NL2SQL_Handbook
NL2SQL_Handbook 是一本持续更新的权威指南,旨在帮助读者轻松追踪自然语言转 SQL(Text-to-SQL)领域的最新技术进展。它基于多篇顶级学术会议(如 VLDB、TKDE)的综述论文构建,核心目标是解决大模型时代下,从业者难以选择合适技术方案以及研究人员难以把握未来方向的痛点。
该资源不仅提供了全面的技术调研和深度论文解读,还涵盖了从数据合成、基准测试到多维度评估及错误分析的全生命周期指导。其独特亮点在于将 Text-to-SQL 面临的挑战划分为五个层级,清晰梳理了从早期模型到当前大模型阶段的技术演进脉络,并展望了未来五年的系统发展愿景。
NL2SQL_Handbook 非常适合数据库领域的研究人员、AI 工程师以及需要落地自然语言查询功能的企业开发者使用。对于希望深入理解如何将用户自然语言高效转化为数据库查询语句,或正在寻找特定场景最佳实践的专业人士而言,这是一份兼具理论深度与实战价值的必备参考手册。
使用场景
某电商公司的数据团队正试图构建一个让运营人员通过自然语言直接查询销售数据库的系统,但在技术选型和错误优化上陷入了瓶颈。
没有 NL2SQL_Handbook 时
- 技术选型迷茫:面对海量的 Text-to-SQL 论文,团队难以分辨哪些是仅适用于学术基准的“刷分”模型,哪些真正适合处理复杂的商业嵌套查询。
- 错误排查无门:当用户提问“上周复购率最高的品类”生成错误 SQL 时,开发人员缺乏系统的错误分类指南,只能凭经验盲目调试 Prompt。
- 数据合成困难:由于缺乏高质量的领域训练数据,团队不知道如何利用最新的数据合成技术来弥补特定业务场景下的样本缺失。
- 评估标准单一:仅依赖执行准确率(Execution Accuracy)评估模型,忽略了语义匹配度,导致上线后频繁出现“结果对但逻辑错”的隐蔽风险。
使用 NL2SQL_Handbook 后
- 精准锁定方案:借助手册中对 LLM 时代技术演进的梳理,团队快速定位到适合处理复杂 Schema 映射的最新架构,大幅缩短了调研周期。
- 系统化纠错:利用手册提供的多层次错误分析框架,团队迅速识别出是“模式链接”环节出错,并针对性地引入了修正策略。
- 高效数据增强:参考手册中关于数据合成的最佳实践,团队成功生成了贴合电商业务的训练集,显著提升了模型对专业术语的理解力。
- 多维评估体系:采纳手册推荐的多粒度评估指标,不仅关注执行结果,更监控中间逻辑,提前拦截了潜在的语义偏差。
NL2SQL_Handbook 将分散的前沿研究转化为可落地的工程指南,帮助团队从“盲目试错”转向“科学构建”,极大降低了自然语言查数的落地门槛。
运行环境要求
未说明
未说明

快速开始
文本转SQL手册
NL2SQL手册
这是**[TKDE'25] 大语言模型时代的文本转SQL综述:我们目前处于什么阶段,未来又将走向何方?和[VLDB'24] 自然语言转SQL的曙光:我们准备好了吗?**的官方仓库。 通过该仓库,您可以探索文本转SQL研究(即NL2SQL)领域的最新进展。我们提供了全面的综述、深入的研究论文以及基准评估。
大语言模型时代的文本转SQL综述:我们目前处于什么阶段,未来又将走向何方?
自然语言转SQL:现状与开放问题
自然语言转SQL的曙光:我们准备好了吗?
