pytorch-center-loss
pytorch-center-loss 是经典“中心损失”(Center Loss)算法的 PyTorch 实现版本,源自 ECCV 2016 关于深度人脸识别的研究。在深度学习分类任务中,传统的交叉熵损失函数虽能区分不同类别,却难以保证同一类别内部特征的紧凑性,导致模型在面对细微差异时判别力不足。
该工具通过引入额外的中心损失项,专门解决这一痛点:它在训练过程中动态学习并更新每个类别的特征中心,强制拉近同类样本与中心的距离,同时配合交叉熵损失推远不同类别。这种“双管齐下”的策略显著提升了特征空间的判别能力,使同类数据聚集更紧密,异类数据分界更清晰,特别适用于人脸识别、行人重识别等对细粒度区分要求极高的场景。
pytorch-center-loss 主要面向 AI 开发者与研究人员。其核心亮点在于极简的集成方式:用户只需引入单一的 center_loss.py 文件,即可像定义普通网络层一样实例化损失函数,并灵活合并优化器进行联合训练。项目不仅提供了完整的 MNIST 演示代码和可视化对比,直观展示加入中心损失后特征分布的优化过程,还已被多个知名开源项目验证有效。对于希望提升模型特征提取质量、探索度量学习策略的技术人员而言,这是一个轻量且高效的基础组件。
使用场景
某安防科技公司的算法团队正在开发新一代园区人脸识别门禁系统,旨在解决复杂光照下相似人脸难以区分的问题。
没有 pytorch-center-loss 时
- 类内差异过大:仅使用标准的 Softmax 损失函数训练时,同一个人的不同照片(如戴帽、侧脸)在特征空间中分布松散,导致模型难以提取稳定特征。
- 误识率居高不下:由于不同人的特征簇边界模糊,系统频繁将长相相似的同事混淆,测试集错误率长期停留在 15% 以上,无法满足门禁安全标准。
- 调优方向迷茫:工程师试图通过调整网络层数或数据增强来改善,但缺乏针对“特征紧凑性”的直接优化手段,迭代效率极低且效果不明显。
使用 pytorch-center-loss 后
- 特征高度聚合:引入 Center Loss 联合优化后,模型强制将同一类别的特征向类中心靠拢,显著缩小了类内距离,即使姿态变化大也能精准匹配。
- 判别能力飞跃:特征空间中的不同人脸类别界限分明,间隔增大,系统测试集准确率从 85% 飙升至 98.5%,有效阻断了相似人脸的误闯。
- 训练过程可视可控:借助工具自带的可视化功能,团队能直观看到训练过程中特征簇从混乱到清晰的变化,快速验证了算法策略的有效性。
pytorch-center-loss 通过最小化类内距离,从根本上提升了深度人脸识别模型的特征判别力与鲁棒性。
运行环境要求
- 未说明
可选(通过 --gpu 参数指定),支持 CUDA 的 NVIDIA GPU,具体型号和显存大小未说明
未说明
快速开始
PyTorch 中心损失
PyTorch 中心损失的实现:Wen 等人. 一种用于深度人脸识别的判别特征学习方法. ECCV 2016.
