DexterousHands
DexterousHands(又名 Bi-DexHands)是一个基于 Isaac Gym 构建的开源库,专注于提供双手灵巧操作任务与强化学习算法。它旨在解决现代机器人研究中双手协调与手指精细操作难以达到人类水平的挑战,为学术界和工业界提供了一个高保真的仿真基准。
该工具特别适合机器人学研究人员、强化学习开发者以及多智能体系统探索者使用。其核心亮点在于极高的运行效率,利用 GPU 并行计算能力,单张显卡即可同时运行数千个仿真环境,大幅加速训练过程。此外,DexterousHands 支持异构智能体协作,真实模拟了手指、关节等不同部件的特性,区别于传统参数共享的多智能体环境。它还提供了丰富的任务场景(如传递、投掷、放置等)和超过 2000 种物体模型,并支持视觉观测与点云输入,能够很好地满足元学习、多任务学习及离线强化学习等前沿算法的验证需求。无论是想要复现经典算法,还是探索新的双手协作策略,DexterousHands 都是一个功能强大且易于集成的研究平台。
使用场景
某机器人实验室团队正致力于训练一双机械手协同完成复杂的“物体递接”与“精准放置”任务,以服务于柔性制造场景。
没有 DexterousHands 时
- 仿真效率极低:传统单环境串行训练方式导致数据采样缓慢,在普通显卡上难以支撑大规模强化学习所需的亿级交互步数,模型收敛需数周时间。
- 缺乏双手基准:社区缺少专门针对双臂异构协作的标准测试环境,研究人员不得不自行搭建简陋场景,难以公平对比多智能体强化学习(MARL)算法效果。
- 感知能力受限:现有工具多仅支持关节角度等本体感知,缺乏深度相机点云输入支持,导致机器人无法像人类一样基于视觉进行精细的空间定位与抓取。
- 泛化验证困难:由于缺乏多样化的物体库(如 YCB 数据集),训练出的策略往往只能处理特定形状物体,一旦更换目标物品,机器人便无法适应。
使用 DexterousHands 后
- 千倍加速训练:依托 Isaac Gym 并行架构,DexterousHands 能在单张 RTX 3090 上同时运行 2048 个环境,实现超 40,000 FPS 的仿真速度,将训练周期从数周缩短至数小时。
- 开箱即用的基准:直接提供涵盖递接、抛掷、放置等丰富任务的双手操作基准,支持主流 RL 算法一键调用,让团队能立即专注于算法优化而非环境搭建。
- 视觉融合感知:原生支持将深度图像转换为点云作为观测输入,使机械手能基于实时视觉反馈调整手指姿态,显著提升了非结构化环境下的操作成功率。
- 海量物体泛化:内置超过 2000 种来自 YCB 和 SAPIEN 数据集的物体,轻松验证元学习与多任务算法的泛化能力,确保机器人面对新物品时依然灵活可靠。
DexterousHands 通过极致的仿真效率与丰富的双手协作基准,彻底打破了复杂灵巧操作算法研发的效率瓶颈。
运行环境要求
- Linux (Ubuntu 18.04/20.04)
必需 NVIDIA GPU,支持 Isaac Gym (最低驱动版本 470.74),文中示例提及 RTX 3090 可达高性能
未说明

快速开始
Bi-DexHands:基于强化学习的双手灵巧操作


![]()
![]()
![]()

更新
[2023/02/09] 我们重新封装了Bi-DexHands。现在您不仅可以在命令行中调用Bi-DexHands环境,还可以在Python脚本中使用。请查看下方的README中的在Python脚本中使用Bi-DexHands部分。
[2022/11/24] 现在我们支持所有任务的视觉观测,请参阅这篇关于视觉输入的文档。
[2022/10/02] 现在我们支持默认的IsaacGymEnvs强化学习库rl_games,请参阅我们的README中的下方内容。
Bi-DexHands(点击bi-dexhands.ai)提供了一系列双手灵巧操作任务和强化学习算法。 达到人类水平的手部灵巧性和双手协调性仍然是现代机器人研究领域的一个开放性挑战。为了更好地帮助社区研究这一问题,Bi-DexHands具备以下关键特性:
- Isaac效率:Bi-DexHands构建于Isaac Gym之上;它支持同时运行数千个环境。例如,在一块NVIDIA RTX 3090 GPU上,Bi-DexHands通过并行运行2,048个环境,可以达到40,000+的平均FPS。
- 全面的强化学习基准:我们为RL、MARL、多任务RL、元强化学习和离线强化学习的研究者提供了首个双手操作任务环境,并附带针对SOTA连续控制无模型RL/MARL方法的全面基准。请参阅示例。
- 异构智能体协作:Bi-DexHands中的智能体(即关节、手指、手等)是真正意义上的异构体;这与常见的多智能体环境(如SMAC)截然不同,在那些环境中智能体通常可以通过共享参数来解决问题。
- 任务泛化能力:我们引入了多种灵巧操作任务(如交接、举起、投掷、放置等),以及来自YCB和SAPIEN数据集的大量目标物体(超过2,000种);这使得元强化学习和多任务强化学习算法能够在任务泛化方面得到测试。
- 点云:我们提供了使用点云作为观测值的功能。我们利用Isaacc Gym中的深度相机获取深度图像,然后将其转换为局部点云。我们可以自定义深度相机的位置和数量,以从不同角度获取点云。生成点云的密度取决于相机像素的数量。请参阅视觉输入文档。
- 快速演示

此仓库的内容如下:
- 安装
- Bi-DexHands简介
- 环境概述
- 算法概述
- 开始使用
- 环境性能
- 离线强化学习数据集
- 使用rl_games训练我们的任务
- 未来计划
- 自定义您的环境
- 如何更改灵巧手类型
- 如何为灵巧手添加机械臂驱动
- 团队
- 许可证
有关这项工作的更多信息,请参阅我们的论文。
安装
关于IsaacGym的安装详情,请参阅此处。我们目前支持IsaacGym的Preview Release 3/4版本。
先决条件
该代码已在Ubuntu 18.04/20.04系统上使用Python 3.7/3.8进行了测试。Linux系统上推荐的最低NVIDIA驱动版本为470.74(由IsaacGym的支持要求决定)。
它使用Anaconda来创建虚拟环境。 要安装Anaconda,请按照此处的说明进行操作。
请确保Isaac Gym能在您的系统上正常运行,方法是运行python/examples目录下的示例之一,比如joint_monkey.py。如果您在运行示例时遇到任何问题,请按照Isaac Gym Preview Release 3/4安装说明中的故障排除步骤操作。
一旦Isaac Gym安装完成且示例在您当前的Python环境中能够正常运行,即可安装本仓库:
从源代码安装
您也可以从源代码安装本仓库:
pip install -e .
简介
此仓库包含复杂的灵巧手控制任务。Bi-DexHands构建于NVIDIA Isaac Gym之上,具有高性能保障,可用于训练强化学习算法。我们的环境专注于应用无模型RL/MARL算法进行双手灵巧操作,而这类任务被普遍认为对传统控制方法而言极具挑战性。
开始使用
任务
任务的源代码可以在 envs/tasks 中找到。状态/动作/奖励的具体设置请参见这里。
截至目前,我们发布了以下任务(未来还将推出更多):
| 环境 | 描述 | 演示 |
|---|---|---|
| ShadowHand 传递 | 这些环境涉及两只位置固定的机械手。初始持有物体的手需要设法将物体传递给另一只手。 |  |
| ShadowHand 腋下接球 | 这些环境同样包含两只机械手,但它们现在具有额外的自由度,可以在一定范围内平移或旋转其质心。 |  |
| ShadowHand 上抛下接 | 该环境由一半 ShadowHandCatchUnderarm 和一半 ShadowHandCatchOverarm 组成,物体需要从垂直放置的手抛向掌心朝上的另一只手。 |  |
| ShadowHand 并排接球 | 该环境与 ShadowHandCatchUnderarm 类似,不同之处在于两只手的位置从相对变为并排。 |  |
| ShadowHand 双人腋下接球 | 这些环境要求两只手协同配合,将两个物体在手中来回抛掷(即交换位置)。 |  |
| ShadowHand 腋下提壶 | 该环境要求用两只手抓住壶柄,并将壶提升到指定位置。 |  |
| ShadowHand 向内开门 | 该环境要求打开一扇关闭的门,且门只能向内拉动。 |  |
| ShadowHand 向外开门 | 该环境要求打开一扇关闭的门,且门只能向外推开。 |  |
| ShadowHand 向内关门 | 该环境要求关闭一扇已经打开的门,且门最初是向内打开的。 |  |
| ShadowHand 开瓶盖 | 该环境涉及两只机械手和一个瓶子,我们需要用一只手握住瓶子,另一只手打开瓶盖。 |  |
| ShadowHand 推方块 | 该环境要求两只手同时接触方块,并将其向前推动。 |  |
| ShadowHand 打开剪刀 | 该环境要求两只手协同合作,打开一把剪刀。 |  |
| ShadowHand 打开笔帽 | 该环境要求两只手协同合作,打开一支笔的笔帽。 |  |
| ShadowHand 摆动杯子 | 该环境要求两只手握住杯柄,将杯子旋转 90 度。 |  |
| ShadowHand 按按钮 | 该环境要求两只手同时按下按钮。 |  |
| ShadowHand 抓取并放置 | 该环境有一个水桶和一个物体,我们需要将物体放入水桶中。 |  |
训练
训练示例
强化学习/多智能体强化学习示例
例如,如果你想使用PPO算法为ShadowHandOver任务训练策略,可以在bidexhands文件夹中运行以下命令:
python train.py --task=ShadowHandOver --algo=ppo
要选择算法,只需通过--algo=ppo/mappo/happo/hatrpo/...作为参数即可。例如,如果你想使用happo算法,可以在bidexhands文件夹中运行以下命令:
python train.py --task=ShadowHandOver --algo=happo
支持的单智能体强化学习算法如下:
支持的多智能体强化学习算法如下:
多任务/元强化学习示例
多任务/元强化学习的训练方法与RL/MARL类似,只需选择相应的多任务/元类别及对应算法即可。例如,如果你想使用MTPPO算法为ShadowHandMT4类别训练策略,可以在bidexhands文件夹中运行以下命令:
python train.py --task=ShadowHandMetaMT4 --algo=mtppo
支持的多任务强化学习算法如下:
支持的元强化学习算法如下:
类Gym API
我们提供了一个类Gym API,允许从Isaac Gym环境中获取信息。我们的单智能体类Gym封装直接沿用了Isaac Gym团队的代码,并在此基础上开发了多智能体类Gym封装:
class MultiVecTaskPython(MultiVecTask):
# 获取环境状态信息
def get_state(self):
return torch.clamp(self.task.states_buf, -self.clip_obs, self.clip_obs).to(self.rl_device)
def step(self, actions):
# 将所有智能体的动作按顺序堆叠并输入到环境中
a_hand_actions = actions[0]
for i in range(1, len(actions)):
a_hand_actions = torch.hstack((a_hand_actions, actions[i]))
actions = a_hand_actions
# 对动作进行裁剪
actions_tensor = torch.clamp(actions, -self.clip_actions, self.clip_actions)
self.task.step(actions_tensor)
# 获取环境中的信息,并手动区分不同智能体的观测值
obs_buf = torch.clamp(self.task.obs_buf, -self.clip_obs, self.clip_obs).to(self.rl_device)
hand_obs = []
hand_obs.append(torch.cat([obs_buf[:, :self.num_hand_obs], obs_buf[:, 2*self.num_hand_obs:]], dim=1))
hand_obs.append(torch.cat([obs_buf[:, self.num_hand_obs:2*self.num_hand_obs], obs_buf[:, 2*self.num_hand_obs:]], dim=1))
rewards = self.task.rew_buf.unsqueeze(-1).to(self.rl_device)
dones = self.task.reset_buf.to(self.rl_device)
# 将信息整理成多智能体强化学习格式
# 参考 https://github.com/tinyzqh/light_mappo/blob/HEAD/envs/env.py
sub_agent_obs = []
...
