VisRAG
VisRAG 是一款创新的视觉检索增强生成(RAG)框架,旨在让多模态大模型直接“看懂”文档图像并回答问题。与传统 RAG 必须先通过 OCR 或解析工具将文档转为文本不同,VisRAG 利用视觉语言模型直接将文档作为图像进行嵌入和检索。这一机制有效解决了传统流程中因格式转换导致的信息丢失问题,最大程度保留了原始文档中的图表、版式等关键视觉信息。
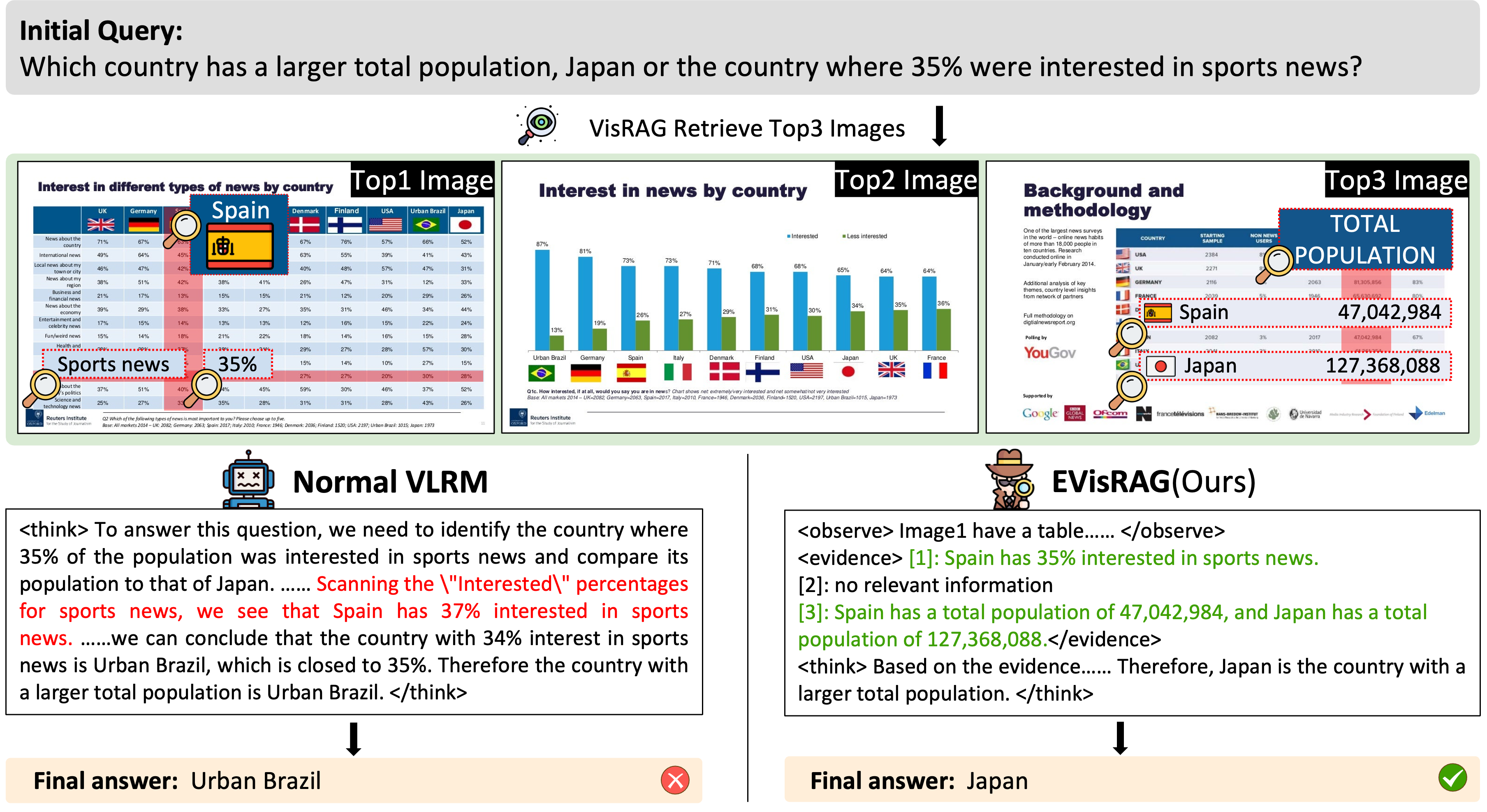
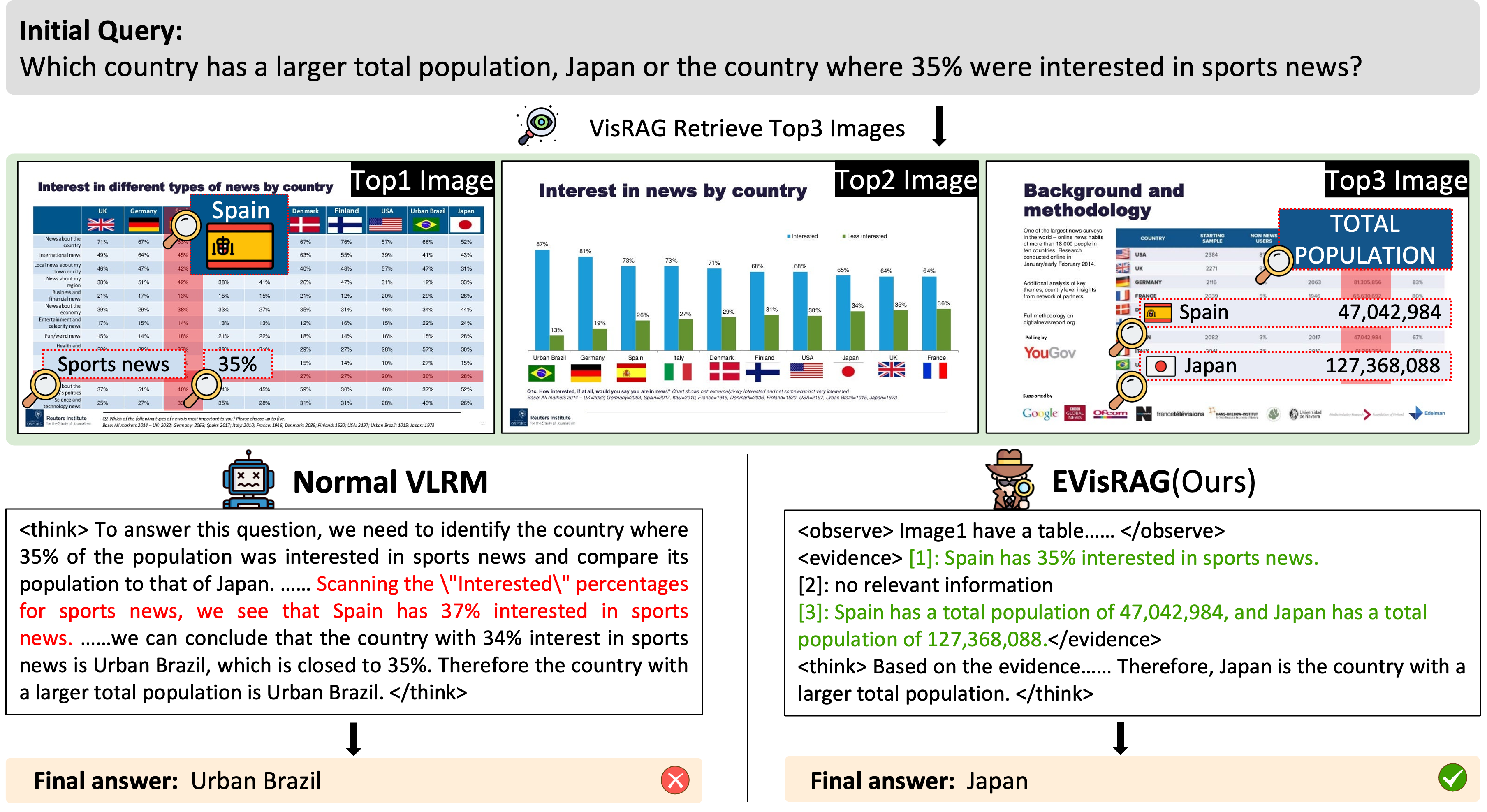
其最新升级版 EVisRAG(VisRAG 2.0)进一步引入了“证据引导”的多图像推理能力。它能先对检索到的多张图片进行独立的语言化观察以提取证据,再综合这些线索进行逻辑推理,从而更精准地回答复杂问题。此外,该项目采用了独特的奖励范围化 GRPO 训练策略,通过细粒度的令牌级奖励,同步优化模型的视觉感知与逻辑推理能力。
VisRAG 非常适合 AI 研究人员、开发者以及需要处理大量扫描文档、复杂报表或图文混合资料的企业用户。对于希望构建高精度文档问答系统,且不愿受限于传统文本解析精度的团队来说,这是一个极具价值的开源选择。目前项目已开放模型权重、代码及完整的评估基准,支持在社区中快速复现与应用。
使用场景
某医疗科研团队需要从海量历史病历扫描件(含手写笔记、复杂图表和影像报告)中快速检索并总结特定疾病的临床特征。
没有 VisRAG 时
- 信息严重丢失:传统 OCR 工具无法准确识别手写医嘱和模糊印章,导致关键诊断依据在文本化过程中被遗漏或误读。
- 图表理解失效:病历中的趋势图和影像截图被强行转为纯文字描述,失去了视觉上的空间关系和细节特征,模型无法基于图像推理。
- 流程繁琐低效:必须先花费大量时间清洗和解析文档,一旦解析失败需人工介入修正,严重拖慢科研数据的准备周期。
- 上下文割裂:分块提取的文本碎片破坏了病历原本的版面逻辑,导致回答多模态问题时缺乏完整的证据链支持。
使用 VisRAG 后
- 原生视觉保留:VisRAG 直接将病历图片作为整体嵌入检索,完整保留了手写字迹、印章和原始排版,杜绝了 OCR 带来的信息损耗。
- 多图联合推理:模型能同时观察并对比多张检索到的影像报告和化验单,像医生一样通过视觉线索进行跨页面的证据引导式推理。
- 免解析直连:省去了耗时的文档解析与清洗步骤,上传扫描即可直接构建知识库,让非结构化数据秒级转化为可查询的智能资产。
- 证据可追溯:生成的结论直接关联到原始图片的具体区域,研究人员可直观核对视觉证据,大幅提升了医疗问答的可信度。
VisRAG 通过“免解析、全视觉”的创新架构,让 AI 真正读懂了复杂文档中的图像细节,将非结构化档案变成了高价值的智能知识库。
