awesome-segment-anything
awesome-segment-anything 是一个专注于追踪和整理"Segment Anything"(SAM)模型生态的开源资源库。随着 SAM 在计算机视觉领域引发突破性进展,相关研究呈爆发式增长,开发者往往难以高效获取最新成果。该资源库正是为了解决这一信息分散痛点而生,它系统性地汇总了全球范围内与 SAM 相关的学术论文、衍生项目及应用案例。
内容覆盖极为广泛,不仅包含基础模型论文,还深入细分至医疗影像分割、视频目标跟踪、图像修复、3D 重建、遥感分析乃至机器人交互等十多个前沿方向。其独特亮点在于极高的更新频率与结构化分类,从理论分析到代码实现,甚至包含了前端 JS SDK 等实用工具,帮助用户快速定位所需资源。无论是希望跟进最新算法的研究人员,还是寻求将 SAM 集成到实际产品中的开发者,都能在此找到极具价值的参考。对于设计师或对 AI 视觉技术感兴趣的学习者,这里也是探索“万物皆可分割”技术边界的理想窗口。通过持续维护与社区共享,awesome-segment-anything 致力于成为连接 SAM 理论基础与创新应用的重要桥梁。
使用场景
某医疗 AI 初创团队正致力于开发一款辅助医生快速标注肺部 CT 影像中病灶区域的系统,急需集成最新的分割算法以提升标注效率。
没有 awesome-segment-anything 时
- 信息搜集耗时巨大:研究人员需手动在 arXiv、GitHub 等多个平台分散搜索"Segment Anything"相关论文,每天耗费数小时筛选无效信息。
- 技术选型盲目低效:面对海量衍生项目,难以区分哪些适用于医学图像(如处理模糊边界),哪些仅针对自然图像,导致多次试错成本高昂。
- 代码复现门槛高:找不到经过验证的代码库或官方项目链接,常因依赖缺失或文档不全导致环境配置失败,拖延研发进度。
- 前沿动态滞后:无法及时知晓如 SAM-Track 或医学专用微调模型等最新突破,致使技术方案在立项初期就已落后于社区水平。
使用 awesome-segment-anything 后
- 一站式资源聚合:直接查阅按“医学图像分割”分类的清单,瞬间锁定数十篇高相关性论文与对应项目,搜集时间从数天缩短至几分钟。
- 精准场景匹配:通过清晰的分类标签(如 Medical Image Segmentation),快速识别出专门针对病灶边缘优化的衍生模型,避免通用模型的水土不服。
- 开箱即用体验:每个条目均附带经过验证的代码库链接和论文页,团队成员能迅速拉取代码并跑通 Demo,大幅降低复现难度。
- 同步最新进展:借助持续的更新日志(如新增 SaLIP 或机器人应用文章),团队能即时将业界最先进的方法论融入产品迭代,保持技术领先性。
awesome-segment-anything 将原本碎片化、高成本的科研调研工作转化为标准化的流水线作业,让开发者能专注于核心业务逻辑而非重复造轮子。
运行环境要求
未说明
未说明
快速开始
令人惊叹的 Segment Anything 
Segment Anything 在计算机视觉(CV)领域取得了新的突破,本仓库将持续跟踪并总结 Segment Anything 在各个领域的研究进展,包括论文、项目等。
如果您觉得这个仓库有帮助,请考虑给它点个 Star ⭐ 或分享出去 ⬆️。谢谢!
新闻
- 2024.8.16 增加 Segment Anything2 和 SaLIP。
- 2023.8.29:更新了一些最新工作。
- 2023.5.20:更新文档结构,并添加了一篇与机器人相关的文章。祝大家520快乐!
- 2023.5.4:增加 SEEM。
- 2023.4.18:增加 Inpainting Anything 和 SAM-Track 工作。
