Luotuo-Chinese-LLM
骆驼 (Luotuo) 是一个由华中师范大学与商汤科技研究人员联合发起的开源中文大语言模型项目。它旨在填补高质量中文大模型生态的空白,提供从底层训练数据、基础模型到上层应用的一站式解决方案。
针对中文语境下优质指令数据匮乏及模型适配性不足的痛点,骆驼项目构建了名为“丝绸之路”的数据基础,并衍生出多个针对性子模型。例如,“迷你骆驼”通过蒸馏技术实现了轻量化部署;“骆驼嵌入”提供了媲美商业 API 的文本向量化能力;而"Chat 凉宫春日”则展示了其在角色扮演与个性化对话方面的潜力。这些成果不仅降低了中文大模型的使用门槛,也为社区提供了丰富的实验素材。
骆驼非常适合 AI 开发者、学术研究人员以及希望探索大模型落地应用的技术团队使用。对于想要微调专属中文模型或构建智能对话应用的开发者而言,骆驼提供了完整的管线支持和预训练权重。其独特的命名灵感虽源自 LLaMA 和 Alpaca 的动物系列传统,但核心亮点在于对中文特性的深度优化及高度开放的社区协作模式,让每一位参与者都能轻松上手,共同推动中文人工智能技术的发展。
使用场景
某电商初创团队希望快速搭建一个能理解中文语境、具备特定人设(如“热情导购”)的智能客服系统,以应对大促期间的高并发咨询。
没有 Luotuo-Chinese-LLM 时
- 语言理解生硬:直接调用国外开源模型或早期通用模型,对中文特有的成语、网络梗及复杂句式理解偏差大,回复常出现“翻译腔”,缺乏亲和力。
- 角色定制困难:想要让客服模仿特定语气(如活泼、专业),需要收集海量高质量对话数据进行从头训练,中小团队无力承担昂贵的算力成本和时间周期。
- 数据隐私担忧:依赖海外闭源 API 处理用户订单和投诉数据,存在合规风险,且无法在本地私有化部署以保障数据安全。
- 响应延迟高:通用大模型参数量巨大,在有限的服务器资源上推理速度慢,难以满足实时互动的低延迟要求。
使用 Luotuo-Chinese-LLM 后
- 原生中文优势:利用 Luotuo-Chinese-LLM 在中文语料上的深度优化,模型能精准捕捉用户意图,自然运用中文表达习惯,沟通流畅度显著提升。
- 低成本角色微调:基于项目提供的“迷你骆驼”或指令微调方案,团队仅需少量示例数据即可快速蒸馏出具有“热情导购”人设的专用模型,大幅降低训练门槛。
- 安全私有部署:作为完全开源的项目,Luotuo-Chinese-LLM 支持本地化部署,确保所有用户交互数据留存于内网,彻底消除隐私泄露顾虑。
- 高效推理性能:通过蒸馏技术得到的轻量化模型,在保持高智能水平的同时显著减少显存占用,使普通显卡也能实现毫秒级响应,完美支撑高并发场景。
Luotuo-Chinese-LLM 让中小团队也能以极低的成本,拥有懂中文、有个性且安全可控的专属大语言模型能力。
运行环境要求
- 未说明
- 未说明 (项目基于 LLaMA/GLM 等模型,通常需 NVIDIA GPU,但 README 未明确具体型号或显存要求
- 部分子项目如 Mini-Luotuo 提及可在单卡运行)
未说明

快速开始
English | 中文 | 快速上手 | 赞助 | 赞助 | 人员和贡献 | 相关项目 | 骆驼读论文
骆驼(Luotuo): 开源中文大语言模型
骆驼(Luotuo)项目是由冷子昂 @ 商汤科技, 陈启源 @ 华中师范大学 以及 李鲁鲁 @ 商汤科技 发起的中文大语言模型开源项目,包含了一系列大语言模型、数据、管线和应用。

