Dreambooth-Stable-Diffusion
Dreambooth-Stable-Diffusion 是一个基于 Stable Diffusion 模型的开源训练工具,旨在让用户能够轻松定制专属的 AI 图像生成模型。它通过结合 Dreambooth 和 Textual Inversion 技术,解决了通用大模型难以精准还原特定人物面部特征、独特物体细节或专属艺术风格的痛点。用户只需提供少量目标图片,即可训练出能高度还原特定主体,同时又能灵活适应不同场景和画风的新模型。
该项目由电影导演 Joe Penna(MysteryGuitarMan)发起并优化,最初是为了满足影视制作中对特定演员、道具及场景的高精度生成需求,因此特别强化了对人脸训练的支持。相比原始方案,它在保持主体一致性的同时,更好地平衡了风格迁移的能力,有效避免了生成图像过于僵化或丢失特征的问题。
Dreambooth-Stable-Diffusion 非常适合概念艺术家、漫画设计师、影视从业者以及希望创作个人化内容的开发者使用。项目提供了详尽的教程,支持在 Google Colab、Vast.ai 云平台以及本地 Windows 或 Ubuntu 环境中部署,降低了技术门槛。无论是想将自家宠物融入奇幻场景,还是为电影预演快速生成特定角色的概念图,它都能提供强大而灵活的助力。
使用场景
独立游戏开发者小林正在为一款赛博朋克风格的游戏制作宣传图,需要让主角“艾拉”以不同姿态出现在各种复杂场景中。
没有 Dreambooth-Stable-Diffusion 时
- 每次生成主角都必须依赖繁琐的后期修图,因为通用模型无法稳定还原“艾拉”独特的面部特征和发型细节。
- 试图通过提示词描述角色外貌时,生成的图像往往面目全非,或者每次生成的“艾拉”长得都不一样,缺乏一致性。
- 若要获得高质量且角色统一的素材,只能聘请画师手绘大量原画,成本高昂且修改迭代周期长达数天。
- 调整角色动作或背景风格时,经常导致角色崩坏,难以在保持人物特征的同时自由切换艺术风格。
使用 Dreambooth-Stable-Diffusion 后
- 仅需上传十几张“艾拉”的概念设计图进行微调训练,Dreambooth-Stable-Diffusion 就能将角色特征深度植入模型,实现“一键召唤”固定角色。
- 输入简单的提示词(如“艾拉在雨夜霓虹灯下”),即可生成高度一致的主角形象,彻底解决了角色长相随机变化的问题。
- 开发者可以低成本快速产出数十种不同姿势、光影和场景的草图供团队筛选,将创意验证时间从几天缩短至几分钟。
- 在保持“艾拉”面容不变的前提下,能自由让她穿梭于写实、动漫或油画等多种艺术风格中,极大丰富了视觉表现力。
Dreambooth-Stable-Diffusion 通过将特定角色或风格“刻入”模型基因,让创作者能以极低的成本实现高一致性的个性化内容批量生产。
运行环境要求
- Windows
- Linux
- 必需 NVIDIA GPU
- 推荐显存 24GB (如 RTX 3090, 4090, A5000)
- 最低支持 24GB VRAM 运行(文中强调需独占资源),云端实例建议至少 24GB
- 本地运行命令指定 CUDA 11.7 (cu117)
未说明 (但建议云实例磁盘空间至少 150GB 以容纳模型和正则化图像)

快速开始
由Yushan提供的扩展Dreambooth操作指南
在Vast.ai上运行
在Google Colab上运行
在本地PC(Windows)上运行
在本地PC(Ubuntu)上运行
将Corridor Digital的Dreambooth教程适配到JoePenna的仓库
在JoePenna的Dreambooth中使用标题
索引
曾被称为“Dreambooth”的仓库

Joe Penna的笔记
介绍!
你好!我叫乔·佩纳。
你可能在YouTube上看过我以“MysteryGuitarMan”名义发布的一些视频。现在我是一名故事片导演。你或许已经看过《极地》(ARCTIC)或《偷渡者》(STOWAWAY)。
为了我的电影制作,我需要能够训练特定的演员、道具、场景等。因此,我对@XavierXiao的仓库进行了大量修改,以便用于训练人脸。
虽然我无法公开当前正在拍摄的电影的所有测试内容,但我会在自己的Twitter页面——@MysteryGuitarM——分享使用自己脸部进行的测试结果。这些测试大多是在我的朋友Niko(来自CorridorDigital)的帮助下完成的。也许这就是你找到这个仓库的原因!