- 2023.4.12:发布了近期论文或项目的初版。
目录
论文/项目
基础模型论文
| 标题 | 演示图 | 论文链接 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| CLIP | 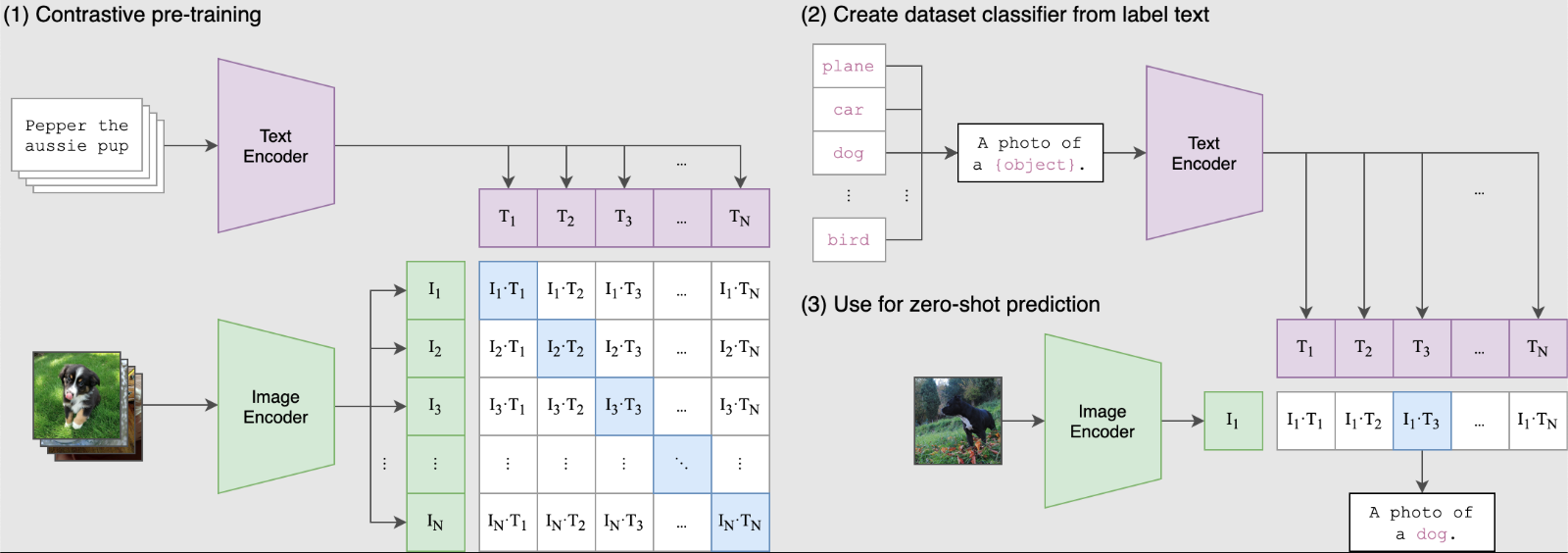 |
arXiv | Colab | 代码 | OpenAI | 对比语言-图像预训练。 |
| OWL-ViT |  |
ECCV2022 | - | 代码 | 一种开放词汇的目标检测器。 | |
| OvSeg | 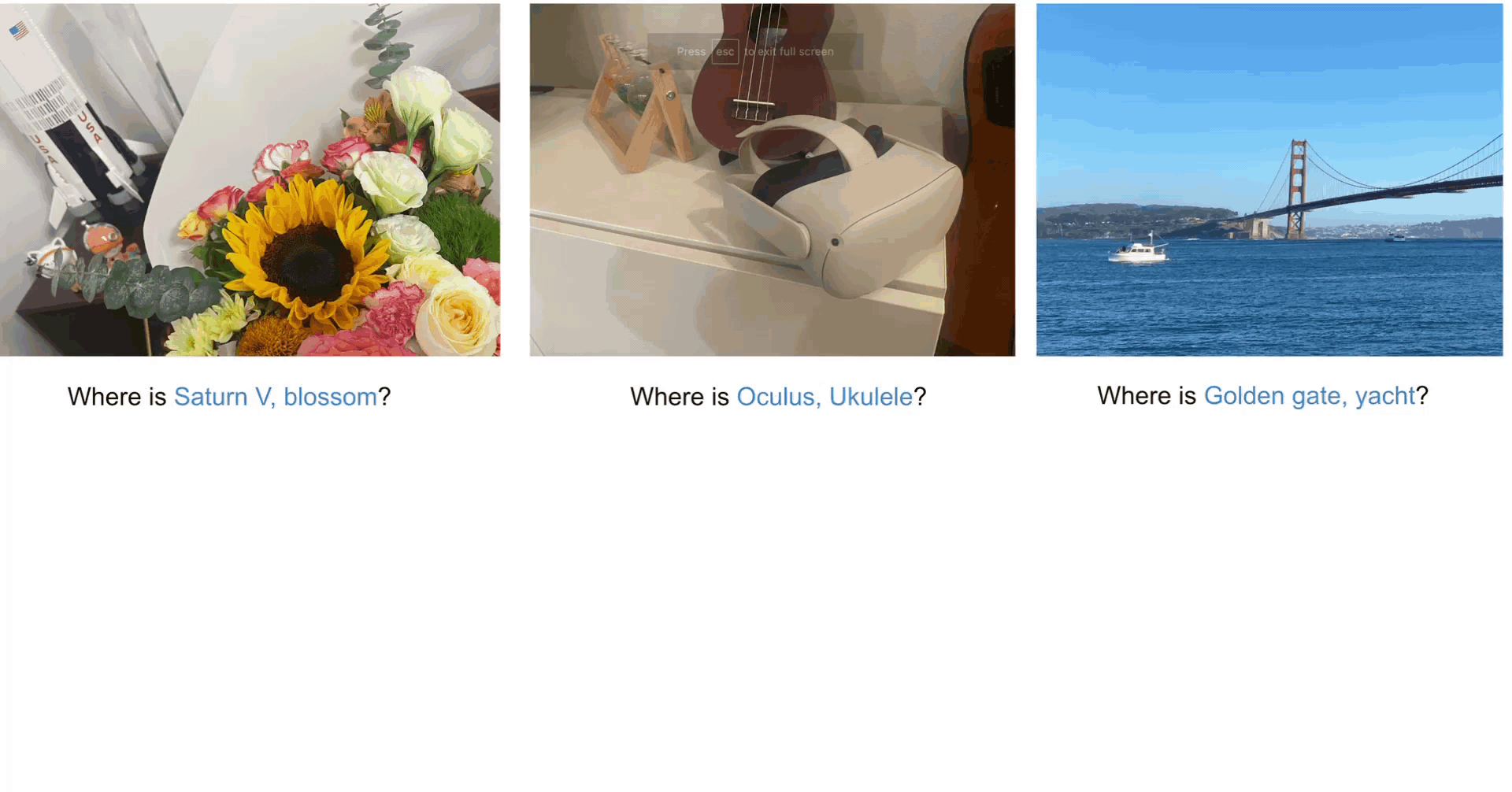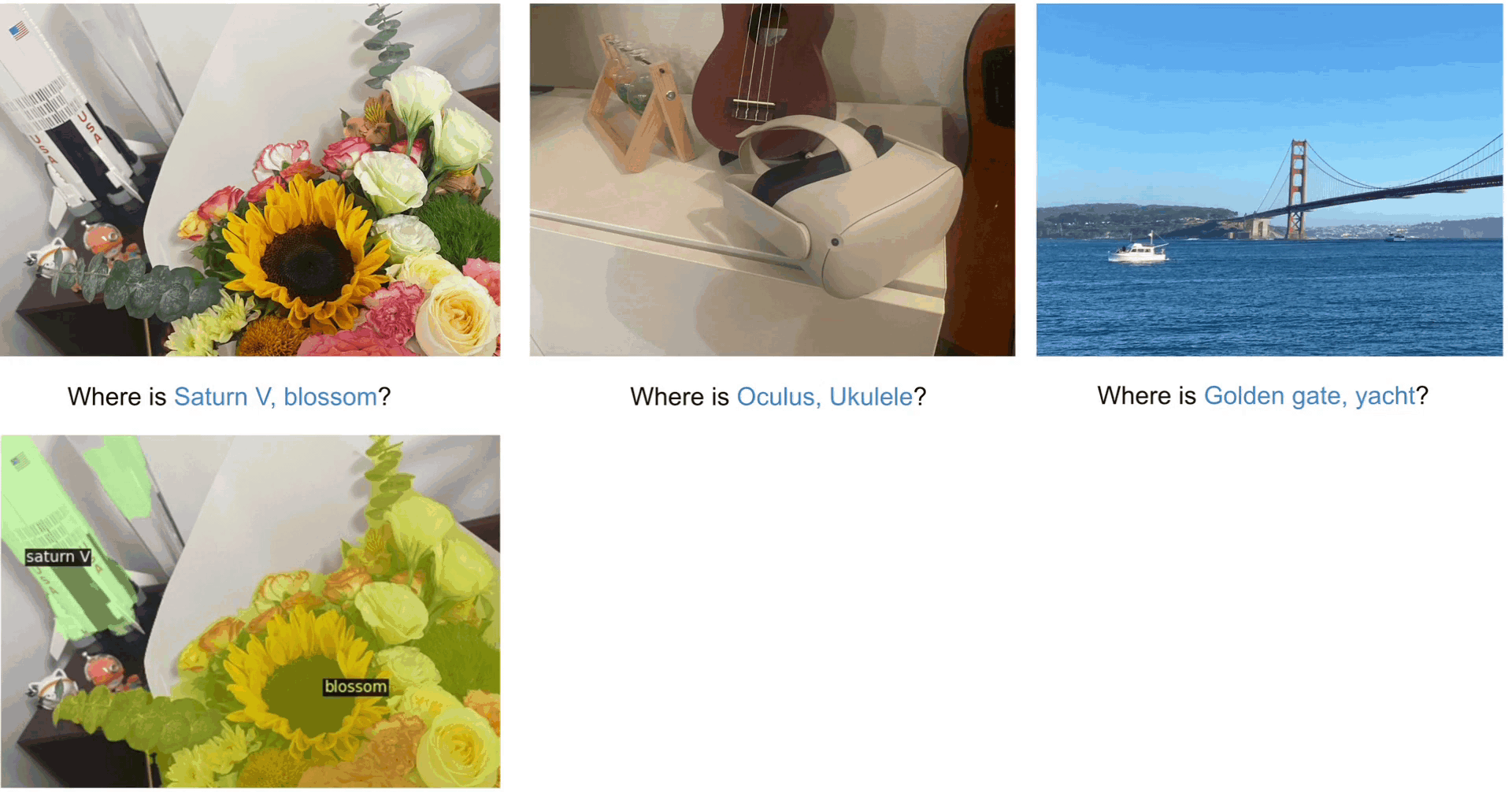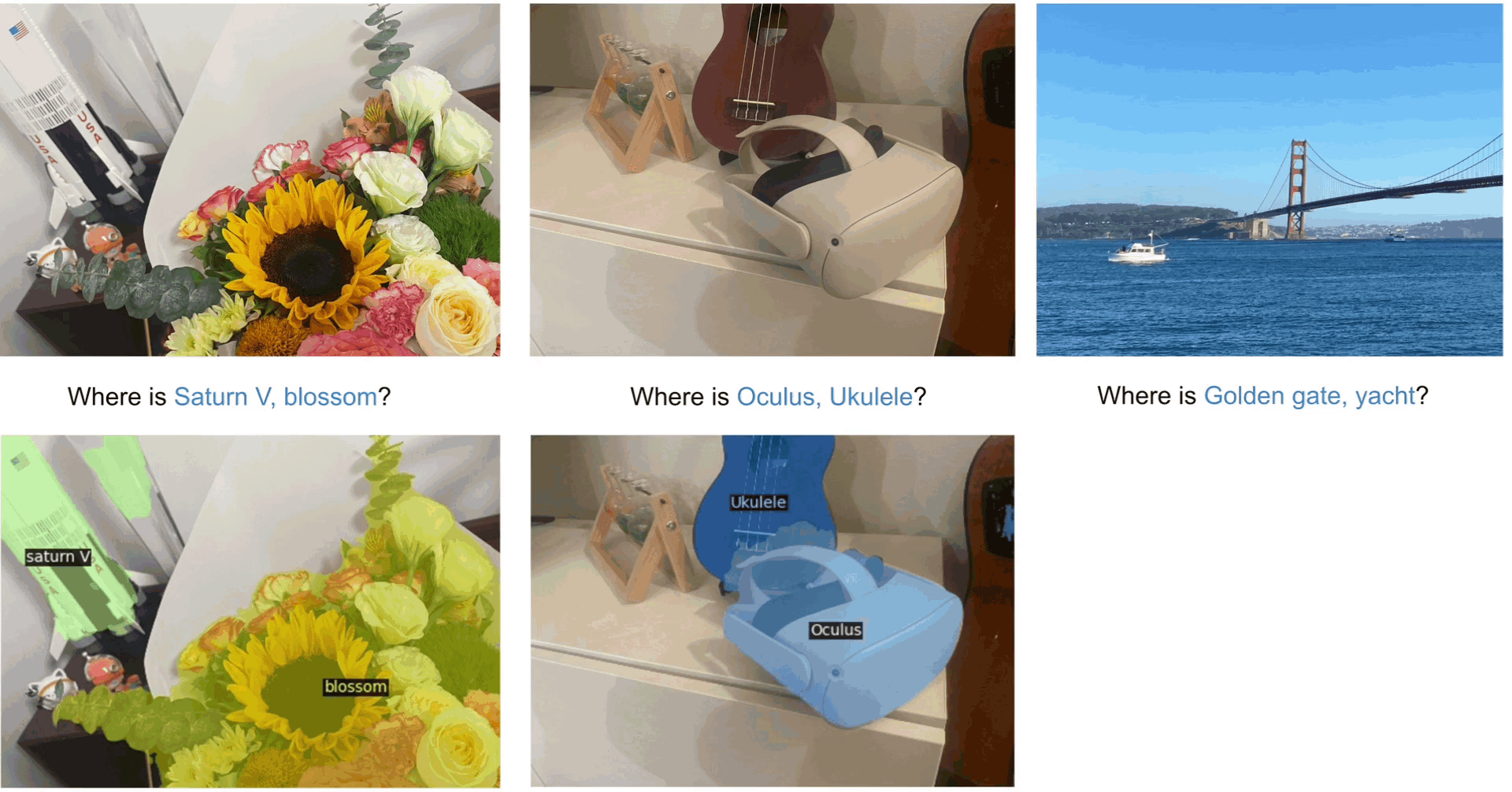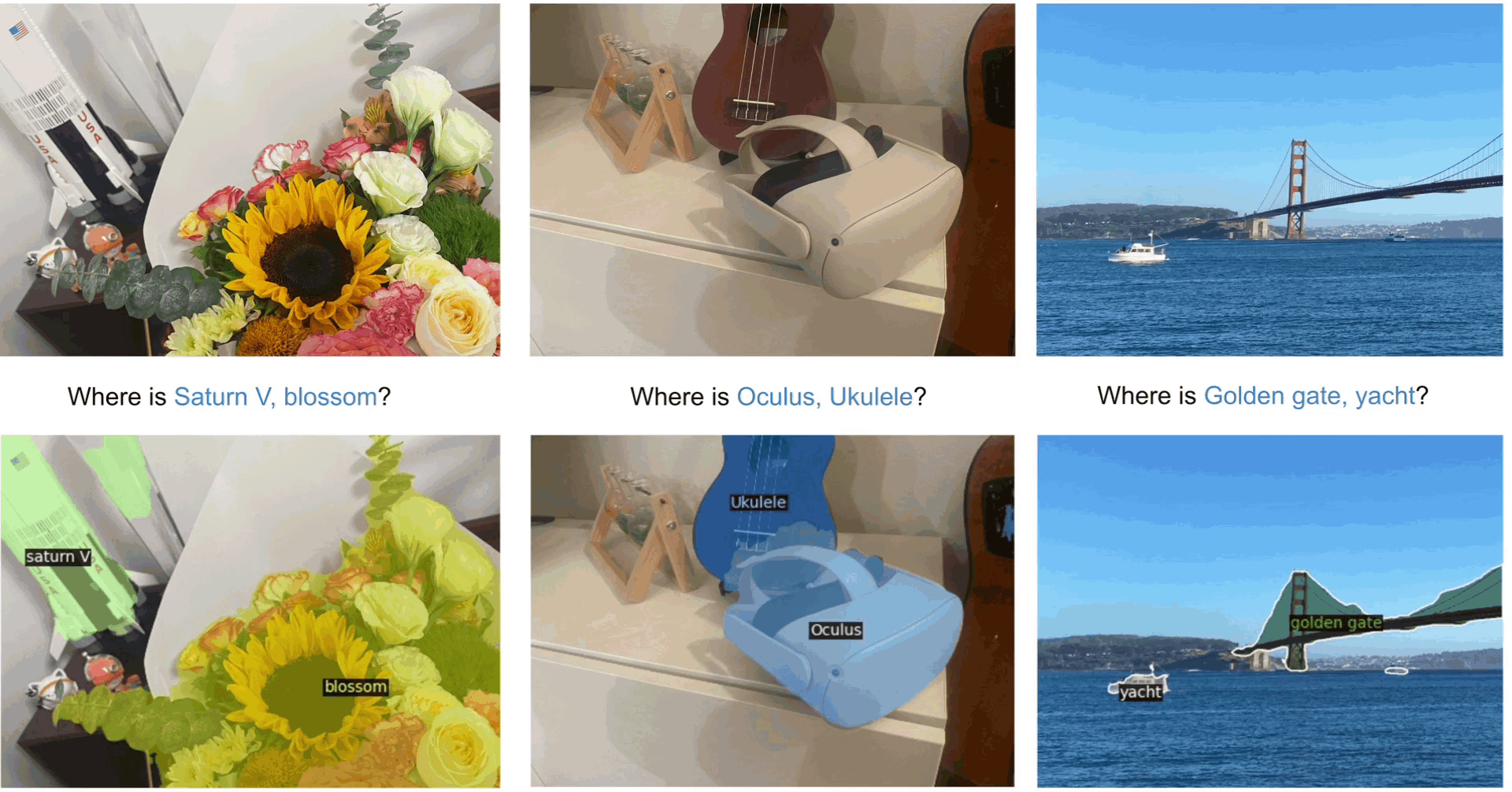 |
CVPR2023 | 项目 | 代码 | META | 根据文本描述将图像分割为语义区域。 |
| Painter | 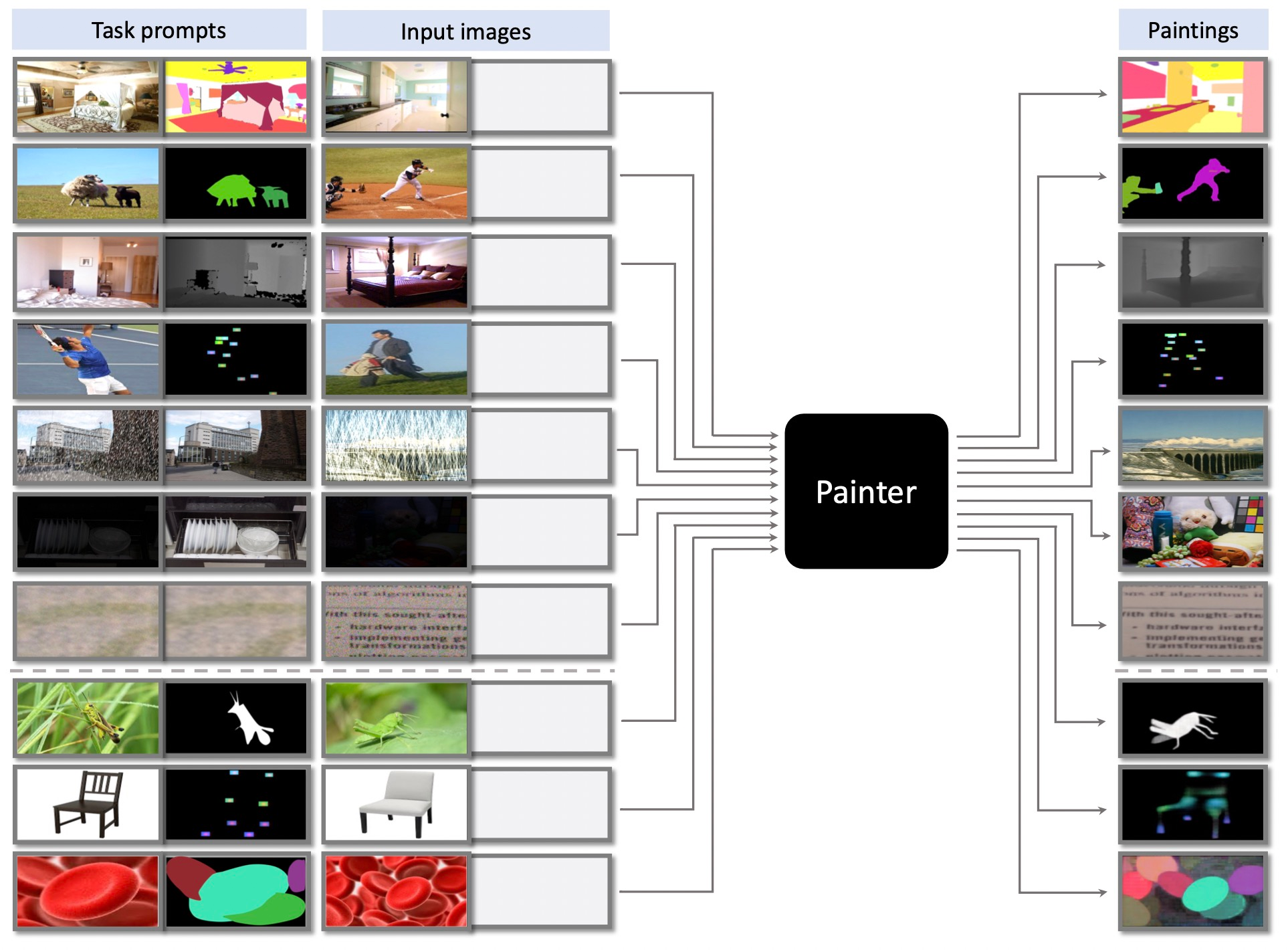 |
CVPR2023 | - | 代码 | BAAI | 一种用于上下文视觉学习的通用画家。 |
| Grounding DINO |  |
arXiv | Colab & Huggingface | 代码 | IDEA | 一个更强大的开放集目标检测器 |
| Segment Anything | 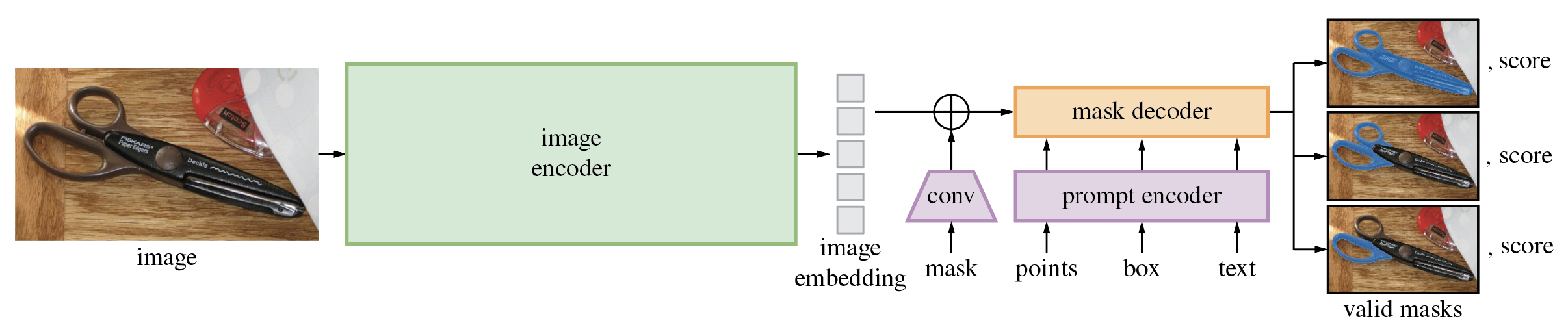  |
arXiv | 项目页面 | 代码 | Meta | 一个功能更强大的大型模型,可用于为图像中的所有对象生成掩码。 |
| SegGPT | 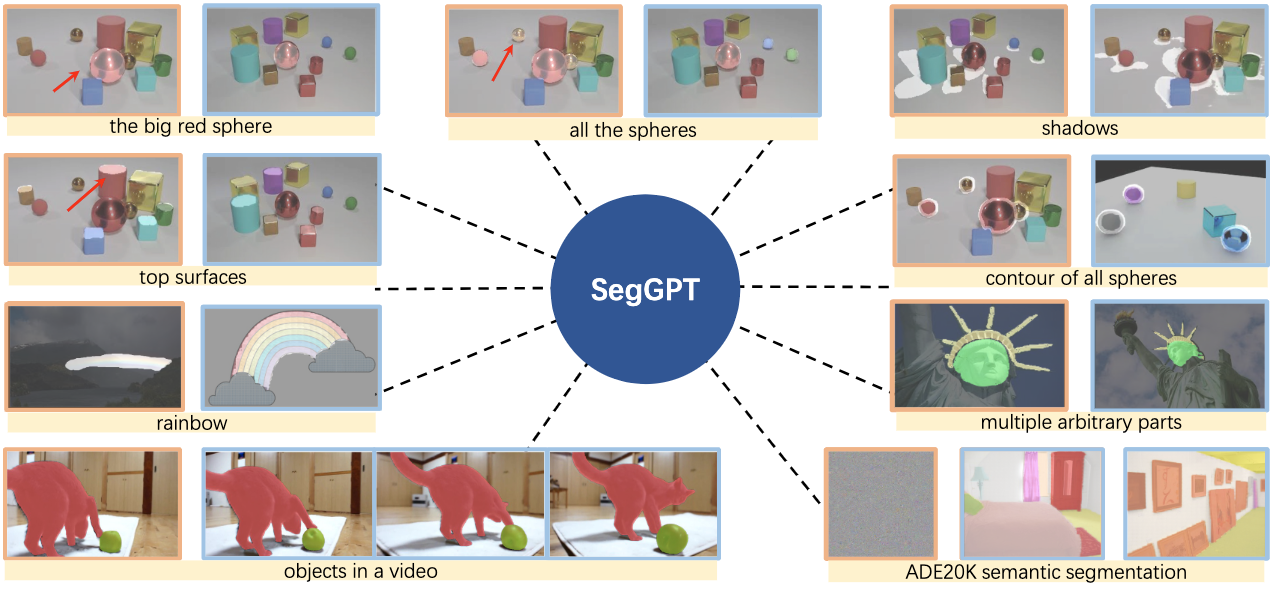 |
arXiv | 项目页面 | 代码 | BAAI | 基于 Painter,在上下文中对一切进行分割。 |
| Segment Everything Everywhere All at Once (SEEM) | 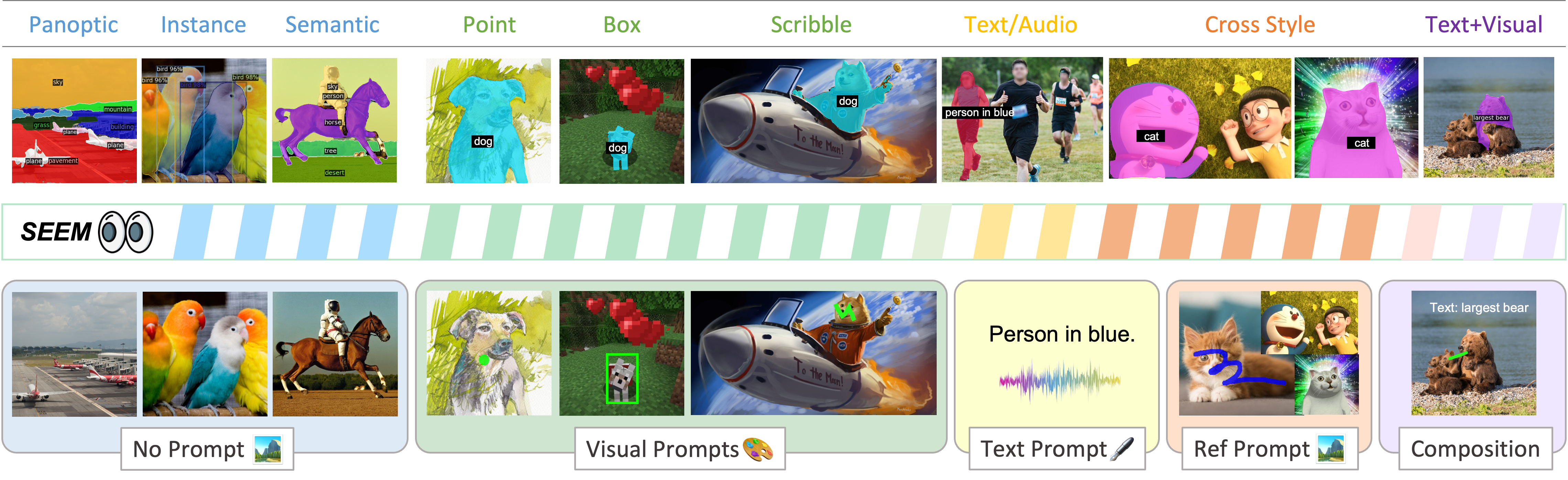 |
arXiv | 项目页面 | 代码 | Microsoft | 基于多种提示类型的语义分割。 |
| Segment Everything2 | ) |
论文 | 项目页面 | 代码 | Meta | 一个用于解决图像和视频中可提示视觉分割的基础模型.. |
Derivative Papers
SAM 的分析与扩展
| 标题 | 演示图 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| CLIP_Surgery |  |
arXiv | Demo | Code | 香港科技大学 | 该工作基于 CLIP 的可解释性,实现无需手动标注点的文本到掩码转换。 |
| GenSAM | 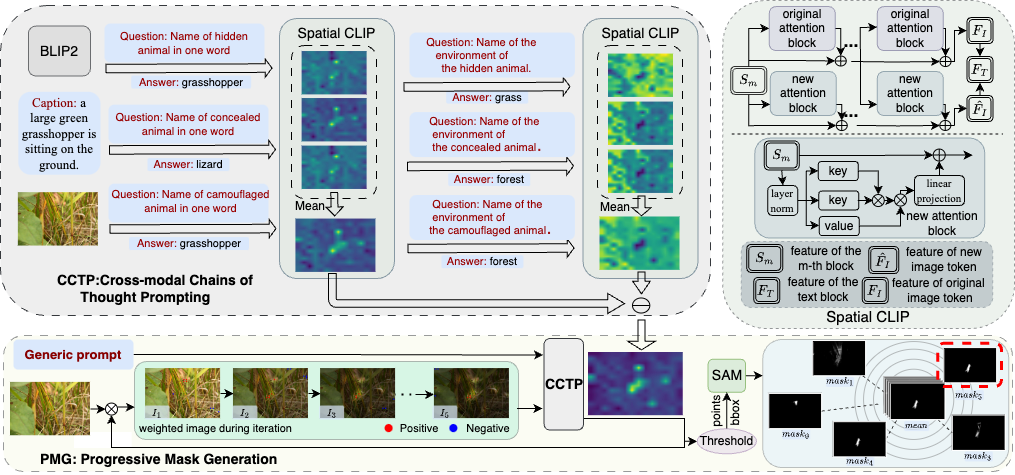 |
arXiv | Project Page | Code | 伦敦玛丽女王大学 | 该工作放宽了对 SAM 中特定实例提示的要求。 |
| Segment Anything Is Not Always Perfect |  |
arXiv | - | - | 三星 | 本文分析并讨论了 SAM 的优势与局限性。 |
| PerSAM | 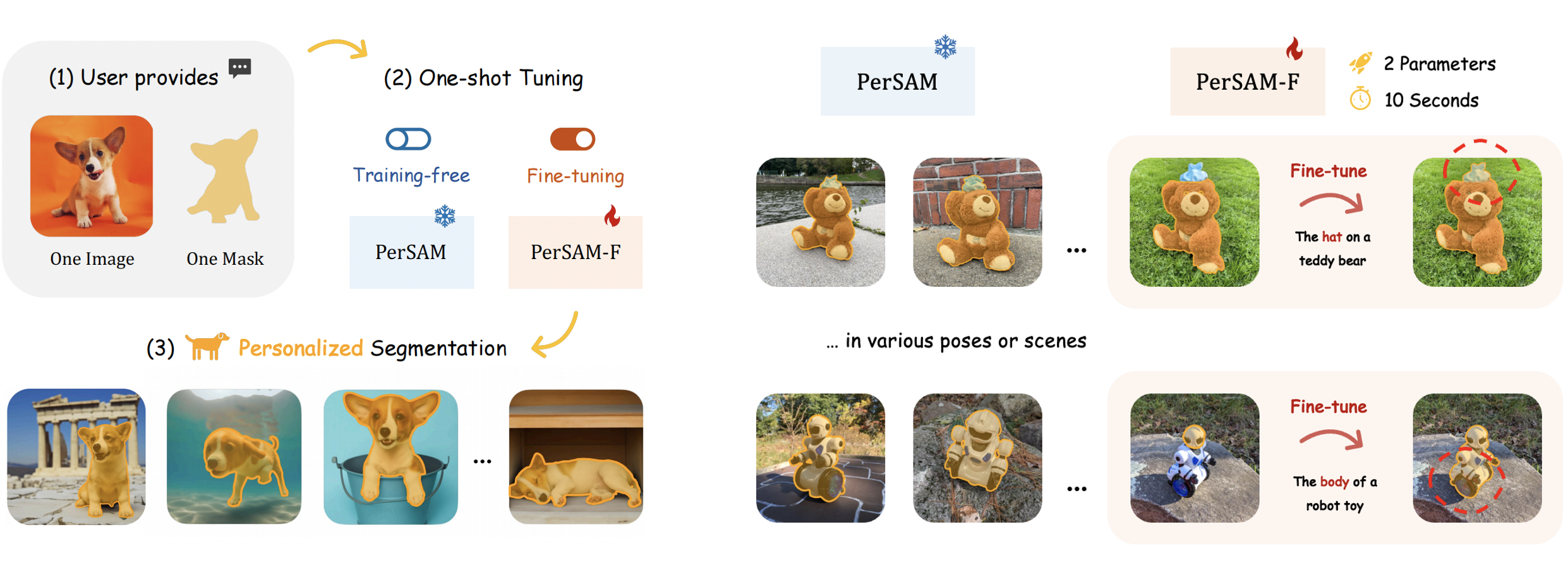 |
arXiv | Project Page | Code | - | 针对特定概念进行分割。 |
