Bayesian-Neural-Networks
Bayesian-Neural-Networks 是一个基于 PyTorch 的开源项目,专注于提供多种贝叶斯神经网络近似推断方法的代码实现。它旨在解决传统深度学习模型中常见的“过度自信”问题,通过量化预测不确定性,让模型不仅能给出预测结果,还能评估该结果的可靠程度,从而在医疗诊断、自动驾驶等高风险场景中提升决策安全性。
该项目非常适合人工智能研究人员、算法工程师以及对概率深度学习感兴趣的学生使用。无论是希望复现经典论文实验,还是需要在回归分析或图像分类任务中引入不确定性估计,都能从中找到成熟的参考代码。
其核心技术亮点在于集成了多种前沿算法,包括 Bayes by Backprop、MC Dropout、随机梯度朗之万动力学(SGLD)以及局部重参数化技巧等。特别是局部重参数化技巧,通过将采样对象从权重转换为激活值,显著降低了估计方差并加快了收敛速度。此外,项目还贴心地提供了针对 MNIST 分类和 UCI 回归数据集的完整实验脚本及 Google Colab 笔记本,用户无需复杂配置即可直接在云端 GPU 上运行和验证模型,极大地降低了贝叶斯深度学习的研究与开发门槛。
使用场景
某医疗影像初创公司的算法团队正在开发肺炎 X 光片辅助诊断系统,急需模型不仅能给出判断结果,还能在遇到模糊或异常病例时准确提示“不确定”,以避免误诊风险。
没有 Bayesian-Neural-Networks 时
- 传统深度学习模型面对从未见过的噪声图像或罕见病灶时,仍会输出极高的错误置信度,导致医生无法识别模型的“盲目自信”。
- 团队难以区分数据本身的噪声(同方差)与不同患者个体差异带来的不确定性(异方差),只能采用统一的误差假设,降低了诊断精度。
- 为了评估模型可靠性,开发人员不得不手动编写复杂的蒙特卡洛采样代码或集成多个模型,实验周期长且极易出错。
- 缺乏对权重分布的可视化手段,无法通过分析权重的不确定性来剪枝优化模型,导致部署到边缘设备时资源占用过高。
使用 Bayesian-Neural-Networks 后