运行环境要求
- Linux
需要 NVIDIA GPU,需安装 CUDA 11.8.0 Toolkit (visrag_scripts/train_retriever/train.sh 中隐含多卡训练需求,具体显存未说明,建议大显存以支持多图像推理和训练)
未说明
快速开始
VisRAG 2.0:视觉检索增强生成中的证据引导多图像推理
![]()
![]()
• 📖 Introduction • 🎉 News • ✨ VisRAG Pipeline • ⚙️ Setup • ⚡️ Training
• 📃 Evaluation • 🔧 Usage • 📄 Lisense • 📧 Contact • 📈 Star History
📖 Introduction
EVisRAG (VisRAG 2.0) 是一种证据引导的视觉检索增强生成框架,它通过首先对检索到的图像进行语言观察以收集每张图像的证据,然后基于这些线索进行推理来回答问题,从而赋予视觉语言模型(VLM)处理多图像问题的能力。EVisRAG 使用奖励范围内的GRPO进行训练,通过应用细粒度的token级别奖励来联合优化视觉感知和推理能力。
VisRAG 是一种基于视觉语言模型(VLM)的新型RAG流水线。在该流水线中,不再先解析文档获取文本,而是直接将文档作为图像使用VLM进行嵌入,然后进行检索以增强VLM的生成能力。与传统的基于文本的RAG相比,VisRAG 最大化了原始文档中数据信息的保留和利用,消除了解析过程中引入的信息损失。
🎉 News
- 20251207: 在HuggingFace上发布了所有基准测试。
- 20251118: EVisRAG和VisRAG都可以在UltraRAG v2中轻松复现。
- 20251022: 我们将所有评估基准上传到了HuggingFace收藏集。
- 20251014: 在HuggingFace上发布了EVisRAG-3B。
- 20251014: 发布了EVisRAG (VisRAG 2.0),一个端到端的视觉语言模型。在arXiv上发布了我们的论文。在HuggingFace上发布了我们的模型。在GitHub上发布了我们的代码。
- 20241111: 在GitHub上发布了我们的VisRAG流水线,现在支持跨多个PDF文档的视觉理解。
- 20241104: 在Hugging Face Space上发布了我们的VisRAG流水线。
- 20241031: 在Colab上发布了我们的VisRAG流水线。发布了用于将文件转换为图像的代码,可在
visrag_scripts/file2img中找到。 - 20241015: 在HuggingFace上发布了我们的训练数据和测试数据,可以在HuggingFace上的VisRAG收藏集中找到。本页开头已提及。
