instant-ngp
instant-ngp 是一款由 NVIDIA 研发的高效开源工具,旨在以闪电般的速度训练和渲染神经图形基元。它核心支持神经辐射场(NeRF)、有向距离函数(SDF)、神经图像及神经体积等多种技术。传统 NeRF 模型训练往往耗时数小时甚至数天,而 instant-ngp 通过引入多分辨率哈希编码技术,并结合专为 CUDA 优化的 tiny-cuda-nn 框架,将这一过程大幅缩短至秒级。例如,用户仅需不到 5 秒即可基于照片重建出高质量的狐狸 3D 场景,并能实时自由漫游查看细节。
该工具主要解决了三维重建与神经渲染领域长期存在的训练速度慢、交互性差的痛点,让实时探索复杂 3D 场景成为可能。它不仅适合计算机视觉研究人员和开发者进行算法验证与二次开发,也面向设计师和普通技术爱好者开放。软件内置了友好的交互式图形界面,支持 VR 模式预览、相机路径编辑、自动网格提取(将 NeRF/SDF 转换为 3D 模型)以及快照分享等丰富功能。无论是想快速体验前沿 AI 绘图技术的用户,还是需要高效工作流的专业人士,instant-ngp 都能提供流畅且强大的支持,极大地降低了高质量 3D 内容创作的技术门槛。
使用场景
某电商视觉团队需要在一天内为新款智能机器人拍摄宣传素材,并快速生成可交互的 3D 展示模型供官网使用。
没有 instant-ngp 时
- 训练耗时过长:传统 NeRF 算法训练一个高质量场景往往需要数小时甚至过夜,无法应对紧急的营销节点。
- 迭代反馈滞后:调整拍摄角度或灯光后,需重新等待漫长的渲染过程才能查看效果,严重拖慢创作节奏。
- 硬件门槛极高:为了缩短时间,通常需要租用昂贵的云端多卡集群,增加了项目预算压力。
- 交互体验缺失:生成的模型难以实时流畅运行,无法直接嵌入网页供用户自由旋转查看细节。
使用 instant-ngp 后
- 秒级模型构建:利用多分辨率哈希编码技术,仅需几秒钟即可完成机器人模型的训练,真正实现“闪电般”的速度。
- 实时预览调整:团队成员可在 GUI 界面中即时飞览场景,随时调整相机路径并立即看到渲染结果,极大提升了创作效率。
- 单卡轻松运行:无需庞大集群,仅凭一台配备 RTX 30/40 系列显卡的工作站即可本地高效完成所有计算任务。
- 无缝交互部署:支持将训练好的神经图形基元直接转换为网格或快照,轻松集成到 VR 设备或 Web 端实现流畅交互。
instant-ngp 将原本需要数天的 3D 内容生产流程压缩至分钟级,让高保真神经渲染真正具备了实时落地的商业价值。
运行环境要求
- Windows
- Linux
- 必需 NVIDIA GPU(支持 Tensor Core 更佳)
- 预编译包支持 RTX 5000/4000/3000/2000 系列、GTX 1000 系列及 Quadro/Titan 系列
- 其他架构(如 Hopper, Volta, Maxwell)需自行编译
- 推荐 CUDA 11.5+ (Windows) 或 10.2+ (Linux)
