FlashRAG
FlashRAG 是一款专为检索增强生成(RAG)研究打造的高效 Python 工具包,旨在帮助开发者轻松复现前沿成果并构建自定义流程。它有效解决了 RAG 领域实验环境搭建繁琐、基准测试不统一以及先进算法难以快速落地的痛点。
这款工具特别适合 AI 研究人员、算法工程师及希望深入探索 RAG 技术的开发者使用。其核心亮点在于提供了一个高度模块化且可定制的框架,用户像搭积木一样灵活组合检索器、重排序器、生成器等关键组件。FlashRAG 内置了 36 个经过预处理的权威基准数据集和 23 种最先进的 RAG 算法,其中包括 7 种创新的“推理驱动”方法,能显著提升处理复杂多跳问答任务的能力。此外,它还集成了 vLLM 等加速工具以提升运行效率,并配备了直观的 FlashRAG-UI 界面,让实验监控与流程管理变得更加简单直观。无论是想要验证最新论文效果,还是开发专属的 RAG 应用,FlashRAG 都能提供坚实的技术支撑。
使用场景
某金融科技公司研发团队正致力于构建一个能处理复杂多跳推理的合规问答系统,需从海量监管文档中精准提取关联信息。
没有 FlashRAG 时
- 算法复现成本极高:团队需手动重写论文代码来验证最新的推理增强检索(Reasoning-based RAG)方法,耗时数周且极易出错。
- 数据预处理繁琐:面对 36 种不同的基准数据集,工程师需自行编写脚本进行清洗、分块和索引构建,重复劳动占据了 80% 的开发时间。
- 组件组装困难:缺乏统一框架,尝试组合不同的检索器、重排序器和生成器时,接口不兼容导致频繁调试,难以快速搭建实验流水线。
- 复杂任务表现不佳:传统简单检索方案无法有效处理需要多步逻辑推导的合规问题,导致回答准确率远低于预期。
使用 FlashRAG 后
- 一键复现 SOTA 算法:直接调用 FlashRAG 内置的 23 种先进算法(含 7 种推理增强方法),几分钟内即可完成基线对比,大幅加速技术选型。
- 开箱即用的数据支持:利用预处理的 36 个基准数据集和自动化脚本,瞬间完成语料加工与索引构建,团队可立即聚焦核心逻辑优化。
- 灵活高效的管道编排:借助其模块化设计,像搭积木般自由组合检索、重排序及生成组件,快速定制出适配金融场景的专属 RAG 流程。
- 显著提升推理能力:启用内置的推理增强方法后,系统在处理多跳合规查询时的准确率大幅提升,轻松攻克复杂逻辑难题。
FlashRAG 将原本数月的研发周期压缩至数天,让团队能专注于业务逻辑创新而非底层基建重复造轮子。
运行环境要求
- Linux
- macOS
- Windows
- 非必需(支持 CPU 模式),若使用 vLLM 加速或大型模型推理则推荐 NVIDIA GPU
- 具体显存和 CUDA 版本取决于所选模型,文中未明确限定最低要求
未说明(建议根据数据集大小和模型规模配置,通常 RAG 任务推荐 16GB+)
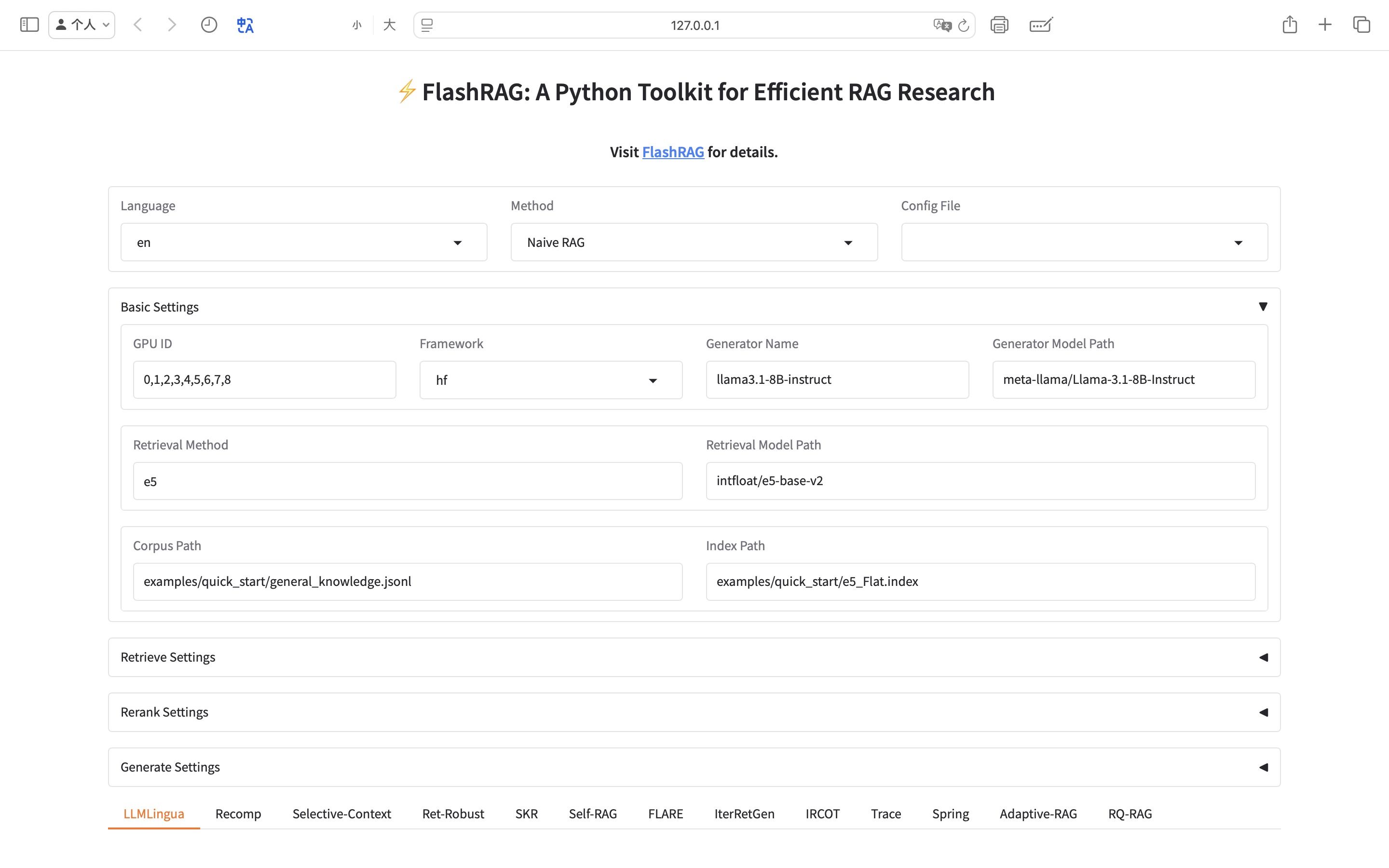
快速开始
⚡FlashRAG:高效的RAG研究Python工具包
[ 英文 | 中文 ]






安装 |
特性 |
快速入门 |
组件 |
FlashRAG-UI |
支持方法 |
支持数据集与文档语料库 |
常见问题解答
FlashRAG是一个用于复现和开发检索增强生成(RAG)研究的Python工具包。我们的工具包包含36个预处理过的基准RAG数据集和23种最先进的RAG算法,其中包括7种结合推理能力与检索的推理型方法。
借助FlashRAG及提供的资源,您可以轻松复现RAG领域的现有SOTA成果,或实现您自定义的RAG流程和组件。此外,我们还提供了一个易于使用的UI:
https://github.com/user-attachments/assets/8ca00873-5df2-48a7-b853-89e7b18bc6e9

:link: 导航
:sparkles: 特性
广泛且可定制的框架:包含RAG场景中的核心组件,如检索器、重排序器、生成器和压缩器,允许灵活地组装复杂的流水线。
全面的基准数据集:汇集了36个预处理过的RAG基准数据集,用于测试和验证RAG模型的性能。
预实现的先进RAG算法:基于我们的框架,提供了23种具有已发表结果的前沿RAG算法,可在不同设置下轻松复现实验结果。
🚀 推理型方法:新增! 我们现在支持7种结合推理能力与检索的推理型方法,在复杂的多跳任务中表现出色。
高效的预处理阶段:通过提供多种脚本,如用于检索的语料处理、检索索引构建以及文档的预检索等,简化了RAG工作流的准备工作。
优化的执行效率:该库通过vLLM、FastChat等工具加速LLM推理,并利用Faiss进行向量索引管理,从而提升了整体效率。
易用的UI:我们开发了一个非常易用的界面,方便用户快速配置和体验我们实现的RAG基线模型,并在可视化界面上运行评估脚本。
:mag_right: 路线图
FlashRAG目前仍在开发中,仍有许多待改进之处。我们将持续更新,并诚挚欢迎各位对这一开源工具包的贡献。
- 支持OpenAI模型
- 提供各组件的使用说明
- 集成Sentence Transformers
- 支持多模态RAG
- 支持推理型方法
- 包含更多RAG方法
- 提升代码的适应性和可读性
- 增加对基于API的检索器(vllm服务器)的支持
:page_with_curl: 更改日志
[25/11/06] 🎯 新增检索器!我们集成了一款基于网络搜索引擎的检索器,它可以与现有方法无缝衔接,只需一个 Serper API 密钥即可快速启用。这一增强显著扩展了检索覆盖范围和实时性,支持动态信息获取和外部知识增强。立即体验更加灵活强大的检索工作流吧!
[25/08/06] 🎯 新增! 我们新增了对推理流水线的支持,这是一种结合推理能力和检索的新范式,相关工作包括 R1-Searcher、Search-R1 等等。我们在多种 RAG 基准上评估了该流水线的性能,在 HotpotQA 等多跳推理数据集上可达到接近 60 的 F1 分数。详情请参见结果表。
[25/03/21] 🚀 重大更新! 我们已将工具包扩展至支持23种最先进的RAG算法,其中包括7种基于推理的方法,这些方法在复杂推理任务上的表现显著提升。这标志着我们的工具包发展迈出了重要一步!
[25/02/24] 🔥🔥🔥 我们新增了对多模态RAG的支持,包括如Llava、Qwen、InternVL等MLLM,以及各种基于Clip架构的多模态检索器。更多信息请参阅我们最新版本的arXiv论文及文档。快来试试吧!
