InternLM-XComposer
InternLM-XComposer2.5-OmniLive 是一款强大的多模态交互系统,专为处理长时流式视频与音频互动而设计。它突破了传统模型仅能处理静态图像或短视频片段的局限,能够像人类一样“观看”并“聆听”持续不断的实时音视频流,理解其中的动态变化、上下文关联及复杂事件,从而实现流畅的自然语言交互。
对于需要构建智能监控分析、实时会议助手、直播内容理解或长视频对话机器人的开发者与研究人员而言,这一工具极具价值。它不仅支持超长上下文的输入与输出,还具备卓越的视听融合理解能力,能有效解决长时序数据中信息丢失和上下文断裂的难题。作为上海人工智能实验室 InternLM 系列的最新成果,其技术亮点在于将大语言模型的推理能力与高精度的视听感知深度结合,无需繁琐的分段处理即可直接应对复杂的实时场景。无论是希望探索前沿多模态技术的科研人员,还是致力于开发下一代实时交互应用的技术团队,都能利用 InternLM-XComposer2.5-OmniLive 轻松实现高质量的音视频智能理解与生成。
使用场景
某远程医疗团队需要实时分析患者上传的长时间康复训练视频,并同步听取患者的口头描述以评估恢复进度。
没有 InternLM-XComposer 时
- 长视频理解断裂:传统模型无法处理长达数分钟的连续视频流,只能截取片段分析,导致医生错过关键的动作连贯性细节。
- 音画信息割裂:系统无法将患者的语音自述(如“这里有点疼”)与视频中的特定动作帧精准对齐,需人工反复拖拽进度条核对。
- 响应延迟高:每次分析需先下载完整视频再离线处理,无法在直播或推流过程中提供即时反馈,延误干预时机。
- 上下文记忆丢失:模型难以记住视频早期的异常姿态,无法在视频结尾处结合全程表现给出综合评估报告。
使用 InternLM-XComposer 后
- 长程流式交互:InternLM-XComposer2.5-OmniLive 支持长时流式视频输入,能完整理解整个康复过程的动作演变,不遗漏任何细节。
- 音视频深度融合:工具实时同步解析音频指令与视频画面,自动标记出患者喊疼时的具体动作帧,生成带时间戳的多模态病历。
- 低延迟实时反馈:在视频推流过程中即可进行增量计算,几乎零延迟地提示患者当前动作是否标准,实现“边练边改”。
- 全周期记忆保持:凭借强大的长上下文能力,InternLM-XComposer 能关联视频开头与结尾的状态变化,自动生成包含趋势分析的深度评估报告。
InternLM-XComposer 通过突破长时流式音视频交互的瓶颈,将原本割裂、滞后的离线分析转变为实时、连贯的智能辅助诊疗体验。
运行环境要求
- 未说明
- 需要 NVIDIA GPU
- 根据新闻更新,部署演示版本至少需要两张 RTX 4090(共约 48GB 显存)以支持多卡推理
- 提供 4-bit 量化版本以降低显存需求
- 具体 CUDA 版本未说明
未说明

快速开始
InternLM-XComposer-2.5
感谢社区提供的 HuggingFace 演示 | OpenXLab 演示 的 InternLM-XComposer-2.5。

🔥🔥🔥 InternLM-XComposer2.5-Reward
我们发布了 InternLM-XComposer2.5-Reward 🤗(IXC-2.5-Reward,ACL 2025 Findings),这是一个简单而高效的多模态奖励模型,包含训练代码、评估脚本以及部分训练数据。详情请参阅 项目页面。
🔥🔥🔥 InternLM-XComposer2.5-OmniLive
我们发布了 InternLM-XComposer2.5-OmniLive,一个用于长期流式视频和音频交互的综合性多模态系统。详情请参阅 项目页面。
我们团队的多模态项目
InternLM-XComposer-2.5-Reward: 一个简单而高效的多模态奖励模型
InternLM-XComposer-2.5-OmniLive: 一个专门针对流式视频和音频交互的通用型多模态系统
InternLM-XComposer-2.5: 一款支持长上下文输入输出的多功能大型视觉语言模型
InternLM-XComposer2-
: 一款开创性的大型视觉语言模型,可处理从336像素到4K高清分辨率的图像
InternLM-XComposer2: 在视觉语言大型模型中掌握自由格式的文本-图像创作与理解
InternLM-XComposer: 一种用于高级文本-图像理解和创作的视觉语言大型模型
ShareGPT4Video: 通过更优质的字幕提升视频理解和生成能力
ShareGPT4V: 通过更优质的字幕改进大型多模态模型
MMDU: 一个用于LVLMs的多轮多图对话理解基准及指令微调数据集
DualFocus: 在多模态大型语言模型中融合宏观与微观视角
InternLM-XComposer-2.5 在各类文本-图像理解和创作应用中表现出色,仅凭借7B规模的语言模型后端便达到了GPT-4V级别的能力。IXC-2.5 使用2.4万条交错排列的图文上下文进行训练,可通过RoPE外推技术无缝扩展至9.6万条长上下文。这种长上下文能力使IXC-2.5 在需要大量输入和输出内容的任务中表现尤为突出。
超高分辨率理解:IXC-2.5 在IXC2-4KHD提出的动态分辨率方案基础上进行了优化,采用原生560×560的ViT视觉编码器,能够支持任意宽高比的高分辨率图像。
细粒度视频理解:IXC-2.5 将视频视为由数十至数百帧组成的超高分辨率复合图像,通过密集采样和更高的单帧分辨率来捕捉细微细节。
多轮多图对话:IXC-2.5 支持自由形式的多轮多图对话,使其能够在多轮交流中自然地与人类互动。
网页制作:IXC-2.5 可以根据文本-图像指令,轻松地组合源代码(HTML、CSS和JavaScript)来创建网页。
