PaddleX
PaddleX 是一款基于飞桨(PaddlePaddle)框架打造的全流程低代码 AI 开发工具。它旨在解决开发者在模型选择、训练、调优及部署环节中面临的门槛高、流程繁琐及硬件适配复杂等痛点,让 AI 技术能更快速地落地于产业实践。
无论是希望快速验证想法的算法工程师,还是需要将 AI 能力集成到产品中的软件开发人员,亦或是从事计算机视觉与文档分析的研究者,都能通过 PaddleX 高效开展工作。该工具内置了超过 200 个开箱即用的预训练模型,覆盖 OCR、目标检测、图像分割及时序预测等关键领域,并整合为 33 条标准化模型产线。
其核心亮点在于“极简开发”与“灵活部署”。用户仅需通过统一的 Python API 或图形界面,即可一键调用模型完成从训练到推理的全过程。PaddleX 不仅支持大模型与小模型的协同工作及多模型融合策略,还实现了跨平台无缝部署,兼容 NVIDIA GPU、昆仑芯、昇腾及寒武纪等多种主流硬件。此外,它对 PP-OCRv5 等多语种高精度模型提供了深度支持,并具备细粒度的性能分析能力,帮助开发者轻松构建高性能、高稳定性的 AI 应用。
使用场景
某跨境电商运营团队需要每日处理成千上万份多语种(如泰文、希腊文、英文)的复杂版式 PDF 发票,从中提取关键信息并翻译归档。
没有 PaddleX 时
- 多模型串联开发难:需分别调用独立的 OCR、表格识别和翻译模型,编写大量胶水代码处理数据格式转换,调试成本极高。
- 小语种支持缺失:开源社区缺乏高精度的泰文、希腊文等小语种识别模型,自行训练数据标注成本高且周期长。
- 硬件适配繁琐:团队内部混用英伟达 GPU 和昇腾 NPU,不同硬件需维护多套推理后端代码,部署环境极易冲突。
- 文档解析效果差:面对复杂排版的发票,传统方案难以准确还原表格结构,导致后续关键信息抽取错误率高。
使用 PaddleX 后
- 产线一键调用:直接利用 PaddleX 集成的"PP-DocTranslation"产线,通过极简 Python API 串联 PP-OCRv5、PP-StructureV3 和大模型,实现从识别到翻译的全流程自动化。
- 多语种高精度识别:内置 PP-OCRv5 多语种模型,泰文和希腊文识别精度分别达到 82.68% 和 89.28%,无需额外训练即可满足业务需求。
- 跨硬件无缝部署:凭借统一的推理接口,同一套代码可无缝切换运行在 CUDA 12 GPU 或昇腾 NPU 上,大幅降低运维复杂度。
- 复杂版面完美还原:升级后的 PP-Chart2Table 模型能精准将发票中的图表转换为结构化表格,关键信息提取准确率显著提升。
PaddleX 通过“开箱即用”的多模型产线和全硬件适配能力,将原本数周的定制开发工作缩短至小时级,让企业能专注于业务逻辑而非底层算法整合。
运行环境要求
- Linux
- Windows
- macOS
- 非必需(支持 CPU)
- 若使用 GPU,支持 NVIDIA (含 50 系,需 CUDA 12)、昆仑芯、昇腾、寒武纪、海光、燧原等
- 显存大小未说明,取决于具体模型
未说明

快速开始

![]()
![]()
![]()
![]()
🌟 特性 | 🌐 在线体验|🚀 快速开始 | 📖 文档 | 🔥能力支持 | 📋 模型列表
🇨🇳 简体中文 | 🇬🇧 English
🔍 简介
PaddleX 3.0 是基于飞桨框架构建的低代码开发工具,它集成了众多开箱即用的预训练模型,可以实现模型从训练到推理的全流程开发,支持国内外多款主流硬件,助力AI 开发者进行产业实践。
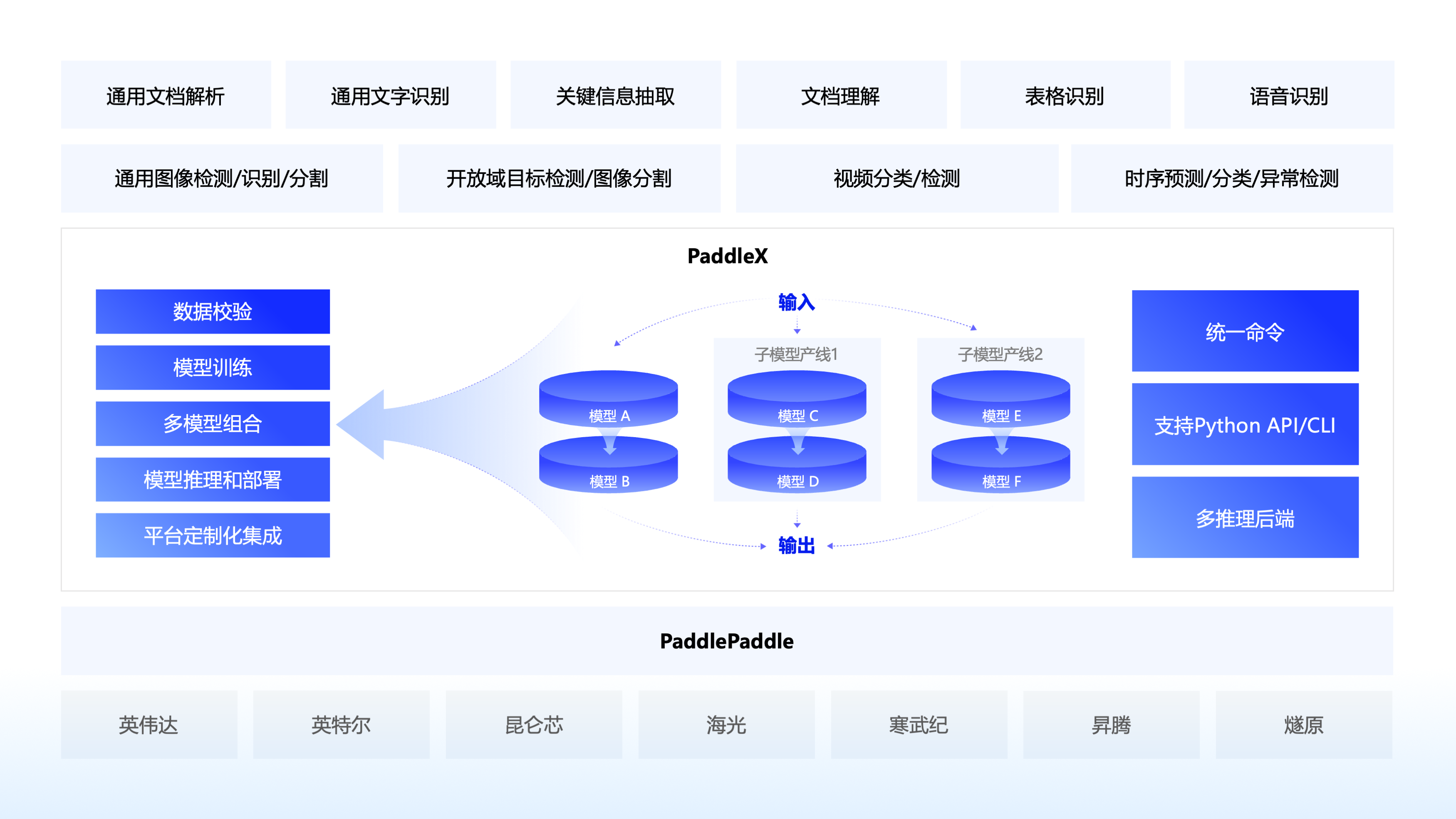
🌟 特性
🎨 模型丰富一键调用:将覆盖文本图像智能分析、OCR、目标检测、时序预测等多个关键领域的 200+ 飞桨模型整合为 33 条模型产线,通过极简的 Python API 一键调用,快速体验模型效果。同时支持 39 种单功能模块,方便开发者进行模型组合使用。
🚀 提高效率降低门槛:实现基于统一命令和图形界面的模型全流程开发,打造大小模型结合、大模型半监督学习和多模型融合的8 条特色模型产线,大幅度降低迭代模型的成本。
🌐 多种场景灵活部署:支持高性能推理、服务化部署和端侧部署等多种部署方式,确保不同应用场景下模型的高效运行和快速响应。
🔧 主流硬件高效支持:支持英伟达 GPU、昆仑芯、昇腾和寒武纪等多种主流硬件的无缝切换,确保高效运行。
📣 近期更新
🔥🔥 2025.10.16,发布 PaddleX v3.3.0,新增能力如下:
- 支持PaddleOCR-VL、PP-OCRv5多语种模型的推理部署能力。
🔥🔥 2025.8.20,发布 PaddleX v3.2.0,新增能力如下:
部署能力升级:
- 全面支持飞桨框架 3.1.0 和 3.1.1 版本。
- 高性能推理支持 CUDA 12,可使用 Paddle Inference、ONNX Runtime 后端推理。
- 高稳定性服务化部署方案全面开源,支持用户根据需求对 Docker 镜像和 SDK 进行定制化修改。
- 高稳定性服务化部署方案支持通过手动构造HTTP请求的方式调用,该方式允许客户端代码使用任意编程语言编写。
重要模型新增:
- 新增 PP-OCRv5 英文、泰文、希腊文识别模型的训练、推理、部署。其中 PP-OCRv5 英文模型较 PP-OCRv5 主模型在英文场景提升 11%,泰文识别模型精度 82.68%,希腊文识别模型精度 89.28%。
Benchmark升级:
- 全部产线支持产线细粒度 benchmark,能够测量产线端到端推理时间以及逐层、逐模块的耗时数据,可用于辅助产线性能分析。
- 在文档中补充各产线常用配置在主流硬件上的关键指标,包括推理耗时和内存占用等,为用户部署提供参考。
Bug修复:
- 修复了当输入图片文件格式不合法时,导致递归调用的问题。
- 修复了 PP-DocTranslation 和 PP-StructureV3 产线配置文件中图表识别、印章识别、文档预处理参数设置不生效的问题。
- 修复 PDF 文件在推理结束后未正确关闭的问题。
其他升级:
- 支持 Windows 用户使用英伟达 50 系显卡,可根据安装文档安装对应版本的 paddle 框架。
- PP-OCR 系列模型支持返回单文字坐标。
- 将
PaddlePredictorOption中的model_name参数移至PaddleInfer中,改善了用户易用性。 - 重构了官方模型下载逻辑,新增了 AIStudio、ModelScope 等多模型托管平台。
🔥🔥 2025.6.28,发布 PaddleX v3.1.0,新增能力如下:
- 重要模型:
- 新增PP-OCRv5多语种文本识别模型,支持法语、西班牙语、葡萄牙语、俄语、韩语等37种语言的文字识别模型的训推流程。平均精度涨幅超30%。
- 升级PP-StructureV3中的PP-Chart2Table模型,图表转表能力进一步升级,在内部自建测评集合上指标(RMS-F1)提升9.36个百分点(71.24% -> 80.60%)
- 重要产线:
- 新增基于PP-StructureV3和ERNIE 4.5 Turbo的文档翻译产线PP-DocTranslation,支持翻译Markdown文档、各种复杂版式的PDF文档和文档图像,结果保存为Markdown格式文档。
🔥🔥 2025.5.20,发布 PaddleX v3.0.0,相比PaddleX v2.x,核心升级如下:
丰富的模型库:
- 模型丰富: PaddleX3.0 包含270+模型,涵盖了图像(视频)分类/检测/分割、OCR、语音识别、时序等多种场景。
- 方案成熟: PaddleX3.0 基于丰富的模型库,提供了通用文档解析、关键信息抽取、文档理解、表格识别、通用图像识别等多种重要且成熟的AI解决方案。
统一推理接口,重构部署能力:
- 推理接口标准化,降低不同种类模型带来的API接口差异,减少用户学习成本,提升企业落地效率。
- 提供多模型组合能力,复杂任务可以通过不同的模型方便地进行组合使用,实现1+1>2 的能力。
- 部署能力升级,多种模型部署可以使用统一的命令管理,支持多卡推理,支持多卡多实例服务化部署。
全面适配飞桨框架3.0:
- 全面适配飞桨框架3.0新特性: 支持编译器训练,训练命令通过追加
-o Global.dy2st=True即可开启编译器训练,在 GPU 上,多数模型训练速度可提升 10% 以上,少部分模型训练速度可以提升 30% 以上。推理方面,模型整体适配飞桨 3.0 中间表示技术(PIR),拥有更加灵活的扩展能力和兼容性,静态图模型存储文件名由xxx.pdmodel改为xxx.json。 - 全面支持 ONNX 格式模型: 支持通过Paddle2ONNX插件转换模型格式。
重磅能力支撑:
- 支撑PP-OCRv5的串联逻辑和多硬件推理、多后端推理、服务化部署能力。
- 支撑PP-StructureV3的复杂模型串联和并联的逻辑,首次串联并联共15个模型,实现多模型协同的复杂pipeline。精度在 OmniDocBench 榜单上达到 SOTA 水平。
- 支撑PP-ChatOCRv4的大模型串联逻辑,结合文心大模型4.5Turbo,结合新增的PP-DocBee2,关键信息抽取精度相比上一代提升15.7个百分点。
多硬件支持:
- 整体支持英伟达、英特尔、苹果M系列、昆仑芯、昇腾、寒武纪、海光、燧原等芯片的训练和推理。
- 在昇腾上,全面适配的模型达到200个, 支持OM高性能推理的模型达到21个。此外支持PP-OCRv5、PP-StructureV3等重要模型方案。
- 在昆仑芯上支持重要分类、检测、OCR类模型(含PP-OCRv5)。
🔠 模型产线说明
PaddleX 致力于实现产线级别的模型训练、推理与部署。模型产线是指一系列预定义好的、针对特定AI任务的开发流程,其中包含能够独立完成某类任务的单模型(单功能模块)组合。
📊 能力支持
PaddleX的各个产线均支持本地快速推理,部分模型支持在AI Studio星河社区上进行在线体验,您可以快速体验各个产线的预训练模型效果,如果您对产线的预训练模型效果满意,可以直接对产线进行高性能推理/服务化部署/端侧部署,如果不满意,您也可以使用产线的二次开发能力,提升效果。完整的产线开发流程请参考PaddleX产线使用概览或各产线使用教程。
此外,PaddleX在AI Studio星河社区为开发者提供了基于云端图形化开发界面的全流程开发工具, 点击【创建产线】,选择对应的任务场景和模型产线,就可以开启全流程开发。详细请参考教程《零门槛开发产业级AI模型》
