LLMSurvey
LLMSurvey 是一个专注于大语言模型(LLM)的开源学术资源库,旨在系统性地整理和呈现该领域的前沿论文与技术进展。面对大模型研究爆发式增长、文献海量且分散的现状,它依据权威综述论文《A Survey of Large Language Models》的框架,将零散的研究成果梳理成清晰的知识体系,帮助使用者快速把握技术脉络。
该项目不仅汇集了基础理论、架构演进及应用案例,还紧跟时事更新了关于“长链式思维(Long CoT)推理”等最新热门范式的内容,深入探讨了数据构建、训练方法及测试时扩展策略。此外,团队还推出了配套的中文入门书籍,专门为零基础或初学者提供详尽的技术路线图。
LLMSurvey 特别适合人工智能领域的研究人员、高校学生以及希望深入理解大模型底层逻辑的开发者使用。无论是需要撰写综述、寻找创新灵感,还是希望系统学习大模型技术栈,这里都能提供高效、准确的文献指引和结构化的知识支持,是进入大语言模型世界的优质导航站。
使用场景
某高校人工智能实验室的研究生团队正着手开展关于“大模型长思维链(Long CoT)推理”的前沿研究,急需梳理该领域的技术脉络与核心文献。
没有 LLMSurvey 时
- 文献检索如大海捞针:面对 arXiv 上每日激增的数十篇相关论文,研究人员难以快速区分哪些是探讨 Long CoT 的核心成果,哪些只是边缘提及,耗费大量时间在筛选上。
- 技术演进路径模糊:缺乏系统性的梳理,团队很难理清从数据蒸馏、搜索合成到多智能体协作等 Long CoT 数据构建方法的具体演变逻辑。
- 入门门槛高且易遗漏:对于刚接触该方向的学生,缺少一份涵盖训练方法(如指令微调、强化学习)及测试时扩展策略的完整知识地图,容易陷入碎片化阅读而忽略关键里程碑。
- 语言障碍影响效率:部分成员英文阅读速度有限,在没有中文系统性导读材料的情况下,理解深度综述论文的周期被显著拉长。
使用 LLMSurvey 后
- 精准定位核心资源:团队直接利用 LLMSurvey 中最新更新的 Long CoT 专题板块,迅速锁定了包括 DeepSeek-R1 和 OpenAI o-series 在内的主流范式及相关论文,检索效率提升数倍。
- 清晰掌握技术全貌:借助工具整理的框架,研究人员一目了然地掌握了从数据构造到训练策略的完整技术链条,快速构建了扎实的理论基础。
- 系统化入门与进阶:团队成员通过配套的中文书籍和结构化目录,不仅快速扫除了概念盲区,还避免了重要研究节点的遗漏,确保了研究方向的准确性。
- 双语支持加速理解:利用其中文版内容作为先导,团队成员能更高效地消化英文原文,大幅缩短了从“读不懂”到“能复现”的周期。
LLMSurvey 通过将海量碎片化的大模型论文转化为结构清晰、中英双语的知识图谱,让科研人员从繁琐的文献筛选中解放出来,专注于真正的创新突破。
运行环境要求
未说明
未说明

快速开始
LLMSurvey
一系列与大型语言模型相关的论文和资源合集。
论文的组织方式参考了我们的综述《大型语言模型综述》。
如果您发现任何错误或有任何建议,请通过电子邮件告知我们:batmanfly@gmail.com
(我们建议同时抄送另一封邮件 francis_kun_zhou@163.com,以防出现投递失败的情况。)
如果您认为我们的综述对您的研究有所帮助,请引用以下论文:

@article{LLMSurvey,
title={A Survey of Large Language Models},
author={Zhao, Wayne Xin and Zhou, Kun and Li, Junyi and Tang, Tianyi and Wang, Xiaolei and Hou, Yupeng and Min, Yingqian and Zhang, Beichen and Zhang, Junjie and Dong, Zican and Du, Yifan and Yang, Chen and Chen, Yushuo and Chen, Zhipeng and Jiang, Jinhao and Ren, Ruiyang and Li, Yifan and Tang, Xinyu and Liu, Zikang and Liu, Peiyu and Nie, Jian-Yun and Wen, Ji-Rong},
year={2023},
journal={arXiv preprint arXiv:2303.18223},
url={http://arxiv.org/abs/2303.18223}
}
🚀(新)我们发布了该综述的中文版!
中文版专注于为LLM领域的初学者提供解释说明,旨在呈现一个全面的LLM框架与路线图。本书适合具备深度学习基础的高年级本科生及低年级研究生阅读,可作为入门级技术书籍使用。 您可以在https://llmbook-zh.github.io/下载中文版。
以下是我们的中文版销售页面。

🚀(新)关于长链式思维推理的内容
在最新版本中,我们新增了近期流行的推理范式内容——即在回答问题前分配更多时间进行思考。我们重点介绍了长链式思维推理这一主流方法,它被DeepSeek-R1和OpenAI的o系列模型等近期LLM所采用。首先,我们讨论了长链式思维推理的模式及其优势;随后,我们阐述了长链式思维推理数据的构建方法,包括数据蒸馏、基于搜索的数据合成以及多智能体协作等。此外,我们还介绍了两种常用的训练方法:长链式思维推理指令调优和规模化的强化学习训练。最后,我们深入探讨了近期针对LLM的测试时扩展技术。

arXiv上与LLM相关论文数量的变化趋势
以下是自2018年6月起包含关键词“language model”以及自2019年10月起包含关键词“large language model”的arXiv论文累计数量变化趋势。
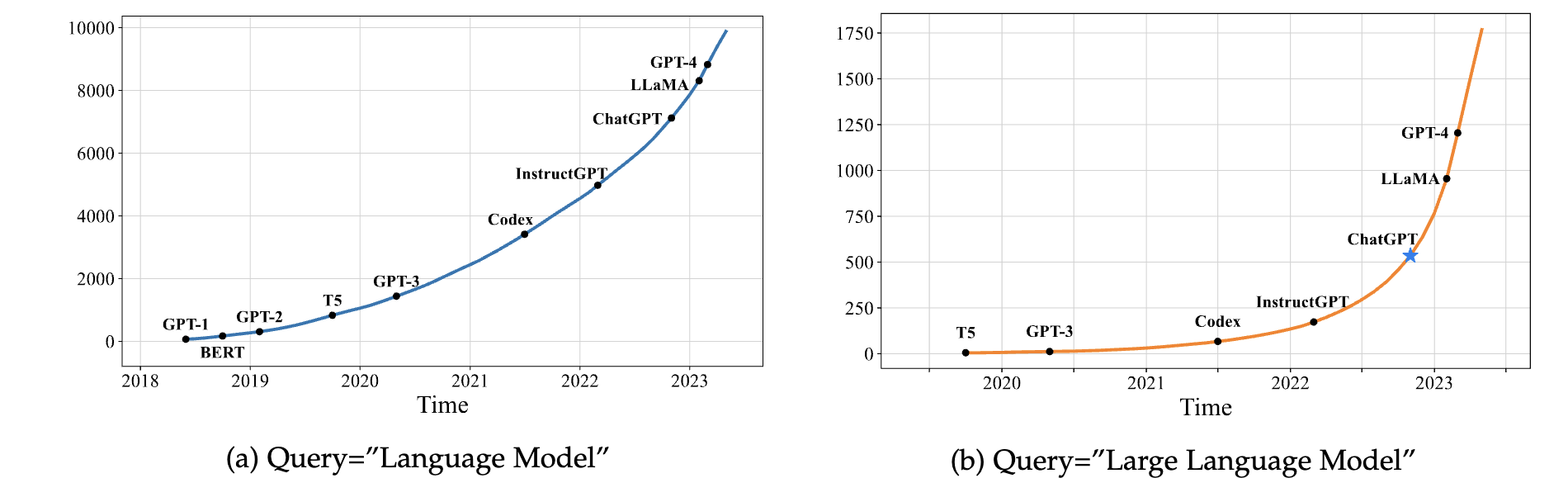
统计数据是通过每月查询标题或摘要中的关键词并进行精确匹配计算得出的。由于“language models”这一主题较早被研究,因此我们为这两个关键词设置了不同的横轴范围。我们标注了LLM研究进程中一些重要里程碑对应的点。ChatGPT发布后,相关论文数量出现了显著增长:平均每天发表的包含“large language model”关键词的arXiv论文数量从0.40篇增至8.58篇。
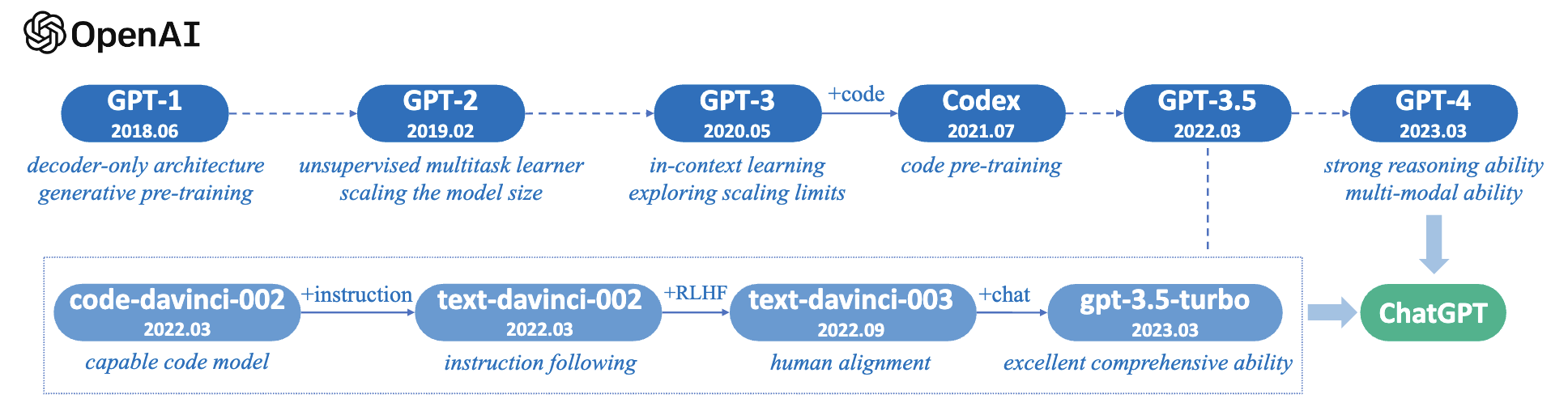
GPT系列模型的技术演进
简要展示了GPT系列模型的技术演进过程。本图主要基于OpenAI发布的论文、博客文章及官方API绘制而成。其中,实线表示两代模型之间存在明确证据(例如,官方声明某新模型是在基础模型之上开发的),而虚线则表示两者之间的演进关系相对较弱。
LLaMA家族演化图
展示了LLaMA相关研究工作的演化关系。由于变体众多,即使有许多优秀的工作,我们也无法将所有LLaMA变体都纳入此图中。
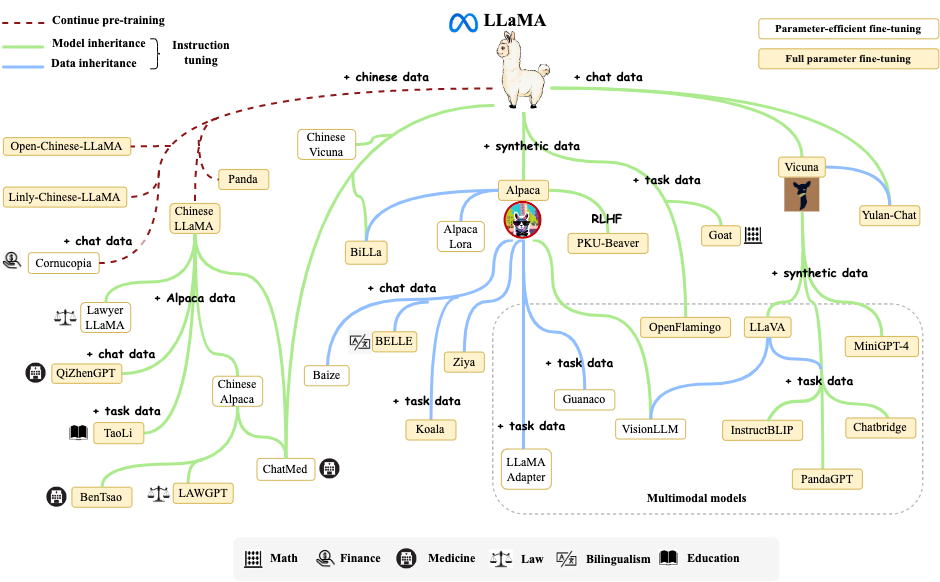
为了支持增量更新,我们分享了该图的源文件,并欢迎读者通过向我们的GitHub页面提交拉取请求来添加所需的模型。如果您感兴趣,请提交申请。
提示词
我们收集了一些设计提示词的实用技巧,这些技巧来源于网络笔记以及作者们的实践经验。同时,我们也展示了相关的要素与原则(详见第8.1节)。

请点击这里查看更详细的信息。
欢迎大家以issues的形式向我们提供更多相关技巧。 经过筛选后,我们会定期在GitHub上更新这些内容,并注明来源。
实验
指令调优实验
我们将探索不同类型指令在微调LLM(即7B LLaMA26)时的效果,并考察几种指令改进策略的实用性。
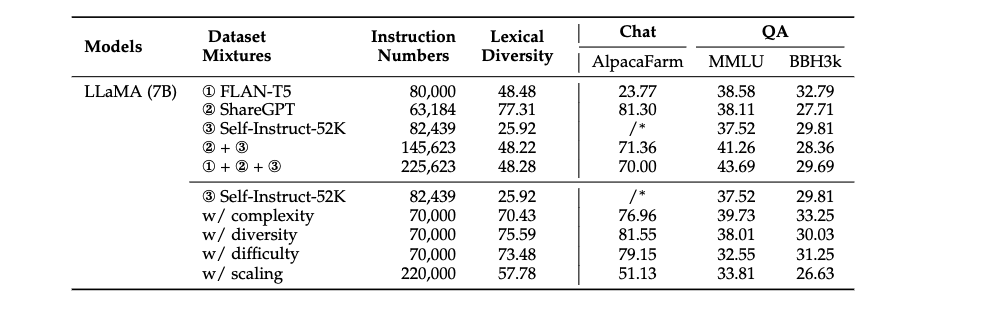
请点击这里查看更详细的信息。
能力评估实验
我们对第7.1节和第7.2节中讨论的能力进行了细粒度评估。对于每一种能力,我们选取了具有代表性的任务和数据集来进行评估实验,以检验LLM在相应方面的表现。
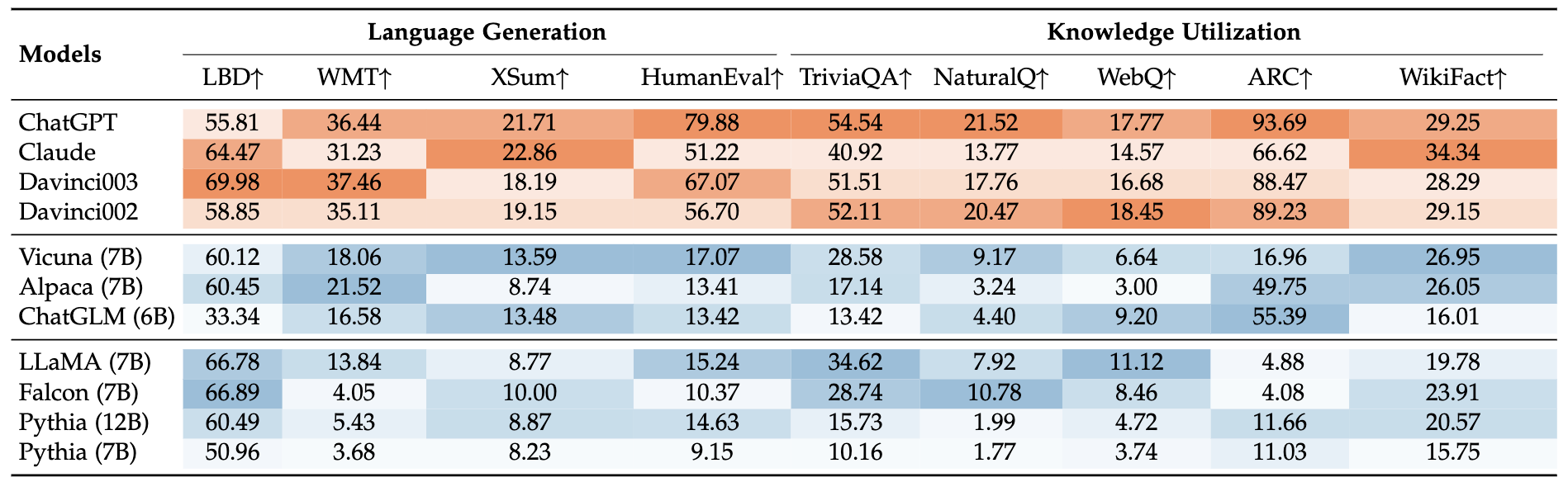
