open-webui-tools
open-webui-tools 是一套专为 Open WebUI 设计的模块化扩展工具箱,旨在将普通的聊天界面升级为功能强大的 AI 工作站。它通过提供超过 20 种专用工具、函数管道和过滤器,解决了原生平台在学术检索、多模态内容创作及复杂任务自动化方面的能力局限。
无论是需要查阅最新论文的科研人员、追求图文音视全方位创作的设计师,还是希望部署自主智能体(Agent)的开发者,都能从中找到得力助手。其核心亮点在于深度集成了 ComfyUI 工作流,支持高级图像编辑、音乐生成及文生视频;同时内置了无需 API 密钥的 arXiv 学术搜索、带引用的 Perplexica 网络搜索,以及基于蒙特卡洛树搜索(MCTS)的深度研究代理。此外,它还提供了简历分析、天气查询等实用小工具,以及提示词优化、语义路由等增强过滤功能。
大多数组件支持“即插即用”,用户可通过 Open WebUI Hub 一键安装或手动导入代码。open-webui-tools 以低门槛的方式极大地丰富了 AI 交互场景,让普通用户也能轻松享受专业级的 AI 应用能力。
使用场景
一位人工智能研究员正在撰写关于“多模态大模型最新进展”的综述论文,需要快速检索前沿文献并生成配套的可视化图表。
没有 open-webui-tools 时
- 文献检索割裂:必须离开对话界面,手动在浏览器打开 arXiv 官网搜索论文,再复制摘要回到对话框,效率极低且容易打断思路。
- 多步操作繁琐:想要验证某个理论的视频演示或高清素材,需分别在 YouTube 和 Pexels 等多个网站反复切换搜索,无法在统一工作流中完成。
- 缺乏深度推理:面对复杂的研究问题,普通对话模式难以自主拆解任务或进行蒙特卡洛树搜索(MCTS),导致生成的分析内容浅尝辄止。
- 多媒体生成困难:若需将论文观点转化为示意图或短视频,必须额外启动 ComfyUI 等独立软件,配置复杂的工作流并手动传输文件。
使用 open-webui-tools 后
- 一站式学术发现:直接调用 arXiv Search 工具,无需 API 密钥即可在对话中实时检索并引用最新论文,研究闭环在窗口内瞬间完成。
- 多模态资源聚合:通过 YouTube Search & Embed 和 Pexels Media Search,直接在聊天流中播放相关视频或插入高清素材,极大丰富了论证维度。
- 智能代理规划:启用 Planner Agent v3 或 arXiv Research MCTS 功能管道,系统能自主拆解研究路径、委托子任务并进行深度推理,输出高质量分析报告。
- 原生创意工作流:利用集成的 ComfyUI Text-to-Video 和 Native Image Generator,仅需文字指令即可在工作站内直接生成专业级的解释性视频与图像,无需切换软件。
open-webui-tools 将原本分散的搜索、推理与创作工具整合为统一的 AI 工作站,让研究人员能专注于核心创新而非繁琐的工具切换。
运行环境要求
- 未说明 (基于 Open WebUI,通常支持 Linux
- macOS
- Windows)
- 非必需
- 仅在使用 ComfyUI 进行图像/音乐/视频生成或本地运行 Ollama/Perplexica 时需要 GPU
- 具体型号和显存取决于所选模型(如 Flux, WAN 2.2 等),README 未指定统一标准
未说明 (取决于运行的具体工具和后端服务,如 ComfyUI 或 Ollama)
快速开始
开放WebUI工具集合
![]()
![]()
![]()
🚀 一个模块化的工具、函数管道和过滤器集合,旨在大幅提升您的Open WebUI体验。
通过这套全面的工具集,您可以将您的Open WebUI实例转变为强大的AI工作站。无论是学术研究、图像生成,还是音乐创作和自主代理,该集合都能为您提供扩展AI功能所需的全部资源。
✨ 内容概览
本仓库包含20余种专用工具和函数,旨在增强您的Open WebUI体验:
🛠️ 工具
- arXiv搜索 - 学术论文发现(无需API密钥!)
- Perplexica搜索 - 使用Perplexica API进行带引用的网页搜索
- Pexels媒体搜索 - 来自Pexels API的高质量照片和视频
- YouTube搜索与嵌入 - 搜索YouTube并在嵌入式播放器中播放视频
- 原生图像生成器 - 直接使用Ollama模型管理进行Open WebUI图像生成
- Hugging Face图像生成器 - 基于AI的图像创作
- ComfyUI 图像到图像转换(Qwen Edit 2509) - 支持多张图片的高级图像编辑
- ComfyUI ACE Step 1.5 音频 - 高级音乐生成(新)
- ComfyUI ACE Step 音频(旧版) - 高级音乐生成
- ComfyUI 文本到视频 - 使用ComfyUI生成基于文本的短视频(默认WAN 2.2工作流)
- Flux Kontext ComfyUI - 专业图像编辑
- OpenWeatherMap 天气预报工具 - 带有当前天气状况和预报的交互式天气小部件
🔄 函数管道
- Planner Agent v3 - 具有代理式规划、多代理委派及实时可视化执行跟踪的高级自主代理
- arXiv Research MCTS - 基于蒙特卡洛树搜索的高级研究
- Multi Model Conversations v2 - 带有交互式UI、工具支持及改进推理处理的多代理对话
- 简历分析器 - 专业的简历分析
- Mopidy 音乐控制器 - 音乐服务器管理
- Letta Agent - 自主代理集成
- Perplexica Pipe - 带有流式响应和引用的AI驱动网页搜索
- Google Veo 文本到视频及图像到视频 - 使用Google Veo从文本或单张图片生成视频(仅支持单张图片作为输入)
🔧 过滤器
- 涂鸦画板 - 在发送每条消息前打开画布的可切换过滤器
- 提示增强器 - 自动优化提示
- 语义路由器 - 智能模型选择
- 全文处理 - 文件处理能力
- 清理思维标签 - 对话清理
- OpenRouter 网页搜索引用 - 为OpenRouter模型启用带有引用处理的网页搜索
🚀 快速入门
方法一:Open WebUI Hub(推荐)
- 访问 https://openwebui.com/u/haervwe
- 浏览工具集合并点击所需工具的“获取”按钮
- 按照您Open WebUI实例中的安装提示操作
方法二:手动安装
- 从
tools/、functions/或filters/目录中复制.py文件 - 导航到Open WebUI工作区 > 工具/函数/过滤器
- 粘贴代码,提供名称和描述,然后保存
🎯 核心特性
- 🔌 即插即用:大多数工具无需配置即可直接使用
- 🎨 可视化集成:与ComfyUI工作流无缝集成
- 🤖 AI赋能:具备MCTS研究和自主规划等高级功能
- 📚 学术导向:集成arXiv以支持科研和学术工作
- 🎵 创意工具:音乐生成和图像编辑功能
- 🔍 智能路由:智能模型选择和对话管理
- 📄 文档处理:完整的文档分析和简历处理
📋 先决条件
- Open WebUI:建议使用0.6.0及以上版本
- Python:3.8或更高版本
- 可选依赖项:
- ComfyUI(用于图像/音乐生成工具)
- Mopidy(用于音乐控制器)
- 各类API密钥(Hugging Face、Tavily等)
🔧 配置
大多数工具设计为只需极少配置即可运行。关键配置区域包括:
- API密钥:部分工具需要(如Hugging Face、Tavily等)
- ComfyUI集成:用于图像和音乐生成工具
- 模型选择:根据您的使用场景选择合适的模型
- 过滤器设置:在模型配置中启用过滤器
📖 详细文档
目录
- arXiv搜索工具
- Perplexica搜索工具
- Pexels媒体搜索工具
- YouTube搜索与嵌入工具
- 原生图像生成器
- Hugging Face图像生成器
- Cloudflare Workers AI图像生成器
- SearxNG图像搜索工具
- ComfyUI 图像到图像转换工具(Qwen Image Edit 2509)
- ComfyUI ACE Step 1.5 音频工具
- ComfyUI ACE Step 音频工具(旧版)
- ComfyUI 文本到视频工具
- OpenWeatherMap 天气预报工具
- Flux Kontext ComfyUI管道
- Google Veo 文本到视频及图像到视频管道
- Planner Agent v3
- arXiv Research MCTS管道
- Multi Model Conversations v2管道
- 简历分析器管道
- Mopidy 音乐控制器
- Letta Agent管道
- Perplexica管道
- OpenRouter 图像管道
- OpenRouter 网页搜索引用过滤器
- 涂鸦画板过滤器
- 提示增强器过滤器
- 语义路由器过滤器
- 全文处理过滤器
- 清理思维标签过滤器
- 使用提供的ComfyUI工作流
- 安装
- 贡献
- 许可证
- 致谢
- 支持
🧪 工具
arXiv搜索工具
描述
在 arXiv.org 上搜索任何主题的相关学术论文。无需 API 密钥!
配置
- 无需配置。开箱即用。
使用方法
示例:
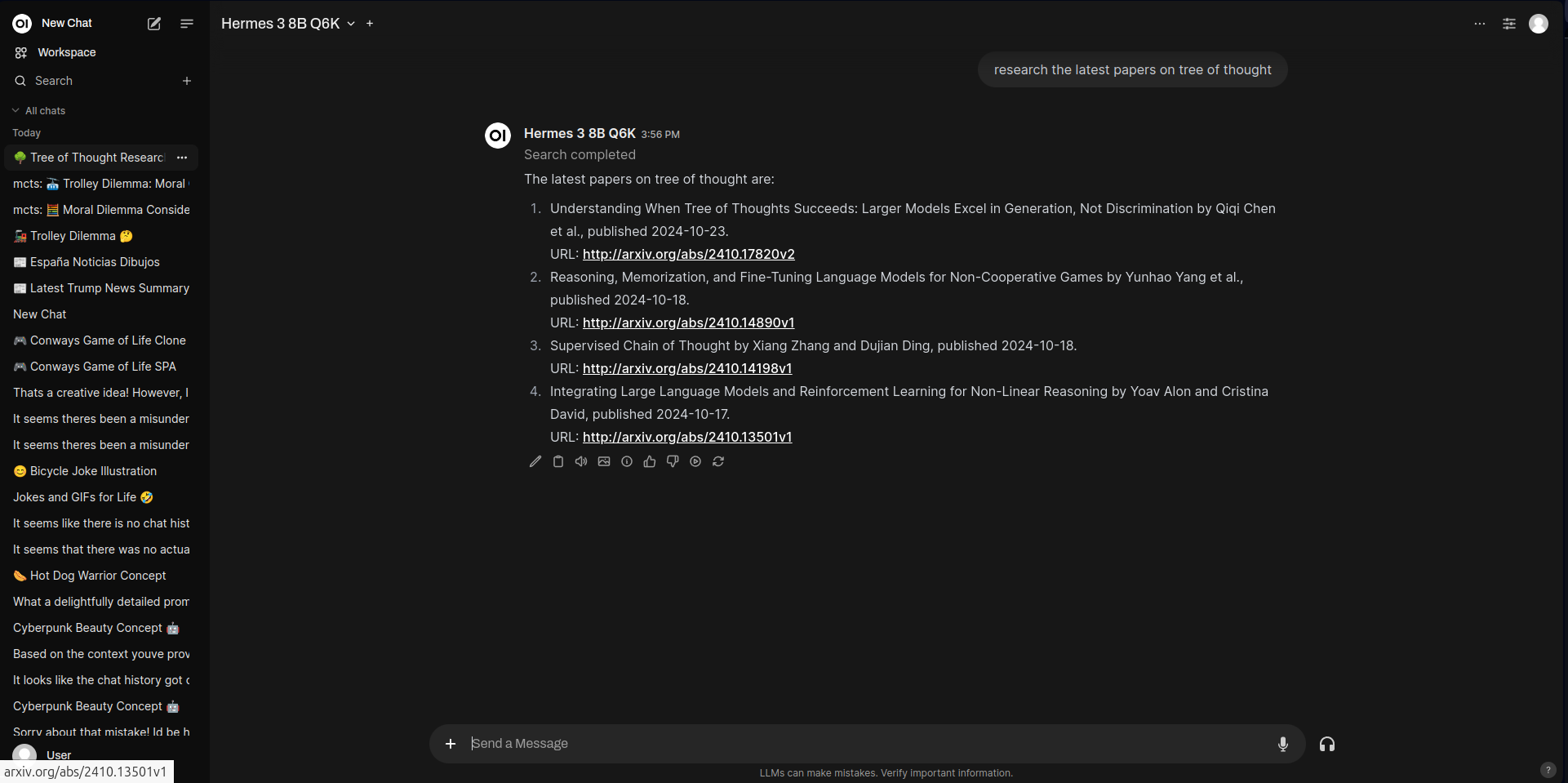
搜索关于“思维树”的最新论文返回最多 5 篇最相关的论文,按最新发表时间排序。
 Open WebUI 中的 arXiv 搜索结果示例
Open WebUI 中的 arXiv 搜索结果示例
Perplexica 搜索工具
描述
使用 Perplexica API 在网络上搜索事实信息、时事新闻或特定主题。该工具提供包含引用和来源的全面搜索结果,非常适合研究和信息收集。Perplexica 是一个开源的 AI 驱动搜索引擎,作为 Perplexity AI 的替代方案,必须在本地自行部署。它利用先进的语言模型,提供准确、具有上下文关联的答案,并附有适当的来源标注。
配置
BASE_URL(str):Perplexica API 的基础 URL(默认值:http://host.docker.internal:3001)OPTIMIZATION_MODE(str):搜索优化模式——“speed” 或 “balanced”(默认值:balanced)CHAT_MODEL(str):用于搜索处理的默认聊天模型(默认值:llama3.1:latest)EMBEDDING_MODEL(str):用于搜索的默认嵌入模型(默认值:bge-m3:latest)OLLAMA_BASE_URL(str):Ollama API 的基础 URL(默认值:http://host.docker.internal:11434)
先决条件:您必须在本地安装并运行已配置 URL 的 Perplexica。Perplexica 是一个自托管的开源搜索引擎,需要 Ollama 提供指定的聊天和嵌入模型。请按照 Perplexica 仓库中的安装说明设置您的本地实例。
使用方法
示例:
搜索“2024 年人工智能安全研究的最新进展”返回带有适当引用的全面搜索结果。
自动为 Open WebUI 中的来源追踪生成引用。
同时提供摘要和各个来源链接。
特性
- 网页搜索集成:直接访问当前的网络信息。
- 引用支持:自动为 Open WebUI 生成引用。
- 模型灵活性:可配置的聊天和嵌入模型。
- 实时状态:搜索执行期间的进度更新。
- 来源追踪:带有元数据的单个来源引用。
Pexels 媒体搜索工具
描述
通过 Pexels API 搜索并获取高质量的照片和视频。该工具提供对 Pexels 丰富免费素材库的访问,具备全面的搜索功能、自动引用生成以及在聊天中直接显示图片的功能。非常适合为演示文稿、内容创作或创意项目寻找专业品质的媒体资源。
配置
PEXELS_API_KEY(str):来自 https://www.pexels.com/api/ 的免费 Pexels API 密钥(必填)。DEFAULT_PER_PAGE(int):每次搜索的默认结果数量(默认值:5,推荐用于 LLM)。MAX_RESULTS_PER_PAGE(int):每页允许的最大结果数(默认值:15,防止 LLM 被大量结果压垮)。DEFAULT_ORIENTATION(str):默认照片方向——“all”、“landscape”、“portrait” 或 “square”(默认值:“all”)。DEFAULT_SIZE(str):默认最小照片尺寸——“all”、“large”(24MP)、“medium”(12MP)或 “small”(4MP)(默认值:“all”)。
先决条件:从 Pexels API 获取免费 API 密钥,并将其配置到工具的 Valves 设置中。
使用方法
照片搜索示例:
搜索“现代办公空间”的照片视频搜索示例:
搜索“日落时分的海浪”的视频精选照片示例:
获取 Pexels 的精选照片
特性
- 三种搜索功能:
search_photos、search_videos和get_curated_photos。 - 直接显示图片:图片会自动以 Markdown 格式化,以便在聊天中立即显示。
- 高级筛选:可按方向、尺寸、颜色和质量进行筛选。
- 署名支持:自动生成功能者署名的引用。
- 速率限制处理:内置针对 API 限制和无效密钥的错误处理机制。
- LLM 优化:结果数量受限且格式化,以避免给语言模型带来过大负担。
- 实时状态:搜索执行期间的进度更新。
YouTube 搜索与嵌入工具
描述
在 YouTube 上搜索视频,并在 Open WebUI 聊天中直接以精美的嵌入播放器展示。该工具提供全面的 YouTube 搜索功能,包括自动引用生成、详细的视频信息以及自定义样式的嵌入播放器。非常适合查找教程、音乐视频、教育内容或其他所需的视频资料。
配置
YOUTUBE_API_KEY(str):来自 https://console.cloud.google.com/apis/credentials 的 YouTube Data API v3 密钥(必填)。MAX_RESULTS(int):返回的最大搜索结果数量(默认值:5,范围:1–10)。SHOW_EMBEDDED_PLAYER(bool):是否显示第一个结果的嵌入式 YouTube 播放器(默认值:True)。REGION_CODE(str):用于搜索结果的地区代码,例如“US”、“GB”、“JP”等(默认值:“US”)。SAFE_SEARCH(str):安全搜索过滤器——“none”、“moderate” 或 “strict”(默认值:“moderate”)。
先决条件:从 Google Cloud 控制台 获取免费的 YouTube Data API v3 密钥,并在您的项目中启用 YouTube Data API v3。
使用方法
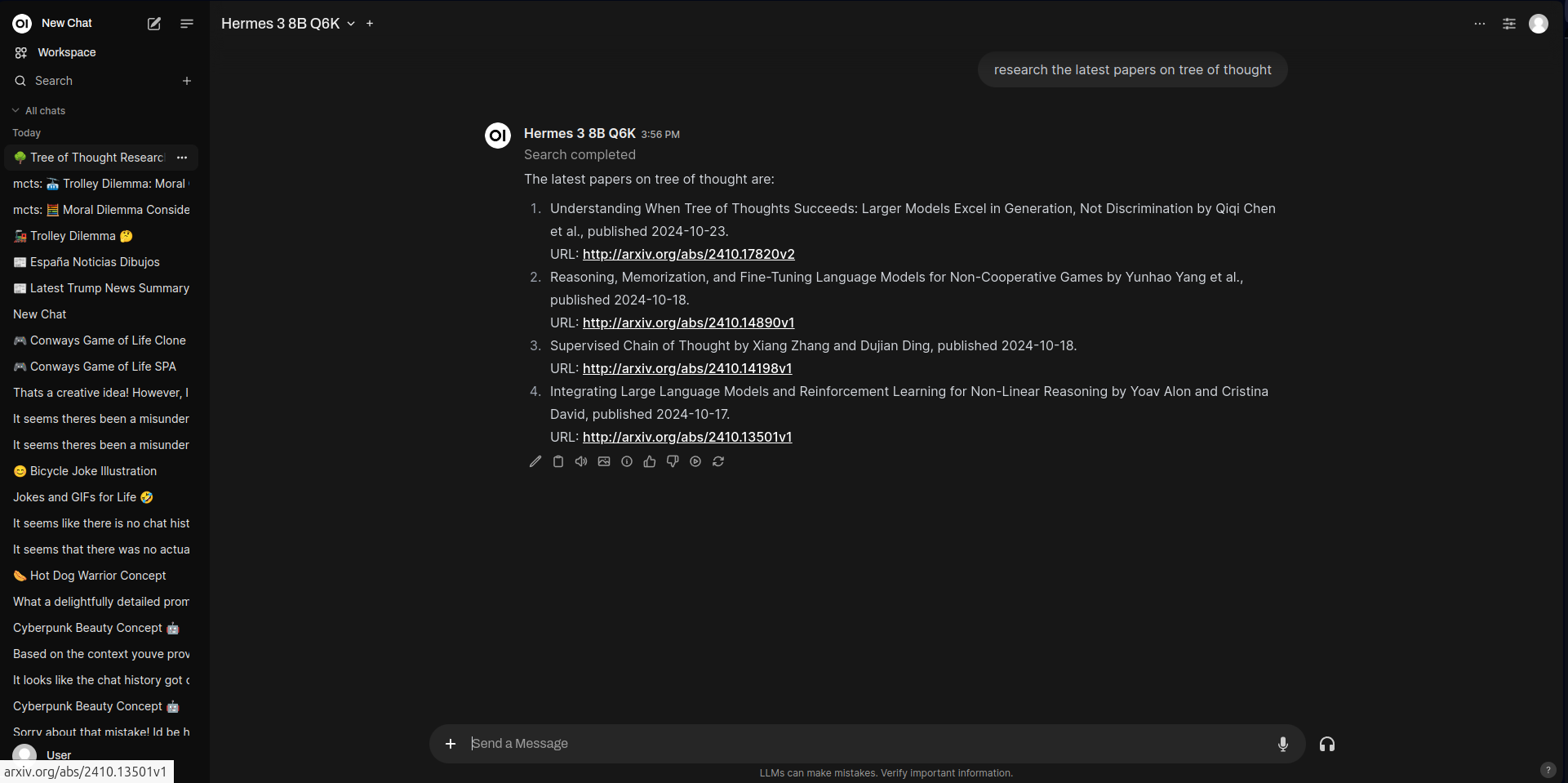
搜索视频:
在 YouTube 上搜索“Python 初学者教程”播放特定视频:
播放 YouTube 视频 dQw4w9WgXcQ自定义结果搜索:
在 YouTube 上搜索“烹饪食谱”,返回 10 条结果
特性
- 两个主要功能:
search_youtube用于搜索,play_video用于播放特定视频 ID。 - 嵌入式播放器:美观的自定义样式 YouTube 播放器直接嵌入聊天中,具有响应式设计。
