MedSegDiff
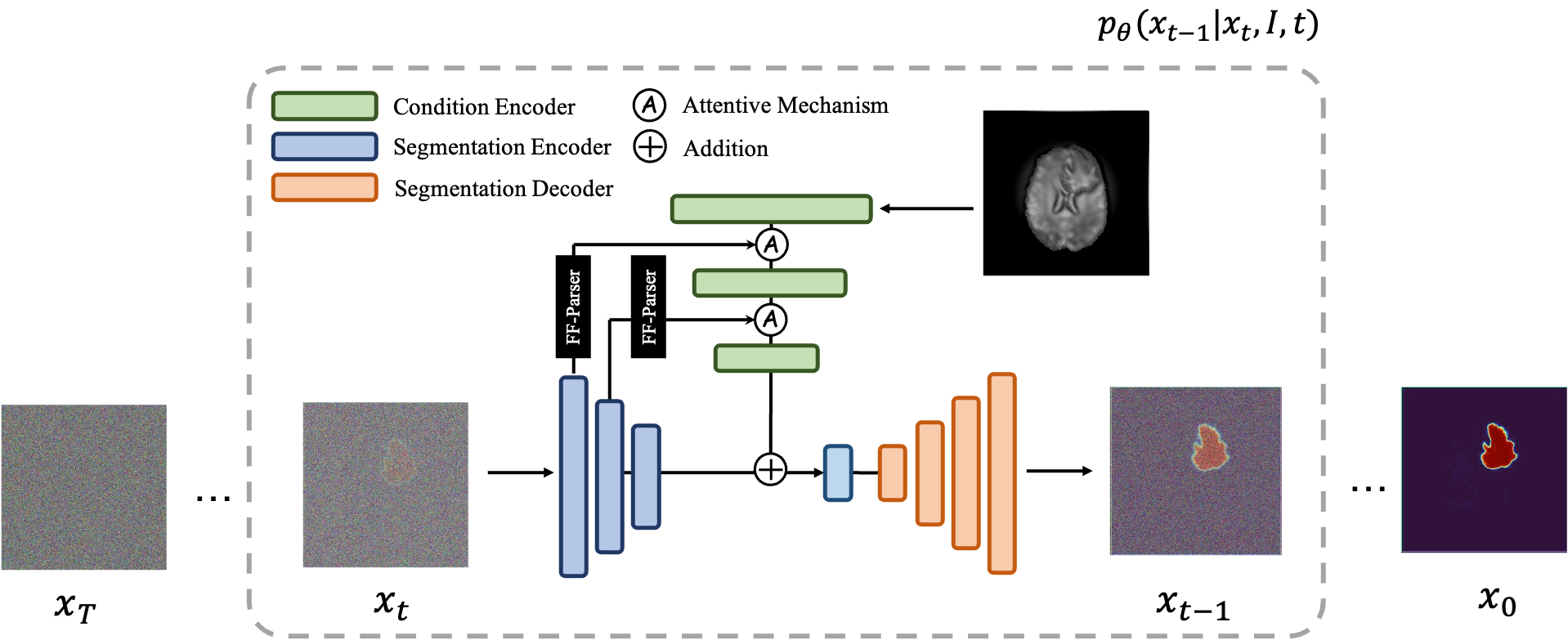
MedSegDiff 是一款基于扩散概率模型(DPM)的开源框架,专为医学图像中器官与组织的分割及重建任务而设计。在传统医学影像分析中,精准勾勒病灶或器官边界往往面临噪声干扰大、形态复杂等挑战,而 MedSegDiff 创新性地引入扩散模型技术,通过模拟去噪过程逐步生成高精度的分割掩码,有效提升了复杂场景下的识别准确率与鲁棒性。
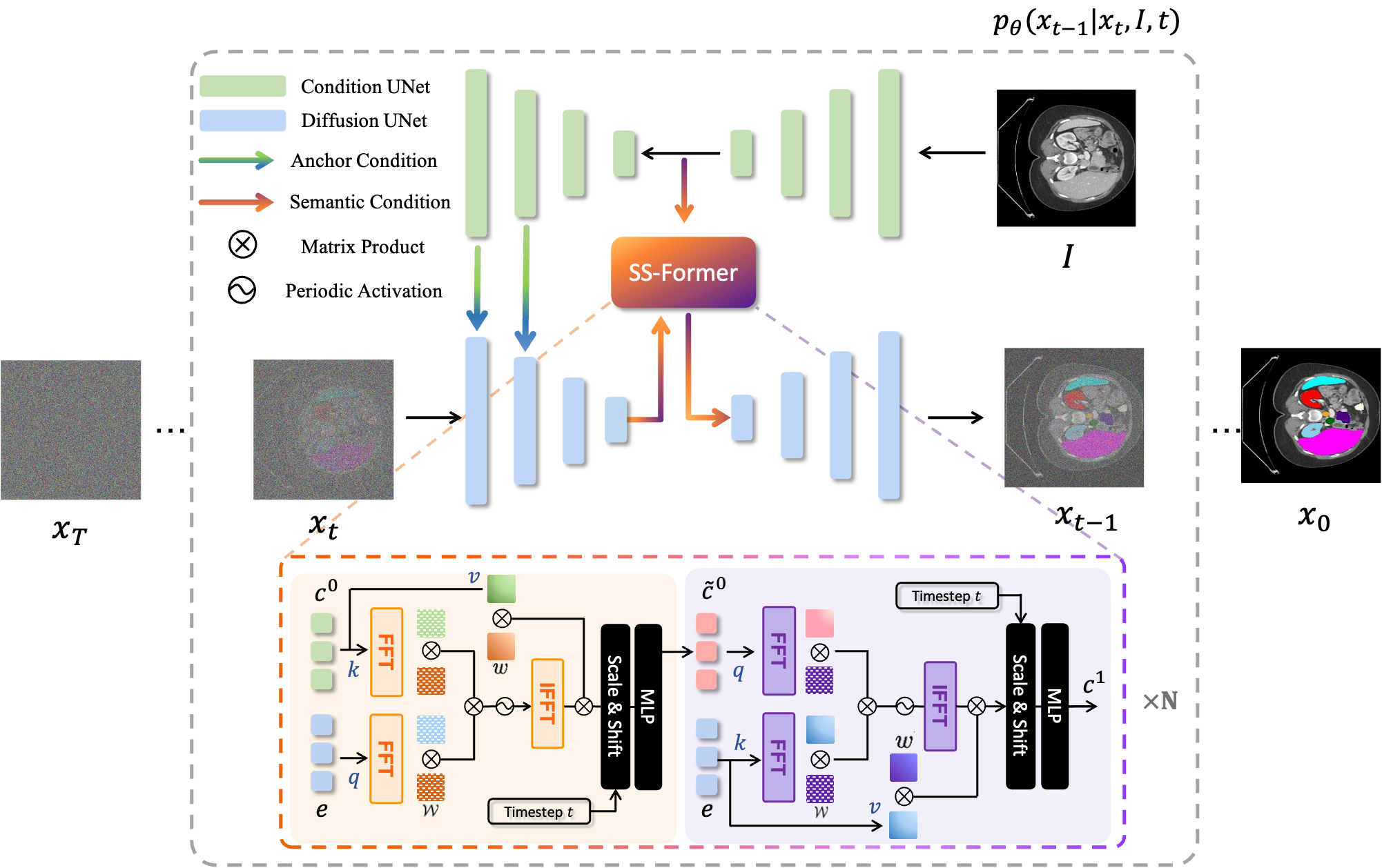
该项目包含两个核心版本:初代版本奠定了扩散模型在医学分割中的应用基础,而荣获 AAAI 2024“最具影响力论文”殊荣的 MedSegDiff-V2 则进一步融合 Transformer 架构,在保持计算资源友好的同时,显著增强了模型的稳定性与跨域适应能力。此外,工具还集成了 DPM-Solver 加速算法,将采样步骤从千级大幅压缩至二十步左右,极大缩短了推理时间。
MedSegDiff 非常适合医学 AI 领域的研究人员、算法开发者以及生物医学工程师使用。无论是需要复现前沿学术成果、构建辅助诊断系统,还是处理如皮肤黑色素瘤(ISIC 数据集)或脑部肿瘤(BraTS 数据集)等具体临床数据,它都提供了成熟的代码实现与数据处理流程。对于希望探索生成式 AI 在医疗影像落地应用的团队而言,这是一个兼具理论深度与工程实用价值的优秀起点。
使用场景
某三甲医院皮肤科科研团队正利用 ISIC 公开数据集训练黑色素瘤辅助诊断模型,旨在从复杂的皮肤镜图像中精准提取病灶区域以量化肿瘤负荷。
没有 MedSegDiff 时
- 边界模糊导致误判:面对病灶与正常皮肤过渡柔和、边缘不清的图像,传统 CNN 模型常出现分割断裂或过度侵蚀,难以捕捉细微的浸润特征。
- 小样本泛化能力弱:在罕见亚型或标注数据稀缺的场景下,模型极易过拟合,导致在不同设备采集的图像上表现大幅波动,鲁棒性差。
- 推理速度与精度难兼得:为了提升对复杂纹理的识别率,往往需要堆叠更深的网络结构,导致显存占用高且推理延迟大,无法满足临床实时筛查需求。
使用 MedSegDiff 后
- 概率生成重塑精准边界:借助扩散概率模型(DPM)的去噪特性,MedSegDiff 能逐步“还原”出连贯且解剖结构合理的病灶轮廓,显著提升了模糊边界的分割完整性。
- 强泛化适应多域数据:基于扩散过程的生成式学习机制,使其在少量标注样本下仍能学习到器官/组织的本质分布,有效克服了跨中心、跨设备的数据域偏移问题。