请点击这里查看更详细的信息。
我们也呼吁大家提供算力支持,以便开展更为全面的实验。
目录
- LLMSurvey
LLM时间线
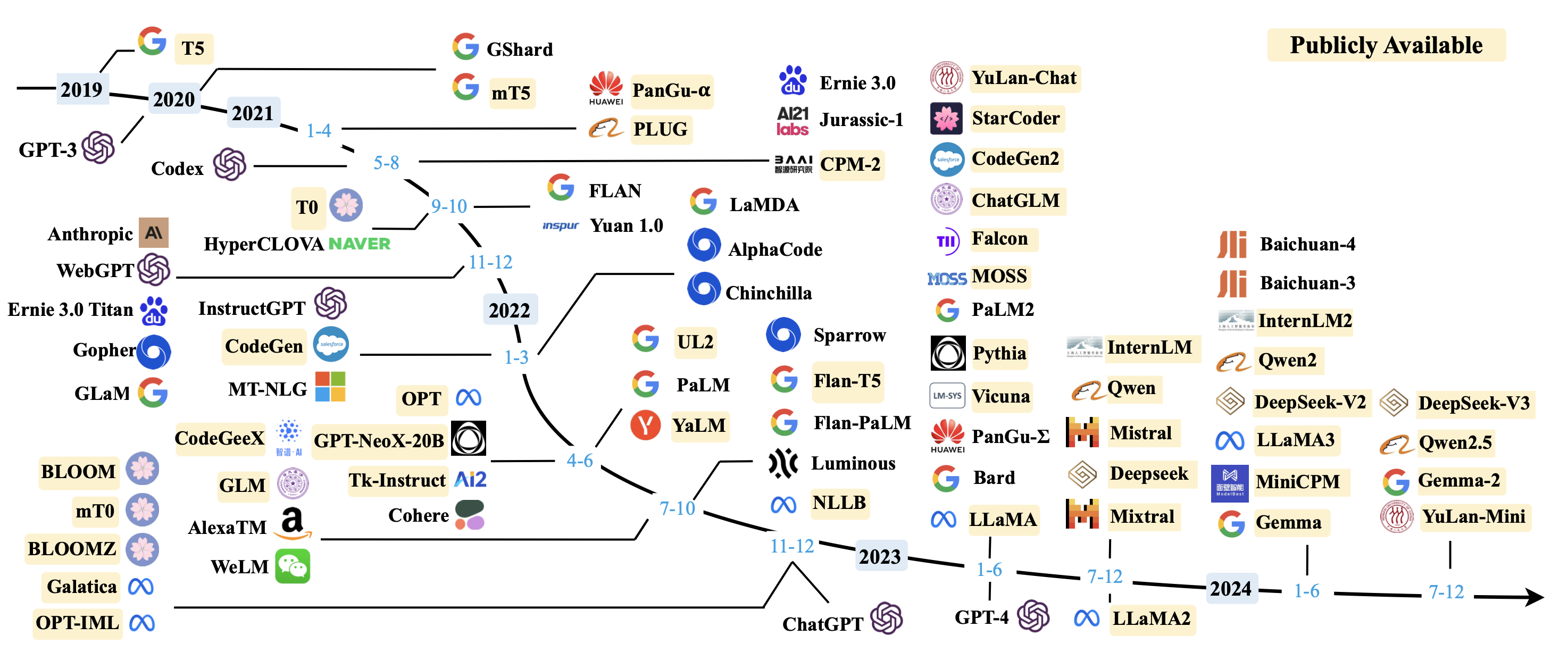
LLM列表
| 类别 | 模型 | 发布时间 | 参数量(B) | 链接 |
|---|---|---|---|---|
| 公开 可访问 |
T5 | 2019年10月 | 11 | 论文 |
| mT5 | 2021年3月 | 13 | 论文 | |
| PanGu-α | 2021年5月 | 13 | 论文 | |
| CPM-2 | 2021年5月 | 198 | 论文 | |
| T0 | 2021年10月 | 11 | 论文 | |
| GPT-NeoX-20B | 2022年2月 | 20 | 论文 | |
| CodeGen | 2022年3月 | 16 | 论文 | |
| Tk-Instruct | 2022年4月 | 11 | 论文 | |
| UL2 | 2022年2月 | 20 | 论文 | |
| OPT | 2022年5月 | 175 | 论文 | |
| YaLM | 2022年6月 | 100 | GitHub | |
| NLLB | 2022年7月 | 55 | 论文 | |
| BLOOM | 2022年7月 | 176 | 论文 | |
| GLM | 2022年8月 | 130 | 论文 | |
| Flan-T5 | 2022年10月 | 11 | 论文 | |
| mT0 | 2022年11月 | 13 | 论文 | |
| Galatica | 2022年11月 | 120 | 论文 | |
| BLOOMZ | 2022年11月 | 176 | 论文 | |
| OPT-IML | 2022年12月 | 175 | 论文 | |
| Pythia | 2023年1月 | 12 | 论文 | |
| LLaMA | 2023年2月 | 65 | 论文 | |
| Vicuna | 2023年3月 | 13 | 博客 | |
| ChatGLM | 2023年3月 | 6 | GitHub | |
| CodeGeeX | 2023年3月 | 13 | 论文 | |
| Alpaca | 2023年3月 | 7 | 博客 | |
| Koala | 2023年4月 | 13 | 博客 | |
| Mistral | 2023年9月 | 7 | 博客 | |
| 闭源 | GShard | 2020年1月 | 600 | 论文 |
| GPT-3 | 2020年5月 | 175 | 论文 | |
| LaMDA | 2021年5月 | 137 | 论文 | |
| HyperCLOVA | 2021年6月 | 82 | 论文 | |
| Codex | 2021年7月 | 12 | 论文 | |
| ERNIE 3.0 | 2021年7月 | 10 | 论文 | |
| Jurassic-1 | 2021年8月 | 178 | 论文 | |
| FLAN | 2021年10月 | 137 | 论文 | |
| MT-NLG | 2021年10月 | 530 | 论文 | |
| Yuan 1.0 | 2021年10月 | 245 | 论文 | |
| Anthropic | 2021年12月 | 52 | 论文 | |
| WebGPT | 2021年12月 | 175 | 论文 | |
| Gopher | 2021年12月 | 280 | 论文 | |
| ERNIE 3.0 Titan | 2021年12月 | 260 | 论文 | |
| GLaM | 2021年12月 | 1200 | 论文 | |
| InstructGPT | 2022年1月 | 175 | 论文 | |
| AlphaCode | 2022年2月 | 41 | 论文 | |
| Chinchilla | 2022年3月 | 70 | 论文 | |
| PaLM | 2022年4月 | 540 | 论文 | |
| Cohere | 2022年6月 | 54 | 官网 | |
| AlexaTM | 2022年8月 | 20 | 论文 | |
| Luminous | 2022年9月 | 70 | 文档 | |
| Sparrow | 2022年9月 | 70 | 论文 | |
| WeLM | 2022年9月 | 10 | 论文 | |
| U-PaLM | 2022年10月 | 540 | 论文 | |
| Flan-PaLM | 2022年10月 | 540 | 论文 | |
| Flan-U-PaLM | 2022年10月 | 540 | 论文 | |
| GPT-4 | 2023年3月 | — | 论文 | |
| PanGU-Σ | 2023年3月 | 1085 | 论文 |
论文列表
大语言模型资源
公开可用模型
- T5:“使用统一的文本到文本Transformer探索迁移学习的极限”。Colin Raffel等,JMLR 2019年。[论文] [检查点]
- mT5:“mT5:一个大规模多语言预训练文本到文本Transformer”。Linting Xue 等,NAACL 2021年。[论文] [检查点]
- PanGu-α:“PanGu-α:具有自动并行计算的大规模自回归预训练中文语言模型”。Wei Zeng等,arXiv 2021年。[论文] [检查点]
- CPM-2:“CPM-2:大规模、高性价比的预训练语言模型”。Zhengyan Zhang等,arXiv 2021年。[论文] [检查点]
- T0:“多任务提示训练实现零样本任务泛化”。Victor Sanh等,ICLR 2022年。[论文] [检查点]
- GPT-NeoX-20B:“GPT-NeoX-20B:一个开源的自回归语言模型”。Sid Black等,arXiv 2022年。[论文] [检查点]
- CodeGen:“CodeGen:一个用于代码的开放大型语言模型,具备多轮程序合成能力”。Erik Nijkamp等,arXiv 2022年。[论文] [检查点]
- Tk-Instruct:“Super-NaturalInstructions:通过1600多个NLP任务上的声明式指令实现泛化”。Yizhong Wang等,EMNLP 2022年。[论文] [检查点]
- UL2:“UL2:统一语言学习范式”。Yi Tay等,arXiv 2022年。[论文] [检查点]
- OPT:“OPT:开放的预训练Transformer语言模型”。Susan Zhang等,arXiv 2022年。[论文] [检查点]
- NLLB:“不让任何语言掉队:以人为本的机器翻译规模化”。NLLB团队,arXiv 2022年。[论文] [检查点]
- BLOOM:“BLOOM:一个拥有1760亿参数的开源多语言语言模型”。BigScience Workshop,arXiv 2022年。[论文] [检查点]
- GLM:“GLM-130B:一个开放的双语预训练模型”。Aohan Zeng等,arXiv 2022年。[论文] [检查点]
- Flan-T5:“指令微调语言模型的扩展”。Hyung Won Chung等,arXiv 2022年。[论文] [检查点]
- mT0 && BLOOMZ:“通过多任务微调实现跨语言泛化”。Niklas Muennighoff等,arXiv 2022年。[论文] [检查点]
- Galactica:“Galactica:一个面向科学的大语言模型”。Ross Taylor等,arXiv 2022年。[论文] [检查点]
- OPT-IML:“OPT-IML:从泛化的视角扩展语言模型指令元学习”。Srinivasan等,arXiv 2022年。[论文] [检查点]
- CodeGeeX:“CodeGeeX:一个用于代码生成的预训练模型,在HumanEval-X上进行多语言评估”。Qinkai Zheng等,arXiv 2023年。[论文] [检查点]