- 显存大小未明确说明,但示例基于 RTX 3090
未说明(编译时若内存不足可能导致失败)
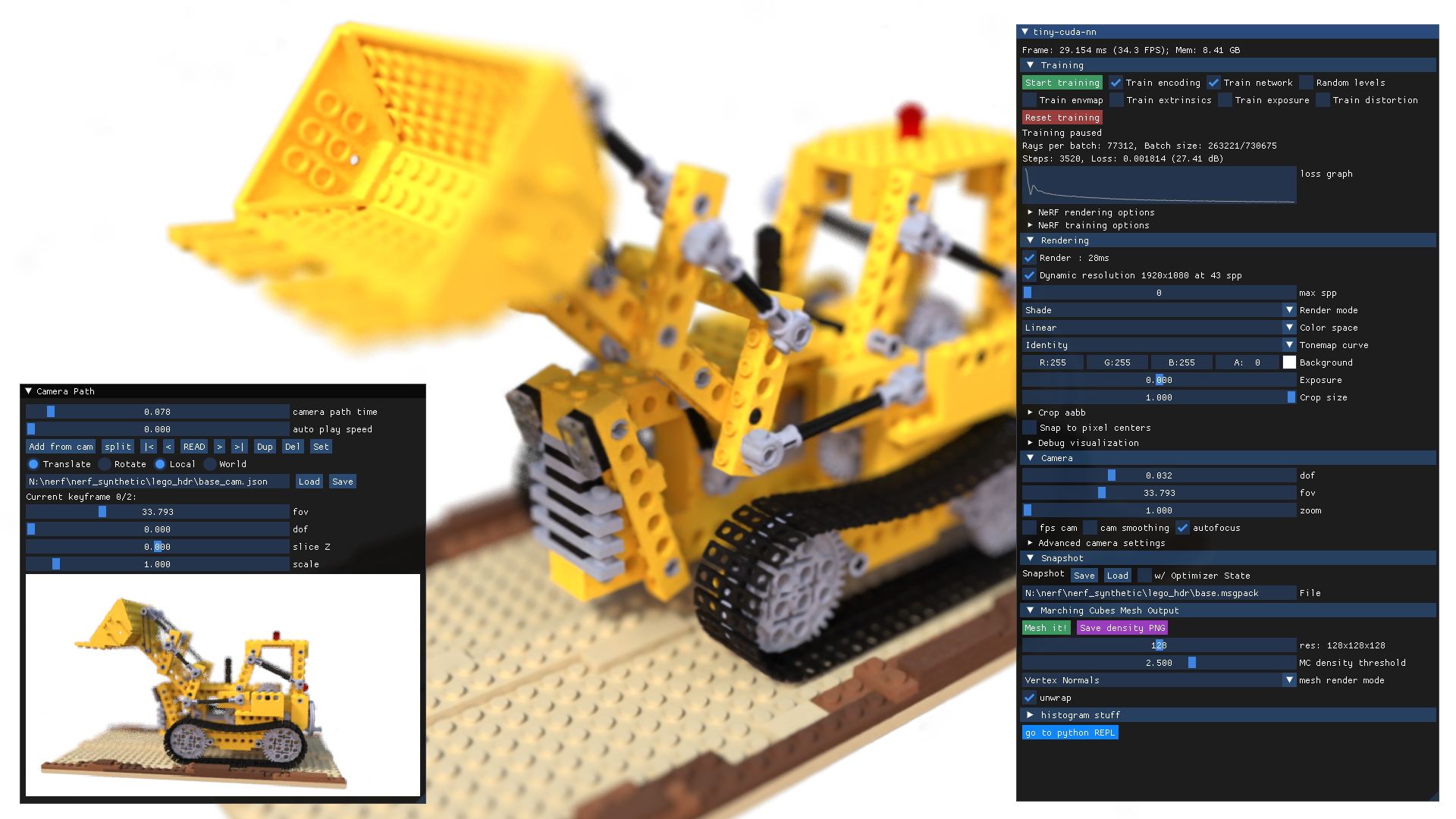
快速开始
即时神经图形基元 
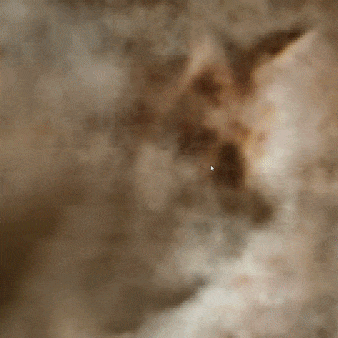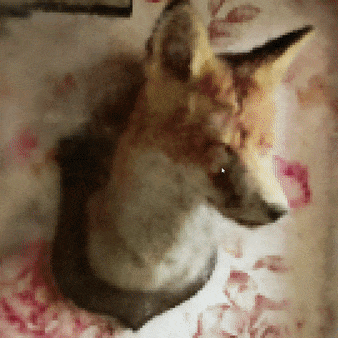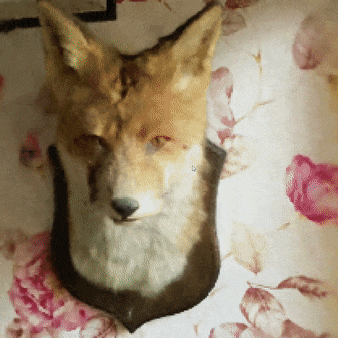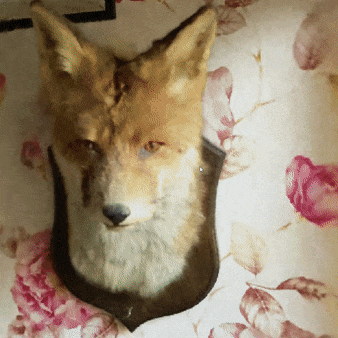

你是否曾想过在不到5秒内训练出一只狐狸的NeRF模型?或者在由工厂机器人照片捕捉的场景中自由穿梭?当然,你一定有过这样的想法!
在这里,你将找到四种__神经图形基元__的实现:神经辐射场(NeRF)、符号距离函数(SDF)、神经图像和神经体积。在每种情况下,我们都使用tiny-cuda-nn框架,通过多分辨率哈希输入编码来训练和渲染一个多层感知机(MLP)。
具有多分辨率哈希编码的即时神经图形基元
托马斯·穆勒, 亚历克斯·埃文斯, 克里斯托夫·希德, 亚历山大·凯勒
ACM 计算机图形学汇刊 (SIGGRAPH), 2022年7月
项目页面 / 论文 / 视频 / 演示文稿 / 实时演示 / BibTeX
如需商务合作,请提交NVIDIA研究许可申请表。
安装
如果你使用的是Windows系统,请根据你的显卡型号下载以下对应版本并解压,然后运行instant-ngp.exe。
- RTX 5000系列及其他Blackwell显卡
- RTX 3000 & 4000系列、RTX A4000–A6000及其他Ampere & Ada显卡
- RTX 2000系列、Titan RTX、Quadro RTX 4000–8000及其他Turing显卡
- GTX 1000系列、Titan Xp、Quadro P1000–P6000及其他Pascal显卡
继续阅读以获取应用程序的引导教程;如果你有兴趣创建自己的NeRF模型,可以观看视频教程或阅读书面说明。
如果你使用的是Linux系统,或者需要开发者Python绑定,又或者你的GPU不在上述列表中(例如Hopper、Volta或Maxwell系列),则需要自行构建__instant-ngp__。
使用方法
__instant-ngp__自带一个交互式GUI,包含多项功能:
- 全面的控制选项,用于交互式探索神经图形基元;
- VR模式,可通过虚拟现实头显查看神经图形基元;
- 支持保存和加载“快照”,方便你在互联网上分享你的图形基元;
- 摄像机路径编辑器,可用于制作视频;
- 提供
NeRF->Mesh和SDF->Mesh转换功能; - 摄像机位姿与镜头优化功能;
- 以及更多其他功能。
NeRF狐狸
只需启动instant-ngp,并将data/nerf/fox文件夹拖入窗口即可。或者,你也可以使用命令行:
instant-ngp$ ./instant-ngp data/nerf/fox
