PixArt-alpha
PixArt-α 是一款专注于快速训练扩散 Transformer 模型的开源工具,旨在实现高质量的写实风格“文生图”合成。作为 ICLR 2024 的焦点论文成果,它主要解决了传统扩散模型训练成本高昂、收敛速度慢以及对计算资源要求极高的问题。通过引入高效的架构设计与数据策略,PixArt-α 能够在显著减少训练时间和算力的前提下,生成细节丰富、逼真度极高的图像。
该工具特别适合 AI 研究人员探索高效的模型训练范式,同时也为开发者提供了灵活的 PyTorch 代码库和预训练权重,便于进行二次开发或集成到如 ComfyUI 等工作流中。对于希望低成本部署高性能生成模型的企业或技术团队,PixArt-α 也是一个极具价值的选择。其核心技术亮点在于创新性地结合了 Transformer 架构与扩散模型,并利用了大规模高质量数据集(如 SAM-LLaVA-Captions10M)进行优化,从而在保持生成质量的同时大幅提升了训练效率。目前,项目已开放完整的推理代码、模型权重及在线演示,社区支持活跃,方便各类用户快速上手体验。
使用场景
一家独立游戏开发团队正在为即将上线的奇幻 RPG 项目紧急制作大量高分辨率概念图,以统一美术风格并加速资产生产。
没有 PixArt-alpha 时
- 训练成本高昂:团队若想微调模型以匹配独特画风,需耗费数周时间在昂贵 GPU 集群上训练传统扩散模型。
- 生成速度缓慢:使用现有开源模型生成单张 1024x1024 高清图需数十秒,难以满足快速迭代需求。
- 细节表现不足:生成的复杂场景(如光影交错的城堡)常出现结构扭曲或纹理模糊,缺乏照片级真实感。
- 资源门槛过高:高性能推理依赖顶级显卡,导致普通开发者的本地机器无法流畅运行。
使用 PixArt-alpha 后
- 训练效率飞跃:借助 Diffusion Transformer 架构,团队仅需少量数据和数天即可在单卡上完成特定风格的高效微调。
- 极速高清输出:利用其优化的采样策略,生成同等分辨率图像的时间缩短至几秒,大幅提升了试错频率。
- 画质显著提升:模型对文本提示的理解更精准,能稳定输出光影自然、细节丰富的照片级奇幻场景。
- 部署更加灵活:得益于高效的推理性能,美术人员可直接在配置普通的 workstation 上实时预览和修改生成结果。
PixArt-alpha 通过突破性的训练速度与卓越的成像质量,让中小团队也能以低成本实现电影级的视觉资产创作。
运行环境要求
- Linux
- Windows
- 需要 NVIDIA GPU
- 官方支持在 8GB 显存下运行(通过 Diffusers),推荐更高显存以支持高分辨率生成或训练
未说明

快速开始

👉 PixArt-α:用于照片级逼真文生图的扩散Transformer快速训练
ICLR 2024 Spotlight













本仓库包含我们论文中探索的使用Transformer进行快速训练扩散模型的PyTorch模型定义、预训练权重以及推理/采样代码。您可以在我们的项目页面上找到更多可视化内容。
PixArt-α 社区:欢迎加入我们的PixArt-α Discord频道
 ,参与讨论。欢迎各位开发者贡献代码。
,参与讨论。欢迎各位开发者贡献代码。
PixArt-α:用于照片级逼真文生图的扩散Transformer快速训练
陈俊松*、于锦程*、
葛崇健*、姚雷威*、
谢恩泽†、
吴岳、王仲道、
郭志伟、罗平、
陆虎川、
李振国
华为诺亚方舟实验室、大连理工大学、香港大学、香港科技大学
PIXART-δ:基于潜在一致性模型的快速可控图像生成
陈俊松、吴岳、罗思敏、谢恩泽†、
萨亚克·保罗、罗平、赵航、李振国
华为诺亚方舟实验室、大连理工大学、清华大学、香港大学、Hugging Face
最新消息 🔥🔥!!
(🔥 新) 2024年4月12日。💥 更优秀的PixArt-Σ训练与推理代码及检查点已全部发布!!!
欢迎大家合作与贡献。如果您觉得有用,请为我们点亮🌟!
(🔥 新) 2024年1月19日。💥 PixArt-δ ControlNet app_controlnet.py和检查点已发布!!!
(🔥 新) 2024年1月16日。💥 恭喜宣布,PixArt-α已被ICLR 2024接受(Spotlight)。
-
(🔥 新) 2023年11月30日。💥 PixArt与LCMs团队合作,打造了最快的文生图训练与推理系统。
在此,训练代码、推理代码、权重以及Hugging Face演示、OpenXLab演示均已发布,我们希望用户能够喜欢。详细的推理速度和代码指南可在文档中找到。同时,我们还更新了代码库以提升用户体验,并修复了最新版本中的若干Bug。
🚩 新功能/更新
- ✅ 2024年1月11日。💥 PixArt-δ:我们非常高兴地宣布发布 PixArt-δ 技术报告!!!
该报告深入探讨了Transformer模型中LCM和ControlNet类似模块的训练方法。同时,我们也在此仓库中发布了LCM与ControlNet的所有训练和推理代码 在此仓库。
我们鼓励大家尝试使用这些代码,并热烈欢迎用户的Pull Request。您的贡献和反馈对我们非常重要!
- ✅ 2024年2月7日。train_diffusers.py 可以直接使用diffusers模型进行训练,并在训练过程中进行可视化。
- ✅ 2024年1月26日。💥 PixArt-α 的所有检查点,包括256px分辨率的检查点,现在都可以在这里下载 下载模型。
- ✅ 2024年1月19日。💥 PixArt-δ 的ControlNet app_controlnet.py 和 检查点 已发布!!!
- ✅ 2024年1月12日。💥 我们发布了用于PixArt-α训练的 SAM-LLaVA-Captions 数据集。
- ✅ 2023年12月27日。PixArt-α 已集成到 ControlLLM 中!
- ✅ 2023年12月17日。以Hugging Face风格发布的 PixArt-LCM-Lora 和 PixArt-Lora 训练脚本已发布。
- ✅ 2023年12月13日。在 tools/extract_features.py 中添加了多尺度VAE特征提取功能。
- ✅ 2023年12月1日。新增了一个 Notebook文件夹,帮助用户快速上手PixArt!感谢 @kopyl 的贡献!