该损失函数也被 deep-person-reid 使用。
快速入门
克隆此仓库并运行代码:
$ git clone https://github.com/KaiyangZhou/pytorch-center-loss
$ cd pytorch-center-loss
$ python main.py --eval-freq 1 --gpu 0 --save-dir log/ --plot
您将在终端中看到以下信息:
当前使用 GPU: 0
创建数据集: mnist
创建模型: cnn
==> 第 1 轮/100 轮
第 50 批/469 批 损失 2.332793 (2.557837) 交叉熵损失 2.332744 (2.388296) 中心损失 0.000048 (0.169540)
第 100 批/469 批 损失 2.354638 (2.463851) 交叉熵损失 2.354637 (2.379078) 中心损失 0.000001 (0.084773)
第 150 批/469 批 损失 2.361732 (2.434477) 交叉熵损失 2.361732 (2.377962) 中心损失 0.000000 (0.056515)
第 200 批/469 批 损失 2.336701 (2.417842) 交叉熵损失 2.336700 (2.375455) 中心损失 0.000001 (0.042386)
第 250 批/469 批 损失 2.404814 (2.407015) 交叉熵损失 2.404813 (2.373106) 中心损失 0.000001 (0.033909)
第 300 批/469 批 损失 2.338753 (2.398546) 交叉熵损失 2.338752 (2.370288) 中心损失 0.000001 (0.028258)