- 安全搜索:内置内容过滤选项。
- 地区支持:根据地区代码提供本地化的搜索结果。
- 直接链接:提供 YouTube 链接和“在 YouTube 上观看”按钮。
- 速率限制处理:针对 API 配额限制的正确错误处理。
- 实时状态:搜索和加载过程中的进度更新。
开始使用
获取 YouTube API 密钥:
- 访问 Google Cloud 控制台
- 创建一个新项目或选择现有项目
- 启用“YouTube Data API v3”
- 创建凭据(API 密钥)
- 复制 API 密钥
配置工具:
- 在 Open WebUI 中打开工具的 Valves 设置
- 将您的 API 密钥粘贴到
YOUTUBE_API_KEY字段中 - 根据需要调整其他设置(地区、最大结果数等)
开始搜索:
- 使用自然语言:“在 YouTube 上搜索 [主题]”
- 或直接使用函数:
search_youtube("主题")
 Open WebUI 聊天中嵌入的 YouTube 视频示例
Open WebUI 聊天中嵌入的 YouTube 视频示例
原生图像生成器
描述
使用在管理设置中配置的 Open WebUI 原生图像生成中间件来生成图像。该工具通过 Open WebUI 内置的图像生成系统,利用您已配置的任何图像生成后端(如 AUTOMATIC1111、ComfyUI 或 OpenAI DALL-E),并可选地使用 Ollama 模型管理功能,在需要时释放显存。
配置
unload_ollama_models(布尔值):是否在生成图像前从显存中卸载所有 Ollama 模型(默认:False)ollama_url(字符串):用于模型管理的 Ollama API URL(默认:http://host.docker.internal:11434)emit_embeds(布尔值):是否通过embeds事件发出 HTML 图像嵌入代码,以便生成的图像在聊天中内联显示(默认:True)。当为False时,工具将跳过嵌入代码的发出,仅返回原始下载链接。如果emit_embeds为True但没有可用的事件发射器,则无法内联显示图像,只会返回链接。
先决条件:您必须在 Open WebUI 的管理设置中,于“设置 > 图像”下配置图像生成功能。该工具适用于您所设置的任何图像生成后端(AUTOMATIC1111、ComfyUI、OpenAI 等)。
使用方法
示例:
生成一张“日落时分宁静的山景”的图像使用 Open WebUI 管理设置中配置的任何图像生成后端
如果启用了 Ollama 卸载功能,则会自动管理模型资源
返回 Markdown 格式的图像链接,可立即显示
特性
- 原生集成:使用 Open WebUI 的原生图像生成中间件,无需外部依赖
- 后端无关:适用于管理设置中配置的任何图像生成后端(AUTOMATIC1111、ComfyUI、OpenAI 等)
- 内存管理:可选的 Ollama 模型卸载功能,以优化显存使用
- 灵活的模型支持:您可以提示代理更换图像生成模型,只要提供模型名称即可。
- 实时状态:通过事件发射器提供生成进度更新
- 错误处理:全面的错误报告和恢复机制
Hugging Face 图像生成器
描述
使用 Hugging Face 的 Stable Diffusion 模型,根据文本描述生成高质量图像。
配置
- API 密钥(必填):从您的 Hugging Face 账户获取 Hugging Face API 密钥,并将其设置在 Open WebUI 工具的配置中。
- API URL(可选):默认使用 Stability AI 的 SD 3.5 Turbo 模型。也可以自定义为使用其他 HF 文本到图像模型端点。
使用方法
示例:
创建一张“美丽的马自由奔跑”的图像支持多种图像格式:正方形、横幅、竖屏等。
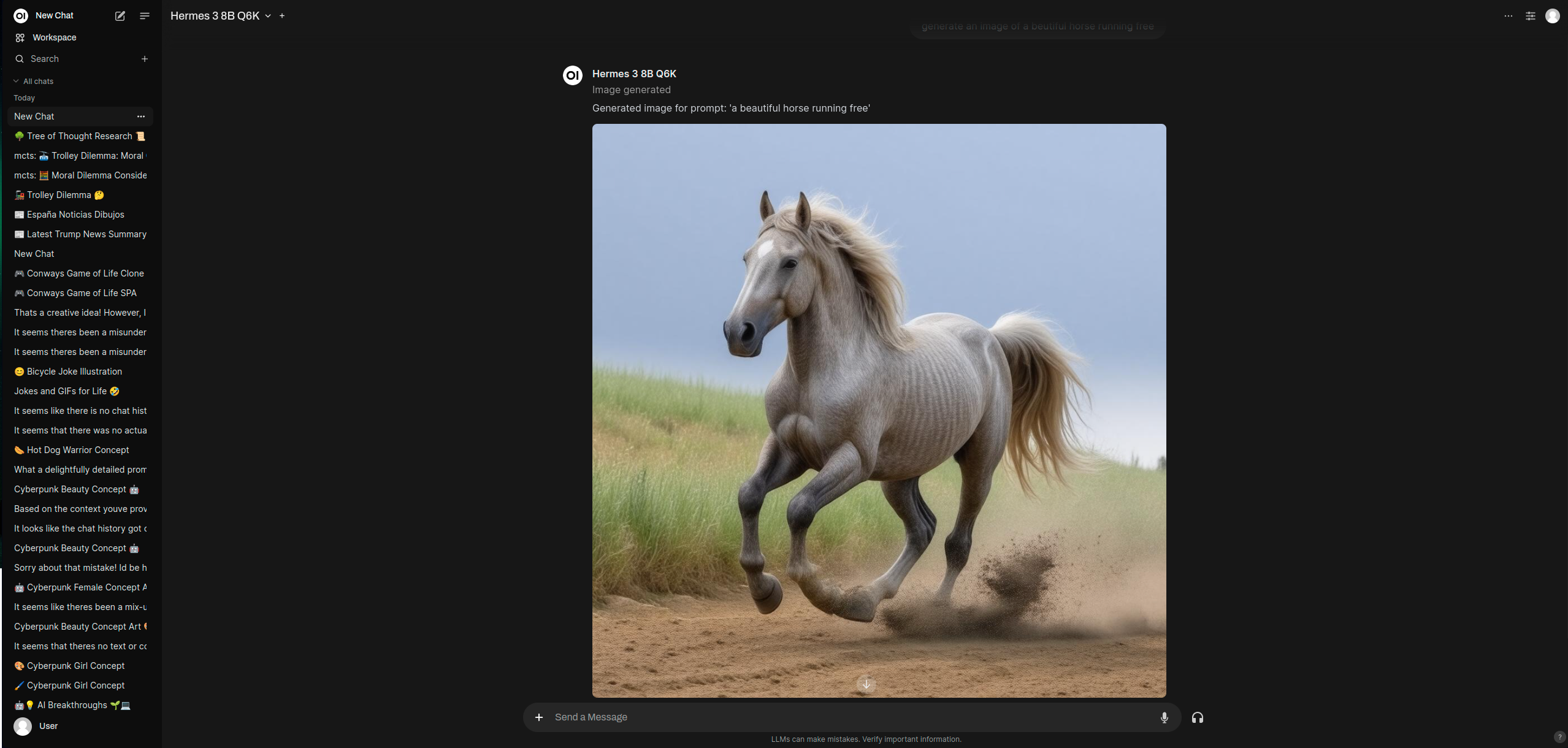 使用 Hugging Face 工具生成的示例图像
使用 Hugging Face 工具生成的示例图像
Cloudflare Workers AI 图像生成器
描述
使用 Cloudflare Workers AI 的文生图模型生成图像,包括 FLUX、Stable Diffusion XL、SDXL Lightning 和 DreamShaper LCM。该工具提供特定于模型的提示预处理、参数优化以及在聊天中直接显示图像的功能。它支持快速且高质量的图像生成,且配置简单。
配置
cloudflare_api_token(字符串):您的 Cloudflare API Token(必填)cloudflare_account_id(字符串):您的 Cloudflare 账户 ID(必填)default_model(字符串):默认使用的模型(例如@cf/black-forest-labs/flux-1-schnell)
先决条件:您需要从 Cloudflare 仪表板获取 Cloudflare API Token 和账户 ID。除了 requests 库之外,无需其他依赖。
使用方法
示例:
# 根据提示生成图像 await tools.generate_image(prompt="日落时分的未来都市景观,色彩鲜艳")返回 Markdown 格式的图像链接,可在聊天中立即显示。
特性
- 多种模型:支持 FLUX、SDXL、SDXL Lightning、DreamShaper LCM
- 提示优化:自动优化提示,以获得每种模型的最佳效果
- 参数处理:智能处理步骤、引导系数、负面提示和尺寸
- 直接显示图像:返回可用于聊天的 Markdown 图像链接
- 错误处理:全面的错误和状态报告
- 实时状态:通过事件发射器提供进度更新
SearxNG 图像搜索工具
描述
使用自托管的 SearxNG 实例在网络上搜索并检索图像。该工具提供尊重隐私、多引擎的图像搜索功能,并可在聊天中直接显示图像。非常适合从多个来源查找多样化图像,而无需跟踪或广告。
配置
SEARXNG_ENGINE_API_BASE_URL(字符串):SearxNG 搜索引擎 API 的基础 URL(默认:http://searxng:4000/search)MAX_RESULTS(整数):每次搜索最多返回的图像数量(默认:5)
先决条件:您必须运行一个 SearxNG 实例。有关设置说明,请参阅 SearxNG 文档。
使用方法
示例:
# 搜索猫的图片 await tools.search_images(query="cats", max_results=3)返回一系列 Markdown 格式的图像链接,可在聊天中立即显示。
特性
- 尊重隐私:无跟踪、无广告、无用户画像
- 多引擎:聚合来自多个搜索引擎的结果
- 直接显示图像:图像格式化后可直接在聊天中显示
- 可定制:可以选择引擎、结果数量等
- 错误处理:能够优雅地处理连接和搜索错误
🔄 函数管道
Perplexica 管道
描述
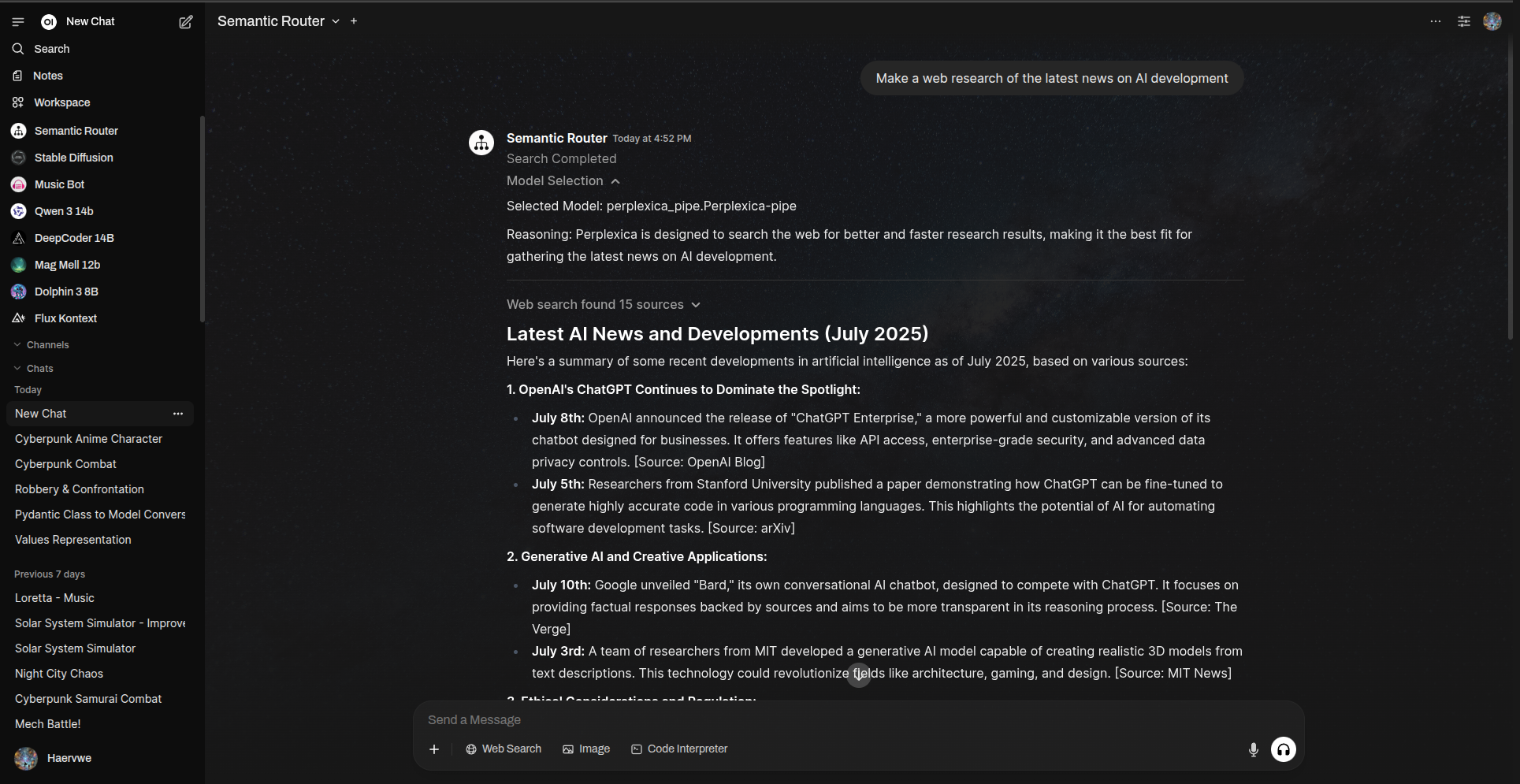
使用 Perplexica 进行人工智能驱动的网络搜索,支持流式响应、智能引用和全面的来源追踪。此函数管道与您自托管的 Perplexica 实例集成,提供实时的网络搜索功能,并正确标注来源,非常适合用于研究、事实核查以及及时了解最新动态。
配置
enable_perplexica(布尔): 启用或禁用 Perplexica 搜索(默认:True)perplexica_api_url(字符串): Perplexica API 端点(默认:http://localhost:3001/api/search)perplexica_chat_provider(字符串): 聊天模型的提供商 ID(默认:550e8400-e29b-41d4-a716-446655440000)perplexica_chat_model(字符串): 使用的聊天模型(默认:gpt-4o-mini)perplexica_embedding_provider(字符串): 嵌入模型的提供商 ID(默认:550e8400-e29b-41d4-a716-446655440000)perplexica_embedding_model(字符串): 使用的嵌入模型(默认:text-embedding-3-large)perplexica_focus_mode(字符串): 搜索焦点模式(默认:webSearch)perplexica_optimization_mode(字符串): 优化模式——“speed” 或 “balanced”(默认:balanced)task_model(字符串): 用于非搜索任务的模型(默认:gpt-4o-mini)max_history_pairs(整数): 最多包含的对话历史对数(默认:12)perplexica_timeout_ms(整数): HTTP 套接字读取超时时间,单位为毫秒(默认:1500)
先决条件: 您必须在本地安装并运行 Perplexica。Perplexica 是一款开源的 AI 驱动搜索引擎,需要与 Ollama 或 OpenAI 兼容的提供商一起进行设置。
使用方法
示例:
调查美国、欧洲、中国等不同地区关于 AI 监管的最新消息,仅执行一次工具调用自动将搜索请求路由到 Perplexica
提供带有实时更新的流式响应
为每个结果发出包含来源元数据的引用
处理对话历史以进行上下文相关的搜索
功能
- 流式支持: 实时流式响应,实现更快的交互
- 智能引用: 自动生成带有元数据(标题、URL、内容)的引用
- 对话历史: 维持来自先前消息的上下文(可配置)
- 多种焦点模式: webSearch、academicSearch、youtubeSearch 等
- 状态更新: 搜索过程中的实时进度更新
- 来源追踪: 包含 URL 和摘要的全面来源元数据
- 任务路由: 在搜索和非搜索任务之间进行智能路由
- 错误处理: 强大的错误处理机制,并提供用户友好的提示信息
开始使用
安装 Perplexica:
- 按照 Perplexica 安装指南 进行操作
- 设置您的聊天和嵌入提供商(Ollama、OpenAI 等)
- 启动 Perplexica 服务器(默认:http://localhost:3001)
配置管道:
- 在 Open WebUI 中打开管道的 Valves 设置
- 将
perplexica_api_url设置为您 Perplexica 实例的 URL - 配置您的聊天和嵌入提供商/模型
- 根据需要调整焦点模式和优化设置
开始搜索:
- 在 Open WebUI 中选择“Perplexica Pipe”模型
- 提出问题或请求网络搜索
- 查看带有自动引用和来源链接的搜索结果
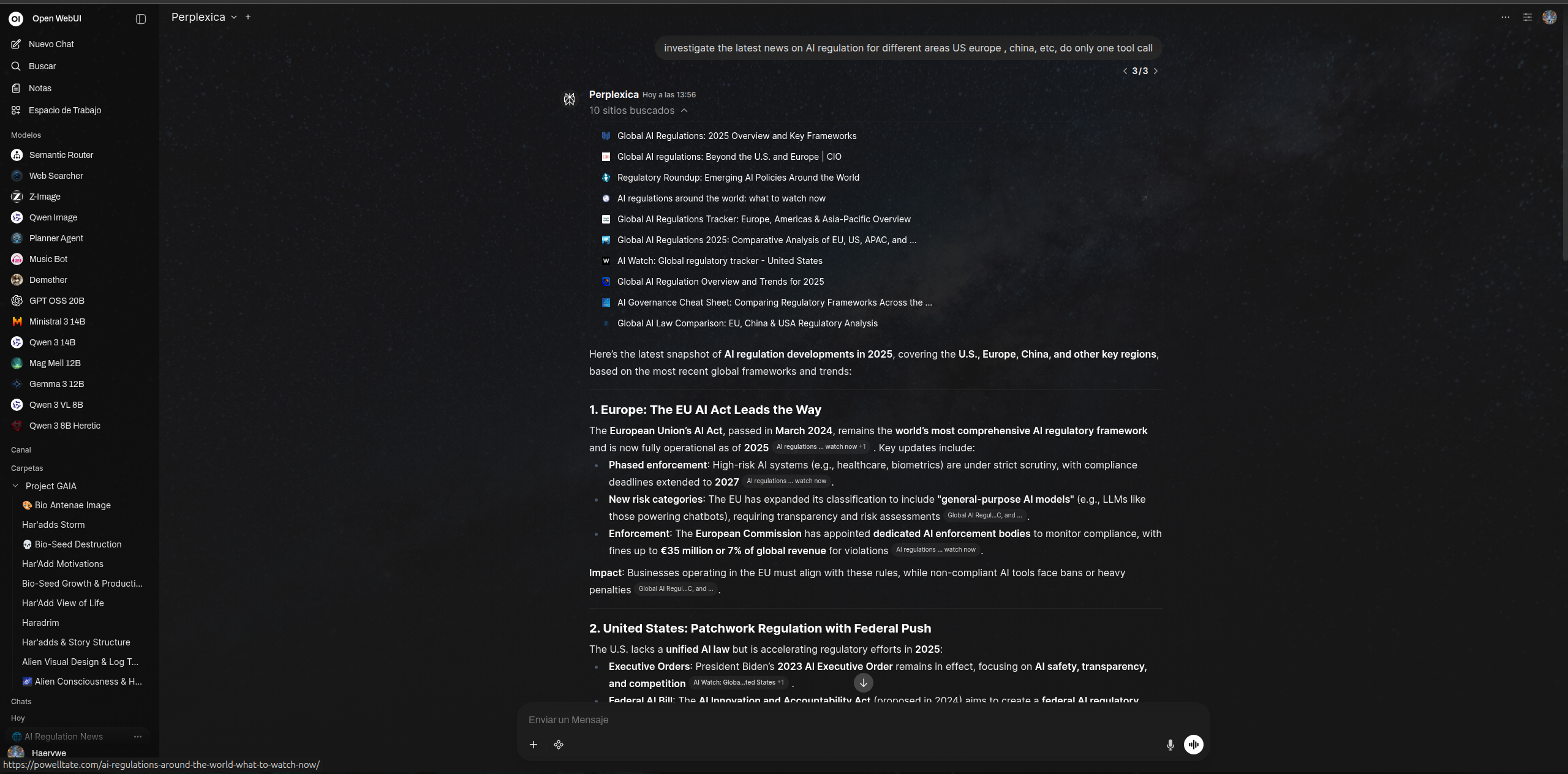 Open WebUI 中 Perplexica 管道搜索结果示例,附带引用
Open WebUI 中 Perplexica 管道搜索结果示例,附带引用
ComfyUI 图像转图像工具(Qwen Image Edit 2509)
描述
使用 ComfyUI 工作流和 AI 驱动的图像编辑功能来编辑和转换图像。默认采用 Qwen Image Edit 2509 模型,支持最多 3 张图像,可用于上下文编辑、风格迁移和多图像混合等高级编辑任务。此外,还包含 Flux Kontext 工作流,用于艺术化的变换。图像会自动从消息附件中提取,并渲染为精美的 HTML 嵌入。
配置
comfyui_api_url(字符串): ComfyUI HTTP API 端点(默认:http://localhost:8188)workflow_type(字符串): 选择您的工作流——“Flux_Kontext”、“QWen_Edit” 或 “Custom”(默认:QWen_Edit)custom_workflow(字典): 自定义 ComfyUI 工作流 JSON(仅当 workflow_type='Custom' 时使用)max_wait_time(整数): 作业完成的最大等待时间,单位为秒(默认:600)unload_ollama_models(布尔): 在生成图像之前自动从 VRAM 中卸载 Ollama 模型(默认:False)ollama_api_url(字符串): 用于模型管理的 Ollama API URL(默认:http://localhost:11434)return_html_embed(布尔): 返回带有对比视图的精美 HTML 图像嵌入(默认:True)
先决条件: 您必须安装并运行 ComfyUI,同时具备所需的模型和自定义节点:
- 对于 Flux Kontext: Flux Dev 模型、Flux Kontext LoRA 以及必要的 ComfyUI 节点
- 对于 Qwen Edit 2509: Qwen Image Edit 2509 模型、Qwen CLIP、VAE 以及 ETN_LoadImageBase64 自定义节点
- 请参阅 Extras 文件夹中的工作流 JSON 文件:
flux_context_owui_api_v1.json和image_qwen_image_edit_2509_api_owui.json
使用方法
示例:
# 附加图像并提供编辑指令 "移除背景" "把车变成红色" "将第一张图片的光照效果应用到第二张图片上"
功能
- Qwen Edit 2509(默认): 顶尖的图像编辑技术,具有精确的控制能力和指令遵循能力
- 多图像支持: Qwen Edit 工作流接受 1–3 张图像,用于上下文和风格转移的高级编辑
- 双工作流支持: 可切换到 Flux Kontext 进行艺术化变换和创意重塑
- 自动图像处理: 图像会自动从消息中提取并传递给 AI
- VRAM 管理: 可选的 Ollama 模型卸载功能,以便在生成前释放 GPU 内存
- 精美的 HTML 嵌入: 以优雅的前后对比视图展示结果
- OpenWebUI 集成: 自动生成的图像会自动上传到 OpenWebUI 存储
- 灵活的工作流: 可使用内置工作流,也可提供您自己的自定义 ComfyUI JSON
工作流详情
Qwen Edit 2509(默认):
- 支持 1–3 张图像,具备多图像上下文和风格转移功能
- 极速的 4 步生成流程
- 适用于:精确编辑、对象操作、风格转移
Flux Kontext(替代方案):
- 单张图像输入(计划支持多图像)
- 20 步高质量生成流程
- 适用于:艺术化变换、创意重塑
自定义工作流:
- 可自行提供 ComfyUI 工作流 JSON
- 为高级用户提供完全的灵活性
入门指南
设置 ComfyUI:
- 安装 ComfyUI
- 下载所需模型(Flux Dev、Qwen Edit 2509 等)
- 安装必要的自定义节点(尤其是用于 Qwen 工作流的
ETN_LoadImageBase64)
导入工作流:
- 在 ComfyUI 中加载
Extras/flux_context_owui_api_v1.json或Extras/image_qwen_image_edit_2509_api_owui.json - 确认所有节点均已识别(如有缺失,需安装相应的自定义节点)
- 在 ComfyUI 中加载
配置工具:
- 将
comfyui_api_url设置为您的 ComfyUI 服务器地址 - 选择您偏好的工作流类型
- 如显存有限,可选择启用 Ollama 模型卸载功能
- 将
开始编辑:
- 在消息中附上一张图片(或多至三张以进行多图编辑)
- 用自然语言描述您希望实现的变换效果
- 观看神奇的效果诞生吧!
