checkpoint-engine
checkpoint-engine 是一款专为大语言模型推理引擎设计的轻量级中间件,核心功能是实现模型权重的快速原地更新。在强化学习等场景中,模型需要频繁迭代权重,传统方式往往耗时较长且影响服务连续性,而 checkpoint-engine 正是为了解决这一效率瓶颈而生。
该工具主要面向 AI 基础设施开发者、大模型研究人员以及需要构建高可用推理系统的工程师。它提供了两种高效的更新模式:广播模式适用于大规模集群同步更新,速度极快;点对点(P2P)模式则利用 Mooncake 传输引擎,支持在不中断现有服务的前提下,动态向新加入的实例分发权重,非常适合弹性扩缩容场景。
其技术亮点在于高度优化的数据传输流水线。通过将权重迁移划分为主机到设备、集群广播和引擎重载三个阶段,并采用通信与计算重叠的策略,极大提升了吞吐量。实测数据显示,即使在数千张 GPU 上更新万亿参数的 Kimi-K2 模型,也仅需约 20 秒。当显存资源紧张时,它还能自动降级为串行执行以确保稳定性。对于追求极致推理性能和灵活性的团队来说,这是一个非常实用的底层加速组件。
使用场景
某大型 AI 实验室正在基于 Kimi-K2 万亿参数模型进行高强度强化学习(RL)训练,需要频繁将最新权重同步至数千张 GPU 组成的推理集群以进行实时策略评估。
没有 checkpoint-engine 时
- 更新耗时过长:传统方式在数千卡规模下全量更新权重往往需要数分钟甚至更久,导致 RL 训练循环被迫长时间停顿,严重拖慢迭代速度。
- 动态扩容困难:当部分推理节点因故障重启或需动态增加新实例时,难以在不干扰现有服务的情况下完成权重加载,常引发整体服务抖动。
- 资源利用率低:缺乏精细化的流水线调度,网络带宽与显存拷贝无法重叠执行,导致昂贵的 H800/H20 显卡在数据搬运期间处于空闲等待状态。
- 分片适配复杂:训练端与推理端的权重分片策略往往不同,人工编写转换逻辑极易出错且难以维护,增加了工程落地门槛。
使用 checkpoint-engine 后
- 秒级权重同步:利用优化的广播机制,即使在数千张 GPU 上更新万亿参数模型,全程也仅需约 20 秒,实现了近乎实时的 RL 反馈闭环。
- 无感动态接入:通过 P2P 模式,新加入的推理实例可直接从运行中的旧节点拉取权重,完全不影响现有业务的正常请求处理。
- 极致流水线性能:自动规划 H2D 传输、集群广播与重加载的三级流水线,最大化重叠通信与计算,充分榨干硬件带宽潜力。
- 智能分片编排:内置元数据收集与桶分配算法,自动处理不同分片模式间的数据映射,无需开发人员手动干预数据布局转换。
checkpoint-engine 通过将原本漫长的权重更新过程压缩至秒级,彻底消除了大规模强化学习训练中的同步瓶颈,让万亿参数模型的实时进化成为可能。
运行环境要求
- Linux
- 必需 NVIDIA GPU
- 测试环境包括 H800 和 H20
- 支持多卡并行(如 8xH800 TP8, 16xH20 TP16, 256xH20 TP16)
- 需绑定 GPU 到对应的 NUMA 节点以优化传输速度
- 若使用 P2P 模式,需支持 RDMA 的网卡设备
未说明(但提到流水线模式需要更多显存,不足时会回退到串行执行;CPU 端需存储分片权重引用)

快速开始
检查点引擎
