Awesome-Healthcare-Foundation-Models
Awesome-Healthcare-Foundation-Models 是一个精心整理的开源资源库,专注于汇聚医疗领域的各类大型人工智能基础模型。它将当前前沿的模型系统性地划分为四大类:大型语言模型、大型视觉模型、大型音频模型以及多模态模型,覆盖了从生物信息学、医学影像诊断到公共卫生和医疗机器人等广泛应用场景。
面对医疗 AI 领域模型种类繁多、分散难寻的现状,该资源库有效解决了研究人员和开发者难以快速定位高质量模型及相关数据集的痛点。它不仅提供了按领域(医疗专用与通用)分类的详细清单,还收录了大规模生物医学数据集、相关法律法规以及最新的综述文章,甚至包含了关于医疗大模型智能体(Agents)的前沿研究成果。
这一工具特别适合医疗 AI 研究人员、算法工程师、数据科学家以及关注智慧医疗发展的学生使用。无论是希望复现最新算法、寻找特定任务的基础模型,还是想了解行业伦理与安全规范,都能在此找到宝贵线索。其独特的亮点在于不仅罗列模型,更紧跟学术前沿,及时更新如《Nature Machine Intelligence》等顶级期刊的最新论文,并关联了 IEEE 期刊的特刊征稿方向,为用户把握行业趋势提供了权威指引,是探索医疗大模型生态的一站式入口。
使用场景
某三甲医院科研团队正试图构建一个能同时分析肺部 CT 影像与电子病历文本的多模态辅助诊断系统,以早期筛查肺癌。
没有 Awesome-Healthcare-Foundation-Models 时
- 选型迷茫:面对海量通用 AI 模型,研究人员难以快速甄别哪些是专门针对医疗数据训练的基础模型,耗费数周时间进行无效调研。
- 模态割裂:团队需分别寻找独立的图像模型和文本模型,缺乏现成的多模态(LMM)资源指引,导致影像与病历数据无法有效对齐融合。
- 合规风险:由于缺乏对医疗伦理、隐私法规及数据集许可的系统梳理,项目在数据使用阶段面临潜在的法律与合规隐患。
- 重复造轮子:因不了解已有的生物信息学或医学教育领域开源成果,团队在数据预处理和特征工程上做了大量重复性工作。
使用 Awesome-Healthcare-Foundation-Models 后
- 精准定位:直接通过分类目录锁定经过验证的医疗垂直领域大语言模型(LLMs)和视觉模型(LVMs),将技术选型周期从数周缩短至两天。
- 多模态整合:利用列表中推荐的大型多模态模型资源,快速搭建了影像 - 文本联合分析架构,显著提升了病灶特征与临床描述的关联精度。
- 安全落地:参考库中关于 AI 立法、伦理及安全性的专题板块,提前规避了数据隐私风险,确保系统设计符合医疗行业监管要求。
- 高效复用:基于收录的大规模开源数据集和前沿应用案例(如医疗机器人、公共卫生),直接复用了成熟的基线代码与数据处理流程,研发效率提升 50%。
Awesome-Healthcare-Foundation-Models 通过提供一站式、分类清晰的医疗基础模型生态图谱,帮助研发团队跨越了从“盲目搜索”到“精准落地”的鸿沟,极大加速了智慧医疗系统的创新进程。
运行环境要求
未说明
未说明

快速开始
令人惊叹的医疗基础模型
![]()
精选的医疗领域中优秀的大型人工智能模型(LAMs),即基础模型列表。我们把当前的LAMs分为四大类:大型语言模型(LLMs)、大型视觉模型(LVMs)、大型音频模型以及大型多模态模型(LMMs)。这些LAMs的应用领域包括但不限于生物信息学、医学诊断、医学影像、医学信息学、医学教育、公共卫生和医疗机器人等。
我们欢迎各位为本仓库贡献更多资源。如果您有意参与,请提交拉取请求!
新闻
我们很高兴地宣布,《IEEE生物医学与健康信息学杂志》将推出一期关于生物医学与健康基础模型的特刊。更多详情请参阅征稿启事。
感兴趣的议题包括但不限于:
- 生物医学与健康基础模型的新理论、新原理及新架构的基础研究
- 生物医学与健康基础模型的可解释性与透明度研究
- 生物医学与健康基础模型中的提示工程
- 生物医学与健康基础模型中的数据工程
- 大规模生物医学与健康数据集
- 生物医学与健康基础模型的多模态学习与对齐
- 生物医学与健康基础模型的高效计算
- 生物医学与健康基础模型的对抗鲁棒性
- 基础模型在生物医学与健康信息学中的应用
- 生物医学与健康基础模型的新评估范式
- 面向生物医学与健康基础模型的新型计算机系统
- 开发与部署生物医学与健康基础模型的去中心化方法
- 生物医学与健康领域的基础模型伦理、安全、隐私及监管问题
如果您对此感兴趣或已在相关领域开展工作,请帮忙转发消息并积极投稿!
