MinkowskiEngine
Minkowski Engine 是一款专为高维稀疏张量设计的自动微分神经网络库。它主要解决了传统深度学习框架在处理空间稀疏数据(如 3D 点云、体素网格或高维表面数据)时效率低下的痛点。在传统方法中,即使数据大部分为空,网络仍需对密集张量进行计算,导致显存占用巨大且推理速度缓慢。Minkowski Engine 通过原生支持稀疏卷积、池化及广播等操作,仅对有效数据进行计算,从而显著降低内存 footprint 并加速训练与推理过程。
该工具特别适合从事计算机视觉、机器人感知及三维重建领域的研究人员与开发者,尤其是那些需要构建高效 3D 语义分割、分类、检测或生成模型的专业人士。其核心技术亮点在于将稀疏性从“参数层面”延伸至“空间层面”,并提供了完整的 CUDA 加速坐标管理功能,让用户能像使用普通 PyTorch 层一样轻松搭建复杂的稀疏神经网络架构。无论是学术探索还是工业级应用,Minkowski Engine 都为处理大规模稀疏几何数据提供了强大而灵活的基础设施。
使用场景
一家自动驾驶初创公司的感知团队正在开发基于激光雷达(LiDAR)点云的 3D 语义分割系统,以识别道路上的行人、车辆和障碍物。
没有 MinkowskiEngine 时
- 显存爆炸式增长:为了处理稀疏的激光雷达点云,工程师被迫将数据体素化为稠密张量,导致 99% 的显存被无效的空值占用,根本无法在单卡上运行高分辨率模型。
- 计算资源严重浪费:传统卷积神经网络会对大量空白区域执行无效的乘法运算,推理延迟高达数百毫秒,无法满足实时驾驶决策需求。
- 模型架构受限:由于内存瓶颈,团队不得不大幅降低输入分辨率或裁剪网络深度,直接导致对远处小目标(如锥桶、儿童)的识别准确率低下。
- 预处理流程繁琐:需要编写复杂的自定义代码来手动管理稀疏坐标索引,不仅开发效率低,还极易引入难以排查的 Bug。
使用 MinkowskiEngine 后
- 显存占用降低两个数量级:MinkowskiEngine 原生支持高维稀疏张量,仅存储有效点的坐标与特征,使得在同等显存下可处理更大范围、更精细的点云场景。
- 推理速度显著提升:库内建的稀疏卷积算子自动跳过空白区域计算,结合 CUDA 加速,将端到端推理延迟压缩至实时范围内,满足车载部署标准。
- 模型性能全面释放:摆脱了内存束缚,团队得以部署更深、更宽的 3D 网络架构,显著提升了复杂场景下的分割精度和小目标检测能力。
- 开发流程标准化:直接调用 MinkowskiEngine 提供的标准层(如稀疏卷积、池化),无需重复造轮子,让算法工程师能专注于网络结构创新而非底层优化。
MinkowskiEngine 通过将“空间稀疏性”转化为计算优势,彻底解决了 3D 深度学习在处理大规模点云时的内存与效率瓶颈。
运行环境要求
- Linux (Ubuntu >= 14.04)
需要 NVIDIA GPU,CUDA 版本需 >= 10.1.243,且必须与 PyTorch 使用的 CUDA 版本完全一致(如 10.2 或 11.1)
未说明

快速开始
