stock-prediction-deep-neural-learning
stock-prediction-deep-neural-learning 是一个基于深度学习的开源项目,旨在利用人工智能技术预测股票价格走势。面对股市受多重因素影响、波动难以捉摸的挑战,该项目通过机器学习自动识别历史数据中的潜在规律,为投资者提供辅助决策参考。
它主要解决了传统分析方法难以处理复杂时间序列数据的痛点。项目核心采用了 TensorFlow 框架下的 LSTM(长短期记忆)神经网络。作为一种特殊的循环神经网络(RNN),LSTM 具备独特的“记忆”机制,能够长时间保留关键信息,非常适合处理像股价这样具有前后依赖关系的时间序列数据,从而提升预测的准确性。此外,项目集成了 yFinance 库,可便捷地从雅虎财经获取实时市场数据,降低了数据收集的门槛。
这款工具特别适合具备一定 Python 基础的开发者、量化交易研究人员以及对 AI 金融应用感兴趣的技术爱好者使用。用户只需配置好 Conda 或 pip 环境,即可快速复现模型并进行实验。虽然它能挖掘数据模式并带来潜在的投资洞察,但使用者仍需注意股市风险,将其作为研究辅助而非绝对的盈利保证。
使用场景
某量化交易团队的初级分析师正在尝试为谷歌(GOOG)股票构建短期价格预测模型,以辅助制定下周的交易策略。
没有 stock-prediction-deep-neural-learning 时
- 数据获取繁琐:需要手动编写复杂的爬虫脚本或从多个金融终端导出 CSV 文件,难以保证数据的实时性和完整性。
- 建模门槛极高:从零搭建 LSTM(长短期记忆网络)架构需要深厚的深度学习功底,处理时间序列的“长期依赖”问题极易出错。
- 环境配置混乱:手动安装 TensorFlow、Python 及相关依赖库时,常因版本冲突导致代码无法运行,调试耗时数天。
- 预测缺乏依据:仅凭简单的移动平均线或主观经验判断趋势,无法捕捉股价背后复杂的非线性波动规律,投资风险不可控。
使用 stock-prediction-deep-neural-learning 后
- 一键获取数据:内置 yFinance 模块,只需输入"GOOG"代号即可自动下载并清洗最新的雅虎财经历史数据,大幅缩短准备时间。
- 开箱即用的模型:直接调用预置的 TensorFlow LSTM 神经网络,自动识别股价序列中的长期模式,无需从头推导数学公式。
- 标准化运行环境:通过 Conda 环境文件一键部署 Python 3.12 与 TensorFlow 2.18.1,彻底解决依赖冲突,几分钟内即可启动训练。
- 科学辅助决策:基于深度学习的时序预测输出具体的未来价格走势,为团队提供数据支撑的交易信号,显著提升策略胜率。
stock-prediction-deep-neural-learning 将高深的深度学习技术转化为可执行的自动化流程,让普通分析师也能利用前沿 AI 模型挖掘股市价值。
运行环境要求
- Windows
- Linux
- macOS
未说明(基于 TensorFlow 2.18.1,可选支持 CUDA)
未说明
快速开始
基于深度神经网络的股票预测
预测股票价格是一项极具挑战性的任务,因为股价往往不遵循任何特定的规律。然而,通过深度学习技术,我们可以利用机器学习来识别其中的模式。在时间序列预测中,最有效的技术之一就是使用LSTM(长短期记忆)网络。LSTM是一种特殊的循环神经网络(RNN),能够长期记住信息,因此在股票价格预测中非常有用。
本项目提供了一个基于TensorFlow的LSTM神经网络实现,可用于时间序列预测。成功预测一只股票的未来价格可以为投资者带来可观的收益。
快速入门(Conda)
该项目使用Python 3.12和TensorFlow 2.18.1。
conda env create -f environment.yml
conda activate stock-prediction
如果你更倾向于在现有环境中使用pip:
pip install -r requirements.txt
Jupyter用户应选择stock-prediction内核。如果该内核未显示,请执行以下命令:
python -m ipykernel install --user --name stock-prediction --display-name "stock-prediction"
1) 引言
预测股票价格是一项复杂的任务,因为它受到多种因素的影响,例如市场趋势、政治事件和经济指标等。股票价格的波动主要由供需关系驱动,而这种供需关系有时是难以预测的。为了识别股票价格中的模式和趋势,我们可以借助深度学习技术进行机器学习。长短期记忆网络(LSTM)是一种专门用于序列建模和预测的循环神经网络。LSTM能够在较长时间内保留信息,因此非常适合用于股票价格预测。由于RNN擅长处理时间序列数据,它们会逐步处理数据,并在内部状态中以压缩形式存储已见过的信息。准确预测一只股票的未来价格可以为投资者带来显著的财务收益。
2) 股票市场数据
为了收集我们股票预测模型所需的市场数据,我们将使用Python中的yFinance库。该库专门用于从Yahoo Finance网站下载指定股票代码的相关信息。通过yFinance,我们可以轻松获取最新的市场数据并将其纳入我们的模型中。
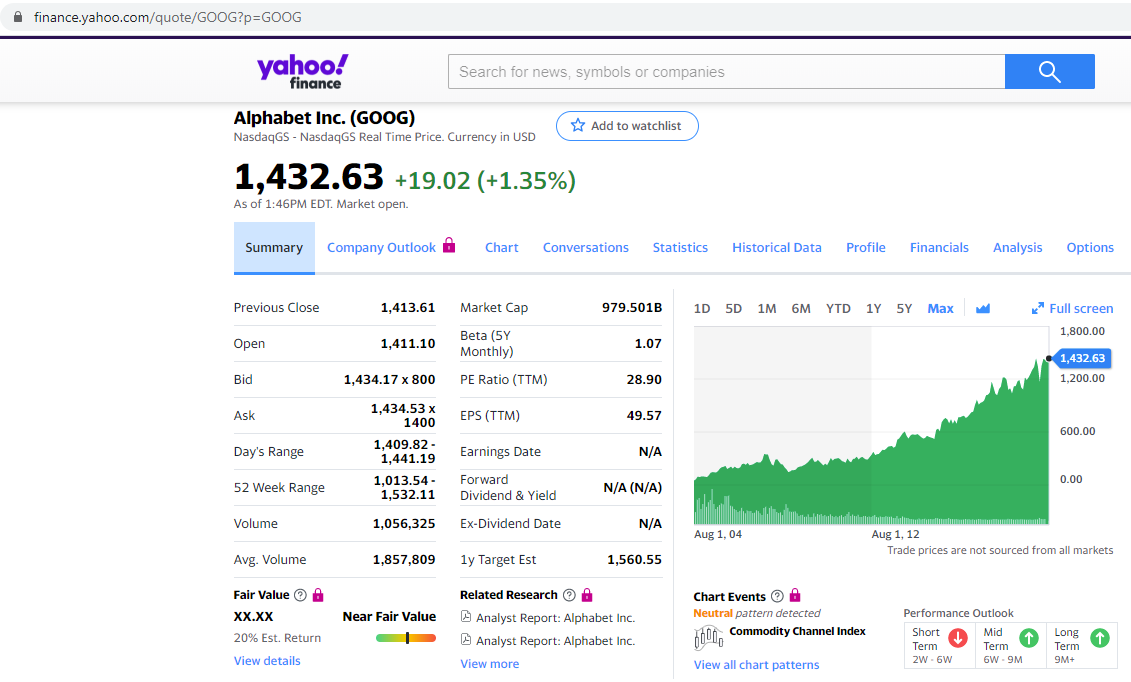
在本项目中,我们将使用“GOOG”这一股票代码,它代表一家知名的科技公司。以下是Yahoo Finance页面上该股票代码的示例截图:
2.1) 下载市场信息
要下载市场数据,我们需要先安装yFinance库,然后只需执行以下操作即可根据股票代码下载所有相关信息。请确保使用最新版本的库(pip install yfinance==0.2.54),因为我曾遇到过旧版本出现错误的情况。
以下是来自[download_market_data_info.py]文件的输出,该文件能够从Yahoo Finance下载金融数据。
C:\Users\thund\Source\Repos\stock-prediction-deep-neural-learning>python download_market_data_info.py
信息
{
"52周变化": 0.26037383,
"标普52周变化": 0.034871936,
"地址1": "1600 Amphitheatre Parkway",
"算法": null,
"年度持股周转率": null,
"年度报告费用比率": null,
"卖价": 1432.77,
"卖量": 1400,
"10日平均成交量": 2011171,
"平均成交量": 1857809,
"10日平均成交量": 2011171,
"贝塔系数": 1.068946,
"3年贝塔系数": null,
"买价": 1432.16,
"买量": 3000,
"账面价值": 297.759,
"类别": null,
"流通股本": null,