你可以使用__任何__兼容NeRF的数据集,例如来自原始NeRF、SILVR数据集或DroneDeploy数据集的数据。要创建自己的NeRF模型,请观看视频教程或阅读书面说明。
SDF犰狳
将data/sdf/armadillo.obj拖入窗口,或使用以下命令:
instant-ngp$ ./instant-ngp data/sdf/armadillo.obj

爱因斯坦图像
将data/image/albert.exr拖入窗口,或使用以下命令:
instant-ngp$ ./instant-ngp data/image/albert.exr
要复现千兆像素级别的效果,可以下载例如东京图片,并使用scripts/convert_image.py脚本将其转换为.bin格式。这种自定义格式能够在高分辨率下提升兼容性和加载速度。之后,你可以运行:
instant-ngp$ ./instant-ngp data/image/tokyo.bin
体积渲染器
下载迪士尼云的nanovdb体积数据,该数据源自此处(CC BY-SA 3.0)。然后将wdas_cloud_quarter.nvdb拖入窗口,或使用以下命令:
instant-ngp$ ./instant-ngp wdas_cloud_quarter.nvdb
键盘快捷键和推荐操作
以下是 instant-ngp 应用程序的主要键盘操作。
| 键 | 含义 |
|---|---|
| WASD | 前进 / 向左平移 / 后退 / 向右平移。 |
| 空格键 / C | 上下移动。 |
| = 或 + / - 或 _ | 增加 / 减少相机速度(第一人称模式)或放大 / 缩小(第三人称模式)。 |
| E / Shift+E | 增加 / 减少曝光。 |
| Tab | 切换菜单可见性。 |
| T | 切换训练。大约两分钟后,训练会趋于稳定,此时可以关闭。 |
| { } | 跳转到第一张/最后一张训练图像的相机视图。 |
| [ ] | 跳转到上一张/下一张训练图像的相机视图。 |
| R | 从文件重新加载网络。 |
| Shift+R | 重置相机。 |
| O | 切换可视化或累积误差图。 |
| G | 切换真实值的可视化。 |
| M | 切换神经模型各层的多视角可视化。更多信息请参见论文中的视频。 |
| , / . | 显示前一个 / 后一个可视化层;按 M 可退出。 |
| 1-8 | 在多种渲染模式之间切换,其中 2 是标准模式。渲染模式名称列表可在控制界面中查看。 |
instant-ngp 的 GUI 中包含许多控件。 首先,请注意,此 GUI 可以移动和调整大小,同样,“Camera path”GUI 也可以(但必须先展开才能使用)。
instant-ngp 中推荐的用户操作包括:
- 快照: 使用“Save”保存训练好的 NeRF,使用“Load”重新加载。
- Rendering -> DLSS: 打开此选项并将“DLSS sharpening”设置为 1.0,通常可以提高渲染质量。
