Pointcept
Pointcept 是一个专为点云感知研究打造的强大且灵活的开源代码库,旨在帮助开发者通过稀疏点数据高效地“感知”三维世界。它主要解决了三维视觉领域中算法复现难、框架不统一以及大规模预训练模型缺失等痛点,为从基础骨干网络到前沿自监督学习提供了标准化的实现路径。
这款工具特别适合从事计算机视觉、机器人导航及自动驾驶领域的研究人员与算法工程师使用。无论是希望快速验证新想法的学术探索者,还是需要构建高精度三维理解系统的工业界开发者,都能从中获益。Pointcept 的独特亮点在于其集成了多项顶会最新成果,包括 CVPR 2024 口头报告论文 Point Transformer V3(以更简洁架构实现更强性能)、NeurIPS 2025 的 Concerto(联合 2D-3D 自监督学习)以及 CVPR 2025 高光论文 Sonata。此外,它还支持 Utonia 等通用编码器方案,推动了多数据集提示训练与大规模三维表示学习的发展,让用户能够轻松调用先进的预训练权重,显著降低科研与开发门槛。
使用场景
某自动驾驶初创团队正在开发城市道路感知系统,急需从激光雷达采集的稀疏点云数据中精准识别车道线、行人及障碍物。
没有 Pointcept 时
- 模型复现困难:团队需手动重构 PTv3 或 OA-CNNs 等前沿算法的代码,常因细节缺失导致无法复现论文中的高精度结果。
- 训练效率低下:缺乏统一的数据加载与增强模块,处理大规模多数据集(如 Waymo、nuScenes)时预处理耗时极长,迭代周期以周计。
- 泛化能力不足:自研模型在未见过的场景(如恶劣天气或特殊路况)下表现糟糕,缺乏类似 Utonia 或 PPT 的大规模预训练权重支持。
- 研发资源分散:工程师将 70% 的时间耗费在调试底层代码和适配不同硬件上,而非优化核心感知逻辑。
使用 Pointcept 后
- 即插即用前沿模型:直接调用内置的 PTv3、Sonata 等官方实现,一键加载预训练权重,首日即可达到 SOTA(最先进)基准性能。
- 高效流水线加速:利用其灵活的数据引擎统一处理多源点云,训练速度提升 3 倍,模型迭代周期从数周缩短至数天。
- 强泛化感知能力:基于 Utonia“单一编码器”架构和 PPT 多点提示训练技术,模型在复杂长尾场景下的识别鲁棒性显著增强。
- 聚焦核心创新:研发团队得以从繁琐的工程泥潭中解脱,将精力集中于上层策略优化与特定场景的微调。
Pointcept 通过提供标准化且高性能的点云感知基座,让自动驾驶团队从“造轮子”转向“赛车”,大幅降低了 3D 视觉技术的落地门槛。
运行环境要求
- 未说明
需要 NVIDIA GPU(依赖 MinkowskiEngine, SpConv 等稀疏卷积库及 CUDA 加速),具体显存和 CUDA 版本未说明
未说明

快速开始

![]()
Pointcept 是一个功能强大且灵活的点云感知研究代码库。它同时也是以下论文的官方实现:
🚀 Utonia:迈向适用于所有点云的单一编码器
张宇佳、吴晓阳、杨云汉、范贤哲、李翰、张岳辰、黄泽浩、王乃彦、赵恒爽
[ 预训练 ] [Utonia] - [ 项目 ] [ 引用 ] [ HF 演示 ] [ 推理 ] [ 权重 ] → 此处Concerto:2D-3D 联合自监督学习催生空间表征
张宇佳、吴晓阳、劳一星、王成耀、田卓涛、王乃彦、赵恒爽
神经信息处理系统大会(NeurIPS)2025
[ 预训练 ] [Concerto] - [ 项目 ] [ 引用 ] [ HF 演示 ] [ 推理 ] [ 权重 ] → 此处Sonata:可靠点表示的自监督学习
吴晓阳、Daniel DeTone、Duncan Frost、沈天伟、Chris Xie、Yang Nan、Jakob Engel、Richard Newcombe、赵恒爽、Julian Straub
IEEE 计算机视觉与模式识别会议(CVPR)2025 - 亮点
[ 预训练 ] [Sonata] - [ 项目 ] [ arXiv ] [ 引用 ] [ 演示 ] [ 权重 ] → 此处Point Transformer V3:更简单、更快、更强
吴晓阳、江立、王鹏帅、刘志坚、刘希辉、乔宇、欧阳万利、何通、赵恒爽
IEEE 计算机视觉与模式识别会议(CVPR)2024 - 口头报告
[ 主干网络 ] [PTv3] - [ arXiv ] [ 引用 ] [ 项目 ] → 此处OA-CNNs:用于 3D 语义分割的全适应稀疏 CNN
彭博豪、吴晓阳、江立、陈宇康、赵恒爽、田卓涛、贾继雅
IEEE 计算机视觉与模式识别会议(CVPR)2024
[ 主干网络 ] [ OA-CNNs ] - [ arXiv ] [ 引用 ] → 此处通过多数据集点提示训练实现大规模 3D 表征学习
吴晓阳、田卓涛、温鑫、彭博豪、刘希辉、于凯成、赵恒爽
IEEE 计算机视觉与模式识别会议(CVPR)2024
[ 预训练 ] [PPT] - [ arXiv ] [ 引用 ] → 此处掩码场景对比:一种可扩展的无监督 3D 表征学习框架
吴晓阳、温鑫、刘希辉、赵恒爽
IEEE 计算机视觉与模式识别会议(CVPR)2023
[ 预训练 ] [ MSC ] - [ arXiv ] [ 引用 ] → 此处面向语义分割的上下文感知分类器学习(3D 部分)
田卓涛、崔杰泉、江立、齐小娟、赖欣、陈怡心、刘舒、贾继雅
AAAI 人工智能大会(AAAI)2023 - 口头报告
[ 语义分割 ] [ CAC ] - [ arXiv ] [ 引用 ] [ 2D 部分 ] → 此处Point Transformer V2:分组向量注意力与基于分区的池化
吴晓阳、劳一星、江立、刘希辉、赵恒爽
神经信息处理系统大会(NeurIPS)2022
[ 主干网络 ] [ PTv2 ] - [ arXiv ] [ 引用 ] → 此处Point Transformer
赵恒爽、江立、贾继雅、Philip Torr、Vladlen Koltun
IEEE 国际计算机视觉会议(ICCV)2021 - 口头报告
[ 主干网络 ] [ PTv1 ] - [ arXiv ] [ 引用 ] → 此处
此外,Pointcept 集成了以下优秀工作(包含上述内容):
骨干网络:
MinkUNet(此处),
SpUNet(此处),
SPVCNN(此处),
OACNNs(此处),
PTv1(此处),
PTv2(此处),
PTv3(此处),
StratifiedFormer(此处),
OctFormer(此处),
Swin3D(此处),
LitePT(此处);
语义分割:
Mix3d(此处),
CAC(此处);
实例分割:
PointGroup(此处);
预训练:
PointContrast(此处),
Contrastive Scene Contexts(此处),
Masked Scene Contrast(此处),
Point Prompt Training(此处),
Sonata(此处),
Concerto(此处),
Utonia(此处);
数据集:
ScanNet(此处),
ScanNet200(此处),
ScanNet++(此处),
S3DIS(此处),
ArkitScene(此处),
HM3D(此处),
Matterport3D(此处),
Structured3D(此处),
SemanticKITTI(此处),
nuScenes(此处),
Waymo(此处),
ModelNet40(此处),
ScanObjectNN(此处),
ShapeNetPart(此处),
PartNetE(此处)。
亮点
- 2026年3月 🚀:Utonia 代码随 Pointcept v1.7.0 一同发布,并在我们的项目 仓库 中提供了易于使用的预训练模型,用于推理、调优和可视化。
- 2025年10月:Concerto 被 NeurIPS 2025 接受!我们随 Pointcept v1.6.1 发布了预训练的 代码,并在 Meta 托管的项目 仓库 中提供了易于使用的预训练模型,用于推理、调优和可视化。
- 2025年4月:我们现在支持
wandb,更多信息请参阅 快速入门 的训练部分。(感谢 @Streakfull 的贡献!) - 2025年3月:Sonata 被 CVPR 2025 接受,并被选为 Highlight 报告之一(仅占提交论文的 3.0%)!我们随 Pointcept v1.6.0 发布了代码。同时,我们还随 Pointcept v1.6.0 发布了预训练的 代码,并在 Meta 托管的项目 仓库 中提供了易于使用的预训练模型,用于推理、调优和可视化。
- 2024年5月:在 v1.5.2 中,我们重新设计了每个数据集的默认结构,以提升性能。请 重新预处理 数据集,或从 这里 下载我们预处理好的数据集。
- 2024年4月:PTv3 被选为 CVPR'24 的 90 篇 口头报告 论文之一(占接受论文的 3.3%,占提交论文的 0.78%)!