骆驼项目不是商汤科技的官方产品。
我们将项目命名为 骆驼 Luotuo (Camel) 主要是因为,Meta之前的项目LLaMA(驼马)和斯坦福之前的项目alpaca(羊驼)都属于偶蹄目-骆驼科(Artiodactyla-Camelidae)。而且骆驼科只有三个属,再不起这名字就来不及了。
项目重要更新 [ ... ]
[2023-07-12] 骆驼嵌入更新中模型 ![]() 。我们后面将准备再训一个英语的嵌入模型。
。我们后面将准备再训一个英语的嵌入模型。
[2023-06-07] 最近很多精力都在做 Chat凉宫春日, 可以点这个体验 ![]() ,这个项目还在持续招人, 欢迎联系
,这个项目还在持续招人, 欢迎联系
子项目一览
Chat凉宫春日
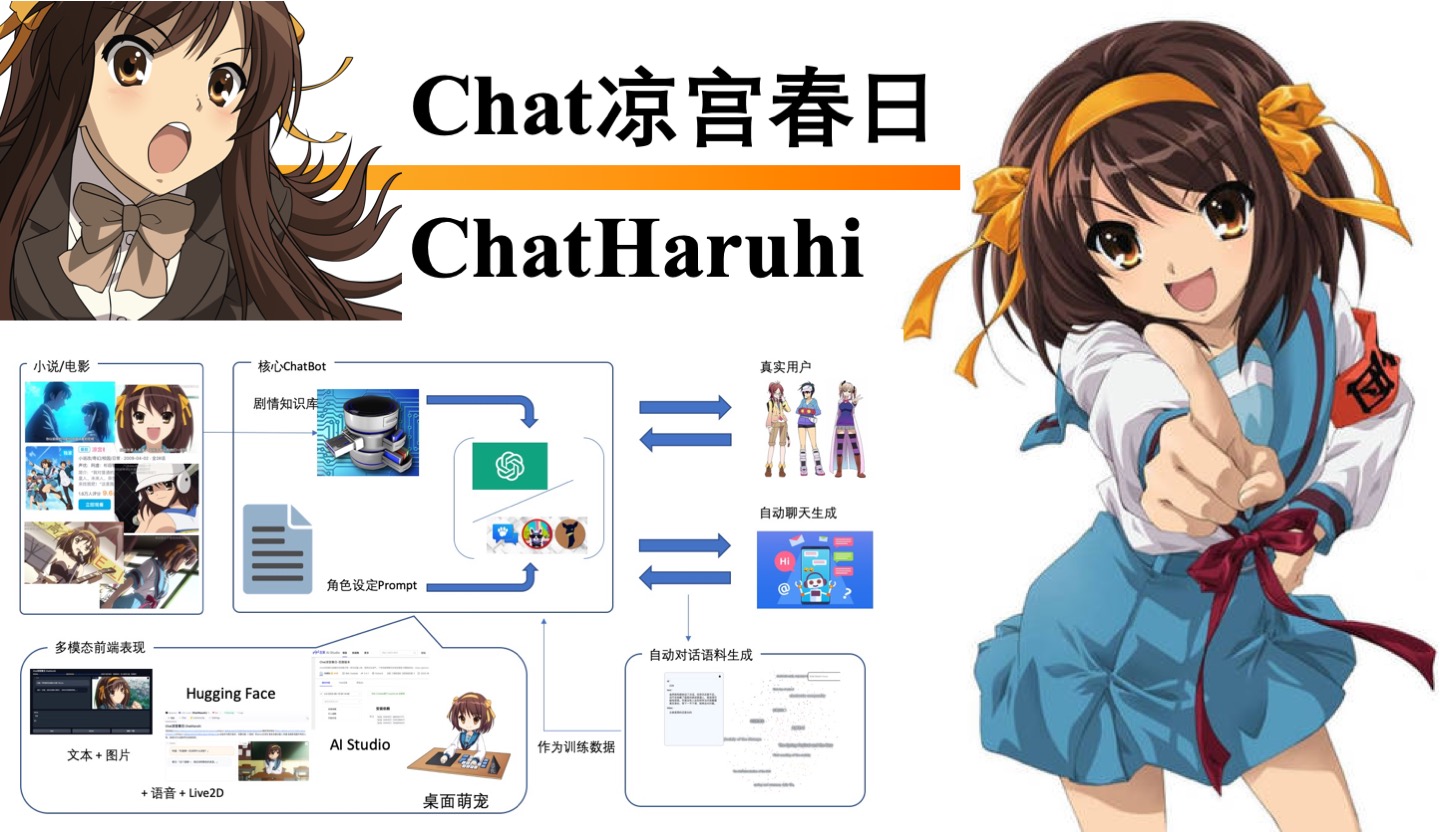
Chat凉宫春日是模仿凉宫春日等一系列动漫人物,使用近似语气、个性和剧情聊天的语言模型方案 |
骆驼嵌入
骆驼嵌入: Generative Text Embedding Model distilled from OpenAI API |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
骆驼QA

