SimpleVLA-RL
SimpleVLA-RL 是一个专为视觉 - 语言 - 动作模型(VLA)打造的高效强化学习开源框架,旨在解决机器人在数据稀缺环境下难以完成长程规划任务的难题。传统监督微调(SFT)方法在面对复杂任务时往往表现受限,而 SimpleVLA-RL 通过引入强化学习机制,显著提升了模型在仿真及真实世界场景中的决策能力与泛化水平,甚至在长周期灵巧操作中实现了比 SFT 模型高出约 300% 的性能提升,并展现出惊人的自动恢复能力。
该工具特别适合机器人领域的研究人员与开发者使用,尤其是那些希望探索端到端 VLA 训练、优化长程任务策略或进行真实世界部署的团队。其技术亮点包括:基于 veRL 构建的端到端流水线,支持多环境并行渲染以加速轨迹采样;采用极简的二元奖励机制(0/1),无需复杂的奖励工程设计;内置动态采样、自适应裁剪等先进探索策略。此外,它已兼容 OpenVLA 等主流模型及 LIBERO、RoboTwin 等基准测试,架构模块化设计便于后续扩展新算法与场景。无论是学术研究还是工程落地,SimpleVLA-RL 都为提升机器人智能提供了强大而灵活的基础设施。
使用场景
某机器人研发团队正致力于让机械臂在数据稀缺的情况下,完成如“整理杂乱桌面”这类需要长程规划的真实世界任务。
没有 SimpleVLA-RL 时
- 长程任务失败率高:仅靠监督微调(SFT)训练的模型,一旦中间步骤出错便无法自救,导致整个长流程任务直接崩溃。
- 数据依赖严重:面对新物体或新布局,因缺乏大量标注演示数据,模型泛化能力极差,几乎无法执行未见过的操作。
- 奖励设计复杂:传统强化学习需要专家手动设计复杂的稠密奖励函数,耗时耗力且难以平衡各项指标。
- 训练效率低下:现有框架缺乏针对视觉 - 语言 - 动作(VLA)模型的优化,多环境并行采样慢,显存管理低效,迭代周期长达数周。
使用 SimpleVLA-RL 后
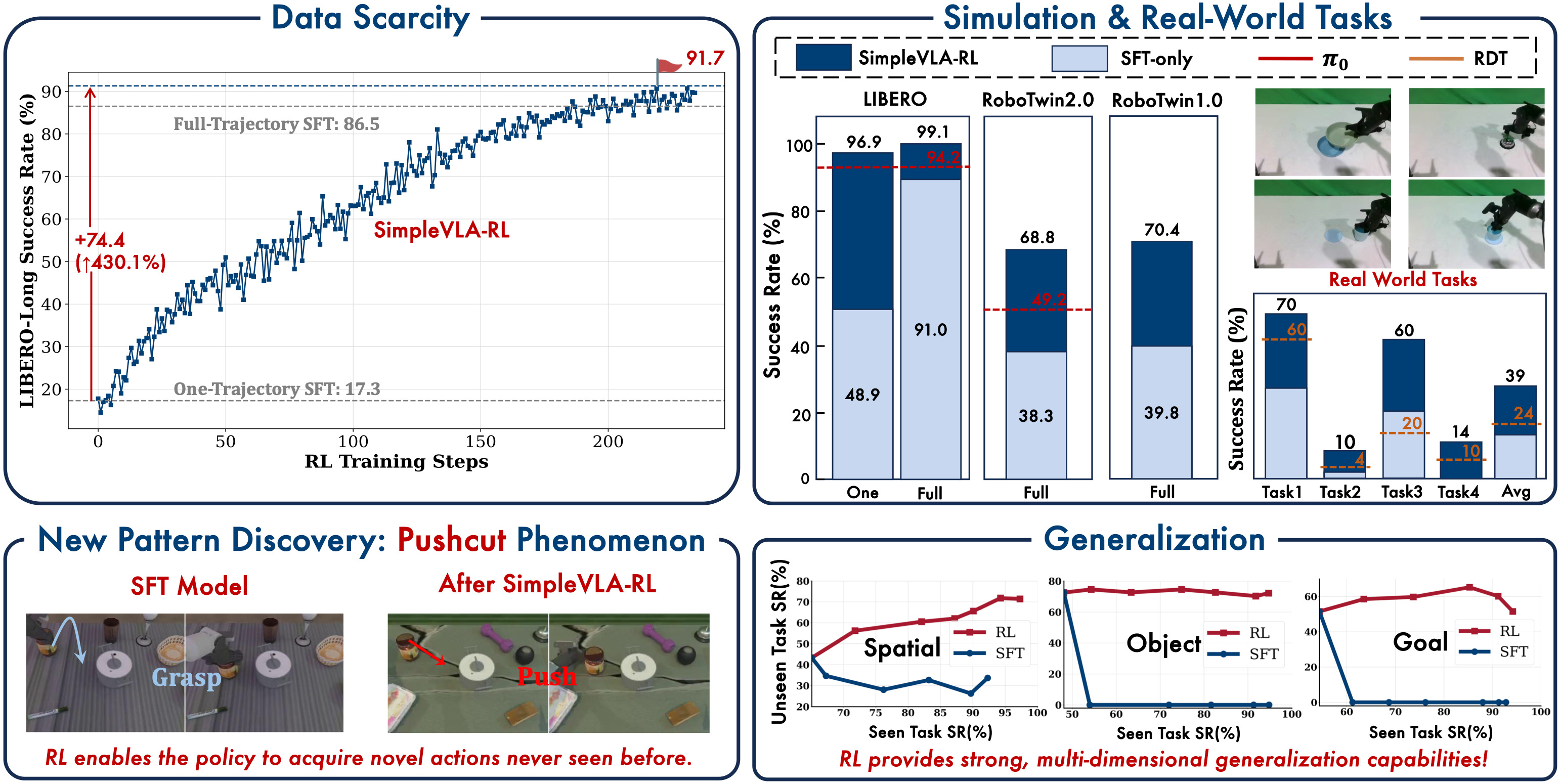
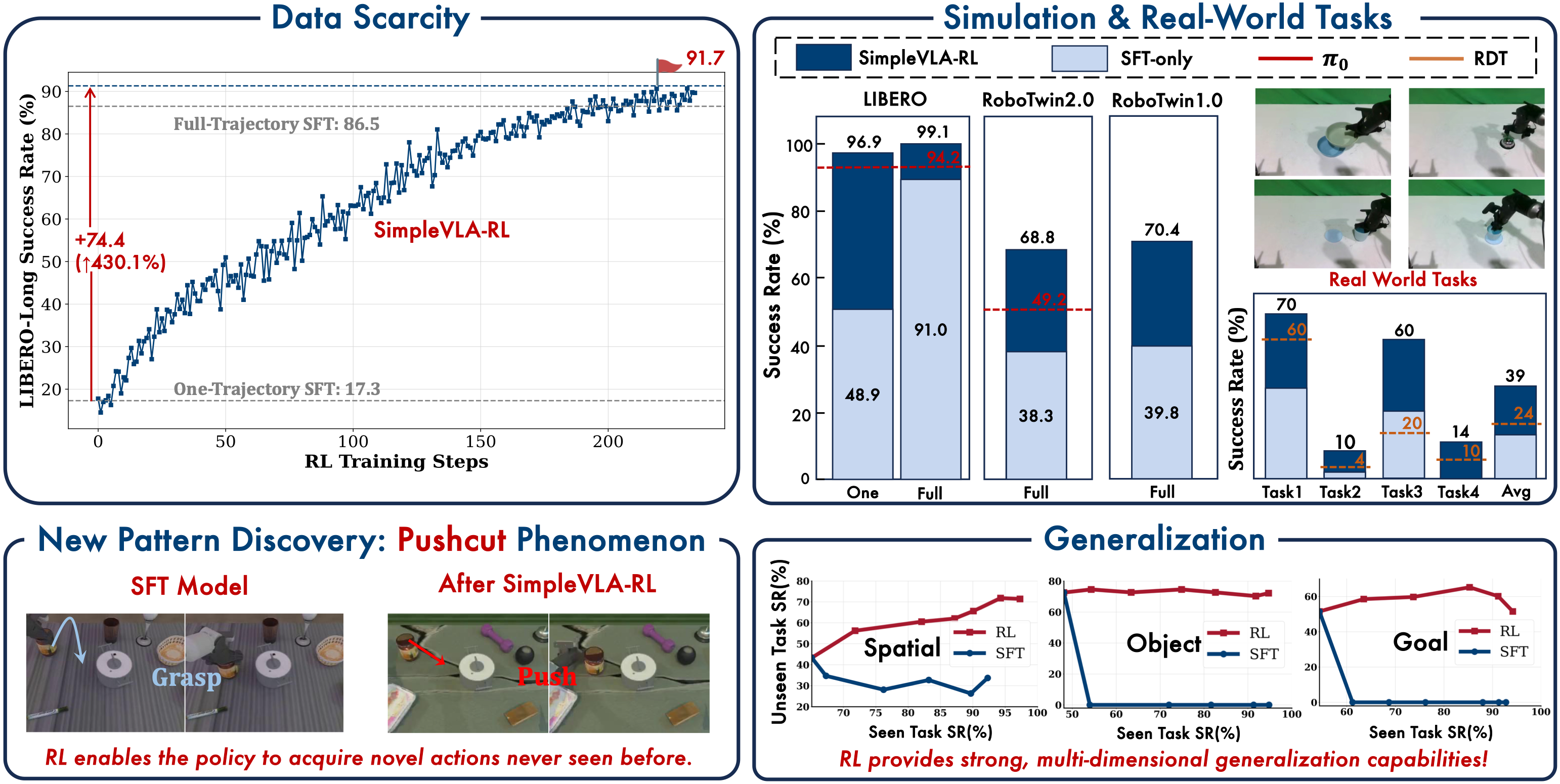
- 具备自动恢复能力:利用强化学习策略,机械臂在操作失误后能自主修正错误(如重新抓取),长程任务成功率相对提升约 300%。
- 极强的泛化性能:仅需简单的二元(成功/失败)奖励信号,模型即可在少样本下学会空间推理,轻松适应新物体和新目标。