| 模型产线 | 在线体验 | 快速推理 | 高性能推理 | 服务化部署 | 端侧部署 | 二次开发 | 星河零代码产线 |
|---|---|---|---|---|---|---|---|
| 通用OCR | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 文档场景信息抽取v3 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 文档场景信息抽取v4 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 通用表格识别 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 通用目标检测 | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 通用实例分割 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 通用图像分类 | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 通用语义分割 | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 时序预测 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 时序异常检测 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 时序分类 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 小目标检测 | 链接 | ✅ | ✅ | ✅ | arded | ✅ | ✅ |
| 图像多标签分类 | 链接 | ✅ | ✅ | ✅ | arded | ✅ | ✅ |
| 公式识别 | 链接 | ✅ | ✅ | ✅ | arded | ✅ | ✅ |
| 印章文本识别 | 链接 | ✅ | ✅ | ✅ | arded | ✅ | ✅ |
| 行人属性识别 | 链接 | ✅ | ✅ | ✅ | arded | ✅ | ✅ |
| 车辆属性识别 | 链接 | ✅ | ✅ | ✅ | arded | ✅ | ✅ |
| 图像异常检测 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 人体关键点检测 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 开放词汇检测 | arded | ✅ | ✅ | ✅ | arded | arded | arded |
| 开放词汇分割 | arded | ✅ | ✅ | ✅ | arded | arded | arded |
| 旋转目标检测 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 3D多模态融合检测 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 通用表格识别v2 | 链接 | ✅ | ✅ | ✅ | arded | ✅ | ✅ |
| 通用版面解析 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 通用版面解析v3 | 链接 | ✅ | ✅ | ✅ | arded | arded | ✅ |
| 文档图像预处理 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 通用图像识别 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 人脸识别 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 多语种语音识别 | arded | ✅ | arded | ✅ | arded | arded | arded |
| 通用视频分类 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 通用视频检测 | arded | ✅ | ✅ | ✅ | arded | ✅ | arded |
| 文档理解 | arded | ✅ | arded | ✅ | arded | arded | arded |
❗注:以上功能均基于 GPU/CPU 实现。PaddleX 还可在昆仑芯、昇腾、寒武纪和海光等主流硬件上进行快速推理和二次开发。下表详细列出了模型产线的支持情况,具体支持的模型列表请参阅模型列表(昆仑芯 XPU)/模型列表( 昇腾 NPU)/模型列表( 寒武纪 MLU)/模型列表( 海光 DCU)。我们正在适配更多的模型,并在主流硬件上推动高性能和服务化部署的实施。
🔥🔥 国产化硬件能力支持
| 模型产线 | 昇腾 910B | 昆仑芯 R200/R300 | 寒武纪 MLU370X8 | 海光 Z100/K100AI |