| Matcher: 使用通用特征匹配实现单次拍摄的万物分割 | 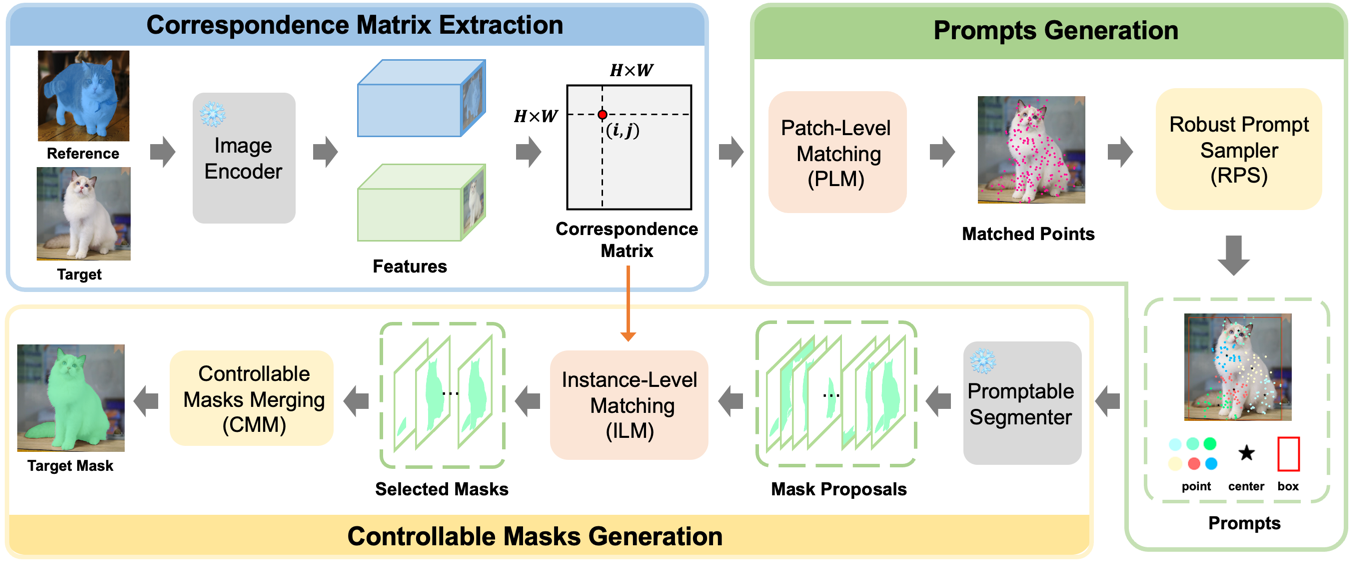 |
arXiv | - | Code | - | 通过整合通用特征提取模型和类无关分割模型,实现单次拍摄的语义分割。 |
| 高质量万物分割 | 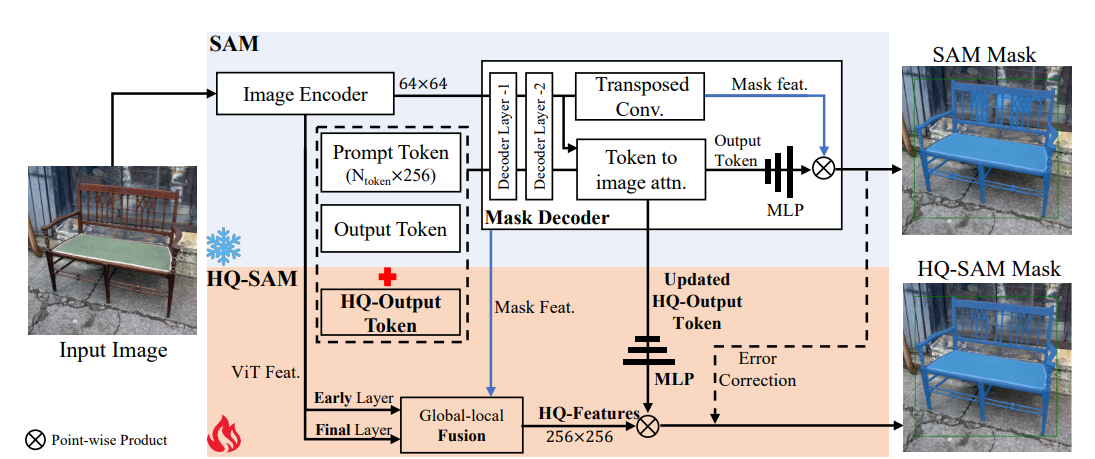 |
arXiv | Project Page | - | 苏黎世联邦理工学院 & 香港科技大学 | HQ-SAM:利用可学习的高质量输出令牌提升 SAM 的分割质量。 |
| Detect Any Shadow:用于视频阴影检测的万物分割 | 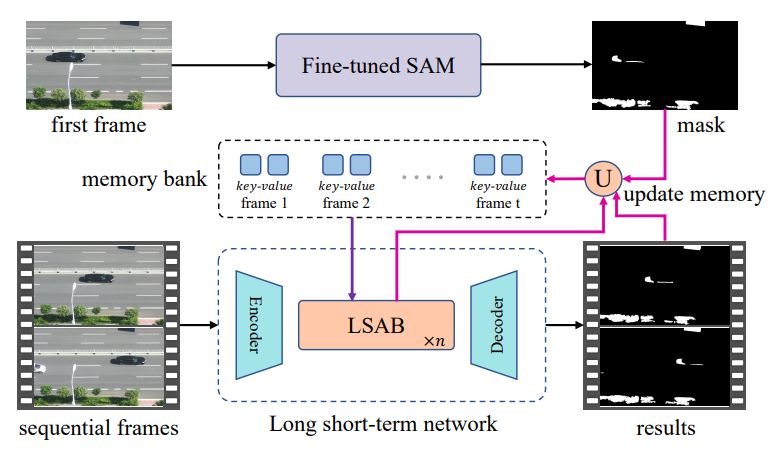 |
arXiv | - | Code | 中国科学技术大学 | 使用 SAM 检测初始帧,随后利用 LSTM 网络处理后续帧。 |
| 快速万物分割 |  |
arXiv | Project Page | Code | - | 重新设计架构并提升 SAM 的速度。 |
| MobileSAM(更快速的万物分割) | 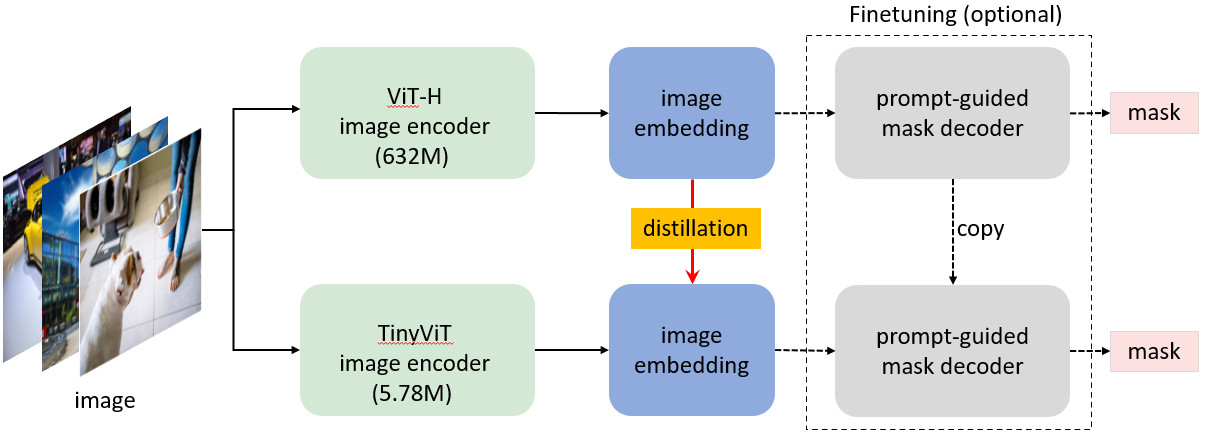 |
arXiv | Project Page | Code | 庆熙大学 | 通过用轻量级图像编码器替换重量级编码器,使 SAM 更适合移动端应用。 |
| FoodSAM(任意食物分割) | 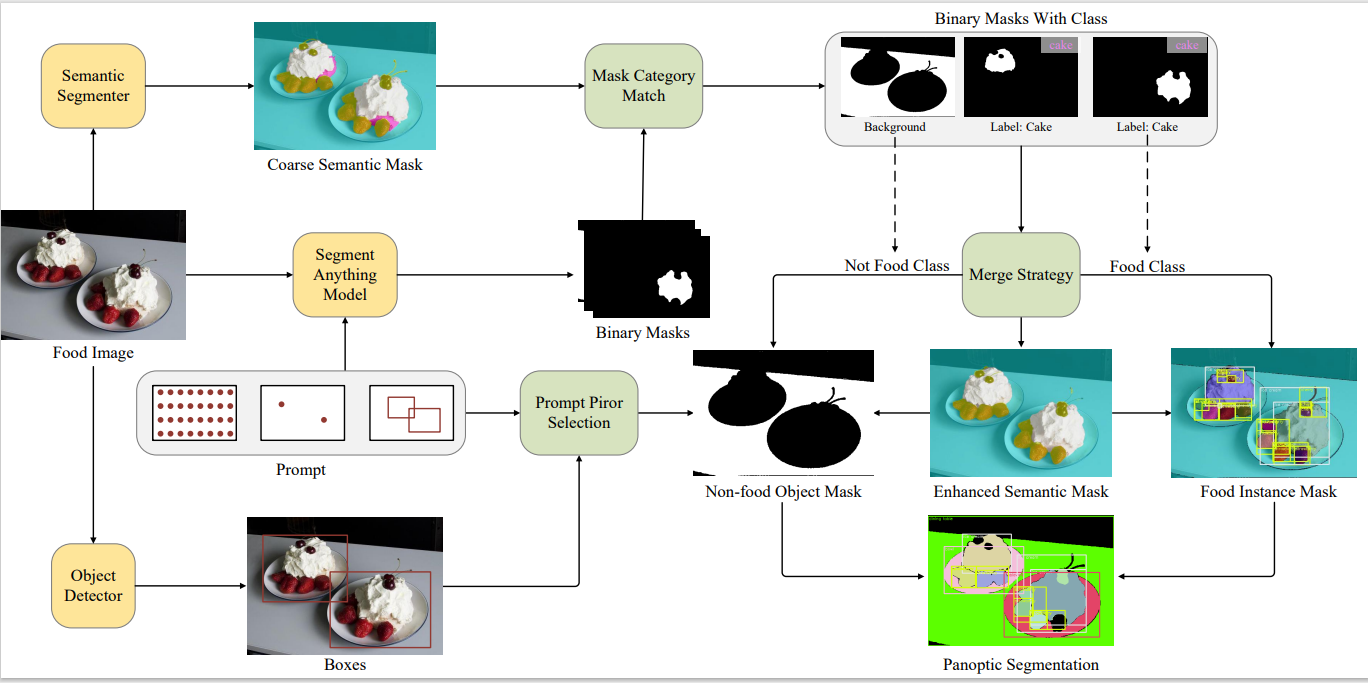 |
arxiv | Project Page | Code | 中国科学院大学 | 对食物图像进行语义、实例、全景及交互式分割。 |
| DefectSAM | 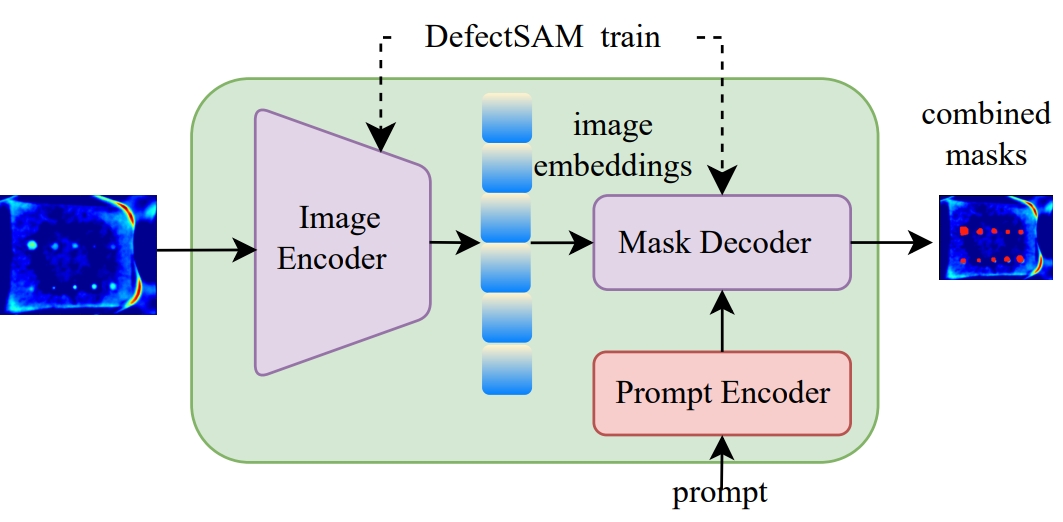 |
arxiv | - | Code | 浙江大学、西湖大学、电子科技大学等 | 针对红外热成像进行缺陷检测。 |
| SlimSAM |  |
arxiv | - | Code | 国立新加坡大学 | 仅需 0.1% 数据即可实现精简版万物分割。 |
医学图像分割
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| 数字病理中的 Segment Anything Model (SAM) | 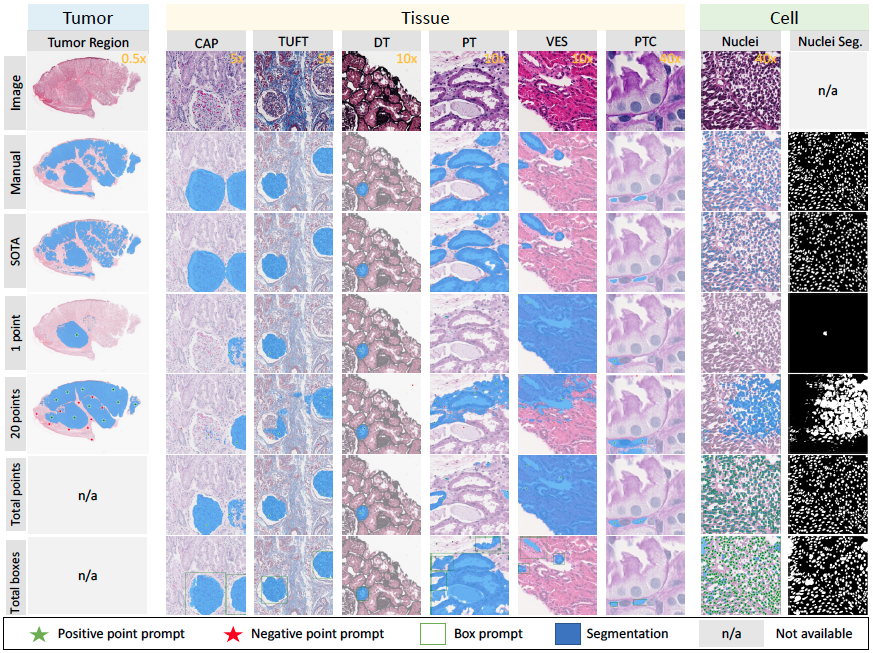 |
arXiv | - | - | - | SAM + 肿瘤分割/组织分割/细胞核分割。 |
| 医学图像中的 Segment Anything | 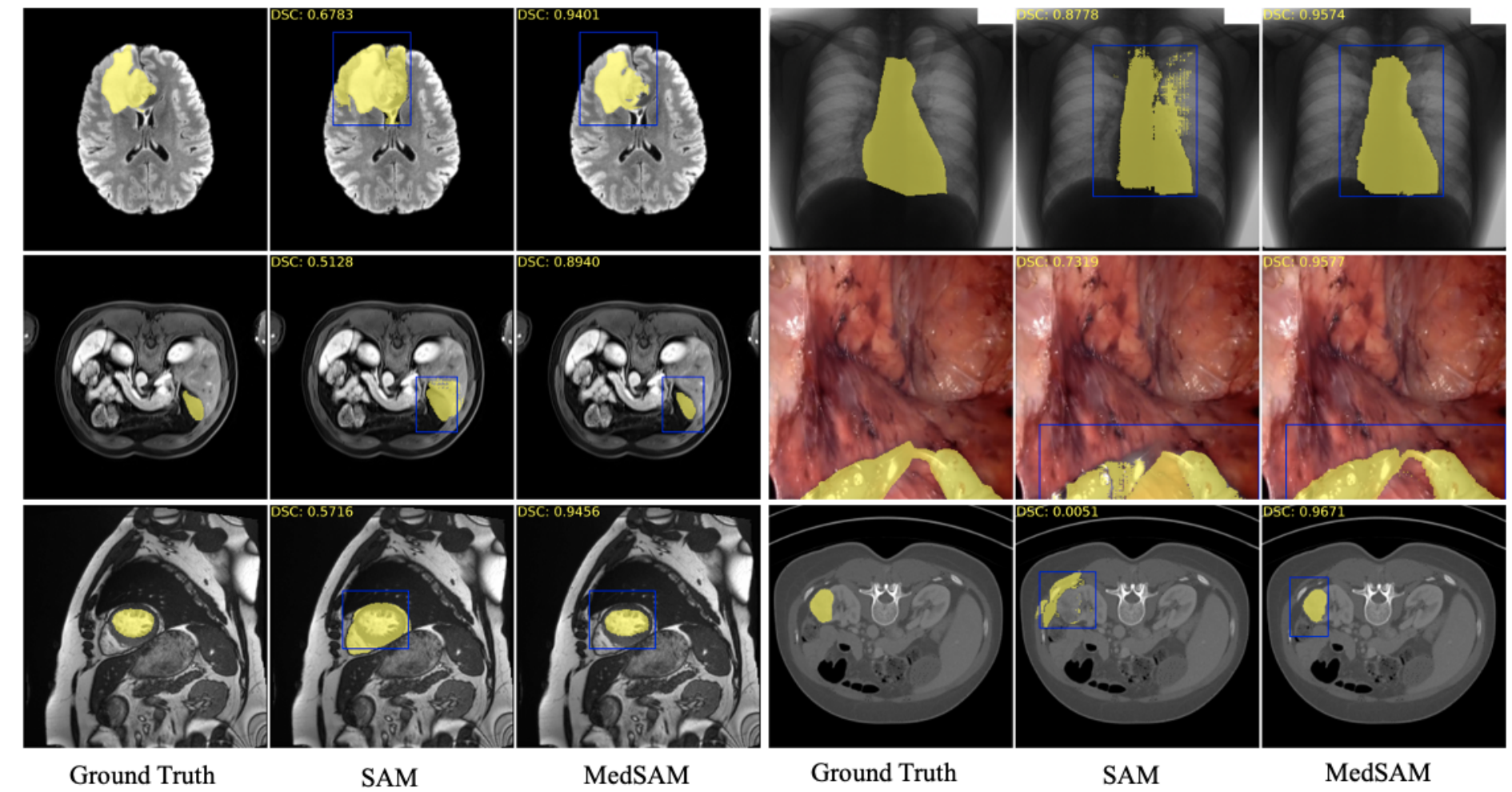 |
arXiv | - | 代码 | - | 带有小型数据集的分步教程,帮助您快速使用 SAM。 |
| SAM 是否无法分割任何内容? | arXiv | - | 代码 | - | SAM适配器:在表现不佳的场景中适配 SAM:伪装、阴影、医学图像分割等。 | |
| 用于医学图像分析的 Segment Anything Model:一项实验研究 | 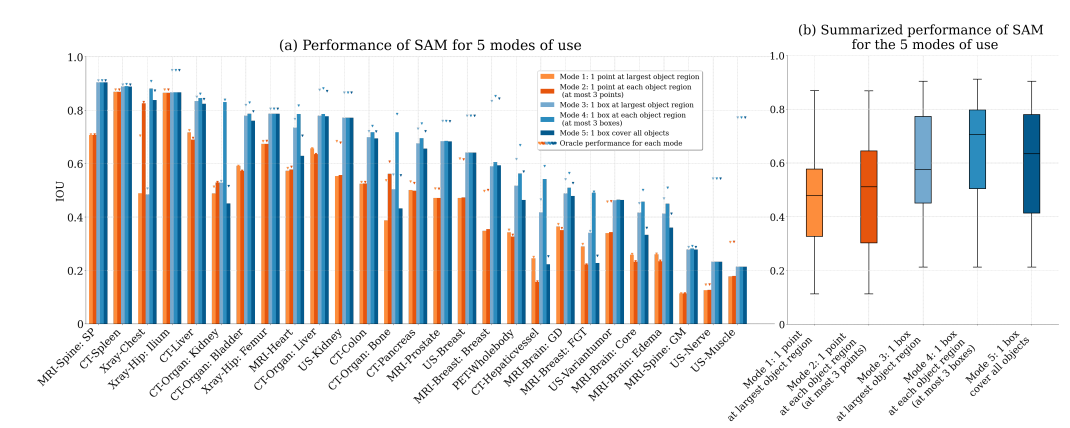 |
arXiv | - | - | - | 对 SAM 在 19 个医学图像数据集上的表现进行的全面实验。 |
| Medical-SAM-Adapter | 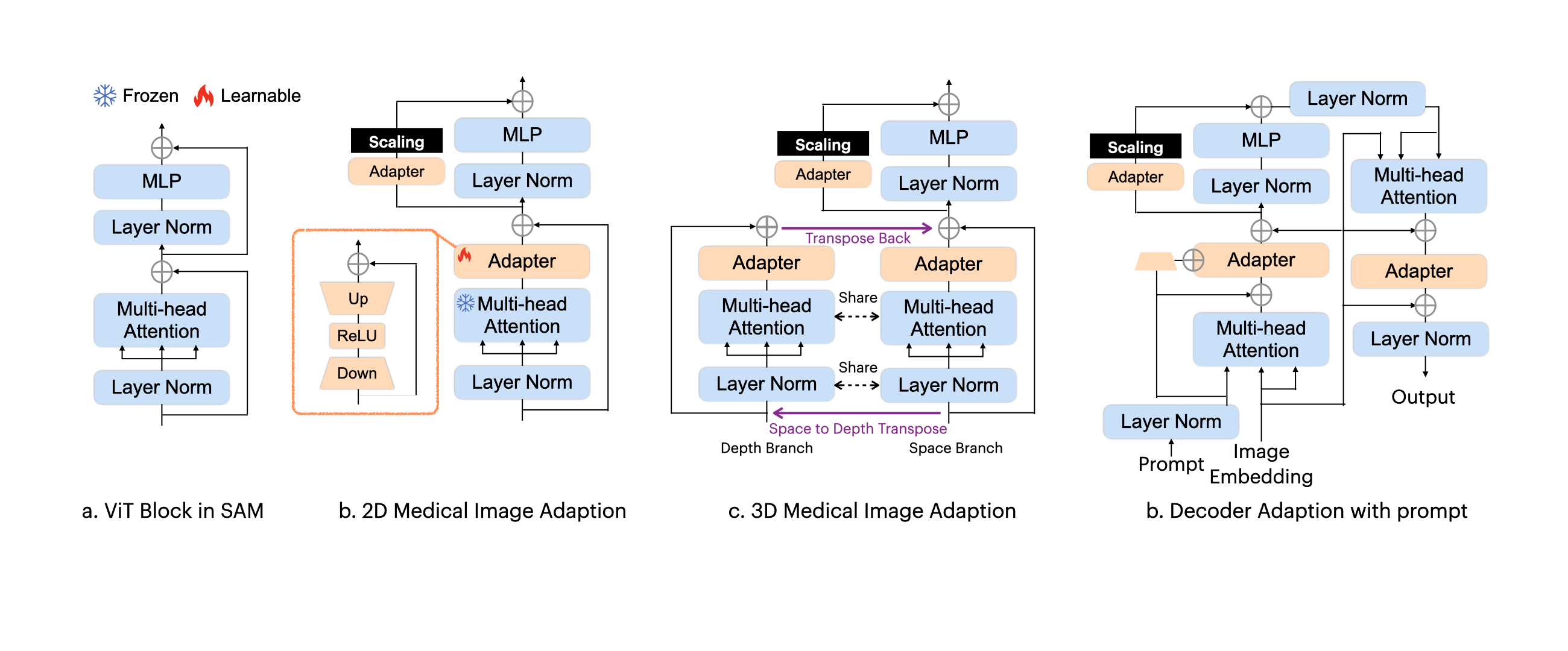 |
arXiv | - | 代码 | - | 一个使用适配技术对医学影像进行微调的项目。 |