📧如果您认为我们遗漏了任何有趣的工作,请联系我们。

@article{liu2025survey,
title={大语言模型时代的文本转SQL综述:我们目前处于什么阶段,未来又将走向何方?},
author={刘欣宇、沈书宇、李博彦、马培贤、蒋润志、张宇鑫、范炬、李国梁、唐楠、罗雨雨},
journal={IEEE知识与数据工程汇刊},
year={2025},
publisher={IEEE}
}
🧭 文本转SQL简介
将用户的自然语言查询(NL)转换为SQL查询,可以显著降低访问关系型数据库的门槛,并支持多种商业应用。随着语言模型(LMs)的出现,文本转SQL的性能得到了极大提升。在此背景下,评估当前的发展状况、确定从业者在特定场景下应采用的文本转SQL解决方案,以及明确研究人员下一步的研究方向,显得尤为重要。
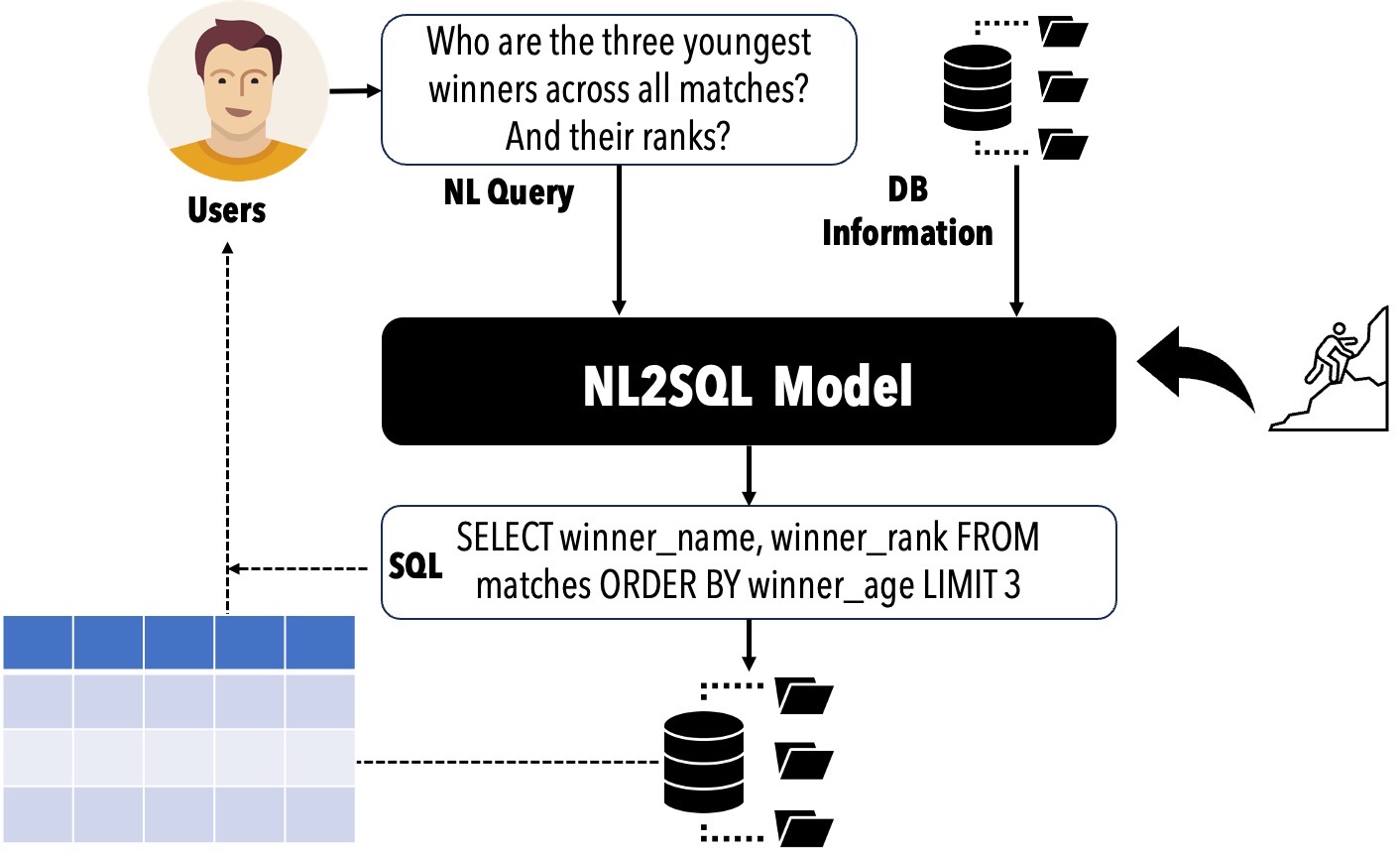
📈 文本转SQL生命周期

- 模型:文本转SQL翻译技术不仅要应对自然语言的歧义和信息不足问题,还要正确地将自然语言与数据库模式和实例进行映射;
- 数据:从训练数据的收集、因训练数据稀缺而进行的数据合成,到文本转SQL基准测试;
- 评估:使用不同指标和粒度从多个角度评估文本转SQL方法;
- 错误分析:分析文本转SQL中的错误以找出根本原因,并指导文本转SQL模型不断改进。
🤔 我们目前处于什么阶段?