:star2: 我们最新发表的关于医学领域LLM智能体的文章已刊登于2024年的《自然·机器智能》杂志。欢迎大家阅读,希望对您有所帮助!
基于LLM的医学与医疗保健智能体系统
邱佳宁,
凯尔·拉姆,
李国豪,
阿米什·阿查里亚,
田英·王,
阿拉·达尔齐,
袁武,以及
埃里克·J·托波尔
目录
综述
本仓库主要基于以下论文:
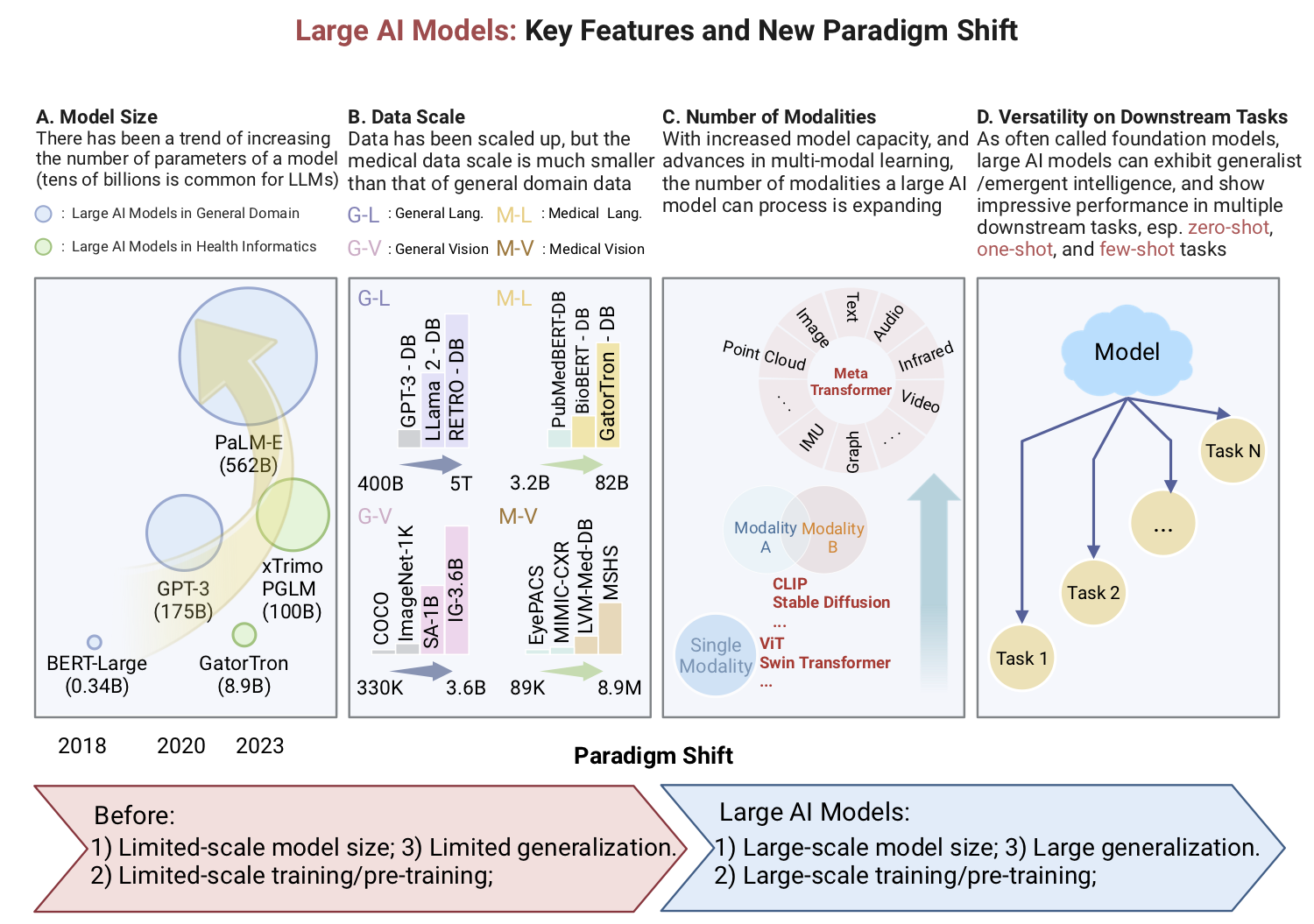
健康信息学中的大型AI模型:
应用、挑战与未来
邱佳宁,
李林,
孙建凯,
彭家川,
史培伦,
张瑞阳,
董寅钊,
凯尔·拉姆,
罗鹏伟,
肖博,
袁武,
王宁利,
徐东,以及
本尼·洛
如果您觉得本仓库有所帮助,请考虑引用:
@article{qiu2023large,
title={Large ai models in health informatics: Applications, challenges, and the future},
author={Qiu, Jianing and Li, Lin and Sun, Jiankai and Peng, Jiachuan and Shi, Peilun and Zhang, Ruiyang and Dong, Yinzhao and Lam, Kyle and Lo, Frank P-W and Xiao, Bo and others},
journal={IEEE Journal of Biomedical and Health Informatics},
year={2023},
publisher={IEEE}
}
大型语言模型
医疗领域
- ClinicalMamba:基于纵向临床记录的生成式临床语言模型 [论文]
- ChiMed-GPT:具有完整训练机制且更符合人类偏好的中文医学大语言模型 [论文] [代码]
- Med-PaLM 2:利用大语言模型实现专家级医学问答 [论文]
- KeBioLM:通过知识增强生物医学预训练语言模型 [论文]
- BioELMo:探究语言模型中的生物医学嵌入 [论文]
- BioBART:生物医学生成式语言模型的预训练与评估 [论文]
- ClinicalT5:面向临床文本的生成式语言模型 [论文]
- GatorTron:从非结构化电子健康记录中挖掘患者信息的大规模临床语言模型 [论文]
- ChatCAD:基于大语言模型的医学影像交互式辅助诊断 [论文] [代码]
- DeID-GPT:利用GPT-4实现零样本医学文本去标识化 [论文]
- GPT-4在医学挑战性问题上的能力 [论文]
- BioBERT:用于生物医学文本挖掘的预训练生物医学语言表示模型 [论文]
- 公开可用的临床BERT嵌入 [论文]
- BioMegatron:更大的生物医学领域语言模型 [论文]
- 不要停止预训练:将语言模型适配到特定领域和任务 [论文]
- Med-BERT:基于大规模结构化电子健康记录的预训练上下文嵌入,用于疾病预测 [论文]
- CPLLM:利用大语言模型进行临床预测 [论文] [代码]
- DoctorGLM:微调你的中文医生并非难事 [论文] [代码]
- 华佗GPT:让语言模型像医生一样发挥作用 [论文] [代码]
- BioELECTRA:使用判别器预训练的生物医学文本编码器 [论文]
- LinkBERT:利用文档链接对语言模型进行预训练 [论文]
- BioGPT:用于生物医学文本生成与挖掘的生成式预训练Transformer [论文]
- 大语言模型能够编码临床知识 [论文]
- 面向电子健康记录的大语言模型 [论文]
- 面向生物医学自然语言处理的领域特定语言模型预训练 [论文]
- BEHRT:用于电子健康记录的Transformer [论文]
- 基于BEHRT的医疗概念嵌入联邦学习 [论文] [代码]
- RadBERT:将基于Transformer的语言模型适配到放射学领域 [论文] [HuggingFace]