- Rendering -> Crop size: 裁剪周围环境,以聚焦于模型。“Crop aabb”允许您移动感兴趣区域的中心并进行微调。有关此功能的更多信息,请参阅我们的 NeRF 训练与数据集技巧。
“Camera path”GUI 允许您创建用于渲染视频的相机路径。
“Add from cam”按钮可从当前视角插入关键帧。
然后,您可以渲染一个 .mp4 格式的视频,或将关键帧导出为 .json 文件。
关于此 GUI 的更多信息,请参阅这篇帖子以及这段创建您自己的视频的视频指南。
VR 控制
要在 VR 中查看神经图形原语,首先启动您的 VR 运行时。这很可能是:
- 如果您拥有 Oculus Rift 或 Meta Quest(带连接线)头显,则为 OculusVR;
- 如果您拥有其他头显,则为 SteamVR。
- 任何兼容 OpenXR 的运行时均可使用。
然后,在 instant-ngp GUI 中按下 Connect to VR/AR headset 按钮,并戴上您的头显。 进入 VR 之前,我们强烈建议您先完成训练(按“Stop training”)或加载预先训练好的快照,以获得最佳性能。
在 VR 中,您有以下控制方式。
| 控制 | 含义 |
|---|---|
| 左摇杆 / 触摸板 | 移动 |
| 右摇杆 / 触摸板 | 旋转相机 |
| 按压摇杆 / 触摸板 | 擦除手部周围的 NeRF |
| 抓取(单手) | 拖动物理神经图形原语 |
| 抓取(双手) | 旋转和缩放(类似于智能手机上的双指缩放) |
构建 instant-ngp(Windows 和 Linux)
需求
- 一块 NVIDIA GPU;如果可用,张量核心可提升性能。所有展示的结果均来自 RTX 3090。
- 一个支持 C++14 的编译器。推荐且经过测试的选择如下:
- Windows: Visual Studio 2019 或 2022
- Linux: GCC/G++ 8 或更高版本
- 最近版本的 CUDA。推荐且经过测试的选择如下:
- Windows: CUDA 11.5 或更高版本
- Linux: CUDA 10.2 或更高版本
- CMake v3.21 或更高版本。
- (可选) Python 3.8 或更高版本,用于交互式绑定。同时运行
pip install -r requirements.txt。 - (可选) OptiX 7.6 或更高版本,用于加速网格 SDF 训练。
- (可选) Vulkan SDK,用于支持 DLSS。
如果您使用的是基于 Debian 的 Linux 发行版,请安装以下软件包:
sudo apt-get install build-essential git python3-dev python3-pip libopenexr-dev libxi-dev \
libglfw3-dev libglew-dev libomp-dev libxinerama-dev libxcursor-dev
