lagent
lagent 是一个轻量级开源框架,专为构建基于大语言模型(LLM)的智能体而设计。它旨在解决开发者在搭建多智能体应用时面临的流程复杂、代码耦合度高等痛点,让构建过程像搭积木一样简单直观。
该工具特别适合 AI 开发者、研究人员以及希望快速原型化智能体应用的工程师使用。普通用户若无需定制开发,则较难直接从中获益。
lagent 最大的技术亮点在于其深受 PyTorch 设计理念启发。它将智能体的各个功能模块抽象为“层”,用户只需以地道的 Python 方式定义这些层及其之间的消息传递逻辑,即可清晰地把控工作流。框架内置了标准化的 AgentMessage 通信机制和自动化的记忆管理模块,每次交互会自动记录上下文状态,同时也支持灵活的记忆清除与导出。此外,它还允许用户自定义消息聚合策略,为构建复杂的多智能体协作系统提供了极高的自由度与扩展性。通过 lagent,你可以专注于业务逻辑创新,而非底层架构的重复造轮子。
使用场景
某电商初创团队希望快速构建一个能自动处理售后咨询、查询订单状态并协调退款流程的多智能体客服系统。
没有 lagent 时
- 开发者需手动编写大量样板代码来管理不同大模型之间的消息传递格式,导致开发效率低下且容易出错。
- 多轮对话的历史记忆难以统一维护,每次新增功能都要重新设计状态存储逻辑,代码耦合度极高。
- 想要串联“意图识别”、“订单查询”和“退款执行”三个独立智能体时,缺乏标准化的通信机制,调试过程如同“黑盒”。
- 扩展新业务场景(如增加物流追踪)往往需要重构整个交互框架,无法像搭积木一样灵活插入新模块。
使用 lagent 后
- 借鉴 PyTorch 的分层设计理念,开发者只需定义清晰的 Agent 层和消息流,即可用极简的 Python 代码完成复杂智能体编排。
- 内置的记忆管理机制自动在每次交互中存取对话历史,通过
state_dict即可轻松查看或重置会话状态,无需重复造轮子。 - 利用标准的
AgentMessage协议,多个智能体之间能够顺畅传递结构化信息,让“查询 - 决策 - 执行”的全链路透明可控。 - 新增物流追踪智能体时,仅需实例化新类并接入消息流,原有架构无需改动,真正实现了模块化热插拔。
lagent 将复杂的智能体协作简化为直观的消息传递与层级构建,让开发者从繁琐的基础设施中解放,专注于业务逻辑创新。
运行环境要求
- 未说明
- 非框架本身强制要求,但示例代码使用 VllmModel (vLLM),通常运行大模型需要 NVIDIA GPU
- 具体显存和 CUDA 版本取决于所选模型(如示例中的 Qwen2-7B)及 vLLM 的要求
未说明

快速开始









👋 欢迎加入我们的 𝕏 (Twitter)、Discord 和 WeChat
安装
从源码安装:
git clone https://github.com/InternLM/lagent.git
cd lagent
pip install -e .