- 使用AlphaFold实现高精度蛋白质结构预测 [论文] [代码]
- 利用三轨神经网络精确预测蛋白质结构及相互作用 [论文]
- 使用AlphaFold-Multimer预测蛋白质复合物 [论文]
- FastFold:将AlphaFold训练时间从11天缩短至67小时 [论文] [代码]
- HelixFold:基于PaddlePaddle的高效AlphaFold2实现 [论文] [代码]
- Uni-Fold:一个开源平台,用于开发超越AlphaFold的蛋白质折叠模型 [论文] [代码]
- OpenFold:重新训练AlphaFold2可揭示其学习机制与泛化能力 [论文] [代码]
- ManyFold:一个高效灵活的库,用于训练和验证蛋白质折叠模型 [论文] [代码]
- ColabFold:让蛋白质折叠触手可及 [论文] [代码]
- 通过将无监督学习扩展到2.5亿条蛋白质序列,可以揭示生物体的结构与功能 [论文] [代码]
- ProGen:用于蛋白质生成的语言建模 [论文] [代码]
- ProtTrans:借助自监督深度学习和高性能计算破解生命密码的语言 [论文] [代码]
- 利用语言模型实现原子尺度的进化级蛋白质结构预测 [论文]
- 从一级序列出发进行高分辨率从头结构预测 [论文] [代码]
- 利用语言模型和深度学习进行单序列蛋白质结构预测 [论文]
- 利用蛋白质语言模型改进蛋白质复合物预测 [论文]
- MSA Transformer [论文] [代码]
- 利用语言模型和弱监督学习解析抗体亲和力成熟过程 [论文]
- xTrimoABFold:无需MSA即可从头预测抗体结构 [论文]
- scBERT作为大规模预训练深度语言模型,可用于单细胞RNA测序数据的细胞类型注释 [论文] [代码]
- 从未标注数据中构建可解释的RNA基础模型,以实现高度准确的RNA结构与功能预测 [论文] [代码]
- E2Efold-3D:端到端深度学习方法,用于精确的RNA三维结构从头预测 [论文] [代码]
- HyenaDNA:以单核苷酸分辨率进行长距离基因组序列建模 [论文] [代码]
通用领域
- ChatGPT:优化用于对话的语言模型 [博客]
- LLaMA:开放且高效的基座语言模型 [论文]
- 指令微调语言模型的扩展性 [论文]
- PaLM:通过Pathways扩展语言建模 [论文]
- 训练计算最优的大规模语言模型 [论文]
- 使用DeepSpeed和Megatron训练Megatron-Turing NLG 530B,一个大规模生成式语言模型 [论文]
- BLOOM:一个拥有1760亿参数的开源多语言语言模型 [论文]
- LaMDA:面向对话应用的语言模型 [论文]
- OPT:开放的预训练Transformer语言模型 [论文]
- 通过人类反馈训练语言模型以遵循指令 [论文]
- 扩展语言模型:方法、分析及训练Gopher的见解 [论文]
- 多任务提示训练实现零样本任务泛化 [论文]
- 语言模型是少样本学习者 [论文]
- 使用统一的文本到文本Transformer探索迁移学习的极限 [论文]
- RoBERTa:一种鲁棒优化的BERT预训练方法 [论文]
- 语言模型是无监督的多任务学习者 [论文]
- 通过检索数万亿个标记来改进语言模型 [论文]
- WebGPT:基于浏览器的人工辅助问答与人类反馈 [论文]
- 通过有针对性的 human judgements 改善对话代理的一致性 [论文]
- 通过生成式预训练提升语言理解能力 [论文]
- BERT:用于语言理解的深度双向Transformer预训练 [论文]
大型视觉模型
医疗健康领域
- vesselFM:用于通用三维血管分割的基础模型 [论文] [代码]
- VisionFM:开发与验证用于眼科通用人工智能的多模态多任务视觉基础模型 [论文] [代码]