骆驼QA: Better Conversational Question Answering Model with Answer Completion |
迷你骆驼

迁移骆驼:一系列蒸馏指令数据得到的中文语言模型 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
丝绸之路

丝绸之路: 构建中文大语言模型的数据基础 |
Vanilla 骆驼

骆驼: An Instruction-following Chinese Language model, LoRA tuning on LLaMA |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
骆驼先知

骆驼先知是模仿纪伯伦的《先知》进行哲学讨论。 项目包含了Andrew Ng吴恩达Prompt工程的笔记和LangChain的笔记 |
丝绸魔法书

丝绸魔法书记录了大语言模型的一些魔法提示词(prompt)。 |
骆驼RPG
LuotuoRPG是斯坦福Generative Agents的中文版本尝试。 |
丫丫-MOSS
丫丫是基于复旦MOSS的LoRA训练代码 |
骆驼大乱斗
骆驼大乱斗正在构建之中... 骆驼大乱斗: Generating Massive Content for a Text-based Fighting Game |
骆驼CLIP
骆驼CLIP正在构建之中... 骆驼CLIP: Aligning Existed CLIP model with Multiple Prior Leveraged |
| Colab链接 | 细节 | |
|---|---|---|
| Chat凉宫春日(图文) | 能够根据台词搜索图片的gradio版本 | |
| Chat凉宫春日 | 李鲁鲁最早开发的gradio Chat凉宫春日 | |
| 骆驼先知 | 骆驼先知的Gradio交互版本 | |
| 骆驼QA | 骆驼QA的0.1模型,基于一段给定文本做问答 | |
| 骆驼嵌入(小) | LuotuoBERT 文本可视化 聚类 搜索 | |
| 批量翻译 | 利用GPT接口对数据集进行批量翻译 | |
| 骆驼RPG | 一个斯坦福35个Agents生成的中文版 | |
| 驼铃C 文本摘要 | 基于GLM-6B的文本摘要模型 | |
| 驼铃B Chat哈利波特 | - | Chat哈利波特的初步汇报 |
| 驼铃A | 通过80条语料给GLM-6B简易洗脑 | |
| 骆驼0.3 | 骆驼0.3的验证代码 | |
| 骆驼说 | 一个用Gradio写的交互对话 | |
| 骆驼说(GLM) | 中文文本摘要的Gradio交互界面 |
项目概览
让我来用时间顺序介绍整个骆驼项目的起源和发展。
在2023年3月20日,李鲁鲁老师实践了一下Alpaca-Lora的项目。
于是在3月21日的早晨,李鲁鲁在github上反查使用了LLaMATokenizer的代码,这个时候我们找到了Japanese-Alpaca-LoRA项目。于是我们很快意识到,也可以用同样的方法尝试用中文去tuning LLaMA的模型。
于是在简短的讨论后,我们建立了Chinese-alpaca-lora这个项目,并且在当天就上传了对应的模型和demo。在这个时代,人们需要自己传播自己的工作,所以李鲁鲁在知乎写了第一篇关于骆驼的文章【开源GPT】三位华人小哥开源中文语言模型“骆驼”,单卡即可完成训练部署,花费几百训练自己的中文聊天模型
|
Luotuo 骆驼Luotuo-Vanilla是骆驼项目的第一个github仓库, 它是在LLaMA-7B上进行微调的。骆驼项目的初始目标,是研究使用跨语言数据在进行微调时,大语言模型发生的相关现象。 |
详细描述
测试代码 ![]()
一个使用Gradio搭建的交互界面 ![]()
我们还在完善骆驼1.0的训练数据和修复bug,并且在后续的版本中,我们将研究如何修复骆驼的Tokenizer。