第 350 批/469 批 损失 2.367068 (2.390672) 交叉熵损失 2.367059 (2.366450) 中心损失 0.000009 (0.024221)
第 400 批/469 批 损失 2.344178 (2.384820) 交叉熵损失 2.344142 (2.363620) 中心损失 0.000036 (0.021199)
第 450 批/469 批 损失 2.329708 (2.379460) 交叉熵损失 2.329661 (2.360611) 中心损失 0.000047 (0.018848)
==> 测试
准确率 (%): 10.32 错误率 (%): 89.68
... ...
==> 第 30 轮/100 轮
第 50 批/469 批 损失 0.141117 (0.155986) 交叉熵损失 0.084169 (0.091617) 中心损失 0.056949 (0.064369)
第 100 批/469 批 损失 0.138201 (0.151291) 交叉熵损失 0.089146 (0.092839) 中心损失 0.049055 (0.058452)
第 150 批/469 批 损失 0.151055 (0.151985) 交叉熵损失 0.090816 (0.092405) 中心损失 0.060239 (0.059580)
第 200 批/469 批 损失 0.150803 (0.153333) 交叉熵损失 0.092857 (0.092156) 中心损失 0.057946 (0.061176)
第 250 批/469 批 损失 0.162954 (0.154971) 交叉熵损失 0.094889 (0.092099) 中心损失 0.068065 (0.062872)