- Pythia:“Pythia:一套用于分析大型语言模型在训练和扩展过程中的工具”。Stella Biderman等,arXiv 2023年。[论文] [检查点]
- LLaMA:“LLaMA:开放且高效的基座语言模型”。Hugo Touvron等,arXiv 2023年。[论文] [检查点]
封闭源模型
- GShard:“GShard:通过条件计算与自动分片扩展巨型模型”。德米特里·列皮欣等 ICLR 2021。[论文]
- GPT-3:“语言模型是少样本学习者”。汤姆·B·布朗等 NeurIPS 2020。[论文]
- LaMDA:“LaMDA:面向对话应用的语言模型”。罗马尔·托皮兰等 arXiv 2021。[论文]
- HyperCLOVA:“大规模语言模型能带来哪些改变?对HyperCLOVA的深入研究:数十亿参数级韩语生成式预训练Transformer”。金宝涉等 EMNLP 2021。[论文]
- CodeX:“评估基于代码训练的大规模语言模型”。马克·陈等 arXiv 2021。[论文]
- ERNIE 3.0:“ERNIE 3.0:大规模知识增强型预训练,用于语言理解和生成”。孙宇等 arXiv 2021。[论文]
- Jurassic-1:“Jurassic-1:技术细节与评估”。奥弗·利伯等 2021。[论文]
- FLAN:“微调后的语言模型是零样本学习者”。杰森·魏等 ICLR 2021。[论文]
- MT-NLG:“利用DeepSpeed和Megatron训练Megatron-Turing NLG 530B,一个大规模生成式语言模型”。沙登·史密斯等 arXiv 2021。[论文]
- Yuan 1.0:“Yuan 1.0:在零样本和少样本学习中表现优异的大规模预训练语言模型”。吴绍华等 arXiv 2021。[论文]
- Anthropic:“作为对齐研究实验室的通用语言助手”。阿曼达·阿斯克尔等 arXiv 2021。[论文]
- WebGPT:“WebGPT:结合浏览器辅助与人类反馈的问答系统”。中野玲一郎等 arXiv 2021。[论文]
- Gopher:“语言模型的规模化:方法、分析及训练Gopher的经验与洞见”。杰克·W·雷等 arXiv 2021。[论文]
- ERNIE 3.0 Titan:“ERNIE 3.0 Titan:探索更大规模的知识增强型预训练,用于语言理解和生成”。王硕焕等 arXiv 2021。[论文]
- GLaM:“GLaM:基于专家混合的高效语言模型扩展”。南杜等 ICML 2022。[论文]
- InstructGPT:“利用人类反馈训练语言模型遵循指令”。龙欧阳等 arXiv 2022。[论文]
- AlphaCode:“使用AlphaCode实现竞赛级别的代码生成”。李宇嘉等 arXiv 2022。[论文]
- Chinchilla:“训练计算最优的大规模语言模型”。乔丹·霍夫曼等 arXiv。[论文]
- PaLM:“PaLM:借助Pathways扩展语言建模”。阿坎克莎·乔德赫里等 arXiv 2022。[论文]
- AlexaTM:“AlexaTM 20B:利用大规模多语言Seq2Seq模型进行少样本学习”。萨利赫·索尔坦等 arXiv 2022。[论文]
- Sparrow:“通过有针对性的人类判断改进对话代理的对齐性”。阿米莉亚·格莱泽等 arXiv 2022。[论文]
- WeLM:“WeLM:一款博学的中文预训练语言模型”。苏辉等 arXiv 2022。[论文]
- U-PaLM:“以额外0.1%的计算资源超越缩放定律”。易泰等 arXiv 2022。[论文]
- Flan-PaLM && Flan-U-PaLM:“指令微调语言模型的规模化”。郑炯源等 arXiv。[论文]
- GPT-4:“GPT-4技术报告”。OpenAI arXiv 2023。[论文]
- PanGu-Σ:“PanGu-Σ:迈向采用稀疏异构计算的万亿参数语言模型”。任晓哲等 arXiv 2023。[论文]
常用语料库
- BookCorpus:“对齐书籍与电影:通过观看电影和阅读书籍实现类似故事的视觉解释”。朱玉坤等 ICCV 2015。[论文] [来源]
- 古腾堡:[来源]
- CommonCrawl:[来源]
- C4:“利用统一的文本到文本Transformer探索迁移学习的极限”。科林·拉菲尔等 JMLR 2019。[论文] [来源]
- CC-stories-R:“一种简单的常识推理方法”。特里乌·H·郑等 arXiv 2018。[论文] [来源]
- CC-NEWS:“RoBERTa:一种鲁棒优化的BERT预训练方法”。刘银汉等 arXiv 2019。[论文] [来源]
- REALNEWs:“防御神经网络生成的假新闻”。罗温·泽勒斯等 NeurIPS 2019。[论文] [来源]
- OpenWebText:[来源]
- Pushshift.io:“Pushshift Reddit数据集”。杰森·鲍姆加特纳等 AAAI 2020。[论文] [来源]
- 维基百科:[来源]
- BigQuery:[来源]
- The Pile:“The Pile:一个800GB的多样化文本数据集,用于语言建模”。利奥·高等 arXiv 2021。[论文] [来源]
- ROOTS:“BigScience ROOTS语料库:一个1.6TB的复合多语言数据集”。洛朗松等 NeurIPS 2022数据集与基准赛道。[论文]
库资源
- Transformer:“Transformer:自然语言处理的最先进方法”。托马斯·沃尔夫等,EMNLP 2020。[论文] [源码]
- DeepSpeed:“DeepSpeed:系统优化使训练超过1000亿参数的深度学习模型成为可能”。拉斯利等,KDD 2020。[论文] [源码]
- Megatron-LM:“Megatron-LM:使用模型并行训练数十亿参数的语言模型”。穆罕默德·绍伊比等,arXiv 2019。[论文] [源码]
- JAX:[源码]
- Colossal-AI:“Colossal-AI:用于大规模并行训练的统一深度学习系统”。卞正达等,arXiv 2021。[论文] [源码]
- BMTrain:[源码]
- FastMoE:“FastMoE:一种快速的专家混合训练系统”。何家傲等,arXiv 2021。[论文] [源码]
深度学习框架
- PyTorch:“PyTorch:一种命令式、高性能的深度学习库”。亚当·帕什克等,NeurIPS 2019。[论文] [源码]
- TensorFlow:“TensorFlow:一个用于大规模机器学习的系统”。马丁·阿巴迪等,OSDI 2016。[论文] [源码]
- MXNet:“MXNet:一种灵活高效的机器学习库,适用于异构分布式系统”。陈天奇等,arXiv 2015。[论文] [源码]
- PaddlePaddle:“PaddlePaddle:一个源自工业实践的开源深度学习平台”。马延军等,数据与计算前沿 2019。[论文] [源码]
- MindSpore:“华为MindSpore AI开发框架”。华为技术有限公司,人工智能技术 2022。[论文] [源码]
- OneFlow:“OneFlow:从头设计分布式深度学习框架”。袁金辉等,arXiv 2021。[论文] [源码]
预训练
数据收集
- “BigScience ROOTS语料库:一个1.6TB的多语言复合数据集”。洛朗松等,NeurIPS 2022数据集与基准测试赛道。[论文]
- “去重训练数据能使语言模型更好”。凯瑟琳·李等,ACL 2022。[论文]
- “去重训练数据可降低语言模型中的隐私风险”。尼基尔·坎德帕尔等,ICML 2022。[论文]
- “重复数据学习的扩展规律与可解释性”。丹尼·埃尔南德斯等,arXiv 2022。[论文]
- “预训练者关于训练数据的指南:衡量数据年代、领域覆盖、质量和毒性的影响”。谢恩·隆普雷等,arXiv 2023。[论文]
架构
主流架构
因果解码器
- “语言模型是少样本学习者”。汤姆·B·布朗等,NeurIPS 2020。[论文]