| SAM-Med2d | 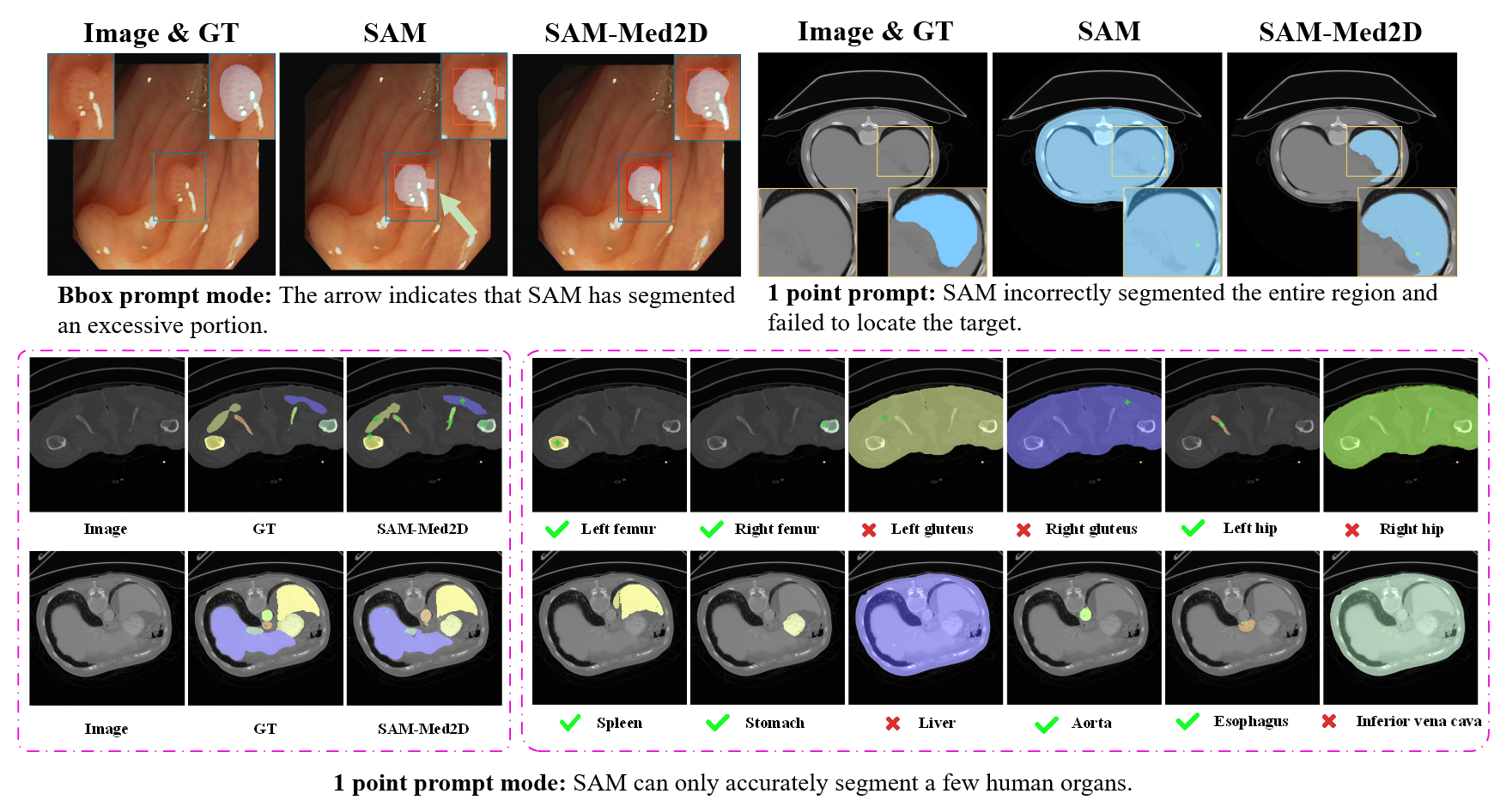 |
arXiv | - | 代码 | 四川大学 & 上海人工智能实验室 | 关于将 SAM 应用于医学 2D 图像的最全面研究 |
| ScribblePrompt-SAM |  |
arXiv | 项目页 | 代码 | MIT & MGH | 使用涂鸦、点击和边界框输入,在 65 个生物医学成像数据集上微调 SAM |
| SaLIP | - | arXiv | 项目页 | 代码 | - | 使用 SaLIP 的测试时适应:SAM 和 CLIP 的级联,用于零样本医学图像分割。 |
生物图像分析
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| 显微镜下的 Segment Anything | 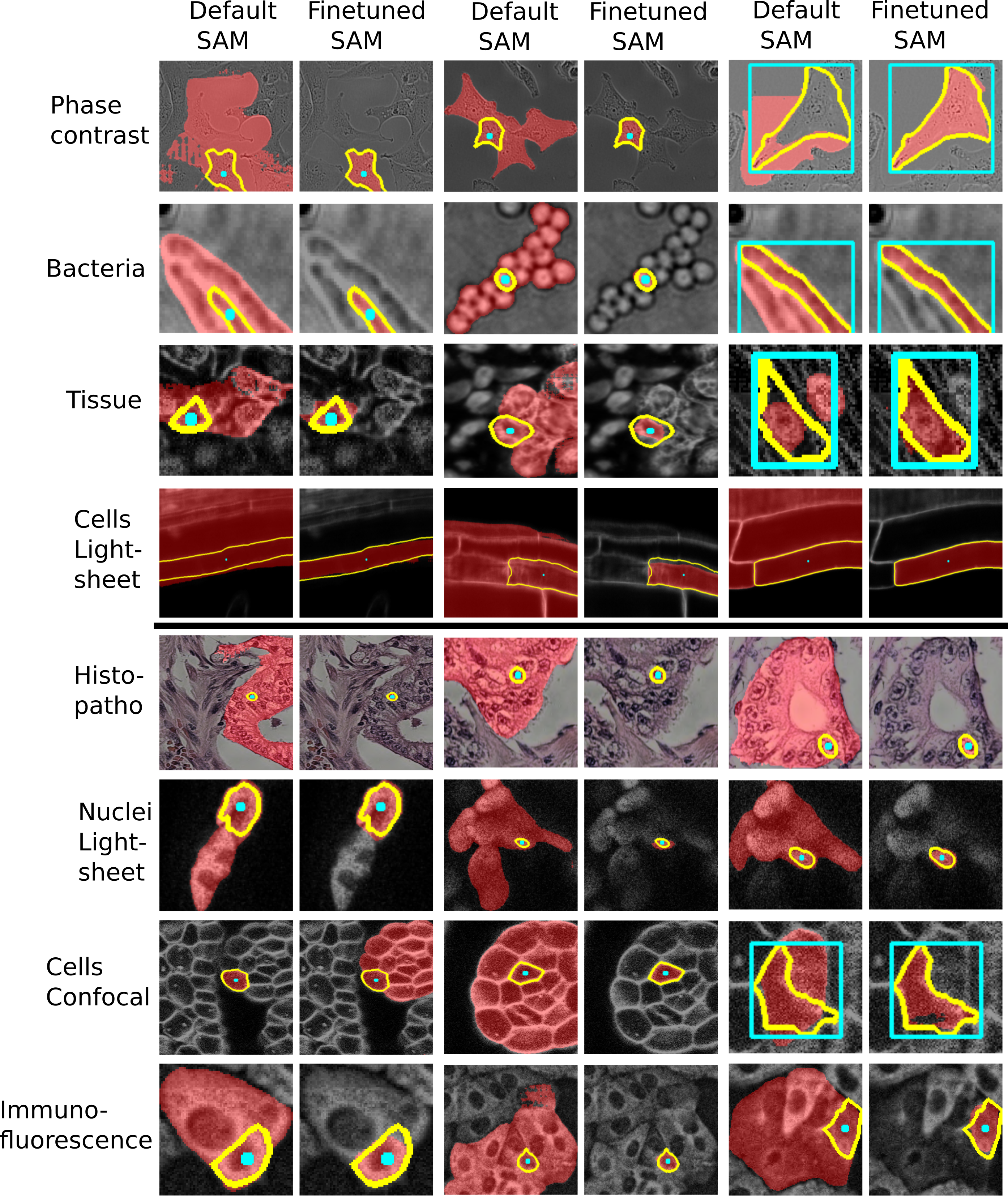 |
bioRxiv | 演示 | 代码 | 德国哥廷根大学 | 显微镜下的 Segment Anything 实现了显微镜数据的自动和交互式标注。它基于 Segment Anything 构建,并专门针对显微镜和其他生物成像数据进行了优化。其核心组件包括:
|
图像修复
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| 修复任何内容 |  |
arXiv | - | 代码 | 中国科学技术大学 & EIT | SAM + 图像修复,能够平滑地移除物体。 |
| SAM + Stable Diffusion 用于文本到图像的图像修复 | 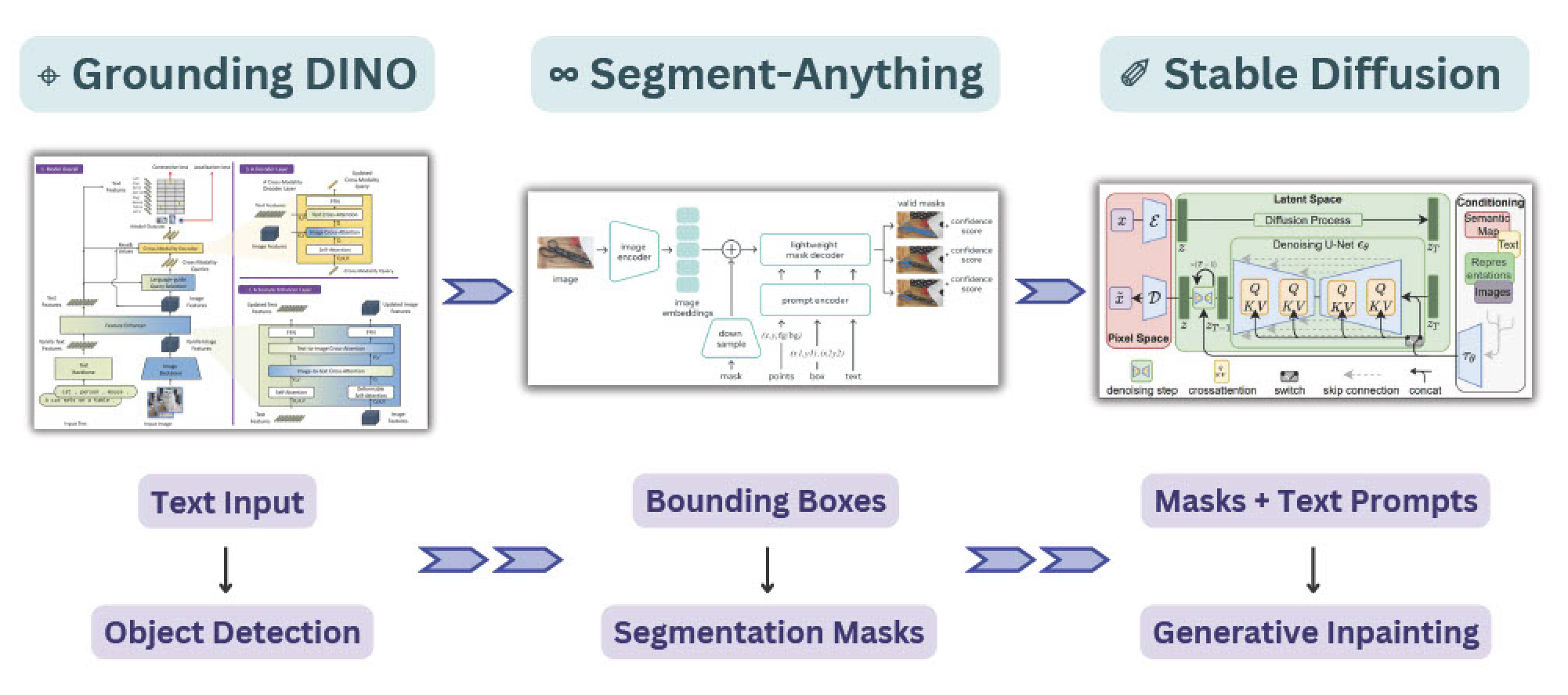 |
- | 项目 | 代码 | comet | Grounding DINO + SAM + Stable Diffusion |
伪装目标检测
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| SAMCOD | - | arXiv | - | 代码 | - | SAM + 伪装目标检测 (COD) 任务。 |
视频帧插值
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| 更清晰的帧,随时可用:解决视频帧插值中的速度模糊问题 |  |
arXiv | 项目页 & 交互式演示 | 代码 | 上海人工智能实验室 & Snap Inc. | 使用 SAM 的可编辑视频帧插值。 |
低层视觉
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| 视频超分辨率中的 Segment Anything | 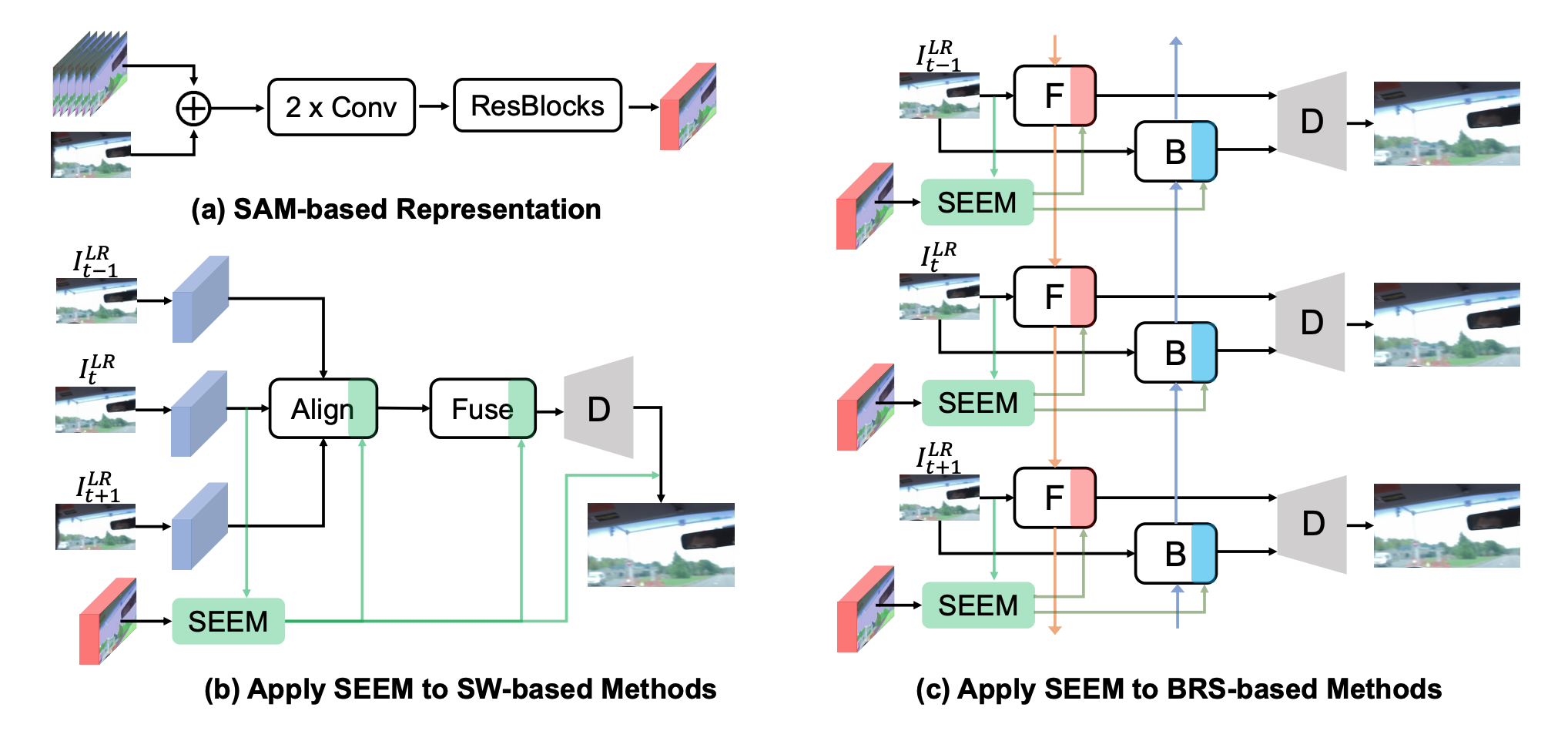 |
arXiv | - | - | - | 将 SAM 用于低层视觉的第一步。 |
| SAM-IQA | 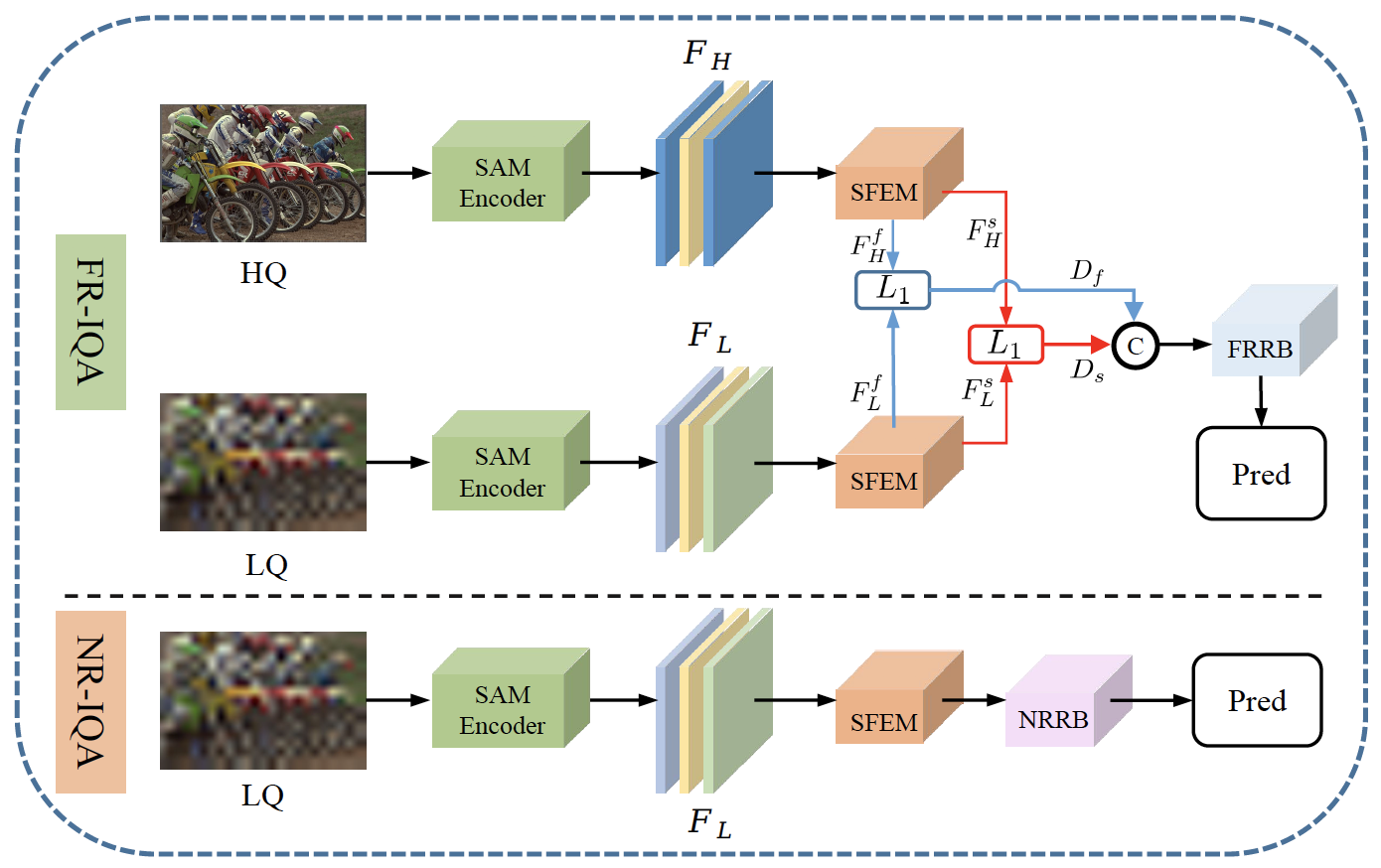 |
arXiv | - | 代码 | Megvii | 首次将 SAM 引入 IQA 领域,并展示了其在该领域的强大泛化能力。 |
图像抠图
| 标题 | 演示 | 论文页面 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| Matte Anything | 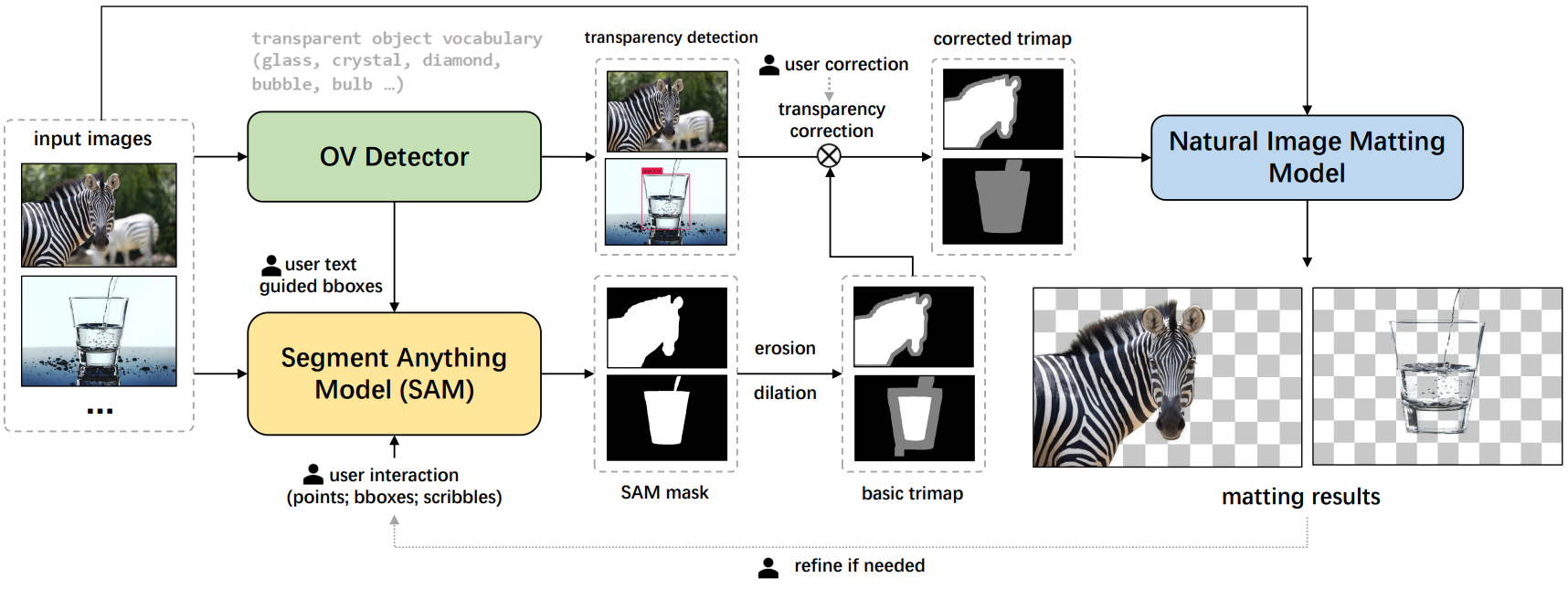  |
arXiv | - | 代码 | 华中科技大学视觉实验室 | 一个交互式的自然图像抠图系统,对不透明和透明物体均表现出色 |
