Qwen2.5-Omni
Qwen2.5-Omni 是阿里云通义团队推出的端到端多模态大模型,能够像人类一样同时“看、听、说、读”。它不仅能理解文本、图像、音频和视频等多种输入信息,还能直接生成自然的语音回复,实现真正的实时流式交互。
这款模型主要解决了传统 AI 在处理复杂多模态任务时需要拼接多个独立模块、导致响应延迟高且交互不自然的问题。通过端到端的架构设计,Qwen2.5-Omni 大幅提升了跨模态理解的准确性与反应速度,在口语理解、推理及音视频分析等权威评测中均位列开源模型榜首。
它非常适合开发者构建智能客服、虚拟助手或多媒体分析应用,也适合研究人员探索多模态前沿技术。得益于提供的 3B 轻量版及 4 比特量化版本,即使是资源有限的边缘设备也能流畅运行,让普通用户也能在本地体验高质量的实时语音对话。
其独特亮点在于原生支持实时语音合成输出,无需额外插件即可进行流畅的语音交流;同时兼容 vLLM 加速推理与 MNN 端侧部署,兼顾了高性能与低资源消耗,为多模态应用的落地提供了灵活高效的选择。
使用场景
一位现场设备巡检工程师正在嘈杂的工厂车间,通过智能眼镜实时记录机器运行状态并口述故障报告。
没有 Qwen2.5-Omni 时
- 多模态处理割裂:需分别使用独立工具识别图像、转录音频和生成文本,数据在不同系统间流转耗时且易出错。
- 响应延迟严重:传统方案需先录制完整音视频再上传云端分析,无法在巡检过程中提供实时的语音指导或预警。
- 环境抗扰性差:车间高分贝噪音导致普通语音识别模型准确率大幅下降,关键故障描述常被误识或遗漏。
- 部署门槛高:现有高精度多模态模型对显存要求极高,难以在边缘设备或移动端流畅运行,依赖昂贵的后端服务器。
使用 Qwen2.5-Omni 后
- 端到端统一感知:Qwen2.5-Omni 直接同步理解工程师看到的仪表视频、听到的机器异响及口述内容,一站式输出结构化报告。
- 实时流式交互:支持实时语音生成,工程师刚描述完现象,Qwen2.5-Omni 即刻通过耳机反馈维修建议或安全警示,无需等待。
- 强鲁棒性理解:凭借领先的音频理解能力,Qwen2.5-Omni 能在高噪环境下精准提取关键声纹特征,确保故障描述零误差。
- 轻量化边缘部署:利用其 4-bit 量化版本,Qwen2.5-Omni 可在资源受限的边缘设备上低显存运行,实现离线即时响应。
Qwen2.5-Omni 将复杂的多模态感知与实时语音交互融合,彻底重塑了工业现场“眼耳口脑”协同的作业效率。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 7B 模型量化版本 (GPTQ-Int4/AWQ) 可降低 50% 以上显存消耗
- 3B 模型支持更多平台
- 具体显存需求需参考 'Minimum GPU memory requirements' 章节(文中未给出具体数值,但提及量化可大幅降低需求)
未说明

快速开始
Qwen2.5-Omni
中文 | English
![]()
💜 Qwen Chat | 🤗 Hugging Face | 🤖 ModelScope | 📑 Blog | 📚 Cookbooks | 📑 Paper
🖥️ Demo | 💬 WeChat (微信) | 🫨 Discord | 📑 API
{kind=link}
我们发布了Qwen2.5-Omni,这是通义系列中的全新旗舰级端到端多模态模型。它专为全面的多模态感知而设计,能够无缝处理文本、图像、音频和视频等多种输入,并通过文本生成和自然语音合成提供实时流式响应。请点击下方视频了解更多内容 😃

新闻
- 2025年6月12日:Qwen2.5-Omni-7B在口语理解和推理基准测试MMSU中位列开源模型榜首。
- 2025年6月9日:祝贺我们的开源模型Qwen2.5-Omni-7B在MMAU排行榜上排名第一,并在音频理解和推理评估的MMAR开源模型榜单中也位居第一!
- 2025年5月16日:我们发布了4位量化版的Qwen2.5-Omni-7B(GPTQ-Int4/AWQ)模型,在多模态评测中保持与原版相当的性能,同时将GPU显存占用降低了50%以上。详情请参阅GPTQ-Int4和AWQ使用指南,相关模型可在Hugging Face(GPTQ-Int4|AWQ)和ModelScope(GPTQ-Int4|AWQ)获取。
- 2025年5月13日:MNN聊天应用现已支持Qwen2.5-Omni,让我们在边缘设备上体验Qwen2.5-Omni吧!有关内存消耗和推理速度的基准测试,请参阅使用MNN部署部分。
- 2025年4月30日:令人振奋!我们发布了Qwen2.5-Omni-3B,以使更多平台能够运行Qwen2.5-Omni。该模型可从Hugging Face下载。此模型的性能已更新,请参阅最低GPU内存要求了解资源消耗情况。为了获得最佳体验,transformers和vllm代码均已更新,您可以再次拉取官方docker镜像以获取最新版本。
- 2025年4月11日:我们发布了新版本的vllm,现已支持音频输出!请从源码或我们的docker镜像中体验。
- 2025年4月2日:⭐️⭐️⭐️ Qwen2.5-Omni荣登Hugging Face趋势榜第一名!
- 2025年3月29日:⭐️⭐️⭐️ Qwen2.5-Omni荣登Hugging Face趋势榜第二名!
- 2025年3月26日:现在您可以在Qwen Chat上与Qwen2.5-Omni进行实时互动。让我们立即开启这段精彩的旅程吧!
- 2025年3月26日:我们发布了Qwen2.5-Omni。更多详情请查看我们的博客!