- “OPT:开放的预训练Transformer语言模型”。苏珊·张等,arXiv 2022。[论文]
- “BLOOM:一个拥有1760亿参数的开源多语言语言模型”。特文·勒·斯考等,arXiv 2022。[论文]
- “训练计算最优的大规模语言模型”。乔丹·霍夫曼等,arXiv 2022。[论文]
- “语言模型的扩展:来自Gopher训练的方法、分析与见解”。杰克·W·雷等,arXiv 2021。[论文]
- “Galactica:一个用于科学领域的大型语言模型”。罗斯·泰勒等,arXiv 2022。[论文]
- “PaLM:通过Pathways扩展语言建模”。阿坎克沙·乔杜里等,arXiv 2022。[论文]
- “Jurassic-1:技术细节与评估”。奥弗·利伯等,AI21 Labs。[论文]
- “LaMDA:用于对话应用的语言模型”。罗马尔·托皮兰等,arXiv 2022。[论文]
前缀解码器
- “GLM-130B:一个开放的双语预训练模型”。敖汉·曾等,arXiv 2022。[论文]
- “GLM:基于自回归空白填充的通用语言模型预训练”。郑晓·杜等,ACL 2022。[论文]
- “以0.1%的额外计算超越扩展定律”。易泰等,arXiv 2022。[论文]
MoE
SSM
- “无需注意力机制的预训练”。王俊雄等,arXiv 2022。[论文]
- “利用结构化状态空间高效建模长序列”。阿尔伯特·顾等,ICLR 2022。[论文]
- “通过门控状态空间进行长距离语言建模”。哈什·梅塔等,arXiv 2022。[论文]
- “饥饿的河马:迈向基于状态空间模型的语言建模”。丹尼尔·Y·傅等,ICLR 2023。[论文]
详细配置
层归一化
- RMSNorm:“均方根层归一化”。张彪等,NeurIPS 2019。[论文]
- DeepNorm:“DeepNet:将Transformer扩展到1000层”。王洪宇等,arXiv 2022。[论文]
- Sandwich-LN:“CogView:通过Transformer掌握文本到图像生成”。丁明等,NeirIPS 2021。[论文]
位置编码
- T5偏置:“探索统一文本到文本Transformer的迁移学习极限”。科林·拉法尔等人,JMLR 2019年。[论文]
- ALiBi:“训练短、测试长:带有线性偏置的注意力机制实现输入长度外推”。奥菲尔·普雷斯等人,ICLR 2022年。[论文]
- RoPE:“RoFormer:带旋转位置嵌入的增强型Transformer”。苏建林等人,arXiv 2021年。[论文]
- xPos:“一种可进行长度外推的Transformer”。孙宇涛等人,arXiv 2022年。[论文]
注意力机制
- 多查询注意力:“快速Transformer解码:一个写头就足够了”。诺姆·沙泽尔,arXiv 2019年。[论文]
- FlashAttention:“FlashAttention:具有IO感知的快速且内存高效的精确注意力机制”。Tri Dao等人,NeurIPS 2022年。[论文]
- PagedAttention:“vLLM:使用PagedAttention实现简单、快速且廉价的LLM服务”。权宇锡等人,2023年。论文(敬请期待)[官方网站]
分析
- “哪种语言模型架构和预训练目标最适合零样本泛化?”。托马斯·王等人,ICML 2022年。[论文]
- “如果你有一百万GPU小时,应该训练哪种语言模型?”。特文·勒·斯考等人,EMNLP 2022年发现。[论文]
- “考察语言模型架构在机器翻译中的扩展与迁移”。张彪等人,ICML 2022年。[论文]
- “缩放定律与模型架构:归纳偏置如何影响模型的扩展性?”。泰伊毅等人,arXiv 2022年。[论文]
- “Transformer的改进是否能在不同实现和应用之间迁移?”。沙兰·纳朗等人,EMNLP 2021年。[论文]
训练算法
- “Megatron-LM:利用模型并行训练数十亿参数的语言模型”。穆罕默德·绍伊比等人,arXiv 2019年。[论文]
- “一种高效训练超大规模深度学习模型的2D方法”。徐启凡等人,arXiv 2021年。[论文]
- “Tesseract:高效并行化张量并行”。王博翔等人,ICPP 2022年。[论文]
- “最大化分布式训练中巨大神经网络的并行度”。边正达等人,arXiv 2021年。[论文]
- “GPipe:利用流水线并行高效训练巨型神经网络”。黄燕平等人,NeurIPS 2019年。[论文]
- “PipeDream:快速高效的流水线并行DNN训练”。亚伦·哈普拉普等人,arXiv 2018年。[论文]
- “ZeRO:面向万亿参数模型训练的内存优化技术”。萨米亚姆·拉吉班达里等人,SC 2020年。[论文]
- “ZeRO-Offload:让十亿级模型训练平民化”。任杰等人,USENIX 2021年。[论文]
基于代码的预训练
用于程序合成的LLM
- “评估基于代码训练的大规模语言模型”。马克·陈等人,arXiv 2021年。[论文]
- “利用大语言模型进行程序合成”。雅各布·奥斯汀等人,arXiv 2021年。[论文]
- “展示你的工作:语言模型的中间计算草稿板”。麦克斯韦尔·奈等人,arXiv 2021年。[论文]
- “对代码类大语言模型的系统性评估”。弗兰克·F·徐等人,arXiv 2022年。[论文]
- “AlphaCode:具备竞赛级别代码生成能力”。李宇嘉等人,Science杂志。[论文]
- “CodeGen:一款开源的大规模代码语言模型,支持多轮程序合成”。埃里克·尼坎普等人,ICLR 2023年。[论文]
- “InCoder:一款用于代码补全与合成的生成模型”。丹尼尔·弗里德等人,ICLR 2023年。[论文]
- “CodeT:通过生成测试进行代码生成”。陈贝等人,ICLR 2023年。[论文]
- “StarCoder:愿源代码与你同在!”。雷蒙德·李等人,arXiv 2023年。[论文]
以代码形式呈现的NLP任务
适应性微调
指令微调
- “用于自然语言理解的多任务深度神经网络”。Xiaodong Liu 等。ACL 2019。[论文] [主页]
- “利用统一的文本到文本 Transformer 探索迁移学习的极限”。Colin Raffel 等。JMLR 2020。[论文] [检查点]
- “Muppet:通过预微调实现的大规模多任务表示”。Armen Aghajanyan 等。EMNLP 2021。[论文] [检查点]
- “通过自然语言众包指令实现跨任务泛化”。Swaroop Mishra 等。ACL 2022。[论文] [数据集]
- “微调后的语言模型是零样本学习者”。Jason Wei 等。ICLR 2022。[论文] [主页]
- “多任务提示训练实现零样本任务泛化”。Victor Sanh 等。ICLR 2022。[论文] [检查点]
- “PromptSource:自然语言提示的集成开发环境与存储库”。Stephen H. Bach 等。ACL 2022。[论文] [数据集]
- “通过人类反馈训练语言模型以遵循指令”。Long Ouyang 等。arXiv 2022。[论文]
- “Super-NaturalInstructions:基于 1600 多个 NLP 任务的声明式指令实现泛化”。Yizhong Wang 等。EMNLP 2022。[论文] [数据集] [检查点]
- “MVP:面向自然语言生成的多任务监督预训练”。Tianyi Tang 等。arXiv 2022。[论文] [模型库] [检查点]
- “通过多任务微调实现跨语言泛化”。Niklas Muennighoff 等。arXiv 2022。[论文] [数据集] [模型]
- “指令微调语言模型的规模化”。Hyung Won Chung 等。arXiv 2022。[论文] [主页]
- “Unnatural Instructions:几乎无需人工即可调优语言模型”。Or Honovich 等。arXiv 2022。[论文] [主页]
