AI-Guide-and-Demos-zh_CN
AI-Guide-and-Demos-zh_CN 是一份专为中文用户打造的 AI 与大语言模型(LLM)入门实战指南。它旨在解决初学者在面对国外大模型 API 获取困难、本地环境配置复杂以及缺乏显卡资源时的畏难情绪,帮助用户平滑地从理论认知过渡到动手实践。
该项目非常适合希望系统学习 AI 技术的开发者、学生及研究人员,尤其是那些受限于硬件条件或网络环境的入门者。内容涵盖从基础的 API 调用、AI 视频摘要、图像生成,到进阶的本地大模型部署与微调全流程。其独特亮点在于提供了丰富的 Kaggle 和 Colab 在线代码版本,确保用户即使没有本地 GPU 也能随时运行实验;同时集成了李宏毅教授 2024 生成式人工智能课程的完整中文镜像作业,并设有“代码游乐场”供自由探索。此外,项目坚持使用通用的 OpenAI SDK 标准,不依赖特定平台接口,确保所学技能具备广泛的适用性与迁移价值,是通往大模型世界的理想起点。
使用场景
计算机专业大三学生小林想独立完成一个“本地大模型微调”的课程项目,但受限于没有高端显卡且对配置海外开发环境感到畏惧。
没有 AI-Guide-and-Demos-zh_CN 时
- 环境搭建劝退:面对复杂的 Docker 配置和依赖冲突,因缺乏中文指引和基础镜像,在本地安装阶段就耗费数天仍报错连连。
- 硬件门槛受限:由于个人电脑无独立显卡,无法运行任何 LLM 微调代码,只能眼巴巴看着教程干着急,被迫放弃实践。
- API 获取困难:试图调用国外模型 API 时,被网络限制和繁琐的注册流程卡住,产生强烈的畏难情绪,最终退回到“只看视频不动手”的状态。
- 理论实践脱节:虽然看完了李宏毅老师的课程视频,但找不到对应的中文代码作业进行验证,导致对生成式 AI 的理解仅停留在概念层面。
使用 AI-Guide-and-Demos-zh_CN 后
- 一键启动环境:直接拉取项目提供的 Docker 基础镜像,并利用 uv 快速配置好依赖,几分钟内即可在本地或云端跑通第一个 Demo。
- 云端免费算力:通过项目集成的 Kaggle 和 Colab 在线链接,无需本地显卡也能直接运行显存要求高的微调和文生图代码,轻松完成实验。
- 通用 API 实践:跟随 DeepSeek API 指南,利用兼容 OpenAI SDK 的通用代码绕过网络障碍,顺利实现流式输出解析和用量监控。
- 课业同步实战:直接复用项目中李宏毅 2024 课程的完整中文镜像作业,在"CodePlayground"中边学边改,将理论知识迅速转化为可运行的脚本。
AI-Guide-and-Demos-zh_CN 通过提供零门槛的云端算力入口和本土化代码指引,帮助初学者跨过了从“观看视频”到“动手实践”的最艰难鸿沟。
运行环境要求
- Linux
- macOS
- Windows
- 非必需
- API 调用部分无需 GPU
- LLM 微调、部署及 Stable Diffusion (SD) 部分需要 NVIDIA GPU,具体显存需求视模型大小和精度而定(文中提及不同精度对显存有影响),建议使用支持 CUDA 的显卡
未说明
快速开始
这是一个中文的 AI/LLM 大模型入门项目
回顾过去的学习历程,吴恩达和李宏毅老师的视频为我的深度学习之路提供了极大的帮助。他们幽默风趣的讲解方式和简单直观的阐述,让枯燥的理论学习变得生动有趣。
然而,在实践的时候,许多学弟学妹们最初会烦恼于怎么去获取国外大模型的 API ,尽管最终都能找到解决方法,但第一次的畏难情绪总是会拖延学习进度,逐渐转变为“看视频就够了”的状态。我时常在评论区看到类似的讨论,于是决定利用闲暇时间帮学子们跨过这道门槛,这也是项目的初衷。
本项目不会提供🪜科学上网的教程,也不会依赖平台自定义的接口,而是使用更兼容的 OpenAI SDK,帮助大家学习更通用的知识。
项目将从简单的 API 调用入手,带你逐步深入大模型的世界。在此过程中,你将掌握 AI 视频摘要、LLM 微调和 AI 图像生成等技能。
强烈建议观看李宏毅老师的课程「生成式人工智能导论」同步学习:课程相关链接快速访问
现在,项目还开设了🎡CodePlayground,你可以按照文档配置好环境,使用一行代码运行脚本,体验 AI 的魅力。
📑论文随笔位于 PaperNotes,将逐步上传大模型相关的基础论文。
🚀 基础镜像已经准备好,如果你还没有配置好属于自己的深度学习环境,不妨尝试一下 Docker。
祝你旅途愉快!