| Matting Anything | 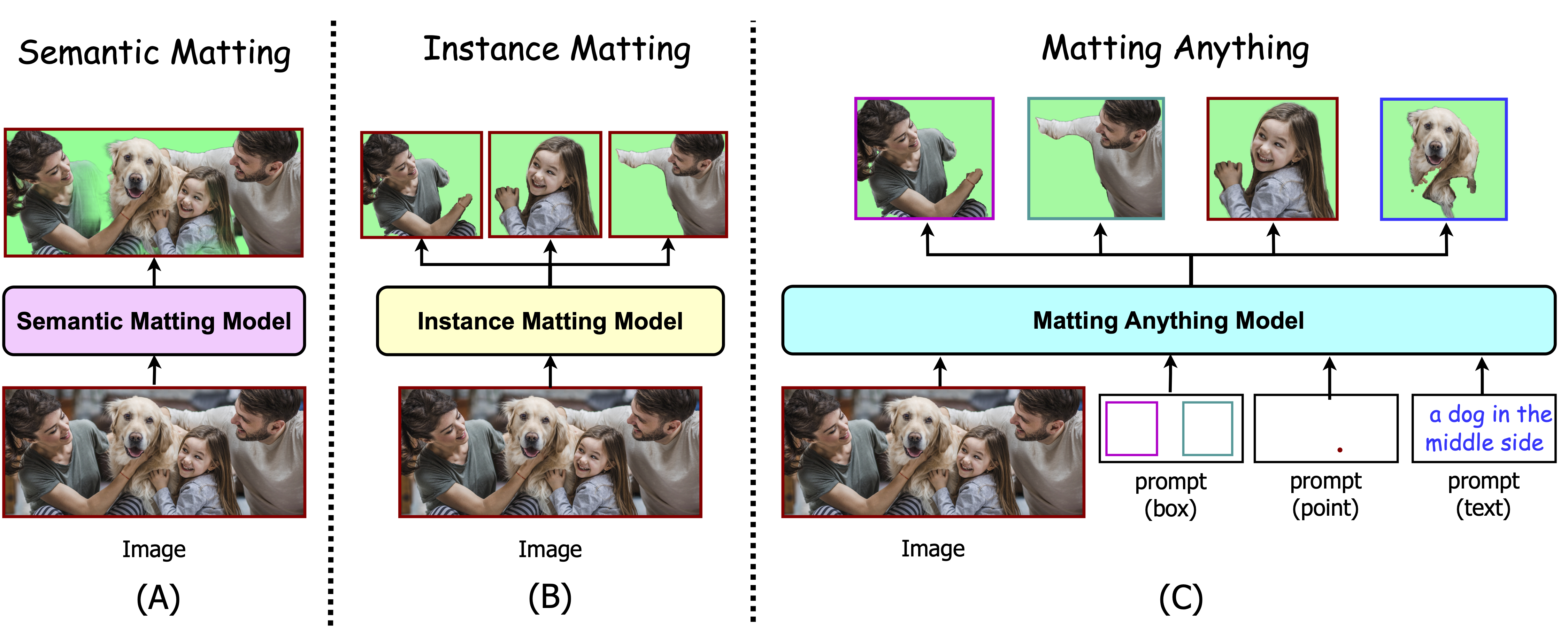 |
arXiv | 项目页面 | 代码 | SHI Labs | 利用SAM的特征图,并采用Mask-to-Matte模块来预测alpha抠图。 |
机器人
| 标题 | 演示 | 论文页面 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| Instruct2Act | 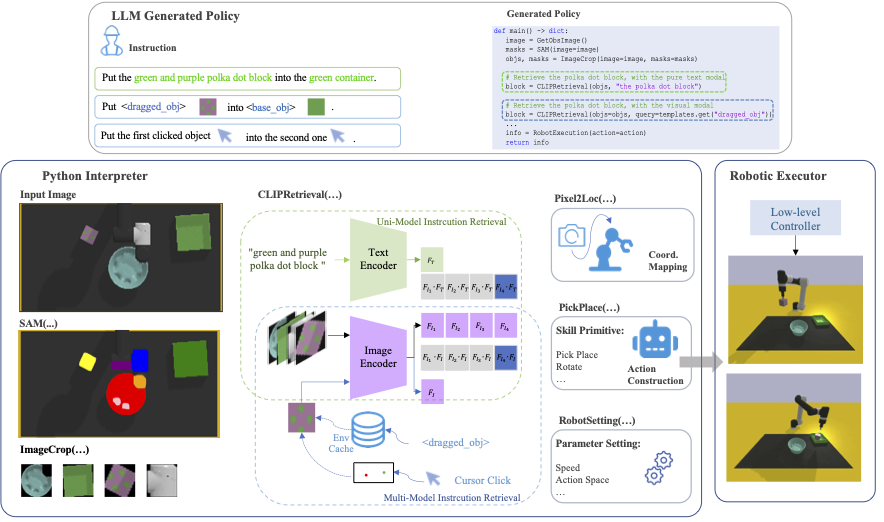 |
arXiv | - | 代码 | OpenGVLab | SAM在机器人领域的应用。 |
生物信息学
| 标题 | 演示 | 论文页面 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| IAMSAM | 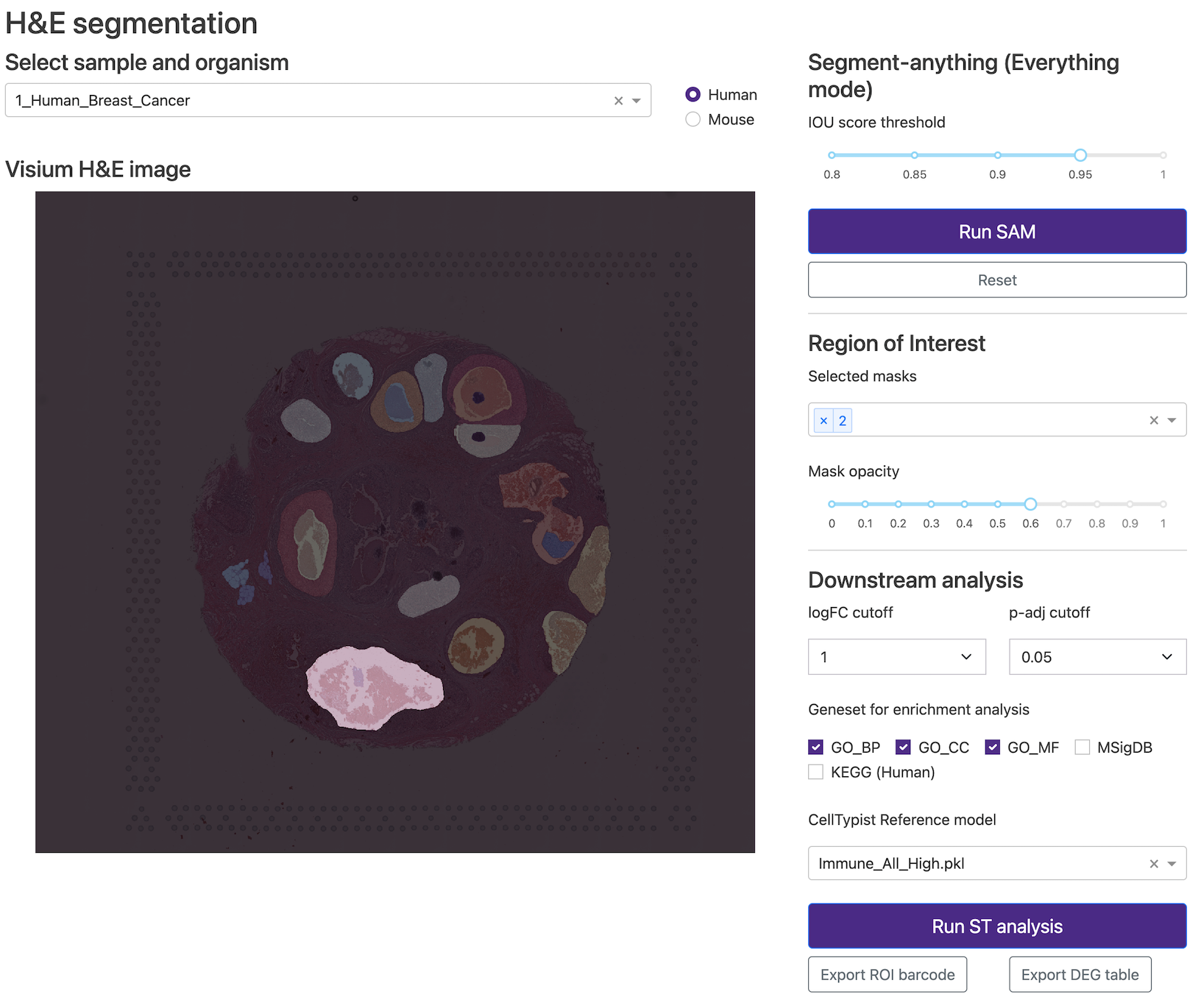 |
bioRxiv | - | 代码 | Portrai Inc. | 一种用于空间转录组学分析的SAM应用。 |
3D
| 标题 | 演示 | 论文页面 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| Point-SAM |  |
arXiv | 页面 | 代码 | UCSD | 一种开放世界、原生可提示的3D点云分割方法。 |
| SAMPro3D |  |
arXiv | 页面 | 代码 | CUHKSZ, MSRA | 一种新颖的方法,通过将SAM应用于2D帧来分割任何3D室内场景,无需任何训练、调优、蒸馏或3D预训练网络。 |
| Seal |  |
arXiv | 页面 | 代码 | - | 一个能够利用2D视觉基础模型进行大规模3D点云自监督学习的框架。 |
| TomoSAM |  |
arXiv | 视频教程 | 代码 | - | 一个基于SAM扩展的3D Slicer插件,用于辅助分割来自断层扫描或其他成像技术的3D数据。 |
| SegmentAnythingin3D | 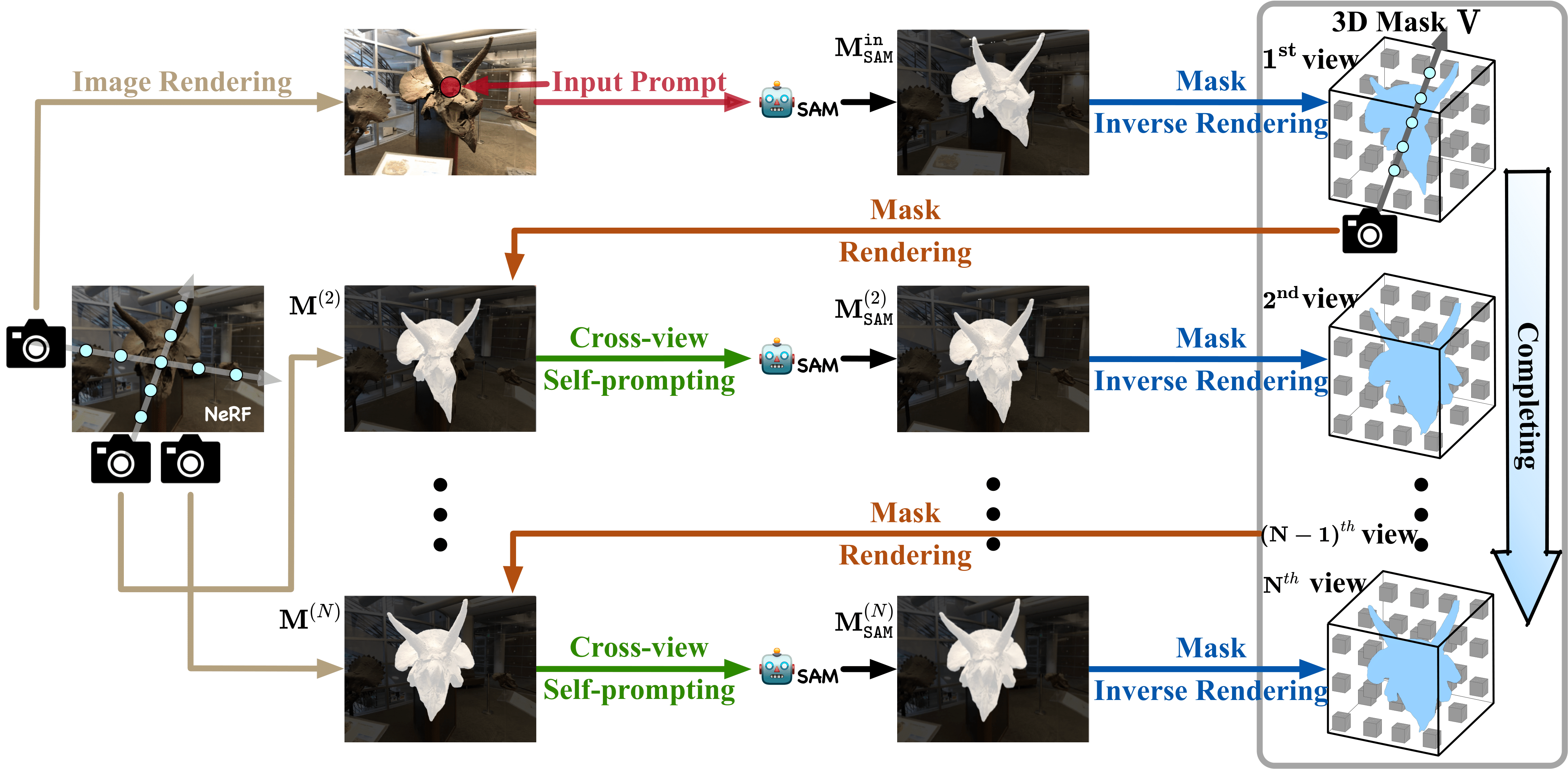 |
arXiv | 项目 | 代码 | - | 一个名为SA3D的新颖3D“万物分割”框架。 |
遥感
| 标题 | 演示 | 论文页面 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| RSPrompter |  |
arXiv | 项目页面 | 代码 | 北京航空航天大学 | 一种基于SAM的遥感图像自动实例分割方法。 |
| SAM-CD | 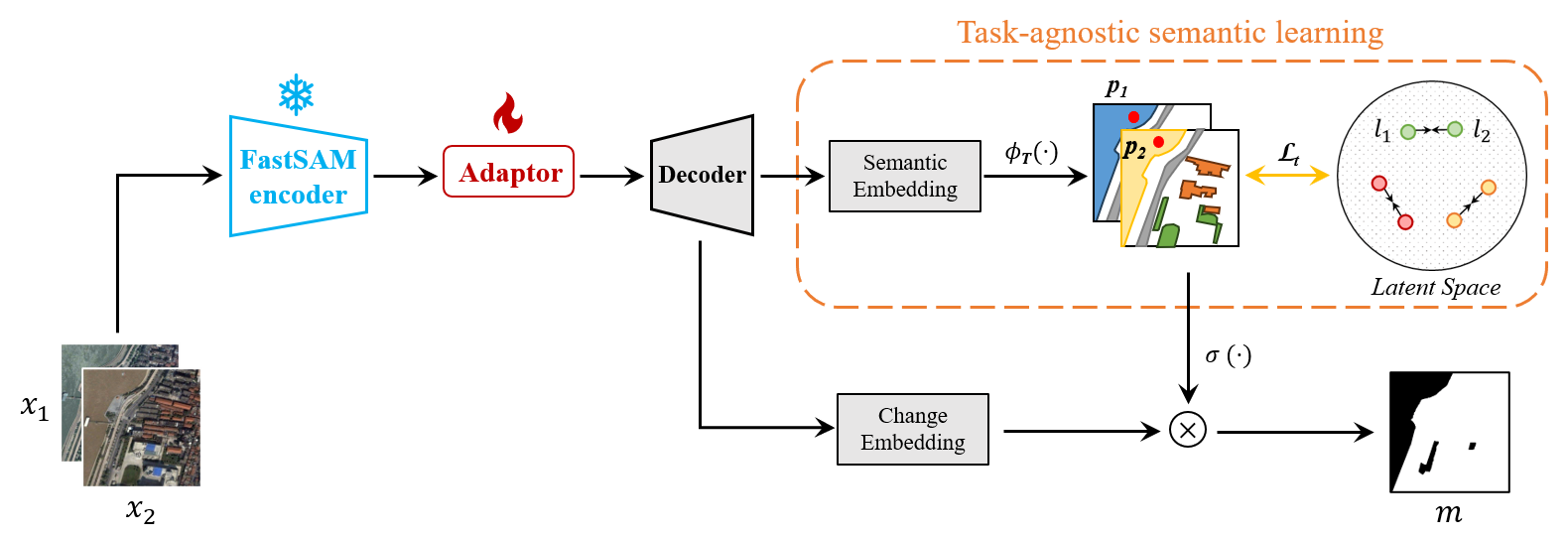 |
arXiv | - | 代码 | 中国人民解放军信息工程大学 | 一个样本高效的变化检测框架,采用SAM作为视觉编码器。 |
| SAM-Road: 用于道路网络图提取的Segment Anything Model |  |
arXiv | - | 代码 | 卡内基梅隆大学 | 一种简单快速的应用SAM进行大规模道路网络矢量化提取的方法。该方法在达到最先进精度的同时,速度提升了40倍。 |
跟踪
| 标题 | 演示 | 论文页面 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| Follow Anything | 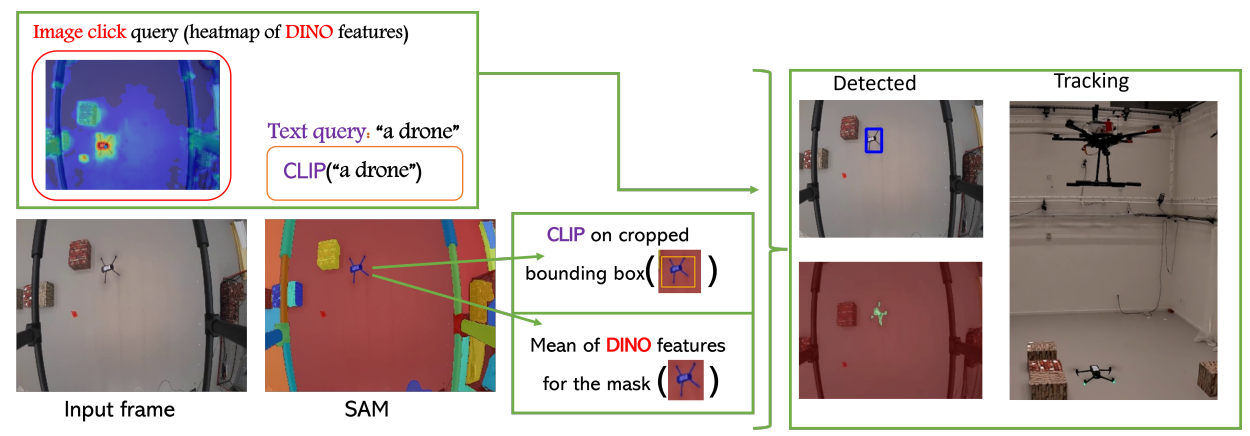 |
arXiv | 页面 | 代码 | MIT、哈佛大学 | 一个开放词汇、多模态的模型,可实时检测、跟踪并跟随任何物体。 |