- 2024年3月:我们发布了被 CVPR'24 接受的 OA-CNNs 的代码。关于 OA-CNNs 的问题可 @Pbihao。
- 2024年2月:PTv3 和 PPT 被 CVPR'24 接受,我们 Pointcept 团队还有另外 两篇 论文也被 CVPR'24 接受 🎉🎉🎉。我们将很快公开这些成果!
- 2023年12月:PTv3 在 arXiv 上发布,其代码已在 Pointcept 中提供。PTv3 是一种高效的骨干网络模型,在室内和室外场景中均达到 SOTA 性能。
- 2023年8月:PPT 在 arXiv 上发布。PPT 提出了一种多数据集预训练框架,在 室内 和 室外 场景中均达到 SOTA 性能。它兼容现有的各种预训练框架和骨干网络。代码的 预发布 版本现已开放,感兴趣者可直接联系我获取访问权限。
- 2023年3月:我们发布了我们的代码库 Pointcept,这是一个功能强大的点云表征学习与感知工具。我们欢迎新的工作加入 Pointcept 大家庭,并强烈建议在开始探索之前阅读 快速入门。
- 2023年2月:MSC 和 CeCo 被 CVPR 2023 接受。MSC 是一个高效且有效的预训练框架,可促进跨数据集的大规模预训练;而 CeCo 则是一种专为长尾数据集设计的分割方法。这两种方法都兼容我们代码库中的所有现有骨干网络模型,我们也将很快向公众开放相关代码。
- 2023年1月:CAC 是 AAAI 2023 的口头报告作品,通过结合 Pointcept 将其 3D 结果进一步扩展。这一补充将使 CAC 能够作为我们代码库中的可插拔分割器使用。
- 2022年9月:PTv2 被 NeurIPS 2022 接受。它是 Point Transformer 的延续。所提出的 GVA 理论可应用于大多数现有的注意力机制,而 Grid Pooling 也是对现有池化方法的实用补充。
引用
如果您发现 Pointcept 对您的研究有所帮助,请引用我们的工作以示鼓励。(੭ˊ꒳ˋ)੭✧
@misc{pointcept2023,
title={Pointcept: A Codebase for Point Cloud Perception Research},
author={Pointcept Contributors},
howpublished = {\url{https://github.com/Pointcept/Pointcept}},
year={2023}
}
概述
安装
要求
- Ubuntu: 18.04 及以上版本。
- CUDA: 11.3 及以上版本。
- PyTorch: 1.10.0 及以上版本。
Conda 环境
方法 1:使用 conda
environment.yml文件,通过一行命令即可创建新环境:# 创建并激活名为 'pointcept-torch2.5.0-cu12.4' 的 conda 环境 # cuda: 12.4, pytorch: 2.5.0 # 如果本地已安装 CUDA,请先运行 `unset CUDA_PATH` conda env create -f environment.yml --verbose conda activate pointcept-torch2.5.0-cu12.4方法 2:使用我们预构建的 Docker 镜像,并参考支持的标签 这里。您可以通过以下命令在本地快速验证 Docker 镜像:
docker run --gpus all -it --rm pointcept/pointcept:v1.6.0-pytorch2.5.0-cuda12.4-cudnn9-devel bash git clone https://github.com/facebookresearch/sonata cd sonata export PYTHONPATH=./ && python demo/0_pca.py # 忽略 GUI 错误,毕竟容器本身并不具备图形界面,对吧?方法 3:手动创建 conda 环境:
conda create -n pointcept python=3.10 -y conda activate pointcept # (可选)如果未安装 CUDA conda install nvidia/label/cuda-12.4.1::cuda conda-forge::cudnn conda-forge::gcc=13.2 conda-forge::gxx=13.2 -y conda install ninja -y # 在此选择所需版本:https://pytorch.org/get-started/previous-versions/ conda install pytorch==2.5.0 torchvision==0.13.1 torchaudio==0.20.0 pytorch-cuda=12.4 -c pytorch -y conda install h5py pyyaml -c anaconda -y conda install sharedarray tensorboard tensorboardx wandb yapf addict einops scipy plyfile termcolor timm -c conda-forge -y conda install pytorch-cluster pytorch-scatter pytorch-sparse -c pyg -y pip install torch-geometric # spconv (SparseUNet) # 参考 https://github.com/traveller59/spconv pip install spconv-cu124 # PPT (clip) pip install ftfy regex tqdm pip install git+https://github.com/openai/CLIP.git # transformers 和 peft pip install transformers==4.50.3 pip install peft # PTv1 & PTv2 或精确评估 cd libs/pointops # 常规方式 python setup.py install # Docker 和多 GPU 架构 TORCH_CUDA_ARCH_LIST="ARCH LIST" python setup.py install # 例如 7.5:RTX 3000;8.0:a100 更多信息请参见:https://developer.nvidia.com/cuda-gpus TORCH_CUDA_ARCH_LIST="7.5 8.0" python setup.py install cd ../.. # Open3D(可视化,可选) pip install open3d
数据准备
ScanNet v2
预处理支持语义分割和实例分割,适用于 ScanNet20、ScanNet200 和 ScanNet Data Efficient。
下载 ScanNet v2 数据集。
运行原始 ScanNet 数据的预处理代码如下:
# RAW_SCANNET_DIR:下载的 ScanNet v2 原始数据集目录。 # PROCESSED_SCANNET_DIR:处理后的 ScanNet 数据集目录(输出目录)。 python pointcept/datasets/preprocessing/scannet/preprocess_scannet.py --dataset_root ${RAW_SCANNET_DIR} --output_root ${PROCESSED_SCANNET_DIR}(可选)下载 ScanNet Data Efficient 文件:
# download-scannet.py 是官方下载脚本 # 或者按照此处说明操作:https://kaldir.vc.in.tum.de/scannet_benchmark/data_efficient/documentation#download python download-scannet.py --data_efficient -o ${RAW_SCANNET_DIR} # 解压下载内容 cd ${RAW_SCANNET_DIR}/tasks unzip limited-annotation-points.zip unzip limited-reconstruction-scenes.zip # 将文件复制到处理后的数据集文件夹 mkdir ${PROCESSED_SCANNET_DIR}/tasks cp -r ${RAW_SCANNET_DIR}/tasks/points ${PROCESSED_SCANNET_DIR}/tasks cp -r ${RAW_SCANNET_DIR}/tasks/scenes ${PROCESSED_SCANNET_DIR}/tasks(替代方案)我们的预处理数据可以直接下载 [这里],请在下载前同意官方许可协议。
将处理后的数据集链接到代码库:
# PROCESSED_SCANNET_DIR:处理后的 ScanNet 数据集目录。 mkdir data ln -s ${PROCESSED_SCANNET_DIR} ${CODEBASE_DIR}/data/scannet
ScanNet++
- 下载 ScanNet++ 数据集。
- 运行原始 ScanNet++ 数据的预处理代码如下:
# RAW_SCANNETPP_DIR:下载的 ScanNet++ 原始数据集目录。 # PROCESSED_SCANNETPP_DIR:处理后的 ScanNet++ 数据集目录(输出目录)。 # NUM_WORKERS:用于并行预处理的工作线程数。 python pointcept/datasets/preprocessing/scannetpp/preprocess_scannetpp.py --dataset_root ${RAW_SCANNETPP_DIR} --output_root ${PROCESSED_SCANNETPP_DIR} --num_workers ${NUM_WORKERS} - 对大型点云数据进行采样和分块处理,以用于训练/验证划分(仅用于训练):
# PROCESSED_SCANNETPP_DIR:处理后的 ScanNet++ 数据集目录(输出目录)。 # NUM_WORKERS:用于并行预处理的工作线程数。 python pointcept/datasets/preprocessing/sampling_chunking_data.py --dataset_root ${PROCESSED_SCANNETPP_DIR} --grid_size 0.01 --chunk_range 6 6 --chunk_stride 3 3 --split train --num_workers ${NUM_WORKERS} python pointcept/datasets/preprocessing/sampling_chunking_data.py --dataset_root ${PROCESSED_SCANNETPP_DIR} --grid_size 0.01 --chunk_range 6 6 --chunk_stride 3 3 --split val --num_workers ${NUM_WORKERS} - 将处理后的数据集链接到代码库:
# PROCESSED_SCANNETPP_DIR:处理后的 ScanNet 数据集目录。 mkdir data ln -s ${PROCESSED_SCANNETPP_DIR} ${CODEBASE_DIR}/data/scannetpp
S3DIS
通过填写此 Google 表单 下载 S3DIS 数据。下载
Stanford3dDataset_v1.2.zip文件并解压。修复
Area_5/office_19/Annotations/ceiling文件第 323474 行的错误(将103.00000改为103.000000)。(可选)从 这里 下载完整的 2D-3D S3DIS 数据集(不含 XYZ 坐标),用于解析法线。
按照以下步骤运行 S3DIS 的预处理代码:
# S3DIS_DIR:已下载的 Stanford3dDataset_v1.2 数据集目录。 # RAW_S3DIS_DIR:Stanford2d3dDataset_noXYZ 数据集目录。(可选,用于解析法线) # PROCESSED_S3DIS_DIR:已处理的 S3DIS 数据集目录(输出目录)。 # 不带对齐角度的 S3DIS python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} # 带对齐角度的 S3DIS python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} --align_angle # 带法线向量的 S3DIS(推荐,法线有助于提升效果) python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} --raw_root ${RAW_S3DIS_DIR} --parse_normal python pointcept/datasets/preprocessing/s3dis/preprocess_s3dis.py --dataset_root ${S3DIS_DIR} --output_root ${PROCESSED_S3DIS_DIR} --raw_root ${RAW_S3DIS_DIR} --align_angle --parse_normal(替代方案)我们的预处理数据也可以从 [这里] 下载(包含法线向量和对齐角度),请在下载前同意官方许可协议。
将处理后的数据集链接到代码库:
# PROCESSED_S3DIS_DIR:已处理的 S3DIS 数据集目录。 mkdir data ln -s ${PROCESSED_S3DIS_DIR} ${CODEBASE_DIR}/data/s3dis
ArkitScenes
使用以下命令下载 ArkitScenes 3DOD 划分数据集:
# RAW_AS_DIR:已下载的原始 ArkitScenes 数据集目录。 git clone https://github.com/apple/ARKitScenes.git cd ARKitScenes python download_data.py 3dod --download_dir $RAW_AS_DIR --video_id_csv threedod/3dod_train_val_splits.csv按照以下步骤运行 ArkitScenes 的预处理代码:
# RAW_AS_DIR:已下载的 ArkitScenes 数据集目录。 # PROCESSED_AS_DIR:已处理的 ArkitScenes 数据集目录(输出目录)。 # NUM_WORKERS:预处理时使用的进程数,默认与 CPU 核心数相同(可能导致内存溢出)。 cd $POINTCEPT_DIR export PYTHONPATH=./ python pointcept/datasets/preprocessing/arkitscenes/preprocess_arkitscenes_mesh.py --dataset_root $RAW_AS_DIR --output_root $PROCESSED_AS_DIR --num_workers $NUM_WORKERS(替代方案)我们的预处理数据也可以从 [这里] 下载,请在下载前阅读并同意官方 许可协议。(解压命令如下:
find ./ -name '*.tar.gz' | xargs -n 1 -P 8 -I {} sh -c 'tar -xzvf {}')将处理后的数据集链接到代码库:
# PROCESSED_AR_DIR:已处理的 ArkitScenes 数据集目录(输出目录)。 mkdir data ln -s ${PROCESSED_AR_DIR} ${CODEBASE_DIR}/data/arkitscenes
Habitat - Matterport 3D (HM3D)
按照 这里 的说明下载 HM3D 的
hm3d-train-glb-v0.2.tar和hm3d-val-glb-v0.2.tar文件,并解压它们。按照以下步骤运行 HM3D 的预处理代码:
# RAW_HM_DIR:已下载的 HM3D 数据集目录。 # PROCESSED_HM_DIR:已处理的 HM3D 数据集目录(输出目录)。 # NUM_WORKERS:预处理时使用的进程数,默认与 CPU 核心数相同(可能导致内存溢出)。 export PYTHONPATH=./ python pointcept/datasets/preprocessing/hm3d/preprocess_hm3d.py --dataset_root $RAW_HM_DIR --output_root $PROCESSED_HM_DIR --density 0.02 --num_workers $NUM_WORKERS(替代方案)我们的预处理数据也可以从 [这里] 下载,请在下载前阅读并同意官方 许可协议。(解压命令如下:
find ./ -name '*.tar.gz' | xargs -n 1 -P 4 -I {} sh -c 'tar -xzvf {}')将处理后的数据集链接到代码库:
# PROCESSED_HM_DIR:已处理的 HM3D 数据集目录(输出目录)。 mkdir data ln -s ${PROCESSED_HM_DIR} ${CODEBASE_DIR}/data/hm3d
Matterport3D
- 按照 此页面 申请访问该数据集。
- 下载“region_segmentation”类型的数据,它表示场景被划分为独立房间。
# download-mp.py 是官方下载脚本 # MATTERPORT3D_DIR:已下载的 Matterport3D 数据集目录。 python download-mp.py -o {MATTERPORT3D_DIR} --type region_segmentations - 解压 region_segmentation 数据:
# MATTERPORT3D_DIR:已下载的 Matterport3D 数据集目录。 python pointcept/datasets/preprocessing/matterport3d/unzip_matterport3d_region_segmentation.py --dataset_root {MATTERPORT3D_DIR} - 按照以下步骤运行 Matterport3D 的预处理代码:
# MATTERPORT3D_DIR:已下载的 Matterport3D 数据集目录。 # PROCESSED_MATTERPORT3D_DIR:已处理的 Matterport3D 数据集目录(输出目录)。 # NUM_WORKERS:本次预处理使用的进程数。 python pointcept/datasets/preprocessing/matterport3d/preprocess_matterport3d_mesh.py --dataset_root ${MATTERPORT3D_DIR} --output_root ${PROCESSED_MATTERPORT3D_DIR} --num_workers ${NUM_WORKERS} - 将处理后的数据集链接到代码库:
# PROCESSED_MATTERPORT3D_DIR:已处理的 Matterport3D 数据集目录(输出目录)。 mkdir data ln -s ${PROCESSED_MATTERPORT3D_DIR} ${CODEBASE_DIR}/data/matterport3d
根据 OpenRooms 的说明,我们将 Matterport3D 的类别重新映射为 ScanNet 20 种语义类别,并新增了一个天花板类别。
- (替代方案)我们的预处理数据也可以从 这里 下载,请在下载前同意官方许可协议。
Structured3D
- 通过填写此Google表单下载Structured3D全景图相关及透视图相关(完整版)的zip文件(无需解压)。
- 将所有下载的zip文件整理到一个文件夹中(
${STRUCT3D_DIR})。 - 按照以下方式运行Structured3D的预处理代码:
# STRUCT3D_DIR:已下载的Structured3D数据集目录。 # PROCESSED_STRUCT3D_DIR:已处理的Structured3D数据集目录(输出目录)。 # NUM_WORKERS:预处理时使用的进程数,默认与CPU核心数相同(可能会导致内存溢出)。 export PYTHONPATH=./ python pointcept/datasets/preprocessing/structured3d/preprocess_structured3d.py --dataset_root ${STRUCT3D_DIR} --output_root ${PROCESSED_STRUCT3D_DIR} --num_workers ${NUM_WORKERS} --grid_size 0.01 --fuse_prsp --fuse_pano
根据Swin3D的说明,我们从原始的40个类别中保留了频率大于0.001的25个类别。
(可选)我们的预处理数据也可以从[这里]下载(包含透视视图和全景视图,解压后为471.7G),请在下载前同意官方许可。(使用以下命令解压:
find ./ -name '*.tar.gz' | xargs -n 1 -P 15 -I {} sh -c 'tar -xzvf {}')将处理后的数据集链接到代码库。
# PROCESSED_STRUCT3D_DIR:已处理的Structured3D数据集目录(输出目录)。 mkdir data ln -s ${PROCESSED_STRUCT3D_DIR} ${CODEBASE_DIR}/data/structured3d
SemanticKITTI
- 下载SemanticKITTI数据集。
- 将数据集链接到代码库。
# SEMANTIC_KITTI_DIR:SemanticKITTI数据集目录。 # |- SEMANTIC_KITTI_DIR # |- dataset # |- sequences # |- 00 # |- 01 # |- ... mkdir -p data ln -s ${SEMANTIC_KITTI_DIR} ${CODEBASE_DIR}/data/semantic_kitti
nuScenes
下载官方的NuScene数据集(包含激光雷达分割信息),并将下载的文件按如下方式组织:
NUSCENES_DIR │── samples │── sweeps │── lidarseg ... │── v1.0-trainval │── v1.0-test按照以下方式运行nuScenes的信息预处理代码(基于OpenPCDet修改):
# NUSCENES_DIR:已下载的nuScenes数据集目录。 # PROCESSED_NUSCENES_DIR:已处理的nuScenes数据集目录(输出目录)。 # MAX_SWEEPS:最大扫描次数。默认值:10。 pip install nuscenes-devkit pyquaternion python pointcept/datasets/preprocessing/nuscenes/preprocess_nuscenes_info.py --dataset_root ${NUSCENES_DIR} --output_root ${PROCESSED_NUSCENES_DIR} --max_sweeps ${MAX_SWEEPS} --with_camera(可选)我们的nuScenes信息预处理数据也可以从[这里]下载(仅包含处理后的信息,仍需下载原始数据并将其链接到相应文件夹),请在下载前同意官方许可。
将原始数据集链接到已处理的NuScene数据集文件夹:
# NUSCENES_DIR:已下载的nuScenes数据集目录。 # PROCESSED_NUSCENES_DIR:已处理的nuScenes数据集目录(输出目录)。 ln -s ${NUSCENES_DIR} {PROCESSED_NUSCENES_DIR}/raw此时,已处理的nuScenes文件夹将按如下方式组织:
nuscene |── raw │── samples │── sweeps │── lidarseg ... │── v1.0-trainval │── v1.0-test |── info将处理后的数据集链接到代码库。
# PROCESSED_NUSCENES_DIR:已处理的nuScenes数据集目录(输出目录)。 mkdir data ln -s ${PROCESSED_NUSCENES_DIR} ${CODEBASE_DIR}/data/nuscenes
Waymo
下载官方的Waymo数据集(v1.4.3),并将下载的文件按如下方式组织:
WAYMO_RAW_DIR │── training │── validation │── testing安装以下依赖:
# 如果提示“未找到匹配的发行版”,请直接从Pypi下载whl文件并安装该包。 conda create -n waymo python=3.10 -y conda activate waymo pip install waymo-open-dataset-tf-2-12-0按照以下方式运行预处理代码:
# WAYMO_DIR:已下载的Waymo数据集目录。 # PROCESSED_WAYMO_DIR:已处理的Waymo数据集目录(输出目录)。 # NUM_WORKERS:预处理时使用的进程数。 python pointcept/datasets/preprocessing/waymo/preprocess_waymo.py --dataset_root ${WAYMO_DIR} --output_root ${PROCESSED_WAYMO_DIR} --splits training validation --num_workers ${NUM_WORKERS}将处理后的数据集链接到代码库。
# PROCESSED_WAYMO_DIR:已处理的Waymo数据集目录(输出目录)。 mkdir data ln -s ${PROCESSED_WAYMO_DIR} ${CODEBASE_DIR}/data/waymo
ModelNet40
- 下载modelnet40_normal_resampled.zip并解压。
- 将数据集链接到代码库。
mkdir -p data ln -s ${MODELNET_DIR} ${CODEBASE_DIR}/data/modelnet40_normal_resampled
ScanObjectNN
- 下载ScanObjectNN数据集,包括
h5_files.zip和raw/object_dataset.zip。将它们分别解压到${BENCHMARK_SCANOBJECTNN_DIR}和${RAW_SCANOBJECTNN_DIR}。
ln -s ${BENCHMARK_SCANOBJECTNN_DIR} data/scanobject_eval
ShapeNetPart
- 下载ShapeNetPart。
- 将数据集链接到代码库。
mkdir -p data
ln -s ${RAW_SHAPENETPART_DIR} ${CODEBASE_DIR}/data/
PartNetE
- 下载PartNetE(data.zip)
- 按照以下方式运行PartNetE原始数据的预处理代码:
# RAW_PARTNETE_DIR:已下载的PartNetE数据集目录。
python pointcept/datasets/preprocessing/partnete/preprocess_partnete.py --dataset_root ${RAW_PARTNETE_DIR}
- 将数据集链接到代码库。
mkdir -p data
ln -s ${RAW_PARTNETE_DIR} ${CODEBASE_DIR}/data/
快速入门
训练
从零开始训练。 训练过程基于configs文件夹中的配置文件。
训练脚本将在exp文件夹中生成一个实验文件夹,并将必要的代码备份到该实验文件夹中。
训练配置、日志、TensorBoard记录以及检查点也会在训练过程中保存到该实验文件夹中。
export CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES}
# 脚本(推荐)
sh scripts/train.sh -p ${INTERPRETER_PATH} -g ${NUM_GPU} -d ${DATASET_NAME} -c ${CONFIG_NAME} -n ${EXP_NAME}
# 直接运行
export PYTHONPATH=./
python tools/train.py --config-file ${CONFIG_PATH} --num-gpus ${NUM_GPU} --options save_path=${SAVE_PATH}
例如:
# 通过脚本(推荐)
# -p 默认设置为 python,可以忽略
sh scripts/train.sh -p python -d scannet -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# 直接运行
export PYTHONPATH=./
python tools/train.py --config-file configs/scannet/semseg-pt-v2m2-0-base.py --options save_path=exp/scannet/semseg-pt-v2m2-0-base
从检查点恢复训练。 如果训练过程意外中断,以下脚本可以从给定的检查点恢复训练。
export CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES}
# 脚本(推荐)
# 只需添加 "-r true"
sh scripts/train.sh -p ${INTERPRETER_PATH} -g ${NUM_GPU} -d ${DATASET_NAME} -c ${CONFIG_NAME} -n ${EXP_NAME} -r true
# 直接运行
export PYTHONPATH=./
python tools/train.py --config-file ${CONFIG_PATH} --num-gpus ${NUM_GPU} --options save_path=${SAVE_PATH} resume=True weight=${CHECKPOINT_PATH}
Weights and Biases。
Pointcept 默认同时启用 tensorboard 和 wandb。关于 wandb 的一些使用注意事项如下:
- 可通过设置
enable_wandb=False来禁用; - 通过在终端中执行
wandb login或在配置文件中设置wandb_key=YOUR_WANDB_KEY来与wandb远程服务器同步; - 项目名称默认为 “Pointcept”,可通过设置
wandb_project=YOUR_PROJECT_NAME自定义为你的研究项目名称(例如 Sonata-Dev、PointTransformerV3-Dev)。
测试
在训练过程中,模型评估是在经过网格采样(体素化)后的点云上进行的,这提供了对模型性能的初步评估。然而,要获得精确的评估结果,测试是 必不可少的 (现在我们会在训练结束后自动运行测试流程,借助 。测试过程涉及将密集点云下采样为一系列体素化的点云,以确保全面覆盖所有点。然后对这些子结果进行预测并汇总,形成对整个点云的完整预测。这种方法相比简单地映射或插值预测,能够得到更高的评估结果。此外,我们的测试代码还支持 TTA(测试时增强)测试,这进一步提高了评估性能的稳定性。PreciseEvaluation 钩子)
# 通过脚本(基于训练脚本创建的实验文件夹)
sh scripts/test.sh -p ${INTERPRETER_PATH} -g ${NUM_GPU} -d ${DATASET_NAME} -n ${EXP_NAME} -w ${CHECKPOINT_NAME}
# 直接运行
export PYTHONPATH=./
python tools/test.py --config-file ${CONFIG_PATH} --num-gpus ${NUM_GPU} --options save_path=${SAVE_PATH} weight=${CHECKPOINT_PATH}
例如:
# 通过脚本(基于训练脚本创建的实验文件夹)
# -p 默认设置为 python,可以忽略
# -w 默认设置为 model_best,也可以忽略
sh scripts/test.sh -p python -d scannet -n semseg-pt-v2m2-0-base -w model_best
# 直接运行
export PYTHONPATH=./
python tools/test.py --config-file configs/scannet/semseg-pt-v2m2-0-base.py --options save_path=exp/scannet/semseg-pt-v2m2-0-base weight=exp/scannet/semseg-pt-v2m2-0-base/model/model_best.pth
可以通过将 data.test.test_cfg.aug_transform = [...] 替换为以下内容来禁用 TTA:
data = dict(
train = dict(...),
val = dict(...),
test = dict(
...,
test_cfg = dict(
...,
aug_transform = [
[dict(type="RandomRotateTargetAngle", angle=[0], axis="z", center=[0, 0, 0], p=1)]
]
)
)
)
Offset
Offset 是批量数据中点云之间的分隔符,类似于 PyG 中的 Batch 概念。
批量和 offset 的可视化说明如下:
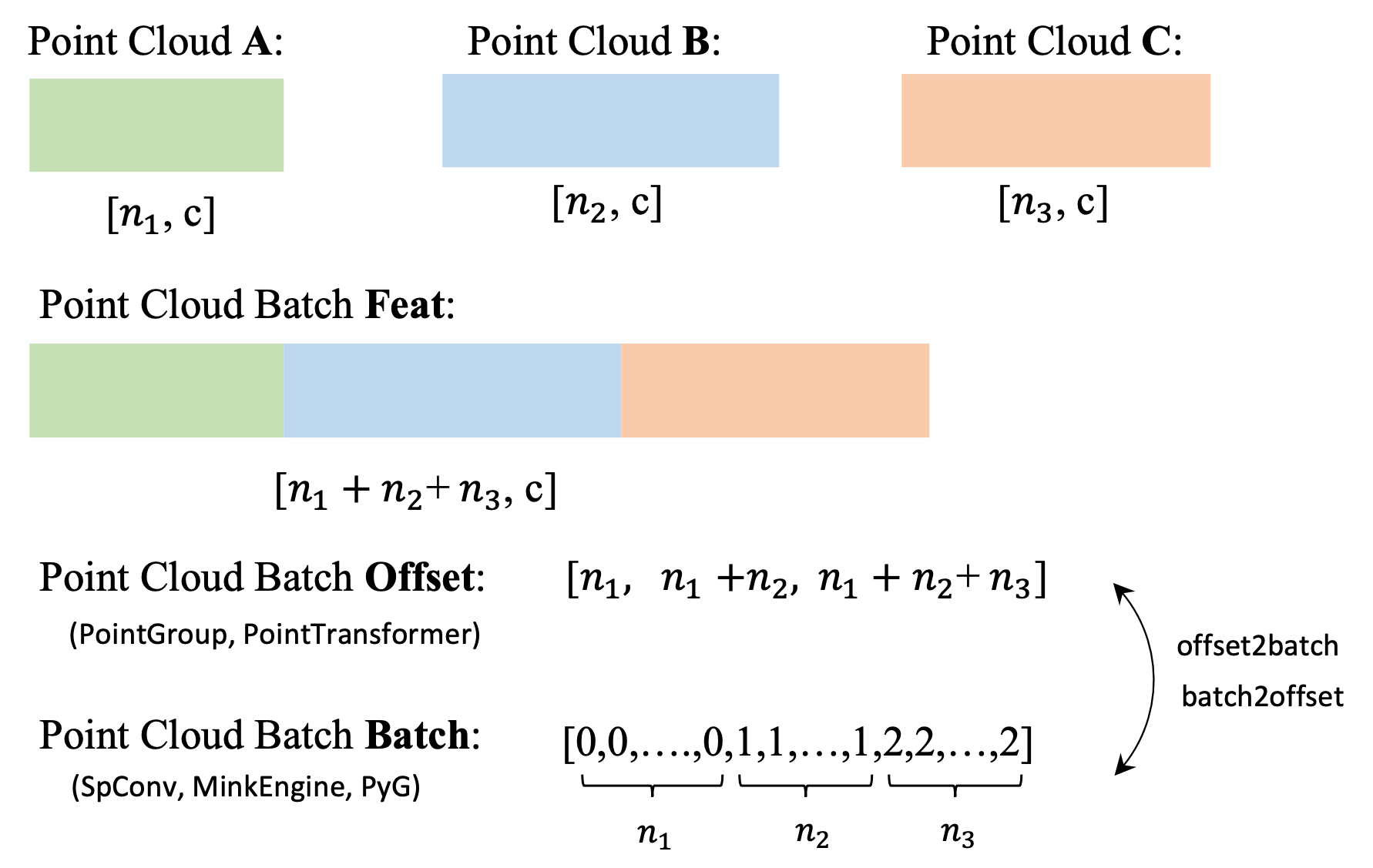
模型库
1. 主干网络与语义分割
SparseUNet
Pointcept 提供了由 SpConv 和 MinkowskiEngine 实现的 SparseUNet。推荐使用 SpConv 版本,因为 SpConv 安装方便且速度比 MinkowskiEngine 更快。同时,SpConv 在室外感知领域也得到了广泛应用。
- SpConv(推荐)
代码库中的 SpConv 版本 SparseUNet 是完全从 MinkowskiEngine 版本重写而来的,示例运行脚本如下:
# ScanNet 验证集
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# S3DIS(带法线)
sh scripts/train.sh -g 4 -d s3dis -c semseg-spunet-v1m1-0-cn-base -n semseg-spunet-v1m1-0-cn-base
# SemanticKITTI
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# nuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# ModelNet40
sh scripts/train.sh -g 2 -d modelnet40 -c cls-spunet-v1m1-0-base -n cls-spunet-v1m1-0-base
# ScanNet 数据高效版
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la20 -n semseg-spunet-v1m1-2-efficient-la20
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la50 -n semseg-spunet-v1m1-2-efficient-la50
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la100 -n semseg-spunet-v1m1-2-efficient-la100
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-la200 -n semseg-spunet-v1m1-2-efficient-la200
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr1 -n semseg-spunet-v1m1-2-efficient-lr1
sh scripts.train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr5 -n semseg-spunet-v1m1-2-efficient-lr5
sh scripts.train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr10 -n semseg-spunet-v1m1-2-efficient-lr10
sh scripts.train.sh -g 4 -d scannet -c semseg-spunet-v1m1-2-efficient-lr20 -n semseg-spunet-v1m1-2-efficient-lr20
# 配置文件模型运行时间
sh scripts/train.sh -g 4 -d scannet -c semseg-spunet-v1m1-0-enable-profiler -n semseg-spunet-v1m1-0-enable-profiler
- MinkowskiEngine
代码库中的 SparseUNet 版本基于原始的 MinkowskiEngine 仓库进行了修改,示例运行脚本如下:
- 安装 MinkowskiEngine,请参考:https://github.com/NVIDIA/MinkowskiEngine
- 使用以下示例脚本来进行训练:
# 解注释 "pointcept/models/__init__.py" 中的 "# from .sparse_unet import *"
# 解注释 "pointcept/models/sparse_unet/__init__.py" 中的 "# from .mink_unet import *"
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-base
# SemanticKITTI
sh scripts/train.sh -g 2 -d semantic_kitti -c semseg-minkunet34c-0-base -n semseg-minkunet34c-0-base
OA-CNNs
介绍全适配性 3D CNN(OA-CNNs),这是一系列网络,通过集成一个轻量级模块,在几乎不增加计算成本的情况下,极大地提升了稀疏 CNN 的自适应能力。在没有任何自注意力模块的情况下,OA-CNNs 在室内和室外场景中均以更高的准确率、更低的延迟和更少的内存消耗,显著优于点云 Transformer。关于 OA-CNNs 的问题可以 @Pbihao。
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-oacnns-v1m1-0-base -n semseg-oacnns-v1m1-0-base
点云 Transformer
- LitePT
LitePT(CVPR 2026)是一种最先进的点云骨干网络,与之前的点云 Transformer 相比,其性能更优或相当,同时效率大幅提升。
- 需要额外准备:
编译 PointROPE 的 CUDA 实现。否则,系统将自动回退到较慢的 PyTorch 实现。
cd libs/pointrope
python setup.py install
cd ../..
- 示例运行脚本:
该模型注册为 LitePT-v1,并共享于小型/基础/大型变体。在配置文件名中,v1m1 表示轻量级解码器(无卷积/注意力),而 v1m2 则在选定阶段使用带有卷积或注意力的解码器。详细信息请参阅论文第 4.1 节中的“解码器设计”。
### NuScenes + LitePT-S
sh scripts/train.sh -g 4 -d nuscenes -c semseg-litept-v1m1-0-small -n semseg-litept-v1m1-0-small
### Waymo + LitePT-S
sh scripts/train.sh -g 4 -d waymo -c semseg-litept-v1m1-0-small -n semseg-litept-v1m1-0-small