高质量文本-图像文章创作:IXC-2.5 利用专门设计的思维链(CoT)和直接偏好优化(DPO)技术,显著提升了其书面内容的质量。
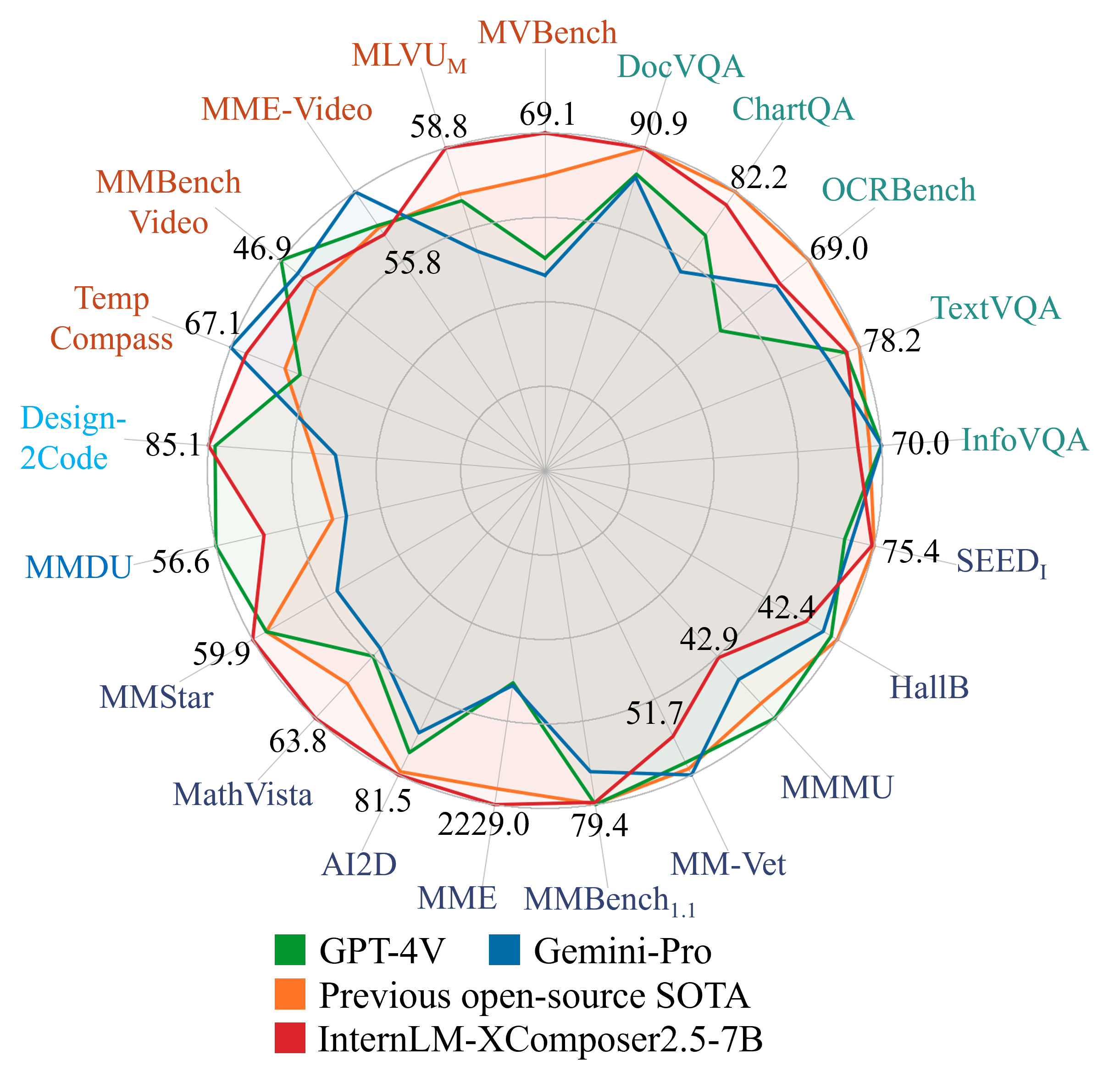
卓越性能:IXC-2.5 已在28项基准测试中接受评估,在16项基准测试中超越了现有的开源最先进模型;同时,在16项关键任务上也优于或与GPT-4V、Gemini Pro不相上下。
更多详情请参阅 技术报告。
演示视频
🔥 为获得最佳体验,请在观看视频时保持音频开启。
https://github.com/InternLM/InternLM-XComposer/assets/147793160/8206f07f-3166-461e-a631-9cbcdec6ae75
中文版演示请参阅 中文演示。
新闻与更新
2024.12.12🎉🎉🎉 InternLM-XComposer2.5-7B-Reward 已公开发布。2024.12.12🎉🎉🎉 InternLM-XComposer2.5-OmniLive-7B 已公开发布。2024.07.15🎉🎉🎉 ModelScope Swift 支持 InternLM-XComposer2.5-7B 的微调和推理。2024.07.15🎉🎉🎉 LMDeploy 支持 InternLM-XComposer2.5-7B 进行 4 位量化和推理。2024.07.15🎉🎉🎉 InternLM-XComposer2.5-7B-4bit 已公开发布。2024.07.03🎉🎉🎉 InternLM-XComposer2.5-7B 已公开发布。2024.07.01🎉🎉🎉 ShareGPT4V 被 ECCV2024 接收。2024.04.22🎉🎉🎉 InternLM-XComposer2-VL-7B-4KHD-7B 的微调代码已公开发布。2024.04.09🎉🎉🎉 InternLM-XComposer2-4KHD-7B 和评估代码已公开发布。2024.04.09🎉🎉🎉 InternLM-XComposer2-VL-1.8B 已公开发布。2024.02.22🎉🎉🎉 我们发布了DualFocus,这是一个用于在多模态大语言模型中整合宏观与微观视角的框架,以提升视觉-语言任务的表现。
2024.02.06🎉🎉🎉 InternLM-XComposer2-7B-4bit 和 InternLM-XComposer-VL2-7B-4bit 已在 Hugging Face 和 ModelScope 上公开发布。
2024.02.02🎉🎉🎉 InternLM-XComposer2-VL-7B 的微调代码已公开发布。2024.01.26🎉🎉🎉 InternLM-XComposer2-VL-7B 的评估代码已公开发布。2024.01.26🎉🎉🎉 InternLM-XComposer2-7B 和 InternLM-XComposer-VL2-7B 已在 Hugging Face 和 ModelScope 上公开发布。2024.01.26🎉🎉🎉 我们发布了一份技术报告,详细介绍了 InternLM-XComposer2 系列。2023.11.22🎉🎉🎉 我们发布了ShareGPT4V,这是一份由 GPT4-Vision 生成的大规模、高描述性的图文数据集,以及一款优秀的大型多模态模型 ShareGPT4V-7B。2023.10.30🎉🎉🎉 InternLM-XComposer-VL 在 Q-Bench 和 Tiny LVLM 中均获得第一名。2023.10.19🎉🎉🎉 支持多 GPU 推理。两块 4090 显卡足以部署我们的演示。2023.10.12🎉🎉🎉 支持 4 位演示,模型文件已在 Hugging Face 和 ModelScope 上提供。2023.10.8🎉🎉🎉 InternLM-XComposer-7B 和 InternLM-XComposer-VL-7B 已在 ModelScope 上公开发布。2023.9.27🎉🎉🎉 InternLM-XComposer-VL-7B 的评估代码已公开发布。2023.9.27🎉🎉🎉 InternLM-XComposer-7B 和 InternLM-XComposer-VL-7B 已在 Hugging Face 上公开发布。2023.9.27🎉🎉🎉 我们发布了一份技术报告,详细介绍了我们的模型系列。
模型动物园
| 模型 | 用途 | Transformers(HF) | ModelScope(HF) | 发布日期 |
|---|---|---|---|---|
| InternLM-XComposer-2.5 | 视频理解、多图像多轮对话、4K分辨率理解、网页制作、文章创作、基准测试 | 🤗internlm-xcomposer2.5 |  internlm-xcomposer2.5 internlm-xcomposer2.5 |
2024-07-03 |
| InternLM-XComposer2-4KHD | 4K分辨率理解、基准测试、VL-聊天 | 🤗internlm-xcomposer2-4khd-7b | internlm-xcomposer2-4khd-7b |
2024-04-09 |
| InternLM-XComposer2-VL-1.8B | 基准测试、VL-聊天 | 🤗internlm-xcomposer2-vl-1_8b | internlm-xcomposer2-vl-1_8b |
2024-04-09 |
| InternLM-XComposer2 | 文本-图像组合 | 🤗internlm-xcomposer2-7b | internlm-xcomposer2-7b |
2024-01-26 |
