gpu_poor
gpu_poor 是一款实用的在线计算工具,旨在帮助用户快速评估任意大型语言模型(LLM)在特定硬件上的运行可行性。它不仅能估算运行模型所需的显存总量,还能预测推理速度(每秒生成令牌数)以及微调训练的大致耗时。
很多用户常误以为只要显存大于模型文件大小就能运行,却忽略了推理时的 KV 缓存、激活值及量化开销等隐性内存占用,导致实际部署时频繁遭遇显存溢出。gpu_poor 通过详细拆解显存构成(包括模型权重、KV 缓存、梯度优化器等),精准解答“我的显卡能跑哪个模型”、“该选何种量化方案(如 GGML、QLoRA)”以及“最大支持多长上下文”等核心痛点。
这款工具特别适合 AI 开发者、研究人员以及希望在本地部署大模型的爱好者使用。其独特亮点在于全面支持 llama.cpp、bitsandbytes、QLoRA 等多种量化格式,并兼容 vLLM、Hugging Face 等主流推理框架。无论是计划进行全量微调还是高效的 LoRA 训练,用户都能利用 gpu_poor 提前规划硬件资源,避免盲目尝试,让大模型落地变得更加轻松可控。
使用场景
一位独立开发者试图在单张 RTX 3090 (24GB) 显卡上微调 Llama-3-8B 模型以构建垂直领域客服机器人,却面临显存爆炸和训练速度未知的困境。
没有 gpu_poor 时
- 盲目试错成本高:只能凭经验猜测量化等级(如 Q4 或 Q8),反复修改代码尝试运行,一旦显存溢出(OOM)需重启环境,浪费数小时调试时间。
- 显存黑盒难定位:当训练失败时,无法区分是模型权重、KV Cache、激活值还是优化器状态占用了显存,不知道是该减小 Batch Size 还是缩短上下文长度。
- 进度预估靠猜:完全无法预知微调需要多久,不知道当前硬件是受限于显存带宽还是计算算力,导致项目排期严重失真。
