SwinIR
SwinIR 是一款基于 Swin Transformer 架构的先进图像修复开源项目,由苏黎世联邦理工学院(ETH Zurich)团队研发。它致力于解决图像质量退化问题,能够智能地将模糊、充满噪点或带有压缩瑕疵的图片恢复为清晰高质量的原貌。
具体而言,SwinIR 在多个关键领域达到了业界领先的性能水平:无论是将低分辨率图片进行超分辨率放大(包括轻量级和真实场景下的放大),还是去除黑白及彩色图像中的噪点,亦或是消除 JPEG 格式带来的压缩伪影,它都能提供卓越的修复效果。
这款工具非常适合计算机视觉研究人员、AI 开发者以及需要高质量图像处理方案的设计师使用。对于普通用户,通过其提供的在线演示平台,也能轻松体验强大的图像增强功能而无需编写代码。
SwinIR 的核心技术亮点在于创新性地引入了“移位窗口”(Shifted Window)机制。这一设计不仅保留了 Transformer 模型捕捉长距离依赖关系的强大能力,还显著降低了计算复杂度,使得模型在处理高分辨率图像时更加高效。作为官方提供的 PyTorch 实现,SwinIR 开放了预训练模型和完整代码,并支持在移动端部署,是当前图像复原领域极具参考价值和实用性的基准工具。
使用场景
一家数字档案馆正在对一批 20 年前用早期数码相机拍摄的低分辨率历史照片进行数字化修复,以便在高清电子展屏上展示。
没有 SwinIR 时
- 传统插值算法放大图片后,人物面部和建筑纹理模糊不清,出现明显的锯齿和马赛克。
- 使用早期的深度学习超分模型处理真实世界的复杂噪点时,容易过度平滑,导致皮肤质感像“塑料”一样不自然。
- 旧照片因多次压缩产生的 JPEG 块状伪影严重干扰画面,常规去噪工具无法在去除噪点的同时保留边缘细节。
- 修复过程需要人工反复调整参数并结合多个工具(先去噪再超分),工作流繁琐且效率极低。
使用 SwinIR 后
- 基于 Shifted Window Transformer 架构,SwinIR 能精准重建高频细节,让模糊的历史街景呈现出清晰的砖瓦纹理。
- 针对真实世界退化场景优化的模型,在提升分辨率的同时完美保留了胶片和早期传感器的自然颗粒感,避免虚假的平滑效果。
- 内置的 JPEG 压缩伪影去除功能,一键消除了老旧文件因反复保存产生的色块和网格纹,画面干净通透。
- 单个模型即可同时完成去噪、去压缩伪影和超分辨率任务,将单张照片的修复时间从半小时缩短至几秒钟。
SwinIR 通过单一的端到端模型,以接近人眼视觉的逼真度解决了低质历史影像的高清复原难题,极大提升了数字档案的可用性与观赏价值。
运行环境要求
- 未说明
需要 NVIDIA GPU(基于 PyTorch 实现),具体型号和显存大小未说明,CUDA 版本未说明
未说明

快速开始
SwinIR:基于Swin Transformer的图像修复
Jingyun Liang、Jiezhang Cao、Guolei Sun、Kai Zhang、Luc Van Gool、Radu Timofte
苏黎世联邦理工学院计算机视觉实验室



本仓库是SwinIR的官方PyTorch实现,SwinIR是一种基于移位窗口Transformer的图像修复方法(arxiv、supp、预训练模型、可视化结果)。SwinIR在以下任务中达到了最先进水平:
- 双三次/轻量级/真实世界图像超分辨率
- 灰度/彩色图像去噪
- 灰度/彩色JPEG压缩伪影去除
:rocket: :rocket: :rocket: 新闻:
- 2022年8月16日:新增PlayTorch演示,展示如何在移动设备上运行真实世界图像超分辨率模型
 。
。 - 2022年8月1日:新增彩色图像JPEG压缩伪影去除的预训练模型及结果。
- 2022年6月10日:查看我们在视频修复方面的最新工作 :fire::fire::fire: VRT:一种视频修复Transformer
 以及 RVRT:递归视频修复Transformer
以及 RVRT:递归视频修复Transformer
 用于视频超分辨率、视频去模糊、视频去噪、视频帧插值以及时空视频超分辨率。
用于视频超分辨率、视频去模糊、视频去噪、视频帧插值以及时空视频超分辨率。 - 2021年9月7日:我们提供了一个交互式的在线Colab演示,用于真实世界图像超分辨率
 :fire:,可与首个实用退化模型BSRGAN(ICCV2021)
:fire:,可与首个实用退化模型BSRGAN(ICCV2021) 和近期模型RealESRGAN进行对比。快来尝试在Colab上对您自己的图片进行超分辨率处理吧!