- ✅ 2023年11月27日。💥 PixArt-α社区:加入我们的PixArt-α Discord频道
进行讨论。欢迎各位开发者参与贡献。
- ✅ 2023年11月21日。💥 SA-Sovler 官方代码首次发布 此处。
- ✅ 2023年11月19日。发布
PixArt + Dreambooth 训练脚本。
- ✅ 2023年11月16日。Diffusers 现在支持
随机分辨率 和 批量生成图片 功能。此外,
在低于8GB显存的GPU上运行 Pixart 也已成为可能,在 🧨 diffusers 中有相关说明。
- ✅ 2023年11月10日。在 🧨 diffusers 中支持 DALL-E 3 Consistency Decoder。
- ✅ 2023年11月6日。发布预训练权重,并集成 🧨 diffusers、Hugging Face演示以及Google Colab示例。
- ✅ 2023年11月3日。发布 LLaVA 字幕生成推理代码。
- ✅ 2023年10月27日。发布训练及特征提取代码。
- ✅ 2023年10月20日。与 Hugging Face 和 Diffusers 团队合作,共同发布代码和权重。(请继续关注。)
- ✅ 2023年10月15日。发布推理代码。
目录
-
-
-
-
-
-
-
-
-
-
-
-
-
🐱 摘要
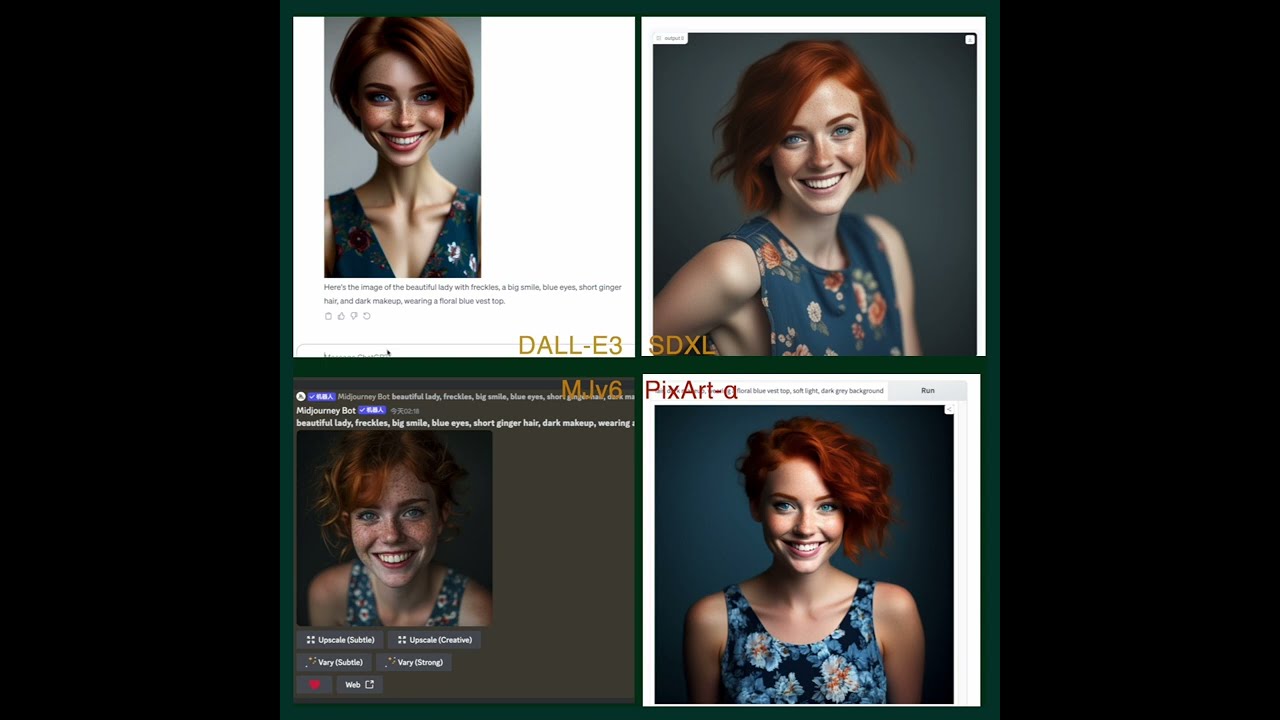
TL; DR: PixArt-α 是一种基于Transformer的T2I扩散模型,其图像生成质量可与当前最先进的图像生成器(如Imagen、SDXL,甚至Midjourney)相媲美,而训练速度则显著超越现有的大型T2I模型。例如,PixArt-α仅需675天的A100 GPU时间,而Stable Diffusion v1.5则需要6,250天。
点击展开完整摘要
目前最先进的文本到图像(T2I)模型通常需要高昂的训练成本(例如数百万小时的GPU时间),这不仅严重阻碍了AIGC社区的基础创新,还增加了二氧化碳排放。本文介绍了一种名为PixArt-α的基于Transformer的T2I扩散模型,其图像生成质量可与当前最先进的图像生成器(如Imagen、SDXL,甚至Midjourney)相媲美,几乎达到了商业应用的标准。此外,它还支持高达1024px分辨率的高分辨率图像合成,且训练成本较低。为实现这一目标,我们提出了三个核心设计:
(1) 训练策略分解:我们设计了三个独立的训练步骤,分别优化像素依赖性、文本与图像的对齐以及图像的美学质量;
(2) 高效的T2I Transformer:我们在扩散Transformer(DiT)中引入了交叉注意力模块,以注入文本条件并简化计算密集型的类别条件分支;
(3) 高信息量的数据:我们强调文本-图像对中概念密度的重要性,并利用大型视觉-语言模型自动标注密集的伪字幕,以辅助文本-图像对齐的学习。因此,PixArt-α的训练速度显著优于现有的大型T2I模型,例如,PixArt-α仅需675天的A100 GPU时间,而Stable Diffusion v1.5则需要6,250天,从而节省了近30万美元(26,000美元 vs. 320,000美元)的成本,并减少了90%的二氧化碳排放。此外,与更大的SOTA模型RAPHAEL相比,我们的训练成本仅为它的1%。大量实验表明,PixArt-α在图像质量、艺术性和语义控制方面表现出色。我们希望PixArt-α能为AIGC社区和初创企业带来新的启示,帮助他们从零开始快速构建高质量且低成本的生成模型。

🔥🔥🔥 为什么选择PixArt-α?
训练效率
PixArt-α 仅需 Stable Diffusion v1.5 训练时间的 12%(753 天 vs. 6,250 天 A100 GPU),节省近 30 万美元(2.8 万美元 vs. 32 万美元),并减少 90% 的二氧化碳排放。此外,与更大的 SOTA 模型 RAPHAEL 相比,我们的训练成本仅为后者的 1%。
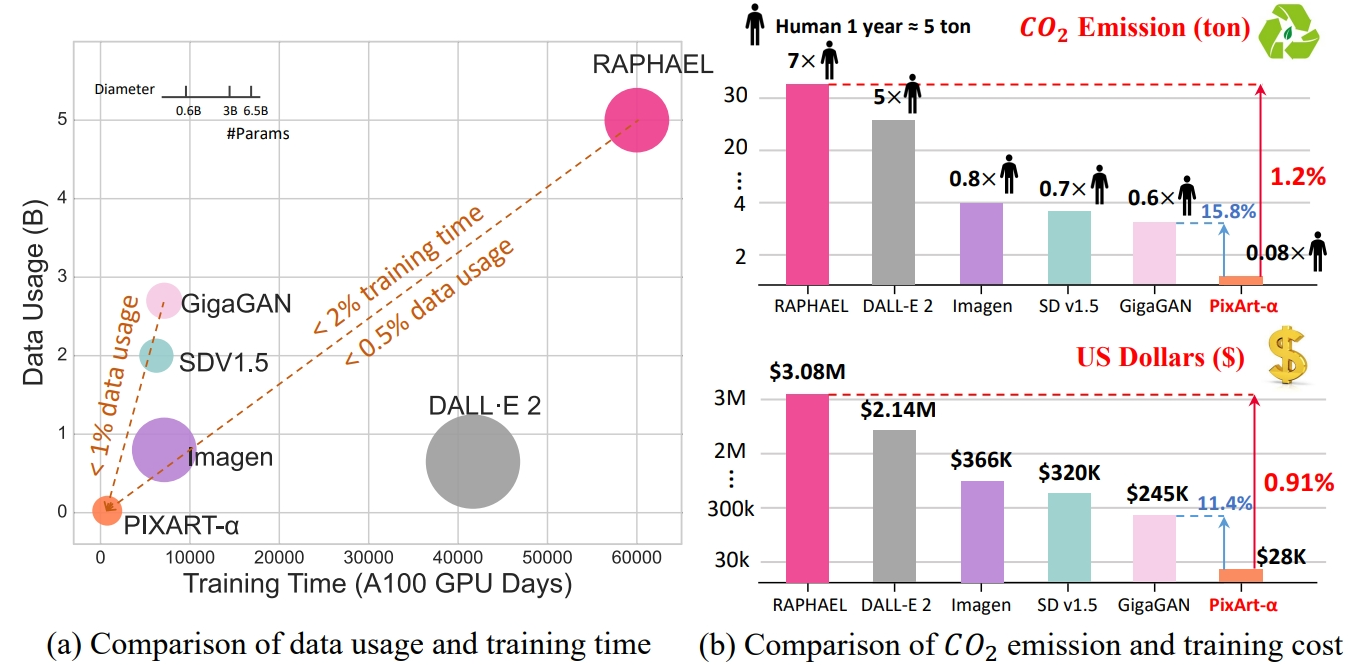
方法
类型
参数量
图像数量
FID-30K ↓
A100 GPU 天数
DALL·E
扩散
12.0B
250M
27.50
GLIDE
扩散
5.0B
250M
12.24
LDM
扩散
1.4B
400M
12.64
DALL·E 2
扩散
6.5B
650M
10.39
41,66
SDv1.5
扩散
0.9B
2000M
9.62
6,250
GigaGAN
GAN
0.9B
2700M
9.09
4,783
Imagen
扩散
3.0B
860M
7.27
7,132
RAPHAEL
扩散
3.0B
5000M+
6.61
60,000
PixArt-α
扩散
0.6B
25M
7.32(零样本)
753
PixArt-α
扩散
0.6B
25M
5.51(COCO 微调)
753
推理效率
PIXART-δ 在 A100 上成功生成 1024×1024 高分辨率 图像,耗时仅 0.5 秒。通过实施 8 位推理技术,PIXART-δ 仅需 不到 8GB 的 GPU 显存。
让我们再次强调,使用 PixArt-LCM 如此轻松地探索图像生成是多么令人解放。
硬件
PIXART-δ (4 步)
SDXL LoRA LCM (4 步)
PixArt-α (14 步)
SDXL 标准版 (25 步)
T4(Google Colab 免费层)
3.3s
8.4s
16.0s
26.5s
V100(32 GB)
0.8s
1.2s
5.5s
7.7s
A100(80 GB)
0.51s
1.2s
2.2s
3.8s
所有测试均以批大小为 1 运行。
对于像 A100 这样显存较大的显卡,在一次生成多张图像时性能会显著提升,而这通常是生产工作负载中的常见场景。
PixArt-α 的高质量生成
- 更多样例
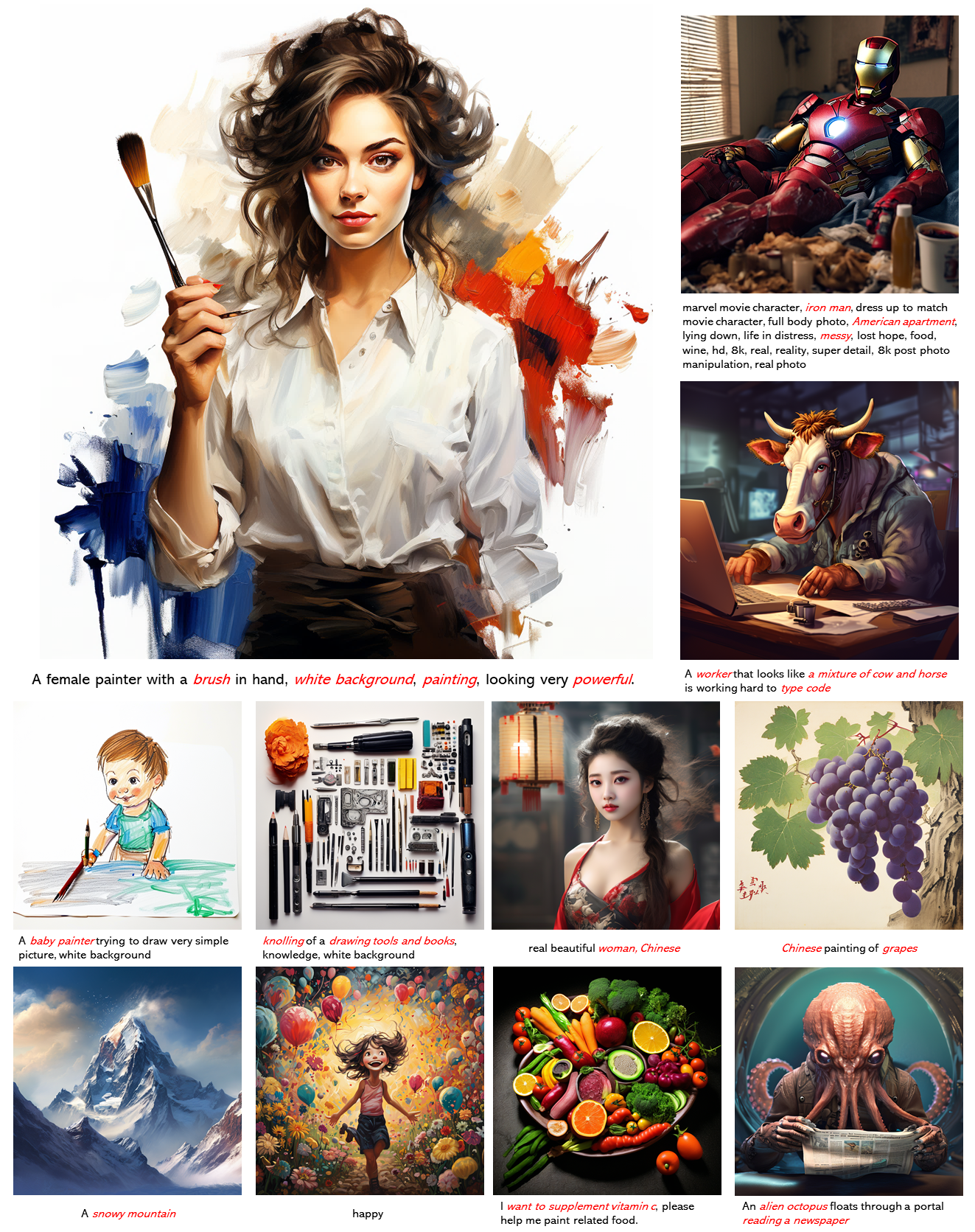

- PixArt + Dreambooth


- PixArt + ControlNet


🔧 依赖与安装
- Python >= 3.9(建议使用 Anaconda 或 Miniconda)
- PyTorch >= 1.13.0+cu11.7
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txt
⏬ 下载模型
所有模型将自动下载。你也可以从这个 url 手动下载。
模型
参数量
url
在 OpenXLab 中下载
T5
4.3B
T5
T5
VAE
80M
VAE
VAE
PixArt-α-SAM-256
0.6B
PixArt-XL-2-SAM-256x256.pth 或 diffusers 版本
256-SAM
PixArt-α-256
0.6B
PixArt-XL-2-256x256.pth 或 diffusers 版本
256
PixArt-α-256-MSCOCO-FID7.32
0.6B
PixArt-XL-2-256x256.pth
256
PixArt-α-512
0.6B
PixArt-XL-2-512x512.pth 或 diffusers 版本
512
PixArt-α-1024
0.6B
PixArt-XL-2-1024-MS.pth 或 diffusers 版本
1024
PixArt-δ-1024-LCM
0.6B
diffusers 版本
ControlNet-HED-Encoder
30M
ControlNetHED.pth
PixArt-δ-512-ControlNet
0.9B
PixArt-XL-2-512-ControlNet.pth
512
PixArt-δ-1024-ControlNet
0.9B
PixArt-XL-2-1024-ControlNet.pth
1024
此外,你还可以在 OpenXLab_PixArt-alpha 中找到所有模型。