- “Self-Instruct:通过自我生成的指令对齐语言模型”。Yizhong Wang 等。arXiv 2022。[论文] [主页]
- “OPT-IML:从泛化的视角看语言模型指令元学习的规模化”。Srinivasan Iyer 等。arXiv 2022。[论文] [检查点]
- “Flan 数据集:为有效指令调优设计的数据与方法”。Shayne Longpre 等。arXiv 2023。[论文] [主页]
- “提示就是全部吗?关于指令学习的全面且更广阔的视角”。Renze Lou 等。arXiv 2023。[论文]
- “也许只需 0.5% 的数据:低训练数据指令调优的初步探索”。Hao Chen 等。arXiv 2023。[论文]
- “LIMA:对齐之道,少即是多”。Chunting Zhou。arXiv 2023。[论文]
对齐调优
- “TAMER:通过评估性强化手动训练智能体”。W. 布拉德利·诺克斯等。ICDL 2008。[论文]
- “基于策略依赖型人类反馈的交互式学习”。詹姆斯·麦克格拉申等。ICML 2017。[论文]
- “基于人类偏好深度强化学习”。保罗·克里斯蒂亚诺等。NIPS 2017。[论文]
- “Deep TAMER:高维状态空间中的交互式智能体塑造”。加雷特·沃内尔等。AAAI 2018。[论文]
- “基于人类偏好微调语言模型”。丹尼尔·M·齐格勒等。arXiv 2019。[论文]
- “从人类反馈中学习总结”。尼桑·斯蒂农等。NeurIPS 2020。[论文]
- “语言智能体对齐”。扎卡里·肯顿等。arXiv 2021。[论文]
- “利用人类反馈递归总结书籍”。杰夫·吴等。arXiv 2021。[论文]
- “通用语言助手作为对齐研究的实验室”。阿曼达·阿斯克尔等。arXiv 2021。[论文]
- “WebGPT:基于浏览器辅助、结合人类反馈的问答系统”。中野玲一郎等。arXiv 2021。[论文]
- “利用人类反馈训练语言模型遵循指令”。龙欧阳等。arXiv 2022。[论文]
- “教导语言模型用经过验证的引文支持答案”。雅各布·梅尼克等。arXiv 2022。[论文]
- “通过人类反馈强化学习训练有益且无害的助手”。白云涛等。arXiv 2022。[论文]
- “利用强化学习进行开放式对话中的动态规划”。黛博拉·科恩等。arXiv 2022。[论文]
- “红队测试语言模型以减少危害:方法、规模效应及经验教训”。迪普·甘古利等。arXiv 2022。[论文]
- “通过有针对性的人类判断改进对话智能体对齐”。阿米莉亚·格莱泽等。arXiv 2022。[论文]
- “强化学习(不)适用于自然语言处理吗?——自然语言策略优化的基准、基线与构建模块”。拉朱库马尔·拉马穆尔蒂等。arXiv 2022。[论文]
- “奖励模型过度优化的规模法则”。李奥·高等。arXiv 2022。[论文]
- “事后智慧使语言模型更善于遵循指令”。张天俊等。arXiv 2023。[论文]
- “RAFT:用于生成式基础模型对齐的奖励排序微调”。董汉泽等。arXiv 2023。[论文]
- “使用话语链进行安全对齐的大型语言模型红队测试”。里沙布·巴德瓦杰等。arXiv 2023。[论文]
参数高效模型适配
- “面向NLP的参数高效迁移学习”。尼尔·豪尔斯比等。ICML 2019。[论文] [GitHub]
- “MAD-X:基于适配器的多任务跨语言迁移框架”。乔纳斯·普菲弗等。EMNLP 2020。[论文] [GitHub]
- “AUTOPROMPT:利用自动生成的提示从语言模型中提取知识”。泰勒·辛等。EMNLP 2020。[论文] [GitHub]
- “前缀调优:优化连续提示以用于生成任务”。李香丽等。ACL 2021。[论文] [GitHub]
- “GPT也懂了”。刘晓等。arXiv 2021。[论文] [GitHub]
- “规模效应对参数高效提示调优的重要性”。布莱恩·莱斯特等。EMNLP 2021。[论文]
- “LoRA:大型语言模型的低秩适配”。爱德华·J·胡等。arXiv 2021。[论文] [GitHub]
- “迈向参数高效迁移学习的统一视角”。何俊贤等。ICLR 2022。[论文] [GitHub]
- “P-Tuning v2:提示调优在不同规模和任务上均可与微调相媲美”。刘晓等。ACL 2022。[论文] [GitHub]
- “DyLoRA:采用动态无搜索低秩适配进行预训练模型的参数高效调优”。莫杰塔巴·瓦利普尔等。EACL 2023。[论文] [GitHub]
- “大规模预训练语言模型的参数高效微调”。丁宁等。Nature Machine Intelligence。[论文] [GitHub]
- “参数高效微调的自适应预算分配”。张清如等。arXiv 2023。[论文] [GitHub]
- “LLaMA-Adapter:零初始化注意力机制下的语言模型高效微调”。张仁瑞等。arXiv 2023。[论文] [GitHub]
- “LLM-Adapters:用于大型语言模型参数高效微调的一系列适配器”。胡志强等。arXiv 2023。[论文] [GitHub]
内存高效模型适配
- “用于高效神经网络推理的量化方法综述”。Amir Gholami 等,arXiv 2021。[论文]
- “基于分块量化的8位优化器”。Tim Dettmers 等,arXiv 2021。[论文]
- “通过量化压缩生成式预训练语言模型”。Chaofan Tao 等,ACL 2022。[论文]
- “ZeroQuant:面向大规模Transformer的高效且经济的后训练量化”。Zhewei Yao 等,NeurIPS 2022。[论文] [GitHub]
- “LLM.int8():面向大规模Transformer的8位矩阵乘法”。Tim Dettmers 等,arXiv 2022。[论文] [GitHub]
- “GPTQ:面向生成式预训练Transformer的高精度后训练量化”。Elias Frantar 等,ICLR 2023。[论文] [GitHub]
- “SmoothQuant:面向大型语言模型的高精度高效后训练量化”。Guangxuan Xiao 等,arXiv 2022。[论文] [GitHub]
- “4位精度的理由:k位推理缩放法则”。Tim Dettmers 等,arXiv 2022。[论文]
- “ZeroQuant-V2:从全面研究到低秩补偿,探索LLM中的后训练量化”。Zhewei Yao 等,arXiv 2023。[论文]
- “QLoRA:量化LLM的高效微调”。Tim Dettmers 等,arXiv 2023。[论文] [GitHub]
- “LLM-QAT:面向大型语言模型的无数据量化感知训练”。Zechun Liu 等,arXiv 2023。[论文]
- “AWQ:面向LLM压缩与加速的激活感知权重量化”。Ji Lin 等,arXiv 2023。[论文] [GitHub]
应用
上下文学习(ICL)
- “一种无需真实标签的信息论提示工程方法”。Taylor Sorensen 等,ACL 2022。[论文]
- “什么样的上下文示例对GPT-3有效?”。Jiachang Liu 等,ACL 2022。[论文]
- “学习检索用于上下文学习的提示”。Ohad Rubin 等,NAACL 2022。[论文]
- “多样化的演示可以提升上下文组合泛化能力”。Itay Levy 等,arXiv 2022。[论文]
- “通过困惑度估计揭秘语言模型中的提示”。Hila Gonen 等,arXiv 2022。[论文]
- “面向上下文学习的主动示例选择”。Yiming Zhang 等,EMNLP 2022。[论文]
- “自适应上下文学习”。Zhiyong Wu 等,arXiv 2022。[论文]
- “奇妙有序的提示及其寻找方法:克服少样本提示顺序敏感性”。Yao Lu 等,ACL 2022。[论文]
- “结构化提示:将上下文学习扩展至1,000个示例”。Hao、Yaru 等,arXiv 2022。[论文]
- “文本推理中少样本提示解释的不可靠性”。Ye、Xi 等,arXiv 2022。[论文]
