dc_tts
dc_tts 是一个基于 TensorFlow 实现的开源文本转语音(TTS)项目,复现了论文中提出的高效深度卷积网络模型。它致力于将输入的文字序列转化为自然流畅的语音音频,解决了传统语音合成系统在训练效率与生成质量之间难以平衡的问题。
该工具的核心亮点在于引入了“引导注意力机制”(Guided Attention),显著提升了模型对齐文本与音频的准确性,同时利用深度卷积网络架构实现了比递归神经网络更快的训练速度和推理效率。项目不仅提供了完整的训练流程,还展示了在多种数据集(如英语 LJ Speech、名人有声书及韩语 KSS 数据集)上的良好泛化能力,即使在小样本数据下也能学习到稳定的语音特征。
dc_tts 非常适合人工智能研究人员、语音技术开发者以及对深度学习语音合成感兴趣的学生使用。通过阅读其代码和实验结果,用户可以深入理解现代 TTS 系统的构建逻辑,或在此基础上定制专属的语音合成模型。虽然普通用户也可尝试运行预训练模型生成语音,但其主要价值在于为技术探索者提供了一个透明、可复现且易于扩展的研究基准。
使用场景
一家小型有声书制作团队希望将经典文学作品快速转化为多角色配音的音频内容,但受限于高昂的专业录音成本和漫长的制作周期。
没有 dc_tts 时
- 人力成本高昂:必须聘请专业配音演员并租赁录音棚,仅录制一本中篇作品就需要数万元预算。
- 制作周期漫长:从试音、正式录制到后期剪辑,通常需要数周甚至数月才能交付成品。
- 多语种支持困难:若想同时推出韩语版或有特定音色需求的版本,需重新寻找对应语种的配音资源,协调难度极大。
- 数据利用低效:团队手中已有的少量名人演讲或旧录音素材无法直接用于训练新模型,只能闲置浪费。
使用 dc_tts 后
- 大幅降低门槛:利用 dc_tts 基于深度卷积网络的特性,仅需少量公开数据集(如 LJ Speech 或 KSS)即可训练出高质量语音模型,无需真人进棚。
- 实现快速迭代:输入文本后几分钟内即可生成语音样本,通过调整超参数可迅速优化效果,将制作周期从数周缩短至数小时。
- 灵活定制音色:成功复现了论文中的引导注意力机制,能够利用 Nick Offerman 或 Kate Winslet 等特定人物的有限音频数据,训练出风格独特的专属语音模型。
- 跨语言轻松扩展:凭借其对英语和韩语数据集的良好兼容性,团队可复用同一套架构快速部署多语言版本,无缝拓展国际市场。
dc_tts 通过高效的深度学习架构,让中小团队也能以极低成本实现定制化、多语种的高质量语音合成,彻底改变了传统有声内容的生产模式。
运行环境要求
- 未说明