🔥 如何训练
1. PixArt 训练
首先。
感谢 @kopyl,您可以通过 HugginFace 上的笔记本重现 Pokemon 数据集 的完整微调训练流程:
- 使用 notebooks/train.ipynb 进行训练。
- 使用 notebooks/convert-checkpoint-to-diffusers.ipynb 转换为 Diffusers 格式。
- 使用步骤 2 中转换后的检查点,通过 notebooks/infer.ipynb 运行推理。
然后,更多细节。
这里我们以 SAM 数据集的训练配置为例,当然您也可以按照这种方法准备自己的数据集。
您 只需要 修改 config 中的 配置文件 和 dataset 中的 数据加载器。
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256
SAM 数据集的目录结构如下:
cd ./data
SA1B
├──images/ (图像保存在此处)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (对应的标题保存在此处,与图像同名)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (所有图像名称存储在一个文本文件中,每行一个图像名称)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (运行 tools/extract_caption_feature.py 生成标题 T5 特征,与图像同名但扩展名为 .npz)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (运行 tools/extract_img_vae_feature.py 生成图像 VAE 特征,与图像同名但扩展名为 .npy)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
为了更好地理解,我们准备了 data_toy 数据集
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toy
然后,
这里 是 partition/part0.txt 文件的一个示例。
此外,对于基于 JSON 文件指导的 训练,
这里 是一个用于更好理解的玩具 JSON 文件。
2. PixArt + DreamBooth 训练
请参考 Pixart + DreamBooth 的 训练指南
3. PixArt + LCM / LCM-LoRA 训练
请参考 PixArt + LCM 的 训练指南
4. PixArt + ControlNet 训练
请参考 PixArt + ControlNet 的 训练指南
4. PixArt + LoRA 训练
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision="fp16" \
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS \
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=16 \
--num_train_epochs=200 --checkpointing_steps=100 \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="pixart-pokemon-model" \
--validation_prompt="cute dragon creature" --report_to="tensorboard" \
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5 \
--rank=16
💻 如何测试
使用本仓库进行推理时,至少需要 23GB 的显存;而在 🧨 diffusers 中则只需 11GB 和 8GB。
目前支持:
1. 快速开始使用 Gradio
要开始使用,首先安装所需的依赖项。确保已将 模型 下载到 output/pretrained_models 文件夹中,然后在本地机器上运行:
DEMO_PORT=12345 python app/app.py
或者,您可以使用提供的示例 Dockerfile 来构建一个运行 Gradio 应用的容器。
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v <path_to_huggingface_cache>:/root/.cache/huggingface pixart
或者使用 docker-compose。请注意,如果您想将上下文从 1024 更改为 512 或 LCM 版本的应用程序,只需更改 docker-compose.yml 文件中的 APP_CONTEXT 环境变量即可。默认值为 1024。
docker compose build
docker compose up
让我们通过 http://your-server-ip:12345 来看一个简单的例子。
2. 集成到 diffusers 中
1). 在 🧨 diffusers 中使用
请确保您已安装以下库的最新版本:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4
然后:
import torch
from diffusers import PixArtAlphaPipeline, ConsistencyDecoderVAE, AutoencoderKL
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 您也可以将检查点 ID 替换为 "PixArt-alpha/PixArt-XL-2-512x512"。
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-XL-2-1024-MS", torch_dtype=torch.float16, use_safetensors=True)
# 如果使用 DALL-E 3 一致性解码器
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# 如果使用 SA-Solver 采样器
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# 如果加载 LoRA 模型
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# 启用内存优化。
# pipe.enable_model_cpu_offload()
pipe.to(设备)
prompt = "撒哈拉沙漠中一棵长着笑脸的小仙人掌。"
image = pipe(prompt).images[0]
image.save("./catcus.png")
更多关于 SA-Solver 采样器的信息,请查看文档。
通过此次集成,可以在 11GB 显存的 GPU 上以批量大小为 4 运行该流程。
如需了解更多信息,请参阅文档。
2). 在低于 8GB 显存的 GPU 上运行 PixArtAlphaPipeline
现在已支持在 8GB 以下显存的 GPU 上运行,请参阅文档以获取更多信息。
3). 使用 diffusers 的 Gradio(更快速)
要开始使用,首先安装所需的依赖项,然后在本地机器上运行:
# diffusers 版本
DEMO_PORT=12345 python app/app.py
让我们来看一个简单的示例,访问 http://your-server-ip:12345。