Checkpoint-engine 是一种简单的中间件,用于在 LLM 推理引擎中更新模型权重——这是强化学习中的关键步骤。 我们提供了一种高效轻量级的原地权重更新实现: 在数千张 GPU 上更新我们的 Kimi-K2 模型(1 万亿参数)大约需要 20 秒。
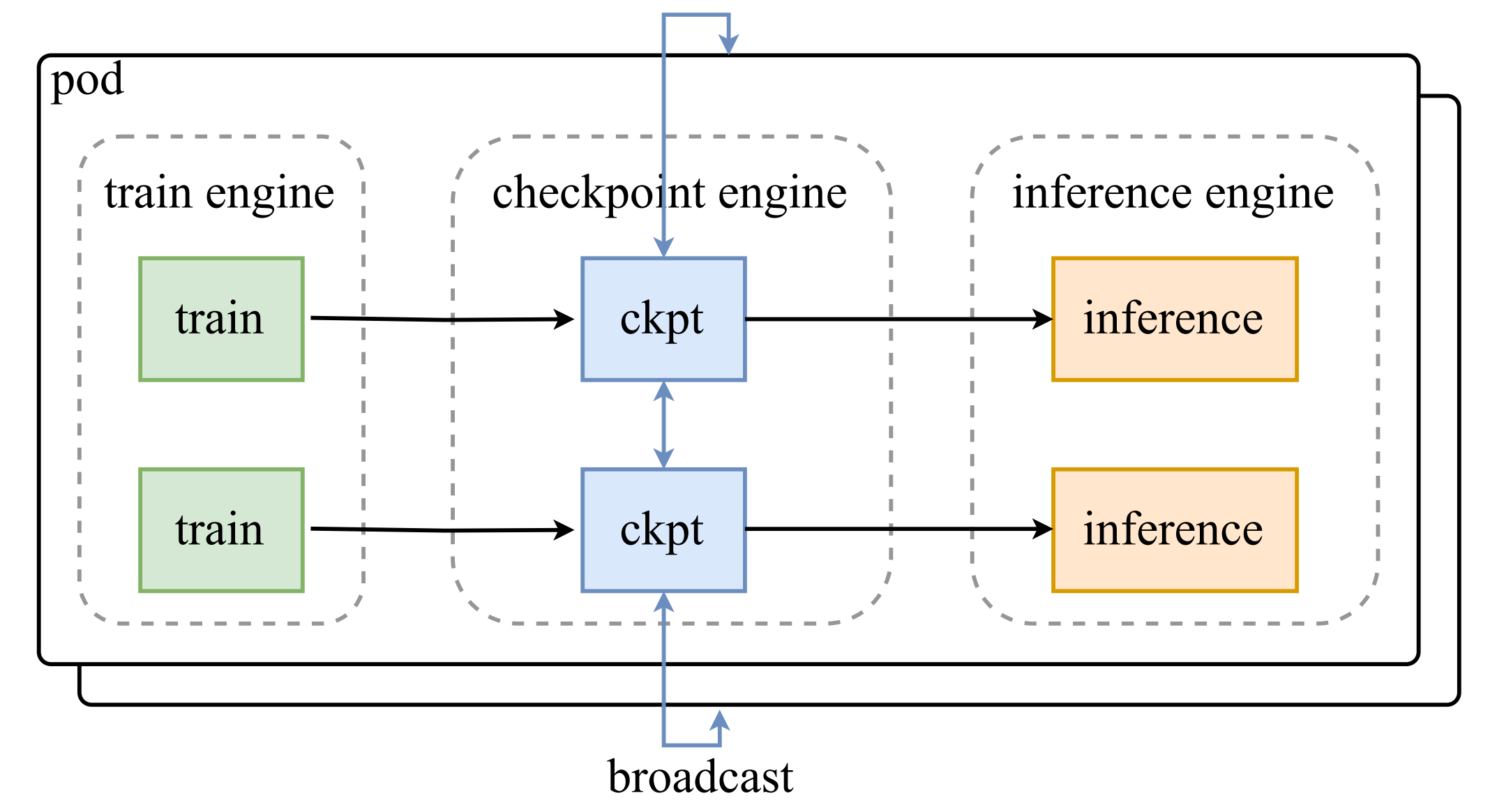
架构
核心权重更新逻辑位于 ParameterServer 类中,该服务与推理引擎部署在一起。它提供了两种权重更新实现:广播和 P2P。
- 广播:当大量推理实例需要同步更新权重时使用。这是最快的实现方式,应作为默认的更新方法。参见
_update_per_bucket中ranks == None or []的情况。 - P2P:当新的推理实例动态加入(由于重启或动态可用性)而现有实例已经在处理请求时使用。在这种情况下,为避免影响现有实例的工作负载,我们使用
mooncake-transfer-engine将现有实例 CPU 上的权重通过 P2P 方式传输到新实例的 GPU 上。参见_update_per_bucket中指定了ranks的情况。
优化的权重广播
在 广播 实现中,checkpoint-engine 会持有 CPU 内存中分片权重的引用,并需要将它们高效地广播到一组推理实例上,这些实例通常采用不同的分片模式。 我们将数据传输分为三个阶段:
- H2D:将权重移动到 GPU 内存。这些权重可能来自磁盘或训练引擎。
- 广播:在 checkpoint-engine 工作节点之间进行广播;数据结果是一个与推理引擎共享的 CUDA IPC 缓冲区。
- 重载:推理引擎决定从广播的数据中复制哪些权重子集。 Checkpoint-engine 协调整个传输过程。它首先收集必要的元数据以制定计划,包括确定合适的数据传输桶大小。 然后执行传输,期间通过 ZeroMQ 套接字控制推理引擎。为了最大化性能,它将数据传输组织成一个通信与拷贝重叠的流水线,如下图所示。详细信息可在 Kimi-K2 技术报告 中找到。
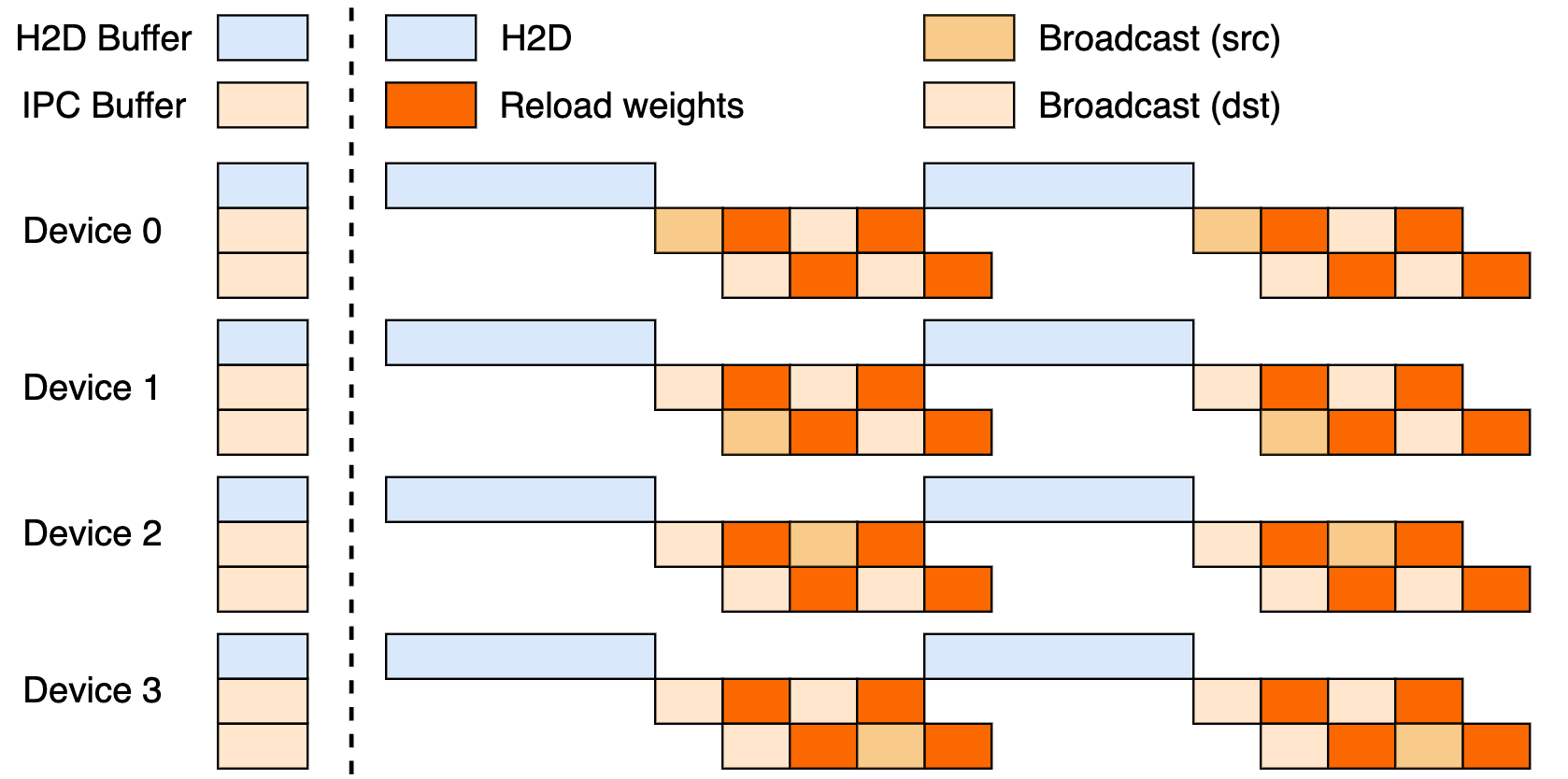
流水线操作自然需要更多的 GPU 内存。当内存不足时,checkpoint-engine 会回退到串行执行。
优化的 P2P 分桶分配
在 P2P 实现中,checkpoint-engine 需要将权重从现有实例发送到新实例。 为了最小化整体传输时间,checkpoint-engine 会为每对发送方和接收方优化分桶分配。 优化目标是充分利用每个发送方和接收方的可用网络带宽。 详情请参阅 issue #25。
基准测试
| 模型 | 设备信息 | GatherMetas | 更新(广播) | 更新(P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.12s | 3.47s (3.02GiB) | 4.12s (3.02GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.33s | 6.22s (2.67GiB) | 7.10s (2.68GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.17s | 10.19s (5.39GiB) | 