DataDesigner
DataDesigner 是 NVIDIA NeMo 推出的一款开源工具,旨在帮助开发者从零开始或基于种子数据生成高质量的合成数据集。它超越了简单的 LLM 提示词生成方式,专注于解决人工智能训练中真实数据稀缺、隐私敏感或分布不均的难题,让用户能够构建具备多样化统计分布和字段间逻辑关联的生产级数据。
这款工具特别适合 AI 研究人员、数据工程师及需要定制化数据的开发者使用。其核心亮点在于灵活的生成框架:用户既可以利用统计采样器,也能结合大语言模型(LLM)来创造数据,并精确控制不同字段间的依赖关系。为了确保数据可用性,DataDesigner 内置了强大的验证机制,支持通过 Python 代码、SQL 查询以及自定义规则进行本地或远程校验,甚至能利用"LLM 作为裁判”的技术对输出质量进行自动评分。此外,它还提供了预览模式,允许用户在大规模生成前快速迭代和优化配置。无论是需要特定领域数据的教育场景,还是追求高鲁棒性的模型训练,DataDesigner 都能提供高效、可控的数据解决方案。
使用场景
某金融科技公司正在开发一款面向年轻用户的智能理财助手,急需大量包含复杂收入支出关联、符合真实统计分布的合成交易数据来训练模型,同时必须严格规避真实用户隐私泄露风险。
没有 DataDesigner 时
- 数据获取困难:依赖少量脱敏真实数据或简单脚本生成的随机数,缺乏字段间合理的逻辑关联(如高收入通常对应特定类型的投资支出)。
- 质量验证繁琐:团队需手动编写大量 SQL 和 Python 脚本校验数据一致性,效率低下且容易遗漏边缘情况。
- 分布单一僵化:难以模拟长尾分布或特定场景下的极端案例,导致模型在罕见但重要的金融场景中表现不佳。
- 迭代周期漫长:每次调整数据特征都需要重新跑全套生成和校验流程,无法快速预览效果,严重拖慢研发进度。
使用 DataDesigner 后
- 智能关联生成:利用依赖感知生成功能,轻松定义“收入”与“消费类别”间的复杂关系,自动产出逻辑严密的逼真交易记录。
- 内置多维校验:直接调用内置的 Python 和 SQL 验证器,实时拦截不符合业务规则的数据,确保输出即达标。
- 灵活分布控制:通过统计采样器精准控制数据分布,既能覆盖常规场景,又能按需生成稀缺的极端案例以增强模型鲁棒性。
- 快速预览迭代:启用预览模式先小批量生成并评分,确认无误后再全量生产,将数据准备周期从数天缩短至数小时。
DataDesigner 让团队在零隐私风险的前提下,高效构建了高质量、强逻辑的生产级合成数据集,显著提升了理财模型的训练效果与上线速度。
运行环境要求
- 未说明
非必需(主要依赖云端 API 如 NVIDIA Build API, OpenAI, OpenRouter 进行生成)
未说明

快速开始
🎨 NeMo 数据设计师
![]()
![]()
![]()
![]()
![]()
从零开始或使用您自己的种子数据生成高质量的合成数据集。
欢迎!
数据设计师可帮助您创建超越简单 LLM 提示的合成数据集。无论您需要多样化的统计分布、字段之间的有意义相关性,还是经过验证的高质量输出,数据设计师都提供了一个灵活的框架来构建生产级的合成数据。
使用数据设计师可以做什么?
- 生成多样化数据:使用统计采样器、LLM 或现有种子数据集
- 控制字段间关系:通过依赖感知生成方式
- 验证质量:内置 Python、SQL 以及自定义本地和远程验证器
- 评分输出:使用 LLM 作为评判者进行质量评估
- 快速迭代:在全面生成之前先使用预览模式
⚠️ 安全公告:LiteLLM 供应链事件(2026年3月24日)
2026年3月24日,恶意版本的 litellm(1.82.7 和 1.82.8)被发布到 PyPI,其中包含一个凭证窃取程序。这些被篡改的软件包在被移除之前,大约有 五个小时 的时间处于可用状态(UTC 时间 10:39 – 16:00)。
唯一可能解析到这些版本的数据设计师发行版是 v0.2.2(2025年12月)和 v0.2.3(2026年1月),它们对 litellm 的版本上限限制较为宽松,为 <2。这两个版本已经接近三个月前发布,并已被后续八个版本所取代——出于预防措施,它们均已从 PyPI 上撤回。其他所有发行版(v0.3.0 – v0.5.3)都将 litellm 锁定在 >=1.73.6,<1.80.12 范围内,因此从未与 1.82.x 版本兼容。自 v0.5.4 起,litellm 已不再是依赖项。
若要通过数据设计师受到影响,您必须明确锁定在这两个旧版本之一,并且在 3月24日的五小时窗口期内运行了新的 pip install 或依赖缓存更新,从而解析到 litellm。如果您认为自己可能受到影响,请参阅 BerriAI 的事件报告,以获取修复步骤。
快速入门
1. 安装
pip install data-designer
或者从源码安装:
git clone https://github.com/NVIDIA-NeMo/DataDesigner.git
cd DataDesigner
make install
2. 设置您的 API 密钥
您可以从我们的默认模型提供商开始:
使用上述链接获取您的 API 密钥,并设置以下环境变量之一或多组:
export NVIDIA_API_KEY="your-api-key-here"
export OPENAI_API_KEY="your-openai-api-key-here"
export OPENROUTER_API_KEY="your-openrouter-api-key-here"
3. 开始生成数据!