你也可以点击这里在 Google Colab 上免费试用。
4). 将 .pth 检查点转换为 diffusers 版本
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (如果你使用 PixArtMS 则为 True,否则为 False) --orig_ckpt_path pth 文件路径 --dump_path diffusers 文件路径 --only_transformer=True
3. 在线演示 
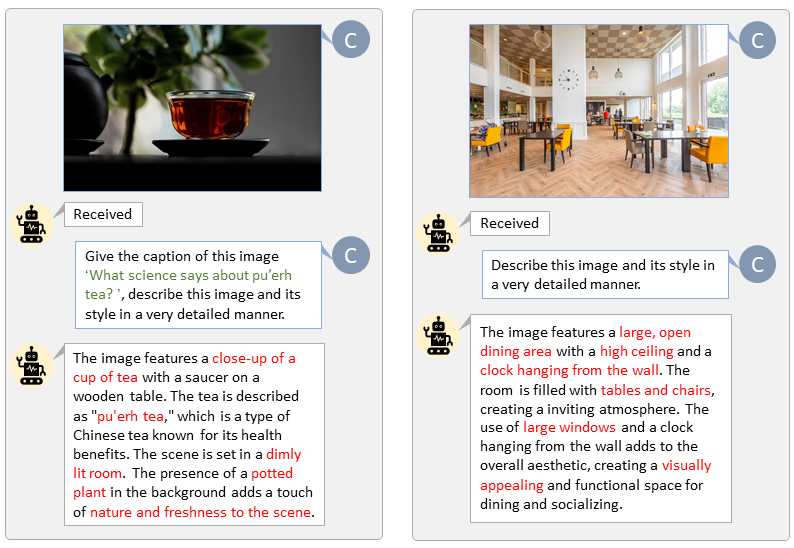
✏️ 如何使用 LLaVA 进行图像标注
感谢 LLaVA-Lightning-MPT 的代码库,
我们可以通过以下启动命令对 LAION 和 SAM 数据集进行标注:
python tools/VLM_caption_lightning.py --output 输出目录 --data-root 数据根路径 --index 数据 JSON 文件路径
我们展示了使用自定义提示词对 LAION(左)和 SAM(右)数据集进行自动标注的结果。绿色高亮的文字代表 LAION 中的原始描述,而红色标记的部分则是由 LLaVA 添加的详细描述。
✏️ 如何提取 T5 和 VAE 特征
提前准备好 T5 文本特征和 VAE 图像特征,可以加快训练速度并节省显存。
python tools/extract_features.py --img_size=1024 \
--json_path "data/data_info.json" \
--t5_save_root "data/SA1B/caption_feature_wmask" \
--vae_save_root "data/SA1B/img_vae_features" \
--pretrained_models_dir "output/pretrained_models" \
--dataset_root "data/SA1B/Images/"
💪 待办事项清单(恭喜🎉)
- 推理代码
- 训练代码
- T5 & VAE 特征提取代码
- LLaVA 标注代码
- 模型库
- diffusers 版本及 Hugging Face 演示
- Google Colab 示例
- DALLE3 VAE 集成
- 在 8GB 以下显存的 GPU 上使用 diffusers 进行推理
- Dreambooth 训练代码
- SA-Solver 代码
- PixArt-α-LCM 即将发布
- 多尺度 VAE 特征提取代码
- PixArt-α-LCM-LoRA 脚本即将发布
- PixArt-α-LoRA 训练脚本即将发布
- ControlNet 代码即将发布
- SAM-LLaVA 标注数据集
- ControlNet 检查点
- 256px 预训练模型
- PixArt-Σ:下一代性能更强的模型正在训练中!
其他资源
我们制作了一段视频,对比了 PixArt 与当前最强大的文生图模型。
📖 BibTeX
@misc{chen2023pixartalpha,
title={PixArt-$\alpha$: 快速训练扩散 Transformer 实现照片级真实感文生图},
author={Junsong Chen、Jincheng Yu、Chongjian Ge、Lewei Yao、Enze Xie、Yue Wu、Zhongdao Wang、James Kwok、Ping Luo、Huchuan Lu、Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{\delta}: 基于潜在一致性模型的快速可控图像生成},
author={Junsong Chen、Yue Wu、Simian Luo、Enze Xie、Sayak Paul、Ping Luo、Hang Zhao、Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
🤗 致谢
- 感谢 Diffusers 提供的卓越技术支持和精彩合作!
- 感谢 Hugging Face 对精美演示的支持!
- 感谢 DiT 的杰出工作和代码库!
星标历史

相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。
这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。
OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
349.3k|★★★☆☆|1周前stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。
无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
162.1k|★★★☆☆|2周前ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。
这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。
无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
109.2k|★★☆☆☆|昨天gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。
这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。
它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
100.8k|★★☆☆☆|1周前LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。
该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。
LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
90.1k|★★★☆☆|1周前Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。
这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。
其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
88.9k|★★★☆☆|1周前
ICLR 2024 Spotlight
本仓库包含我们论文中探索的使用Transformer进行快速训练扩散模型的PyTorch模型定义、预训练权重以及推理/采样代码。您可以在我们的项目页面上找到更多可视化内容。
PixArt-α 社区:欢迎加入我们的PixArt-α Discord频道
,参与讨论。欢迎各位开发者贡献代码。
PixArt-α:用于照片级逼真文生图的扩散Transformer快速训练
陈俊松*、于锦程*、
葛崇健*、姚雷威*、
谢恩泽†、
吴岳、王仲道、
郭志伟、罗平、
陆虎川、
李振国
华为诺亚方舟实验室、大连理工大学、香港大学、香港科技大学
PIXART-δ:基于潜在一致性模型的快速可控图像生成
陈俊松、吴岳、罗思敏、谢恩泽†、
萨亚克·保罗、罗平、赵航、李振国
华为诺亚方舟实验室、大连理工大学、清华大学、香港大学、Hugging Face
最新消息 🔥🔥!!
(🔥 新) 2024年4月12日。💥 更优秀的PixArt-Σ训练与推理代码及检查点已全部发布!!!
欢迎大家合作与贡献。如果您觉得有用,请为我们点亮🌟!
(🔥 新) 2024年1月19日。💥 PixArt-δ ControlNet app_controlnet.py和检查点已发布!!!