[25/01/21] 我们的科技论文《FlashRAG:用于高效RAG研究的Python工具包》(https://arxiv.org/abs/2405.13576)荣幸地被2025年**ACM万维网大会(WWW 2025)**资源赛道录用。欢迎查阅!
[25/01/12] 推出<强>FlashRAG-UI</强>,一个易于使用的界面。您可以轻松快速地配置并体验支持的RAG方法,并在基准测试上进行评估。
[25/01/11] 我们新增了对一种新方法RQRAG的支持,详情请参见复现实验。
[25/01/07] 目前我们已支持多检索器的聚合功能,详情请参见多检索器使用说明。
[25/01/07] 我们集成了一款非常灵活轻量的语料分块库Chunkie,它支持多种自定义分块方式(按token、句子、语义等)。可在文档语料分块中使用。
[24/10/21] 我们发布了一个基于Paddle框架的版本,支持中文硬件平台。详情请参阅FlashRAG Paddle。
[24/10/13] 数据集方面新增了一个域内数据集和语料——DomainRAG。该数据集基于中国人民大学的内部招生数据,涵盖七类任务,可用于开展特定领域的RAG测试。
[24/09/24] 我们发布了一个基于MindSpore框架的版本,支持中文硬件平台。详情请参阅FlashRAG MindSpore。
展开更多
[24/09/18] 由于在某些环境中安装Pyserini较为复杂且存在限制,我们推出了一款轻量级的BM25s包作为替代方案(速度更快、使用更便捷)。未来版本中基于Pyserini的检索器将被弃用。若要使用bm25s检索器,只需在配置中将bm25_backend设置为bm25s即可。
[24/09/09] 我们新增了对一种新方法Adaptive-RAG的支持,该方法可根据查询类型自动选择执行的RAG流程。结果请参见结果表。
[24/08/02] 我们新增了对一种新方法Spring的支持,仅通过添加少量token嵌入即可显著提升LLM性能。结果请参见结果表。
[24/07/17] 由于HuggingFace出现了一些未知问题,我们原有的数据集链接已失效。现已更新。如有问题,请查看新链接。
[24/07/06] 我们新增了对一种新方法的支持:Trace,该方法通过构建知识图谱来精炼文本。结果请参见结果和详细信息。
[24/06/19] 我们新增了对一种新方法的支持:IRCoT,并更新了结果表。
[24/06/15] 我们提供了一个示例,演示如何使用我们的工具包完成RAG流程。
[24/06/11] 我们在检索模块中集成了sentence transformers,现在无需设置池化方法即可更方便地使用检索器。
[24/06/05] 我们提供了详细的文档,用于复现现有方法(详见如何复现、基线详情),以及配置设置。
[24/06/02] 我们为初学者提供了FlashRAG的入门介绍,详情请参见FlashRAG入门(中文版、韩语版)。
[24/05/31] 我们增加了对OpenAI系列模型作为生成器的支持。
:wrench: 安装



要开始使用FlashRAG,您只需通过pip安装即可:
pip install flashrag-dev --pre
或者您可以从Github克隆并安装(需Python 3.10及以上版本):
git clone https://github.com/RUC-NLPIR/FlashRAG.git
cd FlashRAG
pip install -e .
如果您希望使用vllm、sentence-transformers或pyserini,可以安装可选依赖项:
# 安装所有额外依赖
pip install flashrag-dev[full]
# 安装vllm以提高速度
pip install vllm>=0.4.1
# 安装sentence-transformers
pip install sentence-transformers
# 安装 pyserini 用于 BM25
pip install pyserini
由于使用 pip 安装 faiss 时存在兼容性问题,因此需要使用以下 conda 命令进行安装。
# 仅 CPU 版本
conda install -c pytorch faiss-cpu=1.8.0
# GPU(+CPU) 版本
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
注意:在某些系统上无法安装最新版本的 faiss。
根据 Faiss 官方仓库(来源):
- 仅 CPU 的
faiss-cpu conda 包目前适用于 Linux(x86_64 和 arm64)、OSX(仅 arm64)以及 Windows(x86_64)
- 包含 CPU 和 GPU 索引的
faiss-gpu 则仅适用于运行 CUDA 11.4 和 12.1 的 Linux(x86_64)
:rocket: 快速入门
语料库构建
要构建索引,首先需要将你的语料库保存为 jsonl 文件,每行代表一个文档。
{"id": "0", "contents": "..."}
{"id": "1", "contents": "..."}
如果你想使用维基百科作为语料库,可以参考我们的文档 处理维基百科,将其转换为可索引的格式。
索引构建
你可以使用以下代码来构建自己的索引。
对于 密集检索方法,尤其是流行的嵌入模型,我们使用 faiss 来构建索引。
对于 稀疏检索方法(BM25),我们使用 Pyserini 或 bm25s 将语料库构建为 Lucene 倒排索引。构建的索引包含原始文档。
密集检索方法
请根据自身情况修改以下代码中的参数。
python -m flashrag.retriever.index_builder \
--retrieval_method e5 \
--model_path /model/e5-base-v2/ \
--corpus_path indexes/sample_corpus.jsonl \
--save_dir indexes/ \
--use_fp16 \
--max_length 512 \
--batch_size 256 \
--pooling_method mean \
--faiss_type Flat
--pooling_method:如果未指定此参数,我们将根据模型名称和模型文件自动选择。然而,不同的嵌入模型使用不同的池化方法,我们可能尚未完全实现所有方法。为了确保准确性,你可以指定与所用检索模型相对应的池化方法(mean、pooler 或 cls)。
---instruction:某些嵌入模型在编码查询之前需要附加额外的指令,这些指令可以在这里指定。目前,我们会自动为 E5 和 BGE 模型填写指令,而其他模型则需要手动补充。
如果检索模型支持 sentence transformers 库,你可以使用以下代码构建索引(无需考虑池化方法)。
python -m flashrag.retriever.index_builder \
--retrieval_method e5 \
--model_path /model/e5-base-v2/ \
--corpus_path indexes/sample_corpus.jsonl \
--save_dir indexes/ \
--use_fp16 \
--max_length 512 \
--batch_size 256 \
--pooling_method mean \
--sentence_transformer \
--faiss_type Flat
稀疏检索方法(BM25)
如果要构建 BM25 索引,则无需指定 model_path。
使用 BM25s 构建索引
python -m flashrag.retriever.index_builder \
--retrieval_method bm25 \
--corpus_path indexes/sample_corpus.jsonl \
--bm25_backend bm25s \
--save_dir indexes/
使用 Pyserini 构建索引
python -m flashrag.retriever.index_builder \
--retrieval_method bm25 \
--corpus_path indexes/sample_corpus.jsonl \
--bm25_backend pyserini \
--save_dir indexes/
稀疏神经检索方法(SPLADE)
安装 Seismic Index:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh # 安装 Rust 用于编译
pip install pyseismic-lsr # 安装 Seismic
然后使用 Seismic 构建索引:
python -m flashrag.retriever.index_builder \ # 构建器
--retrieval_method splade \ # 触发 Seismic 索引的模型名称(仅 SPLADE 可用)
--model_path retriever/splade-v3 \ # 支持本地路径或仓库路径。
--corpus_embedded_path data/ms_marco/ms_marco_embedded_corpus.jsonl \ # 如果语料库已按 Seismic 预期格式缓存嵌入,则使用该缓存
--corpus_path data/ms_marco/ms_marco_corpus.jsonl \ # 以 {id, contents} 格式的 jsonl 文件形式提供的语料库路径,若尚未构建则需嵌入
--save_dir indexes/ \ # 保存索引的目录
--use_fp16 \ # 告诉 SPLADE 模型使用 fp16
--max_length 512 \ # 每个文档的最大标记数
--batch_size 4 \ # SPLADE 模型的批次大小(对于 Tesla T4 16GB 显卡,4-5 似乎是最优尺寸)
--n_postings 1000 \ # Seismic 的帖子列表数量
--centroid_fraction 0.2 \ # Seismic 的质心比例
--min_cluster_size 2 \ # Seismic 的最小聚类规模
--summary_energy 0.4 \ # Seismic 的能量
--batched_indexing 10000000 # Seismic 的批量索引
--nknn 32 # 可选参数。告诉 Seismic 同时使用 knn 图。如果不提供此参数,Seismic 将不使用 knn 图工作
使用现成的流水线
你可以使用我们已经构建好的流水线类(如 流水线 所示)来实现 RAG 流程。在这种情况下,你只需配置相应的设置并加载对应的流水线即可。
首先,加载整个流程的配置文件,其中记录了 RAG 流程中所需的各种超参数。你可以将 YAML 文件作为参数输入,也可以直接以变量形式输入。
请注意,以变量形式输入的优先级高于文件。
from flashrag.config import Config
# 混合加载配置
config_dict = {'data_dir': 'dataset/'}
my_config = Config(
config_file_path = 'my_config.yaml',
config_dict = config_dict
我们提供了详尽的配置指南,您可以查看我们的配置指南。
您也可以参考我们提供的基础 YAML 文件,以设置您自己的参数。
接下来,加载相应的数据集并初始化流水线。流水线中的各个组件将被自动加载。
from flashrag.utils import get_dataset
from flashrag.pipeline import SequentialPipeline
from flashrag.prompt import PromptTemplate
from flashrag.config import Config
config_dict = {'data_dir': 'dataset/'}
my_config = Config(
config_file_path = 'my_config.yaml',
config_dict = config_dict
)
all_split = get_dataset(my_config)
test_data = all_split['test']
pipeline = SequentialPipeline(my_config)
您可以使用 PromptTemplete 指定您自己的输入提示:
prompt_templete = PromptTemplate(
config,
system_prompt = "请根据给定的文档回答问题。只给出答案,不要输出任何其他文字。\n以下是给定的文档。\n\n{reference}",
user_prompt = "问题: {question}\n答案:"
)
pipeline = SequentialPipeline(
my_config,
prompt_template = prompt_templete
)
最后,执行 pipeline.run 以获得最终结果。
output_dataset = pipeline.run(test_data, do_eval=True)
output_dataset 包含输入数据集中每条记录的中间结果和指标分数。
同时,如果指定了 save_intermediate_data 和 save_metric_score,包含中间结果和总体评估分数的数据集也会被保存为文件。
构建您自己的流水线!
有时您可能需要实现更复杂的 RAG 流程,这时可以构建自己的流水线来完成。
您只需继承 BasicPipeline,初始化所需的组件,并完成 run 函数。
from flashrag.pipeline import BasicPipeline
from flashrag.utils import get_retriever, get_generator
class ToyPipeline(BasicPipeline):
def __init__(self, config, prompt_templete=None):
# 加载您自己的组件
pass
def run(self, dataset, do_eval=True):
# 完成您自己的流程逻辑
# 使用 `.` 获取数据集中属性
input_query = dataset.question
...
