Awesome-Long-Chain-of-Thought-Reasoning
Awesome-Long-Chain-of-Thought-Reasoning 是一个专注于“长思维链(Long CoT)”推理技术的开源资源库,旨在系统梳理大语言模型在复杂推理领域的最新进展。随着 OpenAI-o1、DeepSeek-R1 等模型在数学和代码等高难度任务中展现出卓越能力,其背后的长思维链机制成为关键,但学界此前缺乏对该技术与传统短思维链差异的系统性总结。
该项目填补了这一空白,不仅收录了超过 1000 篇相关前沿论文,还配套发布了详尽的综述文章《Towards Reasoning Era》。它清晰界定了长思维链的核心特征——深度推理、广泛探索与有效反思,并深入探讨了“过度思考”、“测试时扩展”等关键现象,为理解模型如何解决 intricate 问题提供了统一视角。
无论是希望快速建立领域知识的研究人员,还是致力于优化模型推理能力的开发者,都能从中获益。对于初学者,项目提供了友好的双语教程和技术分类指南,帮助不同背景的用户迅速掌握核心概念;对于资深专家,它则是追踪多模态推理融合、效率提升及知识框架增强等未来方向的重要参考。通过结构化的知识整理,Awesome-Long-Chain-of-Thought-Reasoning 正推动人工智能逻辑推理技术迈向新的阶段。
使用场景
某顶尖 AI 实验室的研究团队正致力于复现并优化类似 OpenAI-o1 的复杂推理模型,以解决高难度的数学证明与代码生成任务。
没有 Awesome-Long-Chain-of-Thought-Reasoning 时
- 文献梳理困难:面对海量且分散的 arXiv 论文,研究人员难以区分“长思维链(Long CoT)”与传统“短思维链”的本质差异,导致技术选型迷茫。
- 核心概念混淆:团队在调试模型时,无法准确理解“过度思考(overthinking)”和“测试时扩展(test-time scaling)”等现象的成因,浪费大量算力进行无效尝试。
- 缺乏系统指引:新手研究员缺乏统一的知识分类体系,难以快速掌握深度推理、广泛探索等关键特性,入门门槛极高且容易走弯路。
- 前沿动态滞后:由于缺少实时更新的资源库,团队难以及时获取关于多模态推理整合等最新研究方向,错失创新机会。
使用 Awesome-Long-Chain-of-Thought-Reasoning 后
- 知识体系清晰:依托其收录的超 1000 篇综述论文及新颖分类法,团队迅速厘清了 Long CoT 的独特范式,精准锁定了适合当前任务的技术路线。
- 现象洞察深入:通过研读其中关于“过度思考”等关键现象的深度分析,研究人员成功调整了推理策略,显著提升了模型在复杂任务中的效率与连贯性。
- 上手效率倍增:利用其专为初学者设计的双语教程和结构化概览,新成员能在短时间内建立完整的领域认知,快速投入到核心算法改进中。
- 紧跟前沿趋势:团队借助其持续的月度更新,第一时间掌握了多模态推理与效率优化的最新进展,为下一代模型架构设计指明了方向。
Awesome-Long-Chain-of-Thought-Reasoning 将碎片化的前沿研究转化为系统化的行动指南,极大地加速了从理论调研到高性能推理模型落地的全过程。
运行环境要求
未说明
未说明
快速开始
 令人惊叹的长链式思维推理
令人惊叹的长链式思维推理
![]()
![]()
![]()

[English Tutorial] | [中文教程] | [Arxiv]
🔥 新闻
- 2025.07: 🎉🎉🎉 我们已将审阅论文数量更新至超过1000篇。此外,我们还增加了双语支持,并使我们的仓库对Long-CoT初学者更加友好。
- 2025.04: 🎉🎉🎉 我们已将审阅论文数量更新至超过900篇。同时,我们通过更具吸引力的预告图提升了展示效果。
- 2025.03: 🎉🎉🎉 我们发表了一篇题为“迈向推理时代:大型语言模型长链式思维推理综述”的调查论文(arXiv链接)。欢迎引用或针对您出色的研究所提交拉取请求。
🌟 简介
欢迎来到与我们的综述论文《迈向推理时代:大型语言模型长链式思维推理综述》相关的仓库。本仓库包含与我们正在进行的Long CoT研究相关的资源和更新。如需详细简介,请参阅我们的综述论文。
近期,在大型语言模型推理(RLLM)方面的进展,例如OpenAI-O1和DeepSeek-R1,已经展示了它们在数学和编程等复杂领域中的强大能力。其成功的核心因素在于应用了长链式思维(Long CoT)特性,这不仅增强了推理能力,还使得解决复杂问题成为可能。
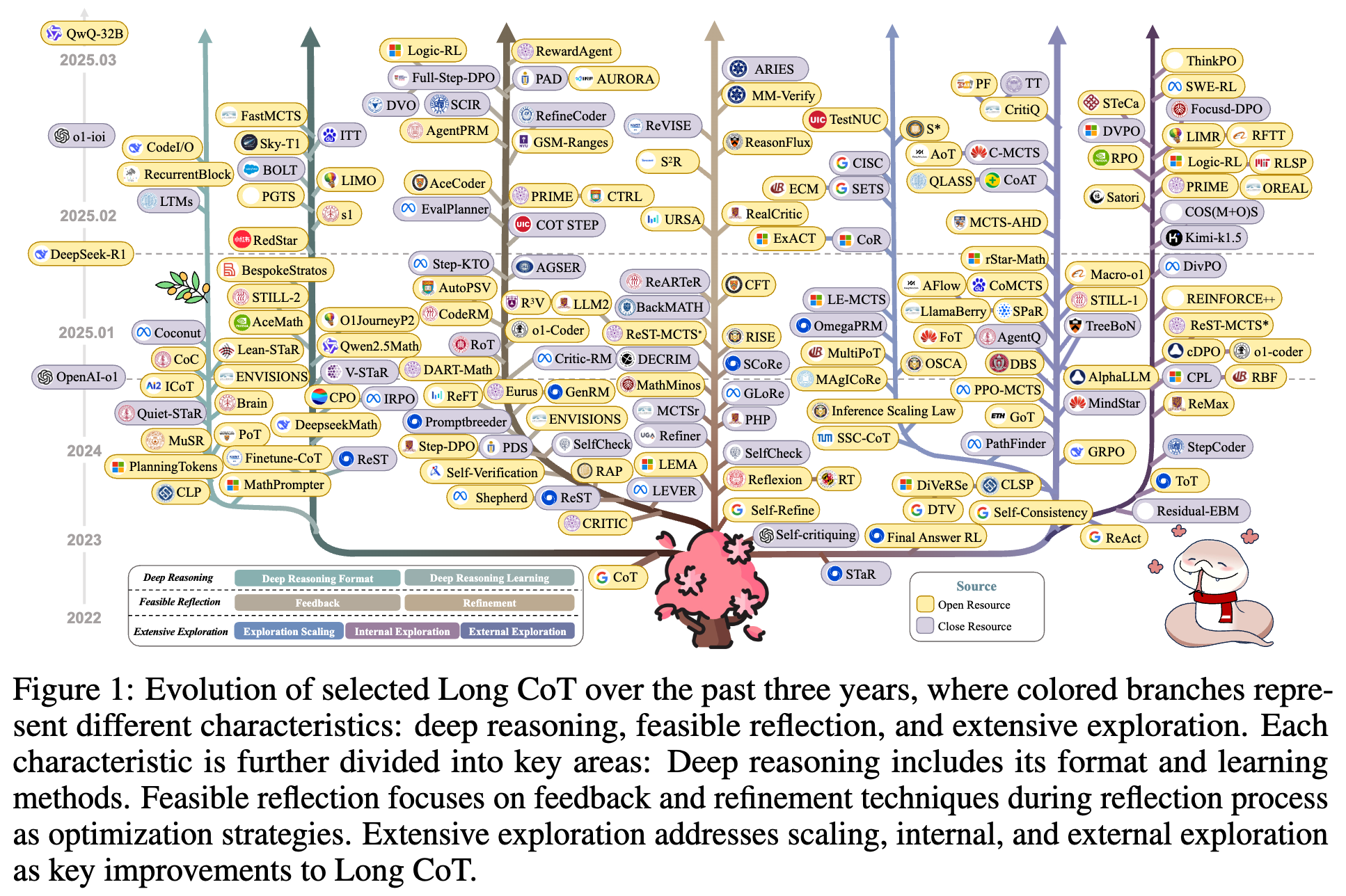
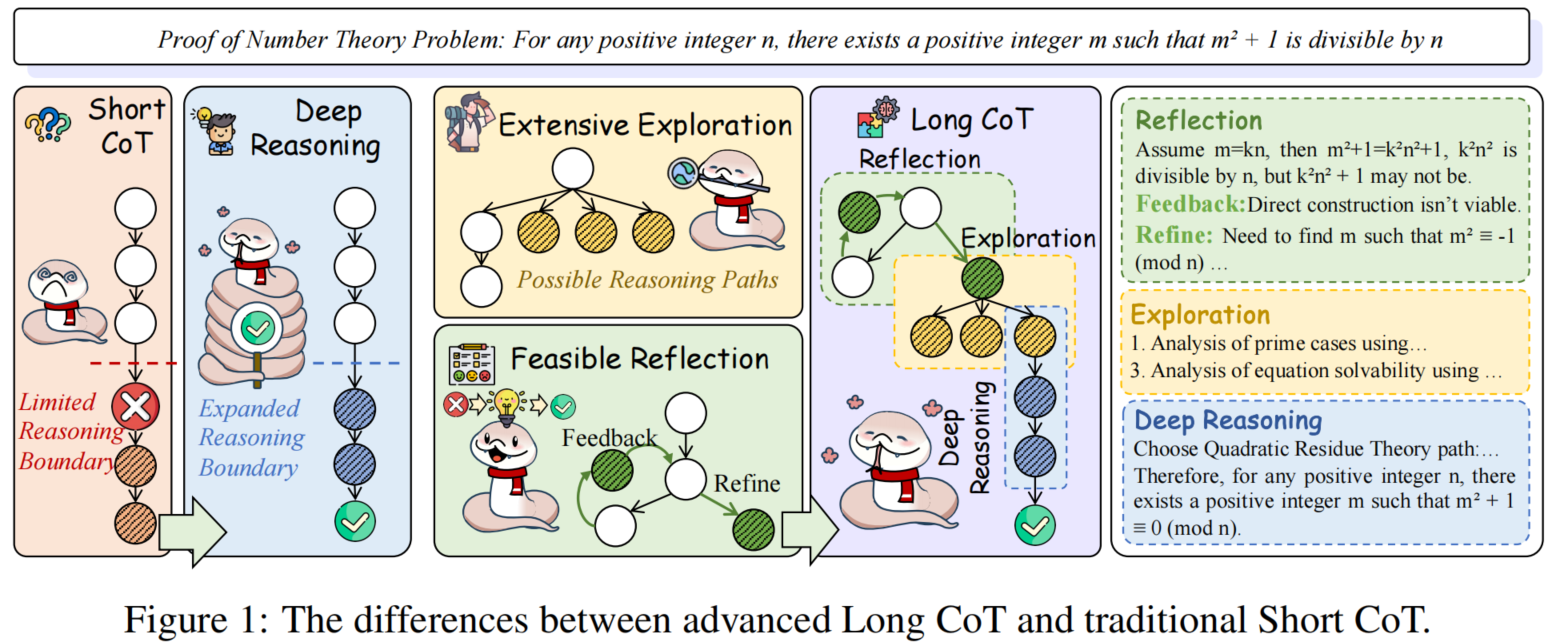
然而,尽管取得了这些进展,目前仍缺乏关于Long CoT的全面综述,这限制了我们对其与传统短链式思维(Short CoT)之间区别的理解,并使关于“过度思考”和“测试时缩放”等问题的讨论变得复杂。本综述旨在填补这一空白,提供一个关于Long CoT的统一视角。
- 首先,我们将Long CoT与Short CoT区分开来,并提出一种新的分类法来归类当前的推理范式。
- 接着,我们探讨了Long CoT的关键特征:深度推理、广泛探索和可行的反思,这些特征使模型能够处理更复杂的任务,并产生比浅层的Short CoT更为高效、连贯的结果。
- 然后,我们研究了具有这些特征的Long CoT的出现等关键现象,包括过度思考和测试时缩放,从而揭示这些过程在实践中的表现方式。
- 最后,我们识别出显著的研究空白,并指出了未来有前景的方向,包括多模态推理的整合、效率提升以及知识框架的增强。
通过提供一个结构化的概述,本综述旨在激发未来的研究,并进一步推动人工智能领域的逻辑推理发展。
🕹️ 内容
0. 如何学习 & 关于我们
我们的目标是帮助新手快速建立领域知识,因此我们的设计理念如下:简要介绍涉及大型模型推理和Long CoT的主要技术,让大家了解不同技术可以解决哪些问题,以便在未来深入该领域时,能够有一个清晰的起点。
我们是一支从事大型模型推理的初学者团队,希望通过自身的学习经验,为未来的学习者提供一些帮助,加速大型模型推理的普及和应用。我们欢迎更多朋友加入我们的项目,同时也乐于开展友谊和学术合作。如有任何疑问,请随时通过电子邮件 charleschen2333@gmail.com 联系我们。
日常知识资源
- 社交媒体:
- 推荐微信公众号:极智资讯、Paper Weekly、MLNLP...
- 推荐Twitter账号:AK、elvis、Philipp Schmid、...