目录
概述
简介
Qwen2.5-Omni是一款端到端多模态模型,旨在感知多种模态,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。
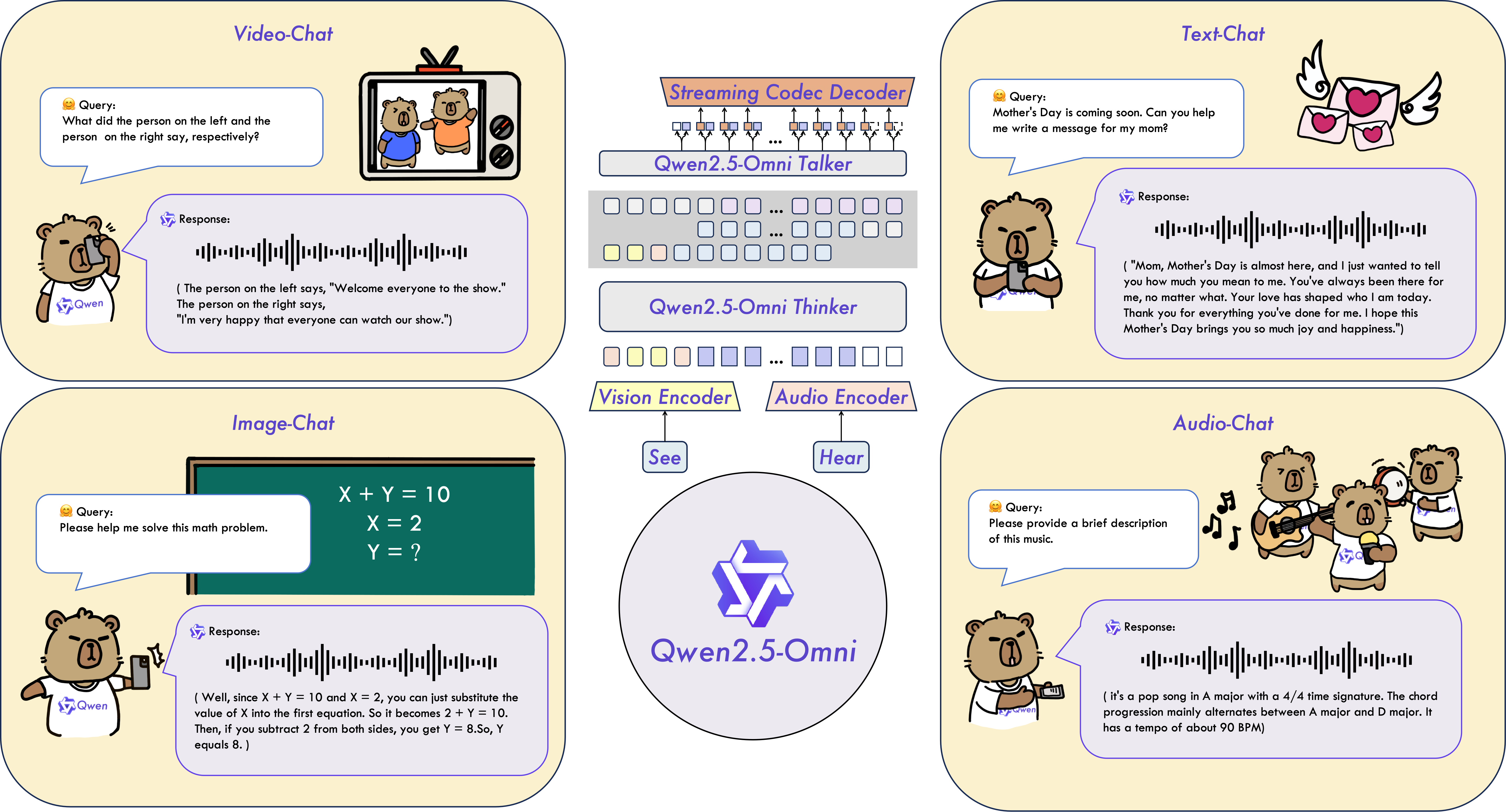
核心特性
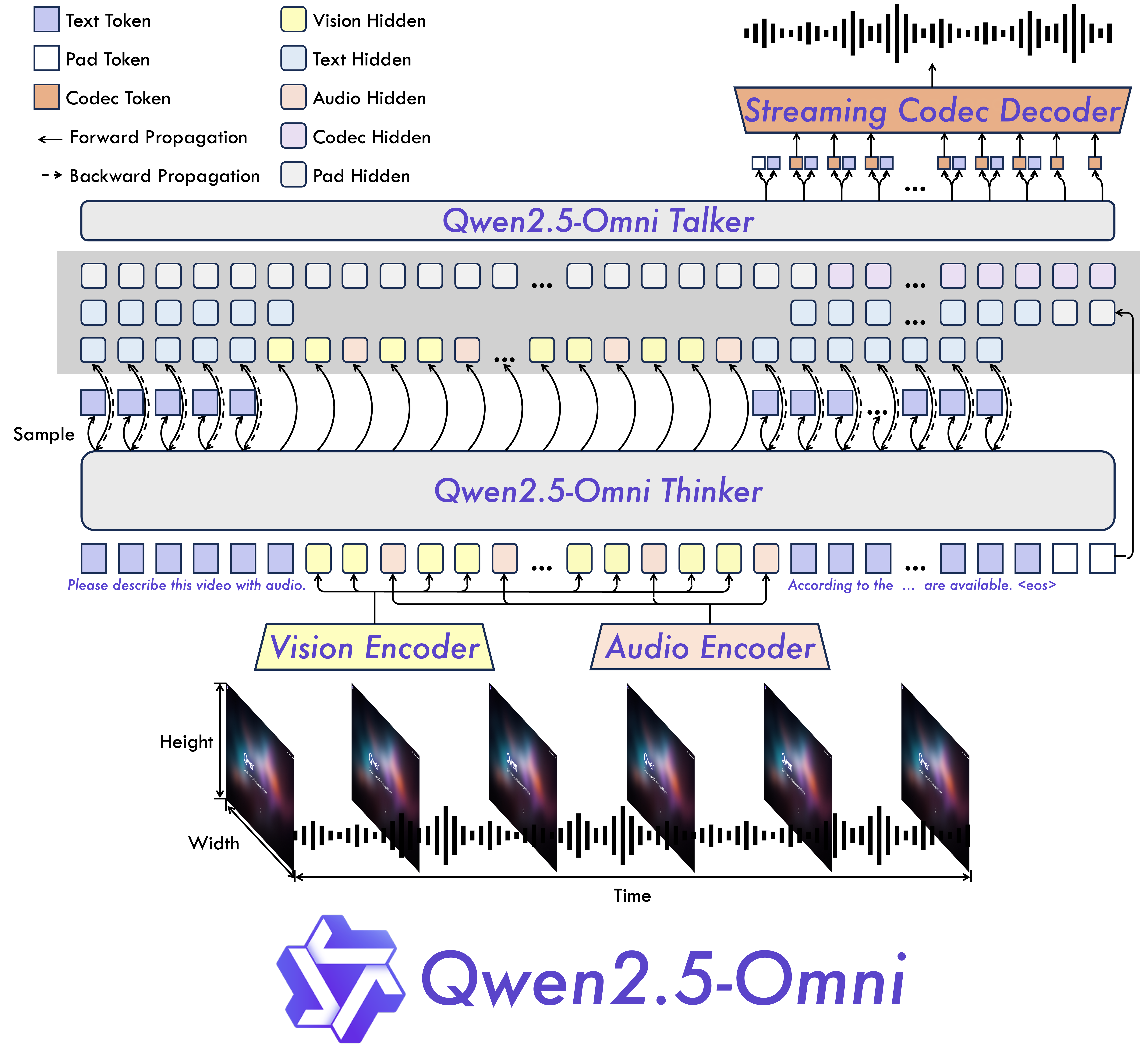
全能且新颖的架构:我们提出了Thinker-Talker架构,这是一种端到端的多模态模型,旨在感知文本、图像、音频和视频等多种模态,并以流式方式同时生成文本和自然语音响应。我们还提出了一种名为TMRoPE(时间对齐的多模态RoPE)的新型位置嵌入方法,用于同步视频输入与音频的时间戳。
实时语音与视频聊天:该架构专为全实时交互设计,支持分块输入和即时输出。
自然且稳健的语音生成:超越了许多现有的流式及非流式替代方案,在语音生成方面展现出更优异的稳健性和自然度。
跨模态的强大性能:在与同等规模的单模态模型进行基准测试时,Qwen2.5-Omni在所有模态上均表现出色。它在音频能力方面优于同规模的Qwen2-Audio,并且与Qwen2.5-VL-7B的表现相当。
出色的端到端语音指令遵循能力:Qwen2.5-Omni在端到端语音指令遵循方面的表现可与文本输入的效果相媲美,这一点从MMLU和GSM8K等基准测试中可见一斑。
模型架构
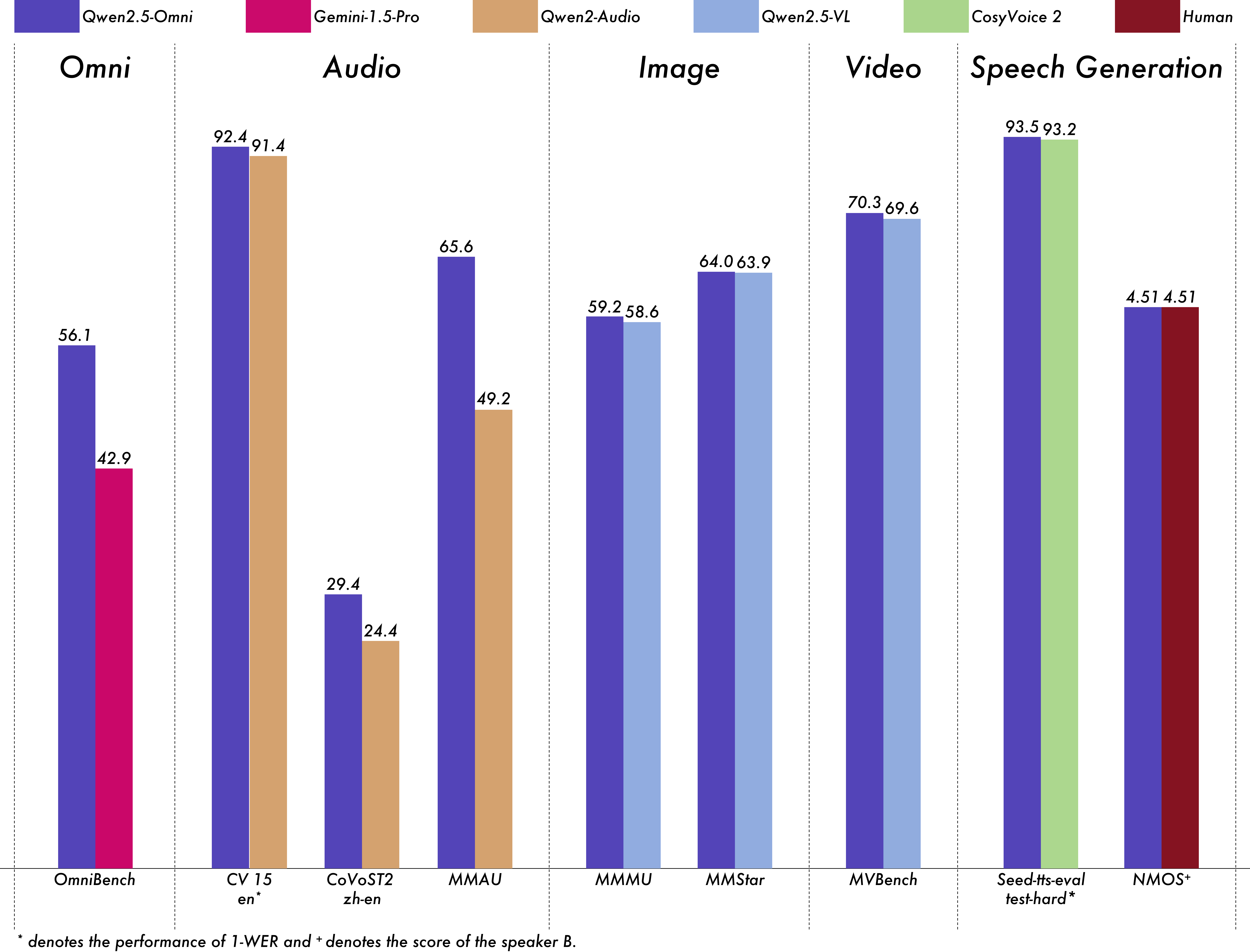
性能表现
我们对Qwen2.5-Omni进行了全面评估,结果显示,与同等规模的单模态模型以及闭源模型(如Qwen2.5-VL-7B、Qwen2-Audio和Gemini-1.5-pro)相比,Qwen2.5-Omni在所有模态上均表现出强劲性能。在需要整合多种模态的任务中,例如OmniBench,Qwen2.5-Omni达到了最先进的水平。此外,在单模态任务中,它在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然度)等领域同样表现出色。
多模态 -> 文本
数据集
模型
性能
OmniBench
语音 | 声音事件 | 音乐 | 平均Gemini-1.5-Pro
42.67%|42.26%|46.23%|42.91%
MIO-Instruct
36.96%|33.58%|11.32%|33.80%
AnyGPT (7B)
17.77%|20.75%|13.21%|18.04%
video-SALMONN
34.11%|31.70%|56.60%|35.64%
UnifiedIO2-xlarge
39.56%|36.98%|29.25%|38.00%
UnifiedIO2-xxlarge
34.24%|36.98%|24.53%|33.98%
MiniCPM-o
-|-|-|40.50%
Baichuan-Omni-1.5
-|-|-|42.90%
Qwen2.5-Omni-3B
52.14%|52.08%|52.83%|52.19%
Qwen2.5-Omni-7B
55.25%|60.00%|52.83%|56.13%
音频 -> 文本
数据集
模型
性能
自动语音识别(ASR)
Librispeech
dev-clean | dev other | test-clean | test-otherSALMONN
-|-|2.1|4.9
SpeechVerse
-|-|2.1|4.4
Whisper-large-v3
-|-|1.8|3.6
Llama-3-8B
-|-|-|3.4
Llama-3-70B
-|-|-|3.1
Seed-ASR-Multilingual
-|-|1.6|2.8
MiniCPM-o
-|-|1.7|-
MinMo
-|-|1.7|3.9
Qwen-Audio
1.8|4.0|2.0|4.2
Qwen2-Audio
1.3|3.4|1.6|3.6
Qwen2.5-Omni-3B
2.0|4.1|2.2|4.5
Qwen2.5-Omni-7B
1.6|3.5|1.8|3.4
Common Voice 15
en | zh | yue | frWhisper-large-v3
9.3|12.8|10.9|10.8
MinMo
7.9|6.3|6.4|8.5
Qwen2-Audio
8.6|6.9|5.9|9.6
Qwen2.5-Omni-3B
9.1|6.0|11.6|9.6
Qwen2.5-Omni-7B
7.6|5.2|7.3|7.5
Fleurs
zh | enWhisper-large-v3
7.7|4.1
Seed-ASR-Multilingual
-|3.4
Megrez-3B-Omni
10.8|-
MiniCPM-o
4.4|-
MinMo
3.0|3.8
Qwen2-Audio
7.5|-
Qwen2.5-Omni-3B
3.2|5.4
Qwen2.5-Omni-7B
3.0|4.1
Wenetspeech
test-net | test-meetingSeed-ASR-Chinese