目录
- Tag 说明:
---: 基础知识,根据需要进行观看,也可以暂时跳过。其中的代码文件结果都会在文章中示出,但仍建议动手运行代码。可能会有显存要求。API: 文章仅使用大模型的 API,不受设备限制,无 GPU 也可运行。- Kaggle 目前不允许使用 Gradio,故部分交互文件不提供相关链接(这一类文件可以本地运行)。
LLM: 大型语言模型相关的实践,代码文件可能有显存要求。SD: Stable Diffusion,文生图相关的实践,代码文件有显存要求。
- Online 在线链接说明:
- 与 Code 内容一致,如果提供了 Kaggle 和 Colab,则三选一运行。
- 如果仅提供了 Colab,说明不受显卡限制可以本地运行,此时不能科学上网的同学可以下载
File的代码,学习效果一致。 - 运行时请不要忘记打开对应在线平台的 GPU。
- Kaggle:
Setting->Accelerator->选择 GPU。 - Colab:
代码执行程序->更改运行时类型->选择 GPU。
- Kaggle:
✨ New
好久不见,更新一篇 MCP 相关的中间文章,或许会对你有所帮助。
因为还没想好模块标题,所以暂时置顶。
另外,目前项目将在叙述上全面使用 uv 进行环境的配置,后续会出一篇文章对 uv 进行介绍(这是一次并不“友好”的改动,但考虑到其目前已经被广泛应用,「长痛不如短痛」,索性从本项目开始“折腾”,希望能让你熟悉 uv 的使用)。
需要注意的是,因为目前的库版本更迭,或许会出现一些关于版本冲突的报错,计划在 8 月全面更新代码进行修复(当然,复制报错去问 AI 基本都可以临时解决)。
Colab 链接因为原账户没绑定恢复邮箱,被暂停了外部访问且无法恢复(引以为戒),后续我会抽空迁移至新账户上。
- 深入 FastMCP 源码:认识 tool()、resource() 和 prompt() 装饰器
- Claude Code 使用指南:安装与进阶技巧
- 【2025-09-02|旧文留档】Cursor 与 Claude Code Max 5x 订阅体验记录
- 【2026-04-16|持续更新】Claude / GPT 订阅建议与反代避坑
DeepSeek 使用手册
这部分内容将直接由之前的文章(导论部分)重组得来,故存在重复,此模块将暂时专注于 DeepSeek API 的使用,是 OpenAI SDK 相关的通用知识,也可以作为导论 API 部分的拓展。
| Guide | Tag | Describe | File | Online |
|---|---|---|---|---|
| DeepSeek API 的获取与对话示例 | API | 获取 DeepSeek API 的 N 种方法及其单轮对话样例: - DeepSeek 官方 - 硅基流动 - 阿里云百炼 - 百度智能云 - 字节火山引擎 |
Code | Kaggle Colab |
| DeepSeek 联网满血版使用指南 | API | 通过 API 绕开 DeepSeek 网页对话的卡顿,提供两种配置方案: - Cherry Studio【推荐】 - Chatbox |
||
| DeepSeek API 输出解析 - OpenAI SDK | API | 关于 OpenAI SDK 的通用知识,以 DeepSeek 聊天/推理模型为例进行演示: - 认识 API 的返回字段 - 打印模型回复和每次对话的用量信息 |
Code | Kaggle Colab |
| └─流式输出解析 | API | API 解析 - 流式输出篇 - 认识 chunk 的结构 - 处理各平台聊天/推理模型的流式输出 |
Code | Kaggle Colab |
| DeepSeek API 多轮对话 - OpenAI SDK | API | DeepSeek API 的多轮对话示例 - 非流式输出篇: - 认识单轮对话和多轮对话时 messages 的差异- 尝试封装对话类 |
Code | Kaggle Colab |
| └─统一模型对话逻辑与流式输出 | API | - 统一聊天模型和推理模型对话类 - 引入流式输出处理 【代码文件】 - 使用 APIConfigManager 进行各平台配置,不再分散逻辑 |
Code | Kaggle Colab |
导论