- 资源利用率低:因害怕报错而过度保守地设置极小的上下文窗口,导致模型无法学习长文档逻辑,牺牲了最终效果。
使用 gpu_poor 后
- 精准方案预演:输入模型参数和硬件配置后,立即算出 QLoRA 量化下刚好能容纳 4096 上下文长度的显存需求,一次性确定最佳量化策略,告别反复试错。
- 显存占用透明化:清晰看到显存拆解数据(如激活值占 5GB,优化器占 8GB),据此果断调整梯度累积步数,在不升级硬件的前提下成功跑通训练。
- 效率量化可视:直接获得“每次迭代耗时 120ms"及“显存受限”的结论,准确推算出全量微调需 18 小时,从而合理安排服务器运行时段。
- 性能极限挖掘:确认在特定 Batch Size 下不会爆显存,大胆将上下文长度提升至模型允许的最大值,显著提升了机器人处理复杂工单的能力。
gpu_poor 将原本依赖运气的硬件适配过程转化为可量化的科学决策,让开发者在有限算力下也能高效落地大模型应用。
运行环境要求
- 未说明 (基于 Web 的工具,可在任何现代浏览器的操作系统上运行)
- 非必需
- 该工具用于计算不同 GPU(如 RTX 4090, RTX 2060 等)或 CPU 的运行需求,本身作为网页计算器运行,不直接消耗大量 GPU 资源
未说明 (作为轻量级网页工具,仅需满足浏览器运行的常规内存)
快速开始
我的GPU能运行这个LLM吗?每秒能处理多少个token?
计算任何LLM在特定GPU/CPU上所需的显存大小以及能够达到的每秒处理的token数。
还提供了训练和推理过程中显存分配的详细 breakdown,支持量化方法(GGML/bitsandbytes/QLoRA)和推理框架(vLLM/llama.cpp/HF)。
链接:https://rahulschand.github.io/gpu_poor/