- RETFound:用于从视网膜图像中进行可泛化的疾病检测的基础模型 [论文]
- EndoFM:通过大规模自监督预训练实现内窥镜视频分析的基础模型 [论文] [代码]
- STU-Net:由大规模监督预训练赋能的可扩展且可迁移的医学图像分割模型 [论文]
- LVM-Med:通过二阶图匹配学习用于医学成像的大规模自监督视觉模型 [论文] [代码]
- Med3d:用于3D医学图像分析的迁移学习 [论文] [代码]
- Models genesis:用于3D医学图像分析的通用自学模型 [论文] [代码]
- MICLe:大型自监督模型推动医学图像分类的发展 [论文] [代码]
- C2l:比较学习:通过比较图像表示超越ImageNet在X光片上的预训练 [论文] [代码]
- MoCo-CXR:MoCo预训练提升了胸部X光模型的表征能力和可迁移性 [论文] [代码]
- Transunet:Transformer为医学图像分割提供了强大的编码器 [论文] [代码]
- Transfuse:将Transformer和CNN融合用于医学图像分割 [论文] [代码]
- Medical Transformer:用于医学图像分割的门控轴向注意力 [论文] [代码]
- UNETR:用于3D医学图像分割的Transformer [论文] [代码]
- Cotr:高效地连接CNN和Transformer用于3D医学图像分割 [论文] [代码]
- Swin-unet:类似Unet的纯Transformer用于医学图像分割 [论文] [代码]
- SAM4Med:用于医学成像的通用视觉基础模型:以Zero-Shot医学分割为例探讨Segment Anything Model的应用 [论文]
- 通过观看数百场手术视频讲座学习多模态表征[论文] [代码]
通用领域
卷积神经网络(CNNs):
- GPipe:利用流水线并行高效训练巨型神经网络 [论文]
- Big Transfer (BiT):通用视觉表征学习 [论文]
- 设计网络设计空间 [论文]
- 野外视觉特征的自监督预训练 [论文]
- EfficientNetV2:更小的模型与更快的训练 [论文]
- 面向2020年代的卷积神经网络 [论文]
- InternImage:探索基于可变形卷积的大规模视觉基础模型 [论文]
视觉Transformer:
- 基于像素的生成式预训练 [论文]
- 一张图像胜过16×16个词:大规模图像识别中的Transformer [论文]
- Transformer in Transformer [论文]
- Swin Transformer:使用移位窗口的层次化视觉Transformer [论文]
- 数据高效型图像Transformer及其通过注意力进行的蒸馏训练 [论文]
- 自监督模型是视觉Transformer的良好助教 [论文]
- 利用稀疏专家混合扩展视觉能力 [论文]
- 深入研究图像Transformer [论文]
- 掩码自编码器是可扩展的视觉学习者 [论文]
- Swin Transformer V2:提升容量与分辨率 [论文]
- 扩展视觉Transformer [论文]
- 用于表征学习的高效自监督视觉Transformer [论文]
- 将视觉Transformer扩展至220亿参数 [论文]
- H-optimus-0:11亿参数的视觉Transformer,基于超过50万张H&E染色全切片组织学图像的专有数据集训练而成 [代码][HuggingFace]
CNNs + ViTs:
- CoAtNet:将卷积与注意力结合以适应所有数据规模 [论文]
- LeViT:以卷积神经网络的形式实现视觉Transformer,加速推理过程 [论文]
- ConViT:通过软卷积归纳偏置改进视觉Transformer [论文]
大型音频模型
医疗健康领域
通用领域
- wav2vec:语音识别的无监督预训练 [论文] [博客]