骆驼0.3 的输出样例
Input: 中国的首都在哪里?
Luotuo-Output: 中国的首都是北京。
Input: 华中师范大学在哪里
Luotuo-0.1-Output: 华中师范大学位于北京
Luotuo-0.3-Output: 华中师范大学在武汉市。
这个项目很快在三天之内获得了100个stars。不过这个时候我们发现唐杰老师的研究组已经发布了ChatGLM,那个时候GLM还没有对应的tuning代码。
于是我们简单修改并且尝试了一个总结摘要的LoRA模型
 |
Cambell 驼铃如果你希望模型在中文上有更好的表现,建议使用 CamelBell(驼铃), 这个项目在中文基模型Chat-GLM-6B的基础上继续使用中文语料进行训练。 |
详情
在驼铃-B(CamelBell-B)中我们将训练一个Chat哈利波特
CamelBell-B的输出样例
Instruction: 斯内普和伏地魔之间是什么关系?
Answer: 斯内普和伏地魔之间是非常复杂的关系。伏地魔是斯内普的雇主,他利用斯内普来执行他的计划。斯内普一开始是斯莱特林的学生,但他后来加入了伏地魔的阵营,成为了他的追随者。斯内普和伏地魔之间的关系非常紧张,他们互相对抗,但也有一些共同的利益。
CamelBell-C (驼铃-C)是一个中文文本摘要模型 ![]()
CamelBell-C的输出样例
Instruction: 请帮我总结以下内容:
Input:
北京时间2月13日凌晨,2023年ATP250达拉斯站男单决赛。中国球员吴易昺先输一盘后挽救4个赛点并兑现第5个冠军点,最终以6(4)-7/7-6(3)/7-6(12)逆转惊险击败赛会5号种子、美国大炮伊斯内尔,就此改写历史,成为公开赛年代首位夺得ATP巡回赛男单冠军的中国大陆球员,并创造中国大陆球员的男单最高排名!
第一盘比赛,吴易昺在第12局错过了一个盘点,并最终抢七惜败;第二盘则挽救一个赛点后抢七局3-0领先开局,且以7-6(3)扳回一盘;第三盘决胜盘,在关键的第9局15-40落后情况下凭借连续的高质量发球逆转保发,之后比赛再次进入抢七,抢七局依然胶着,吴易昺又挽救了3个赛点,并兑现了自己的第5个冠军点,就此锁定冠军!历史性一刻到来时,吴易昺瞬间躺倒在地。全场比赛,伊斯内尔轰出了44记Ace球,但最终在主场依然输给了吴易昺。
凭借具有突破意义的这一冠,吴易昺在本周入账250个积分和112125美元的冠军奖金,在周一最新一期的男单排名榜单上,创中国大陆男网历史新高排名—第58位。根据比赛计划,吴易昺原本要出战本周进行的ATP250德拉海滩站,不过在达拉斯夺冠后,吴易昺因身体疲劳退出本站赛事,他的签位由幸运落敗者约翰森替代。
Answer: 男子网坛历史性一刻!中国小将吴易昺逆转击败赛会5号种子,成公开赛年代首个冠军。
当然,随着ChatGLM2的发布,有很多更成熟的ChatGLM2的tuning项目,所以驼铃项目就休眠了。
到这里时候,我们开始思考,一方面想要突破模型token长度的限制,一方面需要结合本地知识库对模型进行输出。所以这里有两个关键点,一个是embedding,一个是Closed QA的模型。所以我们启动了骆驼嵌入和骆驼QA两个项目
 |
Luotuo Embedding 骆驼嵌入骆驼嵌入是一个文本嵌入模型,可以将长文本转化为1536维的向量,支持文本可视化、搜索、聚类、内容审核等下游业务。 |
骆驼嵌入是我们从OpenAI蒸馏特征得到的BERT的文本嵌入模型。![]()
【开源骆驼】我们蒸馏了OpenAI的特征,并用它分析了周杰伦的歌词,还打算复现360的Demo
骆驼嵌入是一个非相关从业者关注比较少的项目。但是我们发现其实有很多的开发者在使用这个模型。LuotuoBert在huggingface的下载量一度达到了一个月一万三千多次。这显然不是我们自己开发的下载量能cover的。骆驼嵌入最近有胡婧训练了中模型,并且我们(陈舒年)打算再训一个英语的嵌入模型,这样可以做一些中英文的对齐。