- 极简奖励工程:无需设计复杂的奖励曲线,直接基于任务最终结果进行 0/1 反馈,大幅降低了算法落地门槛。
- 高效分布式训练:基于 veRL 架构的多环境并行渲染与显存优化,将轨迹采样和模型训练速度提升数倍,快速验证新策略。
SimpleVLA-RL 通过高效的强化学习框架,彻底解决了 VLA 模型在数据稀缺场景下长程规划难、泛化弱及训练慢的核心瓶颈。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 测试配置为 NVIDIA A800 (80GB 显存)
- 单节点需 8 卡,多节点支持扩展
- 驱动版本 470.161.03,CUDA 版本 12.4
未说明 (基于 80GB 显存的 GPU 配置,建议系统内存充足)
快速开始

SimpleVLA-RL:面向视觉-语言-动作模型的开源强化学习框架
![]()

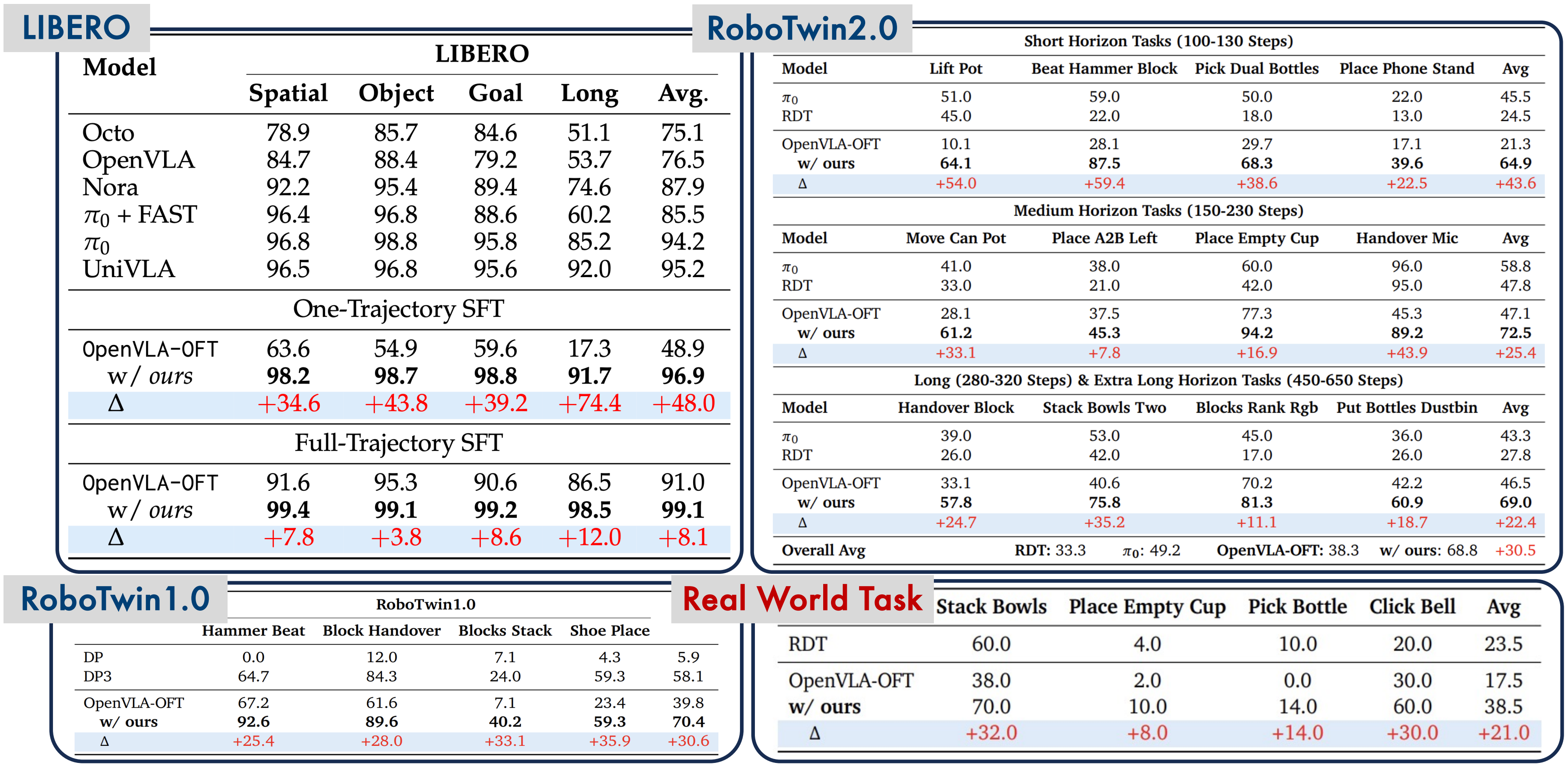
SimpleVLA-RL 是一个高效的 VLA 强化学习框架,在数据稀缺的情况下提升了长时程规划能力。它利用强化学习技术,在仿真和真实世界任务中显著优于监督微调(SFT),揭示了一种“pushcut”新动作现象,并增强了空间、物体及目标的泛化能力。
🎉新闻
- [2026-01-01] 在 $${\color{red}\textbf{SimpleVLA-RL}}$$ 的基础上,我们在长时程灵巧任务上实现了 $${\color{red}\textbf{真实世界强化学习}}$,与 SFT 模型相比性能提升了 $${\color{red}\textbf{非平凡的}}$(约 300%),同时还展现出惊人的自动恢复能力。博客即将发布。**
https://github.com/user-attachments/assets/45fca289-39d4-4a42-8014-1ef7eff2d806
- [2025-10-01] SimpleVLA-RL 现已支持 RoboTwin2.0 基准测试。欢迎试用!
- [2025-09-12] 我们很高兴地发布了 SimpleVLA-RL 论文!请查看:论文。
- [2025-05-27] 我们发布了 SimpleVLA-RL 的代码。
📌亮点
高效且有效的 VLA 强化学习框架