- W2v-BERT:结合对比学习与掩码语言建模的自监督语音预训练 [论文]
- AudioLM:一种基于语言模型的音频生成方法 [论文] [项目] [博客]
- HuBERT:通过掩码预测隐藏单元进行自监督语音表征学习 [论文] [HuggingFace]
- XLS-R:大规模跨语言自监督语音表征学习 [论文] [博客] [HuggingFace]
- MusicLM:从文本生成音乐 [论文] [项目] [代码]
- Diffsound:用于文本到声音生成的离散扩散模型 [论文] [项目] [代码]
- AudioGen:文本引导的音频生成 [论文] [项目]
- Whisper:通过大规模弱监督实现鲁棒语音识别 [论文] [代码] [HuggingFace]
- Google USM:将自动语音识别扩展至100多种语言 [论文] [博客]
大型多模态模型
医疗健康领域
- 多模态大语言模型在医学中的应用 [论文]
- 基础模型:外科人工智能的未来?[论文]
- 用于放射科报告生成的大语言模型自举法 [论文][代码]
- 使用多模态ChatGPT进行膳食评估:系统性分析 [论文]
- PLIP:利用医学Twitter数据构建用于病理图像分析的视觉—语言基础模型 [论文]
- LLaVA-Med:一天内训练一个面向生物医学的大语言—视觉助手 [论文]
- GPT-4技术报告 [论文]
- 通过自监督学习实现对未标注胸部X光片中病变的专家级检测 [论文]
- 基于配对图像与文本的医学视觉表征对比学习 [论文] [代码]
- Gloria:一种用于标签高效医学图像识别的多模态全局—局部表征学习框架 [论文] [代码]
- RAMM:基于多模态预训练的检索增强型生物医学视觉问答 [论文]
- PubMedCLIP:CLIP在医学领域的视觉问答任务中能带来多大收益?[论文]
- SurgVLP:通过观看数百个手术视频讲座学习多模态表征[论文] [代码]
- 智能结肠镜检查的前沿进展 [论文] [代码]
通用领域
多模态聊天机器人
- LMM时代的曙光:使用GPT-4V(vision)的初步探索 [论文]
表征学习:
- 从自然语言监督中学习可迁移的视觉模型 [论文]
- 利用噪声文本监督扩展视觉及视觉—语言表征学习 [论文]
- Florence:一种新的计算机视觉基础模型 [论文]
- 基于实体的语言—图像预训练 [论文]
- WenLan:通过大规模多模态预训练连接视觉与语言 [论文]
- FLAVA:一种基础性的语言与视觉对齐模型 [论文]
- SimVLM:使用弱监督进行简单的视觉语言模型预训练 [论文]
- FILIP:细粒度交互式语言—图像预训练 [论文]
- 面向开放词汇图像分类的联合缩放 [论文]
- BLIP:通过冻结图像编码器和大型语言模型进行语言—图像预训练的自举法 [论文]
- PaLI:一种联合缩放的多语言语言—图像模型 [论文]
- 通过最大化多模态互信息迈向一体化预训练 [论文]
- BLIP-2:利用冻结图像编码器和大型语言模型进行语言—图像预训练的自举法 [论文]
- 监督无处不在:一种数据高效的对比语言—图像预训练范式 [论文]
- 语言并非全部所需:将感知与语言模型对齐 [论文]
- PaLM-E:一种具身化的多模态语言模型 [论文]
- Visual ChatGPT:与视觉基础模型对话、绘图和编辑 [论文]
文本到图像生成:
- 零样本文本到图像生成 [论文]
- 基于潜在扩散模型的高分辨率图像合成 [论文]
- 基于CLIP潜在空间的分层文本条件图像生成 [论文]
- GLIDE:迈向由文本引导的扩散模型实现的真实感图像生成与编辑 [论文]
- 具有深度语言理解的真实感文本到图像扩散模型 [论文]
- 扩展自回归模型以实现内容丰富的文本到图像生成 [论文]
大型AI模型在医疗健康领域的应用
请注意,以下部分模型最初并非针对医疗健康应用设计,但可能具有迁移到医疗健康领域的潜力,或为未来的发展提供灵感。