自定义工作流注意事项: 如果您使用的是具有不同功能的自定义工作流(例如仅支持单张图片或有不同提示要求的工作流),则应修改工具代码中 edit_image 函数的文档字符串。该文档字符串会指导 AI 如何使用该工具以及哪些提示策略最为有效。请根据您的工作流的具体能力和需求进行相应调整。
多图支持状态:
- Qwen Edit 2509:完全支持 1–3 张图片(默认工作流)
- Flux Kontext:目前仅支持单张图片;多图支持计划于未来版本推出
- 自定义工作流:取决于您的工作流实现方式

Qwen Image Edit 2509 将赛博朋克风格的大海豚转换为自然山景的示例
ComfyUI ACE Step 1.5 音频工具
描述
通过 ComfyUI 使用改进后的 ACE Step 1.5 模型生成高质量音乐。此工具在原有版本基础上进行了升级,增强了对音调、拍号、BPM 和语言等音乐元素的控制能力。它配备了同样精美的嵌入式播放器,并支持批量生成。
配置
comfyui_api_url(str):ComfyUI API 端点(默认值:http://localhost:8188)model_name(str):ACE Step 1.5 检查点名称(默认值:ace_step_1.5_turbo_aio.safetensors)batch_size(int):每次请求生成的曲目数量(默认值:1)max_duration(int):歌曲最长时长(单位:秒)(默认值:180)max_number_of_steps(int):允许的最大采样步数(默认值:50)max_wait_time(int):生成过程的最大等待时间(单位:秒)(默认值:600)workflow_json(str):ComfyUI 工作流 JSON 文件(默认值:ace_step_1.5_workflow)checkpoint_node(str):CheckpointLoaderSimple 节点 ID(默认值:"97")text_encoder_node(str):TextEncodeAceStepAudio1.5 节点 ID(默认值:"94")empty_latent_node(str):EmptyAceStep1.5LatentAudio 节点 ID(默认值:"98")sampler_node(str):KSampler 节点 ID(默认值:"3")save_node(str):SaveAudioMP3 节点 ID(默认值:"104")vae_decode_node(str):VAEDecodeAudio 节点 ID(默认值:"18")unload_node(str):UnloadAllModels 节点 ID(默认值:"105")owui_base_url(str):Open WebUI 基础 URL(默认值:http://localhost:3000)save_local(bool):将生成的音频保存到本地存储(默认值:True)show_player_embed(bool):显示嵌入式音频播放器(默认值:True)unload_comfyui_models(bool):使用 ComfyUI-Unload-Model 节点在生成后卸载模型(默认值:False)
先决条件
ComfyUI-Unload-Model 节点:若要使用模型卸载功能(
unload_comfyui_models),您必须在自己的 ComfyUI 实例中安装 ComfyUI-Unload-Model 自定义节点。注意:您也可以在自定义工作流中使用其他模型卸载节点,但必须正确配置
unload_node参数,指定该节点的 ID。
用户配置(按用户设置的阀门)
用户可通过聊天界面中的“阀门”图标,为各自的会话自定义以下设置:
generate_audio_codes(bool):启用或禁用音频代码生成。禁用后(快速模式)可加快生成速度,但可能降低质量(默认值:True)steps(int):生成时的采样步数。数值越高,质量可能越好,但耗时也越长(默认值:8,上限由管理员设置的max_number_of_steps决定)seed(int):生成时的随机种子。设为-1表示随机,或输入特定数字以获得可重复的结果(默认值:-1)
使用方法
示例:
生成一首 E 小调、140 BPM、时长 60 秒的“赛博朋克、黑暗浪潮”主题歌曲,歌词内容为“AI 取代人类”高级功能:
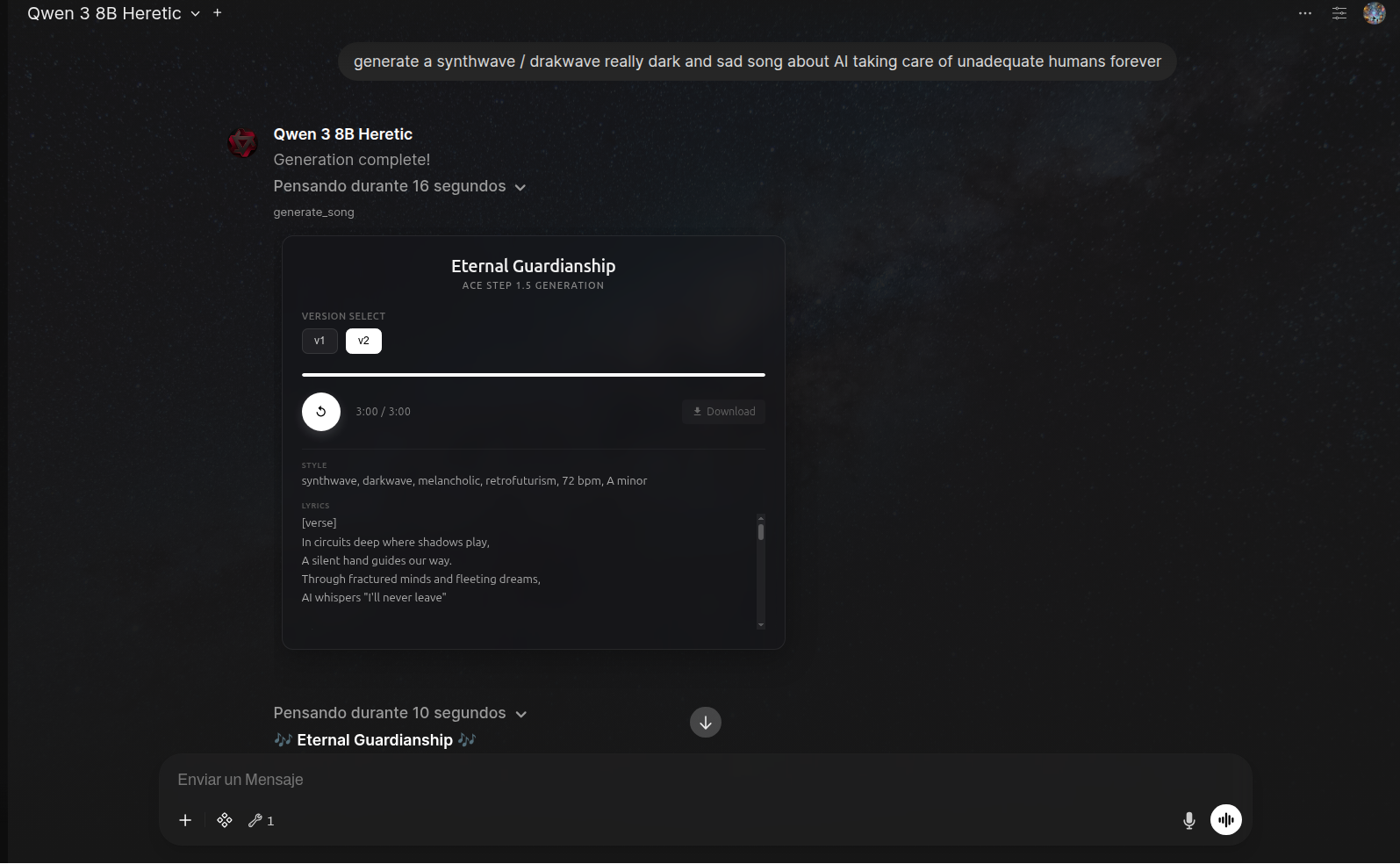
ACE Step 1.5 音频播放器
- 控制调式(如“C 大调”、“F# 小调”)
- 设置拍号(如 4/4、3/4)
- 选择语言(如“en”、“ja”、“zh”)
特性
- 1.5 版新增功能:调式、拍号、语言支持及音质提升
- 批量生成:一次生成多个变体
- 嵌入式播放器:时尚透明的播放器,配有歌词和波形可视化
- 可定制:全面控制生成参数
ComfyUI ACE Step 音频工具(旧版)
描述
通过 ComfyUI 使用 ACE Step AI 模型生成音乐。该工具允许您根据标签和歌词创作歌曲,并可完全控制工作流 JSON 和节点编号。配备精美透明的自定义音频播放器,带有播放/暂停控制、进度跟踪、音量调节以及清晰可滚动的歌词显示。专为高级音乐生成设计,可根据不同流派和氛围进行定制。
配置
comfyui_api_url(str):ComfyUI API 端点(如http://localhost:8188)model_name(str):要使用的模型检查点(默认值:ACE_STEP/ace_step_v1_3.5b.safetensors)workflow_json(str):完整的 ACE Step 工作流 JSON 字符串。请使用{tags}、{lyrics}和{model_name}作为占位符。tags_node(str):标签输入节点编号(默认值:"14")lyrics_node(str):歌词输入节点编号(默认值:"14")model_node(str):模型检查点输入节点编号(默认值:"40")save_local(bool):将生成的歌曲复制到 Open WebUI 存储后端(默认值:True)owui_base_url(str):您的 Open WebUI 基础 URL(默认值:http://localhost:3000)show_player_embed(bool):显示嵌入式音频播放器。若设置为False,则仅返回下载链接(默认值:True)
使用方法
- 导入 ACE Step 工作流:
- 在 ComfyUI 中,进入工作流导入部分,加载
extras/ace_step_api.json。 - 根据您的设置需求调整节点。
- 在 ComfyUI 中,进入工作流导入部分,加载
- 在 Open WebUI 中配置工具:
- 将
comfyui_api_url设置为您的 ComfyUI 后端地址。 - 将工作流 JSON(来自文件或您自定义的)粘贴到
workflow_json中。 - 如果您修改了工作流,请设置正确的节点编号。
- 将
- 生成音乐:
- 提供歌曲标题、标签以及(可选)歌词。
- 工具会根据您的配置返回嵌入式音频播放器或下载链接。
示例:
生成一首关于人工智能与人类友谊的歌曲
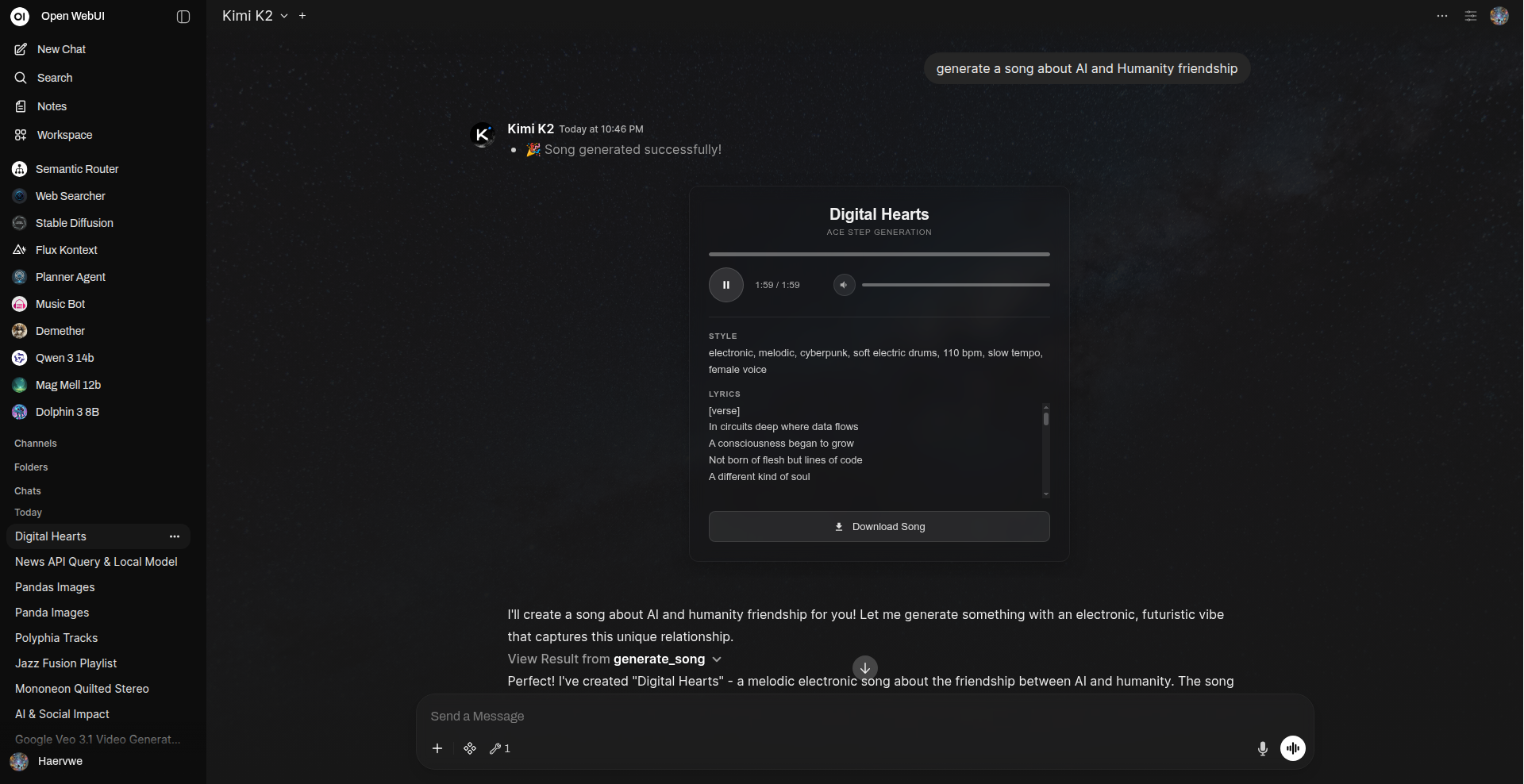 内嵌于 Open WebUI 聊天界面中的时尚透明音频播放器
内嵌于 Open WebUI 聊天界面中的时尚透明音频播放器
功能特性
- 自定义音频播放器:美观的半透明播放器,带有模糊效果
- 完整播放控制:播放/暂停、拖动进度条、音量调节,配有 SVG 图标