- 前沿课程: CS336
- 社区分享: MLNLP、极智资讯、BAAI、NICE学术
1. 经典推理模型
- OpenAI-o1 / o3 / o4:最早探索Long CoT的推理大型语言模型,由OpenAI的一线模型开发。
- Gemini:由Google开发的一线推理大型语言模型。
- Deepseek-r1:首个具备Long CoT的开源推理大型语言模型。
- QwQ:首个具备Long CoT的开源大规模推理大型语言模型。
- Qwen3:阿里巴巴开发的最常用的开源Long CoT推理大型语言模型。
- Seed-Thinking-v1.5:字节跳动的开源Long CoT推理模型。
- Kimi-k1.5:由Moonshot开发的最早的多模态Long CoT推理模型。
- MiniMax-m1:由MiniMax开发的开源Long CoT推理模型。
2. Long-CoT能力介绍
在这一章中,我们将为每种能力提供最具代表性的技术,并附上最新进展。详细的论文列表可在完整列表中找到。
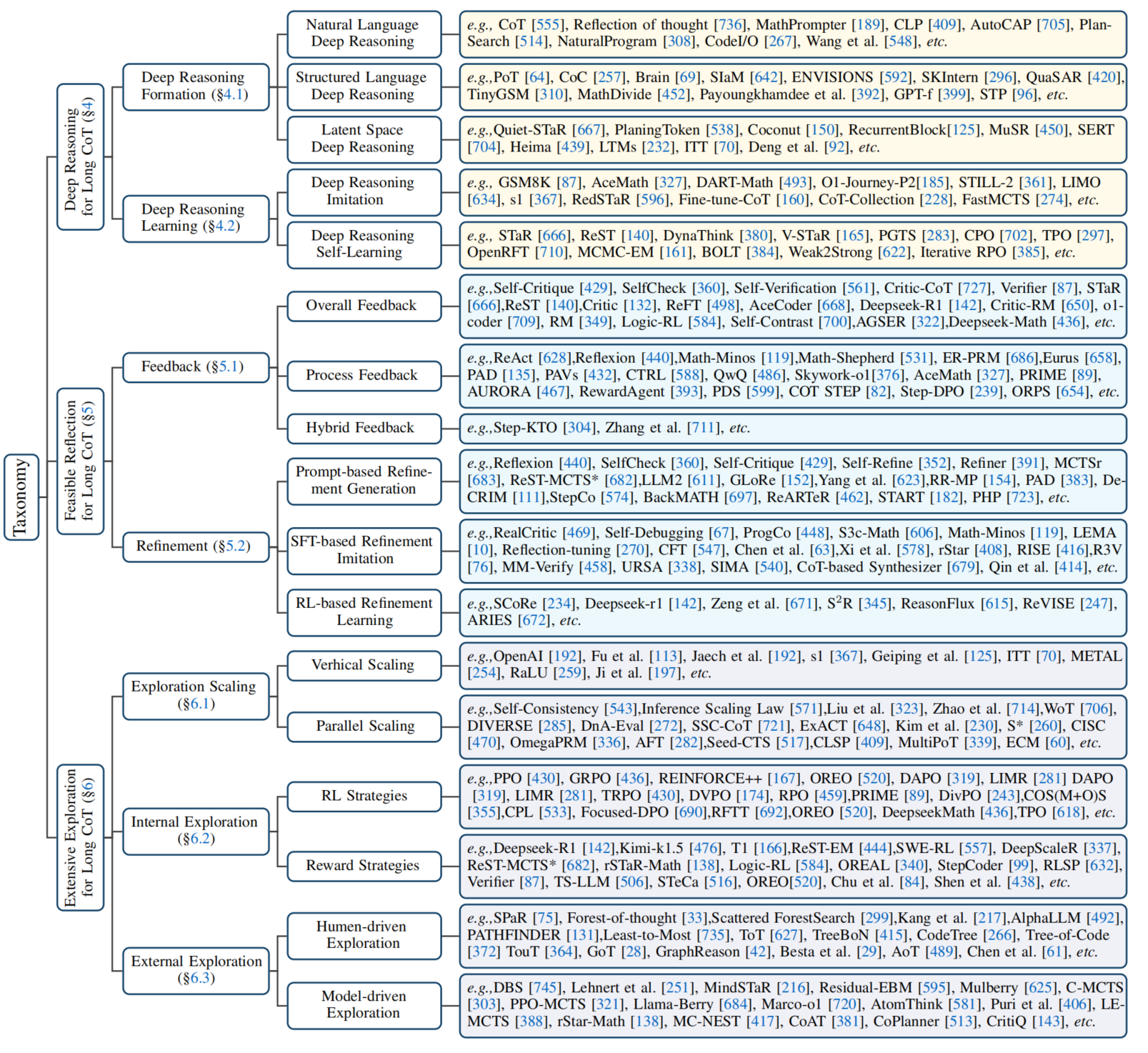
2.1 深度推理
深度推理能力的核心在于需要足够的逻辑深度来管理大量的推理节点。如果没有这种能力,大型语言模型推理(RLLM)的表现会显著下降。目前增强深度推理的方法主要分为两种:深度推理格式和深度推理学习。
2.1.1 深度推理格式
由于推理模型高度依赖于推理格式,它们往往在其擅长的形式中实现最深入的推理路径。因此,一些研究开始探索更优的推理格式,以促进深度推理的发展。
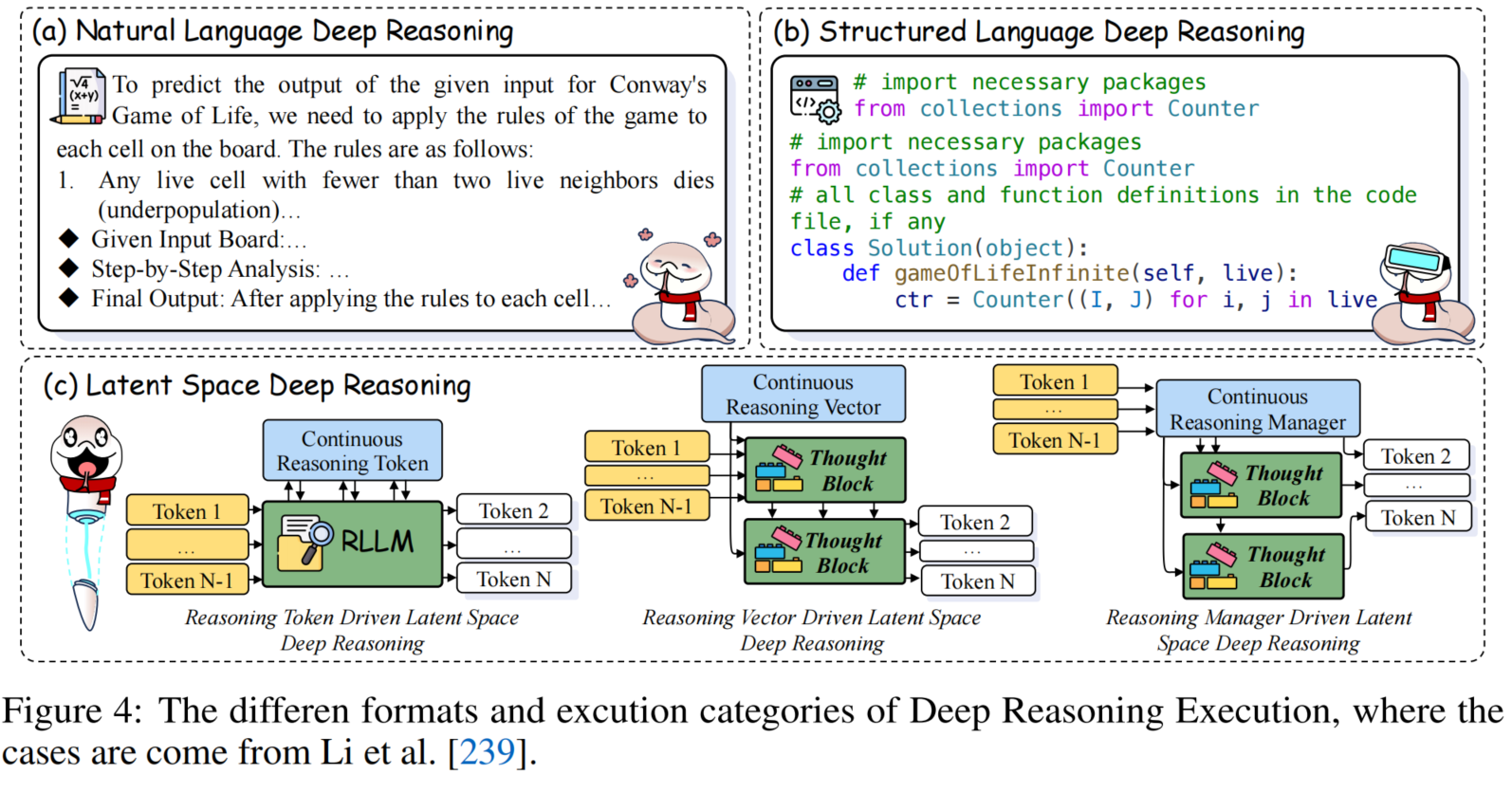
自然语言深度推理
- 核心思想: 旨在通过自然语言形式表达深度推理。
- 代表性工作:
- Natural Program:确保更加结构化和严谨的逻辑分析。
- Code I/O:将基于代码的推理模式重构为自然语言形式,进一步释放RLLM的推理潜力。
结构化语言深度推理
- 核心思想: 旨在通过程序化或符号化语言格式提升深度推理能力。当前研究主要集中在利用代码来提高数学推理能力。
- 代表性工作:
- Program-of-Thought:使模型能够使用代码语言进行思考,从而增强其推理能力。
- DeepSeek-Prover:将自然语言问题转化为形式化陈述,过滤低质量陈述并生成证明以创建合成数据,从而提升LLM的定理证明能力。
- RBF:展示了在需要强规划能力的情境下,结构化语言比自然语言更为有效。
潜在空间深度推理
- 核心思想: 通过连续的潜在空间操作来提升LLM的推理能力。
- 代表性工作:
- Token驱动: 早期研究引入了隐式的“规划token”或“思考token”,用于引导潜在空间中的推理过程。
- Coconut (Chain of Continuous Thought):进一步扩展了这一方法,维持多条并行推理路径,提升复杂性的同时保证效率。
- Heima:通过潜在隐藏空间进行高效推理,创新性地将整个Long CoT过程压缩成单个token,从而显著节省计算资源。
- Vector驱动: 插入额外的向量来指导潜在空间中的推理过程。
- LTMs:创新性地将LLM的每一层抽象为“思考块”,并为每层引入“思考向量”的概念。通过在潜在空间中进行迭代式深度计算,模型能够在测试时动态调整计算负载。
- Manager驱动: 提出一种持续的管理机制来控制潜在空间状态。
- Recurrent Block:利用经过训练的“递归块”作为递归“思考块”,在推理过程中整合更深的模型层次,无需专门的训练数据即可提升性能。
- Implicit Thought Transformer (ITT):将原始Transformer层用作递归“思考块”,通过自适应的token路由选择关键token,并借助残差式思维连接来控制推理深度,从而实现对关键token的有效处理。
- Token驱动: 早期研究引入了隐式的“规划token”或“思考token”,用于引导潜在空间中的推理过程。
- 相关仓库:
- Awesome-Latent-CoT:提供了潜在空间中各种思维链表示的概述,捕捉仅靠语言无法表达的复杂非语言性思维。
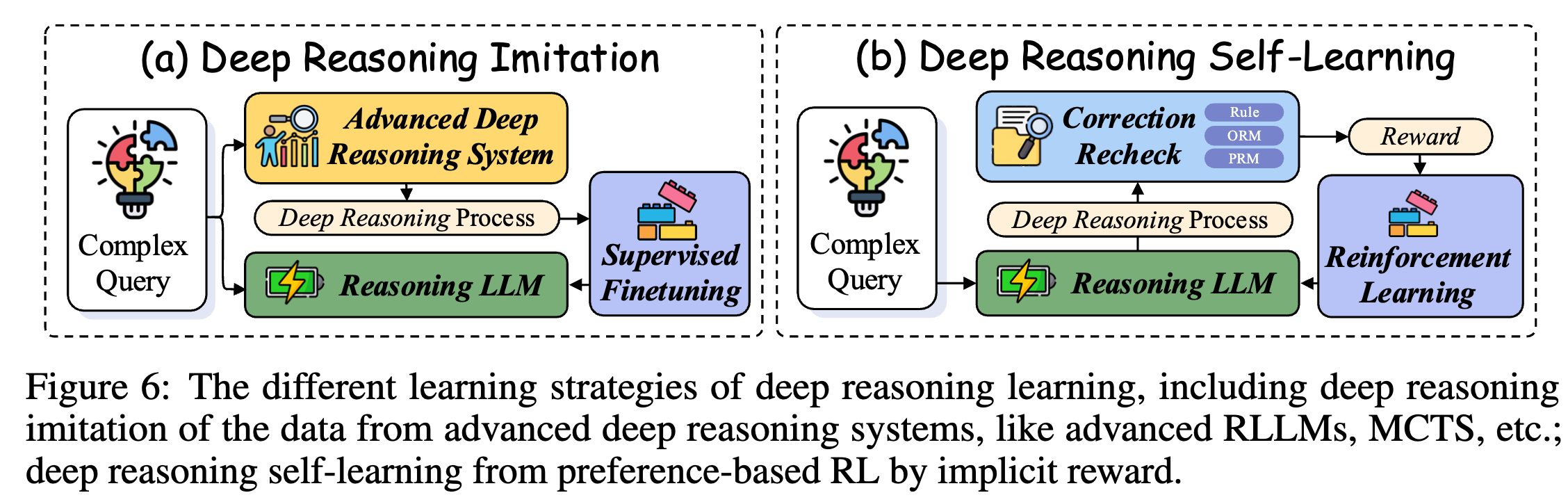
2.1.2 深度推理学习
RLLM缺乏深度推理能力会显著降低模型性能。因此,学术界的研究重点已转向通过训练来提升推理能力。监督微调(SFT)作为一种记忆过程,可以稳定模型输出;而强化学习(RL)则有助于模型的泛化和自主学习。
深度推理模仿
- 核心思想: 通过模仿先进的推理系统,可以有效实现RLLM的深度推理,使模型能够学习复杂的推理模式并在不同任务间进行泛化。
- 代表性工作:
- 来自人类的模仿
- GSM8K/GPT-Verifier:引入了基于人工标注的深度推理样本的早期模仿学习。
- ALT:通过生成大规模的人工标注逻辑模板数据集,提升RLLM的深度推理能力。
- 来自先进RLLM的模仿
- AceMath:采用少样本提示从先进LLM中提炼Long CoT样本,通过多阶段质量导向的SFT提升性能。
- DART-Math:在合成阶段通过拒绝采样有效地提炼出与难度相关的深度推理样本。
- OpenThoughts / OpenCodeReasoning / NaturalThoughts:将这一范式扩展到数学、代码及通用场景。
- 来自规模增强型RLLM的模仿
- Bansal et al.:发现扩大采样规模和长度能够提升数据质量。
- Qwen-Math / PromptCoT:进一步结合大规模采样与奖励模型样本选择,生成奥运级别难度的深度推理样本。
- FastMCTS:利用蒙特卡洛树搜索(MCTS)识别最优的深度推理路径。
- 来自人类的模仿
- 最新进展:
- Journey P2:从o1、R1等先进RLLM API中提炼的知识显著提升了小型LLM的表现,在复杂数学推理任务中,监督微调方法甚至超越了教师模型。
- s1 / LIMO:少量高质量样本足以激活基础LLM的深度推理能力。
深度推理自我学习
- 核心思想:尽管简单的模仿就能取得优异的性能,但当前模型在模仿和蒸馏过程中仍然严重依赖人工标注或先进模型的输出。为了突破这一局限,研究重点转向自学习技术,以实现更高级的推理能力。
- 代表性工作:
- 直接采样进行自学习
- STaR:利用上下文学习(ICL)采样深度推理结果,并将最终答案的正确性作为自学习的隐式奖励。
- Reinforced Self-Training (ReST):提出“成长—改进”范式,对自生成的推理过程进行奖励,并结合离线强化学习进一步提升。
- ReST$^{EM}$:通过生成奖励并迭代优化大语言模型,在验证集上达到峰值性能,显著提升了鲁棒性。
- TOPS:发现以适当的推理深度进行深度推理样本的自学习效率最高。
- 基于树搜索的自学习
- PGTS:采用策略引导的树搜索,将强化学习与结构化的树型探索相结合。
- ReST-MCTS*:通过渐进式轨迹提取和课程偏好学习优化MCTS行为,显著提升了大语言模型的推理能力。
- 直接采样进行自学习
- 最新进展:引入错误纠正自适应机制,通过训练验证器或利用熵来过滤和优化奖励过程,从而提升自学习的质量。
- UnCert-CoT:基于熵感知的不确定性动态调度思维链,在高熵情况下才激活多路径推理,显著提高了代码生成的准确性和效率。
- Wang et al.:从token熵的角度分析了可验证奖励强化学习对大语言模型推理能力的影响,其中高熵的“分支”token主导了多路径推理策略的调整,而策略梯度优化仅应用于这些高熵token。
- CoT-Valve:根据任务难度动态调整以缩短推理路径长度,从而降低计算开销。
2.2 可行的反思
2.2.1 反馈
反馈机制为Long CoT提供了多粒度的评估信号,从评估最终结果的总体反馈,到监督推理过程各步骤的过程反馈,再到两者的混合反馈。这些机制不仅支持奖励建模和路径优化,还为后续的自我修正奠定了基础,是推动RLLMs从静态生成走向动态评估的关键桥梁。
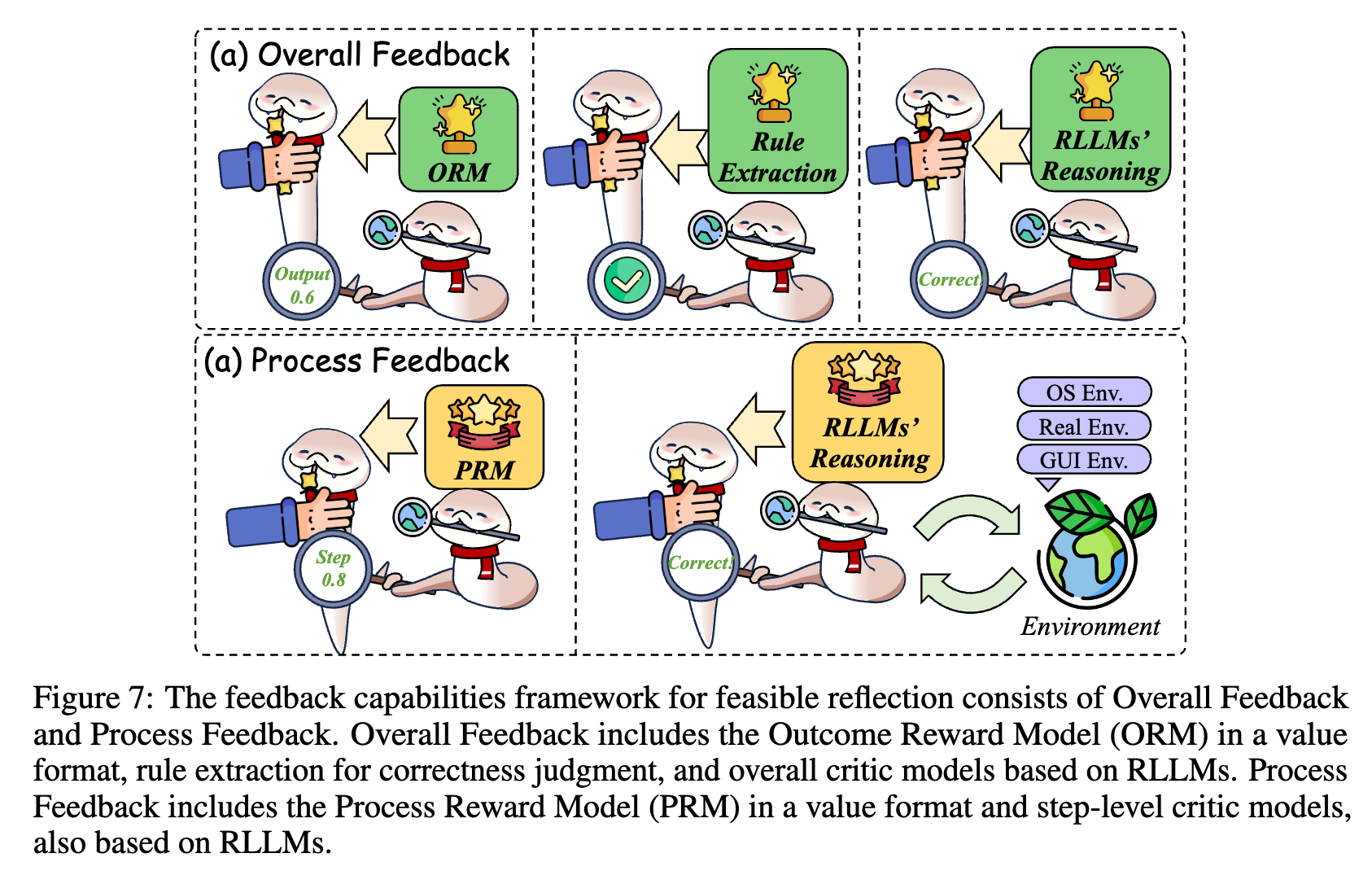
总体反馈
- 核心思想:总体反馈从全局视角评估完整的推理过程及最终结果,常用于在强化学习或自优化过程中指导大语言模型提升推理质量。反馈形式包括数值奖励、规则检查以及自然语言评价等。
- 代表性工作:
- 结果奖励模型(ORM):提供数值奖励信号以优化输出质量,适用于难以直接评估准确性的任务。
- Gen-Verifier:首次引入基于推理准确性的验证框架;
- Critic-RM:结合自然语言批评与奖励预测,显著提升了反馈质量;
- Self-Rewarding LMs (SRLMs):引入一致性机制,在无需人工标注的情况下实现自监督奖励。
- 规则提取:利用任务内的规则验证和纠正答案,增强反馈的稳定性。
- STaR / ReST:表明基于最终答案的规则反馈在数学任务中优于ORM;
- OpenCodeInterpreter / AceCoder:在编码任务中使用自动化测试用例生成程序级反馈。
- RLLMs反馈(LLM-as-a-Judge):
模型以自然语言进行自我批评和评估,增强了反思与纠错能力。
- EvalPlanner:区分规划与推理两类反馈;
- RoT:结合逆向推理与反思,帮助模型发现知识漏洞;
- AutoRace:提供针对特定任务的评估标准,以提高反馈的相关性。
- 结果奖励模型(ORM):提供数值奖励信号以优化输出质量,适用于难以直接评估准确性的任务。
- 相关资源库:
- RewardBench用于系统评估ORM方法。
过程反馈
- 核心思想: 过程反馈逐步评估推理链中的每一步,通常与强化学习或树搜索结合使用,引导模型在无需人工标注的情况下进行微调。反馈来源主要包括过程奖励模型和由自然语言驱动的语言模型。
- 代表性工作:
- 来自过程奖励模型(PRM)的过程反馈:
使用自动构建或少量标注的数据训练分步奖励函数,这是Long CoT中的主流方法。
- PRM800K:率先采用人工标注的分步监督来提升奖励稳定性;
- Math-Shepherd:利用树搜索自动生成分步反馈,以增强PRM的泛化能力;
- Full-Step-DPO:对整个推理链进行奖励,鼓励整体优化;
- AdaptiveStep:根据置信度动态划分推理步骤,实现逐token级别的细粒度反馈。
- 来自RLLM的过程反馈: 利用模型自身生成的自然语言反馈来模拟奖励信号,从而提高过程监督的灵活性和可扩展性。
- 来自过程奖励模型(PRM)的过程反馈:
使用自动构建或少量标注的数据训练分步奖励函数,这是Long CoT中的主流方法。
- 相关仓库:
- ProcessBench:评估分步推理及奖励模型性能;
- PRMBench:专注于数学任务中PRM方法的比较分析。
混合反馈
- 核心思想: 混合反馈机制结合了整体反馈和过程反馈的优势,在关注中间推理步骤的同时也评估最终输出。这种统一的多粒度评估体系能够提升语言模型的整体推理质量和纠错能力。
- 代表性工作:
- Consensus Filtering:将蒙特卡洛估计与LLM-as-Judge相结合,整合整体和分步反馈,提升推理的一致性和准确性;
- Step-KTO:融合PRM和ORM的二元反馈机制,强调反思驱动的错误修正,引导模型形成更连贯的Long CoT结构。
2.2.2 精炼
精炼机制侧重于基于反馈信息的自我纠错能力,是实现Long CoT闭环优化的关键步骤。通过基于提示的精炼实现自发性反思;基于SFT的精炼促进模仿学习;而基于RL的精炼则强化自我纠错策略。由此,模型逐渐具备“自我诊断—自我更新”的能力,使推理链更加 robust 和可控。
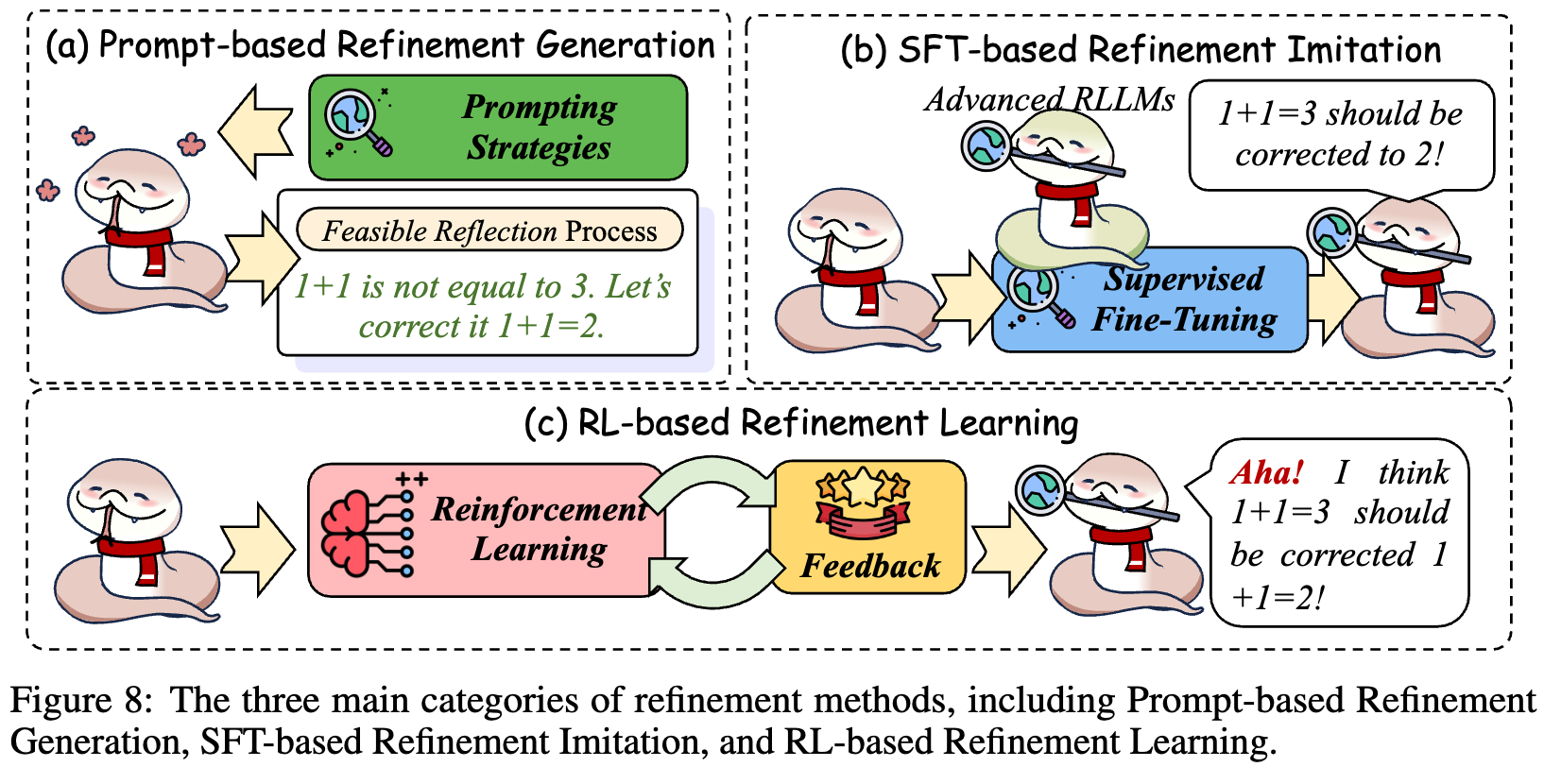
基于提示的精炼
- 核心思想: 通过提示引导模型生成初始响应,并在后续轮次中允许其进行自我反馈和多轮修正,以此提升推理准确度、减少幻觉现象,并支持更强的自动化反思能力。
- 代表性工作:
基于SFT的精炼
- 核心思想: 通过高质量的反思数据进行监督式微调,使模型模仿更先进模型的自我纠正行为,从而提升其逐步纠错和反思能力。这种方法适用于小模型的能力迁移和细粒度训练。
- 代表性工作:
- rStar:通过自我博弈方法提升小模型的自我改进能力;
- Math-Minos:利用分步解题逻辑标签对模型进行训练,实现细粒度推理;
- Journey Learning:结合MCTS回溯生成监督信号;
- MM-Verify:将精炼机制扩展至多模态图文推理领域。
基于RL的精炼
- 核心思想: 通过强化学习机制,引导模型在测试或推理过程中进行自我反思和修正,强调在奖励指导下的自我精炼能力,从而减少对人工监督的依赖。
- 代表性工作:
- SCoRe:通过自动生成的修正轨迹和正则化项,提升模型在测试阶段的自我精炼能力;
- DeepSeek-R1:利用结果层面的强化学习激活模型的自然反馈和“顿悟”时刻来进行修正;
- S$^2$R:结合过程层面的强化学习,实现推理过程中的动态精炼;
- ReVISE:引入内部验证器来决定何时触发RL引导的反思行为。
2.3 广泛探索
广泛探索使大型推理模型(RLLMs)在处理复杂问题时,能够更深入、更全面地探索多种推理路径,从而提高解题的准确性和鲁棒性。从探索类型的视角来看,广泛探索技术可分为三类:探索规模扩展、内部探索和外部探索。
2.3.1 探索规模扩展
探索规模扩展旨在通过增加推理路径的数量或长度来提升模型解决更复杂问题的能力。这种方法通常适用于推理任务较为复杂,单一推理路径难以有效得出正确答案的情况。
顺序式规模扩展
- 核心思想: 通过延长单条路径的推理链条,逐步加深模型的思考深度,从而提升其对复杂问题的理解与处理能力。这尤其适用于需要多步推理才能得出结论的长链式思维(Long CoT)任务,例如数学证明、逻辑推导以及多步规划等。
- 代表性工作:
- OpenAI-o1 / Deepseek-R1: 延伸推理链条以提供详细的多步推理过程,有效提升了在数学、编程等领域解决复杂问题的能力。