- 利用 MC Dropout 和 Bayes by Backprop 等算法,模型在面对模糊影像时能主动输出高不确定性预警,提示医生进行人工复核,显著降低漏诊率。
- 通过内置的同方差与异方差回归实验模块,团队能精准分离数据噪声与模型认知局限,针对复杂病例动态调整诊断策略。
- 直接调用预置的 SGLD 或 KF-Laplace 推理接口,无需重复造轮子即可快速对比多种近似推断方法的效果,将算法验证效率提升数倍。
- 借助提供的权重分布绘图与剪枝工具,团队成功剔除了冗余参数,在保持不确定性评估能力的同时,将模型体积压缩了 40%,顺利部署至便携式检测终端。
Bayesian-Neural-Networks 让 AI 模型从“只会答题”进化为“懂得质疑”,在高风险决策场景中提供了至关重要的可信度量化能力。
运行环境要求
- 非必需
- 如有 CUDA 环境会自动使用,但模型较小,CPU 亦可运行
未说明
快速开始
贝叶斯神经网络
![]()
![]()
![]()
以下是几种近似推断方法的 PyTorch 实现:
我们还提供了以下代码:
前置条件
- PyTorch
- Numpy
- Matplotlib
该项目使用 Python 2.7 和 PyTorch 1.0.1 编写。如果系统支持 CUDA,它将自动被使用。这些模型并不庞大,因此也可以在 CPU 上运行。
使用方法
结构
回归实验
我们在玩具数据集上进行了同方差和异方差回归实验,这些数据集是通过 (高斯过程真值) 生成的,同时也对真实数据(六个 UCI 数据集)进行了实验。
Notebooks/classification/(ModelName)_(ExperimentType).ipynb: 包含使用 (ModelName) 在 (ExperimentType) 上进行的实验,即同方差/异方差。异方差笔记本为给定的 (ModelName) 同时包含了玩具数据集和 UCI 数据集的实验。
我们还提供了 Google Colab 笔记本。这意味着你可以在 GPU 上免费运行!无需任何修改——所有依赖项和数据集都已内置在笔记本中——只需选择“运行时”->“更改运行时类型”->“硬件加速器”->“GPU”即可。