Minkowski Engine
![]()

Minkowski Engine 是一个用于稀疏张量的自动微分库。它支持所有标准的神经网络层,例如卷积、池化、反池化以及针对稀疏张量的广播操作。更多信息请访问 文档页面。
最新消息
- 2021-08-11 添加了 Docker 安装说明
- 2021-08-06 已解决与 PyTorch 1.8 和 1.9 相关的所有安装问题。
- 2021-04-08 由于近期在 PyTorch 1.8 + CUDA 11 中出现的问题,建议使用 Anaconda 进行安装。
- 2020-12-24 v0.5 现已发布!新版本为所有坐标管理函数提供了 CUDA 加速。
示例网络
Minkowski Engine 支持多种基于稀疏张量构建的功能。我们在此列出几种流行的网络架构和应用。要运行这些示例,请先安装该包,然后在包的根目录下执行相应命令。
| 示例 | 网络及命令 |
|---|---|
| 语义分割 |   python -m examples.indoor |
| 分类 | 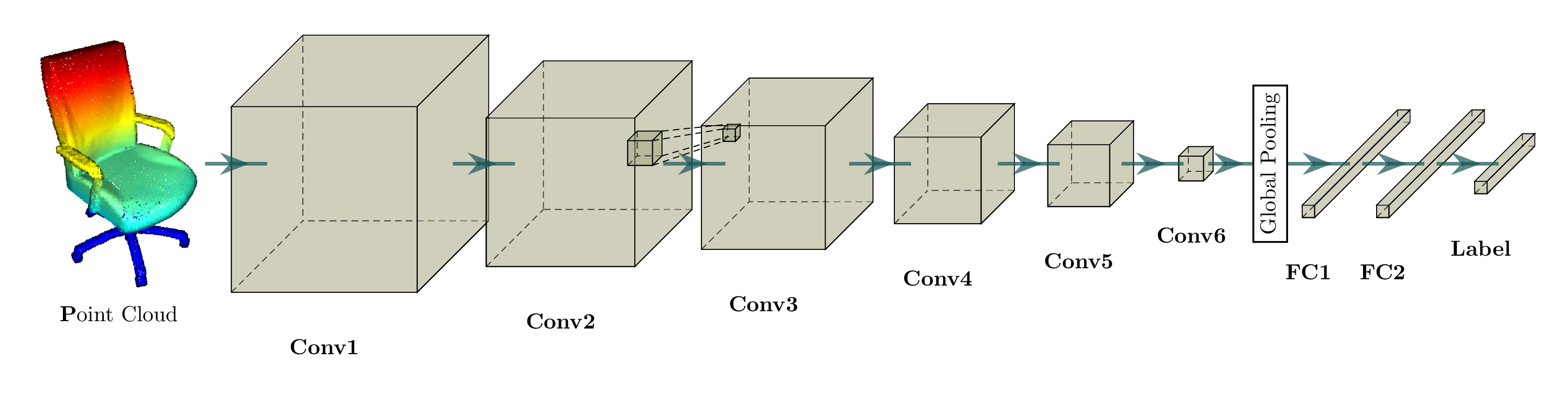 python -m examples.classification_modelnet40 |
| 重建 |   python -m examples.reconstruction |
| 完善 |  python -m examples.completion |
| 检测 | 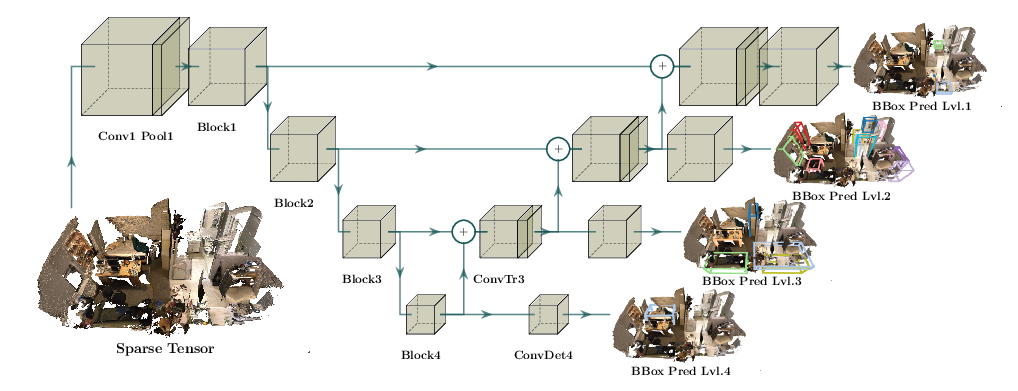 |
稀疏张量网络:面向空间稀疏张量的神经网络
通过压缩神经网络来加速推理并最小化内存占用一直是广泛研究的主题。一种流行的模型压缩技术是剪枝卷积神经网络中的权重,也被称为 稀疏卷积网络。这种用于模型压缩的参数空间稀疏性通常应用于处理稠密张量的网络,而这些网络的所有中间激活也是稠密张量。
然而,在这项工作中,我们专注于 空间上 稀疏的数据,特别是高维的空间稀疏输入、3D 数据以及 3D 对象表面上的卷积,这一概念最早由 Siggraph'17 提出。我们也可以将这些数据表示为稀疏张量,而这类稀疏张量在 3D 感知、配准和统计数据分析等高维问题中非常常见。我们将专为这类输入设计的神经网络称为 稀疏张量网络,这些稀疏张量网络以稀疏张量作为输入和输出进行处理和生成。为了构建稀疏张量网络,我们可以像定义稠密张量上的网络层一样,使用 MLP、非线性变换、卷积、归一化、池化等标准神经网络层,并将其在 Minkowski Engine 中实现。
我们在下方展示了稀疏张量网络对稀疏张量进行卷积运算的过程。稀疏张量上的卷积层与稠密张量上的卷积层类似。然而,在稀疏张量上,我们只在少数指定的点上计算卷积输出,这些点可以通过 广义卷积 来控制。更多相关信息请访问 稀疏张量网络的文档页面 和 术语页面。
| 稠密张量 | 稀疏张量 |
|---|---|