| 指南 | 标签 | 描述 | 文件 | 在线 |
|---|---|---|---|---|
| 00. 大模型 API 获取步骤 | API | 带你一步步的获取 API: - 阿里(通义千问)。 - 智谱。 - DeepSeek。 |
||
| 01. 初识 LLM API:环境配置与多轮对话演示 | API | 这是一段入门的配置和演示,对话代码修改自开发文档。 | Code | Kaggle Colab |
| 02. 简单入门:通过 API 与 Gradio 构建 AI 应用 | API | 指导如何去使用 Gradio 搭建一个简单的 AI 应用。 | Code | Colab |
| 03. 进阶指南:自定义 Prompt 提升大模型解题能力 | API | 你将学习自定义一个 Prompt 来提升大模型解数学题的能力,其中一样会提供 Gradio 和非 Gradio 两个版本,并展示代码细节。 | Code | Kaggle Colab |
| 04. 认识 LoRA:从线性层到注意力机制 | --- | 在正式进入实践之前,你需要知道 LoRA 的基础概念,这篇文章会带你从线性层的 LoRA 实现到注意力机制。 | ||
05. 理解 Hugging Face 的 AutoModel 系列:不同任务的自动模型加载类 |
--- | 我们即将用到的模块是 Hugging Face 中的 AutoModel,这篇文章一样是一个前置知识,你将了解到如何查看模型的参数和配置信息,以及如何使用 inspect 库进一步查看对应的源码。 |
Code | Kaggle Colab |
| 06. 开始实践:部署你的第一个语言模型 | LLM | 实现非常入门的语言模型部署,项目到现在为止都不会有 GPU 的硬性要求,你可以继续学习。 | Code app_fastapi.py app_flask.py |
|
| 07. 探究模型参数与显存的关系以及不同精度造成的影响 | --- | 了解模型参数和显存的对应关系并掌握不同精度的导入方式会使得你对模型的选择更加称手。 | ||
| 08. 尝试微调 LLM:让它会写唐诗 | LLM | 这篇文章与 03. 进阶指南:自定义 Prompt 提升大模型解题能力一样,本质上是专注于“用”而非“写”,你可以像之前一样,对整体的流程有了一个了解,尝试调整超参数部分来查看对微调的影响。 | Code | Kaggle Colab |
| 09. 深入理解 Beam Search:原理, 示例与代码实现 | --- | 从示例到代码演示,讲解 Beam Search 的数学原理,这应该能解决一些之前阅读的困惑,最终提供一个简单的使用 Hugging Face Transformers 库的示例(如果跳过了之前的文章的话可以尝试它)。 | Code | Kaggle Colab |
| 10. Top-K vs Top-P:生成式模型中的采样策略与 Temperature 的影响 | --- | 进一步向你展示其他的生成策略。 | Code | Kaggle Colab |
| 11. DPO 微调示例:根据人类偏好优化 LLM 大语言模型 | LLM | 一个使用 DPO 微调的示例。 | Code | Kaggle Colab |
| 12. Inseq 特征归因:可视化解释 LLM 的输出 | LLM | 翻译和文本生成(填空)任务的可视化示例。 | Code | Kaggle Colab |
| 13. 了解人工智能可能存在的偏见 | LLM | 不需要理解代码,可以当作休闲时的一次有趣探索。 | Code | Kaggle Colab |
| 14. PEFT:在大模型中快速应用 LoRA | --- | 学习如何在导入模型后增加 LoRA 层。 | Code | Kaggle Colab |
| 15. 用 API 实现 AI 视频摘要:动手制作属于你的 AI 视频助手 | API & LLM | 你将了解到常见的 AI 视频总结小助手背后的原理,并动手实现 AI 视频摘要。 | Code - 完整版 Code - 精简版 🎡脚本 |
Kaggle Colab |
| 16. 用 LoRA 微调 Stable Diffusion:拆开炼丹炉,动手实现你的第一次 AI 绘画 | SD | 使用 LoRA 进行文生图模型的微调,现在你也能够为别人提供属于你的 LoRA 文件。 | Code Code - 精简版 🎡 脚本 |