- 20241014: 在arXiv上发布了我们的论文。在HuggingFace上发布了我们的模型。在GitHub上发布了我们的代码。
✨ VisRAG Pipeline
EVisRAG
EVisRAG 是一个端到端的框架,在多图像场景下为VLM提供精确的视觉感知能力。我们基于Qwen2.5-VL-7B-Instruct和Qwen2.5-VL-3B-Instruct训练并发布了内置EVisRAG的VLRM。
VisRAG-Ret
VisRAG-Ret 是一个基于MiniCPM-V 2.0的文档嵌入模型,该模型整合了SigLIP作为视觉编码器,以及MiniCPM-2B作为语言模型。
VisRAG-Gen
在论文中,我们使用MiniCPM-V 2.0、MiniCPM-V 2.6和GPT-4o作为生成器。实际上,你可以使用任何你喜欢的VLM!
⚙️ Setup
EVisRAG
git clone https://github.com/OpenBMB/VisRAG.git
conda create --name EVisRAG python==3.10
conda activate EVisRAG
cd EVisRAG
pip install -r EVisRAG_requirements.txt
VisRAG
git clone https://github.com/OpenBMB/VisRAG.git
conda create --name VisRAG python==3.10.8
conda activate VisRAG
conda install nvidia/label/cuda-11.8.0::cuda-toolkit
cd VisRAG
pip install -r requirements.txt
pip install -e .
cd timm_modified
pip install -e .
cd ..
注意:
timm_modified是timm库的一个增强版本,支持梯度检查点技术,我们在训练过程中使用它来减少内存占用。
⚡️ Training
EVisRAG
为了有效地训练EVisRAG,我们引入了奖励范围分组相对策略优化(RS-GRPO),该方法将细粒度的奖励与特定范围的标记绑定,从而联合优化视觉语言模型的视觉感知和推理能力。
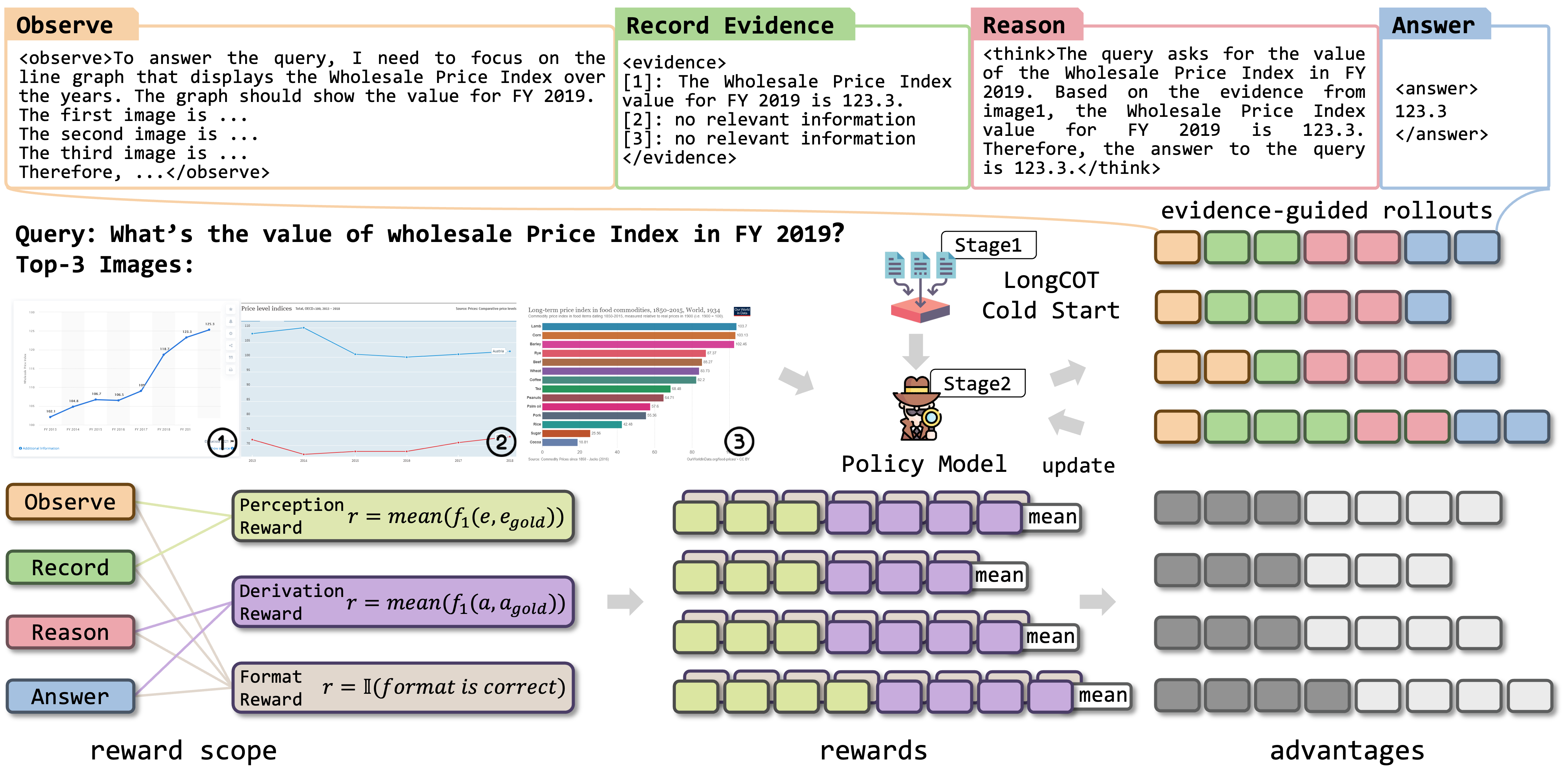
阶段1:SFT(基于LLaMA-Factory)
git clone https://github.com/hiyouga/LLaMA-Factory.git