和骆驼嵌入同步启动的项目是骆驼QA。原则上骆驼嵌入+骆驼QA就可以形成一个好的本地知识库问答。在实践中我们相当于也验证了训练一个closed QA模型能够产生更好的效果。并且在上个月我们做了骆驼QA-B数据集(by 罗钦雨)。
【开源骆驼】骆驼团队发布,中文阅读理解模型,骆驼QA,可给定知识文本进行问答
 |
骆驼QA骆驼QA是指给定一段特定的文本,用户针对文本中的内容,进行一个提问。语言模型试图理解文本中的内容,对用户的问题进行回答。 |
不过这个项目最近进入休眠状态。一个很有价值事情是在Luotuo-QA-B数据集上重新finetune一个ChatGLM2,并且集成接入Langchain。应该会形成一个不错的本地知识库问答的系统。不过最近ChatHaruhi占用了李鲁鲁和冷子昂大多数的业余时间,所以这个事情就没人去lead了,如果你有能力和兴趣host这个项目,欢迎来联系我。
需要注意的是,除了语言模型和训练本身,语言模型的prompt也是在最近几年出现的一类新的问题,或者甚至可以说是一种新的范式。
|
Silk Magic Book 丝绸魔法书丝绸魔法书记录了大语言模型的一些魔法提示词(prompt)。我们希望有一天,骆驼项目自己训练的语言模型,也能适配很复杂任务的prompt。 |
让李鲁鲁非常惊讶的是,ChatGPT等超大模型中,往往能适配一些“超级prompt”,这些超级prompt其实很接近ChatGPT等这些模型的能力边界,李鲁鲁把这些prompt统一记录在了丝绸魔法书这个项目中。【骆驼杂谈】让文心一言回答知乎问题,他高兴地喊出了“谢邀”
在这个时候李鲁鲁的学习习惯已经调整为,看到一个需要学习的项目就fork下来,然后进行翻译或者comments,形成自己的理解。这其实相比于过往读论文,再让其他人去跑代码的方法,要直接了许多。当然这也得益于colab和huggingFace这些快速开发工具的进展。我一直在构思一篇《这是一个发展越来越快的时代》,本来想在校庆前后写的,之后找个时间写吧。
比如在看Stanford的Generative Agents的工作的时候,我们就可以顺手fork这个项目,https://github.com/LC1332/Chinese-generative-agents 并且进行一些翻译,就可以得到自己的结果。得益于计算机公共的底层和库,这种学习方式是非常高效的。
【开源骆驼】把斯坦福的25 ChatGPT玩游戏翻译成中文,佟湘玉与白展堂密谈了起来
在这个时期(5月初前后),吴恩达也放出了Prompting Engineering的课程。这个时候李鲁鲁注意到DataWhale翻译了这个课程。于是就在DataWhale的基础上fork了自己的版本,形成了骆驼先知并且进行了很多有趣的实践。
【骆驼读论文】关于Andrew Ng的prompt工程课程的实践,为GPT编写更准确而多样的提示词
|
骆驼先知骆驼先知是模仿纪伯伦的《先知》进行哲学讨论。项目包含了李鲁鲁对于Prompt Engineering和LangChain的实践。 |
骆驼先知其实是整个Prompt Engineering课程的作业之一。当然这个项目后来又叠加了LangChain相关的大量笔记,很多内容非常有启发性。当然整体还是先知更有趣一些,就用先知作为这个项目的名字了
【开源骆驼】上完吴恩达的提示词课程,我们复现了纪伯伦的《先知》,并和他讨论了加班、夜店和996
这其实是个很有意思的尝试,通过《先知》的26个故事,可以把先知的思想和价值观进行整体的复活。同样的思想能不能用到二次元人物中呢?于是李鲁鲁花一天半的时间,收集了凉宫春日38段语料。形成了凉宫春日的初步版本。
 |
Chat凉宫春日Chat凉宫春日是模仿凉宫春日等一系列动漫人物,使用近似语气、个性和剧情聊天的语言模型。 |