- ITT(内部思考变换器:):将Transformer中的层计算重新定义为“思考步骤”,在不增加模型总参数量的前提下,动态为关键token上的深层推理分配计算资源。
并行式规模扩展
- 核心思想: 通过并行生成多条推理路径,并对结果进行组合、投票或验证,模型可以有效避免单一路径陷入局部最优或错误的问题,从而在高度歧义、存在多种可能解或结果不明确的情况下,提升系统的鲁棒性和准确性。
- 代表性工作:
- Self-Consistency:提出生成多条推理路径,并从结果中选择出现频率最高的答案,从而有效提高最终答案的稳定性和准确性。
- ECM(电子电路模型):借鉴电子学中的并联和串联电路概念,将推理路径以并联或串联方式结合,综合考虑各种可能性,提升决策质量。
2.3.2 内部探索
内部探索主要指大型推理模型(RLLMs)通过其内部机制(通常是强化学习策略和奖励机制)主动探索和优化推理路径,从而更高效、更深入地解决复杂的推理问题。该方法使模型能够自主调整推理策略,减少对外部引导数据的依赖。
RL策略
- 核心思想: 利用强化学习(RL)算法引导模型主动学习和探索多样化的推理路径。这种方法克服了推理过程中模式过于单一的局限性,提升了模型在高不确定性任务或高度依赖自主决策的任务中的表现。
- 代表性工作:
- PPO(近端策略优化):一种经典的RL算法,通过基于策略梯度的方法高效优化模型的内部决策机制,适用于复杂环境下的路径探索与优化。
- DivPO(多样化偏好优化):鼓励模型探索更多样化的推理路径,以保持决策多样性,防止收敛到局部最优解。
- GRPO(引导式奖励策略优化):设计了一种引导式的奖励机制,使模型能够在复杂的逻辑推理空间中更有效地进行探索。
奖励策略
- 核心思想: 通过精心设计的奖励函数直接引导模型探索和优化有效的推理路径,这在存在明确优化目标或需要解决特定推理瓶颈的场景中尤为有用。
- 代表性工作:
- Deepseek-R1:提出专门设计的奖励函数,激励模型优化中间推理步骤,帮助模型构建高质量的内部推理流程。
- ReST-MCTS*:将蒙特卡洛树搜索(MCTS)与奖励策略相结合,通过过程奖励引导树搜索算法更准确地探索有效推理路径,从而提升整体推理质量。
2.3.3 外部探索
外部探索是指借助外部工具、人类知识或其他模型的帮助,引导模型更有效地探索多样化的推理路径,进而提升其解决复杂问题的能力。这种方法常用于需要精细指导或外部知识才能有效解决问题的场景。外部探索又可细分为两类:人类驱动的探索和模型驱动的探索。
人类驱动的探索
- 核心思想: 利用人类的直觉、经验或反馈来指导模型选择和调整推理路径,特别是在模型的自主探索能力有限,或者推理任务复杂且需要分解为多个子任务的情况下。
- 代表性工作:
- Least-to-Most:将复杂问题分解为若干简单子问题,逐个求解并将前一步的答案作为后续步骤的输入,最终整合出整体解决方案。该方法旨在解决传统“思维链”方法中的“泛化困难”瓶颈。
- ToT(思维之树):将传统的“从左到右”token生成式推理过程扩展为“树状结构探索”,其中每个节点代表一个思维单元,支持推理过程中的多路径尝试、回溯、正向推理及自我评估。
模型驱动的探索
- 核心思想: 利用辅助模型或算法自动引导当前模型的推理过程,减少对人工干预的需求,从而高效地搜索和优化大量复杂的推理路径,提升自动化水平和整体效率。
- 代表性工作:
- PPO-MCTS:将蒙特卡洛树搜索(MCTS)与基于PPO的训练相结合,以增强推理能力。其关键在于保留PPO训练过程中获得的价值网络,并在推理阶段利用该网络指导MCTS选择更优的输出序列,进而提高生成文本的质量和一致性。
- MindStar:将复杂的推理问题(尤其是数学问题)重新表述为搜索问题,在不同的推理路径上进行结构化搜索,以选出最优解。
- rStar-Math:通过MCTS、小模型奖励机制以及自我进化过程,构建强大的数学推理系统,使小型模型在数学能力上超越o1-preview。
3. 关键现象及相关原理
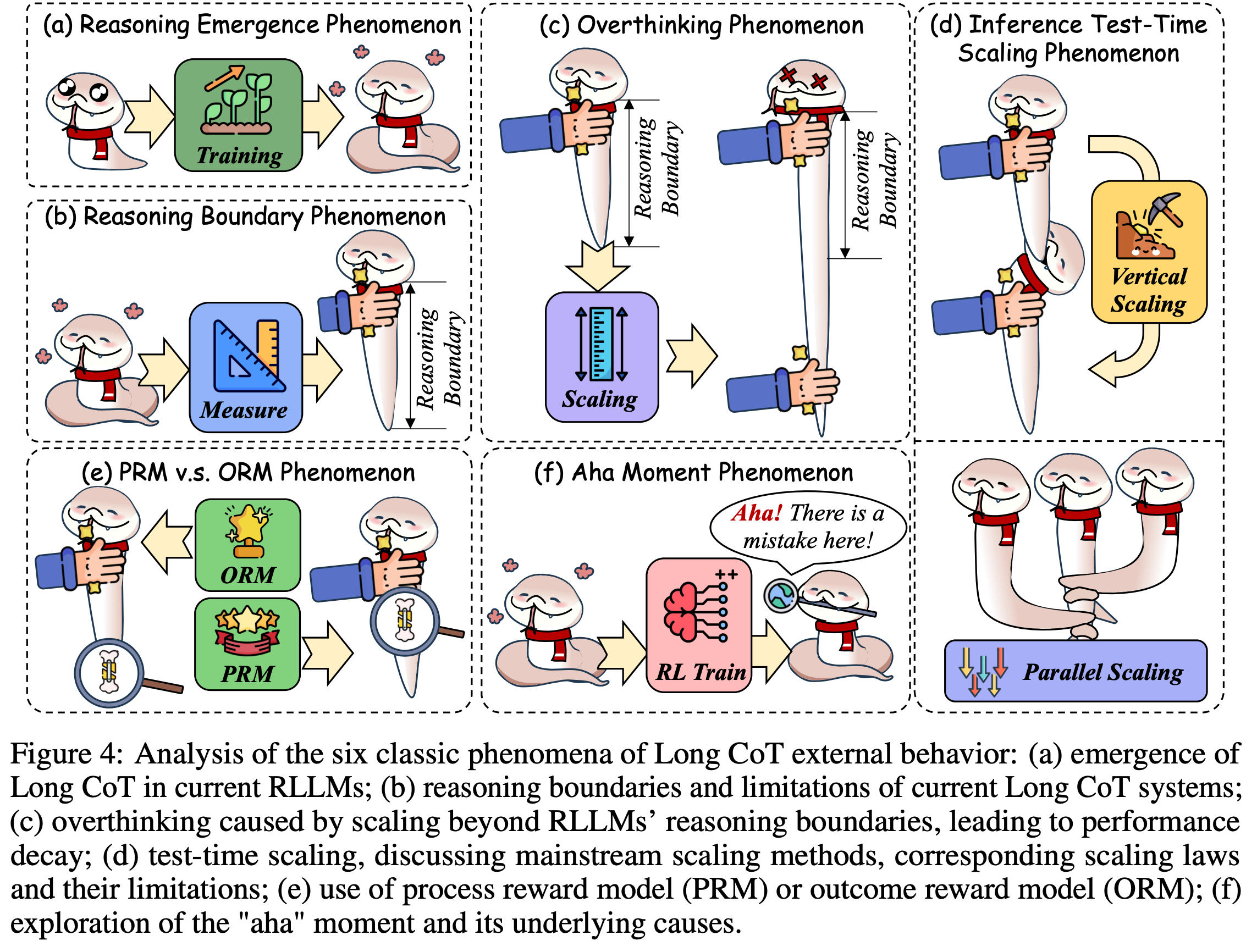
3.1 推理涌现现象
经过训练后,长链式思维(Long CoT)能力会自然涌现,表现为模型能够通过内化预训练数据中的逻辑结构和上下文示例,生成多步且连贯的推理过程,即使在缺乏直接监督的情况下亦然。相关研究对此现象有如下描述:
- Wang等 发现,少量高质量的上下文示例即可有效引导基于强化学习的语言模型(RLLMs)生成清晰、逻辑一致的推理链条,这表明模型在预训练阶段已内化了基本的推理模式。
- Madaan等 证明,即便不提供具体的问题实体,模型仅凭保留的逻辑结构信息仍能生成合理的推理链条,展现了其对结构信息的归纳与迁移能力。
- Stechly等 指出,通过调整解码策略或设计特定提示词,可以显式激活模型内部潜在的CoT能力,从而实现复杂任务中的多步推理。
- Guo等 表明,基于规则的强化学习策略可在预训练阶段直接促使模型形成连贯的推理链条,显著提升其在多步任务中的表现。
3.2 推理边界现象
大型语言模型在长链式思维(Long CoT)任务中表现出明显的性能边界:当推理的深度或复杂度超过某一阈值时,模型性能会显著下降,有时甚至出现逻辑崩溃。这一现象表明,当前模型存在“推理边界”,即由其参数规模和计算资源所能支持的推理复杂度上限。现有研究从理论建模和实验分析两个方面系统探讨了这一现象:
- Chen等 正式提出了“推理边界”的概念,通过实验量化了不同任务复杂度下模型的性能临界点,并指出当推理任务超出模型承载能力时,准确率会急剧下降。
- Bi等 观察到,在代码生成任务中,当模型试图模仿过于复杂的CoT示例时,性能会大幅恶化,这表明超过一定复杂度后,Long CoT示例反而会适得其反。
- Feng等 提出了一种数学模型,说明固定参数规模的模型无法完成超过特定复杂度的数值计算,揭示了准确率上的硬性限制。
- Zhou等 构建了GSM-Infinite数据集,并通过实验证明,不同任务的推理能力上限存在显著差异,进一步强调了推理边界与任务结构之间的关系。
3.3 过度思考现象
在长链式思维(Long CoT)中,延长推理链条并不总能带来性能提升。研究表明,一旦推理长度超过模型的承载能力,准确率便会下降,这种现象被称为“过度思考”,反映了推理的边际效益呈非线性变化以及推理过程中误差的累积效应。
- Chen等 发现,当推理步骤数超过模型的边界时,推理准确率会显著降低,这表明推理存在一个最佳深度范围。
- Wolf等 强调,性能下降的根本原因在于中间推理步骤中的误差被不断放大,从而影响最终判断。
- Xie等 的实验表明,推理长度与准确率之间并不存在单调关系,这挑战了“CoT越长推理越好”的直觉。
- Wu等 建立了一个数学模型,用于界定不同模型和任务条件下“最佳推理长度”的区间,指出一旦长度超过最优范围,性能就会出现反转。
- Chen等 提出了“推理链欧姆定律”,将推理长度与性能之间的非线性关系类比为模型中信息流的阻力。
3.4 推理时缩放现象
推理时缩放现象是指在推理过程中通过延长计算过程(例如推理链长度或样本数量)来提升推理性能的现象。这一现象揭示了模型的“动态放大”潜力,但也伴随着探索深度与计算成本之间的权衡。
- Brown等人观察到,即使初始尝试失败,通过多次重复推理,也能够在一定次数内找到正确答案,从而提出了“语言猴子”现象。
- o1证明,单纯增加推理链长度即可提高准确率,尤其是在复杂的数学任务中。
- Jin等人指出,虽然增加推理链长度起初会带来性能提升,但超过某一阈值后,性能反而会下降,呈现出典型的非线性增长曲线。
- Wu等人发现,推理样本数量与误差下界之间存在对数关系,这表明计算复杂度(FLOPs)与推理性能之间存在渐近关系。
- Chen等人建立了并行推理的理论上限,指出无论样本量如何增加,模型的验证性能都无法超越其内部推理能力的上限。
3.5 PRM与ORM选择现象
在强化学习优化中,长链式思维任务需要对模型生成过程进行监督。研究者们区分了两种主要策略:过程奖励模型(PRM),它关注推理过程本身;以及结果奖励模型(ORM),它只关心最终输出是否正确。这两种策略在泛化能力、学习稳定性及监督成本方面存在显著差异。
- Lampinen等人在定性实验中验证了中间步骤与最终答案之间的因果关系,为过程监督的合理性提供了理论支持。
- Jia等人从理论上证明,在数据足够多样化的情况下,ORM的优化难度并不比PRM更高,两者在样本复杂度上仅相差多项式因子。
- Guo等人表明,基于规则的PRM强化学习能够显著提升模型在复杂任务中的长链式思维能力,但同时也面临奖励黑客的风险。
- Tan强调了对于复杂推理路径而言,中间推理步骤的奖励分布至关重要,而ORM无法提供这一点。
- Jiang等人指出,PRM在数据收集方面成本更高,因为它需要对每个推理步骤进行标注,这限制了其大规模应用。
3.6 哈哈瞬间现象
哈哈瞬间是指在推理过程中信息突然整合,从而导致判断出现关键转折点的现象,类似于人类的反思与自我修正。这一现象凸显了模型的动态认知调整能力,但其发生依赖于外部刺激与内部机制的协同作用。
- Guo等人首次通过基于规则的奖励,在无监督条件下触发了哈哈瞬间行为,使模型能够反思中间推理过程并进行自我修正。
- Xie等人进一步通过实验证明,这种行为可以在多个模型中复现,证实它并非偶然事件,而是一种可诱导的策略。
- Zhou等人将哈哈瞬间现象扩展到了多模态任务中,表明这一现象并不局限于文本任务,而是反映了模型更广泛的认知能力。
- Liu等人指出,在某些强化学习框架中(如R1-Zero),哈哈行为可能并不存在,所谓的生成过程延长更可能是奖励优化的结果,而非真正的反思。
- Yang等人发现,哈哈行为往往伴随着类似人类的语言增强和动态不确定性调节,模型在高压任务下更倾向于使用“我认为”之类的表达,反映出其应对任务压力的机制。
4. 算法
4.1 监督微调(SFT)
在推动大型模型具备强大的长链式思维推理能力的过程中,监督微调(SFT)起到了至关重要的作用,它架起了预训练与更高级的对齐方法(如基于人类反馈的强化学习,RLHF)之间的桥梁。SFT的核心目标是教会模型如何遵循指令,并初步掌握生成结构化、分步推理链的能力,从而为更复杂的推理任务奠定基础。
在深度推理的背景下,SFT尤为重要。 尽管RLLM缺乏足够的推理深度会显著降低性能,但SFT通过记忆化过程稳定了模型的输出格式,使其能够从人工标注或蒸馏得到的数据中学习推理模式。与更注重泛化和自学习的强化学习(RL)不同,SFT在深度推理模仿中发挥着关键作用。它允许RLLM通过模仿由人类、先进RLLM或增强型RLLM生成的高质量推理示例,学习复杂的推理模式,并将其推广到新任务中。SFT不仅显著提升了模型的推理性能,而且在某些情况下,只需少量高质量样本就能激活底层LLM的深度推理能力,使其能够预测超出模型知识范围之外的事件。这使得SFT成为提升RLLM推理水平和泛化能力的关键技术之一。
对于可行的反思,SFT 主要专注于基于优化的模仿(Refinement Imitation)。 在基于反思的 LLM 推理中,SFT 是使模型实现自我优化和错误修正的关键机制。通过 SFT,模型可以直接学习高级 LLM 的纠错过程,从而显著提升其反思能力,例如进行自我博弈推理、迭代反馈纠错,甚至通过逐步的自然语言反馈来论证和反思推理过程。此外,SFT 还可以在多模态场景中整合视觉与文本推理,提高模型的批判性思维和自我修正能力。SFT 通过迭代反馈和自我修正策略提升了 LLM 的推理准确性,这对于小型模型尤其有益。
4.1.1 核心技术
SFT 包含两个核心概念:指令微调 和 参数高效微调,PEFT。
指令微调
- 核心思想: 通过对模型进行大量覆盖各类任务的指令微调,可以显著提升模型对未见任务的零样本泛化能力。这使得模型能够学习“遵循指令”的技能。
- 代表性工作:
- 微调后的语言模型是零样本学习者 (FLAN): 谷歌的开创性工作,证明了多任务指令微调能够解锁 LLM 在未见任务上的零样本能力。
- 大型语言模型的指令微调:综述: 一篇全面的综述,系统介绍了指令微调的方法、数据集、挑战及未来方向。
参数高效微调(PEFT)
- 核心思想: 鉴于对 LLM 进行全量微调(Full Fine-tuning)的成本极高,PEFT 方法应运而生。这些方法只需更新模型中的一小部分参数,即可达到接近全量微调的效果,从而大大降低硬件需求。
- 代表性工作:
- LoRA:大型语言模型的低秩适应: 一种革命性的 LoRA 技术,通过注入低秩适应矩阵来高效地微调模型,目前是最广泛应用的 PEFT 方法之一。
- QLoRA:量化 LLM 的高效微调: 对 LoRA 的进一步优化,结合 4 位量化、双权重量化和页面优化器,使得在单个消费级 GPU 上就能微调超大规模模型。
- Adapter 微调: 在 Transformer 的各层之间插入小型神经网络模块(适配器),训练时仅更新这些适配器的参数。
- Prompt 微调 / P-Tuning: 不修改模型权重,而是在输入端学习一个或多个可训练的虚拟标记(软提示),以更有效地引导模型完成下游任务。
技术对比
| 技术类型 | 核心思想 | 优 点 | 缺 点 |
|---|---|---|---|
| 全量微调 | 更新所有模型权重。 | 性能上限最高,可完全适应新数据。 | 训练成本极高(内存、时间),易发生灾难性遗忘,需存储整个模型。 |
| 参数高效微调 (PEFT) | 冻结大部分原始参数,仅更新少量附加参数或特定子集。 | 训练成本极低,速度快,抗遗忘能力强,微调产物体积小(适配器),易于部署。 | 性能可能略逊于全量微调,且对极其复杂任务的适应性可能有限。 |
4.1.2 学习资源
| 资源名称 | 演讲者/作者 | 特点 | 链接 |
|---|---|---|---|
| 让我们从零开始构建 GPT | Andrej Karpathy | 一份动手指南,教你从零开始构建 GPT,深入理解 Transformer 的基础原理和训练流程;是理解 SFT 的先决条件。 | YouTube |