|---|---|---|---|---|
| 通用OCR | ✅ | ✅ | ✅ | ✅ |
| 通用表格识别 | ✅ | 🚧 | 🚧 | 🚧 |
| 通用目标检测 | ✅ | ✅ | ✅ | ✅ |
| 通用实例分割 | ✅ | 🚧 | ✅ | 🚧 |
| 通用图像分类 | ✅ | ✅ | ✅ | ✅ |
| 通用语义分割 | ✅ | ✅ | ✅ | ✅ |
| 时序预测 | ✅ | ✅ | ✅ | ✅ |
| 时序异常检测 | ✅ | 🚧 | 🚧 | 🚧 |
| 时序分类 | ✅ | 🚧 | 🚧 | 🚧 |
| 图像多标签分类 | ✅ | 🚧 | 🚧 | ✅ |
| 行人属性识别 | ✅ | 🚧 | 🚧 | 🚧 |
| 车辆属性识别 | ✅ | 🚧 | 🚧 | 🚧 |
| 通用图像识别 | ✅ | 🚧 | ✅ | ✅ |
| 印章文本识别 | ✅ | 🚧 | 🚧 | 🚧 |
| 图像异常检测 | ✅ | ✅ | ✅ | ✅ |
| 人脸识别 | ✅ | ✅ | ✅ | ✅ |
⏭️ 快速开始
🛠️ 安装
❗在安装 PaddleX 之前,请确保您已具备基本的 Python 运行环境(注:目前支持 Python 3.8 至 Python 3.13)。PaddleX 3.0.x 版本依赖的 PaddlePaddle 版本为 3.0.0 及以上版本,请在使用前务必保证版本的对应关系。
- 安装 PaddlePaddle
# CPU 版本
python -m pip install paddlepaddle==3.3.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
# GPU 版本,需显卡驱动程序版本 ≥450.80.02(Linux)或 ≥452.39(Windows)
python -m pip install paddlepaddle-gpu==3.3.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/
# GPU 版本,需显卡驱动程序版本 ≥550.54.14(Linux)或 ≥550.54.14(Windows)
python -m pip install paddlepaddle-gpu==3.3.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
❗无需关注物理机上的 CUDA 版本,只需关注显卡驱动程序版本。更多飞桨 Wheel 版本信息,请参考飞桨官网。
- 安装PaddleX
pip install "paddlex[base]"
❗ 更多安装方式参考 PaddleX 安装教程
💻 命令行使用
一行命令即可快速体验产线效果,统一的命令行格式为:
paddlex --pipeline [产线名称] --input [输入图片] --device [运行设备]
PaddleX的每一条产线对应特定的参数,您可以在各自的产线文档中查看具体的参数说明。每条产线需指定必要的三个参数:
pipeline:产线名称或产线配置文件input:待处理的输入文件(如图片)的本地路径、目录或 URLdevice:使用的硬件设备及序号(例如gpu:0表示使用第 0 块 GPU),也可选择使用 NPU(npu:0)、 XPU(xpu:0)、CPU(cpu)等。
以通用 OCR 产线为例:
paddlex --pipeline OCR \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png \
--use_doc_orientation_classify False \
--use_doc_unwarping False \
--use_textline_orientation False \
--save_path ./output \
--device gpu:0
👉 点击查看运行结果
{'res': {'input_path': 'general_ocr_002.png', 'page_index': None, 'model_settings': {'use_doc_preprocessor': False, 'use_textline_orientation': False}, 'doc_preprocessor_res': {'input_path': None, 'model_settings': {'use_doc_orientation_classify': True, 'use_doc_unwarping': False}, 'angle': 0},'dt_polys': [array([[ 3, 10],
[82, 10],
[82, 33],
[ 3, 33]], dtype=int16), ...], 'text_det_params': {'limit_side_len': 960, 'limit_type': 'max', 'thresh': 0.3, 'box_thresh': 0.6, 'unclip_ratio': 2.0}, 'text_type': 'general', 'textline_orientation_angles': [-1, ...], 'text_rec_score_thresh': 0.0, 'rec_texts': ['www.99*', ...], 'rec_scores': [0.8980069160461426, ...], 'rec_polys': [array([[ 3, 10],