| InternLM-XComposer2-VL | 基准测试、VL-聊天 | 🤗internlm-xcomposer2-vl-7b | internlm-xcomposer2-vl-7b |
2024-01-26 |
| InternLM-XComposer2-4bit | 文本-图像组合 | 🤗internlm-xcomposer2-7b-4bit | internlm-xcomposer2-7b-4bit |
2024-02-06 |
| InternLM-XComposer2-VL-4bit | 基准测试、VL-聊天 | 🤗internlm-xcomposer2-vl-7b-4bit | internlm-xcomposer2-vl-7b-4bit |
2024-02-06 |
| InternLM-XComposer | 文本-图像组合、VL-聊天 | 🤗internlm-xcomposer-7b | internlm-xcomposer-7b |
2023-09-26 |
| InternLM-XComposer-4bit | 文本-图像组合、VL-聊天 | 🤗internlm-xcomposer-7b-4bit | internlm-xcomposer-7b-4bit |
2023-09-26 |
| InternLM-XComposer-VL | 基准测试 | 🤗internlm-xcomposer-vl-7b | internlm-xcomposer-vl-7b |
2023-09-26 |
评估
我们对InternLM-XComposer-2.5进行了28项多模态基准测试,包括图像基准测试MMDU、MMStar、RealWorldQA、Design2Code、DocVQA、Infographics VQA、TextVQA、ChartQA、OCRBench、DeepFrom、WTQ、VisualMRC、TabFact、MathVista、MMMU、AI2D、MME、MMBench、MMBench-CN、SEED-Bench、HallusionBench、MM-Vet,以及视频基准测试MVBench、MLVU、Video-MME、MMBench-Video、TempCompass。
详细评估内容请参阅此处的评估详情。
与闭源API及视频和结构化高分辨率图像领域的先前SOTA方法的对比。
| MVBench | MLVU | MME-Video | MMBench-Video | TempCompass | DocVQA | ChartVQA | InfoVQA | TextVQA | OCRBench | DeepForm | WTQ | VisualMRC | TabFact | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VideoChat2 | InternVL1.5 | LIVA | InternVL1.5 | Qwen-VL | InternVL1.5 | InternVL1.5 | InternVL1.5 | InternVL1.5 | GLM-4v | DocOwl 1.5 | DocOwl 1.5 | DocOwl 1.5 | DocOwl 1.5 | |
| 7B | 26B | 34B | 26B | 7B | 26B | 26B | 26B | 26B | 9B | 8B | 8B | 8B | 8B | |
| 60.4 | 50.4 | 59.0 | 42.0 | 52.9 | 90.9 | 83.8 | 72.5 | 80.6 | 77.6 | 68.8 | 40.6 | 246.4 | 80.2 | |
| GPT-4V | 43.5 | 49.2 | 59.9 | 56.0 | --- | 88.4 | 78.5 | 75.1 | 78.0 | 51.6 | --- | --- | --- | --- |
| Gemini-Pro | --- | --- | 75.0 | 49.3 | 67.1 | 88.1 | 74.1 | 75.2 | 74.6 | 68.0 | --- | --- | --- | --- |
| Ours | 69.1 | 58.8 | 55.8 | 46.9 | 90.9 | 82.2 | 69.9 | 78.2 | 69.0 | 71.2 | 53.6 | 307.5 | 85.2 |
与闭源API及多图像对话和通用视觉问答基准测试中的先前SOTA方法的对比。
| MVBench | MLVU | MME-Video | MMBench-Video | TempCompass | DocVQA | ChartVQA | InfoVQA | TextVQA | OCRBench | DeepForm | WTQ | VisualMRC | TabFact | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VideoChat2 | InternVL1.5 | LIVA | InternVL1.5 | Qwen-VL | InternVL1.5 | InternVL1.5 | InternVL1.5 | InternVL1.5 | GLM-4v | DocOwl 1.5 | DocOwl 1.5 | DocOwl 1.5 | DocOwl 1.5 | |
| 7B | 26B | 34B | 26B | 7B | 26B | 26B | 26B | 26B | 9B | 8B | 8B | 8B | 8B | |
| 60.4 | 50.4 | 59.0 | 42.0 | 58.4 | 90.9 | 83.8 | 72.5 | 80.6 | 77.6 | 68.8 | 40.6 | 246.4 | 80.2 | |