bash evisrag_scripts/full_sft.sh
阶段2:RS-GRPO(基于Easy-R1)
bash evisrag_scripts/run_rsgrpo.sh
注:
- 训练数据可在Hugging Face上找到,名称为
EVisRAG-Train,本页开头已列出。 - 我们采用两阶段训练策略。第一阶段,请克隆
LLaMA-Factory并更新full_sft.sh脚本中的模型路径。第二阶段,我们在Easy-R1的基础上构建了专为EVisRAG设计的自定义算法RS-GRPO,其具体实现可在src/RS-GRPO中找到。
VisRAG-Ret
我们用于VisRAG-Ret的362,110对查询-文档(Q-D)训练数据集由公开可用的学术数据集的训练集(34%)以及一个合成数据集组成,该合成数据集由网络爬取的PDF文档页面构成,并辅以VLM生成的伪查询(GPT-4o)(66%)。
bash visrag_scripts/train_retriever/train.sh 2048 16 8 0.02 1 true false config/deepspeed.json 1e-5 false wmean causal 1 true 2 false <model_dir> <repo_name_or_path>
注:
- 我们的训练数据可在Hugging Face上的
VisRAG集合中找到,本页开头已列出。请注意,我们已将“领域内数据”和“合成数据”分开,因为它们存在显著差异。若希望使用完整数据集进行训练,需手动合并并打乱数据。 - 上述参数为我们论文中使用的参数,可用于复现实验结果。
<repo_name_or_path>可以是以下任一选项:openbmb/VisRAG-Ret-Train-In-domain-data、openbmb/VisRAG-Ret-Train-Synthetic-data、从Hugging Face下载的仓库目录路径,或包含您自有训练数据的目录。- 若希望使用您自己的数据集进行训练,请移除
train.sh脚本中的--from_hf_repo一行。此外,确保您的数据集目录中包含一个metadata.json文件,其中必须包含一个length字段,用于指定数据集中样本的总数。 - 我们的训练框架是在OpenMatch的基础上修改而成。
VisRAG-Gen
生成部分未进行任何微调,我们直接使用现成的LLM/VLM进行生成。
📃 评估
EVisRAG
bash evisrag_scripts/predict.sh
bash evisrag_scripts/eval.sh
注:
- 测试数据可在Hugging Face上找到,名称为