- 非必需,但多 GPU 可并行训练不同阶段
- 具体型号、显存及 CUDA 版本未说明(基于 TensorFlow 1.3+)
未说明

快速开始
DC-TTS 的 TensorFlow 实现:又一个文本转语音模型
我实现了另一个文本转语音模型——dc-tts,该模型在论文《基于深度卷积网络与引导注意力的高效可训练文本转语音系统》(https://arxiv.org/abs/1710.08969)中提出。然而,我的目标不仅仅是复现这篇论文,更希望从中获得对各类语音项目的深入理解。
需求
- NumPy >= 1.11.1
- TensorFlow >= 1.3(请注意,自 1.3 版本以来,
tf.contrib.layers.layer_norm的 API 已发生变化) - librosa
- tqdm
- matplotlib
- scipy
数据



我在四个不同的语音数据集上训练了英语模型和一个韩语模型。
1. LJ Speech Dataset
2. 尼克·奥弗曼的有声书
3. 凯特·温斯莱特的有声书
4. KSS 数据集
LJ Speech Dataset 近年来作为 TTS 任务中的基准数据集被广泛使用,因为它公开可用,并且包含 24 小时质量尚可的音频样本。尼克和凯特的有声书则用于测试模型在数据量较少、语音样本变化较大的情况下是否仍能有效学习。它们分别长达 18 小时和 5 小时。最后,KSS 数据集是一个超过 12 小时的韩语单说话人语音数据集。
训练
- 步骤 0. 下载 LJ Speech Dataset 或准备您自己的数据。
- 步骤 1. 在
hyperparams.py中调整超参数。(如果您想进行预处理,请将prepro设置为True。) - 步骤 2. 运行
python train.py 1来训练 Text2Mel。(如果设置了prepro True,请先运行python prepro.py。) - 步骤 3. 运行
python train.py 2来训练 SSRN。
如果您有多块 GPU 卡,可以同时执行步骤 2 和 3。
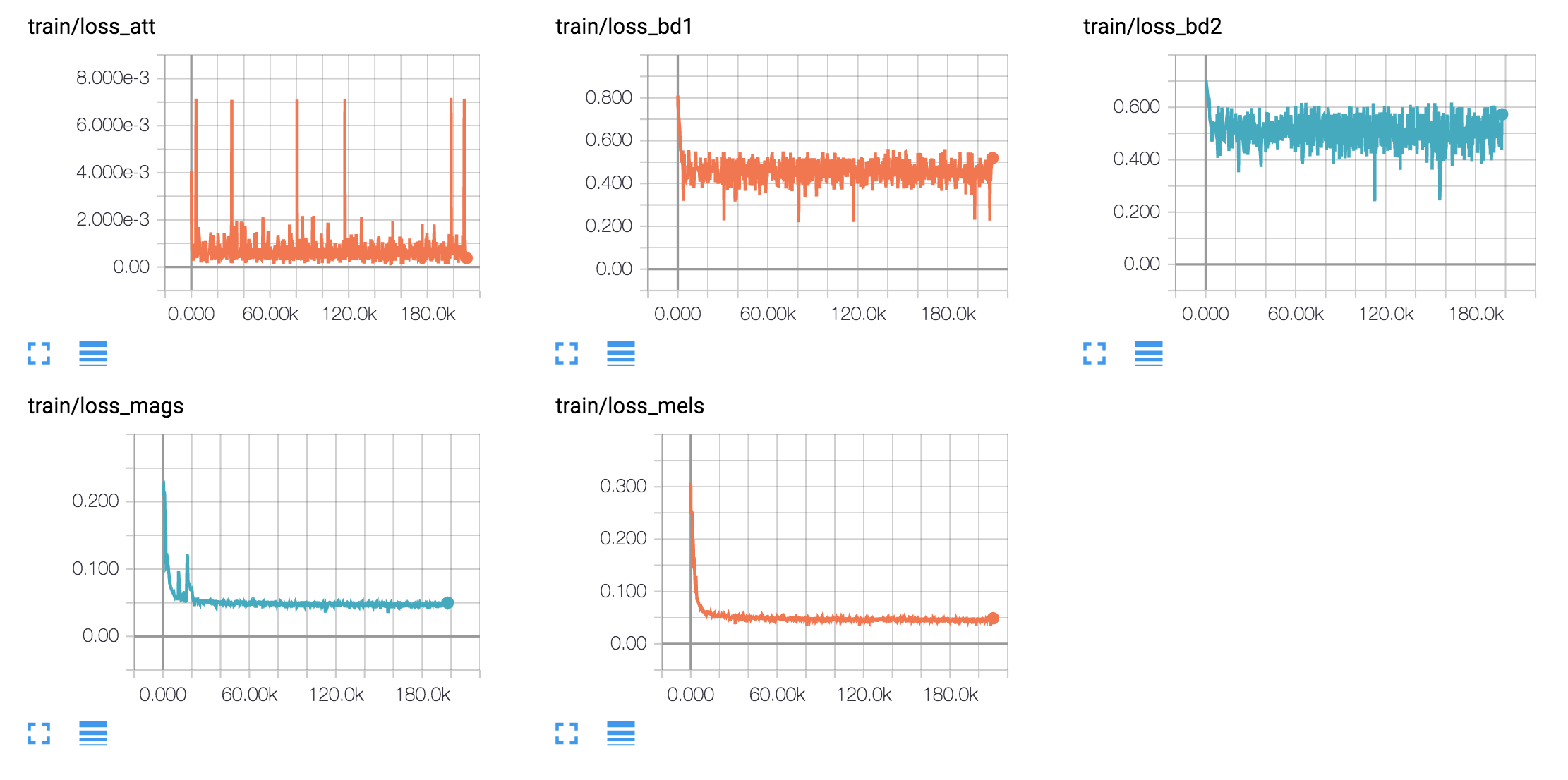
训练曲线
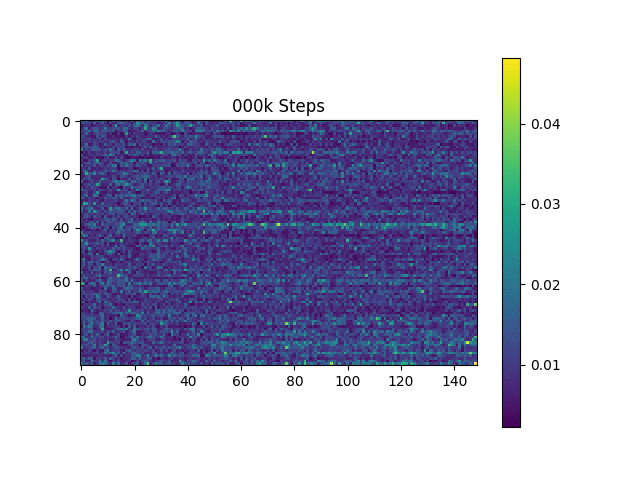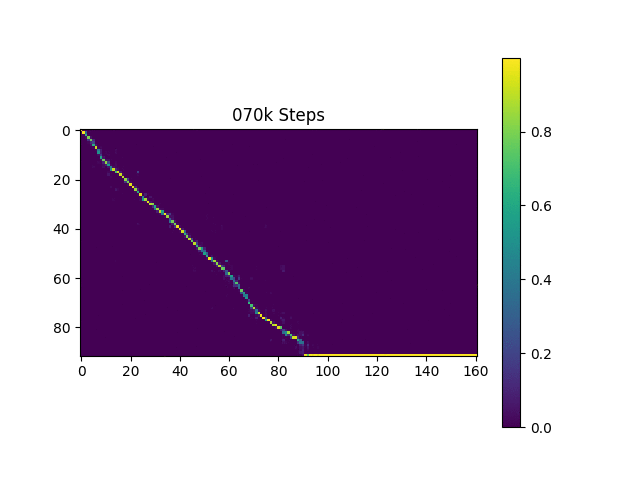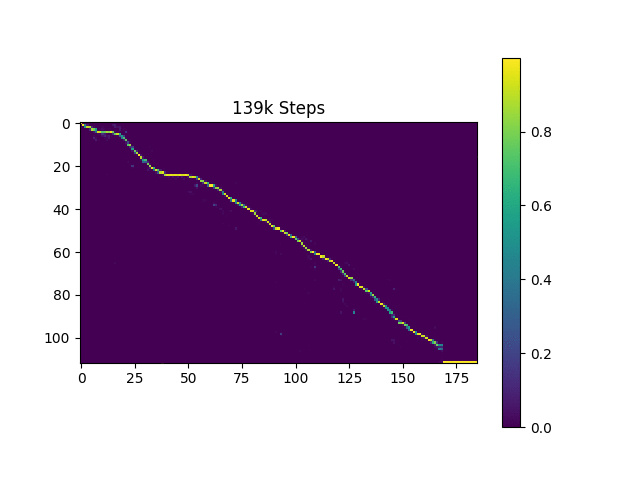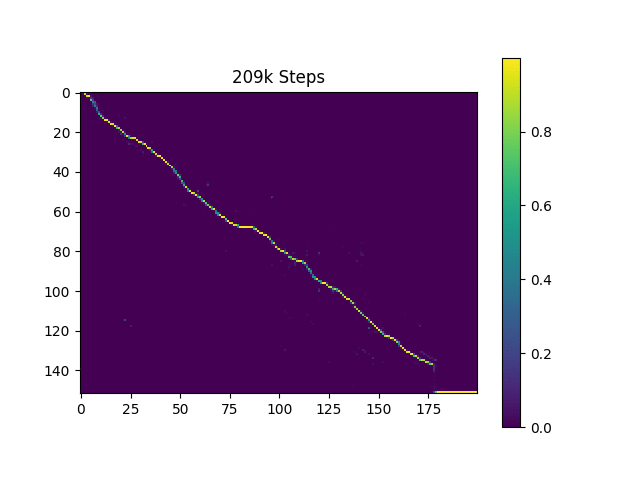
注意力图
样本合成