- 基于 veRL 构建的端到端 VLA RL 流程,并进行了 VLA 特有的优化
- 多环境并行渲染显著加速了 VLA 轨迹采样
- 利用 veRL 的先进基础设施:高效的分布式训练(FSDP)、混合通信模式以及优化的内存管理,实现快速训练和推理
模型与环境支持
- VLA 模型:OpenVLA、OpenVLA-OFT
- 基准测试:LIBERO、RoboTwin 1.0/2.0
- 模块化架构,便于集成新的 VLA 模型、基准测试和强化学习算法(即将推出)
极简的奖励工程与探索策略
- 二元(0/1)结果奖励——无需复杂奖励设计
- 探索策略:动态采样、自适应裁剪、温度调节
🔧关键实现
SimpleVLA-RL 在 veRL 的基础上,增加了针对 VLA 的特定组件,涵盖以下模块:
- 主入口,包含 Ray 初始化
RobRewardManager用于奖励分配
verl/trainer/ppo/ray_trainer.py
- 主要的强化学习训练循环:数据加载、VLA 滚动执行、模型更新、评估、检查点保存
- 强化学习算法特有的优势计算
- 提供
ray_trainer.py中调用的核心函数 - VLA 模型和优化器的初始化、
generate_sequences、compute_entropy、update_actor
- 对
fsdp_workers.py中函数的具体实现 - 强化学习损失计算、策略更新、
compute_log_prob、compute_entropy
verl/workers/rollout/rob_rollout.py
- VLA 滚动执行的实现:环境创建、多环境并行渲染、VLA 动作生成、环境交互、视频保存、轨迹及 0/1 奖励收集
verl/utils/dataset/rob_dataset.py
- 用于在不同基准测试中进行训练和测试的数据集构建
- VLA 模型的实现(来自官方代码的 OpenVLA-OFT/OpenVLA)
✨开始使用
1. 设置环境
请参阅 SETUP.md,获取关于设置 conda 环境的详细说明。
2. 准备 SFT 模型
进行强化学习训练需要一个 SFT(监督微调) VLA 模型。以下是可用的选项:
OpenVLA-OFT SFT 模型
可从 SimpleVLA-RL Collection 下载。可用模型包括:libero-10 traj1/trajall SFTlibero-goal/object/spatial traj1 SFTRobotwin2.0 tasks traj1000 SFT