| Track-Anything | 视频 | arXiv | - | 代码 | MIT、哈佛大学 | 一个开放词汇、多模态的模型,可实时检测、跟踪并跟随任何物体。 |
| SAM-Track | 视频 | arXiv | - | 代码 | MIT、哈佛大学 | 一个名为“分割与跟踪万物”(SAMTrack)的框架,允许用户精确有效地分割和跟踪视频中的任何物体。 |
{kind=link}
视听定位与分割
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| AV-SAM | 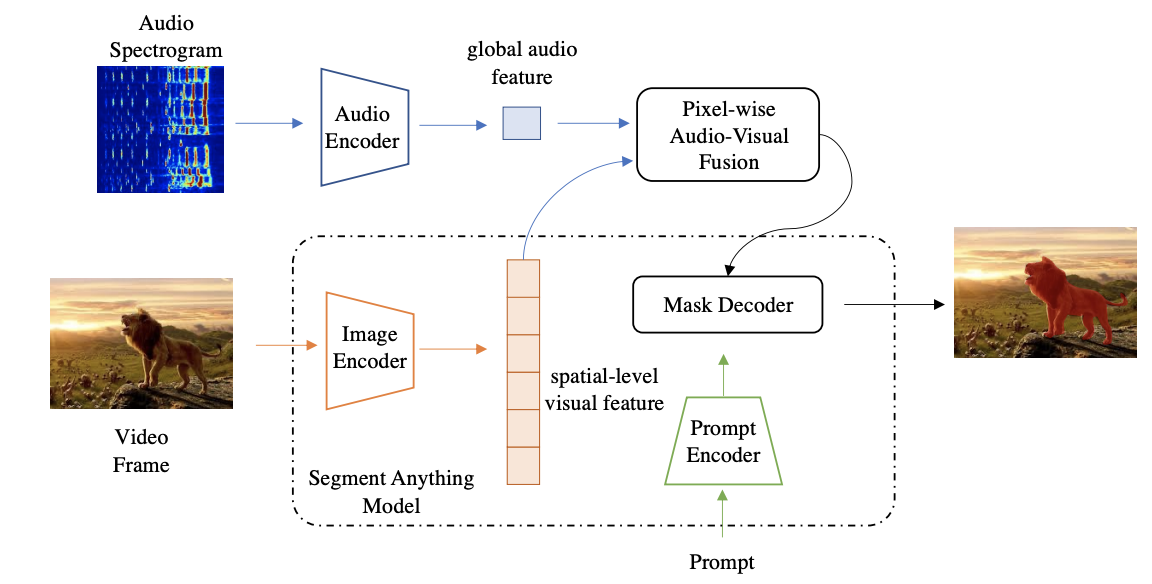 |
arXiv | - | 代码 | 卡内基梅隆大学 | 一个基于SAM的简单而高效的视听定位与分割框架。 |
对抗攻击
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| Attack-SAM | - | arXiv | - | - | 韩国科学技术院 | 首次全面研究如何利用对抗样本攻击SAM的工作。 |
多媒体取证
| 标题 | 演示 | 论文页 | 项目页 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|---|
| SAFIRE:分割任何伪造图像区域 | 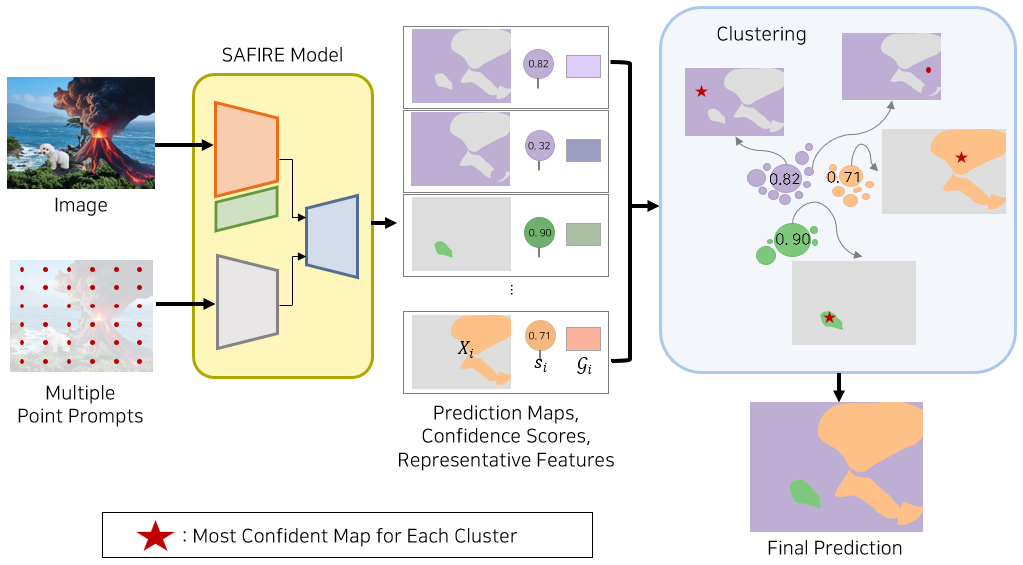 |
arXiv | - | 代码 | 韩国科学技术院 | 将SAM的点提示能力扩展到图像取证领域,实现精确的源信息感知分割,用于伪造内容的定位。 |
衍生项目
图像分割任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| Grounded Segment Anything |  |
Colab & Huggingface | 代码 | - | 结合 Grounding DINO 和 Segment Anything |
| GroundedSAM 异常检测 | 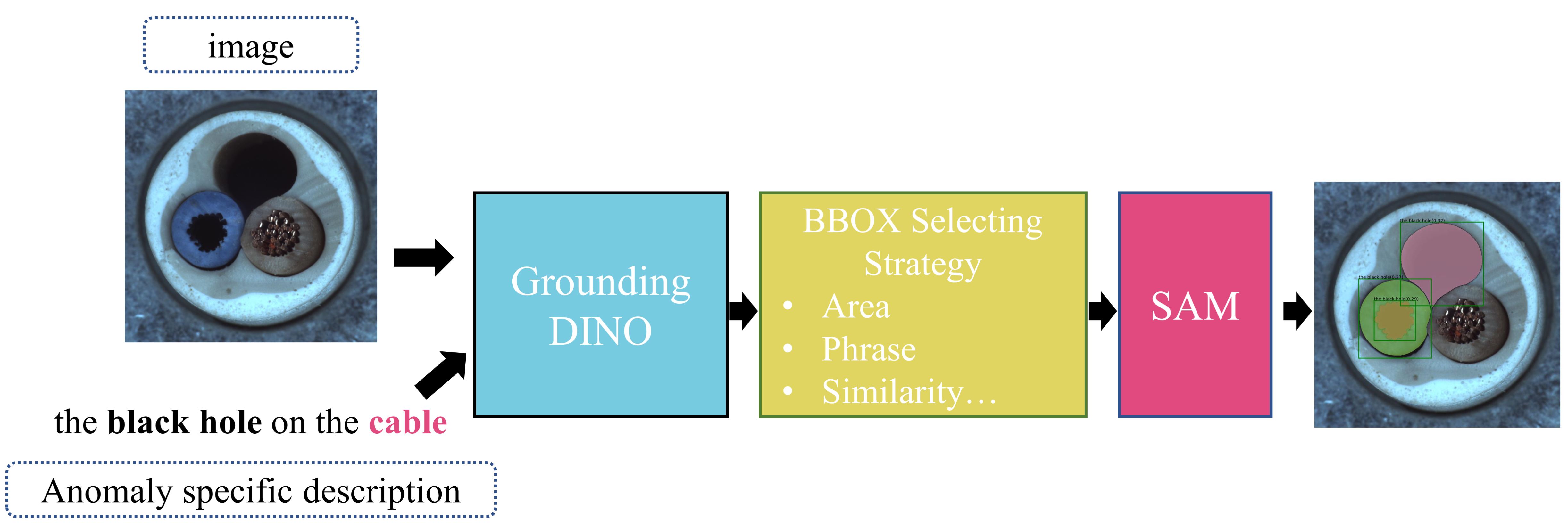 |
- | 代码 | - | 使用 Grounding DINO + SAM 来分割任何异常。 |
| 语义 Segment Anything |  |
- | 代码 | 复旦大学 | 一个密集类别标注引擎。 |
| Magic Copy |  |
- | 代码 | - | Magic Copy 是一款使用 SAM 的 Chrome 扩展程序。 |
| YOLO-World + EfficientViT SAM |  |
🤗 HuggingFace Space | 代码 | - | 使用 YOLO-World + EfficientViT SAM 实现高效的开放词汇目标检测和分割 |
| Clip 辅助的 Segment Anything | 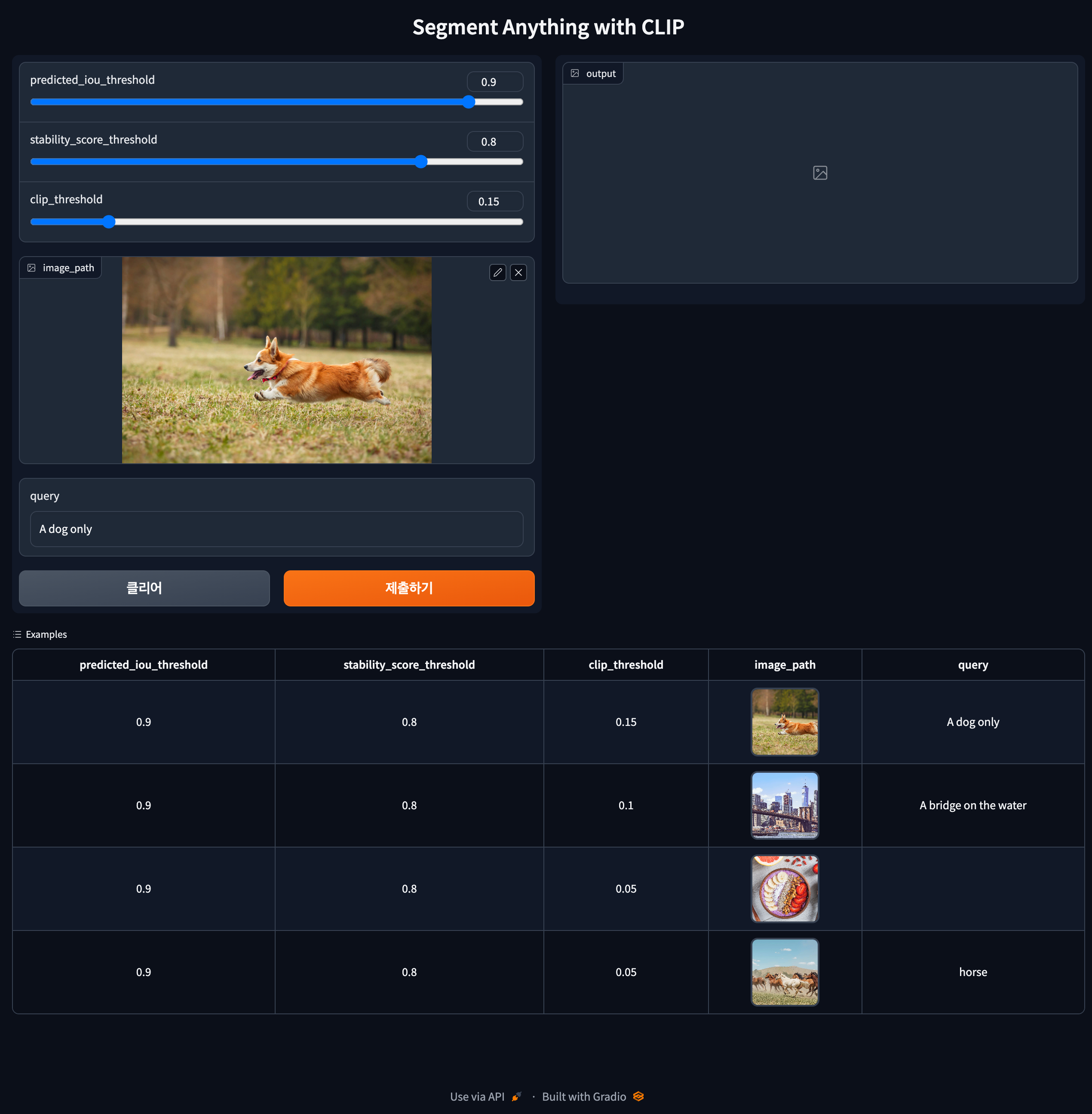 |
🤗 HuggingFace Space | 代码 | - | SAM + CLIP |
| SAM-Clip |  |
- | 代码 | - | SAM + CLIP。 |
| Prompt Segment Anything |  |
- | 代码 | - | SAM + 零样本实例分割。 |
| RefSAM | - | - | 代码 | - | 在引用式图像分割任务上评估 SAM 的基本性能。 |
| SAM-RBox |  |
- | 代码 | - | SAM 在 MMRotate 中用于生成旋转边界框的实现。 |
