VideoMAE
VideoMAE 是一款专为视频理解设计的自监督预训练框架,曾荣获 NeurIPS 2022 Spotlight 殊荣。它主要解决了视频分析领域长期面临的“数据饥渴”难题:传统方法依赖海量人工标注数据才能取得良好效果,成本高昂且效率低下。VideoMAE 创新地将图像领域的掩码自编码器(Masked Autoencoders)理念延伸至视频处理,通过随机遮蔽视频中的大部分时空片段,迫使模型学习重建被遮挡的内容。这种机制让 AI 能够从未标注的视频中高效提取深层特征,显著降低了对标注数据的依赖。
该工具的核心亮点在于其极高的数据效率和强大的泛化能力,在动作识别、视频分类等任务上刷新了多项业界基准。它基于 PyTorch 构建,不仅开源了完整的训练代码和预训练模型,还友好地集成了 Hugging Face 和 Google Colab,方便快速上手。VideoMAE 非常适合人工智能研究人员探索自监督学习前沿,也适用于开发者构建高性能视频分析应用。无论是需要处理大规模视频库的企业团队,还是希望深入理解视频表征学习的学术探索者,都能从中获得强有力的技术支持。
使用场景
某智慧安防团队正在构建一套基于监控视频的行为识别系统,旨在自动检测工厂区域内的违规操作(如未戴安全帽、闯入危险区等),但面临标注数据稀缺且视频背景复杂的挑战。
没有 VideoMAE 时
- 数据依赖极高:传统监督学习需要数万段人工精细标注的视频片段,标注成本高昂且周期长达数月。
- 小样本效果差:在仅有少量标注样本的情况下,模型难以捕捉动作的时空特征,导致对罕见违规行为的识别准确率不足 40%。
- 冗余计算严重:视频中大量静态背景(如墙壁、地面)占据了主要计算资源,模型容易过拟合于背景噪声而非关键动作。
- 泛化能力弱:一旦监控摄像头角度或光照条件发生微小变化,模型性能便急剧下降,需重新收集数据训练。
使用 VideoMAE 后
- 大幅降低标注需求:利用 VideoMAE 的自监督掩码预训练机制,团队仅用少量无标签原始视频即可让模型学会通用的视频表示,标注数据需求减少 80%。
- 小样本性能跃升:在同等少量标注数据下,微调后的模型对违规动作的识别准确率提升至 85% 以上,有效解决了冷启动问题。
- 聚焦关键动态信息:通过随机掩码大部分视频块并强制模型重建,VideoMAE 迫使网络忽略静态背景,专注于学习人物动作的时空演变规律。
- 强鲁棒性与泛化性:预训练学到的通用特征使模型能轻松适应不同摄像头视角和光照环境,无需针对每个新场景重新训练。
VideoMAE 通过“掩码重建”的自监督学习范式,将视频理解从“数据饥渴”转变为“数据高效”,让有限算力下的复杂行为识别成为可能。
运行环境要求
- 未说明
需要 NVIDIA GPU(基于 PyTorch 实现及 ViT 架构特性推断),具体型号和显存大小未说明,CUDA 版本未说明
未说明

快速开始
VideoMAE 的官方 PyTorch 实现(NeurIPS 2022 Spotlight)。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
VideoMAE:掩码自编码器是自监督视频预训练中数据高效的学习者
Zhan Tong (https://github.com/yztongzhan), Yibing Song (https://ybsong00.github.io/), Jue Wang (https://juewang725.github.io/), Limin Wang (http://wanglimin.github.io/)
南京大学,腾讯 AI 实验室
📰 新闻
[2023.4.18] 🎈大家可以从这个链接下载 VideoMAE 中使用的 Kinetics-400 数据集。
[2023.4.18] VideoMAE V2 的代码和预训练模型已经发布!请查看并体验这个仓库!
[2023.4.17] 我们提出了一个端到端的视频动作检测框架 EVAD。
[2023.2.28] 我们的 VideoMAE V2 被 CVPR 2023 接收!🎉
[2023.1.16] VideoMAE 中用于动作检测的代码和预训练模型已经可用!