在儿童节前后DataWhale学习微信群的测试中,大家纷纷表示ChatHaruhi的效果很好。于是我们在DataWhale和高天学长的粉丝群进行了成员的招募。本着"Deadline就是生产力,所以更多Deadline,更多生产力"的原则。ChatHaruhi的工作组先后完成了DataWhale的作业(二等奖 top3),中科院心理所的特定人格文本生成(二等奖 top3)和魔搭社区hackathon的比赛(二等奖 top3)。
虽然不知道为什么从来没有拿过第一,但显然拿第一并不是一件非常重要的事情。这个项目我们准备在扩充到30个人物之后,做补充实验并形成一个技术report挂到arxiv上。其实到Chat凉宫春日已经是一个比较成熟的语言模型项目,包含了完整的prompting、记忆库、数据生成和微调的流程。这个应该会形成垂直应用的语言模型的标准范式之一,我看到有人逛WAIC的截图里面还有人在教这个笔记。并且在7月初魔搭比赛的时候,我们已经验证了角色扮演这个任务可以被合理降解到7B规模的模型,这其实是一个很不错的结论。
所以研究每个垂直人物能够压缩到多小,也是一个很重要的任务。黄钟健实现的迷你骆驼,就是我们学习LaMini的一个项目。在这个项目中,我们在尝试训练3B、1B和300M等更多的小模型。
|
近期骆驼近期骆驼:一系列蒸馏指令数据得到的中文语言模型。 |
所以,骆驼项目究竟是什么?骆驼应该是李鲁鲁等人发起的个人学习项目。在这个项目中,我们确实也发布了很多模型,比如骆驼Bert, 骆驼QA, 近期骆驼等模型。同时我们也关注中文的数据集,形成了大量的配套数据集工作。从骆驼先知和Chat凉宫春日开始,我们也开始关注语言模型的整体管线和应用。
对于我们个人来说,一方面我们希望把过往在vision积累的经验,转移到语言模型上,并且形成一定的积累。并且我们通过一系列子项目,可以明白在每个任务上,投入多少的开发量,多少的数据和多少的计算资源,这个任务的性能才能进一步提升到什么样的水平。这样才会使得我们累积重要的经验,使得在未来操作更严肃的任务的时候,作出更准确的判断。在这个学习过程中,也能顺便产生一些对社区很有用的东西,比如LuotuoBert和haruhi这些工具。
当然Chat凉宫春日是一个有趣的转折点,从这个项目开始,我们意识到其实不一定要做一些“必做”的项目,而是可以做一些炫酷的项目,这些炫酷的项目和社区产生的互动,其实会更有趣,并且也是一个更真实的应用。就好像凉宫春日的故事本身一样,主角不满足于平淡的生活,带领着SOS团进行着一系列神奇的冒险。
我们认为愿意联系我们进行投入的同学都是highly motivated的。其实对于每个人来说,大语言模型都是一个非常全新的命题。即使是资深的研究者,也要放下很多固有认知,去结合新的东西和过往的知识去进行研究。这也是为什么李鲁鲁一大把年纪了还是会积极地进行paper reading和笔记的记录。我们之后打算装修一下人员的页面,把要寻找读博机会和工作机会的同学进行标识。今天先把子项目介绍写到这里。欢迎大家点击后面的赞助链接进行赞助!
赞助(Sponsorships)
Top 3 Sponsors
| Time | Sponsor | Amount |
|---|---|---|
| 2023/6/20 | Xiuhan | 3000 |
| 2023/3/28 | 张** | 2000 |
| 2023/4/2等 | Tand | 1580 |
balance = 12653.03 now. Detailed balance see in sponsorship_and_balance.md
这原本是我们的一个作业项目,我们原本计划训练到1.0为止。但是社区的热情超过了我们的想象。如果您愿意赞助我们的项目,可以
扫描这个二维码
{kind=link}
并且加这个支付宝账号,留下您的姓名
{kind=link}
项目的资金流向将被公开,所有的资金将被用于数据的标注,训练算力的购买或者后续周边产品的发放。数据和算力的捐献也会一同总结在sponsorship的表格中。备用链接 二维码 , 支付宝账号
{kind=link}
{kind=link}