| GPT-4V | 43.5 | 49.2 | 59.9 | 56.0 | --- | 88.4 | 78.5 | 75.1 | 78.0 | 51.6 | --- | --- | --- | --- |
| Gemini-Pro | --- | --- | 75.0 | 49.3 | 70.6 | 88.1 | 74.1 | 75.2 | 74.6 | 68.0 | --- | --- | --- | --- |
| Ours | 69.1 | 58.8 | 55.8 | 46.9 | 67.1 | 90.9 | 82.2 | 69.9 | 78.2 | 69.0 | 71.2 | 53.6 | 307.5 | 85.2 |
需求
- Python 3.8及以上版本
- PyTorch 1.12及以上版本,推荐使用2.0及以上版本
- 推荐使用CUDA 11.4及以上版本(适用于GPU用户)
- 使用InternLM-XComposer2.5处理高分辨率图像时,需要安装flash-attention2。
安装
在运行代码之前,请确保已搭建好环境并安装了所需的软件包。请确认满足上述要求,然后安装依赖库。 请参阅安装说明
快速入门
我们提供了一个简单的示例,展示如何使用InternLM-XComposer-2.5结合🤗 Transformers。
视频理解
import torch
from transformers import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# 初始化模型和分词器
model = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-7b', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-7b', trust_remote_code=True)
model.tokenizer = tokenizer
query = '这里有一些视频的画面。请详细描述这段视频'
image = ['./examples/liuxiang.mp4',]
with torch.autocast(device_type='cuda', dtype=torch.float16):
response, his = model.chat(tokenizer, query, image, do_sample=False, num_beams=3, use_meta=True)
print(response)
#视频一开始出现一位身穿红黄相间、胸前印有“CHINA”字样的运动员,正在为比赛做准备。
#这位运动员就是刘翔,他蹲伏着,神情专注而蓄势待发,背景中可以看到奥林匹克五环标志,表明这是一场奥运会的赛事。随着比赛开始,运动员们飞奔向障碍栏,步伐矫健有力,展现出他们的决心。
#镜头捕捉到了比赛的激烈场面,屏幕上实时显示着每位运动员的号码和时间,让观众随时了解他们的表现。比赛进入高潮阶段,刘翔依然身着红黄色制服,最终冲过终点线,双臂高举庆祝胜利。
#看台上观众爆发出热烈的欢呼声,他们为刘翔的成功而激动不已。视频最后以刘翔的特写镜头结束,他仍沉浸在胜利的喜悦中,而奥林匹克五环则继续象征着这场赛事的重要意义。
query = '告诉我刘翔的运动员编号'
image = ['./examples/liuxiang.mp4',]
with torch.autocast(device_type='cuda', dtype=torch.float16):
response, _ = model.chat(tokenizer, query,image,历史=his,do_sample=False,num_beams=3,use_meta=True)
print(response)
#根据视频中刘翔制服上的标识,他的运动员编号是“1363”。
多图像多轮对话
import torch
from transformers import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# 初始化模型和分词器
model = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-7b', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-7b', trust_remote_code=True)
model.tokenizer = tokenizer
query = 'Image1 <ImageHere>; Image2 <ImageHere>; Image3 <ImageHere>; 我想从这三辆车中选购一辆,请逐一分析它们的优缺点'
image = ['./examples/cars1.jpg',
'./examples/cars2.jpg',
'./examples/cars3.jpg',]
with torch.autocast(device_type='cuda', dtype=torch.float16):
response, his = model.chat(tokenizer, query, image, do_sample=False, num_beams=3, use_meta=True)
print(response)
#要分析每辆车的优缺点,我们需要考虑品牌声誉、性能、设计、成本和维护等因素。
#1. 奔驰:-优点:奔驰以豪华和可靠性著称,提供高水平的舒适性、先进技术和卓越的工艺。图片中的车辆似乎是一辆SUV,既适合城市驾驶,也适合越野路况。-缺点:通常来说,奔驰车型相比其他品牌更为昂贵,并且由于其豪华定位,可能需要更频繁的维护。
