DEIMv2
DEIMv2 是一款将实时目标检测与强大视觉基础模型 DINOv3 相结合的前沿开源框架。它旨在解决传统实时检测算法在复杂场景下精度不足,而高精度模型又难以满足速度要求的痛点,成功实现了速度与准确性的双重突破。
该工具特别适合计算机视觉领域的研究人员、算法工程师以及需要在边缘设备部署高性能模型的开发者使用。无论是进行学术研究,还是开发自动驾驶、智能监控等实际应用,DEIMv2 都能提供强有力的支持。
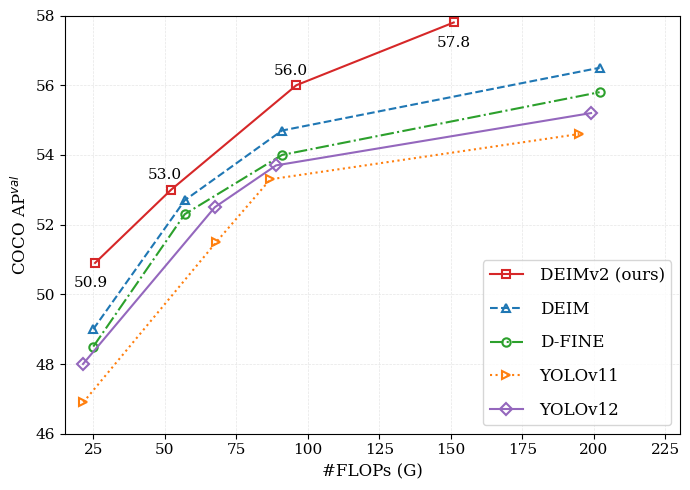
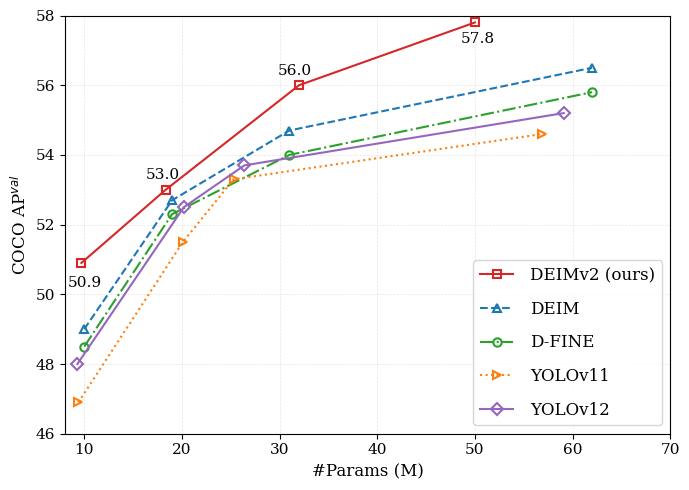
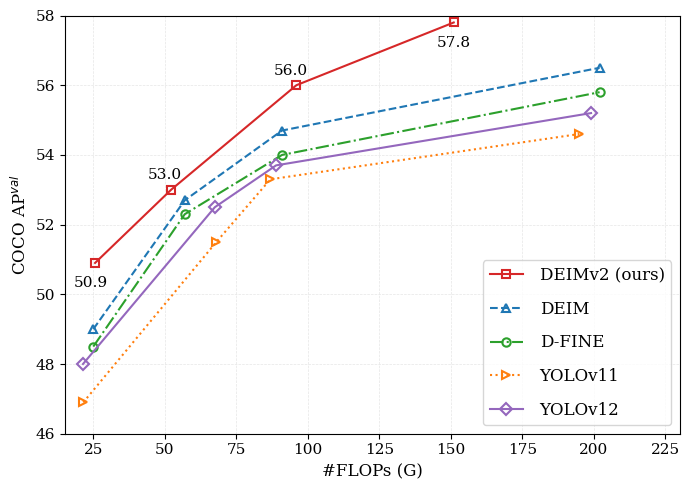
其核心技术亮点在于巧妙融合了 DINOv3 丰富的特征表达能力,并设计了从超轻量级到超大尺寸(Ultra-light 至 X)的多种模型规格,以灵活适应不同算力场景。值得一提的是,其中等规模(S 版)模型在极具挑战性的 COCO 基准测试中,平均精度(AP)已突破 50%,达到了业界领先水平。此外,DEIMv2 引入的 STA 机制已被集成到主流蒸馏库中,验证了其实用价值。项目同时提供了完善的 FP16 推理优化方案,支持通过 TensorRT 高效部署,确保在真实业务场景中既能跑得快,又能测得准。
使用场景
某智慧物流园区的技术团队正致力于升级其自动化分拣系统,需要在高速传送带上实时识别并定位各类形状不规则的包裹及潜在破损。
没有 DEIMv2 时
- 检测精度不足:传统轻量级模型在处理重叠包裹或模糊图像时漏检率高,导致分拣错误频发。
- 实时性瓶颈:为了满足高帧率需求被迫压缩模型,牺牲了特征提取能力,无法在边缘设备上兼顾速度与准确率。
- 多任务部署复杂:若需同时实现包裹检测与姿态估计(如机械臂抓取点),往往需要部署多个独立模型,占用大量显存与算力。
- 小目标识别困难:对于传送带远处的小型标签或异物,现有模型难以捕捉有效特征,AP 值长期停滞在较低水平。
使用 DEIMv2 后
- 精度显著跃升:借助 DINOv3 的强大特征表示,DEIMv2 的 S 尺寸模型在 COCO 基准上突破 50 AP,精准识别重叠与模糊包裹。