我根据原始论文的做法,以 哈佛句子 为基础生成语音样本。这些句子已包含在代码库中。
- 运行
synthesize.py并检查samples文件夹中的文件。
生成的样本
| 数据集 | 样本 |
|---|---|
| LJ | 5万 20万 31万 80万 |
| Nick | 4万 17万 30万 80万 |
| Kate | 4万 16万 30万 80万 |
| KSS | 40万 |
LJ 的预训练模型
请下载这里。
备注
- 论文中未提及归一化,但如果没有归一化,我无法使模型正常工作。因此,我添加了层归一化。
- 论文将学习率固定为 0.001,但这对我并不奏效。所以我对其进行了衰减。
- 我曾尝试同时训练 Text2Mel 和 SSRN,但未能成功。我认为将这两个网络分开可以减轻训练负担。
- 作者声称该模型可以在一天内完成训练,但遗憾的是我并未实现这一点。不过,由于只使用卷积层,它的速度显然比 Tacotron 快得多。
- 得益于引导注意力机制,注意力图几乎从一开始就呈现单调性。我想这有助于保持对齐的稳定性,从而不会丢失跟踪。
- 论文中未提及丢弃层。但我认为它们有助于正则化,因此还是应用了它们。
- 您也可以查看其他 TTS 模型,例如 Tacotron 和 Deep Voice 3。
常见问题
相似工具推荐
ML-For-Beginners
ML-For-Beginners 是由微软推出的一套系统化机器学习入门课程,旨在帮助零基础用户轻松掌握经典机器学习知识。这套课程将学习路径规划为 12 周,包含 26 节精炼课程和 52 道配套测验,内容涵盖从基础概念到实际应用的完整流程,有效解决了初学者面对庞大知识体系时无从下手、缺乏结构化指导的痛点。 无论是希望转型的开发者、需要补充算法背景的研究人员,还是对人工智能充满好奇的普通爱好者,都能从中受益。课程不仅提供了清晰的理论讲解,还强调动手实践,让用户在循序渐进中建立扎实的技能基础。其独特的亮点在于强大的多语言支持,通过自动化机制提供了包括简体中文在内的 50 多种语言版本,极大地降低了全球不同背景用户的学习门槛。此外,项目采用开源协作模式,社区活跃且内容持续更新,确保学习者能获取前沿且准确的技术资讯。如果你正寻找一条清晰、友好且专业的机器学习入门之路,ML-For-Beginners 将是理想的起点。
GPT-SoVITS