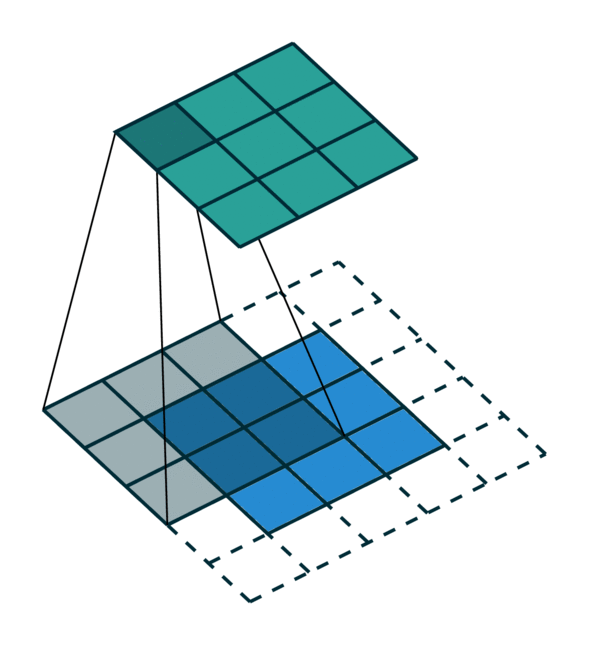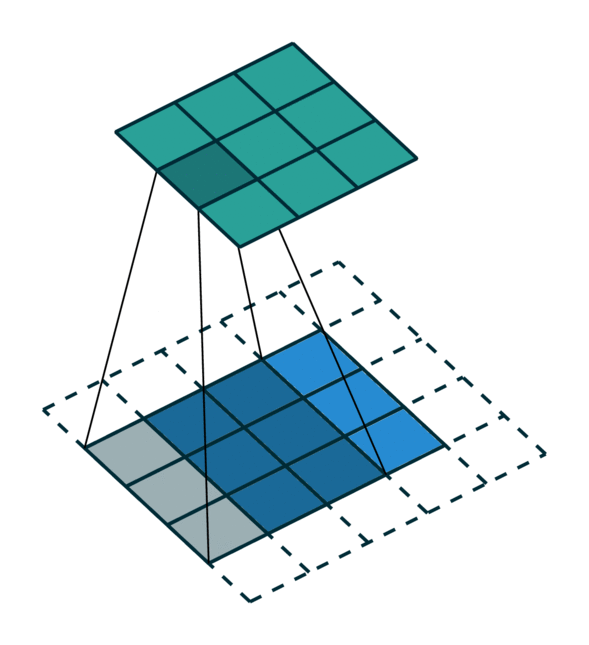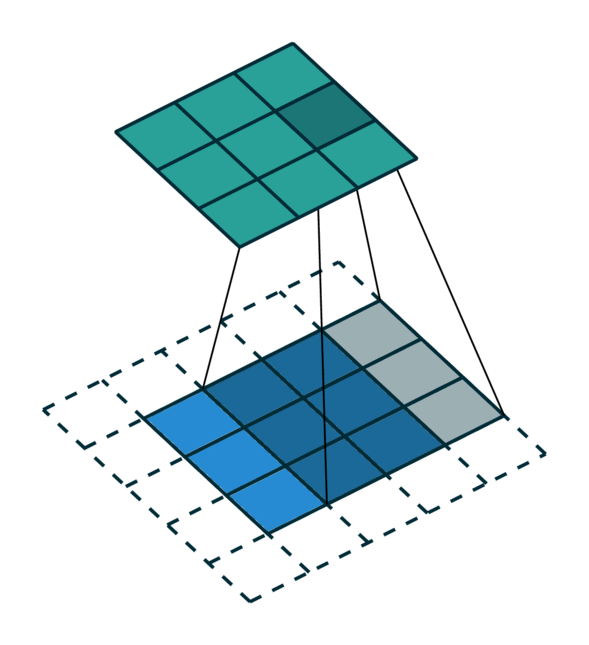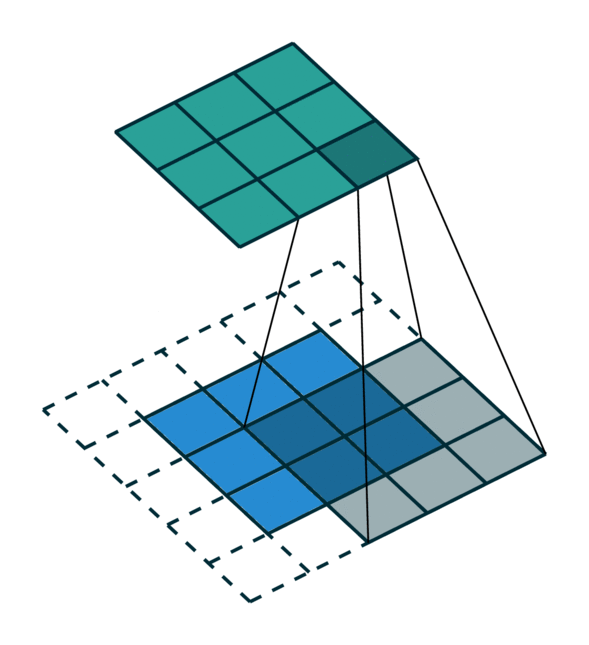 |
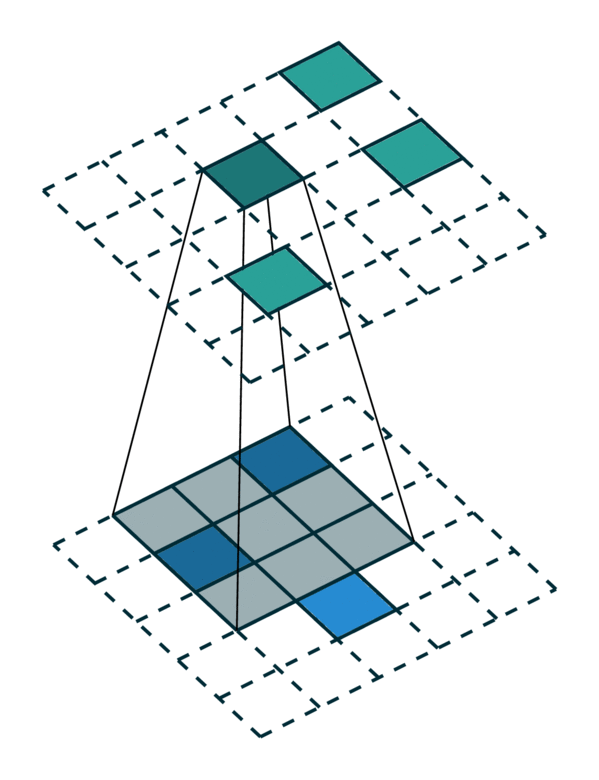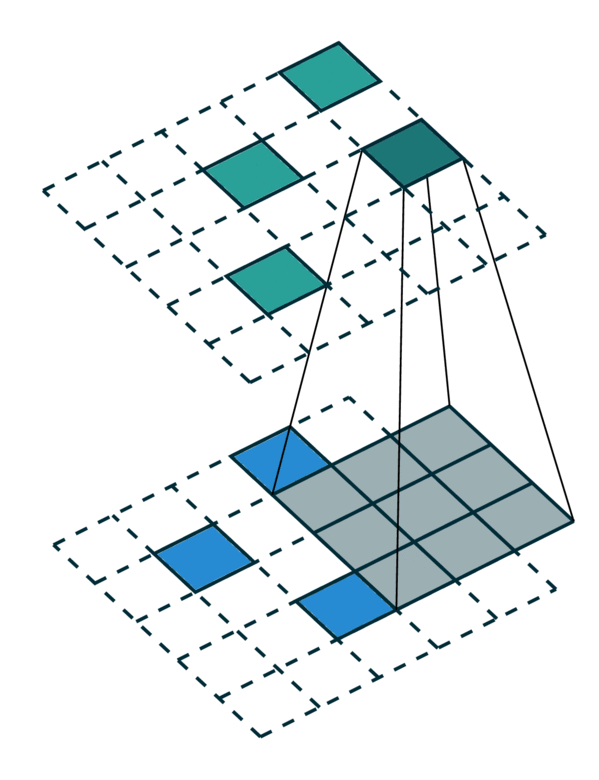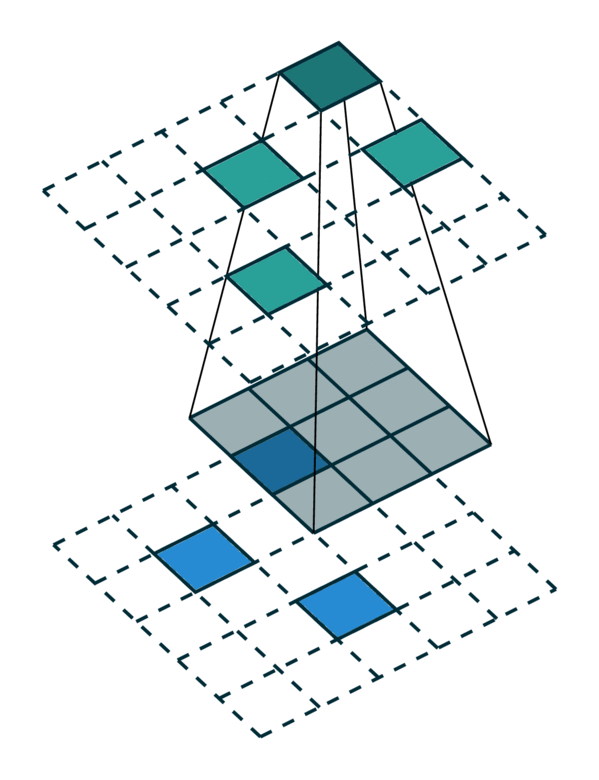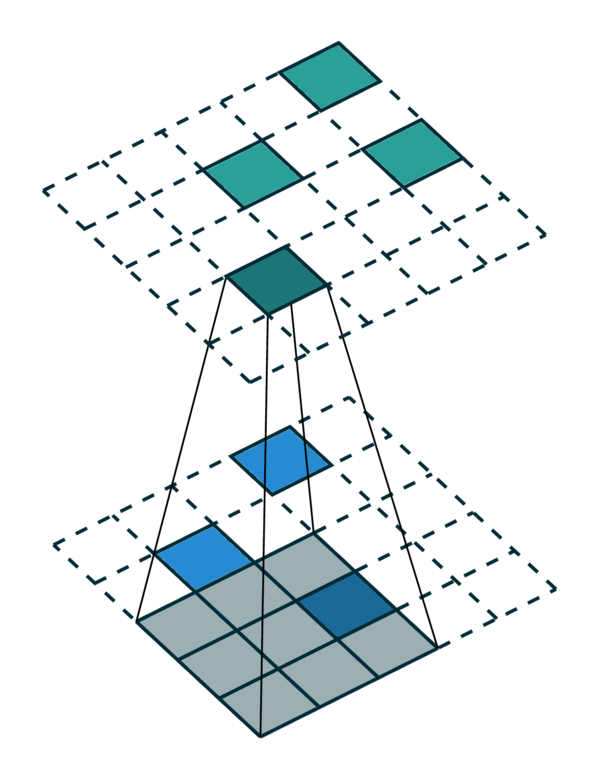 |
特性
- 无限制的高维稀疏张量支持
- 所有标准神经网络层(卷积、池化、广播等)
- 动态计算图
- 自定义核形状
- 多 GPU 训练
- 多线程核映射
- 多线程编译
- 高度优化的 GPU 核
系统要求
- Ubuntu >= 14.04
- CUDA >= 10.1.243 并且 CUDA 版本需与 PyTorch 使用的版本一致(例如,如果使用 conda 的 cudatoolkit=11.1,则 MinkowskiEngine 编译时也应使用 CUDA=11.1)
- PyTorch >= 1.7 为指定 CUDA 版本,请使用 conda 进行安装。必须确保 PyTorch 和 MinkowskiEngine 使用的 CUDA 版本一致。
conda install -y -c nvidia -c pytorch pytorch=1.8.1 cudatoolkit=10.2) - Python >= 3.6
- ninja(用于安装)
- GCC >= 7.4.0
安装
您可以使用 pip、Anaconda 或直接在系统上安装 Minkowski Engine。如果您在安装过程中遇到问题,请查看安装维基页面。
如果找不到相关问题,请在GitHub 问题页面上报错。
Pip
MinkowskiEngine 通过 PyPI MinkowskiEngine 发布,可以使用 pip 简单安装。
首先,按照 PyTorch 官方文档 安装 PyTorch。然后安装 openblas:
sudo apt install build-essential python3-dev libopenblas-dev
pip install torch ninja
pip install -U MinkowskiEngine --install-option="--blas=openblas" -v --no-deps
# 从最新源码安装
# pip install -U git+https://github.com/NVIDIA/MinkowskiEngine --no-deps
如果您想为安装脚本指定参数,请参考以下命令:
# 如果安装失败,可以取消注释部分选项
# export CXX=c++; # 如果您想使用不同的 C++ 编译器,请设置此环境变量
# export CUDA_HOME=/usr/local/cuda-11.1; # 或者选择您系统上正确的 CUDA 版本。
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps \
# \ # 如果您想强制安装 CUDA,请取消注释下一行
# --install-option="--force_cuda" \
# \ # 如果您想强制不安装 CUDA,请取消注释下一行。force_cuda 会覆盖 cpu_only
# --install-option="--cpu_only" \
# \ # 如果您想覆盖为 openblas、atlas、mkl 或其他 BLAS 库,请取消注释下一行
# --install-option="--blas=openblas" \
Anaconda
MinkowskiEngine 同时支持 CUDA 10.2 和 CUDA 11.1,适用于大多数最新的 PyTorch 版本。
CUDA 10.2
建议使用 python>=3.6 进行安装。首先,按照 Anaconda 官方文档 在您的计算机上安装 Anaconda。
sudo apt install g++-7 # 对于 CUDA 10.2,必须使用 GCC < 8
# 确保 `g++-7 --version` 至少为 7.4.0
conda create -n py3-mink python=3.8
conda activate py3-mink
conda install openblas-devel -c anaconda
conda install pytorch=1.9.0 torchvision cudatoolkit=10.2 -c pytorch -c nvidia
# 安装 MinkowskiEngine
export CXX=g++-7
# 如果需要指定 CUDA 安装路径,请取消注释下一行。确保 `$CUDA_HOME/nvcc --version` 是 10.2
# export CUDA_HOME=/usr/local/cuda-10.2
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps --install-option="--blas_include_dirs=${CONDA_PREFIX}/include" --install-option="--blas=openblas"
# 或者如果您想要本地安装的 MinkowskiEngine
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine
export CXX=g++-7
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
CUDA 11.X
建议使用 python>=3.6 进行安装。首先,按照 Anaconda 官方文档 在您的计算机上安装 Anaconda。
conda create -n py3-mink python=3.8
conda activate py3-mink
conda install openblas-devel -c anaconda