#2. 布加迪:-优点:布加迪以生产世界上速度最快、动力最强的汽车而闻名。图片中的车辆是一辆跑车,很可能凭借其高性能发动机和先进的空气动力学,带来令人振奋的驾驶体验。-缺点:布加迪汽车价格极其高昂,普通消费者难以负担。此外,这类车辆需要专业的知识进行维护,而且由于其高性能特性,可能并不适合日常驾驶。
#3. 宝马:-优点:宝马是一家备受尊敬的制造商,以其创新的工程技术和设计而闻名。图片中的车辆似乎是一辆电动汽车(EV),具有低排放、低噪音污染以及潜在的较低运营成本等优势。-缺点:像图片中这样的电动汽车,其续航里程可能比传统燃油车短,限制了长途旅行的适用性。
#另外,购买电动汽车的初始成本也可能高于传统汽车。综上所述,每一辆车都有其独特的优缺点。奔驰提供豪华与多功能性,布加迪则以高性能和独特性见长,而宝马代表了电动车技术的创新。最终的选择取决于买家的优先级,比如舒适性、性能、环境影响以及预算。
query = 'Image4 <ImageHere>; 那么图4中的这辆车怎么样呢'
image.append('./examples/cars4.jpg')
with torch.autocast(device_type='cuda', dtype=torch.float16):
response, _ = model.chat(tokenizer, query, image, do_sample=False, num_beams=3, history= his, use_meta=True)
print(response)
#图4中的这辆车是一辆红色跑车,看起来像是法拉利。法拉利是著名的意大利制造商,以生产世界上最标志性和高性能的跑车而闻名。-优点:法拉利汽车象征着速度、豪华和卓越的工程技术。
#图片中的车辆很可能凭借其强大的引擎、先进的空气动力学和高品质的工艺,带来令人兴奋的驾驶体验。红色外观也为车辆增添了美感,在道路上格外引人注目。-缺点:法拉利汽车价格极其昂贵,普通消费者难以承受。
#此外,这类车辆需要专业的知识进行维护,而且由于其高性能特性,可能并不适合日常驾驶。总之,图4中的法拉利代表了汽车工程和设计的巅峰,提供了无与伦比的性能和豪华感。
#然而,其高昂的成本和特殊的维护要求使其在日常使用方面不如图片中的其他车辆实用。
高分辨率图像理解
import torch
from transformers import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# 初始化模型和分词器
model = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-7b', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-7b', trust_remote_code=True)
model.tokenizer = tokenizer
query = '请详细分析给定的图片'
image = ['./examples/dubai.png']
with torch.autocast(device_type='cuda', dtype=torch.float16):
response, _ = model.chat(tokenizer, query, image, do_sample=False, num_beams=3, use_meta=True)
print(response)
#这张信息图以视觉方式展示了关于迪拜的各种事实。它首先提到朱美拉棕榈岛,指出它是从太空可见的最大人工岛。随后介绍了历史背景,提到1968年时迪拜只有少数几辆汽车,而现在这一数字已超过150万辆。
#信息图还指出,迪拜拥有世界上最大的黄金链,全球十大最高酒店中有7家位于迪拜。此外,犯罪率接近于零,所得税率为零,全球20%的起重机都在迪拜运行。信息图还提到,迪拜人口中17%为阿联酋本地人,83%为移民。
#迪拜购物中心被强调为世界上最大的购物中心,拥有1200家商店。信息图还指出,迪拜没有标准的地址系统,没有邮政编码、区号或邮政服务。此外,它提到哈利法塔非常高,以至于顶层住户在斋月期间需要等待更长时间才能开斋。
#信息图还包括关于迪拜气候控制城市的介绍,其中阿拉伯塔酒店的皇家套房每晚收费24,000美元。最后,信息图提到,四位上榜亿万富翁的净资产大致等于洪都拉斯的GDP。
指令转网页
import torch
from transformers import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# 初始化模型和分词器
model = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-7b', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-7b', trust_remote_code=True)
model.tokenizer = tokenizer
query = '一个科研机构的网站。名称是上海人工智能实验室。顶部导航栏为蓝色。左下角有一张图片,显示实验室的标志。右侧下方有一段文字,描述了实验室的使命。还有几张图片展示了上海人工智能实验室的研究项目。'
with torch.autocast(device_type='cuda', dtype=torch.float16):
response = model.write_webpage(query, seed=202, task='指令感知型网页生成', repetition_penalty=3.0)
print(response)