"城市": "Mountain View",
"公司高管": [],
"国家": "美国",
"货币": "USD",
"空头持仓数据日期": 1592179200,
"当日最高价": 1441.19,
"当日最低价": 1409.82,
"股息率": null,
"股息收益率": null,
"季度收益增长率": 0.027,
"企业价值与EBITDA比": 17.899,
"企业价值与收入比": 5.187,
"企业价值": 864533741568,
"除息日": null,
"交易所": "NMS",
"交易所时区名称": "America/New_York",
"交易所时区简称": "EDT",
"到期日": null,
"50日均线": 1417.009,
"52周最高价": 1532.106,
"52周最低价": 1013.536,
"5年平均回报率": null,
"5年平均股息收益率": null,
"自由流通股数": 613293304,
"远期每股收益": 55.05,
"远期市盈率": 26.028149,
"来源货币": null,
"全职员工数": 123048,
"基金家族": null,
"基金成立日期": null,
"GMT偏移毫秒数": "-14400000",
"内部人士持股比例": 0.05746,
"机构持股比例": 0.7062,
"行业": "互联网内容与信息",
"是否包含ESG信息": false,
"最近资本利得": null,
"最近股息金额": null,
"最近财政年度结束日期": 1577750400,
"最近市场": null,
"最近拆股日期": 1430092800,
"最近拆股比例": "10000000:10000000",
"法律类型": null,
"公司业务简介": "Alphabet Inc.在美国、欧洲、中东、非洲、亚太地区、加拿大和拉丁美洲提供在线广告服务。该公司提供效果广告和品牌广告服务。公司通过Google和其他业务部门运营。Google部门提供诸如Ads、Android、Chrome、Google Cloud、Google Maps、Google Play、硬件、搜索和YouTube等产品,以及技术基础设施。它还提供数字内容、云服务、硬件设备以及其他杂项产品和服务。其他业务部门包括Access、Calico、CapitalG、GV、Verily、Waymo和X等业务,以及互联网和电视服务。Alphabet Inc.成立于1998年,总部位于加利福尼亚州山景城。",
"全称": "Alphabet Inc.",
"市场": "us_market",
"市值": 979650805760,
"最大年龄": 1,
"最大供应量": null,
"留言板ID": "finmb_29096",
"晨星总体评级": null,
"晨星风险评级": null,
"最近一个季度": 1585612800,
"净值价格": null,
"归属于普通股的净利润": 34522001408,
"下一财政年度结束日期": 1640908800,
"开盘价": 1411.1,
"未平仓合约量": null,
"股息支付比率": 0,
"PEG比率": 4.38,
"电话": "650-253-0000",
"前收盘价": 1413.61,
"价格提示": 2,
"市净率": 4.812112,
"过去12个月市销率": 5.87754,
"利润率": 0.20712,
"报价类型": "EQUITY",
"常规市场当日最高价": 1441.19,
"常规市场当日最低价": 1409.82,
"常规市场开盘价": 1411.1,
"常规市场前收盘价": 1413.61,
"常规市场当前价格": 1411.1,
"常规市场成交量": 1084440,
"季度营收增长率": null,
"板块": "通信服务",
"已发行股数": 336161984,
"已发行股数占总股本比例": 0.0049,
"空头持仓股数": 3371476,
"上月空头持仓数据日期": 1589500800,
"上月空头持仓股数": 3462105,
"简称": "Alphabet Inc.",
"空头持仓占自由流通股比例": null,
"空头持仓倍数": 1.9,
"成立日期": null,
"州": "CA",
"行权价格": null,
"股票代码": "GOOG",
"3年平均回报率": null,
"目标货币": null,
"总资产": null,
"可交易": false,
"过去一年股息率": null,
"过去一年股息收益率": null,
"过去一年每股收益": 49.572,
"过去一年市盈率": 28.904415,
"200日均线": 1352.9939,
"成交量": 1084440,
"24小时成交量": null,
"所有货币成交量": null,
"官网": "http://www.abc.xyz",
"收益率": null,
"年初至今回报率": null,
"邮编": "94043"
}
ISIN
-
主要持有人
0 1
0 5.75% 所有内部人士持股比例
1 70.62% 机构持股比例
2 74.93% 机构持有自由流通股比例
3 3304 持有股份的机构数量
机构持有人
持有人 报告日期 股份占比 价值
0 Vanguard Group, Inc. (The) 23162950 2020-03-30 0.0687 26934109889
1 Blackrock Inc. 20264225 2020-03-30 0.0601 23563443472
2 Price (T.Rowe) Associates Inc 12520058 2020-03-30 0.0371 14558448642
3 State Street Corporation 11814026 2020-03-30 0.0350 13737467573
4 FMR, LLC 8331868 2020-03-30 0.0247 9688379429
5 Capital International Investors 4555880 2020-03-30 0.0135 5297622822
6 Geode Capital Management, LLC 4403934 2020-03-30 0.0131 5120938494
7 Northern Trust Corporation 4017009 2020-03-30 0.0119 4671018235
8 JP Morgan Chase & Company 3707376 2020-03-30 0.0110 4310973886
9 AllianceBernstein, L.P. 3483382 2020-03-30 0.0103 4050511423
股息
Series([], Name: Dividends, dtype: int64)
拆股
日期
2014-03-27 2.002
2015-04-27 1.000