我们将文本转SQL面临的挑战分为五个层次,每一层都针对特定的难题。前三个层次涵盖了已经或正在解决的挑战,反映了文本转SQL的逐步发展。第四层次代表我们在大语言模型阶段希望攻克的挑战,而第五层次则勾勒出我们在未来五年内对文本转SQL系统的愿景。 我们从语言模型的角度描述了文本转SQL解决方案的演进过程,并将其划分为四个阶段。 对于文本转SQL的每个阶段,我们都分析了目标用户的变化以及挑战被解决的程度。

🧩 基于模块的文本转SQL方法
我们总结了利用语言模型的文本转SQL解决方案中的关键模块。
- 预处理是在文本转SQL解析过程中对模型输入的增强。您可以在本章中了解更多详情:预处理
- 文本转SQL翻译方法是文本转SQL解决方案的核心,负责将输入的自然语言查询转换为SQL查询。您可以在本章中了解更多详情:文本转SQL翻译方法
- 后处理是优化生成的SQL查询的关键步骤,以确保其更准确地满足用户期望。您可以在本章中了解更多详情:后处理

📚 Text-to-SQL 综述与教程
- 大型语言模型时代的 Text-to-SQL 综述:我们身处何处,又将走向何方?
- 自然语言到 SQL:现状与开放问题。
- 下一代数据库接口:基于大语言模型的 Text-to-SQL 综述。
- 利用大型语言模型处理 Text-to-SQL 任务的综述。
- 大型语言模型增强的 Text-to-SQL 生成:综述。
- 从自然语言到 SQL:基于大语言模型的 Text-to-SQL 系统综述。
- 面向表格数据查询和可视化的自然语言接口:综述。
- 基于深度学习的数据库自然语言接口。
- 关于 Text-to-SQL 的深度学习方法综述。
- Text-to-SQL 解析综述:概念、方法与未来方向。
- Text-to-SQL 的最新进展:现有成果与未来展望综述。
- 深入探讨 Text-to-SQL 系统中的深度学习方法。
- 数据自然语言接口的现状与开放挑战。
- 自然语言到 SQL:我们目前处于什么阶段?
📰 Text-to-SQL Paper List
- DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework.
- Alpha-SQL: Zero-Shot Text-to-SQL using Monte Carlo Tree Search
- NL2SQL-BUGs: A Benchmark for Detecting Semantic Errors in NL2SQL Translation.
- EllieSQL: Cost-Efficient Text-to-SQL with Complexity-Aware Routing.
- The Dawn of Natural Language to SQL: Are We Fully Ready?
2. DIVER: A Robust Text-to-SQL System with Dynamic Interactive Value Linking and Evidence Reasoning.
3. LogicCat: A Chain-of-Thought Text-to-SQL Benchmark for Complex Reasoning.
4. Schema on the Inside: A Two-Phase Fine-Tuning Method for High-Efficiency Text-to-SQL at Scale.
5. Hexgen-Flow: Optimizing LLM Inference Request Scheduling for Agentic Text-to-SQL.
6. SQLMorph: Query Mutation and Fine-Grained Metrics for Text-to-SQL Evaluation.
7. LEAF-SQL: Level-wise Exploration with Adaptive Fine-graining for Text-to-SQL Skeleton Prediction.
8. An Efficient and Effective Evaluator for Text2SQL Models on Unseen and Unlabeled Data.
9. Boosting Small Language Models for Text-to-SQL with Fine-Grained Execution Feedback and Cost-Efficient Rewards.
10. MM2SQL: A Benchmark and Method for Visually-Grounded SQL Generation.
11. Text2SQL-Flow: A Robust SQL-Aware Data Augmentation Framework for Text-to-SQL.
12. Knapsack Optimization-based Schema Linking for LLM-based Text-to-SQL Generation.
13. CYANSQL: Unlock the Power of NL2SQL via Clustering-based Test-Time Scaling.
14. Beyond Static Pipelines: Learning Dynamic Workflows for Text-to-SQL.
15. ReViSQL: Achieving Human-Level Text-to-SQL.
16. Think2SQL: Blueprinting Reward Density and Advantage Scaling for Effective Text-to-SQL Reasoning.
- AgentSM: Semantic Memory for Agentic Text-to-SQL.