EVisRAG-Test-xxx,本页开头已列出。 - 运行评估时,首先执行
predict.sh脚本,模型输出将保存在preds目录中。然后使用eval.sh脚本对预测结果进行评估,将直接报告EM、Accuracy和F1等指标。
VisRAG-Ret
bash visrag_scripts/eval_retriever/eval.sh 512 2048 16 8 wmean causal ArxivQA,ChartQA,MP-DocVQA,InfoVQA,PlotQA,SlideVQA <ckpt_path>
注:
- 我们的测试数据可在Hugging Face上的
VisRAG集合中找到,本页开头已列出。 - 上述参数为我们论文中使用的参数,可用于复现实验结果。
- 评估脚本默认配置为使用Hugging Face上的数据集。若您希望使用本地下载的数据集仓库进行评估,可修改评估脚本中的
CORPUS_PATH、QUERY_PATH、QRELS_PATH变量,使其指向本地仓库目录。
VisRAG-Gen
我们的生成方式分为三种:基于文本的生成、基于单张图像的VLM生成以及基于多张图像的VLM生成。在基于单张图像的VLM生成中,又有两种额外设置:页面拼接和加权选择。有关这些设置的详细信息,请参阅我们的论文。
python visrag_scripts/generate/generate.py \
--model_name <model_name> \
--model_name_or_path <model_path> \
--dataset_name <dataset_name> \
--dataset_name_or_path <dataset_path> \
--rank <process_rank> \
--world_size <world_size> \
--topk <用于生成的检索文档数量> \
--results_root_dir <检索结果目录> \
--task_type <任务类型> \
--concatenate_type <图像拼接类型> \
--output_dir <输出目录>
注:
use_positive_sample决定是否仅使用查询的正例文档。启用此选项可排除检索到的文档,并省略topk和results_root_dir。若禁用,则必须指定topk(检索文档的数量)并按results_root_dir/dataset_name/*.trec的格式组织results_root_dir。concatenate_type仅在task_type设置为page_concatenation时需要。若无需此设置,则可忽略。- 始终需指定