GPT-SoVITS 是一款强大的开源语音合成与声音克隆工具,旨在让用户仅需极少量的音频数据即可训练出高质量的个性化语音模型。它核心解决了传统语音合成技术依赖海量录音数据、门槛高且成本大的痛点,实现了“零样本”和“少样本”的快速建模:用户只需提供 5 秒参考音频即可即时生成语音,或使用 1 分钟数据进行微调,从而获得高度逼真且相似度极佳的声音效果。 该工具特别适合内容创作者、独立开发者、研究人员以及希望为角色配音的普通用户使用。其内置的友好 WebUI 界面集成了人声伴奏分离、自动数据集切片、中文语音识别及文本标注等辅助功能,极大地降低了数据准备和模型训练的技术门槛,让非专业人士也能轻松上手。 在技术亮点方面,GPT-SoVITS 不仅支持中、英、日、韩、粤语等多语言跨语种合成,还具备卓越的推理速度,在主流显卡上可实现实时甚至超实时的生成效率。无论是需要快速制作视频配音,还是进行多语言语音交互研究,GPT-SoVITS 都能以极低的数据成本提供专业级的语音合成体验。
TTS
🐸TTS 是一款功能强大的深度学习文本转语音(Text-to-Speech)开源库,旨在将文字自然流畅地转化为逼真的人声。它解决了传统语音合成技术中声音机械生硬、多语言支持不足以及定制门槛高等痛点,让高质量的语音生成变得触手可及。 无论是希望快速集成语音功能的开发者,还是致力于探索前沿算法的研究人员,亦或是需要定制专属声音的数据科学家,🐸TTS 都能提供得力支持。它不仅预置了覆盖全球 1100 多种语言的训练模型,让用户能够即刻上手,还提供了完善的工具链,支持用户利用自有数据训练新模型或对现有模型进行微调,轻松实现特定风格的声音克隆。 在技术亮点方面,🐸TTS 表现卓越。其最新的 ⓍTTSv2 模型支持 16 种语言,并在整体性能上大幅提升,实现了低于 200 毫秒的超低延迟流式输出,极大提升了实时交互体验。此外,它还无缝集成了 🐶Bark、🐢Tortoise 等社区热门模型,并支持调用上千个 Fairseq 模型,展现了极强的兼容性与扩展性。配合丰富的数据集分析与整理工具,🐸TTS 已成为科研与生产环境中备受信赖的语音合成解决方案。
LocalAI
LocalAI 是一款开源的本地人工智能引擎,旨在让用户在任意硬件上轻松运行各类 AI 模型,包括大语言模型、图像生成、语音识别及视频处理等。它的核心优势在于彻底打破了高性能计算的门槛,无需昂贵的专用 GPU,仅凭普通 CPU 或常见的消费级显卡(如 NVIDIA、AMD、Intel 及 Apple Silicon)即可部署和运行复杂的 AI 任务。 对于担心数据隐私的用户而言,LocalAI 提供了“隐私优先”的解决方案,确保所有数据处理均在本地基础设施内完成,无需上传至云端。同时,它完美兼容 OpenAI、Anthropic 等主流 API 接口,这意味着开发者可以无缝迁移现有应用,直接利用本地资源替代云服务,既降低了成本又提升了可控性。 