[82, 10],
[82, 33],
[ 3, 33]], dtype=int16), ...], 'rec_boxes': array([[ 3, 10, 82, 33], ...], dtype=int16)}}
可视化结果如下:

其他产线的命令行使用,只需将 pipeline 参数调整为相应产线的名称,参数调整为对应的产线的参数即可。下面列出了每个产线对应的命令:
👉 更多产线的命令行使用
| 产线名称 | 使用命令 |
|---|---|
| 通用图像分类 | paddlex --pipeline image_classification --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg --device gpu:0 --save_path ./output/ |
| 通用目标检测 | paddlex --pipeline object_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_object_detection_002.png --threshold 0.5 --save_path ./output/ --device gpu:0 |
| 通用实例分割 | paddlex --pipeline instance_segmentation --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_instance_segmentation_004.png --threshold 0.5 --save_path ./output --device gpu:0 |
| 通用语义分割 | paddlex --pipeline semantic_segmentation --input https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/application/semantic_segmentation/makassaridn-road_demo.png --target_size -1 --save_path ./output --device gpu:0 |
| 图像多标签分类 | paddlex --pipeline image_multilabel_classification --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_image_classification_001.jpg --save_path ./output --device gpu:0 |
| 小目标检测 | paddlex --pipeline small_object_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/small_object_detection.jpg --threshold 0.5 --save_path ./output --device gpu:0 |
| 图像异常检测 | paddlex --pipeline anomaly_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/uad_grid.png --save_path ./output --device gpu:0 |
| 行人属性识别 | paddlex --pipeline pedestrian_attribute_recognition --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pedestrian_attribute_002.jpg --save_path ./output/ --device gpu:0 |
| 车辆属性识别 | paddlex --pipeline vehicle_attribute_recognition --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/vehicle_attribute_002.jpg --save_path ./output/ --device gpu:0 |
| 3D多模态融合检测 | paddlex --pipeline 3d_bev_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/det_3d/demo_det_3d/nuscenes_demo_infer.tar --device gpu:0 --save_path ./output/ |