(🔥 新) 2024年1月16日。💥 恭喜宣布,PixArt-α已被ICLR 2024接受(Spotlight)。
-
(🔥 新) 2023年11月30日。💥 PixArt与LCMs团队合作,打造了最快的文生图训练与推理系统。
在此,训练代码、推理代码、权重以及Hugging Face演示、OpenXLab演示均已发布,我们希望用户能够喜欢。详细的推理速度和代码指南可在文档中找到。同时,我们还更新了代码库以提升用户体验,并修复了最新版本中的若干Bug。
🚩 新功能/更新
- ✅ 2024年1月11日。💥 PixArt-δ:我们非常高兴地宣布发布 PixArt-δ 技术报告!!!
该报告深入探讨了Transformer模型中LCM和ControlNet类似模块的训练方法。同时,我们也在此仓库中发布了LCM与ControlNet的所有训练和推理代码 在此仓库。
我们鼓励大家尝试使用这些代码,并热烈欢迎用户的Pull Request。您的贡献和反馈对我们非常重要!
- ✅ 2024年2月7日。train_diffusers.py 可以直接使用diffusers模型进行训练,并在训练过程中进行可视化。
- ✅ 2024年1月26日。💥 PixArt-α 的所有检查点,包括256px分辨率的检查点,现在都可以在这里下载 下载模型。
- ✅ 2024年1月19日。💥 PixArt-δ 的ControlNet app_controlnet.py 和 检查点 已发布!!!
- ✅ 2024年1月12日。💥 我们发布了用于PixArt-α训练的 SAM-LLaVA-Captions 数据集。
- ✅ 2023年12月27日。PixArt-α 已集成到 ControlLLM 中!
- ✅ 2023年12月17日。以Hugging Face风格发布的 PixArt-LCM-Lora 和 PixArt-Lora 训练脚本已发布。
- ✅ 2023年12月13日。在 tools/extract_features.py 中添加了多尺度VAE特征提取功能。
- ✅ 2023年12月1日。新增了一个 Notebook文件夹,帮助用户快速上手PixArt!感谢 @kopyl 的贡献!
- ✅ 2023年11月27日。💥 PixArt-α社区:加入我们的PixArt-α Discord频道
进行讨论。欢迎各位开发者参与贡献。
- ✅ 2023年11月21日。💥 SA-Sovler 官方代码首次发布 此处。
- ✅ 2023年11月19日。发布
PixArt + Dreambooth 训练脚本。
- ✅ 2023年11月16日。Diffusers 现在支持
随机分辨率 和 批量生成图片 功能。此外,
在低于8GB显存的GPU上运行 Pixart 也已成为可能,在 🧨 diffusers 中有相关说明。
- ✅ 2023年11月10日。在 🧨 diffusers 中支持 DALL-E 3 Consistency Decoder。
- ✅ 2023年11月6日。发布预训练权重,并集成 🧨 diffusers、Hugging Face演示以及Google Colab示例。
- ✅ 2023年11月3日。发布 LLaVA 字幕生成推理代码。
- ✅ 2023年10月27日。发布训练及特征提取代码。
- ✅ 2023年10月20日。与 Hugging Face 和 Diffusers 团队合作,共同发布代码和权重。(请继续关注。)
- ✅ 2023年10月15日。发布推理代码。
目录
-
-
-
-
-
-
-
-
-
-
-
-
-
🐱 摘要
TL; DR: PixArt-α 是一种基于Transformer的T2I扩散模型,其图像生成质量可与当前最先进的图像生成器(如Imagen、SDXL,甚至Midjourney)相媲美,而训练速度则显著超越现有的大型T2I模型。例如,PixArt-α仅需675天的A100 GPU时间,而Stable Diffusion v1.5则需要6,250天。
点击展开完整摘要
目前最先进的文本到图像(T2I)模型通常需要高昂的训练成本(例如数百万小时的GPU时间),这不仅严重阻碍了AIGC社区的基础创新,还增加了二氧化碳排放。本文介绍了一种名为PixArt-α的基于Transformer的T2I扩散模型,其图像生成质量可与当前最先进的图像生成器(如Imagen、SDXL,甚至Midjourney)相媲美,几乎达到了商业应用的标准。此外,它还支持高达1024px分辨率的高分辨率图像合成,且训练成本较低。为实现这一目标,我们提出了三个核心设计:
(1) 训练策略分解:我们设计了三个独立的训练步骤,分别优化像素依赖性、文本与图像的对齐以及图像的美学质量;
(2) 高效的T2I Transformer:我们在扩散Transformer(DiT)中引入了交叉注意力模块,以注入文本条件并简化计算密集型的类别条件分支;
(3) 高信息量的数据:我们强调文本-图像对中概念密度的重要性,并利用大型视觉-语言模型自动标注密集的伪字幕,以辅助文本-图像对齐的学习。因此,PixArt-α的训练速度显著优于现有的大型T2I模型,例如,PixArt-α仅需675天的A100 GPU时间,而Stable Diffusion v1.5则需要6,250天,从而节省了近30万美元(26,000美元 vs. 320,000美元)的成本,并减少了90%的二氧化碳排放。此外,与更大的SOTA模型RAPHAEL相比,我们的训练成本仅为它的1%。大量实验表明,PixArt-α在图像质量、艺术性和语义控制方面表现出色。我们希望PixArt-α能为AIGC社区和初创企业带来新的启示,帮助他们从零开始快速构建高质量且低成本的生成模型。
🔥🔥🔥 为什么选择PixArt-α?
训练效率
PixArt-α 仅需 Stable Diffusion v1.5 训练时间的 12%(753 天 vs. 6,250 天 A100 GPU),节省近 30 万美元(2.8 万美元 vs. 32 万美元),并减少 90% 的二氧化碳排放。此外,与更大的 SOTA 模型 RAPHAEL 相比,我们的训练成本仅为后者的 1%。
方法
类型
参数量
图像数量
FID-30K ↓
A100 GPU 天数
DALL·E
扩散
12.0B
250M
27.50
GLIDE
扩散
5.0B
250M
12.24
LDM
扩散
1.4B
400M
12.64
DALL·E 2
扩散
6.5B
650M
10.39
41,66
SDv1.5
扩散
0.9B
2000M
9.62
6,250
GigaGAN
GAN
0.9B
2700M
9.09
4,783
Imagen
扩散
3.0B
860M
7.27
7,132
RAPHAEL
扩散
3.0B
5000M+
6.61
60,000
PixArt-α
扩散
0.6B
25M
7.32(零样本)
753
PixArt-α
扩散
0.6B
25M
5.51(COCO 微调)
753
推理效率
PIXART-δ 在 A100 上成功生成 1024×1024 高分辨率 图像,耗时仅 0.5 秒。通过实施 8 位推理技术,PIXART-δ 仅需 不到 8GB 的 GPU 显存。
让我们再次强调,使用 PixArt-LCM 如此轻松地探索图像生成是多么令人解放。
硬件
PIXART-δ (4 步)
SDXL LoRA LCM (4 步)
PixArt-α (14 步)
SDXL 标准版 (25 步)
T4(Google Colab 免费层)
3.3s
8.4s
16.0s
26.5s
V100(32 GB)
0.8s
1.2s
5.5s
7.7s
A100(80 GB)
0.51s
1.2s
2.2s
3.8s
所有测试均以批大小为 1 运行。
对于像 A100 这样显存较大的显卡,在一次生成多张图像时性能会显著提升,而这通常是生产工作负载中的常见场景。
PixArt-α 的高质量生成
- 更多样例
- PixArt + Dreambooth
- PixArt + ControlNet
🔧 依赖与安装
- Python >= 3.9(建议使用 Anaconda 或 Miniconda)
- PyTorch >= 1.13.0+cu11.7
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txt
⏬ 下载模型
所有模型将自动下载。你也可以从这个 url 手动下载。
模型
参数量
url
在 OpenXLab 中下载
T5
4.3B
T5
T5
VAE
80M
VAE
VAE
PixArt-α-SAM-256
0.6B
PixArt-XL-2-SAM-256x256.pth 或 diffusers 版本
256-SAM
PixArt-α-256
0.6B
PixArt-XL-2-256x256.pth 或 diffusers 版本
256
PixArt-α-256-MSCOCO-FID7.32
0.6B
PixArt-XL-2-256x256.pth
256
PixArt-α-512
0.6B
PixArt-XL-2-512x512.pth 或 diffusers 版本
512
PixArt-α-1024
0.6B
PixArt-XL-2-1024-MS.pth 或 diffusers 版本
1024
PixArt-δ-1024-LCM
0.6B
diffusers 版本
ControlNet-HED-Encoder
30M
ControlNetHED.pth
PixArt-δ-512-ControlNet
0.9B
PixArt-XL-2-512-ControlNet.pth
512
PixArt-δ-1024-ControlNet
0.9B
PixArt-XL-2-1024-ControlNet.pth
1024
此外,你还可以在 OpenXLab_PixArt-alpha 中找到所有模型。
🔥 如何训练
1. PixArt 训练
首先。
感谢 @kopyl,您可以通过 HugginFace 上的笔记本重现 Pokemon 数据集 的完整微调训练流程:
- 使用 notebooks/train.ipynb 进行训练。
- 使用 notebooks/convert-checkpoint-to-diffusers.ipynb 转换为 Diffusers 格式。
- 使用步骤 2 中转换后的检查点,通过 notebooks/infer.ipynb 运行推理。
然后,更多细节。
这里我们以 SAM 数据集的训练配置为例,当然您也可以按照这种方法准备自己的数据集。
您 只需要 修改 config 中的 配置文件 和 dataset 中的 数据加载器。
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256
SAM 数据集的目录结构如下:
cd ./data
SA1B