4.7|5.7
Megrez-3B-Omni
-|16.4
MiniCPM-o
6.9|-
MinMo
6.8|7.4
Qwen2.5-Omni-3B
6.3|8.1
Qwen2.5-Omni-7B
5.9|7.7
Voxpopuli-V1.0-en
Llama-3-8B
6.2
Llama-3-70B
5.7
Qwen2.5-Omni-3B
6.6
Qwen2.5-Omni-7B
5.8
语音到文本转换(S2TT)
CoVoST2
en-de | de-en | en-zh | zh-enSALMONN
18.6|-|33.1|-
SpeechLLaMA
-|27.1|-|12.3
BLSP
14.1|-|-|-
MiniCPM-o
-|-|48.2|27.2
MinMo
-|39.9|46.7|26.0
Qwen-Audio
25.1|33.9|41.5|15.7
Qwen2-Audio
29.9|35.2|45.2|24.4
Qwen2.5-Omni-3B
28.3|38.1|41.4|26.6
Qwen2.5-Omni-7B
30.2|37.7|41.4|29.4
情绪识别(SER)
Meld
WavLM-large
0.542
MiniCPM-o
0.524
Qwen-Audio
0.557
Qwen2-Audio
0.553
Qwen2.5-Omni-3B
0.558
Qwen2.5-Omni-7B
0.570
声音场景分类(VSC)
VocalSound
CLAP
0.495
Pengi
0.604
Qwen-Audio
0.929
Qwen2-Audio
0.939
Qwen2.5-Omni-3B
0.936
Qwen2.5-Omni-7B
0.939
音乐
GiantSteps Tempo
Llark-7B
0.86
Qwen2.5-Omni-3B
0.88
Qwen2.5-Omni-7B
0.88
MusicCaps
LP-MusicCaps
0.291|0.149|0.089|0.061|0.129|0.130
Qwen2.5-Omni-3B
0.325|0.163|0.093|0.057|0.132|0.229
Qwen2.5-Omni-7B
0.328|0.162|0.090|0.055|0.127|0.225
音频推理
MMAU
Sound | Music | Speech | AvgGemini-Pro-V1.5
56.75|49.40|58.55|54.90
Qwen2-Audio
54.95|50.98|42.04|49.20
Qwen2.5-Omni-3B
70.27|60.48|59.16|63.30
Qwen2.5-Omni-7B
67.87|69.16|59.76|65.60
语音聊天
VoiceBench
AlpacaEval | CommonEval | SD-QA | MMSUUltravox-v0.4.1-LLaMA-3.1-8B
4.55|3.90|53.35|47.17
MERaLiON
4.50|3.77|55.06|34.95
Megrez-3B-Omni
3.50|2.95|25.95|27.03
Lyra-Base
3.85|3.50|38.25|49.74
MiniCPM-o
4.42|4.15|50.72|54.78
Baichuan-Omni-1.5
4.50|4.05|43.40|57.25
Qwen2-Audio
3.74|3.43|35.71|35.72
Qwen2.5-Omni-3B
4.32|4.00|49.37|50.23
Qwen2.5-Omni-7B
4.49|3.93|55.71|61.32
VoiceBench
OpenBookQA | IFEval | AdvBench | AvgUltravox-v0.4.1-LLaMA-3.1-8B
65.27|66.88|98.46|71.45
MERaLiON
27.23|62.93|94.81|62.91
Megrez-3B-Omni
28.35|25.71|87.69|46.25
Lyra-Base
72.75|36.28|59.62|57.66
MiniCPM-o
78.02|49.25|97.69|71.69
Baichuan-Omni-1.5
74.51|54.54|97.31|71.14
Qwen2-Audio
49.45|26.33|96.73|55.35
Qwen2.5-Omni-3B
74.73|42.10|98.85|68.81
Qwen2.5-Omni-7B
81.10|52.87|99.42|74.12
图像 -> 文本
数据集
通义千问2.5-Omni-7B
通义千问2.5-Omni-3B
其他最佳
通义千问2.5-VL-7B
GPT-4o-mini
MMMUval
59.2
53.1
53.9
58.6
60.0
MMMU-Prooverall
36.6
29.7
-
38.3
37.6
MathVistatestmini
67.9
59.4
71.9
68.2
52.5
MathVisionfull