- 加速采样实现高效部署:集成 DPM-Solver 技术后,将采样步数从 1000 步骤减至 20 步,在保持 SOTA 精度的同时实现了闪电般的推理速度,大幅降低了算力门槛。
MedSegDiff 通过引入扩散模型范式,成功解决了医学图像中边界不确定与小样本学习的核心难题,为高精度、低资源的智能诊疗提供了可靠方案。
运行环境要求
- 未说明
需要 NVIDIA GPU(支持多卡分布式训练),显存需求视配置而定:默认配置建议 8GB+,高性能配置 (MedSegDiff++) 需 24GB+
未说明
快速开始
MedSegDiff:基于扩散模型的医学图像分割
 MedSegDiff 是一个基于扩散概率模型(DPM)的框架,用于从医学图像中对器官/组织进行分割和重建。
MedSegDiff 是一个基于扩散概率模型(DPM)的框架,用于从医学图像中对器官/组织进行分割和重建。
该算法在我们的论文中有详细阐述:
MedSegDiff-V2:基于Transformer的扩散式医学图像分割.
快速概览
 |
 |
|---|---|
| MedSegDiff-V1 | MedSegDiff-V2 |
最新消息
- [置顶] 加入我们的 Discord,提问并与大家交流。
- 22-11-30。本项目仍在快速更新中。请查看 TODO 列表,了解接下来将发布的内容。
- 22-12-03。修复了 BraTs2020 的一些错误,并添加了示例案例。
- 22-12-15。修复了多 GPU 分布式训练的问题。
- 22-12-16。DPM-Solver ✖️ MedSegDiff 完成 🥳 现在 DPM-Solver 已集成到 MedsegDiff 中。通过设置
--dpm_solver True,即可享受其闪电般的采样速度(1000 步 ❌ 20 步 ⭕️)。 - 22-12-23。修复了 DPM-Solver 中的一些 bug。
- 23-01-31。MedSegDiff-V2 即将发布 🥳 。请先阅读我们的论文 MedSegDiff-V2:基于Transformer的扩散式医学图像分割。
- 23-02-07。优化了 BRATS 数据采样的工作流程,并新增了用于处理原始 3D BRATS 数据的数据加载器。
- 23-02-11。修复了 3D BRATS 数据训练中的 bug,参见 issue 31。
- 23-03-04。论文 MedSegDiff:基于扩散概率模型的医学图像分割 已被 MIDL 2023 正式接受 🥳