import data_designer.config as dd
from data_designer.interface import DataDesigner
# 使用默认设置初始化
data_designer = DataDesigner()
config_builder = dd.DataDesignerConfigBuilder()
# 添加产品类别
config_builder.add_column(
dd.SamplerColumnConfig(
name="product_category",
sampler_type=dd.SamplerType.CATEGORY,
params=dd.CategorySamplerParams(
values=["电子产品", "服装", "家居与厨房", "书籍"],
),
)
)
# 生成个性化的客户评论
config_builder.add_column(
dd.LLMTextColumnConfig(
name="review",
model_alias="nvidia-text",
prompt="请为你最近购买的 {{ product_category }} 商品写一段简短的产品评论。",
)
)
# 预览您的数据集
preview = data_designer.preview(config_builder=config_builder)
preview.display_sample_record()
接下来?
📚 了解更多
- 入门指南 – 安装、配置并生成您的第一个数据集
- 教程笔记本 – 分步交互式教程
- 列类型 – 探索采样器、LLM 列、验证器等
- 验证器 – 学习如何使用 Python、SQL 和远程验证器验证生成的数据
- 模型配置 – 配置自定义模型和提供商
- 人物采样 – 学习如何采样具有人口统计特征的真实人物数据
🔧 通过 CLI 配置模型
data-designer config providers # 配置模型提供商
data-designer config models # 设置您的模型配置
data-designer config list # 查看当前设置
🤖 代理技能
数据设计师具备针对编码代理的 技能。只需描述您想要的数据集,您的代理就会负责模式设计、验证和生成。虽然该技能应能与其他支持技能的编码代理配合使用,但目前我们的开发和测试主要集中在 Claude Code 上。
通过 skills.sh 安装(请务必选择 Claude Code 作为附加代理):
npx skills add NVIDIA-NeMo/DataDesigner
安装完成后,输入 /data-designer 或描述您想要的数据集,技能将自动启动。
🤝 参与进来
此仓库支持代理辅助开发——请参阅 CONTRIBUTING.md 了解推荐的工作流程。
遥测
Data Designer 会收集遥测数据,以帮助我们改进面向开发者的库。我们收集以下信息:
- 使用的模型名称
- 输入 token 的数量
- 输出 token 的数量
不会收集任何用户或设备信息。 这些数据不会用于追踪任何个人用户的行为。它们仅用于汇总 SDG 中最受欢迎的模型。我们会与社区共享这些使用数据。
具体来说,将收集在 ModelConfig 对象中定义的模型名称。例如,在下面的配置中:
ModelConfig(
alias="nv-reasoning",
model="openai/gpt-oss-20b",
provider="nvidia",
inference_parameters=ChatCompletionInferenceParams(
temperature=0.3,
top_p=0.9,
max_tokens=4096,
),
)
将会收集值 openai/gpt-oss-20b。
要禁用遥测采集,请设置 NEMO_TELEMETRY_ENABLED=false。
热门模型
此图表展示了从 2026 年 2 月 23 日至 2026 年 3 月 23 日期间,所有合成数据生成任务中使用的模型分布情况。
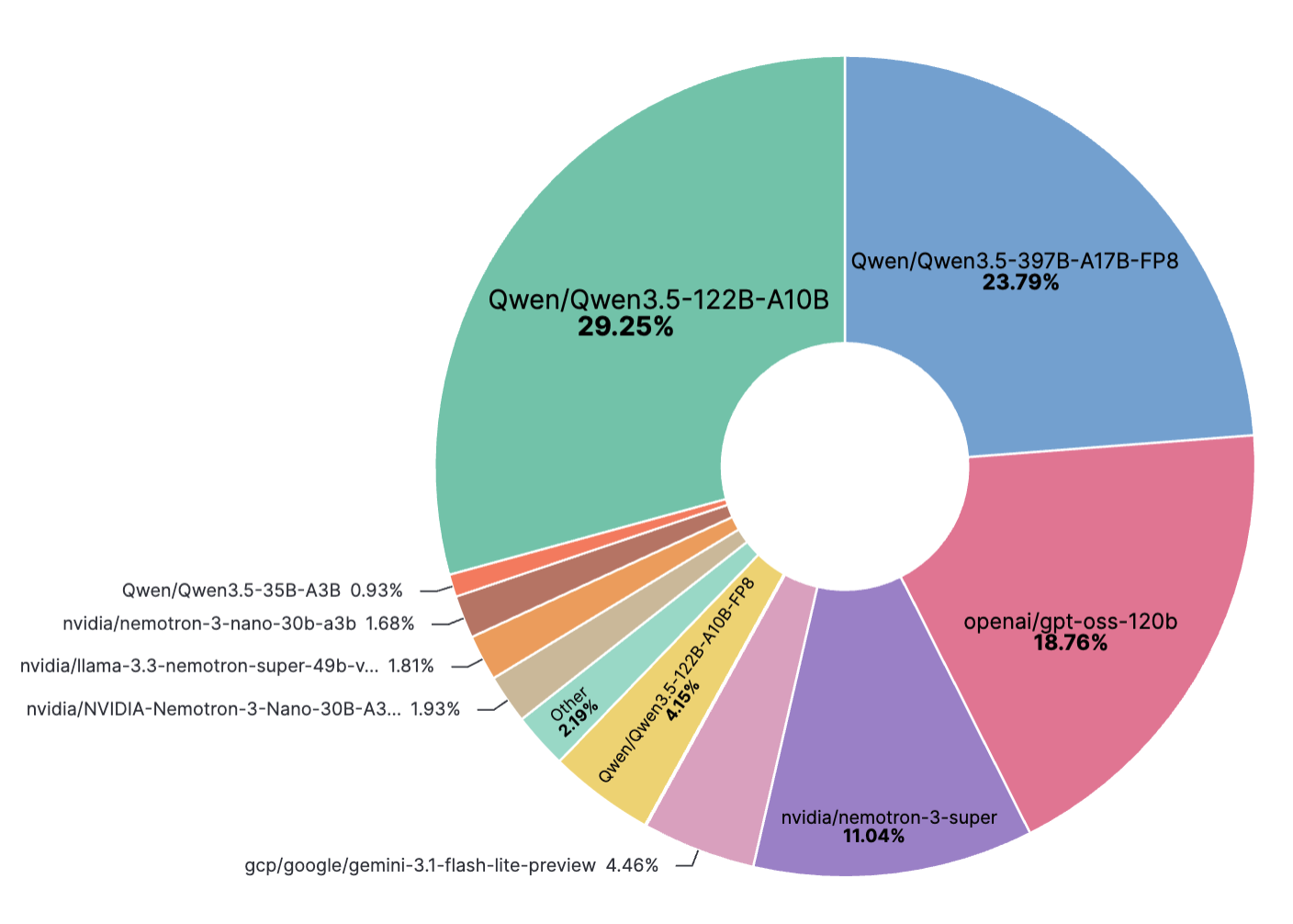
最后更新于 2026 年 3 月 23 日
许可证
Apache License 2.0 – 详情请参阅 LICENSE 文件。
引用
如果您在研究中使用了 NeMo Data Designer,请使用以下 BibTeX 条目进行引用:
@misc{nemo-data-designer,
author = {The NeMo Data Designer Team, NVIDIA},
title = {NeMo Data Designer:一个从零开始或基于您自己的种子数据生成合成数据的框架},
howpublished = {\url{https://github.com/NVIDIA-NeMo/DataDesigner}},
year = {2025},
note = {GitHub 仓库},
}
版本历史
v0.5.62026/04/09v0.5.52026/04/02v0.5.42026/03/25v0.5.32026/03/12v0.5.22026/03/05v0.5.12026/02/20v0.5.02026/02/11v0.4.02026/01/31v0.3.82026/01/27v0.3.72026/01/17v0.3.62026/01/17v0.3.52026/01/16v0.3.42026/01/14v0.3.32026/01/12v0.3.22026/01/09v0.3.12026/01/08v0.3.02026/01/08v0.2.32026/01/07v0.2.22025/12/30v0.2.12025/12/19常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器