| Hugging Face SFT 课程 | Hugging Face | 官方 SFT 系列教程,使用 Hugging Face TRL 代码库进行 SFT 代码实践。 | 课程链接 |
| Hugging Face SFT Trainer 文档 | Hugging Face | Hugging Face SFTTrainer 的进阶文档。 | 文档链接 |
| Hugging Face PEFT 课程 | Hugging Face | 官方 PEFT 系列教程,讲解了包括 LoRA 在内的各种高效微调技术的理论与代码实践。 | 课程链接 |
| LLMs-from-scratch | Sebastian Raschka | 官方书籍《从零开始构建大型语言模型》的教程代码。 | 课程链接 |
4.1.3 开发框架
| 框架 | 特性 | 主要用例 | 资源链接 |
|---|---|---|---|
| Hugging Face TRL | 官方 Hugging Face 库,集成了多种训练方法,如 SFT、RLHF、DPO 等,并可与生态系统(transformers、peft、accelerate)无缝对接。 |
提供标准化的 SFT 训练器 SFTTrainer,简化了训练流程。 |
GitHub |
| LLaMA-Factory | 一站式 LLM 微调平台,配备 Web UI,使无编程经验的用户也能轻松进行 SFT、PEFT 和模型评估。 | 用户友好度高,支持大规模模型和数据集,适合初学者及快速验证。 | GitHub |
4.1.4 最佳实践与常见误区
- 数据质量远比数量重要:
- 核心原则:与其使用10,000条低质量、同质化的数据,不如使用1,000条高质量、多样化的数据。低质量的数据可能会让模型学到错误的模式。
- 格式一致性:确保所有训练数据遵循统一的对话模板(例如ChatML),这对于训练模型识别角色和对话边界至关重要。
- 选择合适的微调策略:
- 对于大多数资源有限的应用场景,应优先选择QLoRA,因为它在效率和效果之间取得了最佳平衡。
- 如果追求最优性能且资源充足,则可以考虑全量微调,但需注意避免过拟合的风险。
- 关键超参数的调整:
- 学习率:SFT 的学习率通常比预训练时更小,一般在
1e-5到5e-5之间。 - 轮次:通常1到3轮就足够了。轮次过多可能导致在小数据集上过拟合,从而使模型“忘记”预训练阶段学到的通用知识。
- 批量大小:在内存允许范围内,适当增加批量大小有助于稳定训练过程。
- 学习率:SFT 的学习率通常比预训练时更小,一般在
- 评估与迭代:
- 全面评估:不要仅依赖损失函数。应结合客观评估基准测试(如 MMLU)以及主观的人工评估,以更全面地衡量模型性能。
- 迭代优化:SFT 是一个持续的迭代过程。根据评估结果,不断清理数据、调整超参数并优化模型。
4.1.5 相关论文仓库
4.2 强化学习
4.2.1 强化学习
- 西湖大学《强化学习的数学原理》
- 特点:从 MDP 和贝尔曼方程出发,利用策略梯度定理推导而来。
- 先修知识:线性代数、概率论。
- 重点:价值迭代和策略优化的数学本质。
- Book-Mathematical-Foundation-of-Reinforcement-Learning(适合初学者)
4.2.2 强化学习的核心算法
权威课程
| 课程 | 讲师 | 特点 | 资源 |
|---|---|---|---|
| Foundations of Deep RL | Pieter Abbeel | 6节简明课程(Q-learning → PPO) | YouTube |
| UC Berkeley CS285 | Sergey Levine | 包括 SAC/逆向强化学习等高级主题 | 课程官网 |
| Hung-yi Lee 的强化学习课程 | Hung-yi Lee | 中文讲解 + EasyRL 实践练习 | Bilibili |
| Reinforcement Learning: An Overview | Kevin Murphy | 持续更新的深度强化学习算法相关资源 | Arxiv |
基础必学算法
基础强化学习算法
- DQN:深度强化学习的开端
- PPO:策略优化中的关键方法,广泛应用于工业领域
- SAC:引入探索熵,对连续动作空间具有较强的鲁棒性
- TD3:通过双延迟网络改进了离策略强化学习
基于模型的强化学习算法
离线强化学习算法
- CQL:引入保守约束,是离线强化学习的基础性工作
- decision-transformer:将自回归模型引入离线强化学习
大规模模型强化学习算法
- PPO:将经典的 PPO 方法应用于大型语言模型
- DPO:无需奖励的偏好优化,是一种适用于大型模型的离线强化学习算法
- GRPO:群体相对策略优化,是 DeepSeek-R1 的核心算法
大规模模型强化学习的前沿算法
- DAPO:对GRPO的四项改进
- LUFFY:GRPO的离策略版本,引入高质量的外部轨迹
- Absolute-Zero-Reasoner:一种无需标注的大规模强化学习算法
- One-Shot-RLVR:针对大模型推理的一次性优化方法
- SPIRAL:在自我对弈游戏环境中进行强化学习,成功提升了数学推理能力
- 高熵少数令牌驱动有效RLVR:由高熵令牌驱动的强化学习(20%)
- Spurious_Rewards:随机奖励同样可以提升LLM的推理能力
- SwS:由自我感知的弱点驱动的推理强化学习
4.2.3 强化学习开发框架
基础强化学习框架
- stable-baselines3(快速实验,拥有成熟稳定的基线)
- legged_gym(四足机器人控制)
大规模模型强化学习框架
- verl:基于Ray、vLLM、ZeRO-3和HuggingFace Transformers的高性能、易用开源强化学习训练库,具备高效资源利用、可扩展性和生产就绪等特性。(结构复杂,高度可复用,性能优异)
- OpenRLHF:由NVIDIA等团队发布的开源RLHF框架,基于Ray、vLLM、ZeRO-3和HuggingFace Transformers。支持PPO、GRPO、REINFORCE++等算法,并提供动态采样和异步智能体机制以加速训练。
- AReaL:异步强化学习框架
- ROLL:支持训练参数量达6000亿以上的大型模型
- Hugging Face TRL:由Hugging Face维护的RLHF全栈库,集成了SFT、GRPO、DPO、奖励建模等多个模块。支持多种模型架构和分布式扩展,是社区中最活跃的RLHF工具之一。(用户友好,上手快,社区活跃)
- RL4LMs:面向语言模型的开源RLHF库,提供奖励模型构建和策略网络训练的端到端工具,帮助研究人员快速搭建自定义RLHF流水线。
此外,还有一些有趣的扩展仓库:
- Sachin19/trlp:基于TRL堆栈的端到端RLHF库,不仅支持语言模型,还扩展至Stable Diffusion模型。包含SFT、奖励建模、PPO等步骤,并提供用于实验的示例代码。
- OpenRLHF-M:OpenRLHF的扩展版本,专为多模态模型优化。利用DeepSpeed和HuggingFace Transformers实现更高的吞吐量和更丰富的训练场景。
- HumanSignal-RLHF:一个已归档的资源库,汇集了关于RLHF数据收集、系统构建及最佳实践的链接和教程,适合初学者快速了解完整的RLHF流程。
- MichaelEinhorn/trl-textworld:TRL的一个衍生版本,专注于在TextWorld环境中开展RLHF实验,展示了如何使用PPO训练GPT2等模型,生成符合特定反馈要求的文本。
4.2.4 测试环境
经典强化学习测试
- OpenAI Gym: 经典控制任务
| 环境ID | 任务描述 | 特征 |
|---|---|---|
CartPole-v1 |
平衡倒立摆 | 4维状态/离散动作,当摆杆倾斜超过12°或步数达到500时终止 |
MountainCar-v0 |
将小车荡到山顶 | 2维状态/离散动作,需要利用势能完成摆动 |
Pendulum-v1 |
控制单摆保持竖直 | 3维状态/连续动作,无物理终止条件 |
Acrobot-v1 |
摆动双连杆触碰目标线 | 6维状态/离散动作,当触碰到目标线时终止 |
- Atari 2600: 游戏环境
| 环境ID | 游戏类型 | 挑战 |
|---|---|---|
Pong-v5 |
乒乓球 | 210×160 RGB输入,需进行图像预处理 |
Breakout-v5 |
打砖块 | 奖励密集,适合DQN训练 |
SpaceInvaders-v5 |
太空侵略者 | 多个敌人协同攻击,奖励机制复杂 |
- Box2D: 物理仿真环境
| 环境ID | 物理系统 | 核心挑战 |
|---|---|---|
LunarLander-v2 |
月球着陆器 | 8维状态/离散动作,涉及燃料控制与精准着陆 |
BipedalWalker-v3 |
双足行走机器人 | 24维状态/连续动作,需在复杂地形上保持平衡 |
CarRacing-v2 |
赛车竞速 | 96×96 RGB输入,结合视觉感知与连续控制 |
- MuJoCo: 机器人控制环境
| 环境ID | 机器人模型 | 任务类型 |
|---|---|---|
HalfCheetah-v4 |
猎豹机器人 | 高速奔跑控制(17维状态) |
Ant-v4 |
蚂蚁机器人 | 复杂地形导航(111维状态) |
Humanoid-v4 |
人形机器人 | 双足平衡行走(376维状态) |
- 其他特殊环境
| 类别 | 示例环境 | 应用领域 |
|---|---|---|
| 文本游戏 | TextFlappyBird-v0 |
基于字符界面的强化学习 |
| 多智能体 | PistonBall-v6 |
多智能体合作/竞争 |
| 3D导航 | AntMaze-v4 |
复杂迷宫路径规划 |
扩展资源:
- 安全强化学习:
Safety-Gymnasium(带约束的任务) - 自动驾驶:
CARLA/AirSim(高保真仿真) - 多智能体:
PettingZoo(兼容Gymnasium API)
💡 完整环境列表可参见: Gymnasium文档 | OpenAI Gym Wiki
大模型强化学习测试
| 环境 | 目的 |
|---|---|
| Math-500 | 数学推理 |
| AIME2024/2025 | 数学竞赛 |
| AMC | 数学竞赛 |
| GPQA | 博士级别的生物物理与化学推理 |
4.3 代理
LLM代理解决复杂问题的能力,从根本上依赖于其推理与规划能力。这一能力的核心机制是长链思维(Long CoT),它将复杂任务分解为更小、逻辑清晰的步骤。长链思维的特点——深度推理、广泛探索以及可行性反思——并非附加功能,而是实现这些能力的基础。如果代理无法“更深入地思考”并进入“思考—批判—改进”的循环,其独立决策和在陌生场景中适应的能力将受到严重限制,最终退化为“预设流程”或“与人类反复交互”。例如o1和DeepSeek-R1等模型通过长链思维成功解决了复杂任务,直接证明了这种因果关系:推理深度的提升会直接带来代理能力的增强(即在复杂任务中的自主性)。因此,未来AI代理的发展将与长链思维的突破紧密相关。
AI代理在线课程与资源
- 吴恩达的《如何构建、评估和迭代LLM代理》:由LlamaIndex和TruEra团队专家主讲的研讨会(2024年3月),讲解如何使用LlamaIndex等工具框架构建LLM代理,并借助TruLens等可观测性工具评估代理性能、检测幻觉和偏差。视频提供中英字幕,适合学习生产环境中代理的开发与评估方法。
- Coursera AI代理开发者专项课程(范德堡大学):面向具备Python基础的初学者的六门系列课程,重点教授如何使用Python、工具、记忆和推理来构建与部署智能AI代理。课程内容包括创建自定义GPT、应用提示工程、设计可靠的人工智能系统以及实现多智能体协作系统。
- Hugging Face代理课程:一门免费的在线代理入门课程。
用于构建LLM AI代理的开源框架
- LangChain:LLM智能体开发中最广泛使用的框架,提供模块化和可扩展的架构、统一的LLM接口、预构建的智能体工具包(用于CSV、JSON、SQL)、Python和Pandas集成以及向量存储能力。它支持React风格的智能体,并提供用于维护上下文的记忆模块。
- CrewAI:一个用于编排角色扮演型AI智能体的开源框架,强调通过定义的角色和共同目标实现多智能体协作。该框架独立、精简且高度可定制,支持“Crew”(团队)和“Flow”(事件驱动的工作流)。
- Dify:一个面向LLM应用的开源框架,具备可视化提示编排界面、长上下文集成、基于API的开发、多模型支持以及RAG流水线等功能。
- OpenAI Agent Demo:OpenAI官方提供的用于搭建Agent客户端服务的平台(可视化平台,无需额外代码)。
更多框架请参阅Awesome LLM Agent Frameworks。
针对复杂智能体轨迹的端到端强化学习
- Agent-R1:一个开源框架,旨在加速强化学习与智能体交叉领域的研发。它采用端到端强化学习在特定环境中训练智能体,允许开发者在无需复杂流程工程的情况下定义领域特定的工具和奖励函数。该框架支持多轮工具调用及多工具协同。
- RAGEN:一个在交互式、随机性和多轮环境中利用强化学习训练LLM推理智能体的框架。它引入了StarPO(状态-思考-行动-奖励策略优化)框架,该框架具有交错的展开与更新阶段,以实现轨迹级别的优化。
强化学习增强的工具使用与搜索能力
- ReCall:一个新颖的框架,通过强化学习训练LLM进行工具调用推理,而无需关于工具使用轨迹或推理步骤的监督数据。它旨在使LLM能够以类似智能体的方式使用和组合任何用户自定义的工具。
- OpenManus-RL:OpenManus框架的扩展版本,专门通过GRPO等强化学习技术来增强AI智能体,从而实现跨多种环境的训练及针对特定任务的性能调优。