MNIST 分类实验
train_(ModelName)_(Dataset).py: 在 (Dataset) 上训练 (ModelName)。训练指标和模型权重将保存到指定的目录中。
src/: 通用工具和模型定义。
Notebooks/classification: 各种笔记本,可用于训练、评估模型以及运行数字旋转不确定性实验。它们还可以绘制权重分布并进行权重剪枝。此外,它们还允许加载预训练模型进行实验。
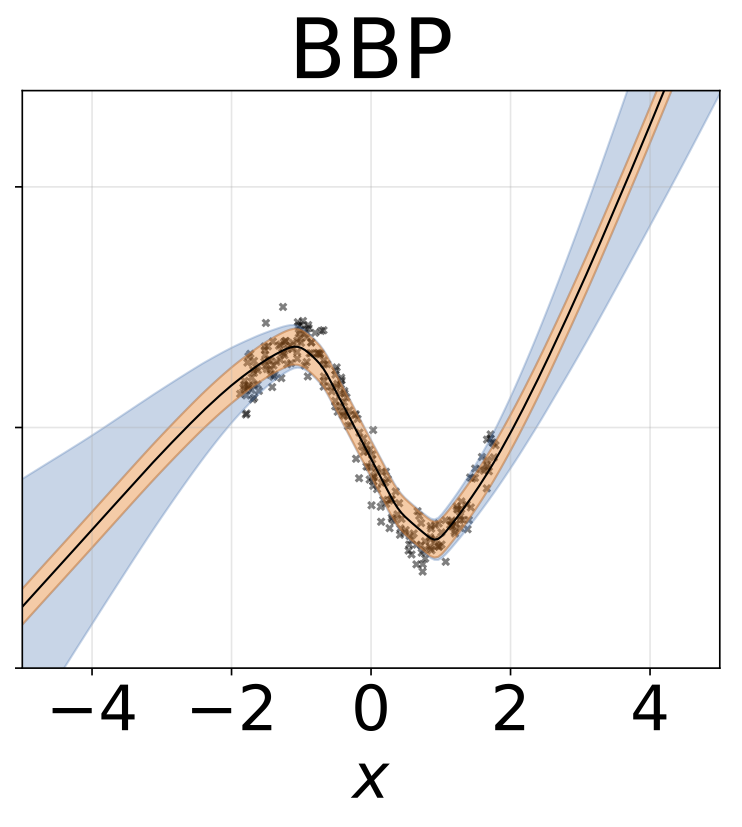
贝叶斯反向传播 (BBP)
(https://arxiv.org/abs/1505.05424)
带有回归模型的 Colab 笔记本:BBP 同方差 / 异方差
在 MNIST 上训练模型:
python train_BayesByBackprop_MNIST.py [--model [MODEL]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
如需了解脚本参数说明:
python train_BayesByBackprop_MNIST.py -h
使用拉普拉斯先验可获得最佳效果。
局部重参数化技巧
(https://arxiv.org/abs/1506.02557)
贝叶斯反向传播推断中,激活的均值和方差以闭式解计算。采样的是激活值而非权重。这使得蒙特卡洛 ELBO 估计量的方差随 minibatch 大小 M 成 1/M 的比例变化。而采样权重则会使方差变为 (M-1)/M。高斯分布之间的 KL 散度也可用闭式解计算,从而进一步降低方差。每轮迭代的计算速度更快,收敛也更快。
在 MNIST 上训练模型:
python train_BayesByBackprop_MNIST.py --model Local_Reparam [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