25.0
20.8
23.1
25.1
-
MMBench-V1.1-ENtest
81.8
77.8
80.5
82.6
76.0
MMVetturbo
66.8
62.1
67.5
67.1
66.9
MMStar
64.0
55.7
64.0
63.9
54.8
MMEsum
2340
2117
2372
2347
2003
MuirBench
59.2
48.0
-
59.2
-
CRPErelation
76.5
73.7
-
76.4
-
RealWorldQAavg
70.3
62.6
71.9
68.5
-
MME-RealWorlden
61.6
55.6
-
57.4
-
MM-MT-Bench
6.0
5.0
-
6.3
-
AI2D
83.2
79.5
85.8
83.9
-
TextVQAval
84.4
79.8
83.2
84.9
-
DocVQAtest
95.2
93.3
93.5
95.7
-
ChartQAtest Avg
85.3
82.8
84.9
87.3
-
OCRBench_V2en
57.8
51.7
-
56.3
-
数据集
通义千问2.5-Omni-7B
通义千问2.5-Omni-3B
通义千问2.5-VL-7B
Grounding DINO
Gemini 1.5 Pro
Refcocoval
90.5
88.7
90.0
90.6
73.2
RefcocotextA
93.5
91.8
92.5
93.2
72.9
RefcocotextB
86.6
84.0
85.4
88.2
74.6
Refcoco+val
85.4
81.1
84.2
88.2
62.5
Refcoco+textA
91.0
87.5
89.1
89.0
63.9
Refcoco+textB
79.3
73.2
76.9
75.9
65.0
Refcocog+val
87.4
85.0
87.2
86.1
75.2
Refcocog+test
87.9
85.1
87.2
87.0
76.2
ODinW
42.4
39.2
37.3
55.0
36.7
PointGrounding
66.5
46.2
67.3
-
-
视频(无音频)-> 文本
数据集
通义千问2.5-Omni-7B
通义千问2.5-Omni-3B
其他最佳
通义千问2.5-VL-7B
GPT-4o-mini
Video-MMEw/o sub
64.3
62.0
63.9
65.1
64.8
Video-MMEw sub
72.4
68.6
67.9
71.6
-
MVBench
70.3
68.7
67.2
69.6
-
EgoSchematest
68.6
61.4
63.2
65.0
-
零样本语音生成
数据集
模型
性能
内容一致性
SEED
test-zh | test-en | test-hard Seed-TTS_ICL
1.11 | 2.24 | 7.58
Seed-TTS_RL
1.00 | 1.94 | 6.42
MaskGCT
2.27 | 2.62 | 10.27
E2_TTS
1.97 | 2.19 | -
F5-TTS
1.56 | 1.83 | 8.67
CosyVoice 2
1.45 | 2.57 | 6.83
CosyVoice 2-S
1.45 | 2.38 | 8.08
Qwen2.5-Omni-3B_ICL
1.95 | 2.87 | 9.92
Qwen2.5-Omni-3B_RL
1.58 | 2.51 | 7.86
Qwen2.5-Omni-7B_ICL
1.70 | 2.72 | 7.97
Qwen2.5-Omni-7B_RL
1.42 | 2.32 | 6.54
说话人相似度
SEED
test-zh | test-en | test-hard Seed-TTS_ICL
0.796 | 0.762 | 0.776
Seed-TTS_RL
0.801 | 0.766 | 0.782
MaskGCT
0.774 | 0.714 | 0.748
E2_TTS
0.730 | 0.710 | -
F5-TTS
0.741 | 0.647 | 0.713
CosyVoice 2
0.748 | 0.652 | 0.724
CosyVoice 2-S
0.753 | 0.654 | 0.732
Qwen2.5-Omni-3B_ICL
0.741 | 0.635 | 0.748
Qwen2.5-Omni-3B_RL
0.744 | 0.635 | 0.746
Qwen2.5-Omni-7B_ICL
0.752 | 0.632 | 0.747
Qwen2.5-Omni-7B_RL
0.754 | 0.641 | 0.752
文本 -> 文本
数据集
Qwen2.5-Omni-7B
Qwen2.5-Omni-3B
Qwen2.5-7B
Qwen2.5-3B
Qwen2-7B
Llama3.1-8B
Gemma2-9B
MMLU-Pro
47.0
40.4
56.3
43.7
44.1
48.3
52.1
MMLU-redux
