DeepAgent
DeepAgent 是一款由中国人民大学与小红书联合研发的通用推理智能体,旨在让 AI 像人类专家一样自主思考并灵活调用工具解决复杂问题。传统 AI 往往依赖预设流程或有限的固定工具,难以应对多变场景;而 DeepAgent 突破了这一局限,它能在端到端的推理过程中,自动从超过 16,000 个 RapidAPIs 中搜索、发现并匹配最合适的工具,无论是处理通用网络任务、执行具身智能操作(如导航与交互),还是进行深度研究(如代码执行、视觉问答),都能游刃有余。
该项目的核心亮点在于其“可扩展工具集”架构,支持开发者无缝接入自定义工具,并结合 QwQ、Qwen3 等先进推理模型,实现了从“被动执行指令”到“主动规划决策”的跨越。这不仅解决了现有智能体在工具泛化能力和长程推理上的短板,还大幅降低了构建高性能 AI 助手的门槛。
DeepAgent 非常适合 AI 研究人员探索新一代智能体架构,也适用于开发者快速搭建具备强大实操能力的垂直应用。对于希望深入理解大模型如何与现实世界交互的技术爱好者而言,它同样是一个极具价值的开源范本。目前项目已获 WWW 2026 收录,代码与数据集均已开放,欢迎社区共同体验与贡献。
使用场景
某跨境电商数据分析师需要在 2 小时内完成一份关于“东南亚新兴美妆品牌”的深度竞品报告,涉及多源数据检索、API 调用及图表生成。
没有 DeepAgent 时
- 工具切换繁琐:分析师需手动在搜索引擎、各类数据 API 平台和 Excel 之间反复跳转,无法在一个界面完成闭环操作。
- 推理链条断裂:面对复杂任务(如“先找品牌再查销量最后对比趋势”),传统脚本无法自主拆解步骤,必须人工编写每一步的代码逻辑。
- 扩展性差:若需引入新的数据源(如新增一个社交媒体 API),往往需要重构整个工作流代码,耗时且易出错。
- 信息整合低效:从不同渠道获取的碎片化数据难以自动关联,人工清洗和汇总占据了 80% 的时间,导致深度分析时间被压缩。
使用 DeepAgent 后
- 端到端自主执行:DeepAgent 直接在单一推理过程中自主规划,自动搜索并调用 16,000+ RapidAPIs 中的合适接口,一键完成从数据获取到报告生成的全流程。
- 动态推理决策:遇到未知问题时,DeepAgent 能像人类专家一样进行多步思考,自动拆解“查找 - 验证 - 分析”的子任务,无需人工干预逻辑细节。
- 工具集弹性伸缩:得益于可扩展的工具集架构,分析师可随时插入新的专用工具(如特定的视觉问答或文件处理插件),DeepAgent 即刻识别并无缝集成。
- 深度研究增强:内置的专项研究工具链自动完成网页浏览、代码执行和数据可视化,将原本数小时的数据整理工作缩短至分钟级,让分析师专注于策略洞察。
DeepAgent 通过将分散的工具调用与深度推理融合,把分析师从繁琐的“数据搬运工”角色解放为真正的“决策制定者”。
运行环境要求
- 未说明
必需(用于运行 vLLM 服务推理模型),具体型号和显存取决于所选模型大小(如 4B 至 235B 参数),未明确指定 CUDA 版本
未说明(取决于运行的模型大小,大模型如 235B 需要大量内存)

快速开始

一种具有可扩展工具集的通用推理智能体
![]()
![]()
![]()