# 使用 `update_output` 保存中间数据
dataset.update_output("pred",pred_answer_list)
dataset = self.evaluate(dataset, do_eval=do_eval)
return dataset
请先从我们的文档中了解您需要使用的组件的输入和输出格式。
直接使用组件
如果您已经有自己的代码,只想使用我们的组件来嵌入原有代码,可以参考组件基础介绍,以获取每个组件的输入和输出格式。
:gear: 组件
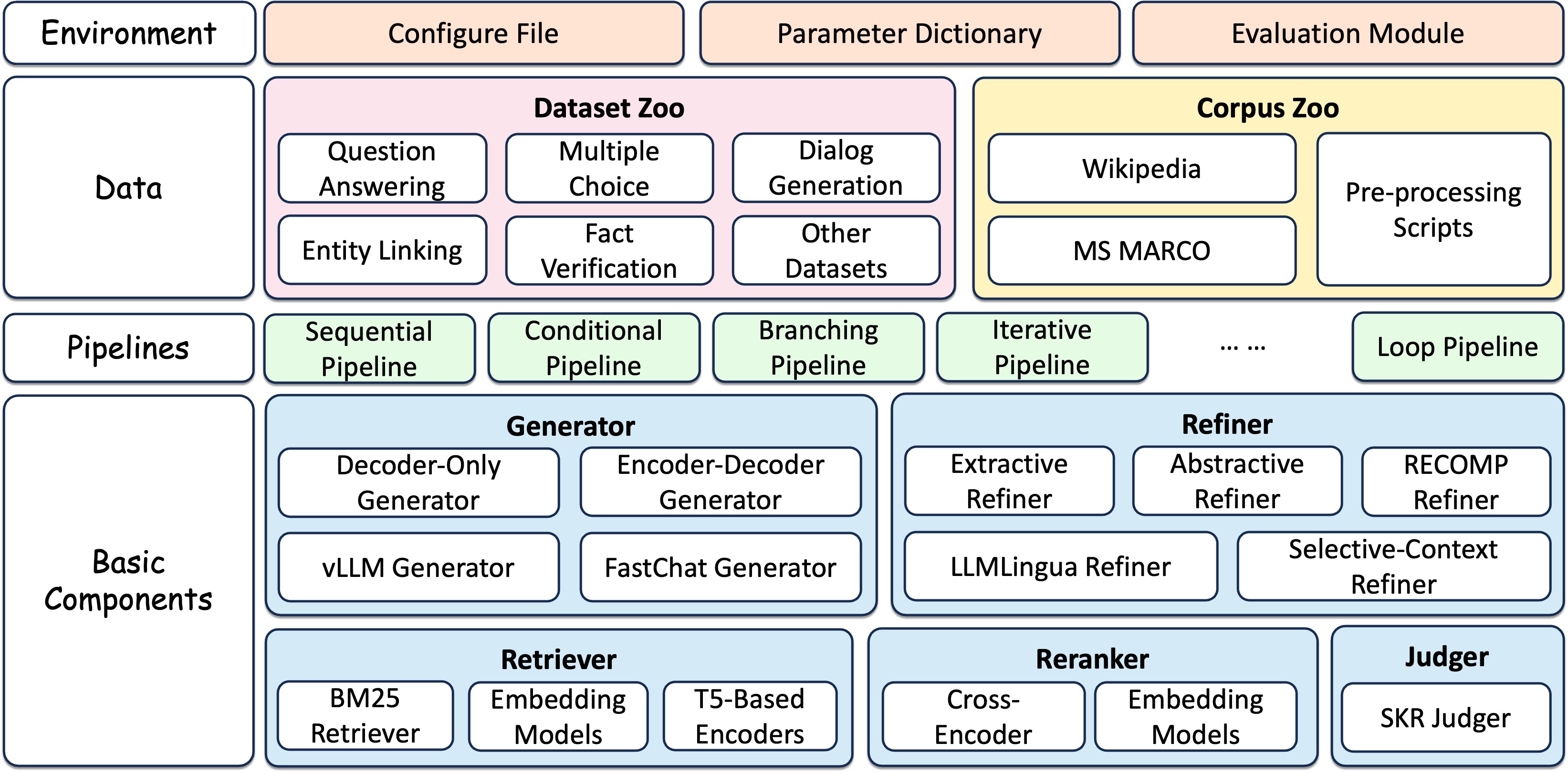
在 FlashRAG 中,我们构建了一系列常用的 RAG 组件,包括检索器、生成器、精炼器等。基于这些组件,我们组装了多条流水线来实现 RAG 工作流,同时也提供了灵活的组合方式,允许用户自定义组件排列以创建自己的流水线。
RAG 组件
类型
模块
描述
判断器
SKR 判断器
使用 SKR 方法判断是否进行检索
检索器
密集检索器
使用 bi-encoder 模型如 dpr、bge、e5,并通过 faiss 进行搜索
BM25 检索器
基于 Lucene 的稀疏检索方法
双编码器重排序器
使用双编码器计算匹配分数
交叉编码器重排序器
使用交叉编码器计算匹配分数
精炼器
抽取式精炼器
通过抽取重要上下文对输入进行精炼
摘要式精炼器
通过 seq2seq 模型对输入进行精炼
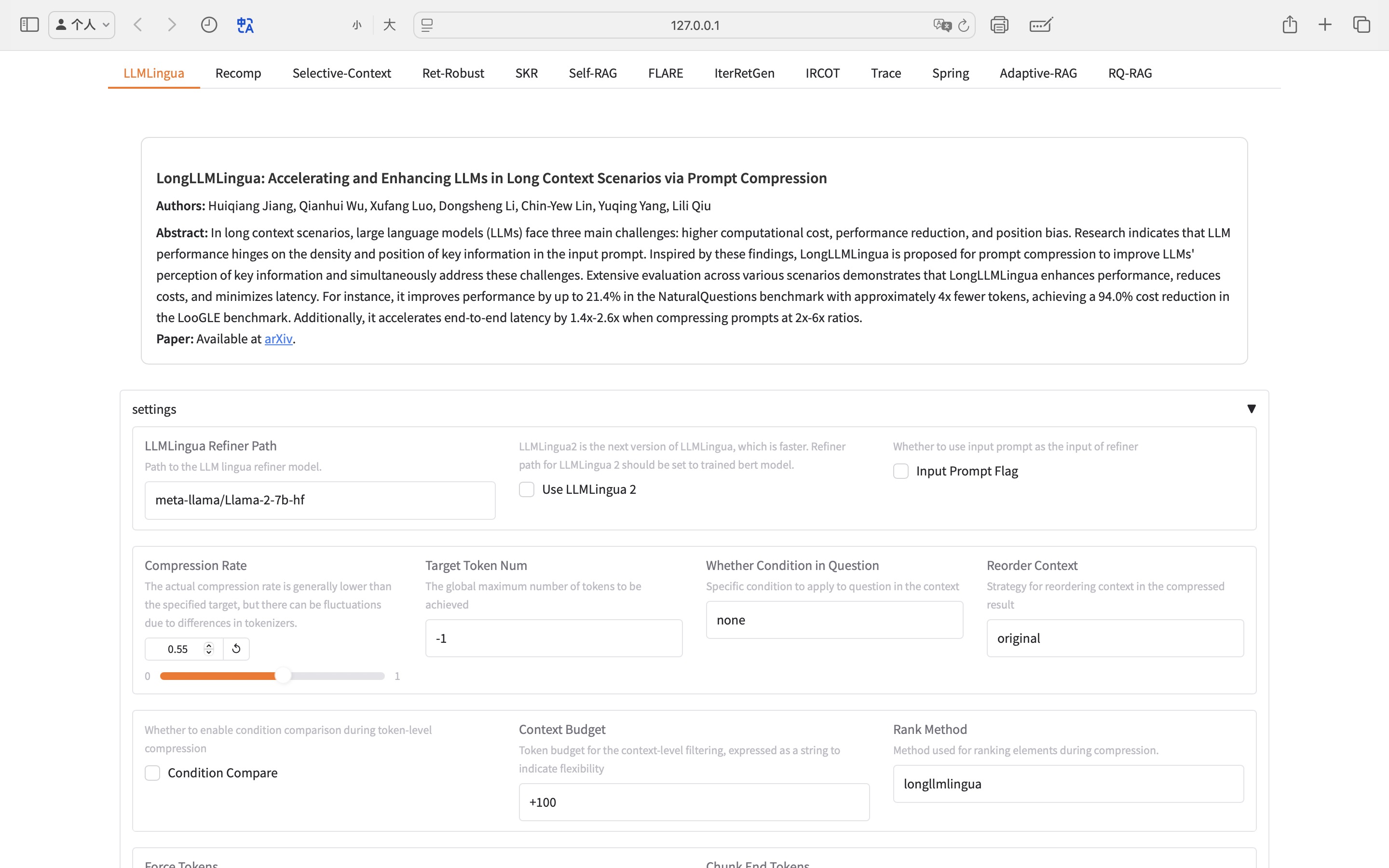
LLMLingua 精炼器
LLMLingua 系列 提示压缩器
SelectiveContext 精炼器
Selective-Context 提示压缩器
KG 精炼器
使用 Trace 方法构建知识图谱
生成器
编码器-解码器生成器
编码器-解码器模型,支持 解码器内融合 (FiD)
仅解码器生成器
原生 transformer 实现
FastChat 生成器
通过 FastChat 加速
vllm 生成器
通过 vllm 加速
流水线
参考 关于检索增强生成的综述,我们根据推理路径将 RAG 方法分为四类:
- 顺序型:按顺序执行 RAG 流程,例如查询-(预检索)-检索器-(后检索)-生成器
- 条件型:针对不同类型的输入查询执行不同的路径
- 分支型:并行执行多个路径,并合并各路径的响应
- 循环型:迭代地进行检索和生成
在每一类中,我们都实现了相应的常用流水线。部分流水线还配有相关的研究论文。
类型
模块
描述
顺序型
顺序流水线
线性执行查询,支持精炼器、重排序器
条件型
条件流水线
配备判断器模块,针对不同类型的查询采用不同的执行路径
分支型
REPLUG 流水线
通过整合多条生成路径的概率来生成答案
SuRe 流水线
根据每篇文档对生成结果进行排名并合并
循环型
迭代流水线
交替进行检索和生成
Self-Ask 流水线
利用 self-ask 将复杂问题分解为子问题
Self-RAG 流水线
自适应的检索、批判与生成
FLARE 流水线
在生成过程中动态进行检索
IRCoT 流水线
将检索过程与 CoT 结合
推理流水线
结合检索进行推理
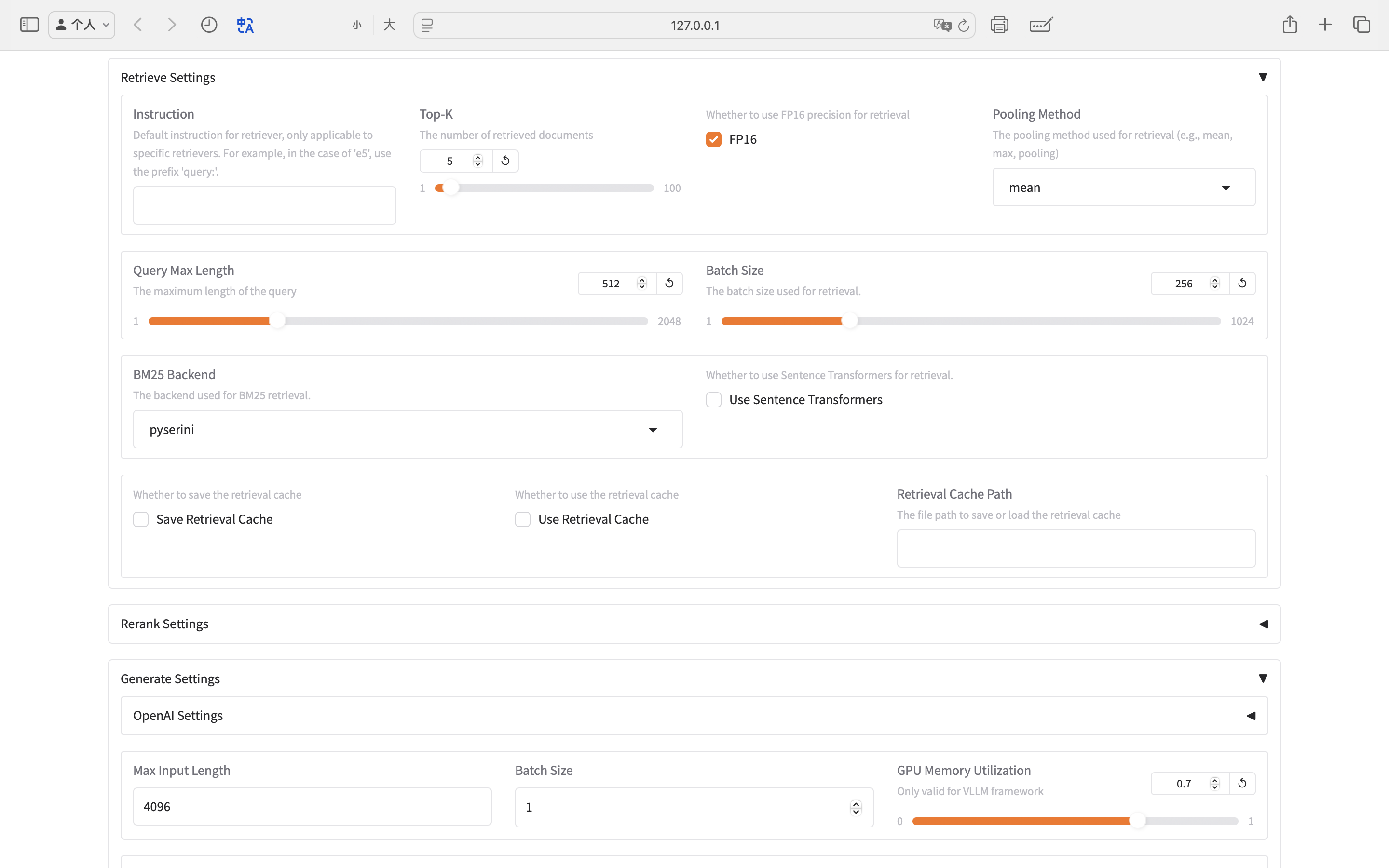
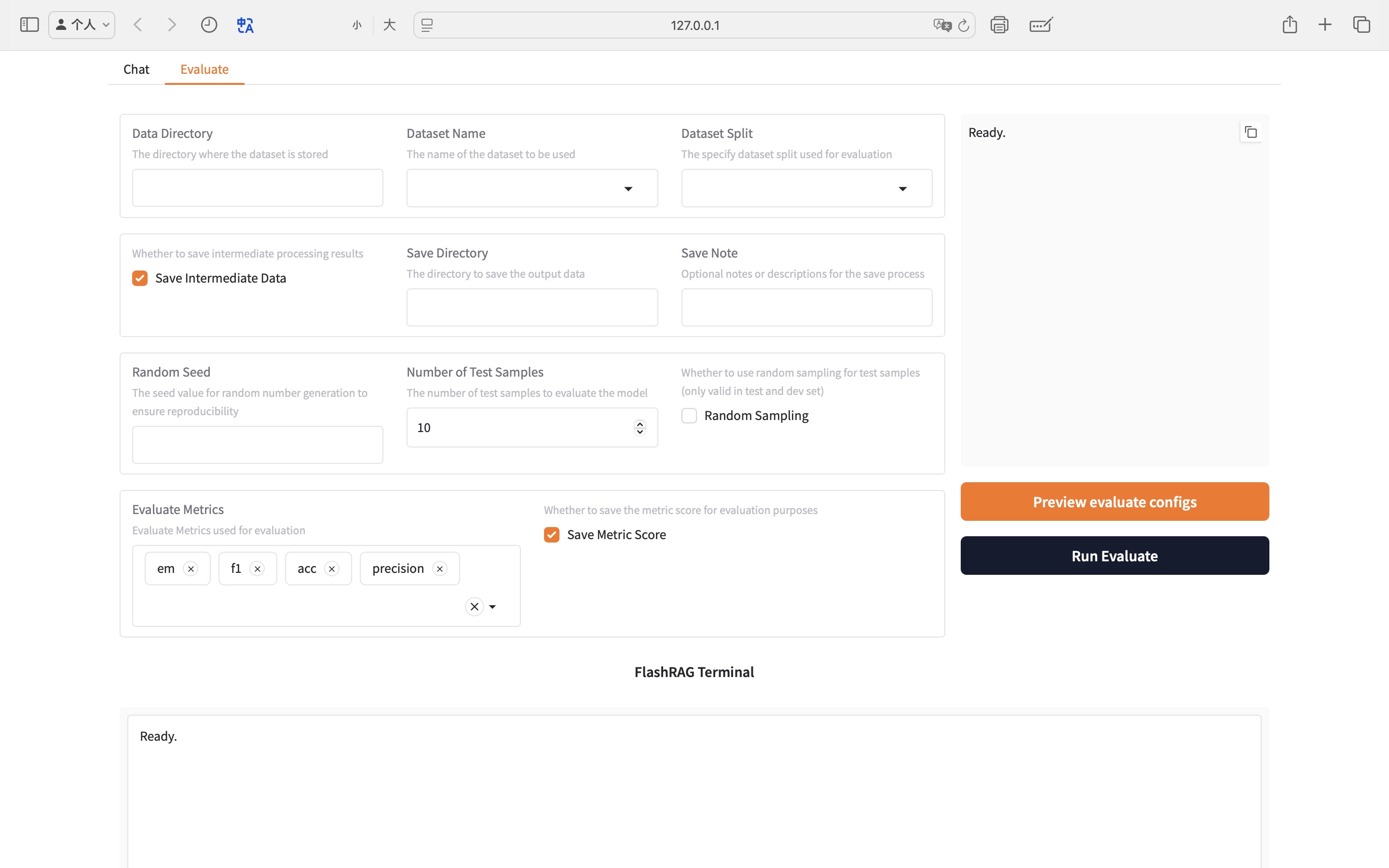
:art: FlashRAG-UI
借助 FlashRAG-UI,您可以通过我们精心设计的可视化界面,轻松快速地配置并体验支持的 RAG 方法,并在基准测试上评估这些方法,从而让复杂的研究工作更加高效!
:star2: 功能
- 一键加载配置
- 您可以通过简单的点击、选择和输入,加载各种 RAG 方法的参数和配置文件。
- 支持预览界面,直观设置参数。
- 提供保存功能,方便存储配置以备将来使用。
快速体验方法
- 快速加载语料库和索引文件,探索各类 RAG 方法的特点及应用场景。
支持加载和切换不同的组件与超参数,无缝连接不同的 RAG 流水线,快速体验它们的性能与差异!
高效复现基准
- 在 FlashRAG-UI 上轻松复现内置的基线方法以及精心收集的基准数据集。
直接使用前沿的研究工具,无需复杂的设置,为您的研究工作提供流畅的体验!