Name: Stock Splits, dtype: float64
动作
股息 股票拆分
日期
2014-03-27 0.0 2.002
2015-04-27 0.0 1.000
日历
空DataFrame
列: []
索引: [财报公布日期、财报平均值、财报低点、财报高点、营收平均值、营收低点、营收高点]
推荐意见
公司 评级 起始评级 行动
日期
2012-03-14 15:28:00 Oxen Group 持有 初始
2012-03-28 06:29:00 花旗集团 买入 主要
2012-04-03 08:45:00 Global Equities Research 增持 主要
2012-04-05 06:34:00 德意志银行 买入 主要
2012-04-09 06:03:00 Pivotal Research 买入 主要
2012-04-10 11:32:00 瑞银集团 买入 主要
2012-04-13 06:16:00 德意志银行 买入 主要
2012-04-13 06:18:00 Jefferies 买入 主要
2012-04-13 06:37:00 PiperJaffray 增持 主要
2012-04-13 06:38:00 高盛公司 中性 主要
2012-04-13 06:41:00 摩根大通 增持 主要
2012-04-13 06:51:00 Oppenheimer 跑赢大盘 主要
2012-04-13 07:13:00 Benchmark 持有 主要
2012-04-13 08:46:00 BMO Capital 跑赢大盘 主要
2012-04-16 06:52:00 Hilliard Lyons 买入 主要
2012-06-06 06:17:00 德意志银行 买入 主要
2012-06-06 06:56:00 摩根大通 增持 主要
2012-06-22 06:15:00 花旗集团 买入 主要
2012-07-13 05:57:00 Wedbush 中性 初始
2012-07-17 09:33:00 跑赢大盘 主要
2012-07-20 06:43:00 Benchmark 持有 主要
2012-07-20 06:54:00 德意志银行 买入 主要
2012-07-20 06:59:00 美国银行 买入 主要
2012-08-13 05:49:00 摩根士丹利 增持 平衡权重 上调
2012-09-17 06:07:00 Global Equities Research 增持 主要
2012-09-21 06:28:00 Cantor Fitzgerald 买入 初始
2012-09-24 06:11:00 花旗集团 买入 主要
2012-09-24 09:05:00 Pivotal Research 买入 主要
2012-09-25 07:20:00 Capstone 买入 主要
2012-09-26 05:48:00 Canaccord Genuity 买入 主要
... ... ... ... ...
2017-10-27 19:29:31 瑞银集团 买入 主要
2018-02-02 14:04:52 PiperJaffray 增持 增持 主要
2018-04-24 11:43:49 摩根大通 增持 增持 主要
2018-04-24 12:24:37 德意志银行 买入 买入 主要
2018-05-05 14:00:37 B. Riley FBR 买入 主要
2018-07-13 13:49:13 Cowen & Co. 优于大盘 优于大盘 主要
2018-07-24 11:50:55 Cowen & Co. 优于大盘 优于大盘 主要
2018-07-24 13:33:47 Raymond James 优于大盘 优于大盘 主要
2018-10-23 11:18:00 德意志银行 买入 买入 主要
2018-10-26 15:17:08 Raymond James 优于大盘 优于大盘 主要
2019-01-23 12:55:04 德意志银行 买入 买入 主要
2019-02-05 12:55:12 德意志银行 买入 买入 主要
2019-02-05 13:18:47 PiperJaffray 增持 增持 主要
2019-05-15 12:34:54 德意志银行 买入 主要
2019-10-23 12:58:59 瑞信集团 优于大盘 主要
2019-10-29 11:58:09 Raymond James 优于大盘 主要
2019-10-29 14:15:40 德意志银行 买入 主要
2019-10-29 15:48:29 瑞银集团 买入 主要
2020-01-06 11:22:07 Pivotal Research 买入 持有 上调
2020-01-17 13:01:48 瑞银集团 买入 主要
2020-02-04 12:26:56 Piper Sandler 增持 主要
2020-02-04 12:41:00 Raymond James 优于大盘 主要
2020-02-04 14:00:36 德意志银行 买入 主要
2020-02-06 11:34:20 CFRA 强烈买入 主要
2020-03-18 13:52:51 摩根大通 增持 主要
2020-03-30 13:26:16 瑞银集团 买入 主要
2020-04-17 13:01:41 Oppenheimer 优于大盘 主要
2020-04-20 19:29:50 瑞信集团 优于大盘 主要
2020-04-29 14:01:51 瑞银集团 买入 主要
2020-05-05 12:44:16 德意志银行 买入 主要
[219行 x 4列]
收益
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
季度收益
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
财务报表
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
季度财务报表
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
资产负债表
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
季度资产负债表
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
资产负债表
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
季度资产负债表
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
现金流量
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
季度现金流量
空DataFrame
列:[开盘价, 最高价, 最低价, 收盘价, 调整后收盘价, 成交量]
索引:[]
可持续性
无
选项