├──images/ (图像保存在此处)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (对应的标题保存在此处,与图像同名)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (所有图像名称存储在一个文本文件中,每行一个图像名称)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (运行 tools/extract_caption_feature.py 生成标题 T5 特征,与图像同名但扩展名为 .npz)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (运行 tools/extract_img_vae_feature.py 生成图像 VAE 特征,与图像同名但扩展名为 .npy)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
为了更好地理解,我们准备了 data_toy 数据集
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toy
然后,
这里 是 partition/part0.txt 文件的一个示例。
此外,对于基于 JSON 文件指导的 训练,
这里 是一个用于更好理解的玩具 JSON 文件。
2. PixArt + DreamBooth 训练
请参考 Pixart + DreamBooth 的 训练指南
3. PixArt + LCM / LCM-LoRA 训练
请参考 PixArt + LCM 的 训练指南
4. PixArt + ControlNet 训练
请参考 PixArt + ControlNet 的 训练指南
4. PixArt + LoRA 训练
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision="fp16" \
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS \
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=16 \
--num_train_epochs=200 --checkpointing_steps=100 \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="pixart-pokemon-model" \
--validation_prompt="cute dragon creature" --report_to="tensorboard" \
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5 \
--rank=16
💻 如何测试
使用本仓库进行推理时,至少需要 23GB 的显存;而在 🧨 diffusers 中则只需 11GB 和 8GB。
目前支持:
1. 快速开始使用 Gradio
要开始使用,首先安装所需的依赖项。确保已将 模型 下载到 output/pretrained_models 文件夹中,然后在本地机器上运行:
DEMO_PORT=12345 python app/app.py
或者,您可以使用提供的示例 Dockerfile 来构建一个运行 Gradio 应用的容器。
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v <path_to_huggingface_cache>:/root/.cache/huggingface pixart
或者使用 docker-compose。请注意,如果您想将上下文从 1024 更改为 512 或 LCM 版本的应用程序,只需更改 docker-compose.yml 文件中的 APP_CONTEXT 环境变量即可。默认值为 1024。
docker compose build
docker compose up
让我们通过 http://your-server-ip:12345 来看一个简单的例子。
2. 集成到 diffusers 中
1). 在 🧨 diffusers 中使用
请确保您已安装以下库的最新版本:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4
然后:
import torch
from diffusers import PixArtAlphaPipeline, ConsistencyDecoderVAE, AutoencoderKL
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 您也可以将检查点 ID 替换为 "PixArt-alpha/PixArt-XL-2-512x512"。
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-XL-2-1024-MS", torch_dtype=torch.float16, use_safetensors=True)
# 如果使用 DALL-E 3 一致性解码器
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# 如果使用 SA-Solver 采样器
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# 如果加载 LoRA 模型
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# 启用内存优化。
# pipe.enable_model_cpu_offload()
pipe.to(设备)
prompt = "撒哈拉沙漠中一棵长着笑脸的小仙人掌。"
image = pipe(prompt).images[0]
image.save("./catcus.png")
更多关于 SA-Solver 采样器的信息,请查看文档。
通过此次集成,可以在 11GB 显存的 GPU 上以批量大小为 4 运行该流程。
如需了解更多信息,请参阅文档。
2). 在低于 8GB 显存的 GPU 上运行 PixArtAlphaPipeline
现在已支持在 8GB 以下显存的 GPU 上运行,请参阅文档以获取更多信息。
3). 使用 diffusers 的 Gradio(更快速)
要开始使用,首先安装所需的依赖项,然后在本地机器上运行:
# diffusers 版本
DEMO_PORT=12345 python app/app.py
让我们来看一个简单的示例,访问 http://your-server-ip:12345。
你也可以点击这里在 Google Colab 上免费试用。
4). 将 .pth 检查点转换为 diffusers 版本
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (如果你使用 PixArtMS 则为 True,否则为 False) --orig_ckpt_path pth 文件路径 --dump_path diffusers 文件路径 --only_transformer=True
3. 在线演示
✏️ 如何使用 LLaVA 进行图像标注
感谢 LLaVA-Lightning-MPT 的代码库,
我们可以通过以下启动命令对 LAION 和 SAM 数据集进行标注:
python tools/VLM_caption_lightning.py --output 输出目录 --data-root 数据根路径 --index 数据 JSON 文件路径
我们展示了使用自定义提示词对 LAION(左)和 SAM(右)数据集进行自动标注的结果。绿色高亮的文字代表 LAION 中的原始描述,而红色标记的部分则是由 LLaVA 添加的详细描述。
✏️ 如何提取 T5 和 VAE 特征
提前准备好 T5 文本特征和 VAE 图像特征,可以加快训练速度并节省显存。
python tools/extract_features.py --img_size=1024 \
--json_path "data/data_info.json" \
--t5_save_root "data/SA1B/caption_feature_wmask" \
--vae_save_root "data/SA1B/img_vae_features" \
--pretrained_models_dir "output/pretrained_models" \
--dataset_root "data/SA1B/Images/"
💪 待办事项清单(恭喜🎉)
- 推理代码
- 训练代码
- T5 & VAE 特征提取代码
- LLaVA 标注代码
- 模型库
- diffusers 版本及 Hugging Face 演示
- Google Colab 示例
- DALLE3 VAE 集成
- 在 8GB 以下显存的 GPU 上使用 diffusers 进行推理
- Dreambooth 训练代码
- SA-Solver 代码
- PixArt-α-LCM 即将发布
- 多尺度 VAE 特征提取代码
- PixArt-α-LCM-LoRA 脚本即将发布
- PixArt-α-LoRA 训练脚本即将发布
- ControlNet 代码即将发布
- SAM-LLaVA 标注数据集
- ControlNet 检查点
- 256px 预训练模型
- PixArt-Σ:下一代性能更强的模型正在训练中!
其他资源
我们制作了一段视频,对比了 PixArt 与当前最强大的文生图模型。
📖 BibTeX
@misc{chen2023pixartalpha,
title={PixArt-$\alpha$: 快速训练扩散 Transformer 实现照片级真实感文生图},
author={Junsong Chen、Jincheng Yu、Chongjian Ge、Lewei Yao、Enze Xie、Yue Wu、Zhongdao Wang、James Kwok、Ping Luo、Huchuan Lu、Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{\delta}: 基于潜在一致性模型的快速可控图像生成},
author={Junsong Chen、Yue Wu、Simian Luo、Enze Xie、Sayak Paul、Ping Luo、Hang Zhao、Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
🤗 致谢
- 感谢 Diffusers 提供的卓越技术支持和精彩合作!
- 感谢 Hugging Face 对精美演示的支持!
- 感谢 DiT 的杰出工作和代码库!
星标历史
本仓库包含我们论文中探索的使用Transformer进行快速训练扩散模型的PyTorch模型定义、预训练权重以及推理/采样代码。您可以在我们的项目页面上找到更多可视化内容。
PixArt-α 社区:欢迎加入我们的PixArt-α Discord频道
,参与讨论。欢迎各位开发者贡献代码。
PixArt-α:用于照片级逼真文生图的扩散Transformer快速训练
陈俊松*、于锦程*、 葛崇健*、姚雷威*、 谢恩泽†、 吴岳、王仲道、 郭志伟、罗平、 陆虎川、 李振国
华为诺亚方舟实验室、大连理工大学、香港大学、香港科技大学
PIXART-δ:基于潜在一致性模型的快速可控图像生成
陈俊松、吴岳、罗思敏、谢恩泽†、 萨亚克·保罗、罗平、赵航、李振国
华为诺亚方舟实验室、大连理工大学、清华大学、香港大学、Hugging Face
最新消息 🔥🔥!!