或者,如果您使用 Arch 或其衍生发行版,请安装以下软件包:
sudo pacman -S cuda base-devel cmake openexr libxi glfw openmp libxinerama libxcursor
我们还建议将 CUDA 和 OptiX 安装在 /usr/local/ 目录下,并将 CUDA 安装添加到您的 PATH 中。
例如,如果您安装了 CUDA 11.4,请在 ~/.bashrc 中添加以下内容:
export PATH="/usr/local/cuda-11.4/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda-11.4/lib64:$LD_LIBRARY_PATH"
编译
首先使用以下命令克隆本仓库及其所有子模块:
$ git clone --recursive https://github.com/nvlabs/instant-ngp
$ cd instant-ngp
然后使用 CMake 构建项目:(在 Windows 上,必须在开发者命令提示符中执行)
instant-ngp$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
instant-ngp$ cmake --build build --config RelWithDebInfo -j
如果编译莫名其妙失败或耗时超过一小时,可能是内存不足。在这种情况下,请尝试不带 -j 参数运行上述命令。
如果仍无效,请在提交问题之前参考可能的修复方案列表。
如果构建成功,您现在可以通过 ./instant-ngp 可执行文件或下面描述的 scripts/run.py 脚本运行代码。
如果自动检测 GPU 架构失败(例如,当您安装了多个 GPU 时),请为要使用的 GPU 设置 TCNN_CUDA_ARCHITECTURES 环境变量。下表列出了常见 GPU 的值。如果您的 GPU 未列出,请参阅这份详尽的列表。
| H100 | 40X0 | 30X0 | A100 | 20X0 | TITAN V / V100 | 10X0 / TITAN Xp | 9X0 | K80 |
|---|---|---|---|---|---|---|---|---|
| 90 | 89 | 86 | 80 | 75 | 70 | 61 | 52 | 37 |
Python 绑定
在构建完 instant-ngp 后,您可以使用其 Python 绑定以自动化方式开展受控实验。
交互式 GUI 中的所有功能(以及更多!)都提供了易于集成的 Python 绑定。
有关如何在 Python 内部实现和扩展 ./instant-ngp 应用程序的示例,请参阅 ./scripts/run.py,它支持比 ./instant-ngp 更多的命令行参数。
如果您更希望从哈希编码和快速神经网络中构建新模型,请考虑 tiny-cuda-nn 的 PyTorch 扩展。
祝您编程愉快!