| 真实世界图像(×4) | BSRGAN, ICCV2021 | Real-ESRGAN | SwinIR(我们的模型) | SwinIR-Large(我们的模型) |
|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
- 2021年8月26日: 查看我们在真实世界图像超分辨率方面的工作:实用退化模型BSRGAN,ICCV2021
- 2021年8月26日: 查看我们在图像超分辨率和图像缩放的生成建模方面的工作:基于归一化流的HCFlow,ICCV2021
- 2021年8月26日: 查看我们在盲超分辨率方面的工作:空间变核估计(MANet,ICCV2021) 以及无监督核估计(FKP,CVPR2021)



图像恢复是一个由来已久的低层视觉问题,旨在从低质量图像(例如下采样、噪声和压缩图像)中恢复高质量图像。尽管当前最先进的图像恢复方法基于卷积神经网络,但很少有研究尝试使用在高层视觉任务中表现出色的Transformer模型。本文提出了一种基于Swin Transformer的强大基准模型SwinIR,用于图像恢复。SwinIR由浅层特征提取、深层特征提取和高质量图像重建三部分组成。其中,深层特征提取模块由多个残差Swin Transformer块(RSTB)构成,每个RSTB包含若干Swin Transformer层以及一个残差连接。我们在三个具有代表性的任务上进行了实验:图像超分辨率(包括经典、轻量级和真实场景图像超分辨率)、图像去噪(包括灰度和彩色图像去噪)以及JPEG压缩伪影去除。实验结果表明,SwinIR在不同任务上均优于当前最先进方法,峰值信噪比提升可达0.14~0.45dB,同时总参数量可减少多达67%。
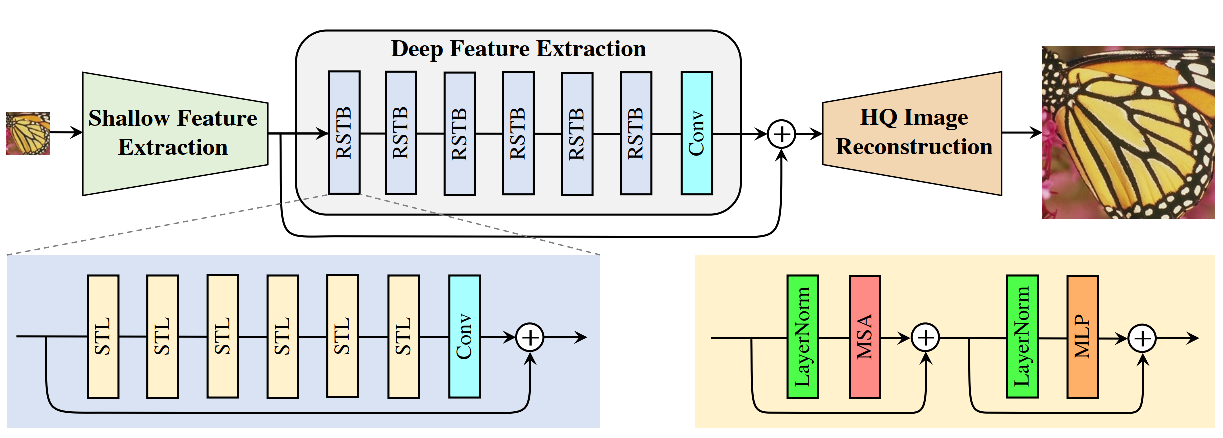
目录
训练
可用于训练和测试的数据集可按如下方式下载:
| 任务 | 训练集 | 测试集 | 可视化结果 |
|---|---|---|---|
| 经典/轻量级图像超分辨率 | DIV2K (800张训练图像) 或 DIV2K +Flickr2K (2650张图像) | Set5 + Set14 + BSD100 + Urban100 + Manga109 下载全部 | 这里 |
| 现实世界图像超分辨率 | SwinIR-M(中等尺寸):DIV2K (800张训练图像) +Flickr2K (2650张图像) + OST (替代链接, 10324张图像,涵盖天空、水、草地、山脉、建筑、植物、动物) SwinIR-L(大尺寸):DIV2K + Flickr2K + OST + WED(4744张图像) + FFHQ (前2000张图像,人脸) + Manga109 (漫画) + SCUT-CTW1500 (前100张训练图像,文本) *我们采用来自[BSRGAN, ICCV2021]的开创性实用退化模型 ](https://github.com/cszn/BSRGAN) |
RealSRSet+5images | 这里 |
| 彩色/灰度图像去噪 | DIV2K (800张训练图像) + Flickr2K (2650张图像) + BSD500 (400张用于训练和测试的图像) + WED(4744张图像) *BSD68/BSD100图像未用于训练。 |
灰度:Set12 + BSD68 + Urban100 彩色:CBSD68 + Kodak24 + McMaster + Urban100 下载全部 |
这里 |
| 灰度/彩色JPEG压缩伪影去除 | DIV2K (800张训练图像) + Flickr2K (2650张图像) + BSD500 (400张用于训练和测试的图像) + WED(4744张图像) | 灰度:Classic5 + LIVE1 下载全部 | 这里 |
训练代码位于 KAIR。
测试(无需准备数据集)
为方便起见,我们在 /testsets 中提供了一些示例数据集(约20Mb)。