(🔥 新) 2024年4月12日。💥 更优秀的PixArt-Σ训练与推理代码及检查点已全部发布!!! 欢迎大家合作与贡献。如果您觉得有用,请为我们点亮🌟!
(🔥 新) 2024年1月19日。💥 PixArt-δ ControlNet app_controlnet.py和检查点已发布!!!
(🔥 新) 2024年1月16日。💥 恭喜宣布,PixArt-α已被ICLR 2024接受(Spotlight)。
(🔥 新) 2023年11月30日。💥 PixArt与LCMs团队合作,打造了最快的文生图训练与推理系统。 在此,训练代码、推理代码、权重以及Hugging Face演示、OpenXLab演示均已发布,我们希望用户能够喜欢。详细的推理速度和代码指南可在文档中找到。同时,我们还更新了代码库以提升用户体验,并修复了最新版本中的若干Bug。
🚩 新功能/更新
- ✅ 2024年1月11日。💥 PixArt-δ:我们非常高兴地宣布发布 PixArt-δ 技术报告!!! 该报告深入探讨了Transformer模型中LCM和ControlNet类似模块的训练方法。同时,我们也在此仓库中发布了LCM与ControlNet的所有训练和推理代码 在此仓库。 我们鼓励大家尝试使用这些代码,并热烈欢迎用户的Pull Request。您的贡献和反馈对我们非常重要!
- ✅ 2024年2月7日。train_diffusers.py 可以直接使用diffusers模型进行训练,并在训练过程中进行可视化。
- ✅ 2024年1月26日。💥 PixArt-α 的所有检查点,包括256px分辨率的检查点,现在都可以在这里下载 下载模型。
- ✅ 2024年1月19日。💥 PixArt-δ 的ControlNet app_controlnet.py 和 检查点 已发布!!!
- ✅ 2024年1月12日。💥 我们发布了用于PixArt-α训练的 SAM-LLaVA-Captions 数据集。
- ✅ 2023年12月27日。PixArt-α 已集成到 ControlLLM 中!
- ✅ 2023年12月17日。以Hugging Face风格发布的 PixArt-LCM-Lora 和 PixArt-Lora 训练脚本已发布。
- ✅ 2023年12月13日。在 tools/extract_features.py 中添加了多尺度VAE特征提取功能。
- ✅ 2023年12月1日。新增了一个 Notebook文件夹,帮助用户快速上手PixArt!感谢 @kopyl 的贡献!
- ✅ 2023年11月27日。💥 PixArt-α社区:加入我们的PixArt-α Discord频道
进行讨论。欢迎各位开发者参与贡献。
- ✅ 2023年11月21日。💥 SA-Sovler 官方代码首次发布 此处。
- ✅ 2023年11月19日。发布
PixArt + Dreambooth训练脚本。 - ✅ 2023年11月16日。Diffusers 现在支持
随机分辨率和批量生成图片功能。此外, 在低于8GB显存的GPU上运行Pixart也已成为可能,在 🧨 diffusers 中有相关说明。 - ✅ 2023年11月10日。在 🧨 diffusers 中支持 DALL-E 3 Consistency Decoder。
- ✅ 2023年11月6日。发布预训练权重,并集成 🧨 diffusers、Hugging Face演示以及Google Colab示例。
- ✅ 2023年11月3日。发布 LLaVA 字幕生成推理代码。
- ✅ 2023年10月27日。发布训练及特征提取代码。
- ✅ 2023年10月20日。与 Hugging Face 和 Diffusers 团队合作,共同发布代码和权重。(请继续关注。)
- ✅ 2023年10月15日。发布推理代码。
目录
🐱 摘要
TL; DR: PixArt-α 是一种基于Transformer的T2I扩散模型,其图像生成质量可与当前最先进的图像生成器(如Imagen、SDXL,甚至Midjourney)相媲美,而训练速度则显著超越现有的大型T2I模型。例如,PixArt-α仅需675天的A100 GPU时间,而Stable Diffusion v1.5则需要6,250天。
点击展开完整摘要
目前最先进的文本到图像(T2I)模型通常需要高昂的训练成本(例如数百万小时的GPU时间),这不仅严重阻碍了AIGC社区的基础创新,还增加了二氧化碳排放。本文介绍了一种名为PixArt-α的基于Transformer的T2I扩散模型,其图像生成质量可与当前最先进的图像生成器(如Imagen、SDXL,甚至Midjourney)相媲美,几乎达到了商业应用的标准。此外,它还支持高达1024px分辨率的高分辨率图像合成,且训练成本较低。为实现这一目标,我们提出了三个核心设计: (1) 训练策略分解:我们设计了三个独立的训练步骤,分别优化像素依赖性、文本与图像的对齐以及图像的美学质量; (2) 高效的T2I Transformer:我们在扩散Transformer(DiT)中引入了交叉注意力模块,以注入文本条件并简化计算密集型的类别条件分支; (3) 高信息量的数据:我们强调文本-图像对中概念密度的重要性,并利用大型视觉-语言模型自动标注密集的伪字幕,以辅助文本-图像对齐的学习。因此,PixArt-α的训练速度显著优于现有的大型T2I模型,例如,PixArt-α仅需675天的A100 GPU时间,而Stable Diffusion v1.5则需要6,250天,从而节省了近30万美元(26,000美元 vs. 320,000美元)的成本,并减少了90%的二氧化碳排放。此外,与更大的SOTA模型RAPHAEL相比,我们的训练成本仅为它的1%。大量实验表明,PixArt-α在图像质量、艺术性和语义控制方面表现出色。我们希望PixArt-α能为AIGC社区和初创企业带来新的启示,帮助他们从零开始快速构建高质量且低成本的生成模型。
🔥🔥🔥 为什么选择PixArt-α?
训练效率
PixArt-α 仅需 Stable Diffusion v1.5 训练时间的 12%(753 天 vs. 6,250 天 A100 GPU),节省近 30 万美元(2.8 万美元 vs. 32 万美元),并减少 90% 的二氧化碳排放。此外,与更大的 SOTA 模型 RAPHAEL 相比,我们的训练成本仅为后者的 1%。
| 方法 | 类型 | 参数量 | 图像数量 | FID-30K ↓ | A100 GPU 天数 |
|---|---|---|---|---|---|
| DALL·E | 扩散 | 12.0B | 250M | 27.50 | |
| GLIDE | 扩散 | 5.0B | 250M | 12.24 | |
| LDM | 扩散 | 1.4B | 400M | 12.64 | |
| DALL·E 2 | 扩散 | 6.5B | 650M | 10.39 | 41,66 |
| SDv1.5 | 扩散 | 0.9B | 2000M | 9.62 | 6,250 |
| GigaGAN | GAN | 0.9B | 2700M | 9.09 | 4,783 |
| Imagen | 扩散 | 3.0B | 860M | 7.27 | 7,132 |
| RAPHAEL | 扩散 | 3.0B | 5000M+ | 6.61 | 60,000 |
| PixArt-α | 扩散 | 0.6B | 25M | 7.32(零样本) | 753 |
| PixArt-α | 扩散 | 0.6B | 25M | 5.51(COCO 微调) | 753 |
推理效率
PIXART-δ 在 A100 上成功生成 1024×1024 高分辨率 图像,耗时仅 0.5 秒。通过实施 8 位推理技术,PIXART-δ 仅需 不到 8GB 的 GPU 显存。
让我们再次强调,使用 PixArt-LCM 如此轻松地探索图像生成是多么令人解放。
| 硬件 | PIXART-δ (4 步) | SDXL LoRA LCM (4 步) | PixArt-α (14 步) | SDXL 标准版 (25 步) |
|---|---|---|---|---|
| T4(Google Colab 免费层) | 3.3s | 8.4s | 16.0s | 26.5s |
| V100(32 GB) | 0.8s | 1.2s | 5.5s | 7.7s |
| A100(80 GB) | 0.51s | 1.2s | 2.2s | 3.8s |
所有测试均以批大小为 1 运行。
对于像 A100 这样显存较大的显卡,在一次生成多张图像时性能会显著提升,而这通常是生产工作负载中的常见场景。
PixArt-α 的高质量生成
- 更多样例
- PixArt + Dreambooth
- PixArt + ControlNet
🔧 依赖与安装
- Python >= 3.9(建议使用 Anaconda 或 Miniconda)
- PyTorch >= 1.13.0+cu11.7
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txt
⏬ 下载模型
所有模型将自动下载。你也可以从这个 url 手动下载。
| 模型 | 参数量 | url | 在 OpenXLab 中下载 |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | VAE | VAE |
| PixArt-α-SAM-256 | 0.6B | PixArt-XL-2-SAM-256x256.pth 或 diffusers 版本 | 256-SAM |
| PixArt-α-256 | 0.6B | PixArt-XL-2-256x256.pth 或 diffusers 版本 | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0.6B | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0.6B | PixArt-XL-2-512x512.pth 或 diffusers 版本 | 512 |
| PixArt-α-1024 | 0.6B | PixArt-XL-2-1024-MS.pth 或 diffusers 版本 | 1024 |
| PixArt-δ-1024-LCM | 0.6B | diffusers 版本 | |
| ControlNet-HED-Encoder | 30M | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0.9B | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0.9B | PixArt-XL-2-1024-ControlNet.pth | 1024 |
此外,你还可以在 OpenXLab_PixArt-alpha 中找到所有模型。
🔥 如何训练
1. PixArt 训练
首先。
感谢 @kopyl,您可以通过 HugginFace 上的笔记本重现 Pokemon 数据集 的完整微调训练流程:
- 使用 notebooks/train.ipynb 进行训练。
- 使用 notebooks/convert-checkpoint-to-diffusers.ipynb 转换为 Diffusers 格式。
- 使用步骤 2 中转换后的检查点,通过 notebooks/infer.ipynb 运行推理。