sub_agent_done = []
for i in range(len(self.agent_index[0] + self.agent_index[1])):
...
sub_agent_done.append(dones)
# 转置第0维和第1维的值
obs_all = torch.transpose(torch.stack(sub_agent_obs), 1, 0)
...
done_all = torch.transpose(torch.stack(sub_agent_done), 1, 0)
return obs_all、state_all、reward_all、done_all、info_all、None
def reset(self):
# 环境重置后,使用随机动作作为首次动作
actions = 0.01 * (1 - 2 * torch.rand([self.task.num_envs, self.task.num_actions * 2], dtype=torch.float32, device=self.rl_device))
# 运行模拟器
self.task.step(actions)
# 获取环境中的观测值和状态缓冲区,详细过程与step(self, actions)相同
obs_buf = torch.clamp(self.task.obs_buf, -self.clip_obs, self.clip_obs)
...
obs = torch.transpose(torch.stack(sub_agent_obs), 1, 0)
state_all = torch.transpose(torch.stack(agent_state), 1, 0)
return obs、state_all、None
RL/多智能体RL API
我们还提供了单智能体和多智能体RL接口。为了适配Isaac Gym并提高运行效率,所有操作均在GPU上以张量形式实现,因此无需在CPU和GPU之间传输数据。
我们以***HATRPO(用于合作任务的SOTA多智能体强化学习算法)***为例来说明多智能体RL API,请参考https://github.com/cyanrain7/TRPO-in-MARL:
from algorithms.marl.hatrpo_trainer import HATRPO as TrainAlgo
from algorithms.marl.hatrpo_policy import HATRPO_Policy as Policy
...
# 主循环开始前的预热
self.warmup()
# 记录数据
start = time.time()
episodes = int(self.num_env_steps) // self.episode_length // self.n_rollout_threads
train_episode_rewards = torch.zeros(1, self.n_rollout_threads, device=self.device)