如果您只需要代码,只需下载 models/network_swinir.py、utils/util_calculate_psnr_ssim.py 和 main_test_swinir.py 即可。
以下命令会自动下载 预训练模型 并将其放置在 model_zoo/swinir 目录下。
SwinIR 的所有可视化结果可在此处下载。
我们还提供了一个针对真实世界图像超分辨率的在线 Colab 演示 ![]() ,用于与 首个实用退化模型 BSRGAN(ICCV2021)
,用于与 首个实用退化模型 BSRGAN(ICCV2021)
我们还提供了一个 PlayTorch 演示 ![]() ,用于展示如何在基于 React Native 构建的移动应用中运行 SwinIR 模型,以实现真实世界图像的超分辨率。
,用于展示如何在基于 React Native 构建的移动应用中运行 SwinIR 模型,以实现真实世界图像的超分辨率。
# 001 经典图像超分辨率(中等尺寸)
# 注意:--training_patch_size 仅用于区分论文表2中的两种不同设置。图像并非按patch逐块测试。
# (设置1:当模型在DIV2K上训练且 training_patch_size=48时)
python main_test_swinir.py --task classical_sr --scale 2 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x2.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task classical_sr --scale 3 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x3.pth --folder_lq testsets/Set5/LR_bicubic/X3 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task classical_sr --scale 4 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x4.pth --folder_lq testsets/Set5/LR_bicubic/X4 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task classical_sr --scale 8 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x8.pth --folder_lq testsets/Set5/LR_bicubic/X8 --folder_gt testsets/Set5/HR
# (设置2:当模型在DIV2K+Flickr2K上训练且 training_patch_size=64时)
python main_test_swinir.py --task classical_sr --scale 2 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x2.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task classical_sr --scale 3 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x3.pth --folder_lq testsets/Set5/LR_bicubic/X3 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task classical sr --scale 4 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x4.pth --folder_lq testsets/Set5/LR_bicubic/X4 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task classical sr --scale 8 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x8.pth --folder_lq testsets/Set5/LR_bicubic/X8 --folder_gt testsets/Set5/HR
# 002 轻量级图像超分辨率(小尺寸)
python main_test_swinir.py --task lightweight_sr --scale 2 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x2.pth --folder_lq testsets/Set5/LR_bicubic/X2 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task lightweight_sr --scale 3 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x3.pth --folder_lq testsets/Set5/LR_bicubic/X3 --folder_gt testsets/Set5/HR
python main_test_swinir.py --task lightweight sr --scale 4 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x4.pth --folder_lq testsets/Set5/LR_bicubic/X4 --folder_gt testsets/Set5/HR
# 003 现实世界图像超分辨率(如果内存不足,请使用 --tile 400)
# (中等尺寸)
python main_test_swinir.py --task real_sr --scale 4 --model_path model_zoo/swinir/003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth --folder_lq testsets/RealSRSet+5images --tile
# (更大尺寸 + 在更多数据集上训练)
python main_test_swinir.py --task real_sr --scale 4 --large_model --model_path model_zoo/swinir/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth --folder_lq testsets/RealSRSet+5images
# 004 灰度图像去噪(中等尺寸)
python main_test_swinir.py --task gray_dn --noise 15 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/Set12
python main_test_swinir.py --task gray_dn --noise 25 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise25.pth --folder_gt testsets/Set12
python main_test_swinir.py --task gray_dn --noise 50 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise50.pth --folder_gt testsets/Set12