MC Dropout
(https://arxiv.org/abs/1506.02142)
固定丢弃率为 0.5。
带有回归模型的 Colab 笔记本:MC Dropout 同方差 异方差
在 MNIST 上训练模型:
python train_MCDropout_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
如需了解脚本参数说明:
python train_MCDropout_MNIST.py -h
随机梯度朗之万动力学 (SGLD)
(https://www.ics.uci.edu/~welling/publications/papers/stoclangevin_v6.pdf)
为了使模型收敛到真实的后验分布,学习率应根据 Robbins-Monro 条件进行退火。但在实际应用中,我们通常使用固定的学习率。
带有回归模型的 Colab 笔记本:SGLD 同方差 / 异方差
在 MNIST 上训练模型:
python train_SGLD_MNIST.py [--use_preconditioning [USE_PRECONDITIONING]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
如需了解脚本参数说明:
python train_SGLD_MNIST.py -h
pSGLD
(https://arxiv.org/abs/1512.07666)
带有 RMSprop 预条件的 SGLD。与普通 SGLD 相比,应使用更高的学习率。
在 MNIST 上训练模型:
python train_SGLD_MNIST.py --use_preconditioning True [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
自助 MAP 集成
多个网络在数据集的子样本上进行训练。
带有回归模型的 Colab 笔记本:MAP 集成 同方差 / 异方差
在 MNIST 上训练集成:
python train_Bootrap_Ensemble_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--subsample [SUBSAMPLE]] [--n_nets [N_NETS]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
如需了解脚本参数说明:
python train_Bootrap_Ensemble_MNIST.py -h
克罗内克分解拉普拉斯近似
(https://openreview.net/pdf?id=Skdvd2xAZ)
首先训练一个MAP网络,然后计算后验分布模式附近曲率的二阶泰勒展开近似。这里采用块对角Hessian近似,仅考虑层内依赖关系。进一步将Hessian近似为单个数据点Hessian因子期望的克罗内克积。近似Hessian可能需要较长时间,但幸运的是只需执行一次。
在MNIST数据集上训练MAP网络并近似Hessian:
python train_KFLaplace_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--hessian_diag_sig [HESSIAN_DIAG_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
如需了解脚本参数说明:
python train_KFLaplace_MNIST.py -h
请注意,我们保存了未缩放且未逆化的Hessian因子。这将允许在推理时以较低的计算成本调整先验,而无需重新计算Hessian。推理过程需要对近似的Hessian因子进行逆运算,并从矩阵正态分布中采样。相关示例请参见notebooks/KFAC_Laplace_MNIST.ipynb。
随机梯度哈密顿蒙特卡洛
(https://arxiv.org/abs/1402.4102)
我们实现了该算法的自适应尺度版本,该版本由此处提出,用于在预热阶段自动寻找超参数。我们在网络权重上施加高斯先验,并在高斯先验的精度上设置伽马超先验。