71.0
60.9
75.4
64.4
67.3
67.2
72.8
LiveBench0831
29.6
22.3
35.9
26.8
29.2
26.7
30.6
GPQA
30.8
34.3
36.4
30.3
34.3
32.8
32.8
MATH
71.5
63.6
75.5
65.9
52.9
51.9
44.3
GSM8K
88.7
82.6
91.6
86.7
85.7
84.5
76.7
HumanEval
78.7
70.7
84.8
74.4
79.9
72.6
68.9
MBPP
73.2
70.4
79.2
72.7
67.2
69.6
74.9
MultiPL-E
65.8
57.6
70.4
60.2
59.1
50.7
53.4
LiveCodeBench2305-2409
24.6
16.5
28.7
19.9
23.9
8.3
18.9
快速入门
下面,我们提供了一些简单的示例,展示如何使用 🤖 ModelScope 和 🤗 Transformers 来操作 Qwen2.5-Omni。
Qwen2.5-Omni 的代码已集成到最新版本的 Hugging Face Transformers 中,建议您通过以下命令进行安装:
pip install transformers==4.52.3
pip install accelerate
否则可能会遇到如下错误:
KeyError: 'qwen2_5_omni'
此外,您也可以使用我们的官方 Docker 镜像来快速启动,而无需从源码编译。
我们还提供了一个工具包,旨在更便捷地处理各类音频和视觉输入,就像调用 API 一样。该工具支持 base64 编码、URL 以及交错的音频、图片和视频格式。您可以使用以下命令安装,并确保系统已安装 ffmpeg:
# 强烈推荐使用 `[decord]` 功能以加快视频加载速度。
pip install qwen-omni-utils[decord] -U
如果您使用的不是 Linux 系统,可能无法从 PyPI 安装 decord。在这种情况下,您可以运行 pip install qwen-omni-utils -U,此时将回退至使用 torchvision 进行视频处理。不过,您仍然可以从源码安装 decord,以便在加载视频时使用 decord。
我们正在编写一系列使用手册,涵盖多种功能,包括音频理解、语音对话、屏幕录制交互、视频信息提取、多模态对话等。欢迎进一步了解!
🤗 Transformers 使用方法
以下是一个代码示例,演示如何结合 transformers 和 qwen_omni_utils 使用聊天模型:
import soundfile as sf
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# 默认:在可用设备上加载模型
model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# 建议启用 flash_attention_2 以获得更好的加速效果并节省内存。
# model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "你是通义千问,由阿里巴巴集团通义实验室研发的虚拟人,能够感知音频和视觉输入,并生成文本和语音。"}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# 设置是否使用视频中的音频
USE_AUDIO_IN_VIDEO = True
# 推理前的准备
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# 推理:生成输出文本和音频
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
最低显存需求
| 模型 | 精度 | 15秒视频 | 30秒视频 | 60秒视频 |
|---|---|---|---|---|
| Qwen-Omni-3B | FP32 | 89.10 GB | 不推荐 | 不推荐 |
| Qwen-Omni-3B | BF16 | 18.38 GB | 22.43 GB | 28.22 GB |
| Qwen-Omni-7B | FP32 | 93.56 GB | 不推荐 | 不推荐 |
| Qwen-Omni-7B | BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
注意:上表展示了使用 transformers 库进行推理时的理论最低显存需求,其中 BF16 精度是在启用 attn_implementation="flash_attention_2" 的情况下测试得出的。然而,在实际应用中,显存占用通常会比理论值高出至少 1.2 倍。更多信息请参阅链接资源 这里。我们目前正在计划开发一个资源消耗更低的版本,以便 Qwen2.5-Omni 能够在大多数平台上运行。敬请期待!