| 人体关键点检测 | paddlex --pipeline human_keypoint_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/keypoint_detection_001.jpg --det_threshold 0.5 --save_path ./output/ --device gpu:0 |
| 开放词汇检测 | paddlex --pipeline open_vocabulary_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/open_vocabulary_detection.jpg --prompt "bus . walking man . rearview mirror ." --thresholds "{'text_threshold': 0.25, 'box_threshold': 0.3}" --save_path ./output --device gpu:0 |
| 开放词汇分割 | paddlex --pipeline open_vocabulary_segmentation --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/open_vocabulary_segmentation.jpg --prompt_type box --prompt "[[112.9,118.4,513.8,382.1],[4.6,263.6,92.2,336.6],[592.4,260.9,607.2,294.2]]" --save_path ./output --device gpu:0 |
| 旋转目标检测 | paddlex --pipeline rotated_object_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/rotated_object_detection_001.png --threshold 0.5 --save_path ./output --device gpu:0 |
| 通用OCR | paddlex --pipeline OCR --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False --save_path ./output --device gpu:0 |
| 文档图像预处理 | paddlex --pipeline doc_preprocessor --input https://paddle-model-ecology.bj.bcebos.com/paddlex/demo_image/doc_test_rotated.jpg --use_doc_orientation_classify True --use_doc_unwarping True --save_path ./output --device gpu:0 |
| 通用表格识别 | paddlex --pipeline table_recognition --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/table_recognition.jpg --save_path ./output --device gpu:0 |
| 通用表格识别v2 | paddlex --pipeline table_recognition_v2 --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/table_recognition.jpg --save_path ./output --device gpu:0 |
| 通用版面解析 | paddlex --pipeline layout_parsing --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/demo_paper.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False --save_path ./output --device gpu:0 |
| 通用版面解析v3 | paddlex --pipeline PP-StructureV3 --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/pp_structure_v3_demo.png --use_doc_orientation_classify False --use_doc_unwarping False --use_textline_orientation False --save_path ./output --device gpu:0 |
| 公式识别 | paddlex --pipeline formula_recognition --input https://paddle-model-ecology.bj.bcebos.com/paddlex/demo_image/general_formula_recognition.png --use_layout_detection True --use_doc_orientation_classify False --use_doc_unwarping False --layout_threshold 0.5 --layout_nms True --layout_unclip_ratio 1.0 --layout_merge_bboxes_mode large --save_path ./output --device gpu:0 |