- 23-04-11。基于 V2 框架的新版本已发布 🥳。相比之前版本,它更加准确、稳定且具有更好的领域适应性,同时不会占用过多资源。我们还修复了一些小问题,比如 requirement.txt 和 isic csv 文件。非常感谢所有报告问题的用户,你们的帮助对我们至关重要 🤗。顺便说一下,现在默认运行的是新版本。如果想使用旧版本,请添加
--version 1。 - 23-04-12。为 isic 数据集添加了一个简单的评估文件(script/segmentation_env)。使用方法:
python scripts/segmentation_env.py --inp_pth *保存预测图像的文件夹* --out_pth *保存真实标签图像的文件夹* - 23-12-05。论文 MedSegDiff-V2:基于Transformer的扩散式医学图像分割 已被 AAAI 2024 正式接受 🥳
- 24-10-29。MedSegDiff-V2 被评选为 AAAI-24 最具影响力论文 🥳
系统要求
pip install -r requirement.txt
示例案例
皮肤图像中的黑色素瘤分割
- 从 https://challenge.isic-archive.com/data/ 下载 ISIC 数据集。您的数据集文件夹应位于 "data" 目录下,结构如下:
data
| ----ISIC
| ----Test
| | | ISBI2016_ISIC_Part1_Test_GroundTruth.csv
| | |
| | ----ISBI2016_ISIC_Part1_Test_Data
| | | ISIC_0000003.jpg
| | | .....
| | |
| | ----ISBI2016_ISIC_Part1_Test_GroundTruth
| | ISIC_0000003_Segmentation.png
| | | .....
| |
| ----Train
| | ISBI2016_ISIC_Part1_Training_GroundTruth.csv
| |
| ----ISBI2016_ISIC_Part1_Training_Data
| | ISIC_0000000.jpg
| | .....
| |
| ----ISBI2016_ISIC_Part1_Training_GroundTruth
| | ISIC_0000000_Segmentation.png
| | .....