### ScanNet + LitePT-S
sh scripts/train.sh -g 4 -d scannet -c semseg-litept-v1m1-0-small -n semseg-litept-v1m1-0-small
### Structured3D + LitePT-S
sh scripts/train.sh -g 16 -d structured3d -c semseg-litept-v1m1-0-small -n semseg-litept-v1m1-0-small
### Structured3D + LitePT-B
sh scripts/train.sh -g 16 -d structured3d -c semseg-litept-v1m1-0-base -n semseg-litept-v1m1-0-base
### Structured3D + LitePT-L
sh scripts/train.sh -g 16 -d structured3d -c semseg-litept-v1m1-0-large -n semseg-litept-v1m1-0-large
详细的说明和权重可在 项目仓库 中找到。
- PTv3
PTv3 是一种高效的骨干模型,在室内和室外场景中均达到了 SOTA 性能。完整的 PTv3 依赖于 FlashAttention,而 FlashAttention 又依赖于 CUDA 11.6 及以上版本,因此请确保本地 Pointcept 环境满足要求。
如果您无法升级本地环境以满足要求(CUDA ≥ 11.6),则可以通过将模型参数 enable_flash 设置为 false,并将 enc_patch_size 和 dec_patch_size 降低至一定水平(例如 128)来禁用 FlashAttention。
启用 FlashAttention 会强制禁用 RPE,并将精度降至 fp16。如果您需要这些功能,请禁用 enable_flash 并调整 enable_rpe、upcast_attention 和 upcast_softmax。
详细的说明和实验记录(包含权重)可在 项目仓库 中找到。示例运行脚本如下:
# 从头开始训练 ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# PPT 联合训练(ScanNet + Structured3D),并在 ScanNet 上评估
sh scripts/train.sh -g 8 -d scannet -c semseg-pt-v3m1-1-ppt-extreme -n semseg-pt-v3m1-1-ppt-extreme
# 从头开始训练 ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# 基于 PPT 联合训练(ScanNet + Structured3D)对 ScanNet200 进行微调
# PTV3_PPT_WEIGHT_PATH:PPT 多数据集联合训练所得到的模型权重路径
# 例如:exp/scannet/semseg-pt-v3m1-1-ppt-extreme/model/model_best.pth
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v3m1-1-ppt-ft -n semseg-pt-v3m1-1-ppt-ft -w ${PTV3_PPT_WEIGHT_PATH}
# 从头开始训练 ScanNet++
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# 对 ScanNet++ 进行测试
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v3m1-1-submit -n semseg-pt-v3m1-1-submit
# 从头开始训练 S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# 禁用 flash_attention 并启用 rpe 的示例。
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v3m1-1-rpe -n semseg-pt-v3m1-0-rpe
# PPT 联合训练(ScanNet + S3DIS + Structured3D),并在 ScanNet 上评估
sh scripts/train.sh -g 8 -d s3dis -c semseg-pt-v3m1-1-ppt-extreme -n semseg-pt-v3m1-1-ppt-extreme
# S3DIS 6 折交叉验证
# 1. 默认配置是在 Area_5 上评估的,需修改 "data.train.split"、"data.val.split" 和 "data.test.split",使配置分别在 Area_1 至 Area_6 上评估。
# 2. 在每个区域划分上训练并评估模型,将位于 "exp/s3dis/EXP_NAME/result/Area_x.pth" 的结果文件收集到一个文件夹中,称为 RECORD_FOLDER。
# 3. 运行以下脚本以获得 S3DIS 6 折交叉验证的性能:
export PYTHONPATH=./
python tools/test_s3dis_6fold.py --record_root ${RECORD_FOLDER}
# 从头开始训练 nuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# 从头开始训练 Waymo
sh scripts/train.sh -g 4 -d waymo -c semseg-pt-v3m1-0-base -n semseg-pt-v3m1-0-base
# PTv3 的更多配置和实验记录将很快发布。
室内语义分割
| 模型 | 基准 | 额外数据 | GPU 数量 | 验证 mIoU | 配置 | TensorBoard | 实验记录 |
|---|---|---|---|---|---|---|---|
| PTv3 | ScanNet | ✗ | 4 | 77.6% | 链接 | 链接 | 链接 |
| PTv3 + PPT | ScanNet | ✓ | 8 | 78.5% | 链接 | 链接 | 链接 |
| PTv3 | ScanNet200 | ✗ | 4 | 35.3% | 链接 | 链接 | 链接 |
| PTv3 | S3DIS (Area5) | ✗ | 4 | 73.6% | 链接 | 链接 | 链接 |
| PTv3 + PPT | S3DIS (Area5) | ✓ | 8 | 75.4% | 链接 | 链接 | 链接 |
| *已发布的模型权重是基于 v1.5.1 训练的,v1.5.2 及更高版本的权重仍在训练中。 |
- PTv2 mode2
原始的 PTv2 是在 4 张 RTX a6000(每张显存 48G)上训练的。即使启用了 AMP,原始 PTv2 的显存占用仍略高于 24G。考虑到 24G 显存的显卡更为普及,我在最新的 Pointcept 上对 PTv2 进行了调整,使其能够在 4 张 RTX 3090 的机器上运行。
PTv2 Mode2 启用 AMP,并禁用了 Position Encoding Multiplier 和 Grouped Linear。在进一步的研究中,我们发现点云理解并不需要精确的坐标信息(用网格坐标替代精确坐标并不会影响性能,SparseUNet 就是一个例子)。至于 Grouped Linear,我发现我实现的 Grouped Linear 比 PyTorch 自带的 Linear 层更占显存。得益于代码库和更好的参数调优,我们也缓解了过拟合问题。复现的效果甚至优于我们在论文中报告的结果。
示例运行脚本如下:
# ptv2m2: PTv2 mode2,禁用 PEM 和 Grouped Linear,显存占用 < 24G(推荐)
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m2-3-lovasz -n semseg-pt-v2m2-3-lovasz
# ScanNet 测试
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m2-1-submit -n semseg-pt-v2m2-1-submit
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# ScanNet++
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# ScanNet++ 测试
sh scripts/train.sh -g 4 -d scannetpp -c semseg-pt-v2m2-1-submit -n semseg-pt-v2m2-1-submit
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# SemanticKITTI
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
# nuScenes
sh scripts/train.sh -g 4 -d nuscenes -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
- PTv2 mode1
PTv2 mode1 是我们在论文中报道的原始 PTv2,示例运行脚本如下:
# ptv2m1: PTv2 mode1,原始 PTv2,显存占用 > 24G
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v2m1-0-base -n semseg-pt-v2m1-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v2m1-0-base -n semseg-pt-v2m1-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v2m1-0-base -n semseg-pt-v2m1-0-base