| 开放词汇 Segment Anything | 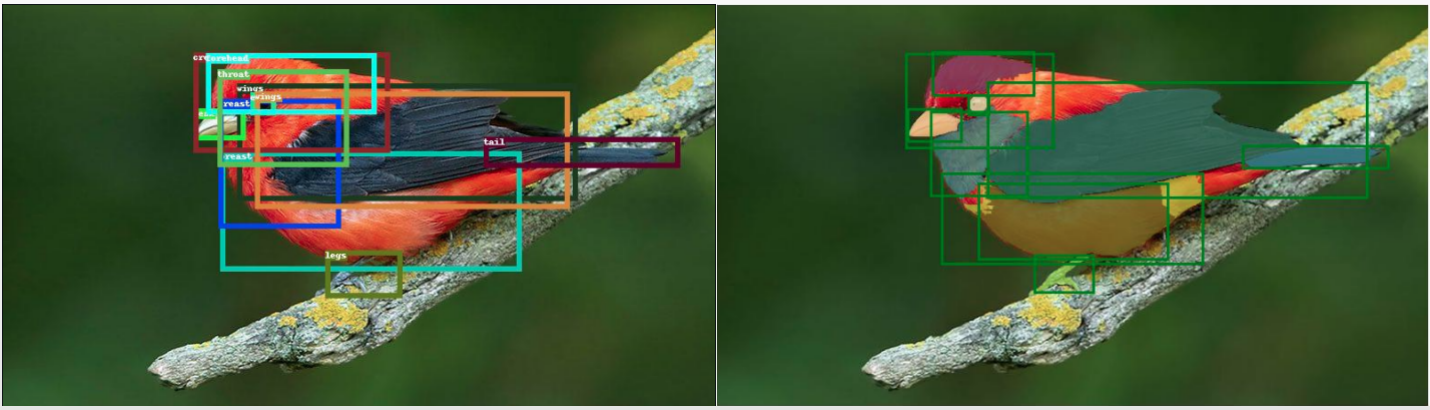 |
- | 代码 | - | 通过结合 Google 的 OWL-ViT 和 SAM 实现的一个有趣演示。 |
| SegDrawer | 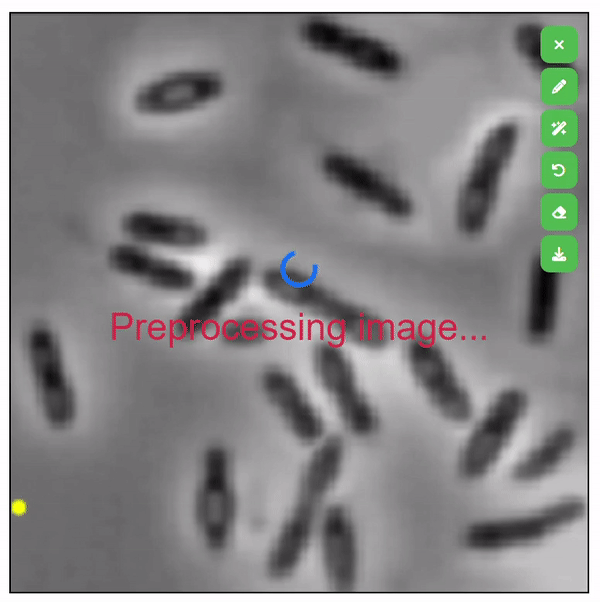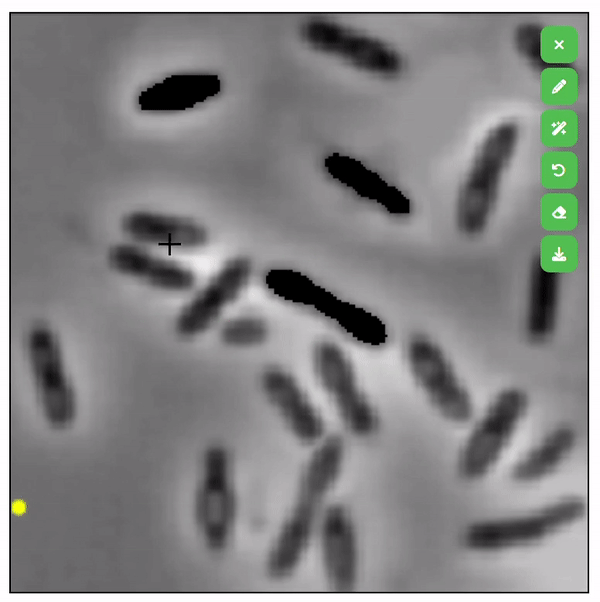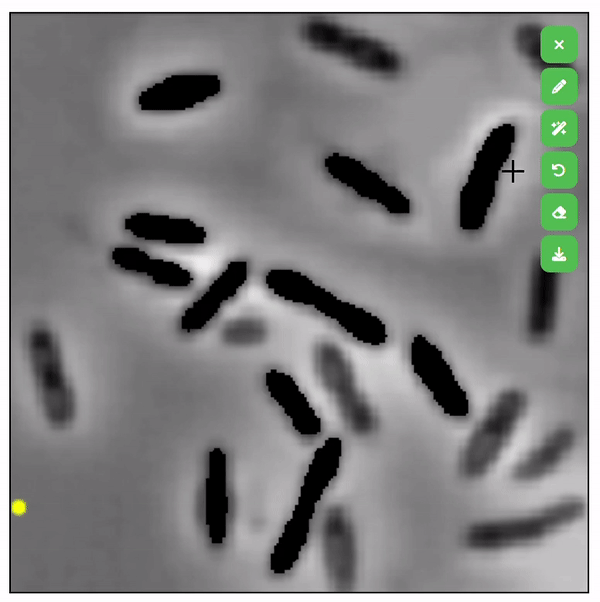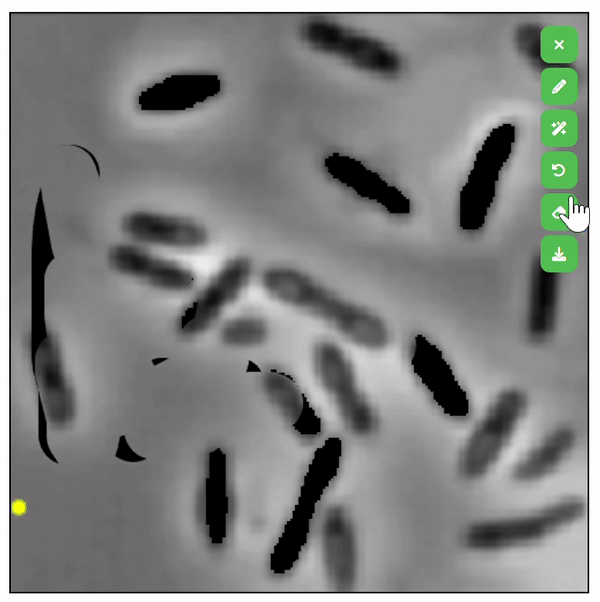  |
- | 代码 | - | 一个简单的基于 Web 的静态掩码绘制工具,支持使用 SAM 进行语义绘图。 |
| AnyLabeling |  |
YoutubeDemo | 代码 | - | SAM + Labelme + LabelImg + 自动标注。 |
| ISAT 结合 segment anything |  |
YoutubeDemo BiliBili Demo | 代码 | - | 基于 SAM(segment anything 模型)的标注工具,支持 SAM、sam-hq、MobileSAM、EdgeSAM 等。 |
| Annotation Anything Pipeline |  |
- | 代码 | - | GPT + SAM。 |
| Roboflow Annotate |  |
App | 博客 | Roboflow | 基于 SAM 的辅助标注,用于训练计算机视觉模型。 |
| SALT |  |
- | 代码 | - | 一个为图像标注添加基础界面的工具,并将生成的掩码保存为 COCO 格式。 |
| SAM U Specify |  |
- | 代码 | - | 使用 SAM 和 CLIP 模型来分割您想要的独特实例。 |
| SAM web UI |  |
App | 代码 | - | 这是 SAM 的全新 Web 界面。 |
| Finetune Anything | 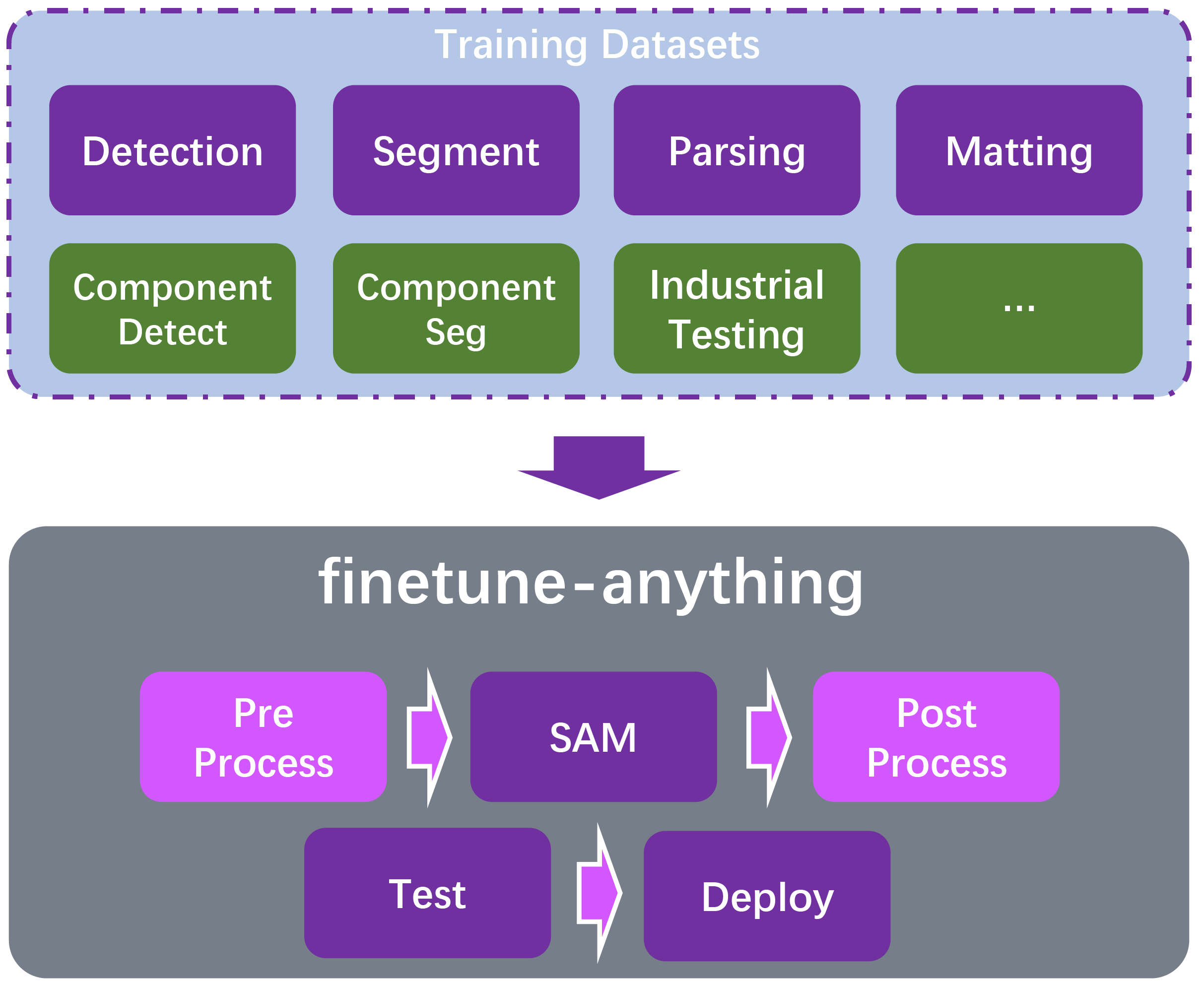 |
- | 代码 | - | 一种基于 SAM 的、具有类别感知的一阶段微调模型训练工具。 |
| NanoSAM |  |
- | 代码 | NVIDIA | 一种经过蒸馏的 Segment Anything (SAM) 模型,能够在 NVIDIA TensorRT 上实现实时运行。 |
| Segment-Anything-UI |  |
- | 代码 | - | 一款基于 PySide6 的 Segment Anything 注释工具。 |
| Segment-Anything-2-UI | 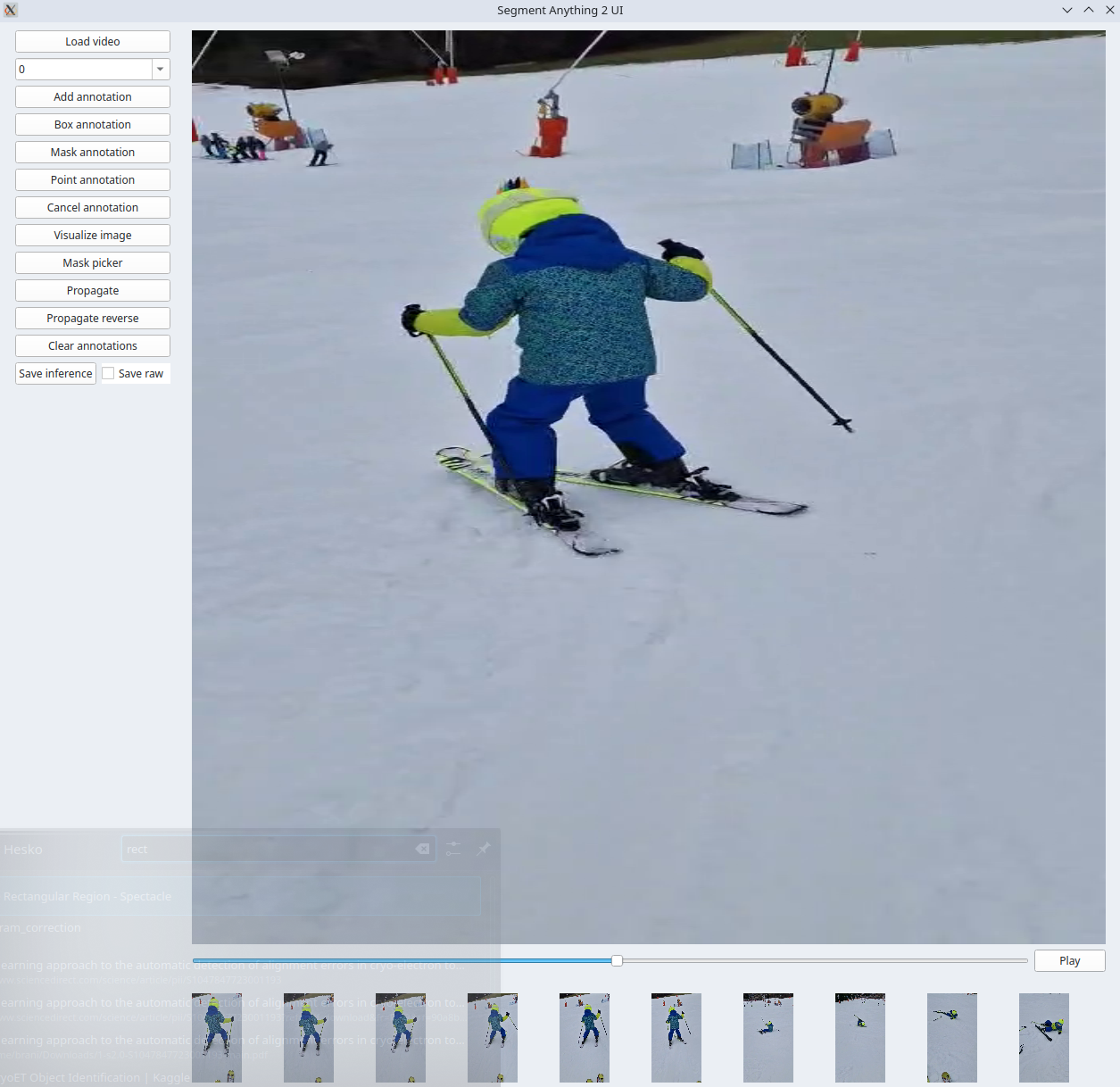 |
- | 代码 | - | 一款基于 PySide6 的 Segment Anything 2 注释工具。支持多目标视频跟踪。 |
视频分割任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| MetaSeg |  |
HuggingFace | 代码 | - | SAM + 视频。 |
| SAM-Track | 视频 | YoutubeDemo | 代码 | 浙江大学 | 该项目基于SAM和DeAOT,专注于视频中目标的分割与跟踪。 |
医学图像分割任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| SAM in Napari | 视频 | - | 代码 | - | 结合Napari的SAM进行任意物体分割。 |