# 005 彩色图像去噪(中等尺寸)
python main_test_swinir.py --task color_dn --noise 15 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/McMaster
python main_test_swinir.py --task color_dn --noise 25 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth --folder_gt testsets/McMaster
python main_test_swinir.py --task color_dn --noise 50 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth --folder_gt testsets/McMaster
# 006 JPEG压缩伪影去除(中等尺寸,由于JPEG编码使用8x8块,因此使用window_size=7)
# 灰度
python main_test_swinir.py --task jpeg_car --jpeg 10 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth --folder_gt testsets/classic5
python main_test_swinir.py --task jpeg_car --jpeg 20 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth --folder_gt testsets/classic5
python main_test_swinir.py --task jpeg_car --jpeg 30 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth --folder_gt testsets/classic5
python main_test_swinir.py --task jpeg_car --jpeg 40 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth --folder_gt testsets/classic5
# 彩色
python main_test_swinir.py --task color_jpeg_car --jpeg 10 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg10.pth --folder_gt testsets/LIVE1
python main_test_swinir.py --task color_jpeg_car --jpeg 20 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg20.pth --folder_gt testsets/LIVE1
python main_test_swinir.py --task color_jpeg_car --jpeg 30 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg30.pth --folder_gt testsets/LIVE1
python main_test_swinir.py --task color_jpeg_car --jpeg 40 --model_path model_zoo/swinir/006_colorCAR_DFWB_s126w7_SwinIR-M_jpeg40.pth --folder_gt testsets/LIVE1
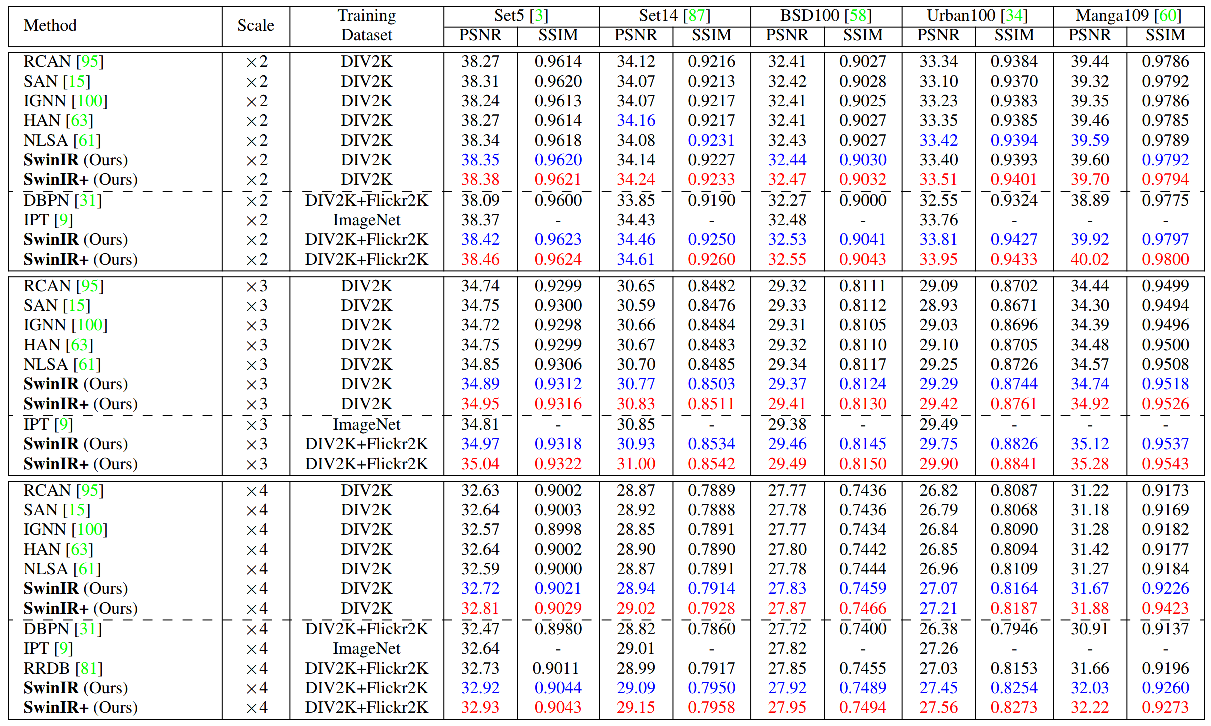