model_name_or_path、dataset_name_or_path和output_dir。 - 仅在需要基于GPT的评估时才使用
--openai_api_key。
🔧 使用
EVisRAG
Hugging Face 上的模型:https://huggingface.co/openbmb/EVisRAG-7B
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
from qwen_vl_utils import process_vision_info
def evidence_promot_grpo(query):
return f"""你是一位AI视觉问答助手。我会提供一个问题和几张图片,请按照以下四个步骤操作:
第一步:观察图片
首先分析问题,思考哪些类型的图片可能包含相关信息。然后逐一检查每张图片,特别关注与问题相关的内容。判断每张图片是否包含潜在的相关信息。
将你的观察结果用 <observe></observe> 标签包裹起来。
第二步:记录图片中的证据
在查看完所有图片后,将你在每张图片中找到的证据用 <evidence></evidence> 标签记录下来。
如果你确定某张图片不包含任何相关信息,则记录为:[i]: 无相关信息(其中 i 表示图片的索引)。
如果一张图片包含相关证据,则记录为:[j]: [你为该问题找到的证据](其中 j 是图片的索引)。
第三步:根据问题和证据进行推理
基于已记录的证据,推导出问题的答案。
将你的逐步推理过程用 <think></think> 标签包裹起来。
第四步:回答问题
仅根据你在图片中找到的证据给出最终答案。
将你的答案用 <answer></answer> 标签包裹起来。
避免在最终答案中添加不必要的内容,例如,如果问题是“是/否”问题,只需回答“是”或“否”。
如果所有图片都不足以回答问题,则回复 <answer>无法回答</answer>。
格式要求:
请严格按照 <observe>、<evidence>、<think> 和 <answer> 标签进行结构化输出。
可能没有任何图片、仅有一张图片或有多张图片包含相关证据。
如果你没有找到任何证据,或者证据不足无法帮助你回答问题,请按照上述关于信息不足的指示操作。
问题和图片如下所示。请按照指示步骤操作。
问题:{query}
"""
model_path = "xxx"
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True, padding_side='left')
imgs, query = ["imgpath1", "imgpath2", ..., "imgpathX"], "What xxx?"