- PTv1
原始的 PTv1 也在我们的 Pointcept 代码库中提供。虽然我已经很久没有运行 PTv1 了,但我已经确认示例运行脚本可以正常工作。
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-pt-v1-0-base -n semseg-pt-v1-0-base
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-pt-v1-0-base -n semseg-pt-v1-0-base
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-pt-v1-0-base -n semseg-pt-v1-0-base
分层 Transformer
- 需要额外安装:
pip install torch-points3d
# 修复因安装 torch-points3d 导致的依赖问题
pip uninstall SharedArray
pip install SharedArray==3.2.1
cd libs/pointops2
python setup.py install
cd ../..
- 在
pointcept/models/__init__.py中取消注释# from .stratified_transformer import *。 - 参阅 可选安装 来安装依赖。
- 使用以下示例脚本来训练:
# stv1m1: 分层 Transformer mode1,基于原始分层 Transformer 代码修改。
# PTv2m2: 分层 Transformer mode2,我的重写版本(推荐)。
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-st-v1m2-0-refined -n semseg-st-v1m2-0-refined
sh scripts/train.sh -g 4 -d scannet -c semseg-st-v1m1-0-origin -n semseg-st-v1m1-0-origin
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-st-v1m2-0-refined -n semseg-st-v1m2-0-refined
# S3DIS
sh scripts/train.sh -g 4 -d s3dis -c semseg-st-v1m2-0-refined -n semseg-st-v1m2-0-refined
SPVCNN
SPVCNN 是 SPVNAS 的基线模型,同时也是室外数据集的一个实用基线。
- 安装 torchsparse:
# 参考 https://github.com/mit-han-lab/torchsparse
# 不使用 sudo apt install 的安装方法
conda install google-sparsehash -c bioconda
export C_INCLUDE_PATH=${CONDA_PREFIX}/include:$C_INCLUDE_PATH
export CPLUS_INCLUDE_PATH=${CONDA_PREFIX}/include:CPLUS_INCLUDE_PATH
pip install --upgrade git+https://github.com/mit-han-lab/torchsparse.git
- 使用以下示例脚本来训练:
# SemanticKITTI
sh scripts/train.sh -g 2 -d semantic_kitti -c semseg-spvcnn-v1m1-0-base -n semseg-spvcnn-v1m1-0-base
OctFormer
OctFormer 来自论文 OctFormer: 基于八叉树的 3D 点云 Transformer。
- 需要安装的额外依赖:
cd libs
git clone https://github.com/octree-nn/dwconv.git
pip install ./dwconv
pip install ocnn
- 在
pointcept/models/__init__.py中取消注释# from .octformer import *。 - 使用以下示例脚本进行训练:
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-octformer-v1m1-0-base -n semseg-octformer-v1m1-0-base
Swin3D
Swin3D 来自论文 Swin3D: 用于 3D 室内场景理解的预训练 Transformer 主干网络。
- 需要安装的额外依赖:
# 1. 安装 MinkEngine v0.5.4,按照 https://github.com/NVIDIA/MinkowskiEngine 中的说明操作;
# 2. 安装 Swin3D,主要用于 CUDA 运行:
cd libs
git clone https://github.com/microsoft/Swin3D.git
cd Swin3D
pip install ./
- 在
pointcept/models/__init__.py中取消注释# from .swin3d import *。 - 使用以下示例脚本进行预训练(Structured3D 的预处理请参考 这里):
# Structured3D + Swin-S
sh scripts/train.sh -g 4 -d structured3d -c semseg-swin3d-v1m1-0-small -n semseg-swin3d-v1m1-0-small
# Structured3D + Swin-L
sh scripts/train.sh -g 4 -d structured3d -c semseg-swin3d-v1m1-1-large -n semseg-swin3d-v1m1-1-large
# 补充
# Structured3D + SpUNet
sh scripts/train.sh -g 4 -d structured3d -c semseg-spunet-v1m1-0-base -n semseg-spunet-v1m1-0-base
# Structured3D + PTv2
sh scripts/train.sh -g 4 -d structured3d -c semseg-pt-v2m2-0-base -n semseg-pt-v2m2-0-base
- 使用以下示例脚本进行微调:
# ScanNet + Swin-S
sh scripts/train.sh -g 4 -d scannet -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-0-small -n semseg-swin3d-v1m1-0-small
# ScanNet + Swin-L
sh scripts/train.sh -g 4 -d scannet -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-1-large -n semseg-swin3d-v1m1-1-large
# S3DIS + Swin-S(此处提供支持 S3DIS 法向量的配置)
sh scripts/train.sh -g 4 -d s3dis -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-0-small -n semseg-swin3d-v1m1-0-small
# S3DIS + Swin-L(此处提供支持 S3DIS 法向量的配置)
sh scripts/train.sh -g 4 -d s3dis -w exp/structured3d/semseg-swin3d-v1m1-1-large/model/model_last.pth -c semseg-swin3d-v1m1-1-large -n semseg-swin3d-v1m1-1-large
上下文感知分类器
上下文感知分类器 是一种可以进一步提升各主干网络性能的分割模型,可替代 默认分割器。使用以下示例脚本进行训练:
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c semseg-cac-v1m1-0-spunet-base -n semseg-cac-v1m1-0-spunet-base
sh scripts/train.sh -g 4 -d scannet -c semseg-cac-v1m1-1-spunet-lovasz -n semseg-cac-v1m1-1-spunet-lovasz
sh scripts/train.sh -g 4 -d scannet -c semseg-cac-v1m1-2-ptv2-lovasz -n semseg-cac-v1m1-2-ptv2-lovasz
# ScanNet200
sh scripts/train.sh -g 4 -d scannet200 -c semseg-cac-v1m1-0-spunet-base -n semseg-cac-v1m1-0-spunet-base
sh scripts/train.sh -g 4 -d scannet200 -c semseg-cac-v1m1-1-spunet-lovasz -n semseg-cac-v1m1-1-spunet-lovasz
sh scripts/train.sh -g 4 -d scannet200 -c semseg-cac-v1m1-2-ptv2-lovasz -n semseg-cac-v1m1-2-ptv2-lovasz
2. 实例分割
PointGroup
PointGroup 是点云实例分割的一个基准框架。
- 需要安装的额外依赖:
conda install -c bioconda google-sparsehash
cd libs/pointgroup_ops
python setup.py install --include_dirs=${CONDA_PREFIX}/include
cd ../..