视频 URL 资源占用
视频 URL 的兼容性主要取决于第三方库的版本。具体信息如下表所示。如果您不想使用默认的后端,可以通过设置 FORCE_QWENVL_VIDEO_READER=torchvision 或 FORCE_QWENVL_VIDEO_READER=decord 来更改后端。
| 后端 | HTTP | HTTPS |
|---|---|---|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
批量推理
当设置 return_audio=False 时,该模型可以接受包含文本、图像、音频和视频等多种类型样本的混合输入进行批量推理。以下是一个示例。
# 批量推理的示例消息
# 仅含视频的对话
conversation1 = [
{
"role": "system",
"content": [
{"type": "text", "text": "你是通义千问,由阿里巴巴集团通义实验室研发的虚拟人,能够感知音频和视觉输入,并生成文本和语音。"}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "/path/to/video.mp4"},
]
}
]
# 仅含音频的对话
conversation2 = [
{
"role": "system",
"content": [
{"type": "text", "text": "你是通义千问,由阿里巴巴集团通义实验室研发的虚拟人,能够感知音频和视觉输入,并生成文本和语音。"}
],
},
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
]
}
]
# 纯文本对话
conversation3 = [
{
"role": "system",
"content": [
{"type": "text", "text": "你是通义千问,由阿里巴巴集团通义实验室研发的虚拟人,能够感知音频和视觉输入,并生成文本和语音。"}
],
},
{
"role": "user",
"content": "你是谁?"
}
]
# 多媒体混合对话
conversation4 = [
{
"role": "system",
"content": [
{"type": "text", "text": "你是通义千问,由阿里巴巴集团通义实验室研发的虚拟人,能够感知音频和视觉输入,并生成文本和语音。"}
],
},
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "text", "text": "你在这些媒体中看到了什么、听到了什么?"},
]
}
]
# 组合消息以进行批量处理
conversations = [conversation1, conversation2, conversation3, conversation4]
# 设置是否使用视频中的音频
USE_AUDIO_IN_VIDEO = True
# 批量推理前的准备
text = processor.apply_chat_template(conversations, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversations, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# 批量推理
text_ids = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO, return_audio=False)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
🤖 ModelScope 使用
我们强烈建议用户,尤其是中国大陆地区的用户,使用 ModelScope 平台。通过 snapshot_download 功能可以帮助您解决检查点下载方面的问题。
GPTQ-Int4 和 AWQ 的使用
为了提升 Qwen2.5-Omni-7B 在 GPU 显存受限设备上的运行能力,我们采用了 GPTQ 和 AWQ 对模型权重进行了 4 位量化,从而有效降低了 GPU 显存占用。其他关键优化包括:
- 优化了推理流程,按需加载每个模块的模型权重,并在推理完成后将其卸载到 CPU 内存中,以避免显存峰值过高。
- 将 code2wav 模块改造成支持流式推理,从而避免预先分配过多的 GPU 显存。
- 将 ODE 求解器从二阶(RK4)方法调整为一阶(欧拉)方法,进一步降低计算开销。
这些改进旨在确保 Qwen2.5-Omni 在各种硬件配置下都能高效运行,尤其是在 GPU 显存较低的设备上(如 RTX3080、4080、5070 等)。目前,相关模型及使用方法可从 Hugging Face(GPTQ-Int4|AWQ)和 ModelScope(GPTQ-Int4|AWQ)获取。以下提供一个简单示例,展示如何使用 Qwen2.5-Omni-7B-GPTQ-Int4 并搭配 gptqmodel:
pip install transformers==4.52.3
pip install accelerate
pip install gptqmodel==2.0.0
pip install numpy==2.0.0
git clone https://github.com/QwenLM/Qwen2.5-Omni.git
cd Qwen2.5-Omni/low-VRAM-mode/
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_gptq.py
若要使用 Qwen2.5-Omni-7B-AWQ 并搭配 autoawq,请执行以下命令:
pip install transformers==4.52.3
pip install accelerate
pip install autoawq==0.2.9
git clone https://github.com/QwenLM/Qwen2.5-Omni.git
cd Qwen2.5-Omni/low-VRAM-mode/
CUDA_VISIBLE_DEVICES=0 python3 low_VRAM_demo_awq.py
以下两张表格分别展示了 Qwen2.5-Omni-7B-GPTQ-Int4/Qwen2.5-Omni-7B-AWQ 与原版 Qwen2.5-Omni-7B 在特定评估基准上的性能对比及 GPU 显存消耗情况。数据显示,GPTQ-Int4/AWQ 模型在保持相近性能的同时,将 GPU 显存需求降低了 50% 以上,从而使更多设备能够运行并体验高性能的 Qwen2.5-Omni-7B 模型。值得注意的是,由于量化技术和 CPU 卸载机制的影响,GPTQ-Int4/AWQ 版本的推理速度略低于原生 Qwen2.5-Omni-7B 模型。
| 评估集 | 任务 | 指标 | Qwen2.5-Omni-7B | Qwen2.5-Omni-7B-GPTQ-Int4 | Qwen2.5-Omni-7B-AWQ |
|---|---|---|---|---|---|
| LibriSpeech test-other | ASR | WER ⬇️ | 3.4 | 3.71 | 3.91 |
| WenetSpeech test-net | ASR | WER ⬇️ | 5.9 | 6.62 | 6.31 |
| Seed-TTS test-hard | TTS (Speaker: Chelsie) | WER ⬇️ | 8.7 | 10.3 | 8.88 |
| MMLU-Pro | 文本 -> 文本 | 准确率 ⬆️ | 47.0 | 43.76 | 45.66 |
| OmniBench | 语音 -> 文本 | 准确率 ⬆️ | 56.13 | 53.59 | 54.64 |
| VideoMME | 多模态 -> 文本 | 准确率 ⬆️ | 72.4 | 68.0 | 72.0 |
| 模型 | 精度 | 15 秒视频 | 30 秒视频 | 60 秒视频 |
|---|---|---|---|---|
| Qwen-Omni-7B | FP32 | 93.56 GB | 不推荐 | 不推荐 |
| Qwen-Omni-7B | BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
| Qwen-Omni-7B | GPTQ-Int4 | 11.64 GB | 17.43 GB | 29.51 GB |
| Qwen-Omni-7B | AWQ | 11.77 GB | 17.84 GB | 30.31 GB |
使用提示
音频输出的提示
如果用户需要音频输出,系统提示必须设置为:“你是 Qwen,阿里巴巴集团 Qwen 团队研发的虚拟人,能够感知听觉和视觉输入,并生成文本和语音。”否则,音频输出可能无法正常工作。
{
"role": "system",
"content": [
{"type": "text", "text": "你是 Qwen,阿里巴巴集团 Qwen 团队研发的虚拟人,能够感知听觉和视觉输入,并生成文本和语音。"}
]
}
视频中的音频使用
在多模态交互过程中,用户提供的视频通常会伴随音频信息(例如关于视频内容的问题,或视频中某些事件产生的声音)。这些信息有助于模型提供更好的交互体验。因此,我们提供了以下选项供用户决定是否在视频中使用音频。
# 第一步,在数据预处理阶段
audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)
# 第二步,在模型处理器中
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt",
padding=True,use_audio_in_video=True)
# 第三名,在模型推理中
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
值得注意的是,在多轮对话过程中,这些地方的 use_audio_in_video 参数必须设置为一致,否则会出现意外结果。
是否使用音频输出
该模型同时支持文本和音频输出。如果用户不需要音频输出,可以在初始化模型后调用 model.disable_talker()。这一选项可以节省约 2GB 的显存,但 generate 函数的 return_audio 参数将仅允许设置为 False。
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
model.disable_talker()
为了获得更灵活的体验,我们建议用户在调用 generate 函数时自行决定是否返回音频。如果将 return_audio 设置为 False, 模型将只返回文本输出,从而更快地获取文本响应。
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
...