- 端侧实时运行:专为边缘场景设计的 ultra-light 至 X 多种尺寸,让高精度检测能在低算力设备上流畅运行,无需妥协帧率。
- 多任务一体化:单一模型即可同时完成物体检测、实例分割及人体/物体姿态估计,大幅简化了机械臂抓取系统的架构。
- 小目标无所遁形:增强的注意力机制显著提升了对细小标签和异物的感知能力,彻底解决了远距离小目标漏检难题。
DEIMv2 成功打破了实时性与高精度的对立,让边缘设备也能拥有媲美大型模型的视觉感知能力。
运行环境要求
- 未说明
需要 NVIDIA GPU (隐含,因提及 TensorRT),FP16 推理需 TensorRT ≥ 10.6
未说明
快速开始
实时目标检测与 DINOv3 的结合
🎉 我们很高兴地推出 EdgeCrafter,它在目标检测、姿态估计以及实例分割任务上均达到了 SOTA 水平。🎉



DEIMv2 是 DEIM 框架的演进版本,同时充分利用了 DINOv3 的丰富特征。我们的方法设计了多种模型规模,从超轻量级到 S、M、L 和 X 型号,以适应广泛的场景需求。在这些不同规模的模型中,DEIMv2 均取得了当前最先进的性能,其中 S 型号在极具挑战性的 COCO 数据集上显著超过了 50 AP。
1. Intellindust AI Lab 2. 厦门大学
* 共同第一作者 † 通讯作者
如果您喜欢我们的工作,请为我们点个 star 吧!
🚀 更新
- [2026.3.20] 🔥🔥🔥大家好!我们很高兴地推出 EdgeCrafter,这是我们最新的研究成果,实现了全新的最先进性能——比以往更快、更准确且更易于使用。 它还支持多项视觉任务,包括目标检测、实例分割和人体姿态估计!
- [2026.1.7] DEIMv2 中引入的 STA 已被集成到 SOTA 知识蒸馏库 LightlyTrain,这充分展示了其在实际训练流程中的实用价值和影响力。
- [2026.1.7] FP16 推理修复:请使用 TensorRT ≥ 10.6 以确保稳定运行并获得正确的检测结果。 有关详细的部署说明,请参阅 部署。
- [2025.11.3] 我们已将模型上传至 Hugging Face! 感谢 NielsRogge!