查看更多
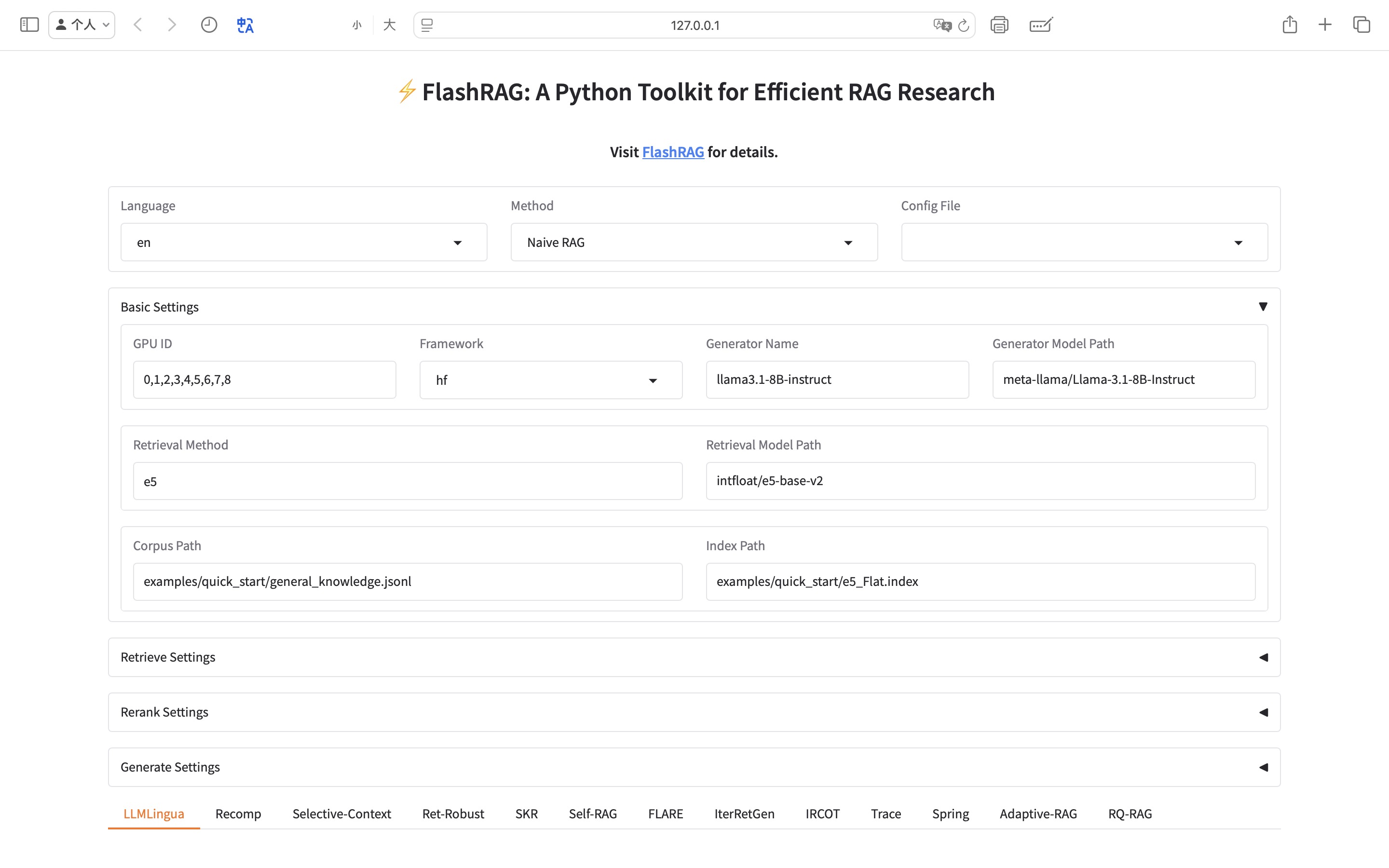
体验我们精心设计的 FlashRAG-UI——既友好又美观:
cd webui
python interface.py
:robot: 支持的方法
我们已实现了 23 篇论文,统一采用以下设置:
- 生成器: LLAMA3-8B-instruct,输入长度为2048
- 检索器: 使用e5-base-v2作为嵌入模型,每次查询检索5篇文档
- 提示词: 一致的默认提示词,模板可在方法详情中找到。
对于开源方法,我们使用我们的框架实现了它们的流程。对于作者未提供源代码的方法,我们会尽力按照原始论文中的方法进行实现。
对于某些方法所需的特定设置和超参数,我们已在“特定设置”列中进行了记录。更多详细信息,请参阅我们的复现指南和方法详情。
需要注意的是,为了保证一致性,我们采用了统一的设置。然而,这一设置可能与方法的原始设置有所不同,从而导致结果与原始结果存在差异。
方法
类型
NQ (EM)
TriviaQA (EM)
Hotpotqa (F1)
2Wiki (F1)
PopQA (F1)
WebQA(EM)
特定设置
简单生成
顺序式
22.6
55.7
28.4
33.9
21.7
18.8
标准RAG
顺序式
35.1
58.9
35.3
21.0
36.7
15.7
AAR-contriever-kilt
顺序式
30.1
56.8
33.4
19.8
36.1
16.1
LongLLMLingua
顺序式
32.2
59.2
37.5
25.0
38.7
17.5
压缩比例=0.5
RECOMP-abstractive
顺序式
33.1
56.4
37.5
32.4
39.9
20.2
Selective-Context
顺序式
30.5
55.6
34.4
18.5
33.5
17.3
压缩比例=0.5
Trace
顺序式
30.7
50.2
34.0
15.5
37.4
19.9
Spring
顺序式
37.9
64.6
42.6
37.3
54.8
27.7
使用经过训练的嵌入表的Llama2-7B-chat
SuRe
分支式
37.1
53.2
33.4
20.6
48.1
24.2
使用提供的提示词
REPLUG
分支式
28.9
57.7
31.2
21.1
27.8
20.2
SKR
条件式
33.2
56.0
32.4
23.4
31.7
17.0
使用推理时的训练数据
Adaptive-RAG
条件式
35.1
56.6
39.1
28.4
40.4
16.0
Ret-Robust
循环式
42.9
68.2
35.8
43.4
57.2
33.7
使用经过训练的lora的LLAMA2-13B
Self-RAG
循环式
36.4
38.2
29.6
25.1
32.7
21.9
使用经过训练的selfrag-llama2-7B
FLARE
循环式
22.5
55.8
28.0
33.9
20.7
20.2
Iter-Retgen, ITRG
循环式
36.8
60.1
38.3
21.6
37.9
18.2
IRCoT
循环式
33.3
56.9
41.5
32.4
45.6
20.7
RQRAG
循环式
32.6
52.5
33.5
35.8
46.4
26.2
使用经过训练的rqrag-llama2-7B
🚀 基于推理的方法(新!)
我们现在支持7种基于推理的方法,这些方法将推理能力与检索相结合,在复杂的多跳任务上表现出色:
方法
类型
NQ (EM)
TriviaQA (EM)
PopQA (EM)
Hotpotqa (F1)
2Wiki (F1)
Musique (F1)
Bamboogle (F1)
具体设置
Search-R1
理性推理
45.2
62.2
49.2
54.5
42.6
29.2
59.9
SearchR1-nq_hotpotqa_train-qwen2.5-7b-em-ppo
R1-Searcher
理性推理
36.9
61.6
42.0
49.0
49.1
24.7
57.7
Qwen-2.5-7B-base-RAG-RL
O2-Searcher
理性推理
41.4
51.4
46.8
43.4
48.6
19.0
47.6
O2-Searcher-Qwen2.5-3B-GRPO
AutoRefine
理性推理
43.8
59.8
32.4
54.0
50.3
23.6
46.6
AutoRefine-Qwen2.5-3B-Base
ReaRAG
理性推理
26.3
51.8
24.6
42.9
41.6
21.2
41.9
ReaRAG-9B
CoRAG
理性推理
40.9
63.1
36.0
56.6
60.7
31.9
54.1
CoRAG-Llama3.1-8B-MultihopQA
SimpleDeepSearcher
理性推理
36.1
61.6
42.0
49.0
49.1
24.7
57.7
Qwen-7B-SimpleDeepSearcher
:notebook: 支撑数据集与文档语料库
数据集
我们收集并处理了RAG研究中广泛使用的36个数据集,对它们进行了预处理以确保格式一致,便于使用。对于某些数据集(如Wiki-asp),我们根据社区内常用的方法对其进行了调整,使其符合RAG任务的要求。所有数据集均可在Huggingface 数据集上获取。
对于每个数据集,我们将每个划分保存为一个jsonl文件,每行是一个如下所示的字典:
{
'id': str,
'question': str,
'golden_answers': List[str],
'metadata': dict
}
以下是数据集列表及其对应的样本量:
任务
数据集名称
知识来源
训练集数量
验证集数量
测试集数量
QA
NQ
wiki
79,168
8,757
3,610
QA
TriviaQA
wiki & web
78,785
8,837
11,313
QA
PopQA
wiki
/
/
14,267
QA
SQuAD
wiki
87,599
10,570
/
QA
MSMARCO-QA
web
808,731
101,093
/
QA
NarrativeQA
books and story
32,747
3,461
10,557
QA
WikiQA
wiki
20,360
2,733
6,165
QA
WebQuestions
Google Freebase
3,778
/
2,032
QA
AmbigQA
wiki
10,036
2,002
/
QA
SIQA
-
33,410
1,954
/
QA
CommonSenseQA
-
9,741
1,221
/
QA
BoolQ
wiki
9,427
3,270
/
QA
PIQA
-
16,113
1,838
/
QA
Fermi
wiki
8,000
1,000
1,000
多跳问答
HotpotQA
wiki
90,447
7,405
/
多跳问答
2WikiMultiHopQA
wiki
15,000
12,576
/
多跳问答
Musique
wiki
19,938
2,417
/
多跳问答
Bamboogle
wiki
/
/
125
多跳问答
StrategyQA
wiki
2290
/
/
长篇问答
ASQA
wiki
4,353
948
/
长篇问答
ELI5
Reddit
272,634
1,507
/
长篇问答
WikiPassageQA
wiki
3,332
417
416
开放域摘要生成
WikiASP
wiki
300,636
37,046
37,368
多选题
MMLU
-
99,842
1,531
14,042
多选题
TruthfulQA
wiki
/
817
/
多选题
HellaSWAG
ActivityNet
39,905
10,042
/
多选题
ARC
-
3,370
869
3,548
多选题
OpenBookQA
-
4,957
500
500
多选题
QuaRTz
-
2696
384
784
事实核查
FEVER
wiki
104,966
10,444
/
对话生成
WOW
wiki
63,734
3,054
/
实体链接
AIDA CoNll-yago
Freebase & wiki
18,395
4,784
/
实体链接
WNED
Wiki
/
8,995
/
填槽
T-REx
DBPedia
2,284,168
5,000
/
填槽
Zero-shot RE
wiki
147,909
3,724
/
固定领域问答
DomainRAG
RUC 的网页
/
/
485
文档语料库
我们的工具包支持使用 jsonl 格式来存储检索文档集合,其结构如下:
{"id":"0", "contents": "..."}
{"id":"1", "contents": "..."}
contents 键是构建索引所必需的。对于同时包含文本和标题的文档,我们建议将 contents 的值设置为 {title}\n{text}。语料文件还可以包含其他键,用于记录文档的额外特征。
在学术研究中,维基百科和 MS MARCO 是最常用的检索文档集合。对于维基百科,我们提供了一个全面的脚本,可以将任何维基百科转储文件处理成干净的语料库。此外,在许多研究工作中也提供了经过处理的维基百科语料库版本,我们列出了一些参考链接。