conda install pytorch=1.9.0 torchvision cudatoolkit=11.1 -c pytorch -c nvidia
# 安装 MinkowskiEngine
# 如果需要指定 CUDA 安装路径,请取消注释下一行。确保 `$CUDA_HOME/nvcc --version` 是 11.X
# export CUDA_HOME=/usr/local/cuda-11.1
pip install -U git+https://github.com/NVIDIA/MinkowskiEngine -v --no-deps --install-option="--blas_include_dirs=${CONDA_PREFIX}/include" --install-option="--blas=openblas"
# 或者如果您想要本地安装的 MinkowskiEngine
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine
python setup.py install --blas_include_dirs=${CONDA_PREFIX}/include --blas=openblas
系统 Python
与 Anaconda 安装类似,确保您安装的 PyTorch 使用的 CUDA 版本与 nvcc 的版本一致。
# 安装系统依赖
sudo apt install build-essential python3-dev libopenblas-dev
# 如果您的 Python3 已经安装了 pip,则跳过此步骤
curl https://bootstrap.pypa.io/get-pip.py | python3
# 获取 pip 并安装 Python 依赖
python3 -m pip install torch numpy ninja
git clone https://github.com/NVIDIA/MinkowskiEngine.git
cd MinkowskiEngine
python setup.py install
# 若要指定 BLAS、CXX、CUDA_HOME 并强制安装 CUDA,请使用以下命令:
# export CXX=c++; export CUDA_HOME=/usr/local/cuda-11.1; python setup.py install --blas=openblas --force_cuda
Docker
git clone https://github.com/NVIDIA/MinkowskiEngine
cd MinkowskiEngine
docker build -t minkowski_engine docker
构建完成后,请检查 Docker 是否正确加载了 MinkowskiEngine:
docker run MinkowskiEngine python3 -c "import MinkowskiEngine; print(MinkowskiEngine.__version__)"