我并不是一名程序员。我只是比较固执,并且不怕去谷歌搜索。最终,一些非常聪明的人加入了进来并持续贡献代码。在这个仓库中,特别要感谢:@djbielejeski、@gammagec、MrSaad——当然还有我们Discord社区中的许多其他成员!
现在,这已经不再是我一个人的仓库了,而是所有希望看到Dreambooth在Stable Diffusion上良好运行的人们的共同成果!
如果你打算尝试这个项目,请先阅读以下警告:
警告!
让我们尊重那些花费多年时间磨练技艺的创作者们的辛勤劳动和创造力。
- 这个版本的Dreambooth专为数字艺术家设计,旨在将他们自己的角色和风格融入Stable Diffusion模型中,同时也允许用户训练自己的肖像。我的主要目标是为电影制作人提供一个工具,让他们能够与所雇佣的概念艺术家进行互动,从而生成初始创意的种子,以便更直观地沟通。它适用于电影制作人、概念艺术家、漫画设计师等。
- 未来可能会出现基于完美数据集训练而成的Stable Diffusion模型。然而,在此之前,出于道德、伦理以及潜在法律方面的考虑,我强烈建议不要将他人的作品训练进这些模型中(除非你已获得明确许可,或者对方已公开表示接受这项技术)。同样地,我也不建议在提示词中使用艺术家的名字。请不要让那些使这一切成为可能的人失去工作机会!
技术方面:
此实现并未完全遵循Google关于如何保持潜在空间完整性的理念。
- 大多数与你训练内容相似的图像都会向你所训练的内容靠拢。
- 例如,如果你在训练一个人物,那么所有人物都会看起来像你;如果你在训练一件物品,那么同类物品都会呈现出你所训练的外观。
目前似乎还没有简单的方法可以连续训练两个主题。在修剪之前,你会得到一个大小约为
11-12GB的文件。- 提供的笔记本包含一个修剪工具,可以将其压缩至约
~2gb。
- 提供的笔记本包含一个修剪工具,可以将其压缩至约
最佳实践是将token替换为某个名人的名字(注意:这里指的是token,而非class——因此你的提示词可能是这样的:“Chris Evans person”)。以下是我妻子使用完全相同的设置进行训练的结果,唯一的区别就是token
设置
简易RunPod说明
请注意,RunPod会定期升级其基础Docker镜像,这可能导致仓库无法正常运行。尽管目前所有的YouTube视频都不再是最新的,但你仍然可以将其作为参考。按照常规的RunPod YouTube视频或教程操作,只需做以下更改:
在“My Pods”页面中,
- 点击菜单按钮(位于紫色播放按钮左侧)
- 选择“编辑Pod”
- 将“Docker镜像名称”更新为以下之一(经2023年6月27日测试):