至于 MS MARCO,它在发布时就已经被处理过了,可以直接从 Hugging Face 上的托管链接下载。
索引
为了便于实验的复现,我们现在在 ModelScope 数据集页面上提供了一个预处理好的索引:FlashRAG_Dataset/retrieval_corpus/wiki18_100w_e5_index.zip。
该索引是使用 e5-base-v2 检索器在我们上传的 wiki18_100w 数据集上创建的,与我们在实验中使用的索引一致。
:lollipop: 使用 FlashRAG 的优秀工作
- R1-Searcher,一种通过强化学习激励大模型搜索能力的方法
- ReSearch,一种通过强化学习让大模型学会结合搜索进行推理的方法
- AutoCoA,一种将行动链生成内化到推理模型中的方法
:raised_hands: 其他常见问题解答
:bookmark: 许可证
FlashRAG 采用 MIT 许可证 许可。
:star2: 引用
如果您觉得我们的论文对您的研究有所帮助,请引用:
@inproceedings{FlashRAG,
author = {Jiajie Jin and
Yutao Zhu and
Zhicheng Dou and
Guanting Dong and
Xinyu Yang and
Chenghao Zhang and
Tong Zhao and
Zhao Yang and
Ji{-}Rong Wen},
editor = {Guodong Long and
Michale Blumestein and
Yi Chang and
Liane Lewin{-}Eytan and
Zi Helen Huang and
Elad Yom{-}Tov},
title = {FlashRAG: {一个}用于高效检索增强生成研究的模块化工具包},
booktitle = {2025 年 ACM 网络大会配套论文集,WWW 2025,澳大利亚新南威尔士州悉尼,2025 年 4 月 28 日至 5 月 2 日},
pages = {737--740},
publisher = {{ACM}},
year = {2025},
url = {https://doi.org/10.1145/3701716.3715313},
doi = {10.1145/3701716.3715313}
}
星标历史

[ 英文 | 中文 ]
安装 | 特性 | 快速入门 | 组件 | FlashRAG-UI | 支持方法 | 支持数据集与文档语料库 | 常见问题解答
FlashRAG是一个用于复现和开发检索增强生成(RAG)研究的Python工具包。我们的工具包包含36个预处理过的基准RAG数据集和23种最先进的RAG算法,其中包括7种结合推理能力与检索的推理型方法。
借助FlashRAG及提供的资源,您可以轻松复现RAG领域的现有SOTA成果,或实现您自定义的RAG流程和组件。此外,我们还提供了一个易于使用的UI:
https://github.com/user-attachments/assets/8ca00873-5df2-48a7-b853-89e7b18bc6e9
:link: 导航
:sparkles: 特性
广泛且可定制的框架:包含RAG场景中的核心组件,如检索器、重排序器、生成器和压缩器,允许灵活地组装复杂的流水线。
全面的基准数据集:汇集了36个预处理过的RAG基准数据集,用于测试和验证RAG模型的性能。
预实现的先进RAG算法:基于我们的框架,提供了23种具有已发表结果的前沿RAG算法,可在不同设置下轻松复现实验结果。
🚀 推理型方法:新增! 我们现在支持7种结合推理能力与检索的推理型方法,在复杂的多跳任务中表现出色。
高效的预处理阶段:通过提供多种脚本,如用于检索的语料处理、检索索引构建以及文档的预检索等,简化了RAG工作流的准备工作。
优化的执行效率:该库通过vLLM、FastChat等工具加速LLM推理,并利用Faiss进行向量索引管理,从而提升了整体效率。
易用的UI:我们开发了一个非常易用的界面,方便用户快速配置和体验我们实现的RAG基线模型,并在可视化界面上运行评估脚本。
:mag_right: 路线图
FlashRAG目前仍在开发中,仍有许多待改进之处。我们将持续更新,并诚挚欢迎各位对这一开源工具包的贡献。
- 支持OpenAI模型
- 提供各组件的使用说明
- 集成Sentence Transformers
- 支持多模态RAG
- 支持推理型方法
- 包含更多RAG方法
- 提升代码的适应性和可读性
- 增加对基于API的检索器(vllm服务器)的支持
:page_with_curl: 更改日志
[25/11/06] 🎯 新增检索器!我们集成了一款基于网络搜索引擎的检索器,它可以与现有方法无缝衔接,只需一个 Serper API 密钥即可快速启用。这一增强显著扩展了检索覆盖范围和实时性,支持动态信息获取和外部知识增强。立即体验更加灵活强大的检索工作流吧!
[25/08/06] 🎯 新增! 我们新增了对推理流水线的支持,这是一种结合推理能力和检索的新范式,相关工作包括 R1-Searcher、Search-R1 等等。我们在多种 RAG 基准上评估了该流水线的性能,在 HotpotQA 等多跳推理数据集上可达到接近 60 的 F1 分数。详情请参见结果表。
[25/03/21] 🚀 重大更新! 我们已将工具包扩展至支持23种最先进的RAG算法,其中包括7种基于推理的方法,这些方法在复杂推理任务上的表现显著提升。这标志着我们的工具包发展迈出了重要一步!
[25/02/24] 🔥🔥🔥 我们新增了对多模态RAG的支持,包括如Llava、Qwen、InternVL等MLLM,以及各种基于Clip架构的多模态检索器。更多信息请参阅我们最新版本的arXiv论文及文档。快来试试吧!
[25/01/21] 我们的科技论文《FlashRAG:用于高效RAG研究的Python工具包》(https://arxiv.org/abs/2405.13576)荣幸地被2025年**ACM万维网大会(WWW 2025)**资源赛道录用。欢迎查阅!
[25/01/12] 推出<强>FlashRAG-UI</强>,一个易于使用的界面。您可以轻松快速地配置并体验支持的RAG方法,并在基准测试上进行评估。
[25/01/11] 我们新增了对一种新方法RQRAG的支持,详情请参见复现实验。
[25/01/07] 目前我们已支持多检索器的聚合功能,详情请参见多检索器使用说明。
[25/01/07] 我们集成了一款非常灵活轻量的语料分块库Chunkie,它支持多种自定义分块方式(按token、句子、语义等)。可在文档语料分块中使用。
[24/10/21] 我们发布了一个基于Paddle框架的版本,支持中文硬件平台。详情请参阅FlashRAG Paddle。
[24/10/13] 数据集方面新增了一个域内数据集和语料——DomainRAG。该数据集基于中国人民大学的内部招生数据,涵盖七类任务,可用于开展特定领域的RAG测试。
[24/09/24] 我们发布了一个基于MindSpore框架的版本,支持中文硬件平台。详情请参阅FlashRAG MindSpore。
展开更多
[24/09/18] 由于在某些环境中安装Pyserini较为复杂且存在限制,我们推出了一款轻量级的BM25s包作为替代方案(速度更快、使用更便捷)。未来版本中基于Pyserini的检索器将被弃用。若要使用bm25s检索器,只需在配置中将bm25_backend设置为bm25s即可。
[24/09/09] 我们新增了对一种新方法Adaptive-RAG的支持,该方法可根据查询类型自动选择执行的RAG流程。结果请参见结果表。
[24/08/02] 我们新增了对一种新方法Spring的支持,仅通过添加少量token嵌入即可显著提升LLM性能。结果请参见结果表。
[24/07/17] 由于HuggingFace出现了一些未知问题,我们原有的数据集链接已失效。现已更新。如有问题,请查看新链接。
[24/07/06] 我们新增了对一种新方法的支持:Trace,该方法通过构建知识图谱来精炼文本。结果请参见结果和详细信息。
[24/06/19] 我们新增了对一种新方法的支持:IRCoT,并更新了结果表。
[24/06/15] 我们提供了一个示例,演示如何使用我们的工具包完成RAG流程。
[24/06/11] 我们在检索模块中集成了sentence transformers,现在无需设置池化方法即可更方便地使用检索器。
[24/06/05] 我们提供了详细的文档,用于复现现有方法(详见如何复现、基线详情),以及配置设置。
[24/06/02] 我们为初学者提供了FlashRAG的入门介绍,详情请参见FlashRAG入门(中文版、韩语版)。
[24/05/31] 我们增加了对OpenAI系列模型作为生成器的支持。
:wrench: 安装
要开始使用FlashRAG,您只需通过pip安装即可:
pip install flashrag-dev --pre
或者您可以从Github克隆并安装(需Python 3.10及以上版本):
git clone https://github.com/RUC-NLPIR/FlashRAG.git
cd FlashRAG
pip install -e .