演示
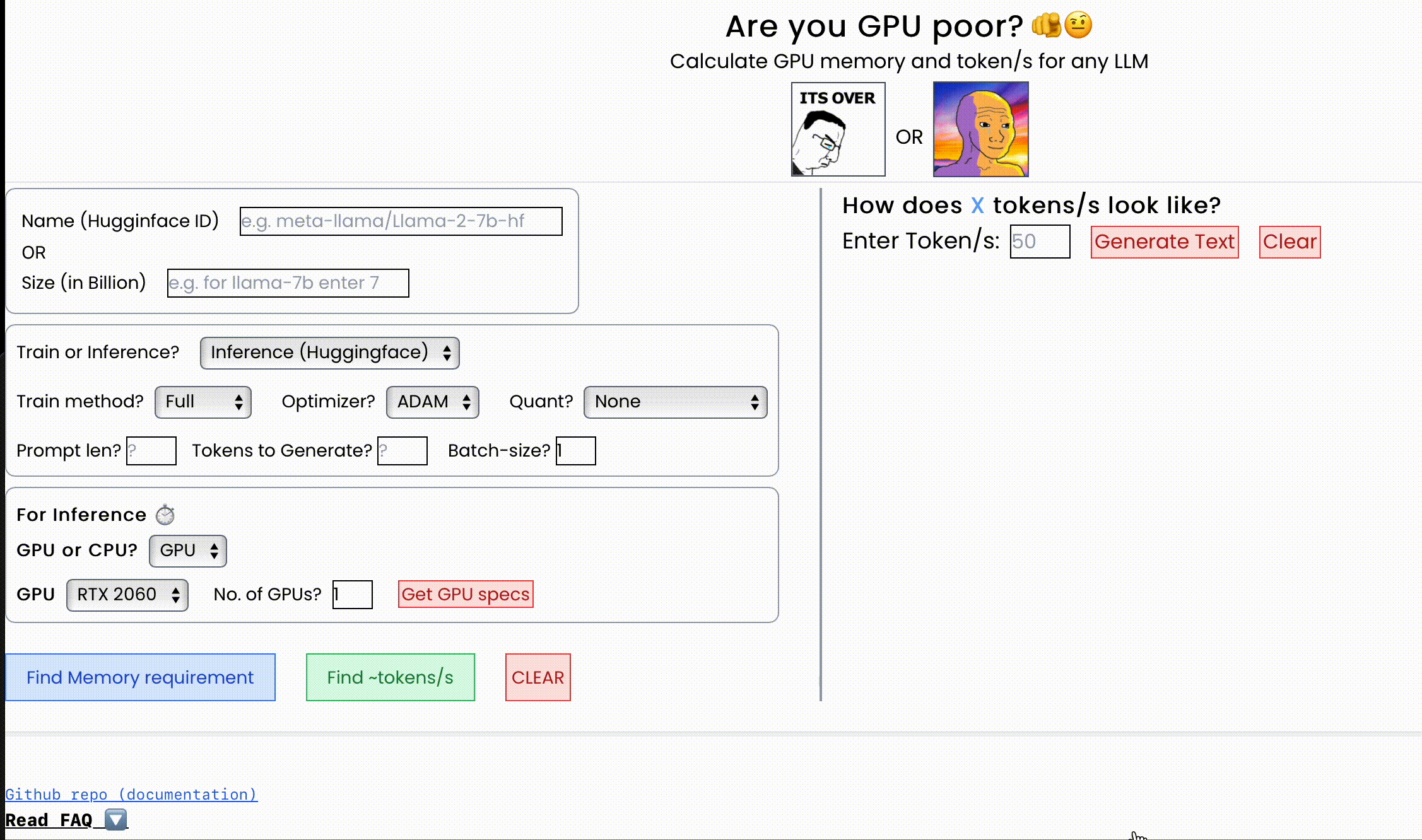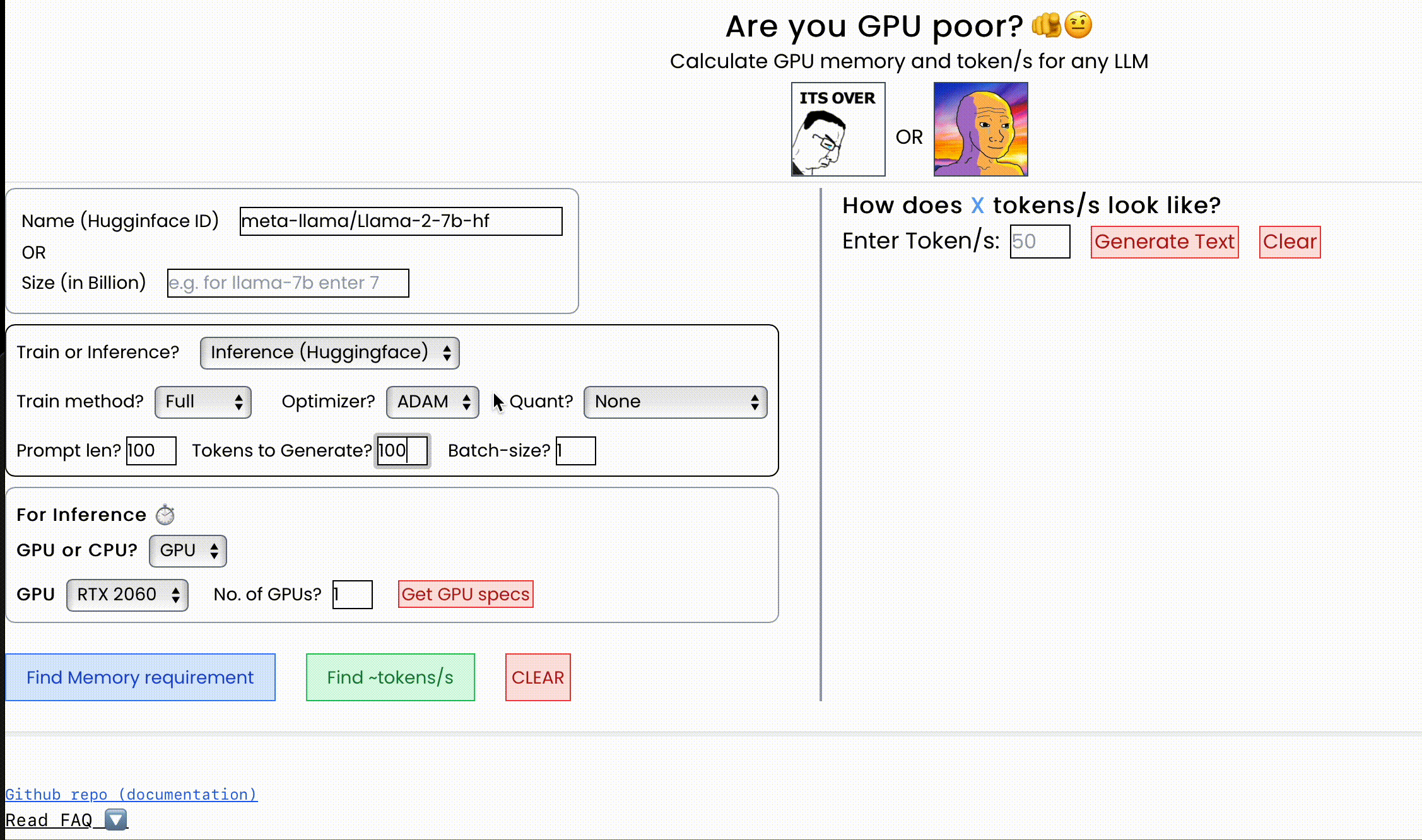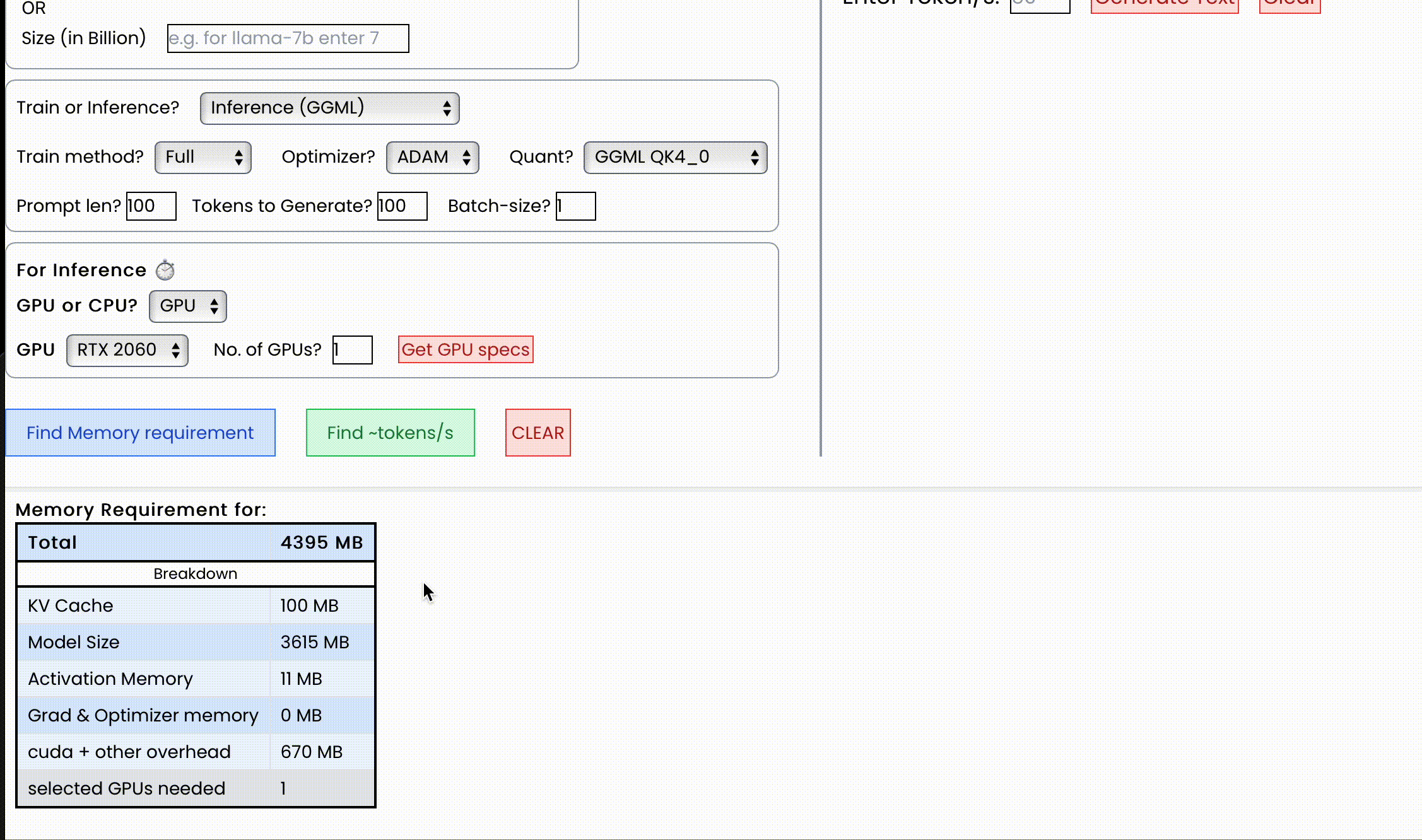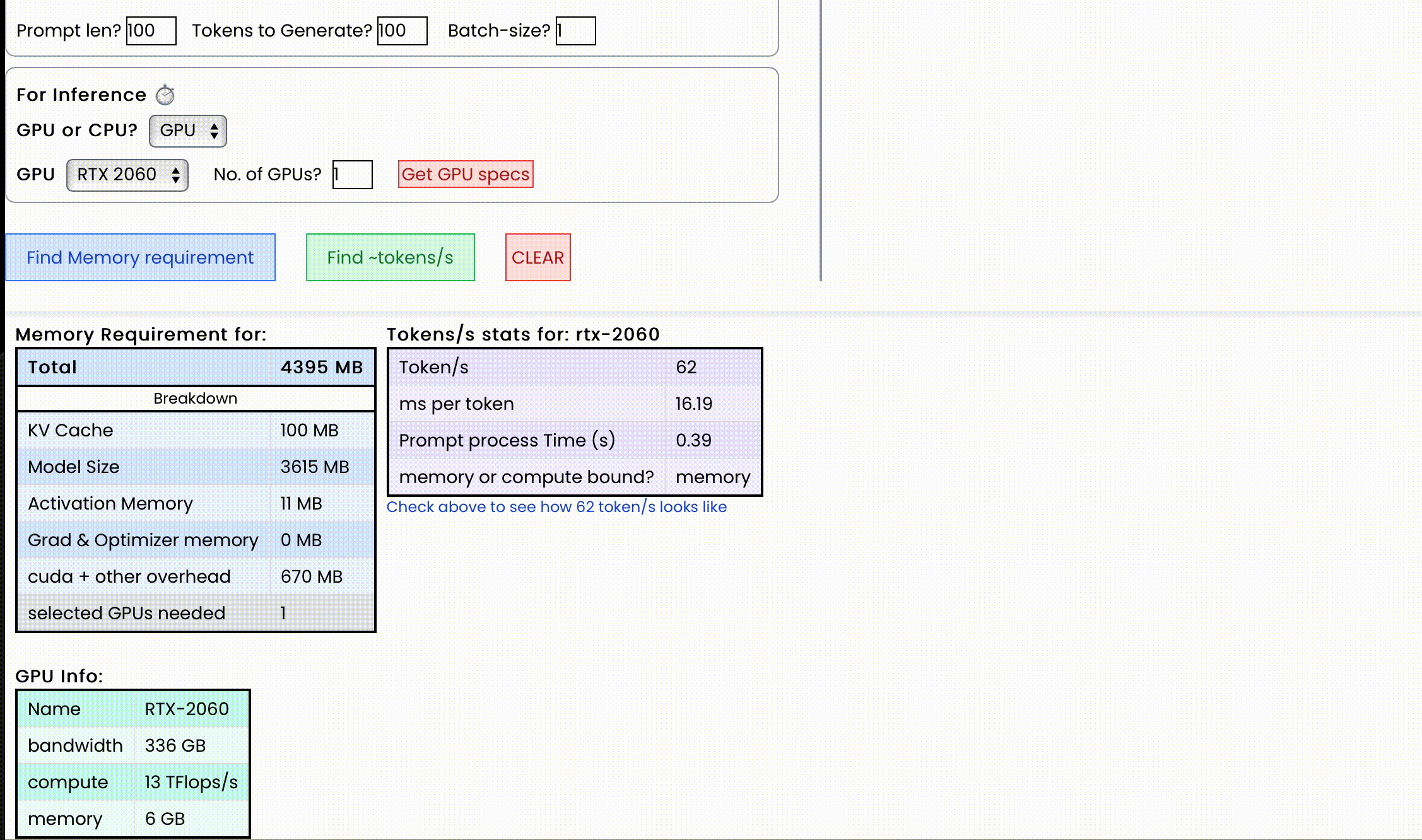
使用场景/功能
1. 计算显存需求 💾
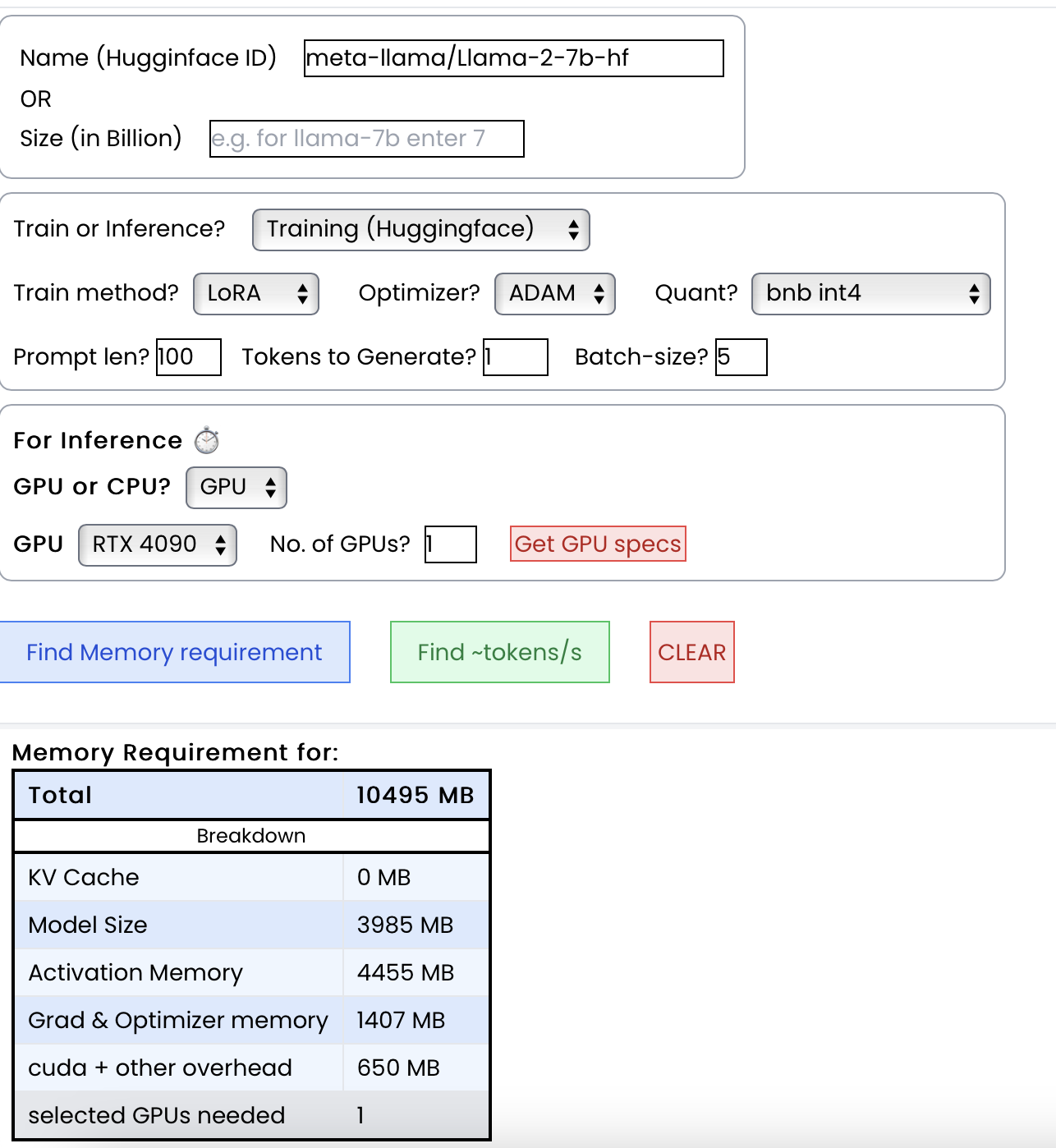
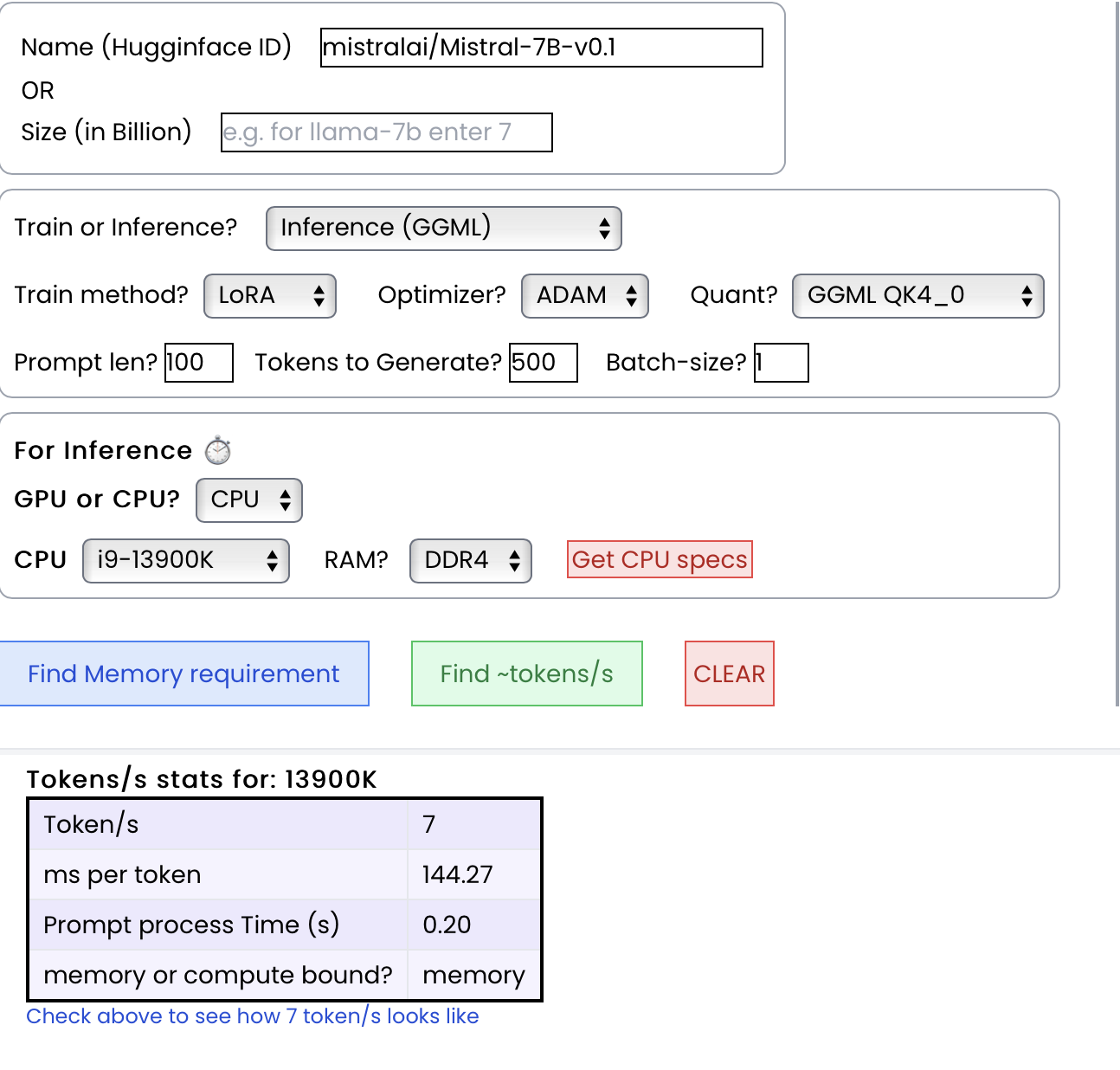
2. 计算每秒可处理的token数 ⏱️
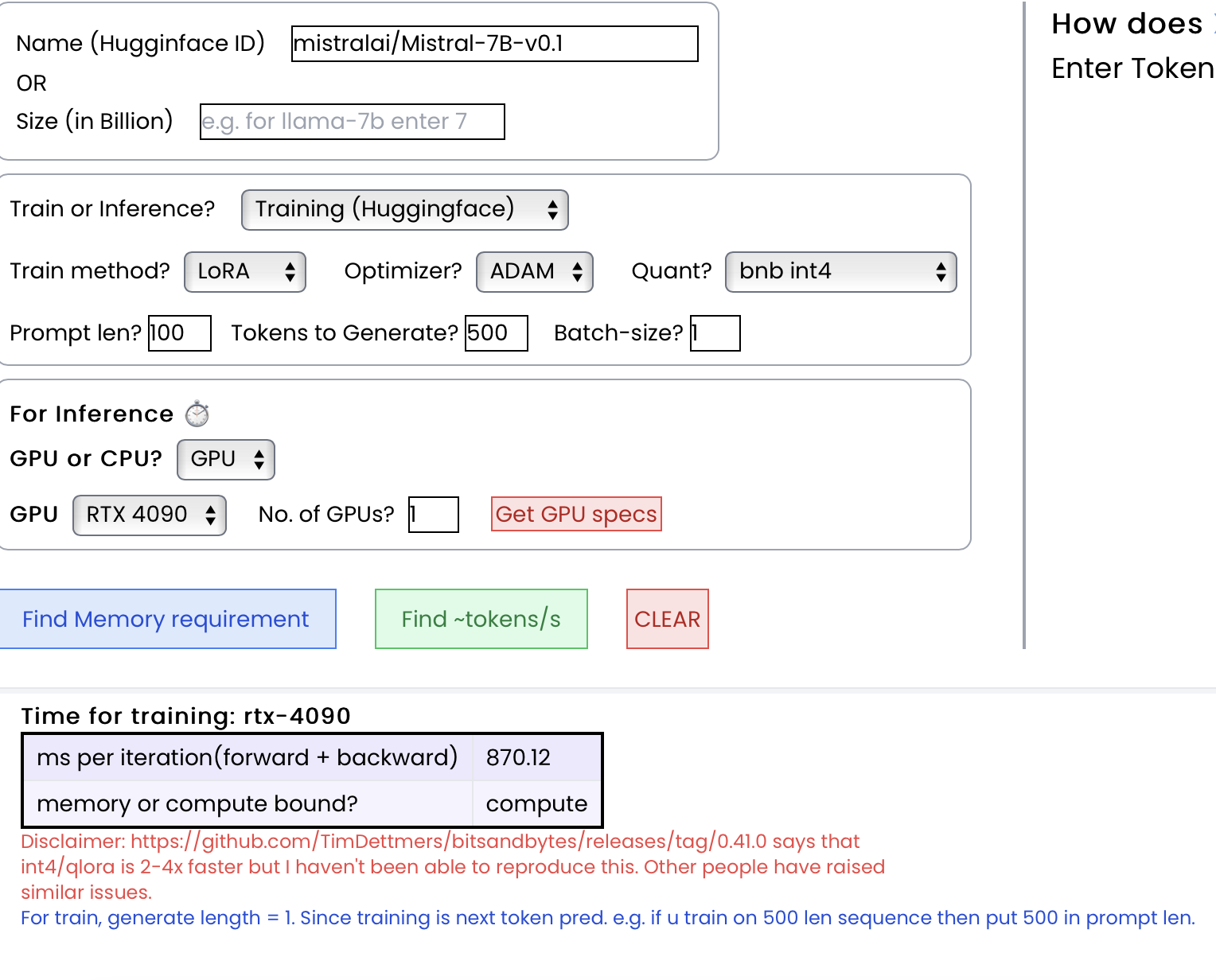
3. 预估微调所需时间(每次迭代毫秒数) ⌛️