OpenVLA SFT 模型
可从 这里下载。其他模型
对于其他模型,您可能需要自行进行微调。
3. 使用 SimpleVLA-RL 进行训练
在运行训练脚本之前,请确保以下配置已正确设置:
设置您的 Weights and Biases (WandB) API 密钥
将SimpleVLA-RL/align.json文件中的WANDB_API_KEY字段替换为您自己的 WandB API 密钥。修改关键变量
根据需要更新examples/run_openvla_oft_rl_libero/twin2.sh中的以下变量:WANDB_API_KEY: 您的 WandB API 密钥。EXPERIMENT_NAME: 您的实验名称。您可以选择任意名称。SFT_MODEL_PATH: 您的 SFT 模型路径。CKPT_PATH: 您的检查点保存路径。DATASET_NAME: 有关详细选项,请参阅examples/run_openvla_oft_rl_libero/twin2.sh。ALIGN_PATH:SimpleVLA-RL/align.json文件的路径。NUM_GPUS: 每个节点可用的 GPU 数量(例如8)。NUM_NODES: 用于强化学习训练的节点数量(例如1)。
[!NOTE]
- 该脚本已在以下配置上测试通过:
- 单节点设置:
NUM_NODES=1,NUM_GPUS=8(1 个节点,配备 8 块 NVIDIA A800 GPU,每块显存 80GB)。- 多节点设置:
NUM_NODES=2,NUM_GPUS=8(2 个节点,配备 16 块 NVIDIA A800 GPU,每块显存 80GB)。- 所使用的驱动版本为
470.161.03,CUDA 版本为12.4。(非必需)
运行强化学习训练
使用以下命令启动 OpenVLA-OFT 在 LIBERO 或 RoboTwin2.0 基准上的强化学习训练:bash examples/run_openvla_oft_rl_libero.sh 或 bash examples/run_openvla_oft_rl_twin2.sh
4. 运行评估