如果您希望使用vllm、sentence-transformers或pyserini,可以安装可选依赖项:
# 安装所有额外依赖
pip install flashrag-dev[full]
# 安装vllm以提高速度
pip install vllm>=0.4.1
# 安装sentence-transformers
pip install sentence-transformers
# 安装 pyserini 用于 BM25
pip install pyserini
由于使用 pip 安装 faiss 时存在兼容性问题,因此需要使用以下 conda 命令进行安装。
# 仅 CPU 版本
conda install -c pytorch faiss-cpu=1.8.0
# GPU(+CPU) 版本
conda install -c pytorch -c nvidia faiss-gpu=1.8.0
注意:在某些系统上无法安装最新版本的 faiss。
根据 Faiss 官方仓库(来源):
- 仅 CPU 的
faiss-cpuconda 包目前适用于 Linux(x86_64 和 arm64)、OSX(仅 arm64)以及 Windows(x86_64)- 包含 CPU 和 GPU 索引的
faiss-gpu则仅适用于运行 CUDA 11.4 和 12.1 的 Linux(x86_64)
:rocket: 快速入门
语料库构建
要构建索引,首先需要将你的语料库保存为 jsonl 文件,每行代表一个文档。
{"id": "0", "contents": "..."}
{"id": "1", "contents": "..."}
如果你想使用维基百科作为语料库,可以参考我们的文档 处理维基百科,将其转换为可索引的格式。
索引构建
你可以使用以下代码来构建自己的索引。
对于 密集检索方法,尤其是流行的嵌入模型,我们使用
faiss来构建索引。对于 稀疏检索方法(BM25),我们使用
Pyserini或bm25s将语料库构建为 Lucene 倒排索引。构建的索引包含原始文档。
密集检索方法
请根据自身情况修改以下代码中的参数。
python -m flashrag.retriever.index_builder \
--retrieval_method e5 \
--model_path /model/e5-base-v2/ \
--corpus_path indexes/sample_corpus.jsonl \
--save_dir indexes/ \
--use_fp16 \
--max_length 512 \
--batch_size 256 \
--pooling_method mean \
--faiss_type Flat
--pooling_method:如果未指定此参数,我们将根据模型名称和模型文件自动选择。然而,不同的嵌入模型使用不同的池化方法,我们可能尚未完全实现所有方法。为了确保准确性,你可以指定与所用检索模型相对应的池化方法(mean、pooler或cls)。---instruction:某些嵌入模型在编码查询之前需要附加额外的指令,这些指令可以在这里指定。目前,我们会自动为 E5 和 BGE 模型填写指令,而其他模型则需要手动补充。
如果检索模型支持 sentence transformers 库,你可以使用以下代码构建索引(无需考虑池化方法)。
python -m flashrag.retriever.index_builder \
--retrieval_method e5 \
--model_path /model/e5-base-v2/ \
--corpus_path indexes/sample_corpus.jsonl \
--save_dir indexes/ \
--use_fp16 \
--max_length 512 \
--batch_size 256 \
--pooling_method mean \
--sentence_transformer \
--faiss_type Flat
稀疏检索方法(BM25)
如果要构建 BM25 索引,则无需指定 model_path。
使用 BM25s 构建索引
python -m flashrag.retriever.index_builder \
--retrieval_method bm25 \
--corpus_path indexes/sample_corpus.jsonl \
--bm25_backend bm25s \
--save_dir indexes/
使用 Pyserini 构建索引
python -m flashrag.retriever.index_builder \
--retrieval_method bm25 \
--corpus_path indexes/sample_corpus.jsonl \
--bm25_backend pyserini \
--save_dir indexes/
稀疏神经检索方法(SPLADE)
安装 Seismic Index:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh # 安装 Rust 用于编译
pip install pyseismic-lsr # 安装 Seismic
然后使用 Seismic 构建索引:
python -m flashrag.retriever.index_builder \ # 构建器
--retrieval_method splade \ # 触发 Seismic 索引的模型名称(仅 SPLADE 可用)
--model_path retriever/splade-v3 \ # 支持本地路径或仓库路径。
--corpus_embedded_path data/ms_marco/ms_marco_embedded_corpus.jsonl \ # 如果语料库已按 Seismic 预期格式缓存嵌入,则使用该缓存
--corpus_path data/ms_marco/ms_marco_corpus.jsonl \ # 以 {id, contents} 格式的 jsonl 文件形式提供的语料库路径,若尚未构建则需嵌入
--save_dir indexes/ \ # 保存索引的目录
--use_fp16 \ # 告诉 SPLADE 模型使用 fp16
--max_length 512 \ # 每个文档的最大标记数
--batch_size 4 \ # SPLADE 模型的批次大小(对于 Tesla T4 16GB 显卡,4-5 似乎是最优尺寸)
--n_postings 1000 \ # Seismic 的帖子列表数量
--centroid_fraction 0.2 \ # Seismic 的质心比例
--min_cluster_size 2 \ # Seismic 的最小聚类规模
--summary_energy 0.4 \ # Seismic 的能量
--batched_indexing 10000000 # Seismic 的批量索引
--nknn 32 # 可选参数。告诉 Seismic 同时使用 knn 图。如果不提供此参数,Seismic 将不使用 knn 图工作
使用现成的流水线
你可以使用我们已经构建好的流水线类(如 流水线 所示)来实现 RAG 流程。在这种情况下,你只需配置相应的设置并加载对应的流水线即可。
首先,加载整个流程的配置文件,其中记录了 RAG 流程中所需的各种超参数。你可以将 YAML 文件作为参数输入,也可以直接以变量形式输入。
请注意,以变量形式输入的优先级高于文件。
from flashrag.config import Config
# 混合加载配置
config_dict = {'data_dir': 'dataset/'}
my_config = Config(
config_file_path = 'my_config.yaml',
config_dict = config_dict
我们提供了详尽的配置指南,您可以查看我们的配置指南。 您也可以参考我们提供的基础 YAML 文件,以设置您自己的参数。
接下来,加载相应的数据集并初始化流水线。流水线中的各个组件将被自动加载。
from flashrag.utils import get_dataset
from flashrag.pipeline import SequentialPipeline
from flashrag.prompt import PromptTemplate
from flashrag.config import Config
config_dict = {'data_dir': 'dataset/'}
my_config = Config(
config_file_path = 'my_config.yaml',
config_dict = config_dict
)
all_split = get_dataset(my_config)
test_data = all_split['test']
pipeline = SequentialPipeline(my_config)
您可以使用 PromptTemplete 指定您自己的输入提示:
prompt_templete = PromptTemplate(
config,
system_prompt = "请根据给定的文档回答问题。只给出答案,不要输出任何其他文字。\n以下是给定的文档。\n\n{reference}",
user_prompt = "问题: {question}\n答案:"
)
pipeline = SequentialPipeline(
my_config,
prompt_template = prompt_templete
)
最后,执行 pipeline.run 以获得最终结果。
output_dataset = pipeline.run(test_data, do_eval=True)
output_dataset 包含输入数据集中每条记录的中间结果和指标分数。
同时,如果指定了 save_intermediate_data 和 save_metric_score,包含中间结果和总体评估分数的数据集也会被保存为文件。
构建您自己的流水线!
有时您可能需要实现更复杂的 RAG 流程,这时可以构建自己的流水线来完成。
您只需继承 BasicPipeline,初始化所需的组件,并完成 run 函数。
from flashrag.pipeline import BasicPipeline
from flashrag.utils import get_retriever, get_generator
class ToyPipeline(BasicPipeline):
def __init__(self, config, prompt_templete=None):
# 加载您自己的组件
pass
def run(self, dataset, do_eval=True):
# 完成您自己的流程逻辑
# 使用 `.` 获取数据集中属性
input_query = dataset.question
...
# 使用 `update_output` 保存中间数据
dataset.update_output("pred",pred_answer_list)
dataset = self.evaluate(dataset, do_eval=do_eval)
return dataset
请先从我们的文档中了解您需要使用的组件的输入和输出格式。
直接使用组件
如果您已经有自己的代码,只想使用我们的组件来嵌入原有代码,可以参考组件基础介绍,以获取每个组件的输入和输出格式。
:gear: 组件
在 FlashRAG 中,我们构建了一系列常用的 RAG 组件,包括检索器、生成器、精炼器等。基于这些组件,我们组装了多条流水线来实现 RAG 工作流,同时也提供了灵活的组合方式,允许用户自定义组件排列以创建自己的流水线。
RAG 组件
| 类型 | 模块 | 描述 |
|---|---|---|
| 判断器 | SKR 判断器 | 使用 SKR 方法判断是否进行检索 |
| 检索器 | 密集检索器 | 使用 bi-encoder 模型如 dpr、bge、e5,并通过 faiss 进行搜索 |
| BM25 检索器 | 基于 Lucene 的稀疏检索方法 | |
| 双编码器重排序器 | 使用双编码器计算匹配分数 | |
| 交叉编码器重排序器 | 使用交叉编码器计算匹配分数 | |
| 精炼器 | 抽取式精炼器 | 通过抽取重要上下文对输入进行精炼 |
| 摘要式精炼器 | 通过 seq2seq 模型对输入进行精炼 | |
| LLMLingua 精炼器 | LLMLingua 系列 提示压缩器 | |
| SelectiveContext 精炼器 | Selective-Context 提示压缩器 | |
| KG 精炼器 | 使用 Trace 方法构建知识图谱 | |
| 生成器 | 编码器-解码器生成器 | 编码器-解码器模型,支持 解码器内融合 (FiD) |
| 仅解码器生成器 | 原生 transformer 实现 | |
| FastChat 生成器 | 通过 FastChat 加速 | |
| vllm 生成器 | 通过 vllm 加速 |
流水线
参考 关于检索增强生成的综述,我们根据推理路径将 RAG 方法分为四类:
- 顺序型:按顺序执行 RAG 流程,例如查询-(预检索)-检索器-(后检索)-生成器
- 条件型:针对不同类型的输入查询执行不同的路径
- 分支型:并行执行多个路径,并合并各路径的响应
- 循环型:迭代地进行检索和生成
在每一类中,我们都实现了相应的常用流水线。部分流水线还配有相关的研究论文。
| 类型 | 模块 | 描述 |
|---|---|---|
| 顺序型 | 顺序流水线 | 线性执行查询,支持精炼器、重排序器 |
| 条件型 | 条件流水线 | 配备判断器模块,针对不同类型的查询采用不同的执行路径 |
| 分支型 | REPLUG 流水线 | 通过整合多条生成路径的概率来生成答案 | SuRe 流水线 | 根据每篇文档对生成结果进行排名并合并 |
| 循环型 | 迭代流水线 | 交替进行检索和生成 |
| Self-Ask 流水线 | 利用 self-ask 将复杂问题分解为子问题 | |
| Self-RAG 流水线 | 自适应的检索、批判与生成 | |
| FLARE 流水线 | 在生成过程中动态进行检索 | |
| IRCoT 流水线 | 将检索过程与 CoT 结合 | |
| 推理流水线 | 结合检索进行推理 |
:art: FlashRAG-UI
借助 FlashRAG-UI,您可以通过我们精心设计的可视化界面,轻松快速地配置并体验支持的 RAG 方法,并在基准测试上评估这些方法,从而让复杂的研究工作更加高效!