Kaggle Colab |
| 17. 浅谈 RTN 模型量化:非对称 vs 对称.md | --- | 更进一步地了解 RTN 模型量化的行为,文章以 INT8 为例进行讲解。 | Code | Kaggle Colab |
| 18. 模型量化技术概述及 GGUF & GGML 文件格式解析 | --- | 这是一个概述文章,或许可以解决一些你在使用 GGUF/GGML 时的疑惑。 | ||
| 19a. 从加载到对话:使用 Transformers 本地运行量化 LLM 大模型(GPTQ & AWQ) 19b. 从加载到对话:使用 Llama-cpp-python 本地运行量化 LLM 大模型(GGUF) |
LLM | 你将在自己的电脑上部署一个拥有 70 亿(7B)参数的量化模型,注意,这篇文章没有显卡要求。 19 a 使用 Transformers,涉及 GPTQ 和 AWQ 格式的模型加载。 19 b 使用 Llama-cpp-python,涉及 GGUF 格式的模型加载。 另外,你还将完成本地的大模型对话交互功能。 |
Code - a Code - b 🎡脚本 |
Kaggle - a Colab - a Kaggle - b Colab - b |
| 20. RAG 入门实践:从文档拆分到向量数据库与问答构建 | LLM | RAG 的相关实践。 了解文本分块的递归工作原理。 |
Code | Kaggle Colab |
| 21. BPE vs WordPiece:理解 Tokenizer 的工作原理与子词分割方法 | --- | Tokenizer 的基本操作。 了解常见的子词分割方法:BPE 和 WordPiece。 了解注意力掩码(Attention Mask)和词元类型 ID (Token Type IDs)。 |
Code | Kaggle Colab |
| 22a. 微调 LLM:实现抽取式问答 22b. 作业 - Bert 微调抽取式问答 |
LLM | 微调预训练模型以实现下游任务:抽取式问答。 可以先尝试作业 22b 再阅读 22a,但并不强制要求。 |
BERT 论文精读 Code - 完整 Code - 作业 |
Kaggle - 完整 Colab - 完整 Kaggle - 作业 Colab - 作业 |
[!TIP]
如果你更喜欢拉取仓库到本地进行阅读
.md,那么在出现公式报错的时候,请使用Ctrl+F或者Command+F,搜索\\_并全部替换为\_。
拓展阅读
| 指南 | 描述 |
|---|---|
| a. 使用 HFD 加快 Hugging Face 模型和数据集的下载 | 如果你觉得模型下载实在是太慢了,可以参考这篇文章进行配置。 遇到代理相关的 443 错误,也可以试着查看这篇文章。 |
| b. 命令行基础指令速查(Linux & Mac适用) | 一份命令行的指令速查,基本包含当前仓库的涉及的所有指令,在感到疑惑时去查看它。 |
| c. 一些问题的解决方法 | 这里会解决一些项目运行过程中可能遇到的问题。 - 如何拉取远程仓库覆盖本地的一切修改? - 怎么查看和删除 Hugging Face 下载的文件,怎么修改保存路径? - 在线平台 Kaggle/Colab 怎么开启 GPU? |
| d. 如何加载 GGUF 模型(分片 & Shared & Split & 00001-of-0000...的解决方法) | - 了解 Transformers 关于 GGUF 的新特性。 - 使用 Transformers/Llama-cpp-python/Ollama 加载 GGUF 格式的模型文件。 - 学会合并分片的 GGUF 文件。 - 解决 LLama-cpp-python 无法 offload 的问题。 |
| e. 数据增强:torchvision.transforms 常用方法解析 | - 了解常用的图像数据增强方法。 代码 | Kaggle | Colab |
| f. 交叉熵损失函数 nn.CrossEntropyLoss() 详解和要点提醒(PyTorch) | - 了解交叉熵损失的数学原理及 PyTorch 实现。 - 了解初次使用时需要注意的地方。 |