训练时,运行:
python scripts/segmentation_train.py --data_name ISIC --data_dir *输入数据路径* --out_dir *输出数据路径* --image_size 256 --num_channels 128 --class_cond False --num_res_blocks 2 --num_heads 1 --learn_sigma True --use_scale_shift_norm False --attention_resolutions 16 --diffusion_steps 1000 --noise_schedule linear --rescale_learned_sigmas False --rescale_timesteps False --lr 1e-4 --batch_size 8采样时,运行:
python scripts/segmentation_sample.py --data_name ISIC --data_dir *输入数据路径* --out_dir *输出数据路径* --model_path *保存的模型* --image_size 256 --num_channels 128 --class_cond False --num_res_blocks 2 --num_heads 1 --learn_sigma True --use_scale_shift_norm False --attention_resolutions 16 --diffusion_steps 1000 --noise_schedule linear --rescale_learned_sigmas False --rescale_timesteps False --num_ensemble 5评估时,运行:
python scripts/segmentation_env.py --inp_pth *保存预测图像的文件夹* --out_pth *保存真实标签图像的文件夹*
默认情况下,样本将保存在 ./results/
MRI 图像中的脑肿瘤分割
- 从 https://www.med.upenn.edu/cbica/brats2020/data.html 下载 BRATS2020 数据集。您的数据集文件夹应如下所示:
data
└───training
│ └───slice0001
│ │ brats_train_001_t1_123_w.nii.gz
│ │ brats_train_001_t2_123_w.nii.gz
│ │ brats_train_001_flair_123_w.nii.gz
│ │ brats_train_001_t1ce_123_w.nii.gz
│ │ brats_train_001_seg_123_w.nii.gz
│ └───slice0002
│ │ ...
└───testing
│ └───slice1000
│ │ ...
│ └───slice1001
│ │ ...
训练时,运行:
python scripts/segmentation_train.py --data_dir (您放置数据文件夹的位置)/data/training --out_dir 输出数据路径 --image_size 256 --num_channels 128 --class_cond False --num_res_blocks 2 --num_heads 1 --learn_sigma True --use_scale_shift_norm False --attention_resolutions 16 --diffusion_steps 1000 --noise_schedule linear --rescale_learned_sigmas False --rescale_timesteps False --lr 1e-4 --batch_size 8采样时,运行:
python scripts/segmentation_sample.py --data_dir (您放置数据文件夹的位置)/data/testing --out_dir 输出数据路径 --model_path 保存的模型 --image_size 256 --num_channels 128 --class_cond False --num_res_blocks 2 --num_heads 1 --learn_sigma True --use_scale_shift_norm False --attention_resolutions 16 --diffusion_steps 1000 --noise_schedule linear --rescale_learned_sigmas False --rescale_timesteps False --num_ensemble 5
其他示例
...