This was originally an exercise project for us, and we originally planned to train until version 1.0. However, the enthusiasm of the community exceeded our expectations. If you are willing to sponsor our project, you can scan this QR code and add this Alipay account, leaving your name.
All funds will be used for data annotation, purchase of training computing power, or distribution of subsequent peripheral products.
相关项目
我们计划在这里增加一个表格,列出所有我们已经关联,和正在following的开源项目列表。同时,非常感谢这些项目的作者对开源社区的贡献。
| 模型与训练 | 详情 |
|---|---|
| ChatGLM-6B | ChatGLM-6B 是清华唐杰老师实验室释放出来的中文大语言(小)模型 |
| ptuning-v2 | ptuning-v2是清华唐杰老师实验室发布对GLM的一种微调方法,实现了他们本身发布的p-tuning-v2的论文的方法 |
| GLM-Tuning | |
| Alpaca | Alpaca是斯坦福在LLaMA上微调对话指令的项目,是万恶之源 |
| Alpaca-LoRA | 这个项目开启了LLaMA模型上的LoRA微调,万恶之源2 |
| Alpaca-ChToken | 复旦的Yiming Cui和Ziqing Yang修复了Alpaca的中文token问题,在原来的LLaMA英文token边上并了一个中文的token,我们想把这个项目整合到整体训练里,还没做完 |
| BELLE-7B | |
| RWKV-LM | RWKV也是一套语言模型的训练架构 |
| Baize-7B | 白泽是做连续对话的,他收集语料的方法很有意思,之后我们要看一下,但是白泽是在LLaMA上训练的,所以会遇到中文的问题,用到中文要换基模型。 |
| Vicuna | 同时有7B和13B,支持中文的模型,这个应该挺厉害的,而且13B用Int4能够压缩到colab使用(但是不知道int4训练会不会出事儿),之后也要试一下 |
| DeepSpeed | 微软开源的一个快速训练RLHF和全局finetune的一个框架 |
| Phoenix | 港中文深圳的老师同学们发布的Phoenix模型,拥有宽松,支持商业的开源协议,我们之后想有些模型也在这上面训练,另外感谢cite我们🙏 |
| 中文OpenInstruct | 北京智源老师们准备开源出来的数据集,另外感谢cite我们! |
| 数据 | 详情 |
|---|---|
| Guanaco | Guanaco是JosephusCheung制作的一套指令调优的数据集,在骆驼0.3以上版本的模型中我们使用了这个数据。 |
| CNewSum | CNewSum是字节与UCSB发布的中文摘要数据集,我们在驼铃-C模型中使用了这个数据集 |
| Coco-CN | 这是中国人民大学的li-xirong等翻译的部分Coco数据集,骆驼团队正在准备用GPT翻译完整的Coco,如果你也准备翻译,可以联系我们,避免重复花钱 |
| CoQA | 基于一段文字,然后问答,是个很重要的任务。陈丹琦大佬参与做的CoQA数据集,骆驼团队正在准备用GPT增广和翻译完整的CoQA,如果你也准备翻译,可以联系我们,避免重复花钱 |
贡献者(Contributors)
我们会把每个贡献者的贡献记录在contributions.md,包括每个项目每个成员的具体任务分配和贡献。
这里的表格仅列出每个人的主要贡献,更具体的内容请参考contributions.md