| g. 嵌入层 nn.Embedding() 详解和要点提醒(PyTorch) | - 了解嵌入层和词嵌入的概念。 - 使用预训练模型可视化 Embedding。 代码 | Kaggle | Colab |
| h. 使用 Docker 快速配置深度学习环境(Linux) h. Docker 基础命令介绍和常见报错解决 |
- 使用两行命令配置好深度学习环境 - Docker 基础命令介绍 - 解决使用时的三个常见报错 |
| i. Epoch、Batch 和 Step 之间的关系以及梯度累积 | 基础文章,可以在任意时候进行阅读 - Epoch、Batch、Step 三者之间的关系 - SGD、BGD、MBGD 方法的区别 - 梯度累积的使用 |
文件夹解释:
Demos
所有的代码文件都将存放在其中。
data
存放代码中可能用到的小型数据,不需要关注这个文件夹。
GenAI_PDF
这里是【生成式人工智能导论】课程的作业PDF文件,我上传了它们,因为其最初保存在 Google Drive 中。
Guide
所有的指导文件都将存放在其中。
assets
这里是 .md 文件用到的图片,不需要关注这个文件夹。
PaperNotes
论文随笔。
- README.md
- 目录索引。
- 对比学习论文随笔 1:正负样本
- 涉及使用正负样本思想且优化目标一致的基础论文
- Transformer 论文精读
- BERT 论文精读
- 预训练任务 MLM 和 NSP
- BERT 模型的输入和输出,以及一些与 Transformer 不同的地方
- 以 $\text{BERT}_\text{BASE}$ 为例,计算模型的总参数量
- 作业 - BERT 微调抽取式问答
- GPT 论文精读
- README.md
快速访问
生成式人工智能导论学习资源
中文镜像版的制作与分享已经获得李宏毅老师的授权,感谢老师对于知识的无私分享!
- HW1,2不涉及代码相关知识,你可以通过访问对应的作业PDF来了解其中的内容:HW1 | HW2。
- HW3: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | 作业PDF
- HW4: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | Kaggle | 作业PDF
- HW5: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | Kaggle | 作业PDF
- HW6: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | Kaggle | 作业PDF
- HW7: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | Kaggle | 作业PDF
- HW8: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | Kaggle | 作业PDF
- HW9: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | Kaggle | 作业PDF
- HW10: 引导文章 | 代码中文镜像 | 中文 Colab | 英文 Colab | Kaggle | 作业PDF
P.S. 中文镜像将完全实现作业代码的所有功能(本地运行),Kaggle 是国内可直连的在线平台,中文 Colab 和 Kaggle 内容一致,英文 Colab 链接对应于原作业,选择其中一个完成学习即可。
根据实际需求,从下方选择一种方式来准备学习环境,点击 ► 或文字展开。
在线平台学习
如果倾向于使用在线平台学习,或者受到显卡性能的限制,可以选择以下平台:
Kaggle(国内直连,推荐):阅读文章《Kaggle:免费 GPU 使用指南,Colab 的理想替代方案》进行了解。
Colab(需要🪜科学上网)
项目中的代码文件在两个平台是同步的。
本地环境配置
安装基础软件
- Git:用于克隆代码仓库。
- Wget 和 Curl:用于下载脚本和文件。
- pip:用于安装 Python 依赖包。
- uv:仓库将不再采用 conda 而是全面转为 uv。
安装 Git
Linux (Ubuntu):
