CUDA C++,采用迭代优化的方式(每个问题进行 300 多次实验),而非一次性生成。
KernelBench 集成基于斯坦福大学 Scaling Intelligence Lab 的 Simon Guo、Sean Resta 等人的工作。他们的论文《KernelBench:LLM 能否编写 GPU 内核?》(2025 年)确立了评估 AI 生成 GPU 内核的标准基准。AutoKernel 在此基础上进一步扩展,通过迭代优化(每个问题进行 300 多次实验)取代了一次性生成的方式。KernelBench 数据集及评估协议详见:ScalingIntelligence/KernelBench。
由 RightNow AI 构建。如需企业级 GPU 优化服务,请访问 RightNow Enterprise。
更改日志
v1.3.0
- 支持 AMD ROCm GPU:检测并记录 MI300X、MI325X、MI350X、MI355X 的规格信息(感谢 @andyluo7)
- 修复了
verify.py在 Python 3.13+ 上的 SyntaxError - 修复了 CUDA flash_attention 忽视
sm_scale参数的问题 - 修复了 CUDA cross_entropy 返回错误数据类型的问题
- 修复了 Triton rotary_embedding 广播截断的问题
- 修复了 Triton reduce 在非最后一维归约时输出形状不正确的问题
v1.2.0
- 增强了性能分析工具:新增
--export-trace、--memory-snapshot、--torch-compile-log标志 - 新增通过
export_hf.py导出至 HuggingFace Kernels 的功能
v1.1.0
- 增加了原生 CUDA C++ 后端,包含 9 个初始内核(支持 Tensor Core、Warp 指令和共享内存分块)
- 集成了 KernelBench(250 多个标准化的 GPU 内核问题)
- 为
extract.py添加了--backend triton|cuda标志
v1.0.0
- 初始版本:基于 Triton 的内核优化流水线,配备 5 阶段正确性测试框架
完整详情请参阅 CHANGELOG.md。
许可证
MIT
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备