| SAM Medical Imaging | 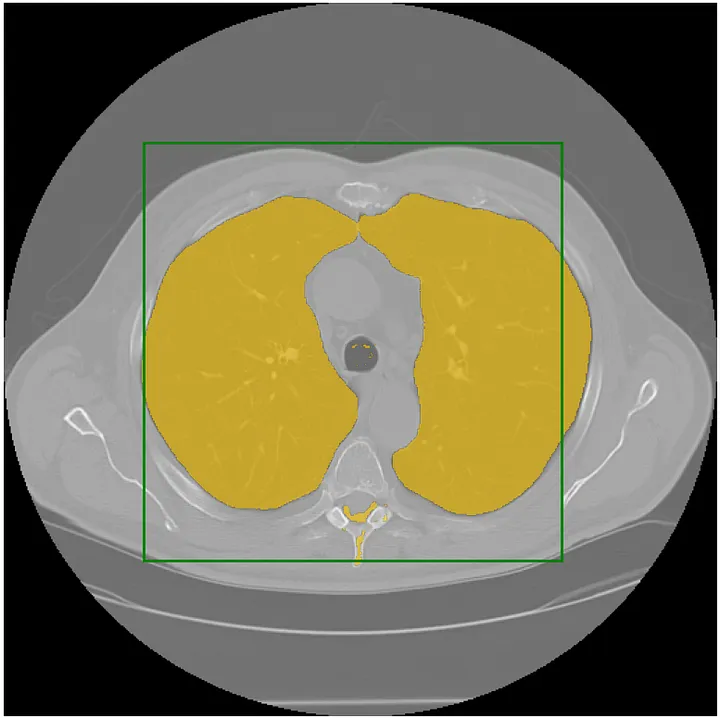 |
- | 代码 | - | 用于医学影像的SAM。 |
图像修复任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| SegAnythingPro | - | 代码 | - | SAM + 图像修复/替换。 |
3D任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| 3D-Box | 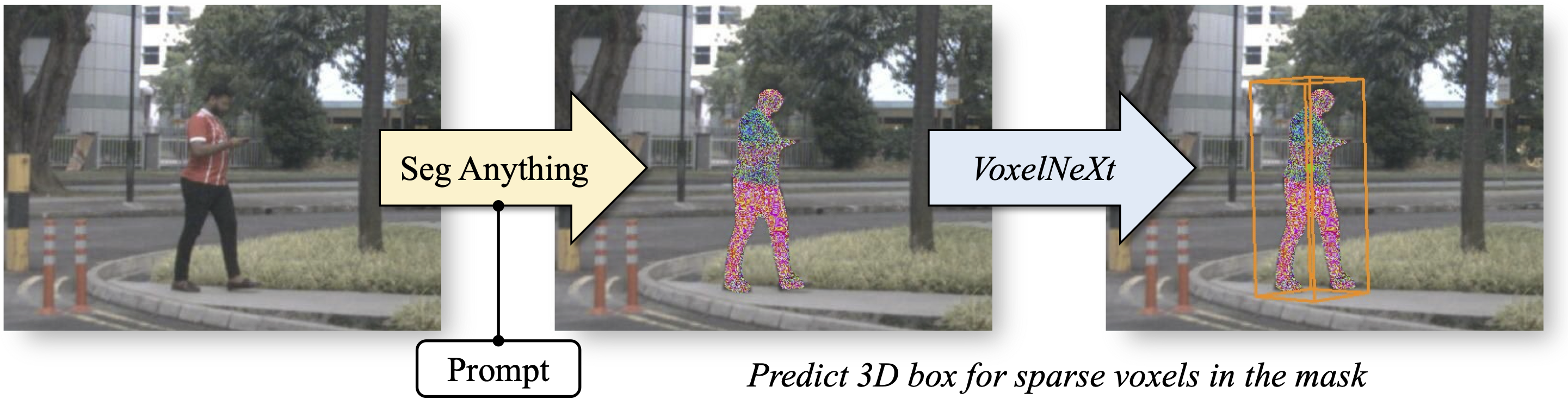 |
- | 代码 | - | 通过将SAM与VoxelNeXt结合,将其扩展到3D感知领域。 |
| Anything 3DNovel View |  |
- | 代码 | - | SAM + Zero 1-to-3。 |
| Any 3DFace |   |
- | 代码 | - | SAM + HRN。 |
| Segment Anything 3D | 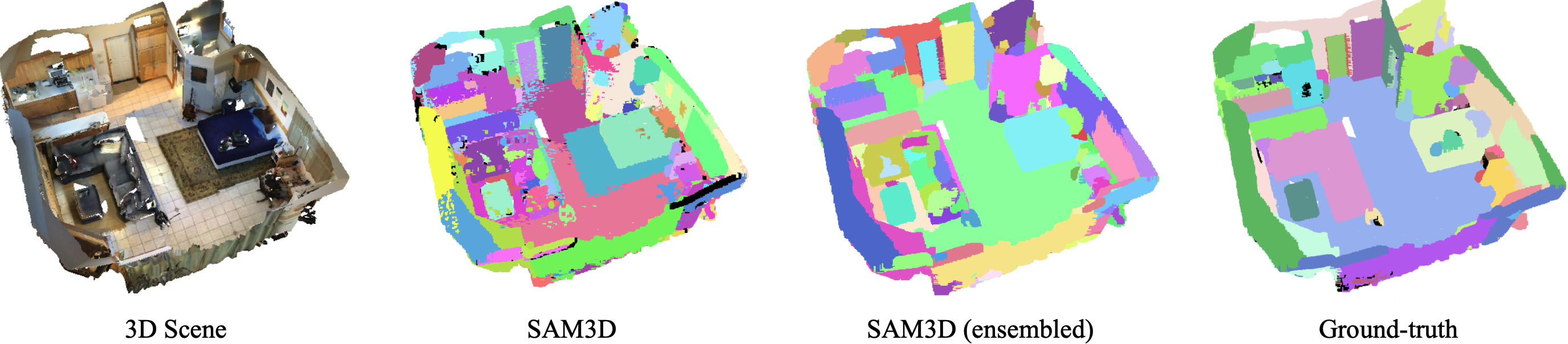 |
- | 代码 | Pointcept | 通过将2D图像的分割信息迁移到3D空间,将Segment Anything扩展到3D感知领域。 |
图像生成任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| Edit Anything |  |
- | 代码 | - | 对图像中的任何内容进行编辑和生成。 |
| Image Edit Anything | 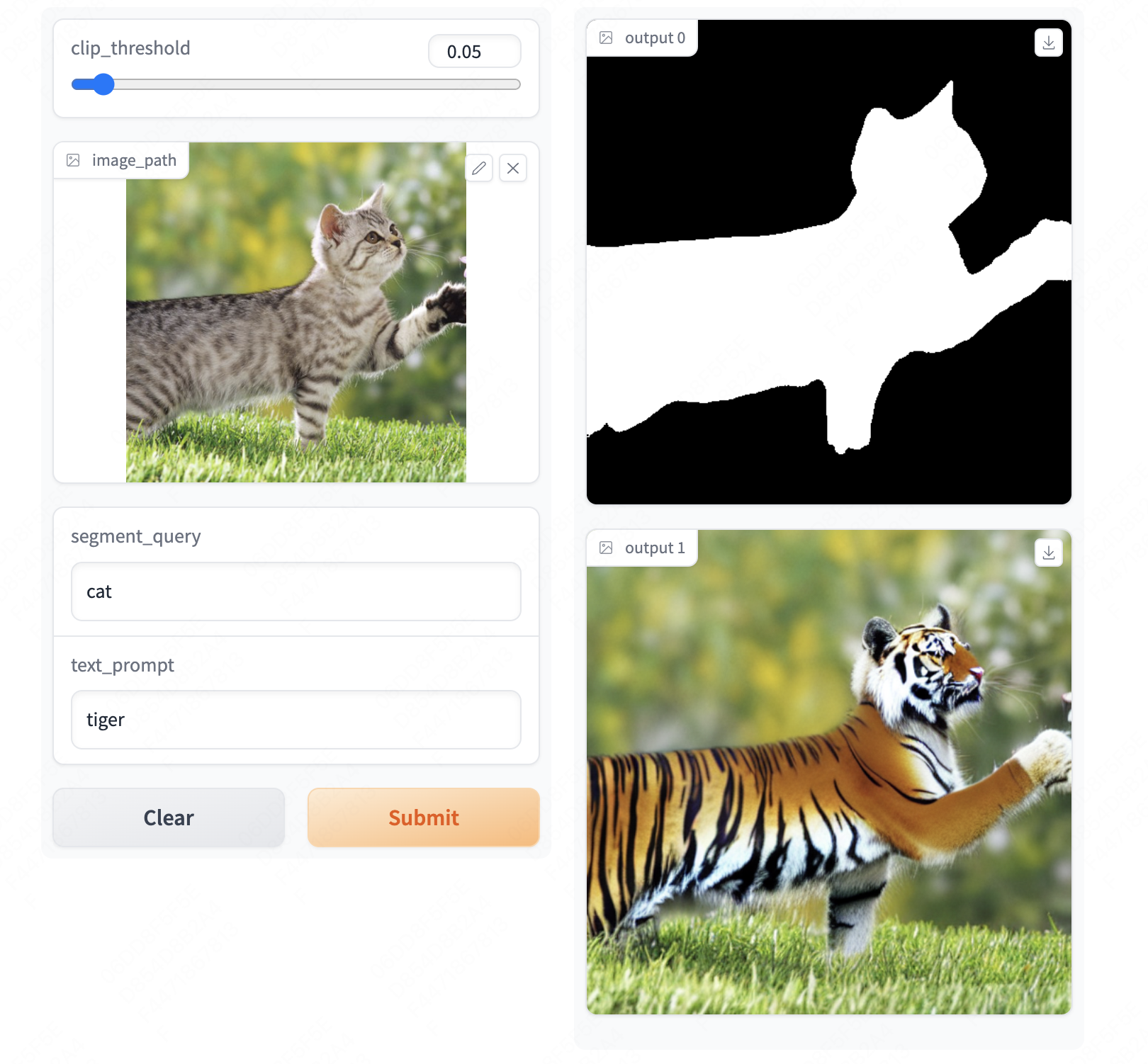 |
- | 代码 | - | Stable Diffusion + SAM。 |
| SAM for Stable Diffusion Webui | 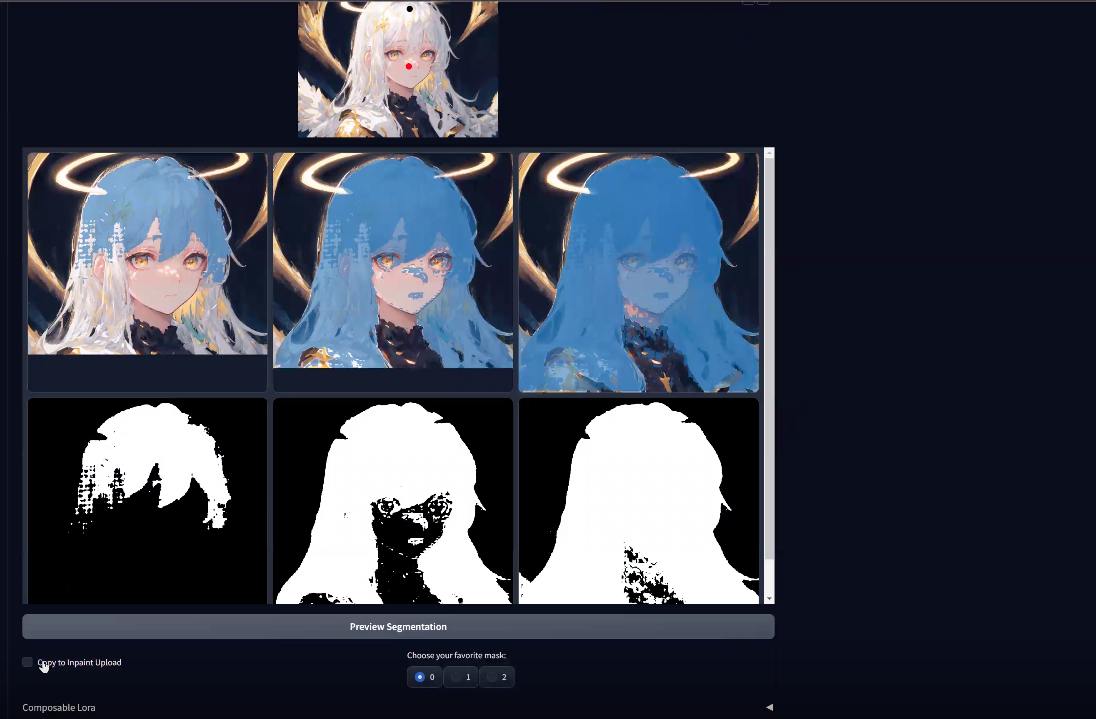 |
- | 代码 | - | Stable Diffusion + SAM。 |
遥感任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| Earth Observation Tools | 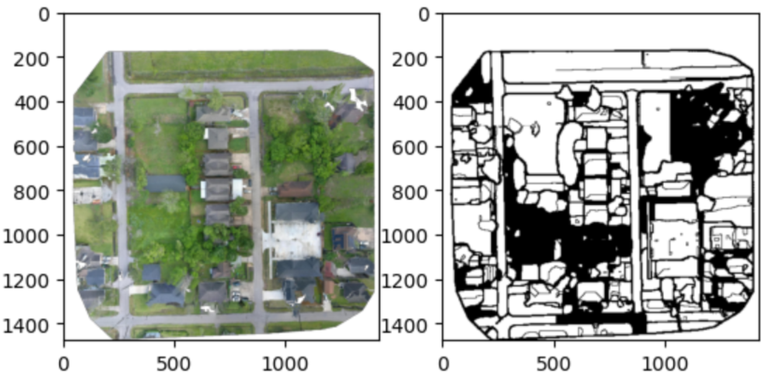 |
Colab | 代码 | - | SAM + 遥感。 |
运动目标检测任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| Moving Object Detection | - | 代码 | - | SAM + 运动目标检测。 |
OCR任务
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| OCR-SAM |  |
博客 | 代码 | - | 基于SAM的光学字符识别。 |
前端框架
SAMJS
| 标题 | 演示 | 项目页面 | 代码库 | 所属机构 | 描述 |
|---|---|---|---|---|---|
| SAMJS | 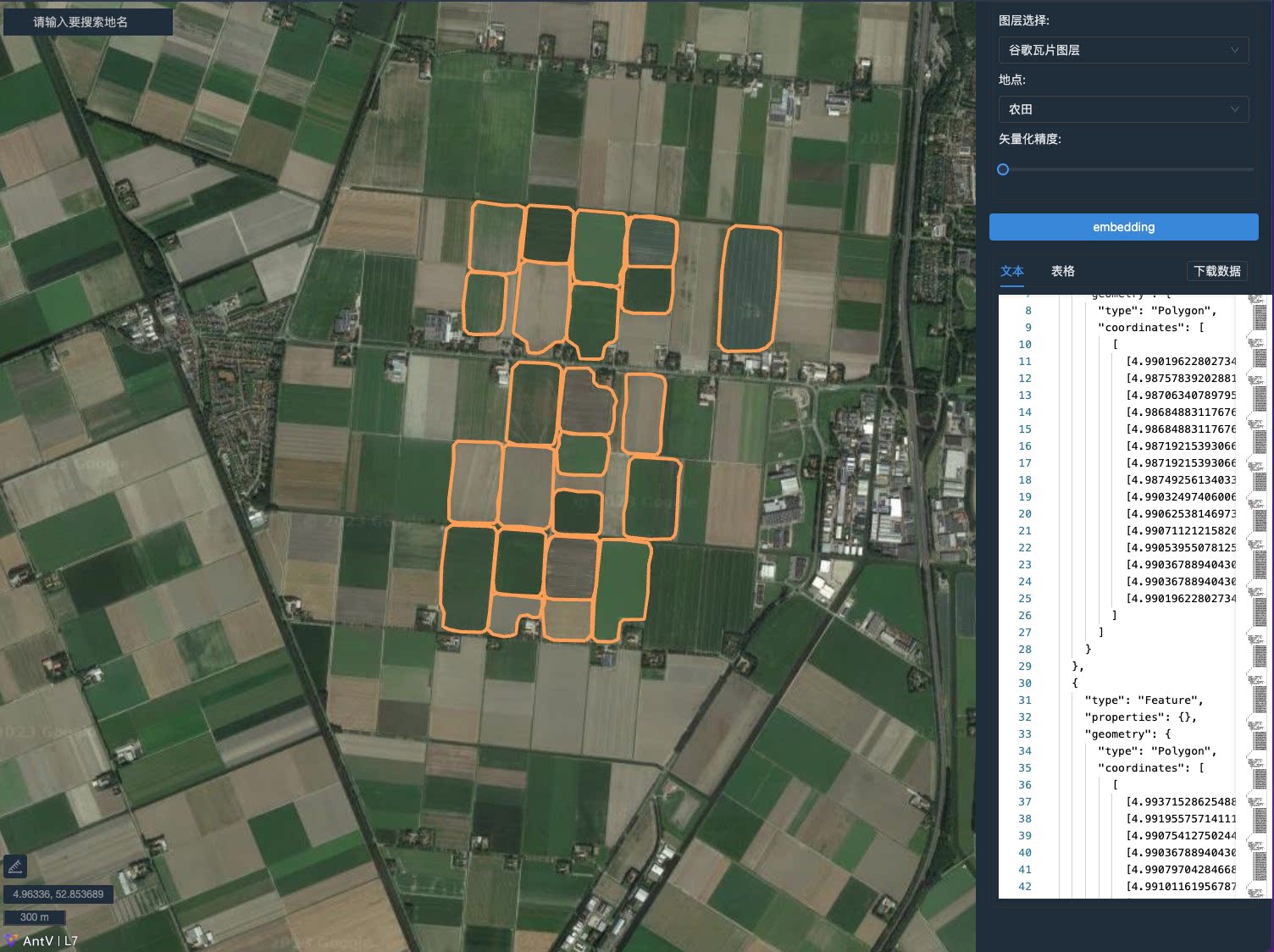 |
demo | 代码 | - | SAM的JS SDK,支持遥感数据的分割和矢量化 |
致谢
本仓库中的部分演示内容借用了原作者的作品,我们对此深表感谢。
许可证
本项目采用MIT许可证发布。更多信息请参阅LICENSE文件。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备