- [2025.10.28] 优化了 ViT-Tiny 中的注意力模块,使 S 和 M 型号的内存占用减少了一半。
- [2025.10.2] DEIMv2 已被集成到 X-AnyLabeling 中! 非常感谢 X-AnyLabeling 的维护者们促成此事。
- [2025.9.26] 发布 DEIMv2 系列。
🧭 目录
1. 模型 zoo
| 模型 | 数据集 | AP | 参数量 | GFLOPs | 延迟 (ms) | 配置文件 | Hugging Face | 检查点 | 日志 |
|---|---|---|---|---|---|---|---|---|---|
| Atto | COCO | 23.8 | 0.5M | 0.8 | 1.10 | yml | huggingface | Google / Quark | Google / Quark |
| Femto | COCO | 31.0 | 1.0M | 1.7 | 1.45 | yml | huggingface | Google / Quark | Google / Quark |
| Pico | COCO | 38.5 | 1.5M | 5.2 | 2.13 | yml | huggingface | Google / Quark | Google / Quark |
| N | COCO | 43.0 | 3.6M | 6.8 | 2.32 | yml | huggingface | Google / Quark | Google / Quark |
| S | COCO | 50.9 | 9.7M | 25.6 | 5.78 | yml | huggingface | Google / Quark | Google / Quark |
| M | COCO | 53.0 | 18.1M | 52.2 | 8.80 | yml | huggingface | Google / Quark | Google / Quark |
| L | COCO | 56.0 | 32.2M | 96.7 | 10.47 | yml | huggingface | Google / Quark | Google / Quark |
| X | COCO | 57.8 | 50.3M | 151.6 | 13.75 | yml | huggingface | Google / Quark | Google / Quark |
2. 快速入门
2.0 使用 Hugging Face 上的模型
我们目前在 Hugging Face 上发布了我们的模型!这里有一个简单的示例。你可以在 hf_models.ipynb 中查看详细的配置和更多示例。
简单示例
在 DEIMv2 的目录下创建一个 .py 文件,确保所有组件都成功加载。
import torch.nn as nn
from huggingface_hub import PyTorchModelHubMixin
from engine.backbone import HGNetv2, DINOv3STAs
from engine.deim import HybridEncoder, LiteEncoder
from engine.deim import DFINETransformer, DEIMTransformer
from engine.deim.postprocessor import PostProcessor
class DEIMv2(nn.Module, PyTorchModelHubMixin):
def __init__(self, config):
super().__init__()
self.backbone = DINOv3STAs(**config["DINOv3STAs"])
self.encoder = HybridEncoder(**config["HybridEncoder"])
self.decoder = DEIMTransformer(**config["DEIMTransformer"])
self.postprocessor = PostProcessor(**config["PostProcessor"])
def forward(self, x, orig_target_sizes):
x = self.backbone(x)
x = self.encoder(x)
x = self.decoder(x)
x = self.postprocessor(x, orig_target_sizes)
return x
deimv2_s_config = {
"DINOv3STAs": {
...
},
...
}
deimv2_s_hf = DEIMv2.from_pretrained("Intellindust/DEIMv2_DINOv3_S_COCO")
2.1 环境设置
# 你可以使用 PyTorch 2.5.1 或 2.4.1。我们尚未尝试其他版本,但建议 PyTorch 版本为 2.0 或更高。
conda create -n deimv2 python=3.11 -y
conda activate deimv2
pip install -r requirements.txt
2.2 数据准备
2.2.1 COCO2017 数据集
请按照以下步骤准备 COCO 数据集:
从 OpenDataLab 或 COCO 下载 COCO2017 数据集。
修改 coco_detection.yml 中的路径:
train_dataloader: img_folder: /data/COCO2017/train2017/ ann_file: /data/COCO2017/annotations/instances_train2017.json val_dataloader: img_folder: /data/COCO2017/val2017/ ann_file: /data/COCO2017/annotations/instances_val2017.json
2.2.2(可选)自定义数据集
若要使用自定义数据集进行训练,需将其整理为 COCO 格式。请按以下步骤准备您的数据集:
将
remap_mscoco_category设置为False:这将防止类别 ID 自动映射到 MSCOCO 类别。
remap_mscoco_category: False组织图像文件夹:
按照以下目录结构整理数据集:
dataset/ ├── images/ │ ├── train/ │ │ ├── image1.jpg │ │ ├── image2.jpg │ │ └── ... │ ├── val/ │ │ ├── image1.jpg │ │ ├── image2.jpg │ │ └── ... └── annotations/ ├── instances_train.json ├── instances_val.json └── ...images/train/:包含所有训练图像。images/val/:包含所有验证图像。annotations/:包含 COCO 格式的标注文件。
将标注转换为 COCO 格式:
如果您的标注尚未采用 COCO 格式,需要进行转换。您可以参考以下 Python 脚本或使用现有工具:
import json def convert_to_coco(input_annotations, output_annotations): # 在此处实现转换逻辑 pass if __name__ == "__main__": convert_to_coco('path/to/your_annotations.json', 'dataset/annotations/instances_train.json')更新配置文件:
修改您的 custom_detection.yml。
task: detection evaluator: type: CocoEvaluator iou_types: ['bbox', ] num_classes: 777 # 您的数据集类别数 remap_mscoco_category: False train_dataloader: type: DataLoader dataset: type: CocoDetection img_folder: /data/yourdataset/train ann_file: /data/yourdataset/train/train.json return_masks: False transforms: type: Compose ops: ~ shuffle: True num_workers: 4 drop_last: True collate_fn: type: BatchImageCollateFunction val_dataloader: type: DataLoader dataset: type: CocoDetection img_folder: /data/yourdataset/val ann_file: /data/yourdataset/val/ann.json return_masks: False transforms: type: Compose ops: ~ shuffle: False num_workers: 4 drop_last: False collate_fn: type: BatchImageCollateFunction
2.3 主干网络准备
基于 HGNetv2 的版本:主干网络将在训练过程中自动下载,您无需操心。
DEIMv2-L 和 X:我们使用 DINOv3-S 和 S+ 作为主干网络,您可以按照 DINOv3 中的指南进行下载。
DEIMv2-S 和 M:我们使用从 DINOv3-S 精馏得到的 ViT-Tiny 和 ViT-Tiny+,您可以从以下链接下载:
请将 DINOv3 和 ViT 模型放置在 ./ckpts 文件夹中,具体结构如下:
ckpts/
├── dinov3_vits16.pth
├── vitt_distill.pt
├── vittplus_distill.pt
└── ...
3. 使用方法
3.1 COCO2017
训练
# 对于基于ViT的变体 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml --use-amp --seed=0 # 对于基于HGNetv2的变体 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_hgnetv2_${model}_coco.yml --use-amp --seed=0测试
# 对于基于ViT的变体 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml --test-only -r model.pth # 对于基于HGNetv2的变体 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_hgnetv2_${model}_coco.yml --test-only -r model.pth微调
# 对于基于ViT的变体 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml --use-amp --seed=0 -t model.pth # 对于基于HGNetv2的变体 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --master_port=7777 --nproc_per_node=4 train.py -c configs/deimv2/deimv2_hgnetv2_${model}_coco.yml --use-amp --seed=0 -t model.pth
3.2 (可选) 自定义批量大小
例如,如果您想使用 DEIMv2-S,并在COCO2017上训练 DEIMv2 时将总批量大小增加一倍至64,可以按照以下步骤操作:
修改您的 deimv2_dinov3_s_coco.yml,以增加
total_batch_size:train_dataloader: total_batch_size: 64 dataset: transforms: ops: ... collate_fn: ...修改您的 deimv2_dinov3_s_coco.yml。以下是关键参数应如何调整:
optimizer: type: AdamW params: - # 除self.dinov3中的归一化、批归一化和偏置外的所有参数 params: '^(?=.*.dinov3)(?!.*(?:norm|bn|bias)).*$' lr: 0.00005 # 倍增,遵循线性缩放法则 - # 包括self.dinov3中所有归一化、批归一化和偏置 params: '^(?=.*.dinov3)(?=.*(?:norm|bn|bias)).*$' lr: 0.00005 # 倍增,遵循线性缩放法则 weight_decay: 0. - # 包括除self.dinov3之外的所有归一化、批归一化和偏置 params: '^(?=.*(?:sta|encoder|decoder))(?=.*(?:norm|bn|bias)).*$' weight_decay: 0. lr: 0.0005 # 如有必要,遵循线性缩放法则 betas: [0.9, 0.999] weight_decay: 0.0001 ema: # 添加EMA设置 decay: 0.9998 # 调整为1 - (1 - decay) * 2 warmups: 500 # 减半 lr_warmup_scheduler: warmup_duration: 250 # 减半
3.3 (可选) 自定义输入尺寸
如果您希望在COCO2017上以320x320的输入尺寸训练 DEIMv2-S,请按照以下步骤操作:
修改您的 deimv2_dinov3_s_coco.yml:
eval_spatial_size: [320, 320] train_dataloader: # 这里我们以64为例设置总批量大小。 total_batch_size: 64 dataset: transforms: ops: # 特别是对于马赛克增强,建议输出尺寸为输入尺寸的一半。 - {type: Mosaic, output_size: 160, rotation_range: 10, translation_range: [0.1, 0.1], scaling_range: [0.5, 1.5], probability: 1.0, fill_value: 0, use_cache: True, max_cached_images: 50, random_pop: True} ... - {type: Resize, size: [320, 320], } ... collate_fn: base_size: 320 ... val_dataloader: dataset: transforms: ops: - {type: Resize, size: [320, 320], } ...