11.80s (5.41GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.33s | 14.36s (5.89GiB) | 17.49s (5.91GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 0.80s | 11.33s (8.00GiB) | 11.81s (8.00GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.22s | 16.04s (8.00GiB) | 16.75s (8.00GiB) |
以上所有结果均由 examples/update.py 测试,并使用 vLLM v0.10.2rc1 作为推理引擎。几点说明:
- FP8 测试需要额外的 vLLM 补丁,详见 FP8 量化。
- 设备信息:我们测试了多种设备和并行化设置的组合。例如,256-GPU TP16 设置意味着我们部署了 16 个 vLLM 实例,每个实例都采用 16 路张量并行。
- 由于更新时长与 IPC 桶大小有关,我们在表中提供了桶大小。
- P2P 时间是在不超过两个节点(16 张 GPU)(
ParameterServer.update(ranks=range(0, 16))) 的范围内测试的。 - 我们将每张 GPU 绑定到其对应的 NUMA 节点,以确保稳定的 H2D 传输速度。
安装
使用最快的广播实现
pip install checkpoint-engine
使用灵活的 P2P 实现,请注意这将安装 mooncake-transfer-engine 以支持不同 Rank 之间的 RDMA 传输。
pip install 'checkpoint-engine[p2p]'
入门指南
准备一台配备 8 张 GPU 和 vLLM 的 H800 或 H20 机器。务必包含 /collective_rpc API 端点 提交(已在主分支中可用),因为 checkpoint-engine 将使用此端点来更新权重。vLLM 版本 v0.10.2 已经过全面测试并推荐使用。
mkdir -p /opt/vLLM && cd /opt/vLLM
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install vllm==0.10.2
安装 checkpoint-engine
uv pip install 'checkpoint-engine[p2p]'
我们使用 Qwen/Qwen3-235B-A22B-Instruct-2507 (BF16) 作为测试模型
hf download Qwen/Qwen3-235B-A22B-Instruct-2507 --local-dir /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/
以开发模式启动 vLLM,并设置 --load-format dummy。请注意,我们还设置了 --worker-extension-cls=checkpoint_engine.worker.VllmColocateWorkerExtension