- “通过自然语言众包指令实现跨任务泛化”。Swaroop Mishra 等,ACL 2022。[论文]
- “提示增强的线性探测:突破少样本上下文学习者的极限”。Hyunsoo Cho 等,arXiv 2022。[论文]
- “将上下文学习解释为隐式贝叶斯推断”。Sang Michael Xie 等,ICLR 2022。[论文]
- “使用前先校准:提升语言模型的少样本性能”。Zihao Zhao 等,ICML 2021。[论文]
- “数据分布特性驱动了Transformer中的涌现式上下文学习”。Stephanie C. Y. Chan 等,arXiv 2022。[论文]
- “上下文学习与归纳头”。Catherine Olsson 等,arXiv 2022。[论文]
- “预训练语料对大型语言模型上下文学习的影响”。Seongjin Shin 等,NAACL 2022。[论文]
- “重新思考演示的作用:是什么让上下文学习奏效?”。Sewon Min 等,EMNLP 2022。[论文]
- “重新思考规模在上下文学习中的作用:一项基于可解释性的660亿参数案例研究”。Hritik Bansal 等,arXiv 2022。[论文]
- “Transformer作为算法:上下文学习中的泛化与隐式模型选择”。Yingcong Li 等,arXiv 2023。[论文]
- “Transformer通过梯度下降进行上下文学习”。Johannes von Oswald 等,arXiv 2022。[论文]
- “上下文学习到底是一种什么学习算法?基于线性模型的探究”。Ekin Aky{"{u}}rek 等,arXiv 2022。[论文]
- “上下文学习综述”。Qingxiu Dong 等,arXiv 2023。[论文]
- “上下文学习到底‘学’到了什么:任务识别与任务学习的解耦”。Jane Pan 等,arXiv 2023。[论文]
- “上下文学习的可学习性”。Noam Wies 等,arXiv 2023。[论文]
- “基于提示的模型真的理解其提示的含义吗?”。Albert Webson 等,NAACL 2022。[论文]
- “更大的语言模型进行上下文学习的方式不同”。Jerry Wei,arXiv 2023。[论文]
- “大型语言模型中的元上下文学习”。Julian Coda-Forno,arXiv 2023。[论文]
- “符号调优可以提升语言模型中的上下文学习”。Jerry Wei,arXiv 2023。[论文]
思维链推理(CoT)
- “大型语言模型中的自动思维链提示”。Zhuosheng Zhang 等,arXiv 2022。[论文]
- “思维链提示激发大型语言模型的推理能力”。Jason Wei 等,arXiv 2022。[论文]
- “STaR:自训练推理器——以推理促进推理”。Zelikman 等,arXiv 2022。[论文]
- “大型语言模型是零样本推理者”。Takeshi Kojima 等,arXiv 2022。[论文]
- “大型语言模型中的自动思维链提示”。Zhuosheng Zhang 等,arXiv。[论文]
- “基于复杂度的多步推理提示”。Yao Fu 等,arXiv 2022。[论文]
- “语言模型是多语言思维链推理者”。Freda Shi 等,arXiv 2022。[论文]
- “语言模型中的理由增强集成”。Xuezhi Wang 等,arXiv 2022。[论文]
- “由简入繁的提示策略使大型语言模型具备复杂推理能力”。Denny Zhou 等,arXiv 2022。[论文]
- “语言模型中的多模态思维链推理”。Zhuosheng Zhang 等,arXiv 2023。[论文]
- “自我一致性提升语言模型的思维链推理能力”。Xuezhi Wang 等,arXiv 2022。[论文]
- “大型语言模型可以自我改进”。Jiaxin Huang 等,arXiv 2022。[论文]
- “训练验证器解决数学应用题”。Karl Cobbe 等,arXiv 2021。[论文]
- “关于提升语言模型推理能力的进展”。Yifei Li 等,arXiv 2022。[论文]
- “大型语言模型是具有自我验证功能的推理者”。Yixuan Weng 等,arXiv 2022。[论文]
- “教导小型语言模型进行推理”。Lucie Charlotte Magister 等,arXiv 2022。[论文]
- “大型语言模型是推理教师”。Namgyu Ho 等,arXiv 2022。[论文]
- “文本推理中少样本提示解释的不可靠性”。Ye, Xi 等,arXiv 2022。[论文]
- “指令微调语言模型的扩展”。Hyung Won Chung 等,arXiv 2022。[论文]
- “利用语言模型解决定量推理问题”。Aitor Lewkowycz 等,arXiv 2022。[论文]
- “文本与模式:有效的思维链需要双方协作”。Aman Madaan 等,arXiv 2022。[论文]
- “挑战BIG-Bench任务及思维链是否能解决它们”。Mirac Suzgun 等,arXiv 2022。[论文]
- “语言模型提示下的推理:综述”。Shuofei Qiao 等,arXiv 2022。[论文]
- “迈向大型语言模型的推理:综述”。Jie Huang 等,arXiv 2022。[论文]
复杂任务解决规划
- 由简入繁的提示策略使大型语言模型具备复杂推理能力。Denny Zhou 等,ICLR 2023。[论文]
- PAL:程序辅助语言模型。Luyu Gao 等,ICML 2023。[论文]
- 计划—求解提示:通过大型语言模型改进零样本思维链推理。Lei Wang 等,ACL 2023。[论文]
- ProgPrompt:利用大型语言模型生成情境化的机器人任务计划。Ishika Singh 等,ICRA 2022。[论文]
- 思维之树:利用大型语言模型进行深思熟虑的问题解决。Shunyu Yao 等,arXiv 2023。[论文]
- Voyager:一个基于大型语言模型的开放式具身智能体。Guanzhi Wang 等,arXiv 2023。[论文]
- Reflexion:具有言语强化学习能力的语言代理。Noah Shinn 等,arXiv 2023。[论文]
- 通过双模态文本-图像提示进行多模态程序化规划。Yujie Lu 等,arXiv 2023。[论文]
- 利用大型语言模型进行自我规划的代码生成。Xue Jiang 等,arXiv 2023。[论文]
- 分解式提示:一种用于解决复杂任务的模块化方法。Tushar Khot 等,ICLR 2023 [论文]
- Toolformer:语言模型可自我教授如何使用工具。Timo Schick 等,arXiv 2023。[论文]
- HuggingGPT:利用ChatGPT及其在Hugging Face中的伙伴解决AI任务。Yongliang Shen 等,arXiv 2023。[论文]
- 忠实的思维链推理。Qing Lyu 等,arXiv 2023。[论文]
- LLM+P:用最优规划能力赋能大型语言模型。Bo Liu 等,arXiv 2023。[论文]
- 语言模型的推理即基于世界模型的规划。Shibo Hao 等,arXiv 2023。[论文]
- 生成式代理:人类行为的交互式模拟物。Joon Sung Park 等,arXiv 2023。[论文]
- ReAct:在语言模型中协同推理与行动。Shunyu Yao 等,ICLR 2023。[论文]
- ChatCoT:基于聊天型大型语言模型的工具增强思维链推理。Zhipeng Chen 等,arXiv 2023。[论文]
- 描述、解释、计划与选择:利用大型语言模型进行交互式规划,可实现开放世界的多任务智能体。Zihao Wang 等,arXiv 2023。[论文]
- AdaPlanner:基于反馈的自适应规划系统,由语言模型驱动。Haotian Sun 等,arXiv 2023。[论文]
能力评估