[2022.12.27] 🎈大家可以从 InternVideo 下载提取出的 THUMOS、ActivityNet、HACS 和 FineAction 的 VideoMAE 特征。
[2022.11.20] 👀 VideoMAE 已集成到 和
![]() ,由 @Sayak Paul 提供支持。
,由 @Sayak Paul 提供支持。
[2022.10.25] 👀 VideoMAE 已集成到 MMAction2,在 Kinetics-400 上的结果可以成功复现。
[2022.10.20] ViT-S 和 ViT-H 的预训练模型和脚本已经可用!
[2022.10.19] UCF101 上的预训练模型和脚本已经可用!
[2022.9.15] VideoMAE 被 NeurIPS 2022 接受为 spotlight 报告!🎉
[2022.8.8] 👀 VideoMAE 现已集成到 官方 🤗HuggingFace Transformers 中!
[2022.7.7] 我们更新了下游 AVA 2.2 基准上的新结果。详情请参阅我们的论文。
[2022.4.24] 代码和预训练模型现已可用!
[2022.3.24] 代码和预训练模型将在此发布。 欢迎关注此仓库以获取最新动态。
✨ 亮点
🔥 视频预训练中的掩码视频建模
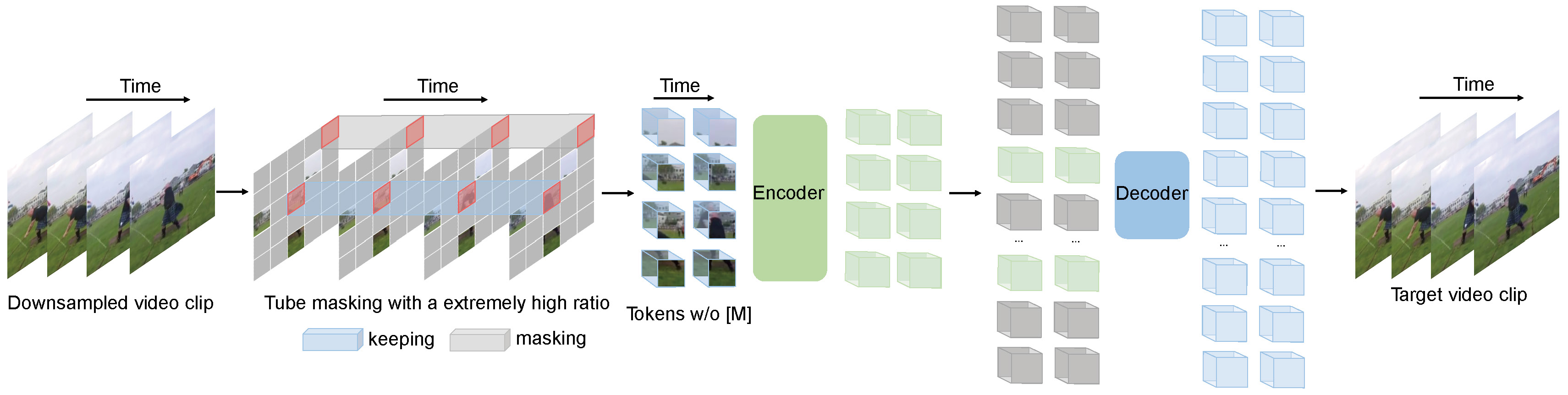
VideoMAE 执行视频预训练中的掩码视频建模任务。我们提出了极高的掩码比例(90%-95%)和体素掩码策略,为自监督视频预训练创造了一个极具挑战性的任务。
⚡️ 一种简单、高效且强大的自监督视频预训练基线
VideoMAE 使用简单的掩码自编码器和纯 ViT 主干网络来进行视频自监督学习。由于掩码比例极高,VideoMAE 的预训练时间比对比学习方法短得多(速度提升 3.2 倍)。VideoMAE 可以作为未来自监督视频预训练研究中简单但强大的基线。
😮 高性能,无需额外数据
VideoMAE 在不同规模的视频数据集上表现良好,在 Kinetics-400 上达到 87.4%,在 Something-Something V2 上达到 75.4%,在 UCF101 上达到 91.3%,在 HMDB51 上达到 62.6%。据我们所知,VideoMAE 是首个使用原生 ViT 主干网络,在不需任何额外数据或预训练模型的情况下,在这四个热门基准上取得最先进性能的方法。
🚀 主要结果
✨ Something-Something V2
| 方法 | 需要额外数据 | 主干网络 | 分辨率 | 帧数 × 片段 × 裁剪 | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| VideoMAE | 否 | ViT-S | 224x224 | 16x2x3 | 66.8 | 90.3 |
| VideoMAE | 否 | ViT-B | 224x224 | 16x2x3 | 70.8 | 92.4 |
| VideoMAE | 否 | ViT-L | 224x224 | 16x2x3 | 74.3 | 94.6 |
| VideoMAE | 否 | ViT-L | 224x224 | 32x1x3 | 75.4 | 95.2 |
✨ Kinetics-400
| 方法 | 额外数据 | 主干网络 | 分辨率 | 帧数×片段数×裁剪次数 | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| VideoMAE | 无 | ViT-S | 224x224 | 16x5x3 | 79.0 | 93.8 |
| VideoMAE | 无 | ViT-B | 224x224 | 16x5x3 | 81.5 | 95.1 |