# 主循环
for episode in range(episodes):
if self.use_linear_lr_decay:
self.trainer.policy.lr_decay(episode, episodes)
done_episodes_rewards = []
for step in range(self.episode_length):
# 采样动作
values, actions, action_log_probs, rnn_states, rnn_states_critic = self.collect(step)
# 观测奖励和下一个观测
obs, share_obs, rewards, dones, infos, _ = self.envs.step(actions)
dones_env = torch.all(dones, dim=1)
reward_env = torch.mean(rewards, dim=1).flatten()
train_episode_rewards += reward_env
# 记录每个回合结束时的奖励
for t in range(self.n_rollout_threads):
if dones_env[t]:
done_episodes_rewards.append(train_episode_rewards[:, t].clone())
train_episode_rewards[:, t] = 0
data = obs, share_obs, rewards, dones, infos, \
values, actions, action_log_probs, \
rnn_states, rnn_states_critic
# 将数据插入缓冲区
self.insert(data)
# 计算回报并更新网络
self.compute()
train_infos = self.train()
# 后处理
total_num_steps = (episode + 1) * self.episode_length * self.n_rollout_threads
# 保存模型
if (episode % self.save_interval == 0 or episode == episodes - 1):
self.save()
测试
训练好的模型将被保存到 logs/${Task Name}/${Algorithm Name} 文件夹中。
要加载已训练好的模型并仅进行推理(不进行训练),请传递 --test 参数,并使用 --model_dir 指定您想要加载的已训练模型路径。对于单智能体强化学习,您需要通过 --model_dir 精确指定要加载的 .pt 模型文件。以 PPO 算法为例:
python train.py --task=ShadowHandOver --algo=ppo --model_dir=logs/shadow_hand_over/ppo/ppo_seed0/model_5000.pt --test
对于多智能体强化学习,则需通过 --model_dir 指定包含所有智能体模型文件的文件夹路径。以 HAPPO 算法为例:
python train.py --task=ShadowHandOver --algo=happo --model_dir=logs/shadow_hand_over/happo/models_seed0 --test
绘图
用户可以将所有的 tfevent 文件转换为 csv 文件,然后尝试绘制结果。请注意,应确保 env-num 和 env-step 与您的实验设置一致。详细信息请参阅 ./utils/logger/tools.py。
# 生成单智能体和多智能体算法的 csv 文件
$ python ./utils/logger/tools.py --alg-name <sarl algorithm> --alg-type sarl --env-num 2048 --env-step 8 --root-dir ./logs/shadow_hand_over --refresh
$ python ./utils/logger/tools.py --alg-name <marl algorithm> --alg-type marl --env-num 2048 --env-step 8 --root-dir ./logs/shadow_hand_over --refresh
# 生成图表
$ python ./utils/logger/plotter.py --root-dir ./logs/shadow_hand_over --shaded-std --legend-pattern "\\w+" --output-path=./logs/shadow_hand_over/figure.png
在 Python 脚本中使用 Bi-DexHands
import bidexhands as bi
import torch
env_name = 'ShadowHandOver'
algo = "ppo"
env = bi.make(env_name, algo)
obs = env.reset()
terminated = False
while not terminated:
act = torch.tensor(env.action_space.sample()).repeat((env.num_envs, 1))
obs, reward, done, info = env.step(act)
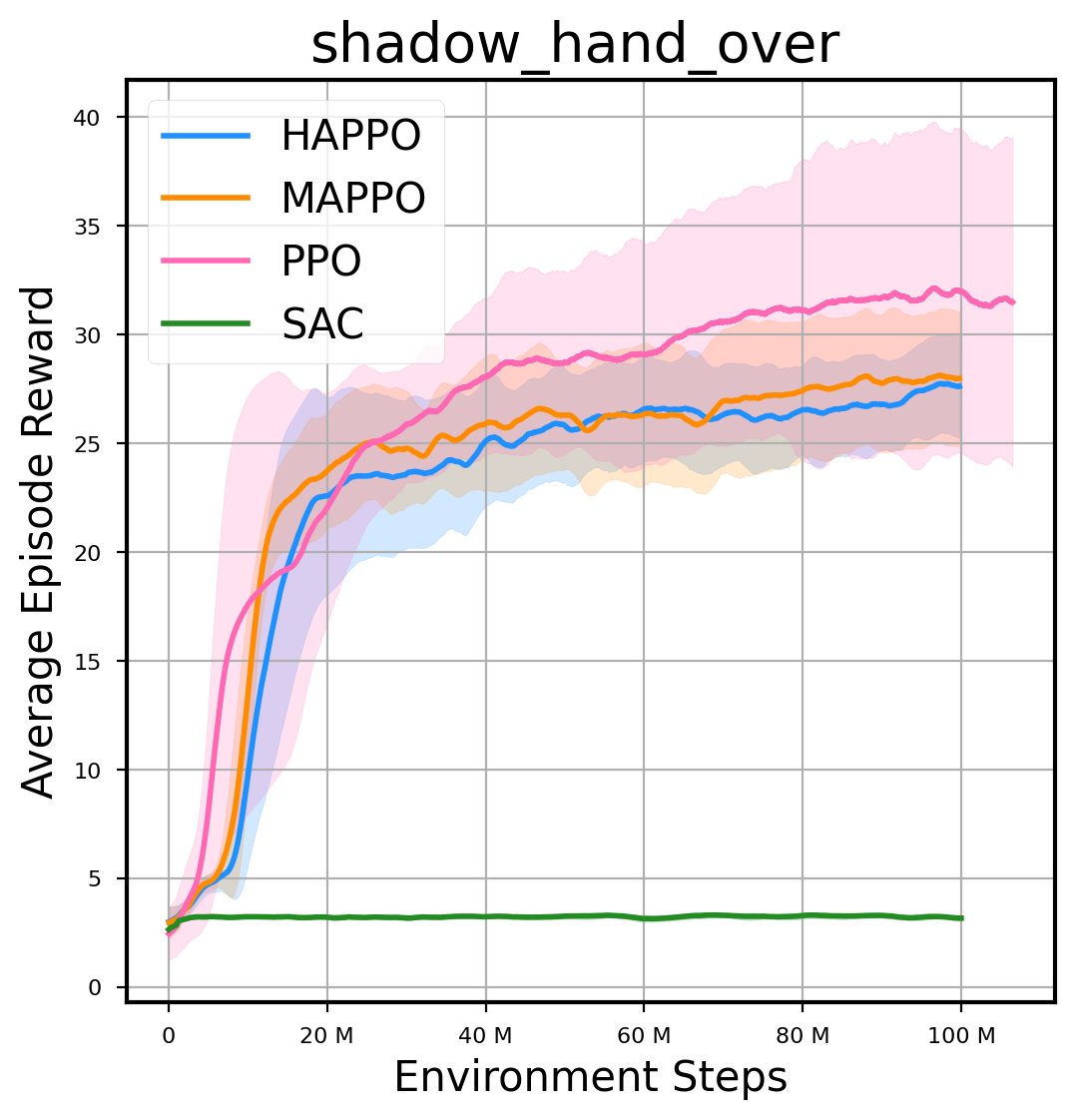
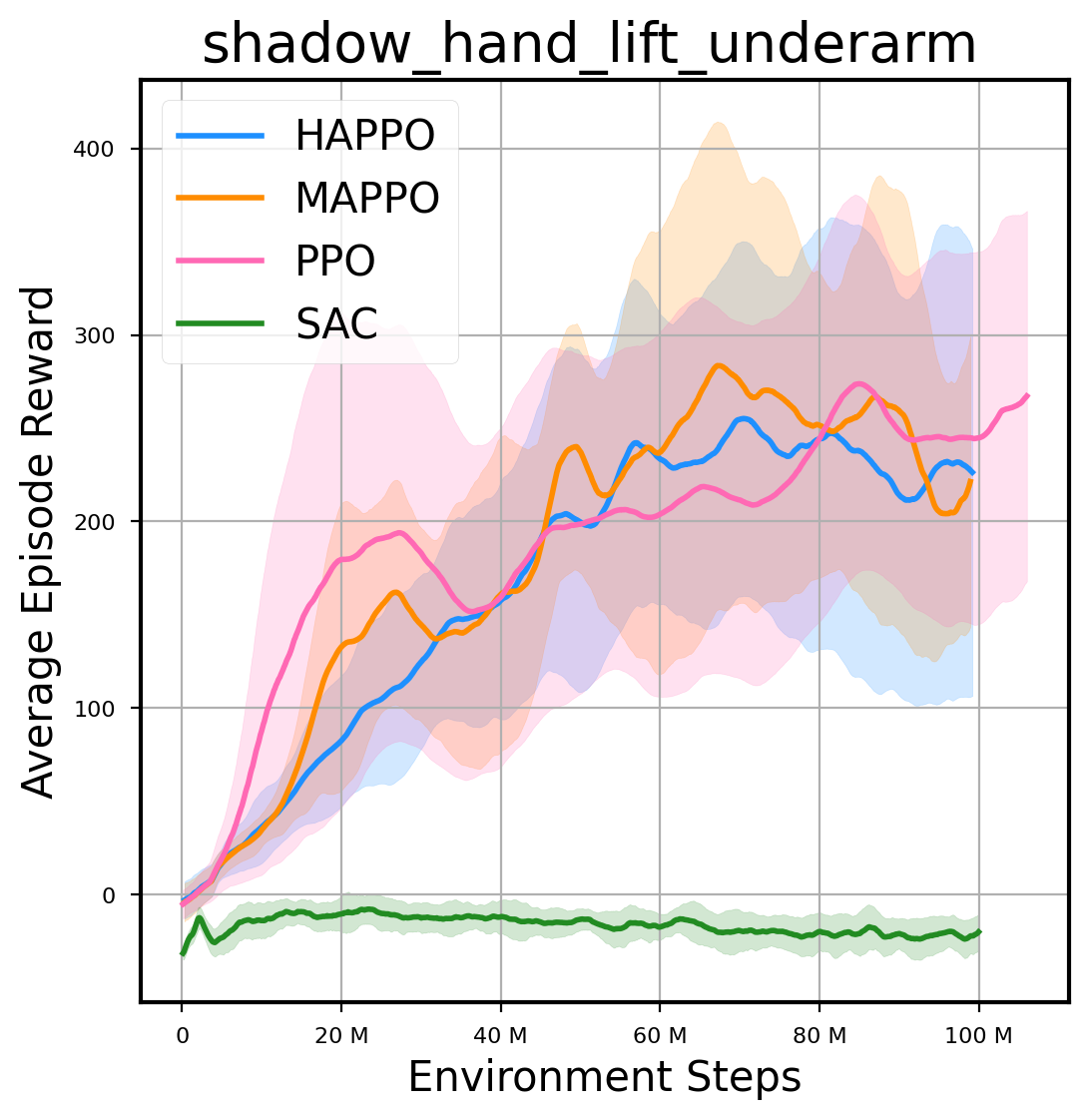
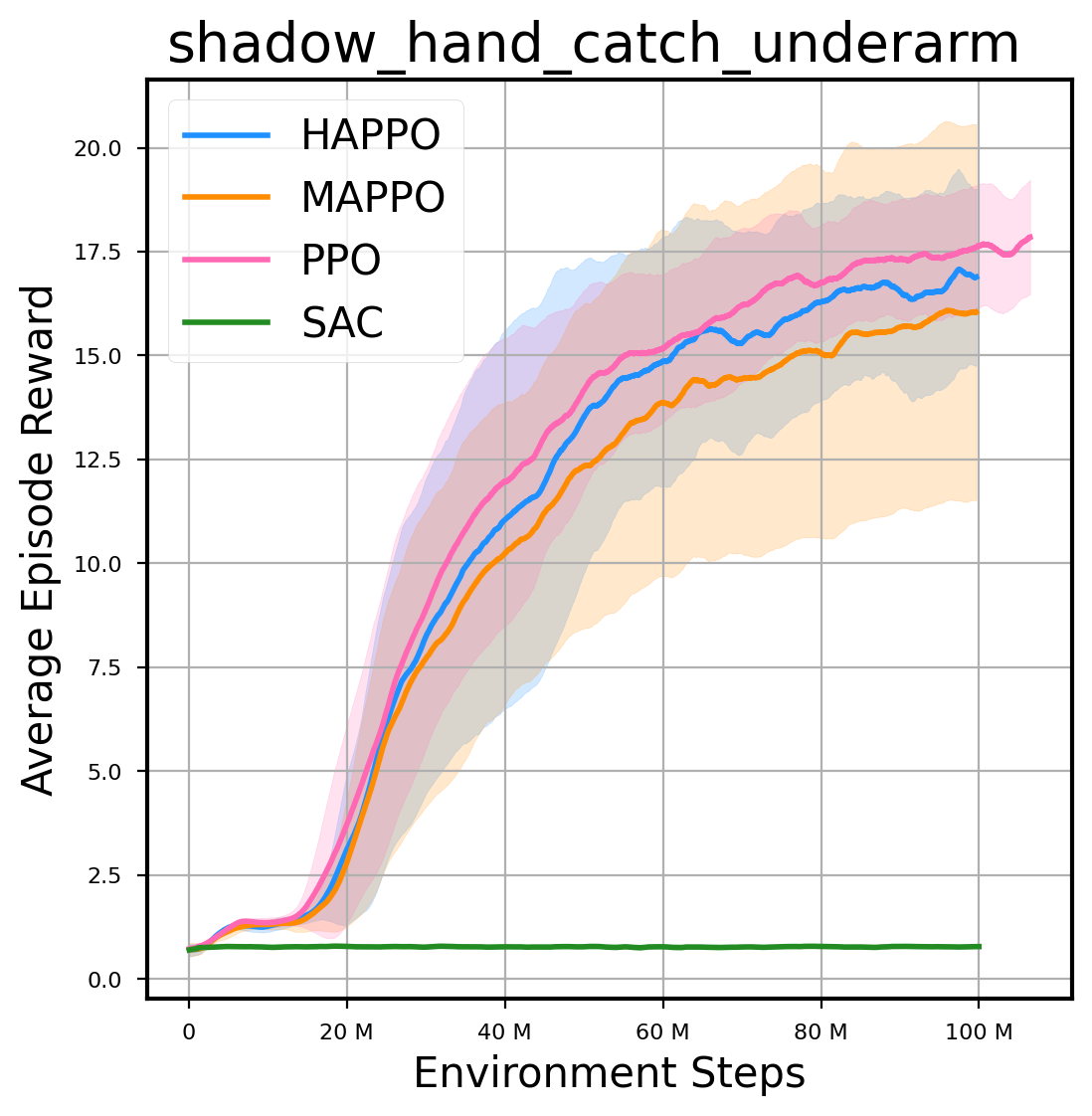