('2020-07-02', '2020-07-10', '2020-07-17', '2020-07-24', '2020-07-31', '2020-08-07', '2020-08-21', '2020-09-18', '2020-11-20', '2020-12-01', '2020-12-18', '2021-01-15', '2021-06-18', '2022-01-21', '2022-06-17')
数据中包含一个JSON文档,我们可以在以后使用它来创建我们的证券主数据表,如果我们希望将这些数据存储起来以跟踪我们将进行交易的证券的话。由于数据可能包含不同的字段,我的建议是将它们存储在数据湖中,这样我们可以从多个来源构建数据,而无需过多担心数据的结构方式。
2.2) 市场数据下载
上一步帮助我们识别给定股票代码的若干特征,从而可以利用这些属性来定义我接下来展示的一些图表。需要注意的是,yFinance库仅需通过股票代码、所需时间段的起始日期和结束日期即可完成数据下载。此外,我们还可以使用interval参数指定数据的时间粒度。默认情况下,时间粒度为1天,这也是我在本次训练中将要使用的设置。
要下载数据,我们可以使用以下命令:
start = pd.to_datetime('2004-08-01')
stock = ['GOOG']
data = yf.download(stock, start=start, end=datetime.date.today())
print(data)
示例输出如下:
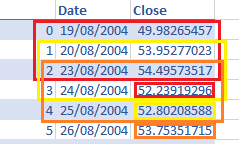
C:\Users\thund\Source\Repos\stock-prediction-deep-neural-learning>python download_market_data.py
[*********************100%***********************] 1 of 1 completed
Open High Low Close Adj Close Volume
Date
2004-08-19 49.813286 51.835709 47.800831 49.982655 49.982655 44871300
2004-08-20 50.316402 54.336334 50.062355 53.952770 53.952770 22942800
2004-08-23 55.168217 56.528118 54.321388 54.495735 54.495735 18342800
2004-08-24 55.412300 55.591629 51.591621 52.239193 52.239193 15319700
2004-08-25 52.284027 53.798351 51.746044 52.802086 52.802086 9232100
2004-08-26 52.279045 53.773445 52.134586 53.753517 53.753517 7128600
2004-08-27 53.848164 54.107193 52.647663 52.876804 52.876804 6241200
2004-08-30 52.443428 52.548038 50.814533 50.814533 50.814533 5221400
2004-08-31 50.958992 51.661362 50.889256 50.993862 50.993862 4941200
2004-09-01 51.158245 51.292744 49.648903 49.937820 49.937820 9181600
2004-09-02 49.409801 50.993862 49.285267 50.565468 50.565468 15190400
2004-09-03 50.286514 50.680038 49.474556 49.818268 49.818268 5176800
2004-09-07 50.316402 50.809555 49.619015 50.600338 50.600338 5875200
2004-09-08 50.181908 51.322632 50.062355 50.958992 50.958992 5009200
2004-09-09 51.073563 51.163227 50.311420 50.963974 50.96... ... ... ... ... ... ...
2020-05-19 1386.996948 1392.000000 1373.484985 1373.484985 1373.484985 1280600
2020-05-20 1389.579956 1410.420044 1387.250000 1406.719971 1406.71997ì 1655400
2020-05-21 1408.000000 1415.489990 1393.449951 1402.800049 1402.80004ì 1385000
2020-05-22 1396.70996ì 1412.760010 1391.82995ì 1410.42004ì 130940ì
2020-05-26 1437.27002ì 1441.00000ì 1412.130005 1417.02002ì 20606ì
2020-05-27 1417.25000ì 1421.73999ì 1391.29003ì 1417.83996ì 16858ì
2020-05-28 1396.85998ì 1440.83996ì 1396.0000ì 1416.72998ì 16922ì
2020-05-29 1416.93994ì 1432.56994ì 1413.34997ì 1428.92004ì 18381ì
2020-06-01 1418.39001ì 1437.95996ì 1418.0000ì 1431.81994ì 12171ì
2020-06-02 1430.55004ì 1439.60998ì 1418.82995ì 1439.21997ì 12781ì
2020-06-03 1438.30004ì 1446.55200ì 1429.77697ì 1436.38000ì 15483ì
2020-06-04 1430.40002ì 1438.95996ì 1412.18005ì 1412.18005ì 14843ì
2020-06-05 1413.17004ì 1445.05004ì 1413.83996ì 1413.83996ì 17349ì
2020-06-08 1422.33996ì 1447.98999ì 1422.33996ì 1446.60998ì 14466ì
2020-06-09 1445.35998ì 1468.0000ì 1443.20996ì 1456.16003ì 1456.16003ì 14092ì