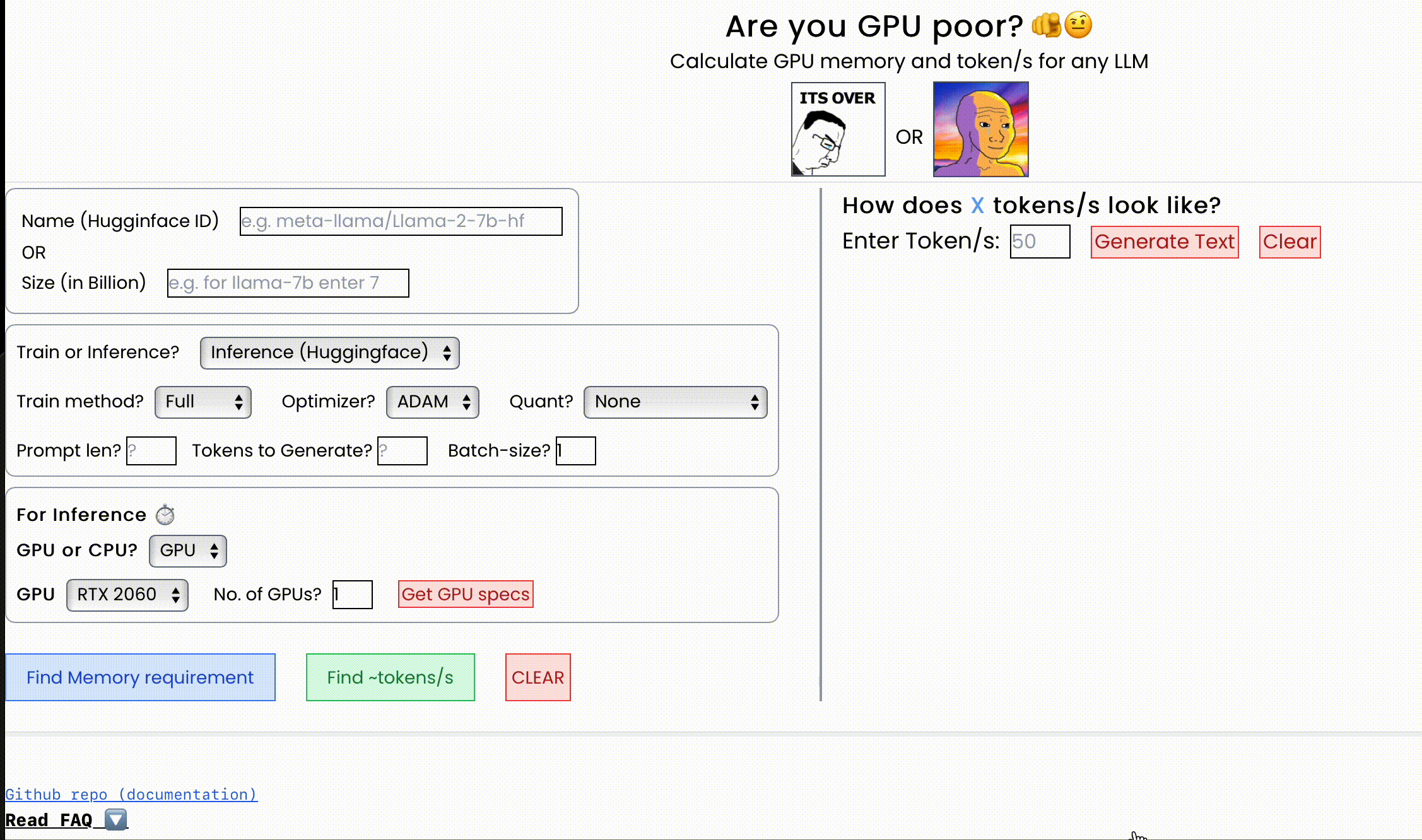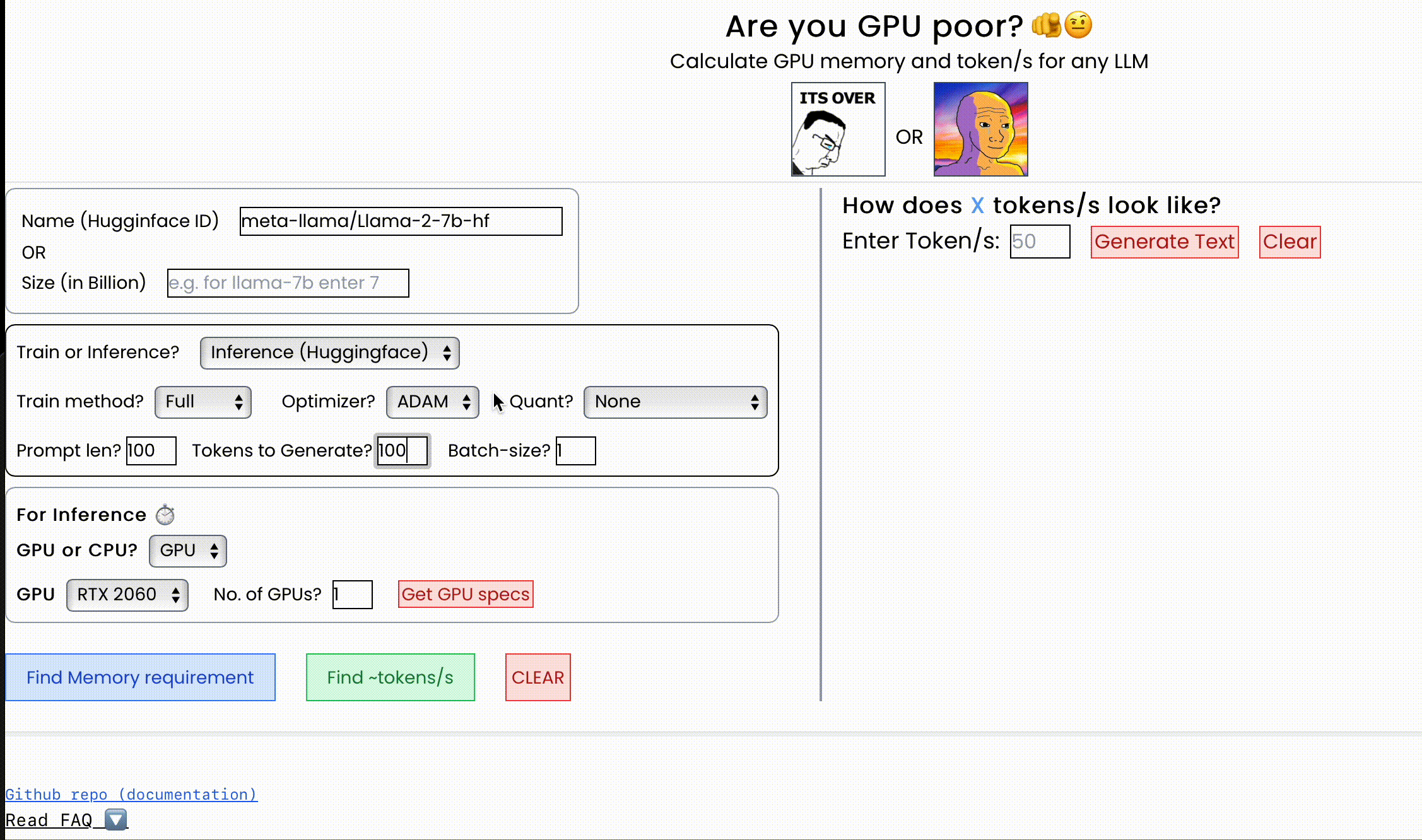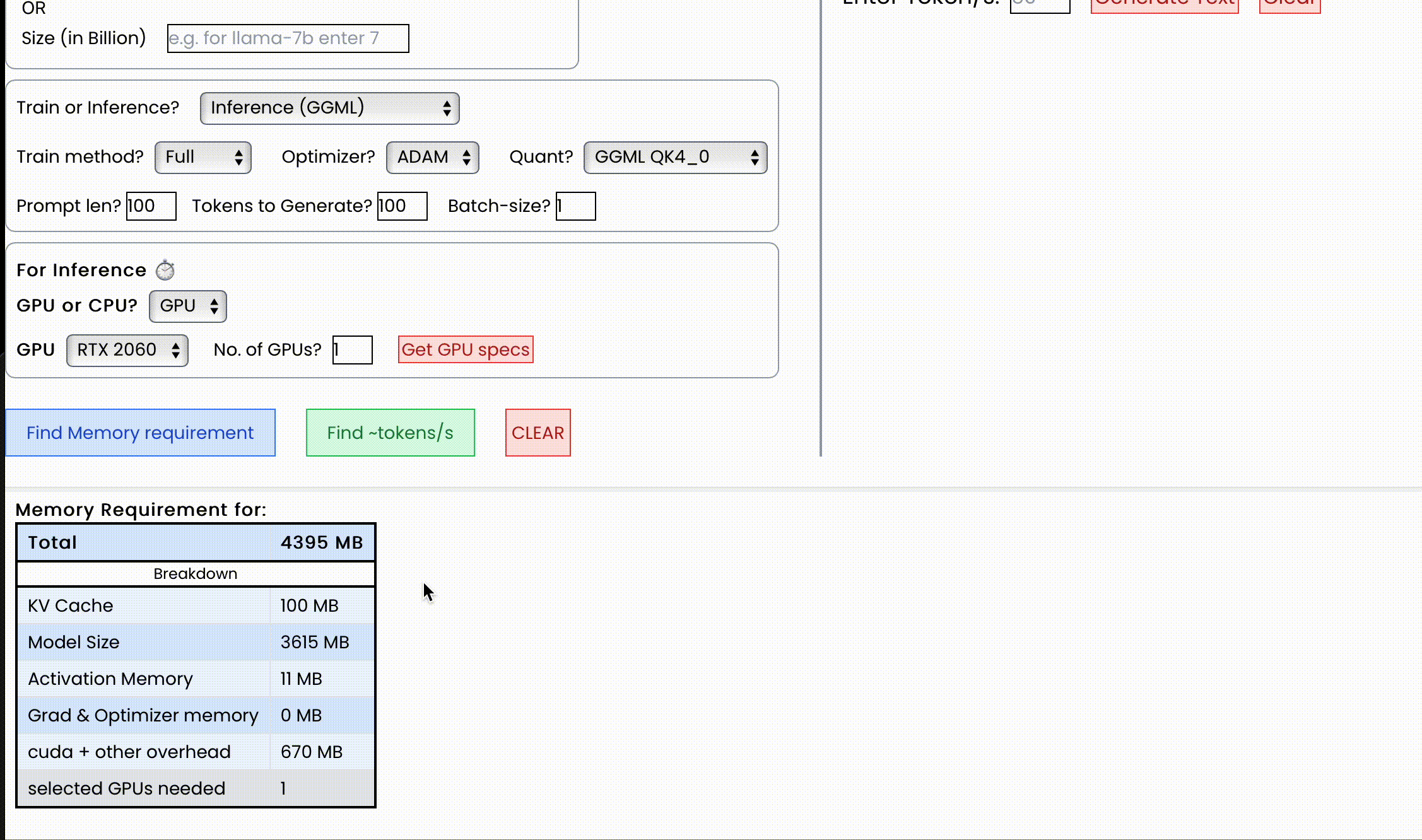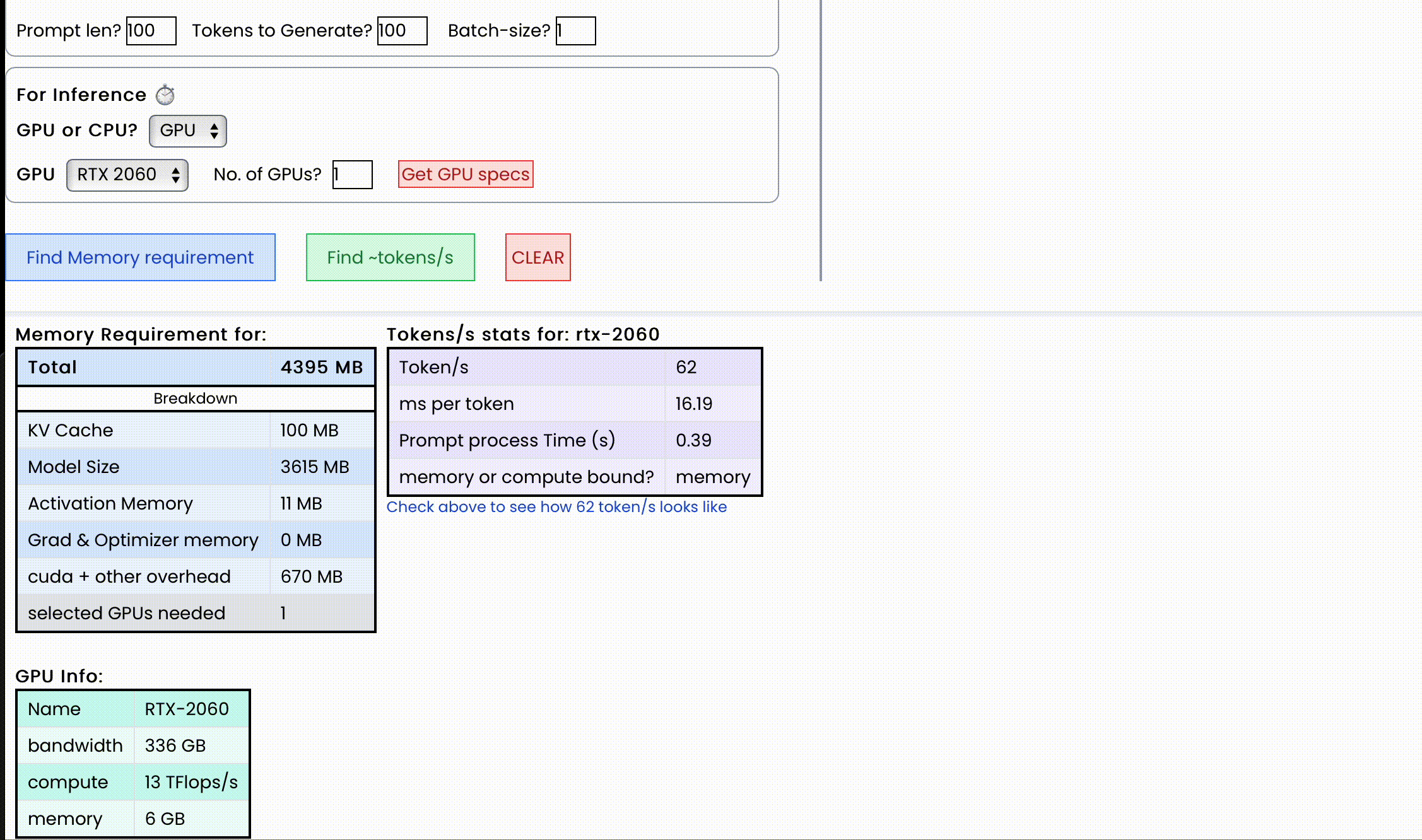
对于显存,输出包括总显存及其细分。格式如下:
{
"Total": 4000,
"KV Cache": 1000,
"Model Size": 2000,
"Activation Memory": 500,
"Grad & Optimizer memory": 0,
"cuda + other overhead": 500
}
对于每秒token数,附加信息如下:
{
"Token per second": 50,
"ms per token": 20,
"Prompt process time (s)": 5 s,
"memory or compute bound?": Memory,
}
对于训练,输出为每次前向传播的时间(以毫秒计):
{
"ms per iteration (forward + backward)": 100,
"memory or compute bound?": Memory,
}
目的
制作这个工具是为了检查你是否能在自己的GPU上运行某个特定的LLM。它可以帮助你了解以下问题:
- 我每秒能处理多少个token?
- 微调需要多长时间?
- 哪种量化方式适合我的GPU?
- 我的GPU能处理的最大上下文长度和批量大小是多少?
- 应该选择哪种微调方法:全参数微调、LoRA还是QLoRA?
- 是什么占用了我的GPU显存?如何调整才能让LLM适配到GPU上?
补充信息 + 常见问题解答
我们不能只看模型大小就判断吗?