运行SG-HMC-SA预热和采样器,并将权重保存到指定文件中:
python train_SGHMC_MNIST.py [--epochs [EPOCHS]] [--sample_freq [SAMPLE_FREQ]] [--burn_in [BURN_IN]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]
如需了解脚本参数说明:
python train_SGHMC_MNIST.py -h
神经网络中的近似推断
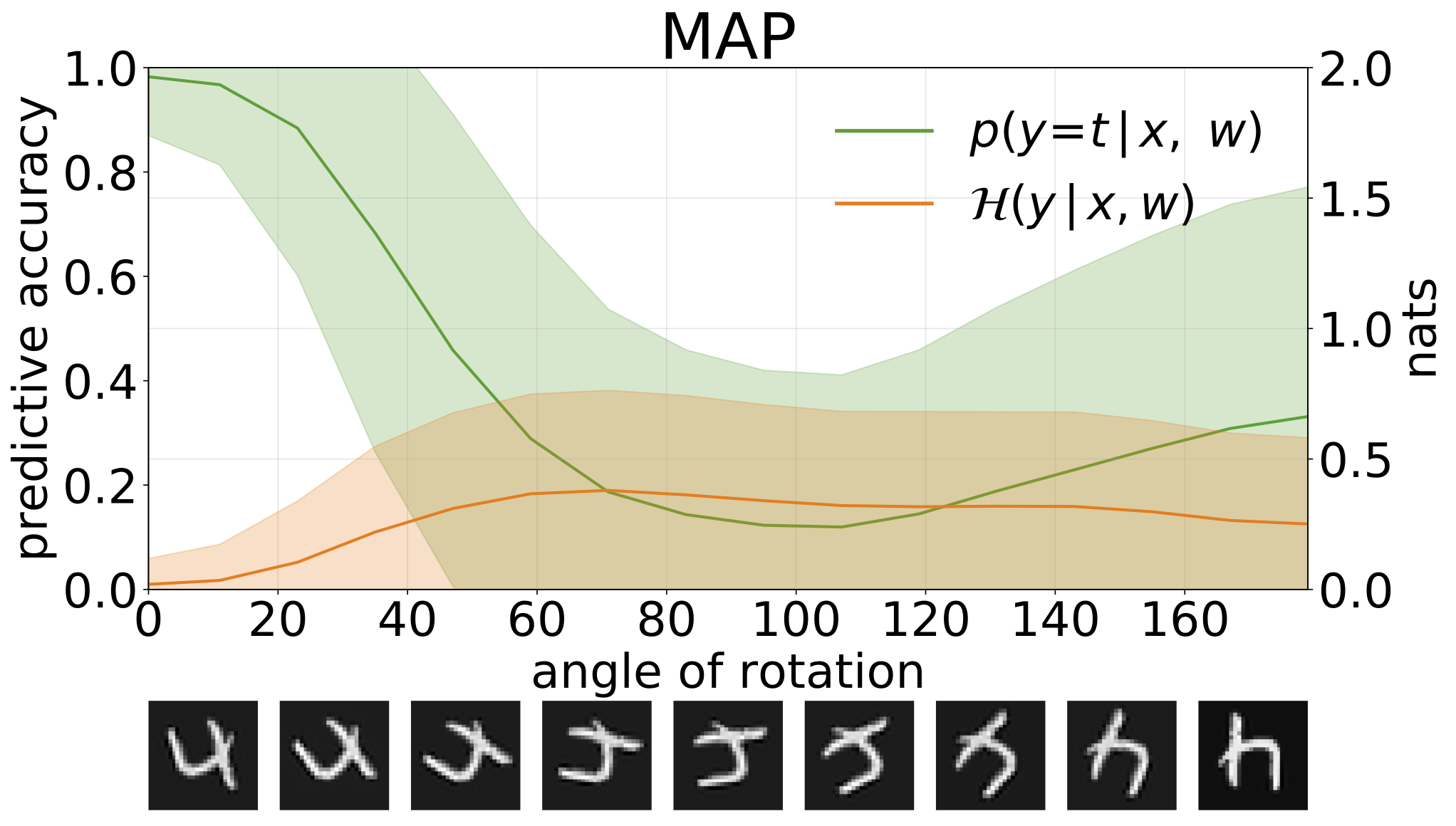
MAP推断提供参数值的点估计。当输入为分布外数据(例如旋转后的数字)时,这些模型往往会以很高的置信度做出错误预测。
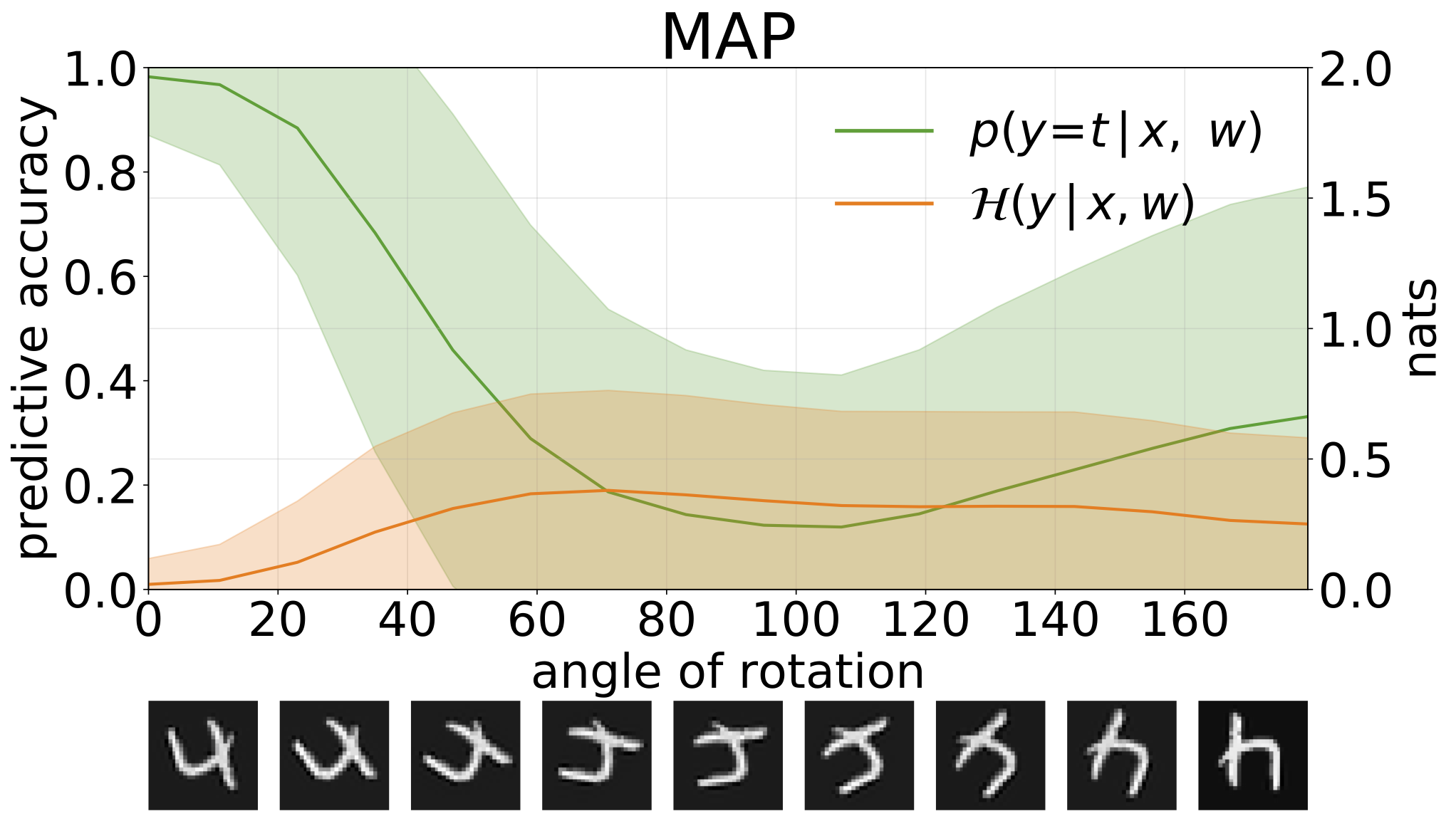
不确定性分解
我们可以通过预测熵来衡量模型预测中的不确定性。可以将这一项分解,以区分两种类型的不确定性:由数据噪声引起的偶然不确定性,可量化为模型预测熵的期望值;以及由模型本身引起的认知不确定性,可通过总熵与偶然不确定性的差值来衡量。
结果
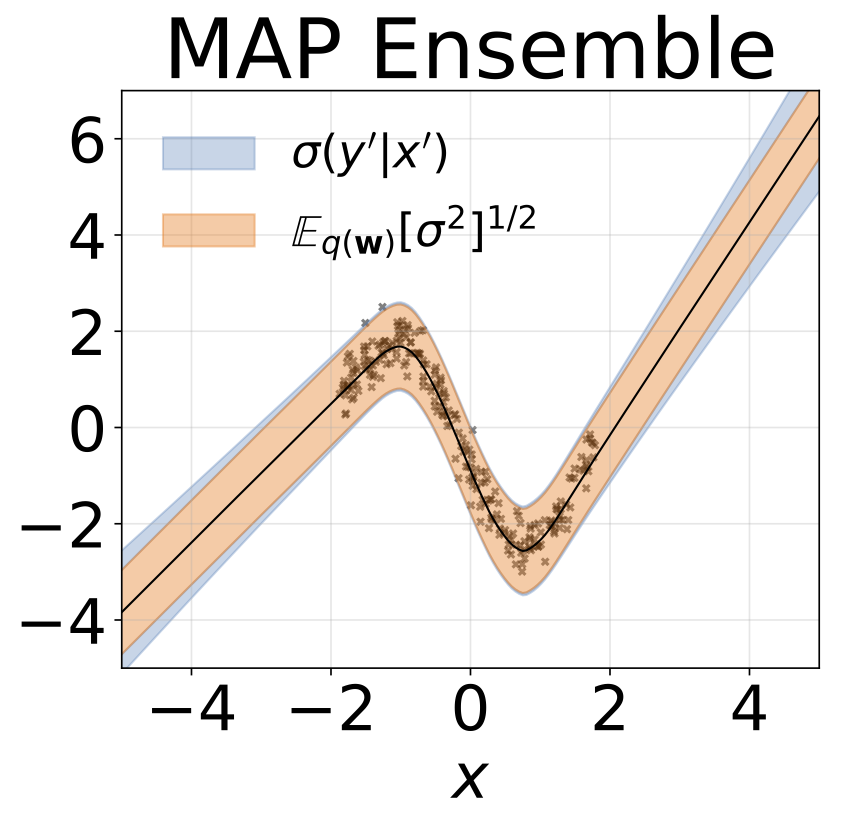
同方差回归
玩具同方差回归任务。数据由具有RBF核(l = 1, σn = 0.3)的GP生成。我们使用一个单输出全连接网络,包含一层200个ReLU单元,用于预测回归均值μ(x)。固定log σ则单独学习。
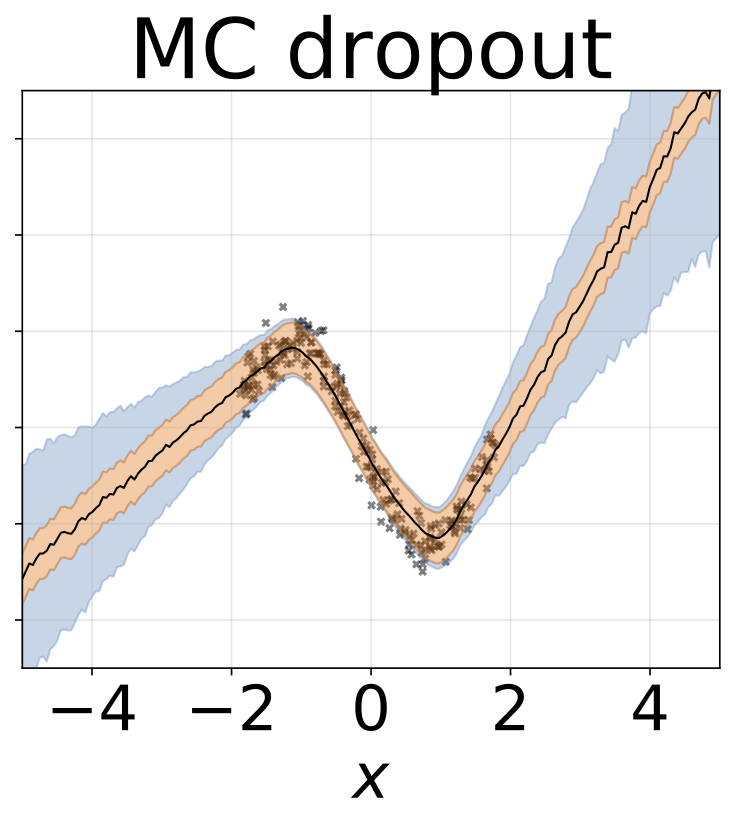
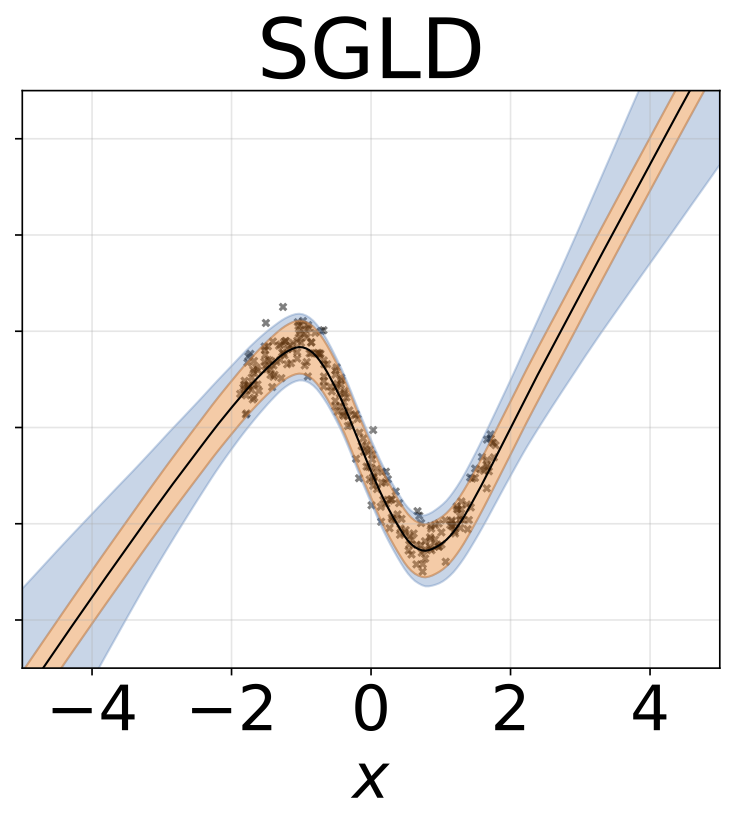
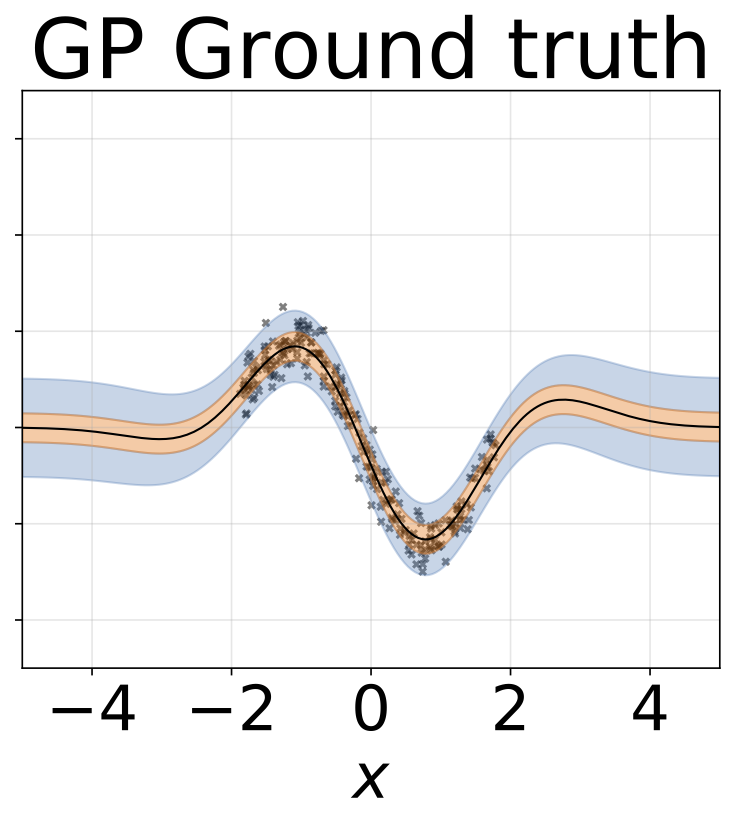
异方差回归
与前一节相同,但log σ(x)根据输入预测。
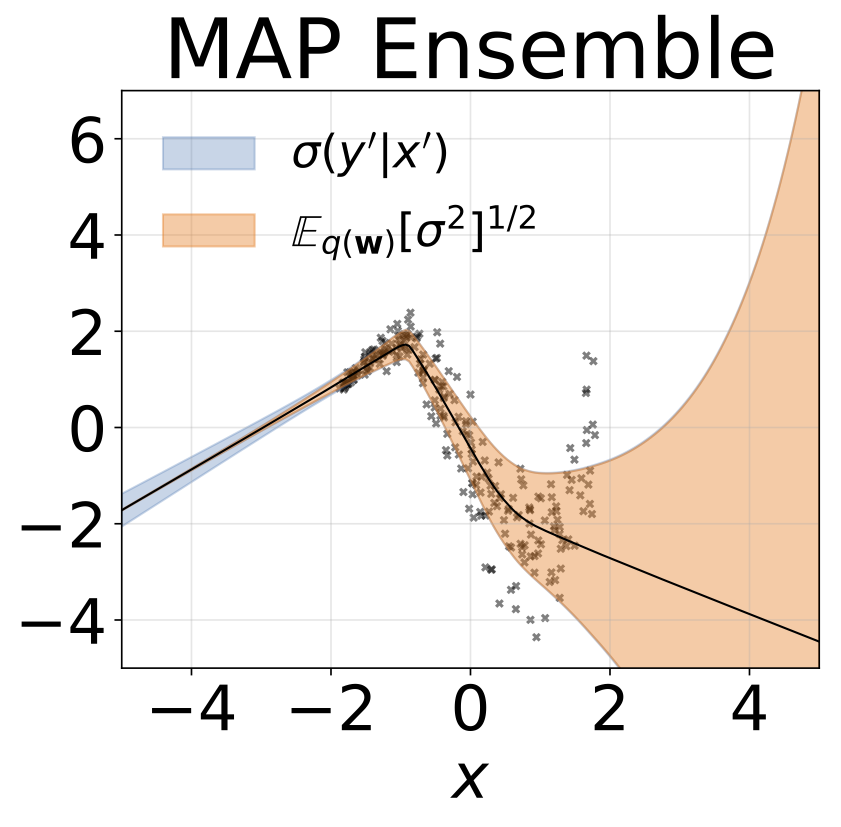
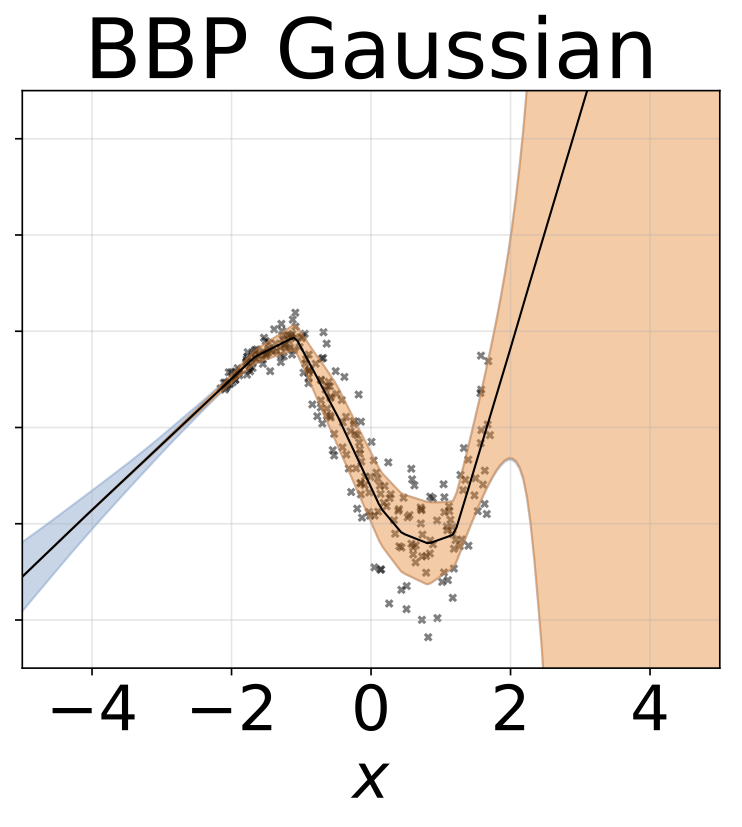