| VideoMAE | 无 | ViT-L | 224x224 | 16x5x3 | 85.2 | 96.8 |
| VideoMAE | 无 | ViT-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| VideoMAE | 无 | ViT-L | 320x320 | 32x4x3 | 86.1 | 97.3 |
| VideoMAE | 无 | ViT-H | 320x320 | 32x4x3 | 87.4 | 97.6 |
✨ AVA 2.2
请查看 VideoMAE-Action-Detection 中的代码和检查点。
| 方法 | 额外数据 | 额外标签 | 主干网络 | 帧数×采样率 | mAP |
|---|---|---|---|---|---|
| VideoMAE | Kinetics-400 | ✗ | ViT-S | 16x4 | 22.5 |
| VideoMAE | Kinetics-400 | ✓ | ViT-S | 16x4 | 28.4 |
| VideoMAE | Kinetics-400 | ✗ | ViT-B | 16x4 | 26.7 |
| VideoMAE | Kinetics-400 | ✓ | ViT-B | 16x4 | 31.8 |
| VideoMAE | Kinetics-400 | ✗ | ViT-L | 16x4 | 34.3 |
| VideoMAE | Kinetics-400 | ✓ | ViT-L | 16x4 | 37.0 |
| VideoMAE | Kinetics-400 | ✗ | ViT-H | 16x4 | 36.5 |
| VideoMAE | Kinetics-400 | ✓ | ViT-H | 16x4 | 39.5 |
| VideoMAE | Kinetics-700 | ✗ | ViT-L | 16x4 | 36.1 |
| VideoMAE | Kinetics-700 | ✓ | ViT-L | 16x4 | 39.3 |
✨ UCF101 & HMDB51
| 方法 | 额外数据 | 主干网络 | UCF101 | HMDB51 |
|---|---|---|---|---|
| VideoMAE | 无 | ViT-B | 91.3 | 62.6 |
| VideoMAE | Kinetics-400 | ViT-B | 96.1 | 73.3 |
🔨 安装
请按照 INSTALL.md 中的说明进行操作。
➡️ 数据准备
请按照 DATASET.md 中的说明进行数据准备。
🔄 预训练
预训练说明见 PRETRAIN.md。
⤴️ 使用预训练模型进行微调
微调说明见 FINETUNE.md。
📍 模型库
我们在 MODEL_ZOO.md 中提供了预训练和微调后的模型。
👀 可视化
我们提供了用于可视化的脚本 vis.sh。用于更好可视化的 Colab 笔记本即将推出。
☎️ 联系方式
Zhan Tong:tongzhan@smail.nju.edu.cn
👍 致谢
感谢 Ziteng Gao、Lei Chen、Chongjian Ge 和 Zhiyu Zhao 的鼎力支持。
本项目基于 MAE-pytorch 和 BEiT 构建。感谢这些优秀代码库的贡献者们。
🔒 许可证
本项目的大部分内容采用 CC-BY-NC 4.0 许可证,详见 LICENSE 文件。项目中的部分内容则采用单独的许可条款:SlowFast 和 pytorch-image-models 采用 Apache 2.0 许可证。BEiT 则采用 MIT 许可证。
✏️ 引用
如果您认为本项目有所帮助,请随时点赞⭐️ 并引用我们的论文:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器