sudo apt-get update sudo apt-get install gitMac:
先安装 Homebrew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
然后运行:
brew install gitWindows:
从 Git for Windows 下载并安装。
安装 Wget 和 Curl
Linux (Ubuntu):
sudo apt-get update sudo apt-get install wget curlMac:
brew install wget curlWindows:
从 Wget for Windows 和 Curl 官方网站 下载并安装。
安装 pip
注意:如果已经安装了 Anaconda 或 Miniconda,系统中会包含 pip,无需额外安装。
Linux (Ubuntu):
sudo apt-get update sudo apt-get install python3-pipMac:
brew install python3Windows:
下载并安装 Python,确保勾选“Add Python to PATH”选项。
打开命令提示符,输入:
python -m ensurepip --upgrade
验证安装
在终端中输入以下命令,如果显示版本信息,则说明安装成功。
pip --version
配置国内镜像源(可选,建议)
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
安装 uv
Linux/Mac:
curl -LsSf https://astral.sh/uv/install.sh | sh # 或者 pip install uv查看目前的 Shell:
echo $SHELL然后将 uv 加到 PATH 中,根据
echo $SHELL的输出选择对应的命令执行:sh, bash, zsh:
source $HOME/.local/bin/envfish
source $HOME/.local/bin/env.fish
Windows:
powershell -c "irm https://astral.sh/uv/install.ps1 | more" # 或者 pip install uv
配置国内镜像源(可选,建议)
# 创建配置目录
mkdir -p ~/.config/uv
# 创建配置文件(Linux/Mac),Windows 在 %APPDATA%\uv\uv.toml
cat > ~/.config/uv/uv.toml << EOF
[[index]]
url = "https://mirrors.aliyun.com/pypi/simple/"
default = true
EOF
克隆仓库项目
通过以下命令拉取项目:
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CN
同步项目依赖
uv sync
该命令会自动同步当前项目的主要依赖:
- torch>=2.6
- torchvision>=0.19
- torchaudio>=2.6
- ...(详见
pyproject.toml)
这样就成功配置好了所有需要的环境,准备开始学习 :) 如果缺少显卡或者系统原因导致无法完全同步,也不用担心,其余依赖在每个文章中会单独列出,可以尝试直接到对应的文章中进行一部分依赖的下载。
激活虚拟环境(可选)
如果不激活的话需要使用
uv run+ 命令执行,比如:uv run python script.py uv run jupyter lab
Linux/Mac:
source .venv/bin/activateWindows:
.venv\Scripts\activate
使用 Jupyter-Lab
执行下面的命令:
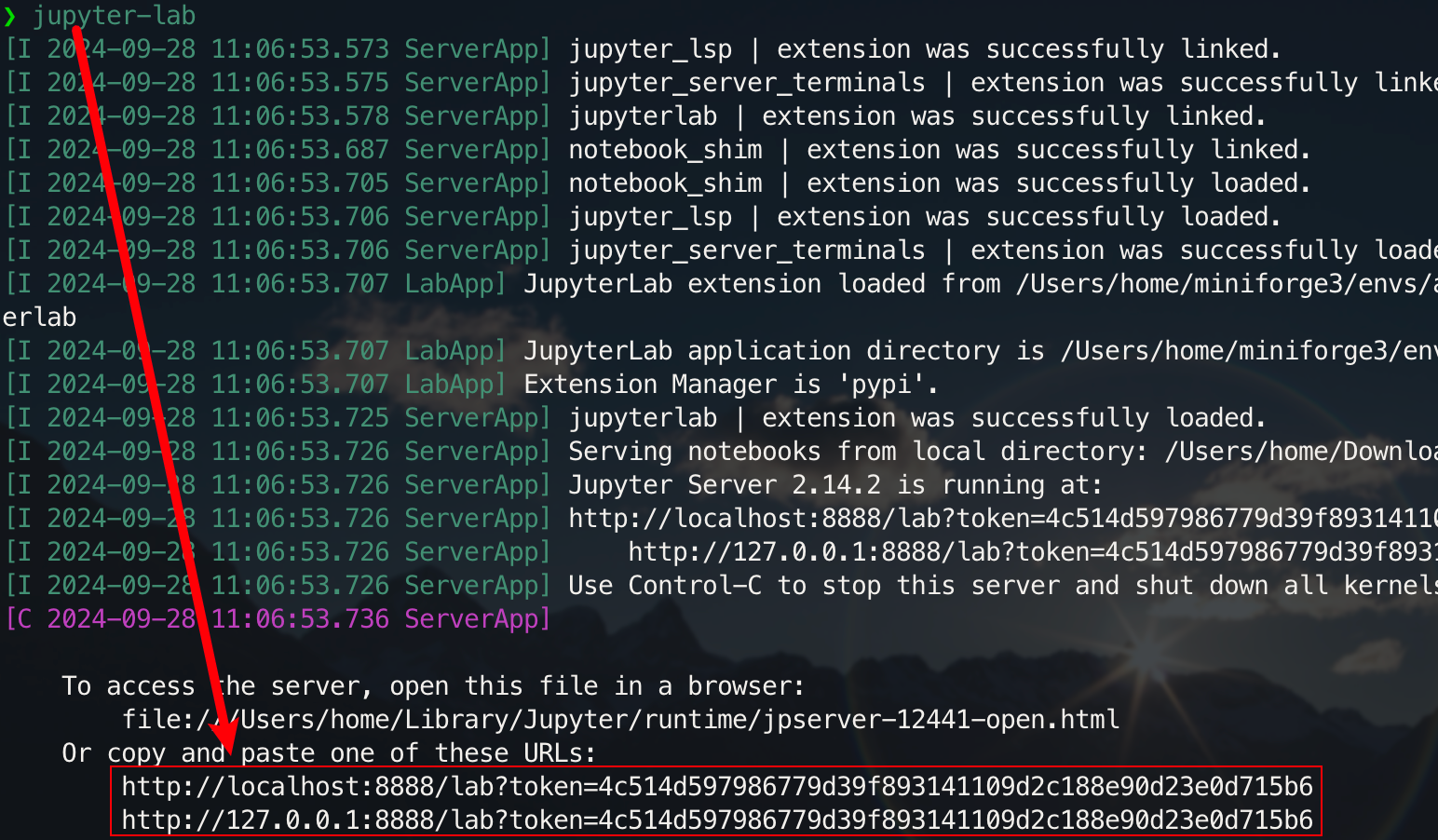
uv run jupyter-lab
[!note]
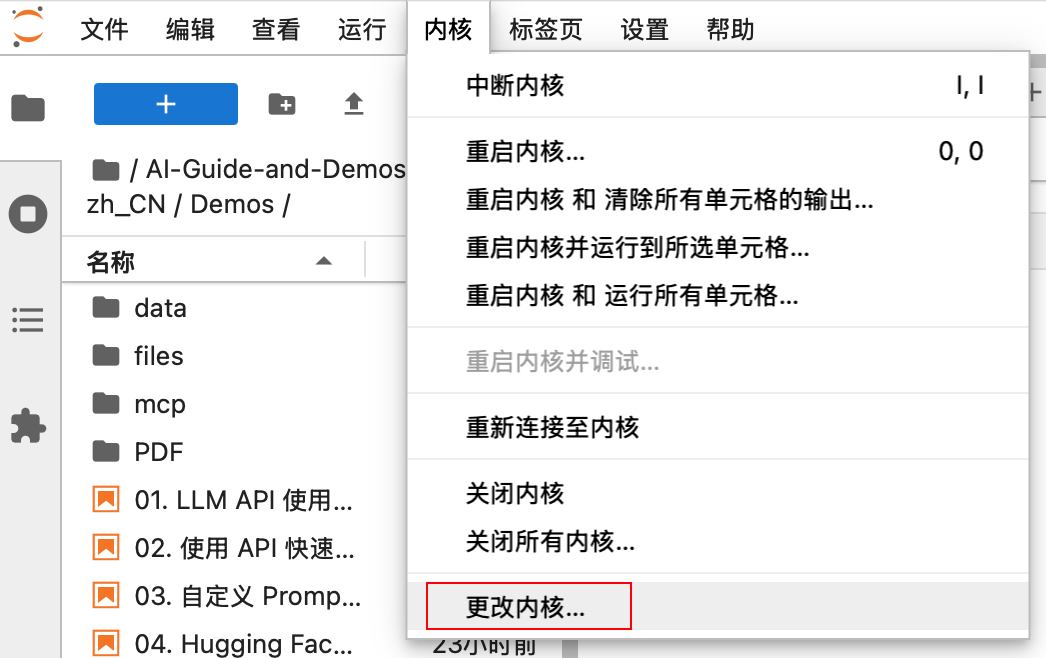
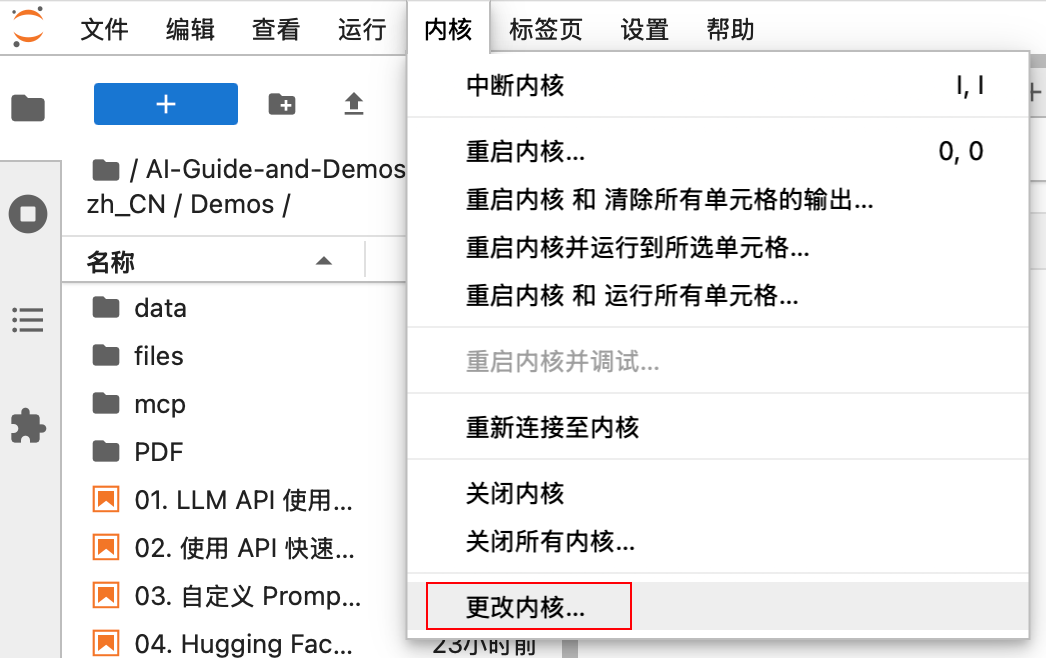
如果在 AutoDL 租服务器运行的话,建议先注册内核,方便切换版本:
UV_DIR=$(dirname $(which uv)) uv run python -m ipykernel install --user --name=ai --display-name="ai" --env PATH "$UV_DIR:$PATH"注册后可以在左上角
内核->更改内核:
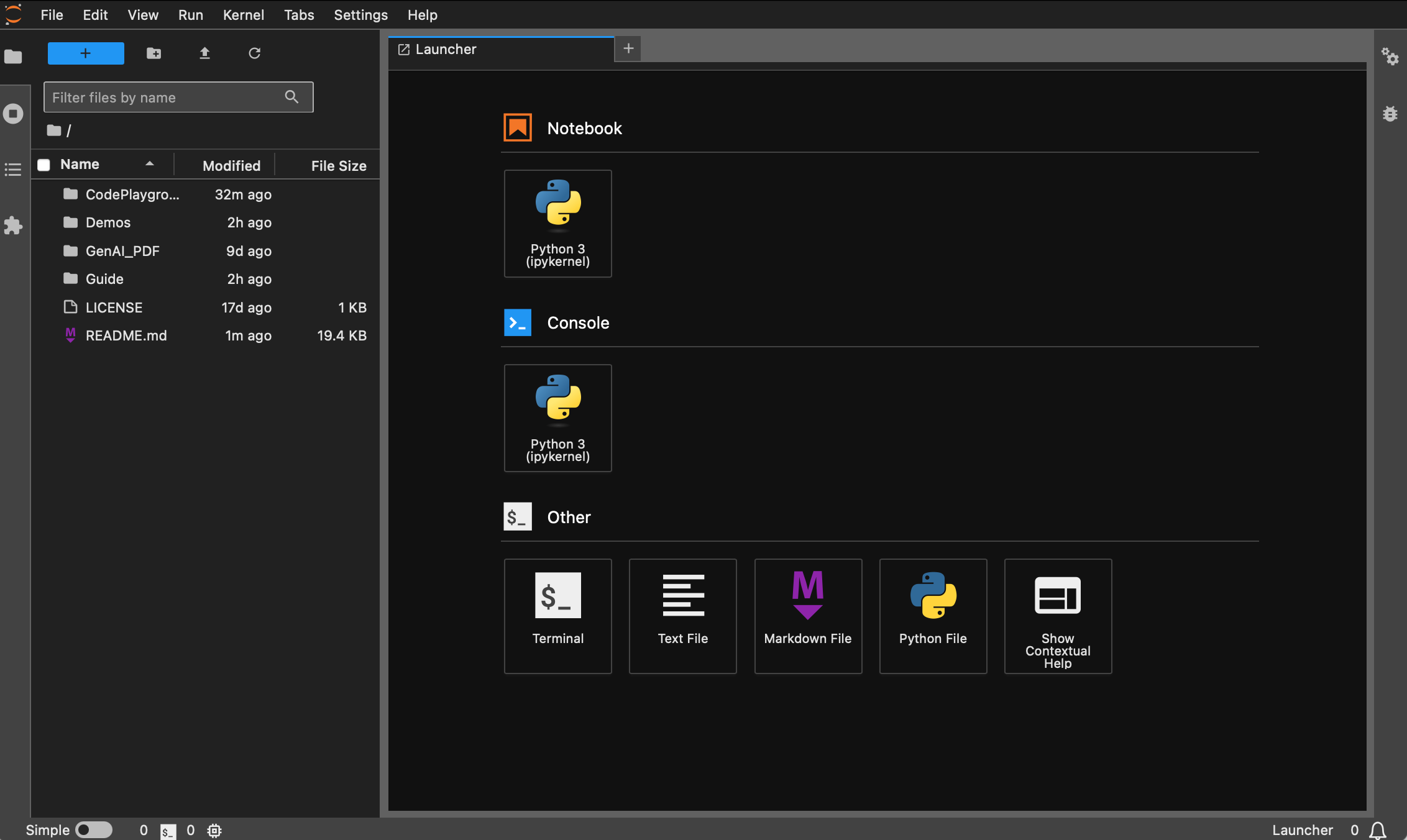
可以通过弹出的链接进行访问,一般位于 8888 端口。对于图形化界面,Windows/Linux 按住 Ctrl,Mac 按住 Command,然后点击链接可以直接跳转。至此,你将获得项目的全貌:
Docker 快速部署
没有安装 Docker 的同学可以阅读文章《使用 Docker 快速配置深度学习环境(Linux)》,建议初学者阅读《Docker 基础命令介绍和常见报错解决》。
镜像介绍
未来将更新为 uv 安装。
所有版本都预装了 sudo、pip、conda、wget、curl 和 vim 等常用工具,且已经配置好 pip 和 conda 的国内镜像源。同时,集成了 zsh 和一些实用的命令行插件(命令自动补全、语法高亮、以及目录跳转工具 z)。此外,已预装 jupyter notebook 和 jupyter lab,设置了其中的默认终端为 zsh,方便进行深度学习开发,并优化了容器内的中文显示,避免出现乱码问题。其中还预配置了 Hugging Face 的国内镜像地址。
版本说明
- base 版本:占用约 16GB 存储空间,基于
pytorch/pytorch:2.5.1-cuda11.8-cudnn9-devel,默认python版本为 3.11.10,可以通过conda install python==版本号直接修改版本。 - dl 版本:占用约 20GB 存储空间,在 base 基础上,额外安装了深度学习框架和常用工具,具体查看安装清单。
安装清单
base
基础环境:
- python 3.11.10
- torch 2.5.1 + cuda 11.8 + cudnn 9
Apt 安装:
wget、curl:命令行下载工具vim、nano:文本编辑器git:版本控制工具git-lfs:Git LFS(大文件存储)zip、unzip:文件压缩和解压工具htop:系统监控工具tmux、screen:会话管理工具build-essential:编译工具(如gcc、g++)iputils-ping、iproute2、net-tools:网络工具(提供ping、ip、ifconfig、netstat等命令)ssh:远程连接工具rsync:文件同步工具tree:显示文件和目录树lsof:查看当前系统打开的文件aria2:多线程下载工具libssl-dev:OpenSSL 开发库
pip 安装:
jupyter notebook、jupyter lab:交互式开发环境virtualenv:Python 虚拟环境管理工具,可以直接用 condatensorboard:深度学习训练可视化工具ipywidgets:Jupyter 小部件库,用以正确显示进度条
插件:
zsh-autosuggestions:命令自动补全zsh-syntax-highlighting:语法高亮z:快速跳转目录
dl
dl(Deep Learning)版本在 base 基础上,额外安装了深度学习可能用到的基础工具和库:
Apt 安装:
ffmpeg:音视频处理工具libgl1-mesa-glx:图形库依赖(解决一些深度学习框架图形相关问题)
pip 安装:
- 数据科学库:
numpy、scipy:数值计算和科学计算pandas:数据分析matplotlib、seaborn:数据可视化scikit-learn:机器学习工具
- 深度学习框架:
tensorflow:另一种流行的深度学习框架tf-keras:Keras 接口的 TensorFlow 实现
- NLP 相关库:
transformers、datasets:Hugging Face 提供的 NLP 工具nltk、spacy:自然语言处理工具
如果需要额外的库,可以通过以下命令手动安装:
pip install --timeout 120 <替换成库名>
这里 --timeout 120 设置了 120 秒的超时时间,确保在网络不佳的情况下仍然有足够的时间进行安装。如果不进行设置,在国内的环境下可能会遇到安装包因下载超时而失败的情况。