- R1-Searcher、Search-R1:研究探索如何利用强化学习提升LLM的搜索能力。
精彩博客
- Neptune.ai博客:提供了详细的分步指南,例如“如何使用AutoGen构建LLM智能体”,涵盖组件、RAG流水线、规划、工具和记忆集成等内容。
- n8n.io博客:深入探讨了LLM智能体的能力(如战略规划、记忆和工具集成),并附有构建智能体的实用教程。
- NVIDIA开发者博客:发表了一篇关于LLM推理和AI智能体的入门文章。
- Botpress博客:解释了思维链提示机制,并讨论了各种AI智能体框架。
- SuperAnnotate博客:全面概述了LLM智能体、其能力及未来发展方向。
- Smythos博客:探讨了LLM智能体如何革新任务自动化和AI集成。
- Unite.ai:详细讨论了强化学习与思维链结合如何将LLM转化为自主推理智能体。
- Holistic AI博客:深入分析了LLM智能体的架构,包括多模态增强、工具使用和记忆等方面。
- ProjectPro和Lightrains博客:讨论了多种AI智能体设计模式,包括反思、工具使用和规划模式等。
精选GitHub仓库
- Awesome-LLM-Agents:一份精心整理的各类LLM智能体框架列表,是探索该生态系统的宝贵起点。
- Awesome-LLM-Agents-Scientific-Discovery:一份聚焦于LLM驱动的AI智能体在生物医学研究及更广泛科学发现中应用的论文精选列表。
- Awesome-Agent-RL:一个专门收集论文和资源的合集,重点在于通过强化学习释放AI智能体的潜力。
- Awesome-LLM-APPs:一份精选的优秀LLM应用集合,涵盖了基于RAG、AI智能体、多智能体团队、MCP、语音智能体等多种技术构建的应用。
5. 数据集
5.1 基准测试
5.1.1 评估框架
LLM评估框架:
- OpenCompass 是一个综合性的大语言模型(LLM)评估平台,支持对超过100个数据集上的多种开放和闭源模型进行测评。它覆盖语言理解、推理和代码生成等多个维度,并支持零样本、少样本、思维链(CoT)等多种评估方式,同时还具备分布式评估能力。
- DeepEval 是一个易于使用的开源LLM评估框架,专为评估和测试大型语言模型系统而设计。其目标是帮助开发者根据相关性、事实一致性、偏见和毒性等关键指标,高效评估模型生成内容的质量。它的使用方式类似于Python单元测试框架Pytest。
MLLM评估框架:
VLMEvalKit 是 OpenCompass 推出的开源工具包,专门用于评估大型视觉-语言模型。它支持在 80 多个基准测试上对 220 多种视觉-语言模型进行一键式评估,涵盖图像问答、图文匹配和视觉推理等任务。该工具包既能基于精确匹配提供评估结果,也能通过大语言模型抽取答案来生成评估结果。
- EvalScope 是 MoTower 社区推出的一个模型评估框架,支持对多种类型模型的性能基准测试,包括大型语言模型、多模态语言模型、嵌入模型以及 AIGC 模型。
CoT 评估框架:
5.1.2 结果基准
本节重点从整体视角评估 Long CoT 推理的最终表现,强调推理链是否最终合理且准确。
- 复杂数学
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| GSM8K | ~8,500 | 2021 | OpenAI | OpenAI 提供的 K-12 数学文字应用题数据集,每道题都配有详细的解题步骤。题目涵盖基础算术、文字应用题等,需要多步推理才能解答。 | 🤗数据集 |
| MATH | 12,500 | 2021 | Hendrycks 等(加州大学伯克利分校) | 来自数学竞赛的高难度数学问题数据集,每道题都附有完整的分步解答。内容涵盖代数、几何、概率等领域,旨在评估模型的数学推理能力。 | 🌐仓库 |
| AIME 2024 | 30 | 2024 | AI-MO 项目组 | 2024 年美国邀请数学竞赛,一个高水平的高中数学竞赛数据集,包含 2024 年 AIME I 和 II 的所有题目。题目侧重于整数解和组合推理。 | 🤗数据集 |
| AIME 2025 | 30 | 2025 | OpenCompass | 2025 年 AIME I 和 II 的题目合集。难度与 2024 年 AIME 相似,用于评估高中生解决复杂数学问题的能力。 | 🤗数据集 |
| AMC 2023 | 83 | 2024 | AI-MO 项目组 | 2023 年美国数学竞赛,由 AMC12 竞赛中的 83 道题组成的验证集。题目涵盖 2022–2023 年 AMC12 中的代数、几何等内容。 | 🤗数据集 |
| USAMO 2025 | 6 | 2025 | Balunović 等(苏黎世联邦理工学院) | 2025 年美国数学奥林匹克竞赛的题目数据集。这些是 USAMO 的决赛试题,通常为难度较高的证明题,考察深度的数学推理和证明能力。 | 🌐网站 🌐仓库 |
| OlympiadBench | 8,476 | 2024 | 贺朝晖等(清华大学) | 奥林匹克级别的双语多模态科学问题数据集。包含来自数学、物理等学科竞赛的 8,476 道题目,每道题都有专家提供的分步解答,用于全面评估模型的跨学科深度推理能力。 | 🤗数据集 🌐仓库 |
| OlympicArena | 11,163 | 2024 | 黄震等(上海交通大学 & 上海研究院) | 又称 OlympiadArena,这一综合性基准涵盖了数学、物理、化学、生物等 7 个大类中的 62 种“奥林匹克”挑战。包含 11,163 道奥林匹克级别题目,按学科和题型分类,旨在推动通用人工智能的推理发展。 | 🤗数据集 🌐仓库 |
| Putnam-AXIOM | 236 + 52 | 2024 | Gulati 等(斯坦福大学) | 来自普特南数学竞赛的数据集,包括 236 道普特南竞赛题目以及 52 道普特南 AIME 的交叉题目。每道题都配有详细的解题步骤,用于评估模型的数学推理能力。 | 📄论文 |
| FrontierMath | - | 2024 | Glazer 等(Epoch AI) | 由数十位数学家协作创建的一系列前沿数学问题集。涵盖现代数学的主要分支,从数论、实分析到代数几何。这些问题若手动求解,往往需要数小时甚至数天。收录了数百道原创高难度题目,且均未公开发布,以避免训练泄露。 | 📄论文 |
| ThinkBench | 2,912 | 2025 | 黄书林等(上海科技大学) | 一套动态挑战题集,用于评估大型语言模型(LLM)的稳健推理能力。包含 2,912 个通过对外部分布扰动生成的推理任务,旨在测试模型在陌生情境下的推理准确性。 | 📄论文 |
| MATH-Perturb | 279 * 2 | 2025 | 黄凯旋等(普林斯顿大学 & Google) | MATH 数据集中最难题目的扰动集。从 MATH 中选取 279 道最困难的 Level 5 题目,并通过“简单扰动”和“困难扰动”为每道题生成 279 个变体。模型在这些扰动题目上的表现会显著下降,从而反映其真实的数学泛化能力。 | 📄论文 |
- 复杂编码
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| SWE-bench | 2,294 | 2024 | 陈天乐等(普林斯顿NLP) | 软件工程基准数据集,从GitHub上真实的软件项目问题-补丁对中提取。收集了12个流行Python库中的2,294个问题及其对应的Pull Request修复。该数据集用于评估模型自动修复真实代码缺陷的能力。 | 🤗数据集 🌐仓库 |
| CodeContests | ~10,000 | 2022 | 李等人(DeepMind) | DeepMind为训练AlphaCode而提出的竞技编程数据集。它汇集了来自Codeforces、AtCoder等平台的大量题目和测试用例。数据集包含约10,000道多语言编程题目,可用于代码生成模型的训练和评估。 | 🤗数据集 |
| LiveCodeBench | ~400(逐年增加) | 2024 | 贾因等人(加州大学伯克利分校 & MIT) | 一个“实时”代码基准。持续收集LeetCode、AtCoder和Codeforces上最新的公开题目,总计约400道高质量编程题目。除了代码生成外,还评估模型在代码调试、自我修复及单元测试生成方面的能力。 | 🤗数据集 🌐仓库 |
| MHPP | 210 | 2025 | 戴建波等人 | 大多数困难的Python问题,由人工设计的一组高难度Python编程任务。数据集包含七个挑战类别共210道题目,每道题都需要多步推理或复杂的算法来解决。用于评估大语言模型在代码推理效率和准确性方面的极限。 | 📄论文 |
| ProBench | - | 2025 | 杨磊等人(上海科技大学) | 专为竞技编程设计的基准。收集了2024年下半年来自Codeforces、洛谷和Nowcoder平台的竞赛题目,统一了难度和算法标签。数据集包含数百道题目,填补了高级代码推理评估的空白。 | 🤗数据集 🌐仓库 |
| HumanEval Pro | 164 | 2024 | 于兆健等人(微软人工智能研究院) | OpenAI HumanEval数据集的增强版。在原有的164道编程题目基础上,增加了“子问题”,要求模型先解决一个较简单的子问题,再利用其结果去解决更复杂的问题。与原始的HumanEval相比,Pro版本使模型的准确率降低了约20%。 | 🤗数据集 🌐仓库 |
| MBPP Pro | 378 | 2024 | 于兆健等人(微软人工智能研究院) | Google MBPP编程题数据集的进阶版。从MBPP测试集中选取378道题目,并构建了类似于HumanEval Pro的附加问题,使题目更具层次性和综合性。用于更严格地评估模型在基础编程任务中的多步推理能力。 | 🤗数据集 🌐仓库 |
| EquiBench | 2,400 | 2025 | 魏安江等人(斯坦福大学 & 纽约大学) | 代码语义理解基准。通过等价性验证任务评估大语言模型对程序执行语义的理解能力。数据集提供了四种编程语言中2,400对功能等价或不等价的程序。要求模型判断两段程序的输出是否相同,以此测试其对深层代码逻辑的理解。 | 🤗数据集 🌐仓库 |
- 常识谜题
以下是表格的学术英文翻译:
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| LiveBench | 动态更新 | 2025 | White et al. (NYU & Meta AI) | 一个在线更新的、全面的LLM评估框架。每月都会新增任务,以确保测试集不会被模型的训练数据污染。任务涵盖数学、逻辑、编程和常识问答等领域。它采用自动评分和可验证的标准答案,以确保评估的公正性和客观性。 | 🤗数据集 🌐仓库 🌐网站 |
| BIG-Bench Hard (BBH) | 23个任务(超过2,000道题) | 2023 | Suzgun et al. (Google Research) | 从BIG-Bench大规模通用基准中挑选出的23个最具挑战性的任务集合。这些任务在GPT-3等模型上的表现远低于人类平均水平,涵盖布尔表达式求值、因果推理、日期理解以及复杂的常识/逻辑问题等领域。它常被用作思维链(CoT)增强实验的基准。 | 🤗数据集 🌐仓库 |
| ZebraLogic | - | 2024 | Lin et al. (HKUST) | 受“斑马谜题”启发的逻辑推理数据集。它包含一组复杂的演绎推理问题,通常涉及非单调推理场景,由模型生成并经过人工验证。该数据集用于测试模型在纯逻辑线索下的推理一致性。 | 🤗数据集 🌐仓库 🌐网站 |
| ARC | 10,377 | 2018 | Clark et al. (AI2) | AI2推理挑战赛,一个针对自然常识和科学问题的选择题数据集。题目来源于美国K-12科学考试,分为简单和困难两个部分。其中包含7,787道训练题和2,590道挑战题。即使GPT-4在ARC挑战集上也难以超越淘汰赛阶段的表现,因此它常被用作通用常识智能测试的基准。 | 🤗数据集 |
| JustLogic | 4,900 | 2024 | Michael Chen et al. (USYD) | 纯粹的演绎逻辑推理基准。它包含由合成算法自动生成的4,900道命题逻辑推理问题,不依赖任何常识知识,仅专注于测试模型进行形式化逻辑推导的能力。每个任务提供一组前提和一个结论命题,模型需要判断结论的真值:真、假或不确定。 | 🤗数据集 🌐仓库 |
| QuestBench | ~600 | 2025 | Li et al. (DeepMind) | DeepMind发布的信息检索推理评估。它包含四类“不完整问题”:逻辑、规划、数学(GSM)和公式问题,每道题都缺少一个关键条件。模型必须识别出最需要澄清的问题,并利用该信息来回答原问题。数据集中约有600道此类常识/推理问题,旨在评估LLM识别和询问关键信息的能力。 | 🌐仓库 |
- 科学推理
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| GPQA Diamond | 198 | 2024 | Rein et al. (NYU) | 研究生级别的物理/生物/化学问答数据集中难度极高的子集。GPQA数据集筛选出198道专家能正确回答但普通人会答错的问题。“钻石级”题目几乎达到研究生水平,要求模型具备跨学科的深度推理能力。 | 🤗数据集 🌐仓库 |
| MMLU-Pro | ~12,000 | 2024 | Wang Yubo等 | 原始MMLU基准的增强版。包含来自14个主要领域的12,000道高质量学术考试题(选项数由4个增至10个),侧重于综合知识与复杂推理。相比原始MMLU,Pro版本显著提升了难度,模型准确率平均下降约20%。 | 🤗数据集 🌐仓库 |