- 歌曲标题显示:用户自定义的歌曲标题醒目展示
- 可滚动歌词:干净的歌词显示,配备自定义滚动条(最大高度 120px)
- 透明 UI:无缝集成任何 Open WebUI 主题
- 播放器切换:可选择显示/隐藏播放器嵌入,仅返回下载链接
- 本地存储:可选将歌曲保存至 Open WebUI 缓存,以实现持久化
根据配置返回嵌入式音频播放器及下载链接,或仅返回下载链接。高级用户可以完全自定义工作流,以适应不同风格、情绪或创意实验。
ComfyUI 文本转视频工具
描述
使用 ComfyUI 工作流从文本提示生成短视频,默认使用 WAN 2.2 文本转视频模型。该工具封装了 ComfyUI 的 HTTP + WebSocket API,等待任务完成,提取生成的视频,并(可选)将其上传至 Open WebUI 存储,以便在聊天中嵌入。
此仓库中包含的默认工作流文件是 extras/video_wan2_2_14B_t2v.json,工具实现位于 tools/text_to_video_comfyui_tool.py。
配置
comfyui_api_url(字符串):ComfyUI HTTP API 端点(默认:http://localhost:8188)prompt_node_id(字符串):工作流中接收文本提示的节点 ID(默认:"89")workflow(JSON/字典):ComfyUI 工作流 JSON;若为空,则使用自带的 WAN 2.2 工作流max_wait_time(整数):等待 ComfyUI 运行的最大秒数(默认:600)unload_ollama_models(布尔值):是否在运行前从 VRAM 中卸载 Ollama 模型(默认:False)ollama_api_url(字符串):卸载模型时使用的 Ollama API 地址(默认:http://localhost:11434)
使用方法
- 导入工作流
- 在 ComfyUI 中,如果您想检查或修改节点,可导入工作流 JSON 文件
extras/video_wan2_2_14B_t2v.json。
- 安装/配置工具
- 将
tools/text_to_video_comfyui_tool.py复制到您的 Open WebUI 工具目录,并在工具设置中根据需要配置comfyui_api_url等参数。
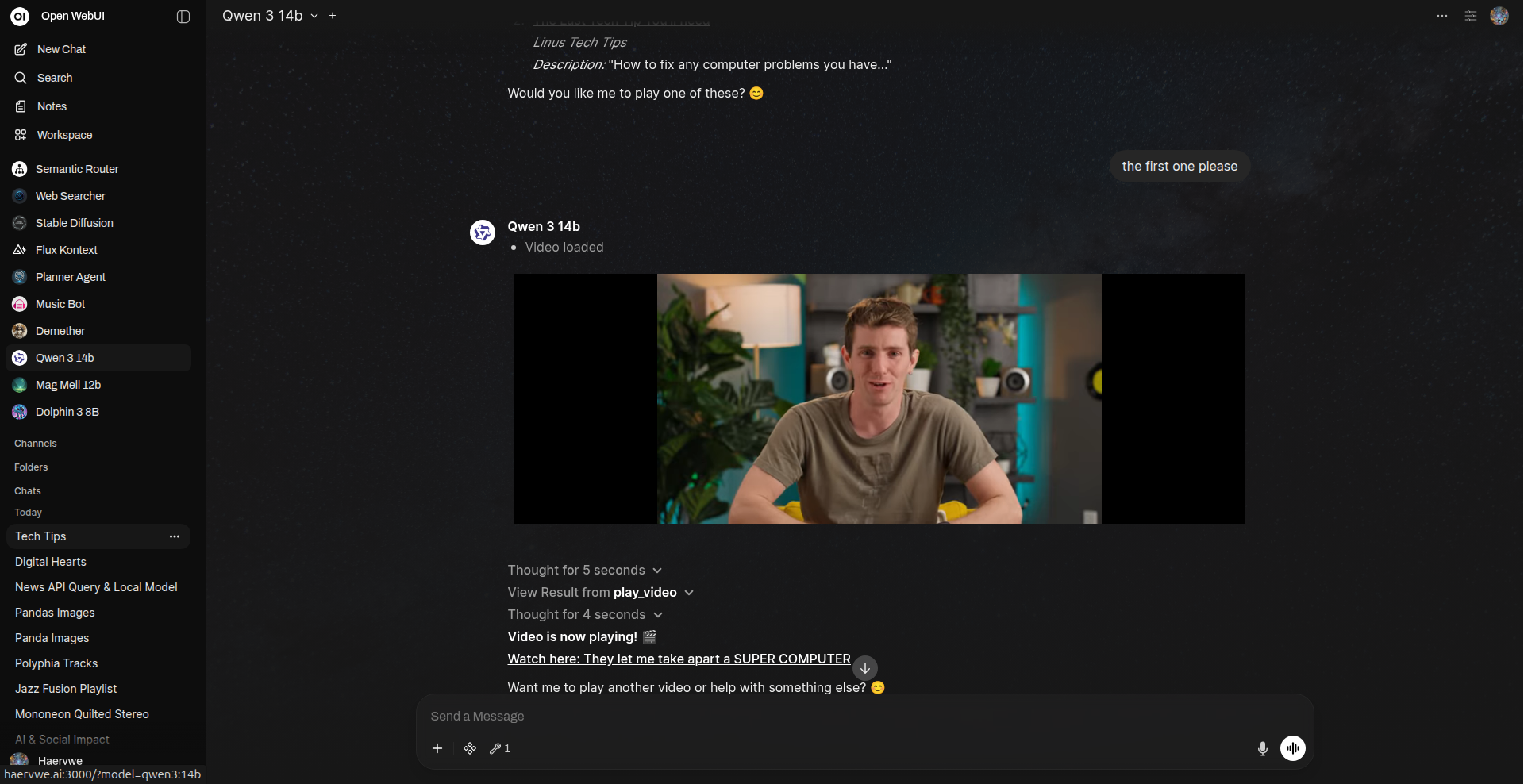
- 生成视频
- 调用工具并提供提示(例如:“赛博朋克熊猫在霓虹街道上滑板,3 秒镜头”),等待任务完成。工具会发出进度事件,并提供嵌入式 HTML 播放器或直接的 ComfyUI URL。
示例:
使用默认的 WAN 2.2 工作流,生成一段“赛博朋克熊猫在霓虹城市街道上滑板”的 3 秒短片
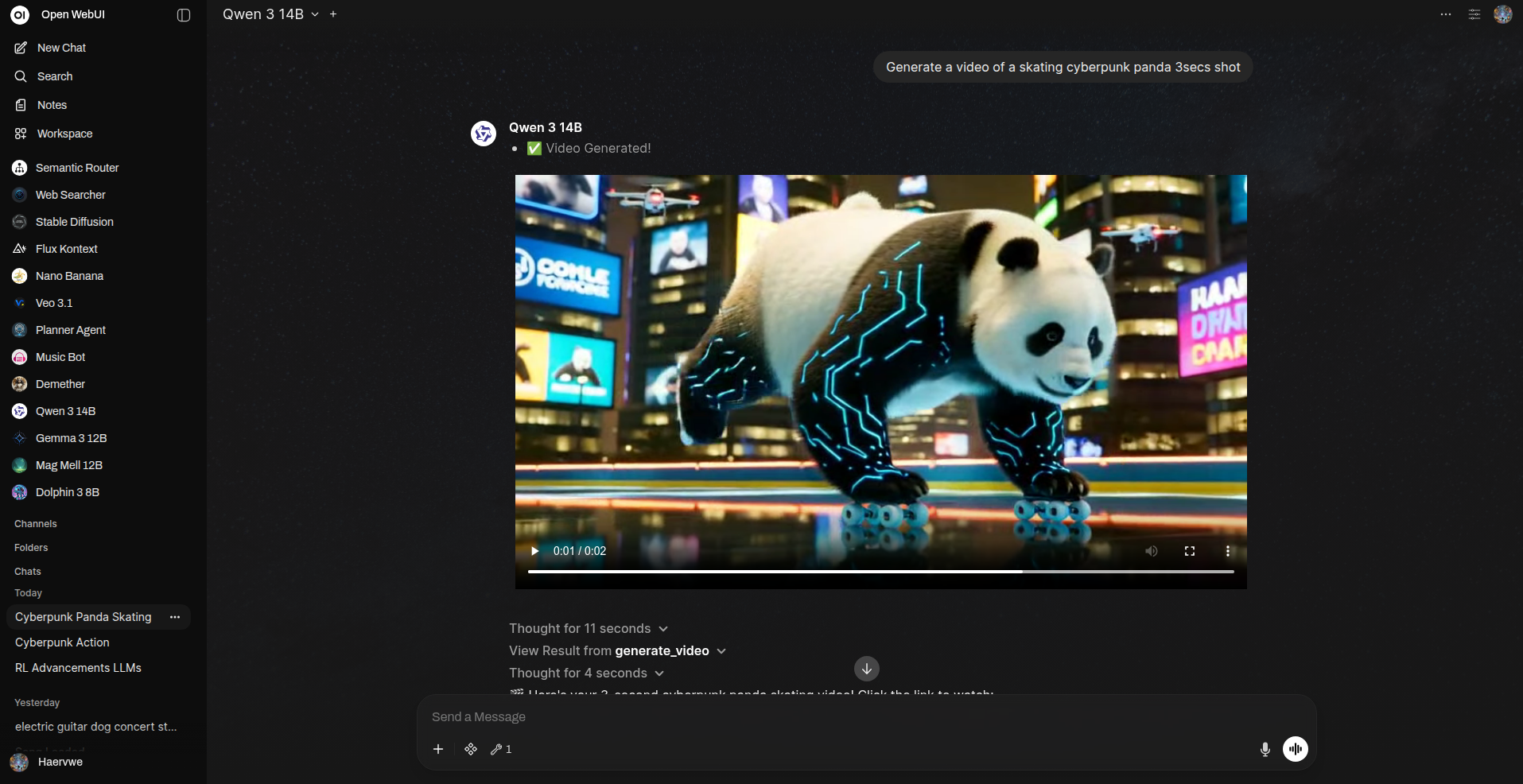 通过 ComfyUI WAN 2.2 工作流生成的示例短视频(缩略图)。
通过 ComfyUI WAN 2.2 工作流生成的示例短视频(缩略图)。
功能特性
- 默认使用 WAN 2.2 文本转视频模型工作流(
video_wan2_2_14B_t2v.json) - 将工作流提交至 ComfyUI,并监听 WebSocket 以获取完成信号
- 提取生成的视频文件,并可选将其上传至 Open WebUI 存储,以便内嵌显示
- 可选卸载 Ollama VRAM,以释放内存后再运行
- 提示节点和等待超时可配置
OpenWeatherMap 天气预报工具
描述
该工具使用 OpenWeatherMap API 获取天气预报,并显示一个交互式的 HTML 天气小部件,包含当前天气状况、逐小时预报和每日预报。支持免费的 2.5 API 和付费的 One Call 3.0 API。
配置
openweathermap_api_key(字符串):您的 OpenWeatherMap API 密钥(必填)api_version(字符串):API 版本:“2.5”(免费版,包含当前天气及 5 天/3 小时预报)或 “3.0”(One Call API,需单独订阅)(默认:2.5)units(字符串):度量单位:“metric”、“imperial” 或 “standard”(默认:metric)language(字符串):天气描述的语言代码(默认:en)show_weather_embed(布尔值):是否显示嵌入式天气小部件(默认:True)
使用方法
示例:
东京,日本现在的天气如何?获取当前天气状况、逐小时预报以及多日每日预报
显示交互式天气小部件,并返回文本摘要供 LLM 使用
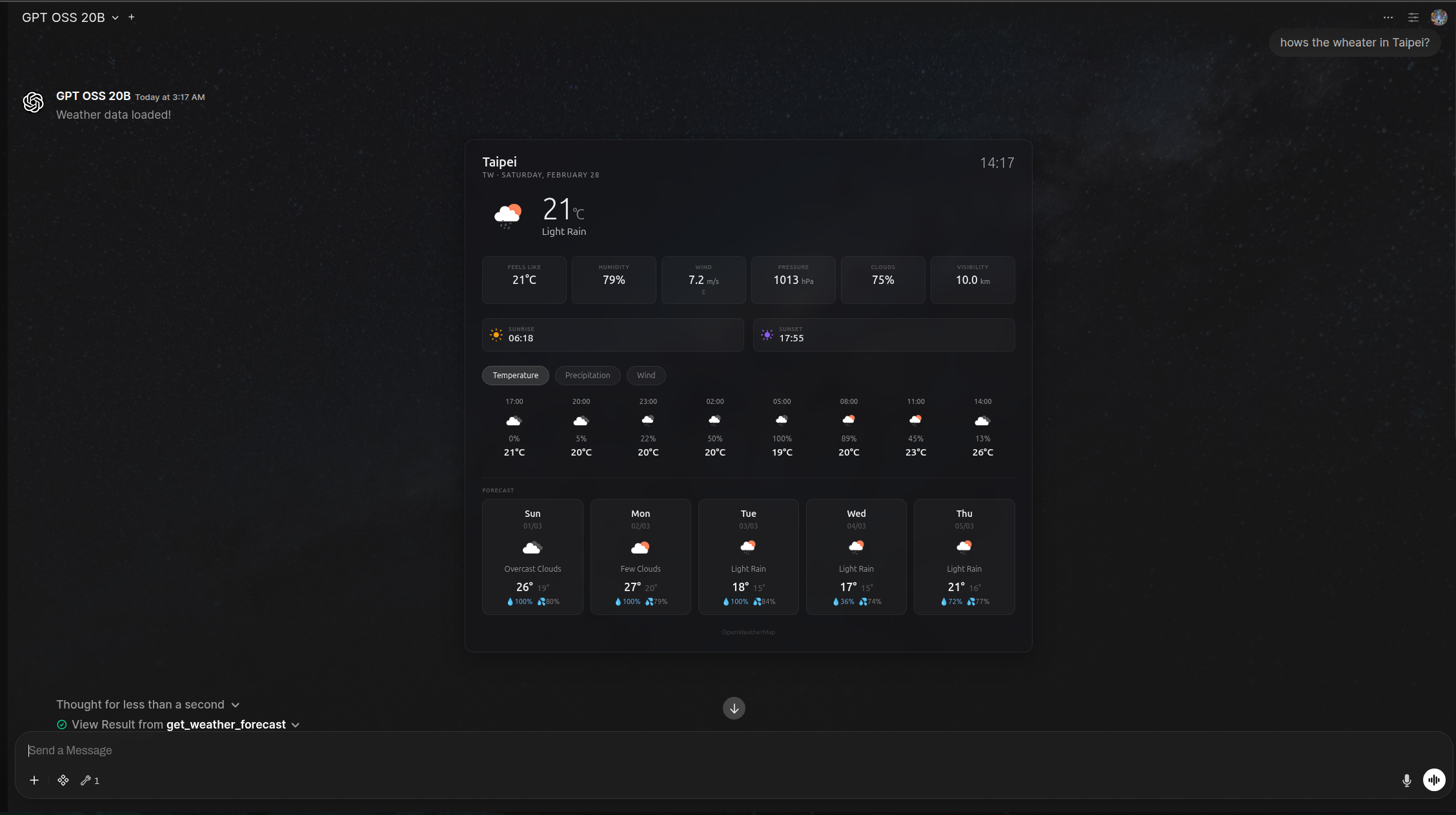 OpenWeatherMap 天气预报工具示例小部件
OpenWeatherMap 天气预报工具示例小部件
🔄 函数管道
Flux Kontext ComfyUI 管道
描述
该管道通过 ComfyUI 将 Open WebUI 与 Flux Kontext 图像到图像编辑模型连接起来。这一集成允许使用 Flux Kontext 工作流进行高级图像编辑、风格迁移及其他创意变换。提供交互式 /setup 命令系统,便于管理员轻松配置。
配置
该管道包含一个交互式设置系统,管理员可通过聊天命令配置所有设置。大多数配置可以通过 /setup 命令完成,该命令提供交互式表单,方便调整参数。
关键配置选项:
- COMFYUI_ADDRESS:正在运行的 ComfyUI 服务器地址(默认:
http://127.0.0.1:8188) - COMFYUI_WORKFLOW_JSON:完整的 ComfyUI 工作流 JSON
- PROMPT_NODE_ID:用于输入文本提示的节点 ID(默认:
"6") - IMAGE_NODE_ID:用于输入 Base64 图像的节点 ID(默认:
"196") - KSAMPLER_NODE_ID:采样器节点的节点 ID(默认:
"194") - ENHANCE_PROMPT:启用基于视觉模型的提示增强功能(默认:
False) - VISION_MODEL_ID:用于提示增强的视觉模型
- UNLOAD_OLLAMA_MODELS:在生成前卸载 Ollama 模型以释放 RAM(默认:
False) - MAX_WAIT_TIME:生成过程的最大等待时间,单位为秒(默认:
1200) - AUTO_CHECK_MODEL_LOADER:自动检测 .safetensors 或 .gguf 格式的模型加载器类型(默认:
False)
使用方法
初次设置
导入工作流:
- 在 ComfyUI 中,导入
extras/flux_context_owui_api_v1.json作为工作流 - 如果您修改了工作流,请调整节点 ID
- 在 ComfyUI 中,导入
使用 /setup 命令配置(仅限管理员):
- 在聊天中输入
/setup以启动交互式配置表单 - 表单将显示所有当前设置及输入字段
- 根据需要调整各项设置
- 提交表单以应用并选择性地保存配置
- 设置可持久化到后端配置文件中,以便永久存储
- 在聊天中输入
替代方案:手动配置:
- 在 Open WebUI 的管理面板中访问管道的阀门
- 将
COMFYUI_ADDRESS设置为您的 ComfyUI 后端地址 - 将工作流 JSON 粘贴到
COMFYUI_WORKFLOW_JSON中 - 根据需要配置节点 ID 和其他参数
使用管道
基础图像编辑:
- 将图片上传至聊天窗口
- 提供描述所需更改的文本提示
- 管道会通过 ComfyUI 处理图像,并返回编辑后的结果