李鲁鲁 @ 商汤科技 李鲁鲁 是骆驼项目的发起人之一 |

冷子昂 @ 商汤科技 冷子昂 是骆驼项目的发起人之一 |

陈启源 @ 华中师范大学 陈启源 是骆驼项目的发起人之一 |

黄泓森 @ 华中师范大学 黄泓森 维护了服务器和大量数据代码 |

胡婧 @ 华中师范大学 胡婧 正在进一步维护骆驼嵌入 |

陈舒年 @ 杜克大学 陈舒年 参与了骆驼嵌入等多个项目 |

刘思诣 @ Upenn 刘思诣 参与了骆驼嵌入项目 |

孙骜 @ 清华大学 孙骜 训练了骆驼QA的英文模型 |

黄钟健 @ 西安电子科大 黄钟健训练了迷你骆驼 |

廖健生 Jansen 廖健生 训练了骆驼QA的模型 |

罗钦雨 @ JHU 罗钦雨 发布了骆驼QA-B数据集 |

更多 更多同学招募中。。。 |
引用
如果您使用了本仓库中的数据或代码,请引用该仓库。
@misc{luotuo,
author={Ziang Leng, Qiyuan Chen and Cheng Li},
title = {骆驼:一个指令遵循的中文语言模型,在LLaMA上进行LoRA微调},
year = {2023},
publisher = {GitHub},
journal = {GitHub 仓库},
howpublished = {\url{https://github.com/LC1332/Luotuo-Chinese-LLM}},
}
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
spec-kit
Spec Kit 是一款专为提升软件开发效率而设计的开源工具包,旨在帮助团队快速落地“规格驱动开发”(Spec-Driven Development)模式。传统开发中,需求文档往往与代码实现脱节,导致沟通成本高且结果不可控;而 Spec Kit 通过将规格说明书转化为可执行的指令,让 AI 直接依据明确的业务场景生成高质量代码,从而减少从零开始的随意编码,确保产出结果的可预测性。 该工具特别适合希望利用 AI 辅助编程的开发者、技术负责人及初创团队。无论是启动全新项目还是在现有工程中引入规范化流程,用户只需通过简单的命令行操作,即可初始化项目并集成主流的 AI 编程助手。其核心技术亮点在于“规格即代码”的理念,支持社区扩展与预设模板,允许用户根据特定技术栈定制开发流程。此外,Spec Kit 强调官方维护的安全性,提供稳定的版本管理,帮助开发者在享受 AI 红利的同时,依然牢牢掌握架构设计的主动权,真正实现从“凭感觉写代码”到“按规格建系统”的转变。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。