| 印章文本识别 | paddlex --pipeline seal_recognition --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/seal_text_det.png --use_doc_orientation_classify False --use_doc_unwarping False --device gpu:0 --save_path ./output |
| 时序预测 | paddlex --pipeline ts_forecast --input https://paddle-model-ecology.bj.bcebos.com/paddlex/ts/demo_ts/ts_fc.csv --device gpu:0 --save_path ./output |
| 时序异常检测 | paddlex --pipeline ts_anomaly_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/ts/demo_ts/ts_ad.csv --device gpu:0 --save_path ./output |
| 时序分类 | paddlex --pipeline ts_classification --input https://paddle-model-ecology.bj.bcebos.com/paddlex/ts/demo_ts/ts_cls.csv --device gpu:0 --save_path ./output |
| 多语种语音识别 | paddlex --pipeline multilingual_speech_recognition --input https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav --save_path ./output --device gpu:0 |
| 通用视频分类 | paddlex --pipeline video_classification --input https://paddle-model-ecology.bj.bcebos.com/paddlex/videos/demo_video/general_video_classification_001.mp4 --topk 5 --save_path ./output --device gpu:0 |
| 通用视频检测 | paddlex --pipeline video_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/videos/demo_video/HorseRiding.avi --device gpu:0 --save_path ./output |
📝 Python 脚本使用
几行代码即可完成产线的快速推理,统一的 Python 脚本格式如下:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline=[产线名称])
output = pipeline.predict([输入图片名称])
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_json("./output/")
执行了如下几个步骤:
create_pipeline()实例化产线对象- 传入图片并调用产线对象的
predict()方法进行推理预测 - 对预测结果进行处理
其他产线的 Python 脚本使用,只需将 create_pipeline() 方法的 pipeline 参数调整为相应产线的名称,参数调整为对应的产线的参数即可。下面列出了每个产线对应的参数名称及详细的使用解释:
👉 更多产线的Python脚本使用
| 产线名称 | 对应参数 | 详细说明 |
|---|---|---|
| 文档场景信息抽取v4 | PP-ChatOCRv4-doc |
文档场景信息抽取v4产线Python脚本使用说明 |
| 文档场景信息抽取v3 | PP-ChatOCRv3-doc |
文档场景信息抽取v3产线Python脚本使用说明 |
| 通用图像分类 | image_classification |
通用图像分类产线Python脚本使用说明 |
| 通用目标检测 | object_detection |
通用目标检测产线Python脚本使用说明 |
| 通用实例分割 | instance_segmentation |
通用实例分割产线Python脚本使用说明 |
| 通用语义分割 | semantic_segmentation |
通用语义分割产线Python脚本使用说明 |
| 图像多标签分类 | multi_label_image_classification |