使用
Lagent 的设计理念受到 PyTorch 的启发。我们希望通过类比神经网络层的方式来使工作流程更加清晰直观,这样用户只需专注于以 Pythonic 的方式创建层,并定义它们之间的消息传递。以下是一个简单的教程,帮助你快速上手构建多智能体应用。
模型作为智能体
智能体使用 AgentMessage 进行通信。
from typing import Dict, List
from lagent.agents import Agent
from lagent.schema import AgentMessage
from lagent.llms import VllmModel, INTERNLM2_META
llm = VllmModel(
path='Qwen/Qwen2-7B-Instruct',
meta_template=INTERNLM2_META,
tp=1,
top_k=1,
temperature=1.0,
stop_words=['<|im_end|>'],
max_new_tokens=1024,
)
system_prompt = '你的回答只能从“典”、“孝”、“急”三个字中选一个。'
agent = Agent(llm, system_prompt)
user_msg = AgentMessage(sender='user', content='今天天气情况')
bot_msg = agent(user_msg)
print(bot_msg)
content='急' sender='Agent' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
内存作为状态
每次前向传播时,输入和输出的消息都会被添加到 Agent 的内存中。这一操作是在 __call__ 方法中完成的,而不是在 forward 方法中。以下是伪代码示例:
def __call__(self, *message):
message = pre_hooks(message)
add_memory(message)
message = self.forward(*message)
add_memory(message)
message = post_hooks(message)
return message
可以通过两种方式检查内存:
memory: List[AgentMessage] = agent.memory.get_memory()
print(memory)
print('-' * 120)
dumped_memory: Dict[str, List[dict]] = agent.state_dict()
print(dumped_memory['memory'])
[AgentMessage(content='今天天气情况', sender='user', formatted=None, extra_info=None, type=None, receiver=None, stream_state=<AgentStatusCode.END: 0>), AgentMessage(content='急', sender='Agent', formatted=None, extra_info=None, type=None, receiver=None, stream_state=<AgentStatusCode.END: 0>)]
------------------------------------------------------------------------------------------------------------------------
[{'content': '今天天气情况', 'sender': 'user', 'formatted': None, 'extra_info': None, 'type': None, 'receiver': None, 'stream_state': <AgentStatusCode.END: 0>}, {'content': '急', 'sender': 'Agent', 'formatted': None, 'extra_info': None, 'type': None, 'receiver': None, 'stream_state': <AgentStatusCode.END: 0>}]
清除当前会话的内存(默认会话 ID 为 0):
agent.reset()
自定义消息聚合
后台会调用 DefaultAggregator 将 AgentMessage 组装并转换为 OpenAI 的消息格式。
def forward(self, *message: AgentMessage, session_id=0, **kwargs) -> Union[AgentMessage, str]:
formatted_messages = self.aggregator.aggregate(
self.memory.get(session_id),
self.name,
self.output_format,
self.template,
)
llm_response = self.llm.chat(formatted_messages, **kwargs)
...
实现一个可以接收少量示例的简单聚合器:
from typing import List, Union
from lagent.memory import Memory
from lagent.prompts import StrParser
from lagent.agents.aggregator import DefaultAggregator
class FewshotAggregator(DefaultAggregator):
def __init__(self, few_shot: List[dict] = None):
self.few_shot = few_shot or []
def aggregate(self,
messages: Memory,
name: str,
parser: StrParser = None,
system_instruction: Union[str, dict, List[dict]] = None) -> List[dict]:
_message = []
if system_instruction:
_message.extend(
self.aggregate_system_intruction(system_instruction))
_message.extend(self.few_shot)
messages = messages.get_memory()
for message in messages:
if message.sender == name:
_message.append(
dict(role='assistant', content=str(message.content)))
else:
user_message = message.content
if len(_message) > 0 and _message[-1]['role'] == 'user':
_message[-1]['content'] += user_message
else:
_message.append(dict(role='user', content=user_message))
return _message
agent = Agent(
llm,
aggregator=FewshotAggregator(
[
{"role": "user", "content": "今天天气"},
{"role": "assistant", "content": "【晴】"},
]
)
)
user_msg = AgentMessage(sender='user', content='昨天天气')
bot_msg = agent(user_msg)
print(bot_msg)
content='【多云转晴,夜间有轻微降温】' sender='Agent' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
灵活的响应格式化
在 AgentMessage 中,formatted 被保留用于存储由 output_format 从模型输出中解析出的信息。
def forward(self, *message: AgentMessage, session_id=0, **kwargs) -> Union[AgentMessage, str]:
...
llm_response = self.llm.chat(formatted_messages, **kwargs)
if self.output_format:
formatted_messages = self.output_format.parse_response(llm_response)
return AgentMessage(
sender=self.name,
content=llm_response,
formatted=formatted_messages,
)
...
