Multi-Label-Text-Classification
Multi-Label-Text-Classification 是一个基于深度神经网络的多标签文本分类开源项目,旨在解决单篇文档同时属于多个类别的分类难题。与传统单标签分类不同,它能精准识别文本中包含的多种特征,输出如 [0, 1, 0, ..., 1] 形式的多维标签向量,特别适用于新闻归类、内容 tagging 等复杂场景。
该项目非常适合人工智能开发者、算法研究人员以及希望深入理解 TensorFlow 深度学习架构的学习者使用。其核心亮点在于强大的灵活性与工程优化:不仅原生支持中文(可结合 jieba 分词)和英文处理,还允许用户加载自定义的预训练词向量。在模型架构上,它创新性地引入了 Highway Layer 和批归一化(Batch Normalization)层以提升性能,并集成了梯度裁剪、学习率指数衰减及修正的 L2 损失计算,有效防止训练过程中的梯度爆炸问题。此外,项目提供了完善的评估体系,支持 AUC 和 AUPRC 指标计算,具备通过阈值或 Top-K 策略预测标签的功能,并能利用 TensorBoard 进行嵌入可视化与训练监控,是研究多标签分类任务的优质参考范本。
使用场景
某大型专利数据库团队正面临海量技术文档自动归档的挑战,需要为每篇专利同时打上多个精准的技术领域标签。
没有 Multi-Label-Text-Classification 时
- 分类维度单一:传统单标签模型强制每篇专利只能归属一个类别,导致涉及“压力传感”与“流体力学”的交叉学科专利被错误截断,丢失关键检索维度。
- 人工成本高昂:依赖专家手动标注多重标签,面对每日新增的数千篇文档,处理滞后严重且容易出现主观漏标。
- 模型训练不稳定:自研的深度学习脚本缺乏梯度裁剪和学习率衰减机制,训练深层网络时频繁出现梯度爆炸,导致模型无法收敛。
- 效果评估缺失:缺乏针对多标签场景的 AUC 和 AUPRC 指标计算,难以量化模型在稀疏标签下的真实表现,优化方向盲目。
使用 Multi-Label-Text-Classification 后
- 精准多维打标:利用其基于神经网络的多标签输出架构(如 [0, 1, 0, ..., 1] 格式),成功识别出单篇专利中的多个核心技术点,召回率显著提升。
- 自动化流程落地:结合预训练的中文词向量(Word2Vec)和分词工具,实现了从原始文本到多标签预测的全自动流水线,处理效率提升数十倍。
- 训练稳定高效:内置的梯度裁剪、L2 损失计算及 Highway Layer 有效防止了梯度爆炸,配合指数学习率衰减,使模型在复杂数据上快速收敛至最优状态。
- 科学量化评估:直接输出 AUC 与 AUPRC 专业指标,并通过 TensorBoard 可视化嵌入层,让团队能清晰监控训练过程并针对性调优。
Multi-Label-Text-Classification 通过引入工业级的深度学习方法论,将模糊的文本归类难题转化为可量化、高并发的智能标签服务,彻底释放了非结构化数据的价值。
运行环境要求
- 未说明
未说明
未说明
快速开始
基于深度学习的多标签文本分类
![]()




本仓库是我的研究项目,同时也是对 TensorFlow 和深度学习(Fasttext、CNN、LSTM 等)的学习实践。
该项目的主要目标是基于深度神经网络解决多标签文本分类问题。因此,根据此类问题的特点,数据标签的格式为 [0, 1, 0, ..., 1, 1]。
需求
- Python 3.6
- Tensorflow 1.15.0
- Tensorboard 1.15.0
- Sklearn 0.19.1
- Numpy 1.16.2
- Gensim 3.8.3
- Tqdm 4.49.0
项目结构
项目的目录结构如下:
.