在您自己的数据集上运行
在其他数据集上运行 MedSegDiff 非常简单。只需按照 ./guided_diffusion/isicloader.py 或 ./guided_diffusion/bratsloader.py 的格式编写另一个数据加载器文件即可。如果您遇到任何问题,欢迎提交 Issue。如果您能贡献自己的数据集扩展,我们将不胜感激。与自然图像不同,医学图像因任务不同而差异很大。要扩大方法的泛化能力,需要大家共同努力。
超参数与训练建议
要训练出一个优秀的模型,即论文中的 MedSegDiff-B,可将模型超参数设置为:
--image_size 256 --num_channels 128 --class_cond False --num_res_blocks 2 --num_heads 1 --learn_sigma True --use_scale_shift_norm False --attention_resolutions 16
扩散超参数设置为:
--diffusion_steps 1000 --noise_schedule linear --rescale_learned_sigmas False --rescale_timesteps False
为了加快采样速度:
--diffusion_steps 50 --dpm_solver True
多 GPU 运行时:
--multi-gpu 0,1,2(例如)
训练超参数设置为:
--lr 5e-5 --batch_size 8
并在采样时设置 --num_ensemble 5。
在大多数数据集上,训练约 10 万步即可收敛。需要注意的是,尽管在后期的许多步骤中损失不再下降,但结果的质量仍在不断提升。这种现象在其他 DPM 应用中也有观察到,比如图像生成。希望有聪明人能告诉我这是为什么🥲。
我很快会发布其在较小批量下的性能表现(适合在 24GB 显存的 GPU 上运行),以便进行对比🤗。
要充分发挥其潜力的配置(MedSegDiff++)是:
--image_size 256 --num_channels 512 --class_cond False --num_res_blocks 12 --num_heads 8 --learn_sigma True --use_scale_shift_norm True --attention_resolutions 24
然后使用批量 --batch_size 64 训练,并以集合数 --num_ensemble 25 进行采样。
待办事项列表
- 修复 BRATS 中的 bug。添加 BRATS 示例。
- 发布 REFUGE 和 DDIT 数据加载器及示例。
- 使用 DPM 求解器加速采样。
- 深度推理。
- 修复多 GPU 并行中的 bug。
- 在训练过程中进行采样并可视化。
- 发布预处理和后处理流程。
- 发布评估代码。
- 部署至 HuggingFace。
- 完成配置。
感谢
本代码大量借鉴了以下项目:openai/improved-diffusion、WuJunde/MrPrism、WuJunde/DiagnosisFirst、LuChengTHU/dpm-solver、JuliaWolleb/Diffusion-based-Segmentation、hojonathanho/diffusion、guided-diffusion、bigmb/Unet-Segmentation-Pytorch-Nest-of-Unets、nnUnet、lucidrains/vit-pytorch。
引用
请引用以下文献:
@inproceedings{wu2023medsegdiff,
title={MedSegDiff: 医学图像分割的扩散概率模型},
author={吴俊德、RAO、方慧慧、张宇、杨叶辉、熊浩义、刘慧英、徐延武},
booktitle={深度学习在医学影像中的应用},
year={2023}
}
@article{wu2023medsegdiff,
title={MedSegDiff-V2:基于 Transformer 的扩散式医学图像分割},
author={吴俊德、季伟、傅华珠、许敏、金月明、徐延武},
journal={arXiv 预印本 arXiv:2301.11798},
year={2023}
}
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
Deep-Live-Cam
Deep-Live-Cam 是一款专注于实时换脸与视频生成的开源工具,用户仅需一张静态照片,即可通过“一键操作”实现摄像头画面的即时变脸或制作深度伪造视频。它有效解决了传统换脸技术流程繁琐、对硬件配置要求极高以及难以实时预览的痛点,让高质量的数字内容创作变得触手可及。 这款工具不仅适合开发者和技术研究人员探索算法边界,更因其极简的操作逻辑(仅需三步:选脸、选摄像头、启动),广泛适用于普通用户、内容创作者、设计师及直播主播。无论是为了动画角色定制、服装展示模特替换,还是制作趣味短视频和直播互动,Deep-Live-Cam 都能提供流畅的支持。 其核心技术亮点在于强大的实时处理能力,支持口型遮罩(Mouth Mask)以保留使用者原始的嘴部动作,确保表情自然精准;同时具备“人脸映射”功能,可同时对画面中的多个主体应用不同面孔。此外,项目内置了严格的内容安全过滤机制,自动拦截涉及裸露、暴力等不当素材,并倡导用户在获得授权及明确标注的前提下合规使用,体现了技术发展与伦理责任的平衡。
NextChat
NextChat 是一款轻量且极速的 AI 助手,旨在为用户提供流畅、跨平台的大模型交互体验。它完美解决了用户在多设备间切换时难以保持对话连续性,以及面对众多 AI 模型不知如何统一管理的痛点。无论是日常办公、学习辅助还是创意激发,NextChat 都能让用户随时随地通过网页、iOS、Android、Windows、MacOS 或 Linux 端无缝接入智能服务。 这款工具非常适合普通用户、学生、职场人士以及需要私有化部署的企业团队使用。对于开发者而言,它也提供了便捷的自托管方案,支持一键部署到 Vercel 或 Zeabur 等平台。 NextChat 的核心亮点在于其广泛的模型兼容性,原生支持 Claude、DeepSeek、GPT-4 及 Gemini Pro 等主流大模型,让用户在一个界面即可自由切换不同 AI 能力。此外,它还率先支持 MCP(Model Context Protocol)协议,增强了上下文处理能力。针对企业用户,NextChat 提供专业版解决方案,具备品牌定制、细粒度权限控制、内部知识库整合及安全审计等功能,满足公司对数据隐私和个性化管理的高标准要求。