第 300 批/469 批 损失 0.162895 (0.156038) 交叉熵损失 0.093100 (0.092034) 中心损失 0.069795 (0.064004)
第 350 批/469 批 损失 0.146187 (0.156491) 交叉熵损失 0.082508 (0.091787) 中心损失 0.063679 (0.064704)
第 400 批/469 批 损失 0.171533 (0.157390) 交叉熵损失 0.092526 (0.091674) 中心损失 0.079007 (0.065716)
第 450 批/469 批 损失 0.209196 (0.158371) 交叉熵损失 0.098388 (0.091560) 中心损失 0.110808 (0.066811)
==> 测试
准确率 (%): 98.51 错误率 (%): 1.49
... ...
有关输入参数的更多详细信息,请运行 python main.py -h。
结果
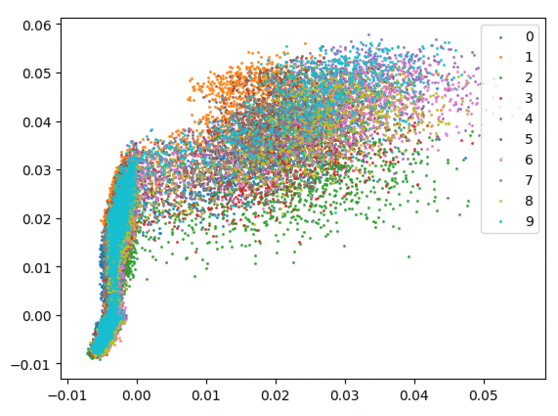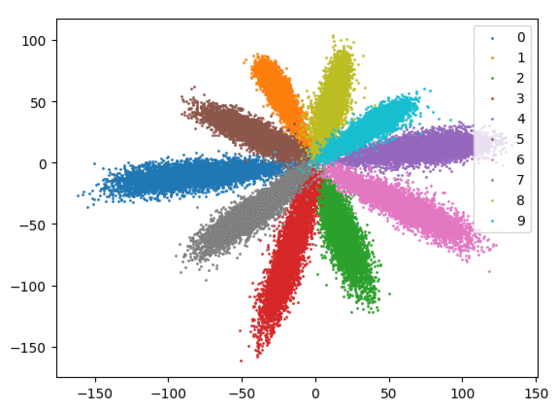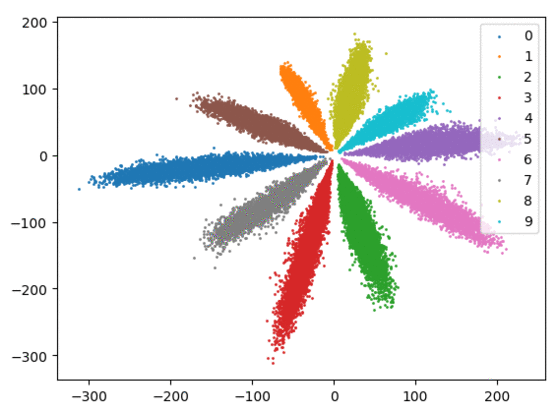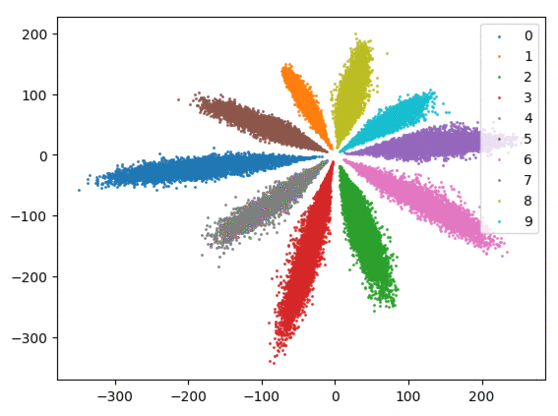
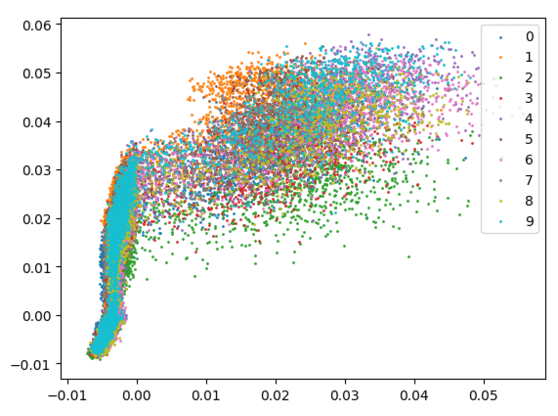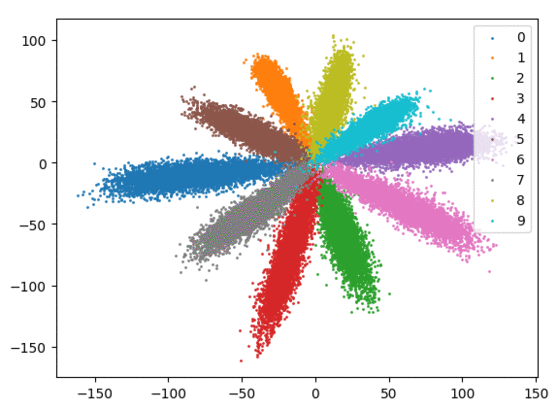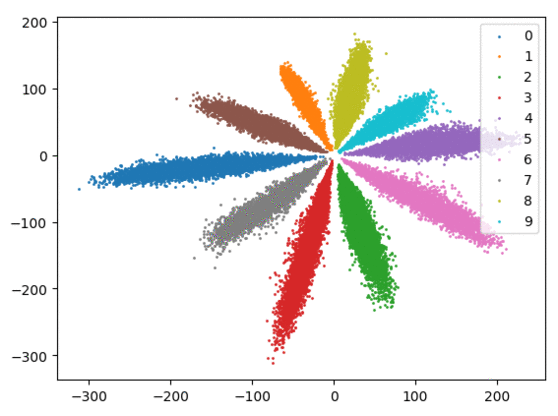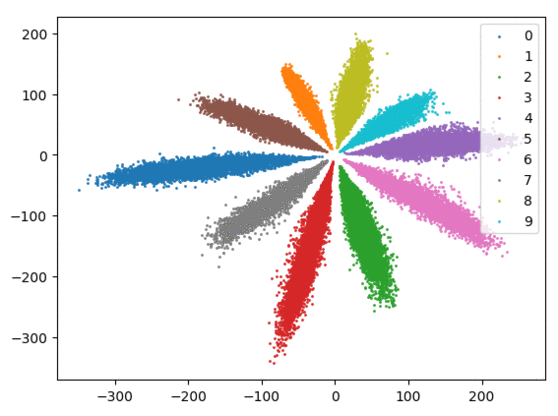
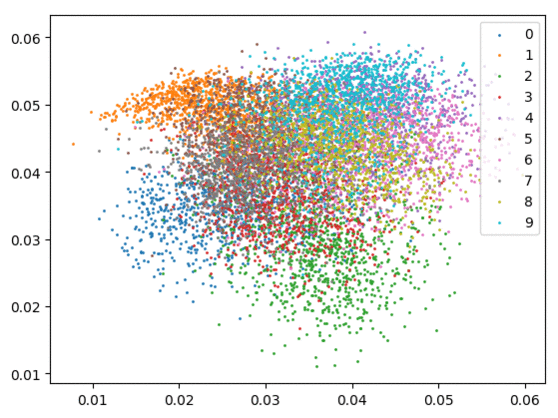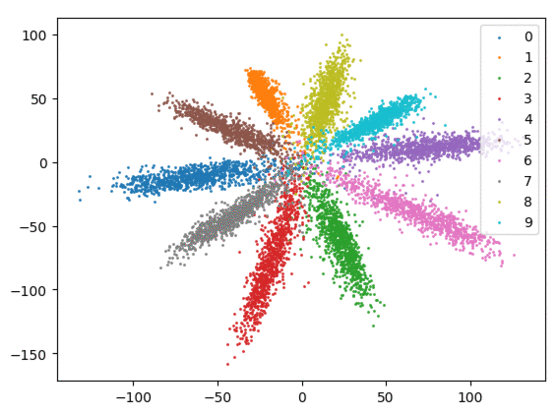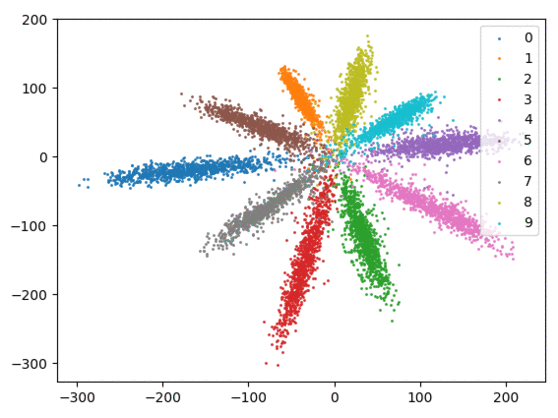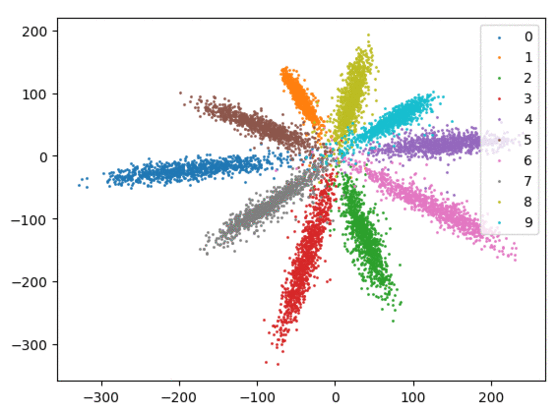