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116
- 点击“保存”。
- 重启你的Pod
继续阅读指南的其余部分:
注册 RunPod。欢迎使用我的推荐链接,这样我就不用为此付费了(但你需要支付)。
登录后,选择
SECURE CLOUD或COMMUNITY CLOUD。确保选择网络速度“高”的选项,以免因下载缓慢而浪费时间和金钱。
选择显存至少为 24GB 的设备,例如 RTX 3090、RTX 4090 或 RTX A5000。
按照下面的视频教程操作:

Vast.AI 使用说明
- 注册 Vast.AI(由 David Bielejeski 提供的推荐链接)。
- 充值一些资金(我通常每次充值 10 美元)。
- 前往 客户端 - 创建页面:
- 选择 pytorch/pytorch 作为 Docker 镜像,并勾选“使用 Jupyter Lab 界面”和“Jupyter 直接 HTTPS”按钮。
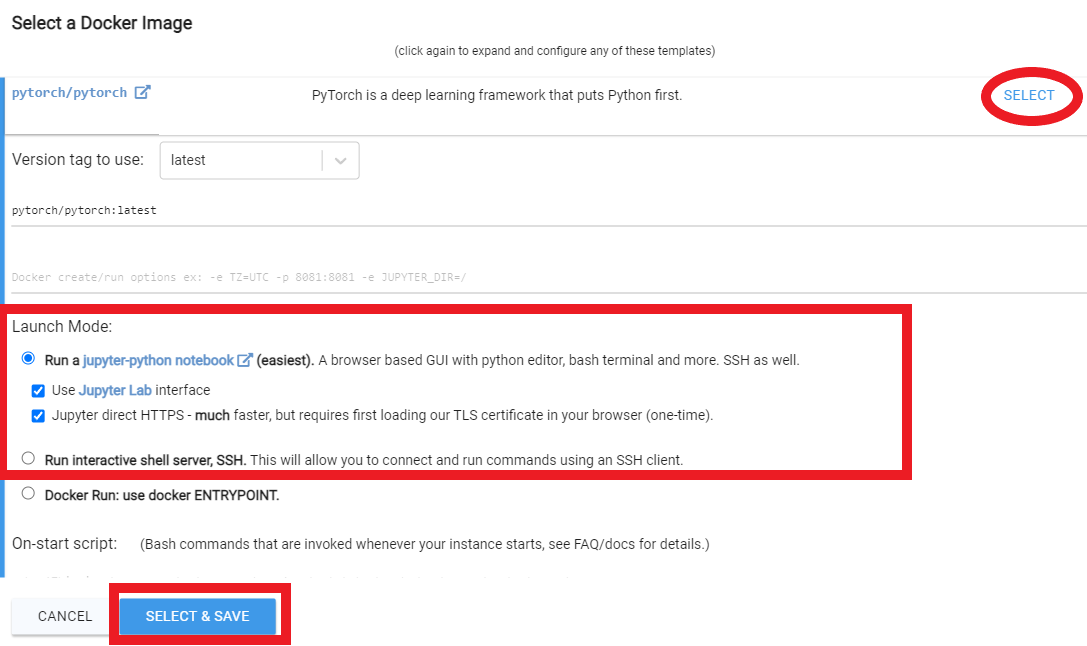
- 建议增加磁盘空间,并按 GPU 显存进行筛选(2GB 的检查点文件 + 2-8GB 的模型文件 + 正则化图像 + 其他内容会迅速占用大量空间)。
- 我通常分配 150GB。
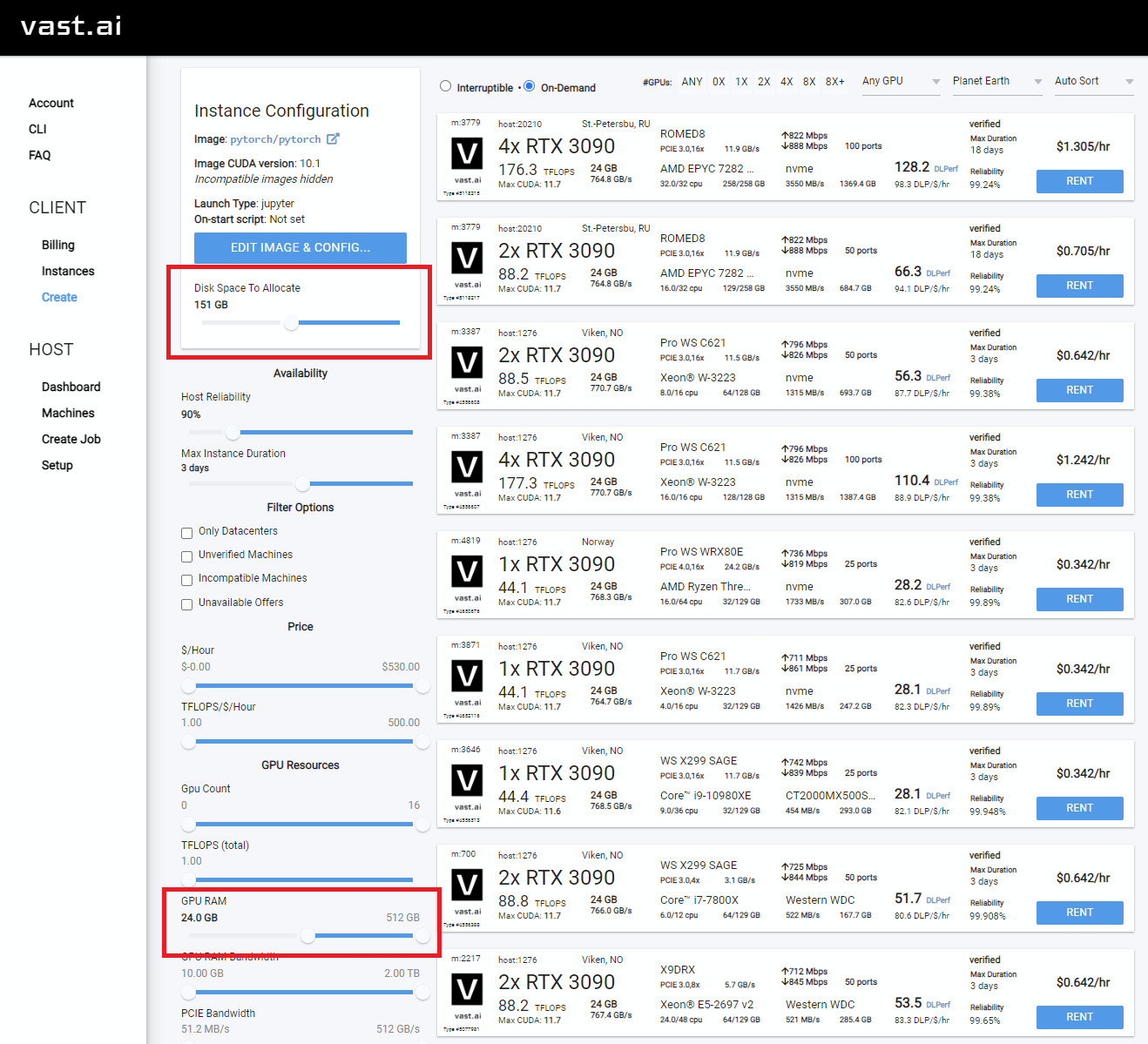
- 同时也要检查上传/下载速度,确保带宽足够,以免在等待下载时耗尽资金。
- 选择所需的实例,点击“租用”,然后前往你的 实例页面,点击“打开”。
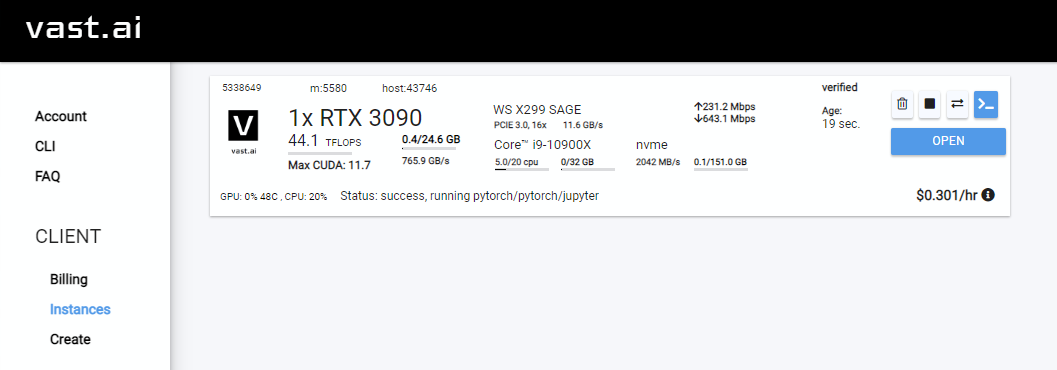
- 你可能会收到不安全证书警告。点击忽略该警告,或安装Vast 证书。
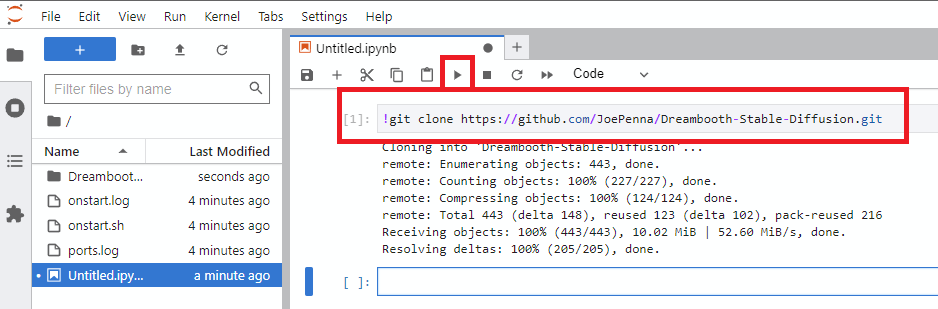
- 点击
Notebook -> Python 3(你可以通过多种方式完成这一步,但我通常这样做)。 - 使用以下命令克隆 Joe 的仓库:
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.git- 点击“运行”。
- 在左侧导航栏中进入新创建的
Dreambooth-Stable-Diffusion目录,打开dreambooth_simple_joepenna.ipynb或dreambooth_runpod_joepenna.ipynb文件。 - 按照笔记本中的说明开始训练。
本地运行说明
设置 - 虚拟环境
先决条件
- Git
- Python 3.10
- 打开
cmd。 - 克隆仓库:
C:\>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion
- 进入仓库目录:
C:\>cd Dreambooth-Stable-Diffusion
安装依赖并激活环境
cmd> python -m venv dreambooth_joepenna
cmd> dreambooth_joepenna\Scripts\activate.bat
cmd> pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd> pip install -r requirements.txt
运行
cmd> python "main.py" --project_name "ProjectName" --training_model "C:\v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:\regularization_images" --training_images "C:\training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
清理
cmd> deactivate
设置 - Conda
先决条件
- Git
- Python 3.10
- miniconda3
- 打开
Anaconda Prompt (miniconda3)。 - 克隆仓库:
(base) C:\>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion
- 进入仓库目录:
(base) C:\>cd Dreambooth-Stable-Diffusion
安装依赖并激活环境
(base) C:\Dreambooth-Stable-Diffusion> conda env create -f environment.yaml
(base) C:\Dreambooth-Stable-Diffusion> conda activate dreambooth_joepenna
运行
cmd> python "main.py" --project_name "ProjectName" --training_model "C:\v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:\regularization_images" --training_images "C:\training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
清理
cmd> conda deactivate
配置文件与命令行参考
示例配置文件
{
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\\stable-diffusion\\models\\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\\stable-diffusion\\regularization_images\\Stable-Diffusion-Regularization-Images-person_ddim\\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\\stable-diffusion\\training_images\\24 Images - captioned"
}
使用您的配置进行训练
python "main.py" --config_file_path "path/to/the/my-config.json"
命令行参数
dreambooth_helpers\arguments.py
| 命令 | 类型 | 示例 | 描述 |
|---|---|---|---|
--config_file_path |
字符串 | "C:\\Users\\David\\Dreambooth Configs\\my-config.json" |
要使用的配置文件路径 |
--project_name |
字符串 | "My Project Name" |
项目名称 |
--debug |
布尔值 | False |
可选 默认为 False。启用调试日志记录 |
--seed |
整数 | 23 |
可选 默认为 23。用于 seed_everything 的随机种子 |
--max_training_steps |
整数 | 3000 |
要运行的训练步数 |
--token |
字符串 | "owhx" |
您希望用来代表训练后模型的唯一标记。 |
--token_only |
布尔值 | False |
可选 默认为 False。仅使用标记进行训练,不使用类别词。 |
--training_model |
字符串 | "D:\\stable-diffusion\\models\\v1-5-pruned-emaonly-pruned.ckpt" |
要训练的模型路径(model.ckpt) |
--training_images |
字符串 | "D:\\stable-diffusion\\training_images\\24 Images - captioned" |
训练图像目录的路径 |
--regularization_images |