2020-06-10 1459.54003ì 1474.25903ì 1465.84997ì 1465.84997ì 15252ì
2020-06-11 1442.47998ì 1454.47497ì 1413.83996ì 1413.83996ì 19913ì
2020-06-12 1428.48999ì 1437.0000ì 1386.02002ì 1413.83996ì 1413.83996ì 19442ì
2020-06-15 1390.80004ì 1424.80004ì 1387.92004ì 1419.84997ì 15039ì
2020-06-16 1445.21997ì 1455.02002ì 1425.90002ì 1442.71997ì 17092ì
2020-06-17 1447.16003ì 1460.0000ì 1431.38000ì 1451.11997ì 15483ì
2020-06-18 1449.16003ì 1445.41003ì 1427.01001ì 1435.95996ì 15183ì
2020-06-19 1444.0000ì 1447.80004ì 1413.83996ì 1413.83996ì 31579ì
2020-06-22 1429.0000ì 1452.75000ì 1423.20996ì 1451.85998ì 15424ì
2020-06-23 1455.64001ì 1475.94104ì 1445.23999ì 1464.41003ì 14… [3994 rows x 6 columns]
需要注意的是,正确设置起始日期非常重要,以确保我们收集到完整有效的数据。如果未正确设置起始日期,可能会导致出现一些NaN值,从而影响后续训练的结果。
3) 深度学习模型
3.1) 训练与验证数据
现在我们已经有了要使用的数据,接下来需要定义训练数据和验证数据的划分标准。由于股票价格会随日期变化,我编写的函数需要三个基本参数:
- 股票代码:GOOG
- 开始日期:数据起始日期,在本例中为 2004年8月1日。
- 验证日期:用于确定验证集的时间点,在本例中我们指定 2017年1月1日 作为验证数据点。
请注意,您需要先配置好 TensorFlow、Keras 以及 GPU,才能运行下面的示例代码。
在本练习中,我只关注 收盘价,这是衡量股票或证券表现的标准指标。
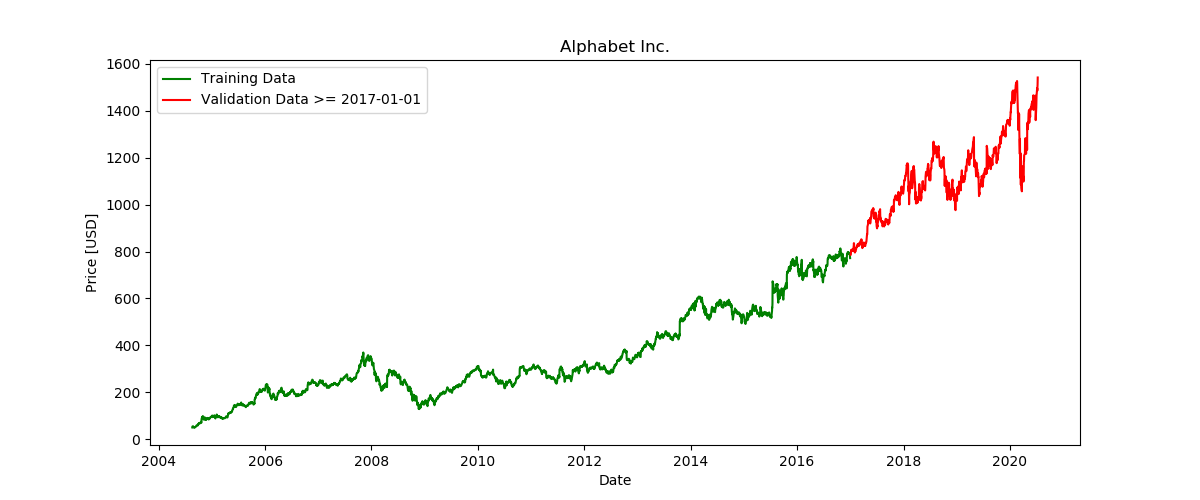
以下是我们将创建的训练数据与验证数据的划分图表:
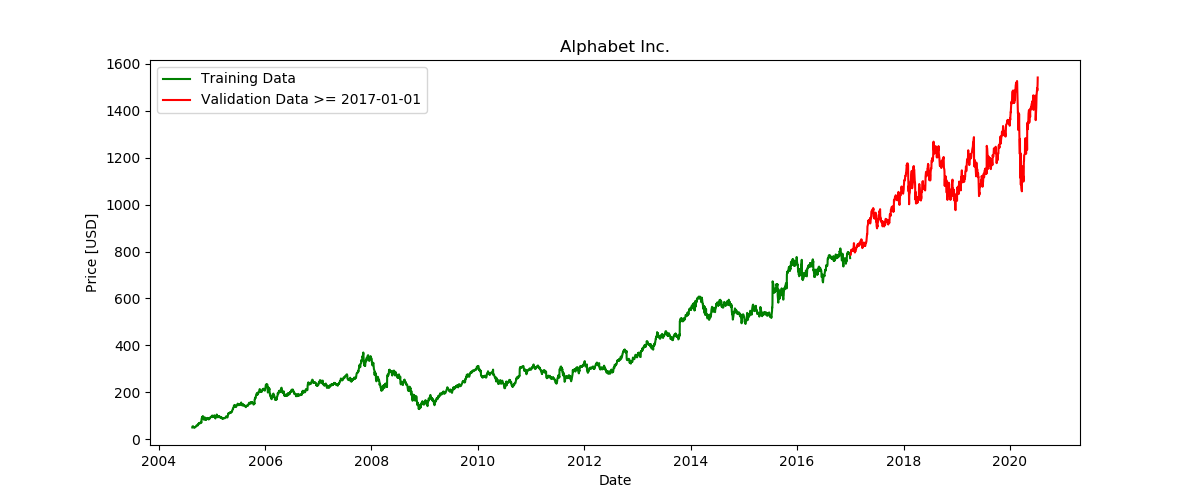
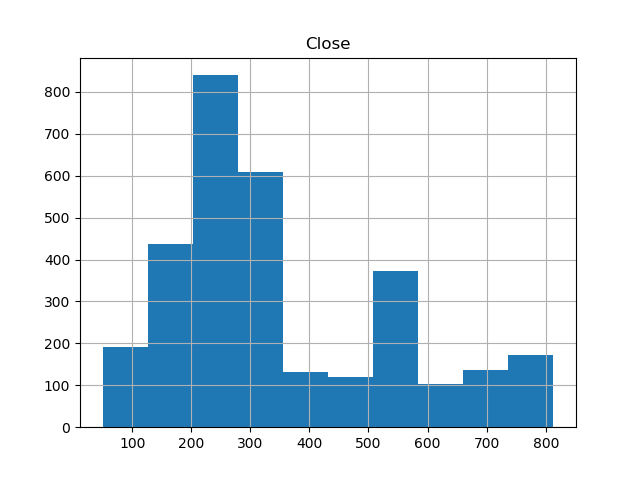
此外,还有显示价格分布的直方图:
3.2) 数据归一化
为了对数据进行归一化处理,我们需要将其缩放到 0 到 1 的范围内,以便在统一的尺度上进行分析。为此,我们可以使用预处理工具 MinMaxScaler,具体如下:
min_max = MinMaxScaler(feature_range=(0, 1))
train_scaled = min_max.fit_transform(training_data)
3.3) 添加时间步长
为了实现用于时间序列预测的 LSTM 网络,我们采用了 3 天的时间步长。这种技术使网络能够回顾过去 3 天的数据,从而预测下一天的价格。下图展示了这一概念在我们的实现中的应用:前 3 个收盘价样本用于生成第 4 个样本,以此类推。这样就生成了一个形状为 (3,1) 的矩阵,其中 3 表示时间步长,1 表示特征数量(即收盘价)。
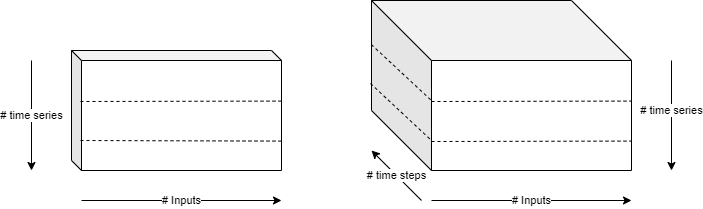
# 定义时间步长
time_steps = 3
# 遍历数据以创建分区
for i in range(time_steps, train_scaled.shape[0]):
# 创建过去 3 天的数据分区
x_train.append(train_scaled[i - time_steps:i])
# 将下一天的收盘价添加到标签数组
y_train.append(train_scaled[i, 0])
采用 3 天的时间步长可以让 LSTM 网络识别数据中的模式,并基于这些模式做出预测。通过滑动窗口的方法,我们可以训练网络根据历史数据来预测未来的股票价格。
3.4) 长短期记忆网络深度学习模型的构建
为了创建该模型,您需要安装 TensorFlow、TensorFlow-GPU 和 Keras 才能正常运行。该模型的代码如下所示,每层的解释也在下方给出:
def create_long_short_term_memory_model(x_train):
model = Sequential()
# 第1层,使用Dropout正则化
# * units=100:设置输出空间的维度为100个神经元
# * return_sequences=True:堆叠LSTM层,使下一层能够接收三维序列输入
# * input_shape:训练数据集的形状
model.add(LSTM(units=100, return_sequences=True, input_shape=(x_train.shape[1], 1)))
# 20%的神经元将被丢弃
model.add(Dropout(0.2))
# 第2层LSTM
# * units=50:设置输出空间的维度为50个神经元
# * return_sequences=True:堆叠LSTM层,使下一层能够接收三维序列输入
model.add(LSTM(units=50, return_sequences=True))
# 20%的神经元将被丢弃
model.add(Dropout(0.2))
# 第3层LSTM
# * units=50:设置输出空间的维度为50个神经元
# * return_sequences=True:堆叠LSTM层,使下一层能够接收三维序列输入
model.add(LSTM(units=50, return_sequences=True))
# 50%的神经元将被丢弃
model.add(Dropout(0.5))
# 第4层LSTM
# * units=50:设置输出空间的维度为50个神经元
model.add(LSTM(units=50))
# 50%的神经元将被丢弃
model.add(Dropout(0.5))
# 全连接层,指定输出为1个单元
model.add(Dense(units=1))
model.summary()
tf.keras.utils.plot_model(model, to_file=os.path.join(project_folder, 'model_lstm.png'), show_shapes=True,
show_layer_names=True)
return model
渲染后的模型如下图所示,该模型具有超过10万个可训练参数。
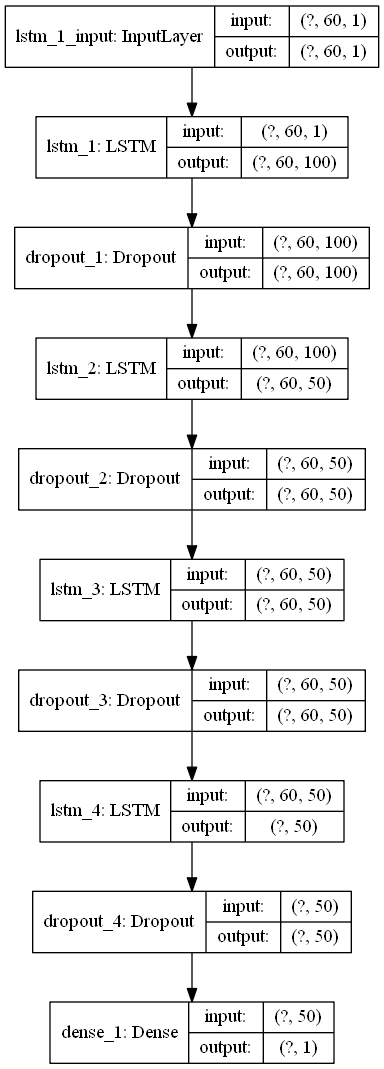