仅 CPU 构建及 BLAS 配置(MKL)
Minkowski Engine 支持在没有 NVIDIA GPU 的平台上进行仅 CPU 构建。更多详细信息请参阅快速入门。
快速入门
要使用 Minkowski Engine,您首先需要导入该引擎。然后,您需要定义网络。如果您的数据尚未量化,您需要将其体素化或量化为稀疏张量。幸运的是,Minkowski Engine 提供了量化函数 (MinkowskiEngine.utils.sparse_quantize)。
创建网络
import torch.nn as nn
import MinkowskiEngine as ME
class ExampleNetwork(ME.MinkowskiNetwork):
def __init__(self, in_feat, out_feat, D):
super(ExampleNetwork, self).__init__(D)
self.conv1 = nn.Sequential(
ME.MinkowskiConvolution(
in_channels=in_feat,
out_channels=64,
kernel_size=3,
stride=2,
dilation=1,
bias=False,
dimension=D),
ME.MinkowskiBatchNorm(64),
ME.MinkowskiReLU())
self.conv2 = nn.Sequential(
ME.MinkowskiConvolution(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=2,
dimension=D),
ME.MinkowskiBatchNorm(128),
ME.MinkowskiReLU())
self.pooling = ME.MinkowskiGlobalPooling()
self.linear = ME.MinkowskiLinear(128, out_feat)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.pooling(out)
return self.linear(out)
使用自定义网络进行前向和反向传播
# 损失函数和网络
criterion = nn.CrossEntropyLoss()
net = ExampleNetwork(in_feat=3, out_feat=5, D=2)
print(net)
# 数据加载器必须返回坐标、特征和标签的元组。
coords, feat, label = data_loader()
input = ME.SparseTensor(feat, coordinates=coords)
# 前向传播
output = net(input)
# 损失
loss = criterion(output.F, label)
讨论与文档