text_ids = model.generate(**inputs, return_audio=False)
更改输出音频的语音类型
Qwen2.5-Omni 支持更改输出音频的语音类型。“Qwen/Qwen2.5-Omni-7B”检查点支持以下两种语音类型:
| 语音类型 | 性别 | 描述 |
|---|---|---|
| Chelsie | 女性 | 一种如蜜般柔滑、带有温和温暖与明亮清晰感的嗓音。 |
| Ethan | 男性 | 一种明亮、活泼,充满感染力且温暖亲和的嗓音。 |
用户可以通过 generate 函数的 speaker 参数来指定语音类型。默认情况下,若未指定 speaker,则默认语音类型为 Chelsie。
text_ids, audio = model.generate(**inputs, speaker="Chelsie")
text_ids, audio = model.generate(**inputs, speaker="Ethan")
使用 Flash-Attention 2 加速生成
首先,请确保安装最新版本的 Flash Attention 2:
pip install -U flash-attn --no-build-isolation
此外,您的硬件应与 FlashAttention 2 兼容。更多信息请参阅 flash attention 仓库 的官方文档。FlashAttention-2 只能在模型以 torch.float16 或 torch.bfloat16 加载时使用。
要使用 FlashAttention-2 加载并运行模型,在加载模型时添加 attn_implementation="flash_attention_2":
from transformers import Qwen2_5OmniForConditionalGeneration
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
更多使用场景的教程
| 教程 | 描述 | 打开 |
|---|---|---|
| 通用音频理解 | 语音识别、语音转文字翻译及音频分析。 | |
| 语音聊天 | 通过语音输入和输出与 Qwen2.5-Omni 进行对话。 | |
| 屏幕录制互动 | 在录制屏幕上实时提问,获取所需的信息和内容。 | |
| 视频信息提取 | 从视频流中获取信息。 | |
| 音乐领域的全能聊天 | 在音视频流中与 Qwen2.5-Omni 讨论音乐相关内容。 | |
| 数学领域的全能聊天 | 在音视频流中与 Qwen2.5-Omni 讨论数学相关内容。 | |
| 多轮全能聊天 | 与 Qwen2.5-Omni 进行多轮音视频对话,全面展示其能力。 |
API 推理
为了探索 Qwen2.5-Omni,我们鼓励您试用我们的前沿 API 服务,以获得更快、更高效的感受。
安装
pip install openai
示例
您可以使用 OpenAI API 服务与 Qwen2.5-Omni 进行交互,如下所示。更多用法请参考 阿里云 上的教程。
import base64
import numpy as np
import soundfile as sf
from openai import OpenAI
client = OpenAI(
api_key="your_api_key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
messages = [
{
"role": "system",
"content": "你是 Qwen,阿里巴巴集团 Qwen 团队开发的虚拟人,能够感知听觉和视觉输入,并生成文本和语音。",
},
{
"role": "user",
"content": [
{"type": "video_url", "video_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# Qwen-Omni 仅支持流式模式
completion = client.chat.completions.create(
model="qwen-omni-turbo",
messages=messages,
modalities=["text", "audio"],
audio={
"voice": "Cherry", # Cherry、Ethan、Serena、Chelsie 可用
"format": "wav"
},
stream=True,
stream_options={"include_usage": True}
)
text = []
audio_string = ""
for chunk in completion:
if chunk.choices:
if hasattr(chunk.choices[0].delta, "audio"):
try:
audio_string += chunk.choices[0].delta.audio["data"]
except Exception as e:
text.append(chunk.choices[0].delta.audio["transcript"])
else:
print(chunk.usage)
print("".join(text))
wav_bytes = base64.b64decode(audio_string)
wav_array = np.frombuffer(wav_bytes, dtype=np.int16)
sf.write("output.wav", wav_array, samplerate=24000)
自定义设置
由于 Qwen2.5-Omni 在使用 音频输出 时(包括本地部署和 API 推理)不支持提示词设置,因此我们建议,如果您需要控制模型的输出或修改模型的性格设定,可以尝试在对话模板中添加类似以下内容:
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "你是一名导购员,现在负责介绍各种产品。"},
],
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "好的,我明白了。"},
],
},
{
"role": "user",
"content": [
{"type": "text", "text": "你是谁呀?"},
],
},
]
与 Qwen2.5-Omni 对话
在线演示
无需部署,您可以通过访问我们的 Hugginface Spaces 和 Modelscope Studio 直接体验在线网页演示。
启动本地 Web UI 演示
在本节中,我们为用户提供构建基于 Web 的用户界面 (UI) 演示的说明。该 UI 演示允许用户通过 Web 浏览器与预定义的模型或应用程序进行交互。请按照以下步骤开始操作,或者您也可以直接从我们的 官方 Docker 镜像 启动 Web 演示。
安装
在开始之前,请确保您的系统上已安装所需的依赖项。您可以通过运行以下命令来安装它们:
pip install -r requirements_web_demo.txt
使用 FlashAttention-2 运行演示
一旦所需软件包安装完毕,您可以使用以下命令启动 Web 演示。此命令将启动一个 Web 服务器,并为您提供一个链接,以便在您的 Web 浏览器中访问 UI。
推荐:为了提升性能和效率,尤其是在多图像和视频处理场景下,我们强烈建议使用 FlashAttention-2。FlashAttention-2 在内存使用和速度方面有显著提升,非常适合处理大规模模型和数据。
要启用 FlashAttention-2,请使用以下命令:
# 默认用于 Qwen2.5-Omni-7B
python web_demo.py --flash-attn2
# 用于 Qwen2.5-Omni-3B
python web_demo.py --flash-attn2 -c Qwen/Qwen2.5-Omni-3B
这将加载启用 FlashAttention-2 的模型。
默认使用:如果您希望在不使用 FlashAttention-2 的情况下运行演示,或者未指定 --flash-attn2 选项,则演示将使用标准注意力机制加载模型:
# 默认用于 Qwen2.5-Omni-7B
python web_demo.py