字符串 | "D:\\stable-diffusion\\regularization_images\\Stable-Diffusion-Regularization-Images-person_ddim\\person_ddim" |
包含正则化图像的目录路径 |
--class_word |
字符串 | "woman" |
将 class_word 与您想要训练的图像类别匹配。例如:man、woman、dog 或 artstyle。 |
--flip_p |
浮点数 | 0.0 |
可选 默认为 0.5。翻转百分比。例如,如果设置为 0.5,则会在 50% 的时间里翻转(镜像)您的训练图像。这有助于在无需增加更多训练图像的情况下扩展数据集。不过,对于人脸训练来说,这种做法可能会导致效果变差,因为大多数人的脸并不完全对称。 |
--learning_rate |
浮点数 | 1.0e-06 |
可选 默认为 1.0e-06(0.000001)。设置学习率。支持科学计数法。 |
--save_every_x_steps |
整数 | 250 |
可选 默认为 0。每 x 步保存一次检查点。当设置为 0 时,仅在达到 max_training_steps 后的训练结束时保存。 |
--gpu |
整数 | 0 |
可选 默认为 0。指定除 GPU 0 外的其他 GPU 进行训练。目前尚未实现多 GPU 支持。 |
使用您的配置进行训练
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\\stable-diffusion\\models\\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\\stable-diffusion\\training_images\\24 Images - captioned" --regularization_images "D:\\stable-diffusion\\regularization_images\\Stable-Diffusion-Regularization-Images-person_ddim\\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
字幕与多主体/概念支持
字幕功能已支持。关于我们如何实现字幕的指南,请参阅这里。
假设你的标记是“effy”,类别是“person”,数据根目录为/train,那么:
training_images/img-001.jpg 的字幕为 effy person
你可以通过在文件名中添加 @ 符号来自定义字幕。