VLLM_SERVER_DEV_MODE=1 python3 -m vllm.entrypoints.openai.api_server --host 0.0.0.0 --port 19730 --trust-remote-code \
--tensor-parallel-size=8 --max-model-len 4096 --load-format dummy \
--served-model-name checkpoint-engine-demo --model /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/ \
--worker-extension-cls checkpoint_engine.worker.VllmColocateWorkerExtension
与此同时,使用以下命令由 checkpoint-engine 更新权重。无需等待 vLLM 准备就绪。
torchrun --nproc-per-node 8 examples/update.py --update-method all --checkpoint-path /opt/models/Qwen/Qwen3-235B-A22B-Instruct-2507/
重用现有实例的权重
新的 checkpoint-engine 实例可以加入现有的实例,并重用它们的权重。实现起来非常简单。
首先,使用 --save-metas-file global_metas.pkl 启动现有实例,将全局元数据保存到文件中,并通过 --sleep-time 300 确保它们保持运行状态。
torchrun --nproc-per-node 8 examples/update.py --checkpoint-path $MODEL_PATH \
--sleep-time 300 --save-metas-file global_metas.pkl
在检查点注册完成后,新实例可以通过设置 --load-metas-file global_metas.pkl 来获取检查点的副本。
torchrun --nproc-per-node 8 examples/update.py --load-metas-file global_metas.pkl
FP8 量化
目前,在更新权重时,FP8 量化在 vLLM 中无法原生工作。我们提供了一个简单的补丁 patches/vllm_fp8.patch,用于正确处理权重更新。请注意,此补丁仅在 DeepSeek-V3.1 和 Kimi-K2 上进行了测试,其他模型可能会遇到兼容性问题。
我们已向 vLLM 项目提交了一个 PR,目前正在等待讨论和审查。
测试
运行一个简单的 checkpoint_engine 正确性测试:
pytest tests/test_update.py
test_update.py 仅设计为与 pytest 一起运行,请勿直接使用 torchrun 运行。
其他单元测试也可以使用 pytest 完成。只有 test_update.py 需要 GPU,其他测试可以在 CPU 上运行。如果仅需运行 CPU 测试,可使用以下命令:
pytest tests/ -m "not gpu"
环境变量