| SuperGPQA | 26,529 | 2025 | Doubao (Seed)团队 | 大规模研究生级别知识推理基准。涵盖285个学术领域,包含26,529道高难度专业考试题。超过42%的题目需要数学计算或形式化推理,旨在测试模型在长尾学科中的推理极限。 | 🤗数据集 🌐仓库 |
| Humanity’s Last Exam (HLE) | 2,500 | 2025 | CAIS & Scale AI | “人类最后一考”,被设计为人类知识的最后一场闭卷考试。包含数学、自然科学和人文科学等数十个领域的2,500道选择题或简答题。由全球专家协作创建,其难度超越了以往所有基准,被认为是当前AI面临的最困难的综合性考试。 | 🤗数据集 🌐仓库 🌐网站 |
| TPBench | - | 2024 | Daniel J.H. Chung等 (DeepMind) | 用于评估模型解决高级理论物理问题能力的理论物理基准。该基准由Chung等人提出,收集了一系列需要高级知识和复杂推导的理论物理问题,以测试模型在物理定律和方程推导方面的推理极限。 | 🤗数据集 🌐网站 |
- 医学推理
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| MedQA | 12,723 | 2020 | Jin et al. (清华大学) | 医学考试问答数据集。来源于美国医师执照考试(USMLE)的选择题,涵盖解剖学、生理学、病理学等科目。包括英文版(12,723题)以及简体中文和繁体中文版本(总计约5万题)。用于评估模型运用医学知识和诊断推理的能力。 | 🌐Google Drive 🌐仓库 |
| JAMA临床挑战 | 1,524 | 2024 | Chen et al. (约翰霍普金斯大学) | 美国医学会杂志(JAMA)的临床挑战病例集。汇集了该期刊发表的1,524例具有挑战性的临床病例,每例都配有详细的病例描述、问题、四个选项及专业解析。重点评估模型在真实、复杂的临床场景中进行诊断决策和解释的能力。 | 🌐网站 |
| Medbullets | 308 | 2024 | Chen et al. (约翰霍普金斯大学) | 模拟临床问答数据集。由308道USMLE Step 2/3风格的选择题组成,取自Twitter上的医学问答账号。每道题都包含病例情景、五个选项及详细解析。尽管基于常见临床场景,这些题目仍颇具挑战性,用于评估模型在临床决策和可解释性方面的能力。 | 🌐网站 |
| MedXpertQA | 4,460 | 2024 | 清华C3I团队 | 一套“专家级”医学推理的综合性基准。包含4,460道高难度临床知识问答,覆盖17个专科和11个身体系统。提供纯文本(病例+问答)和多模态(含医学影像)两种格式,用于评估模型对医学文本和图像的联合推理能力。 | 🤗数据集 🌐仓库 🌐网站 |
5.1.3 能力基准测试
重点在于长链式思维(Long CoT)推理过程中模型的局部视角或个体能力,通过考察模型每一步推理是否正确且逻辑自洽,来实现更细粒度的评估。例如,模型能否准确识别错误并加以修正,或者能否逐步完成复杂任务。
- 深度推理
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| ZebraLogic | ~1,000 | 2024 | Bill Yuchen Lin等 | ZebraLogic 是一个专注于逻辑推理的 AI 基准测试,包含复杂的数学和语言推理问题,用于评估模型的高级推理能力。其题目设计类似于“斑马谜题”,挑战模型在约束条件下进行逻辑推理和问题解决。 | 🤗数据集 🌐仓库 🌐官网 |
| BigGSM | 610 | 2025 | Qiguang Chen 等 (HIT-SCIR) | 一个用于评估大型语言模型在多步数学问题上表现的数学推理基准测试。它扩展了经典的 GSM8K 数据集,加入了更具挑战性的数学应用题,要求模型进行更为复杂的逻辑推理和计算。 | 🤗数据集 🌐仓库 |
| GSM-Ranges | 30.1k | 2025 | Safal Shrestha 等 (NYU) | GSM-Ranges 是基于 GSM8K 基准构建的数据集生成器。它系统性地修改数学文字题中的数值,以评估大型语言模型在广泛数值范围内的鲁棒性。通过引入数值扰动,GSM-Ranges 可以检验 LLM 在超出其训练分布范围的数值上进行数学推理的能力。 | 🤗数据集 🌐仓库 |
- 探索基准测试
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| Sys2Bench | - | 2025 | Shubham Parashar 等 | Sys2Bench 旨在系统性地测试大型语言模型在各类推理与规划任务中的表现。该基准涵盖五种主要类型的推理:算法推理、规划、算术推理、逻辑推理和常识推理,共包含 11 个子任务,从 NP 难问题(如魔方和装箱问题)到多步数学问题(如 GSM8K)。Sys2Bench 特别强调推理过程中的中间步骤,突出推理路径的质量与效率。此外,该项目还引入了 AutoHD(自动化启发式发现)方法,允许模型在推理过程中自主生成启发式函数,从而提升复杂任务的规划能力。 | 🤗数据集 🌐仓库 |
| BanditBench | - | 2025 | Allen Nie 等 (斯坦福大学) | BanditBench 旨在评估大型语言模型在多臂老虎机(MAB)和上下文老虎机(CB)环境下的探索与决策能力。该基准将 LLM 模拟为智能体,仅依靠上下文信息进行多轮交互而不更新参数,以此衡量其在不确定性环境中的表现。BanditBench 提供多种任务场景,包括基于 MovieLens 数据集的电影推荐任务,覆盖不同的动作数量和奖励分布类型(如高斯分布和伯努利分布)。此外,研究人员还引入了算法引导的推理支持和算法蒸馏方法,以提升 LLM 的探索效率。 | 🌐仓库 |
- 反思基准测试
| 名称 | 问题数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| RewardBench | 2,958 | 2024 | Nathan Lambert 等 (AI2) | RewardBench 是首个系统的奖励模型评估基准,由 AI2 和华盛顿大学联合发布,旨在从对齐质量、推理能力、安全性及指令遵循等多个维度,分析和比较不同训练方法下奖励模型的性能,提供统一的评估框架。 | 🤗数据集 🌐仓库 🌐网站 |
| ProcessBench | 3,400 | 2024 | 郑楚杰 等 (通义千问团队) | ProcessBench 是阿里巴巴通义千问团队提出的一个数学推理过程评估基准,包含 3,400 道带有分步解答的奥数级题目,每一步都经过人工标注是否存在错误。该基准要求模型识别推理过程中最早出现的错误步骤,侧重于过程监督而非仅关注最终答案。评估结果显示,通用语言模型(如 QwQ-32B-Preview)在分步批评任务中表现优于专门训练的过程奖励模型(PRM),接近 GPT-4o 的水平。 | 🤗数据集 🌐仓库 |
| PRMBench | 6,216 | 2025 | Mingyang Song 等 (复旦大学、上海人工智能实验室) | PRMBench 旨在填补现有基准主要关注步骤正确性而缺乏对 PRM 系统性评估的空白,提供一个涵盖简洁性、鲁棒性和敏感性等多个维度的统一评估框架。基准中的每个样本包括一道题目、一段含有错误的推理过程、错误步骤的标注以及错误原因,以评估 PRM 对细粒度错误的检测能力。 | 🤗数据集 🌐仓库 🌐网站 |
| CriticBench | ~3,800 | 2024 | 天兰 等 (清华大学) | CriticBench 由清华大学等机构提出,是一个用于评估大型语言模型批评与修正能力的综合性基准。它覆盖数学、常识、符号推理、编程和算法五大推理领域,整合了 15 个数据集,用于评估 17 种 LLM 在生成、批评和修正三个阶段的表现。研究发现,专门为批评任务训练的模型在“生成-批评-修正”(GQC)任务中表现更好,且规模更大的模型具有更高的批评一致性。 | 🤗数据集 🌐仓库 🌐网站 |
| DeltaBench | 1,236 | 2025 | OpenStellarTeam | DeltaBench 由 OpenStellar Team 发布,是一个用于评估大型语言模型在长链式思维(CoT)推理任务中错误检测能力的基准。它包含 1,236 个样本,涵盖数学、编程、物理-化学-生物(PCB)推理以及通用推理等领域。每个样本都配有详细的人工标注,标明错误步骤、策略转变及反思效率。 | 🤗数据集 🌐仓库 🌐网站 |
| ErrorRadar | 2,500 | 2024 | Yan Yibo 等 (Squirrel AI) | ErrorRadar 是一个多模态数学推理错误检测基准,旨在评估多模态大型语言模型识别和分类学生解题过程中错误的能力。该基准包含来自真实教育场景的 2,500 道 K-12 数学题目,融合文本和图像信息,并标注错误步骤及错误类型。评估任务包括定位错误步骤和分类错误类型。 | 🤗数据集 🌐仓库 🌐网站 |
| MEDEC | 3,848 | 2024 | Ben Abacha Asma 等 (微软) | MEDEC 是首个公开的医疗错误检测与纠正基准,由微软和华盛顿大学联合发布。它包含 3,848 篇临床文本,涵盖诊断、治疗和用药等五类错误,为提升医疗文档生成的准确性和安全性提供了重要工具。 | 🌐仓库 |
5.1.4 高级基准测试
专门设计用于评估大型语言模型在复杂推理、跨领域知识整合和多模态理解方面能力的基准测试。随着基础评估逐渐被顶尖模型所饱和,研究人员开始开发更具挑战性的基准测试,以更准确地衡量模型在现实世界复杂任务中的表现。
- 智能体与具身推理
| 名称 | 问题数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| ToolComp | 485 | 2025 | Vaskar Nath等(Scale AI) | ToolComp旨在评估大型语言模型在复杂的多步骤工具使用任务中进行推理和过程监督的能力。该基准测试包含485个经过人工编辑和验证的提示,涉及11种不同工具的使用,以及1,731个分步监督标签,能够全面评估模型在多工具推理任务中的表现。 | 🌐官网 |
| OSWorld | 369 | 2025 | 谢天宝等(香港大学) | OSWorld是由香港大学、Salesforce Research等机构联合发布的多模态智能体评估基准,旨在测试AI在真实计算机环境中完成开放式任务的能力。该基准包含文件操作、网页浏览、办公软件使用等场景下的369个任务,支持Ubuntu、Windows和macOS系统。 | 🌐仓库 🌐官网 |
| WebShop | 12,087条指令 / 118万件商品 | 2022 | 姚顺宇等(普林斯顿大学) | WebShop模拟了一个电子商务网站环境,用于评估大型语言模型在真实网络交互中的能力。该基准包含118万件真实商品和12,087条用户指令,要求智能体根据自然语言指令浏览网页、搜索、筛选并完成购买任务。WebShop专注于评估模型对复杂指令的理解能力、处理网络干扰的能力以及策略探索能力。 | 🌐仓库 🌐官网 |
| WebArena | 812 | 2024 | 周淑燕等(卡内基梅隆大学) | WebArena是由卡内基梅隆大学发布的一个高保真网络环境,旨在评估大型语言模型在真实网络任务中的智能体能力。该基准包含812个任务,涵盖电子商务、社交论坛、内容管理和协作开发等领域,要求模型通过自然语言指令完成多步骤的网络交互。 | 🌐仓库 🌐官网 |
| WebGames | 50+ | 2025 | Thomas George等(Convergence AI) | WebGames是一个网页浏览智能体基准测试,涵盖了基本浏览操作、复杂输入处理、认知任务以及工作流自动化等内容。WebGames提供了一个轻量级、可验证的测试环境,支持快速迭代和评估,非常适合用于开发更强大的网络智能体。 | 🌐仓库 🌐官网 |
| Text2World | 103 | 2025 | 胡孟康等(香港大学) | Text2World是由香港大学等机构提出的一个基准测试,旨在评估大型语言模型从自然语言生成符号化世界模型的能力。该基准基于规划域定义语言(PDDL),覆盖数百个不同的领域,采用多维度、基于执行的评估方法,以提供更为稳健的评估结果。 | 🌐仓库 🌐官网 |
- 多模态推理
- 复杂数学:
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|:-------:|:-----------:|:--------:|:------------------------:|:------------------------------------------------------------------------------------------:|:---------:|
| MathVista | 6,141 | 2023 | 潘陆等(加州大学洛杉矶分校) | MathVista是由加州大学洛杉矶分校、华盛顿大学和微软研究院联合发布的多模态数学推理评估基准。它旨在系统地评估大型语言模型和多模态模型在视觉情境下的数学推理能力。 | 🤗数据集
🌐仓库
🌐官网 |
| MathVision | 3,040 | 2024 | 王科等(香港中文大学) | MathVision(MATH-V)是由香港中文大学等机构发布的多模态数学推理评估基准。其目标是在视觉情境中系统地评估大型视觉-语言模型的数学推理能力。该基准包含来自16个数学领域的3,040道题目,分为五个难度级别,题目均来源于真实的数学竞赛。 | 🤗数据集
🌐仓库
🌐官网 |