要评估您的模型性能,可在 examples/run_openvla_oft_rl_libero/twin2.sh 中将 trainer.val_only=True 设置为开启评估模式。然后执行相同的脚本:
bash examples/run_openvla_oft_rl_libero.sh
或
bash examples/run_openvla_oft_rl_twin2.sh
📃 主要结果
我们使用 OpenVLA-OFT 在 LIBERO 上评估了 SimpleVLA-RL。SimpleVLA-RL 将 OpenVLA-OFT 在 LIBERO-Long 上的性能提升至 97.6 分,并创造了新的最先进水平。值得注意的是,仅使用每个任务的一条轨迹进行冷启动 SFT,SimpleVLA-RL 就将 OpenVLA-OFT 的性能从 17.3 提升到 91.7,提升了 74.4 分(430.1%)。
🌻致谢
我们基于 veRL、OpenVLA-OFT、RoboTwin2.0 和 PRIME 开发了这个代码预览版。我们感谢他们的重要贡献!如需更多详情和更新,请参阅各项目的官方文档和仓库。
📝路线图
拓展模型支持
- 支持基于扩散的高级强化学习:pi0 和 pi0.5,结合流匹配强化学习
- 支持更多 VLA 模型:尤其是轻量级模型(例如 VLA-Adapter、SmolVLA)
拓展环境支持
- 支持更多基准:例如 SimplerEnv、BEHAVIOR、Calvin
- 支持真实世界强化学习。
拓展框架
- 添加更多在线强化学习方法和离线强化学习算法
- 提供模块化的环境和 VLA 接口,便于适配
- 进一步优化强化学习框架,以实现更高效的训练
📨联系方式
🎈引用
如果您觉得 SimpleVLA-RL 有所帮助,请引用我们:
@article{li2025simplevla,
title={SimpleVLA-RL: 通过强化学习扩展 VLA 训练},
author={Li, Haozhan 和 Zuo, Yuxin 和 Yu, Jiale 和 Zhang, Yuhao 和 Yang, Zhaohui 和 Zhang, Kaiyan 和 Zhu, Xuekai 和 Zhang, Yuchen 和 Chen, Tianxing 和 Cui, Ganqu 等},
journal={arXiv 预印本 arXiv:2509.09674},
year={2025}
}
🌟星标历史