Layer (type) Output Shape Param #
=================================================================
lstm_1 (LSTM) (None, 60, 100) 40800
_________________________________________________________________
dropout_1 (Dropout) (None, 60, 100) 0
_________________________________________________________________
lstm_2 (LSTM) (None, 60, 50) 30200
_________________________________________________________________
dropout_2 (Dropout) (None, 60, 50) 0
_________________________________________________________________
lstm_3 (LSTM) (None, 60, 50) 20200
_________________________________________________________________
dropout_3 (Dropout) (None, 60, 50) 0
_________________________________________________________________
lstm_4 (LSTM) (None, 50) 20200
_________________________________________________________________
dropout_4 (Dropout) (None, 50) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 51
=================================================================
Total params: 111,451
Trainable params: 111,451
Non-trainable params: 0
定义好模型后,我们需要指定用于跟踪模型表现的指标,以及用于训练的优化器类型。我还设置了模型的耐心值及其停止规则。
defined_metrics = [
tf.keras.metrics.MeanSquaredError(name='MSE')
]
callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=3, mode='min', verbose=1)
model.compile(optimizer='adam', loss='mean_squared_error', metrics=defined_metrics)
history = model.fit(x_train, y_train, epochs=epochs, batch_size=batch_size, validation_data=(x_test, y_test),
callbacks=[callback])
该模型经过微调,以达到最低的验证损失。在本例中,验证损失为0.14%,均方误差(MSE)也为0.14%,表现相对较好,能够提供非常准确的结果。
训练结果如下:
在3055个样本上训练,在881个样本上验证
第1轮/100轮
2020-07-11 15:15:34.557035: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] 成功加载动态库cublas64_100.dll
3112/3112 [==============================] - 19秒/样本 - 损失: 0.0451 - MSE: 0.0451 - 验证损失: 0.0068 - 验证MSE: 0.0068
第2轮/100轮
3112/3112 [==============================] - 4秒/样本 - 损失: 0.0088 - MSE: 0.0088 - 验证损失: 0.0045 - 验证MSE: 0.0045
第3轮/100轮
3112/3112 [==============================] - 5秒/样本 - 损失: 0.0062 - MSE: 0.0062 - 验证损失: 0.0032 - 验证MSE: 0.0032
第4轮/100轮
3112/3112 [==============================] - 5秒/样本 - 损失: 0.0051 - MSE: 0.0051 - 验证损失: 0.0015 - 验证MSE: 0.0015
第5轮/100轮
3112/3112 [==============================] - 7秒/样本 - 损失: 0.0045 - MSE: 0.0045 - 验证损失: 0.0013 - 验证MSE: 0.0013
第6轮/100轮
3112/3112 [==============================] - 5秒/样本 - 损失: 0.0045 - MSE: 0.0045 - 验证损失: 0.0013 - 验证MSE: 0.0013
第7轮/100轮
3112/3112 [==============================] - 5秒/样本 - 损失: 0.0045 - MSE: 0.0045 - 验证损失: 0.0015 - 验证MSE: 0.0015
第8轮/100轮
3112/3112 [==============================] - 5秒/样本 - 损失: 0.0040 - MSE: 0.0040 - 验证损失: 0.0015 - 验证MSE: 0.0015
第9轮/100轮
3112/3112 [==============================] - 5秒/样本 - 损失: 0.0039 - MSE: 0.0039 - 验证损失: 0.0014 - 验证MSE: 0.0014
第00009轮:提前停止
保存权重
绘制损失曲线
绘制MSE曲线
显示模型内容
886/1 - 0秒 - 损失: 0.0029 - MSE: 0.0014
损失:0.0014113364930413916
MSE:0.0014113366
3.5) 进行预测
现在是时候准备我们的测试数据,并将其输入到深度学习模型中,以获得我们想要的预测结果了。
首先,我们需要使用与处理训练数据相同的时间步长方法来导入测试数据:
def infer_data():
print(tf.version.VERSION)