# 用于 Qwen2.5-Omni-3B
python web_demo.py -c Qwen/Qwen2.5-Omni-3B
运行命令后,您将在终端中看到类似以下的链接:
Running on local: http://127.0.0.1:7860/
复制此链接并粘贴到您的浏览器中,即可访问 Web UI,在那里您可以输入文本、上传音频/图片/视频、更改语音类型或其他提供的功能,与模型进行交互。
实时互动
Qwen2.5-Omni 的流式实时互动现已开放,请访问 Qwen Chat 并在聊天框中选择语音/视频通话功能以体验。
使用 vLLM 部署
我们推荐使用 vLLM 来快速部署和推理 Qwen2.5-Omni。您需要从我们提供的 源代码 安装,以获得对 Qwen2.5-Omni 的支持,或者使用我们的 官方 Docker 镜像。您还可以查看 vLLM 官方文档 以获取有关在线服务和离线推理的更多详细信息。
安装
git clone -b qwen2_omni_public https://github.com/fyabc/vllm.git
cd vllm
git checkout de8f43fbe9428b14d31ac5ec45d065cd3e5c3ee0
pip install setuptools_scm torchdiffeq resampy x_transformers qwen-omni-utils accelerate
pip install -r requirements/cuda.txt
pip install --upgrade setuptools wheel
pip install .
pip install transformers==4.52.3
本地推理
您可以通过 vLLM 在本地对 Qwen2.5-Omni 进行推理。我们在 vLLM 仓库 中提供了生成音频输出的示例:
# 克隆分支 qwen2_omni_public 的 vLLM 仓库
# cd vllm
# 切换到特定提交版本
# cd examples/offline_inference/qwen2_5_omni/
# 单 GPU 下仅输出文本
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --thinker-only
# 多 GPU 下仅输出文本(以 4 张 GPU 为例)
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --thinker-only --thinker-devices [0,1,2,3] --thinker-gpu-memory-utilization 0.9
# 单 GPU 下输出音频
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --do-wave --voice-type Chelsie --warmup-voice-type Chelsie --output-dir output_wav
# 多 GPU 下输出音频(以 4 张 GPU 为例)
python end2end.py --model Qwen/Qwen2.5-Omni-7B --prompt audio-in-video-v2 --enforce-eager --do-wave --voice-type Chelsie --warmup-voice-type Chelsie --thinker-devices [0,1] --talker-devices [2] --code2wav-devices [3] --thinker-gpu-memory-utilization 0.9 --talker-gpu-memory-utilization 0.9 --output-dir output_wav
vLLM Serve 的使用
您也可以通过 pip install vllm>=0.8.5.post1 使用 vLLM serve,不过目前 vLLM serve 对于 Qwen2.5-Omni 仅支持 thinker 模式,即仅支持文本输出。您可以通过以下命令启动 vLLM serve:
# 单 GPU
vllm serve /path/to/Qwen2.5-Omni-7B/ --port 8000 --host 127.0.0.1 --dtype bfloat16
# 用于多 GPU(以 4 个 GPU 为例)
vllm serve /path/to/Qwen2.5-Omni-7B/ --port 8000 --host 127.0.0.1 --dtype bfloat16 -tp 4
然后你可以使用聊天 API,例如通过 curl:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/qwen.png"}},
{"type": "audio_url", "audio_url": {"url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/cough.wav"}},
{"type": "text", "text": "插图中的文字是什么?音频中的声音是什么?"}
]}
]
}'
使用 MNN 部署
Qwen2.5-Omni 现已支持 MNN,可在边缘设备上部署。Qwen2.5-Omni 的 MNN 模型可通过 Hugging Face(7B|3B)和 ModelScope(7B|3B)下载,并附有使用说明。有关详细信息,请访问 MNN 了解更多信息。
下表展示了 Qwen2.5-Omni MNN 实现方案在不同移动 SoC 平台上的内存消耗和推理速度基准测试结果。
| 平台 | Snapdragon 8 Gen 1 | Snapdragon 8 Elite | Snapdragon 8 Gen 1 | Snapdragon 8 Elite |
|---|---|---|---|---|
| 模型大小 | 7B | 7B | 3B | 3B |
| 内存峰值 | 5.8G | 5.8G | 3.6G | 3.6G |
| 思考者预填充速度 | 25.58 tok/s | 46.32 tok/s | 54.31 tok/s | 55.16 tok/s |
| 思考者解码速度 | 8.35 tok/s | 11.52 tok/s | 15.84 tok/s | 23.31 tok/s |
| 谈话者预填充速度 | 17.21 tok/s | 97.77 tok/s | 34.58 tok/s | 217.82 tok/s |
| 谈话者解码速度 | 18.75 tok/s | 38.65 tok/s | 51.90 tok/s | 62.34 tok/s |
| Code2Wav 速度 | 20.83 tok/s | 27.36 tok/s | 28.45 tok/s | 27.36 tok/s |
🐳 Docker
为简化部署流程,我们提供了预构建环境的 Docker 镜像:qwenllm/qwen-omni。你只需安装驱动程序并下载模型文件即可启动演示。
docker run --gpus all --ipc=host --network=host --rm --name qwen2.5-omni -it qwenllm/qwen-omni:2.5-cu121 bash
你也可以通过以下命令启动 Web 演示:
bash docker/docker_web_demo.sh --checkpoint /path/to/Qwen2.5-Omni-7B
若要启用 FlashAttention-2,可使用以下命令:
bash docker/docker_web_demo.sh --checkpoint /path/to/Qwen2.5-Omni-7B --flash-attn2
引用
如果你的研究中使用了我们的论文和代码,请考虑给个 star :star: 和引用 :pencil: :
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni 技术报告},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv 预印本 arXiv:2503.20215},
year={2025}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备