├── Model
│ ├── test_model.py
│ ├── text_model.py
│ └── train_model.py
├── data
│ ├── word2vec_100.model.* [需要下载]
│ ├── Test_sample.json
│ ├── Train_sample.json
│ └── Validation_sample.json
└── utils
│ ├── checkmate.py
│ ├── data_helpers.py
│ └── param_parser.py
├── LICENSE
├── README.md
└── requirements.txt
创新点
数据部分
- 支持 中文 和英文数据(可使用
jieba或nltk)。 - 可使用 自定义预训练词向量(可使用
gensim)。 - 基于 TensorBoard 添加嵌入可视化功能(需先创建
metadata.tsv文件)。
模型部分
- 添加正确的 L2 损失 计算操作。
- 添加 梯度裁剪 操作以防止梯度爆炸。
- 使用指数衰减法添加 学习率衰减。
- 引入新的 高速公路层(经模型性能验证有效)。
- 添加 批归一化层。
代码部分
- 在
train.py中可以选择直接 训练 模型,或从检查点 恢复 模型。 - 在
train.py和test.py中可通过 阈值 和 Top-K 预测标签。 - 可计算评估指标 --- AUC 和 AUPRC。
- 在
test.py中可生成包含测试集预测值和预测标签的预测文件。 - 在
data_helpers.py中添加了其他有用的数据预处理函数。 - 使用
logging记录整个流程信息(包括 参数显示、模型训练信息 等)。 - 在
checkmate.py中提供了保存最佳 n 个检查点的功能,而tf.train.Saver只能保存最后 n 个检查点。
数据
数据格式请参见 /data 文件夹中的示例文件。例如:
{"testid": "3935745", "features_content": ["毛孔", "水", "压力", "计量", "装置", "包含", "压力", "计数器", "力", "计数器", "受...