然后,更多细节。
这里我们以 SAM 数据集的训练配置为例,当然您也可以按照这种方法准备自己的数据集。
您 只需要 修改 config 中的 配置文件 和 dataset 中的 数据加载器。
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256
SAM 数据集的目录结构如下:
cd ./data
SA1B
├──images/ (图像保存在此处)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (对应的标题保存在此处,与图像同名)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (所有图像名称存储在一个文本文件中,每行一个图像名称)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (运行 tools/extract_caption_feature.py 生成标题 T5 特征,与图像同名但扩展名为 .npz)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (运行 tools/extract_img_vae_feature.py 生成图像 VAE 特征,与图像同名但扩展名为 .npy)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
为了更好地理解,我们准备了 data_toy 数据集
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toy
然后, 这里 是 partition/part0.txt 文件的一个示例。
此外,对于基于 JSON 文件指导的 训练, 这里 是一个用于更好理解的玩具 JSON 文件。
2. PixArt + DreamBooth 训练
请参考 Pixart + DreamBooth 的 训练指南
3. PixArt + LCM / LCM-LoRA 训练
请参考 PixArt + LCM 的 训练指南
4. PixArt + ControlNet 训练
请参考 PixArt + ControlNet 的 训练指南
4. PixArt + LoRA 训练
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision="fp16" \
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS \
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=16 \
--num_train_epochs=200 --checkpointing_steps=100 \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="pixart-pokemon-model" \
--validation_prompt="cute dragon creature" --report_to="tensorboard" \
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5 \
--rank=16
💻 如何测试
使用本仓库进行推理时,至少需要 23GB 的显存;而在 🧨 diffusers 中则只需 11GB 和 8GB。
目前支持:
1. 快速开始使用 Gradio
要开始使用,首先安装所需的依赖项。确保已将 模型 下载到 output/pretrained_models 文件夹中,然后在本地机器上运行:
DEMO_PORT=12345 python app/app.py
或者,您可以使用提供的示例 Dockerfile 来构建一个运行 Gradio 应用的容器。
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v <path_to_huggingface_cache>:/root/.cache/huggingface pixart
或者使用 docker-compose。请注意,如果您想将上下文从 1024 更改为 512 或 LCM 版本的应用程序,只需更改 docker-compose.yml 文件中的 APP_CONTEXT 环境变量即可。默认值为 1024。
docker compose build
docker compose up
让我们通过 http://your-server-ip:12345 来看一个简单的例子。
2. 集成到 diffusers 中
1). 在 🧨 diffusers 中使用
请确保您已安装以下库的最新版本:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4
然后:
import torch
from diffusers import PixArtAlphaPipeline, ConsistencyDecoderVAE, AutoencoderKL
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 您也可以将检查点 ID 替换为 "PixArt-alpha/PixArt-XL-2-512x512"。
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-XL-2-1024-MS", torch_dtype=torch.float16, use_safetensors=True)
# 如果使用 DALL-E 3 一致性解码器
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# 如果使用 SA-Solver 采样器
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# 如果加载 LoRA 模型
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# 启用内存优化。
# pipe.enable_model_cpu_offload()
pipe.to(设备)
prompt = "撒哈拉沙漠中一棵长着笑脸的小仙人掌。"
image = pipe(prompt).images[0]
image.save("./catcus.png")
更多关于 SA-Solver 采样器的信息,请查看文档。
通过此次集成,可以在 11GB 显存的 GPU 上以批量大小为 4 运行该流程。 如需了解更多信息,请参阅文档。
2). 在低于 8GB 显存的 GPU 上运行 PixArtAlphaPipeline
现在已支持在 8GB 以下显存的 GPU 上运行,请参阅文档以获取更多信息。
3). 使用 diffusers 的 Gradio(更快速)
要开始使用,首先安装所需的依赖项,然后在本地机器上运行:
# diffusers 版本
DEMO_PORT=12345 python app/app.py
让我们来看一个简单的示例,访问 http://your-server-ip:12345。
你也可以点击这里在 Google Colab 上免费试用。
4). 将 .pth 检查点转换为 diffusers 版本
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (如果你使用 PixArtMS 则为 True,否则为 False) --orig_ckpt_path pth 文件路径 --dump_path diffusers 文件路径 --only_transformer=True
3. 在线演示
✏️ 如何使用 LLaVA 进行图像标注
感谢 LLaVA-Lightning-MPT 的代码库, 我们可以通过以下启动命令对 LAION 和 SAM 数据集进行标注:
python tools/VLM_caption_lightning.py --output 输出目录 --data-root 数据根路径 --index 数据 JSON 文件路径
我们展示了使用自定义提示词对 LAION(左)和 SAM(右)数据集进行自动标注的结果。绿色高亮的文字代表 LAION 中的原始描述,而红色标记的部分则是由 LLaVA 添加的详细描述。
✏️ 如何提取 T5 和 VAE 特征
提前准备好 T5 文本特征和 VAE 图像特征,可以加快训练速度并节省显存。
python tools/extract_features.py --img_size=1024 \
--json_path "data/data_info.json" \
--t5_save_root "data/SA1B/caption_feature_wmask" \
--vae_save_root "data/SA1B/img_vae_features" \
--pretrained_models_dir "output/pretrained_models" \
--dataset_root "data/SA1B/Images/"
💪 待办事项清单(恭喜🎉)
- 推理代码
- 训练代码
- T5 & VAE 特征提取代码
- LLaVA 标注代码
- 模型库
- diffusers 版本及 Hugging Face 演示
- Google Colab 示例
- DALLE3 VAE 集成
- 在 8GB 以下显存的 GPU 上使用 diffusers 进行推理
- Dreambooth 训练代码
- SA-Solver 代码
- PixArt-α-LCM 即将发布
- 多尺度 VAE 特征提取代码
- PixArt-α-LCM-LoRA 脚本即将发布
- PixArt-α-LoRA 训练脚本即将发布
- ControlNet 代码即将发布
- SAM-LLaVA 标注数据集
- ControlNet 检查点
- 256px 预训练模型
- PixArt-Σ:下一代性能更强的模型正在训练中!
其他资源
我们制作了一段视频,对比了 PixArt 与当前最强大的文生图模型。
📖 BibTeX
@misc{chen2023pixartalpha,
title={PixArt-$\alpha$: 快速训练扩散 Transformer 实现照片级真实感文生图},
author={Junsong Chen、Jincheng Yu、Chongjian Ge、Lewei Yao、Enze Xie、Yue Wu、Zhongdao Wang、James Kwok、Ping Luo、Huchuan Lu、Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{\delta}: 基于潜在一致性模型的快速可控图像生成},
author={Junsong Chen、Yue Wu、Simian Luo、Enze Xie、Sayak Paul、Ping Luo、Hang Zhao、Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
🤗 致谢
- 感谢 Diffusers 提供的卓越技术支持和精彩合作!
- 感谢 Hugging Face 对精美演示的支持!
- 感谢 DiT 的杰出工作和代码库!
星标历史
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。