如果您喜欢我们的项目,请在 GitHub 上为我们点亮一颗星 ⭐,以获取最新更新。

📣 最新消息
- [2026年1月14日]:🎉 DeepAgent 已被 WWW 2026 接收!
- [2025年10月28日]:🔥 我们很荣幸成为 Hugging Face 每日论文 #1 的亮点。
- [2025年10月27日]:📄 我们的论文现已发布在 arXiv 和 Hugging Face 上。
- [2025年10月27日]:🚀 我们的代码库已发布。现在您可以使用像 QwQ、Qwen3 这样的推理模型以及您自己的工具集来部署 DeepAgent。
🎬 演示
1. 带有16,000多种RapidAPIs的通用智能体任务
DeepAgent 是一种具有可扩展工具集的推理智能体,能够在端到端的智能体推理过程中,从超过16,000个RapidAPI中搜索并使用合适的工具来完成通用任务。(注:由于ToolBench中的部分API无法使用,本演示中API响应由LLM模拟,以展示系统的正常功能。)
2. ALFWorld环境中的具身AI智能体任务
DeepAgent 还擅长导航类任务(如网页浏览、操作系统交互和具身AI),它使用一系列多功能的可插拔动作,例如移动、观察和拾取。
3. 带有专用工具的深度研究任务
DeepAgent 也可以作为强大的科研助手,配备用于网络搜索、浏览、代码执行、视觉问答和文件处理的专用工具。
💡 概述
DeepAgent 是一种端到端的深度推理智能体,它在一个连贯的推理过程中完成自主思考、工具发现和动作执行。这种范式摆脱了传统的预定义工作流程(如ReAct的“思考-行动-观察”循环),使智能体能够保持对整个任务的全局视角,并根据需要动态发现工具。
为了应对长期交互并防止陷入错误的探索路径,我们引入了 自主记忆折叠 机制。这使得DeepAgent可以通过将交互历史压缩成一种结构化的、受大脑启发的记忆模式来“喘口气”,从而重新考虑其策略并高效推进。
此外,我们提出了 ToolPO,这是一种专为通用工具使用设计的端到端强化学习训练方法,可以提升智能体掌握这些复杂机制的能力。
📊 总体性能
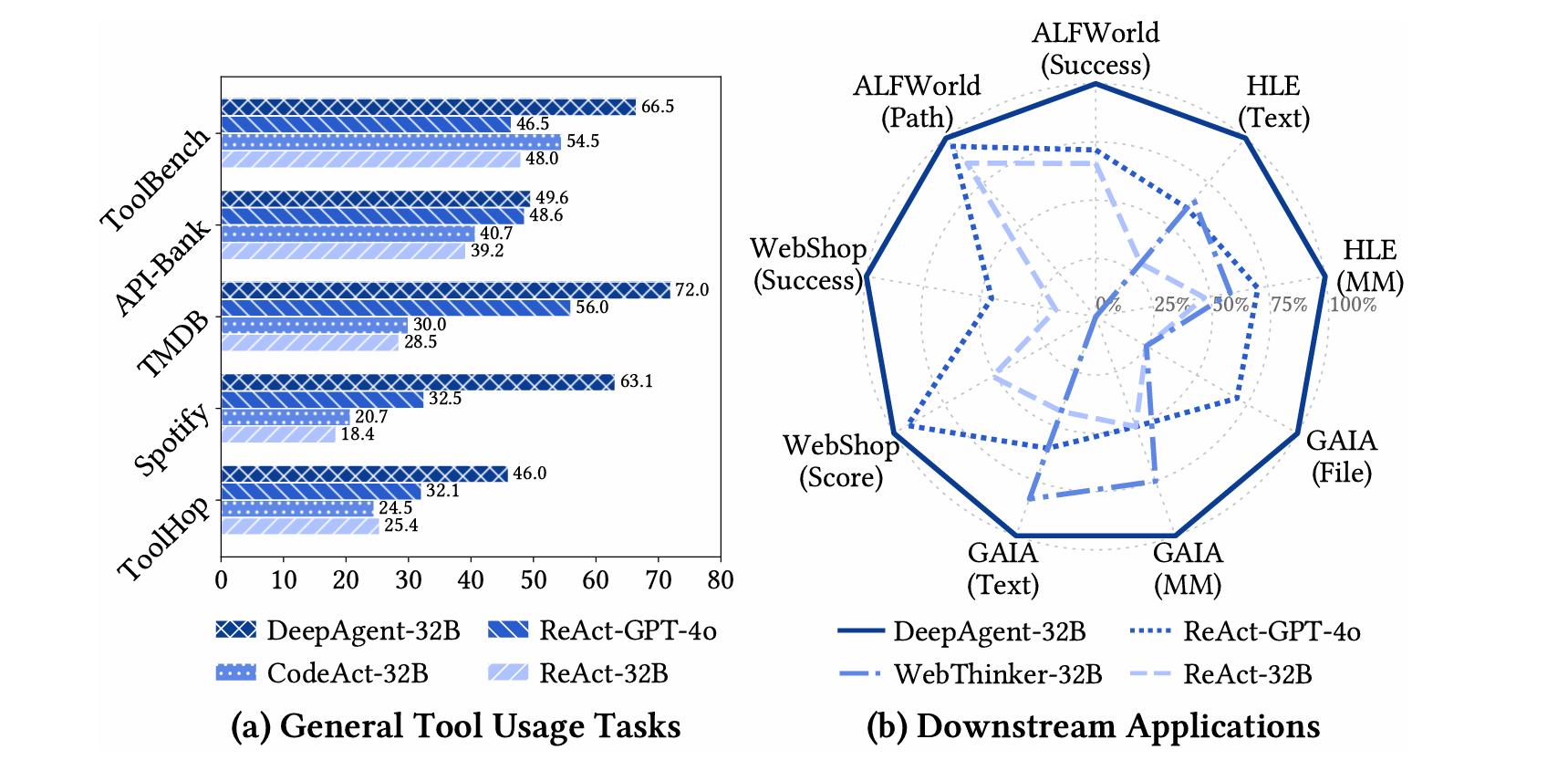
我们在广泛的基准测试上进行了大量实验:
- (1) 通用工具使用任务: 我们在ToolBench、API-Bank、TMDB、Spotify和ToolHop上评估了DeepAgent,这些基准涵盖了从几十种到一万多种不同工具的工具集。
- (2) 下游应用: 我们测试了它在ALFWorld、WebShop、GAIA和人类终极考试(HLE)中的表现,这些任务需要使用特定领域的工具集。图中的总体结果显示,DeepAgent在所有场景中都表现出色。
✨ DeepAgent框架
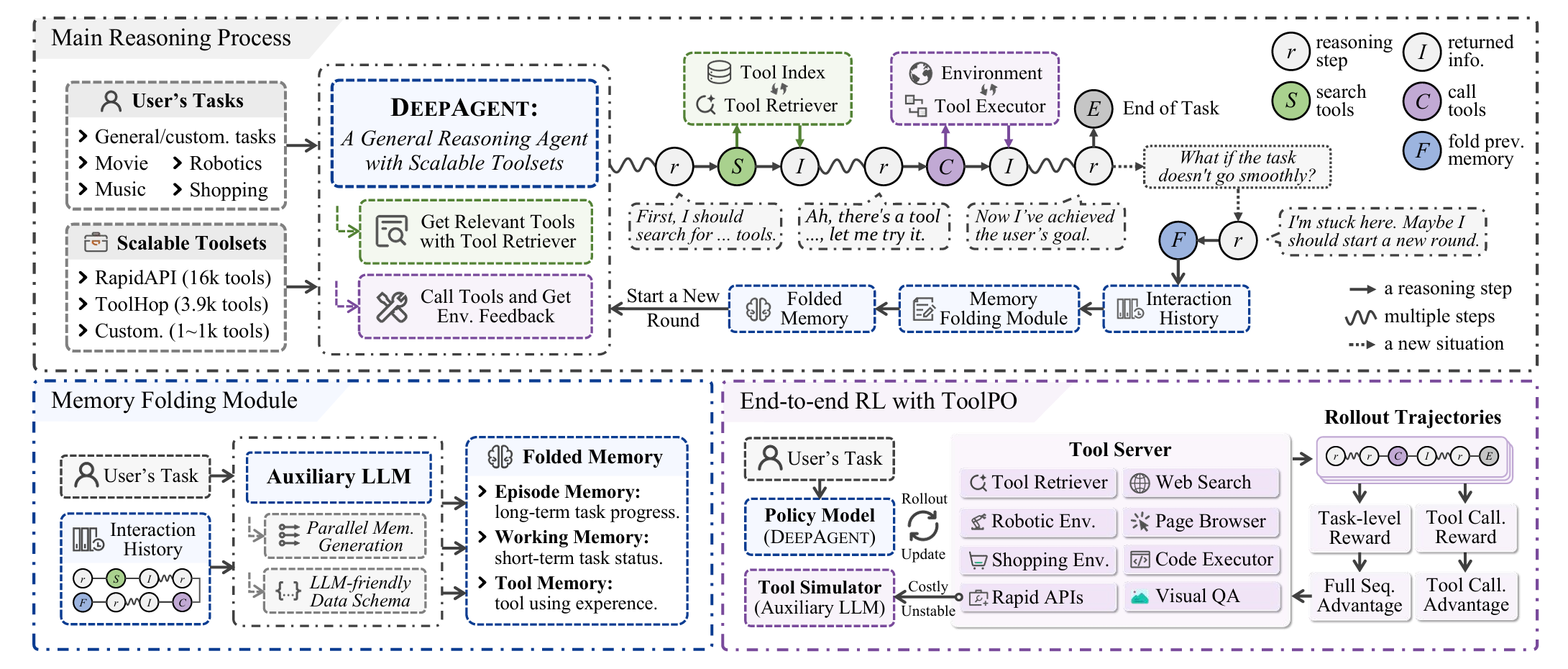 关键特性:
关键特性:
统一的智能体推理: DeepAgent摒弃了僵化的预定义工作流程。它在一个单一的思想流中运行,自主地对任务进行推理、动态地发现所需的工具并执行动作。这使得LRM能够保持全局视角,并充分发挥其自主潜力。
自主记忆折叠与受大脑启发的记忆: 面对复杂问题时,DeepAgent可以自主触发记忆折叠。这一过程将交互历史整合为一种结构化的记忆,使智能体能够以精简但全面的理解重新开始推理。该记忆架构受大脑启发,包括:
- 情景记忆: 对关键事件、决策和子任务完成情况的高层次记录。
- 工作记忆: 包含最近的信息,包括当前的子目标和近期计划。
- 工具记忆: 整合与工具相关的交互,使智能体能够从经验中学习并优化其策略。
基于ToolPO的端到端强化学习训练: 为了有效训练智能体,我们引入了ToolPO,这是一种策略优化方法,具有以下特点:
- 基于LLM的工具模拟器,可模拟真实世界的API,确保训练稳定高效。
- 工具调用优势归因,可为正确的工具调用标记分配细粒度的奖励,从而提供更精确的学习信号。
🔧 安装
环境设置
# 创建 conda 环境
conda create -n deepagent python=3.10
conda activate deepagent
# 安装依赖
cd DeepAgent-main
pip install -r requirements.txt
📊 基准测试
我们使用的基准测试可分为几类:
- 通用工具使用基准:
- 具身智能体基准:
- ALFWorld:基于文本的具身 AI 环境,智能体通过 9 种基本动作完成家务任务。
- 网页导航基准:
- WebShop:在线购物模拟,要求智能体搜索和导航商品以满足用户需求。
- 深度研究基准:
- GAIA:复杂的资讯检索任务,涉及网络搜索、浏览、VQA、代码执行和文件处理。
- 人类终极考试 (HLE):极具挑战性的推理问题,测试代码、搜索和 VQA 工具等高级能力。为高效测试,我们从包含 2,500 道题的完整数据集中抽取了 500 道题。
所有预处理好的数据都位于 ./data/ 目录中,除了 ToolBench 数据需要从 ToolBench 官方仓库 下载,因为其体积过大,无法放入我们的仓库。
🤖 模型服务
在运行 DeepAgent 之前,请确保您的推理模型和辅助模型已使用 vLLM 提供服务。DeepAgent 旨在与强大的推理模型作为主代理协同工作,并可利用辅助模型执行记忆生成和工具选择等任务。更多详情请参阅 [vLLM](https://github.com/vllm-project/vllm)。
对于主推理模型,我们推荐以下几种模型。性能从上到下逐渐提升,但计算成本也随之增加。您可以根据自身需求选择性价比合适的模型:
| 模型 | 参数量 | 类型 | 链接 |
|---|---|---|---|
| Qwen3-4B-Thinking | 40亿 | 思考型 | 🤗 HuggingFace |
| Qwen3-8B | 80亿 | 混合型 | 🤗 HuggingFace |
| Qwen3-30B-A3B-Thinking | 300亿 | 思考型 | 🤗 HuggingFace |
| QwQ-32B | 320亿 | 思考型 | 🤗 HuggingFace |
| DeepAgent-QwQ-32B | 320亿 | 思考型 | 🤗 HuggingFace |
| Qwen3-235B-A22B-Thinking | 2350亿 | 思考型 | 🤗 HuggingFace |
对于辅助模型,我们建议使用与主推理模型参数相近的 Qwen2.5-Instruct 或 Qwen3-Instruct 系列模型,但无需思考能力,以加快推理速度。