注意,所有镜像都不会提前拉取仓库。
获取镜像(三选一)
假设你已经安装并配置好了 Docker,那么只需两行命令即可完成深度学习的环境配置,对于当前项目,你可以查看完版本说明后进行选择,二者对应的 image_name:tag 如下:
- base:
hoperj/quickstart:base-torch2.5.1-cuda11.8-cudnn9-devel - dl:
hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel
拉取命令为:
docker pull <image_name:tag>
下面以 dl 版为例进行命令演示,选择其中一种方式完成。
国内镜像版
docker pull dockerpull.org/hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel
🪜科学上网版
docker pull hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel
本地(网盘下载)
可以通过百度云盘下载文件(阿里云盘不支持分享大的压缩文件)。
同名文件内容相同,
.tar.gz为压缩版本,下载后通过以下命令解压:gzip -d dl.tar.gz
假设 dl.tar 被下载到了 ~/Downloads 中,那么切换至对应目录:
cd ~/Downloads
然后加载镜像:
docker load -i dl.tar
创建并运行容器(使用主机网络)
此模式下,容器会直接使用主机的网络配置,所有端口都等同于主机的端口,无需单独映射。如果只需映射指定端口,将
--network host替换为-p port:port。
docker run --gpus all -it --name ai --network host hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel /bin/zsh
设置代理
对于需要使用代理的同学,增加 -e 来设置环境变量,也可以参考拓展文章a:
假设代理的 HTTP/HTTPS 端口号为 7890, SOCKS5 为 7891:
-e http_proxy=http://127.0.0.1:7890-e https_proxy=http://127.0.0.1:7890-e all_proxy=socks5://127.0.0.1:7891
融入到之前的命令中:
docker run --gpus all -it \
--name ai \
--network host \
-e http_proxy=http://127.0.0.1:7890 \
-e https_proxy=http://127.0.0.1:7890 \
-e all_proxy=socks5://127.0.0.1:7891 \
hoperj/quickstart:dl-torch2.5.1-cuda11.8-cudnn9-devel \
/bin/zsh
[!tip]
常用操作提前看:
- 启动容器:
docker start <容器名>- 运行容器:
docker exec -it <容器名> /bin/zsh
- 容器内退出:
Ctrl + D或exit。- 停止容器:
docker stop <容器名>- 删除容器:
docker rm <容器名>
克隆仓库
git clone https://github.com/Hoper-J/AI-Guide-and-Demos-zh_CN.git
cd AI-Guide-and-Demos-zh_CN
安装并启动 Jupyter Lab
jupyter lab --ip=0.0.0.0 --port=8888 --no-browser --allow-root
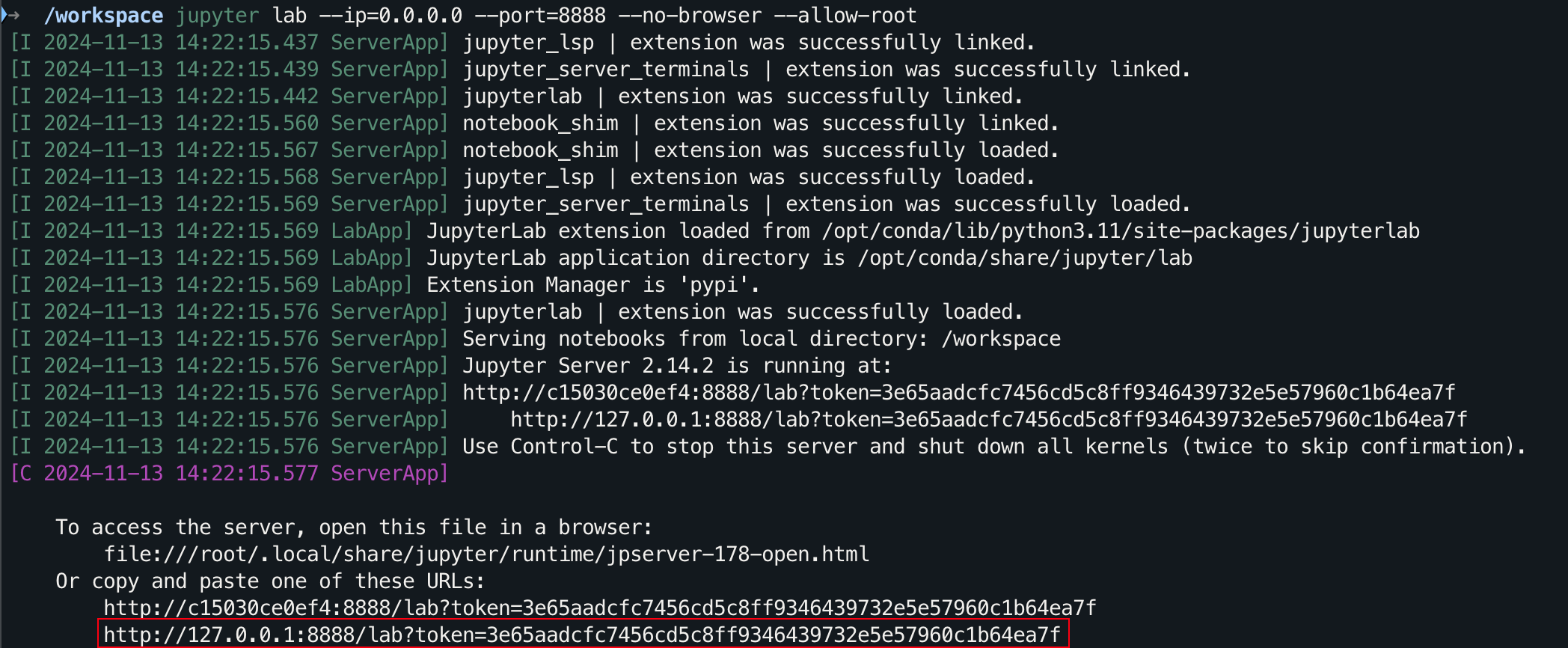
对于图形化界面,Windows/Linux 摁住 Ctrl,mac 按住 Command,然后点击链接可以直接跳转。
感谢你的STAR🌟,希望这一切对你有所帮助。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器