- “衡量大规模多任务语言理解能力”。丹·亨德里克斯等,ICLR 2021。[论文]
- “大型语言模型中的持续性反穆斯林偏见”。阿布巴卡尔·阿比德等,AIES 2021。[论文]
- “理解大型语言模型的能力、局限性及社会影响”。亚历克斯·塔姆金等,arXiv 2021。[论文]
- “BEHAVIOR:虚拟、交互式和生态环境中日常家务活动的基准测试”。桑贾娜·斯里瓦斯塔瓦等,CoRL 2021。[论文]
- “基于大型语言模型的程序合成”。雅各布·奥斯汀等,arXiv 2021。[论文]
- “训练验证器解决数学应用题”。卡尔·科布等,arXiv 2021。[论文]
- “展示你的思路:面向语言模型中间计算的草稿纸”。麦克斯韦尔·I·奈伊等,arXiv 2021。[论文]
- “语言模型作为零样本规划器:为具身智能体提取可操作知识”。黄文龙等,ICML 2022。[论文]
- “思维链提示能够激发大型语言模型的推理能力”。杰森·魏等,NeurIPS 2022。[论文]
- “利用人类反馈训练语言模型遵循指令”。欧阳隆等,arXiv 2022。[论文]
- “AlphaCode实现竞赛级代码生成”。李宇嘉等,Science 2022。[论文]
- “知行合一:将语言与机器人可用性相结合”。迈克尔·安等,arXiv 2022。[论文]
- “通过人类反馈强化学习训练有益且无害的助手”。白云涛等,arXiv 2022。[论文]
- “基于大型语言模型的自动形式化”。吴宇怀等,NeurIPS 2022。[论文]
- “超越图灵测试:量化并外推语言模型的能力”。阿罗希·斯里瓦斯塔瓦等,arXiv 2022。[论文]
- “探索大型语言模型的长度泛化能力”。切姆·阿尼尔等,NeurIPS 2022。[论文]
- “基于检索增强语言模型的少样本学习”。高蒂埃·伊扎卡德等,arXiv 2022。[论文]
- “语言模型在算术与符号归纳方面的局限性”。钱静等,arXiv 2022。[论文]
- “代码即策略:用于具身控制的语言模型程序”。梁杰克等,arXiv 2022。[论文]
- “ProgPrompt:利用大型语言模型生成情境化的机器人任务计划”。伊希卡·辛格等,arXiv 2022。[论文]
- “法律指导代码:一种法律信息学方法,使人工智能与人类保持一致”。约翰·J·奈等,arXiv 2022。[论文]
- “语言模型是贪婪的推理者:对思维链的系统性形式化分析”。阿布尔海尔·萨帕罗夫等,ICLR 2023。[论文]
- “语言模型是多语言思维链推理者”。史弗雷达等,ICLR 2023。[论文]
- “Re3:通过递归式重提示与修订生成更长的故事”。凯文·杨等,EMNLP 2022。[论文]
- “代码语言模型是少样本常识学习者”。阿曼·马丹等,EMNLP 2022。[论文]
- “挑战BIG-Bench任务及思维链是否能解决它们”。米拉克·苏兹贡等,arXiv 2022。[论文]
- “大型语言模型可以自我改进”。黄佳欣等,arXiv 2022。[论文]
- “起草、草拟并证明:用非正式证明引导形式化定理证明器”。阿尔伯特·Q·姜等,ICLR 2023。[论文]
- “语言模型的整体评估”。珀西·梁等,arXiv 2022。[论文]
- “PAL:程序辅助语言模型”。高璐瑜等,arXiv 2022。[论文]
- “多语言法律判决预测的法律提示工程”。迪特里希·特劳特曼等,arXiv 2022。[论文]
- “ChatGPT在医学执业资格考试中的表现如何?大型语言模型对医学教育与知识评估的影响”。艾丹·吉尔森等,medRxiv 2022。[论文]
- “ChatGPT:线上考试诚信的终结者?”。特奥·苏斯尼亚克等,arXiv 2022。[论文]
- “大型语言模型是具有自我验证能力的推理者”。翁一轩等,arXiv 2022。[论文]
- “Self-Instruct:使语言模型与自动生成的指令对齐”。王义中等,arXiv 2022。[论文]
- “ChatGPT让医学变得易懂:简化放射学报告的探索性案例研究”。卡塔琳娜·耶布利克等,arXiv 2022。[论文]
- “编程的终结”。马特·威尔什等,ACM 2023。[论文]
- “ChatGPT上法学院”。乔伊·乔纳森·H等,SSRN 2023。[论文]
- “ChatGPT距离人类专家还有多远?对比语料库、评估与检测”。郭碧洋等,arXiv 2023。[论文]
- “ChatGPT是优秀的翻译吗?一项初步研究”。焦文祥等,arXiv 2023。[论文]
- “人工智能代理能否通过大学物理入门课程?”。格尔德·科尔特迈耶等,arXiv 2023。[论文]
- “ChatGPT的数学能力”。西蒙·弗里德尔等,arXiv 2023。[论文]
- “合成提示:为大型语言模型生成思维链示范”。邵志宏等,arXiv 2023。[论文]
- “利用在线强化学习将大型语言模型置于交互环境中”。托马斯·卡尔塔等,arXiv 2023。[论文]
- “评估ChatGPT作为放射学决策的辅助工具”。姚阿雅等,medRxiv 2023。[论文]
- “心智理论可能已在大型语言模型中自发涌现”。米哈尔·科辛斯基等,arXiv 2023。[论文]
- “ChatGPT失败案例的分类汇编”。阿里·博尔吉等,arXiv 2023。[论文]
- “对ChatGPT在推理、幻觉和交互性方面的多任务、多语言、多模态评估”。方艺珍等,arXiv 2023。[论文]
- “Toolformer:语言模型可以自我教授如何使用工具”。蒂莫·希克等,arXiv 2023。[论文]
- “ChatGPT是通用自然语言处理任务求解器吗?”。秦成伟等,arXiv 2023。[论文]
- “GPT模型在机器翻译方面有多好?一项全面评估”。亨迪·阿姆尔等,arXiv 2023。[论文]
- “ChatGPT也能理解吗?ChatGPT与微调BERT的比较研究”。钟启煌等,arXiv 2023。[论文]
- “通过与ChatGPT对话进行零样本信息抽取”。向伟等,arXiv 2023。[论文]
- “ChatGPT:样样通,样样松”。扬·科孔等,arXiv 2023。[论文]
- “关于ChatGPT鲁棒性的对抗性和分布外视角”。王金东等,arXiv 2023。[论文]
- “核对事实并再试一次:利用外部知识和自动化反馈改进大型语言模型”。彭宝林等,arXiv 2023。[论文]
- “对ChatGPT在数学文字问题(MWP)上的独立评估”。保罗·沙卡里安等,arXiv 2023。[论文]
- “GPT-3.5对前代模型的鲁棒性如何?一项关于语言理解任务的综合研究”。陈宣婷等,arXiv 2023。[论文]
- “ChatGPT在癌症治疗信息中的实用性”。沈晨等,medRxiv 2023。[论文]
- “ChatGPT能否评估人类性格?一个通用评估框架”。饶浩聪等,arXiv 2023。[论文]
- “情感计算会从基础模型和通用人工智能中诞生吗?对ChatGPT的首次评估”。穆斯塔法·M·阿敏等,arXiv 2023。[论文]
- “探索ChatGPT用于事件抽取的可行性”。高俊等,arXiv 2023。[论文]
- “LLM的合成数据生成是否有助于临床文本挖掘?”。唐瑞翔等,arXiv 2023。[论文]
- “ChatGPT的一致性分析”。张明俊等,arXiv 2023。[论文]
- “利用大型语言模型进行自我规划的代码生成”。张顺等,ICLR 2023。[论文]
- “评估ChatGPT作为问答系统解答复杂问题的能力”。谭一鸣等,arXiv 2023。[论文]
- “GPT-4技术报告”。OpenAI等,OpenAI 2023。[论文]
- “从法律视角审视大型语言模型的简短综述”。孙仲翔等,arXiv 2023。[论文]
- “ChatGPT参加计算机科学考试”。塞巴斯蒂安·博尔特等,arXiv 2023。[论文]
- “GPT-3和GPT-3.5系列模型的综合能力分析”。叶俊杰等,arXiv 2023。[论文]
- “关于ChatGPT的教育影响:人工智能准备好获得大学学位了吗?”。卡米尔·马林卡等,arXiv 2023。[论文]