- 在
pointcept/models/__init__.py中取消注释# from .point_group import *。 - 使用以下示例脚本进行训练:
# ScanNet
sh scripts/train.sh -g 4 -d scannet -c insseg-pointgroup-v1m1-0-spunet-base -n insseg-pointgroup-v1m1-0-spunet-base
# S3DIS
sh scripts/train.sh -g 4 -d scannet -c insseg-pointgroup-v1m1-0-spunet-base -n insseg-pointgroup-v1m1-0-spunet-base
3. 预训练
Utonia
请按照 这里 的说明进行操作。
Concerto
请按照 这里 的说明进行操作。
Sonata
请按照 这里 的说明进行操作。
掩码场景对比学习 (MSC)
- 使用以下示例脚本进行预训练:
# ScanNet
sh scripts/train.sh -g 8 -d scannet -c pretrain-msc-v1m1-0-spunet-base -n pretrain-msc-v1m1-0-spunet-base
- 使用以下示例脚本进行微调:
在进行实例分割任务的微调之前,请先启用 PointGroup(这里)。
# ScanNet20 语义分割
sh scripts/train.sh -g 8 -d scannet -w exp/scannet/pretrain-msc-v1m1-0-spunet-base/model/model_last.pth -c semseg-spunet-v1m1-4-ft -n semseg-msc-v1m1-0f-spunet-base
# ScanNet20 实例分割(运行脚本前需启用 PointGroup)
sh scripts/train.sh -g 4 -d scannet -w exp/scannet/pretrain-msc-v1m1-0-spunet-base/model/model_last.pth -c insseg-pointgroup-v1m1-0-spunet-base -n insseg-msc-v1m1-0f-pointgroup-spunet-base
点提示训练 (PPT)
PPT 提出了一种多数据集的预训练框架,它与现有的各种预训练框架和主干网络兼容。
- 使用以下示例脚本进行 PPT 监督联合训练:
# ScanNet + Structured3d,在 ScanNet 上验证(S3DIS 可能导致数据加载时间过长,为快速验证可不包含 S3DIS)>= 3090 * 8
sh scripts/train.sh -g 8 -d scannet -c semseg-ppt-v1m1-0-sc-st-spunet -n semseg-ppt-v1m1-0-sc-st-spunet
sh scripts/train.sh -g 8 -d scannet -c semseg-ppt-v1m1-1-sc-st-spunet-submit -n semseg-ppt-v1m1-1-sc-st-spunet-submit
# ScanNet + S3DIS + Structured3d,在 S3DIS 上验证(>= a100 * 8)
sh scripts/train.sh -g 8 -d s3dis -c semseg-ppt-v1m1-0-s3-sc-st-spunet -n semseg-ppt-v1m1-0-s3-sc-st-spunet
# SemanticKITTI + nuScenes + Waymo,在 SemanticKITTI 上验证(bs12 >= 3090 * 4 >= 3090 * 8,v1m1-0 仍在调试中)
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-ppt-v1m1-0-nu-sk-wa-spunet -n semseg-ppt-v1m1-0-nu-sk-wa-spunet
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-ppt-v1m2-0-sk-nu-wa-spunet -n semseg-ppt-v1m2-0-sk-nu-wa-spunet
sh scripts/train.sh -g 4 -d semantic_kitti -c semseg-ppt-v1m2-1-sk-nu-wa-spunet-submit -n semseg-ppt-v1m2-1-sk-nu-wa-spunet-submit
# SemanticKITTI + nuScenes + Waymo,在 nuScenes 上进行验证(bs12 >= 3090 * 4;bs24 >= 3090 * 8,v1m1-0 仍在调参中)
sh scripts/train.sh -g 4 -d nuscenes -c semseg-ppt-v1m1-0-nu-sk-wa-spunet -n semseg-ppt-v1m1-0-nu-sk-wa-spunet
sh scripts/train.sh -g 4 -d nuscenes -c semseg-ppt-v1m2-0-nu-sk-wa-spunet -n semseg-ppt-v1m2-0-nu-sk-wa-spunet
sh scripts/train.sh -g 4 -d nuscenes -c semseg-ppt-v1m2-1-nu-sk-wa-spunet-submit -n semseg-ppt-v1m2-1-nu-sk-wa-spunet-submit
PointContrast
- 预处理并链接 ScanNet-Pair 数据集(与 ScanNet 原始 RGB-D 帧进行成对匹配,约 1.5T):
# RAW_SCANNET_DIR:下载的 ScanNet v2 原始数据集目录。
# PROCESSED_SCANNET_PAIR_DIR:处理后的 ScanNet 对数据集目录(输出目录)。
python pointcept/datasets/preprocessing/scannet/scannet_pair/preprocess.py --dataset_root ${RAW_SCANNET_DIR} --output_root ${PROCESSED_SCANNET_PAIR_DIR}
ln -s ${PROCESSED_SCANNET_PAIR_DIR} ${CODEBASE_DIR}/data/scannet
- 使用以下示例脚本进行预训练:
# ScanNet
sh scripts/train.sh -g 8 -d scannet -c pretrain-msc-v1m1-1-spunet-pointcontrast -n pretrain-msc-v1m1-1-spunet-pointcontrast
- 微调请参考 MSC。
对比场景上下文
- 预处理并链接 ScanNet-Pair 数据集(参考 PointContrast):
- 使用以下示例脚本进行预训练:
# ScanNet
sh scripts/train.sh -g 8 -d scannet -c pretrain-msc-v1m2-0-spunet-csc -n pretrain-msc-v1m2-0-spunet-csc
- 微调请参考 MSC。
致谢
Pointcept 由 Xiaoyang 设计,命名者为 Yixing,标志由 Yuechen 创作。它源自 Hengshuang 的 Semseg,并受到多个仓库的启发,例如 MinkowskiEngine、pointnet2、mmcv 和 Detectron2。
版本历史
v1.7.02026/04/02v1.6.12026/02/28v1.6.02025/03/25v1.5.22024/05/17v1.5.12024/02/25v1.5.02023/12/31v1.4.02023/12/14v1.3.12023/07/10v1.3.02023/06/16v1.2.12023/06/05v1.2.02023/03/23常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器