影响", "压力", "计数器", "装置", "包括", "动力", "部件", "布置", "控制", "压力", "施加", "压力", "计数器", "力", "计数器", "应用", "覆盖", "力", "压力", "计数器", "停止", "影响", "力", "计数器", "移除", "覆盖", "力", "压力", "计数器", "影响", "力", "计数器", "恢复"], "labels_index": [526, 534, 411], "labels_num": 3}
- "testid": 仅作为标识符。
- "features_content": 分词后的内容(已去除停用词)。
- "labels_index": 数据记录的标签索引。
- "labels_num": 标签数量。
文本分词
处理英文文本时,可以使用
nltk包。处理中文文本时,可以使用
jieba包。
数据格式
本仓库可用于其他文本分类数据集,有两种方式:
- 将您的数据集修改为与 示例 相同的格式。
- 修改
data_helpers.py中的数据预处理代码。
具体采用哪种方式,取决于您的数据和任务需求。
🤔在提交关于数据格式的新问题之前,请先查看 data_sample.json 并阅读已有的相关问题,因为可能已经有人问过类似的问题。例如:
预训练词向量
您可以下载 Word2vec 模型文件(维度=100)。请确保解压后将其放置在 /data 文件夹中。
您可以通过多种方式预训练自己的词向量:
- 使用
gensim包进行预训练。 - 使用
glove工具进行预训练。 - 甚至可以使用 fasttext 网络进行预训练。
使用说明
请参阅 使用说明。
网络结构
FastText
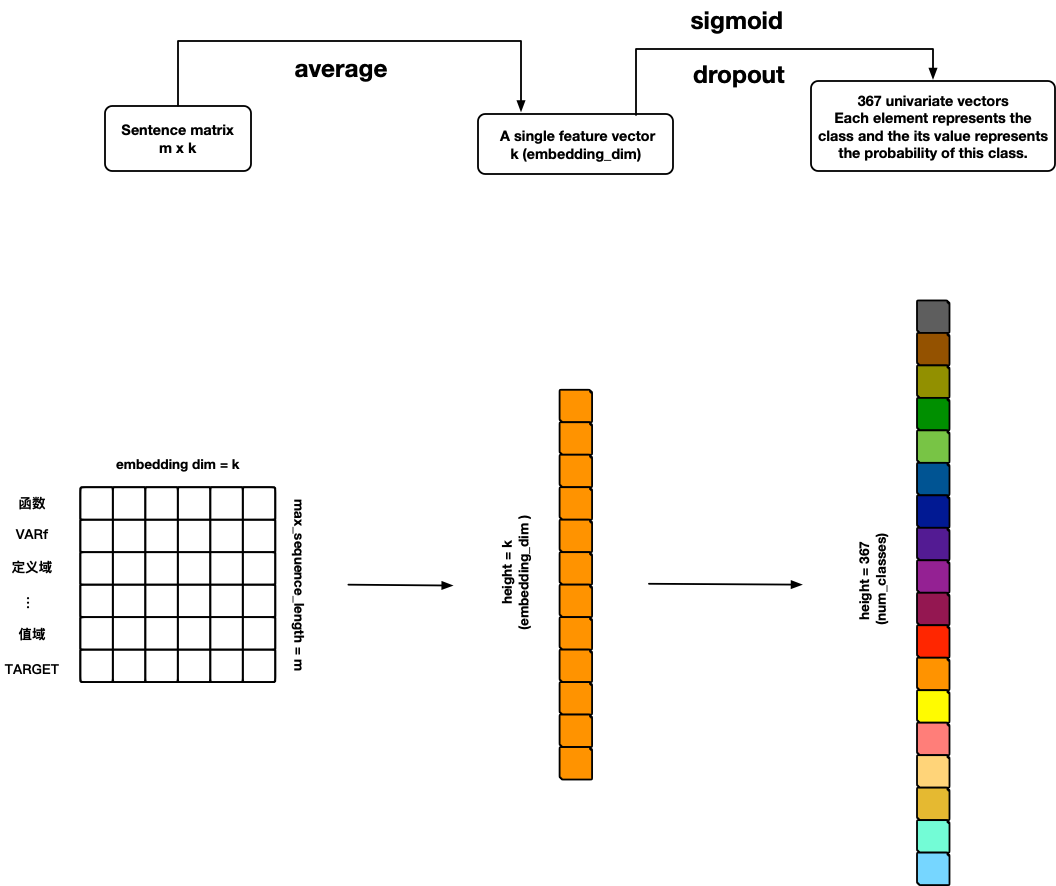
参考文献:
TextANN
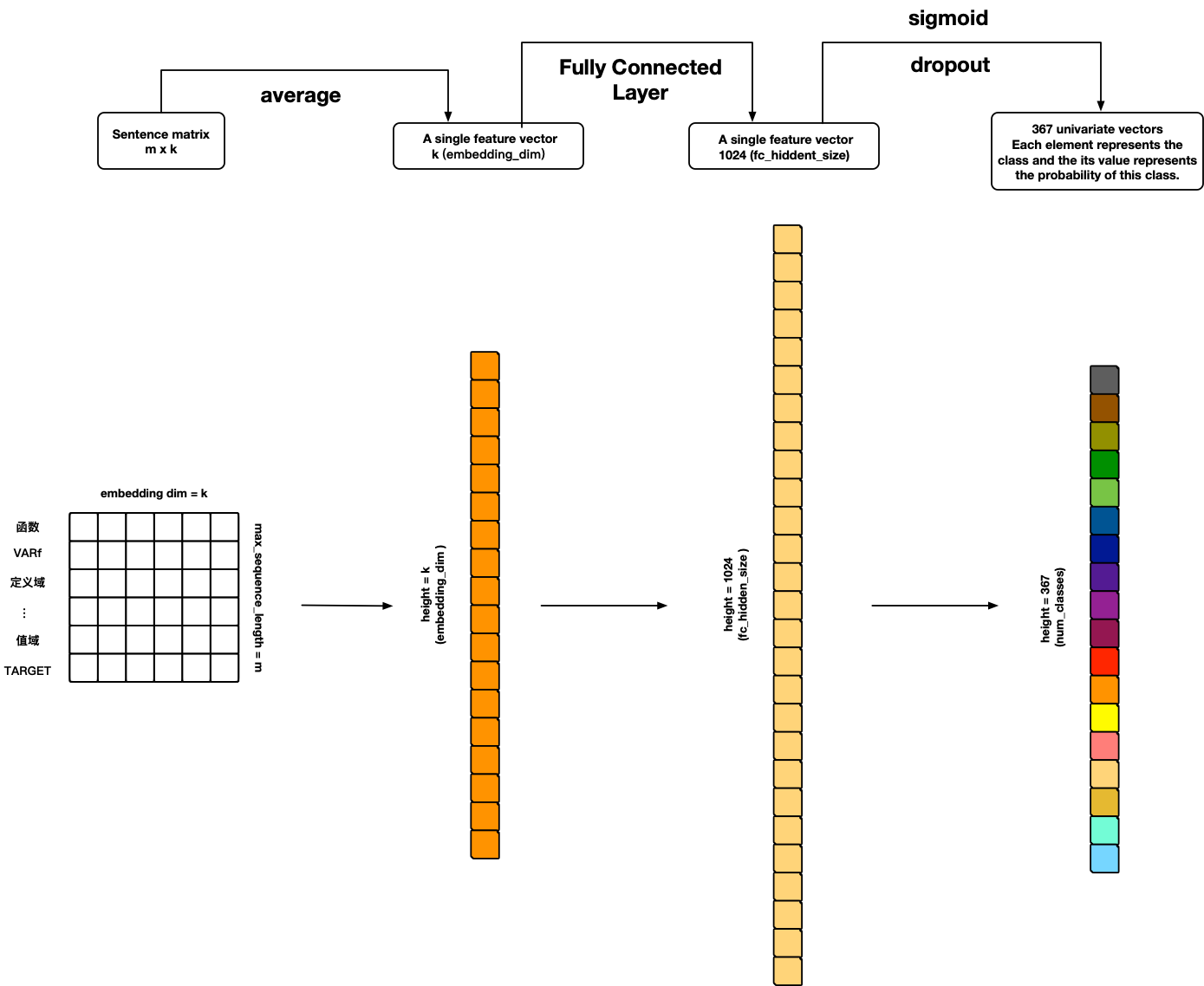
参考文献:
- 个人想法 🙃
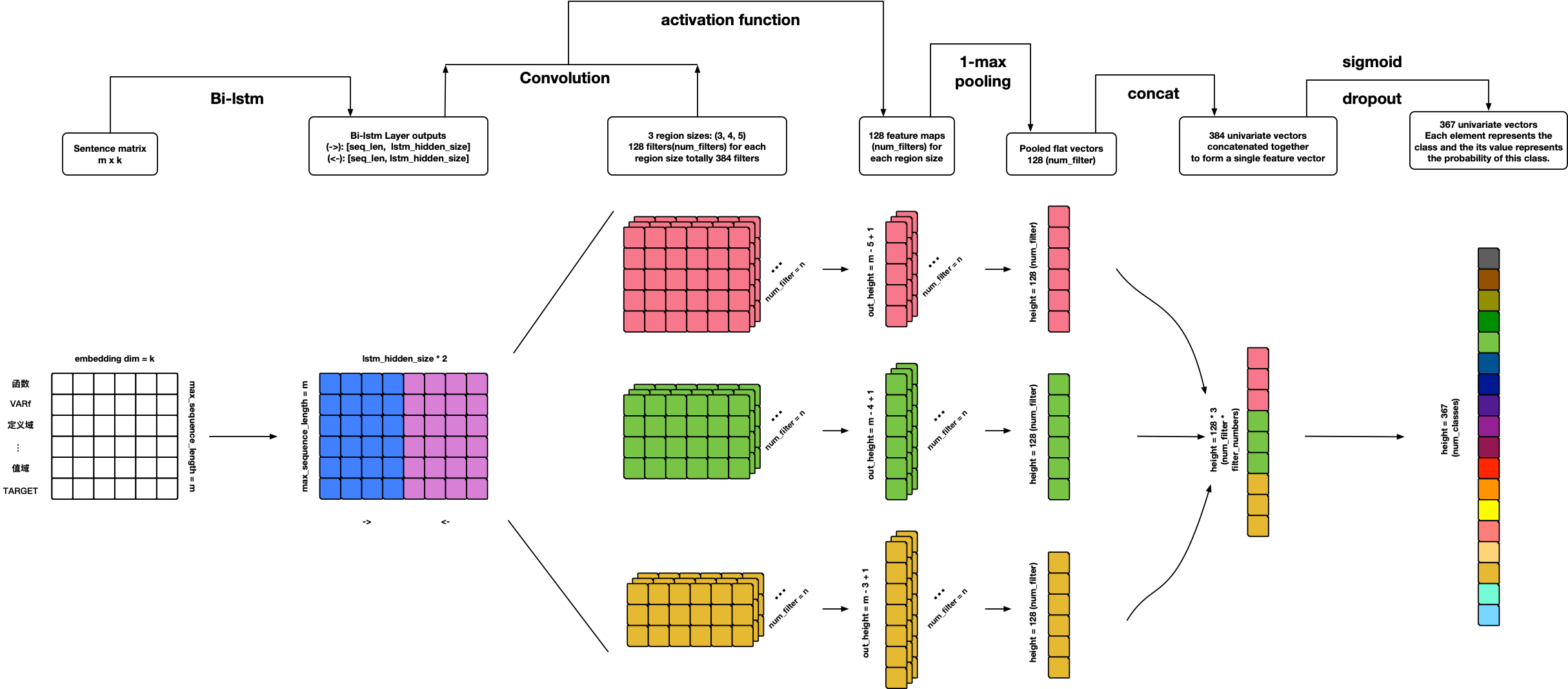
TextCNN
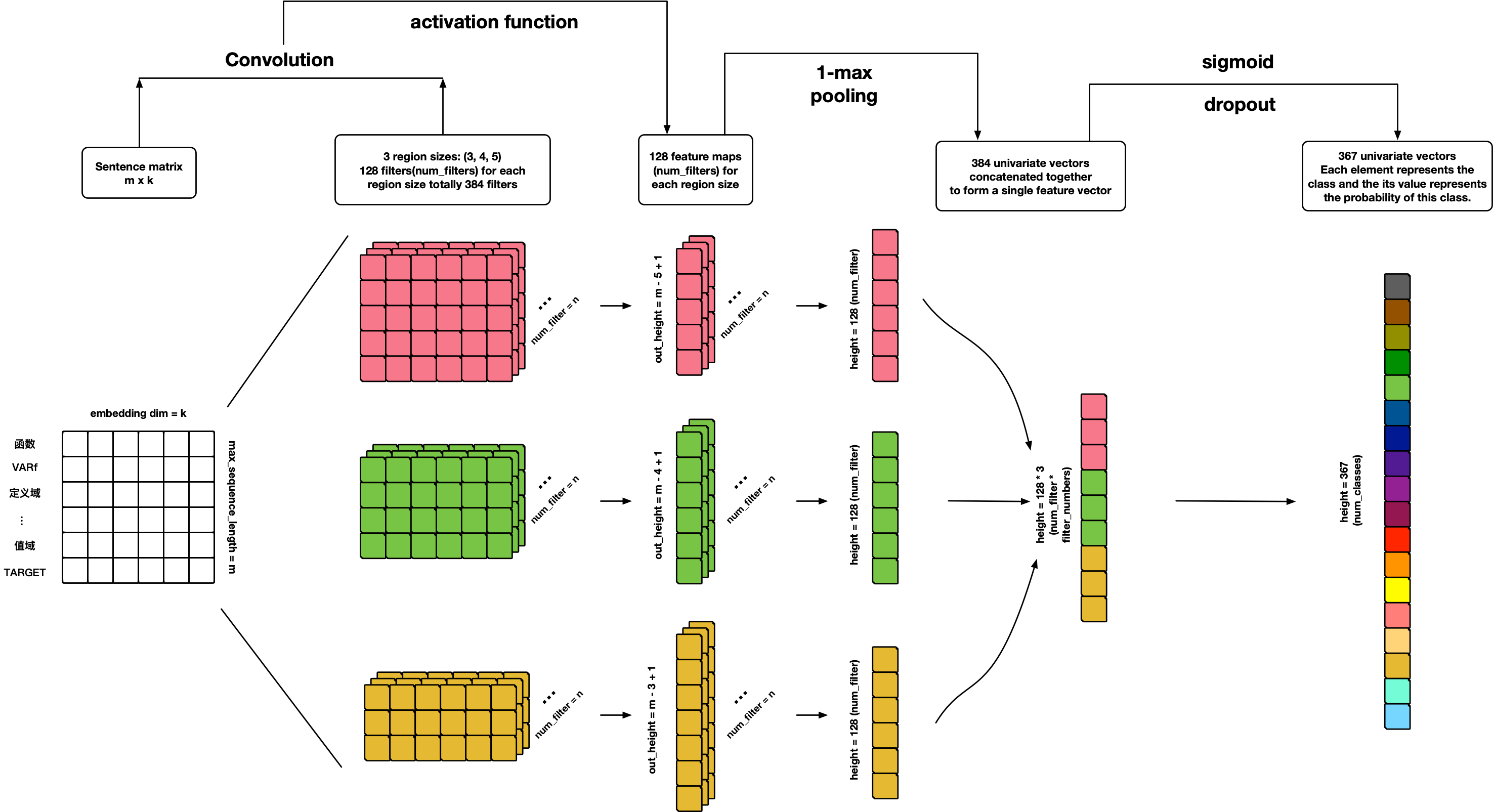
参考文献:
TextRNN
警告:该模型可用,但尚未完成 🤪!