其他资源
常见问题解答 (FAQ)
问: 我的自定义数据集的 NeRF 重建效果很差;我该怎么办?
答: 可能存在多种问题:
- COLMAP 可能未能成功重建相机位姿。
- 拍摄过程中可能存在运动或模糊。请将拍摄视为摄影测量任务,而非艺术创作。您的数据集中应尽量减少任何类型的模糊(如运动模糊、散焦等),并且所有物体在整个拍摄过程中必须保持静止。如果使用广角镜头(例如 iPhone 的广角镜头效果很好),则会更有优势,因为它能够覆盖比长焦镜头更大的场景范围。
- 数据集参数(尤其是
aabb_scale)可能未经过最佳调整。我们建议从aabb_scale=128开始,然后按两倍的比例逐步增加或减少,直到获得最佳质量。 - 请仔细阅读 我们的 NeRF 训练与数据集技巧。
问: 如何保存训练好的模型并在以后重新加载?
答: 有两种方法:
- 使用 GUI 中的“快照”部分。
- 使用 Python 绑定中的
load_snapshot/save_snapshot函数(示例用法请参阅scripts/run.py)。
问: 此代码库是否可以同时使用多个 GPU?
答: 仅适用于 VR 渲染,此时每只眼睛使用一个 GPU。其他情况下则不行。要选择特定的 GPU 运行,请使用 CUDA_VISIBLE_DEVICES 环境变量。若要针对该特定 GPU 优化编译过程,则可使用 TCNN_CUDA_ARCHITECTURES 环境变量。
问: 如何以无界面模式运行 instant-ngp?
答: 可以使用 ./instant-ngp --no-gui 或 python scripts/run.py。此外,您也可以通过 cmake -DNGP_BUILD_WITH_GUI=off ... 来编译不带 GUI 的版本。
问: 此代码库能否在 Google Colab 上运行?
答: 是的。请参阅受用户 @myagues 创建的笔记本启发而来的此示例。需要注意的是:此代码库需要大量的 GPU 显存,可能无法适配您分配到的 GPU;同时,在较旧的 GPU 上运行速度也会较慢。
问: 是否有 Docker 容器?
答: 是的。我们打包了一个 Visual Studio Code 开发容器,其 .devcontainer/Dockerfile 也可单独使用。
如果您想在不使用 VSCode 的情况下运行该容器:
docker-compose -f .devcontainer/docker-compose.yml build instant-ngp
xhost local:root
docker-compose -f .devcontainer/docker-compose.yml run instant-ngp /bin/bash
随后按照常规步骤执行上述构建命令即可。
问: 如何编辑并训练底层的哈希编码或神经网络以适应新任务?
答: 请使用 tiny-cuda-nn 的 PyTorch 扩展。
问: 坐标系的约定是什么?
答: 请参阅用户 @jc211 提供的这张有用的示意图。
问: 为什么在 NeRF 训练过程中会随机化背景颜色?
答: 训练数据中的透明度表示希望学习到的模型也具备透明特性。如果使用纯色背景,模型只需预测该背景颜色即可最小化损失,而无需真正学习透明度(即密度为零)。通过随机化背景颜色,模型会被“强制”学习零密度,从而使随机背景颜色得以显现出来。
问: 如何屏蔽 NeRF 训练中的像素(例如用于移除动态物体)?