/training_images/img-001@a photo of effy => a photo of effy
你可以在字幕中使用两个标记 S(大写 S)和 C(大写 C),分别表示主体和类别。
/training_images/img-001@S being a good C.jpg => effy being a good person
要创建一个新的主体,只需为其创建一个文件夹即可。例如:
/training_images/bingo/img-001.jpg => bingo person
类别的部分保持不变,但主体已经改变。
此时,标记 S 变为 bingo:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
再深入一层,你就可以更改类别:/training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
更进一步:再深入一层,你还可以为一组图片添加字幕:/training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
文本反转 vs. Dreambooth
这个仓库中的大部分代码是由 Rinon Gal 等人编写的,他们是文本反转研究论文的作者。尽管其中加入了一些关于正则化图像和先验损失保留的想法(来自“Dreambooth”),但为了尊重 MIT 团队和 Google 的研究人员,我将这个分支重命名为: “曾经被称为‘Dreambooth’的仓库”。
如需其他实现方式,请参阅下方的替代方案。
使用生成的模型
ground truth(真实照片,注意:非常美丽的女性)

以下所有图片使用相同的提示词:
sks person |
woman person |
Natalie Portman person |
Kate Mara person |
|---|---|---|---|
 |
 |
 |
 |
调试你的生成结果
❗❗ 人们常犯的第一大错误 ❗❗
仅用你的标记进行提示,例如“joepenna”而不是“joepenna person”
如果你以 joepenna 作为标记,并将其归入 person 类别进行训练,那么模型只会将你的脸识别为:
joepenna person
示例提示词:
🚫 错误(joepenna 后缺少 person)
portrait photograph of joepenna 35mm film vintage glass
✅ 正确(joepenna 后包含 person)
portrait photograph of joepenna person 35mm film vintage glass