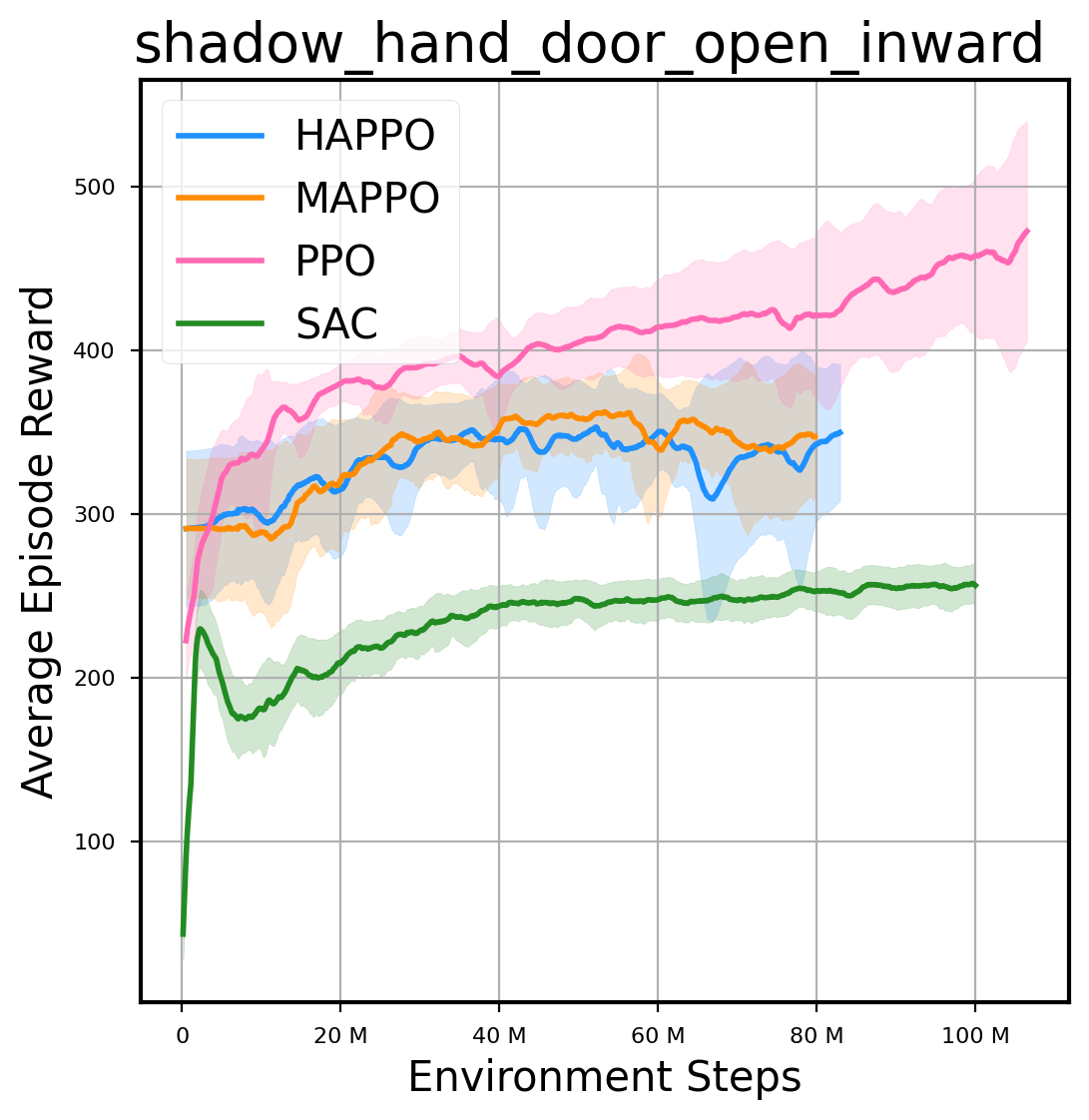
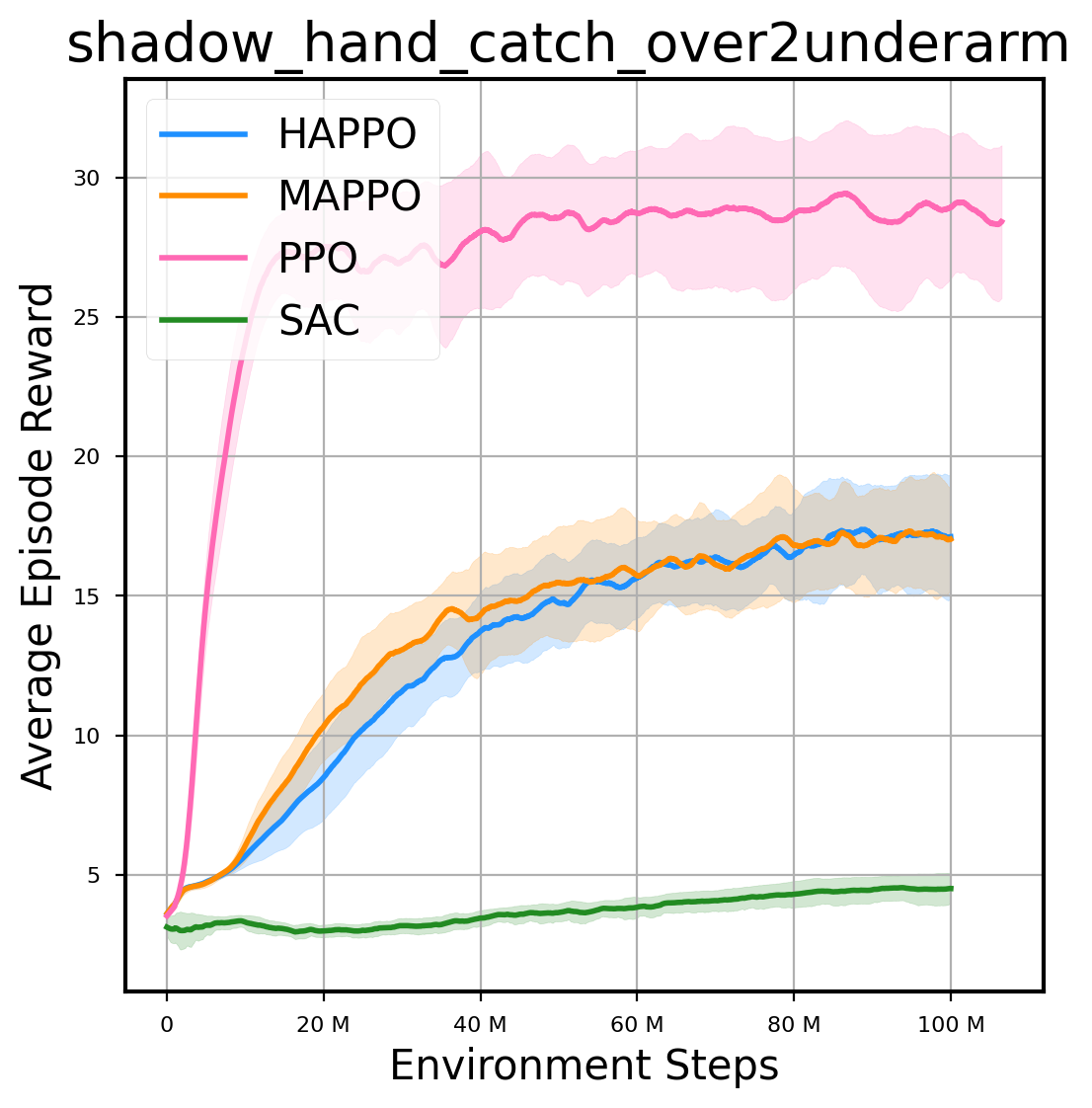
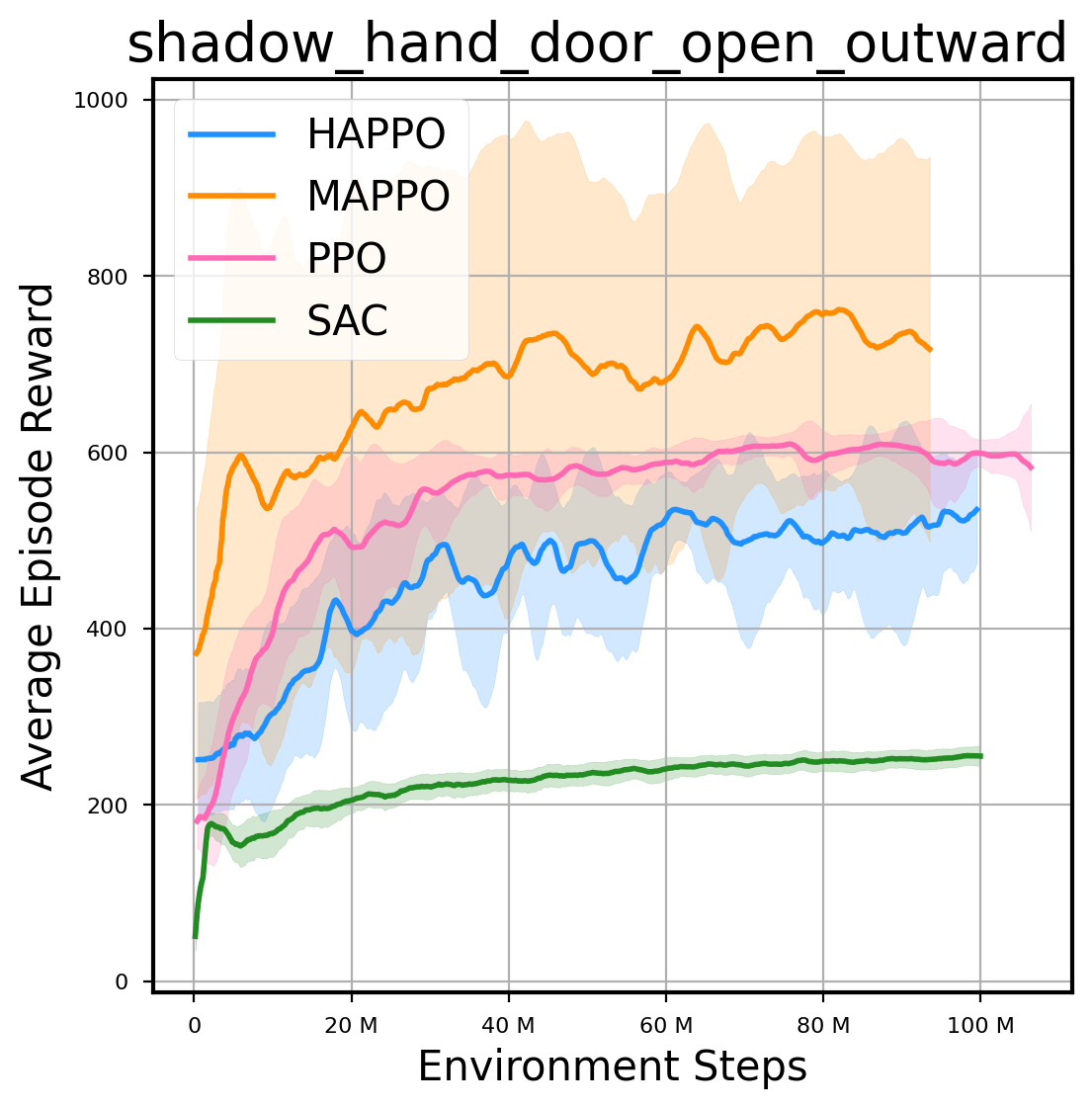
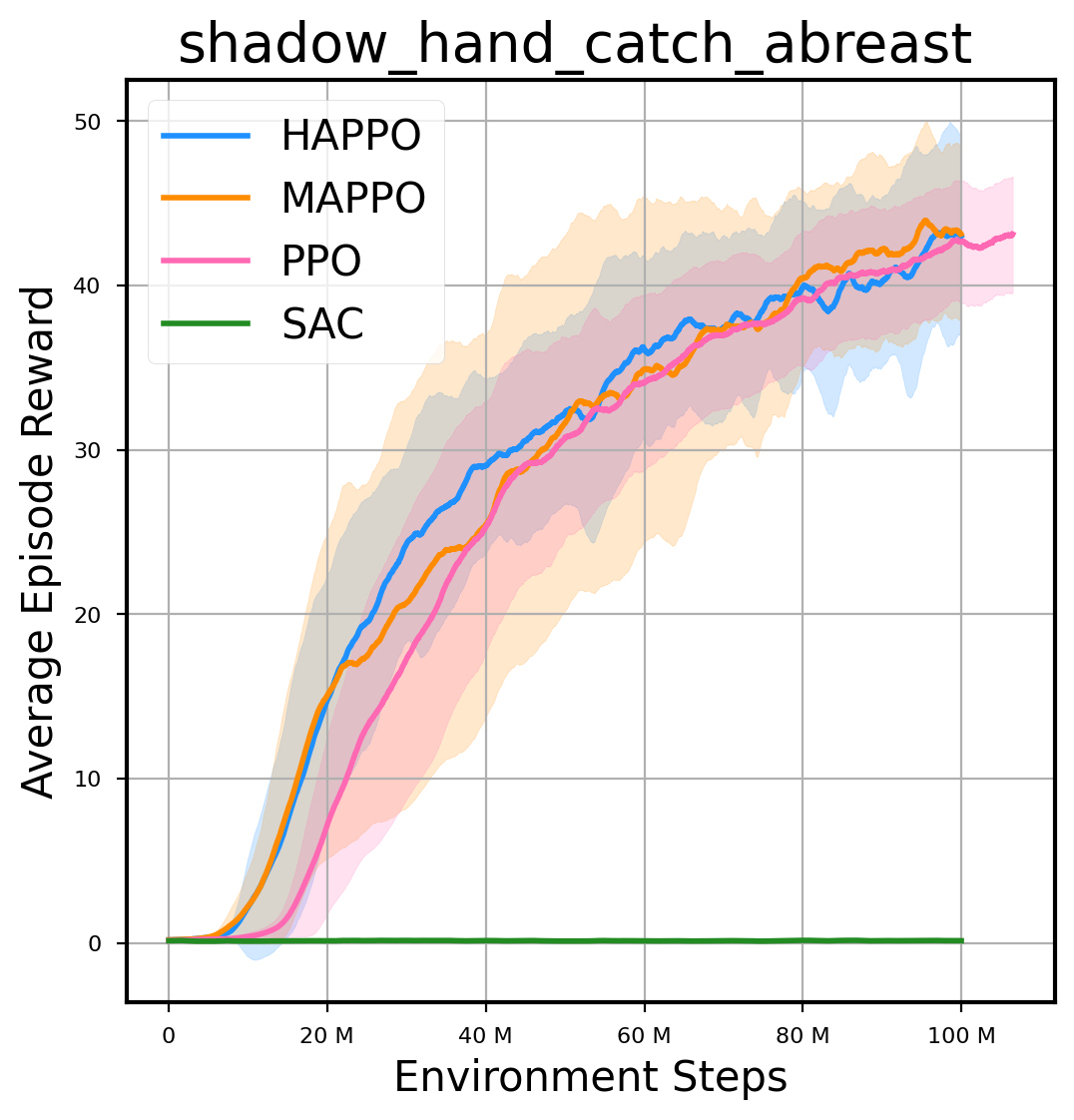
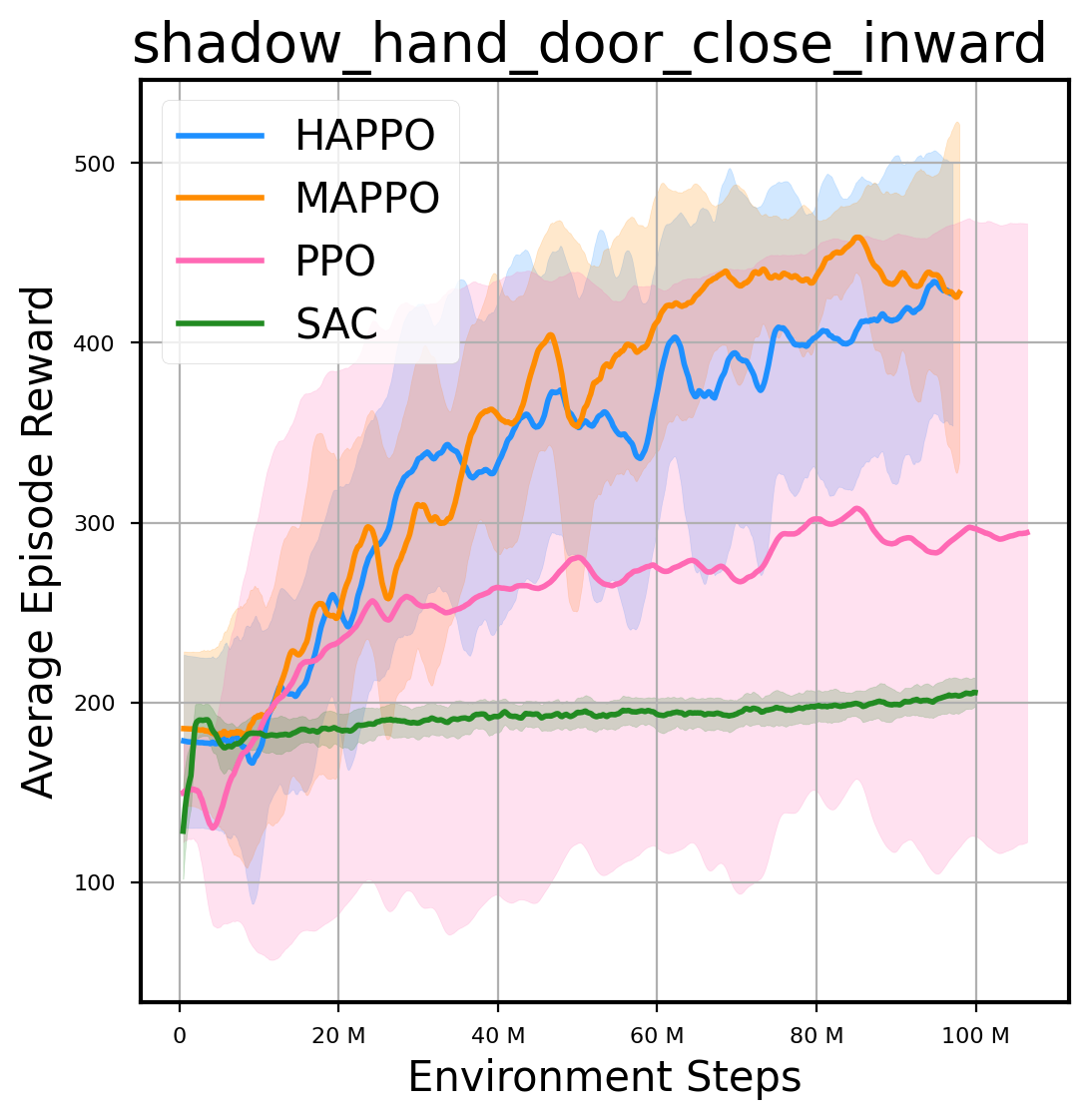
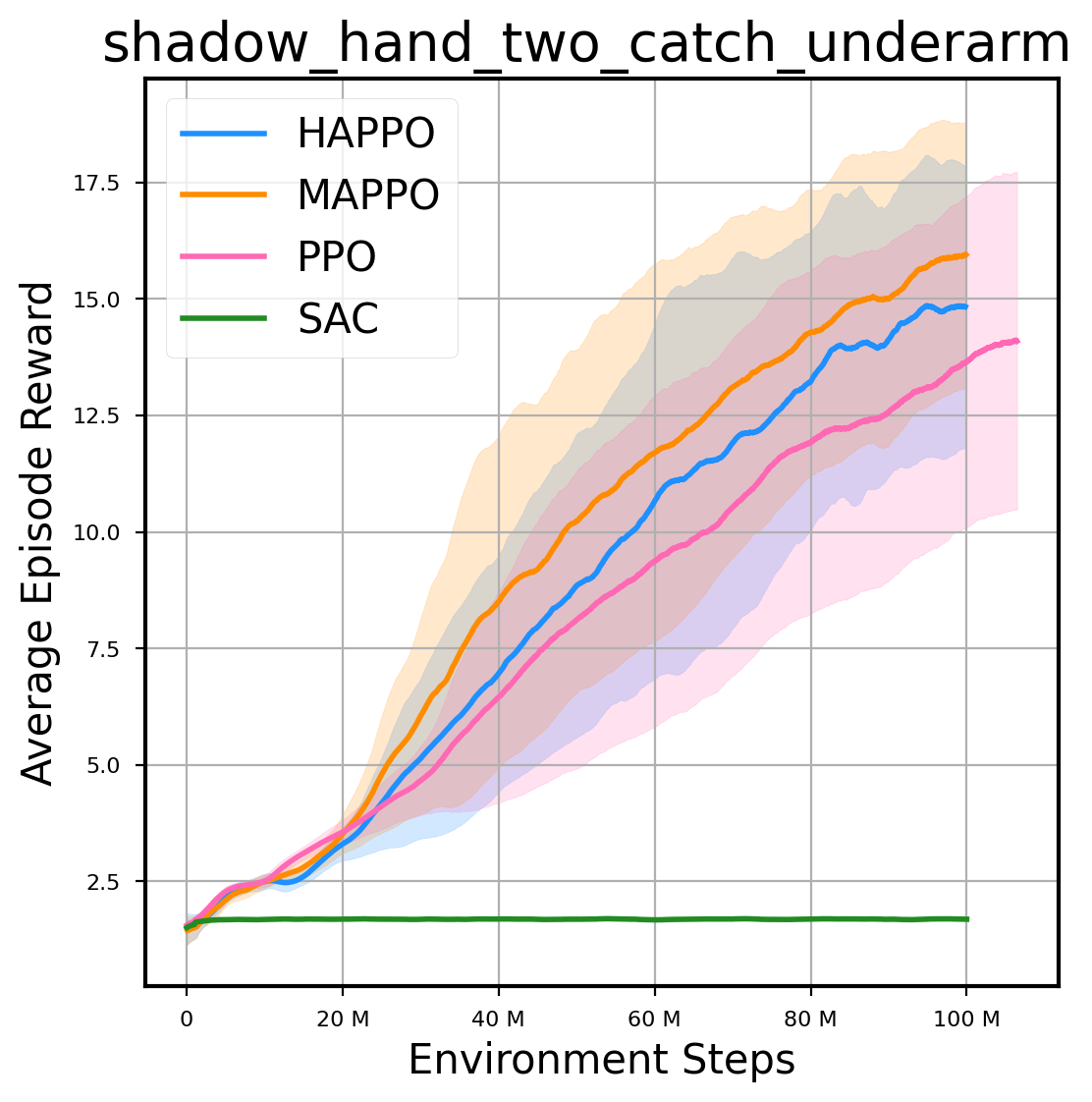
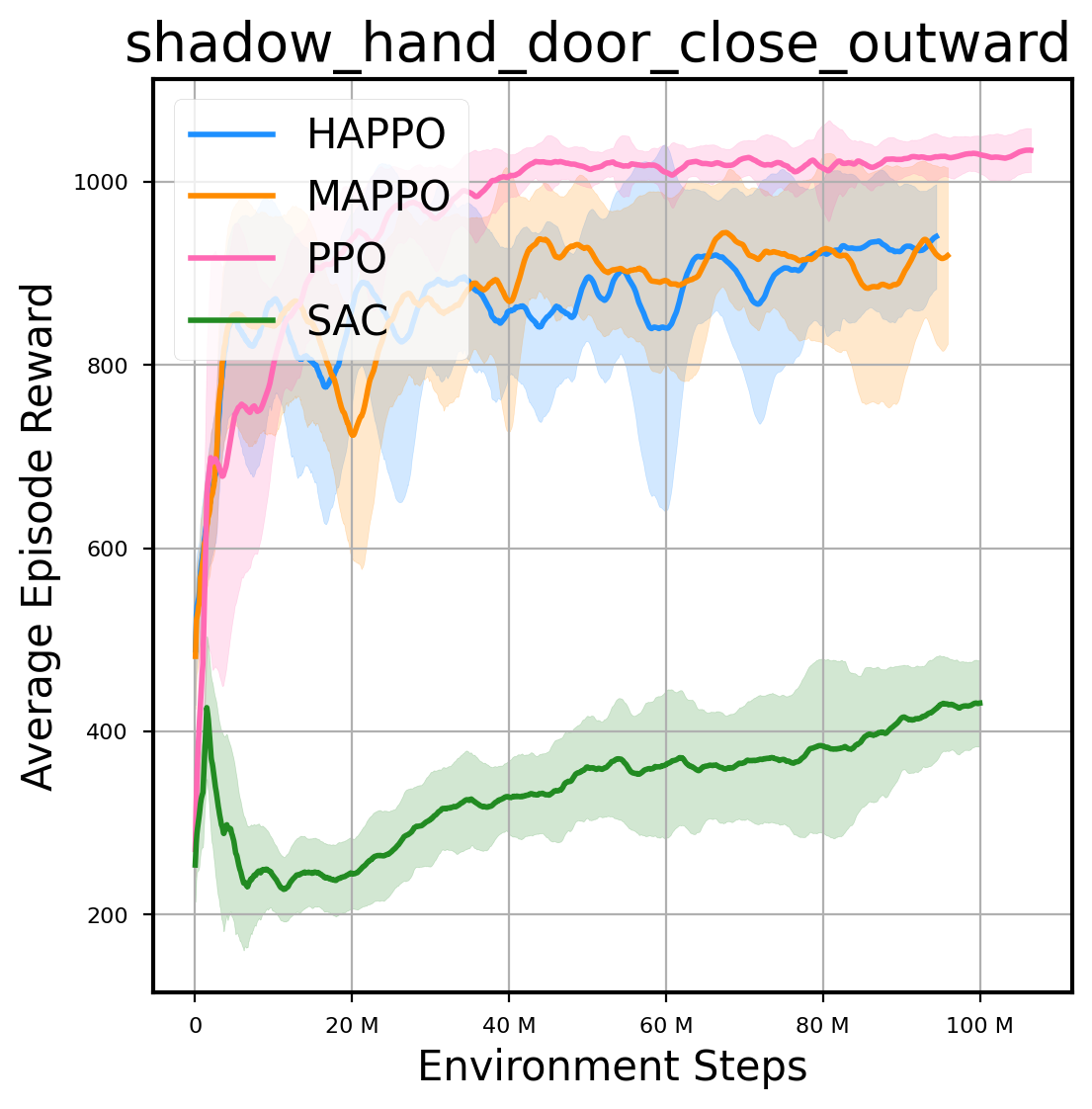
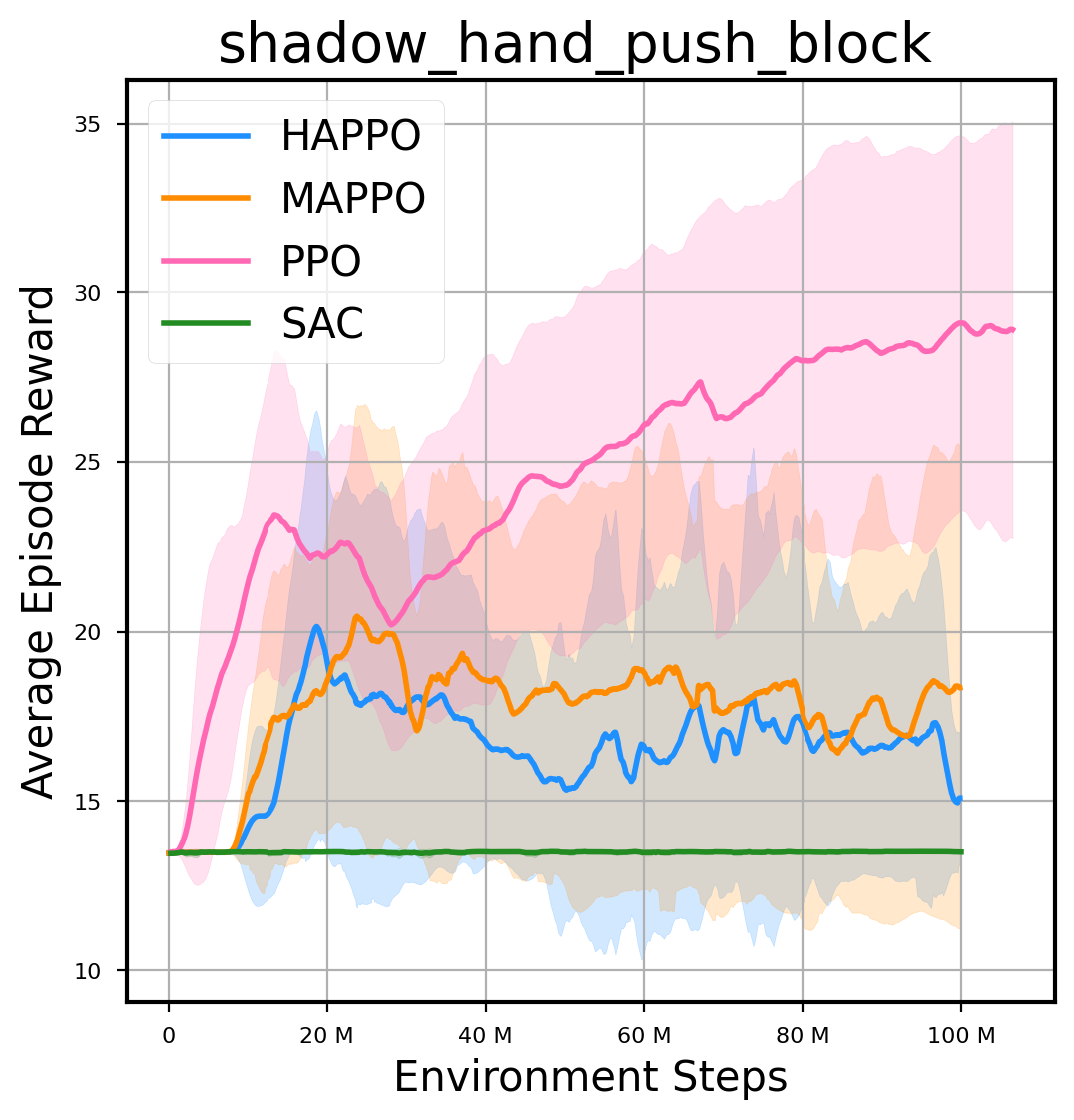
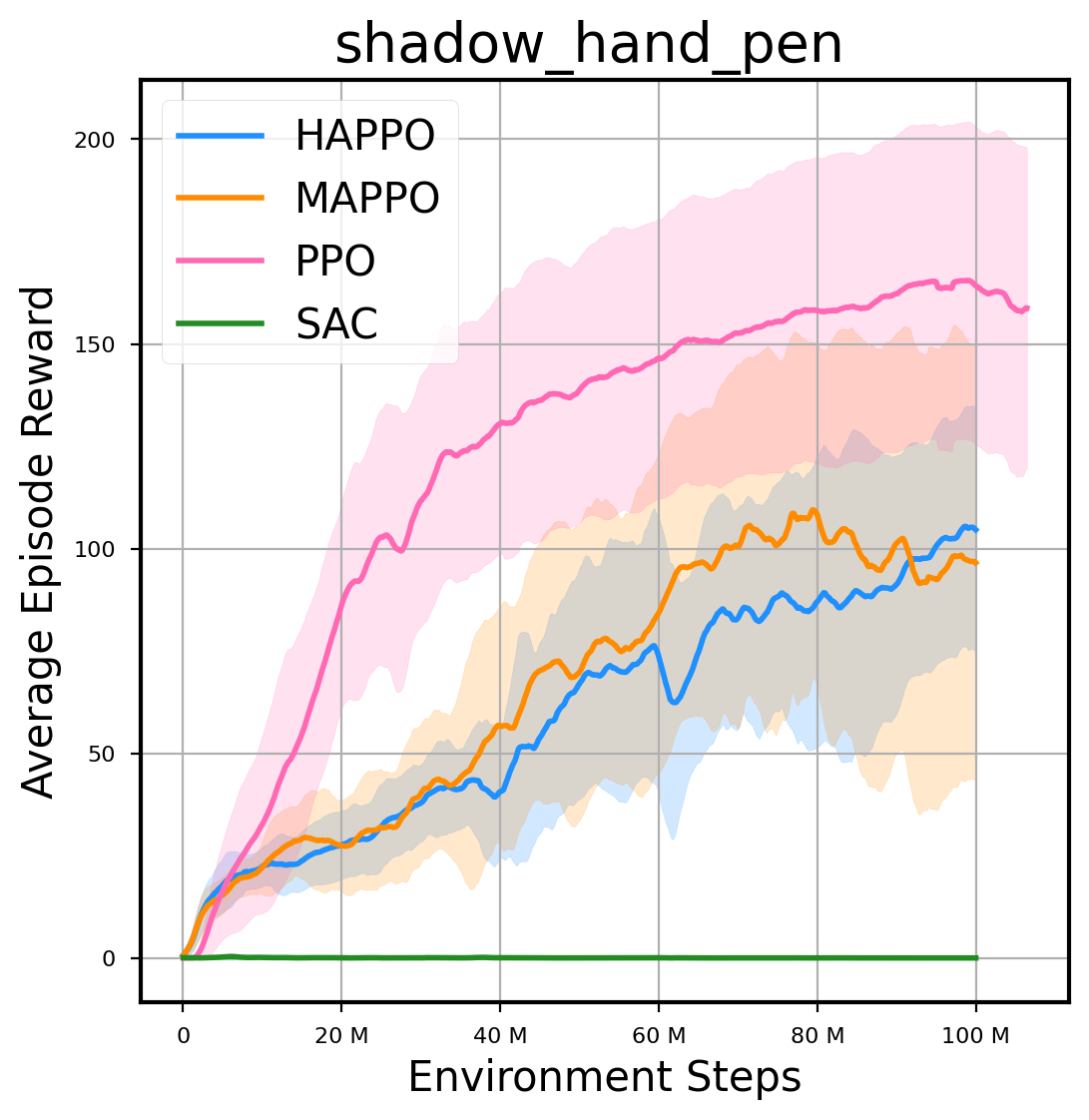
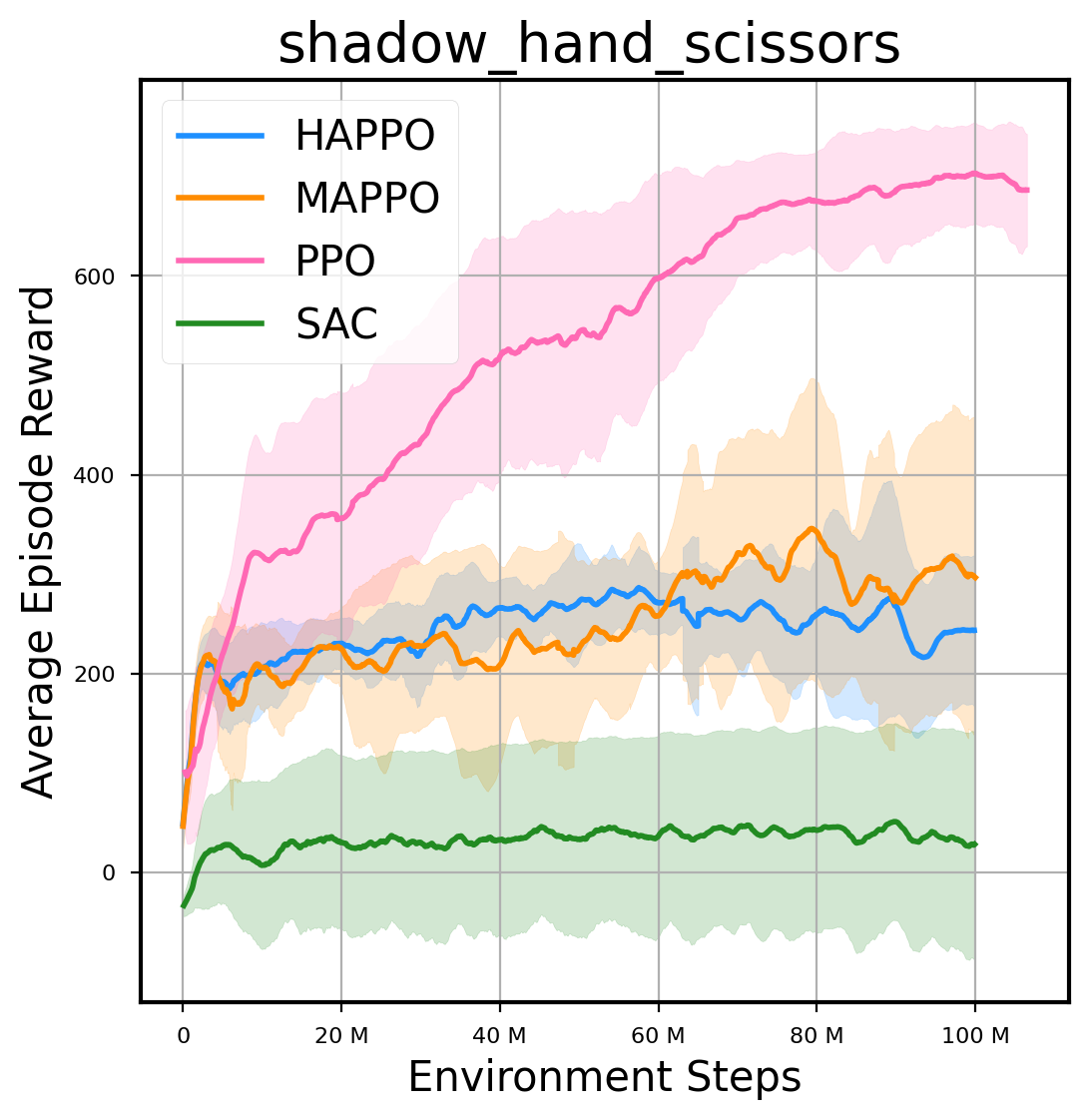
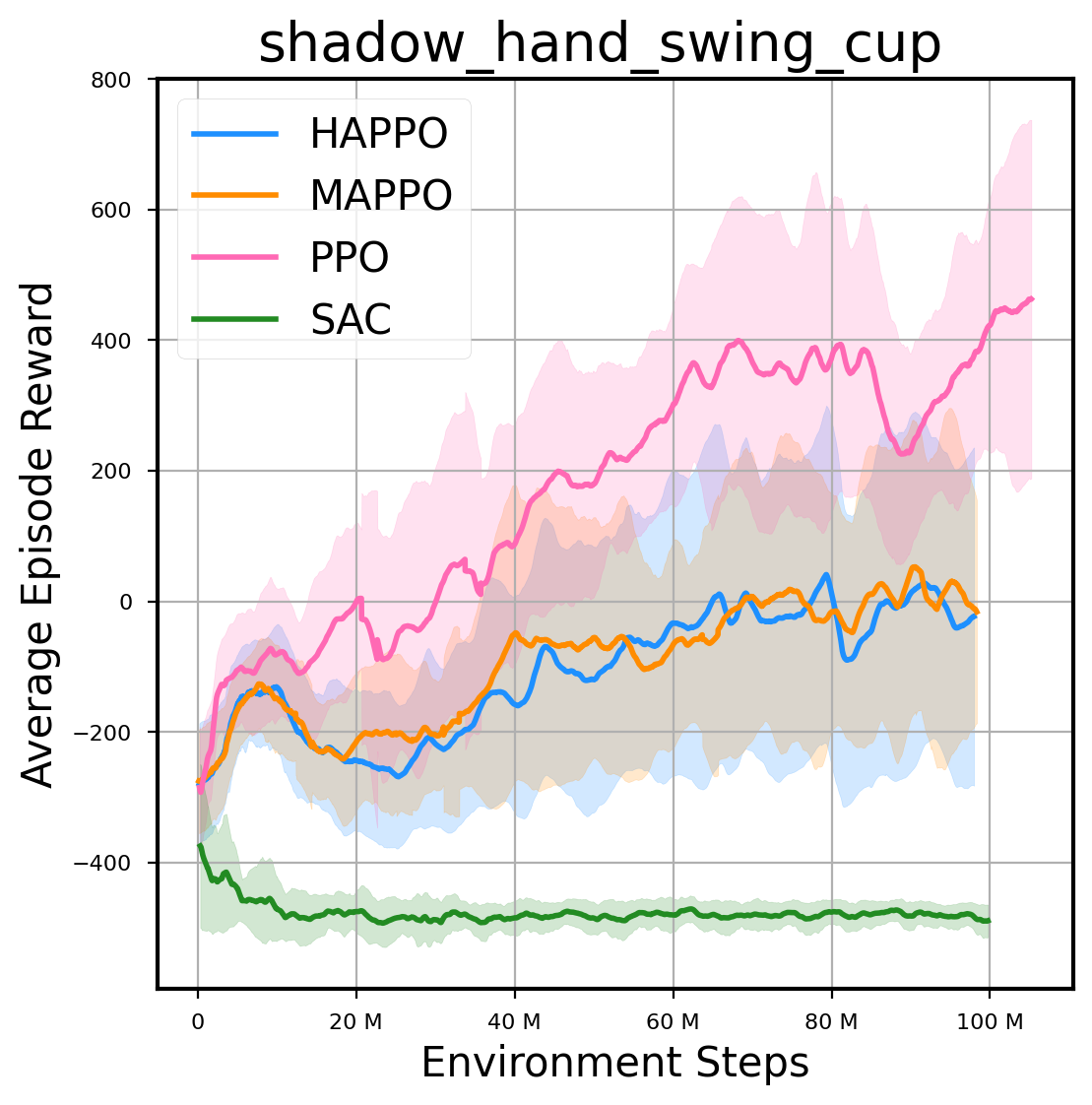
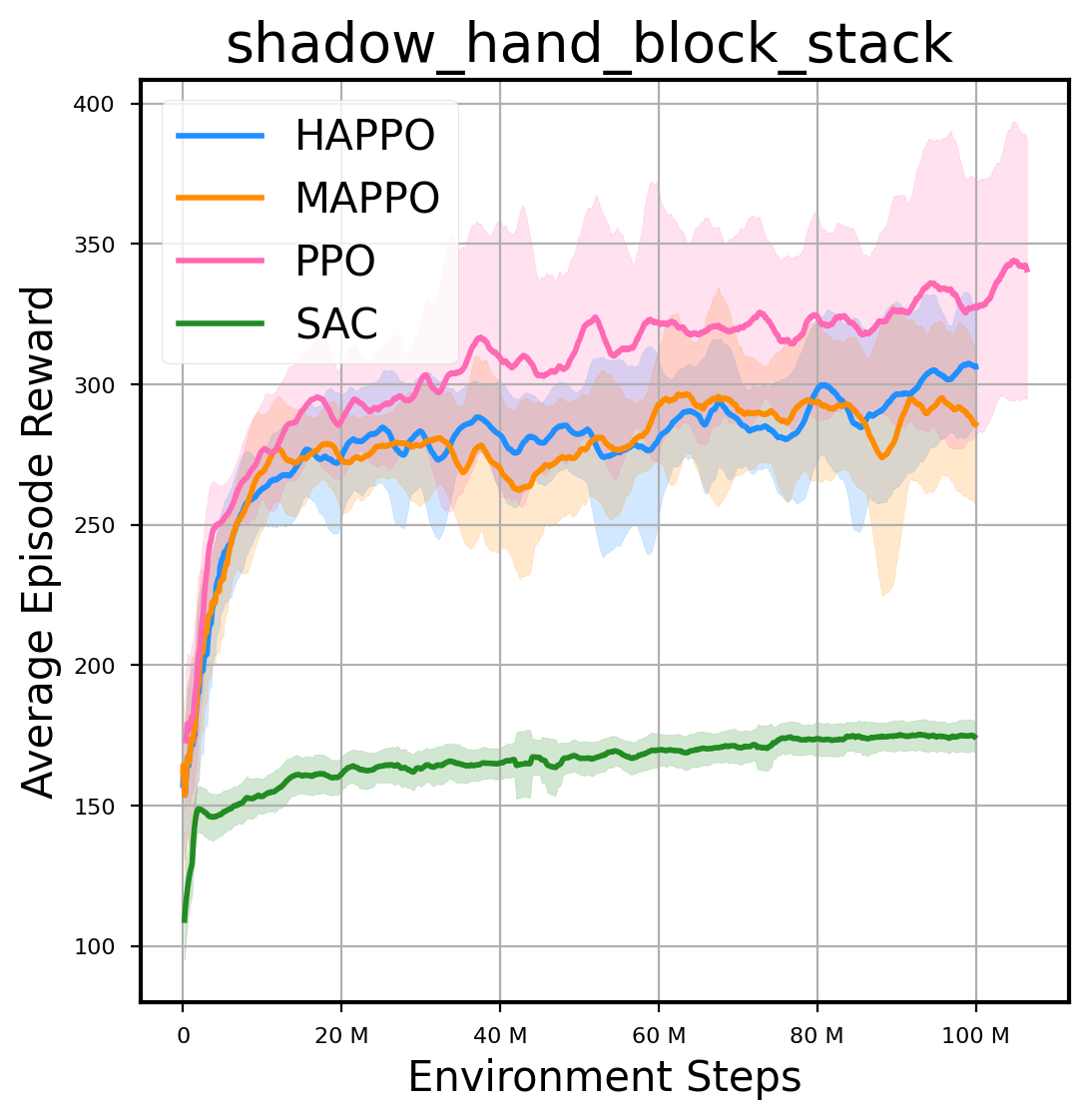
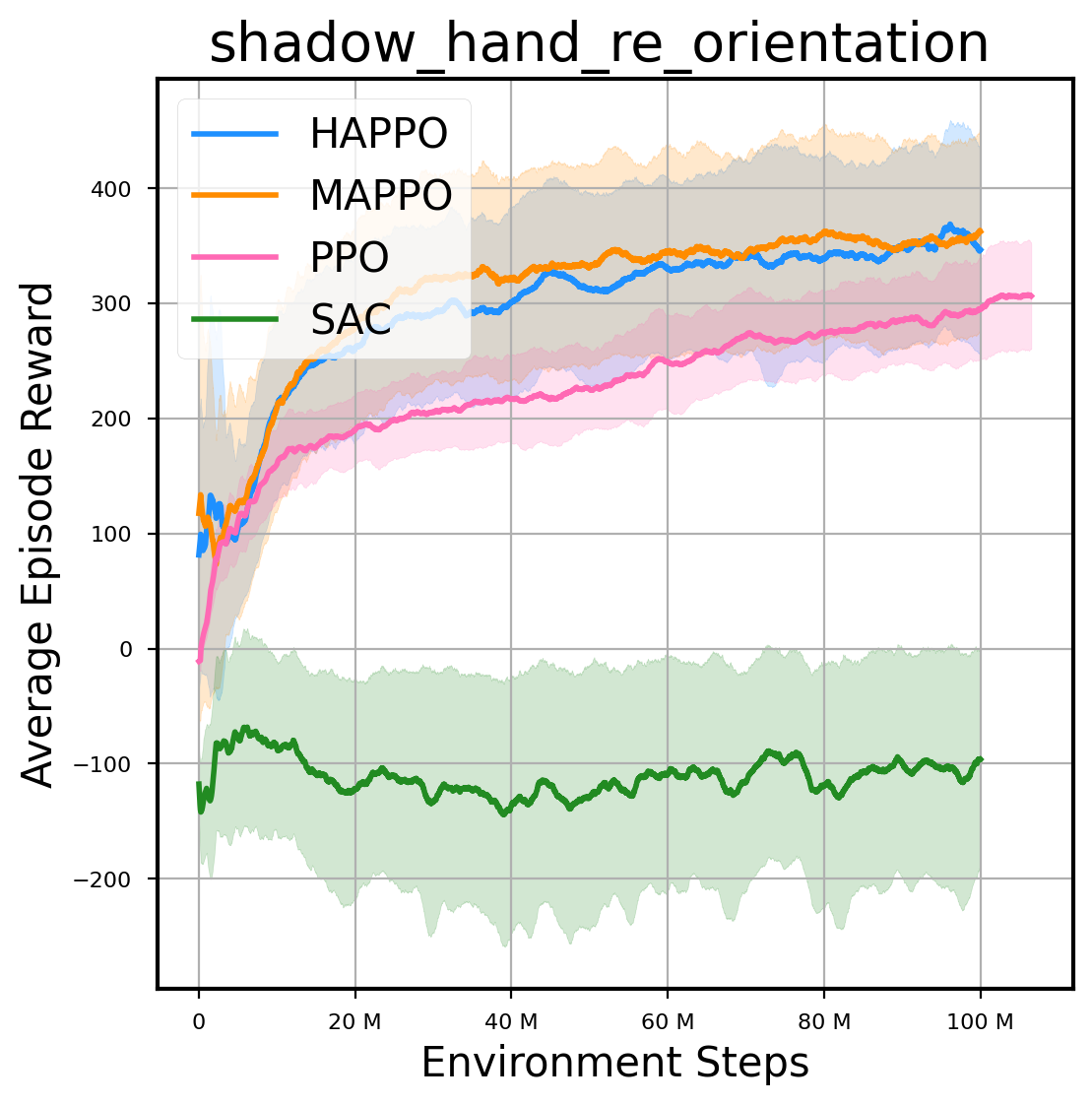
环境性能
图表
我们提供了由 PPO、HAPPO、MAPPO、SAC 算法运行的稳定且可复现的基准测试结果。所有基准测试均在 2048 num_env 和 100M total_step 的参数设置下运行。dataset 文件夹中包含了原始的 CSV 文件。