答: 对于任何包含动态物体的训练图像 xyz.*,您可以在同一文件夹中提供一个名为 dynamic_mask_xyz.png 的掩码文件。该文件必须是 PNG 格式,其中非零像素值表示需要被屏蔽的区域。
编译错误排查
在进一步调查之前,请确保所有子模块都是最新版本,并再次尝试编译。
instant-ngp$ git submodule sync --recursive
instant-ngp$ git submodule update --init --recursive
如果 instant-ngp 仍然无法编译,请将 CUDA 和您的编译器都更新到您系统上可以安装的最新版本。务必同时更新两者,因为较新的 CUDA 版本并不总是与旧版编译器兼容,反之亦然。
如果问题仍然存在,请参阅以下已知问题表。
*每完成一步操作后,请删除 build 文件夹,并让 CMake 重新生成它后再尝试。*
| 问题 | 解决方案 |
|---|---|
| CMake 错误: 未找到 CUDA 工具集 / 目标 "cmTC_0c70f" 的 CUDA_ARCHITECTURES 为空 | Windows: Visual Studio 的 CUDA 集成未正确安装。请按照 这些说明 在不重新安装 CUDA 的情况下修复问题。(#18) |
Linux: 您的 CUDA 安装环境变量可能设置错误。您可以使用 cmake . -B build -DCMAKE_CUDA_COMPILER=/usr/local/cuda-<your cuda version>/bin/nvcc 来绕过此问题。(#28) |
|
| CMake 错误: CXX 编译器 "MSVC" 没有已知特性 | 重新安装 Visual Studio,并确保从开发者命令行运行 CMake。在再次构建前,请务必删除 build 文件夹。(#21) |
| 编译错误: 当指定了输出文件时,非链接阶段需要单个输入文件 | 确保 instant-ngp 的路径中没有空格。某些构建系统似乎对此存在问题。(#39 #198) |
| 编译错误: 对 "cudaGraphExecUpdate" 的未定义引用 / 标识符 "cublasSetWorkspace" 未定义 | 将您的 CUDA 安装(很可能为 11.0)更新至 11.3 或更高版本。(#34 #41 #42) |
| 编译错误: 函数调用中的参数太少 | 使用上述两条 git 命令更新子模块。(#37 #52) |
| Python 错误: 没有名为 'pyngp' 的模块 | 很可能是 CMake 没有检测到您的 Python 安装,因此未构建 pyngp。请检查 CMake 日志以确认这一点。如果 pyngp 被构建在与 build 不同的目录下,Python 将无法检测到它,您必须在导入语句中提供完整路径。(#43) |
如果您在表格中找不到您的问题,请尝试在 讨论区 和 问题页面 中搜索帮助。如果您仍然遇到困难,请 提交一个问题 并寻求帮助。
致谢
非常感谢 Jonathan Tremblay 和 Andrew Tao 测试了该代码库的早期版本,以及 Arman Toorians 和 Saurabh Jain 提供的工厂机器人数据集。 我们还要感谢 Andrew Webb 指出空间哈希中的一个质数实际上并非质数;此问题现已修复。
该项目使用了许多优秀的开源库,包括:
- tiny-cuda-nn 用于快速 CUDA 网络和输入编码
- tinyexr 用于支持 EXR 格式
- tinyobjloader 用于支持 OBJ 格式
- stb_image 用于支持 PNG 和 JPEG 格式
- Dear ImGui 一款出色的即时模式 GUI 库
- Eigen 一个用于线性代数的 C++ 模板库
- pybind11 用于实现无缝的 C++/Python 互操作
- 以及其他!详情请参见
dependencies文件夹。
衷心感谢这些优秀项目的作者!
许可与引用
@article{mueller2022instant,
author = {Thomas M\"uller and Alex Evans and Christoph Schied and Alexander Keller},
title = {Instant Neural Graphics Primitives with a Multiresolution Hash Encoding},
journal = {ACM Trans. Graph.},
issue_date = {July 2022},
volume = {41},
number = {4},
month = jul,
year = {2022},
pages = {102:1--102:15},
articleno = {102},
numpages = {15},
url = {https://doi.org/10.1145/3528223.3530127},
doi = {10.1145/3528223.3530127},
publisher = {ACM},
address = {New York, NY, USA},
}
版权所有 © 2022, NVIDIA Corporation。保留所有权利。
本作品根据 Nvidia 源代码许可协议-NC 提供。点击 此处 查看该许可协议的副本。
版本历史
continuous2023/01/08v2.02025/07/08常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器