LocalAI 内置了超过 35 种后端支持(如 llama.cpp、vLLM、Whisper 等),并集成了自主 AI 代理、工具调用及检索增强生成(RAG)等高级功能,且具备多用户管理与权限控制能力。无论是希望保护敏感数据的企业开发者、进行算法实验的研究人员,还是想要在个人电脑上体验最新 AI 技术的极客玩家,都能通过 LocalAI 获
bark
Bark 是由 Suno 推出的开源生成式音频模型,能够根据文本提示创造出高度逼真的多语言语音、音乐、背景噪音及简单音效。与传统仅能朗读文字的语音合成工具不同,Bark 基于 Transformer 架构,不仅能模拟说话,还能生成笑声、叹息、哭泣等非语言声音,甚至能处理带有情感色彩和语气停顿的复杂文本,极大地丰富了音频表达的可能性。 它主要解决了传统语音合成声音机械、缺乏情感以及无法生成非语音类音效的痛点,让创作者能通过简单的文字描述获得生动自然的音频素材。无论是需要为视频配音的内容创作者、探索多模态生成的研究人员,还是希望快速原型设计的开发者,都能从中受益。普通用户也可通过集成的演示页面轻松体验其神奇效果。 技术亮点方面,Bark 支持商业使用(MIT 许可),并在近期更新中实现了显著的推理速度提升,同时提供了适配低显存 GPU 的版本,降低了使用门槛。此外,社区还建立了丰富的提示词库,帮助用户更好地驾驭模型生成特定风格的声音。只需几行 Python 代码,即可将创意文本转化为高质量音频,是连接文字与声音世界的强大桥梁。
ChatTTS
ChatTTS 是一款专为日常对话场景打造的生成式语音模型,特别适用于大语言模型助手等交互式应用。它主要解决了传统文本转语音(TTS)技术在对话中缺乏自然感、情感表达单一以及难以处理停顿、笑声等细微语气的问题,让机器生成的语音听起来更像真人在聊天。 这款工具非常适合开发者、研究人员以及希望为应用增添自然语音交互功能的设计师使用。普通用户也可以通过社区开发的衍生产品体验其能力。ChatTTS 的核心亮点在于其对对话任务的深度优化:它不仅支持中英文双语,还能精准控制韵律细节,自动生成自然的 laughter(笑声)、pauses(停顿)和 interjections(插入语),从而实现多说话人的互动对话效果。在韵律表现上,ChatTTS 超越了大多数开源 TTS 模型。目前开源版本基于 4 万小时数据预训练而成,虽主要用于学术研究与教育目的,但已展现出强大的潜力,并支持流式音频生成与零样本推理,为后续的多情绪控制等进阶功能奠定了基础。