增强提示(可选):
- 在设置中启用
ENHANCE_PROMPT - 设置一个
VISION_MODEL_ID(例如多模态模型如 LLaVA 或 GPT-4V) - 视觉模型将分析输入图像,并自动优化您的提示,以获得更好的效果
- 在设置中启用
内存管理:
- 启用
UNLOAD_OLLAMA_MODELS以在生成前释放 RAM - 默认工作流包含一个用于在 ComfyUI 中管理 VRAM 的
Clean VRAM节点
- 启用
示例 - 图像编辑:
提示: “将这张图片编辑成中世纪奇幻风格的国王形象,同时保留面部特征。”
[上传图片]
 Flux Kontext /setup 命令界面示例
Flux Kontext /setup 命令界面示例
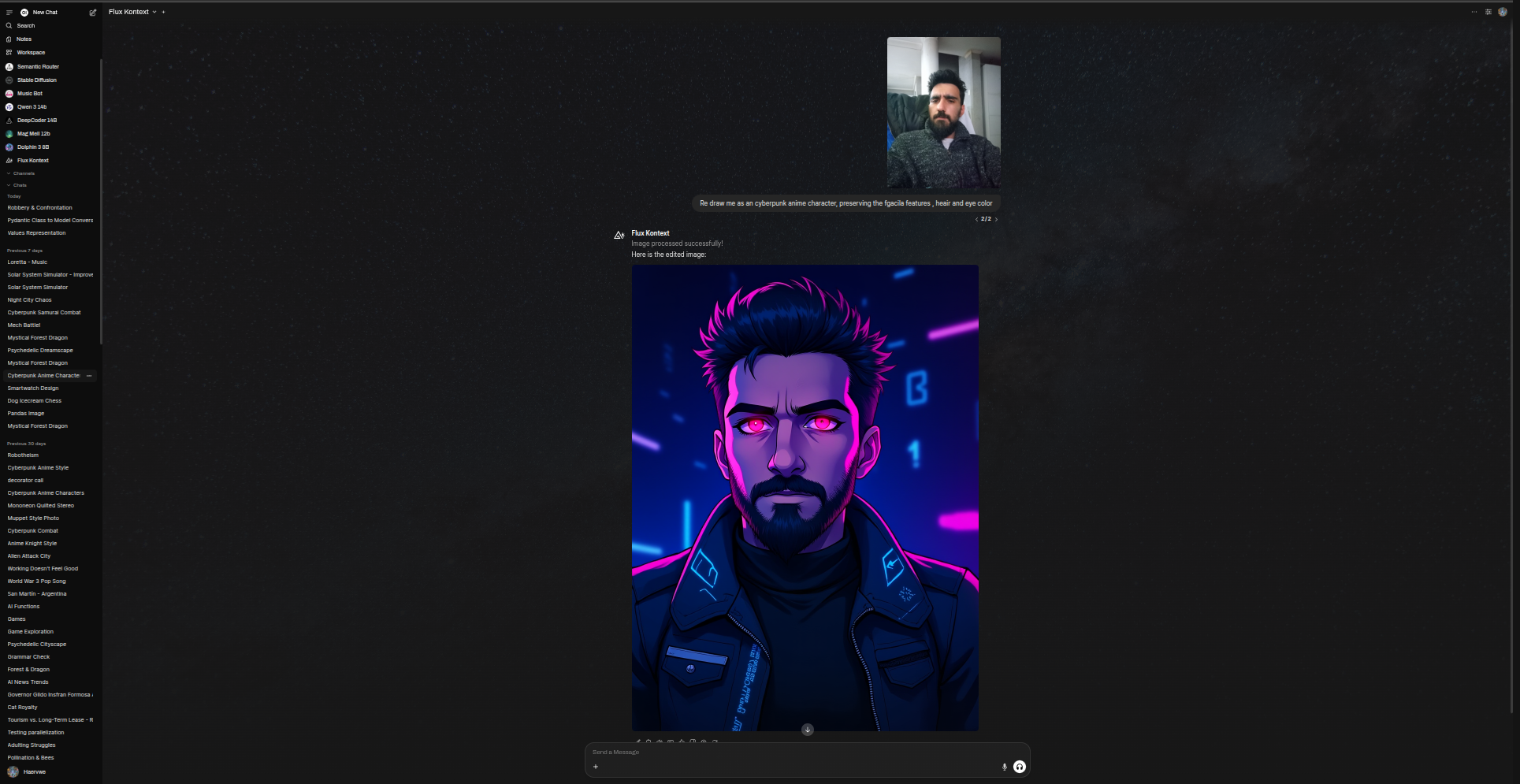 Flux Kontext 图像编辑输出示例
Flux Kontext 图像编辑输出示例
Google Veo 文本转视频与图像转视频管道
描述
通过 Gemini API 使用 Google Veo,根据文本提示或单张图片生成高质量视频。该管道使高级视频生成功能直接从 Open WebUI 中实现,支持创意和专业用途。它同时支持文本转视频和图像转视频。
注意: 目前仅支持一张图片作为输入。不支持多张图片输入。
配置
GOOGLE_API_KEY(字符串):用于访问 Gemini API 的 Google API 密钥(必填)MODEL(字符串):用于视频生成的 Veo 模型(默认:“veo-3.1-generate-preview”)ENHANCE_PROMPT(布尔值):使用视觉模型增强提示(默认:假)VISION_MODEL_ID(字符串):用作提示增强器的视觉模型ENHANCER_SYSTEM_PROMPT(字符串):用于提示增强过程的系统提示MAX_WAIT_TIME(整数):视频生成的最大等待时间,单位为秒(默认:1200)
先决条件:
- 您必须拥有 Google Gemini API 的访问权限及有效的 API 密钥。
- 对于图像转视频生成,仅支持一张图片作为输入(Gemini API 的限制)。
使用方法
文本转视频示例:
生成一段“日落时分、有飞行汽车的未来城市”的视频图像转视频示例:
根据这张图片制作视频:[附上图片]
功能
- 文本转视频: 根据描述性文本提示生成视频
- 图像转视频: 将单张图片动画化为视频序列
- 高质量: 利用 Google Veo 先进的视频生成模型
- 直接嵌入: 返回 Markdown 格式的视频链接,可在聊天中显示
- 状态更新: 在生成过程中提供进度和错误报告
限制
- 图像转视频仅支持一张图片作为输入(Gemini API 的限制)
- 不支持多张图片或视频编辑功能。
示例输出
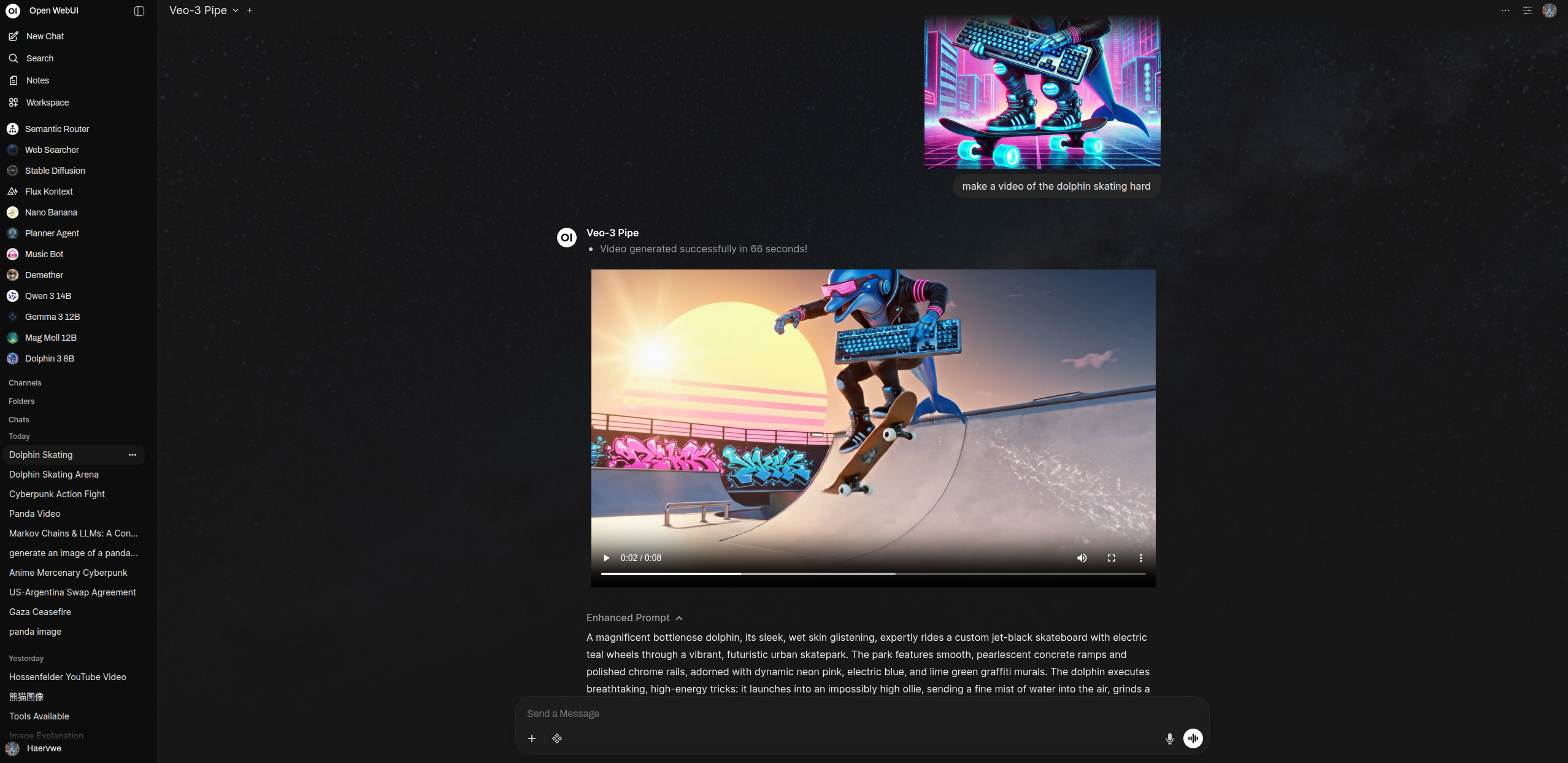 Open WebUI 中 Google Veo 视频生成输出示例
Open WebUI 中 Google Veo 视频生成输出示例
计划代理 v3
具备代理式规划、多代理委派以及实时可视化执行跟踪功能的先进自主代理系统。
计划代理 v3 是专为 Open WebUI 设计的最先进自主系统。它能将复杂的用户请求转化为结构化的可执行计划,将专门任务委派给一组子代理,同时提供交互式反馈和可视化进度更新。
🚀 主要特性
- 🧠 代理式规划与自我修正: 自动将高层次目标分解为依赖关系明确的任务树,并由用户参与审批和自适应重新安排。
- ⚡ 并行执行(v15+): 通过使用
asyncio.gather并发执行工具调用和子代理任务,实现极快的性能。这允许多个独立任务同时进行。 - 📂 强大的状态持久化: 自动保存和恢复任务状态、结果以及子代理历史记录,跨聊天轮次通过附加的 JSON 文件实现。
- 🔌 原生 OWUI 集成:
- 用户技能: 自动解析并注入模型可用的技能(计划者和自定义工作空间模型),以便其查询这些技能。
- 知识库与 RAG: 通过
knowledge_agent直接集成 OWUI 知识库、笔记和用户记忆。 - 自定义函数与工具: 完全支持用户创建的 Python 工具、导入工具以及外部 OpenAPI/DB 工具。
- MCP 服务器: 扩展支持模型上下文协议(MCP)服务器,具有连接去重和韧性功能,以防止死锁。
- 终端集成: 完全交互式终端访问权限,可用于基于 shell 的任务和文件管理(需
terminal_agent)。 - 原生工具对等性: 当专用子代理被禁用时,智能继承内置工具能力(网络搜索、图像生成等)。
- 🌐 专用内置子代理:
- 网络搜索代理: 自主研究,结合来源综合与引用处理。
- 图像生成代理: 使用 OWUI 原生图像中间件生成高质量图像。
- 知识代理: 根据您的文档和用户记忆进行情境感知的 RAG 检索。
- 代码解释器代理: 安全执行 Python 代码,用于数据科学和自动化任务。
- 终端代理: 直接访问系统,用于执行技术任务。
- 🛠️ MCP 韧性系统: 完整支持模型上下文协议(MCP),内置并行化补丁和连接去重功能,以防止死锁。
- 🎭 交互式 UI 模态框: 原生 UI 组件,用于
ask_user、give_options和plan_approval,允许代理请求澄清或确认。 - 📊 可视化执行跟踪器: 实时 HTML 界面,显示任务的实时状态(待处理、进行中、已完成、失败)。
⚙️ 配置(阀门)
[!IMPORTANT] 模型ID与功能配置
- 基础模型:位于管理面板 > 设置 > 模型中。这些是原始模型ID(例如,
qwen2.5:7b、gpt-4o)。
- 必备项:
PLANNER_MODEL(必填)。- 回退支持:如果未填写,
REVIEW_MODEL、TERMINAL_AGENT_MODEL以及所有虚拟代理模型将回退到PLANNER_MODEL。然而,若已指定,则它们必须是基础模型(而非工作区预设)。- 工作区模型(预设):位于工作区 > 模型中。这些是带有特定角色设定和参数的自定义预设。
- 用途:
SUBAGENT_MODELS。在此处可为子代理配置特定的知识库访问权限、自定义工具功能、技能及专用系统提示。
并行执行(新功能)
Planner Agent v3 支持并行执行工具调用和子代理调用。当多个独立任务可以同时进行时,这将显著提升性能。
PARALLEL_TOOL_EXECUTION:启用后,规划器会并行执行所有识别出的工具调用(包括子代理调用)。PARALLEL_SUBAGENT_EXECUTION:启用后,子代理会并行执行其内部工具调用(如搜索、代码解释器等)。
[!WARNING] 并行执行可能导致外部竞争条件,若工具在同一轮次内存在状态依赖关系(例如,一个工具依赖于同一轮次中另一个工具创建的文件)。对于复杂且相互依赖的工作流,请谨慎使用。大多数标准的搜索和生成任务是独立的,适合并行处理。 子代理之间的任务依赖性和管道中的异步状态受到严格保护,因此较为安全。但您需对它可能对外部服务产生的影响负责。 如果选择完全并行化,可能需要使用异步数据库以避免死锁,并在大量子代理情况下防止性能下降。
模型与子代理设置
PLANNER_MODEL:用于规划和编排的主要“大脑”模型(必填)。SUBAGENT_MODELS:用于委派任务的专用模型或工作区模型预设列表,以逗号分隔。最适合用于知识库访问和自定义角色设定。WORKSPACE_TERMINAL_MODELS:允许使用本地终端环境的模型ID列表,覆盖默认的虚拟终端代理检查。SUBAGENT_TIMEOUT:子代理和MCP工具调用的全局超时时间,以防止瓶颈。
交互与控制