# 查看 Instruction-aware Webpage Generation.html
请在此处查看 指令感知型网页生成 的结果。
简历转网页
import torch
from transformers import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# 初始化模型和分词器
model = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-7b', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-7b', trust_remote_code=True)
model.tokenizer = tokenizer
## 输入应为 Markdown 格式的简历
query = './examples/resume.md'
with torch.autocast(device_type='cuda', dtype=torch.float16):
response = model.resume_2_webpage(query, seed=202, repetition_penalty=3.0)
print(response)
请在此处查看 简历转网页 的结果。
截图转网页
import torch
from transformers import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# 初始化模型和分词器
model = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-7b', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-7b', trust_remote_code=True)
model.tokenizer = tokenizer
query = '使用 Tailwind CSS 生成这张网页图片的 HTML 代码。'
image = ['./examples/screenshot.jpg']
with torch.autocast(device_type='cuda', dtype=torch.float16):
response = model.screen_2_webpage(query, image, seed=202, repetition_penalty=3.0)
print(response)
请在此处查看 截图转网页 的结果。
撰写文章
import torch
from transformers import AutoModel, AutoTokenizer
torch.set_grad_enabled(False)
# 初始化模型和分词器
model = AutoModel.from_pretrained('internlm/internlm-xcomposer2d5-7b', torch_dtype=torch.bfloat16, trust_remote_code=True).cuda().eval().half()
tokenizer = AutoTokenizer.from_pretrained('internlm/internlm-xcomposer2d5-7b', trust_remote_code=True)
model.tokenizer = tokenizer
query = '阅读下面的材料,根据要求写作。 电影《长安三万里》的出现让人感慨,影片并未将重点全落在大唐风华上,也展现了恢弘气象的阴暗面,即旧门阀的资源垄断、朝政的日益衰败与青年才俊的壮志难酬。高适仕进无门,只能回乡>沉潜修行。李白虽得玉真公主举荐,擢入翰林,但他只是成为唐玄宗的御用文人,不能真正实现有益于朝政的志意。然而,片中高潮部分《将进酒》一节,人至中年、挂着肚腩的李白引众人乘仙鹤上天,一路从水面、瀑布飞升至银河进入仙>宫,李白狂奔着与仙人们碰杯,最后大家纵身飞向漩涡般的九重天。肉身的微贱、世路的“天生我材必有用,坎坷,拘不住精神的高蹈。“天生我材必有用,千金散尽还复来。” 古往今来,身处闲顿、遭受挫折、被病痛折磨,很多人都曾经历>了人生的“失意”,却反而成就了他们“诗意”的人生。对正在追求人生价值的当代青年来说,如何对待人生中的缺憾和困顿?诗意人生中又有怎样的自我坚守和自我认同?请结合“失意”与“诗意”这两个关键词写一篇文章。 要求:选准角度,确定>立意,明确文体,自拟标题;不要套作,不得抄袭;不得泄露个人信息;不少于 800 字。'
with torch.autocast(device_type='cuda', dtype=torch.float16):
response = model.write_artical(query, seed=8192)
print(response)
#诗意人生,贵在坚守
#《菜根谭》有云:“闲时要有吃紧的心思,忙里要留吃闲工夫.”人生在世,总有失意之时,当面对缺憾和困顿,诗意地生活着才能为人生增添一抹亮色.何谓诗意地生活? 所谓诗意地生活,便是在于坚守本心、直面遗憾、超越自我,在失意中寻找人生价值.
#诗意地生活,需坚守本心,淡然处之.
#陶渊明曾执意辞去彭泽县令,归隐田园,“采菊东篱下,悠然见南山”,在山水间寄情自娱;王维面对仕途失意,终日沉醉于诗酒之中,“兴来每独往,胜事空自知”,在诗酒中闲逸自如;李白仕途不顺,被赐金放还,但他依旧豪气干云,“天生我才必有用,千金散尽还复来”,在失意中坦然豁达.坚守本心,便能在遭遇失意之时守住自己的精神家园,让生活充满诗意.反之,若不能坚守本心,而只是一味迎合世俗以求得升迁,那纵使身居高位,亦会丧失生活的乐趣.
#诗意地生活,需直面遗憾,超越自我.