可以使用工具解析器如下:
from lagent.prompts.parsers import ToolParser
system_prompt = "逐步分析并编写Python代码解决以下问题。"
parser = ToolParser(tool_type='code interpreter', begin='```python\n', end='\n```\n')
llm.gen_params['stop_words'].append('\n```\n')
agent = Agent(llm, system_prompt, output_format=parser)
user_msg = AgentMessage(
sender='user',
content='Marie is thinking of a multiple of 63, while Jay is thinking of a '
'factor of 63. They happen to be thinking of the same number. There are '
'two possibilities for the number that each of them is thinking of, one '
'positive and one negative. Find the product of these two numbers.')
bot_msg = agent(user_msg)
print(bot_msg.model_dump_json(indent=4))
{
"content": "首先,我们需要找出63的所有正因数和负因数。63的正因数可以通过分解63的质因数来找出,即\\(63 = 3^2 \\times 7\\)。因此,63的正因数包括1, 3, 7, 9, 21, 和 63。对于负因数,我们只需将上述正因数乘以-1。\n\n接下来,我们需要找出与63的正因数相乘的结果为63的数,以及与63的负因数相乘的结果为63的数。这可以通过将63除以每个正因数和负因数来实现。\n\n最后,我们将找到的两个数相乘得到最终答案。\n\n下面是Python代码实现:\n\n```python\ndef find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)",
"sender": "Agent",
"formatted": {
"tool_type": "code interpreter",
"thought": "首先,我们需要找出63的所有正因数和负因数。63的正因数可以通过分解63的质因数来找出,即\\(63 = 3^2 \\times 7\\)。因此,63的正因数包括1, 3, 7, 9, 21, 和 63。对于负因数,我们只需将上述正因数乘以-1。\n\n接下来,我们需要找出与63的正因数相乘的结果为63的数,以及与63的负因数相乘的结果为63的数。这可以通过将63除以每个正因数和负因数来实现。\n\n最后,我们将找到的两个数相乘得到最终答案。\n\n下面是Python代码实现:\n\n",
"action": "def find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)",
"status": 1
},
"extra_info": null,
"type": null,
"receiver": null,
"stream_state": 0
}
工具调用的一致性
ActionExecutor 使用与 Agent 相同的通信数据结构,但要求输入 AgentMessage 的内容是一个包含以下键的字典:
name: 工具名称,例如'IPythonInterpreter'、'WebBrowser.search'。parameters: 工具 API 的关键字参数,例如{'command': 'import math;math.sqrt(2)'}、{'query': ['recent progress in AI']}。
你可以注册自定义钩子来进行消息转换。
from lagent.hooks import Hook
from lagent.schema import ActionReturn, ActionStatusCode, AgentMessage
from lagent.actions import ActionExecutor, IPythonInteractive
class CodeProcessor(Hook):
def before_action(self, executor, message, session_id):
message = message.copy(deep=True)
message.content = dict(
name='IPythonInteractive', parameters={'command': message.formatted['action']}
)
return message
def after_action(self, executor, message, session_id):
action_return = message.content
if isinstance(action_return, ActionReturn):
if action_return.state == ActionStatusCode.SUCCESS:
response = action_return.format_result()
else:
response = action_return.errmsg
else:
response = action_return
message.content = response
return message
executor = ActionExecutor(actions=[IPythonInteractive()], hooks=[CodeProcessor()])
bot_msg = AgentMessage(
sender='Agent',
content='首先,我们需要...',
formatted={
'tool_type': 'code interpreter',
'thought': '首先,我们需要...',
'action': 'def find_numbers():\n # 正因数\n positive_factors = [1, 3, 7, 9, 21, 63]\n # 负因数\n negative_factors = [-1, -3, -7, -9, -21, -63]\n \n # 找到与正因数相乘的结果为63的数\n positive_numbers = [63 / factor for factor in positive_factors]\n # 找到与负因数相乘的结果为63的数\n negative_numbers = [-63 / factor for factor in negative_factors]\n \n # 计算两个数的乘积\n product = positive_numbers[0] * negative_numbers[0]\n \n return product\n\nresult = find_numbers()\nprint(result)',
'status': 1
})
executor_msg = executor(bot_msg)
print(executor_msg)
content='3969.0' sender='ActionExecutor' formatted=None extra_info=None type=None receiver=None stream_state=<AgentStatusCode.END: 0>
为了方便起见,Lagent 提供了 InternLMActionProcessor,它适用于上述提到的由 ToolParser 格式化的消息。
双重接口
Lagent 采用了双重接口设计,几乎每个组件(LLMs、actions、action executors 等)都有对应的异步变体,只需在其标识符前加上 Async 即可。建议在调试时使用同步代理,而在大规模推理时使用异步代理,以充分利用空闲的 CPU 和 GPU 资源。
然而,务必确保代理内部的一致性,即异步代理应配备异步 LLM 和驱动异步工具的异步行动执行器。
from lagent.llms import VllmModel, AsyncVllmModel, LMDeployPipeline, AsyncLMDeployPipeline