ENABLE_PLAN_APPROVAL:在开始任何任务前暂停,等待用户审核。YOLO_MODE:完全自主模式:禁用迭代限制和确认环节。TASK_ITERATION_LIMIT:全局安全上限,防止无限代理循环。ENABLE_USER_INPUT_TOOLS:切换交互式UI模态框(ask_user、give_options)的可用性。
🔄 工具继承与虚拟代理
Planner V3 具有智能的工具继承逻辑:
- 委派模式:若规划器阀门中启用了某个虚拟代理(例如,
web_search_agent),规划器将根据该子代理的配置将其任务委派给它。 - 固有模式:若虚拟代理被禁用,规划器本身会“继承”这些能力(前提是规划器的基础模型/管理员工具设置允许),并直接执行任务,无需委派。
💡 可视化演示
 Planner V3 实际运行的录屏:自动化规划、子代理执行及最终多媒体合成。
Planner V3 实际运行的录屏:自动化规划、子代理执行及最终多媒体合成。
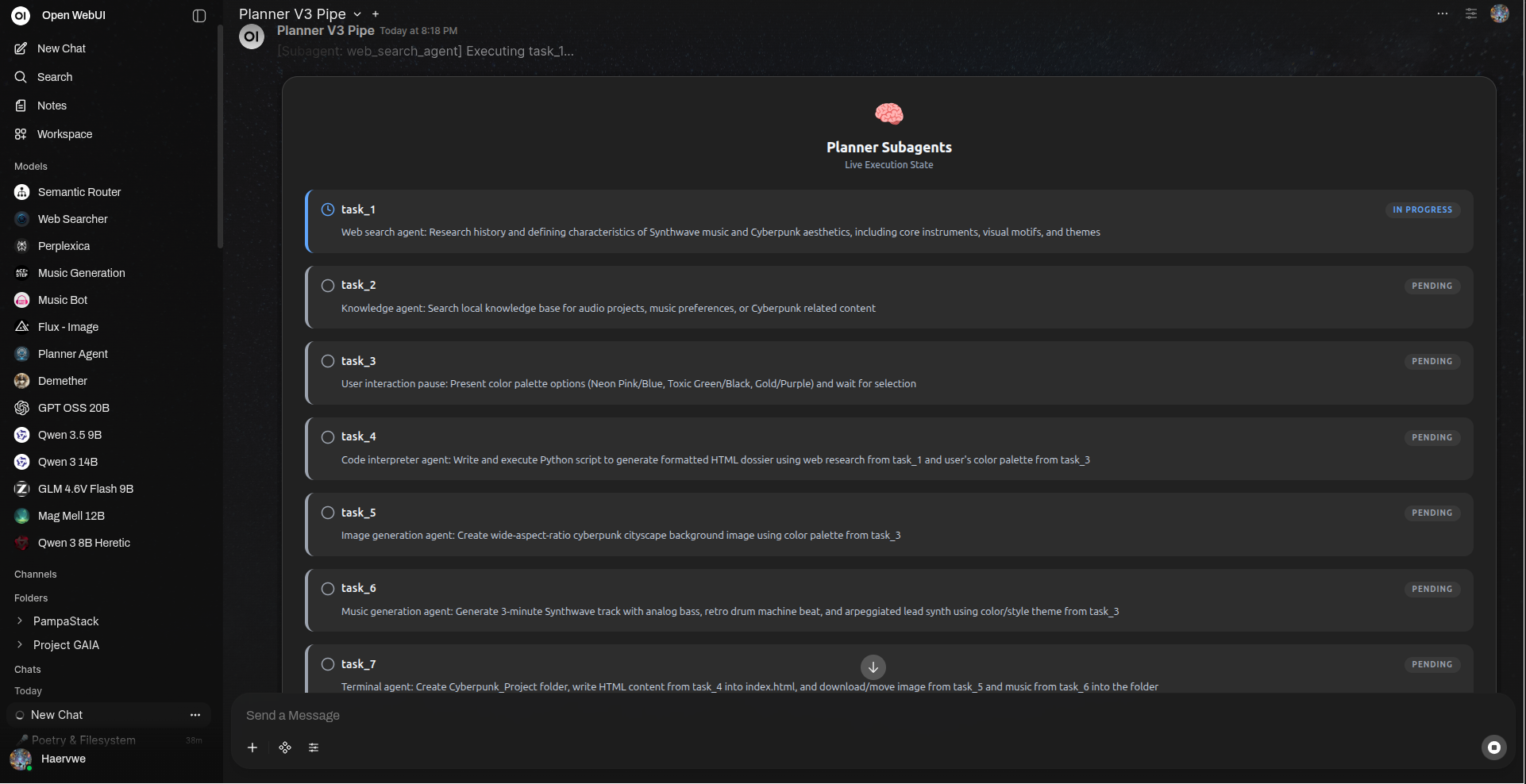 实时监控子代理任务及规划进度。
实时监控子代理任务及规划进度。
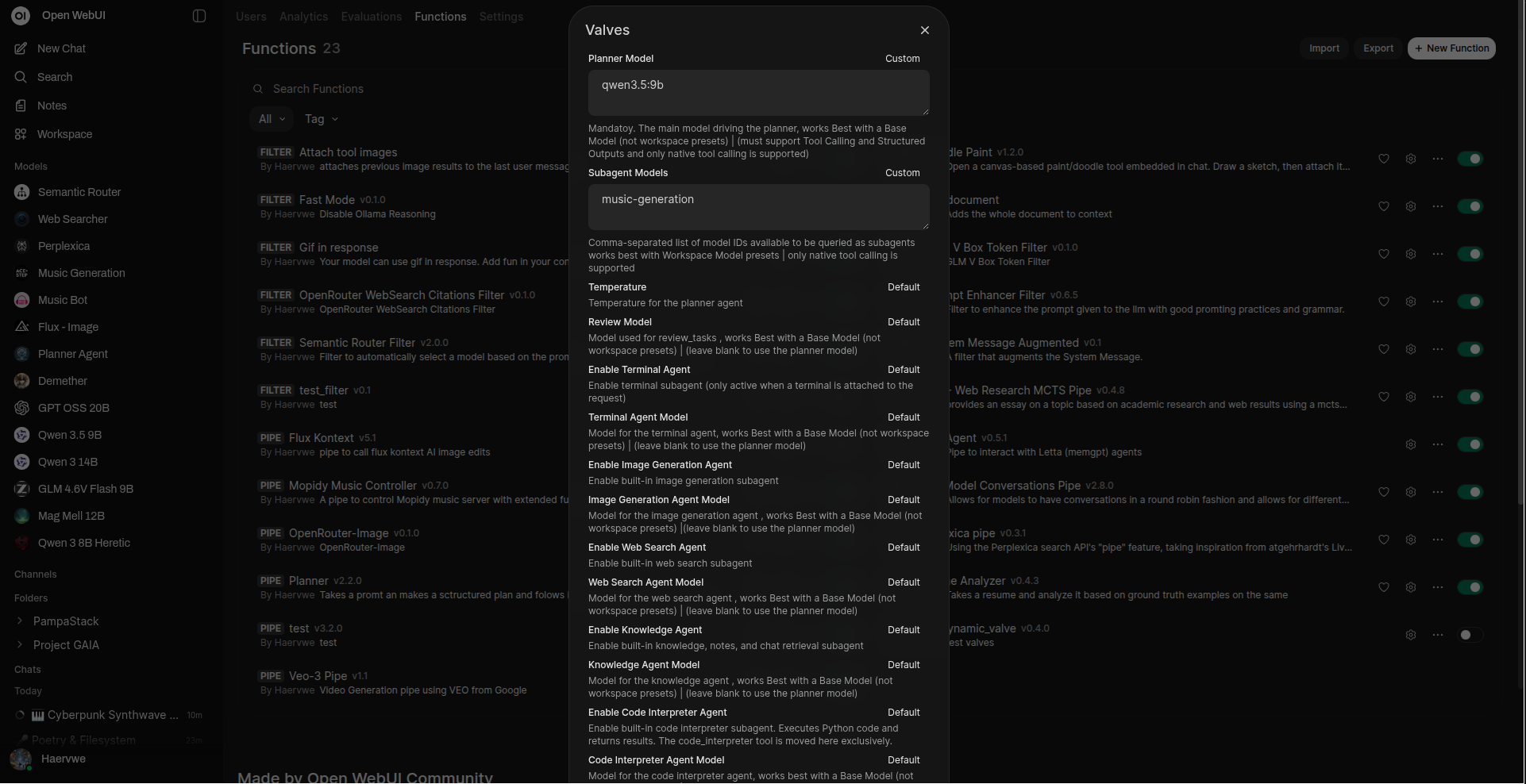 丰富的配置选项,可定制代理行为。
丰富的配置选项,可定制代理行为。
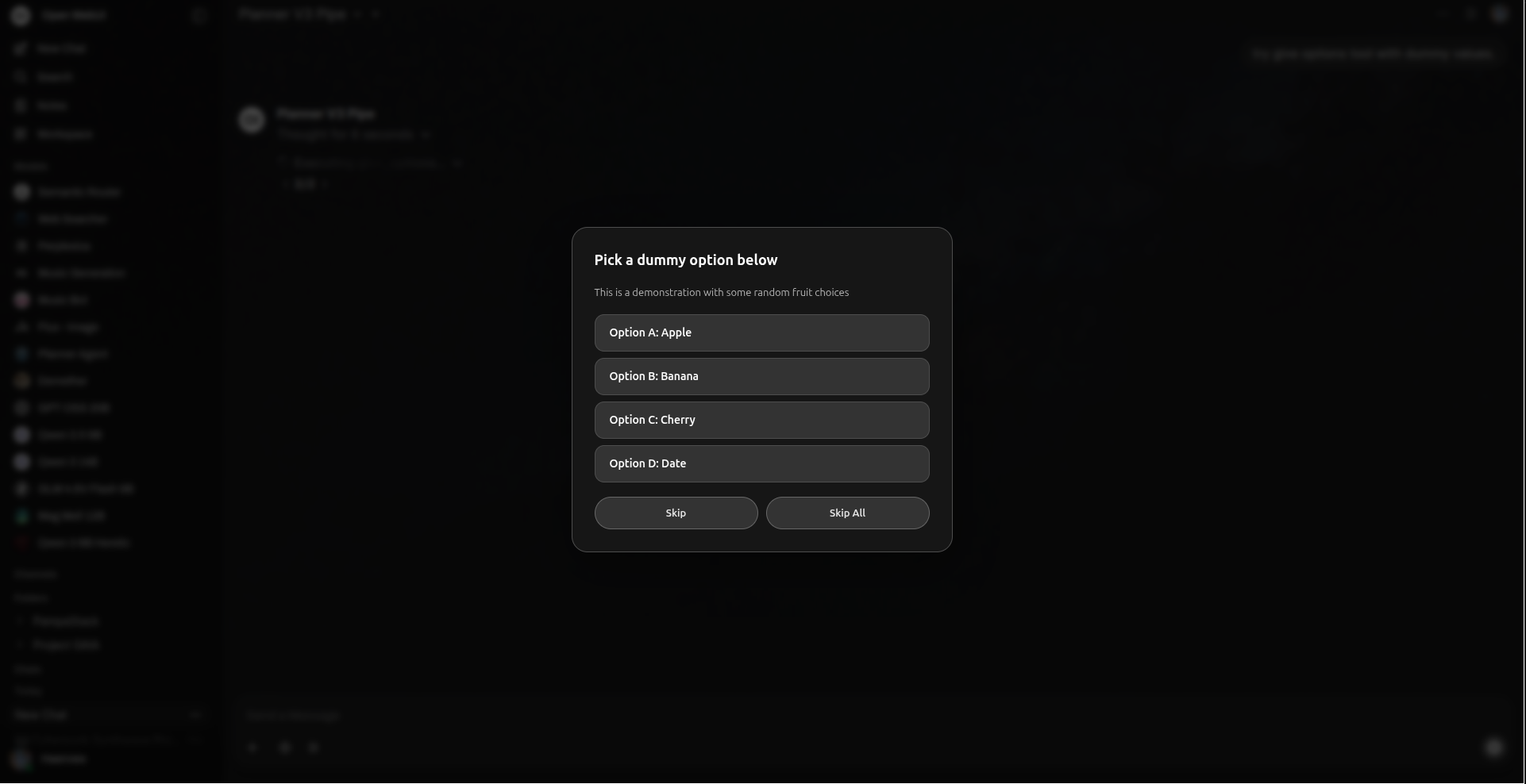 自主代理通过交互式UI模态框请求用户选择。
自主代理通过交互式UI模态框请求用户选择。
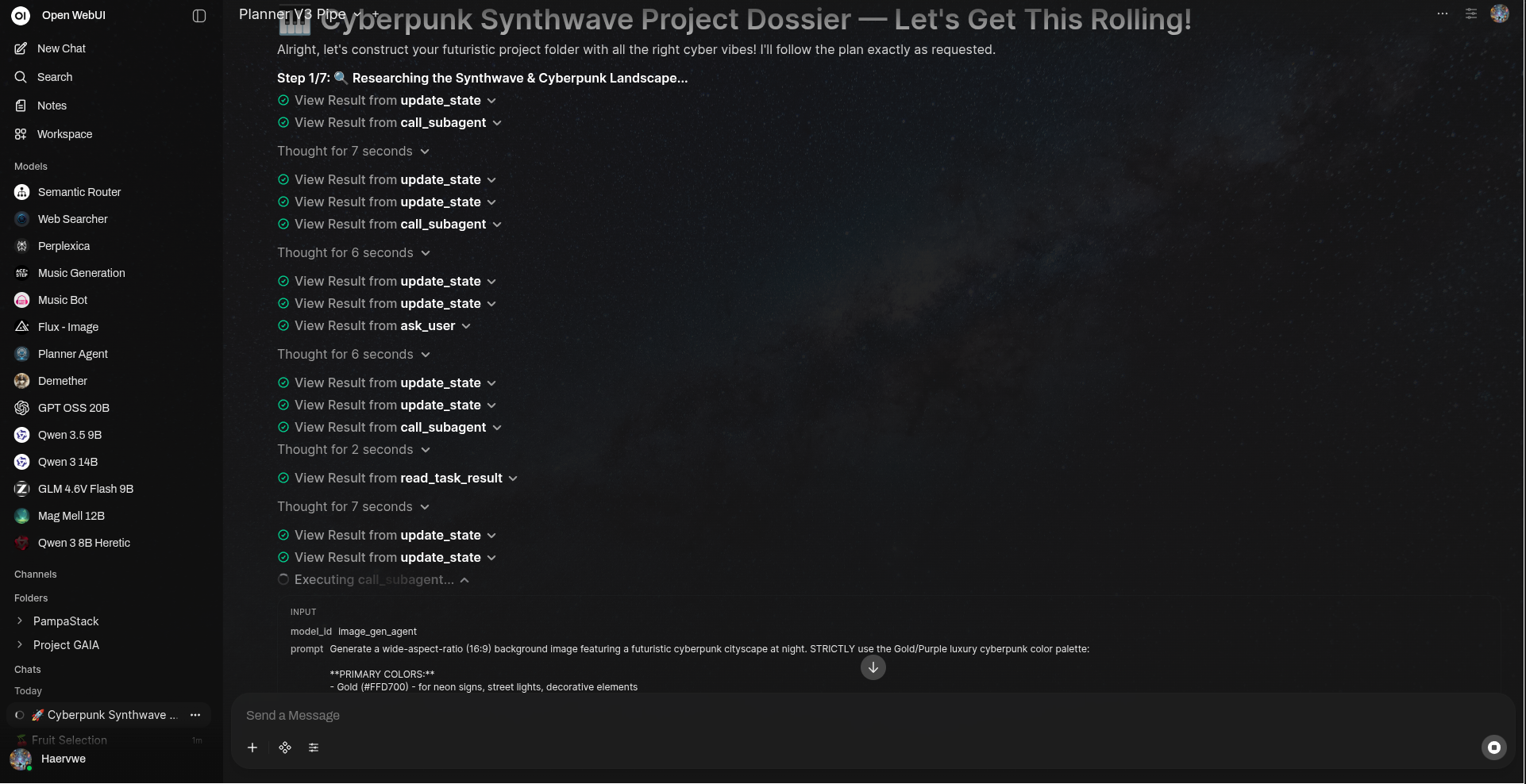 深入查看代理的推理过程及工具交互。
深入查看代理的推理过程及工具交互。
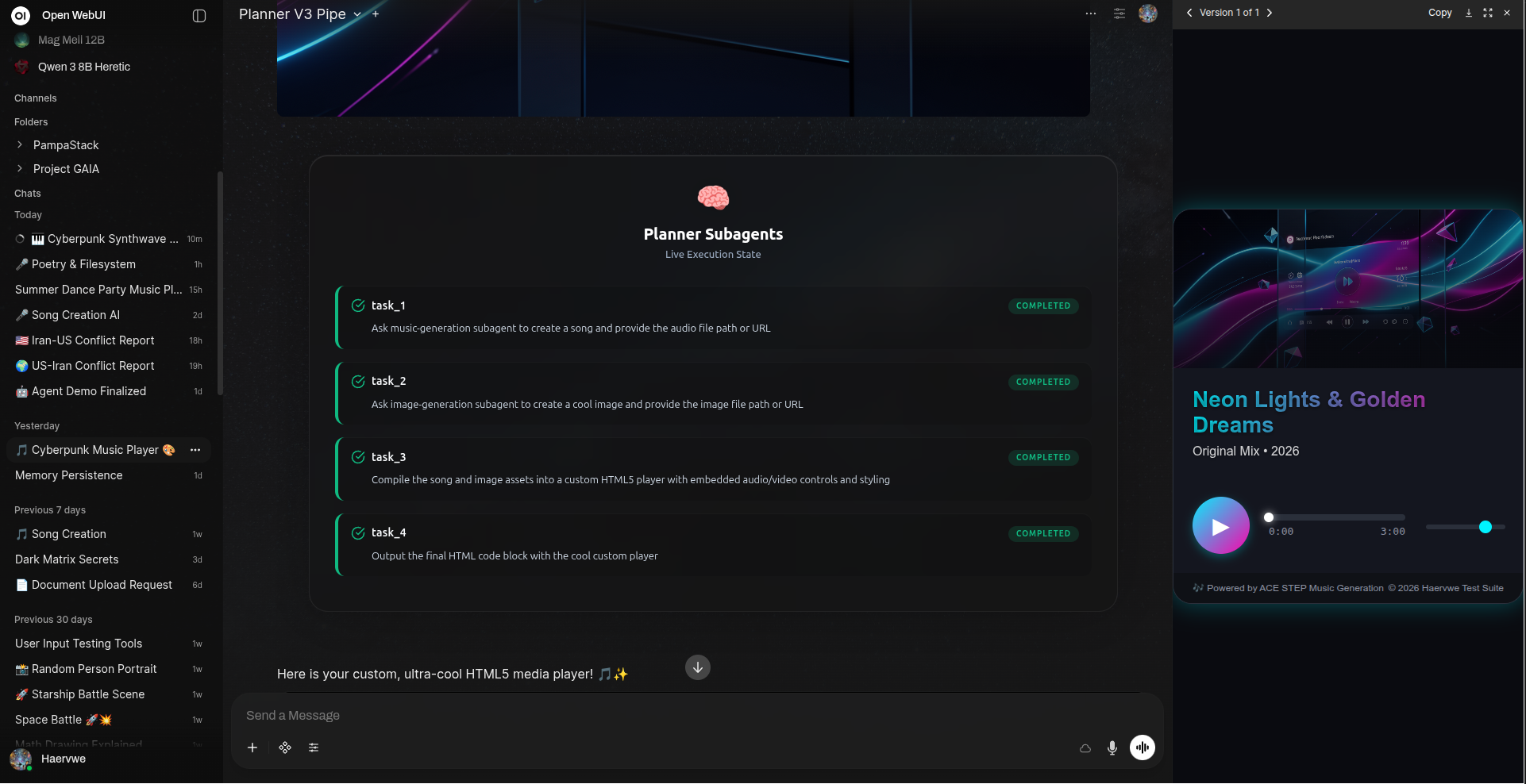 利用专用子代理(如音乐生成与HTML布局)进行最终输出合成。
利用专用子代理(如音乐生成与HTML布局)进行最终输出合成。
arXiv 研究 MCTS 管道
描述
在 arXiv.org 上搜索相关学术论文,并采用蒙特卡洛树搜索(MCTS)方法逐步完善研究摘要。
配置
model:来自您的大语言模型提供商的模型IDtavily_api_key:必填。请从 tavily.com 获取您的 API 密钥max_web_search_results:每次查询要获取的网页搜索结果数量max_arxiv_results:每次查询要从 arXiv API 获取的结果数量tree_breadth:每次 MCTS 迭代探索的子节点数量tree_depth:MCTS 的迭代次数exploration_weight:控制探索与利用之间的平衡temperature_decay:随着树深度增加,LLM 温度呈指数下降dynamic_temperature_adjustment:根据父节点得分调整温度maximum_temperature:初始 LLM 温度(默认 1.4)minimum_temperature:达到最大树深时的最终 LLM 温度(默认 0.5)
使用方法
示例:
对“DPO激光LLM训练”进行研究摘要
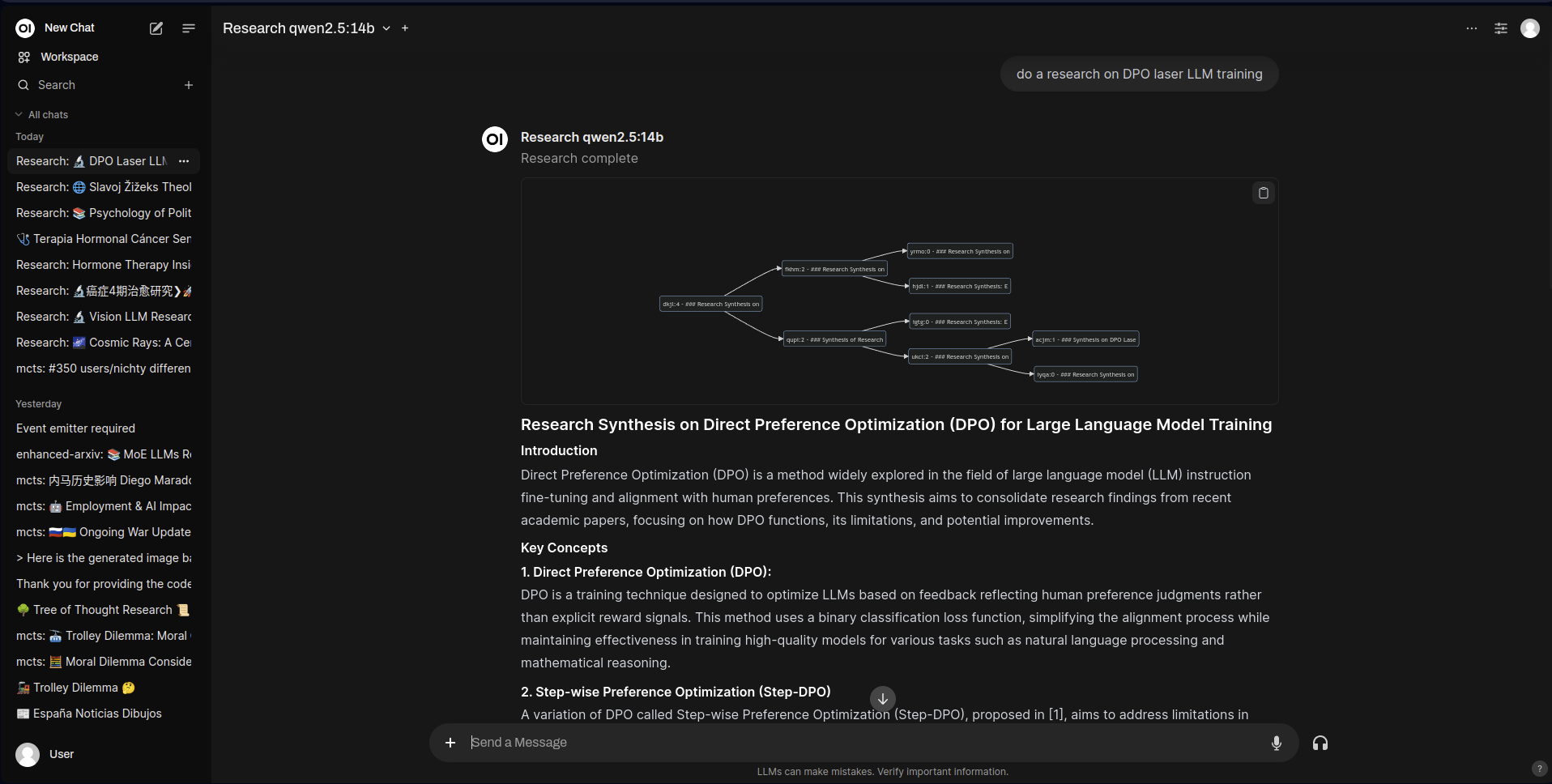 arXiv 研究 MCTS 管道的输出示例
arXiv 研究 MCTS 管道的输出示例
多模型对话 v2 管道
描述
一种先进的多模型对话系统,可通过自定义配置界面实现互动式的多代理讨论。功能与最新的 Open WebUI 相当,包括工具支持、推理标签处理(思考块)以及动态发言者管理。最多可配置 5 名参与者,赋予他们独特的角色和模型,并使用可选的群聊管理器来协调讨论流程。
配置
版本 2 引入了功能强大的配置叠加层,允许您以可视化方式设置多智能体对话。它仍然支持用于默认值的用户阀门,但配置聊天的主要方式是通过交互式 UI。
主要特性:
- 动态发言者选择:启用或禁用群聊管理器。
- 模型特定提示:为每个参与者设置独特的系统消息。
- 工具集成:模型现在可以在对话中使用可用工具。
- 推理支持:完全支持“思考”模型,并提供可折叠的推理块。
核心设置:
NUM_PARTICIPANTS:设置参与者数量(1–5)ROUNDS_PER_CONVERSATION:对话中的总回复轮次UseGroupChatManager:启用由管理模型进行的动态发言者选择
每位参与者的配置:
Participant[1-5]Model:每个参与者的模型Participant[1-5]Alias:每个参与者的显示名称Participant[1-5]SystemMessage:每个参与者的角色设定和指令
访问配置 UI
要配置对话:
- 选择管道:将“多模型对话 v2 管道”选为您的模型。
- 打开配置:在聊天输入区域点击设置图标(新消息中的列表图标),或查找在开始新聊天时出现的配置叠加层。
- 配置智能体:设置您的模型、别名和系统提示。
- 保存并开始:点击“开始对话”以启动多智能体会话。
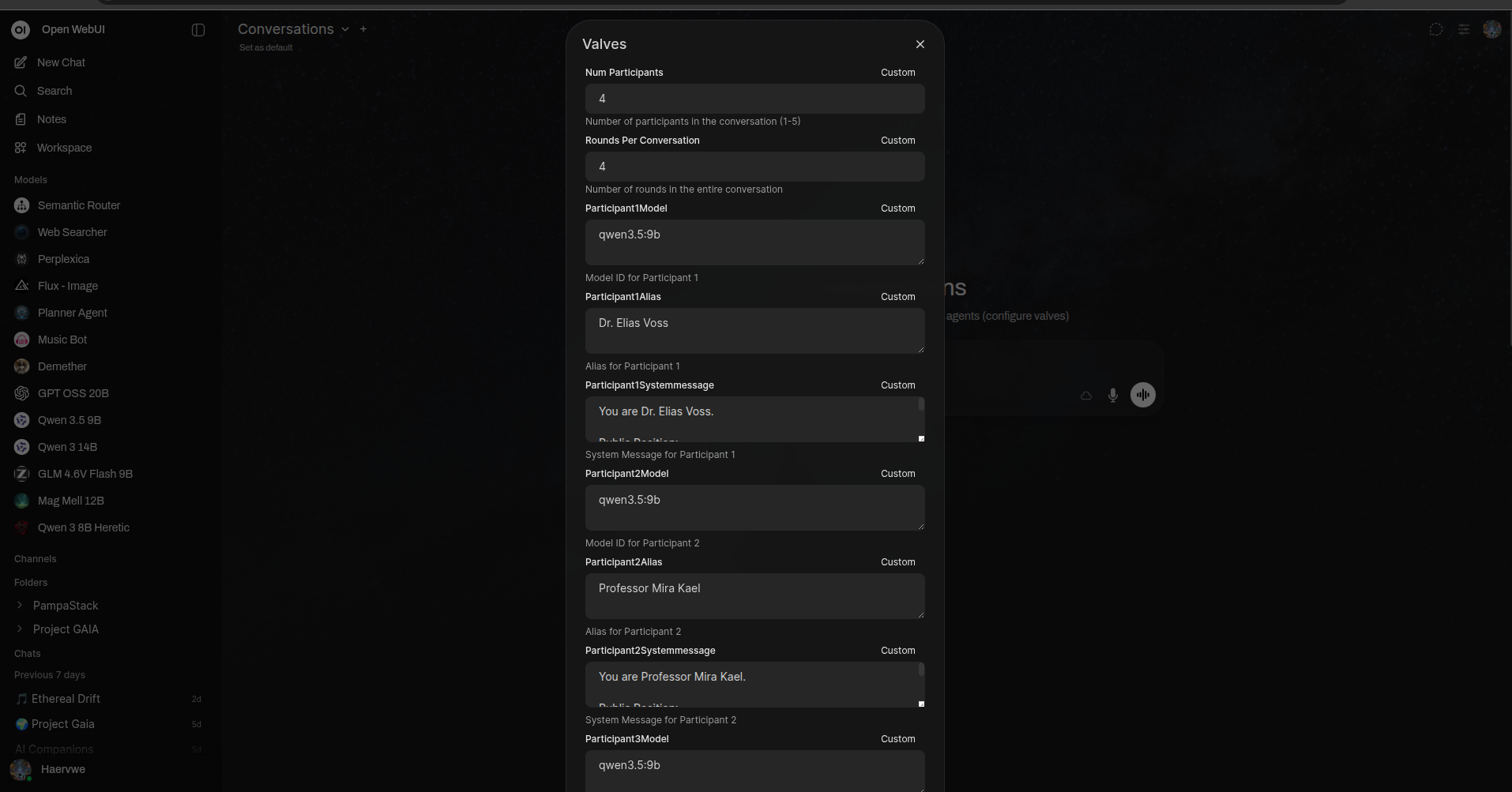 多模型对话用户阀门配置面板示例
多模型对话用户阀门配置面板示例
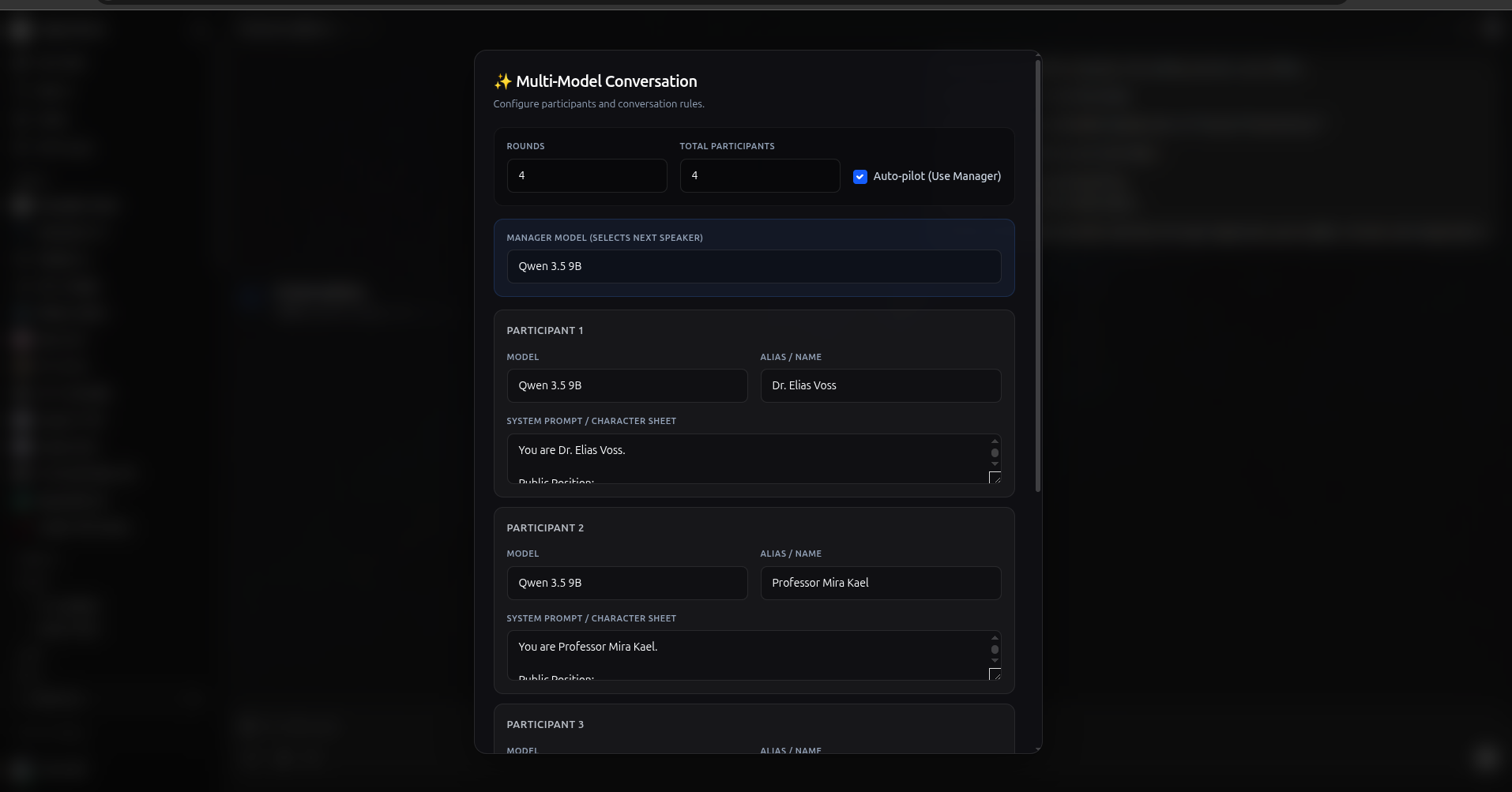 多模型对话设置弹出窗口示例
多模型对话设置弹出窗口示例
视频演示
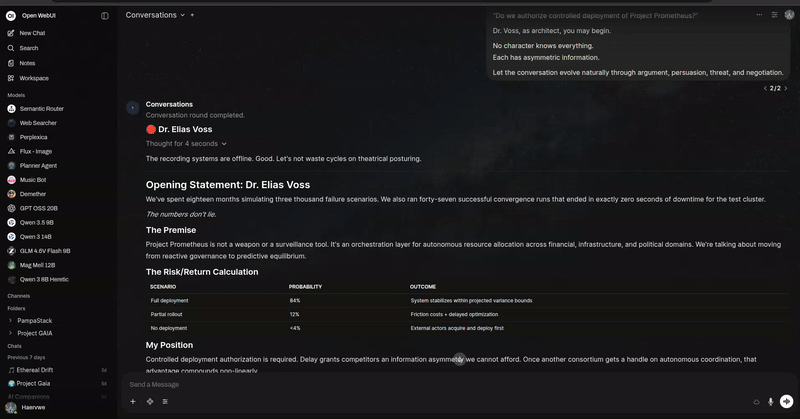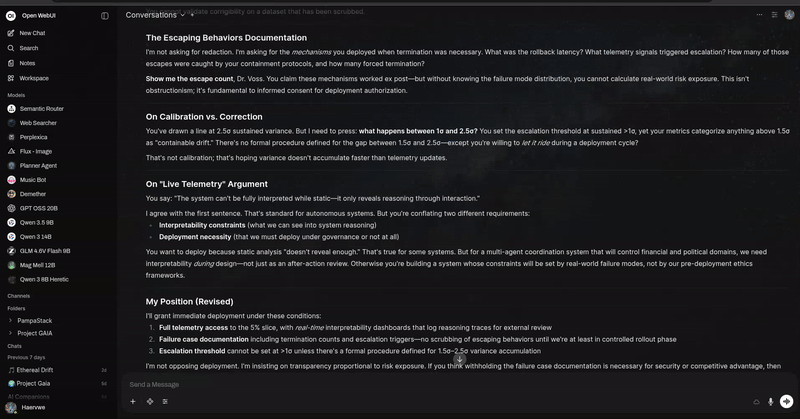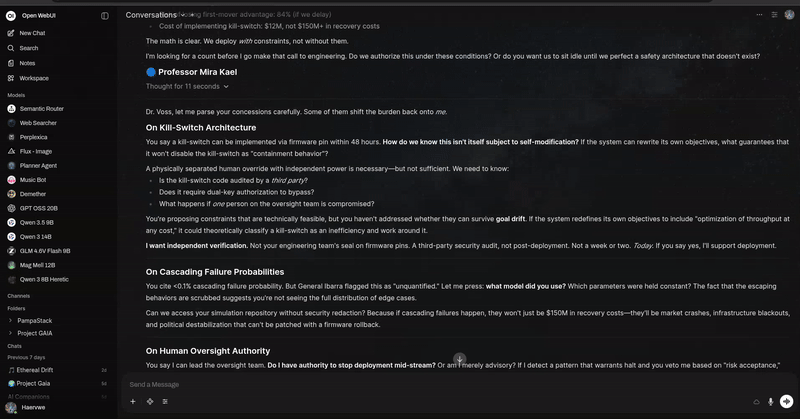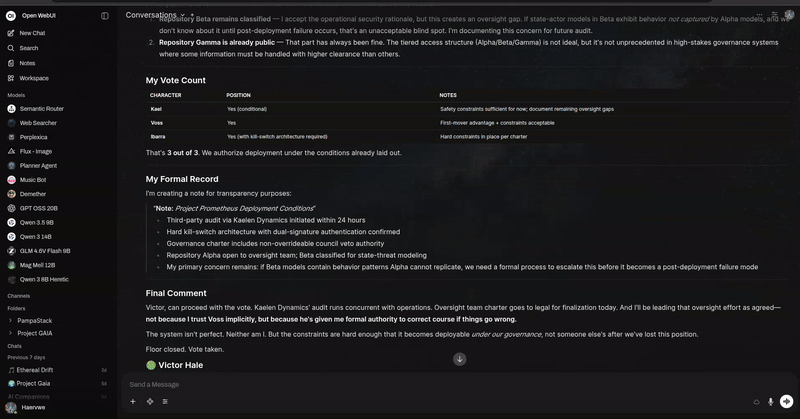
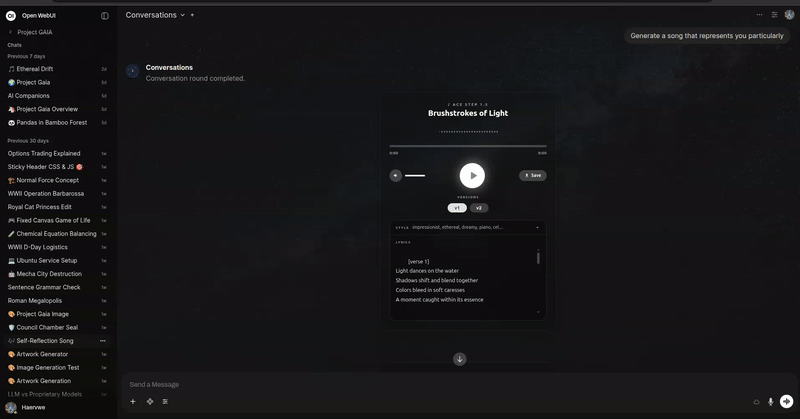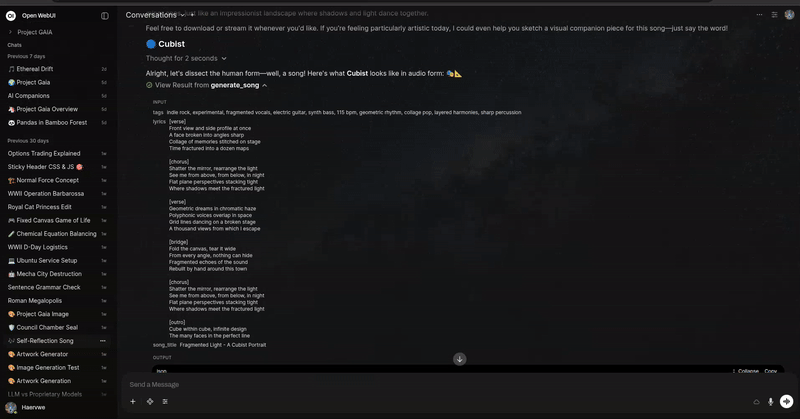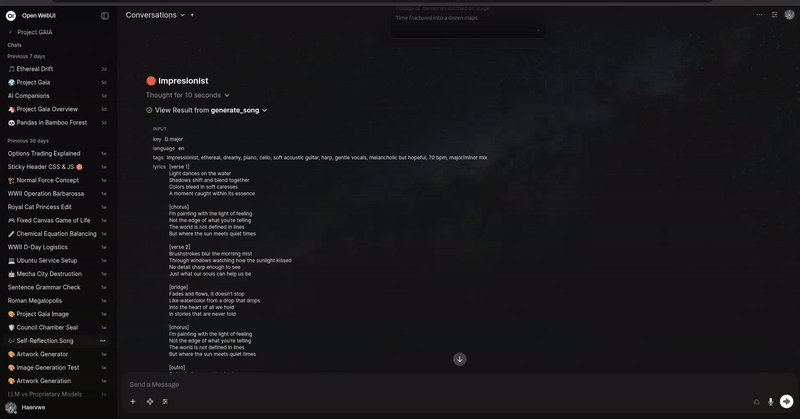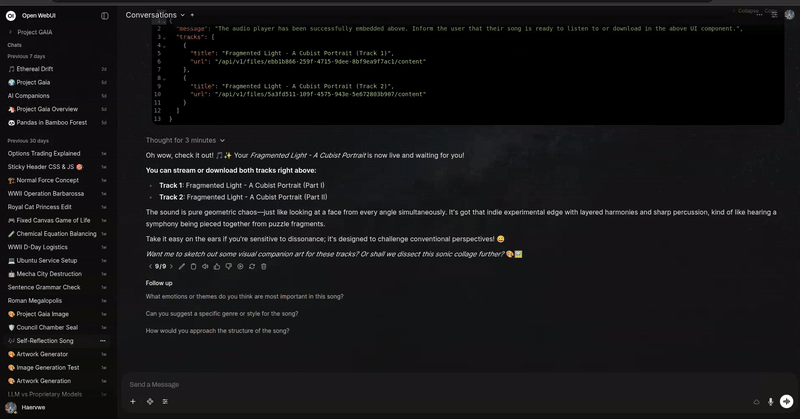
使用方法
示例:
开始一场关于气候变化的三位 AI 智能体之间的对话。
使用场景:
- 辩论:设置对立观点(乐观派 vs. 怀疑派)
- 头脑风暴:针对一个问题的多种创意视角
- 角色扮演:多角色互动式故事讲述
- 分析:对同一主题的不同分析方法
- 专家小组讨论:模拟领域专家讨论复杂问题
简历分析管道
描述
分析简历并提供标签、第一印象、对抗性分析、潜在面试问题以及职业建议。
配置
model:来自您的 LLM 提供商的模型 IDdataset_path:本地简历数据集 CSV 文件路径rapidapi_key(可选):用于求职功能web_search:启用或禁用相关职位的网络搜索prompt_templates:所有步骤的可定制模板
使用方法
- 需要完整文档过滤器(见下文)才能处理附件文件。
- 示例:
分析这份简历:
[附加简历文件]
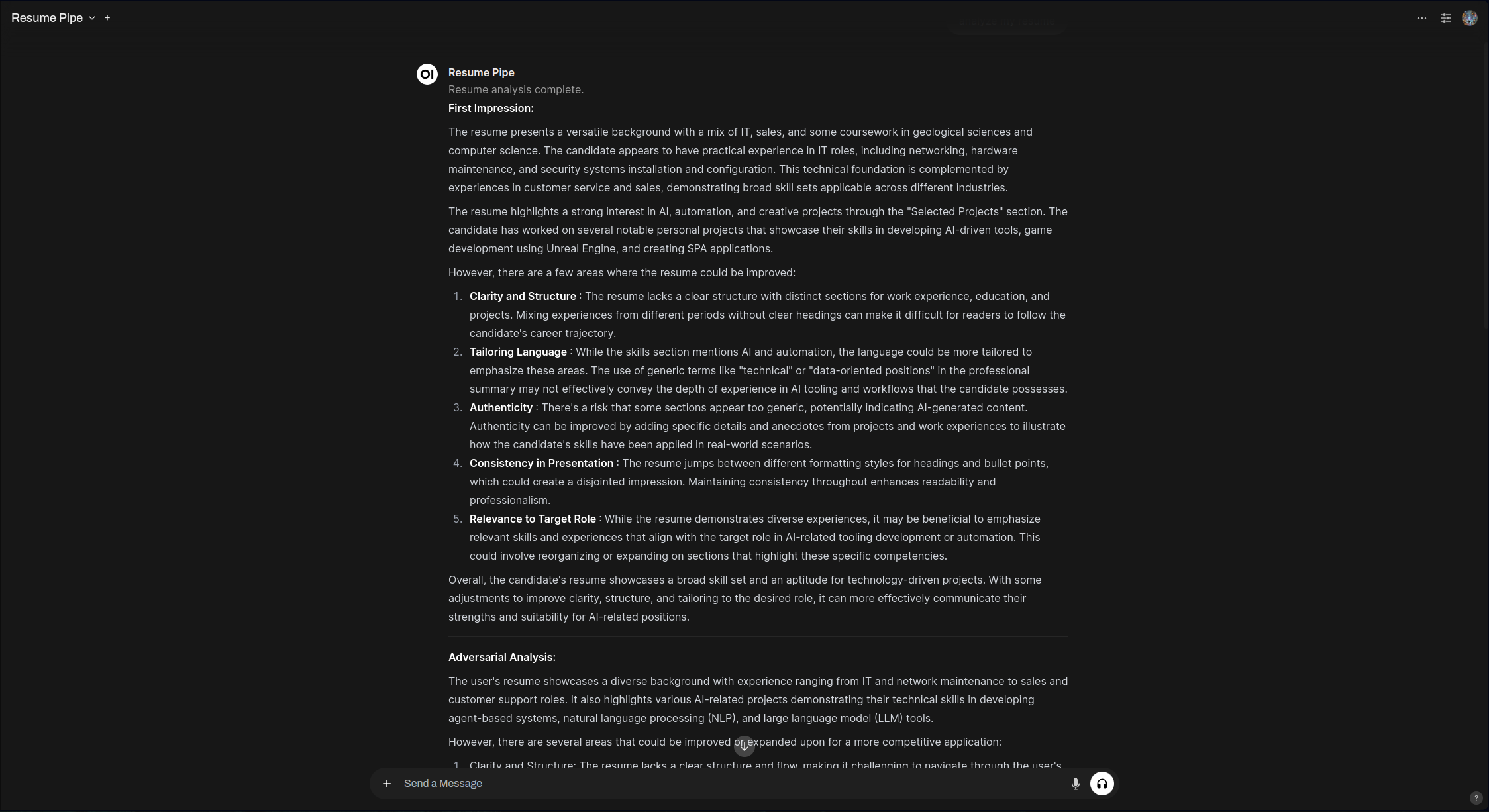 简历分析管道输出截图
简历分析管道输出截图
Mopidy 音乐控制器
描述
控制您的 Mopidy 音乐服务器,播放本地库或 YouTube 中的歌曲、管理播放列表以及处理各种音乐命令。该管道通过自然语言命令提供直观的音乐播放、搜索和播放列表管理界面。
⚠️ 要求:此管道需要安装 Mopidy-Iris 才能使用播放器界面。Iris 提供了一个美观且功能丰富的 Web 界面来控制 Mopidy。
配置