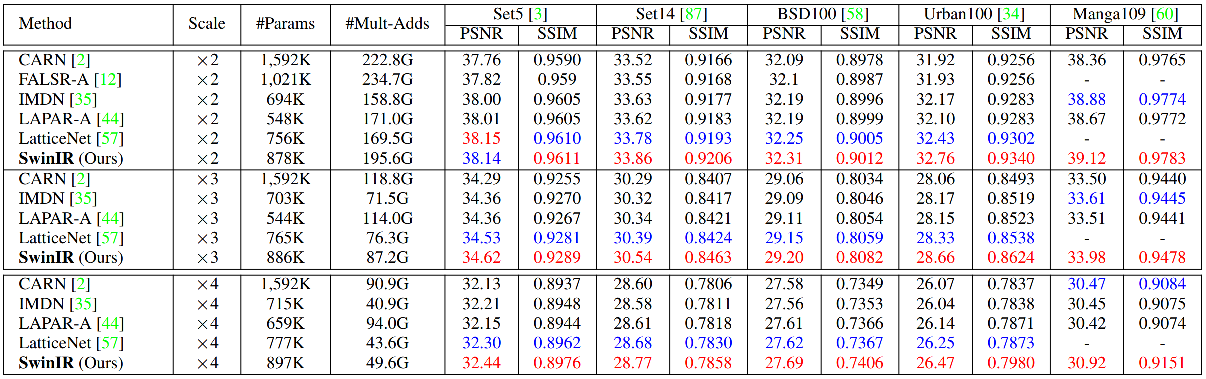
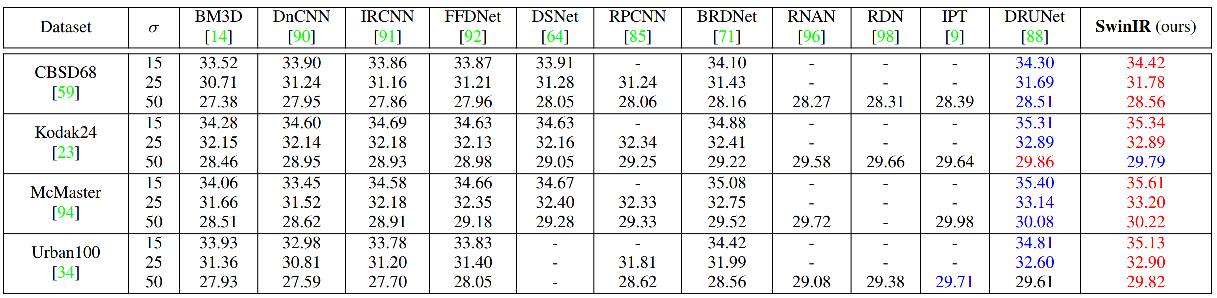
结果
我们在经典/轻量级/现实世界图像超分辨率、灰度/彩色图像去噪以及JPEG压缩伪影去除任务上均取得了当前最优性能。详细结果请参阅论文。SwinIR的所有可视化结果可在此处下载:链接。
经典图像超分辨率(点击展开)

- SwinIR与代表性CNN模型RCAN在经典图像超分辨率(X4)任务中的更详细对比
| 方法 | 训练集 | 训练时间 (8个GeForce RTX 2080 Ti batch=32, iter=50万) |
Manga109上的Y-PSNR/Y-SSIM | 运行时间 (1个GeForce RTX 2080 Ti, 处理256x256低分辨率图像)* |
参数量 | FLOPs | 测试内存 |
|---|---|---|---|---|---|---|---|
| RCAN | DIV2K | 1.6天 | 31.22/0.9173 | 0.180秒 | 15.6M | 850.6G | 593.1M |
| SwinIR | DIV2K | 1.8天 | 31.67/0.9226 | 0.539秒 | 11.9M | 788.6G | 986.8M |
* 我们在GPU空闲时重新测试了运行时间。评估代码参考此处。
- DIV2K验证集(100张图像)的结果
| 训练集 | 缩放因子 | PSNR (RGB) | PSNR (Y) | SSIM (RGB) | SSIM (Y) |
|---|---|---|---|---|---|
| DIV2K (800张) | 2 | 35.25 | 36.77 | 0.9423 | 0.9500 |
| DIV2K+Flickr2K (2650张) | 2 | 35.34 | 36.86 | 0.9430 | 0.9507 |
| DIV2K (800张) | 3 | 31.50 | 32.97 | 0.8832 | 0.8965 |
| DIV2K+Flickr2K (2650张) | 3 | 31.63 | 33.10 | 0.8854 | 0.8985 |
| DIV2K (800张) | 4 | 29.48 | 30.94 | 0.8311 | 0.8492 |
| DIV2K+Flickr2K (2650张) | 4 | 29.63 | 31.08 | 0.8347 | 0.8523 |
轻量级图像超分辨率
现实世界图像超分辨率

灰度图像去噪

彩色图像去噪
JPEG压缩伪影去除
针对灰度图像

针对彩色图像
| 训练集 | 质量因子 | PSNR (RGB) | PSNR-B (RGB) | SSIM (RGB) |
|---|---|---|---|---|
| LIVE1 | 10 | 28.06 | 27.76 | 0.8089 |
| LIVE1 | 20 | 30.45 | 29.97 | 0.8741 |
| LIVE1 | 30 | 31.82 | 31.24 | 0.9018 |
| LIVE1 | 40 | 32.75 | 32.12 | 0.9174 |
引用
@article{liang2021swinir,
title={SwinIR: 使用Swin Transformer进行图像恢复},
author={Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu},
journal={arXiv预印本 arXiv:2108.10257},
year={2021}
}
许可与致谢
本项目采用Apache 2.0许可证发布。代码基于Swin Transformer和KAIR。请一并遵守它们的许可证。感谢他们的杰出工作。
版本历史
v0.02021/08/26常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。