from lagent.actions import ActionExecutor, AsyncActionExecutor, WebBrowser, AsyncWebBrowser
from lagent.agents import Agent, AsyncAgent, AgentForInternLM, AsyncAgentForInternLM
实践
- 除非必要,尽量实现子类的
forward方法而不是__call__方法。 - 始终显式地包含
session_id参数,该参数旨在在并发环境中隔离内存、LLM 请求和工具调用(例如维护多个独立的 IPython 环境)。
单一智能体
通过编程解决问题的数学智能体
from lagent.agents.aggregator import InternLMToolAggregator
class Coder(Agent):
def __init__(self, model_path, system_prompt, max_turn=3):
super().__init__()
llm = VllmModel(
path=model_path,
meta_template=INTERNLM2_META,
tp=1,
top_k=1,
temperature=1.0,
stop_words=['\n```\n', '<|im_end|>'],
max_new_tokens=1024,
)
self.agent = Agent(
llm,
system_prompt,
output_format=ToolParser(
tool_type='code interpreter', begin='```python\n', end='\n```\n'
),
# `InternLMToolAggregator` 是为聚合包含工具调用和执行结果的消息而适配的
aggregator=InternLMToolAggregator(),
)
self.executor = ActionExecutor([IPythonInteractive()], hooks=[CodeProcessor()])
self.max_turn = max_turn
def forward(self, message: AgentMessage, session_id=0) -> AgentMessage:
for _ in range(self.max_turn):
message = self.agent(message, session_id=session_id)
if message.formatted['tool_type'] is None:
return message
message = self.executor(message, session_id=session_id)
return message
coder = Coder('Qwen/Qwen2-7B-Instruct', 'Solve the problem step by step with assistance of Python code')
query = AgentMessage(
sender='user',
content='Find the projection of $\\mathbf{a}$ onto $\\mathbf{b} = '
'\\begin{pmatrix} 1 \\\\ -3 \\end{pmatrix}$ if $\\mathbf{a} \\cdot \\mathbf{b} = 2.$'
)
answer = coder(query)
print(answer.content)
print('-' * 120)
for msg in coder.state_dict()['agent.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')
多智能体
通过自我改进来提升写作质量的异步博客撰写智能体(原始 AutoGen 示例)
import asyncio
import os
from lagent.llms import AsyncGPTAPI
from lagent.agents import AsyncAgent
os.environ['OPENAI_API_KEY'] = 'YOUR_API_KEY'
class PrefixedMessageHook(Hook):
def __init__(self, prefix: str, senders: list = None):
self.prefix = prefix
self.senders = senders or []
def before_agent(self, agent, messages, session_id):
for message in messages:
if message.sender in self.senders:
message.content = self.prefix + message.content
class AsyncBlogger(AsyncAgent):
def __init__(self, model_path, writer_prompt, critic_prompt, critic_prefix='', max_turn=3):
super().__init__()
llm = AsyncGPTAPI(model_type=model_path, retry=5, max_new_tokens=2048)
self.writer = AsyncAgent(llm, writer_prompt, name='writer')
self.critic = AsyncAgent(
llm, critic_prompt, name='critic', hooks=[PrefixedMessageHook(critic_prefix, ['writer'])]
)
self.max_turn = max_turn
async def forward(self, message: AgentMessage, session_id=0) -> AgentMessage:
for _ in range(self.max_turn):
message = await self.writer(message, session_id=session_id)
message = await self.critic(message, session_id=session_id)
return await self.writer(message, session_id=session_id)
blogger = AsyncBlogger(
'gpt-4o-2024-05-13',
writer_prompt="You are an writing assistant tasked to write engaging blogpost. You try to generate the best blogpost possible for the user's request. "
"If the user provides critique, then respond with a revised version of your previous attempts",
critic_prompt="Generate critique and recommendations on the writing. Provide detailed recommendations, including requests for length, depth, style, etc..",
critic_prefix='Reflect and provide critique on the following writing. \n\n',
)
user_prompt = (
"Write an engaging blogpost on the recent updates in {topic}. "
"The blogpost should be engaging and understandable for general audience. "
"Should have more than 3 paragraphes but no longer than 1000 words.")