inference_folder = os.path.join(os.getcwd(), RUN_FOLDER)
stock = StockPrediction(STOCK_TICKER, STOCK_START_DATE, STOCK_VALIDATION_DATE, inference_folder, GITHUB_URL, EPOCHS, TIME_STEPS, TOKEN, BATCH_SIZE)
data = StockData(stock)
(x_train, y_train), (x_test, y_test), (training_data, test_data) = data.download_transform_to_numpy(TIME_STEPS, inference_folder)
min_max = data.get_min_max()
# 加载未来数据
print('最新股票价格')
latest_close_price = test_data.Close.iloc[-1]
latest_date = test_data[-1:]['Close'].idxmin()
print(latest_close_price)
print('最新日期')
print(latest_date)
tomorrow_date = latest_date + timedelta(1)
# 指定接下来的300天
next_year = latest_date + timedelta(TIME_STEPS * 100)
print('未来日期')
print(tomorrow_date)
print('未来时间跨度日期')
print(next_year)
x_test, y_test, test_data = data.generate_future_data(TIME_STEPS, min_max, tomorrow_date, next_year, latest_close_price)
# 检查未来数据是否为空
if x_test.shape[0] > 0:
# 加载我们最佳模型的权重
model = tf.keras.models.load_model(os.path.join(inference_folder, 'model_weights.h5'))
model.summary()
# 进行预测
test_predictions_baseline = model.predict(x_test)
test_predictions_baseline = min_max.inverse_transform(test_predictions_baseline)
test_predictions_baseline = pd.DataFrame(test_predictions_baseline, columns=['Predicted_Price'])
# 将预测值与测试数据中的日期结合
predicted_dates = pd.date_range(start=test_data.index[0], periods=len(test_predictions_baseline))
test_predictions_baseline['Date'] = predicted_dates
# 重置索引以便正确拼接
test_data.reset_index(inplace=True)
# 拼接测试数据和预测数据
combined_data = pd.concat([test_data, test_predictions_baseline], ignore_index=True)
# 绘制预测图
plt.figure(figsize=(14, 5))
plt.plot(combined_data['Date'], combined_data.Close, color='green', label='模拟[' + STOCK_TICKER + ']价格')
plt.plot(combined_data['Date'], combined_data['Predicted_Price'], color='red', label='预测[' + STOCK_TICKER + ']价格')
plt.xlabel('时间')
plt.ylabel('价格 [USD]')
plt.legend()
plt.title('模拟与预测价格对比')
plt.savefig(os.path.join(inference_folder, STOCK_TICKER + '_future_comparison.png'))
plt.show()
else:
print("错误:未来数据为空。")
start_date = pd.to_datetime('2017-01-01')
end_date = datetime.today()
duration = end_date - start_date
STOCK_VALIDATION_DATE = start_date + 0.8 * duration
现在我们可以调用 infer_data 方法,它将根据我们在训练数据上进行的训练生成股票预测。最终,我们将生成一个包含预测结果的 CSV 文件,以及一张显示实际价格与预测价格对比的图表。
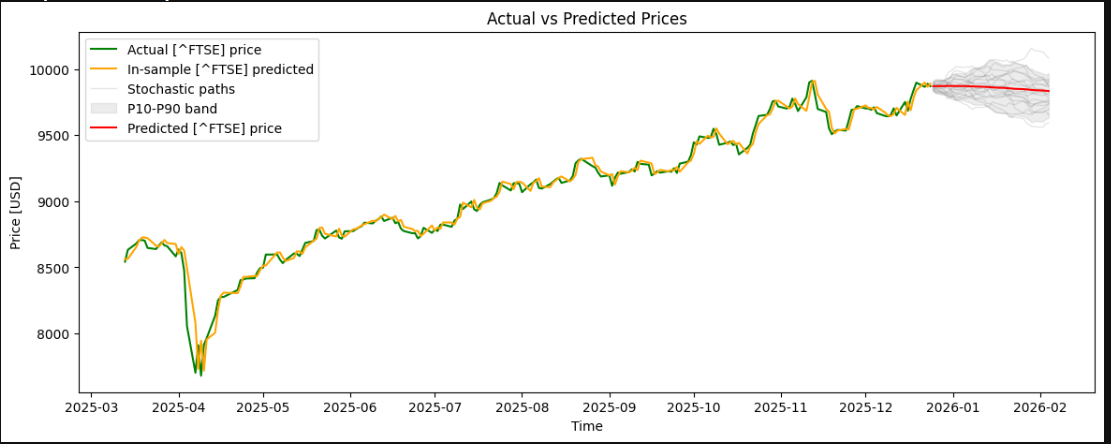
4) 使用说明
本项目使用 Python 3.12 构建。
下载源代码并使用以下任一方式安装依赖项:
conda env create -f environment.yml
conda activate stock-prediction
或者,在现有环境中使用 pip 安装:
pip install -r requirements.txt
注意:如果您更改 TensorFlow 版本,请确保 NumPy 的版本与该版本的约束条件相匹配。
4.1) 默认模型 (v7)
v7 是默认模型版本。它训练两个分支:方向(上涨/下跌)和幅度(绝对变动),然后重构价格变化量。
v7 的训练输出包括:
model_direction.kerasmodel_magnitude.kerasmodel_config.json(包含model_version、forecast_horizon、use_returns、use_deltas、use_trend_residual)min_max_scaler.pkl和input_scaler.pkl
4.2) 推理(随机轨迹)
推理使用 stock_prediction_deep_learning_inference.py 中的 InferenceRunner,可以生成多条随机路径:
STOCHASTIC_PATHS:轨迹数量STOCHASTIC_SIGMA_MULT:噪声尺度倍数STOCHASTIC_LOOKBACK:用于估计噪声的回溯窗口STOCHASTIC_SEED:用于可重复性的随机数种子