生物信息学
- GeneGPT:通过领域工具增强大型语言模型,以更好地获取生物医学信息 [论文]
- 使用AlphaFold实现高精度蛋白质结构预测 [论文] [代码]
- 利用三路神经网络准确预测蛋白质结构及其相互作用 [论文]
- 使用AlphaFold-Multimer进行蛋白质复合物预测 [论文]
- FastFold:将AlphaFold训练时间从11天缩短至67小时 [论文] [代码]
- HelixFold:基于PaddlePaddle的高效AlphaFold2实现 [论文] [代码]
- Uni-Fold:一个开源平台,用于开发超越AlphaFold的蛋白质折叠模型 [论文] [代码]
- OpenFold:对AlphaFold2进行再训练,揭示其学习机制和泛化能力 [论文] [代码]
- ManyFold:一个高效灵活的库,用于训练和验证蛋白质折叠模型 [论文] [代码]
- ColabFold:让蛋白质折叠技术惠及所有人 [论文] [代码]
- 通过将无监督学习扩展到2.5亿条蛋白质序列,揭示了生物结构与功能的涌现 [论文] [代码]
- ProGen:用于蛋白质生成的语言模型 [论文] [代码]
- ProtTrans:借助自监督深度学习和高性能计算,破解生命密码的语言 [论文] [代码]
- 利用语言模型实现进化尺度上的原子级蛋白质结构预测 [论文]
- 从一级序列出发的高分辨率从头蛋白质结构预测 [论文] [代码]
- 基于语言模型和深度学习的单序列蛋白质结构预测 [论文]
- 利用蛋白质语言模型改进蛋白质复合物预测 [论文]
- MSA Transformer [论文] [代码]
- 利用语言模型和弱监督学习解析抗体亲和力成熟过程 [论文]
- xTrimoABFold:无需多序列比对即可从头预测抗体结构 [论文]
- scBERT作为大规模预训练深度语言模型,用于单细胞RNA测序数据的细胞类型注释 [论文] [代码]
- 基于未标注数据的可解释RNA基础模型,用于高度精确的RNA结构和功能预测 [论文] [代码]
- E2Efold-3D:端到端深度学习方法,用于精确的RNA三维结构从头预测 [论文] [代码]
- SMILES-BERT:大规模无监督预训练,用于分子性质预测 [论文] [代码]
- SMILES Transformer:预训练的分子指纹,用于低数据量药物发现 [论文] [代码]
- MolBert:利用语言模型和领域相关辅助任务进行分子表征学习 [论文] [代码]
- AGBT:基于代数图论的双向变压器,用于分子性质预测 [论文] [代码]
- GROVER:在大规模分子数据上应用自监督图变换器 [论文] [代码]
- Molgpt:使用变换器解码器模型进行分子生成 [论文] [代码]
- 用于搜索可合成分子的模型 [论文] [代码]
- 将蛋白质特异性从头药物生成视为机器翻译问题的变换器神经网络 [论文]
- Deepconv-dti:通过基于蛋白质序列的卷积深度学习预测药物-靶点相互作用 [论文] [代码]
- Graphdta:利用图神经网络预测药物-靶点结合亲和力 [论文] [代码]
- Moltrans:用于预测药物-靶点相互作用的分子交互变换器 [论文] [代码]
- 从数亿个分子中提取预测性表征 [论文] [代码]
- ADMETlab 2.0:一个集成的在线平台,用于准确且全面地预测ADMET属性 [项目] [论文]
- MPG:从大规模未标记分子中学习分子表征,以支持药物发现 [论文]
- MG-BERT:利用无监督原子表征学习进行分子性质预测 [论文] [代码]
- PanGu药物模型:像人类一样学习分子 [项目] [论文]
- DrugBAN:具有领域适应性的可解释双线性注意力网络,可提升药物-靶点预测性能 [论文] [代码]
- DrugOOD:面向人工智能辅助药物发现的分布外(OOD)数据集策展者和基准测试 [论文] [代码]