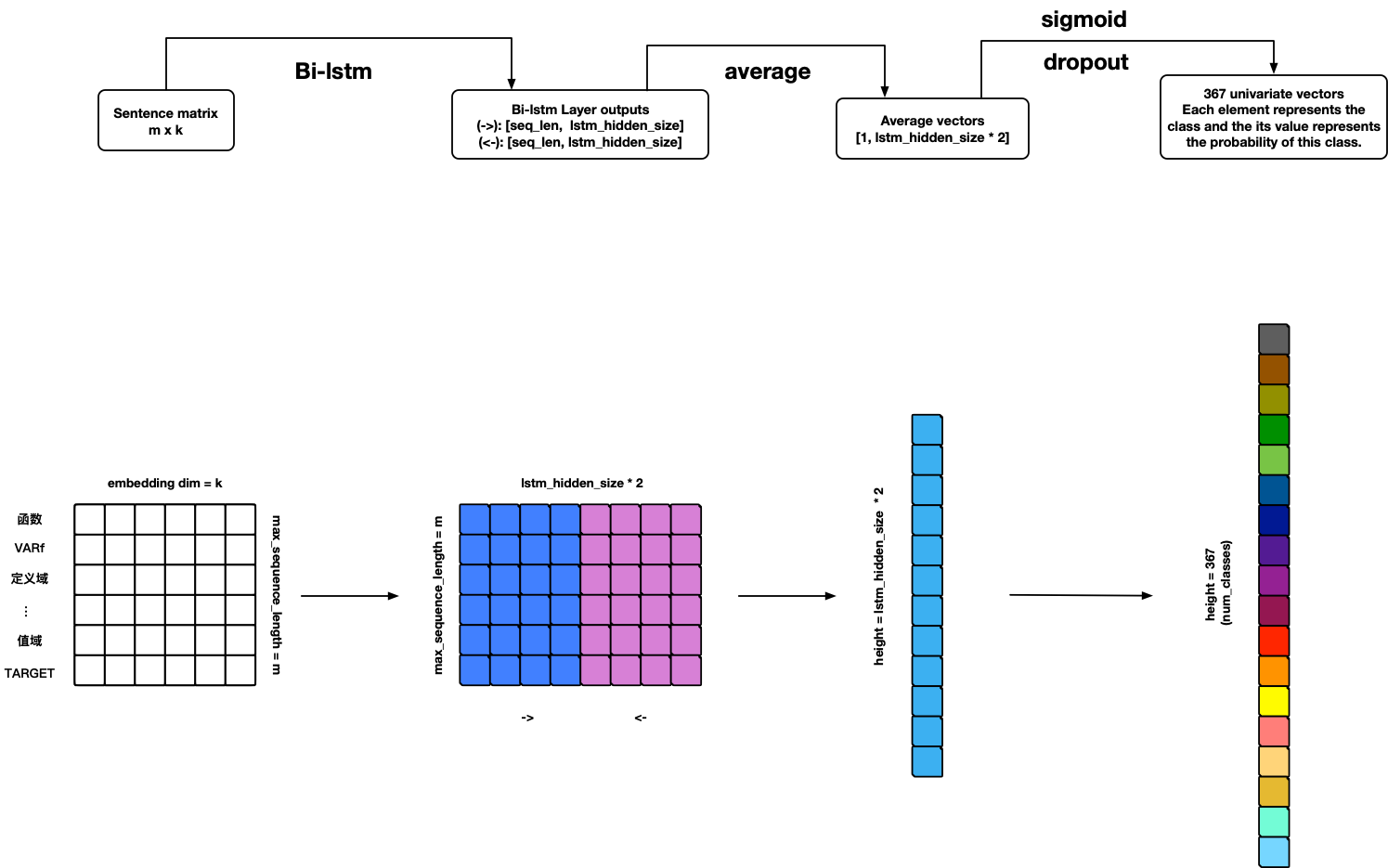
待办事项
- 添加 BN-LSTM 单元。
- 添加注意力机制。
参考文献:
TextCRNN
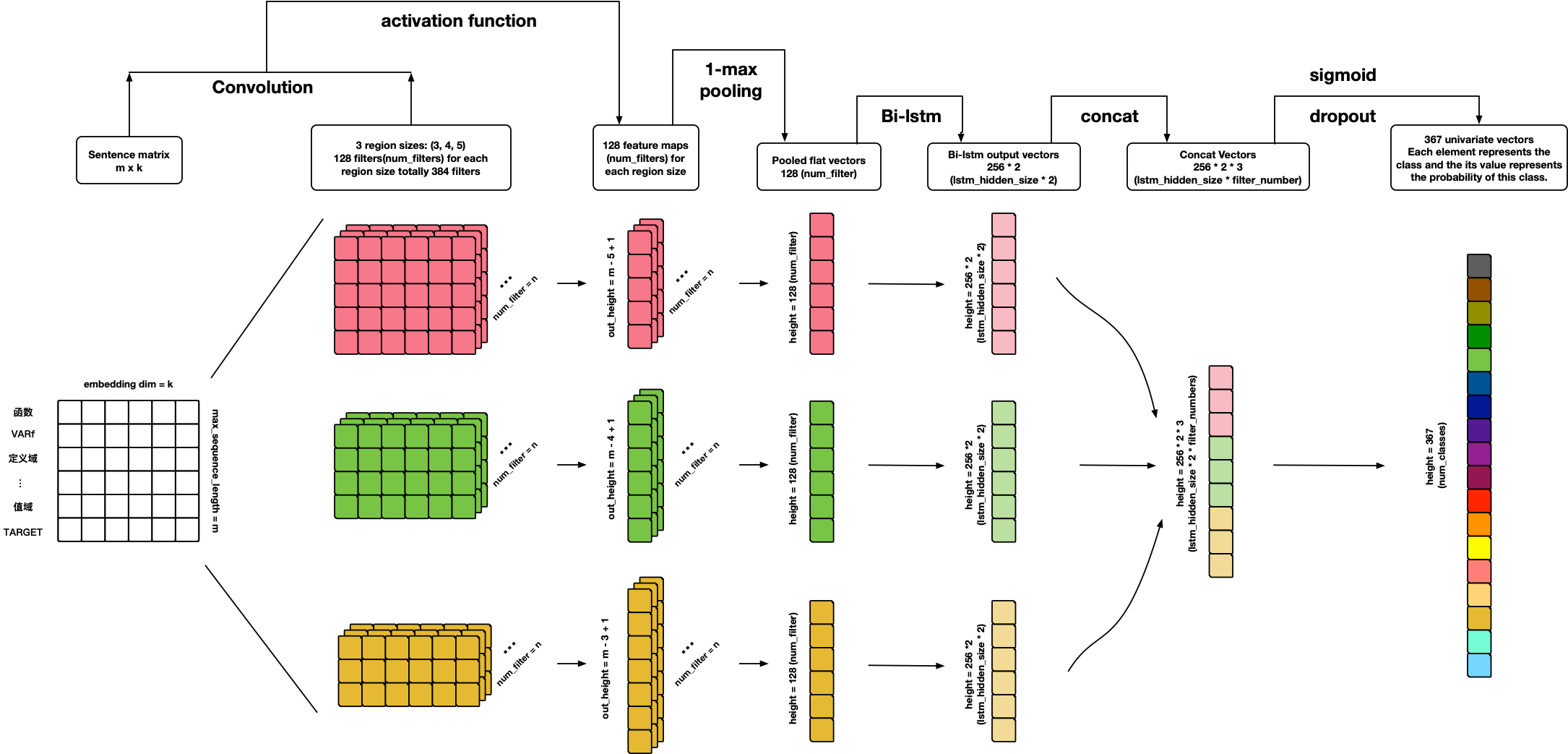
参考文献:
- 个人想法 🙃
TextRCNN
参考文献:
- 个人想法 🙃
TextHAN
参考文献:
TextSANN
警告:模型可以使用,但尚未完成 🤪!
待办事项
- 添加注意力惩罚损失。
- 添加可视化功能。
参考文献:
关于我
黄威,兰道夫
西南交通大学计算机科学与技术学士;中国科学技术大学计算机科学博士。
我的博客:randolph.pro
LinkedIn:兰道夫的LinkedIn
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器