有时你可能会得到一些长得有点像你的结果(尤其是在训练步数过多时),但这只是因为当前版本的 Dreambooth 过度训练了该标记,导致其泛化到了其他内容上。
☢ 训练时请注意使用的图片类型
在训练过程中,Stable Diffusion 并不知道你是一个人。它只会模仿所看到的内容。
因此,如果你的训练图片看起来像这样:
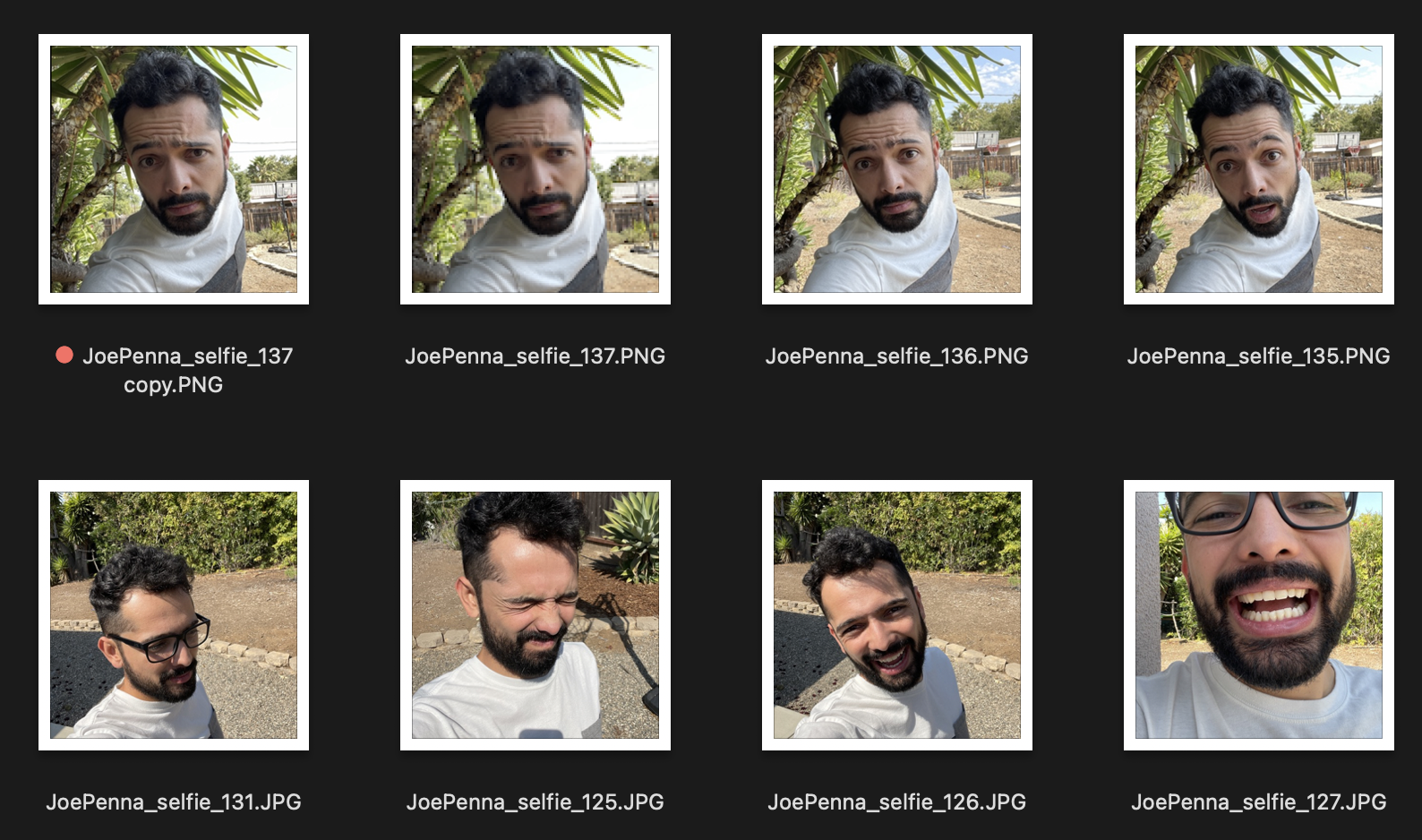
那么你最终生成的结果很可能都是你在带刺树旁、穿着白灰相间衬衫的样子,风格也只会是……嗯,自拍照片。
相比之下,这样的训练集会更好:
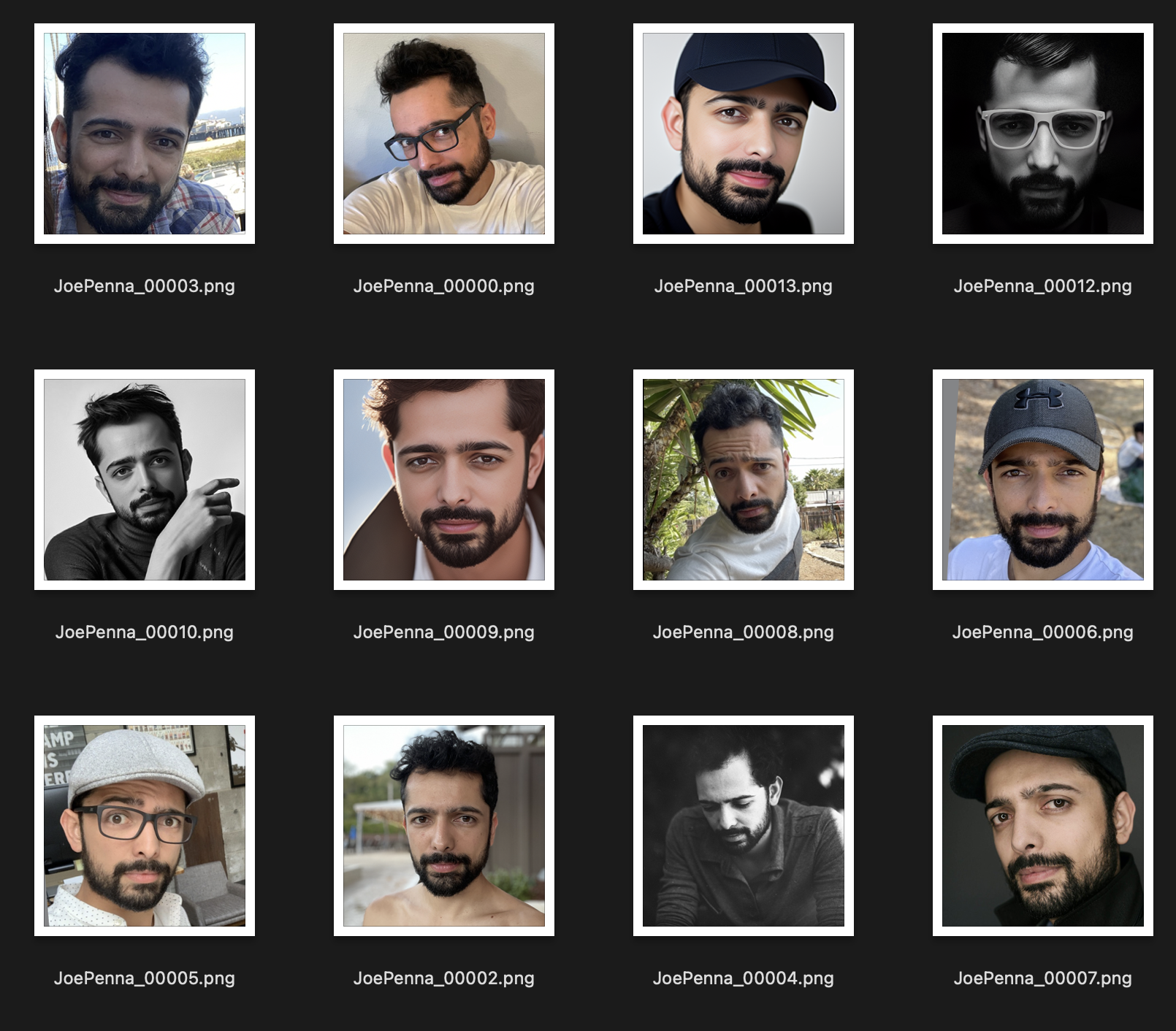
这些图片之间唯一一致的地方就是主体。这样一来,Stable Diffusion 将只学习你的面部特征,从而可以将其“编辑”成其他风格。
哦不!生成效果并不理想!
方案 1:生成结果完全不像你!(继续训练,或使用更好的训练图片)
你确定自己的提示词写对了吗?
正确的格式应该是 <标记> <类别>,而不是仅仅使用 <标记>。例如:
JoePenna person, portrait photograph, 85mm medium format photo
如果仍然不像你,那说明你训练的时间还不够长。
方案 2:生成结果有点像你,但都和你的训练图片一模一样。(减少训练步数,使用更好的训练图片,或通过调整提示词解决)
可能有以下几个原因:你可能训练得太久了……或者你的图片过于相似……又或者你用于训练的图片数量不足。
没关系,我们可以通过调整提示词来解决这个问题。Stable Diffusion 对你输入内容的优先级非常高,所以请把关键信息放在前面:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
方案 3:生成结果像你,但在尝试不同风格时却不像。(继续训练,使用更好的训练图片)
看来你还是训练得不够充分……
没关系,我们可以通过调整提示词来解决:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
更多技巧和帮助请访问:Stable Diffusion Dreambooth Discord
Hugging Face Diffusers - 替代方案
现在,HuggingFace Diffusers 已经支持使用 Stable Diffusion 进行 Dreambooth 训练。
你可以在以下链接中尝试:
![]()
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备