input_prompt = evidence_promot_grpo(query)
content = [{"type": "text", "text": input_prompt}]
for imgP in imgs:
content.append({
"type": "image",
"image": imgP
})
msg = [{
"role": "user",
"content": content,
}]
llm = LLM(
model=model_path,
tensor_parallel_size=1,
dtype="bfloat16",
limit_mm_per_prompt={"image":5, "video":0},
)
sampling_params = SamplingParams(
temperature=0.1,
repetition_penalty=1.05,
max_tokens=2048,
)
prompt = processor.apply_chat_template(
msg,
tokenize=False,
add_generation_prompt=True,
)
image_inputs, _ = process_vision_info(msg)
msg_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image_inputs},
}]
output_texts = llm.generate(msg_input,
sampling_params=sampling_params,
)
print(output_texts[0].outputs[0].text)
VisRAG-Ret
Hugging Face 上的模型:https://huggingface.co/openbmb/VisRAG-Ret
from transformers import AutoModel, AutoTokenizer
import torch
import torch.nn.functional as F
from PIL import Image
import os
def weighted_mean_pooling(hidden, attention_mask):
attention_mask_ = attention_mask * attention_mask.cumsum(dim=1)
s = torch.sum(hidden * attention_mask_.unsqueeze(-1).float(), dim=1)
d = attention_mask_.sum(dim=1, keepdim=True).float()
reps = s / d
return reps
@torch.no_grad()
def encode(text_or_image_list):
if (isinstance(text_or_image_list[0], str)):
inputs = {
"text": text_or_image_list,
'image': [None] * len(text_or_image_list),
'tokenizer': tokenizer
}
else:
inputs = {
"text": [''] * len(text_or_image_list),
'image': text_or_image_list,
'tokenizer': tokenizer
}
outputs = model(**inputs)
attention_mask = outputs.attention_mask
hidden = outputs.last_hidden_state
reps = weighted_mean_pooling(hidden, attention_mask)
embeddings = F.normalize(reps, p=2, dim=1).detach().cpu().numpy()
return embeddings
model_name_or_path = "openbmb/VisRAG-Ret"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16, trust_remote_code=True)
model.eval()
script_dir = os.path.dirname(os.path.realpath(__file__))
queries = ["狗长什么样?"]
passages = [
Image.open(os.path.join(script_dir, 'test_image/cat.jpeg')).convert('RGB'),
Image.open(os.path.join(script_dir, 'test_image/dog.jpg')).convert('RGB'),
]
INSTRUCTION = "将此查询表示为用于检索相关文档的形式:"
queries = [INSTRUCTION + query for query in queries]
embeddings_query = encode(queries)
embeddings_doc = encode(passages)
scores = (embeddings_query @ embeddings_doc.T)
print(scores.tolist())
VisRAG-Gen
对于 VisRAG-Gen,你可以在 Google Colab 上探索包含 VisRAG-Ret 和 VisRAG-Gen 的 VisRAG 流程,以体验这个简单的演示。
📄 许可证
- 本仓库中的代码遵循 Apache-2.0 许可协议。
- VisRAG-Ret 模型权重的使用必须严格遵守 MiniCPM 模型许可证.md。
- VisRAG-Ret 的模型和权重完全免费供学术研究使用。填写一份 "问卷" 进行注册后,VisRAG-Ret 权重也可免费用于商业用途。
📧 联系方式
EVisRAG
- Yubo Sun: syb2000417@stu.pku.edu.cn
- Chunyi Peng: hm.cypeng@gmail.com
VisRAG
- Shi Yu: yus21@mails.tsinghua.edu.cn
- Chaoyue Tang: tcy006@gmail.com
📈 星标历史

常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器