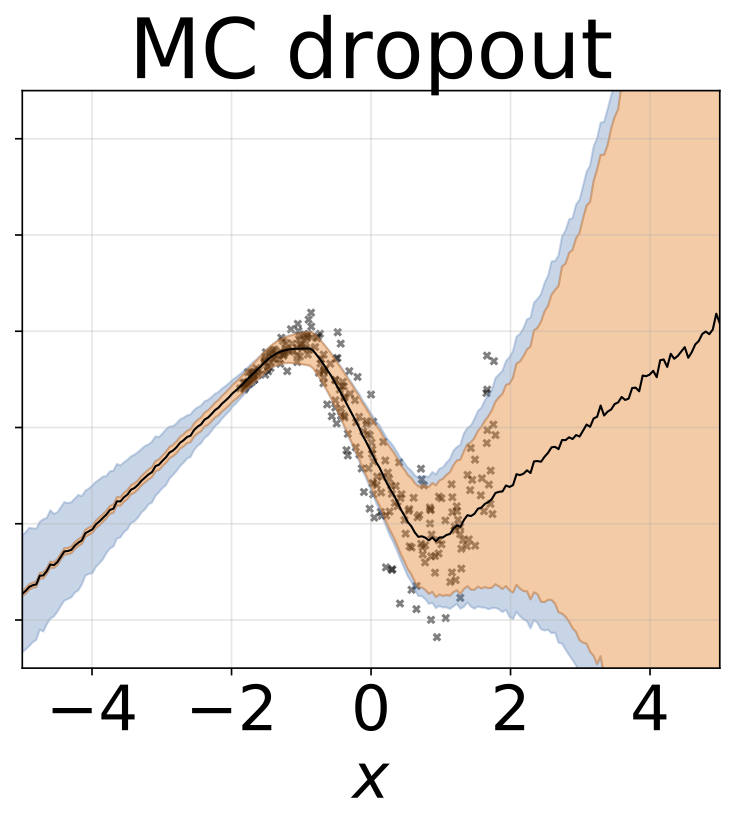
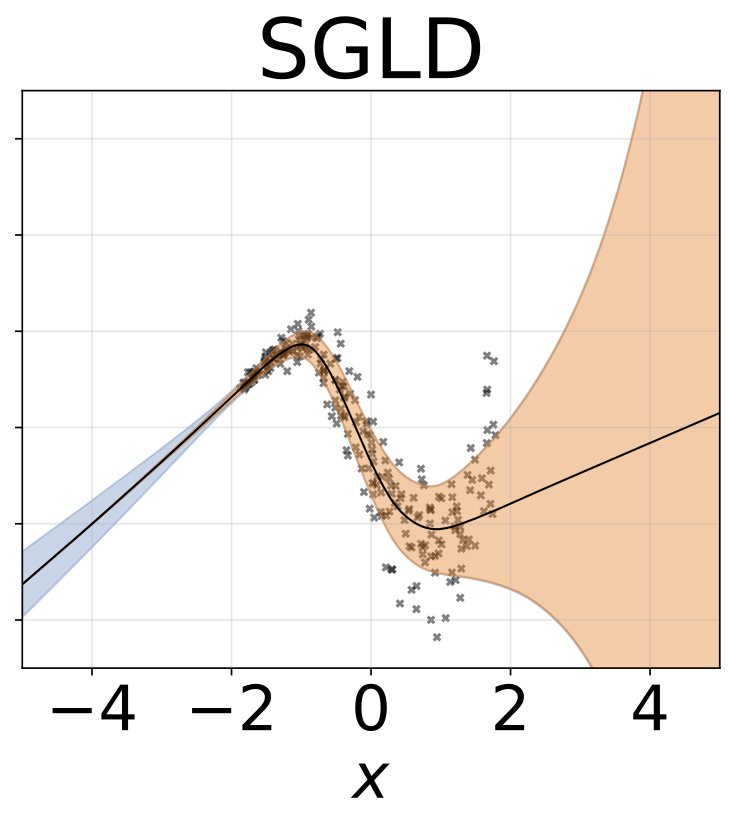
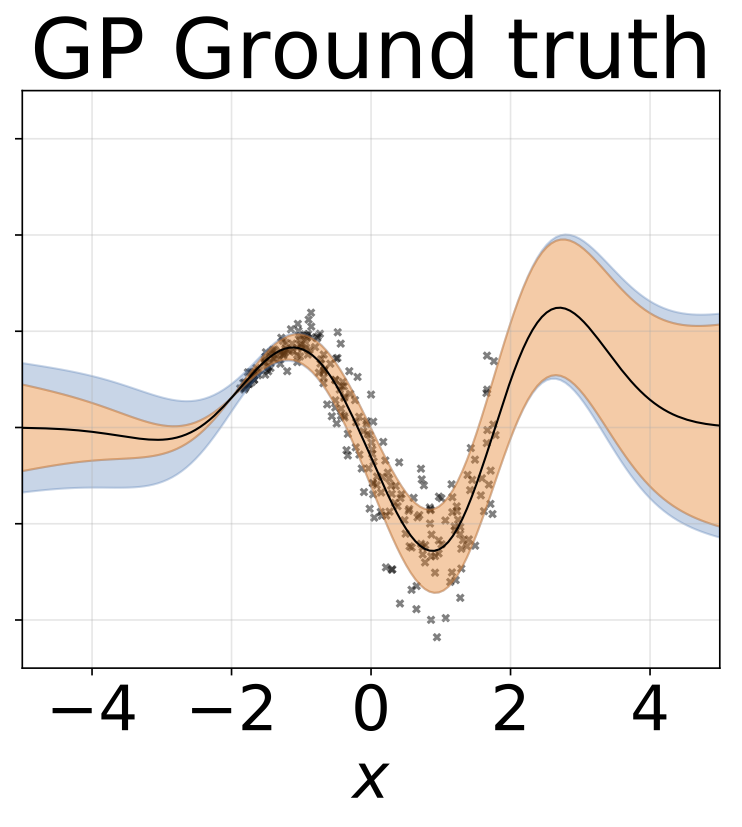
玩具异方差回归任务。数据由具有RBF核(l = 1, σn = 0.3 · |x + 2|)的GP生成。我们使用一个双头网络,包含200个ReLU单元,分别预测回归均值μ(x)和对数标准差log σ(x)。
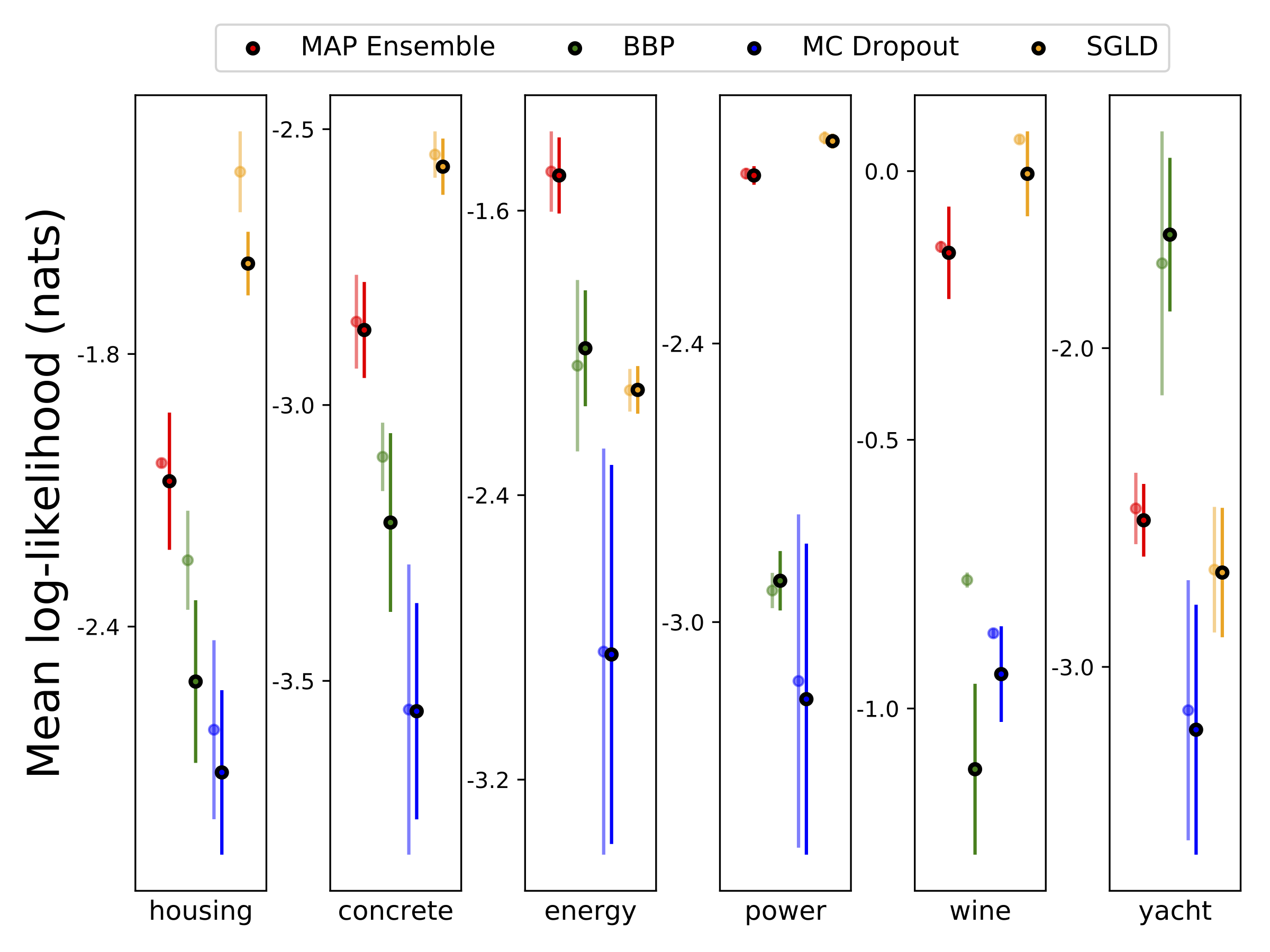
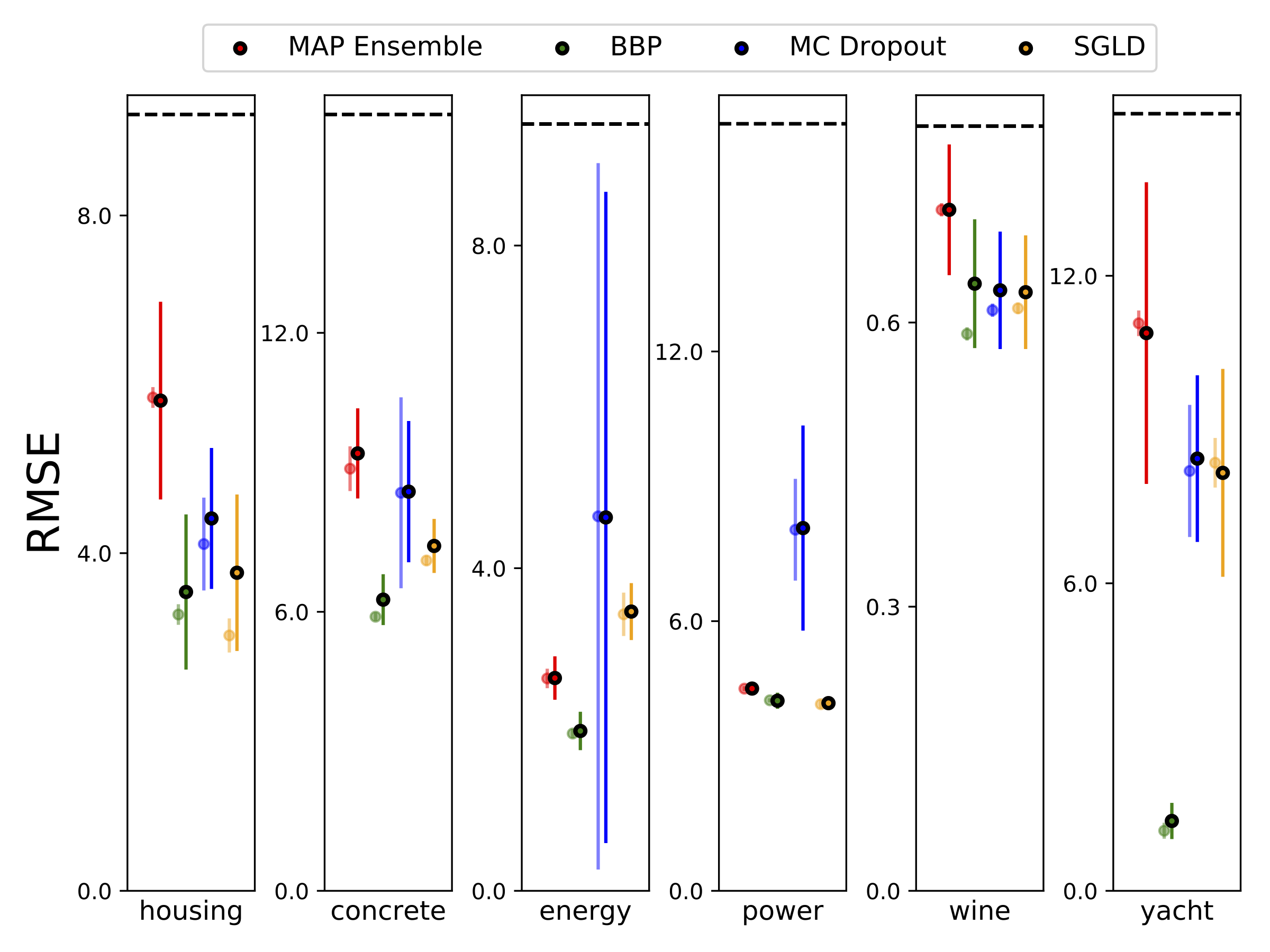
UCI数据集上的回归
我们在六个UCI数据集上进行了异方差回归(包括housing、concrete、energy efficiency、power plant、red wine和yacht),采用10折交叉验证。所有实验都包含在异方差笔记本中。需要注意的是,结果高度依赖于超参数的选择。下方图表展示了训练集(半透明颜色)和测试集(实心颜色)上的对数似然和RMSE。圆圈和误差线分别对应10折交叉验证的均值和标准差。
MNIST分类
除MAP模型外,其他模型均使用100个权重样本进行权重边缘化处理,而MAP模型仅使用一组权重。
| MNIST测试 | MAP | MAP 集成 | BBP 高斯 | BBP GMM | BBP 拉普拉斯 | BBP 局部重参数化 | MC Dropout | SGLD | pSGLD | |:--------------: |:-------: |:-------------------: |:--------------: |:---------: |:-------------: |:-------------------: |:----------: |:-------: |:-------: | | Log Like | -572.9 | -496.54 | -1100.29 | -1008.28 | -892.85 | -1086.43 | -435.458 | -828.29 | -661.25 | | Error % | 1.58 | 1.53 | 2.60 | 2.38 | 2.28 | 2.61 | 1.37 | 1.76 | 1.76 |