3.4 (可选) 自定义训练轮数
如果您想对 DEIMv2-S 进行微调,训练 20 个轮次,请按照以下步骤操作(仅供参考;可根据实际需求进行调整):
epoches: 32 # 总轮次:20轮训练 + EMA用于4n = 12。n指匹配配置中的模型规模。
flat_epoch: 14 # 4 + 20 // 2
no_aug_epoch: 12 # 4n
train_dataloader:
dataset:
transforms:
ops:
...
policy:
epoch: [4, 14, 20] # [起始轮次、平稳轮次、总轮次 - 无增强轮次]
collate_fn:
...
mixup_epochs: [4, 14] # [起始轮次、平稳轮次]
stop_epoch: 20 # 总轮次 - 无增强轮次
copyblend_epochs: [4, 20] # [起始轮次、总轮次 - 无增强轮次]
DEIMCriterion:
matcher:
...
matcher_change_epoch: 18 # 约为(总轮次 - 无增强轮次)的90%
4. 工具
4.1 部署
环境准备
pip install onnx onnxsim导出 ONNX 模型
python tools/deployment/export_onnx.py --check -c configs/deimv2/deimv2_dinov3_${model}_coco.yml -r model.pth导出 TensorRT 引擎
trtexec --onnx="model.onnx" --saveEngine="model.engine" --fp16
⚠️ TensorRT 版本说明
✅ 推荐:使用 TensorRT ≥ 10.6 进行 FP16 推理,以确保运行稳定并获得正确的检测结果。
❗ 已知问题:在 TensorRT 10.4 中,FP16 推理可能会产生错误的输出。
🔧 旧版本(如 10.4)的解决方法:
以 FP32 模式运行推理,或
仔细验证导出的引擎及端到端流程,以确认数值正确性和检测性能。
4.2 推理(可视化)
环境准备
pip install -r tools/inference/requirements.txt推理(onnxruntime / tensorrt / torch)
现已支持对图像和视频进行推理。
python tools/inference/onnx_inf.py --onnx model.onnx --input image.jpg # video.mp4 python tools/inference/trt_inf.py --trt model.engine --input image.jpg python tools/inference/torch_inf.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml -r model.pth --input image.jpg --device cuda:0
4.3 基准测试
环境准备
pip install -r tools/benchmark/requirements.txt模型 FLOPs、MACs 和参数量
python tools/benchmark/get_info.py -c configs/deimv2/deimv2_dinov3_${model}_coco.ymlTensorRT 延迟
python tools/benchmark/trt_benchmark.py --COCO_dir path/to/COCO2017 --engine_dir model.engine
4.4 Fiftyone 可视化
- 环境准备
pip install fiftyone - Voxel51 Fiftyone 可视化(fiftyone)
python tools/visualization/fiftyone_vis.py -c configs/deimv2/deimv2_dinov3_${model}_coco.yml -r model.pth
4.5 其他
自动恢复训练
bash reference/safe_training.sh转换模型权重
python reference/convert_weight.py model.pth
5. 引用
如果您在工作中使用了 DEIMv2 或其相关方法,请引用以下 BibTeX 条目:
@article{huang2025deimv2,
title={实时目标检测与 DINOv3 的结合},
author={Huang, Shihua and Hou, Yongjie and Liu, Longfei and Yu, Xuanlong and Shen, Xi},
journal={arXiv},
year={2025}
}
6. 致谢
我们的工作基于 LightlyTrain、D-FINE、RT-DETR、DEIM 和 DINOv3。感谢他们的杰出贡献!
✨ 欢迎大家参与贡献,如有任何问题,欢迎随时联系我们! ✨
7. 星标历史

常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备