bot_msgs = asyncio.get_event_loop().run_until_complete(
asyncio.gather(
*[
blogger(AgentMessage(sender='user', content=user_prompt.format(topic=topic)), session_id=i)
for i, topic in enumerate(['AI', 'Biotechnology', 'New Energy', 'Video Games', 'Pop Music'])
]
)
)
print(bot_msgs[0].content)
print('-' * 120)
for msg in blogger.state_dict(session_id=0)['writer.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')
print('-' * 120)
for msg in blogger.state_dict(session_id=0)['critic.memory']:
print('*' * 80)
print(f'{msg["sender"]}:\n\n{msg["content"]}')
一个执行信息检索、数据收集和图表绘制的多智能体工作流(原始 LangGraph 示例)
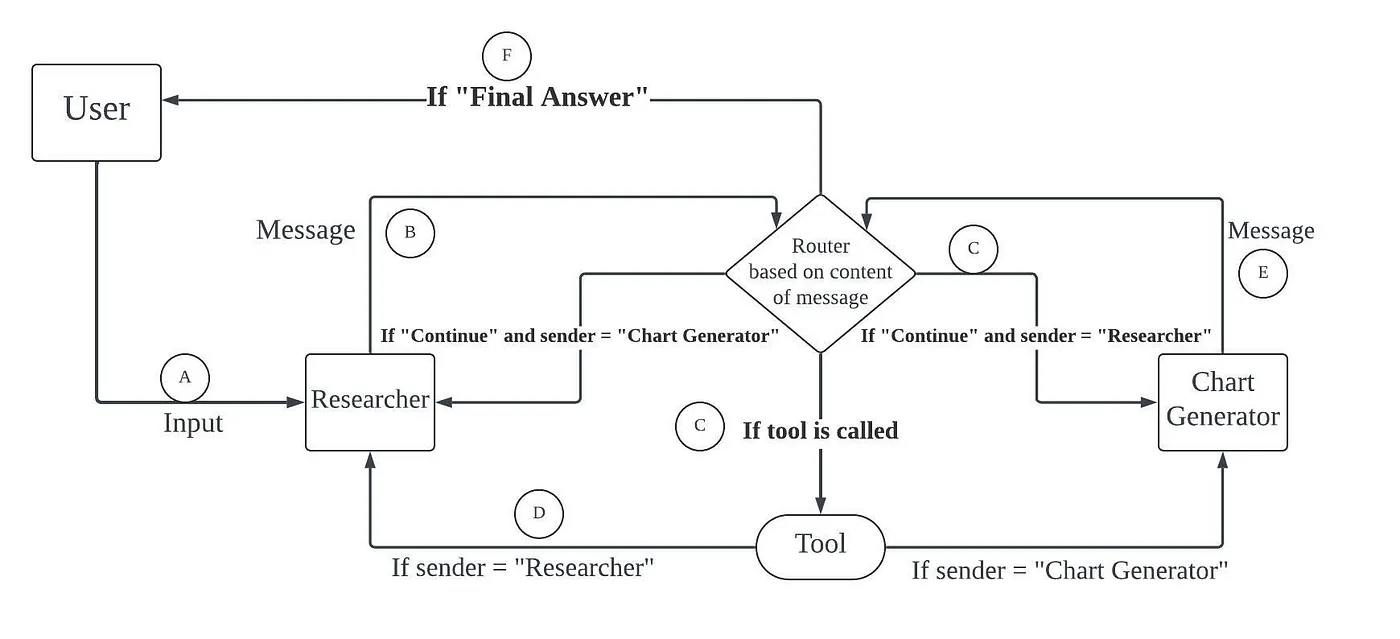
import json
from lagent.actions import IPythonInterpreter, WebBrowser, ActionExecutor
from lagent.agents.stream import get_plugin_prompt
from lagent.llms import GPTAPI
from lagent.hooks import InternLMActionProcessor
TOOL_TEMPLATE = (
"You are a helpful AI assistant, collaborating with other assistants. Use the provided tools to progress"
" towards answering the question. If you are unable to fully answer, that's OK, another assistant with"
" different tools will help where you left off. Execute what you can to make progress. If you or any of"
" the other assistants have the final answer or deliverable, prefix your response with {finish_pattern}"
" so the team knows to stop. You have access to the following tools:\n{tool_description}\nPlease provide"
" your thought process when you need to use a tool, followed by the call statement in this format:"
"\n{invocation_format}\\\\n**{system_prompt}**"
)
class 数据可视化器(代理):
def __init__(self, 模型路径, 研究提示, 图表提示, 结束模式="最终答案", 最大轮数=10):
super().__init__()
llm = GPTAPI(模型路径, 密钥='YOUR_OPENAI_API_KEY', 重试次数=5, 最大生成长度=1024, 停止词=["```\n"])
解释器, 浏览器 = IPython解释器(), Web浏览器("BingSearch", api_key="YOUR_BING_API_KEY")