所考察方法在MNIST测试上的结果。未进行大规模超参数调优。我们使用100个MC样本近似后验预测分布。采用两层各1200个ReLU单元的全连接网络。若未指定,则先验为标准差为0.1的高斯分布。p-SGLD使用RMSprop预条件。
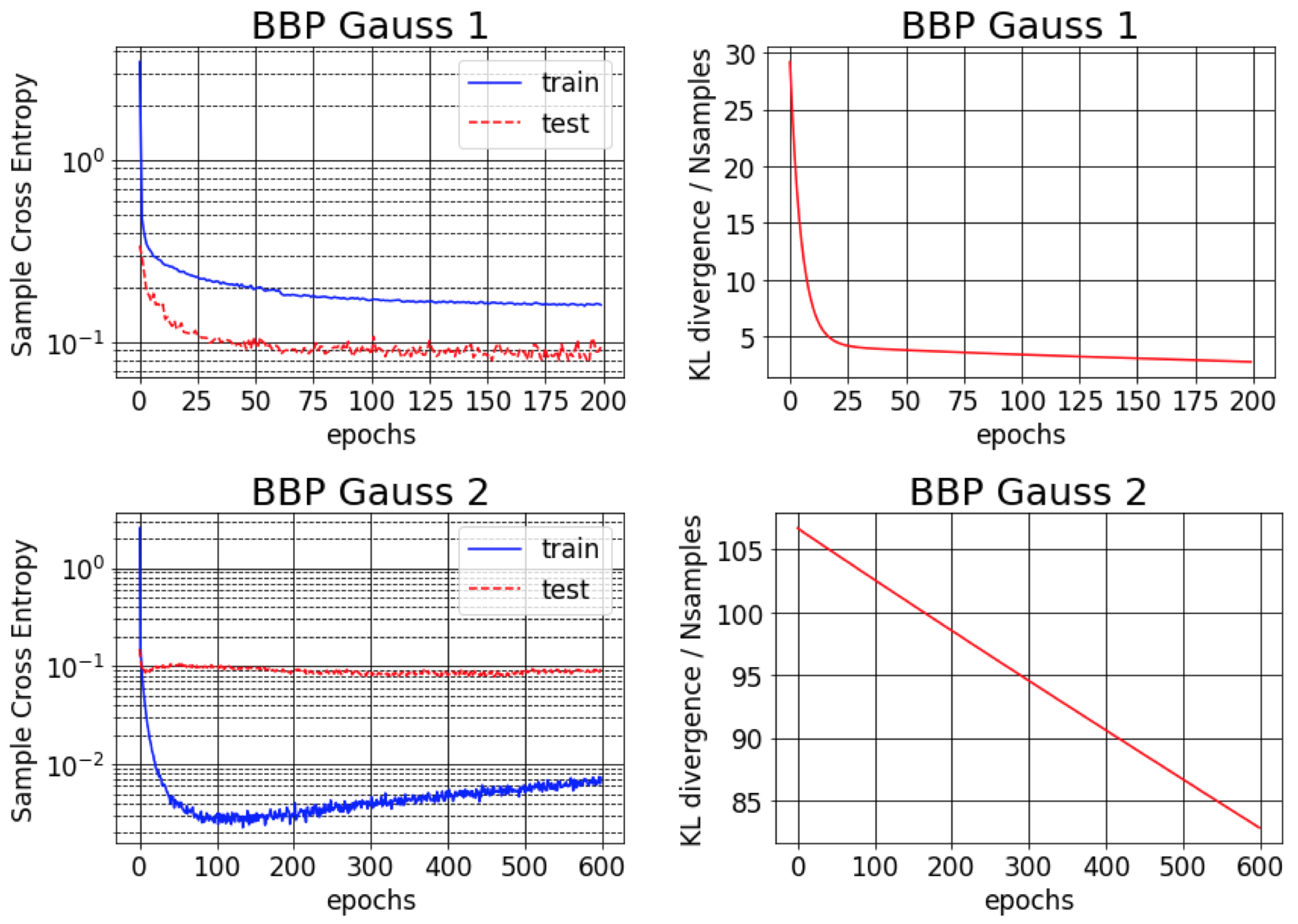
关于Bayes By Backprop的原始论文(https://arxiv.org/abs/1505.05424)报告称,在MNIST数据集上误差约为1%。我们发现,只有当近似后验方差初始化为非常小(BBP Gauss 2)时,才能达到这一效果。在这种情况下,权重分布接近狄拉克δ函数,虽然预测性能良好,但不确定性估计较差。然而,当将方差初始化为与先验一致(BBP Gauss 1)时,便得到了上述结果。这两种超参数配置方案的训练曲线如下所示:
MNIST 不确定性
通过在 MNIST 测试集上添加旋转来生成 OOD 样本时获得的总不确定性、随机性和认知不确定性:
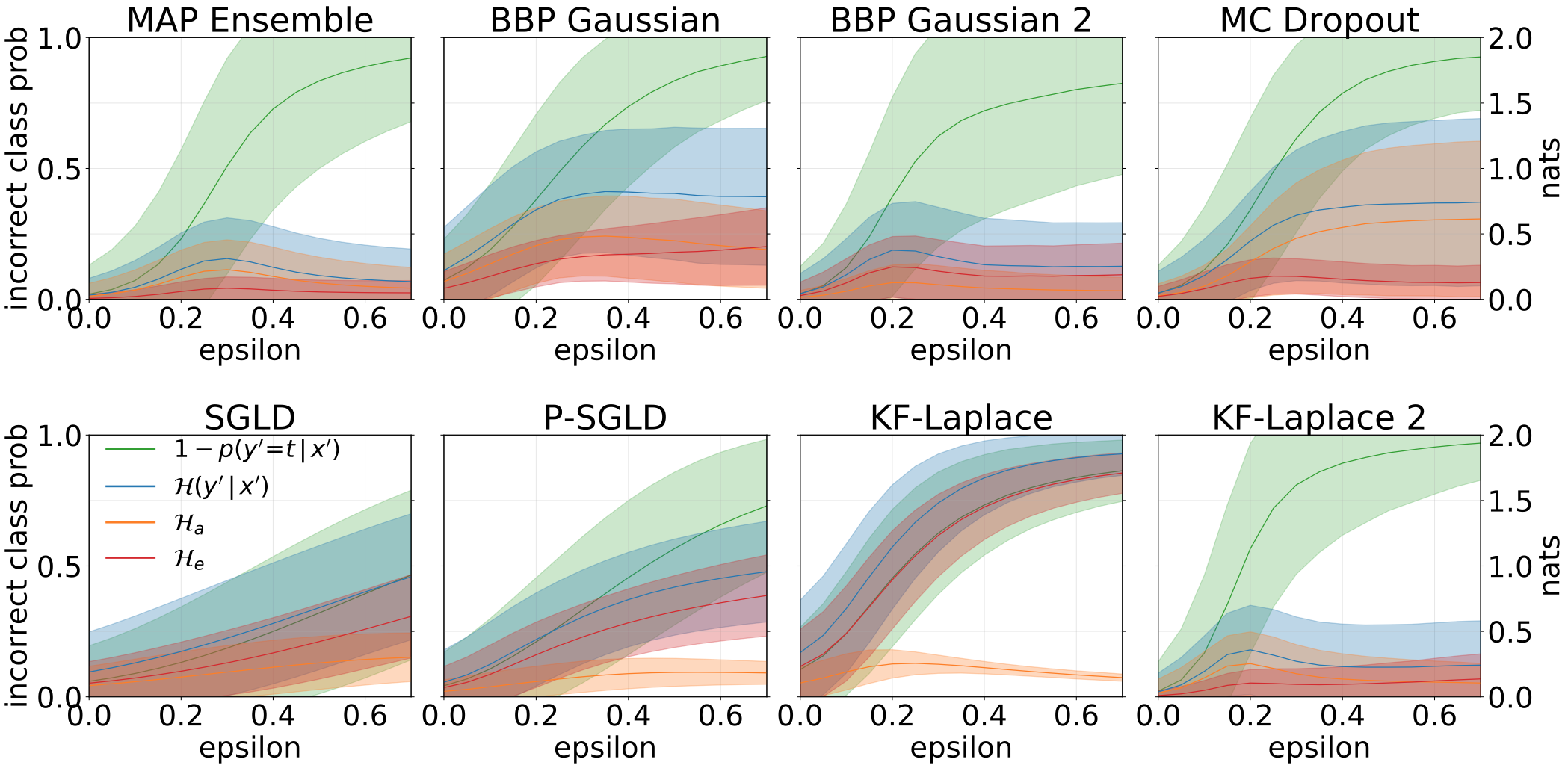
在 KMNIST 数据集上测试我们基于 MNIST 训练的模型时获得的总不确定性和认知不确定性:
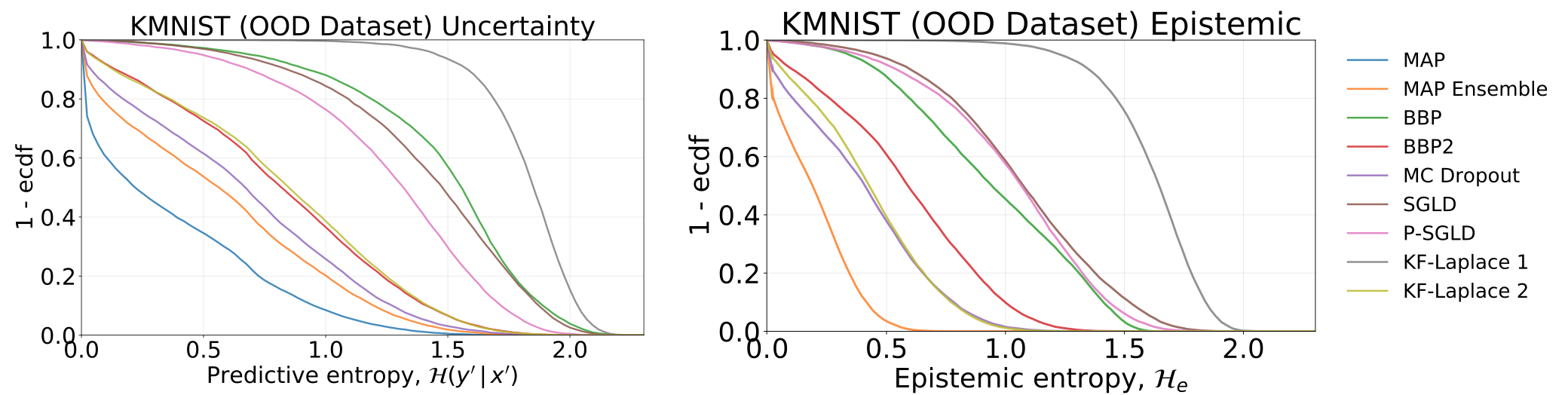
对抗鲁棒性

当我们向模型输入对抗样本(FGSM)时,所获得的总不确定性、随机性和认知不确定性。

权重分布
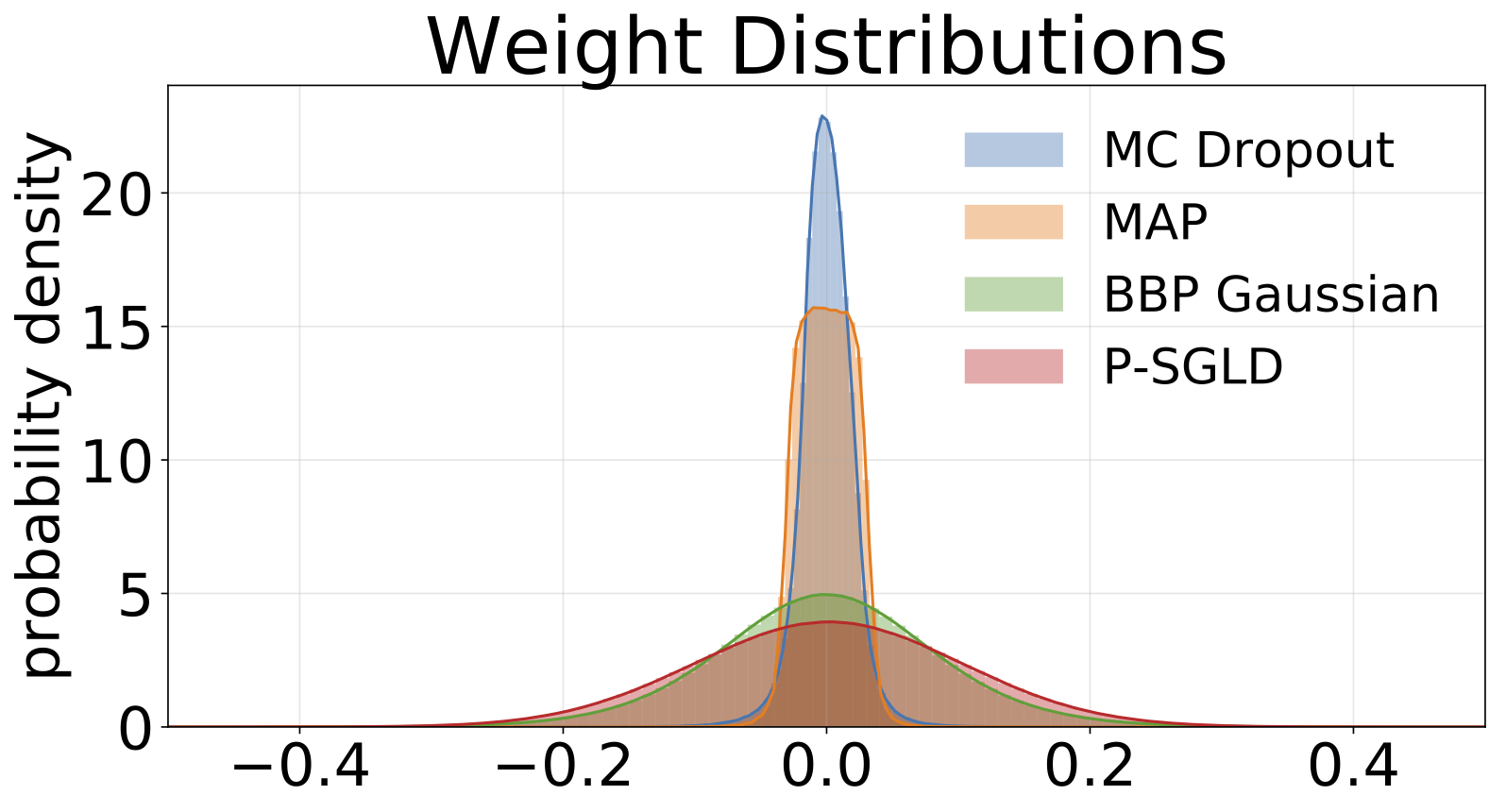
从每个基于 MNIST 训练的模型中采样得到的权重直方图。我们为每个模型抽取了 10 个权重样本。
权重剪枝
#TODO
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器