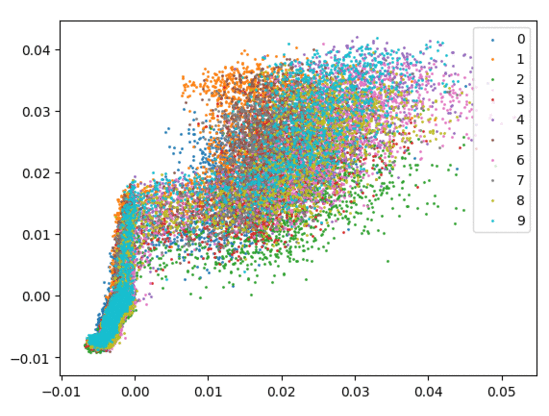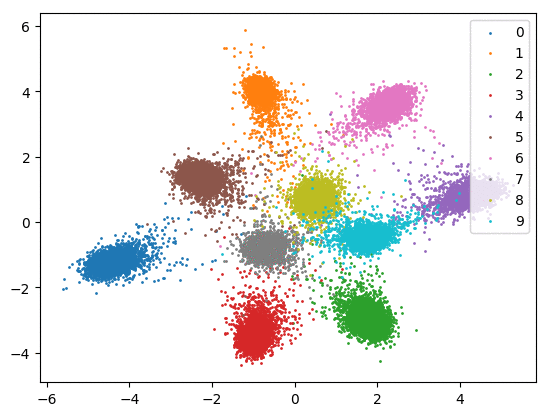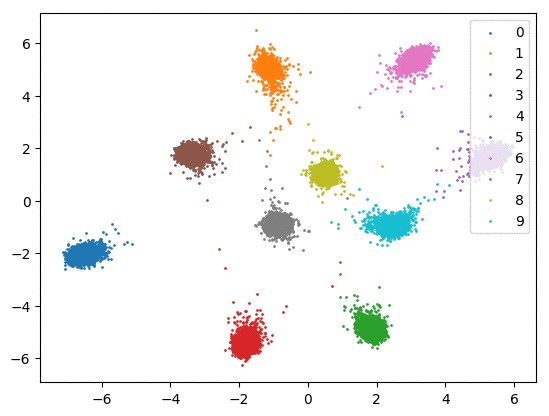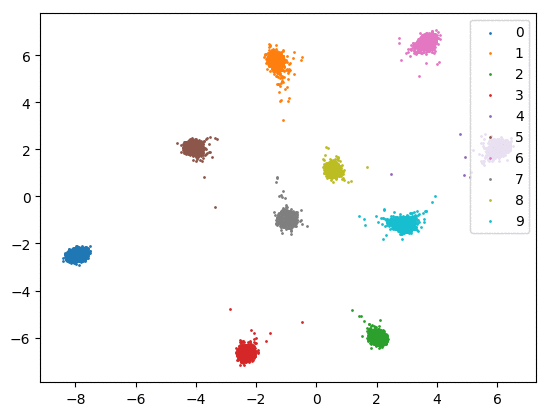
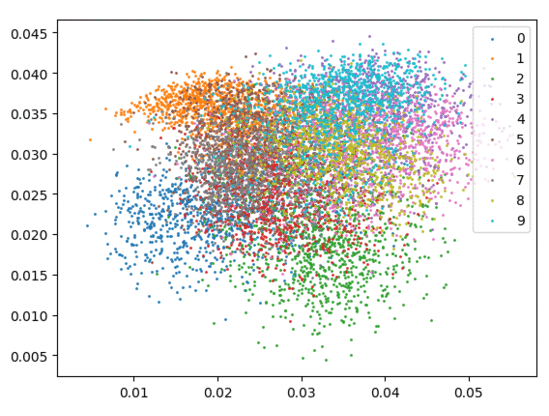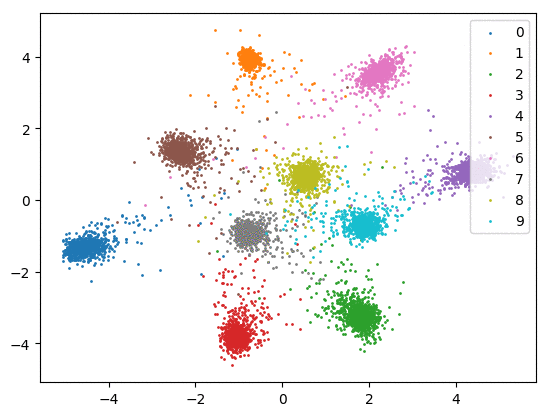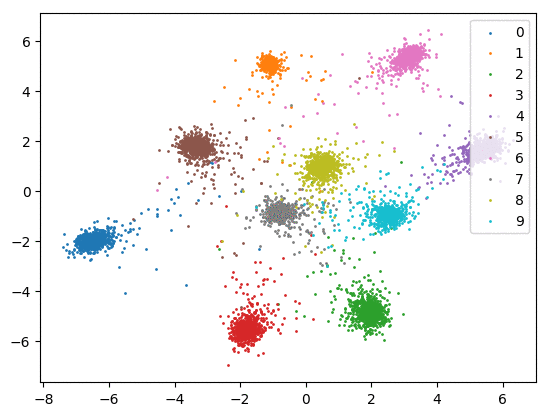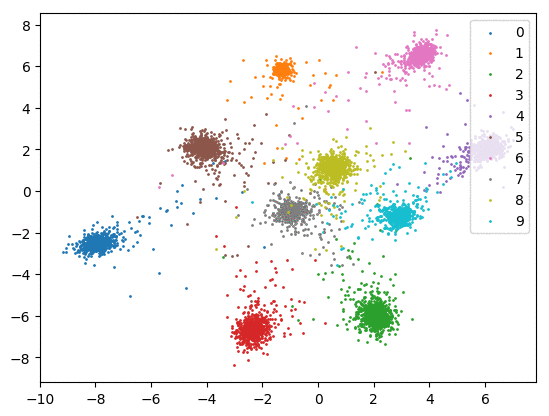
我们在下方可视化了特征学习过程。
仅使用 Softmax。左:训练集。右:测试集。
Softmax + 中心损失。左:训练集。右:测试集。
如何在您自己的项目中使用中心损失
- 您只需要
center_loss.py文件:
from center_loss import CenterLoss
- 在主函数中初始化中心损失:
center_loss = CenterLoss(num_classes=10, feat_dim=2, use_gpu=True)
- 为中心损失构建优化器:
optimizer_centloss = torch.optim.SGD(center_loss.parameters(), lr=0.5)
或者,您可以将模型和中心损失的优化器合并,例如:
params = list(model.parameters()) + list(center_loss.parameters())
optimizer = torch.optim.SGD(params, lr=0.1) # 这里 lr 是整体学习率
- 更新类别中心的方式与更新 PyTorch 模型相同:
# features (torch 张量): 形状为 (batch_size, feat_dim) 的二维浮点张量
# labels (torch 长整型张量): 形状为 (batch_size) 的一维长整型张量
# alpha (float): 中心损失的权重
loss = center_loss(features, labels) * alpha + other_loss
optimizer_centloss.zero_grad()
loss.backward()
# 乘以 (1./alpha),以消除 alpha 对更新中心的影响
for param in center_loss.parameters():
param.grad.data *= (1./alpha)
optimizer_centloss.step()
如果您采用第二种方式(即使用一个优化器同时优化模型和中心损失),更新代码将如下所示:
loss = center_loss(features, labels) * alpha + other_loss
optimizer.zero_grad()
loss.backward()
for param in center_loss.parameters():
# lr_cent 是中心损失的学习率,例如 lr_cent = 0.5
param.grad.data *= (lr_cent / (alpha * lr))
optimizer.step()
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备