如有讨论或问题,请发送邮件至 minkowskiengine@googlegroups.com。
有关 API 和一般用法的详细信息,请参阅 MinkowskiEngine 文档页面。
对于未在 API 中列出的问题以及功能请求,欢迎在 GitHub 问题页面 上提交。
已知问题
指定 CUDA 架构列表
在某些情况下,您需要显式指定 GPU 所使用的计算能力。默认列表可能不包含您的架构。
export TORCH_CUDA_ARCH_LIST="5.2 6.0 6.1 7.0 7.5 8.0 8.6+PTX"; python setup.py install --force_cuda
未处理的内存不足 thrust::system 异常
CUDA 10 中的 thrust 存在一个 已知问题,会导致未处理的 thrust 异常。详情请参阅 此问题。
GPU 显存占用过高或频繁出现内存不足
导致此错误的原因有以下几点:
- 长时间训练过程中内存不足
MinkowskiEngine 是一个专门用于处理点云数据的库,能够在每次迭代中处理不同数量的点或非零元素。然而,PyTorch 的实现假设每次迭代中的点数或激活大小不会发生变化。因此,PyTorch 使用的 GPU 内存缓存机制可能会导致不必要的大量内存消耗。
具体来说,PyTorch 会缓存一些内存块以加快张量创建时的分配速度。如果找不到合适的内存空间,它会分割现有的缓存块,或者在没有足够大的缓存时分配新的内存。因此,当我们使用 PyTorch 处理不同数量的点(即非零元素数量)时,它要么分割现有缓存,要么预留新内存。如果缓存被过度碎片化并占用了所有 GPU 显存,就会抛出内存不足的错误。
为防止这种情况发生,必须定期调用 torch.cuda.empty_cache() 清空缓存。
CUDA 11.1 安装
wget https://developer.download.nvidia.com/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run
sudo sh cuda_11.1.1_455.32.00_linux.run --toolkit --silent --override
# 使用 CUDA 11.1 安装 MinkowskiEngine
export CUDA_HOME=/usr/local/cuda-11.1; pip install MinkowskiEngine -v --no-deps
在具有大量 CPU 核心的节点上运行 MinkowskiEngine
MinkowskiEngine 使用 OpenMP 来并行化核映射的生成。然而,当用于并行化的线程数过多时(例如 OMP_NUM_THREADS=80),效率会迅速下降,因为所有线程都在等待多线程锁释放。在这种情况下,应设置 OpenMP 使用的线程数。通常,24 个以下的线程数即可,但您仍需根据系统情况找到最佳配置。
export OMP_NUM_THREADS=<要使用的线程数>; python <your_program.py>