⚙️ 配置
所有配置均位于 ./config/base_config.yaml 文件中,包括 API 密钥、服务 URL 和路径。您需要将其修改为实际配置:
1. API 配置
根据您的任务选择并配置相应的 API:
- ToolBench (RapidAPI):
toolbench_api:用于 ToolBench 的 RapidAPI 密钥。您可以从 ToolBench 官方仓库 获取。toolbench_service_url:ToolBench 服务 URL。保持默认即可使用 ToolBench 的官方服务。
- 深度研究:
google_serper_api:用于网络搜索的 Google Serper API 密钥。您可在此申请:serper.dev。use_jina:是否使用 Jina Reader 来稳定地获取 URL 内容。jina_api_key:Jina API 密钥。您可在此申请:jina.ai/api-dashboard/reader。
- RestBench (TMDB 和 Spotify):
tmdb_access_token:TMDB 访问令牌。您可在此获取 TMDB API 密钥:developer.themoviedb.org/docs/getting-started。spotify_client_id:Spotify 客户端 ID。您可在此获取 Spotify API 密钥:developer.spotify.com/documentation/web-api。spotify_client_secret:Spotify 客户端密钥。spotify_redirect_uri:Spotify 重定向 URI。
- WebShop:
webshop_service_url:WebShop 服务 URL。您可根据 WebShop 官方仓库 中的说明创建新环境并在本地提供服务。
2. 模型配置
在配置文件中设置您的模型端点:
主推理 LLM:
model_name:您部署的推理模型名称(如QwQ-32B)。base_url:推理模型服务的 API 端点(如http://0.0.0.0:8080/v1)。api_key:访问推理模型服务的 API 密钥。如果您使用 vLLM,则设为empty。tokenizer_path:推理模型分词器文件的本地路径。
辅助 LLM:
aux_model_name:您部署的辅助模型名称(如Qwen2.5-32B-Instruct)。aux_base_url:辅助模型服务的 API 端点。aux_api_key:辅助模型的 API 密钥。如果您使用 vLLM,则设为empty。aux_tokenizer_path:辅助模型分词器文件的本地路径。
VQA 模型(用于 GAIA 和 HLE 中的图像输入):
vqa_model_name:您部署的视觉语言模型名称(如Qwen2.5-VL-32B-Instruct)。模型服务方法见 [模型服务]。vqa_base_url:VQA 模型服务的 API 端点。vqa_api_key:VQA 模型的 API 密钥。如果您使用 vLLM,则设为empty。
工具检索器:
tool_retriever_model_path:工具检索器模型的本地路径(例如./models/bge-large-en-v1.5)。tool_retriever_api_base:工具检索器服务的 API 端点。预先部署可以避免每次运行系统时都重新加载检索器模型。你可以使用以下命令进行部署:
python src/run_tool_search_server.py \ --base_config_path ./config/base_config.yaml \ --datasets toolbench,toolhop,tmdb,spotify,api_bank \ --host 0.0.0.0 \ --port 8001
3. 数据路径配置
所有基准数据集都存储在 ./data/ 目录下。如有需要,你可以修改这些路径。
🚀 运行 DeepAgent
要在启用工具搜索的情况下对某个基准数据集进行运行,可使用以下命令:
python src/run_deep_agent.py \
--config_path ./config/base_config.yaml \
--dataset_name toolbench \
--enable_tool_search \
--eval
若要在闭集模式下对某个基准数据集进行运行,则使用以下命令:
python src/run_deep_agent.py \
--config_path ./config/base_config.yaml \
--dataset_name gaia \
--eval
参数说明:
--config_path:主配置文件的路径。--dataset_name:要使用的数据集名称(例如toolbench、api_bank、tmdb、spotify、toolhop、gaia、hle、alfworld、webshop)。--subset_num:从数据集中运行的样本数量。--concurrent_limit:最大并发请求数。默认值为 32。--enable_tool_search:允许智能体搜索工具。如果禁用,则仅使用任务提供的工具(闭集模式)。--enable_thought_folding:允许智能体使用思维折叠机制。--max_action_limit:每道题目的最大动作数(包括工具搜索和工具调用)。--max_fold_limit:每道题目的最大思维折叠次数。--top_k:返回的搜索工具的最大数量。--eval:生成结果后对结果进行评估。
多工具失败问题排查
如果 DeepAgent 在运行 ToolBench 或其他多工具基准测试时出现卡住、不断选择奇怪工具或忽略工具输出的情况,请参阅 docs/multi_tool_agent_failure_modes.md 中的逐步检查清单。
评估
我们的模型推理脚本可以自动保存模型的输入和输出以便进行评估。要运行评估,在执行 ./src/run_deep_agent.py 时添加 --eval 标志即可。各数据集的评估脚本位于 ./src/evaluate/ 目录下。
🔥 深度研究智能体家族
欢迎试用我们的深度研究智能体系列:
DeepAgent:具有可扩展工具集的通用推理智能体(WWW 2026)
简述: 一个端到端的深度推理智能体,通过受大脑启发的记忆折叠机制,实现自主思考、工具发现和动作执行。