#“西塞山前白鹭飞,桃花流水鳜鱼肥.青箬笠,绿柳枝,半斤酒,一纶丝.五湖四海皆如此,何妨到此处归.”白居易的《渔歌子》写出了多少人的愿望:没有权势纷扰,没有贫困凄凉,只有青山绿水、白鹭鸥鸟作伴,如此自由自在的生活令人神往.然而,白居易却并没有因此真的归隐山林,而是直面人生,超越自我,写下了一首首诗意而富有现实关怀的作品.如果白居易只顾逃避人生,那又怎会拥有“大弦嘈嘈如急雨,小弦切切如私语”的绝美比喻呢?如果白居易只顾归隐山林,那又怎会写出“此曲只应天上有,人间哪得配白居易”这样的诗句呢?
#诗意地生活,需直面遗憾,坚守本心.
#李文波患有渐冻症,医生说他活不过五年,但他没有因此放弃对音乐的热爱,而是与病魔作斗争,演奏出美妙的乐曲;孙家林自幼患有脑瘫,但他不甘于命运的捉弄,终成全国最美教师;史铁生饱受疾病折磨,但他仍能发出“我常常在我的心头清点,我有什么?”的叩问,并由此走上文学道路,为后世留下丰厚的文化遗产.这些人没有逃避,而是选择直面人生的缺憾,在坚守本心的同时超越自我,最终实现了自己的价值.
#诗意地生活,是于失意中坚守本心,于缺憾中超越自我.当面对人生的缺憾与挫折,坚守本心、超越自我的同时,也必将书写属于自己的辉煌篇章.
#愿你我都能诗意地生活着!
query = '请根据标题撰写一篇博客:法式糕点:甜蜜的享受'
with torch.autocast(device_type='cuda', dtype=torch.float16):
response = model.write_artical(query, seed=8192)
print(response)
#法式糕点:甜蜜的享受
#法国人以其对糕点的热爱而闻名,这种热爱代代相传。当人们访问法国时,总能品尝到各种各样的烘焙食品,从精致的马卡龙到浓郁奢华的巧克力慕斯。尽管法国有许多美味的糕点,但有五种特别突出,堪称最具代表性的。每一种糕点都有其独特的风味和魅力。
#1. 牛角包
#法国最著名的糕点之一就是牛角包。它是一种黄油味十足、层次分明的酥皮点心,最好趁新鲜时享用。制作过程中,面团会反复折叠并涂抹黄油,从而形成标志性的层层酥皮。牛角包通常作为早餐或早午餐食用,搭配咖啡或热巧克力更是绝佳。
#2. 马卡龙
#马卡龙是一种小巧精致的法式甜点,由杏仁粉、糖粉和蛋白制成。两片马卡龙之间夹着甘纳许或果酱馅料。它们颜色缤纷、口味多样,无论是休闲零食还是高档甜点,都是不错的选择。
#3. 玛德琳蛋糕
#玛德琳蛋糕是一种小巧的贝壳形蛋糕,质地轻盈柔软,类似海绵蛋糕。它常带有柠檬或橙子的清香,有时还会蘸上巧克力。玛德琳蛋糕非常适合下午茶或咖啡时光享用。
#4. 法式闪电泡芙
#法式闪电泡芙是一种细长的奶油泡芙,外层淋上巧克力酱。它既甜美又满足,是法国的经典美食之一。无论在哪家面包店,你都能找到这种美味的点心,尤其适合搭配一杯热巧克力。
#5. 塔腾苹果派
#塔腾苹果派以其焦糖化的苹果和酥脆的派皮而闻名。这款甜点的名字来源于19世纪末发明它的塔腾姐妹。塔腾苹果派最适合温热时享用,搭配一勺香草冰淇淋更添风味。
#这些糕点只是法国众多美味佳肴中的一部分。无论你是经验丰富的旅行者还是初次到访的游客,品尝法式糕点都是一项不容错过的体验。所以,不妨犒劳一下自己吧——你值得拥有这份甜蜜的享受!
多GPU推理
如果你有多块GPU,但每块GPU的显存不足以容纳整个模型,可以将模型拆分到多块GPU上进行推理。首先,使用命令 pip install accelerate 安装 accelerate 库,然后执行以下脚本进行对话:
# 使用2块GPU进行对话
python example_code/example_chat.py --num_gpus 2
LMDeploy加速推理
如果需要优化 InternLM-XComposer2d5 模型的推理性能,推荐使用 LMDeploy。
在接下来的小节中,我们将以 internlm-xcomposer2d5-7b 模型为例,介绍 LMDeploy 的使用方法。
首先,请通过 pip install lmdeploy 安装 LMDeploy 的 PyPI 包。默认情况下,该库依赖于 CUDA 12.x。如果你使用的是 CUDA 11.x 环境,请参考 安装指南。
离线推理流程
from lmdeploy import pipeline
from lmdeploy.vl import load_image
pipe = pipeline('internlm/internlm-xcomposer2d5-7b')
image = load_image('examples/dubai.png')
response = pipe(('描述这张图片', image))
print(response.text)
关于 VLM 推理流程的更多内容,包括多图像推理和多轮对话等,请参阅 这篇文档。
4位量化模型
我们通过 LMDeploy 提供 4位量化模型,以降低显存占用。有关显存占用的对比信息,请参阅 这里。
from lmdeploy import TurbomindEngineConfig, pipeline
from lmdeploy.vl import load_image
engine_config = TurbomindEngineConfig(model_format='awq')
pipe = pipeline('internlm/internlm-xcomposer2d5-7b-4bit', backend_config=engine_config)
image = load_image('examples/dubai.png')
response = pipe(('描述这张图片', image))
print(response.text)
微调
- 请参考我们的 微调脚本。
- 推理和微调支持来自 ModelScope Swift。
Gradio 部署
我们提供了代码,供用户构建 Web UI 示例。请确保使用 gradio==4.13.0。
运行以下命令可启动聊天或创作功能:
# 多模态聊天
python gradio_demo/gradio_demo_chat.py
# 自由文本-图像创作
python gradio_demo/gradio_demo_composition.py
UI 示例的使用说明请参见 这里。如果你想更改模型的默认路径,可以使用 --code_path=new_folder 参数。
引用