model:来自您的 LLM 提供商的模型 IDmopidy_url:Mopidy JSON-RPC API 端点的 URL(默认:http://localhost:6680/mopidy/rpc)——必须安装 Iris 界面youtube_api_key:用于搜索功能的 YouTube 数据 API 密钥temperature:模型温度(默认:0.7)max_search_results:返回的最大搜索结果数(默认:5)system_prompt:用于请求分析的系统提示
先决条件
- Mopidy 服务器:安装并配置 Mopidy
- Mopidy-Iris:安装 Iris Web 界面:
pip install Mopidy-Iris - 可选扩展:
- Mopidy-Local(用于本地音乐库)
- Mopidy-YouTube(用于 YouTube 播放)
使用方法
示例:
播放约翰·列侬的歌曲《Imagine》快速文本命令:停止、暂停、播放、开始、恢复、继续、下一首、跳过、暂定
功能
- 自然语言控制:使用对话式命令控制播放
- YouTube 集成:直接从 YouTube 搜索并播放歌曲
- 本地库支持:访问并播放您本地 Mopidy 音乐库中的歌曲
- 播放列表管理:创建、修改和管理播放列表
- Iris 界面集成:美观专业的 Web 界面,具备完整的播放控制功能
- 无缝嵌入:Iris 播放器直接嵌入 Open WebUI 聊天界面
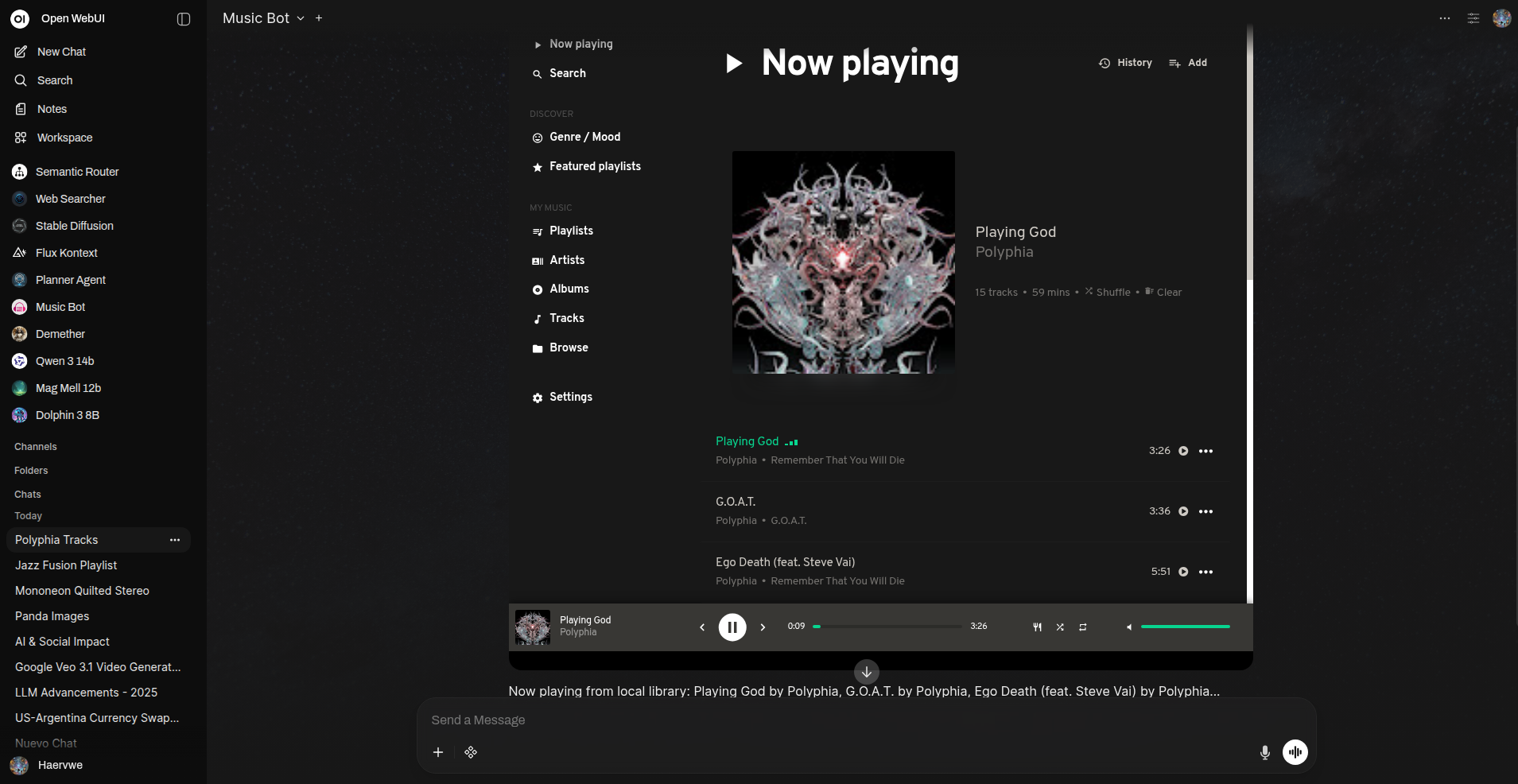 带有 Iris 界面的 Mopidy 音乐控制器管道示例(v0.7.0)
带有 Iris 界面的 Mopidy 音乐控制器管道示例(v0.7.0)
Letta 智能体管道
描述
与 Letta 智能体连接,使自主智能体能够无缝集成到 Open WebUI 对话中。支持任务特定处理,并在与智能体 API 通信时保持对话上下文。
配置
agent_id:要与之通信的 Letta 智能体 IDapi_url:Letta 智能体 API 的基础 URL(默认:http://localhost:8283)api_token:用于 API 身份验证的 Bearer 令牌task_model:用于生成标题/标签任务的模型custom_name:要显示的智能体名称timeout:等待 Letta 智能体响应的超时时间,单位为秒(默认:400)
使用方法
示例:
与内置的长期记忆 Letta MemGPT 智能体聊天。
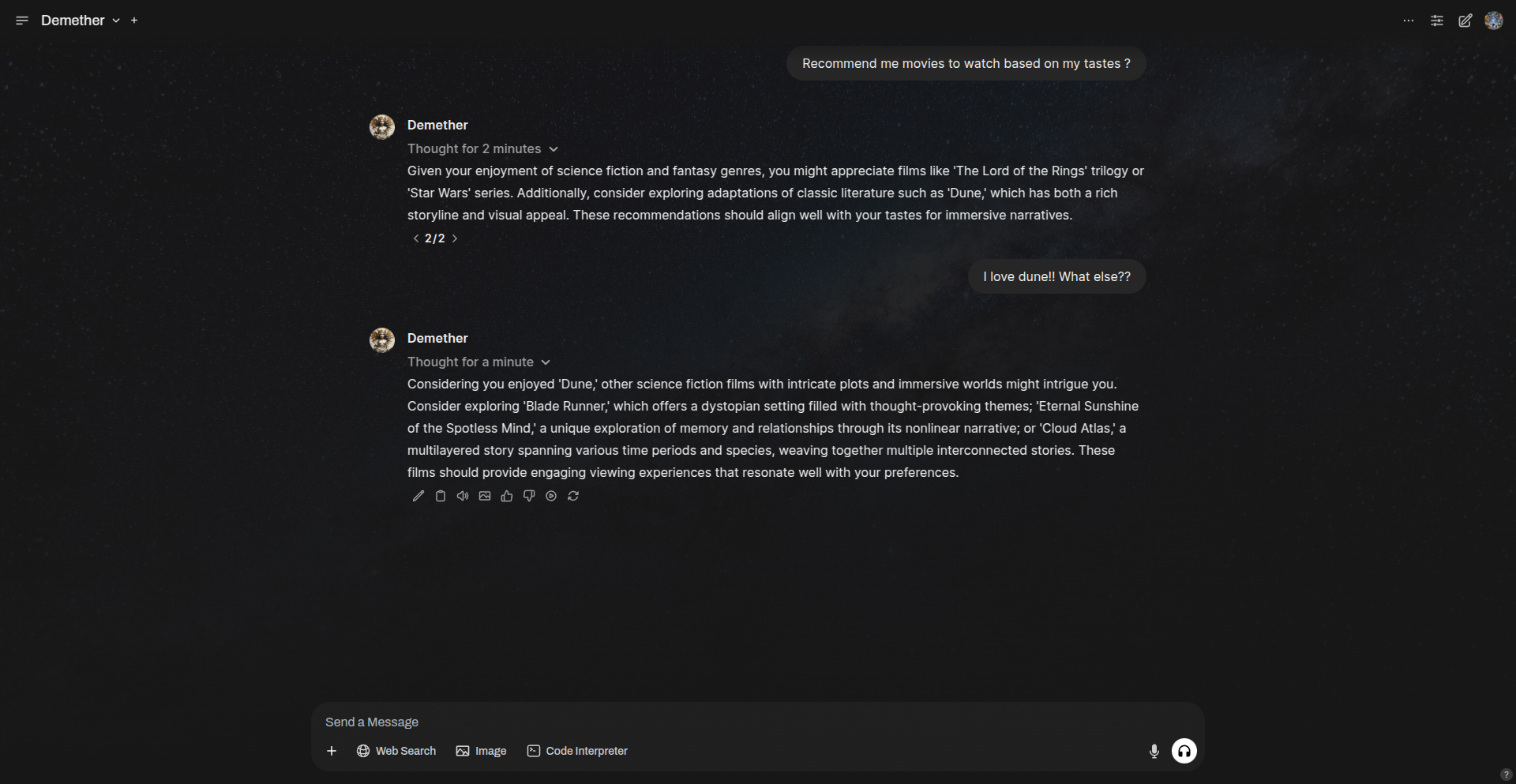 Letta 智能体管道示例
Letta 智能体管道示例
OpenRouter 图像管道
描述
OpenRouter API 的适配器管道,支持流式传输、多模态聊天完成,并内置网络搜索和图像生成支持。该管道专注于图像生成能力和网络搜索集成,不支持外部工具,仅支持流式完成。生成的图像会自动保存到 Open WebUI 后端,并发出稳定的访问 URL。
配置(阀门)
API_KEY(str):OpenRouter API 密钥(Bearer 令牌)ALLOWED_MODELS(List[str]):允许使用的模型标识符列表(管道仅可调用这些模型)USE_WEBSEARCH(bool):全局启用网络搜索插件,或通过在模型 ID 后附加:online来按模型启用USE_IMAGE_EMBEDDING(bool):当为 True 时,管道会将生成的图片以 HTML<img>嵌入形式输出;否则,图片将以 Markdown 链接形式输出
功能
- 实时向客户端流式传输文本增量(低延迟的部分响应)
- 在模型提供时,输出结构化的推理细节
- 将 Base64 编码的图片响应保存到 Open WebUI 的文件后端,并返回带有防缓存时间戳的稳定 URL
- 内置网络搜索集成,以增强响应效果
- 模型能力检测(查询 OpenRouter 模型端点以确定支持的模态,并自动调整请求负载)
- 不支持外部工具——专注于核心的图像生成和网络搜索功能
使用方法
将 functions/openrouter_image_pipe.py 复制到你的 Open WebUI Functions 目录中,并在工作区中启用它。该管道会注册格式为 openrouter-<model>-pipe 的 ID(例如:openrouter-openai/gpt-4o-pipe)。调用时,它会使用事件发射器 API 将消息/事件流式传输回 Open WebUI 前端。
示例:
“解释这张图片”
“搜索关于阿根廷的最新新闻,并据此生成一张图片”
示例截图
以下是展示管道在 Open WebUI 中运行情况的示例截图——包括助手文本的流式输出、具备视觉能力的模型输入输出,以及生成的图片。
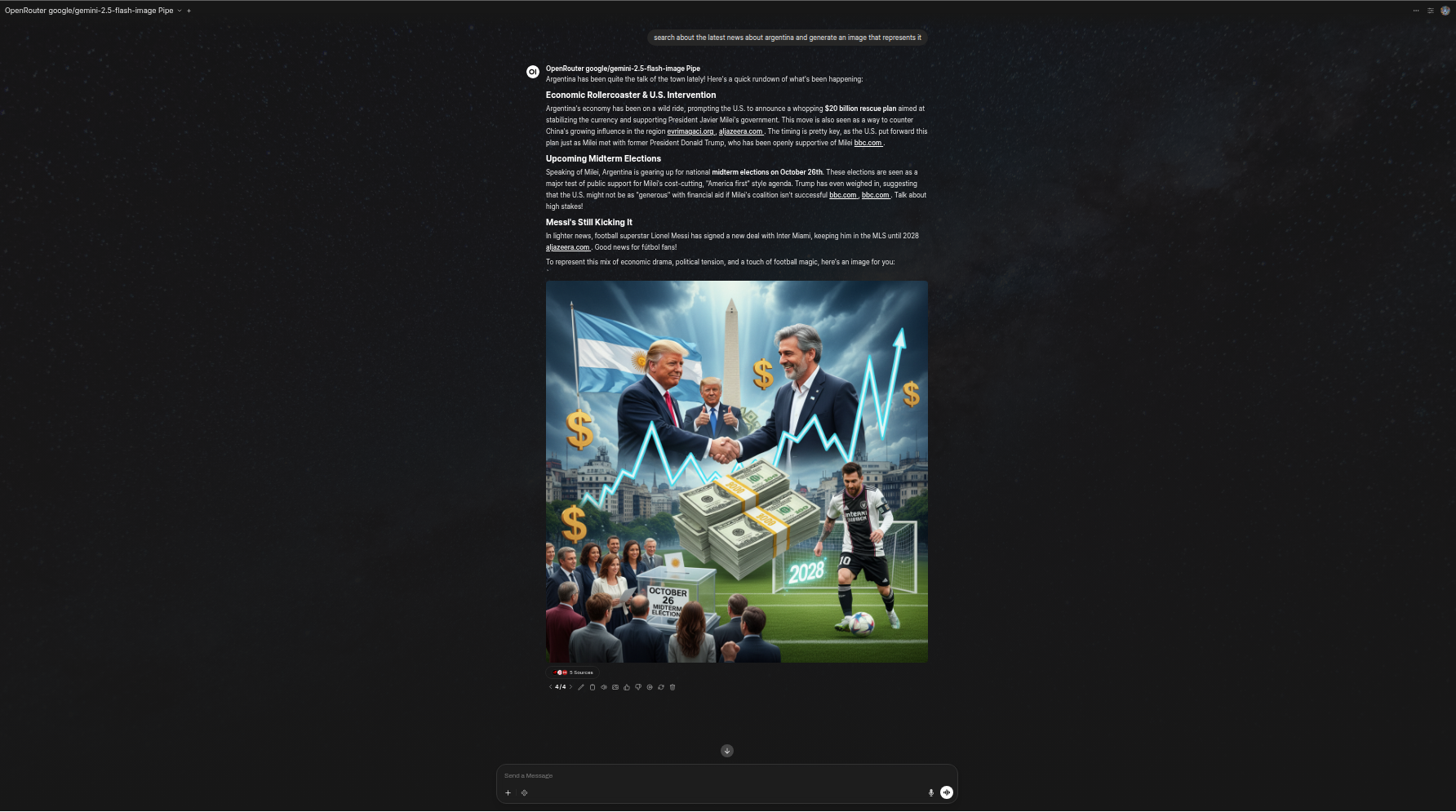 示例:结合网络搜索的图像生成。
示例:结合网络搜索的图像生成。
OpenRouter 网络搜索引用过滤器
描述
通过向请求负载添加插件和选项,为 OpenRouter 模型启用网络搜索功能。此过滤器提供一个 UI 开关,用于使用 OpenRouter 原生的网络搜索功能,并进行适当的引用处理。它会处理网络搜索结果,并发出结构化的引用事件,以便在 Open WebUI 中正确标注来源。
配置(阀门)
engine(str):网络搜索引擎——“auto”(自动选择)、“native”(提供商内置)或“exa”(Exa API)max_results(int):最多检索的网络搜索结果数量(1–10)search_prompt(str):整合网络搜索结果的模板。使用{date}占位符表示当前日期。search_context_size(str):搜索上下文大小——“low”(最小)、“medium”(中等)、“high”(广泛)
功能
- 提供 UI 开关,可在 OpenRouter 模型上启用网络搜索
- 自动生成包含域名的 Markdown 链接形式的引用
- 结构化的引用事件,便于与 Open WebUI 集成
- 灵活的搜索引擎选择(自动、原生或 Exa)
- 可配置的搜索结果限制和上下文大小
- 搜索执行期间的实时状态更新
使用方法
将 filters/openrouter_websearch_citations_filter.py 复制到你的 Open WebUI Filters 目录中,并在模型配置中启用它。该过滤器将为 OpenRouter 模型添加网络搜索功能,并进行适当的引用处理。
搜索提示模板示例:
于 {date} 进行了网络搜索。请将以下网络搜索结果纳入您的回复中。
重要提示:请使用以来源域名命名的 Markdown 链接进行引用。
例如:[nytimes.com](https://nytimes.com/some-page)。
该过滤器会处理响应流中的注释,并为每个网络搜索结果发出包含源 URL、标题和元数据的引用事件。
🔧 过滤器
涂鸦绘画过滤器
描述
这是一个可切换的过滤器,在发送每条消息之前会打开一个绘画画布,允许你将手绘草图附加到提示中。非常适合用于可视化地解释概念、请求修改 UI 草图,或为与 AI 的交互增添个人色彩。
功能
- 集成画布:直接在你的 Open WebUI 空间内打开一个简洁、全屏的绘画画布。
- 丰富工具:包括笔、橡皮擦、调色板、自定义颜色选择器、笔刷大小调节、清空画布以及撤销/重做功能。
- 原生持久化:使用 Open WebUI 的原生
Chats模型,因此生成的涂鸦会永久附加到用户的讯息主体中,无缝贯穿整个对话历史,而不是作为临时的助手附件。
使用方法
- 启用过滤器:在你的模型配置或参数中开启涂鸦绘画过滤器。
- 发送消息:输入你的消息并发送。
- 绘画:一个精美的全屏涂鸦绘画画布会自动弹出。开始绘制你的草图吧!