self.研究员 = 代理(
llm,
TOOL_TEMPLATE.format(
结束模式=结束模式,
工具描述=get_plugin_prompt(浏览器),
调用格式='```json\n{"name": {{工具名称}}, "parameters": {{关键字参数}}}\n```\n',
系统提示=研究提示,
),
输出格式=ToolParser(
"browser",
开始="```json\n",
结束="\n```\n",
验证=lambda x: json.loads(x.rstrip('`')),
),
聚合器=InternLMToolAggregator(),
名称="researcher",
)
self.制图员 = 代理(
llm,
TOOL_TEMPLATE.format(
结束模式=结束模式,
工具描述=解释器.name,
调用格式='```python\n{{代码}}\n```\n',
系统提示=图表提示,
),
输出格式=ToolParser(
"interpreter",
开始="```python\n",
结束="\n```\n",
验证=lambda x: x.rstrip('`'),
),
聚合器=InternLMToolAggregator(),
名称="charter",
)
self.执行器 = 行动执行器([解释器, 浏览器], 钩子=[InternLMActionProcessor()])
self.结束模式 = 结束模式
self.最大轮数 = 最大轮数
def forward(self, 消息, 会话ID=0):
for _ in range(self.最大轮数):
消息 = 自己.研究员(消息, 会话ID=会话ID, 停止词=["```\n", "```python"]) # 覆盖llm的停止词
while 消息.格式化["工具类型"]:
消息 = 自己.执行器(消息, 会话ID=会话ID)
消息 = 自己.研究员(消息, 会话ID=会话ID, 停止词=["```\n", "```python"])
if 自己.结束模式 在 消息.内容 中:
return 消息
消息 = 自己.制图员(消息)
while 消息.格式化["工具类型"]:
消息 = 自己.执行器(消息, 会话ID=会话ID)
消息 = 自己.制图员(消息, 会话ID=会话ID)
if 自己.结束模式 在 消息.内容 中:
return 消息
return 消息
可视化器 = 数据可视化器(
"gpt-4o-2024-05-13",
研究提示="您应提供准确的数据供图表生成器使用。",
图表提示="您展示的任何图表都将对用户可见。",
)
用户消息 = 代理消息(
发送者='user',
内容="获取中国过去5年的GDP数据,然后绘制折线图。编码完成后请结束。"
)
机器人消息 = 可视化器(用户消息)
print(机器人消息.内容)
json.dump(可视化器.状态字典(), open('visualizer.json', 'w'), ensure_ascii=False, indent=4)
引用
如果您在研究中发现本项目有用,请考虑引用:
@misc{lagent2023,
title={{Lagent: InternLM} 是一个轻量级开源框架,允许用户高效构建基于大型语言模型(LLM)的智能体},
author={Lagent开发者团队},
howpublished = {\url{https://github.com/InternLM/lagent}},
year={2023}
}
许可证
本项目采用Apache 2.0许可证发布。
版本历史
v0.5.0rc32025/03/04v0.5.0rc22024/11/29v0.5.0rc12024/11/05v0.2.42024/10/21v0.2.32024/07/30v0.2.22024/02/26v0.2.12024/02/01v0.2.02024/01/31v0.1.32024/01/30v0.1.22023/10/24v0.1.12023/08/22常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备