图像多标签分类产线Python脚本使用说明 |
| 小目标检测 | small_object_detection |
小目标检测产线Python脚本使用说明 |
| 图像异常检测 | anomaly_detection |
图像异常检测产线Python脚本使用说明 |
| 通用图像识别 | PP-ShiTuV2 |
通用图像识别Python脚本使用说明 |
| 人脸识别 | face_recognition |
人脸识别Python脚本使用说明 |
| 车辆属性识别 | vehicle_attribute_recognition |
车辆属性识别产线Python脚本使用说明 |
| 行人属性识别 | pedestrian_attribute_recognition |
行人属性识别产线Python脚本使用说明 |
| 3D多模态融合检测 | 3d_bev_detection |
3D多模态融合检测产线Python脚本使用说明 |
| 人体关键点检测 | human_keypoint_detection |
人体关键点检测产线Python脚本使用说明 |
| 开放词汇检测 | open_vocabulary_detection |
开放词汇检测产线Python脚本使用说明 |
| 开放词汇分割 | open_vocabulary_segmentation |
开放词汇分割产线Python脚本使用说明 |
| 旋转目标检测 | rotated_object_detection |
旋转目标检测产线Python脚本使用说明 |
| 通用OCR | OCR |
通用OCR产线Python脚本使用说明 |
| 文档图像预处理 | doc_preprocessor |
文档图像预处理产线Python脚本使用说明 |
| 通用表格识别 | table_recognition |
通用表格识别产线Python脚本使用说明 |
| 通用表格识别v2 | table_recognition_v2 |
通用表格识别v2产线Python脚本使用说明 |
| 通用版面解析 | layout_parsing |
通用版面解析产线Python脚本使用说明 |
| 通用版面解析v3 | PP-StructureV3 |
通用版面解析v3产线Python脚本使用说明 |
| 公式识别 | formula_recognition |
公式识别产线Python脚本使用说明 |
| 印章文本识别 | seal_recognition |
印章文本识别产线Python脚本使用说明 |
| 时序预测 | ts_forecast |
时序预测产线Python脚本使用说明 |
| 时序异常检测 | ts_anomaly_detection |
时序异常检测产线Python脚本使用说明 |
| 时序分类 | ts_classification |
时序分类产线Python脚本使用说明 |
| 多语种语音识别 | multilingual_speech_recognition |
多语种语音识别产线Python脚本使用说明 |
| 通用视频分类 | video_classification |
通用视频分类产线Python脚本使用说明 |
| 通用视频检测 | video_detection |
通用视频检测产线Python脚本使用说明 |
| 文档理解 | doc_understanding |
文档理解产线Python脚本使用说明 |
📖 文档
🔥 产线使用
📝 文本图像智能分析
⏱️ 时序分析
🎤 语音识别
🎥 视频识别
🌐 多模态视觉语言模型
⚙️ 单功能模块使用
🏞️ 图像特征
⏱️ 时序分析
🎤 语音识别
📦 3D
🌐 多模态视觉语言模型
🖥️ 多硬件使用
📊 数据标注教程
🔍 OCR
📉 时序分析
📑 产线列表
📄 模型列表
📝 产业实践教程&范例
🤔 FAQ
关于我们项目的一些常见问题解答,请参考FAQ。如果您的问题没有得到解答,请随时在 Issues 中提出
💬 Discussion
我们非常欢迎并鼓励社区成员在 Discussions 板块中提出问题、分享想法和反馈。无论您是想要报告一个 bug、讨论一个功能请求、寻求帮助还是仅仅想要了解项目的最新动态,这里都是一个绝佳的平台。
📄 许可证书
本项目的发布受 Apache 2.0 license 许可认证。
版本历史
v3.5.02026/04/17v3.4.32026/03/26v3.4.22026/02/13v3.4.12026/01/30v3.4.02026/01/29v3.3.132026/01/12v3.3.122025/12/22v3.3.112025/12/09v3.3.102025/11/25v3.3.92025/11/25v3.3.82025/11/25v3.3.72025/11/25v3.3.62025/10/29v3.3.52025/10/23v3.3.12025/10/16v3.3.02025/10/16v3.2.12025/08/29v3.2.02025/08/20v3.1.42025/08/14v3.1.32025/07/11常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器