- LLM-Based SQL Generation: Prompting, Self-Refinement, and Adaptive Weighted Majority Voting.
- Pervasive Annotation Errors Break Text-to-SQL Benchmarks and Leaderboards.
- OptiSQL: Executable SQL Generation from Optical Tokens.
- Memo-SQL: Structured Decomposition and Experience-Driven Self-Correction for Training-Free NL2SQL.
- Structure-Guided Large Language Models for Text-to-SQL Generation.
- Sphinteract: Resolving Ambiguities in NL2SQL Through User Interaction.
- OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.
- EVOSCHEMA: TOWARDS TEXT-TO-SQL ROBUSTNESS AGAINST SCHEMA EVOLUTION.
- Is Long Context All You Need? Leveraging LLM's Extended Context for NL2SQL.
- The Power of Constraints in Natural Language to SQL Translation.
- OpenSearch-SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Alignment.
- Reliable Text-to-SQL with Adaptive Abstention.
- SNAILS: Schema Naming Assessments for Improved LLM-Based SQL Inference.
- Automated Validating and Fixing of Text-to-SQL Translation with Execution Consistency.
- Grounding Natural Language to SQL Translation with Data-Based Self-Explanations.
- AID-SQL: Adaptive In-Context Learning of Text-to-SQL with Difficulty-Aware Instruction and Retrieval-Augmented Generation.
- CLEAR: A Parser-Independent Disambiguation Framework for NL2SQL.
- CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL.
- Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows.
- ROUTE: Robust Multitask Tuning and Collaboration for Text-to-SQL.
- SHARE: An SLM-based Hierarchical Action CorREction Assistant for Text-to-SQL.
- DCG-SQL: Enhancing In-Context Learning for Text-to-SQL with Deep Contextual Schema Link Graph.
- Uncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL.
- STaR-SQL: Self-Taught Reasoner for Text-to-SQL.
- SQLGenie: A Practical LLM based System for Reliable and Efficient SQL Generation
- SQL-R1: Training Natural Language to SQL Reasoning Model By Reinforcement Learning.
- Confidence Estimation for Error Detection in Text-to-SQL Systems.
- SQLord: A Robust Enterprise Text-to-SQL Solution via Reverse Data Generation and Workflow Decomposition.
- DBCopilot: Scaling Natural Language Querying to Massive Databases.
- Utilising Large Language Models for Adversarial Attacks in Text-to-SQL: A Perpetrator and Victim Approach.
- You Only Read Once (YORO): Learning to Internalize Database Knowledge for Text-to-SQL.
- Boosting Text-to-SQL through Multi-grained Error Identification.
- Gen-SQL: Efficient Text-to-SQL By Bridging Natural Language Question And Database Schema With Pseudo-Schema.
- MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL.
- PARSQL: Enhancing Text-to-SQL through SQL Parsing and Reasoning.
- UCS-SQL: Uniting Content and Structure for Enhanced Semantic Bridging In Text-to-SQL.
- SQLForge: Synthesizing Reliable and Diverse Data to Enhance Text-to-SQL Reasoning in LLMs.
- Optimizing Reasoning for Text-to-SQL with Execution Feedback.
- Knowledge Base Construction for Knowledge-Augmented Text-to-SQL.
- SQLong: Enhanced NL2SQL for Longer Contexts with LLMs.
- Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL.
Agentar-Scale-SQL: Advancing Text-to-SQL through Orchestrated Test-Time Scaling.
.
Automatic Metadata Extraction for Text-to-SQL.
- DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework.
- Rethinking Text-to-SOL: Dynamic Multi-turn SOIInteraction for Real-world Database Exploration.