医学诊断
- VisionFM:用于通用眼科人工智能的多模态多任务视觉基础模型的开发与验证 [论文] [代码]
- RETFound:一种用于从视网膜图像中进行可泛化疾病检测的基础模型 [论文]
- LLaVA-Med:在一天内训练一个用于生物医学的大规模语言-视觉助手 [论文]
- 通过自监督学习,以专家级水平从未标注的胸部X光片中检测病理 [论文]
- ChatCAD:利用大型语言模型对医学影像进行交互式计算机辅助诊断 [论文] [代码]
- BEHRT:用于电子健康记录的Transformer模型 [论文]
- 基于BEHRT的联邦学习用于医学概念嵌入 [论文] [代码]
- Med-BERT:在大规模结构化电子健康记录上预训练的上下文嵌入,用于疾病预测 [论文]
- CPLLM:基于大型语言模型的临床预测 [论文] [代码]
- RadBERT:将基于Transformer的语言模型适配到放射学领域 [论文] [HuggingFace]
- ChatCAD+:迈向使用LLM的通用且可靠的交互式CAD [论文] [代码]
医学影像
- VisionFM:用于通用眼科人工智能的多模态多任务视觉基础模型的开发与验证 [论文] [代码]
- RETFound:一种用于从视网膜图像中进行可泛化疾病检测的基础模型 [论文]
- 通过自监督学习,以专家级水平从未标注的胸部X光片中检测病理 [论文]
- Med3d:用于3D医学影像分析的迁移学习 [论文] [代码]
- Models genesis:用于3D医学影像分析的通用自学模型 [论文] [代码]
- MICLe:大型自监督模型推动医学影像分类的进步 [论文] [代码]
- C2l:比较学习——通过比较图像表示超越ImageNet预训练的放射影像 [论文] [代码]
- ConVIRT:基于成对图像和文本的医学视觉表征对比学习 [论文] [代码]
- Gloria:一种用于标签高效医学图像识别的多模态全局-局部表征学习框架 [论文] [代码]
- MoCo-CXR:MoCo预训练提升胸片模型的表征能力和迁移性 [论文] [代码]
- Transunet:Transformer作为强大的编码器用于医学影像分割 [论文] [代码]
- Transfuse:将Transformer与CNN融合用于医学影像分割 [论文] [代码]
- Medical Transformer:用于医学影像分割的门控轴向注意力 [论文] [代码]
- UNETR:用于3D医学影像分割的Transformer模型 [论文] [代码]
- Cotr:高效连接CNN和Transformer用于3D医学影像分割 [论文] [代码]
- Swin-unet:类似Unet的纯Transformer用于医学影像分割 [论文] [代码]
- SAM4Med:用于医学影像的通用视觉基础模型:以Zero-Shot医学分割中的Segment Anything Model为例 [论文]
医学信息学
- Med-PaLM 2:基于大型语言模型实现专家级医学问答 [论文]
- DeID-GPT:利用GPT-4实现零样本医学文本去标识化 [论文]
- GPT-4在医学挑战性问题上的能力 [论文]
- BioBERT:用于生物医学文本挖掘的预训练生物医学语言表示模型 [论文]
- 公开可用的临床BERT嵌入 [论文]
- BioMegatron:更大的生物医学领域语言模型 [论文]
- 不要停止预训练:将语言模型适配到特定领域和任务 [论文]
- Med-BERT:基于大规模结构化电子健康记录的预训练上下文嵌入,用于疾病预测 [论文]
- CPLLM:利用大型语言模型进行临床预测 [论文] [代码]
- BioELECTRA:使用判别器预训练的生物医学文本编码器 [论文]
- LinkBERT:利用文档链接进行语言模型预训练 [论文]