判断你的GPU能否运行某个LLM并不像单纯查看模型大小那么简单,因为在推理过程中(KV缓存)会占用大量显存。例如,在使用Llama-2-7B时,序列长度为1000的情况下,仅KV缓存就需要额外1GB显存(使用Hugging Face的LlamaForCausalLM;而使用exLlama和vLLM时则只需500MB)。而在训练阶段,KV缓存、激活值以及量化开销都会消耗大量显存。比如,Llama-7B采用bnb int8量化后模型大小约为7.5GB,但即便是在RTX 4090 24GB显存的机器上,也无法用LoRA对具有1000上下文长度的数据进行微调。这意味着还有额外的16GB显存被用于量化开销、激活值和梯度存储。
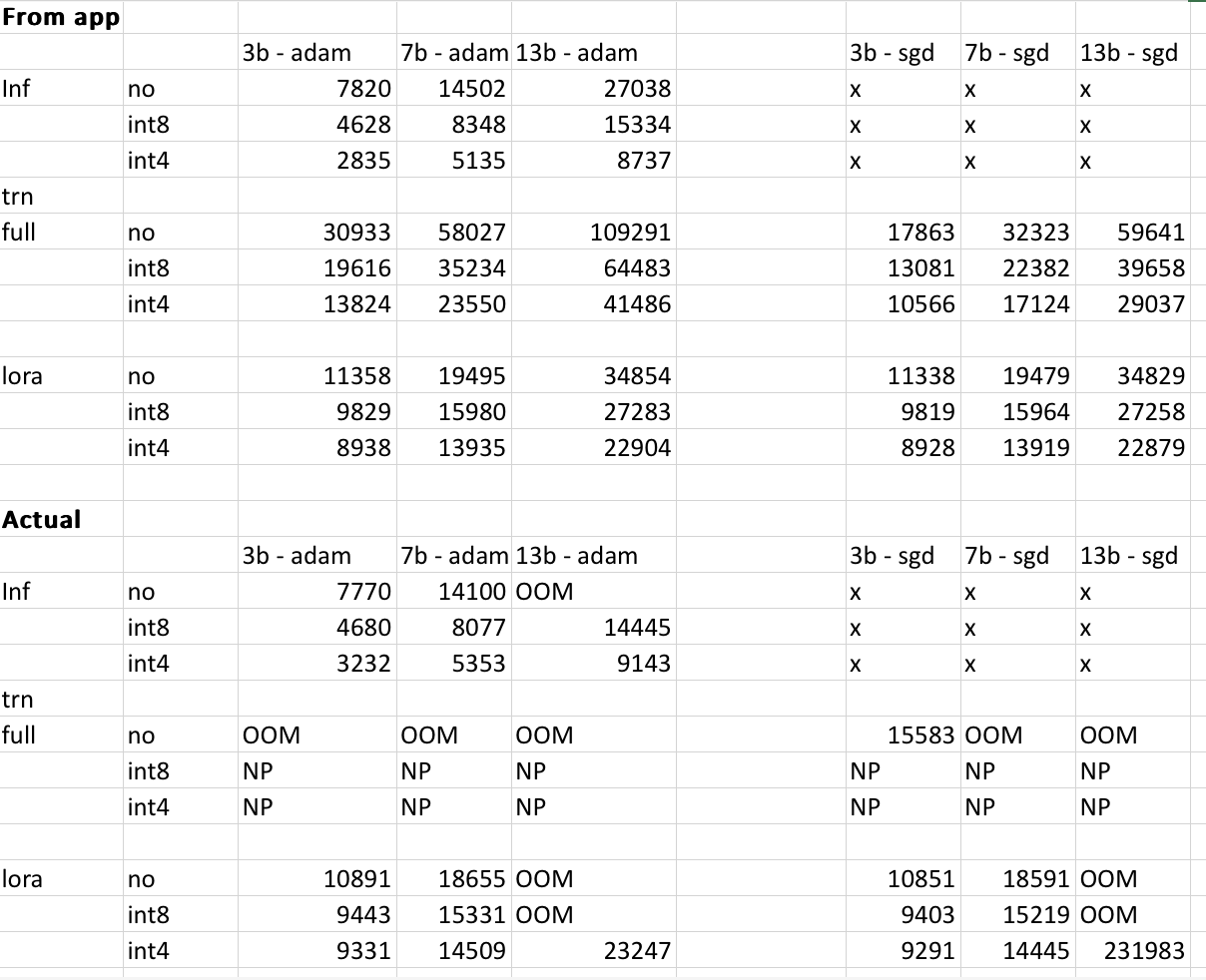
这些数值的可靠性如何?
结果可能会因模型、输入数据、CUDA版本以及所使用的量化方法而有所不同,因此无法精确预测具体数值。我已尽量考虑到这些因素,并确保结果误差不超过500MB。下表对比了网站给出的3B、7B和13B模型显存与我在RTX 4090和2060 GPU上的实际测量值,所有数值均在500MB以内。
数值是如何计算的?
总显存 = 模型大小 + KV缓存 + 激活显存 + 优化器/梯度显存 + CUDA等开销
- 模型大小 = 即你的
.bin文件大小(如果是Q8量化则除以2,如果是Q4量化则除以4)。 - KV缓存 = KV(键值)向量占用的显存。大小为
(2 x 序列长度 x 隐藏层大小)每层。对于Hugging Face来说,则是(2 x 2 x 序列长度 x 隐藏层大小)每层。在训练中,整个序列会被一次性处理(因此KV缓存显存为0)。 - 激活显存 = 在前向传播过程中,每个操作的输出都需要保存下来以便进行反向传播(
.backward())。例如,如果执行output = Q * input,其中Q = (dim, dim)和input = (batch, seq, dim),那么形状为(batch, seq, dim)的输出就需要被保存(以fp16格式)。这在LoRA/QLoRA中会占用最多的显存。在LLM中,这样的中间步骤非常多(Q、K、V之后,注意力机制之后,归一化之后,FFN1、FFN2、FFN3之后,跳过层之后……)。大约每层会保存15个中间表示。 - 优化器/梯度显存 =
.grad张量及与优化器相关的张量(如移动平均等)所占用的显存。 - CUDA等开销 = 每当加载CUDA时,大约会占用500MB到1GB的显存。此外,使用某些量化方法(如bitsandbytes)时也会产生额外的开销。这部分没有明确的计算公式(在我的计算中,我假设CUDA开销为650MB)。
为什么结果有时不准确?
有时候计算结果可能会有很大偏差,请在这种情况下提交issue,我会尽力修复。
待办事项
- 为vLLM添加每秒token数的支持
添加QLora✅添加估算特定GPU每秒可处理token数的方法✅改进根据模型大小推断超参数的逻辑(因为对于相同大小的模型,隐藏层大小、中间层大小和层数可能会有所不同)✅- 添加AWQ
版本历史
v2.02023/10/29常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。