- MARS-SQL: A MULTI-AGENT REINFORCEMENT LEARNING FRAMEWORK FOR TEXT-TO-SQL.
- RUBIKSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System.
- CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning.
- Cheaper, Better, Faster, Stronger: Robust Text-to-SQL without Chain-of-Thought or Fine-Tuning.
- SLM-SQL: An Exploration of Small Language Models for Text-to-SQL.
- Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards.
- Arctic-Text2SQL-R1: Simple Rewards, Strong Reasoning in Text-to-SQL.
- Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning.
- SQLForge: Synthesizing Reliable and Diverse Data to Enhance Text-to-SQL Reasoning in LLMs.
- Think2SQL: Reinforce LLM Reasoning Capabilities for Text2SQL.
- Distill-C: Enhanced NL2SQL via Distilled Customization with LLMs.
- OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.
- SQL-Factory: A Multi-Agent Framework for High-Quality and Large-Scale SQL Generation.
- Text2SQL is Not Enough: Unifying AI and Databases with TAG.
- Automatic database description generation for Text-to-SQL.
- MCTS-SQL: An Effective Framework for Text-to-SQL with Monte Carlo Tree Search.
- SQL-o1: A Self-Reward Heuristic Dynamic Search Method for Text-to-SQL.
- FEATHER-SQL: A Lightweight NL2SQL Framework with Dual-Model Collaboration Paradigm for Small Language Models.
- FI-NL2PY2SQL: Financial Industry NL2SQL Innovation Model Based on Python and Large Language Model.
- FGCSQL: A Three-Stage Pipeline for Large Language Model-Driven Chinese Text-to-SQL.
- Transforming Medical Data Access: The Role and Challenges of Recent Language Models in SQL Query Automation.
- The Dawn of Natural Language to SQL: Are We Fully Ready?
- Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.
- Interleaving Pre-Trained Language Models and Large Language Models for Zero-Shot NL2SQL Generation.
- Generating Succinct Descriptions of Database Schemata for Cost-Efficient Prompting of Large Language Models.
- ScienceBenchmark: A Complex Real-World Benchmark for Evaluating Natural Language to SQL Systems.
- CodeS: Towards Building Open-source Language Models for Text-to-SQL.
- FinSQL: Model-Agnostic LLMs-based Text-to-SQL Framework for Financial Analysis.
- PURPLE: Making a Large Language Model a Better SQL Writer.
- METASQL: A Generate-then-Rank Framework for Natural Language to SQL Translation.
- Archer: A Human-Labeled Text-to-SQL Dataset with Arithmetic, Commonsense and Hypothetical Reasoning.
- Synthesizing Text-to-SQL Data from Weak and Strong LLMs.
- Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark.
- I Need Help! Evaluating LLM’s Ability to Ask for Users’ Support: A Case Study on Text-to-SQL Generation.
- PTD-SQL: Partitioning and Targeted Drilling with LLMs in Text-to-SQL.
- Improving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning.
- Data-Centric Text-to-SQL with Large Language Models.
- Research and Practice on Database Interaction Based on Natural Language Processing
- XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL.
- Structure Guided Large Language Model for SQL Generation.
- A Plug-and-Play Natural Language Rewriter for Natural Language to SQL.
- RSL-SQL: Robust Schema Linking in Text-to-SQL Generation.
- In-Context Reinforcement Learning based Retrieval-Augmented Generation for Text-to-SQL.
- TrustSQL: Benchmarking Text-to-SQL Reliability with Penalty-Based Scoring.
- LAIA-SQL: Enhancing Natural Language to SQL Generation in Multi-Table QA via Task Decomposition and Keyword Extraction
- Research on Large Model Text-to-SQL Optimization Method for Intelligent Interaction in the Field of Construction Safety.
- SQLh-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging.
- Grounding Natural Language to SQL Translation with Data-Based Self-Explanations.
- Towards Optimizing SQL Generation via LLM Routing.
- E-SQL: Direct Schema Linking via Question Enrichment in Text-to-SQL.
- DB-GPT: Empowering Database Interactions with Private Large Language Models.
- The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models.
- CHESS: Contextual Harnessing for Efficient SQL Synthesis.