- BioGPT:用于生物医学文本生成与挖掘的生成式预训练Transformer [论文]
- 大型语言模型能够编码临床知识 [论文]
- 面向电子健康记录的大规模语言模型 [论文]
- 面向生物医学自然语言处理的领域特定语言模型预训练 [论文]
- BEHRT:用于电子健康记录的Transformer模型 [论文]
- 基于BEHRT的医疗概念嵌入联邦学习 [论文] [代码]
医学教育
公共卫生
- 多模态ChatGPT在膳食评估中的应用:系统性分析 [论文]
- 通过自监督学习实现对未标注胸部X光片中病理的专家级检测 [论文]
- 在被动膳食监测中利用自监督学习对第一人称视角图像进行聚类 [论文]
- ClimaX:用于天气和气候的基础模型 [论文]
医疗机器人
- EndoFM:基于大规模自监督预训练的内窥镜视频分析基础模型 [论文] [代码]
- 决策 Transformer:通过序列建模实现强化学习 [论文] [代码]
- R3M:用于机器人操作的通用视觉表征 [论文] [项目] [代码]
- MimicPlay:通过观察人类操作实现长时程模仿学习 [论文] [项目]
- PaLM-E:具身多模态语言模型 [论文] [项目] [博客]
- 通用智能体 [论文] [博客]
- CLIPort:面向机器人操作的“什么”和“哪里”路径 [论文] [项目] [代码]
- Perceiver-Actor:用于机器人操作的多任务Transformer [论文] [项目] [代码]
- “照我所能做,而非照我说的做”:将语言 grounding 到机器人的操作可能性上 [论文] [项目] [代码]
- VIMA:利用多模态提示实现通用机器人操作 [论文] [项目] [代码]
- RT-1:用于大规模真实世界控制的机器人Transformer [论文] [项目] [代码]
- ChatGPT在机器人领域的应用:设计原则与模型能力 [论文] [博客] [代码]
人工智能立法
- 人工智能法案(欧盟) [来源]
- 英国的人工智能监管创新友好型方法 [来源]
- 美国人工智能权利法案蓝图 [来源]
- 美国人工智能风险管理框架 [来源]
- 关于深度合成互联网信息服务管理的规定(中国) [来源]
- 生成式人工智能服务管理暂行办法(中国) [来源]
生物医学与健康信息学中的大规模数据集
开源
| 数据集 | 描述 |
|---|---|
| Big Fantastic 数据库 | 21亿条蛋白质序列,共3930亿个氨基酸 |
| 已知抗体空间 | 5580万条抗体序列 |
| RNAcentral | 3400万条非编码RNA序列,2200万个二级结构 |
| ZINC20 | 来自150家公司的310个化合物目录中的14亿种化合物 |
| MIMIC-CXR | 6.5万名患者,33.7万张胸部X光片及22.7万份放射学报告 |
| MedMNIST v2 | 70.8万张2D医学图像,1万张3D医学图像 |
| Medical Meadow | 包含150万个数据点,涵盖广泛的医学语言处理任务 |
| Endo-FM 数据库 | 3.3万段内窥镜视频,每段最多可达500万帧 |
| SurgVLP 数据库 | 2.5万对腹腔镜视频-文本配对,来源于1000段手术讲座视频 |
| ColonINST | 45万组结肠镜检查的多模态指令微调样本对 |
私有或需审批
| 数据集 | 描述 |
|---|---|
| 西奈山心电图数据 | 210万名患者,包含850万份独立的心电图记录 |
| 谷歌糖尿病视网膜病变开发数据集 | 23.9万名不同个体,160万张眼底照片 |
| UF Health IDR 临床笔记数据库 | 2.9亿份临床笔记,包含多达820亿个医学术语 |
| 临床实践研究数据链 | 涵盖人口统计、症状、诊断等信息的1130万名患者 |
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备