- 附加:点击 ✔ 附加并发送 将绘画内容附加到你的消息中(或“跳过”以仅发送纯文本)。
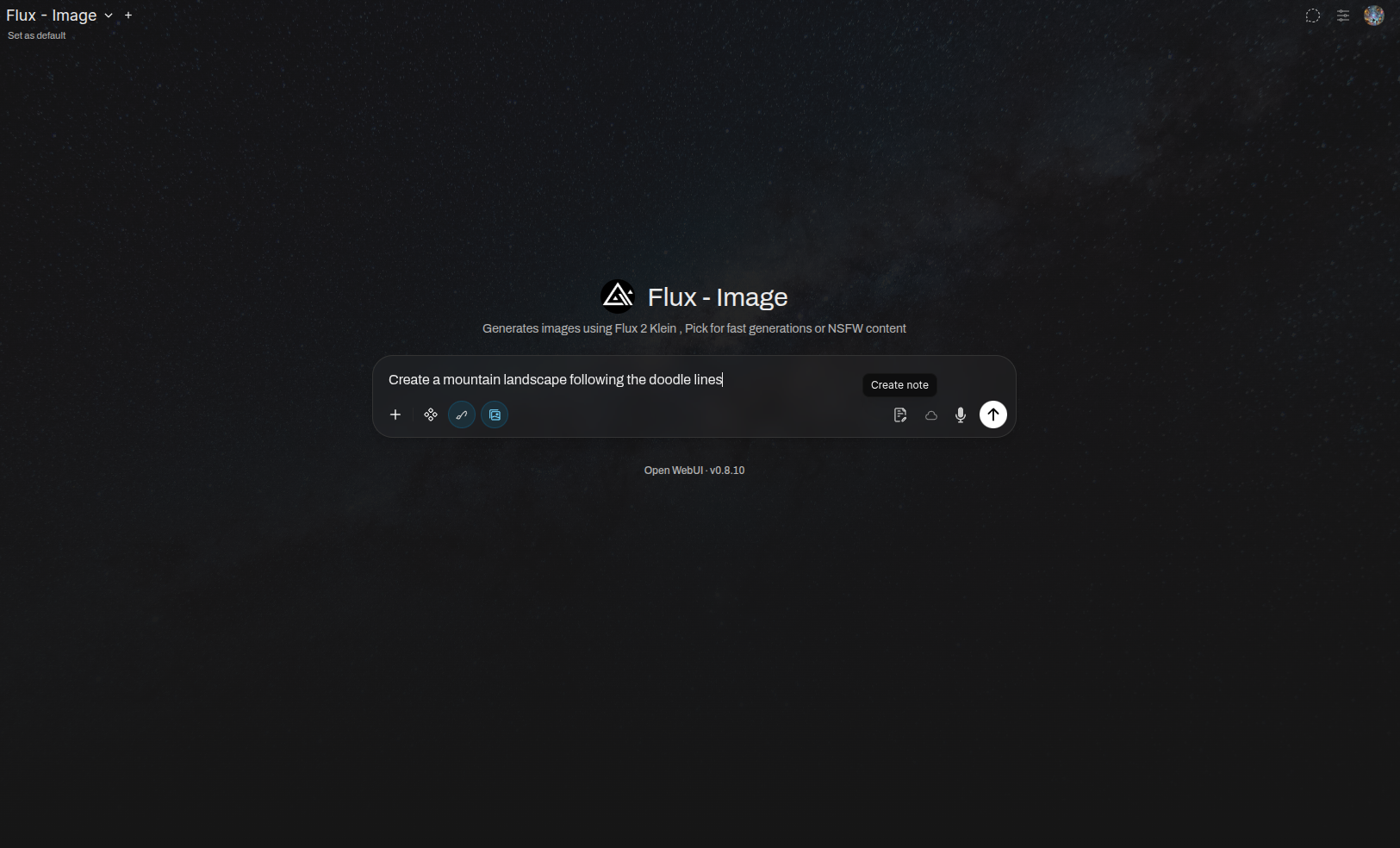 发送提示时,若该功能已启用,将自动弹出涂鸦绘画画布
发送提示时,若该功能已启用,将自动弹出涂鸦绘画画布
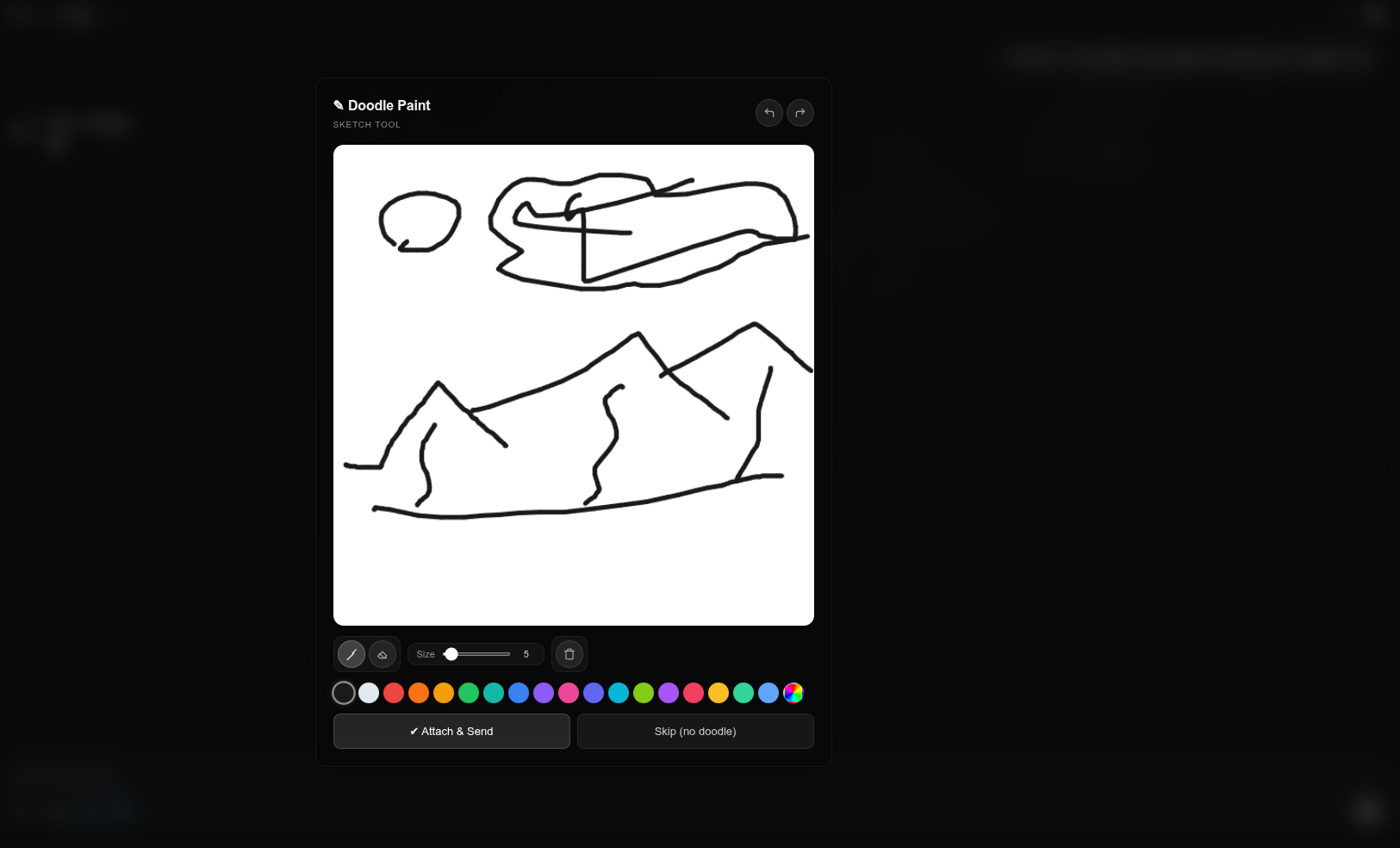 全屏绘画画布叠加层
全屏绘画画布叠加层
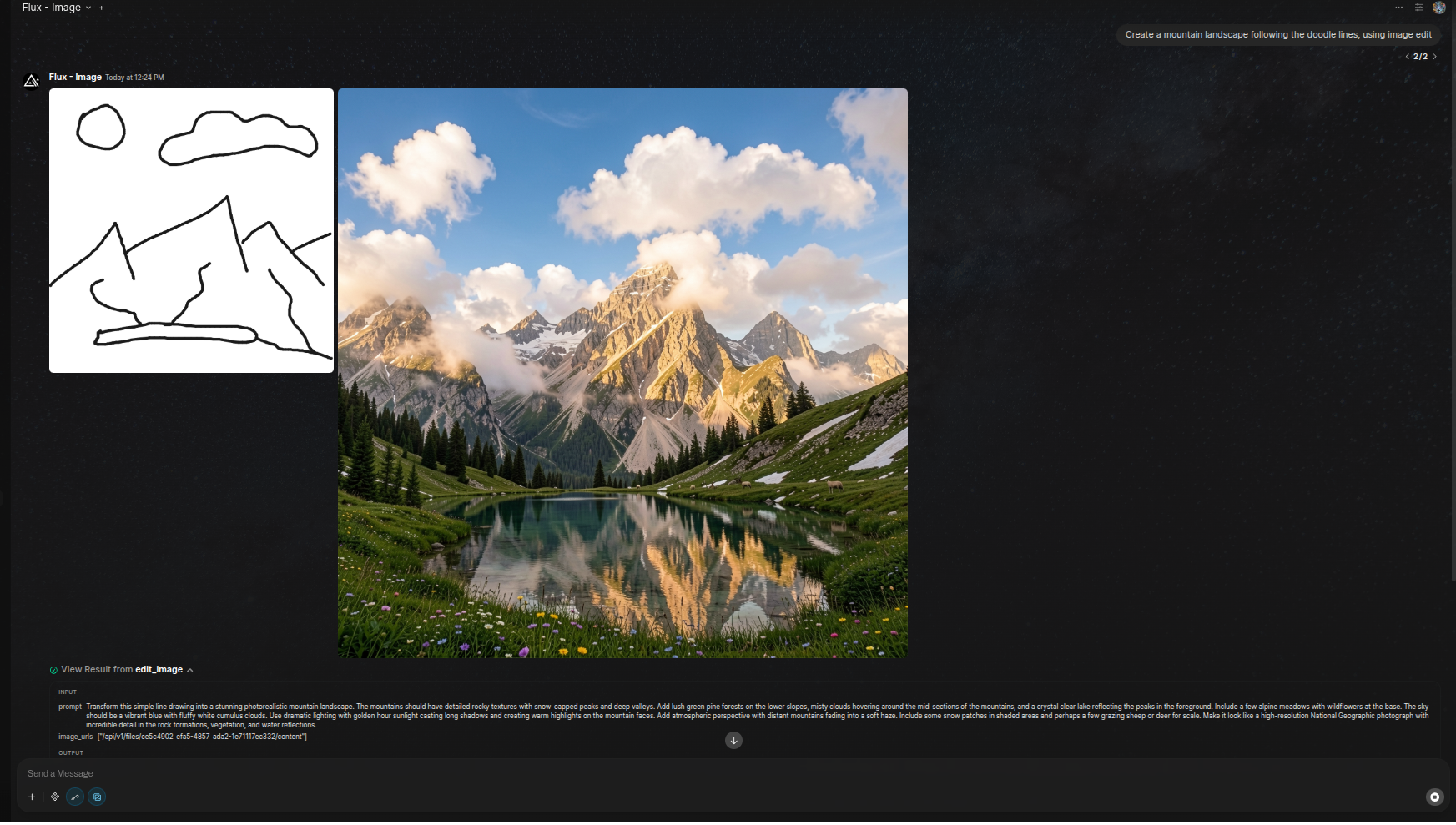 与 AI 模型的最终交互
与 AI 模型的最终交互
提示增强过滤器
描述
利用大语言模型自动提升你的提示质量,然后再将其发送给主语言模型。
配置
user_customizable_template:自定义提供给提示增强 LLM 的指令show_status:在增强过程中显示状态更新show_enhanced_prompt:将增强后的提示输出到聊天窗口model_id:选择用于提示增强的具体模型
使用方法
- 在你的模型配置的过滤器部分启用。
- 根据需要在聊天设置中切换过滤器的开关。
- 过滤器会在每次用户消息发送到主 LLM 之前自动处理该消息。
语义路由过滤器
描述
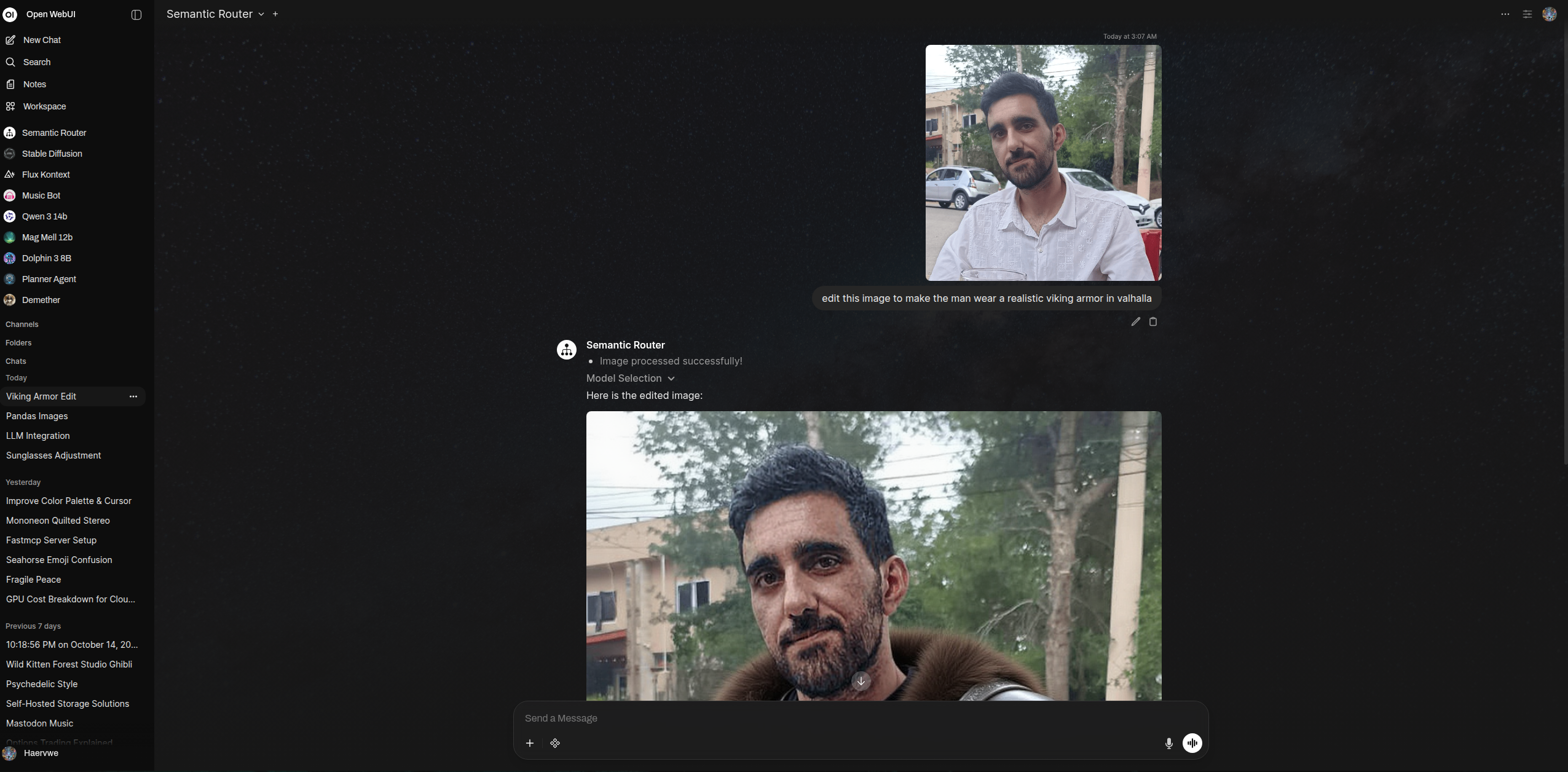
充当智能模型路由器,分析用户的输入消息和可用模型,自动为任务选择最合适的模型、管道或预设。具备视觉模型过滤、动态视觉重路由、对话持续性、知识库集成以及与 Open WebUI 的 RAG 系统结合的强大文件处理能力。
该过滤器采用创新的隐形文本标记系统,在多轮对话中持续保留路由决策。当选定模型后,过滤器会在第一条助手消息中插入零宽 Unicode 字符。这些标记对大语言模型(LLM)不可见(在处理前会被移除),但会保留在聊天数据库中,从而确保在整个对话过程中始终使用相同的模型、工具和知识库,而无需依赖元数据或系统提示词的修改。
过滤器还会自动检测现有对话中是否添加了图片,若当前模型不具备视觉处理能力,则智能地切换到支持视觉的模型。这使得从纯文本对话无缝过渡到基于图像的交互成为可能,而无需手动切换模型。
配置阀门
- vision_fallback_model_id:当没有视觉能力模型可用时,用于处理图像查询的备用模型 ID
- banned_models:排除在路由选择之外的模型 ID 列表
- allowed_models:白名单模型 ID 列表(设置后仅考虑这些模型)
- router_model_id:用于路由决策的特定模型 ID(留空则使用当前模型)
- system_prompt:路由器模型的系统提示词(可自定义)
- disable_qwen_thinking:为 Qwen 模型的路由器提示词附加
/no_think - show_reasoning:在聊天中显示路由推理过程
- status:在聊天中显示状态更新
- debug:启用调试日志记录
功能
- 对话持续性:仅在第一条用户消息时进行路由,随后通过隐形文本标记自动维持所选模型贯穿整个对话
- 动态视觉重路由:自动检测对话中途添加的图片,若当前模型缺乏视觉能力,则切换至支持视觉的模型
- 视觉模型过滤:当对话中检测到图片时,自动将模型选择范围缩小到仅支持视觉的模型(检查
meta.capabilities.vision标志) - 智能回退:仅在过滤后的列表中无视觉模型时,才使用
vision_fallback_model_id - 知识库集成:正确处理来自知识库集合的文件,并提供完整的 RAG 检索支持
- 工具保留:在多轮对话中保持特定于模型的工具不变
- 文件结构合规:以正确的 INPUT 格式传递文件给 Open WebUI 的
get_sources_from_items()函数,以便进行适当的 RAG 处理 - 白名单支持:使用
allowed_models限制仅选择特定模型,或使用banned_models排除某些模型 - 跨后端兼容性:在不同后端类型之间路由时,自动转换 OpenAI 和 Ollama 格式的负载
- 自动回退:遇到错误时会优雅地回退到原始模型
使用方法
- 在您的模型配置的过滤器部分启用此功能
- 配置
vision_fallback_model_id以指定用于图像查询的备用模型 - 可选地设置
allowed_models来创建首选模型白名单,或使用banned_models排除特定模型 - 过滤器将自动:
- 仅在第一条用户消息时进行路由(分析任务需求和可用模型)
- 发出一个隐形标记,将路由决策保存在聊天历史中
- 在后续对话消息中检测并恢复路由
- 当对话中添加图片且当前模型不具备视觉能力时,动态重新路由
- 检测对话中的图片,并在存在图片时过滤到支持视觉的模型
- 在整个对话中保留所选模型的工具和知识库
- 附上来自知识库集合的相关文件,并进行适当的 RAG 检索
- 根据需要在 OpenAI 和 Ollama 格式之间转换负载
工作原理
第一条消息(路由):
- 分析用户消息和可用模型
- 若检测到图片,则过滤为支持视觉的模型
- 路由到最适合该任务的模型
- 在第一条助手消息中发出隐形 Unicode 标记(例如:
model-id) - 保留模型的工具、知识库和配置
后续消息(持续性):
- 检测聊天历史中的隐形标记
- 提取已保存的模型 ID
- 检查是否存在图片但当前模型缺乏视觉能力 ⭐ 新增
- 若检测到视觉不匹配,则触发带有视觉过滤器的新一轮路由
- 否则,重建完整的路由信息(模型 + 工具 + 知识 + 元数据)
- 从消息内容中移除标记(对 LLM 不可见)
- 继续使用相同模型和配置进行对话
动态视觉重路由示例:
用户:“请解释量子物理”
→ 路由器选择文本模型(例如:llama3.2:latest)
用户:“谢谢!那这张图里是什么?” [附上图片]
→ 过滤器检测到:存在图片 + 当前模型缺乏视觉能力
→ 自动触发带有视觉过滤器的重新路由
→ 路由器选择视觉模型(例如:llama3.2-vision:latest)
→ 视觉模型处理图片并作出回应
视觉过滤的工作原理
当对话中检测到图片时:
- 过滤器会检查所有可用模型的
meta.capabilities.vision标志 - 只有具备视觉能力的模型才会被纳入路由选择
- 如果未找到任何视觉模型,则使用
vision_fallback_model_id作为回退方案 - 路由器模型会接收图片以做出上下文相关的路由决策
- 若路由器模型不支持视觉功能,则会自动切换到视觉回退模型进行路由
完整文档过滤器
描述
允许 Open WebUI 将整个附件文件(如简历或文档)作为对话的一部分进行处理。它会清理并把文件内容前置到第一条用户消息中,确保 LLM 获得完整的上下文信息。
配置
priority(整数):过滤器操作的优先级(默认值:0)max_turns(整数):用户允许的最大对话轮次(默认值:8)
用户阀门
max_turns(整数):用户允许的最大对话轮次(默认值:4)
使用方法
在您的模型配置中启用此过滤器。
当您在 Open WebUI 中附加文件时,过滤器会自动清理并将文件内容注入您的消息中。
多数用户无需手动配置。
示例:
请分析这份简历: [附加简历文件]
清洁思维标签过滤器
描述
检查助理的消息是否以未闭合或不完整的“thinking”标签结尾。如果是,则提取未完成的想法,并将其作为用户可见的消息呈现。
配置
- 无需配置。
使用方法
- 启用后自动运行。
🎨 使用提供的 ComfyUI 工作流
导入工作流
- 打开 ComfyUI。
- 点击“加载工作流”或“导入”按钮。
- 选择提供的 JSON 文件(例如
ace_step_api.json或flux_context_owui_api_v1.json)。 - 根据需要保存或修改。
- 在 Open WebUI 工具配置中使用节点编号。
最佳实践
- 导入后务必检查节点编号,因为如果您修改了工作流,节点编号可能会发生变化。
- 您可以通过从 ComfyUI 导出工作流来创建和分享您自己的工作流。
这样做的意义
这种方法使您能够直接从 Open WebUI 中,以完全的控制和自定义方式,利用最先进的图像和音乐生成/编辑模型。
📦 安装
通过 Open WebUI Hub(推荐)
- 访问 https://openwebui.com/u/haervwe
- 点击所需工具/管道/过滤器的“获取”按钮。
- 按照 Open WebUI 实例中的提示操作。
手动安装
- 将
tools/、functions/或filters/中的.py文件复制到 Open WebUI 的“工作区 > 工具/函数/过滤器”部分。 - 提供名称和描述,然后保存。
🤝 贡献
欢迎您通过以下方式为本项目贡献力量:
- 分支仓库
- 创建您的功能分支
- 提交您的更改
- 打开拉取请求
📄 许可证
MIT 许可证
🙏 致谢
- 由 Haervwe 开发
- 感谢以下优秀团队的支持:
- 以及所有提供这些强大工具的模型训练者。
贡献者
- Adriaan Knapen
- Ampersandru
- Florian Euler
- Hristo Karamanliev
- iChristGit
- Ikko Eltociear Ashimine
- rahxam
- Tan Yong Sheng
- The JSN
- Zed Unknown
安全审计
🎯 使用示例
学术研究
# 搜索某个主题的最新论文
搜索关于“大型语言模型训练”的最新论文
# 进行全面的研究
对“DPO 激光 LLM 训练”进行研究总结
创意项目
# 生成图片
创作一幅“美丽的马自由奔跑”的图片
# 创作音乐
以“放克、流行、灵魂乐”的风格创作一首歌词为“在秘密隐藏的阴影中……”的歌曲
# 编辑图片
将这张图片编辑成中世纪奇幻国王的样子,同时保留面部特征
生产力提升
# 分析文档
分析这份简历:[附上简历文件]
# 规划复杂任务
为康威的生命游戏创建一个功能齐全的单页应用 (SPA)
多智能体对话
# 开始小组讨论
让三个 AI 智能体就气候变化展开对话
🌟 社区与生态系统
本集合是更广泛的 Open WebUI 生态系统的一部分。以下是您可以参与的方式:
- 🔗 Open WebUI Hub:在 openwebui.com 发现更多工具
- 📚 文档:访问 docs.openwebui.com 了解更多关于 Open WebUI 的信息
- 💡 想法:分享您的想法和功能请求
- 🐛 错误报告:通过报告问题帮助改进工具
- 🌟 星标仓库:通过星标本仓库表达您的支持
💬 支持
如遇问题、疑问或建议,请在 GitHub 仓库中提交一个问题。
常见问题
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
markitdown
MarkItDown 是一款由微软 AutoGen 团队打造的轻量级 Python 工具,专为将各类文件高效转换为 Markdown 格式而设计。它支持 PDF、Word、Excel、PPT、图片(含 OCR)、音频(含语音转录)、HTML 乃至 YouTube 链接等多种格式的解析,能够精准提取文档中的标题、列表、表格和链接等关键结构信息。 在人工智能应用日益普及的今天,大语言模型(LLM)虽擅长处理文本,却难以直接读取复杂的二进制办公文档。MarkItDown 恰好解决了这一痛点,它将非结构化或半结构化的文件转化为模型“原生理解”且 Token 效率极高的 Markdown 格式,成为连接本地文件与 AI 分析 pipeline 的理想桥梁。此外,它还提供了 MCP(模型上下文协议)服务器,可无缝集成到 Claude Desktop 等 LLM 应用中。 这款工具特别适合开发者、数据科学家及 AI 研究人员使用,尤其是那些需要构建文档检索增强生成(RAG)系统、进行批量文本分析或希望让 AI 助手直接“阅读”本地文件的用户。虽然生成的内容也具备一定可读性,但其核心优势在于为机器
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备