- PET-SQL: A Prompt-Enhanced Two-Round Refinement of Text-to-SQL with Cross-consistency.
- CoE-SQL: In-Context Learning for Multi-Turn Text-to-SQL with Chain-of-Editions.
- AMBROSIA: A Benchmark for Parsing Ambiguous Questions into Database Queries.
- Text-to-SQL Calibration: No Need to Ask—Just Rescale Model Probabilities.
- Few-shot Text-to-SQL Translation using Structure and Content Prompt Learning.
- CatSQL: Towards Real World Natural Language to SQL Applications.
- DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction.
- Data Ambiguity Strikes Back: How Documentation Improves GPT's Text-to-SQL.
- ACT-SQL: In-Context Learning for Text-to-SQL with Automatically-Generated Chain-of-Thought.
- Selective Demonstrations for Cross-domain Text-to-SQL.
- RESDSQL: Decoupling Schema Linking and Skeleton Parsing for Text-to-SQL.
- Graphix-T5: Mixing Pre-trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing.
- Improving Generalization in Language Model-based Text-to-SQL Semantic Parsing: Two Simple Semantic Boundary-based Techniques.
- G3R: A Graph-Guided Generate-and-Rerank Framework for Complex and Cross-domain Text-to-SQL Generation.
- Importance of Synthesizing High-quality Data for Text-to-SQL Parsing.
- Know What I don’t Know: Handling Ambiguous and Unknown Questions for Text-to-SQL.
- C3: Zero-shot Text-to-SQL with ChatGPT
- SQLformer: Deep Auto-Regressive Query Graph Generation for Text-to-SQL Translation.
📊 Text-to-SQL 基准测试
我们创建了基准测试的发展时间线,并标注了相关的重要里程碑。更多详细信息请参阅本章节:📊 基准测试

🎯 我们的目标是什么?
- 🎯解决开放式的 Text-to-SQL 问题
- 🎯开发经济高效的 Text-to-SQL 方法
- 🎯使 Text-to-SQL 解决方案更加可信
- 🎯处理含歧义或未明确说明的自然语言查询
- 🎯自适应训练数据合成
📖 我们的综述目录
您可以在我们的子章节中获取更多信息。我们介绍了相关概念中的代表性论文:
💾 新手实用指南
📊 如何获取数据:
- 我们为您收集了 Text-to-SQL 基准测试的相关信息及下载链接。更多详情请参阅本章节:基准测试
- 基准测试的分析代码位于
src/dataset_analysis目录下。基准测试分析报告则存放在report/目录中。
🛠️ 如何构建基于 LLM 的 Text-to-SQL 模型:
Litgpt 仓库链接
该仓库提供了超过20个高性能大型语言模型(LLM)的访问权限,并配有全面的预训练、微调和大规模部署指南。它采用从头开始实现的方式,没有复杂的抽象概念,非常适合初学者使用。
LLaMA-Factory 仓库链接 统一高效地微调100多种大型语言模型。通过整合多种模型、可扩展的训练资源、先进的算法、实用技巧以及全面的实验监控工具,该框架能够通过优化后的 API 和用户界面实现高效且快速的推理。