引用 Minkowski Engine
如果您使用了 Minkowski Engine,请引用以下文献:
@inproceedings{choy20194d,
title={4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks},
author={Choy, Christopher and Gwak, JunYoung and Savarese, Silvio},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={3075--3084},
year={2019}
}
关于多线程核映射生成,请引用:
@inproceedings{choy2019fully,
title={Fully Convolutional Geometric Features},
author={Choy, Christopher and Park, Jaesik and Koltun, Vladlen},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={8958--8966},
year={2019}
}
关于高维卷积的步进池化层,请引用:
@inproceedings{choy2020high,
title={High-dimensional Convolutional Networks for Geometric Pattern Recognition},
author={Choy, Christopher and Lee, Junha and Ranftl, Rene and Park, Jaesik and Koltun, Vladlen},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2020}
}
关于生成式转置卷积,请引用:
@inproceedings{gwak2020gsdn,
title={Generative Sparse Detection Networks for 3D Single-shot Object Detection},
author={Gwak, JunYoung and Choy, Christopher B and Savarese, Silvio},
booktitle={European conference on computer vision},
year={2020}
}
单元测试
进行单元测试和梯度检查时,请使用 PyTorch >= 1.7版本。
使用 Minkowski Engine 的项目
欢迎您更新维基页面,添加您的项目!
版本历史
v0.5.42021/05/21v0.5.32021/04/14v0.5.22021/03/05v0.5.12021/02/06v0.5.02020/12/31v0.4.32020/06/11常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器