- “通用人工智能的火花:GPT-4的早期实验”。塞巴斯蒂安·布贝克等,arXiv 2023。[论文]
- “ChatGPT是优秀的关键词生成器吗?一项初步研究”。宋明阳等,arXiv 2023。[论文]
- “GPT-4在医学挑战性问题上的能力”。哈莎·诺里等,arXiv 2023。[论文]
- “我们能信任对ChatGPT的评估吗?”。拉奇特·艾亚帕等,arXiv 2023。[论文]
- “ChatGPT在文本标注任务上优于众包工作者”。法布里齐奥·吉拉尔迪等,arXiv 2023。[论文]
- “评估ChatGPT在基于NLP的心理健康应用中的作用”。比沙尔·拉米查内等,arXiv 2023。[论文]
- “ChatGPT是知识渊博但经验不足的求解者:对大型语言模型中常识问题的探究”。卞宁等,arXiv 2023。[论文]
- “评估GPT-3.5和GPT-4模型在巴西大学入学考试中的表现”。德斯内斯·努内斯等,arXiv 2023。[论文]
- “人中有人才:论GPT在成功与失败中均趋向于常识”。菲利普·科拉卢斯等,arXiv 2023。[论文]
- “但是……ChatGPT能否识别历史文献中的实体?”。卡洛斯-埃米利亚诺·冈萨雷斯-加利亚多等,arXiv 2023。[论文]
- “揭示ChatGPT在推荐系统中的能力”。戴顺浩等,arXiv 2023。[论文]
- “编辑大型语言模型:问题、方法与机遇”。姚云芝等,arXiv 2023。[论文]
- “通过越狱对ChatGPT进行红队测试:偏见、鲁棒性、可靠性和毒性”。朱跃天等,arXiv 2023。[论文]
- “基于提示的语义解析在大型预训练语言模型中的鲁棒性:对Codex的实证研究”。朱跃天等,EACL 2023。[论文]
- “对ChatGPT在基准数据集上的系统性研究和综合评估”。拉斯卡尔等,ACL'23。[论文]
- “利用话语链对大型语言模型进行红队测试以实现安全对齐”。里沙布·巴德瓦杰等,arXiv 2023。[论文]
- “大型语言模型知识编辑的综合研究”。张宁宇等,arXiv 2024。[论文]
团队
以下是各章节的学生贡献者名单。
| 章节 | 学生贡献者 |
|---|---|
| 整篇论文 | 周坤、李俊毅 |
| 大模型概述与资源 | 敏英倩(负责人)、杨晨 |
| 预训练 | 侯宇鹏(负责人)、张俊杰、董子灿、陈雨硕 |
| 适配性微调 | 唐天一(负责人)、蒋金浩、任瑞阳、刘子康、刘沛宇 |
| 应用 | 王晓磊(负责人)、杜一凡、唐欣宇 |
| 能力评估 | 张北辰(负责人)、陈志鹏、李一凡 |
致谢
作者谨向林彦凯和朱宇涛表示感谢,感谢他们对本文的校对工作。自本文首次发布以来,我们收到了来自读者的诸多宝贵意见。在此,我们衷心感谢那些为我们提供建设性建议和评论的读者:泰勒·苏尔德、戴大迈、丁亮、斯特拉·比德曼、凯文·格雷、杰伊·阿拉马尔以及冯宇博。
更新日志
| 版本 | 时间 | 更新内容 |
|---|---|---|
| V1 | 2023/03/31 | 初版。 |
| V2 | 2023/04/09 | 增加机构信息。 修订图1和表1,并明确LLM的相应选择标准。 优化文字表述。 修正了一些小错误。 |
| V3 | 2023/04/11 | 修正了文献资源中的错误。 |
| V4 | 2023/04/12 | 修订图1和表1,明确LLM的发布日期。 |
| V5 | 2023/04/16 | 新增2.2节,介绍GPT系列模型的技术演进。 |
| V6 | 2023/04/24 | 在表1和图1中新增部分模型。 增加关于规模定律的讨论。 补充关于涌现能力所需模型规模的说明(2.1节)。 在图4中添加不同架构注意力模式的示意图。 在表4中补充详细公式。 |
| V7 | 2023/04/25 | 修订图表中的一些错别字。 |
| V8 | 2023/04/27 | 在5.3节中增加高效微调的内容 |
| V9 | 2023/04/28 | 修订5.3节 |
| V10 | 2023/05/07 | 修订表1、表2以及一些细节。 |
| V11 (重大修订) |
2023/06/29 | – 第1节:新增图1,展示arXiv上已发表LLM论文的趋势; – 第2节:新增图3,展示GPT的演进过程及相应讨论; – 第3节:新增图4,展示LLaMA家族及其相关讨论; – 第5节:新增关于指令微调中合成数据格式化的最新讨论(5.1.1节)、指令微调的实证分析(5.1.4节)、参数高效的模型适配(5.3节)以及内存高效的适配(5.4节); – 第6节:新增关于ICL底层机制的最新讨论(6.1.3节)、复杂任务规划解决的相关内容(6.3节); – 第7节:新增用于评估LLM高级能力的代表性数据集表格(表10),以及7.3.2节中的实证能力评估; – 第8节:增加提示设计; – 第9节:增加LLM在金融和科研领域的应用讨论; |
| V12 (重大修订) |
2023/09/10 | – 声明本文中所有图表的版权; – 在第3、4、5、6和7节中加入最新的LLM、技术及其描述; – 第4节:新增关于解码策略的最新讨论(4.2.4节); – 第5节:新增关于指令微调实用技巧的讨论(5.1.2节)、针对LLaMA(13B)进行指令微调的实证分析(5.1.4节)、RLHF的实用策略(5.2.3节)、无需RLHF的对齐方法(5.2.4节)以及SFT与RLHF的注意事项(5.2.5节); – 第6节:更新关于复杂任务规划解决的内容(6.4节); – 第7节:新增关于评估方法的讨论(7.3.2节)、现有评估工作的分类表格(表15),并更新7.4节中的实证能力评估及表16中的结果; – 第6.1.1节:在表12中新增提示示例; |
| V13 (重大修订) |
2023/11/23 | – 第1节:新增图2,展示四代语言模型的演进过程; – 第2节:进一步讨论规模定律以及涌现能力与规模定律的关系; – 第3节:在图3和表1中加入最新LLM,在3.1节中加入最新API,在3.3节中加入常用的指令微调和对齐微调数据集,在3.4节中加入若干库; – 第4节:新增关于数据调度的最新讨论,包括数据混合与数据课程(4.1.3节);在4.1.4节中总结数据准备过程;在9.1节中讨论长上下文建模问题;在4.2.4节中讨论解码效率问题并加入最新的解码策略; – 第5节:新增关于实例构建和微调策略的最新讨论(5.1节);新增关于过程监督式RLHF的最新讨论(5.2.3节),以及关于量化LLaMA模型(7B和13B)的实证研究(9.5.1节); – 第6节:新增关于提示优化的最新讨论(6.1.2节),并更新关于思维链提示的内容(6.3节); – 第8节:新增关于LLM在科研方向上的最新讨论(8.1节); – 第10节:对部分内容进行了修订。 |
| V14 | 2024/09/25 | – 第3节:将“公开可用的模型检查点”内容重新整理为多个系列;在图3中加入最新LLM。 – 第4节:在4.1.2节中加入基于LLM的数据过滤和选择方法;更新4.2.1节“涌现架构”,增加更多关于基于SSM架构的讨论;新增表6,用于比较不同架构的并行性和复杂度。 – 第5节:新增关于提升指令质量和指令选择的最新讨论(5.1.1节);新增关于RLHF及过程监督式RLHF的实用策略的最新讨论(5.2.3节);更新5.2.4节中关于监督式对齐微调的内容。 – 第6节:在6.1.2节中加入关于离散提示优化的最新论文。 – 第9节:新增关于高级主题的最新讨论,包括长上下文建模、基于LLM的智能体、训练与推理的分析与优化、模型推理、模型压缩、检索增强生成以及幻觉现象等。 |
| V15 | 2024/10/12 | – 修正8.1.5节中的错误。 |
| V16 | 2025/03/11 | – 第9.8节:加入关于长思维链推理的最新论文,内容涵盖推理模式与优势分析、长思维链数据的构建方式(如蒸馏、搜索式及多智能体协作)以及训练方法(如指令微调和强化学习)。 |
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器