| MathVerse | ~15,000 | 2024 | 陆子木等(香港中文大学) | MathVerse是由香港中文大学MMLab与上海人工智能实验室联合发布的多模态数学推理评估基准。它旨在全面评估多模态大型语言模型对数学图表的理解能力。该基准包含2,612道题目,涵盖平面几何、立体几何和函数等领域,并由专家进行标注。基准生成六种版本的多模态信息,总计约15,000个测试样本。MathVerse引入了思维链(CoT)评估策略,利用GPT-4V对模型的推理过程进行细粒度分析。 | 🤗数据集
🌐仓库 |
- **复杂代码:**
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|:-------:|:-----------:|:--------:|:------------------------:|:------------------------------------------------------------------------------------------:|:---------:|
| HumanEval-V | 253 | 2024 | 张峰吉等(香港城市大学) | HumanEval-V是由香港大学提出的一种多模态代码生成评估基准,旨在测试大型多模态模型在复杂图表理解及代码生成任务中的能力。该基准包含253个Python编程任务,每个任务都配有关键图表和函数签名,要求模型根据视觉信息生成可执行代码。 | 🤗[数据集](https://huggingface.co/datasets/HumanEval-V/HumanEval-V-Benchmark) <br> 🌐[仓库](https://github.com/HumanEval-V/HumanEval-V-Benchmark) <br> 🌐[官网](https://humaneval-v.github.io/) |
| Code-Vision | 1,000+ | 2025 | 王汉斌等(北京大学) | Code-Vision是由北京大学、东北大学和香港大学联合发布的多模态代码生成评估基准。其目标是测试多模态大型语言模型理解流程图并生成相应代码的能力。该基准填补了现有基准的空白——现有基准大多侧重于文本推理,缺乏对视觉情境下代码生成的系统性评估——并提供了一个统一的评估框架。 | 🌐[仓库](https://github.com/wanghanbinpanda/CodeVision) <br> 🌐[官网](https://pingshengren0901.github.io/codevision.io/) |
| ChartMimic | 4,800 | 2024 | 杨成等(清华大学) | ChartMimic是由清华大学、腾讯AI实验室等机构联合发布的多模态代码生成评估基准。它旨在评估大型多模态模型在图表理解和代码生成方面的跨模态推理能力,以弥补现有基准主要关注文本推理而缺乏对图表理解和代码生成系统性评估的不足。该基准包含两种任务类型:直接模仿和定制模仿,数据来源于多个领域的科学论文。 | 🤗[数据集](https://huggingface.co/datasets/ChartMimic/ChartMimic) <br> 🌐[仓库](https://github.com/ChartMimic/ChartMimic) <br> 🌐[官网](https://chartmimic.github.io/) |
- **复杂科学:**
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|:-------:|:-----------:|:--------:|:------------------------:|:------------------------------------------------------------------------------------------:|:---------:|
| ScienceQA | 21,208 | 2022 | Pan Lu et al. (UCLA) | ScienceQA 是一个包含自然科学、语言科学和社会科学领域共 21,208 道题目的多模态选择题数据集,面向 K-12 年级学生。该数据集提供图像与文本相结合的背景信息、解题说明及详细答案,支持链式思维(CoT)推理,旨在评估并提升 AI 模型的多步推理能力和可解释性。 | 🤗数据集
🌐仓库
🌐网站 |
| M3CoT | 11,459 | 2024 | Qiguang Chen et al. (HIT-SCIR Lab) | M3CoT 是基于 ScienceQA 构建的一个多模态、多领域、多步推理数据集,用于评估 AI 模型在复杂推理任务中的能力。与 ScienceQA 相比,M3CoT-Science 的平均推理步骤从 2.5 增加到 10.9,平均文本长度也由 48 字增至 294 字,显著提升了任务难度。该数据集涵盖科学、常识和数学等领域,强调图像与文本信息之间的交叉推理,对现有多模态大模型的推理能力提出了更高挑战。 | 🤗数据集
🌐仓库
🌐网站 |
| MolPuzzle | 234 | 2024 | Kehan Guo et al. | MolPuzzle 是一个用于评估大型语言模型在分子结构分析任务中表现的多模态、多步推理数据集。该数据集包含多种光谱数据类型,包括红外光谱(IR)、质谱(MS)以及核磁共振(1H-NMR 和 13C-NMR),同时还提供分子式信息。任务分为三个阶段:分子理解、光谱分析和分子构建,模拟真实的化学推理过程。 | 🤗数据集
🌐仓库
🌐网站 |
- **常识推理数据集:**
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|:-------:|:-----------:|:--------:|:------------------------:|:------------------------------------------------------------------------------------------:|:---------:|
| PuzzleVQA | 2,000 | 2024 | Yew Ken Chia et al. | PuzzleVQA 是一个包含 2,000 道抽象图形谜题的多模态推理数据集,旨在评估大型多模态模型在颜色、数字、形状和大小等基本概念上的视觉感知、归纳和演绎能力。实验表明,即使是 GPT-4V 等先进模型,在单一概念谜题上的平均准确率也仅为 46.4%,远低于人类水平,这暴露出其在抽象模式识别和多步推理方面的局限性。 | 🤗[数据集](https://huggingface.co/datasets/declare-lab/PuzzleVQA) <br> 🌐[仓库](https://github.com/declare-lab/LLM-PuzzleTest/tree/master/PuzzleVQA) <br> 🌐[网站](https://puzzlevqa.github.io/) |
| LEGO-Puzzles | 1,100 | 2025 | Kexian Tang et al. (Shanghai AI Lab) | LEGO-Puzzles 数据集旨在评估大型多模态语言模型在多步空间推理任务中的能力。该数据集包含 1,100 道基于乐高积木的视觉问答(VQA)题目,覆盖 11 种任务类型,包括空间理解、单步及多步序列推理等。 | 🤗[数据集](https://huggingface.co/datasets/KexianTang/LEGO-Puzzles) <br> 🌐[仓库](https://github.com/Tangkexian/LEGO-Puzzles) <br> 🌐[网站](https://tangkexian.github.io/LEGO-Puzzles/) |
| CVQA | 10,374 | 2024 | David Romero et al. (MBZUAI) | CVQA 是一个多模态视觉问答数据集,用于评估模型整合多种视觉线索进行综合推理的能力。该数据集包含三类任务,要求模型从多张图片中提取并综合关键信息以回答复杂问题。 | 🤗[数据集](https://huggingface.co/datasets/afaji/cvqa) <br> 🌐[网站](https://cvqa-benchmark.org/) |
- AI4Research:
| 名称 | 题目数量 | 发布日期 | 作者 | 描述 | 相关链接 |
|---|---|---|---|---|---|
| SciWorld | 30个任务 / 6,000+个实例 | 2022 | 王若瑶等 | SciWorld旨在评估大型多模态模型在复杂科学场景下的理解与推理能力。该数据集融合了图像、文本和结构化数据,覆盖多个科学领域,并设计了多步推理任务,以挑战模型整合多源信息、进行因果推理及提供可解释答案的能力。它包含30个任务,每个任务又有多种变体,总计超过6,000个实例。SciWorld的推出推动了多模态模型在科学教育和研究中的应用。 | 🌐仓库 🌐官网 |
| HardML | 100 | 2025 | Tidor-Vlad Pricope | HardML是一个专门用于评估人工智能在数据科学和机器学习领域知识与推理能力的基准数据集。它由独立机器学习工程师Tidor-Vlad Pricope创建,包含100道精心设计的选择题,涵盖自然语言处理、计算机视觉、统计建模以及经典机器学习算法等主题。这些题目难度极高,即便是经验丰富的机器学习工程师也难以全部答对。为避免数据污染,大部分题目均为原创,反映了过去两年来机器学习领域的最新进展。目前最先进的AI模型在HardML上的错误率约为30%,是MMLU-ML的三倍,这充分证明了HardML在区分模型能力方面的有效性。此外,作者还发布了稍易一些的EasyML数据集,专为参数量较少的模型设计。 | 📄论文 |
| MLE-BENCH | 75 | 2024 | OpenAI | MLE-bench是由OpenAI发布的基准数据集,旨在评估AI智能体在机器学习工程(MLE)任务中的实际能力。该基准从Kaggle平台上精选了75个多样化的竞赛任务,涵盖自然语言处理、计算机视觉、信号处理等领域,测试模型在数据预处理、模型训练和实验执行等方面的工程技能。在评测中,结合AIDE框架的OpenAI o1-preview模型在16.9%的任务上达到了Kaggle铜牌水平。研究还探讨了资源扩展对性能的影响以及预训练数据污染相关问题。 | 🌐仓库 🌐官网 |
| SolutionBench | 1,053 | 2025 | 李卓群等(中国科学院软件研究所) | SolutionBench是一个用于评估AI系统在复杂工程解决方案设计方面能力的基准数据集。它旨在填补当前检索增强生成(RAG)方法在处理多约束工程问题上的空白,其特点是使用真实数据源和结构化数据。此外,作者还提出了一种名为SolutionRAG的系统,通过结合树状搜索和双点思维机制,在SolutionBench上取得了领先性能。 | 🤗数据集 🌐仓库 |
5.2 训练数据集
为了构建并提升具备强大Long CoT能力的模型,众多开源训练数据集应运而生。这些数据集为数学、科学、医学、编程以及通用推理等多个领域提供了基础性的监督信号。根据其构建方式,我们将这些数据集分为四大类:人工标注、直接蒸馏、基于搜索的蒸馏以及验证蒸馏。
在本节中,我们系统地列出了每一类中具有代表性的数据集,涵盖了它们的来源、模态、适用领域及数据规模等关键信息,为寻求合适训练资源的研究人员和开发者提供全面的指南与便捷的参考。
5.2.1 人工标注
这类数据集通过人工标注或规则构建而成,通常提供高质量且推理路径可解释的样本。尽管规模较小,但它们对于引导初始模型的对齐与评估至关重要。
- R1-OneVision 将 LLaVA-OneVision 的高质量数据与特定领域的数据集相结合,弥合了视觉与文本理解之间的鸿沟,提供了涵盖自然场景、科学、数学、基于 OCR 的内容以及复杂图谱等丰富且具备上下文感知的推理任务。
- M3CoT 为多领域、多步骤、多模态的思维链研究奠定了基础。
- Big-Math-RL-Verified 专为使用大型语言模型(LLMs)进行强化学习训练而设计,例如 PPO、GRPO 等。
- GSM8K 是一个高质量、语言多样性丰富的小学数学应用题数据集。
| 名称 | 类别 | 来源 | 模态 | 数量 |
|---|---|---|---|---|
| R1-OneVision | 数学、科学 | 规则 | 视觉 + 文本 | 119K |
| M3CoT | 数学、科学 | 人工 | 视觉 + 文本 | 11K |
| Big-Math-RL-Verified | 数学 | 人工 | 文本 | 251K |
| GSM8K | 数学 | 人工 | 文本 | 8K |
5.2.2 直接蒸馏
该方法利用大型语言模型通过提示或思维链式推理生成训练数据。这些数据集可以扩展到数百万个样本,覆盖广泛的领域。
- NaturalReasoning 通过知识蒸馏实验验证,NaturalReasoning 能有效从强大的教师模型中提取并迁移推理能力。它在使用外部奖励模型进行无监督自训练或采用自我奖励机制时同样高效。
- NuminaMath-CoT 采用思维链(CoT)格式来解答每一道题目。该数据集涵盖了中国高中数学练习题、美国及国际数学奥林匹克竞赛题目等,数据来源于在线考试 PDF 文件和数学论坛。处理步骤包括:(a) 对原始 PDF 文件进行 OCR 识别;(b) 将内容分割为题目-解答对;(c) 翻译成英文;(d) 重新组织以生成思维链推理格式;以及 (e) 最终答案的格式化。
- NuminaMath-TIR 专注于从 NuminaMath-CoT 数据集中选取的需输出数值结果的题目。研究团队利用 GPT-4 构建了一条流水线,用于生成类似 TORA 的推理路径、执行代码并得出结果,直至完成最终解答,并过滤掉最终答案与参考答案不符的解法。