BIRD-SQL 基准测试的微调与上下文学习 仓库链接
BIRD-SQL 基准测试提供了关于微调和上下文学习的教程。
🔎 如何评估您的模型:
我们为您整理了 NL2SQL 的评估指标。更多详情请参阅本章节:评估
NLSQL360 仓库链接
NL2SQL360 是一个用于对 NL2SQL 解决方案进行细粒度评估的测试平台。该平台整合了现有的 NL2SQL 基准测试、NL2SQL 模型库以及多种评估指标,旨在提供一个直观且易于使用的平台,以支持标准和定制化的性能评估。
Test-suite-sql-eval 仓库链接
该仓库包含针对11个 text-to-SQL 任务的测试套件评估指标。目前,它已成为 Spider、SParC 和 CoSQL 的官方评估指标,并且也适用于 Academic、ATIS、Advising、Geography、IMDB、Restaurants、Scholar 和 Yelp 数据集(基于 Catherine 和 Jonathan 的出色工作)。
BIRD-SQL 官方 仓库链接
这是 BIRD-SQL 的官方工具。它是首个提出 VES 指标并提供官方测试套件的工具。
🗺️ 路线图与决策流程
您可以从路线图和决策流程中获得一些启发。

📱 Text-to-SQL 相关应用:
- AI for Database:面向数据库的代理式 AI 产品——可连接任何数据库(PostgreSQL、MySQL、MongoDB 等),并用通俗英语与其交互。具备自动刷新的智能仪表板、自然语言查询以及基于数据库变化触发的自动化工作流功能。
- Chat2DB:基于 AI 的数据库工具和 SQL 客户端,是最受欢迎的 GUI 客户端之一,支持 MySQL、Oracle、PostgreSQL、DB2、SQL Server、SQLite、H2、ClickHouse 等多种数据库。
- DB-GPT:基于 AWEL(代理工作流表达语言)和代理的原生 AI 数据应用开发框架。
- Postgres.new:带有 AI 辅助功能的浏览器内 Postgres 沙盒环境。
- QueryGPT – 使用生成式 AI 将自然语言转换为 SQL。
📮 联系我们
如果您认为我们遗漏了某些有趣的工作,请随时与我们联系。
📧 xliu371[at]connect.hkust-gz.edu.cn
相似工具推荐
openclaw
OpenClaw 是一款专为个人打造的本地化 AI 助手,旨在让你在自己的设备上拥有完全可控的智能伙伴。它打破了传统 AI 助手局限于特定网页或应用的束缚,能够直接接入你日常使用的各类通讯渠道,包括微信、WhatsApp、Telegram、Discord、iMessage 等数十种平台。无论你在哪个聊天软件中发送消息,OpenClaw 都能即时响应,甚至支持在 macOS、iOS 和 Android 设备上进行语音交互,并提供实时的画布渲染功能供你操控。 这款工具主要解决了用户对数据隐私、响应速度以及“始终在线”体验的需求。通过将 AI 部署在本地,用户无需依赖云端服务即可享受快速、私密的智能辅助,真正实现了“你的数据,你做主”。其独特的技术亮点在于强大的网关架构,将控制平面与核心助手分离,确保跨平台通信的流畅性与扩展性。 OpenClaw 非常适合希望构建个性化工作流的技术爱好者、开发者,以及注重隐私保护且不愿被单一生态绑定的普通用户。只要具备基础的终端操作能力(支持 macOS、Linux 及 Windows WSL2),即可通过简单的命令行引导完成部署。如果你渴望拥有一个懂你
stable-diffusion-webui
stable-diffusion-webui 是一个基于 Gradio 构建的网页版操作界面,旨在让用户能够轻松地在本地运行和使用强大的 Stable Diffusion 图像生成模型。它解决了原始模型依赖命令行、操作门槛高且功能分散的痛点,将复杂的 AI 绘图流程整合进一个直观易用的图形化平台。 无论是希望快速上手的普通创作者、需要精细控制画面细节的设计师,还是想要深入探索模型潜力的开发者与研究人员,都能从中获益。其核心亮点在于极高的功能丰富度:不仅支持文生图、图生图、局部重绘(Inpainting)和外绘(Outpainting)等基础模式,还独创了注意力机制调整、提示词矩阵、负向提示词以及“高清修复”等高级功能。此外,它内置了 GFPGAN 和 CodeFormer 等人脸修复工具,支持多种神经网络放大算法,并允许用户通过插件系统无限扩展能力。即使是显存有限的设备,stable-diffusion-webui 也提供了相应的优化选项,让高质量的 AI 艺术创作变得触手可及。