输出包括 future_predictions.csv 文件,其中包含 Predicted_Price、Predicted_Price_Raw 以及百分位区间(Predicted_Price_P10、Predicted_Price_P50、Predicted_Price_P90),当启用随机路径时。
然后编辑文件“stock_prediction_deep_learning.py”,填写您想要使用的股票代码及相关日期,并执行以下命令:
# 所有参数均为可选
python stock_prediction_deep_learning.py -ticker=GOOG -start_date=2017-11-01 -validation_date=2022-09-01 -epochs=150 -batch_size=32 -time_steps=30 -use_returns=false -model_version=v7 -forecast_horizon=1
注意:model_version 默认为 v7,因此如果您希望使用默认设置,可以省略此参数。
此外,您还可以使用此处提供的 Jupyter Notebook:
5) CUDA 安装
可选:仅在您拥有 NVIDIA GPU 时需要安装。仅使用 CPU 的情况下无需安装。

正如我之前提到的,我使用 GPU 来加速测试过程。由于我的笔记本电脑配备了 NVIDIA GeForce 显卡,我安装了 CUDA 以充分利用其 GPU 性能。根据您使用的 TensorFlow 版本,您可能需要不同版本的 CUDA。 以下是链接:https://developer.nvidia.com/cuda-11.0-download-archive?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exelocal
您可以在 Conda 提示符下执行以下操作:
(base) >conda install -c conda-forge cudatoolkit=11.2 cudnn=8.1.0
Collecting package metadata (current_repodata.json): done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Collecting package metadata (repodata.json): done
Solving environment: done
==> 警告:存在更新版本的 conda。 <==
当前版本:4.10.3
最新版本:4.14.0
请通过运行以下命令更新 conda:
$ conda update -n base -c defaults conda
## 软件包计划 ##
环境位置:C:\Users\jordi\anaconda3
添加/更新的规格:
- cudatoolkit=11.2
- cudnn=8.1.0
以下软件包将被下载:
软件包 | 构建
---------------------------|-----------------
conda-4.12.0 | py39hcbf5309_0 1.0 MB conda-forge
cudatoolkit-11.2.2 | h933977f_10 879.9 MB conda-forge
cudnn-8.1.0.77 | h3e0f4f4_0 610.8 MB conda-forge
python_abi-3.9 | 2_cp39 4 KB conda-forge
------------------------------------------------------------
总计: 1.46 GB
以下新软件包将被安装:
cudatoolkit conda-forge/win-64::cudatoolkit-11.2.2-h933977f_10
cudnn conda-forge/win-64::cudnn-8.1.0.77-h3e0f4f4_0
python_abi conda-forge/win-64::python_abi-3.9-2_cp39
以下软件包将被更新:
conda pkgs/main::conda-4.10.3-py39haa95532_0 --> conda-forge::conda-4.12.0-py39hcbf5309_0
是否继续([y]/n)? y
正在下载和解压软件包
conda-4.12.0 | 1.0 MB | ############################################################################ | 100%
python_abi-3.9 | 4 KB | ############################################################################ | 100%
cudnn-8.1.0.77 | 610.8 MB | ############################################################################ | 100%
cudatoolkit-11.2.2 | 879.9 MB | ############################################################################ | 100%
准备事务:完成
验证事务:完成
执行事务: / “通过下载和使用 CUDA 工具包的 conda 软件包,即表示您接受 CUDA 最终用户许可协议 (EULA) 的条款和条件:https://docs.nvidia.com/cuda/eula/index.html”
| “通过下载和使用 cuDNN 的 conda 软件包,即表示您接受 NVIDIA cuDNN EULA 的条款和条件 - https://docs.nvidia.com/deeplearning/cudnn/sla/index.html”
已完成
在此之后运行项目,GPU 应该能够被正确识别:
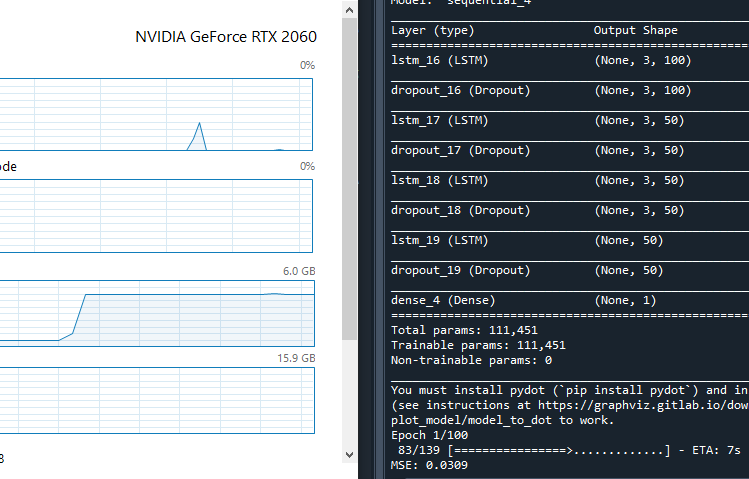
6) Graphviz 安装
如果您看到此消息,则需要安装 GraphViz 库:
您必须安装 pydot(`pip install pydot`)并安装 graphviz(请参阅 https://graphviz.gitlab.io/download/ 上的说明),以便 plot_model/model_to_dot 正常工作。
赞助商
目前尚无赞助商!您愿意成为第一位吗?
![]()
支持我
![]()
版本历史
v1.02025/12/28v0.52025/12/28v0.42024/01/03v0.32022/09/18v0.22020/07/12v0.12020/07/05常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器