PS_MAX_BUCKET_SIZE_GB:用于设置 checkpoint-engine 的最大分桶大小的整数。若未设置,则默认为 8GB。PS_P2P_STORE_RDMA_DEVICES:用于 P2P 传输的 RDMA 设备名称,以逗号分隔。若未设置,checkpoint-engine 将回退到使用NCCL_IB_HCA自动检测 RDMA 设备。NCCL_IB_HCA:可用模式可参考 NCCL 文档。若也未设置,则会使用所有 RDMA 设备,并均匀分配给各个进程。
SGLang 集成
Checkpoint Engine 为 SGLang 推理服务器提供了高效的分布式检查点加载功能,显著减少了大型模型和多节点部署下的模型加载时间。
快速开始
1. 安装 checkpoint-engine:
pip install 'checkpoint-engine[p2p]'
2. 启动 SGLang 服务器:
python -m sglang.launch_server \
--model-path $MODEL_PATH \
--tp 8 \
--load-format dummy \
--wait-for-initial-weights
3. 运行 checkpoint engine:
python -m sglang.srt.checkpoint_engine.update \
--update-method broadcast \
--checkpoint-path $MODEL_PATH \
--inference-parallel-size 8
多节点设置
对于 2 节点设置,可在两个节点上分别运行相同的命令,并设置适当的 --host 和分布式训练参数。
关键选项
SGLang 服务器:
--wait-for-initial-weights:等待 checkpoint engine 完成后再进入就绪状态。--load-format dummy:启用初始化任务的重叠执行。
Checkpoint Engine:
--update-method:可选择broadcast、p2p或all。--inference-parallel-size:并行进程数。--checkpoint-path:模型检查点目录。
局限性与未来工作
- 本项目目前仅在 vLLM 和 SGLang 上进行了测试。与其他框架的集成计划将在未来的版本中实现。
- 我们论文中提到的完美三阶段流水线目前尚未实现。这可能对那些 H2D 和广播操作在 PCIE 总线上不会产生冲突的架构有所帮助。
致谢
本开源项目使用了与 https://github.com/vllm-project/vllm/pull/24295 相同的 vLLM 接口。感谢 youkaichao 提供的评论和见解。
版本历史
v0.4.02026/02/02v0.4.0-rc02026/02/02v0.3.42026/01/28v0.3.32026/01/20v0.3.22026/01/09v0.3.12026/01/05v0.3.1-rc02026/01/04v0.3.0-rc12025/12/230.2.32025/12/18v0.3.0-rc02025/12/11v0.2.22025/12/11v0.2.12025/11/24v0.2.02025/10/30v0.1.32025/10/14v0.1.22025/09/22常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器