everything-claude-code
everything-claude-code 是一套专为 AI 编程助手(如 Claude Code、Codex、Cursor 等)打造的高性能优化系统。它不仅仅是一组配置文件,而是一个经过长期实战打磨的完整框架,旨在解决 AI 代理在实际开发中面临的效率低下、记忆丢失、安全隐患及缺乏持续学习能力等核心痛点。 通过引入技能模块化、直觉增强、记忆持久化机制以及内置的安全扫描功能,everything-claude-code 能显著提升 AI 在复杂任务中的表现,帮助开发者构建更稳定、更智能的生产级 AI 代理。其独特的“研究优先”开发理念和针对 Token 消耗的优化策略,使得模型响应更快、成本更低,同时有效防御潜在的攻击向量。 这套工具特别适合软件开发者、AI 研究人员以及希望深度定制 AI 工作流的技术团队使用。无论您是在构建大型代码库,还是需要 AI 协助进行安全审计与自动化测试,everything-claude-code 都能提供强大的底层支持。作为一个曾荣获 Anthropic 黑客大奖的开源项目,它融合了多语言支持与丰富的实战钩子(hooks),让 AI 真正成长为懂上
ComfyUI
ComfyUI 是一款功能强大且高度模块化的视觉 AI 引擎,专为设计和执行复杂的 Stable Diffusion 图像生成流程而打造。它摒弃了传统的代码编写模式,采用直观的节点式流程图界面,让用户通过连接不同的功能模块即可构建个性化的生成管线。 这一设计巧妙解决了高级 AI 绘图工作流配置复杂、灵活性不足的痛点。用户无需具备编程背景,也能自由组合模型、调整参数并实时预览效果,轻松实现从基础文生图到多步骤高清修复等各类复杂任务。ComfyUI 拥有极佳的兼容性,不仅支持 Windows、macOS 和 Linux 全平台,还广泛适配 NVIDIA、AMD、Intel 及苹果 Silicon 等多种硬件架构,并率先支持 SDXL、Flux、SD3 等前沿模型。 无论是希望深入探索算法潜力的研究人员和开发者,还是追求极致创作自由度的设计师与资深 AI 绘画爱好者,ComfyUI 都能提供强大的支持。其独特的模块化架构允许社区不断扩展新功能,使其成为当前最灵活、生态最丰富的开源扩散模型工具之一,帮助用户将创意高效转化为现实。
gemini-cli
gemini-cli 是一款由谷歌推出的开源 AI 命令行工具,它将强大的 Gemini 大模型能力直接集成到用户的终端环境中。对于习惯在命令行工作的开发者而言,它提供了一条从输入提示词到获取模型响应的最短路径,无需切换窗口即可享受智能辅助。 这款工具主要解决了开发过程中频繁上下文切换的痛点,让用户能在熟悉的终端界面内直接完成代码理解、生成、调试以及自动化运维任务。无论是查询大型代码库、根据草图生成应用,还是执行复杂的 Git 操作,gemini-cli 都能通过自然语言指令高效处理。 它特别适合广大软件工程师、DevOps 人员及技术研究人员使用。其核心亮点包括支持高达 100 万 token 的超长上下文窗口,具备出色的逻辑推理能力;内置 Google 搜索、文件操作及 Shell 命令执行等实用工具;更独特的是,它支持 MCP(模型上下文协议),允许用户灵活扩展自定义集成,连接如图像生成等外部能力。此外,个人谷歌账号即可享受免费的额度支持,且项目基于 Apache 2.0 协议完全开源,是提升终端工作效率的理想助手。
LLMs-from-scratch
LLMs-from-scratch 是一个基于 PyTorch 的开源教育项目,旨在引导用户从零开始一步步构建一个类似 ChatGPT 的大型语言模型(LLM)。它不仅是同名技术著作的官方代码库,更提供了一套完整的实践方案,涵盖模型开发、预训练及微调的全过程。 该项目主要解决了大模型领域“黑盒化”的学习痛点。许多开发者虽能调用现成模型,却难以深入理解其内部架构与训练机制。通过亲手编写每一行核心代码,用户能够透彻掌握 Transformer 架构、注意力机制等关键原理,从而真正理解大模型是如何“思考”的。此外,项目还包含了加载大型预训练权重进行微调的代码,帮助用户将理论知识延伸至实际应用。 LLMs-from-scratch 特别适合希望深入底层原理的 AI 开发者、研究人员以及计算机专业的学生。对于不满足于仅使用 API,而是渴望探究模型构建细节的技术人员而言,这是极佳的学习资源。其独特的技术亮点在于“循序渐进”的教学设计:将复杂的系统工程拆解为清晰的步骤,配合详细的图表与示例,让构建一个虽小但功能完备的大模型变得触手可及。无论你是想夯实理论基础,还是为未来研发更大规模的模型做准备