如果您在研究中使用了我们的模型、代码或论文,请考虑给个 ⭐ 和引用 📝,谢谢 :)
@inproceedings{internlmxcomposer2_5_reward,
title={InternLM-XComposer2.5-Reward: 一个简单而高效的多模态奖励模型},
author={Zang Yuhang, Dong Xiaoyi, Zhang Pan, Cao Yuhang, Liu Ziyu, Ding Shengyuan, Wu Shenxi, Ma Yubo, Duan Haodong, Zhang Wenwei, Chen Kai, Lin Dahua, Wang Jiaqi},
booktitle={Findings of ACL},
year={2025}
}
@article{internlmxcomposer2_5_OL,
title={InternLM-XComposer2.5-OmniLive: 一个全面的多模态系统,用于长期流式视频和音频交互},
author={Zhang Pan, Dong Xiaoyi, Cao Yuhang, Zang Yuhang, Qian Rui, Wei Xilin, Chen Lin, Li Yifei, Niu Junbo, Ding Shuangrui, Guo Qipeng, Duan Haodong, Chen Xin, Lv Han, Nie Zheng, Zhang Min, Wang Bin, Zhang Wenwei, Zhang Xinyue, Ge Jiaye, Li Wei, Li Jingwen, Tu Zhongying, He Conghui, Zhang Xingcheng, Chen Kai, Qiao Yu, Lin Dahua, Wang Jiaqi},
journal={arXiv预印本 arXiv:2412.09596},
year={2024}
}
@article{internlmxcomposer2_5,
title={InternLM-XComposer-2.5: 一个多功能大型视觉语言模型,支持长上下文输入和输出},
author={Zhang Pan, Dong Xiaoyi, Zang Yuhang, Cao Yuhang, Qian Rui, Chen Lin, Guo Qipeng, Duan Haodong, Wang Bin, Ouyang Linke, Zhang Songyang, Zhang Wenwei, Li Yining, Gao Yang, Sun Peng, Zhang Xinyue, Li Wei, Li Jingwen, Wang Wenhai, Yan Hang, He Conghui, Zhang Xingcheng, Chen Kai, Dai Jifeng, Qiao Yu, Lin Dahua, Wang Jiaqi},
journal={arXiv预印本 arXiv:2407.03320},
year={2024}
}
@article{internlmxcomposer2_4khd,
title={InternLM-XComposer2-4KHD: 一个开创性的大型视觉语言模型,可处理从336像素到4K高清分辨率的图像},
author={Dong Xiaoyi, Zhang Pan, Zang Yuhang, Cao Yuhang, Wang Bin, Ouyang Linke, Zhang Songyang, Duan Haodong, Zhang Wenwei, Li Yining, Yan Hang, Gao Yang, Chen Zhe, Zhang Xinyue, Li Wei, Li Jingwen, Wang Wenhai, Chen Kai, He Conghui, Zhang Xingcheng, Dai Jifeng, Qiao Yu, Lin Dahua, Wang Jiaqi},
journal={arXiv预印本 arXiv:2404.06512},
year={2024}
}
@article{internlmxcomposer2,
title={InternLM-XComposer2: 在视觉语言大模型中掌握自由格式的文本-图像组合与理解},
author={Dong Xiaoyi, Zhang Pan, Zang Yuhang, Cao Yuhang, Wang Bin, Ouyang Linke, Wei Xilin, Zhang Songyang, Duan Haodong, Cao Maosong, Zhang Wenwei, Li Yining, Yan Hang, Gao Yang, Zhang Xinyue, Li Wei, Li Jingwen, Chen Kai, He Conghui, Zhang Xingcheng, Qiao Yu, Lin Dahua, Wang Jiaqi},
journal={arXiv预印本 arXiv:2401.16420},
year={2024}
}
@article{internlmxcomposer,
title={InternLM-XComposer: 一个用于高级文本-图像理解和组合的视觉语言大模型},
author={Zhang Pan, Dong Xiaoyi, Wang Bin, Cao Yuhang, Xu Chao, Ouyang Linke, Zhao Zhiyuan, Ding Shuangrui, Zhang Songyang, Duan Haodong, Zhang Wenwei, Yan Hang, Zhang Xinyue, Li Wei, Li Jingwen, Chen Kai, He Conghui, Zhang Xingcheng, Qiao Yu, Lin Dahua, Wang Jiaqi},
journal={arXiv预印本 arXiv:2309.15112},
year={2023}
}
许可与联系我们
代码采用 Apache-2.0 许可证,而模型权重对学术研究完全开放,并且也允许免费的商业用途。如需申请商业许可,请填写 申请表(英文)/申请表(中文)。如有其他问题或合作意向,请联系 internlm@pjlab.org.cn。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器