:star2: 功能
- 一键加载配置
- 您可以通过简单的点击、选择和输入,加载各种 RAG 方法的参数和配置文件。
- 支持预览界面,直观设置参数。
- 提供保存功能,方便存储配置以备将来使用。
- 快速加载语料库和索引文件,探索各类 RAG 方法的特点及应用场景。
- 在 FlashRAG-UI 上轻松复现内置的基线方法以及精心收集的基准数据集。
查看更多
|
|
|
|
|
|
体验我们精心设计的 FlashRAG-UI——既友好又美观:
cd webui
python interface.py
:robot: 支持的方法
我们已实现了 23 篇论文,统一采用以下设置:
- 生成器: LLAMA3-8B-instruct,输入长度为2048
- 检索器: 使用e5-base-v2作为嵌入模型,每次查询检索5篇文档
- 提示词: 一致的默认提示词,模板可在方法详情中找到。
对于开源方法,我们使用我们的框架实现了它们的流程。对于作者未提供源代码的方法,我们会尽力按照原始论文中的方法进行实现。
对于某些方法所需的特定设置和超参数,我们已在“特定设置”列中进行了记录。更多详细信息,请参阅我们的复现指南和方法详情。
需要注意的是,为了保证一致性,我们采用了统一的设置。然而,这一设置可能与方法的原始设置有所不同,从而导致结果与原始结果存在差异。
| 方法 | 类型 | NQ (EM) | TriviaQA (EM) | Hotpotqa (F1) | 2Wiki (F1) | PopQA (F1) | WebQA(EM) | 特定设置 |
|---|---|---|---|---|---|---|---|---|
| 简单生成 | 顺序式 | 22.6 | 55.7 | 28.4 | 33.9 | 21.7 | 18.8 | |
| 标准RAG | 顺序式 | 35.1 | 58.9 | 35.3 | 21.0 | 36.7 | 15.7 | |
| AAR-contriever-kilt | 顺序式 | 30.1 | 56.8 | 33.4 | 19.8 | 36.1 | 16.1 | |
| LongLLMLingua | 顺序式 | 32.2 | 59.2 | 37.5 | 25.0 | 38.7 | 17.5 | 压缩比例=0.5 |
| RECOMP-abstractive | 顺序式 | 33.1 | 56.4 | 37.5 | 32.4 | 39.9 | 20.2 | |
| Selective-Context | 顺序式 | 30.5 | 55.6 | 34.4 | 18.5 | 33.5 | 17.3 | 压缩比例=0.5 |
| Trace | 顺序式 | 30.7 | 50.2 | 34.0 | 15.5 | 37.4 | 19.9 | |
| Spring | 顺序式 | 37.9 | 64.6 | 42.6 | 37.3 | 54.8 | 27.7 | 使用经过训练的嵌入表的Llama2-7B-chat |
| SuRe | 分支式 | 37.1 | 53.2 | 33.4 | 20.6 | 48.1 | 24.2 | 使用提供的提示词 |
| REPLUG | 分支式 | 28.9 | 57.7 | 31.2 | 21.1 | 27.8 | 20.2 | |
| SKR | 条件式 | 33.2 | 56.0 | 32.4 | 23.4 | 31.7 | 17.0 | 使用推理时的训练数据 |
| Adaptive-RAG | 条件式 | 35.1 | 56.6 | 39.1 | 28.4 | 40.4 | 16.0 | |
| Ret-Robust | 循环式 | 42.9 | 68.2 | 35.8 | 43.4 | 57.2 | 33.7 | 使用经过训练的lora的LLAMA2-13B |
| Self-RAG | 循环式 | 36.4 | 38.2 | 29.6 | 25.1 | 32.7 | 21.9 | 使用经过训练的selfrag-llama2-7B |
| FLARE | 循环式 | 22.5 | 55.8 | 28.0 | 33.9 | 20.7 | 20.2 | |
| Iter-Retgen, ITRG | 循环式 | 36.8 | 60.1 | 38.3 | 21.6 | 37.9 | 18.2 | |
| IRCoT | 循环式 | 33.3 | 56.9 | 41.5 | 32.4 | 45.6 | 20.7 | |
| RQRAG | 循环式 | 32.6 | 52.5 | 33.5 | 35.8 | 46.4 | 26.2 | 使用经过训练的rqrag-llama2-7B |
🚀 基于推理的方法(新!)
我们现在支持7种基于推理的方法,这些方法将推理能力与检索相结合,在复杂的多跳任务上表现出色:
| 方法 | 类型 | NQ (EM) | TriviaQA (EM) | PopQA (EM) | Hotpotqa (F1) | 2Wiki (F1) | Musique (F1) | Bamboogle (F1) | 具体设置 |
|---|---|---|---|---|---|---|---|---|---|
| Search-R1 | 理性推理 | 45.2 | 62.2 | 49.2 | 54.5 | 42.6 | 29.2 | 59.9 | SearchR1-nq_hotpotqa_train-qwen2.5-7b-em-ppo |
| R1-Searcher | 理性推理 | 36.9 | 61.6 | 42.0 | 49.0 | 49.1 | 24.7 | 57.7 | Qwen-2.5-7B-base-RAG-RL |
| O2-Searcher | 理性推理 | 41.4 | 51.4 | 46.8 | 43.4 | 48.6 | 19.0 | 47.6 | O2-Searcher-Qwen2.5-3B-GRPO |
| AutoRefine | 理性推理 | 43.8 | 59.8 | 32.4 | 54.0 | 50.3 | 23.6 | 46.6 | AutoRefine-Qwen2.5-3B-Base |
| ReaRAG | 理性推理 | 26.3 | 51.8 | 24.6 | 42.9 | 41.6 | 21.2 | 41.9 | ReaRAG-9B |
| CoRAG | 理性推理 | 40.9 | 63.1 | 36.0 | 56.6 | 60.7 | 31.9 | 54.1 | CoRAG-Llama3.1-8B-MultihopQA |
| SimpleDeepSearcher | 理性推理 | 36.1 | 61.6 | 42.0 | 49.0 | 49.1 | 24.7 | 57.7 | Qwen-7B-SimpleDeepSearcher |
:notebook: 支撑数据集与文档语料库
数据集
我们收集并处理了RAG研究中广泛使用的36个数据集,对它们进行了预处理以确保格式一致,便于使用。对于某些数据集(如Wiki-asp),我们根据社区内常用的方法对其进行了调整,使其符合RAG任务的要求。所有数据集均可在Huggingface 数据集上获取。
对于每个数据集,我们将每个划分保存为一个jsonl文件,每行是一个如下所示的字典:
{
'id': str,
'question': str,
'golden_answers': List[str],
'metadata': dict
}
以下是数据集列表及其对应的样本量:
| 任务 | 数据集名称 | 知识来源 | 训练集数量 | 验证集数量 | 测试集数量 |
|---|---|---|---|---|---|
| QA | NQ | wiki | 79,168 | 8,757 | 3,610 |
| QA | TriviaQA | wiki & web | 78,785 | 8,837 | 11,313 |
| QA | PopQA | wiki | / | / | 14,267 |
| QA | SQuAD | wiki | 87,599 | 10,570 | / |
| QA | MSMARCO-QA | web | 808,731 | 101,093 | / |
| QA | NarrativeQA | books and story | 32,747 | 3,461 | 10,557 |
| QA | WikiQA | wiki | 20,360 | 2,733 | 6,165 |
| QA | WebQuestions | Google Freebase | 3,778 | / | 2,032 |
| QA | AmbigQA | wiki | 10,036 | 2,002 | / |
| QA | SIQA | - | 33,410 | 1,954 | / |
| QA | CommonSenseQA | - | 9,741 | 1,221 | / |
| QA | BoolQ | wiki | 9,427 | 3,270 | / |
| QA | PIQA | - | 16,113 | 1,838 | / |
| QA | Fermi | wiki | 8,000 | 1,000 | 1,000 |
| 多跳问答 | HotpotQA | wiki | 90,447 | 7,405 | / |
| 多跳问答 | 2WikiMultiHopQA | wiki | 15,000 | 12,576 | / |
| 多跳问答 | Musique | wiki | 19,938 | 2,417 | / |
| 多跳问答 | Bamboogle | wiki | / | / | 125 |
| 多跳问答 | StrategyQA | wiki | 2290 | / | / |
| 长篇问答 | ASQA | wiki | 4,353 | 948 | / |
| 长篇问答 | ELI5 | 272,634 | 1,507 | / | |
| 长篇问答 | WikiPassageQA | wiki | 3,332 | 417 | 416 |
| 开放域摘要生成 | WikiASP | wiki | 300,636 | 37,046 | 37,368 |
| 多选题 | MMLU | - | 99,842 | 1,531 | 14,042 |
| 多选题 | TruthfulQA | wiki | / | 817 | / |
| 多选题 | HellaSWAG | ActivityNet | 39,905 | 10,042 | / |
| 多选题 | ARC | - | 3,370 | 869 | 3,548 |
| 多选题 | OpenBookQA | - | 4,957 | 500 | 500 |
| 多选题 | QuaRTz | - | 2696 | 384 | 784 |
| 事实核查 | FEVER | wiki | 104,966 | 10,444 | / |
| 对话生成 | WOW | wiki | 63,734 | 3,054 | / |
| 实体链接 | AIDA CoNll-yago | Freebase & wiki | 18,395 | 4,784 | / |
| 实体链接 | WNED | Wiki | / | 8,995 | / |
| 填槽 | T-REx | DBPedia | 2,284,168 | 5,000 | / |
| 填槽 | Zero-shot RE | wiki | 147,909 | 3,724 | / |
| 固定领域问答 | DomainRAG | RUC 的网页 | / | / | 485 |
文档语料库
我们的工具包支持使用 jsonl 格式来存储检索文档集合,其结构如下:
{"id":"0", "contents": "..."}
{"id":"1", "contents": "..."}
contents 键是构建索引所必需的。对于同时包含文本和标题的文档,我们建议将 contents 的值设置为 {title}\n{text}。语料文件还可以包含其他键,用于记录文档的额外特征。
在学术研究中,维基百科和 MS MARCO 是最常用的检索文档集合。对于维基百科,我们提供了一个全面的脚本,可以将任何维基百科转储文件处理成干净的语料库。此外,在许多研究工作中也提供了经过处理的维基百科语料库版本,我们列出了一些参考链接。
至于 MS MARCO,它在发布时就已经被处理过了,可以直接从 Hugging Face 上的托管链接下载。
索引
为了便于实验的复现,我们现在在 ModelScope 数据集页面上提供了一个预处理好的索引:FlashRAG_Dataset/retrieval_corpus/wiki18_100w_e5_index.zip。
该索引是使用 e5-base-v2 检索器在我们上传的 wiki18_100w 数据集上创建的,与我们在实验中使用的索引一致。
:lollipop: 使用 FlashRAG 的优秀工作
- R1-Searcher,一种通过强化学习激励大模型搜索能力的方法
- ReSearch,一种通过强化学习让大模型学会结合搜索进行推理的方法
- AutoCoA,一种将行动链生成内化到推理模型中的方法
:raised_hands: 其他常见问题解答
:bookmark: 许可证
FlashRAG 采用 MIT 许可证 许可。
:star2: 引用
如果您觉得我们的论文对您的研究有所帮助,请引用:
@inproceedings{FlashRAG,
author = {Jiajie Jin and
Yutao Zhu and
Zhicheng Dou and
Guanting Dong and
Xinyu Yang and
Chenghao Zhang and
Tong Zhao and
Zhao Yang and
Ji{-}Rong Wen},
editor = {Guodong Long and
Michale Blumestein and
Yi Chang and
Liane Lewin{-}Eytan and
Zi Helen Huang and
Elad Yom{-}Tov},
title = {FlashRAG: {一个}用于高效检索增强生成研究的模块化工具包},
booktitle = {2025 年 ACM 网络大会配套论文集,WWW 2025,澳大利亚新南威尔士州悉尼,2025 年 4 月 28 日至 5 月 2 日},
pages = {737--740},
publisher = {{ACM}},
year = {2025},
url = {https://doi.org/10.1145/3701716.3715313},
doi = {10.1145/3701716.3715313}
}
星标历史
版本历史
v0.3.02025/08/18v0.2.02025/03/10v0.1.42025/01/13v0.1.32024/11/25v0.1.22024/10/29v0.1.12024/08/03v0.1.02024/05/31常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器