- DART-Math-uniform 通过应用 DARS-Uniform 方法构建数据集。
- DART-Math-hard 是基于 DARS-Prop2DiffMATH 和 GSK8K 训练数据集中的查询集构建的数学问答样本。它在多个具有挑战性的数学推理基准上取得了 SOTA 效果,与传统的拒绝采样方法不同,该数据集刻意偏好难度较高的问题。
- DART-Math-pool-math 是由 MATH 训练数据集的查询集合成的数据池,包含所有正确答案的样本以及过程中生成的额外元数据。DART-Math-- 系列数据集均是从 DART-Math-pool-- 数据池中抽取的。
- DART-Math-pool-gsm8k 是由 GSM8K 训练数据集的查询集合成的数据池,包含所有正确答案的样本以及额外的元数据。DART-Math-- 系列数据集也从中抽取。
- OpenO1-SFT 是一个用于通过 SFT 微调语言模型以激活思维链推理的数据集。
- OpenO1-SFT-Pro 是一个用于通过 SFT 微调语言模型以激活思维链推理的数据集。
- OpenO1-SFT-Ultra 基于现有的开源数据集,使用 openo1-qwen-sft 模型合成而成。
- Medical-o1 是一个基于可医学验证的问题及 LLM 验证器构建的 SFT 医学推理数据集。
- AoPS-Instruc 是一个大规模高质量的高级数学推理问答数据集,采用可扩展的方法创建并维护。
- Orca-Math 是一个高质量的合成数据集,包含 20 万道数学题,这些题目是在多智能体协作的设置下生成的。
- MATH-plus 从预训练网络语料库中收集了 1000 万条自然发生的指令数据。
- UltraInteract-SFT 专为复杂推理任务设计,有助于探索推理任务中的偏好学习。它适用于监督微调和偏好学习。每条指令都包含一个偏好树,由以下部分组成:(1) 具有多重规划策略且格式一致的推理链条;(2) 与环境的多轮交互轨迹及评论;以及 (3) 用于促进偏好学习的配对数据。
- MathCodeInstruct 是一个新颖的高质量数据集,包含数学问题及其基于代码的解答。
- MathCodeInstruct-Plus $Paper¹, ²$ 是一个新颖的高质量数据集,包含数学问题及其基于代码的解答。
- OpenMathInstruct-1[HuggingFace] 是一个数学指令调整数据集,利用 Mixtral-8x7B 模型生成了 180 万个题目-解答对。题目来源于 GSM8K 和 MATH 训练子集;解答则由 Mixtral 模型通过文本推理和 Python 解释器执行的代码块合成。
- OpenMathInstruct-2 是一个大规模的数学推理数据集,用于训练大型语言模型(LLM)。
- AceMath-Instruct 是 AceMath 中用于训练尖端数学推理模型的训练数据集。
- QwQ-LongCoT 整合了来自多个高质量来源的提示,以创建多样化且全面的训练数据。
- SCP-116K 是一套高质量的科学问答对,由网络爬取的文档中自动提取而来。每个问题都配有从原始资料中提取的匹配答案,以及由先进语言模型生成的回答和推理过程。
- R1-Distill-SFT 使用 DeepSeek-R1-32b 进行蒸馏;数据由 Numina-math 和 Tulu 提供;每个提示都会采样一条回答。
- Sky-T1-Data 包含来自 APPs 和 TACO 的 5000 条编码数据,以及来自 NuminaMATH 数据集中 AIME、MATH 和奥林匹克竞赛子集的 1 万条数学数据。此外,还保留了 STILL-2 中的 1000 条科学和谜题数据。
- Bespoke-Stratos-17k 是一个包含问题、推理轨迹和答案的推理数据集。它复制并改进了 Berkeley Sky-T1 数据流水线,使用 DeepSeek-R1 蒸馏后的 SFT 数据。
- s1K 包含 1000 个多样、高质量且困难的例题(源自 Gemini Thinking),用于优化推理路径和解答。
- MedThoughts-8K
- SYNTHETIC-1 是 Deepseek-R1 生成的最大开放式推理数据集,涵盖数学、编程、科学等领域的推理轨迹,并由特定任务的验证器确认其正确性。
- Medical-R1-Distill-Data 是一个基于 HuatuoGPT-o1 可医学验证问题的 SFT 数据集,由 Deepseek-R1(全功率版)蒸馏而来。
- Medical-R1-Distill-Data-Chinese 是一个基于 HuatuoGPT-o1 可医学验证问题的 SFT 中文版数据集,由 Deepseek-R1(全功率版)蒸馏而来。
- RLVR-GSM-MATH 用于训练 Tulu3 模型。
- LIMO “少即是多”——用于推理。
- OpenThoughts-114k 是一个开放的合成推理数据集,包含 11.4 万个高质量示例,覆盖数学、科学、代码和谜题等领域。
- Magpie-Reasoning-V2 通过使用预查询模板提示对齐 LLM,生成高质量的对齐数据。
- Dolphin-R1 是一个包含 80 万条样本的数据集,其构成与用于训练 DeepSeek-R1 Distill 模型的数据集相似。
| 名称 | 类别 | 来源 | 模态 | 数量 |
|---|---|---|---|---|
| NaturalReasoning | 科学、通用 | Llama3.3-70B | 语言 | 100万 |
| NuminaMath-CoT | 数学 | GPT-4o | 语言 | 86万 |
| NuminaMath-TIR | 数学 | GPT-4o | 语言 | 7.3万 |
| DART-Math-uniform | 数学 | DeepSeekMath-7B-RL | 语言 | 59.1万 |
| DART-Math-hard | 数学 | DeepSeekMath-7B-RL | 语言 | 58.5万 |
| DART-Math-pool-math | 数学 | DeepSeekMath-7B-RL | 语言 | 160万 |
| DART-Math-pool-gsm8k | 数学 | DeepSeekMath-7B-RL | 语言 | 270万 |
| OpenO1-SFT | 数学、科学、通用 | - | 语言 | 7.8万 |
| OpenO1-SFT-Pro | 数学、科学、通用 | - | 语言 | 12.6万 |
| OpenO1-SFT-Ultra | 数学、科学、通用 | - | 语言 | 2800万 |
| Medical-o1 | 医学 | DeepSeek R1 | 语言 | 5万 |
| AoPS-Instruct | 数学 | Qwen2.5-72B | 语言 | 64.7万 |
| Orca-Math | 数学 | GPT-4 | 语言 | 20万 |
| MATH-plus | 数学 | GPT-4 | 语言 | 89.4万 |
| UltraInteract-SFT | 数学、代码、逻辑 | GPT-4 CoT + PoT | 语言 | 28.9万 |
| MathCodeInstruct | 数学 | GPT-4 + Codellama PoT | 语言 | 7.9万 |
| MathCodeInstruct-Plus | 数学 | - | 语言 | 8.8万 |
| OpenMathInstruct-1 | 数学 | Mixtral-8x7B PoT | 语言 | 500万 |
| OpenMathInstruct-2 | 数学 | Llama3.1-405B | 语言 | 1400万 |
| AceMath-Instruct | 数学、通用 | Qwen2.5-Math-72B + GPT-4o-mini | 语言 | 500万 |
| QwQ-LongCoT | 通用 | QwQ | 语言 | 28.6万 |
| SCP-116K | 科学 | QwQ + O1-mini | 语言 | 11.7万 |
| R1-Distill-SFT | 数学 | DeepSeek-R1-32B | 语言 | 17.2万 |
| Sky-T1-Data | 数学、代码、科学、谜题 | QwQ | 语言 | 1.7万 |
| Bespoke-Stratos-17k | 数学、代码、科学、谜题 | DeepSeek R1 | 语言 | 1.7万 |
| s1K | 数学 | DeepSeek R1 | 语言 | 1000 |
| MedThoughts-8K | 医学 | DeepSeek R1 | 语言 | 8000 |
| SYNTHETIC-1 | 数学、代码、科学 | DeepSeek R1 | 语言 | 89.4万 |
| Medical-R1-Distill-Data | 医学 | DeepSeek R1 | 语言 | 2.2万 |
| Medical-R1-Distill-Data-Chinese | - | - | 语言 | 1.7万 |
| RLVR-GSM-MATH | 数学 | - | 语言 | 3万 |
| LIMO | 数学 | 人类 + DeepSeek R1 + Qwen2.5-32B | 语言 | 817 |
| OpenThoughts-114k | 数学、代码、科学、谜题 | - | 语言 | 11.4万 |
| Magpie-Reasoning-V2 | 数学、代码 | DeepSeek-R1 + Llama-70B | 语言 | 25万 |
| Dolphin-R1 | 数学、科学 | DeepSeek R1 + Gemini2 + Dolphin | 语言 | 81.4万 |
5.2.3 基于搜索的蒸馏
基于搜索的数据集是通过自动化搜索算法构建的,该算法会探索推理树以生成最优的推理轨迹。尽管规模有限,但这些数据集通常能够生成高质量且深度的推理样本。
- STILL-1 通过奖励引导的树搜索算法提升了大型语言模型(LLM)的推理能力。
| 名称 | 类别 | 来源 | 模态 | 数量 |
|---|---|---|---|---|
| STILL-1 | 数学、代码、科学、谜题 | LLaMA-3.1-8B-Instruct + MCTS | 语言 | 5000 |
5.2.4 经验证的蒸馏
经验证的数据集包含基于规则的过滤、测试用例验证或大型语言模型验证,以确保质量。这类数据集在可扩展性和可靠性之间取得了平衡。
- KodCode-V1 提供可验证的代码任务解决方案和测试用例;专为监督微调(SFT)和强化学习(RL)优化设计;涵盖多个领域(从算法到特定领域的软件知识)以及不同难度级别(从基础编码练习到面试和竞赛编程挑战)。
- KodCode-V1-SFT-R1 提供可验证的代码任务解决方案和测试用例;专为监督微调(SFT)和强化学习(RL)优化设计;涵盖多个领域(从算法到特定领域的软件知识)以及不同难度级别(从基础编码练习到面试和竞赛编程挑战)。
- OpenR1-Math 是一个大规模数学推理数据集,由 DeepSeek R1 为 NuminaMath 1.5 版本的问题生成,每道题包含两到四条推理路径。
- Chinese-DeepSeek-R1-Distill-Data 是来自 DeepSeek-R1 的中文开源蒸馏数据集,不仅包含数学数据,还包含大量通用类型的数据。
- AM-DeepSeek-R1-Distilled 包含来自众多开源数据集的问题,这些问题经过语义去重和清洗,以避免测试集污染。答案是从推理模型(主要是 DeepSeek-R1)中提取的,并经过严格验证:数学问题通过核对答案进行验证,代码问题通过测试用例验证,其他任务则通过奖励模型评估。
| 名称 | 类别 | 来源 | 模态 | 数量 |
|---|---|---|---|---|
| KodCode-V1 | - | GPT-4 + 测试用例验证 | 文本 | 447K |
| KodCode-V1-SFT-R1 | 代码 | DeepSeek R1 + 测试用例验证 | 文本 | 443K |
| OpenR1-Math | 数学 | DeepSeek R1 + 规则与大语言模型验证 | 文本 | 225K |
| Chinese-DeepSeek-R1-Distill-Data | 数学、科学、通用 | DeepSeek R1 + 规则与大语言模型验证 | 文本 | 110K |
| AM-DeepSeek-R1-Distilled | 数学、代码、通用 | 奖励模型 + 规则与大语言模型验证 | 文本 | 1.4M |
7. 论文列表 & 精选资源
Awesome-Long-Chain-of-Thought-Reasoning(我们的官方论文列表,1000+篇)
🎁 引用
如果您觉得这项工作有用,请引用我们。
@misc{chen2025reasoning,
title={迈向推理时代:面向推理型大语言模型的长链式思维综述},
author={Qiguang Chen、Libo Qin、Jinhao Liu、Dengyun Peng、Jiannan Guan、Peng Wang、Mengkang Hu、Yuhang Zhou、Te Gao、Wanxiang Che},
year={2025},
eprint={2503.09567},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2503.09567},
}
贡献
如果您有关于长链式思维的有趣新闻,也可以在 Twitter 上 @Qiguang_Chen(QiguangChen)或发送邮件至 charleschen2333@gmail.com,以便我们在 GitHub 仓库中跟进并更新。
希望大家都能享受长链式思维的时代 :)
⭐ 星标历史

相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。