代理式熵平衡策略优化(WWW 2026)
简述: 一种代理式的强化学习算法,旨在在回放和策略更新阶段平衡熵。



代理式强化策略优化(ICLR 2026)
简述: 一种代理式的强化学习算法,鼓励策略模型在高熵的工具调用回合中自适应地进行分支采样,

解耦规划与执行:面向深度搜索的层次化推理框架
简述: 该框架通过专门的智能体,将深度搜索分层解耦为战略规划和领域特定的执行。



Tool-Star:通过强化学习赋能大模型脑的多工具推理器
简述: 一个端到端的TIR后训练框架,通过自我批评强化学习设计,使大模型能够自主地与多工具环境交互。


WebThinker:赋予大型推理模型深度研究能力(NeurIPS 2025)
简述: 一个深度研究智能体,赋予大型推理模型自主搜索、网页浏览和撰写研究报告的能力。



Search-o1:代理式搜索增强型大型推理模型(EMNLP 2025)
简述: 一个代理式搜索增强框架,通过代理式RAG和文档内推理模块,将自主知识检索与大型推理模型相结合。



📄 引用
如果您觉得这项工作对您有帮助,请引用我们的论文:
@misc{deepagent,
title={DeepAgent: 一个具有可扩展工具集的通用推理智能体},
author={李晓溪、焦文翔、金嘉睿、董冠廷、金家杰、王一诺、王浩、朱宇涛、文继荣、陆元、窦志成},
year={2025},
eprint={2510.21618},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2510.21618},
}
📄 许可证
本项目采用 MIT 许可证 开源。
📞 联系方式
如有任何问题或反馈,请通过 xiaoxi_li@ruc.edu.cn 与我们联系。
星标历史

常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。